- 6.NULL: The Missing Semester of Your CS Education 原课程总结
参考资料
- 知乎 - 胡津铭 - 6.NULL:恨不相逢“未嫁时”: 介绍 6.NULL
- MIT:The Missing Semester of Your CS Education
- IPADS - Nian Liu - Shell Tutorial
Shell
- GUI vs Shell
- Shell
- Bourne Again SHell (Bash)
basic
- 几个简单的命令:

- 文件导航:Windows 和 unix-like system 之间存在一定的区别
- \ 和 /
- root_directory
- /sys
- cd/cp/mv/rm/mkdir/ls
- I/O 重定向:
- < file 重定向输入到 file
- > file 重定向输出流到文件
- >> file 追加写到文件
- | 管道重定向,链接输出和输入
- 使用重定向过程中需要注意权限问题:
$ sudo find -L /sys/class/backlight -maxdepth 2 -name '*brightness*'
/sys/class/backlight/thinkpad_screen/brightness
$ cd /sys/class/backlight/thinkpad_screen
$ sudo echo 3 > brightness
An error occurred while redirecting file 'brightness'
open: Permission denied
- echo 等程序并不知道 | 的存在,它们只知道从自己的输入输出流中进行读写。 对于上面这种情况, shell (权限为您的当前用户) 在设置 sudo echo 前尝试打开 brightness 文件并写入,但是系统拒绝了 shell 的操作因为此时 shell 不是根用户。所以修改为:
$ echo 3 | sudo tee brightness
- 因为打开 /sys 文件的是 tee 这个程序,并且该程序以 root 权限在运行,因此操作可以进行。 这样您就可以在 /sys 中愉快地玩耍了,例如修改系统中各种LED的状态(路径可能会有所不同):
$ echo 1 | sudo tee /sys/class/leds/input6::scrolllock/brightness
scripts
- shell 中几个特殊的符号
- 注释 #
- 分号:使用分号把多条命令放到一行
- 双分号:case 的分隔
- 空格:空格会分割参数
- 点 .
- 作为文件名的一部分时不会显示,隐藏文件的前缀
- 当前目录 .
- 上一级目录 ..
- 正则表达式匹配单个字符 .
- 引号
- ' ':以'定义的字符串为原义字符串,其中的变量不会被转义
- " ":定义的字符串会将变量值进行替换
foo=bar
echo "$foo"
# 打印 bar
echo '$foo'
# 打印 $foo
- 关键字
- if
- case
- while
- for
- 函数和参数表
- 可以定义函数
- 参数表
- $0 - 脚本名
- $1 - $9 脚本的参数 第一个到第九个
- $@ - 所有参数
- $# - 参数个数
- $? - 前一个命令的返回值
- $$ - 当前脚本的进程识别码
- !! - 完整的上一条命令,包括参数,常见用法,当你因为权限不足执行命令失败时,可以使用 sudo !!再尝试一次。
- $_ - 上一条命令的最后一个参数,如果正在使用交互式 shell,按下 Esc 之后键入 . 来获取这个值
- 其他操作
- $(CMD) 这样的方式来执行CMD 这个命令时,它的输出结果会替换掉 $( CMD )
for file in $(ls)l首先将调用ls ,然后遍历得到的这些返回值
- <( CMD ) 会执行 CMD 并将结果输出到一个临时文件中,并将 <( CMD ) 替换成临时文件名。这在我们希望返回值通过文件而不是STDIN传递时很有用
diff <(ls foo) <(ls bar)会显示文件夹 foo 和 bar 中文件的区别
- $(CMD) 这样的方式来执行CMD 这个命令时,它的输出结果会替换掉 $( CMD )
- 标准输入输出
- stdout
- stdin
- stderr
#!/bin/bash
echo "Starting program at $(date)" # date会被替换成日期和时间
echo "Running program $0 with $# arguments with pid $$"
# 遍历参数列表
for file in "$@"; do
grep foobar "$file" > /dev/null 2> /dev/null
# 如果模式没有找到,则grep退出状态为 1
# 我们将标准输出流和标准错误流重定向到Null,因为我们并不关心这些信息
# 前面的 grep 命令没有找到 foobar 的时候,追加一个 foorbar
if [[ $? -ne 0 ]]; then
echo "File $file does not have any foobar, adding one"
echo "# foobar" >> "$file"
fi
done
- 一些规范和简便写法:
- 在bash中进行比较时,尽量使用双方括号 [[ ]] 而不是单方括号 [ ]
- 通配符:* 和 ?
- foo* 匹配以 foo 开头的所有字符串
- foo? 匹配以 foo+x 的字符串,如 foo1, foo2
- 花括号:{} 自动展开 命令,类似于循环的概念
cp /path/to/project/{foo,bar,baz}.sh /newpathmv *{.py,.sh} foldertouch {foo,bar}/{a..h}
- shell 错误检查工具
ShellCheck - 命令用法查询
- man
- tldr
- find 查找文件/操作文件
# 查找文件
# 查找所有名称为src的文件夹
find . -name src -type d
# 查找所有名称为src的文件夹,不区分大小写
find . -name src -iname -type d
# 查找所有文件夹路径中包含test的python文件
find . -path '*/test/*.py' -type f
# 查找前一天修改的所有文件
find . -mtime -1
# 查找所有大小在500k至10M的tar.gz文件
find . -size +500k -size -10M -name '*.tar.gz'
# 操作文件
# 删除全部扩展名为.tmp 的文件
find . -name '*.tmp' -exec rm {} \;
# 查找全部的 PNG 文件并将其转换为 JPG
find . -name '*.png' -exec convert {} {}.jpg \;
- 其他文件查找工具
- fd: https://github.com/sharkdp/fd
- locate: 可以再执行命令之前执行 updatedb 来更新数据库
# 查找和pwd相关的所有文件
locate pwd
# 搜索etc目录下所有以sh开头的文件
locate /etc/sh
# 搜索etc目录下,所有以i开头的文件
locate /etc/i
# 指定显示数量,限定结果个数
locate -n 3 passwd
# 查找不需要区分大小写时,使用 -i 选项
locate -i -n 5 passwd
# 正则表达式匹配
locate -r ^/var/lib/rpm
# 查看数据库统计信息
locate -S
# 查看passwd统计数量
locate -c passwd
# update相关配置文件
vim /etc/updatedb.conf
- 代码/文本查找 grep, ack, ag, rg
# 查找所有使用了 requests 库的文件
rg -t py 'import requests'
# 查找所有没有写 shebang 的文件(包含隐藏文件)
rg -u --files-without-match "^#!"
# 查找所有的foo字符串,并打印其之后的5行
rg foo -A 5
# 打印匹配的统计信息(匹配的行和文件的数量)
rg --stats PATTERN
- 命令查找
- history
- Ctrl+R
- fzf
- 文件夹导航
- fasd,autojump
- tree
- broot
- nnn
- ranger、
- 习题解答
ls -ahtl --color=auto-a所有文件包括隐藏文件-h文件打印以人类可以理解的格式输出 (例如,使用454M 而不是 454279954)-t文件以最近访问顺序排序--color=auto以彩色文本显示输出结果
find . -type f -name "*.html" | xargs -d '\n' tar -cvzf html.zip# 查找 .html 文件并打包成 zipxargs使用标准输入中的内容作为参数,主要用于 不接受标准输入作为参数的命令-d更改分隔符来分解标准输入,默认分隔符为空格。
tar打包- cvzf
- c 建立压缩
- v 显示所有过程
- z 有 gzip 属性
- f 使用后面跟随的 zip 名
- zxvf
- x 解压
- cvzf
find . -type f -mmin -60 -print0 | xargs -0 ls -lt | head -10# 递归的查找文件夹中最近使用的文件-mmin60- 文件的数据最后一次修改是在60分钟前
- find 后的
print和print0-print在每一个输出后会添加一个回车换行符-print0则不会
-xarg 0xargs 也用 NULL 字符来作为记录的分隔符
Vim
Basic
- 多种操作模式
- 正常模式:在文件中四处移动光标进行修改 (默认)
- 插入模式:插入文本
i - 替换模式:替换文本
R - 可视化(一般,行,块)模式:选中文本块
v一般V行Ctrl-V块 - 命令模式:用于执行命令
:
- 基本概念
- Vim 会维护一系列打开的文件,称为“缓存”
- 一个 Vim 会话包含一系列标签页,每个标签页包含 一系列窗口(分隔面板)每个窗口显示一个缓存
- 缓存和窗口不是一一对应的关系;窗口只是视角。一个缓存可以在_多个_窗口打开,甚至在同一 个标签页内的多个窗口打开。这个功能其实很好用,比如在查看同一个文件的不同部分的时候。
- Vim 默认打开一个标签页,这个标签也包含一个窗口。
- 基本命令:(命令模式下 :)
- q
- w
- wq
- e {文件名} 打开要编辑的文件
- ls 显示打开的缓存
- help {标题} 打开帮助文档
- :help :w 打开 :w 命令的帮助文档
- :help w 打开 w 移动的帮助文档
操作
-
移动 (正常模式下)
- 基本移动:
hjkl(左, 下, 上, 右) - 词:
w(下一个词),b(词初),e(词尾) - 行:
0(行初),^(第一个非空格字符),$(行尾) - 屏幕:
H(屏幕首行),M(屏幕中间),L(屏幕底部) - 翻页:
Ctrl-u(上翻),Ctrl-d(下翻) - 文件:
gg(文件头),G(文件尾) - 行数:
:{行数}<CR>或者{行数}G({行数}为行数) - 杂项:
%(找到配对,比如括号或者 /* */ 之类的注释对) - 查找:
f{字符},t{字符},F{字符},T{字符}- 查找/到 向前/向后 在本行的{字符}
,/;用于导航匹配
- 搜索:
/{正则表达式},n/N用于导航匹配
- 基本移动:
-
编辑
i进入插入模式O/o在之上/之下插入行d{移动命令}删除 {移动命令}dw删除词d$删除到行尾d0删除到行头
c{移动命令}改变 {移动命令}- 例如,
cw改变词
- 例如,
x删除字符(等同于dl)s替换字符(等同于xi)- 可视化模式
+操作- 选中文字,
d删除 或者c改变
- 选中文字,
u撤销,<C-r>重做y复制 / “yank” (其他一些命令比如 d 也会复制)p粘贴
-
计数:你可以用一个计数来结合“名词”和“动词”,这会执行指定操作若干次。
- 3w 向前移动三个词
- 5j 向下移动5行
- 7dw 删除7个词
-
修饰语:你可以用修饰语改变“名词”的意义。修饰语有 i,表示“内部”或者“在内“,和 a, 表示”周围“。
ci(改变当前括号内的内容ci[改变当前方括号内的内容da'删除一个单引号字符串, 包括周围的单引号
自定义 Vim
- Vim 由一个位于 ~/.vimrc 的文本配置文件(包含 Vim 脚本命令)。 你可能会启用很多基本 设置。
" Comments in Vimscript start with a `"`.
" If you open this file in Vim, it'll be syntax highlighted for you.
" Vim is based on Vi. Setting `nocompatible` switches from the default
" Vi-compatibility mode and enables useful Vim functionality. This
" configuration option turns out not to be necessary for the file named
" '~/.vimrc', because Vim automatically enters nocompatible mode if that file
" is present. But we're including it here just in case this config file is
" loaded some other way (e.g. saved as `foo`, and then Vim started with
" `vim -u foo`)."
" Vim基于Vi。设置' nocompatible '从默认的Vi兼容模式切换,并启用有用的Vim功能.
set nocompatible
" 语法高亮"
" Turn on syntax highlighting.
syntax on
" 禁用默认的Vim启动消息"
" Disable the default Vim startup message.
set shortmess+=I
" Show line numbers.
set number
" 这使得可以使用相对行编号模式。 启用number和relativenumber后,当前行显示真实的行号,而所有其他行(上面和下面)都相对于当前行编号。 这是很有用的,因为你可以通过{count}k向上或{count}j向下,一眼就能知道向上或向下跳转到特定行需要哪些计数。 "
" This enables relative line numbering mode. With both number and
" relativenumber enabled, the current line shows the true line number, while
" all other lines (above and below) are numbered relative to the current line.
" This is useful because you can tell, at a glance, what count is needed to
" jump up or down to a particular line, by {count}k to go up or {count}j to go
" down.
set relativenumber
" 总是在底部显示状态行,即使你只有一个窗口打开"
" Always show the status line at the bottom, even if you only have one window open.
set laststatus=2
" The backspace key has slightly unintuitive behavior by default. For example,
" by default, you can't backspace before the insertion point set with 'i'.
" This configuration makes backspace behave more reasonably, in that you can
" backspace over anything.
set backspace=indent,eol,start
" By default, Vim doesn't let you hide a buffer (i.e. have a buffer that isn't
" shown in any window) that has unsaved changes. This is to prevent you from "
" forgetting about unsaved changes and then quitting e.g. via `:qa!`. We find
" hidden buffers helpful enough to disable this protection. See `:help hidden`
" for more information on this.
set hidden
" 默认情况下,退格键有一些不太直观的行为。 例如,在默认情况下,不能在使用'i'设置的插入点之前进行退格操作。 这个配置使退格操作更合理,因为你可以在任何东西上退格。"
" This setting makes search case-insensitive when all characters in the string
" being searched are lowercase. However, the search becomes case-sensitive if
" it contains any capital letters. This makes searching more convenient.
set ignorecase
set smartcase
"在输入时启用搜索,而不是等到按回车键 "
" Enable searching as you type, rather than waiting till you press enter.
set incsearch
" 解绑定一些无用的/恼人的默认键绑定"
" Unbind some useless/annoying default key bindings.
nmap Q <Nop> " 'Q' in normal mode enters Ex mode. You almost never want this.
" Disable audible bell because it's annoying.
set noerrorbells visualbell t_vb=
" 禁用鼠标支持,因为它很烦人。"
" Enable mouse support. You should avoid relying on this too much, but it can
" sometimes be convenient.
set mouse+=a
"尽量避免像使用方向键移动这样的坏习惯。 这不是唯一可能的坏习惯。 例如,按住h/j/k/l键移动,而不是使用更有效的移动命令,也是一个坏习惯。 前者可以通过.vimrc执行,而我们不知道如何防止后者。 在正常模式下做这个… "
" Try to prevent bad habits like using the arrow keys for movement. This is
" not the only possible bad habit. For example, holding down the h/j/k/l keys
" for movement, rather than using more efficient movement commands, is also a
" bad habit. The former is enforceable through a .vimrc, while we don't know
" how to prevent the latter.
" Do this in normal mode...
nnoremap <Left> :echoe "Use h"<CR>
nnoremap <Right> :echoe "Use l"<CR>
nnoremap <Up> :echoe "Use k"<CR>
nnoremap <Down> :echoe "Use j"<CR>
" ...and in insert mode
inoremap <Left> <ESC>:echoe "Use h"<CR>
inoremap <Right> <ESC>:echoe "Use l"<CR>
inoremap <Up> <ESC>:echoe "Use k"<CR>
inoremap <Down> <ESC>:echoe "Use j"<CR>
扩展 Vim
- Vim 有很多扩展插件。跟很多互联网上已经过时的建议相反,你_不_需要在 Vim 使用一个插件 管理器(从 Vim 8.0 开始)。你可以使用内置的插件管理系统。只需要创建一个 ~/.vim/pack/vendor/start/ 的文件夹,然后把插件放到这里(比如通过 git clone)。
- 推荐插件
- ctrlp.vim: 模糊文件查找
- ack.vim: 代码搜索
- nerdtree: 文件浏览器
- vim-easymotion: 魔术操作
- https://vimawesome.com/
其他程序的 Vim 模式
Shell
- 如果你是一个 Bash 用户,用 set -o vi。如果你用 Zsh:bindkey -v。Fish 用 fish_vi_key_bindings。另外,不管利用什么 shell,你可以 export EDITOR=vim。 这是一个用来决定当一个程序需要启动编辑时启动哪个的环境变量。 例如,git 会使用这个编辑器来编辑 commit 信息。
Readline
- 很多程序使用 GNU Readline 库来作为 它们的命令控制行界面。Readline 也支持基本的 Vim 模式, 可以通过在 ~/.inputrc 添加如下行开启:
set editing-mode vi
- 比如,在这个设置下,Python REPL 会支持 Vim 快捷键。
其他
- 甚至有 Vim 的网页浏览快捷键 browsers, 受欢迎的有 用于 Google Chrome 的 Vimium 和用于 Firefox 的 Tridactyl。 你甚至可以在 Jupyter notebooks 中用 Vim 快捷键。 这个列表 中列举了支持类 vim 键位绑定的软件。https://reversed.top/2016-08-13/big-list-of-vim-like-software
Vim 进阶
- 搜索和替换
:s(替换)命令%s/foo/bar/g在整个文件中将 foo 全局替换成 bar%s/\[.*\](\(.*\))/\1/g将有命名的 Markdown 链接替换成简单 URLs
- 多窗口
- 用
:sp/:vsp来分割窗口 - 同一个缓存可以在多个窗口中显示。
- 用
- 宏
q{字符}来开始在寄存器{字符}中录制宏q停止录制@{字符}重放宏- 宏的执行遇错误会停止
{计数}@{字符}执行一个宏{计数}次- 宏可以递归
- 首先用
q{字符}q清除宏 - 录制该宏,用
@{字符}来递归调用该宏 (在录制完成之前不会有任何操作)
- 首先用
- 例子:将 xml 转成 json
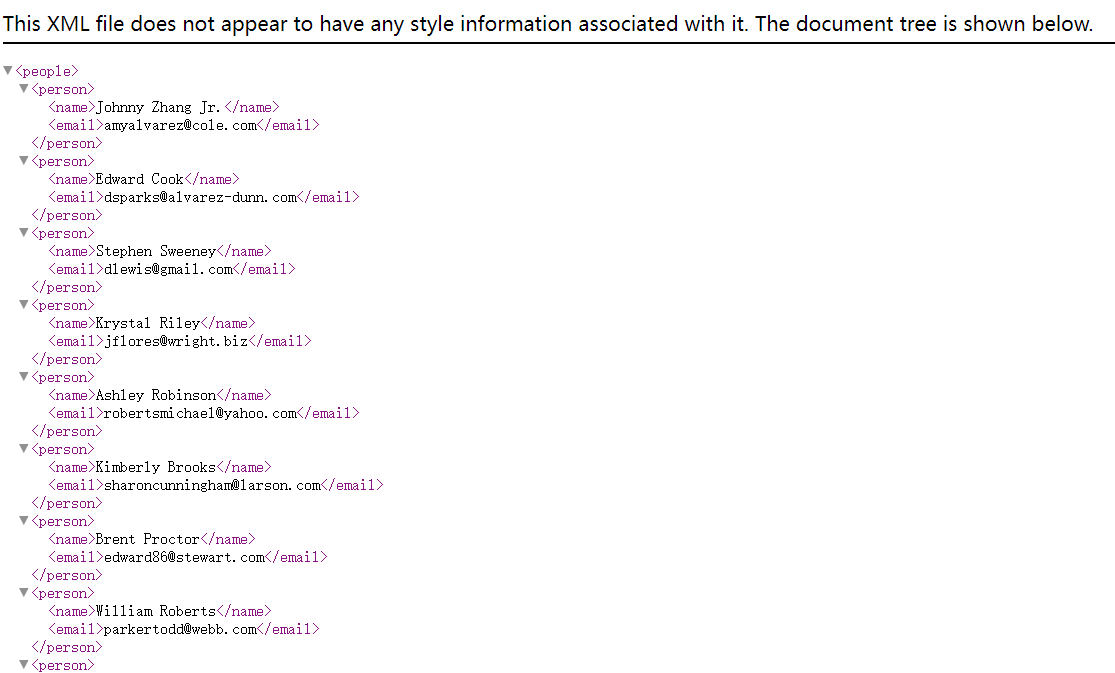
数据整理
简单示例
- 查看远程服务器上的日志信息: 查看 ssh 日志并使用 less 分页器
$ ssh -p 7777 root@localhost 'journalctl | grep sshd | grep "Disconnected from"' | less
$ ssh myserver 'journalctl | grep sshd | grep "Disconnected from"' > ssh.log
$ less ssh.log
- 使用 sed 进一步筛选数据
- s 命令的语法如下:s/REGEX/SUBSTITUTION/, 其中 REGEX 部分是我们需要使用的正则表达式,而 SUBSTITUTION 是用于替换匹配结果的文本。
ssh myserver journalctl
| grep sshd
| grep "Disconnected from"
| sed 's/.*Disconnected from //'
其他
正则表达式
- 正则表达式通常以(尽管并不总是) /开始和结束。大多数的 ASCII 字符都表示它们本来的含义,但是有一些字符确实具有表示匹配行为的“特殊”含义。不同字符所表示的含义,根据正则表达式的实现方式不同,也会有所变化,这一点确实令人沮丧。常见的模式有:
.除换行符之外的”任意单个字符”*匹配前面字符零次或多次+匹配前面字符一次或多次[abc]匹配 a, b 和 c 中的任意一个(RX1|RX2)任何能够匹配RX1 或 RX2的结果^行首$行尾
- sed 的正则表达式有些时候是比较奇怪的,它需要你在这些模式前添加\才能使其具有特殊含义。或者,您也可以添加-E选项来支持这些匹配。
/.*Disconnected from /这个正则表达式可以匹配任何以若干任意字符开头,并接着包含”Disconnected from “的字符串。- 如果有人将 “Disconnected from” 作为自己的用户名,因为默认的 * + 贪婪模式,匹配结果将和预期不符合
"Jan 17 03:13:00 thesquareplanet.com sshd[2631]: Disconnected from invalid user Disconnected from 46.97.239.16 port 55920 [preauth]- 对于某些正则表达式的实现来说,您可以给 * 或 + 增加一个? 后缀使其变成非贪婪模式,但是很可惜 sed 并不支持该后缀。不过,我们可以切换到 perl 的命令行模式,该模式支持编写这样的正则表达式:
perl -pe 's/.*?Disconnected from //' - 假设我们还需要去掉用户名后面的后缀,想要匹配用户名后面的文本,尤其是当这里的用户名可以包含空格时,这个问题变得非常棘手!这里我们需要做的是匹配一整行:
| sed -E 's/.*Disconnected from (invalid |authenticating )?user .* [^ ]+ port [0-9]+( \[preauth\])?$//'
- 使用在线正则表达式在线调试工具 regex debugger 来理解这段表达式,
- 开始的部分和以前是一样的
- 匹配两种类型的“user”(在日志中基于两种前缀区分)
- 匹配属于用户名的所有字符
- 匹配任意一个单词([^ ]+ 会匹配任意非空且不包含空格的序列)
- 匹配单“port”和它后面的一串数字,以及可能存在的后缀[preauth]
- 最后再匹配行尾
- 问题还没有完全解决,日志的内容全部被替换成了空字符串,整个日志的内容因此都被删除了。我们实际上希望能够将用户名保留下来。对此,我们可以使用“捕获组(capture groups)”来完成。被圆括号内的正则表达式匹配到的文本,都会被存入一系列以编号区分的捕获组中。捕获组的内容可以在替换字符串时使用(有些正则表达式的引擎甚至支持替换表达式本身),例如\1、 \2、\3等等,因此可以使用如下命令:
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
继续数据整理
ssh myserver journalctl
| grep sshd
| grep "Disconnected from"
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
- 我们已经得到了一个包含用户名的列表,列表中的用户都曾经尝试过登陆我们的系统。但这还不够,让我们过滤出那些最常出现的用户:
sort排序uniq -c把连续出现的行折叠为一行并使用出现次数作为前缀
ssh myserver journalctl
| grep sshd
| grep "Disconnected from"
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort | uniq -c
- 希望按照出现次数排序,过滤出最常出现的用户名:
sort -n会按照数字顺序对输入进行排序(默认情况下是按照字典序排序-k1,1则表示“仅基于以空格分割的第一列进行排序”。,n部分表示“仅排序到第n个部分”,默认情况是到行尾- 如果我们希望得到登陆次数最少的用户,我们可以使用
head来代替tail,或者使用sort -r来进行倒序排序。
ssh myserver journalctl
| grep sshd
| grep "Disconnected from"
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort | uniq -c
| sort -nk1,1 | tail -n10
- 但我们只想获取用户名,而且不要一行一个地显示。
awk处理文本,'{print $2}' 即为打印第二个部分paste合并行(-s),并指定一个分隔符进行分割 (-d)
ssh myserver journalctl
| grep sshd
| grep "Disconnected from"
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort | uniq -c
| sort -nk1,1 | tail -n10
| awk '{print $2}' | paste -sd,
awk
- 也是一种文本处理工具。awk 程序接受一个模式串(可选),以及一个代码块,指定当模式匹配时应该做何种操作。默认当模式串即匹配所有行(上面命令中当用法)。 在代码块中,$0 表示整行的内容,$1 到 $n 为一行中的 n 个区域,区域的分割基于 awk 的域分隔符(默认是空格,可以通过-F来修改)。在这个例子中,我们的代码意思是:对于每一行文本,打印其第二个部分,也就是用户名。
- 统计一下所有以c 开头,以 e 结尾,并且仅尝试过一次登陆的用户。
$1 == 1匹配 uniq -c 计数,即只是登陆一次$2 ~ /^c[^ ]*e$/匹配对应的正则表达式print $2打印出该用户名wc -l统计输出结果的行数
| awk '$1 == 1 && $2 ~ /^c[^ ]*e$/ { print $2 }' | wc -l
- 既然 awk 是一种编程语言,那么则可以这样:
BEGIN { rows = 0 }
$1 == 1 && $2 ~ /^c[^ ]*e$/ { rows += $1 }
END { print rows }
- BEGIN 也是一种模式,它会匹配输入的开头( END 则匹配结尾)。然后,对每一行第一个部分进行累加,最后将结果输出。事实上,我们完全可以抛弃 grep 和 sed ,因为 awk 就可以解决所有问题。至于怎么做,就留给读者们做课后练习吧。
分析数据
- 讲每行的数字加起来
| paste -sd+ | bc -l
# or
echo "2*($(data | paste -sd+))" | bc -l
- 您可以通过多种方式获取统计数据。如果已经安装了R语言,st是个不错的选择:
ssh myserver journalctl
| grep sshd
| grep "Disconnected from"
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort | uniq -c
| awk '{print $1}' | R --slave -e 'x <- scan(file="stdin", quiet=TRUE); summary(x)'
- R 也是一种编程语言,它非常适合被用来进行数据分析和绘制图表。这里我们不会讲的特别详细, 您只需要知道summary 可以打印某个向量的统计结果。我们将输入的一系列数据存放在一个向量后,利用R语言就可以得到我们想要的统计数据。
- 如果您希望绘制一些简单的图表, gnuplot 可以帮助到您:
ssh myserver journalctl
| grep sshd
| grep "Disconnected from"
| sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/'
| sort | uniq -c
| sort -nk1,1 | tail -n10
| gnuplot -p -e 'set boxwidth 0.5; plot "-" using 1:xtic(2) with boxes'
利用数据整理来确定参数
- 有时候您要利用数据整理技术从一长串列表里找出你所需要安装或移除的东西。我们之前讨论的相关技术配合 xargs 即可实现:
rustup toolchain list | grep nightly | grep -vE "nightly-x86" | sed 's/-x86.*//' | xargs rustup toolchain uninstall
整理二进制数据
- 虽然到目前为止我们的讨论都是基于文本数据,但对于二进制文件其实同样有用。例如我们可以用 ffmpeg 从相机中捕获一张图片,将其转换成灰度图后通过SSH将压缩后的文件发送到远端服务器,并在那里解压、存档并显示。
ffmpeg -loglevel panic -i /dev/video0 -frames 1 -f image2 -
| convert - -colorspace gray -
| gzip
| ssh mymachine 'gzip -d | tee copy.jpg | env DISPLAY=:0 feh -'
命令行环境
- 学习如何同时执行多个不同的进程并追踪它们的状态、如何停止或暂停某个进程以及如何使进程在后台运行。还将学习一些能够改善您的 shell 及其他工具的工作流的方法
任务控制
结束进程 Ctrl-C
- 您的 shell 会使用 UNIX 提供的信号机制执行进程间通信。当一个进程接收到信号时,它会停止执行、处理该信号并基于信号传递的信息来改变其执行。就这一点而言,信号是一种软件中断。
- 当我们输入 Ctrl-C 时,shell 会发送一个SIGINT 信号到进程。
- 下面这个 Python 程序向您展示了捕获信号SIGINT 并忽略它的基本操作,它并不会让程序停止。为了停止这个程序,我们需要使用 SIGQUIT 信号,通过输入
Ctrl-\可以发送该信号。
#!/usr/bin/env python
import signal, time
def handler(signum, time):
print("\nI got a SIGINT, but I am not stopping")
signal.signal(signal.SIGINT, handler)
i = 0
while True:
time.sleep(.1)
print("\r{}".format(i), end="")
i += 1
- 如果我们向这个程序发送两次 SIGINT ,然后再发送一次 SIGQUIT,程序会有什么反应?注意
^是我们在终端输入Ctrl时的表示形式:
$ python sigint.py
24^C
I got a SIGINT, but I am not stopping
26^C
I got a SIGINT, but I am not stopping
30^\[1] 39913 quit python sigint.pyƒ
- 尽管 SIGINT 和 SIGQUIT 都常常用来发出和终止程序相关的请求。SIGTERM 则是一个更加通用的、也更加优雅地退出信号。为了发出这个信号我们需要使用
kill命令, 它的语法是:kill -TERM <PID>。
暂停和后台执行进程
- 信号可以让进程做其他的事情,而不仅仅是终止它们。例如,SIGSTOP 会让进程暂停。在终端中,键入
Ctrl-Z会让 shell 发送SIGTSTP信号。kill -STOP - 我们可以使用
fg或bg命令恢复暂停的工作。它们分别表示在前台继续或在后台继续。 jobs命令会列出当前终端会话中尚未完成的全部任务。您可以使用pid引用这些任务(也可以用pgrep找出 pid)。更加符合直觉的操作是您可以使用百分号 + 任务编号(jobs 会打印任务编号)来选取该任务。如果要选择最近的一个任务,可以使用$!这一特殊参数。- 还有一件事情需要掌握,那就是命令中的
&后缀可以让命令在直接在后台运行,这使得您可以直接在 shell 中继续做其他操作,不过它此时还是会使用 shell 的标准输出,这一点有时会比较恼人(这种情况可以使用 shell 重定向处理)。 - 让已经在运行的进程转到后台运行,您可以键入
Ctrl-Z,然后紧接着再输入bg。注意,后台的进程仍然是您的终端进程的子进程,一旦您关闭终端(会发送另外一个信号SIGHUP),这些后台的进程也会终止。为了防止这种情况发生,您可以使用 nohup (一个用来忽略 SIGHUP 的封装) 来运行程序。针对已经运行的程序,可以使用 disown 。除此之外,您可以使用终端多路复用器来实现,下一章节我们会进行详细地探讨。
$ sleep 1000
^Z
[1] + 18653 suspended sleep 1000
$ nohup sleep 2000 &
[2] 18745
appending output to nohup.out
$ jobs
[1] + suspended sleep 1000
[2] - running nohup sleep 2000
$ bg %1
[1] - 18653 continued sleep 1000
$ jobs
[1] - running sleep 1000
[2] + running nohup sleep 2000
$ kill -STOP %1
[1] + 18653 suspended (signal) sleep 1000
$ jobs
[1] + suspended (signal) sleep 1000
[2] - running nohup sleep 2000
$ kill -SIGHUP %1
[1] + 18653 hangup sleep 1000
$ jobs
[2] + running nohup sleep 2000
$ kill -SIGHUP %2
$ jobs
[2] + running nohup sleep 2000
$ kill %2
[2] + 18745 terminated nohup sleep 2000
$ jobs
- SIGKILL 是一个特殊的信号,它不能被进程捕获并且它会马上结束该进程。不过这样做会有一些副作用,例如留下孤儿进程。
终端多路复用
- 当您在使用命令行时,您通常会希望同时执行多个任务。举例来说,您可以想要同时运行您的编辑器,并在终端的另外一侧执行程序。尽管再打开一个新的终端窗口也能达到目的,使用终端多路复用器则是一种更好的办法。
- 像
tmux这类的终端多路复用器可以允许我们基于面板和标签分割出多个终端窗口,这样您便可以同时与多个 shell 会话进行交互。 - 不仅如此,终端多路复用使我们可以分离当前终端会话并在将来重新连接。
- 这让您操作远端设备时的工作流大大改善,避免了 nohup 和其他类似技巧的使用。
- 现在最流行的终端多路器是 tmux。tmux 是一个高度可定制的工具,您可以使用相关快捷键创建多个标签页并在它们间导航。
- tmux 的快捷键需要我们掌握,它们都是类似
<C-b> x这样的组合,即需要先按下Ctrl+b,松开后再按下x。tmux 中对象的继承结构如下:- 会话:每个会话都是一个独立的工作区,其中包含一个或多个窗口
tmux开始一个新的会话tmux new -s NAME以指定名称开始一个新的会话tmux ls列出当前所有会话- 在 tmux 中输入
<C-b> d,将当前会话分离 tmux a重新连接最后一个会话。您也可以通过-t来指定具体的会话
- 窗口:相当于编辑器或是浏览器中的标签页,从视觉上将一个会话分割为多个部分
<C-b> c创建一个新的窗口,使用<C-d>关闭<C-b> N跳转到第 N 个窗口,注意每个窗口都是有编号的<C-b> p切换到前一个窗口<C-b> n切换到下一个窗口<C-b> ,重命名当前窗口<C-b> w列出当前所有窗口
- 面板:像 vim 中的分屏一样,面板使我们可以在一个屏幕里显示多个 shell
<C-b> "水平分割<C-b> %垂直分割<C-b> <方向>切换到指定方向的面板,<方向>指的是键盘上的方向键<C-b> z切换当前面板的缩放<C-b> [开始往回卷动屏幕。您可以按下空格键来开始选择,回车键复制选中的部分<C-b> <空格>在不同的面板排布间切换
- 会话:每个会话都是一个独立的工作区,其中包含一个或多个窗口
- 其他资料
别名
- 输入一长串包含许多选项的命令会非常麻烦。因此,大多数 shell 都支持设置别名。shell 的别名相当于一个长命令的缩写,shell 会自动将其替换成原本的命令。例如,bash 中的别名语法如下:
alias alias_name="command_to_alias arg1 arg2"
- 注意, =两边是没有空格的,因为 alias 是一个 shell 命令,它只接受一个参数。
- 别名有许多很方便的特性:
# 创建常用命令的缩写
alias ll="ls -lh"
# 能够少输入很多
alias gs="git status"
alias gc="git commit"
alias v="vim"
# 手误打错命令也没关系
alias sl=ls
# 重新定义一些命令行的默认行为
alias mv="mv -i" # -i prompts before overwrite
alias mkdir="mkdir -p" # -p make parent dirs as needed
alias df="df -h" # -h prints human readable format
# 别名可以组合使用
alias la="ls -A"
alias lla="la -l"
# 在忽略某个别名
\ls
# 或者禁用别名
unalias la
# 获取别名的定义
alias ll
# 会打印 ll='ls -lh'
- 值得注意的是,在默认情况下 shell 并不会保存别名。为了让别名持续生效,您需要将配置放进 shell 的启动文件里,像是.bashrc 或 .zshrc,下一节我们就会讲到。
配置文件
- 很多程序的配置都是通过纯文本格式的被称作点文件的配置文件来完成的(之所以称为点文件,是因为它们的文件名以 . 开头,例如
~/.vimrc。也正因为此,它们默认是隐藏文件,ls并不会显示它们)。 - shell 的配置也是通过这类文件完成的。在启动时,您的 shell 程序会读取很多文件以加载其配置项。根据 shell 本身的不同,您从登录开始还是以交互的方式完成这一过程可能会有很大的不同。
- 对于 bash 来说,在大多数系统下,您可以通过编辑
.bashrc或.bash_profile来进行配置。在文件中您可以添加需要在启动时执行的命令,例如上文我们讲到过的别名,或者是您的环境变量。 - 实际上,很多程序都要求您在 shell 的配置文件中包含一行类似
export PATH="$PATH:/path/to/program/bin"的命令,这样才能确保这些程序能够被 shell 找到。 - 还有一些其他的工具也可以通过点文件进行配置:
- bash -
~/.bashrc,~/.bash_profile - git -
~/.gitconfig - vim -
~/.vimrc和~/.vim目录 - ssh -
~/.ssh/config - tmux -
~/.tmux.conf
- bash -
- 我们应该如何管理这些配置文件呢,它们应该在它们的文件夹下,并使用版本控制系统进行管理,然后通过脚本将其 符号链接 到需要的地方。这么做有如下好处:
- 安装简单: 如果您登录了一台新的设备,在这台设备上应用您的配置只需要几分钟的时间;
- 可以执行: 您的工具在任何地方都以相同的配置工作
- 同步: 在一处更新配置文件,可以同步到其他所有地方
- 变更追踪: 您可能要在整个程序员生涯中持续维护这些配置文件,而对于长期项目而言,版本历史是非常重要的
- 配置文件中需要放些什么?您可以通过在线文档和帮助手册了解所使用工具的设置项。另一个方法是在网上搜索有关特定程序的文章,作者们在文章中会分享他们的配置。还有一种方法就是直接浏览其他人的配置文件:您可以在这里找到无数的dotfiles仓库 —— 其中最受欢迎的那些可以在这里找到(我们建议您不要直接复制别人的配置)。这里 也有一些非常有用的资源。
可移植性
- 配置文件的一个常见的痛点是它可能并不能在多种设备上生效。例如,如果您在不同设备上使用的操作系统或者 shell 是不同的,则配置文件是无法生效的。或者,有时您仅希望特定的配置只在某些设备上生效。
- 有一些技巧可以轻松达成这些目的。如果配置文件 if 语句,则您可以借助它针对不同的设备编写不同的配置。例如,您的 shell 可以这样做:
if [[ "$(uname)" == "Linux" ]]; then {do_something}; fi
# 使用和 shell 相关的配置时先检查当前 shell 类型
if [[ "$SHELL" == "zsh" ]]; then {do_something}; fi
# 您也可以针对特定的设备进行配置
if [[ "$(hostname)" == "myServer" ]]; then {do_something}; fi
- 如果配置文件支持 include 功能,您也可以多加利用。例如:~/.gitconfig 可以这样编写:
[include]
path = ~/.gitconfig_local
- 然后我们可以在日常使用的设备上创建配置文件
~/.gitconfig_local来包含与该设备相关的特定配置。您甚至应该创建一个单独的代码仓库来管理这些与设备相关的配置。 - 如果您希望在不同的程序之间共享某些配置,该方法也适用。例如,如果您想要在 bash 和 zsh 中同时启用一些别名,您可以把它们写在 .aliases 里,然后在这两个 shell 里应用:
# Test if ~/.aliases exists and source it
if [ -f ~/.aliases ]; then
source ~/.aliases
fi
远端设备
执行命令
ssh的一个经常被忽视的特性是它可以直接远程执行命令。ssh foobar@server ls可以直接在用foobar的命令下执行ls命令。 想要配合管道来使用也可以,ssh foobar@server ls | grep PATTERN会在本地查询远端ls的输出而ls | ssh foobar@server grep PATTERN会在远端对本地 ls 输出的结果进行查询。
SSH 密钥
- 生成:
ssh-keygen - 可以为密钥设置密码,防止有人持有您的私钥并使用它访问您的服务器。
- 可以使用 ssh-agent 或 gpg-agent ,这样就不需要每次都输入该密码了。
- 检查您是否持有密码并验证它,您可以运行
ssh-keygen -y -f /path/to/key.
基于密钥的认证机制
- ssh 会查询 .ssh/authorized_keys 来确认那些用户可以被允许登录。您可以通过下面的命令将一个公钥拷贝到这里:
cat .ssh/id_ed25519.pub | ssh foobar@remote 'cat >> ~/.ssh/authorized_keys'
ssh-copy-id -i .ssh/id_ed25519.pub foobar@remote
SSH 复制文件
ssh+tee最简单的方法是执行 ssh 命令,然后通过这样的方法利用标准输入实现cat localfile | ssh remote_server tee serverfile。回忆一下,tee 命令会将标准输出写入到一个文件;scp: 当需要拷贝大量的文件或目录时,使用scp 命令则更加方便,因为它可以方便的遍历相关路径。语法如下:scp path/to/local_file remote_host:path/to/remote_file;rsync:对 scp 进行了改进,它可以检测本地和远端的文件以防止重复拷贝。它还可以提供一些诸如符号连接、权限管理等精心打磨的功能。甚至还可以基于--partial标记实现断点续传。rsync 的语法和scp类似;
SSH 端口转发
- 本地端口转发
- 远端设备上的服务监听一个端口,而您希望在本地设备上的一个端口建立连接并转发到远程端口上。
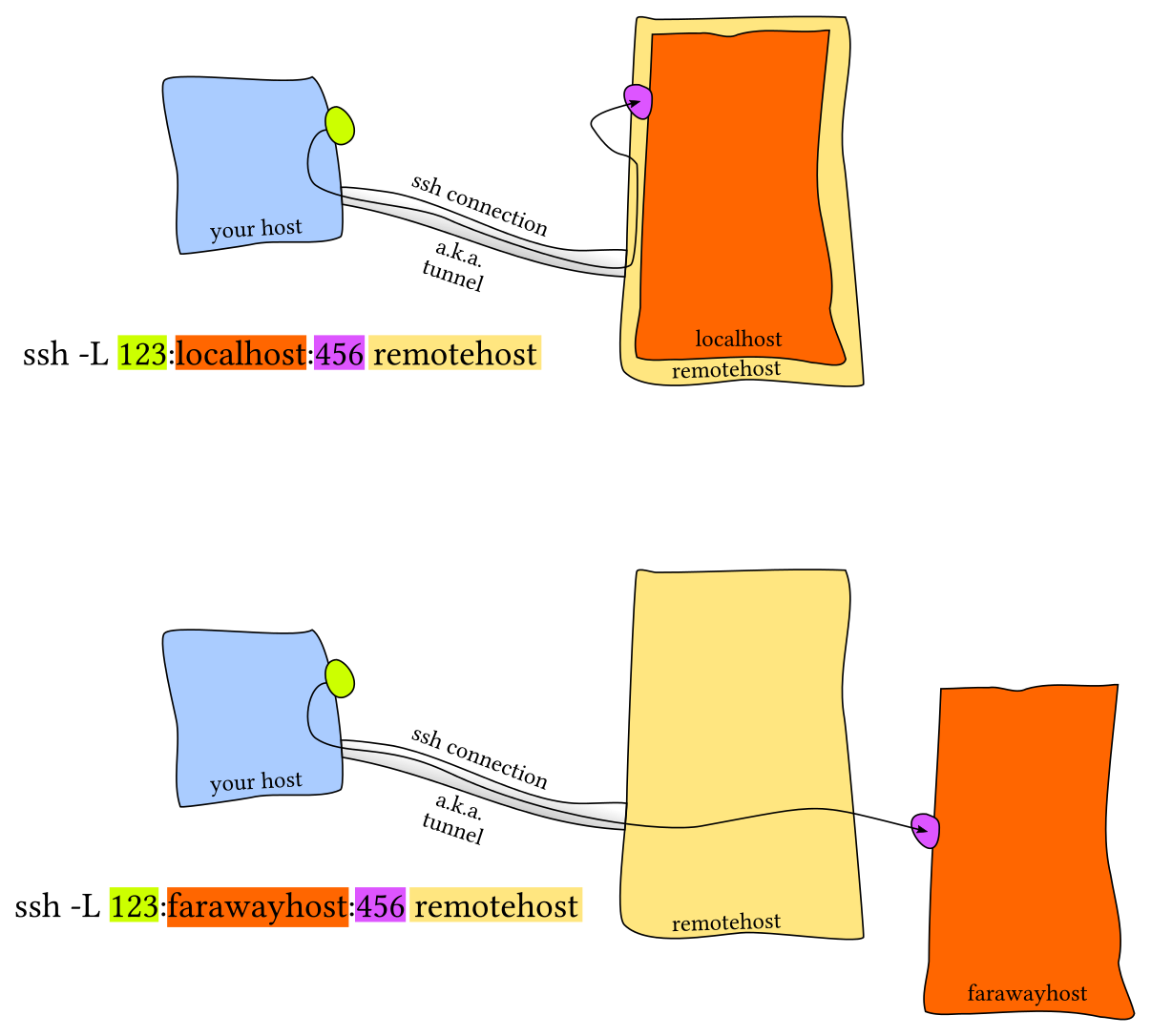
- 例如,我们在远端服务器上运行 Jupyter notebook 并监听 8888 端口。 然后,建立从本地端口 9999 的转发,使用
ssh -L 9999:localhost:8888 foobar@remote_server。这样只需要访问本地的 localhost:9999 即可。
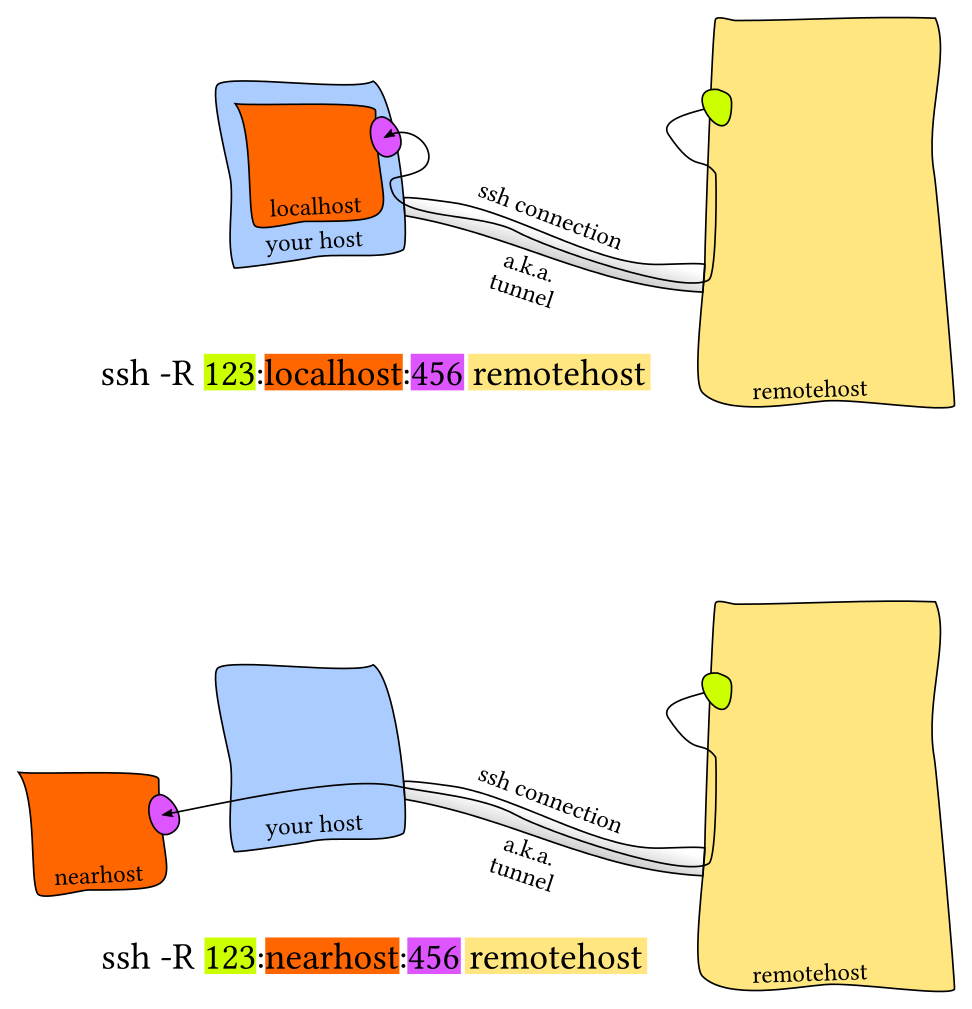
- 远程端口转发
SSH 配置
- ~/.ssh/config.
Host vm
User foobar
HostName 172.16.174.141
Port 2222
IdentityFile ~/.ssh/id_ed25519
LocalForward 9999 localhost:8888
# 在配置文件中也可以使用通配符
Host *.mit.edu
User foobaz
- 这么做的好处是,使用
~/.ssh/config文件来创建别名,类似 scp、rsync和mosh的这些命令都可以读取这个配置并将设置转换为对应的命令行选项。 - 注意,
~/.ssh/config文件也可以被当作配置文件,而且一般情况下也是可以被导入其他配置文件的。不过,如果您将其公开到互联网上,那么其他人都将会看到您的服务器地址、用户名、开放端口等等。这些信息可能会帮助到那些企图攻击您系统的黑客,所以请务必三思。 - 服务器侧的配置通常放在
/etc/ssh/sshd_config。您可以在这里配置免密认证、修改 ssh 端口、开启 X11 转发等等。 您也可以为每个用户单独指定配置。
其他
- 连接远程服务器的一个常见痛点是遇到由关机、休眠或网络环境变化导致的掉线。如果连接的延迟很高也很让人讨厌。Mosh(即 mobile shell )对 ssh 进行了改进,它允许连接漫游、间歇连接及智能本地回显。
- 有时将一个远端文件夹挂载到本地会比较方便, sshfs 可以将远端服务器上的一个文件夹挂载到本地,然后您就可以使用本地的编辑器了。
Shell & 框架
- 在 shell 工具和脚本那节课中我们已经介绍了 bash shell,因为它是目前最通用的 shell,大多数的系统都将其作为默认 shell。但是,它并不是唯一的选项。例如,zsh shell 是 bash 的超集并提供了一些方便的功能:
- 智能替换, **
- 行内替换/通配符扩展
- 拼写纠错
- 更好的 tab 补全和选择
- 路径展开 (cd /u/lo/b 会被展开为 /usr/local/bin)
- 框架 也可以改进您的 shell。比较流行的通用框架包括prezto 或 oh-my-zsh。还有一些更精简的框架,它们往往专注于某一个特定功能,例如zsh 语法高亮 或 zsh 历史子串查询。 像 fish 这样的 shell 包含了很多用户友好的功能,其中一些特性包括:
- 向右对齐
- 命令语法高亮
- 历史子串查询
- 基于手册页面的选项补全
- 更智能的自动补全
- 提示符主题
- 需要注意的是,使用这些框架可能会降低您 shell 的性能,尤其是如果这些框架的代码没有优化或者代码过多。您随时可以测试其性能或禁用某些不常用的功能来实现速度与功能的平衡。
终端模拟器
- 和自定义 shell 一样,花点时间选择适合您的 终端模拟器并进行设置是很有必要的。有许多终端模拟器可供您选择
Git
- 自底向上理解 Git
Git 的数据模型
快照
- Git 将顶级目录中的文件和文件夹作为集合,并通过一系列快照来管理其历史记录。在Git的术语里,文件被称作Blob对象(数据对象),也就是一组数据。目录则被称之为“树”,它将名字与 Blob 对象或树对象进行映射(使得目录中可以包含其他目录)。快照则是被追踪的最顶层的树。例如,一个树看起来可能是这样的:
<root> (tree)
|
+- foo (tree)
| |
| + bar.txt (blob, contents = "hello world")
|
+- baz.txt (blob, contents = "git is wonderful")
- 这个顶层的树包含了两个元素,一个名为 “foo” 的树(它本身包含了一个blob对象 “bar.txt”),以及一个 blob 对象 “baz.txt”。
历史记录建模:关联快照
- 版本控制系统和快照有什么关系呢?线性历史记录是一种最简单的模型,它包含了一组按照时间顺序线性排列的快照。不过处于种种原因,Git 并没有采用这样的模型。
- 在 Git 中,历史记录是一个由快照组成的有向无环图。有向无环图,听上去似乎是什么高大上的数学名词。不过不要怕,您只需要知道这代表 Git 中的每个快照都有一系列的“父辈”,也就是其之前的一系列快照。注意,快照具有多个“父辈”而非一个,因为某个快照可能由多个父辈而来。例如,经过合并后的两条分支。
- 在 Git 中,这些快照被称为“提交”。通过可视化的方式来表示这些历史提交记录时,看起来差不多是这样的:
o <-- o <-- o <-- o
^
\
--- o <-- o
- 上面是一个 ASCII 码构成的简图,其中的 o 表示一次提交(快照)。
- 箭头指向了当前提交的父辈(这是一种“在。。。之前”,而不是“在。。。之后”的关系)。在第三次提交之后,历史记录分岔成了两条独立的分支。这可能因为此时需要同时开发两个不同的特性,它们之间是相互独立的。开发完成后,这些分支可能会被合并并创建一个新的提交,这个新的提交会同时包含这些特性。新的提交会创建一个新的历史记录,看上去像这样(最新的合并提交用粗体标记):
o <-- o <-- o <-- o <---- o
^ /
\ v
--- o <-- o
- Git 中的提交是不可改变的。但这并不代表错误不能被修改,只不过这种“修改”实际上是创建了一个全新的提交记录。而引用(参见下文)则被更新为指向这些新的提交。
数据模型及其伪代码表示
- 以伪代码的形式来学习 Git 的数据模型,可能更加清晰:
// 文件就是一组数据
type blob = array<byte>
// 一个包含文件和目录的目录
type tree = map<string, tree | blob>
// 每个提交都包含一个父辈,元数据和顶层树
type commit = struct {
parent: array<commit>
author: string
message: string
snapshot: tree
}
对象和内存寻址
- Git 中的对象可以是 blob、树或提交:
type object = blob | tree | commit
- Git 在储存数据时,所有的对象都会基于它们的 SHA-1 哈希 进行寻址。
objects = map<string, object>
def store(object):
id = sha1(object)
objects[id] = object
def load(id):
return objects[id]
- Blobs、树和提交都一样,它们都是对象。当它们引用其他对象时,它们并没有真正的在硬盘上保存这些对象,而是仅仅保存了它们的哈希值作为引用。
- 例如,上面例子中的树(可以通过
git cat-file -p 698281bc680d1995c5f4caaf3359721a5a58d48d来进行可视化),看上去是这样的:
100644 blob 4448adbf7ecd394f42ae135bbeed9676e894af85 baz.txt
040000 tree c68d233a33c5c06e0340e4c224f0afca87c8ce87 foo
- 树本身会包含一些指向其他内容的指针,例如 baz.txt (blob) 和 foo (树)。如果我们用
git cat-file -p 4448adbf7ecd394f42ae135bbeed9676e894af85,即通过哈希值查看 baz.txt 的内容,会得到以下信息:
git is wonderful
引用
- 现在,所有的快照都可以通过它们的 SHA-1 哈希值来标记了。但这也太不方便了,谁也记不住一串 40 位的十六进制字符。
- 针对这一问题,Git 的解决方法是给这些哈希值赋予人类可读的名字,也就是引用(references)。引用是指向提交的指针。与对象不同的是,它是可变的(引用可以被更新,指向新的提交)。例如,master 引用通常会指向主分支的最新一次提交。
references = map<string, string>
def update_reference(name, id):
references[name] = id
def read_reference(name):
return references[name]
def load_reference(name_or_id):
if name_or_id in references:
return load(references[name_or_id])
else:
return load(name_or_id)
-
这样,Git 就可以使用诸如 “master” 这样人类可读的名称来表示历史记录中某个特定的提交,而不需要在使用一长串十六进制字符了。
-
有一个细节需要我们注意, 通常情况下,我们会想要知道“我们当前所在位置”,并将其标记下来。这样当我们创建新的快照的时候,我们就可以知道它的相对位置(如何设置它的“父辈”)。在 Git 中,我们当前的位置有一个特殊的索引,它就是 “HEAD”。
仓库
- 最后,我们可以粗略地给出 Git 仓库的定义了:
对象和引用。 - 在硬盘上,Git 仅存储对象和引用:因为其数据模型仅包含这些东西。所有的 git 命令都对应着对提交树的操作,例如增加对象,增加或删除引用。
- 当您输入某个指令时,请思考一下这条命令是如何对底层的图数据结构进行操作的。另一方面,如果您希望修改提交树,例如“丢弃未提交的修改和将 ‘master’ 引用指向提交 5d83f9e 时,有什么命令可以完成该操作(针对这个具体问题,您可以使用
git checkout master;git reset --hard 5d83f9e)
暂存区
- Git 中还包括一个和数据模型完全不相关的概念,但它确是创建提交的接口的一部分。
- 就上面介绍的快照系统来说,您也许会期望它的实现里包括一个 “创建快照” 的命令,该命令能够基于当前工作目录的当前状态创建一个全新的快照。有些版本控制系统确实是这样工作的,但 Git 不是。我们希望简洁的快照,而且每次从当前状态创建快照可能效果并不理想。例如,考虑如下场景,您开发了两个独立的特性,然后您希望创建两个独立的提交,其中第一个提交仅包含第一个特性,而第二个提交仅包含第二个特性。或者,假设您在调试代码时添加了很多打印语句,然后您仅仅希望提交和修复 bug 相关的代码而丢弃所有的打印语句。
- Git 处理这些场景的方法是使用一种叫做 “暂存区(staging area)”的机制,它允许您指定下次快照中要包括那些改动。
Git 的命令行接口
- 不赘述
- 列觉几个可能用的少的
git log --all --graph --decorate可视化历史记录(有向无环图)git diff <revision> <filename>显示某个文件两个版本之间的差异git mergetool使用工具来处理合并冲突git rebase将一系列补丁变基(rebase)为新的基线git clone --depth=1浅克隆(shallow clone),不包括完整的版本历史信息git add -p交互式暂存git rebase -i交互式变基git blame查看最后修改某行的人git bisect通过二分查找搜索历史记录
调试及性能分析
调试代码
- “最有效的 debug 工具就是细致的分析,配合恰当位置的打印语句” — Brian
- 调试代码的第一种方法往往是在您发现问题的地方添加一些打印语句,然后不断重复此过程直到您获取了足够的信息并找到问题的根本原因。
- 另外一个方法是使用日志,而不是临时添加打印语句。日志较普通的打印语句有如下的一些优势:
- 您可以将日志写入文件、socket 或者甚至是发送到远端服务器而不仅仅是标准输出;
- 日志可以支持严重等级(例如 INFO, DEBUG, WARN, ERROR等),这使您可以根据需要过滤日志;
- 对于新发现的问题,很可能您的日志中已经包含了可以帮助您定位问题的足够的信息。
- 有很多技巧可以使日志的可读性变得更好,我最喜欢的一个是技巧是对其进行着色。到目前为止,您应该已经知道,以彩色文本显示终端信息时可读性更好。但是应该如何设置呢?
- ls 和 grep 这样的程序会使用
ANSI escape codes,它是一系列的特殊字符,可以使您的 shell 改变输出结果的颜色。例如,执行echo -e "\e[38;2;255;0;0mThis is red\e[0m"会打印红色的字符串:This is red 。只要您的终端支持真彩色。如果您的终端不支持真彩色(例如 MacOS 的 Terminal.app),您可以使用支持更加广泛的 16 色,例如:”\e[31;1mThis is red\e[0m”。 - 下面这个脚本向您展示了如何在终端中打印多种颜色(只要您的终端支持真彩色)
#!/usr/bin/env bash
for R in $(seq 0 20 255); do
for G in $(seq 0 20 255); do
for B in $(seq 0 20 255); do
printf "\e[38;2;${R};${G};${B}m█\e[0m";
done
done
done
第三方日志系统
- 多数的程序都会将日志保存在您的系统中的某个地方。对于 UNIX 系统来说,程序的日志通常存放在 /var/log。例如, NGINX web 服务器就将其日志存放于/var/log/nginx。
- 目前,系统开始使用 system log,您所有的日志都会保存在这里。大多数(但不是全部的)Linux 系统都会使用 systemd,这是一个系统守护进程,它会控制您系统中的很多东西,例如哪些服务应该启动并运行。systemd 会将日志以某种特殊格式存放于/var/log/journal,您可以使用 journalctl 命令显示这些消息。
- 类似地,在 macOS 系统中是 /var/log/system.log,但是有更多的工具会使用系统日志,它的内容可以使用 log show 显示。
- 对于大多数的 UNIX 系统,您也可以使用dmesg 命令来读取内核的日志。
- 如果您希望将日志加入到系统日志中,您可以使用 logger 这个 shell 程序。下面这个例子显示了如何使用 logger并且如何找到能够将其存入系统日志的条目。
- 不仅如此,大多数的编程语言都支持向系统日志中写日志。
logger "Hello Logs"
# On macOS
log show --last 1m | grep Hello
# On Linux
journalctl --since "1m ago" | grep Hello
- 如果您发现您需要对 journalctl 和 log show 的结果进行大量的过滤,那么此时可以考虑使用它们自带的选项对其结果先过滤一遍再输出。还有一些像 lnav 这样的工具,它为日志文件提供了更好的展现和浏览方式。
调试器
- 当通过打印已经不能满足您的调试需求时,您应该使用调试器。
- 调试器是一种可以允许我们和正在执行的程序进行交互的程序,它可以做到:
- 当到达某一行时将程序暂停;
- 一次一条指令地逐步执行程序;
- 程序崩溃后查看变量的值;
- 满足特定条件时暂停程序;
- 其他高级功能。
- 很多编程语言都有自己的调试器。Python 的调试器是pdb.
- 对于更底层的编程语言,您可能需要了解一下 gdb ( 以及它的改进版 pwndbg) 和 lldb。
- 它们都对类 C 语言的调试进行了优化,它允许您探索任意进程及其机器状态:寄存器、堆栈、程序计数器等。
专门工具
- 即使您需要调试的程序是一个二进制的黑盒程序,仍然有一些工具可以帮助到您。当您的程序需要执行一些只有操作系统内核才能完成的操作时,它需要使用 系统调用。有一些命令可以帮助您追踪您的程序执行的系统调用。在 Linux 中可以使用
strace,在 macOS 和 BSD 中可以使用 dtrace。dtrace 用起来可能有些别扭,因为它使用的是它自有的 D 语言,但是我们可以使用一个叫做 dtruss 的封装使其具有和 strace (更多信息参考 这里)类似的接口 - 下面的例子展现来如何使用
strace或 dtruss 来显示ls 执行时,对stat 系统调用进行追踪对结果。若需要深入了解 strace,这篇文章 值得一读。
# On Linux
sudo strace -e lstat ls -l > /dev/null
4
# On macOS
sudo dtruss -t lstat64_extended ls -l > /dev/null
- 有些情况下,我们需要查看网络数据包才能定位问题。像 tcpdump 和 Wireshark 这样的网络数据包分析工具可以帮助您获取网络数据包的内容并基于不同的条件进行过滤。
静态分析
- 有些问题是您不需要执行代码就能发现的。例如,仔细观察一段代码,您就能发现某个循环变量覆盖了某个已经存在的变量或函数名;或是有个变量在被读取之前并没有被定义。 这种情况下 静态分析 工具就可以帮我们找到问题。静态分析会将程序的源码作为输入然后基于编码规则对其进行分析并对代码的正确性进行推理。
- 下面这段 Python 代码中存在几个问题。 首先,我们的循环变量foo 覆盖了之前定义的函数foo。最后一行,我们还把 bar 错写成了baz,因此当程序完成sleep (一分钟)后,执行到这一行的时候便会崩溃。
import time
def foo():
return 42
for foo in range(5):
print(foo)
bar = 1
bar *= 0.2
time.sleep(60)
print(baz)
- 静态分析工具可以发现此类的问题。当我们使用pyflakes 分析代码的时候,我们会得到与这两处 bug 相关的错误信息。mypy 则是另外一个工具,它可以对代码进行类型检查。这里,mypy 会经过我们bar 起初是一个 int ,然后变成了 float。这些问题都可以在不运行代码的情况下被发现。
$ pyflakes foobar.py
foobar.py:6: redefinition of unused 'foo' from line 3
foobar.py:11: undefined name 'baz'
$ mypy foobar.py
foobar.py:6: error: Incompatible types in assignment (expression has type "int", variable has type "Callable[[], Any]")
foobar.py:9: error: Incompatible types in assignment (expression has type "float", variable has type "int")
foobar.py:11: error: Name 'baz' is not defined
Found 3 errors in 1 file (checked 1 source file)
- 在 shell 工具那一节课的时候,我们介绍了 shellcheck,这是一个类似的工具,但它是应用于 shell 脚本的。
- 大多数的编辑器和 IDE 都支持在编辑界面显示这些工具的分析结果、高亮有警告和错误的位置。 这个过程通常称为 code linting 。风格检查或安全检查的结果同样也可以进行相应的显示。
- 在 vim 中,有 ale 或 syntastic 可以帮助您做同样的事情。 在 Python 中, pylint 和 pep8 是两种用于进行风格检查的工具,而 bandit 工具则用于检查安全相关的问题。
- 对于风格检查和代码格式化,还有以下一些工具可以作为补充:用于 Python 的 black、用于 Go 语言的 gofmt、用于 Rust 的 rustfmt 或是用于 JavaScript, HTML 和 CSS 的 prettier 。这些工具可以自动格式化您的代码,这样代码风格就可以与常见的风格保持一致。 尽管您可能并不想对代码进行风格控制,标准的代码风格有助于方便别人阅读您的代码,也可以方便您阅读它的代码。
性能分析
- 即使您的代码能够向您期望的一样运行,但是如果它消耗了您全部的 CPU 和内存,那么它显然也不是个好程序。算法课上我们通常会介绍大O标记法,但却没教给我们如何找到程序中的热点。 鉴于 过早的优化是万恶之源,您需要学习性能分析和监控工具,它们会帮助您找到程序中最耗时、最耗资源的部分,这样您就可以有针对性的进行性能优化。
计时
- 和调试代码类似,大多数情况下我们只需要打印两处代码之间的时间即可发现问题。下面这个例子中,我们使用了 Python 的 time模块。
import time, random
n = random.randint(1, 10) * 100
# 获取当前时间
start = time.time()
# 执行一些操作
print("Sleeping for {} ms".format(n))
time.sleep(n/1000)
# 比较当前时间和起始时间
print(time.time() - start)
# Output
# Sleeping for 500 ms
# 0.5713930130004883
- 不过,执行时间(wall clock time)也可能会误导您,因为您的电脑可能也在同时运行其他进程,也可能在此期间发生了等待。 对于工具来说,需要区分真实时间、用户时间和系统时间。通常来说,用户时间+系统时间代表了您的进程所消耗的实际 CPU
- 真实时间 - 从程序开始到结束流失掉的真实时间,包括其他进程的执行时间以及阻塞消耗的时间(例如等待 I/O或网络);
- User - CPU 执行用户代码所花费的时间;
- Sys - CPU 执行系统内核代码所花费的时间
- 例如,试着执行一个用于发起 HTTP 请求的命令并在其前面添加 time 前缀。网络不好的情况下您可能会看到下面的输出结果。请求花费了 2s 才完成,但是进程仅花费了 15ms 的 CPU 用户时间和 12ms 的 CPU 内核时间。
$ time curl https://missing.csail.mit.edu &> /dev/null`
real 0m2.561s
user 0m0.015s
sys 0m0.012s
性能分析工具(profilers)
CPU
- 大多数情况下,当人们提及性能分析工具的时候,通常指的是 CPU 性能分析工具。 CPU 性能分析工具有两种: 追踪分析器(tracing)及采样分析器(sampling)。 追踪分析器 会记录程序的每一次函数调用,而采样分析器则只会周期性的监测(通常为每毫秒)您的程序并记录程序堆栈。它们使用这些记录来生成统计信息,显示程序在哪些事情上花费了最多的时间。如果您希望了解更多相关信息,可以参考这篇 介绍性的文章。
- 大多数的编程语言都有一些基于命令行的分析器,我们可以使用它们来分析代码。它们通常可以集成在 IDE 中,但是本节课我们会专注于这些命令行工具本身。
- 在 Python 中,我们使用 cProfile 模块来分析每次函数调用所消耗的时间。 在下面的例子中,我们实现了一个基础的 grep 命令:
#!/usr/bin/env python
import sys, re
def grep(pattern, file):
with open(file, 'r') as f:
print(file)
for i, line in enumerate(f.readlines()):
pattern = re.compile(pattern)
match = pattern.search(line)
if match is not None:
print("{}: {}".format(i, line), end="")
if __name__ == '__main__':
times = int(sys.argv[1])
pattern = sys.argv[2]
for i in range(times):
for file in sys.argv[3:]:
grep(pattern, file)
- 我们可以使用下面的命令来对这段代码进行分析。通过它的输出我们可以知道,IO 消耗了大量的时间,编译正则表达式也比较耗费时间。因为正则表达式只需要编译一次,我们可以将其移动到 for 循环外面来改进性能。
$ python -m cProfile -s tottime grep.py 1000 '^(import|\s*def)[^,]*$' *.py
[omitted program output]
ncalls tottime percall cumtime percall filename:lineno(function)
8000 0.266 0.000 0.292 0.000 {built-in method io.open}
8000 0.153 0.000 0.894 0.000 grep.py:5(grep)
17000 0.101 0.000 0.101 0.000 {built-in method builtins.print}
8000 0.100 0.000 0.129 0.000 {method 'readlines' of '_io._IOBase' objects}
93000 0.097 0.000 0.111 0.000 re.py:286(_compile)
93000 0.069 0.000 0.069 0.000 {method 'search' of '_sre.SRE_Pattern' objects}
93000 0.030 0.000 0.141 0.000 re.py:231(compile)
17000 0.019 0.000 0.029 0.000 codecs.py:318(decode)
1 0.017 0.017 0.911 0.911 grep.py:3(<module>)
[omitted lines]
- 关于 Python 的 cProfile 分析器(以及其他一些类似的分析器),需要注意的是它显示的是每次函数调用的时间。看上去可能快到反直觉,尤其是如果您在代码里面使用了第三方的函数库,因为内部函数调用也会被看作函数调用。
- 更加符合直觉的显示分析信息的方式是包括每行代码的执行时间,这也是行分析器的工作。例如,下面这段 Python 代码会向本课程的网站发起一个请求,然后解析响应返回的页面中的全部 URL:
#!/usr/bin/env python
import requests
from bs4 import BeautifulSoup
# 这个装饰器会告诉行分析器
# 我们想要分析这个函数
@profile
def get_urls():
response = requests.get('https://missing.csail.mit.edu')
s = BeautifulSoup(response.content, 'lxml')
urls = []
for url in s.find_all('a'):
urls.append(url['href'])
if __name__ == '__main__':
get_urls()
- 如果我们使用 Python 的 cProfile 分析器,我们会得到超过2500行的输出结果,即使对其进行排序,我仍然搞不懂时间到底都花在哪了。如果我们使用 line_profiler,它会基于行来显示时间:
$ kernprof -l -v a.py
Wrote profile results to urls.py.lprof
Timer unit: 1e-06 s
Total time: 0.636188 s
File: a.py
Function: get_urls at line 5
Line # Hits Time Per Hit % Time Line Contents
==============================================================
5 @profile
6 def get_urls():
7 1 613909.0 613909.0 96.5 response = requests.get('https://missing.csail.mit.edu')
8 1 21559.0 21559.0 3.4 s = BeautifulSoup(response.content, 'lxml')
9 1 2.0 2.0 0.0 urls = []
10 25 685.0 27.4 0.1 for url in s.find_all('a'):
11 24 33.0 1.4 0.0 urls.append(url['href'])
内存
-
像 C 或者 C++ 这样的语言,内存泄漏会导致您的程序在使用完内存后不去释放它。为了应对内存类的 Bug,我们可以使用类似 Valgrind 这样的工具来检查内存泄漏问题。
-
对于 Python 这类具有垃圾回收机制的语言,内存分析器也是很有用的,因为对于某个对象来说,只要有指针还指向它,那它就不会被回收。
-
下面这个例子及其输出,展示了 memory-profiler 是如何工作的(注意装饰器和 line-profiler 类似)。
@profile
def my_func():
a = [1] * (10 ** 6)
b = [2] * (2 * 10 ** 7)
del b
return a
if __name__ == '__main__':
my_func()
$ python -m memory_profiler example.py
Line # Mem usage Increment Line Contents
==============================================
3 @profile
4 5.97 MB 0.00 MB def my_func():
5 13.61 MB 7.64 MB a = [1] * (10 ** 6)
6 166.20 MB 152.59 MB b = [2] * (2 * 10 ** 7)
7 13.61 MB -152.59 MB del b
8 13.61 MB 0.00 MB return a
事件分析
- 在我们使用strace调试代码的时候,您可能会希望忽略一些特殊的代码并希望在分析时将其当作黑盒处理。
perf命令将 CPU 的区别进行了抽象,它不会报告时间和内存的消耗,而是报告与您的程序相关的系统事件。 - 例如,perf 可以报告不佳的缓存局部性(poor cache locality)、大量的页错误(page faults)或活锁(livelocks)。下面是关于常见命令的简介:
perf list- 列出可以被 pref 追踪的事件;perf stat COMMAND ARG1 ARG2- 收集与某个进程或指令相关的事件;perf record COMMAND ARG1 ARG2- 记录命令执行的采样信息并将统计数据储存在perf.data中;perf report- 格式化并打印 perf.data 中的数据。
可视化
-
使用分析器来分析真实的程序时,由于软件的复杂性,其输出结果中将包含大量的信息。人类是一种视觉动物,非常不善于阅读大量的文字。因此很多工具都提供了可视化分析器输出结果的功能。
-
对于采样分析器来说,常见的显示 CPU 分析数据的形式是 火焰图,火焰图会在 Y 轴显示函数调用关系,并在 X 轴显示其耗时的比例。火焰图同时还是可交互的,您可以深入程序的某一具体部分,并查看其栈追踪(您可以尝试点击下面的图片)。
-
调用图和控制流图可以显示子程序之间的关系,它将函数作为节点并把函数调用作为边。将它们和分析器的信息(例如调用次数、耗时等)放在一起使用时,调用图会变得非常有用,它可以帮助我们分析程序的流程。 在 Python 中您可以使用 pycallgraph 来生成这些图片。
资源监控
- 有时候,分析程序性能的第一步是搞清楚它所消耗的资源。程序变慢通常是因为它所需要的资源不够了。例如,没有足够的内存或者网络连接变慢的时候。
- 有很多很多的工具可以被用来显示不同的系统资源,例如 CPU 占用、内存使用、网络、磁盘使用等。
- 通用监控 - 最流行的工具要数 htop,了,它是 top的改进版。htop 可以显示当前运行进程的多种统计信息。htop 有很多选项和快捷键,常见的有:
进程排序、 t 显示树状结构和 h 打开或折叠线程。 还可以留意一下 glances ,它的实现类似但是用户界面更好。如果需要合并测量全部的进程, dstat 是也是一个非常好用的工具,它可以实时地计算不同子系统资源的度量数据,例如 I/O、网络、 CPU 利用率、上下文切换等等; - I/O 操作 - iotop 可以显示实时 I/O 占用信息而且可以非常方便地检查某个进程是否正在执行大量的磁盘读写操作;
- 磁盘使用 - df 可以显示每个分区的信息,而 du 则可以显示当前目录下每个文件的磁盘使用情况( disk usage)。-h 选项可以使命令以对人类(human)更加友好的格式显示数据;ncdu 是一个交互性更好的 du ,它可以让您在不同目录下导航、删除文件和文件夹;
- 内存使用 - free 可以显示系统当前空闲的内存。内存也可以使用 htop 这样的工具来显示;
- 打开文件 - lsof 可以列出被进程打开的文件信息。 当我们需要查看某个文件是被哪个进程打开的时候,这个命令非常有用;
- 网络连接和配置 - ss 能帮助我们监控网络包的收发情况以及网络接口的显示信息。ss 常见的一个使用场景是找到端口被进程占用的信息。如果要显示路由、网络设备和接口信息,您可以使用 ip 命令。注意,netstat 和 ifconfig 这两个命令已经被前面那些工具所代替了。
- 网络使用 - nethogs 和 iftop 是非常好的用于对网络占用进行监控的交互式命令行工具。
- 通用监控 - 最流行的工具要数 htop,了,它是 top的改进版。htop 可以显示当前运行进程的多种统计信息。htop 有很多选项和快捷键,常见的有:
- 如果您希望测试一下这些工具,您可以使用 stress 命令来为系统人为地增加负载。
专用工具
- 有时候,您只需要对黑盒程序进行基准测试,并依此对软件选择进行评估。 类似 hyperfine 这样的命令行可以帮您快速进行基准测试。例如,我们在 shell 工具和脚本那一节课中我们推荐使用 fd 来代替 find。我们这里可以用hyperfine来比较一下它们。
- 例如,下面的例子中,我们可以看到fd 比 find 要快20倍。
$ hyperfine --warmup 3 'fd -e jpg' 'find . -iname "*.jpg"'
Benchmark #1: fd -e jpg
Time (mean ± σ): 51.4 ms ± 2.9 ms [User: 121.0 ms, System: 160.5 ms]
Range (min … max): 44.2 ms … 60.1 ms 56 runs
Benchmark #2: find . -iname "*.jpg"
Time (mean ± σ): 1.126 s ± 0.101 s [User: 141.1 ms, System: 956.1 ms]
Range (min … max): 0.975 s … 1.287 s 10 runs
Summary
'fd -e jpg' ran
21.89 ± 2.33 times faster than 'find . -iname "*.jpg"'
- 和 debug 一样,浏览器也包含了很多不错的性能分析工具,可以用来分析页面加载,让我们可以搞清楚时间都消耗在什么地方(加载、渲染、脚本等等)。 更多关于 Firefox 和 Chrome的信息可以点击链接。
安全和密码学
熵
- 熵(Entropy) 度量了不确定性并可以用来决定密码的强度。
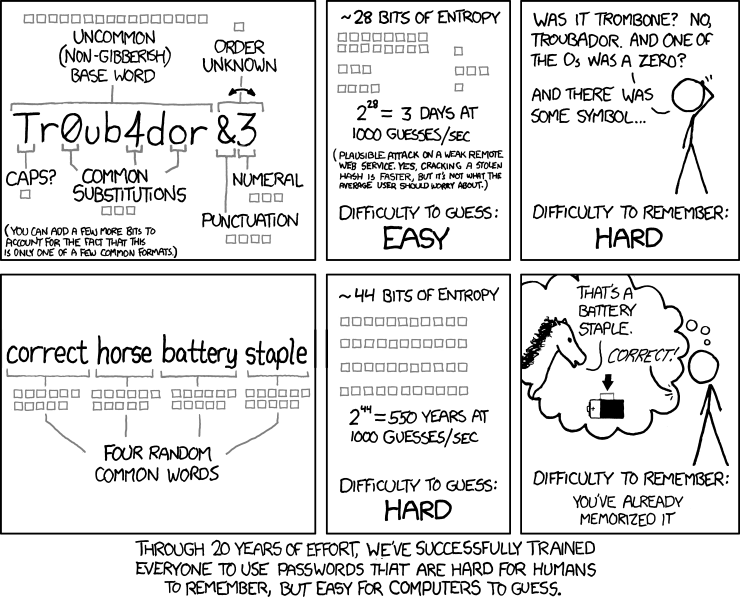
- 熵的单位是 比特。对于一个均匀分布的随机离散变量,熵等于log_2(所有可能的个数,即n)。 扔一次硬币的熵是1比特。掷一次(六面)骰子的熵大约为2.58比特。
- 一般我们认为攻击者了解密码的模型(最小长度,最大长度,可能包含的字符种类等),但是不了解某个密码是如何随机选择的—— 比如掷骰子。
- 使用多少比特的熵取决于应用的威胁模型。 上面的XKCD漫画告诉我们,大约40比特的熵足以对抗在线穷举攻击(受限于网络速度和应用认证机制)。 而对于离线穷举攻击(主要受限于计算速度), 一般需要更强的密码 (比如80比特或更多)。
散列
- 密码散列函数 (Cryptographic hash function) 可以将任意大小的数据映射为一个固定大小的输出。除此之外,还有一些其他特性。 一个散列函数的大概规范如下:
hash(value: array<byte>) -> vector<byte, N> (N对于该函数固定)
- SHA-1是Git中使用的一种散列函数, 它可以将任意大小的输入映射为一个160比特(可被40位十六进制数表示)的输出。 下面我们用sha1sum命令来测试SHA1对几个字符串的输出
$ printf 'hello' | sha1sum
aaf4c61ddcc5e8a2dabede0f3b482cd9aea9434d
$ printf 'hello' | sha1sum
aaf4c61ddcc5e8a2dabede0f3b482cd9aea9434d
$ printf 'Hello' | sha1sum
f7ff9e8b7bb2e09b70935a5d785e0cc5d9d0abf0
- 抽象地讲,散列函数可以被认为是一个不可逆,且看上去随机(但具确定性)的函数 (这就是散列函数的理想模型)。 一个散列函数拥有以下特性:
- 确定性:对于不变的输入永远有相同的输出。
- 不可逆性:对于hash(m) = h,难以通过已知的输出h来计算出原始输入m。
- 目标碰撞抵抗性/弱无碰撞:对于一个给定输入m_1,难以找到m_2 != m_1且hash(m_1) = hash(m_2)。
- 碰撞抵抗性/强无碰撞:难以找到一组满足hash(m_1) = hash(m_2)的输入m_1, m_2(该性质严格强于目标碰撞抵抗性)。
- 注:虽然SHA-1还可以用于特定用途,但它已经不再被认为是一个强密码散列函数。 你可参照密码散列函数的生命周期这个表格了解一些散列函数是何时被发现弱点及破解的。 请注意,针对应用推荐特定的散列函数超出了本课程内容的范畴。 如果选择散列函数对于你的工作非常重要,请先系统学习信息安全及密码学。
密码散列函数的应用
- Git中的内容寻址存储(Content addressed storage):散列函数是一个宽泛的概念(存在非密码学的散列函数),那么Git为什么要特意使用密码散列函数?
- 文件的信息摘要(Message digest):像Linux ISO这样的软件可以从非官方的(有时不太可信的)镜像站下载,所以需要设法确认下载的软件和官方一致。 官方网站一般会在(指向镜像站的)下载链接旁边备注安装文件的哈希值。 用户从镜像站下载安装文件后可以对照公布的哈希值来确定安装文件没有被篡改。
- 承诺机制(Commitment scheme): 假设我希望承诺一个值,但之后再透露它—— 比如在没有一个可信的、双方可见的硬币的情况下在我的脑海中公平的“扔一次硬币”。 我可以选择一个值r = random(),并和你分享它的哈希值h = sha256(r)。 这时你可以开始猜硬币的正反:我们一致同意偶数r代表正面,奇数r代表反面。 你猜完了以后,我告诉你值r的内容,得出胜负。同时你可以使用sha256(r)来检查我分享的哈希值h以确认我没有作弊。
密钥生成函数
- 密钥生成函数 (Key Derivation Functions) 作为密码散列函数的相关概念,被应用于包括生成固定长度,可以使用在其他密码算法中的密钥等方面。 为了对抗穷举法攻击,密钥生成函数通常较慢。
密钥生成函数的应用
- 从密码生成可以在其他加密算法中使用的密钥,比如对称加密算法(见下)。
- 存储登录凭证时不可直接存储明文密码。
- 正确的方法是针对每个用户随机生成一个盐 salt = random(), 并存储盐,以及密钥生成函数对连接了盐的明文密码生成的哈希值
F(password + salt) - 在验证登录请求时,使用输入的密码连接存储的盐重新计算哈希值
KDF(input + salt),并与存储的哈希值对比。
- 正确的方法是针对每个用户随机生成一个盐 salt = random(), 并存储盐,以及密钥生成函数对连接了盐的明文密码生成的哈希值
对称加密
- 说到加密,可能你会首先想到隐藏明文信息。对称加密使用以下几个方法来实现这个功能:
keygen() -> key (这是一个随机方法)
encrypt(plaintext: array<byte>, key) -> array<byte> (输出密文)
decrypt(ciphertext: array<byte>, key) -> array<byte> (输出明文)
- 加密方法
encrypt()输出的密文ciphertext 很难在不知道key的情况下得出明文plaintext。 - 解密方法
decrypt()有明显的正确性。因为功能要求给定密文及其密钥,解密方法必须输出明文:decrypt(encrypt(m, k), k) = m。 - AES 是现在常用的一种对称加密系统。
对称加密的应用
- 加密不信任的云服务上存储的文件。对称加密和密钥生成函数配合起来,就可以使用密码加密文件: 将密码输入密钥生成函数生成密钥
key = KDF(passphrase),然后存储encrypt(file, key)。
非对称加密
- 非对称加密的“非对称”代表在其环境中,使用两个具有不同功能的密钥: 一个是私钥(private key),不向外公布;另一个是公钥(public key),公布公钥不像公布对称加密的共享密钥那样可能影响加密体系的安全性。
- 非对称加密使用以下几个方法来实现加密/解密(encrypt/decrypt),以及签名/验证(sign/verify):
keygen() -> (public key, private key) (这是一个随机方法)
encrypt(plaintext: array<byte>, public key) -> array<byte> (输出密文)
decrypt(ciphertext: array<byte>, private key) -> array<byte> (输出明文)
sign(message: array<byte>, private key) -> array<byte> (生成签名)
verify(message: array<byte>, signature: array<byte>, public key) -> bool (验证签名是否是由和这个公钥相关的私钥生成的)
- 非对称的加密/解密方法和对称的加密/解密方法有类似的特征。
- 信息在非对称加密中使用 公钥 加密, 且输出的密文很难在不知道 私钥 的情况下得出明文。
- 解密方法decrypt()有明显的正确性。 给定密文及私钥,解密方法一定会输出明文:
decrypt(encrypt(m, public key), private key) = m。 - 对称加密和非对称加密可以类比为机械锁。 对称加密就好比一个防盗门:只要是有钥匙的人都可以开门或者锁门。 非对称加密好比一个可以拿下来的挂锁。你可以把打开状态的挂锁(公钥)给任何一个人并保留唯一的钥匙(私钥)。这样他们将给你的信息装进盒子里并用这个挂锁锁上以后,只有你可以用保留的钥匙开锁。
- 签名/验证方法具有和书面签名类似的特征。
- 在不知道 私钥 的情况下,不管需要签名的信息为何,很难计算出一个可以使
verify(message, signature, public key)返回为真的签名。 - 对于使用私钥签名的信息,验证方法验证和私钥相对应的公钥时一定返回为真:
verify(message, sign(message, private key), public key) = true。
非对称加密的应用
- PGP电子邮件加密:用户可以将所使用的公钥在线发布,比如:PGP密钥服务器或 Keybase。任何人都可以向他们发送加密的电子邮件。
- 聊天加密:像 Signal 和 Keybase 使用非对称密钥来建立私密聊天。
- 软件签名:Git 支持用户对提交(commit)和标签(tag)进行GPG签名。任何人都可以使用软件开发者公布的签名公钥验证下载的已签名软件。
密钥分发
- 非对称加密面对的主要挑战是,如何分发公钥并对应现实世界中存在的人或组织。
- Signal的信任模型是,信任用户第一次使用时给出的身份(trust on first use),同时支持用户线下(out-of-band)、面对面交换公钥(Signal里的safety number)。
- PGP使用的是信任网络。简单来说,如果我想加入一个信任网络,则必须让已经在信任网络中的成员对我进行线下验证,比如对比证件。验证无误后,信任网络的成员使用私钥对我的公钥进行签名。这样我就成为了信任网络的一部分。只要我使用签名过的公钥所对应的私钥就可以证明“我是我”。
- Keybase主要使用社交网络证明 (social proof),和一些别的精巧设计。
- 每个信任模型有它们各自的优点:我们更倾向于 Keybase 使用的模型。
案例分析
密码管理器
- 每个人都应该尝试使用密码管理器,比如KeePassXC、pass 和 1Password)。
- 密码管理器会帮助你对每个网站生成随机且复杂(表现为高熵)的密码,并使用你指定的主密码配合密钥生成函数来对称加密它们。
- 你只需要记住一个复杂的主密码,密码管理器就可以生成很多复杂度高且不会重复使用的密码。密码管理器通过这种方式降低密码被猜出的可能,并减少网站信息泄露后对其他网站密码的威胁。
两步验证(双因子验证)
- 两步验证(2FA)要求用户同时使用密码(“你知道的信息”)和一个身份验证器(“你拥有的物品”,比如YubiKey)来消除密码泄露或者钓鱼攻击的威胁。
全盘加密
- 对笔记本电脑的硬盘进行全盘加密是防止因设备丢失而信息泄露的简单且有效方法。 Linux的cryptsetup + LUKS, Windows的BitLocker,或者macOS的FileVault都使用一个由密码保护的对称密钥来加密盘上的所有信息。
聊天加密
- Signal和Keybase使用非对称加密对用户提供端到端(End-to-end)安全性。
- 获取联系人的公钥非常关键。为了保证安全性,应使用线下方式验证Signal或者Keybase的用户公钥,或者信任Keybase用户提供的社交网络证明。
SSH
- 当你运行ssh-keygen命令,它会生成一个非对称密钥对:公钥和私钥(public_key, private_key)。 生成过程中使用的随机数由系统提供的熵决定。这些熵可以来源于硬件事件(hardware events)等。 公钥最终会被分发,它可以直接明文存储。 但是为了防止泄露,私钥必须加密存储。ssh-keygen命令会提示用户输入一个密码,并将它输入密钥生成函数 产生一个密钥。最终,ssh-keygen使用对称加密算法和这个密钥加密私钥。
- 在实际运用中,当服务器已知用户的公钥(存储在.ssh/authorized_keys文件中,一般在用户HOME目录下),尝试连接的客户端可以使用非对称签名来证明用户的身份——这便是挑战应答方式。 简单来说,服务器选择一个随机数字发送给客户端。客户端使用用户私钥对这个数字信息签名后返回服务器。 服务器随后使用.ssh/authorized_keys文件中存储的用户公钥来验证返回的信息是否由所对应的私钥所签名。这种验证方式可以有效证明试图登录的用户持有所需的私钥。
