1996 年发表的 LSM Tree. 原文链接见参考链接【1】
作为 KV 存储中应用最为广泛的存储引擎(数据结构),近年来提出了大量新的优化方案。
此篇为考古文,了解 LSM 设计之初的一些想法以及 LSM 底层原理。
该篇论文只是数据结构和思想的提出,和实际的实现有一定出入。后续结合 Google BigTable 2006 继续学习。
其实我只是为了写作业的文献综述才来考古。/:惭愧<
Abstract
原文首先介绍了一个场景来引入 LSM 诞生的必要性。针对有高性能要求的交易系统,往往需要历史记录表来用于相关交易记录的查询或者故障恢复。当交易系统数据量较大时,就需要借助索引来保证查询效率的高校了。但索引显然是一种空间换时间的算法,在后期新数据写入时,维护索引数据的变化将会带来很大的开销,最常用的基于磁盘的索引结构 B Tree在实时维护索引时常常会 double IO 开销,整个系统的开销也将有大幅度的增加。故需要一种低开销的维护索引的方案。
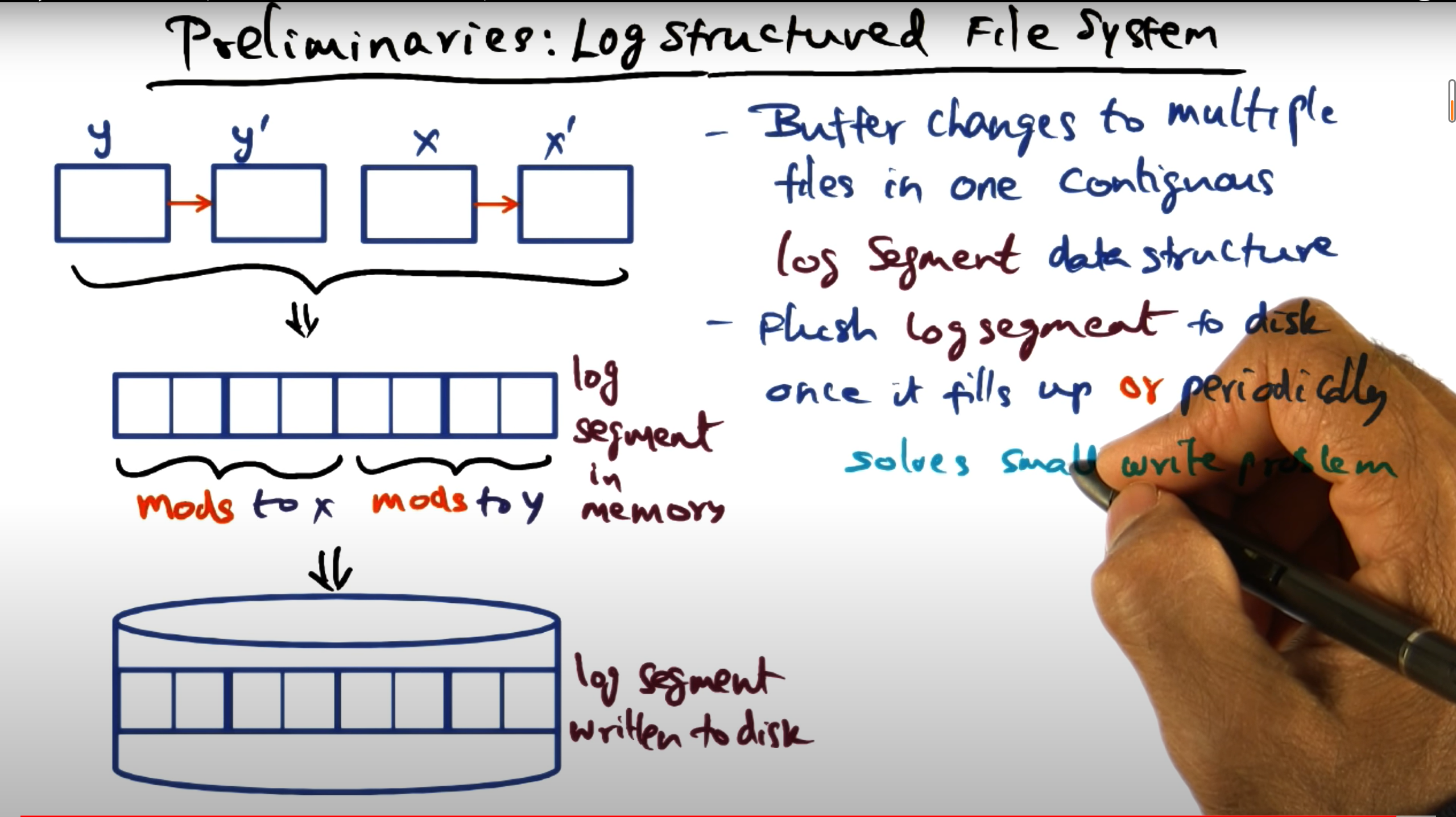
日志结构合并树(LSM-tree)是一种基于磁盘的数据结构,旨在为长时间内经历高记录插入(和删除)率的文件提供低成本索引。核心思想就是将写入推迟(Defer)并转换为批量(Batch)写,首先将大量写入缓存在内存,当积攒到一定程度后,将他们批量写入文件中,这要一次I/O可以进行多条数据的写入,充分利用每一次I/O。同时指出 LSM Tree 更适用于写密集型应用。
Introduction
The five minute rule
适当地引入内存,来规划存储系统的总开销将在成本和效率上都能获益。
参考:https://kernelmaker.github.io/lsm-tree
Design
LSM Tree 的组成
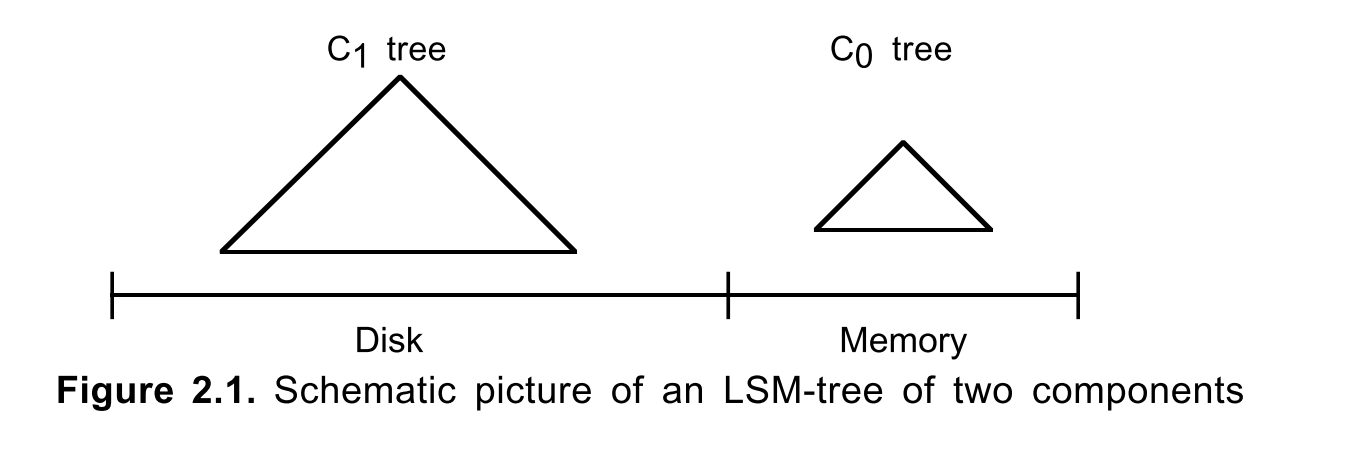
LSM Tree 主要由两部分组成,内存组件和磁盘组件,图示中的 C0 和 C1。C0 组件较小(出于成本考虑,位于在内存中,无需存储大量数据),C1 组件相对较大。
C0 常被用于 C1 的缓冲区,用于吸收突发的读写,C0 类似于 C1 的缓存层。
写流程:首先写日志文件(WAL机制用于故障恢复),然后写 C0,到达一定阈值之后,C0 合并到 C1(刷回)。C0 到 C1 延迟相对较大,数据容易丢,故需要 WAL 机制保证一致性。
读流程:首先读 C0 看是否存在对应的 KV,不存在再去读 C1。
磁盘组件
磁盘组件旨在利用磁盘的顺序读写性能远好于随机读写性能的优势,将数据进行排序,顺序地对磁盘进行 IO。数据结构类似于 B+ Tree,满节点,每一个节点对应数据页。
LSM Tree 中包含两类 Block,Single-Page Block 和 Multi-Page Block。Single-Page Block 其实就是指根节点以及每一层里的单页节点,而 Multi-Page Block 是指根目录下的每个层级上的单页节点序列会被打包,然后一起放入连续的多页磁盘块中(囊括了根节点以下的节点),利于磁盘顺序访问。
内存组件
C0 树不同于 C1 树,由于主要位于内存中,不需要考虑和磁盘交互的数据大小,可以是任意大小,从而充分利用 CPU,所以 C0 树通常不是 B+ 树,一般会是 AVL 树一样的数据结构,效率相对更高。
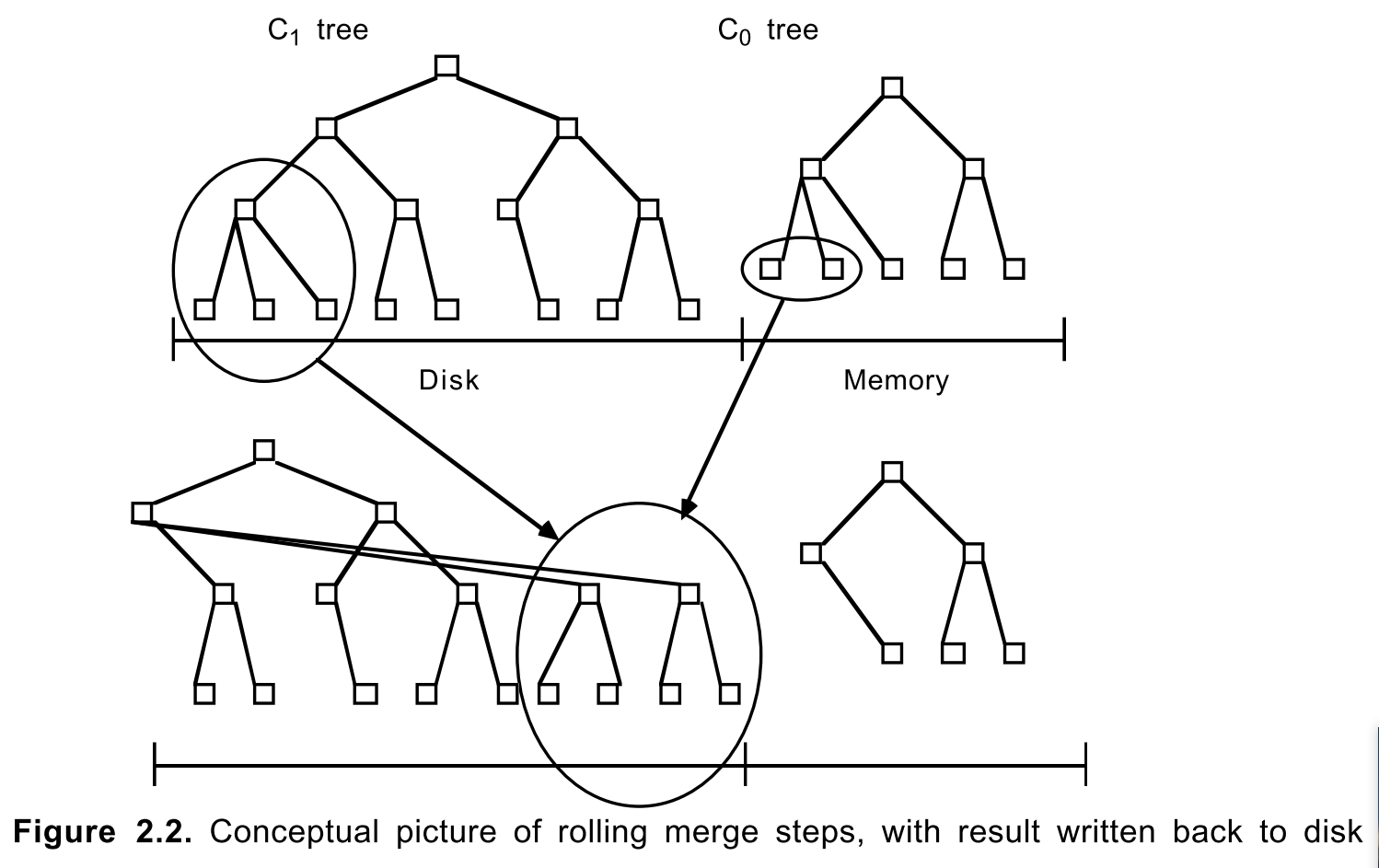
Rolling Merge
先读取包含C1树的叶节点的多页块,这会使得C1中的一系列节点条目驻留到缓存
然后每次合并都会去读取已经被缓存的C1树的一个磁盘页大小的叶节点
接着将第二步中读取到的C1树叶节点上的条目与C0树的叶节点条目进行合并,并减少C0树的大小
合并完成后,会为C1树创建一个已合并的新叶节点(在缓存中,填满后被刷入磁盘)
How a Two Component LSM-tree Grows
Rolling Merge
Process
当增长中的C0树第一次达到阈值的时候
最靠左的一系列条目会以高效批量形式从C0树中删除
然后被重组到C1树(按key递增顺序),将被完全填满
连续的C1树的叶节点会按从左到右的顺序,首先被放置到常驻内存的多页块内的若干初始页上
持续上一步直到该多页块被填满
然后该多页块被刷到磁盘,成为C1树叶节点层的第一部分,常驻磁盘
随着这些连续的叶节点添加的过程,一个C1树的目录节点结构会在内存缓存中被创建(这些上层目录节点被存在单独的多页块缓存或单独的页缓存中,为了更高效利用内存和磁盘。其中还包含分隔点索引,可以将访问精确匹配导向某个下一层级的单页节点而不是多页块,类似B树。这样一来,我们就可在滚动合并或长范围搜索时使用多页块,而在索引精确匹配访问时使用单页节点)
在发生如下情况时,C1的目录节点会被强制刷盘
包含目录节点的多页块缓存满了 -> 只有该多页块会被刷盘
根节点分裂,增加了C1树的深度(大于2) -> 所有多页块刷盘
checkpoint被执行-> 所有多页块刷盘
Others
滚动合并过程中有许多针对一致性和并发访问控制的设计细节。
在磁盘组件 C1 中,合并过程常常会将需要合并的 Multi-Page Block 区分为两种状态,一种是 empty block,即正在取出数据进行合并的 block,一种是 filling block,用于表示现在的合并结果。对应的存在 Empty Node 和 Filling Node,在并发访问时,合并过程中的 Node 将拒绝对该 Node 的其他操作的请求。
一致性的保证则主要体现在合并过后生成的新的数据,仍然需要先写对应的日志文件,再将数据追加写入到磁盘,即存入到磁盘中的新的连续的位置,所以 LSM Tree 中是不存在修改操作的,但是针对老数据对应的块需要进行回收才能保证空间的利用率。
LSM Tree 中本身是受 LogStructured FileSystem 的启发,即将随机小写给转换成批量的顺序写,从而充分利用磁盘的顺序 IO 能力,并减小和磁盘的交互次数。同时其垃圾回收的策略也受 LSF 的影响,由于都是追加写入的方式,需要对以往的老数据块进行垃圾回收。LSF 回收的块可能不全为空,而 LSM 中回收的块全为空,所以 LSM 比 LSF 在垃圾回收方面相对较好。
Log Structured File Systems.
Operations
Query
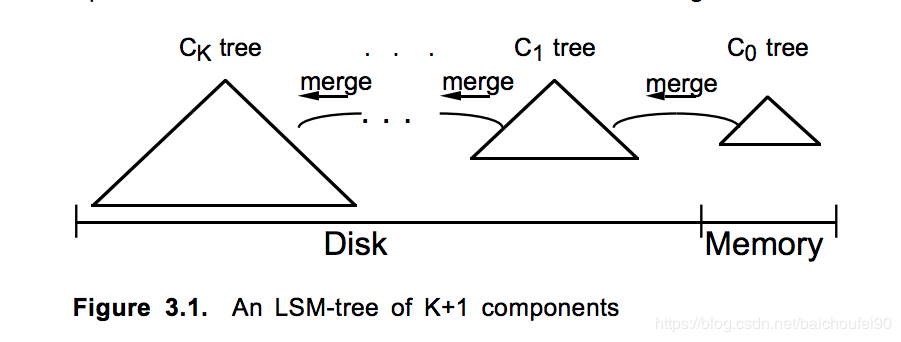
LSM Tree 的查询操作由于存在多个组件,故需要在多个 组件都进行查询,从 C0 到 Ck,为了保证LSM中所有条目都被检查到,就必须让每个精确匹配或范围查找要访问每个Ci组件的索引结构。故后来有很多研究提出了各种各样的对 LSM Tree 写性能的优化方式。
如果记录的生成逻辑就能保证索引唯一性,比如时间戳,那么在较小的一个Ci组件内搜索到结果就可以直接停止搜索直接返回。
再比如,搜索条件中使用了最近的时间戳,我们可以限制搜索范围为那些还没有移动到最大组件的记录所处的序号小的组件上。当合并游标在(Ci,Ci + 1)对中循环徘徊时,我们通常有理由保留Ci中那些最近插入的条目(比如在最近τi秒内),而只允许那些较旧的条目移动到Ci+1中。
在最频繁的查询指向最近插入的值的这种场景中,许多搜索都可在C0树中就完成,这样就使得C0树完全发挥了了自己的内存缓存价值。这是十分重要的性能优化策略。举个例子,被用作短期事务UNDO日志索引,在中止事件中被访问,在创建这些索引后会有大比例是访问短期内的数据,所以我们可以预期大多数这样的索引会驻留在内存中。
通过跟踪每个事务的开始时间,我们可以保证在最后的τ0秒内启动事务的所有日志,例如,将在组件C0中找到,而无需搜索位于磁盘的其他LSM树组件。
Delete Update
删除操作则是新写入一个指定索引的删除状态,在后期进行滚动合并时相应地针对该删除状态和对应的数据进行处理,合并到更大的组件中或者比较对应的数据块无效,在进行查询时对应地进行过滤,垃圾回收时相应地清空对应的存储空间。
更新操作则需要根据实际情况进行区分,如果只改value,相应地更改对应索引地址的数据,如果修改ID,即一些会影响数据索引的操作,则将修改操作对应的转换为 删除+插入。
相关参数理论计算
并发访问
并发问题
查询操作不能同时去访问另一个进程的rolling merge正在修改的磁盘组件的节点内容
针对C0组件的查询和插入操作也不能与正在进行的rolling merge的同时对树的相同部分进行访问
从Ci-1到Ci的rolling merge的游标有时需要越过从Ci到Ci+1的rolling merge的游标,因为数据从Ci-1移出速率>=从Ci移出的速率,这意味着Ci-1所关联的游标的循环周期要更快。因此无论如何,所采用的并发访问机制必须允许这种交错发生,而不能强制要求在交会点,一个进程(移出数据到Ci的那个)必须阻塞在另一个进程(从Ci移出数据的那个)之后。
磁盘组件并发问题
LSM树中用于并发控制访问基于磁盘的组件而导致冲突,所以加锁的单位是树的节点:
正在因滚动合并被修改的节点会被加上写锁。滚动游标使用的写锁会在合并到更大的组件后被释放
正在因搜索而读取的节点会被加上读锁。叶节点上的条目被扫描完了,就会释放
为了防止死锁,设计了目录锁相关方法
内存组件中,假设数据结构为 2-3 树。可以用写锁锁住2-3树的目录节点一个子树,该节点包含要合并到C1节点时受影响范围内的所有条目; 同时,查找操作会用读锁锁定那些处于搜索路径上的2-3树的所有节点,这是一个排他锁。
简书: AVL树,2-3 树,红黑树 为了提高并发,前面章节提到过的C1树的empty block和filling block都会包含整数个C1树中的页大小的节点,并驻留在内存。在合并重组节点时,这些节点会被加上写锁,以阻止对这些记录的其他类型并发访问。
内存组件到磁盘组件的并发
前面讨论的都是基于磁盘的组件间merger时的并发情况,现在说说C0到C1的合并时的并发情况。与其他合并步骤相同,CPU应该专注于合并任务,所以其他访问会被排他的写锁拒绝,当然这个时间会尽可能短。那些会被合并的C0条目应该被提前计算、提前加写锁。除此之外,CPU时间还会由于C0组件以批量的形式删除条目节省时间,而不是每次单独删除而尝试再平衡;C0树可以在整个合并步骤完成后被完全的平衡。
Failover
借鉴了 Log Structured File System 中的 Checkpoint 机制,LSM 中的故障恢复主要是为了保证在 Rolling Merge 过程中可能产生的数据丢失,设置 Checkpoint 则是在某一次 Rolling Merge 之前插入一条对应的日志记录,该日志主要保存此次 Rolling Merge 中插入的相关数据,以及原本缓存在内存中的磁盘组件的相关数据(即一些 Rolling Merge 依赖的磁盘组件上的数据)。
具体流程参考:https://www.cnblogs.com/siegfang/archive/2013/01/12/lsm-tree.html
Summary
LSM 树借鉴了 LSF 的思想,相比于 B Tree,写性能表现更好,主要归功于采用了批量延迟写的方式,同时利用了磁盘顺序 IO 远好于随机 IO 的特性,从而充分利用磁盘的性能。而在数据检索方面,由于多级结构的存在,导致数据的查询效率不高,LSM 更多的是做了内存和磁盘成本的折中妥协。
后续大量研究都从优化 LSM Tree 的读性能,以及优化 Compaction(Merge)过程带来的性能损失为目标,包括一些具体的工业实现 BigTable, LevelDB, RocksDB。
参考链接
Extend
x
感谢您的支持,我会继续努力的!
扫码打赏,你说多少就多少