- 威斯康辛州大学操作系统书籍《Operating Systems: Three Easy Pieces》读书笔记系列之 Virtulization(虚拟化)。本篇为虚拟化技术的基础篇系列第一篇(Processes and API),进程和进程API。
- 突然看到知乎上 关于七龙珠里龟仙人和鹤仙人的讨论,相比之下龟仙人的徒弟之所以更强除了天赋以外,更多的是龟仙人的信奉的理念。基础打好了,一拳一招就是招式。龟仙流的训练方法就是 好好锻炼、好好学习、好好玩耍、好好吃饭、好好睡觉。
- 龟仙流的训练方法字面上仿佛与平安经无异,但传递的其实是习武最本质的内涵。以无法为有法,以无限为有限。做学术亦是如此,所以比起漫无目的地看论文,还是再回顾回顾一知半解的基础吧。
- 威斯康辛州大学操作系统书籍《Operating Systems: Three Easy Pieces》读书笔记系列之 Virtulization(虚拟化)。本篇为虚拟化技术的基础篇系列第一篇(Processes and API),进程和进程API。
Chapter Index
- TODO
Virtualization
Dialogue
- Conversation 以桃子为例,即多人共享一个桃子,但是每个人可能都以为自己完整拥有这个桃子,然后联系到计算机领域中的资源,如 CPU。物理上就有限的 CPU(比如只有一个 CPU),但是当很多用户或者进程使用时,完全以为这个 CPU 就是自己的,这就是虚拟化技术。
Processes
- 进程:运行的程序。
- 程序本身无生命。就是存储在磁盘上的一系列指令的集合,包括一些静态数据,然后等待执行。操作系统会从磁盘中读取出这些指令并执行,从而运行程序。
- 一次可能会运行很多个程序,一个系统看起来可能同时运行了上百上千个程序,系统的易用性使得程序不用考虑是否有 CPU 空闲,所以就引出了关键问题:如何表现出有成百上千个 CPU 的假象? 答案就是 虚拟化。
- CPU 资源常常会使用到 时分共享(time sharing)的技术,即允许一个实体使用该资源一段时间后停止,由另一个实体使用该资源持续一段时间,如此循环往复,来保证资源共享。CPU 上的时分共享最终就能让人感觉到大量程序并发地被执行。
资源共享技术中除了时分共享以外,还有空分共享。如磁盘就是空分共享资源,磁盘上的空间被释放后则可以被其他实体使用。
- 虚拟化需要两层实现:
- 底层实现称之为 mechanism,主要是实现一些低级方法和协议。
- 上层实现为 policy,即需要在操作系统中需要借助一定的数据依据做出某种决策,也称之为调度策略。
抽象:进程
- 操作系统对运行的程序的抽象即为进程。
- 进程的组成,也就是所谓的 machine state:
- memory,正在运行的程序、读取或写入的数据都在内存中,进程可以访问的内存即为进程的一部分(也称地址空间 address space)
- register,寄存器。许多指令需要读取或更新寄存器。还包括一些比较重要的寄存器,如 program counterm (或者叫 instruction pointer) 来指示程序运行的下一个位置,还有 stack pointer 以及 frame pointer 用于管理函数参数、局部变量、返回值地址等。
- 还有一些打开的 I/O 描述符(eg. open file table)
进程 API 分类
- create
- destroy
- wait:等待进程停止运行
- miscellaneous control:常用于暂停某个进程,然后恢复执行
- status:获取进程状态信息
进程创建
- 操作系统运行程序必须做的第一件事是将代码和所有静态数据(例如初始化变量)加载(load)到内存中,加载到进程的地址空间中。程序最初以某种可执行格式驻留在磁盘上(disk,或者在某些现代系统中,在基于闪存的 SSD 上)。因此,将程序和静态数据加载到内存中的过程,需要操作系统从磁盘读取这些字节,并将它们放在内存中的某处(见图 4.1)。
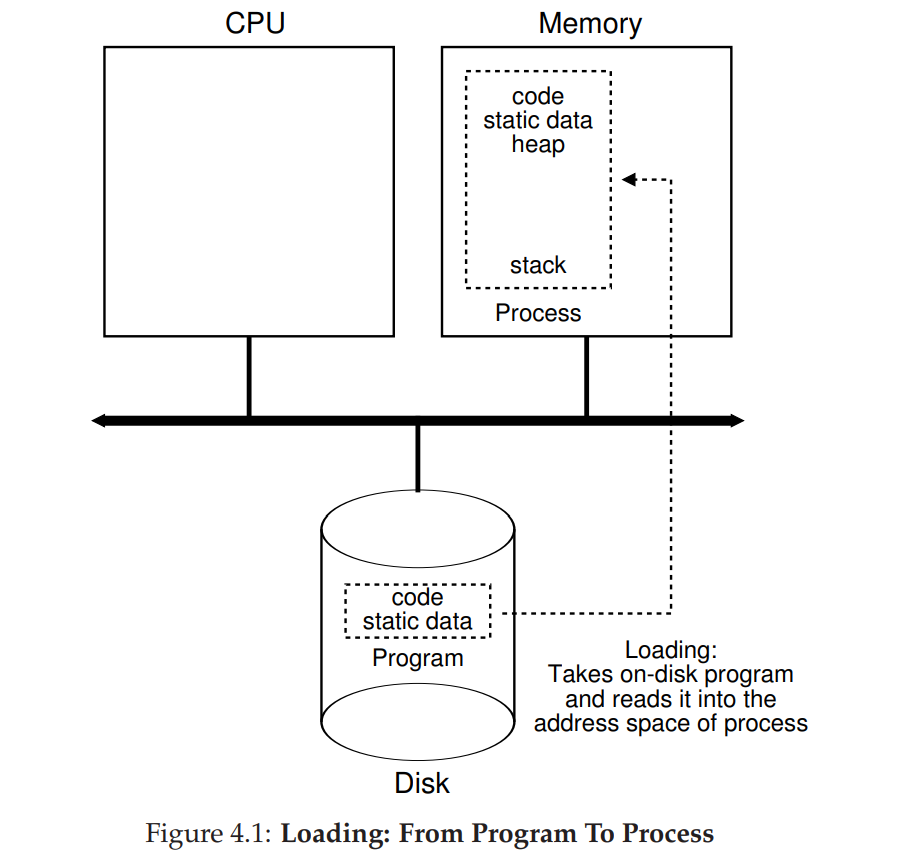
- 在早期的(或简单的)操作系统中,加载过程尽早(eagerly)完成,即在运行程序之前全部完成。现代操作系统惰性(lazily)执行该过程,即仅在程序执行期间需要加载的代码或数据片段,才会加载。
- 将代码和静态数据加载到内存后,操作系统在运行此进程之前还需要执行其他一些操作。必须为程序的运行时栈(run-time stack 或 stack)分配一些内存。C 语言程序使用栈存放局部变量、函数参数和返回地址,操作系统分配这些内存,并提供给进程。操作系统也可能会用参数初始化栈。具体来说,它会将参数填入 main() 函数,即 argc 和 argv 数组。
- 操作系统也可能为程序的堆(heap)分配一些内存。在 C 程序中,堆用于显式请求的动态分配数据。程序通过调用 malloc()来请求这样的空间,并通过调用 free()来明确地释放它。数据结构(如链表、散列表、树和其他有趣的数据结构)需要堆。起初堆会很小。随着程序运行,通过 malloc()库 API 请求更多内存,操作系统可能会参与分配更多内存给进程,以满足这些调用。
- 操作系统还会执行一些 I/O 相关的初始化任务。
- 通过将代码和静态数据加载到内存中,通过创建和初始化栈以及执行与 I/O 设置相关的其他工作,OS 现在(终于)为程序执行搭好了舞台。然后它有最后一项任务:启动程序,在入口处运行,即 main()。通过跳转到 main() 例程,OS 将 CPU 的控制权转移到新创建的进程中,从而程序开始执行。
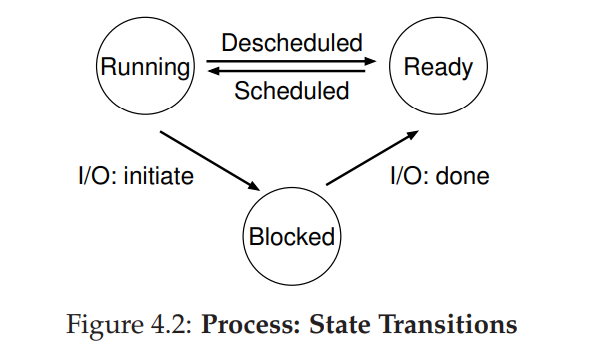
进程状态
- running
- ready
- block
数据结构
- 如下所示为 xv6 内核中进程的数据结构定义。
- context 包含了所有寄存器的信息,便于进程的恢复,也就是我们常常说到的 context switch。所以进程中的上下文切换的本质其实就是寄存器数据的切换。
- proc_state 除了上文所述的三种状态以外还有其他状态,如 EMBRYO 表示进程在创建时处于的状态;ZOMBIE 表示进程已经退出但尚未清理的状态,该状态将允许其他进程检查该进程的执行情况来决定下一步操作。
// the registers xv6 will save and restore
// to stop and subsequently restart a process
struct context {
int eip;
int esp;
int ebx;
int ecx;
int edx;
int esi;
int edi;
int ebp;
};
// the different states a process can be in
enum proc_state { UNUSED, EMBRYO, SLEEPING,
RUNNABLE, RUNNING, ZOMBIE };
// the information xv6 tracks about each process
// including its register context and state
struct proc {
char *mem; // Start of process memory
uint sz; // Size of process memory
char *kstack; // Bottom of kernel stack for this process
enum proc_state state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
void *chan; // If !zero, sleeping on chan
int killed; // If !zero, has been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
struct context context; // Switch here to run process
struct trapframe *tf; // Trap frame for the current interrupt
};
进程列表 process list 被用于跟踪系统中正在运行的所有程序,任何能够同时运行多个程序的操作系统都包含这样的数据结构,进程列表中的每一个进程信息块常常又被称为进程控制块(Process Control Block, PCB)
Process API
- 主要涉及到一组系统调用 fork() 和 exec() 以及 wait() 的使用。
- CRUX:OS 为了创建以及控制进程需要提供什么样的接口?如何设计这些接口以实现强大的功能、易用性和高性能?
fork()
- 用于创建一个新进程。
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4
5 int main(int argc, char *argv[]) {
6 printf("hello world (pid:%d)\n", (int) getpid());
7 int rc = fork();
8 if (rc < 0) {
9 // fork failed
10 fprintf(stderr, "fork failed\n");
11 exit(1);
12 } else if (rc == 0) {
13 // child (new process)
14 printf("hello, I am child (pid:%d)\n", (int) getpid());
15 } else {
16 // parent goes down this path (main)
17 printf("hello, I am parent of %d (pid:%d)\n",
18 rc, (int) getpid());
19 }
20 return 0;
21 }
- 输出如下:p1 进程首先输出了自己的进程 ID (process identifier),然后执行 fork 创建新进程。新创建的进程叫子进程。原进程为父进程。此例中即为 29146 进程创建了子进程 29147。父进程按照原有的逻辑继续执行,子进程则是从 fork 调用后返回,所以才出现如下的输出结果。
- 此时的系统中相当于有两个 p1 进程,但是子进程和父进程不完全相同,除了拥有各自的地址空间、寄存器、PC 以外,fork 的返回值也是不同的。父进程的 fork 返回的是子进程的值,子进程的 fork 返回的是 0。
prompt> ./p1
hello world (pid:29146)
hello, I am parent of 29147 (pid:29146)
hello, I am child (pid:29147)
prompt>
- fork 之后其执行顺序就不太确定了,即此时存在两个活动的进程,如果是单个 CPU,则任何一个进程都有可能去执行,所以输出结果的顺序就不确定了。
prompt> ./p1
hello world (pid:29146)
hello, I am child (pid:29147)
hello, I am parent of 29147 (pid:29146)
prompt>
- CPU Scheduler 决定了某个时刻执行哪个进程。但由于调度程序很复杂,并不能假设某个进程会先执行。这种不确定性就会导致一系列问题,特别是在多线程程序中,也就是我们说的并发。
wait()
- 有时候父进程需要等待子进程执行完毕再决定下一步操作,这时候 wait 就发挥作用了。
- 如下代码中,父进程调用了 wait 延迟自己的执行,直到子进程执行完毕。子进程结束时,wait 才返回父进程。
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <sys/wait.h>
5
6 int
7 main(int argc, char *argv[])
8 {
9 printf("hello world (pid:%d)\n", (int) getpid());
10 int rc = fork();
11 if (rc < 0) { // fork failed; exit
12 fprintf(stderr, "fork failed\n");
13 exit(1);
14 } else if (rc == 0) { // child (new process)
15 printf("hello, I am child (pid:%d)\n", (int) getpid());
16 } else { // parent goes down this path (main)
17 int wc = wait(NULL);
18 printf("hello, I am parent of %d (wc:%d) (pid:%d)\n",
19 rc, wc, (int) getpid());
20 }
21 return 0;
22 }
- 输出结果的顺序一下就明确了,如果父进程先执行,会执行 wait,该调用会在子进程运行结束后才返回,因此还是会等待子进程先执行。
prompt> ./p2
hello world (pid:29266)
hello, I am child (pid:29267)
hello, I am parent of 29267 (wc:29267) (pid:29266)
prompt>
exec()
- 用于执行和父进程不同的程序。
- 如下所示代码中则调用了 execvp() 来执行字符计数程序 wc,并使用 p3.c 作为输入参数
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <string.h>
5 #include <sys/wait.h>
6
7 int
8 main(int argc, char *argv[])
9 {
10 printf("hello world (pid:%d)\n", (int) getpid());
11 int rc = fork();
12 if (rc < 0) { // fork failed; exit
13 fprintf(stderr, "fork failed\n");
14 exit(1);
15 } else if (rc == 0) { // child (new process)
16 printf("hello, I am child (pid:%d)\n", (int) getpid());
17 char *myargs[3];
18 myargs[0] = strdup("wc"); // program: "wc" (word count)
19 myargs[1] = strdup("p3.c"); // argument: file to count
20 myargs[2] = NULL; // marks end of array
21 execvp(myargs[0], myargs); // runs word count
22 printf("this shouldn't print out");
23 } else { // parent goes down this path (main)
24 int wc = wait(NULL);
25 printf("hello, I am parent of %d (wc:%d) (pid:%d)\n",
26 rc, wc, (int) getpid());
27 }
28 return 0;
29 }
- 输出如下所示。exec() 会从可执行程序中加载代码和静态数据,并覆盖写自己的代码段,栈、堆以及其他内存空间也会被初始化,然后操作系统执行该程序,将参数通过 argv 传递给该进程。因此,它并没有创建新进程,而是直接将当前运行的程序(以前的 p3)替换为我同的运行程序(wc)。子进程执行 exec()之后,几乎就像 p3.c 从未运行过一样。对 exec() 的成功调用永远不会返回。
prompt> ./p3
hello world (pid:29383)
hello, I am child (pid:29384)
29 107 1030 p3.c
hello, I am parent of 29384 (wc:29384) (pid:29383)
prompt>
为什么这样设计?
- 分离 fork 和 exec 便于 shell 在 fork 之后 exec 之前调整新程序的环境。
- shell 也是一个用户程序,它首先显示一个提示符(prompt),然后等待用户输入。你可以向它输入一个命令(一个可执行程序的名称及需要的参数),大多数情况下,shell 可以在文件系统中找到这个可执行程序,调用 fork() 创建新进程,并调用 exec() 的某个变体来执行这个可执行程序,调用 wait() 等待该命令完成。子进程执行结束后,shell 从 wait()返回并再次输出一个提示符,等待用户输入下一条命令。
- shell 还可以实现一些有趣的功能,譬如重定向。如下所示将输出结果重定向到文件中
prompt> wc p3.c > newfile.txt
-
shell 实现结果重定向的方式也很简单,当完成子进程的创建后,shell 谁调用 exec() 之前先关闭了标准输出(standard output),打开了文件 newfile.txt。这样,即将运行的程序 wc 的输出结果就被发送到该文件,而不是打印在屏幕上。
-
如下代码展示了重定向的工作原理,是基于对操作系统管理文件描述符方式的假设。具体来说,UNIX 系统从 0 开始寻找可以使用的文件描述符。谁这个例子中,STDOUT_FILENO 将成为第一个可用的文件描述符,因此谁 open()被调用时,得到赋值。然后子进程向标准输出文件描述符的写入(例如通过 printf()这样的函数),都会被透明地转向新打开的文件,而不是屏幕。
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <string.h>
5 #include <fcntl.h>
6 #include <sys/wait.h>
7
8 int
9 main(int argc, char *argv[])
10 {
11 int rc = fork();
12 if (rc < 0) { // fork failed; exit
13 fprintf(stderr, "fork failed\n");
14 exit(1);
15 } else if (rc == 0) { // child: redirect standard output to a file
16 close(STDOUT_FILENO);
17 open("./p4.output", O_CREAT|O_WRONLY|O_TRUNC, S_IRWXU);
18
19 // now exec "wc"...
20 char *myargs[3];
21 myargs[0] = strdup("wc"); // program: "wc" (word count)
22 myargs[1] = strdup("p4.c"); // argument: file to count
23 myargs[2] = NULL; // marks end of array
24 execvp(myargs[0], myargs); // runs word count
25 } else { // parent goes down this path (main)
26 int wc = wait(NULL);
27 }
28 return 0;
29 }
- 输出结果如下。
prompt> ./p4
prompt> cat p4.output
32 109 846 p4.c
prompt>
- UNIX 管谁也是用类似的方式实现的,但用的是 pipe()系统调用。在这种情况下,一个进程的输出被链接到了一个内核管谁(pipe)上(队列),另一个进程的输入也被连接到了同一个管谁上。因此,前一个进程的输出无缝地作为后一个进程的输入,许多命令可以用这种方式串联谁一起,共同完成某项任务。比如通过将 grep、wc 命令用管谁连接可以完成从一个文件中查找某个词,并统计其出现次数的功能:grep -o foo file | wc -l
其他
- 除了上述接口以外,还有很多其他系统调用接口用于进程的管理。譬如
kill()向进程发送信号,还有如暂停等其他指令。为了方便起见,在大多数 UNIX shell中,配置某些按键组合以向当前运行的进程发送特定的信号,如常用的 ctrl-c 来中断进程,ctrl-z 来暂停进程 - 整个信号子系统提供了丰富的基础设施来向流程交付外部事件,包括在各个流程内接收和处理这些信号的方法,以及向各个流程和整个流程组发送信号的方法。为了使用这种通信方式,进程应该使用 signal() 系统调用来“捕捉”各种信号;这样做可以确保当一个特定的信号被传递给一个进程时,它会暂停它的正常执行,并运行一个特定的代码片段来响应这个信号。
- 谁可以发送信号?用户可以启动一个或多个进程,并对它们进行完全控制(暂停它们,杀死它们,等等)。
用户通常只能控制自己的进程;操作系统的工作是将资源(如CPU、内存和磁盘)分配给每个用户(及其进程),以满足总体系统目标。 - ps、top、kill、killall
- “A fork() in the road” by Andrew Baumann, Jonathan Appavoo, Orran Krieger, Timothy Roscoe. HotOS ’19, Bertinoro, Italy. 该文指出了 fork 存在的一些问题,考虑使用 spawn() 来代替 fork(). 参考:fork() 成为负担,需要淘汰 spawn
