- SOSP19 PebblesDB: Building Key-Value Stores using Fragmented Log-Structured Merge Trees
- https://github.com/utsaslab/pebblesdb
Abstract
- LSM 写性能较好,但是遭受严重的写放大,写放大原因其实就是数据结构的问题。
- 本文受跳表的启发,提出了分段LSM树,也就是 Fragmented Log-Structured Merge Trees (FLSM)。引入了 guard 的概念来组织日志,同时避免在相同层重写数据。 本文通过修改 HyperLevelDB 来使用 FLSM 数据结构。测试结果表现较好,写放大改善效果显著。
Introduction
- 主要介绍 KV Store 应用广泛,然后写放大是个很严重的问题,对 SSD 的寿命/磨损以及读写吞吐量都会产生影响。下图描述出写放大有多严重,然后指出以前的解决写放大的方案都有一定的限制。【ATC15 NVMKV】、【SOCC12 Using Vector Interfaces To Deliver Millions Of IOPS From A Networked Key-Value Storage Server】都需要一些特定的硬件,而且可能牺牲例如查询性能的其他方面。但在如今的场景中,常常是需要读写兼顾的。

- 简单分析了造成写放大的原因:因为 LSM 中数据是有序存放的,为了利用顺序写的性能,数据的查询也会相对比较顺序、比较高效。但是当有新的数据写入的时候,为了维持原有的有序性,就会导致一下现有的数据被重写,从而导致大量的写 IO。
- 本文结合了 LSM 和 SkipList 提出了 FLSM,同时提出了一个新的 compaction 算法。FLSM通过极大地减少(在许多情况下,消除)数据重写,而不是将数据分割成更小的块,并使用存储上的 guards 来组织这些块,从而消除了写放大的根源。Guards 提升了 LSM Tree 的检索效率。LSM 的写操作常常会因为 compaction 操作而 block 或者 stall,那么 FLSM 的思想因为极大减少了写 IO,让 compaction 相应地也就更快完成,提升了写吞吐。
- 除此之外,PebblesDB 还使用了一组其他技术,如 Parallel Seeks、aggressive seek-based compaction 以及 sstable-level bloom filters 等技术来减小 FLSM 引入的开销。
- FLSM 数据结构并不适合在初次写操作爆发后涉及大量范围查询的工作负载。但是如果范围查询和写操作是穿插的话,是不会引入开销的。
Contributions
- 设计了新的 FLSM,结合了 Skiplist 和 LSM
- 设计并实现了 PebblesDB,使用 FLSM 和几个重要的优化
- Parallel Seeks
- aggressive seek-based compaction
- sstable-level bloom filters
- 实验表明 PebblesDB 比其他主流 LSM 存储在读写表现上都要更好
Background
KV and LSM
- KV 常见操作和 LSM 树此处不再赘述。只是简单列举几个例子和观点
- B+ Trees 不适用于写密集负载,因为更新树要求随机写,所以写密集都使用了 LSM
- KyotoCabinet
- BerkeleyDB
- LSM 中查询操作定位一个 Key 通常需要两个二分查找:
- 第一次找到对应的 SSTable,根据 SSTable 的起始 Key (单独维护的元数据)
- 第二次在 SSTable 内部找到相应的 Key,如果查询失败,说明不在当前 level
- 每个 Key 都会包含它的版本,找到每一层的那个 Key 需要读取和搜索一个 SStable
- seek() 和 next() 操作都要求在整个键值存储区上定位迭代器,所以使用了多个迭代器来实现,每一层一个迭代器。每个迭代器首先定位到每一层相应的 sstable,然后将迭代器的结果合并。seek() 操作首先找到每一层相应的 SSTables,然后定位 SSTable 迭代器,SSTable 迭代器的结果将合并然后定位到对应的 KV 存储迭代器。next() 操作只是向前推进正确的 sstable 迭代器,再次合并迭代器,并重新定位键值存储迭代器。(这一块可能要等看了源码中的迭代器的部分之后才能理解)
- put() 操作将键-值对和一个单调递增的序号(序列号/版本号)一起写入内存中称为memtable的跳过列表。
- 更新和删除操作都不是就地更新的,因为所有 IO 都是顺序的。相反,一个 Key 插入到数据库中使用了一个更高的序列号,删除一个键相应地就是插入一个特殊的 flag tombstone。因为有更高的序列号,所以最近版本的 flag 会返回给用户。
WA 写放大
- 下图描述了 compaction 的过程,刚开始就只有两层 l0, l1。假定 l0 配置为一次只包含一个 SSTable,到达限制后将触发 compaction,t1 时刻加入了一个 SSTable,达到了 L0 的限制,触发 compaction,t3,t5 也是如此。
- 当压缩一个sstable时,下一层的所有sstable的密钥范围与被压缩的sstable相交的sstable都被重写。在这个例子中,由于所有0级sstable的键范围都与 Level 1 所有的键范围相交,每次Level 0 sstable被压缩后,Level 1 sstable就会被重写。在下面这个最糟糕的例子中,Level1 在 compaction 时可能会被重写 3 次(t2, t4, t6),因此比较高的写放大可以归根于 compaction 操作的多次 SSTable 重写。
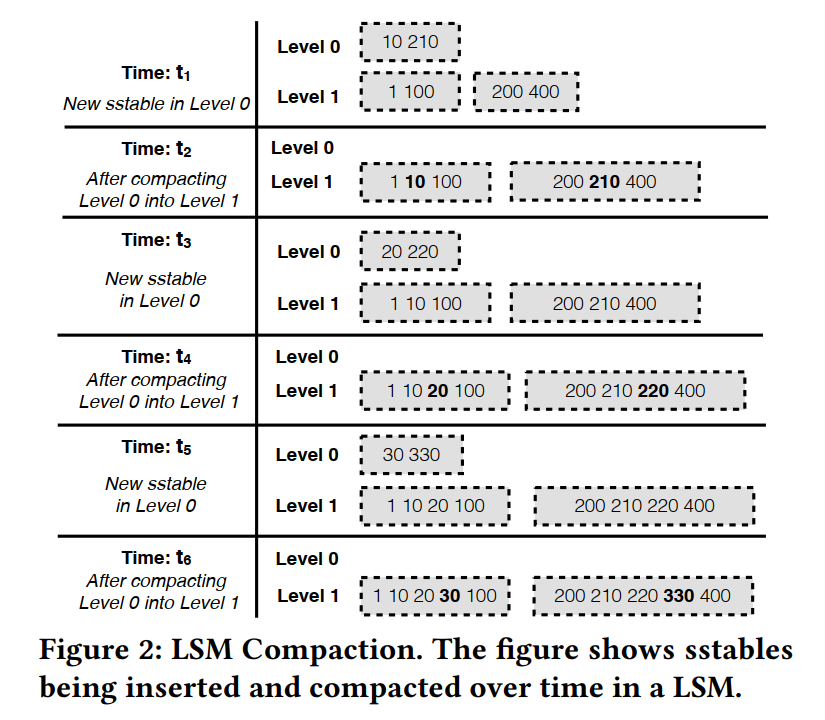
- Challenge: 在LSM中减少写放大的一种简单方法是在压缩期间不合并sstable,而是向每个级别添加新的sstable (FIFO compaction, Universal(tiered) Compaction)。然而,读取和范围查询性能将显著下降,原因有两个。首先,如果没有merge,键值存储将最终包含大量sstable。其次,由于多个 SSTable 现在可以包含相同的键,并且在同一级别上有重叠的键范围,读取操作将不得不检查多个 SSTable (因为无法二分查找sstable),这会导致很大的开销。
FLSM - FRAGMENTED LOG-STRUCTURED MERGE TREES
- 三个目标:低写放大、高写吞吐量和良好的读性能。
- 日志结构的合并树的基本问题是,当新数据被压缩到sstable中时,sstable 通常会被重写多次,FLSM 通过将sstable分割成更小的单元来解决这个问题。FLSM的压缩只是将一个新的sstable片段添加到下一个级别,而不是重写整个sstable。这样做可以确保数据在大多数级别中只写入一次。最后几个最高级别使用了不同的压缩算法。FLSM使用一种新颖的存储布局和使用 Guard 组织数据来实现这一点
Guards
- 传统 LSM 中,每一层包含的 SSTable 都不包含相交的 key ranges(每个 Key 在一个 Level 里只会出现在一个 SSTable 中)。我们的主要观点是,保持这个不变是写放大的根本原因,因为它迫使数据在同一级别上重写。FLSM 丢掉了这一不变性:每一层包含多个 SSTables,且键范围可以重叠,所以一个 Key 可以出现在多个 SSTables 中,但是牺牲了查询性能,所以 FLSM 将 SSTables 组织在 guards 中。
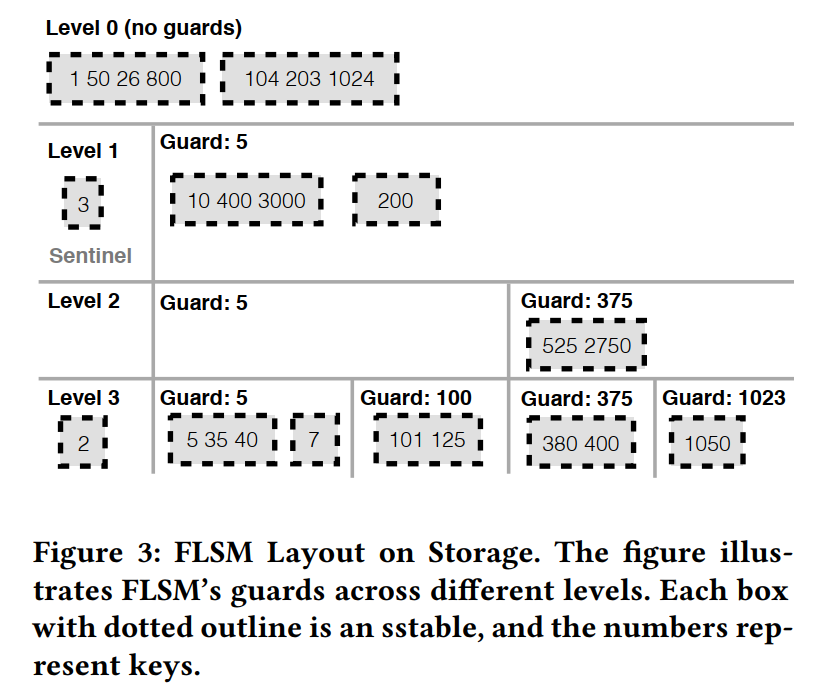
- 每个 level 包含多个 guards,每个 guard 把 key 空间分成很多个不相交的子空间,每个 Guard 都有个关联的 Key,是从 Keys 中选出来的然后插入到 FLSM 中的,每个 Level 比在他之上的 level 都包含更多的 Guard,随着数据越来越深入地进入FLSM,Guard 的粒度(间隔)也越来越大,在跳转列表中,如果一个键是给定 level i 的守卫,那么它将是所有 level > i 的守卫。
- 每个守卫有一组关联的 SSTables,每个 SSTable 是有序的。如果 和 Key 关联, 和 Key 关联,那么范围为 [, ) 的 SSTable 将被关联到 ,小于第一个守卫的对应范围的 SSTable 包含在每层的一个特殊的 sentinel guard 里,最后一个守卫则存储了大于对应 Key 的所有范围的 SSTables,在一个 Level 的 Guards 不会有重叠的范围,因此为了在一个给定的 level 里找到 key,只需要访问对应的一个 Guard。
- 在 FLSM compaction 的时候,一个给定的 Guard 对应的 SSTables 被归并排序然后分段,所以每个子守卫接收到一个新的 SSTable,它进入下一个 level 的子守卫的键范围。
- 下图所示例子,进行 put() 操作:
- 首先被添加到内存中 Memtable,图中未表示,当 Memtable 满了之后被写入到 L0 的 SSTable,L0 没有守卫,只是收集最近写入的 SSTables
- 随着 level 数量的增加,守卫数量也相应增加,但每个 level 的守卫数量不一定呈指数增长
- 每个 Level 有一个哨兵守卫,主要负责对应 Key 小于当前守卫的 SSTables,如下所示,Key < 5 的就被关联到 sentinel guard
- FLSM Level 里的数据部分有序,守卫没有重叠的键范围,但是每个守卫关联的 SSTables 可能会有重叠的键范围。
Selecting Guards
- FLSM 的性能起始会受到 guards 如何选择的显著影响,最差的情况就是一个 guard 包含所有的 SSTable,读和查询一个如此大的 Guard 将导致一个不可接受的延迟的增加。因此,守卫不是静态选择的;而是从插入的键中概率地选择守卫,防止倾斜。
Guard Probability
- 当一个 Key 插入到 FLSM 时,Guard Probability 决定了是否该 Key 成为一个 Guard,
gp(key, i)就是一个 Key 在 level i 成为 guard 的概率。例如,如果 gp 是 1/10,那么每十个插入的 keys 将有一个被随机选择成为一个 guard。gp 被设计成在 level 1 上是最小的,因为该层有最少的守卫,然后随着 level 数的增加概率变大,因为更高的 level 有更多的守卫。以这种方式来选择守卫,将守卫以一种平滑的方式分布在插入的键上,从而可能防止倾斜。 - 更像跳表的是,如果一个 Key K 被选择作为了 level i 的守卫,那么它将成为后续所有 level 的守卫。这样选择守卫将允许在每个守卫之间的间隔在每个更深的 level 中依次被修改。比如上图中,键 5 被选择为 level 1 的守卫,也被选择为 level 2 和 level 3 的守卫。
- FLSM 为了简便是直接选择了插入的键作为守卫,但其实是没有要求一定要在 KV 存储中有相应的 KV 对和守卫相对应。
Other schemes for selecting guards
- 当前选择守卫的方式的优点在于足够简单,很容易计算,而且分布也比较公平,但是呢其实是没有把在压缩期间分区 SSTable 导致的 IO 数量考虑进去的。FLSM 可能会在压缩时为每个级别选择新的守卫,这样就使得 SSTable 分区最小化;然而,这可能会带来倾斜。我们把其他可选的守卫选择方式留到未来的工作中。
Inserting and Deleting Guards
Insert
- 当守卫被选择之后不会被同步地插入到 FLSM 中,因为插入守卫可能导致 SSTables 的分裂或移动,如果一个守卫插入到很多 level,那么就会在这些所有层上都产生 SSTables 的相关变化。因此守卫是异步插入 FLSM 中的。
- 守卫被选出来之后,首先添加到内存中一个较 未提交的守卫列表中,这时候的存储设备上的 SSTable 还不会进行分区,这时候的 FLSM 的读操作就还是按照未提交的守卫不存在的情况下进行的。在下一个 compaction 周期的时候,SSTables 基于老的守卫和未提交的守卫来进行分区和压缩。因为未提交的守卫而需要分裂的 SSTable 被 compacted 到下一层。在 compaction 结束的时候,未提交的守卫再被持久化到存储设备上,然后被添加到整个守卫的集合中。未来的读操作将基于整个守卫集合来进行服务了。
Delete
- 我们发现在我们测试过的很多负载中,其实守卫的删除是不需要的,如果一个守卫对应的 keys 为空那么就可以删除这个守卫,但是空的守卫其实不会产生显著的性能降级,因为 get 和 range query 操作都是为跳过空的守卫的。但是,删除守卫在以下两个场景是有用的:
- 守卫是空的或者当前 level 的数据在守卫之间分布不均的时候
- 更少的守卫整合部分数据可以提高性能的时候
- 守卫的删除和插入是类似的,都是异步的,删除的守卫也被添加到一个内存的集合中,在下一个 compaction 周期的时候,sstable 被重新组织来适应删除守卫后的分布。删除 level i 的守卫 G 是在 compaction 时候 lazy 进行的。在 compaction 的时候,守卫 G 被删除然后对应的 SSTable 将被分去并追加到对应的同一层的相邻的守卫里或者追加到下一层的子守卫里。压缩过程照常进行,因为删除的是 level i 的守卫 G,但是在 level i+1 守卫 G 还是存在的。在压缩结束时,FLSM 持久化包含了删除 level i 层的守卫 G 的元数据信息。如果有需求的话,其他层的守卫也是会按照相似的逻辑去删除。但是需要注意的是,如果 level i 的守卫 G 删除了,那么 levels < i 的守卫 G 都得被删除;FLSM 可以自己选择决定是否删除 levels > i 的守卫。
FLSM Op
Get
- 还是先检查内存里的数据结构,没找到再从磁盘上从 level 0 开始找,找到了肯定就立马返回,因为最靠近 DRAM 的 level 的数据肯定就是最新的。为了确定一个 Key 是否存在于当前 level,首先用一个二分查找找到对应的守卫,即该守卫可能包含该键,守卫找到了,那么对应的 SSTables 也就找到了,再去查对应的 SSTables。
- 所以最坏的情况是,每一层都去读了一个守卫,然后还读取了每个守卫里的所有 SSTables
Range Query
- 范围查询要求收集给定范围的所有 Keys,首先识别出每一层和给定范围有交集的守卫,然后在每一个守卫里,可能很多个 SSTables 都会和给定范围有交集,那么 首先对每一个 SSTable 执行二分查找,以确定整个范围内最小的键,识别范围中下一个最小的键类似于归并排序中的归并过程;但是,不需要执行完整的排序。 当达到范围查询间隔的结束时,操作结束,将查询结果返回给用户。
- 对于 seek 和 next 操作,LSM 的通过合并多个 level 的迭代器来实现,而 FLSM 中的 level 迭代器本身是通过合并相应的的守卫内部sstable 上的迭代器来实现的
Put
- put 操作把数据添加到内存中的 memtable 中,满了之后执行 flush,然后再是 compaction,FLSM 其实就是通过分区 SSTable 并关联到下一个 Level 的守卫来实现 Compaction 从而避免了 SSTable 的重写。
Key Updates and Deletions
- 和 LSM 类似,更新和删除一个 Key 引入了把一个带有序列号或者删除标志的 key 插入存储的开销。查询操作将会忽略带有删除标识的 keys,如果一个 key 的插入导致了守卫的形成,key 的删除是不会导致守卫的删除的。删除一个守卫将引入大量的 compaction work,因此空的 guard 是可能的。
Compaction
- 当一个 guard 积累了一定阈值数量的 SSTables 时,将被压缩到下一层。在这个守卫里的 SSTables 首先被排序然后基于下一层的守卫进行分区,得到新的 SSTables,然后新的 SSTables 被关联到正确的守卫。例如,假设在 Level 1 的一个守卫包含 {1, 20, 45, 101, 245},如果下一层有守卫 1、40、200,SSTable 将被分成三个 SSTable {1, 20}, {45, 101}, and {245} 然后被分别关联到三个守卫,
- 大多数场景下,FLSM 压缩不会重写 sstables,这是 FLSM 减少写放大的核心思想,新的 SSTable 只是很简单地被添加下一层的正确守卫里,但是有两个例外的情况:
- 在最高的 Level,比如 Level 5,该层的 SSTable 在 compaction 中必须被重写,因为没有下一层了。
- 对于第二高的 Level,比如 Level 4,如果在最高级别合并到一个大的 sstable,那么 FLSM 将重写一个sstable到相同的级别(因为如果守卫已满,我们无法在最后一级别附加新的sstable)。如果合并导致 25× 更多的IO,精确的启发式被重写在第二高级别
- FLSM 的 Compaction 可以很简单地就实现并行,因为每次 Compaction 只会涉及到当前守卫和他的子守卫。守卫的选择方式保证了压缩一个守卫不会和同级其他守卫的压缩冲突。例如图 3 中 Level2 的守卫 375 被拆分成 Level3 的守卫 375 和 1023,只有这些守卫在压缩过程中会受到影响。压缩守卫 5,如果有数据的话,是不会影响到正在进行守卫 375 压缩。因此这些守卫压缩就可以同时进行,可以充分由 SSD 的一些内部并行性来充分处理并行 IO,从而减少 Compaction 的整体时间。压缩后的 KV 存储就会有更低的读延迟,因为并行的压缩可以让存储更快地进入到该状态,从而也提升了读吞吐。
Tuning FLSM
- 其实影响读写性能关键参数是:每个守卫中的 SSTables 数量。太多了,查询操作的延迟就很高,因此 FLSM 提供了一个 knob 从而可以调整行为,max_sstables_per_guard,它限制了在FLSM中每个守卫中存在的sstable的最大数量。当守卫中积累了这么多的 SSTables,守卫将被压缩到下一层。
- 调整该参数允许用户在更多写 IO 和低的读延迟之间做 trade-off,有意思的是,如果这个值被设置成了 1,FLSM 表现得就像 LSM 然后有差不多的读写性能,因此 FLSM 可以被看成 LSM 结构的一般化。
Limitations
- FLSM 显著减小了写放大而且压缩也更快(因为 FLSM 的压缩需要更少的读写 IO),由于更快的压缩,写吞吐量也会增加。然而,FLSM数据结构并非没有局限性
- 因为 get 和 range query 需要检索一个守卫里的所有 SSTables,这些操作的延迟相比于 LSM 就增加了。下面将会描述这些延迟如何克服,使用一些比较知名的技术可以减小甚至消除 FLSM 数据结构引入的开销,导致键值存储实现了低写放大、高写吞吐量和高读吞吐量的三连胜。
Asymptotic Analysis
- 使用一个理论模型来对 FLSM 操作进行分析。
Model
- 使用标准的磁盘访问模型 DAM,假设每一个读写操作都可以以一个单位的开销访问大小为 B 的块。为了分析的简便,我们假设 n 个数据被存储在了其中。
Asymptotic Analysis
- 假设 FLSM 中 guard 选择的概率是 1/B,所以在 level i+1 的守卫的数量是 level i 的 B 倍,因为 FLSM 对应的 fanout 是 B,那么很大概率 n 个数据将有 层,每个数据项在每层只有一个,因为数据只会被追加一次而且从来不会在同一层进行重写。导致写开销 。因为 DAM model,FLSM 写了一个包含 B 个项的数据块作为单位开销,那么任何 put 操作的开销均摊之后为 ,超过了整个 compaction 的生命周期,然而,最后一层的 compaction 必须重写数据。所以最后一层的重写会比较大概率地为 倍,然后最终的总的分摊开销为
- FLSM 的守卫引入了一个深度为 B 的跳表,关于 B 跳表的具体理论分析表明每个守卫将会有 个孩子,每个守卫将有最多 个 SSTables,每个 SSTable 将最多会有 个数据项。查询对应的项首先要求找到正确的守卫,然后在守卫内部找到对应的 SSTable,因为最后一层有最多的守卫 ,二分查找开销将被最后一层的开销给统治:,因为有 层需要搜索,这就产生了总的开销为 的内存操作来找到每一层的相应的守卫。
- 然而,在 FLSM 中,守卫和布隆过滤器都是存储在内存中的,FLSM 在二分查找找到每一层对应的守卫时执行 内存操作。然后对于每个守卫找到之后,执行一次布隆过滤器查询,在每个守卫对应的 个 SSTable 上执行,每次查询消耗 在内存操作中。在 DAM 模型中所有的内存操作没有开销。
- 最后,平均下来,布隆过滤器将指示 1 + O(1) 个 SSTables 要读(很大概率),读取这些 SSTables 在 DAM model 中花费 1 + O(1)。因此,一个 get 操作总的读开销只有 O(1)(假设内存足够装下守卫和布隆过滤器)。
- FLSM 不能利用布隆过滤器来优化范围查询,每一层的二分查找仍然是在内存中完成的。对于每一层,二分查找输出一个守卫然后 FLSM 需要读取 O(B) 个关联的 SSTables,所以对应一个范围查询(查询 K 个元素)的总开销是
BUILDING PEBBLESDB OVER FLSM
Improving Read Performance
Overhead Cause
- FLSM 中的 get() 操作将检查每个级别中一个守卫的所有 sstable。相反,在日志结构的合并树中,每个级别只需要检查一个sstable。因此,读操作会在基于 FLSM 的键值存储中产生额外的开销。
Sstable Bloom Filters
- Bloom flter 是一种节省空间的概率数据结构,用于测试一个元素是否在常量时间内出现在给定的集合中。bloom flter可以产生假阳性,但不会产生假阴性。PebblesDb 在每个sstable上附加一个bloom flter,以便有效地检测给定的键是否存在于sstable中。SSTable 的布隆过滤器允许 PebblesDB 避免从存储中读取不必要的sstable,极大地减少了由于FLSM数据结构而产生的读取开销。
- RocksDB 也采用了sstable级别的bloom flters。许多key-value store(包括RocksDB和LevelDB)为sstable的每个块使用bloom flters。如果使用sstable级别的bloom filters,则不需要块级别过滤器。
Improving Range Query Performance
Overhead Cause
- 类似于 get()操作,范围查询(使用seek()和next()调用实现)还需要检查FLSM守卫的所有sstable。因为LSM存储在每个级别只检查一个sstable,所以FLSM存储在范围查询上有很大的开销
Seek-Based Compaction
- 与LevelDB类似,PebblesDb实现由连续seek()操作的阈值次数触发的压缩(默认值:10)。一个守卫中的多个sstable被合并并写入到下一级守卫中。目标是减少一个守卫内sstable的平均数量。PebblesDb也积极地压缩 levels:如果 level i 的大小在 level i+1 的某个阈值比例(默认为25%)内,那么 level i 就被压缩为 level i+1。这种积极的压缩减少了需要搜索seek() 的活动 level 的数量。尽管这样的压缩增加了写 IO,但是 PebblesDb 总体上仍然显著降低了 IO 量
Parallel Seeks
- PebblesDb采用的一种独特的优化方法是使用多个线程并行地搜索sstable以获取seek()。每个线程从存储中读取一个sstable,并对其进行二分搜索。然后将二元搜索的结果合并,并为seek()操作正确定位迭代器。由于这种优化,即使一个守卫包含多个sstable,与LSM seek()延迟相比,FLSM seek()延迟只会带来很小的开销。
- 不能轻率地使用并行查找:如果正在检查的sstable被缓存了,那么使用多个线程的开销要高于并行查找的好处。由于无法知道给定的sstable是否被缓存(因为操作系统可能会在内存压力下删除缓存的sstable),Pebbesdb使用了一个简单的启发式方法:并行查找只在键值存储的最后一层使用。选择这一启发式的原因是,最后一层包含的数据量最大;此外,最后一个级别的数据不是最近的,因此不太可能被缓存。这个简单的启发式方法在实践中似乎很有效。
PebblesDb Operations
- 本节简要描述在PebblesDb中如何实现各种操作,以及它们与在FLSM数据结构上执行相同操作的区别。PebblesDb中的put()操作的处理方式与FLSM中的put操作类似。
Get
- 使用二分查找定位每一层合适的守卫,并在守卫内检索 SSTables。PebblesDB 和 FLSM 在 get 操作不同的地方是利用了 SSTable 级的 BloomFilters 来避免从存储上读取不必要的 SSTables。
Range Query
- PebblesDb处理范围查询的方法是在每个级别中定位适当的守卫,并通过对sstable执行二分查找将迭代器放置在守卫中每个 sstable 的正确位置。PebblesDb 通过并行读取和搜索sstable 来优化这一点,并在接收到连续的 seek() 请求达到阈值时主动压缩 level
Deleting Keys
- PebblesDb 通过将键插入到存储中并标记为已删除的标记来删除键。插入的键的序列号将其标识为键的最新版本,指示PebblesDb丢弃键的以前版本,以便进行读和范围查询操作。注意,bloom flter是在sstable上创建的;由于sstable永远不会就地更新,现有的bloom flter在删除键时不需要修改。标记为删除的键在压缩期间被垃圾收集。
Crash Recovery
- 通过仅附加数据而不覆盖任何数据,peblesdb构建在与LSM相同的基础上,以提供强大的崩溃一致性保证。PebblesDb构建于LevelDB代码库之上,LevelDB已经为这两个数据提供了经过良好测试的崩溃恢复机制(数据,sstable;元数据 MANIFEST file)。PebblesDb只是添加更多的元数据(守卫信息),以便在MANIFEST file中持久化。PebblesDb sstable和LevelDB sstable使用相同的格式。崩溃恢复测试(测试在随机选取的点崩溃后恢复的数据)确保在崩溃后PebblesDb正确恢复插入的数据和相关的guard相关元数据。
Implementation
- PebblesDb 是作为键值存储的LevelDB家族的一个变体实现的。PebblesDb是通过修改HyperLevelDB 来构建的,这是LevelDB的一个变种,在压缩期间改进了并行性和更好的写吞吐量。我们简要地检查了RocksDB代码库,但发现HyperLevelDB代码库更小,文档更完善(源自LevelDB),更容易理解。因此,HyperLevelDB被选择为Pebblesdb的基础
- 我们添加和修改了大约 9100 行代码,大部分的工作都是引入守卫并修改 compaction 操作,因为守卫是建立在sstable之上的,所以PebblesDb能够利用成熟的、经过良好测试的处理sstable的代码。PebblesDb与HyperLevelDB的api兼容,因为所有的更改都在键值存储内部。
Selecting Guards
- 与跳过列表类似,Pebblesdb从插入的键中随机挑选守卫。当一个键被插入时,一个随机数被选择来决定这个键是否是一个守卫。然而,为每次键插入获取一个随机数在计算上是昂贵的;相反,PebblesDb对每个传入的键进行散列,散列的最后几位确定键是否为守卫(以及在哪个级别)。
- 计算上开销较小的 MurmurHash 算法用于散列每个插入的键。可配置参数 top_level_bits 决定了最少连续多少个应该设置散列 Key 的位表示中的有效位(LSBs),以便选择该密钥作为第一级 Level 1 的守卫密钥。另一个参数 bit_decemre 决定每增加一级约束(要设置的 lsb 数量)被放宽的比特数。
- 举个例子,top_level_bits = 17,bit_decrement = 2,level 1 守卫的 key 应该有 17 个连续的在其哈希值中设置的 LSBs,第 2 级的守卫键应该在其哈希值中设置 15 个连续的 LSBs,以此类推。top_level_bits 和 bit_increment 参数需要根据经验确定;根据我们的经验,bit_increment 值为 2 似乎是合理的,但是如果用户希望在 Pebblesdb 中插入超过 1 亿个键,则 top_level_bits 可能需要从默认值 27 增加。过高估计存储中的键数量是无害的(导致许多空的守卫);低估的话可能会导致守卫倾斜
Implementing Guards
- 每个守卫存储关于它所拥有的sstable数量的元数据,sstable中存在的最大和最小的键,以及sstable列表。每个sstable由一个唯一的64位整数表示。守卫与关于键值存储中的sstable的元数据一起被持久化到存储中。在崩溃后从 MANIFEST 和异步 WAL 日志中恢复守卫。守卫数据的恢复被编织到 Keys 和 SSTable 信息的键值存储恢复中。我们还没有在 PebblesDB 中实现删除守卫,因为在我们的实验中,额外的守卫并没有导致读取的显著性能下降,而且保持空守卫的成本相对来说是微不足道的。我们计划在不久的将来实现守卫删除
Multi-threaded Compaction
- 与RocksDB类似,PebblesDb使用多个线程进行后台压缩。每个线程选择一个级别并将其压缩到下一个级别。根据每个级别的数据量选择要压缩的级别。当一个级别被压缩时,只有包含超过阈值数量sstable的守卫被压缩。我们还没有在 PebblesDB 中实现基于守卫的并行压缩;即使没有并行压缩,PebblesDB 中的压缩也比基于 LSM 的存储(如RocksDB)中的压缩快得多。
Limitations
- 这一节描述了传统的基于 LSM 的存储可能比 PebblesDB 更好的选择。
- 首先,如果工作负载数据完全可以全部放在内存中,PebblesDb 具有更高的读取和范围查询延迟。在这样的场景中,读或范围查询请求将不涉及存储 IO,并且在一个守卫中定位正确的守卫和处理sstable 的计算开销将导致更高的延迟。考虑到每天生成和处理的数据量不断增加,大多数数据集不会都在内存中。在数据量很小的少数情况下,将 max_sstables_per_guard 设置为 1,可使PebblesDb 的行为类似于 HyperLevelDB,从而减少读取和范围查询的延迟开销。
- 其次,对于将具有顺序键的数据插入键值存储的工作负载,PebblesDB 的写 IO 要高于基于 LSM 的键值存储。如果数据是按顺序插入的,sstable 不会相互重叠。基于 LSM 的存储可以有效地处理这种情况,只需将 SSTable 从一个级别移动到下一个级别,只修改元数据(而不执行写IO);在 PebblesDb 的情况下,SSTable 在移动到下一个级别时可能会被分区,导致写IO。我们相信现实世界中按顺序插入数据的工作负载很少,因为大多数工作负载是多线程的;在这种罕见的情况下,我们提倡使用基于LSM 的存储,如RocksDB。
- 第三,如果工作负载涉及到初始的写操作突发,然后是大量的小范围查询,那么 PebblesDB 可能不是最好的。对于这种在紧凑的键值存储上的范围查询,与基于 LSM 的存储相比,PebblesDB 的开销很大(30%)。但是,当范围查询变得更大时,开销就会降低,如果范围查询中穿插了插入或更新,开销就会完全消失(如 YCSB-E)。
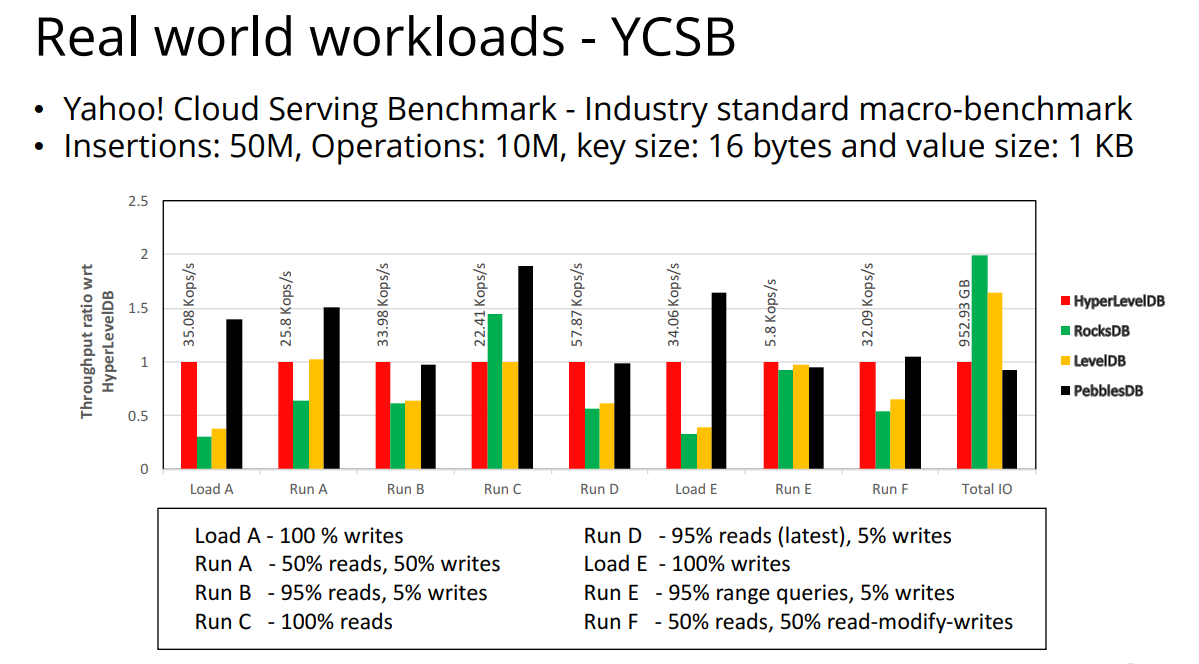
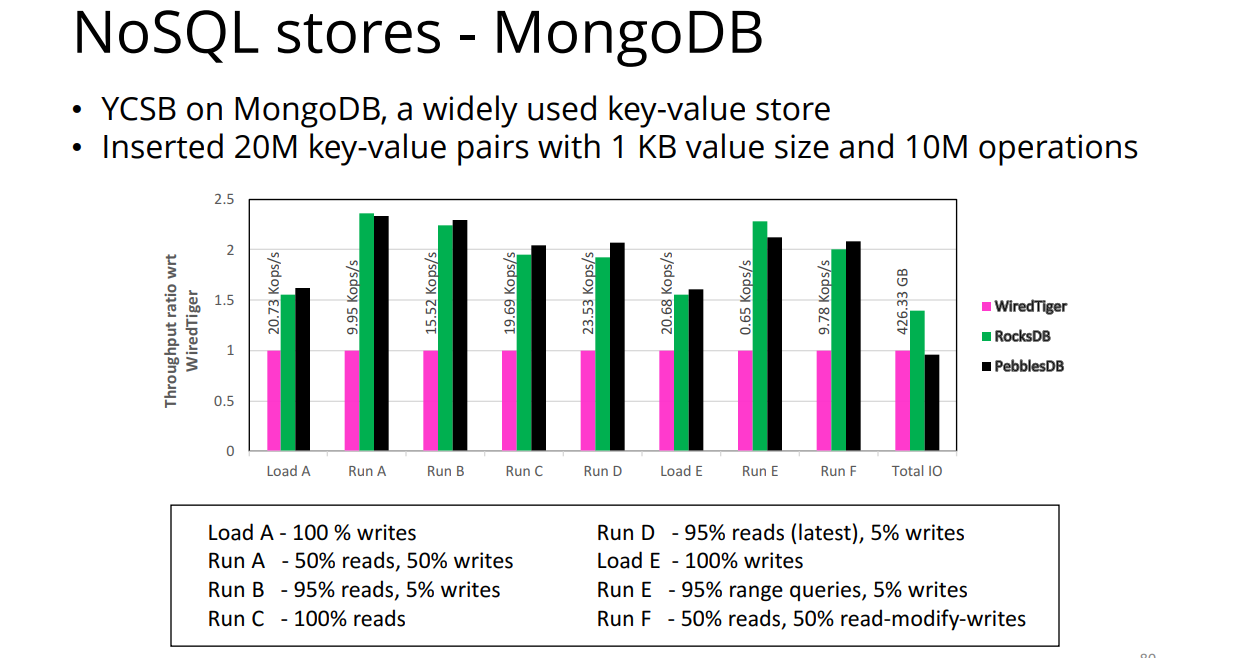
Evaluation