- 本篇为持久化技术的基础篇系列第五篇(局部性和 Fast File System),将以 FFS 为例,可以参考原版论文 A fast file system for UNIX
Chapter Index
- Basic of Persistence
- Basic of Persistence
- File Systems Implementation
- Locality and The Fast File System
- Crash Consistency: FSCK and Journaling
- Log-structured File System
Locality and The Fast File System
- 最早的文件系统其数据结构设计如下。优势在于设计足够简单,也基本实现了文件系统的抽象:文件和目录的层级结构,但存在比较严重的性能问题,大约只能发挥磁盘带宽 2%。其根本原因在于这种文件系统把磁盘当作了随机访问的内存,数据的存放没有考虑到磁盘的特性,所以在定位数据时开销较大。(实际表现可能为数据块离元数据块较远,所以在读取元数据之后再读取数据块的话 seek 操作开销就很大)

- 除此以外,因为没有对空闲空间进行高效的管理,所以可能会造成碎片化,空闲空间列表指向的空闲空间可能散布整个磁盘,在分配文件时,它们只需要获取下一个空闲块,其结果是通过在磁盘上来回访问逻辑上连续的文件,从而显著降低性能。如图所示操作将会造成 E 散布磁盘,磁盘的访问无法充分利用顺序特性。
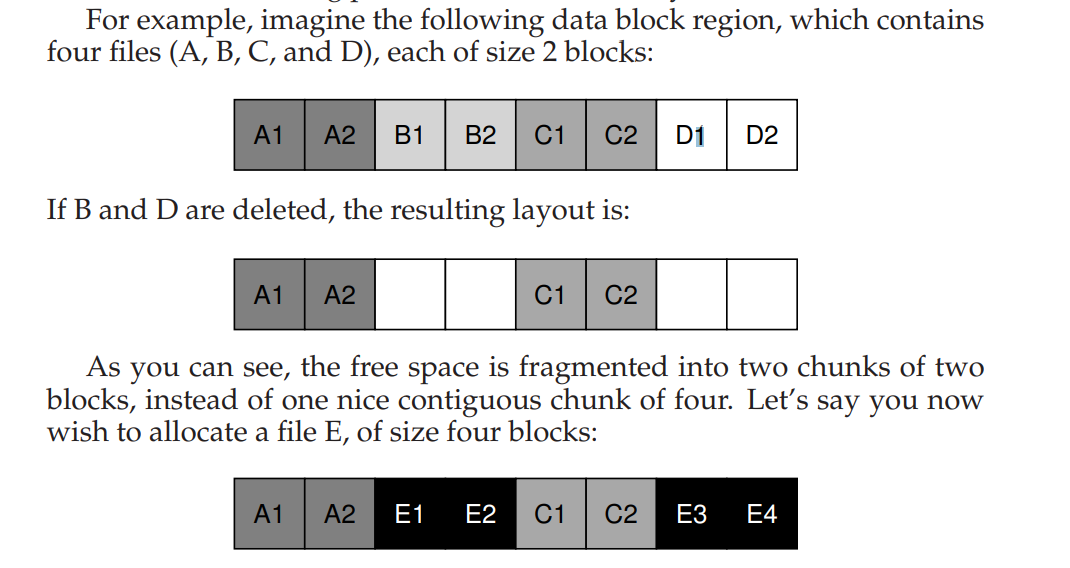
- 所以现在操作系统都会有相应的磁盘碎片整理工具,它们重新组织磁盘上的数据,以连续地放置文件,并为一个或几个相邻区域腾出空闲空间,移动数据,然后重写索引节点,以反映更改。
- 还有一个问题就是块大小,块太小将不利于数据的传输,因为需要进行多次的定位操作,但是可以最小化碎片化的程度。快太大,碎片化就更严重。
- CRUX:如何组织磁盘上的数据提升性能?
FFS: Disk Awareness Is The Solution
- Fast File System (FFS) 基于磁盘感知的分配策略设计了文件系统。该文件系统开启了文件系统的新纪元,即对外仍然暴露相同的 API,只是在底层提供不同的实现。
Organizing Structure: The Cylinder Group
- FFS 将磁盘划分成了多个 Cylinder Groups。一个 Cylinder 对应磁盘上的一组磁道,N 个 Cylinders 组成一组。
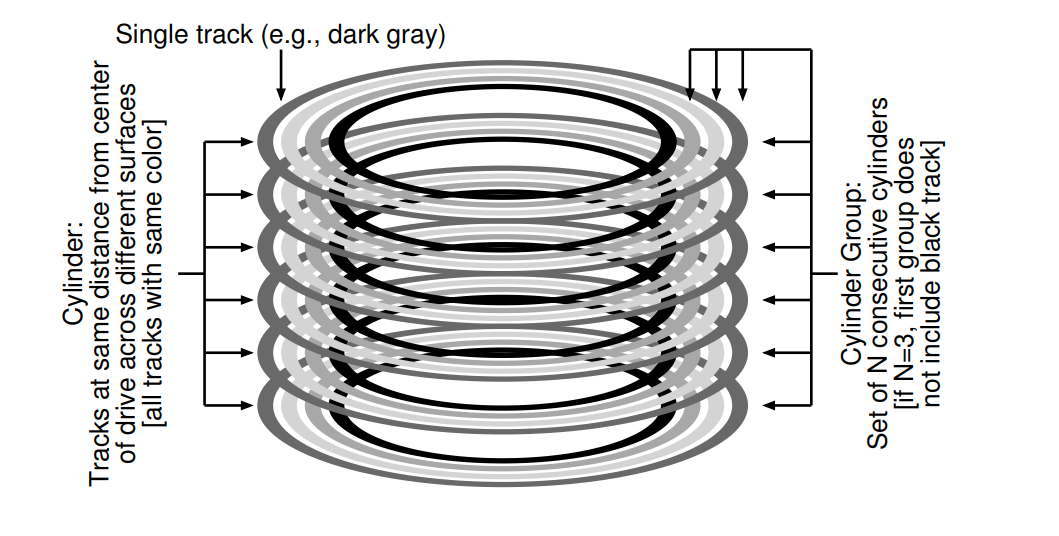
- 现代文件系统对外暴露的是块的逻辑地址空间,并向客户端隐藏了实际的细节。因此现代文件系统将磁盘组织成了 block groups,每一个部分就是磁盘地址空间的一部分。
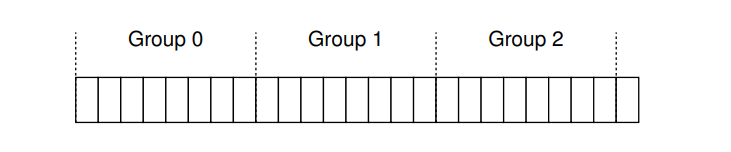
- 不管您把它们称为柱体组还是块组,这些组都是FFS用来提高性能的核心机制。重要的是,通过在同一组中放置两个文件,FFS可以确保逐个访问不会导致跨磁盘查找时间过长。为了使用这些组来存取数据,就需要把文件和目录都放在一个组中,并且该组内只有包含了足够多的信息才能确保高效。如图所示,一个组内需要包含相应的一些信息。
- Super block,每一个组中保留了超级块的副本信息,是为了防止原有的超级块损坏后无法访问文件系统,使用副本可以恢复。
- inode/data bitmap 用于追踪组内 inode 和 data 的分配情况
- 数据块和 vsfs 一样用于存储数据,且作为一个组的最大组成部分。

Policies: How To Allocate Files and Directories
- 核心思想:把相关的数据放在一起
- 目录的放置:找一个组,已分配的目录较少,有大量空闲 inodes。
- 文件的放置:确保数据块和 inode 在一个组中,同一个目录下的文件尽量放在一个目录中
- 假设每组 10 inodes 和 10 data blocks。现在需要放置三个目录
/,/a,/b和四个文件/a/c,/a/d,/a/e,/b/f。假设目录占据一个块,文件占据两个块:
| group | inodes | data |
|---|---|---|
| 0 | /--------- | /--------- |
| 1 | acde------ | accddee--- |
| 2 | bf-------- | bff------- |
| 3 | ---------- | ---------- |
| 4 | ---------- | ---------- |
| 5 | ---------- | ---------- |
| 6 | ---------- | ---------- |
| 7 | ---------- | ---------- |
- 对比散步所有 inode 到所有组的分配策略,为了防止没有组的 inode table 被很快填满:对比之下,对文件/a/c、/a/d和/a/e的访问现在跨越三个组,而不是按FFS方法的一个组。
| group | inodes | data |
|---|---|---|
| 0 | /--------- | /--------- |
| 1 | a--------- | a--------- |
| 2 | b--------- | b--------- |
| 3 | c--------- | cc-------- |
| 4 | d--------- | dd-------- |
| 5 | e--------- | ee-------- |
| 6 | f--------- | ff-------- |
| 7 | ---------- | ---------- |
- 目录中的文件通常是一起访问的:想象一下,编译一堆文件,然后将它们链接到一个可执行文件中,正是因为存在基于命名空间的局部性,确保了相关的文件之间的访问是又好又快的,FFS 才能提高相应的性能。
Measuring File Locality
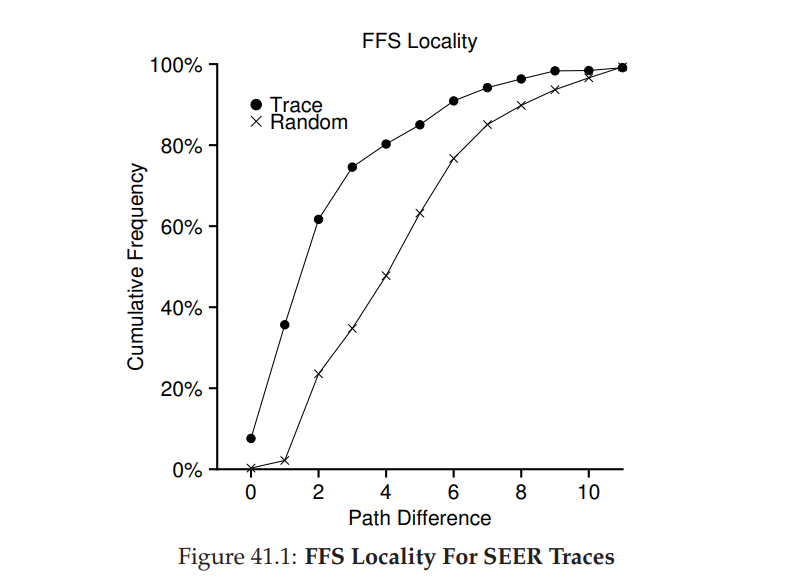
- 使用 SEER 来追踪和分析文件访问的距离。比如打开了文件 f,再打开 f 对应的路径长度为 0,因为是同一个文件,但假如位于同一个目录 dir 下的 f 和 g,先打开了 f 后打开了 g,那么访问距离就变成了 1,简而言之,就是寻找两个文件的相同父目录需要多少次操作。
- 从下图所示的结果发现,约有 7% 的文件访问操作是针对已经打开了的文件,约有 40% 的操作是针对同一个文件或者同一个目录下的文件的访问。因此 FFS 的局部性假设是有一定根据的。
- 除此以外从图中看出约有 25% (看 1 和 2 之间的纵轴差值)的数据访问对应的访问距离为 2,当用户以多层次的方式结构化了一组相关目录并在它们之间一致地跳转时,就会发生这种类型的局部性。比如
proj/src/foo.c和proj/obj/foo.o。FFS 不会捕获这种类型的局部性,因为这样的操作会造成更多的 seek。 - 作为对比,还引入了 Random trace。通过 SEER Trace 中已经存在的文件进行随机的选择来模拟的,并计算对应的距离和分布。所以在随机的负载下,就很少表现出局部性。但是,因为最终每个文件都共享一个共同的祖先(例如根),所以存在一些局部性,因此 random 作为比较点很有用
The Large-File Exception
- 大文件可能直接一次就填满整个数据块组,以这种方式填充块组是不可取的,因为这会防止随后的“相关”文件被放置在这个块组中,从而可能会损害文件访问位置。所以有必要设置单独的策略。
- 大文件的分配策略就是 在第一个组中分配了一定数量的数据块之后,找到其他组继续分配该文件对应的数据块,可能会根据每个组的空间利用情况进行选择。
- 假设一个组 10 inodes, 40 data blocks,文件
/a大小为 30 个块


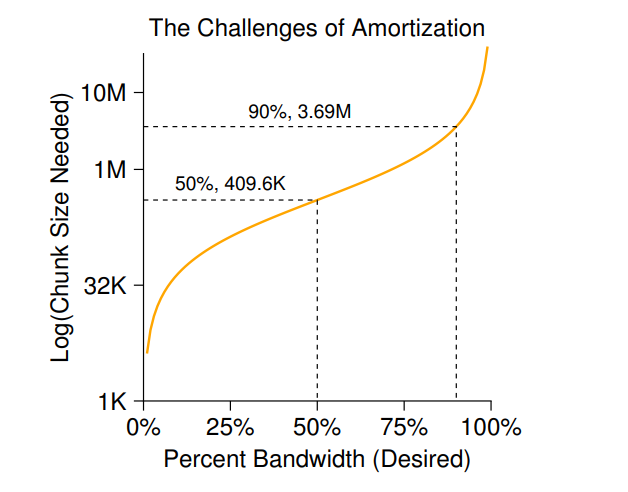
- 但是这样散布之后可能会影响该大文件的访问性能,所以选择分片大小就显得十分重要,如果足够大,那就是大部分时间都在传输,少部分时间在 seek,是一种 amortization 策略。
- 假设定位时间为 10ms,磁盘传输速度为 40MB/S,如果目标是一半时间用于定位,一半时间用于传输,即发挥 50% 的磁盘峰值带宽,那么每 10ms 定位之后就进行 10ms 的传输,对应的可以传输大约 409.6KB 的数据。对应如果发挥 90% 的峰值带宽,大约为 3.69MB,99% 峰值带宽大约为 40.6 MB,对应的离峰值越近,数据块大小也就越大。
- FFS 没有用这种方式来计算大文件在不同组之间的分布,而是采用了一个比较简单的方法,基于本身的 inode 的结构。每一个间接块,以及它所指向的所有块,都被放在不同的组中。4KB 大小的块,32 位地址,在该策略下就意味着 4MB 文件的 1024 个块会被放置到不同的组,唯一的例外是由直接指针指向的文件的第一个 48KB。
- 从图示结果中不难发现磁盘传输率提升的越来越快,因为磁盘制造商擅长将更多的位元塞入同一表面,但与seek相关的驱动器的机械方面(磁盘臂速度和旋转速度)改进得相当缓慢。这意味着,随着时间的推移,机械成本会变得相对更昂贵,因此,为了摊销上述成本,您必须在各个 seek 之间转移更多的数据。
A Few Other Things About FFS
sub-blocks
- 小文件会带来一些磁盘内部的碎片现象,比如 2KB 的文件,使用 4KB 的块则其实是浪费了一半的空间。FFS 的设计者想到了一个简单的办法来解决,引入 sub-blocks,即文件系统可以分配给文件的一些较小的数据块。因此如果创建小文件,譬如 1KB 文件,将直接使用两个 sub-blocks 而不用浪费一个 4KB 的块大小。随着文件大小的增长,文件系统将持续分配 512 字节的块直到 4KB 的大小,在这时候,文件系统将分配一个 4KB 大小的块,并把小块数据复制到该大块中,然后释放掉小块的空间。
- 这个过程可能不够高效,因为引入了额外的工作,譬如为了复制的一些 I/O,FFS 为了避免这种行为,修改了 libc 库,该库将缓冲写操作,然后将写操作直接写到 4KB 大小的块中,因此在大多数场景中完全避免了对小块的特殊处理。
disk layout
- 在 SCSI 以及其他现代设备接口之前,磁盘是比较简易的并且要求主机 CPU 亲历亲为地控制磁盘的操作。在 FFS 中,如果将文件放在磁盘的连续扇区上,就会出现问题。如下图左图所示,在顺序读的过程中,首先读数据块 0,完成之后读取数据块 1,但是读数据快 1 的时候可能发现磁盘已经转动过了,即需要再等待额外的完整的旋转时延才能读取数据块 1.
- FFS 采用了如下右图所示方法,通过在连续的数据块之间间隔一个其他的块的方式,在经过磁盘头之前,FFS 有足够的时间请求下一个块。事实上,FFS 能够计算出具体的需要多少个块来间隔,这个技术被称之为 parameterization,因为 FFS 会计算出磁盘的具体性能参数,并使用这些参数来决定精确的交错布局方案。
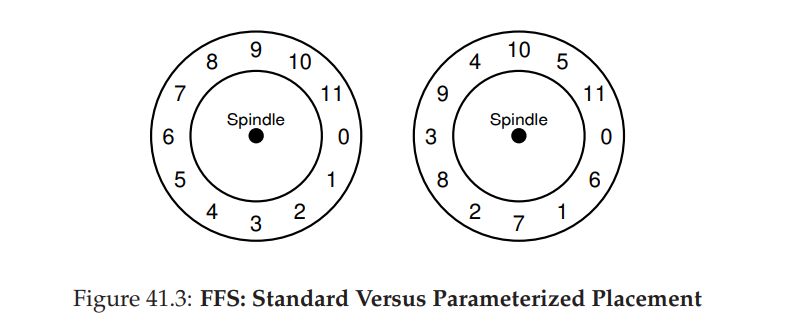
- 这种方法可能也有问题,即性能上可能只能达到峰值的一半,因为扫描一个磁道上的所有数据的话必须旋转两次才可以全部访问到。但现代文件系统内部读取整个磁道,并将其缓冲在一个内部磁盘缓存中(由于这个原因通常称为磁道缓冲区)。即预取。而针对顺序读操作,则直接从对应的 track buffer 中缓存相应的数据。文件系统因此不再需要担心这些难以置信的底层细节。如果设计得当,抽象和高级接口可能是一件好事。
other
- FFS 是首批支持较长的文件名的文件系统之一,从而在文件系统中启用更具表达性的名称,而不是传统的固定大小的方法
- FFS 引入了软链接
- FFS 也引入了 rename 原子操作
- 引入了 advisory shared/exclusive locks 以方便地构建并发程序;
- 引入了 Quotas 机制,让管理员能更合理地对每个用户实施配额限制,包括具体到inode 和 data block 数目的限制。
