该篇文章来自于 ATC2020 Best Paper PinK: High-speed In-storage Key-value Store with Bounded Tails
论文其实是基于一种新的 KV 存储形式 KV-SSD 开展研究的,KV-SSD 近年来常被提及,未来可能作为一种新型存储器件在键值存储系统中使用。
本文的工作主要实现了基于 LSM-Tree 的 KV-SSD,和基于哈希的 KV-SSD 进行了对比。
Abstract
KV 存储的实现主要有 LSM-tree 和 HASH 两种,但相关学术研究和工业应用中 LSM Tree 因为支持更多的操作以及更好的写性能,相比于 HASH 更受欢迎。但是,在资源有限的 KV-SSD 环境下,LSM-tree 很难实现,故 KV-SSD 的环境下常常使用 HASH 实现。
我们提出了 PinK ,一种基于 LSM-tree 实现的 KV-SSD,相比于基于 HASH 实现的 KV-SSD,99th 尾延迟降低了 73%,平均读延迟增加了 42% 但吞吐量提升了 37%。
在资源受限的环境下提升 LSM-tree 的性能的核心思想是 避免使用 BloomFilter,使用少量的 DRAM 来 keep/pin LSM-tree 的顶层数据。
Introduction & Background
KV Store
现有的优化方案
Algorithm:
ATC19 Best Paper - SILK:通过调度 compaction 和带宽分配来集中优化 write 长尾延迟
SIGMOD18 - Dostoevsky:控制 merge 频率在 tiering、leveling 和 lazying leveling 几种不同策略下转换以适应不同的workload
SIGMOD17 - Monkey:对每一层的布隆过滤根据数据规模的大小分配不同的内存空间,从而最小化所有层布隆过滤的假阳率。
System:
VLDB10 - FlashStore:内存维护 HashTable 索引,使用签名代替 Key,CuckooHash 解决冲突,KV 以日志结构形式存储,使用 Flash Memory 作为非易失缓存
FAST16 - WiscKey:KV 分离,Key 存 LSM-Tree,Value 存 Log
Eurosys14 - LOCS:
Architecture:
VLDB16 - Bluecache:基于闪存的分布式KV Store系统,使用了 FPGA
NAND Flash-based SSD
SSD 的具体结构请参考其他博文。eg.
一个比较关键的点,也是本文涉及到的点:FTL 中维护了由 LBA 索引的映射表,对应地指向响应的 flash page。映射表保存在 SSD 控制器 DRAM 中,DRAM 大小通常为 SSD 容量的 0.1%。映射表需要持久化,所以会使用到 SSD 内置的电容来防止突然的断电故障。
KV-SSD
近年来学术和工业界都在考虑将 KV 存储的相关功能从软件层面转移到硬件存储设备层面。
为什么要引入 KV-SSD ?传统的 KV 存储不能完全发挥新型存储器件的性能,如很多支持 NVMe 的设备,结合之前 SOSP19 的一篇论文 [2] ,发现 KV Store 的 bound 已经从磁盘转移到了 CPU,故考虑引入 KV-SSD 来降低 KV 存储对 host 侧的 CPU 和 DRAM 的高占用率,同时减小 I/O 延迟并提高吞吐量。KV SSD 支持的接口对应的规范:全球网络存储工业协会发布的 https://www.snia.org/tech_activities/standards/curr_standards/kvsapi
设计实现 KV-SSD 的两大挑战:有限的 DRAM 资源和有限的 CPU 资源
工业界
Samsung KV-SSD :直接处理 KV 请求,参考文献 [1] 。通过简化软件存储堆栈和合并冗余,KV-SSD 提供了更好的可伸缩性和性能,从而降低了总体 CPU 使用量并将内存释放给用户应用程序。
学术界
ASPLOS19 LightStore: Software-defined Network-attached Key-value Drives :使用 LSM-Tree 实现协议转换,并实现了和数据中心网络直连
KAML: A Flexible, High-Performance Key-Value SSD 实现了内部事务处理、更细粒度的锁和和缓存层
Towards Building a High-performance, Scale-in Keyvalue Storage System.
NVMKV: A Scalable and Lightweight Flash Aware Key-value Store
Bluecache: A Scalable Distributed Flash-based Key-value Store
HASH-Based KV-SSD
SSD DRAM 中维护一个 hashtable, hashtable 有很多个 buckets,每个 bucket 对应的保存了元数据(key 和指向 value 的指针)。假设 Key 为 32B,Value 为 1KB,假设 4TB 的 SSD 中的 bucket 数量为 2 32 2^{32} 2 3 2 36 B ∗ 2 32 = 144 G B 36B * 2^{32}=144 GB 3 6 B ∗ 2 3 2 = 1 4 4 G B
为了降低 DRAM 使用率,可以使用哈希签名来代替 KEY,实际的 KEY 和 Value 一起存储在 flash 中,即便是使用 16bit 的签名还是需要 24GB 的 DRAM,且可能产生签名冲突。所以只能保存部分热数据索引到 DRAM 中,剩余部分需要保存在 flash 中,但是引入了额外的 flash 读取开销。
现在的 KV-SSD 存在的问题
从现如今的 KV-SSD 表现出来的效果来看,在尾延迟和吞吐量方面表现都是 inconsistent (注:至于这个 incosistent 怎么理解,可以看后文的具体描述,大胆猜测一下应该是类似于 unpredictable 的意思 )
现在的 KV-SSD 主要都是基于 HASH 实现的,因为 HASH 实现起来相对容易,但是也就带来了一些局限。基于 HASH 实现的 KV-SSD 主要是在对应的磁盘控制器(DRAM)中维护了一个 HashTable,相应的操作本质就是查表以及对表的管理,但是由于 KV-SSD 的 DRAM 容量有限,数据量大的时候肯定会有部分数据需要放在 Flash 上,简单快速的 DRAM 内查表工作就可能退化成开销较大的访问 FLASH 的查表,同时还需要实现比较复杂的空间管理机制(何时访问 FLASH 进行空间置换,诸如此类)。如果产生了 HASH 冲突,可能就需要访问很多次 FLASH,导致长尾延迟以及吞吐量的下降。
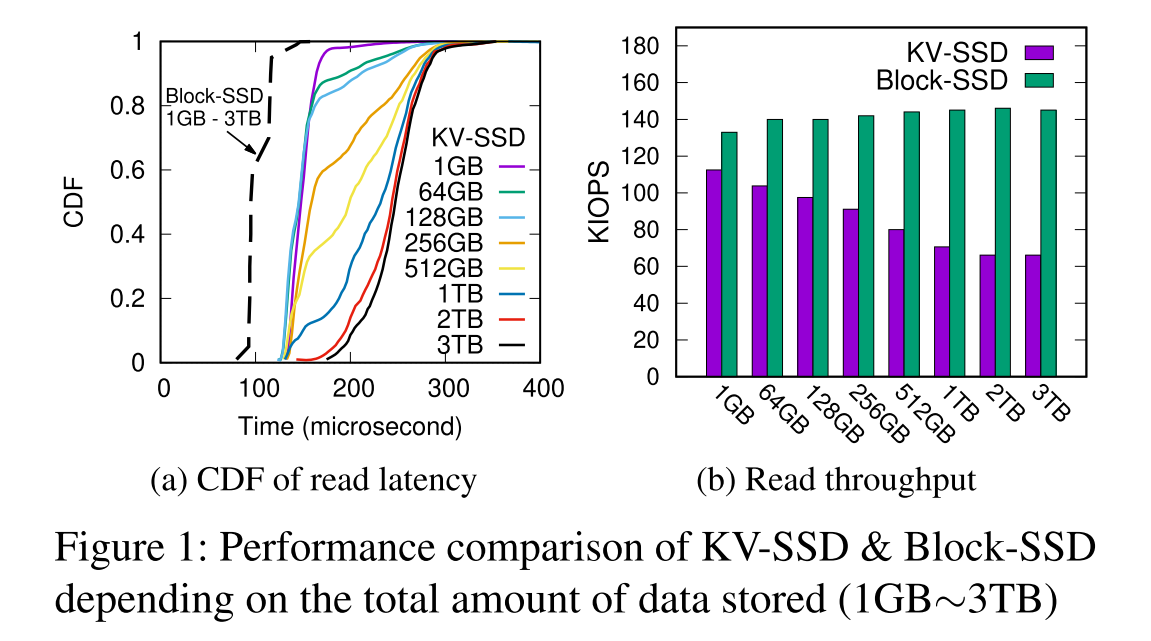
光纸上谈兵不行,做个实验:4TB KV-SSD prototype (KV-PM983),KV pools 从 1GB 到 3TB,平均大小 Key-32B,Value-1KB,3TB 的池对应就可以有 30 亿个 KV。负载 KVBench 10 分钟随机 GET(期间无 GC)。对比测试,对照了使用 4TB Block SSD 和 FIO 测试。
实验结论:在基于哈希的 KV-SSD 实现中,随着存储的 KV 对总数的增加,性能和尾延迟会变得更差,还不如 Block SSD 稳定。(分别测试了 CDF 累积分布函数和吞吐量)
incosistent 的性能表现可能是因为低效的 HASH 冲突解决策略引起的。可以考虑使用最坏情况下常数级的查询的哈希冲突解决策略,如 Cuckoo Hash, Hopscotch 等,来避免长尾延迟,但是这种好处是以降低写入速度和/或频繁重复哈希为代价的。且 HASH 不支持 range query。
性能随着容量的增加显著下降的原因主要是 DRAM 容量的限制导致索引数据太大,不得不频繁访问 Flash
解决方案
从 DRAM 资源有限的角度来考虑,LSM-tree 提供了更好的性能。
在 KV-SSD 中比较常用的 LSM-tree 实现为 LightStore [ [3]] 和 iLSM-SSD [4]
考虑使用 LSM-tree 替代 HASH,因为 LSM-tree 需要使用的 DRAM 更小,对范围查询的支持也较好。但是实验显示,使用了常见的 LSM-Tree 实现的 KV-SSD 并没有表现出预期的效果,在有些场景下甚至比 HASH 性能还差。
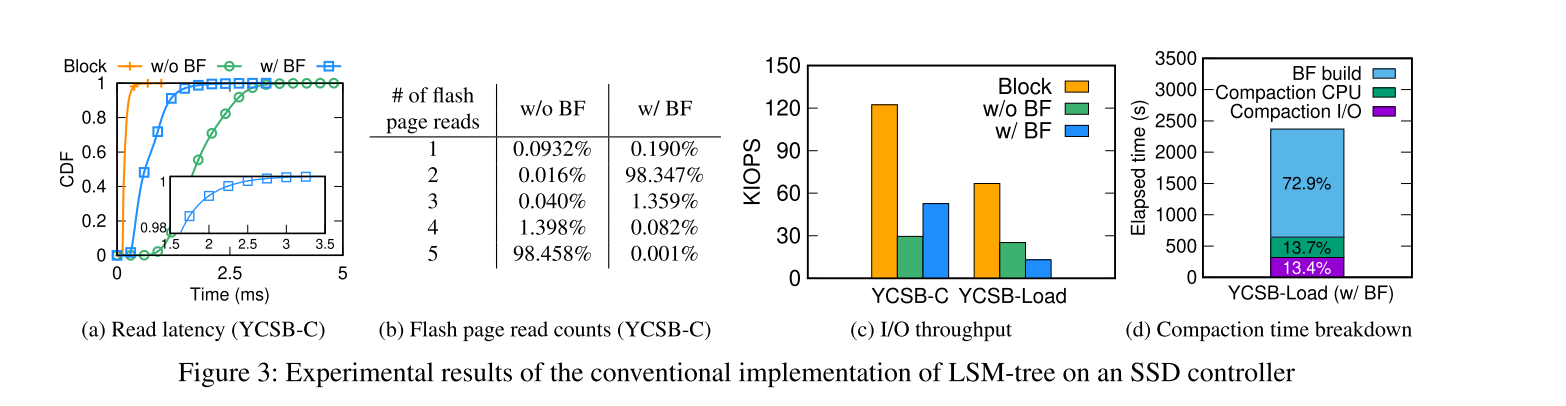
测试结果,如图所示。
没有 BloomFilter,LSM-tree KV-SSD 显示出了比 BlockSSD 更高的延迟。
使用 BloomFilter 会显著降低读的层级数,平均进行一次 flash 上的 page read 就可以读取到数据,读延迟比不带 BloomFilter 更好,但是尾延迟更严重(因为概率性的数据结构导致大约有 1.4% 的读操作会需要超过一次的 flash lookup)。
YCSB-C 的负载下,吞吐量的表现上,带 BloomFilter 的 LSM-tree KV-SSD 不到 Block-SSD 的一半(因为为了获取KV索引来为GET()服务, Monkey 需要两次 flash 读取)。
YCSB-Load 负载下,吞吐量严重下降,主要是因为 GC 产生了影响。我们发现为 GC 移动有效页面涉及到 LSM 树维护的 KV 索引的级联更新。
CPU 的开销,重建 BloomFilter 的开销占据了很大的比重。
通用的 LSM-tree 方案存在的问题
尾延迟: 虽然很多 LSM-tree 实现都使用了 BloomFilter 来改善平均读延迟,但因为 BloomFilter 是概率型数据结构,对于最差的情况下的尾延迟还是没有办法改善,就会出现和 HASH KV-SSD 一样的长尾延迟的情况。严峻的写放大: LSM-tree 本身的问题(压缩会导致 GC,GC 导致更多的 I/O,加剧写放大),应用在 KV-SSD 中可能还会加剧 FTL 的 GC 开销。CPU 占用率高: 这个也是 LSM-tree 本身存在的问题,现在用于 KV-SSD,本身存储设备的处理性能就有限,LSM-Tree 的 filter rebuild 以及 KV 对的压缩排序都需要花费大量的时钟周期,很容易导致 KV-SSD 的控制器处理单元过载,从而显著影响 I/O 性能
本文的方案
Pink :核心思想为 level pinning ,即通过将 top levels 的键值索引 pin 到 DRAM 中来代替 BloomFilter (注:看着是不是很懵,可能直接看设计部分好点,但就暂时理解为 DRAM 里放了个索引来代替了布隆过滤器吧 )因为没了 BloomFilter,使用了 DRAM 内的索引,带来了两个直接的好处:延迟变得 predictable;减少了资源占用。
其他优点主要体现在:
压缩过程减小了对 flash 的 I/O,因为 DRAM 索引排序不需要 I/O 操作,且该索引由内置的电容来保证持久性;
可以批量延迟更新 DRAM 中的 LSM-tree 索引,从而减小 GC I/O 次数;
添加硬件比较器来参与 sort 操作,而无需 CPU 介入,减小 CPU 开销。
注:这儿可能看着还比较抽象,等着看下文的详细设计部分吧
Design
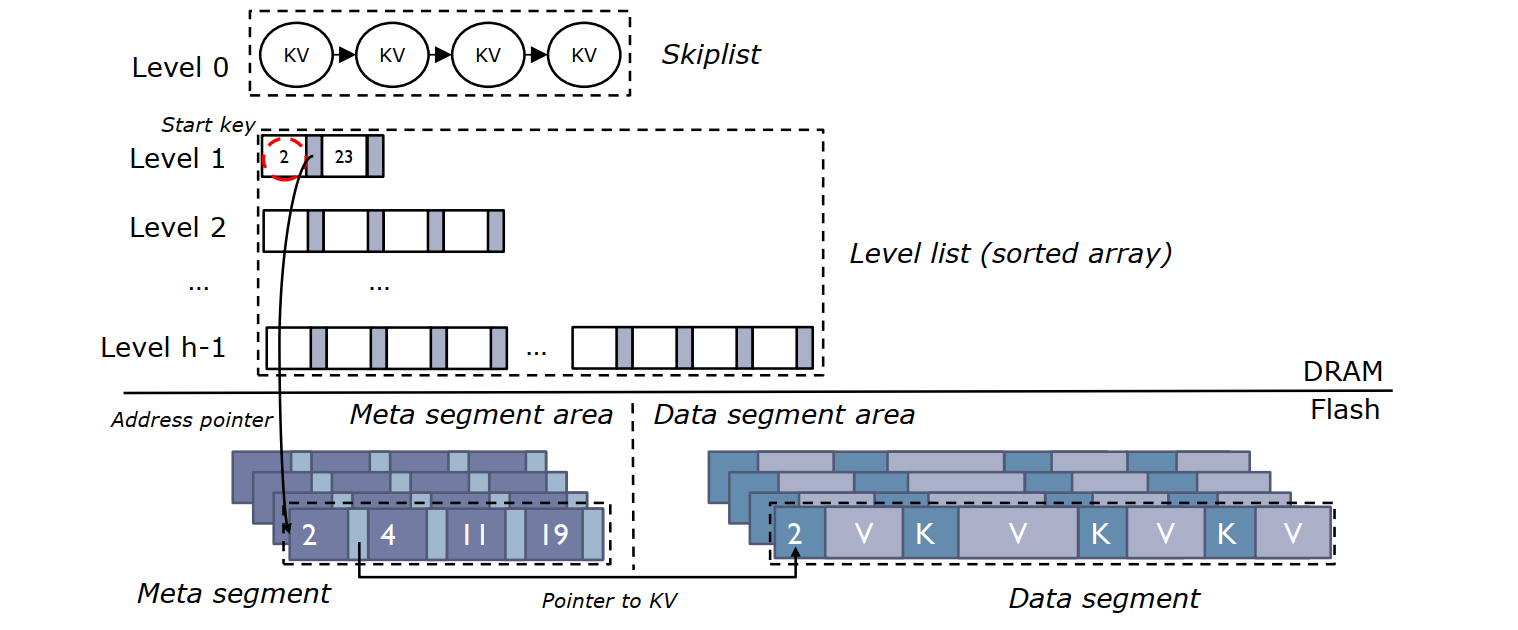
Data Structure
DRAM :a skiplist 和 level lists (由 SSD 电容保护)
skiplist:类似于 write buffer,通常配置的很大以便充分利用 NAND channels 的并行性来向 Flash 刷入数据。对应包含数据 <key size, key, value size, value>
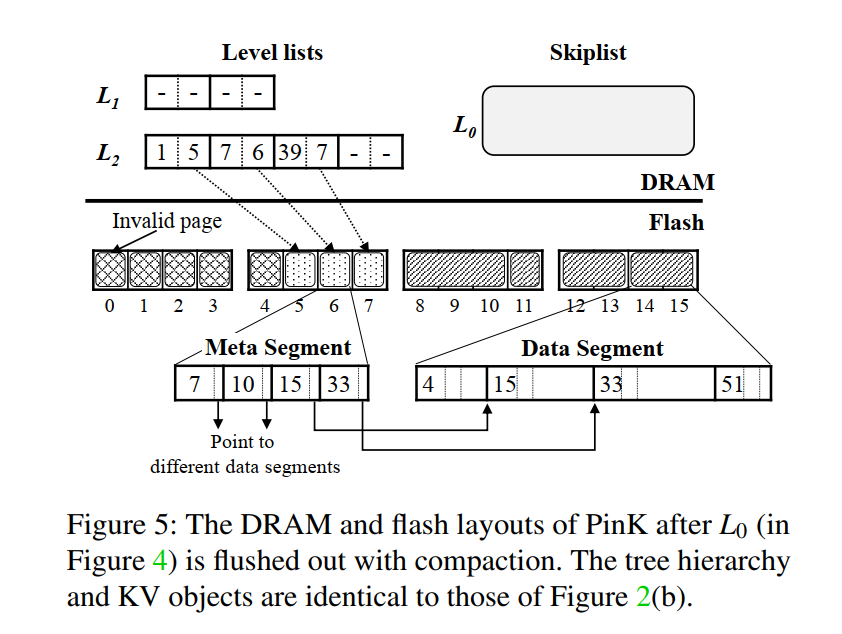
level lists: 每一层被组织成为了具有确定大小指针对组成的数组,第一个指针指向 meta segment 在 flash 中的物理位置,第二个指针指向对应 meta segment 的开始 key。所以 meta segment 的起始 key 被单独存储在了 DRAM 中,
FLASH :meta segments 和 data segments
skiplists 满了之后,元数据和数据分离,刷入到 Flash,元数据包含指向对应数据的指针,数据段中存储了 KEY 以及 Key Size 便于 GC。元数据段大小被固定为 flash page size,但数据段可以是任意大小
meta segment: 由一组 <key, pointer> 组成,按 key 排序,加上一个 header,key 大小可变 16B-128B,,为了利用二分查找,所以维护了 <key, pointer> 的起始位置在 header 中。
和 HASH 相比,PinK 需要使用的 DRAM 更少
Improving I/O Speed with Level Pinning
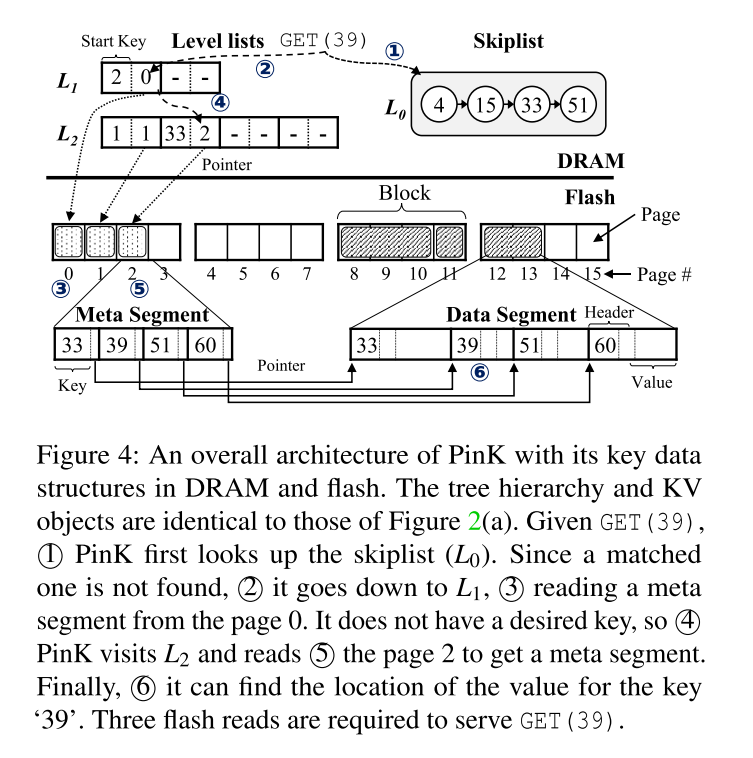
缓解读延迟 :最差的情况下,PinK 需要 O ( h − 1 ) O(h-1) O ( h − 1 ) Level pinning 来代替布隆过滤器,简单粗暴地可以理解如果 LSM-tree 有 h 层,PinK 直接把 top-k 层对应的 meta segments 给放在 DRAM 中。对于读操作,首先看 DRAM 中的 top-k 层有没有该 Key,没有再访问 flash。此时最糟糕的情况下的复杂度降低为 O ( h − k − 1 ) O(h-k-1) O ( h − k − 1 ) Level-pinning 内存需求 :假设 4TB SSD,共 5 层,可以根据 SSD 中 DRAM 的大小来考虑实际需要缓存多少层 meta segement。减少压缩 I/O :因为 meta segment 被缓存在内存中,所以可以直接更新,且不用刷回,因为有电容保护。
理解
图 5 表示了压缩后的数据布局。假设 L1 被固定到了 DRAM,在 L0 刷回之前,首先从 L1 中找到相应的 meta segments(读次数 - 1 )。即图示中的 Page 0,然后进行归并排序,从而得到两个有序的 meta segments,这两个 meta segments 再相应地刷到 L1(写 - 2 )(即图5 中的 Page 3 和 4)。相应地更新 level lists。然后发现 L1 层满了,那么需要刷回到 L2,这时候读取 L1 和 L2 的各自两个 meta segments(读 - 2 )(即图 5 中的 Page 1~4,其中 Page 1 和 2 来自 L2,Page 3 和 4 来自 L1),归并排序后然后写到 L2,得到对应的 Page 5~7。
因为 L1 被固定在 DRAM 上,所以省略了对 L1 的三次 flash 读和两次 flash 写
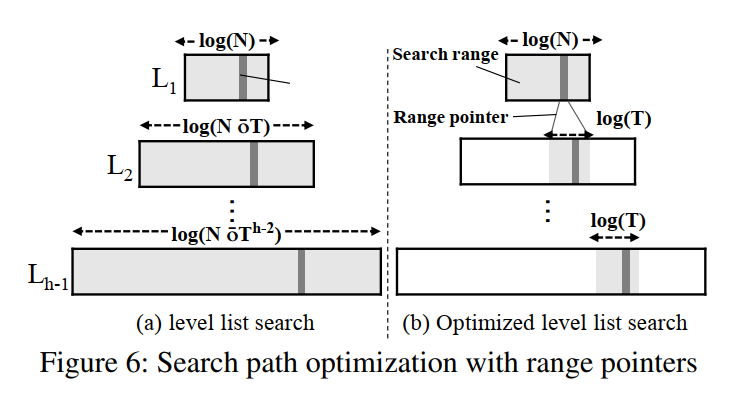
Optimizing Search Path
假设 L 1 L_{1} L 1 L h − 1 L_{h-1} L h − 1 N ∗ T h − 2 N * T ^{h-2} N ∗ T h − 2 O ( h 2 ∗ l o g ( T ) ) O(h^2 * log(T)) O ( h 2 ∗ l o g ( T ) )
为了减小查询的开销,PinK 使用了两个技术:
一个是减少字符串比较的开销,通过使用 key 的前缀,level list 的每个条目都有两个指针,每个指针指向一个 meta segment 和一个 start key string,我们还包含了前缀(即 start key 的前四个字节)。二分查找时,首先比较前缀,只有匹配了才会匹配整个字符串。
通过借用分级级联技术来减少 level list 的搜索范围。level list 的每一个 entry 都会再有一个 4-byte 指针,称之为范围指针,该指针指向下一层的最大的起始 key 但是小于或等于当前 entry 的 key 的位置。例如,在 L 1 L_1 L 1 e L 1 i e_{L_1}^i e L 1 i e L 1 i e_{L_1}^i e L 1 i L 2 L_2 L 2 e L 1 i + 1 e_{L_1}^{i+1} e L 1 i + 1 O ( l o g T ) O(logT) O ( l o g T ) O ( h ∗ l o g ( T ) ) O(h * log(T)) O ( h ∗ l o g ( T ) )
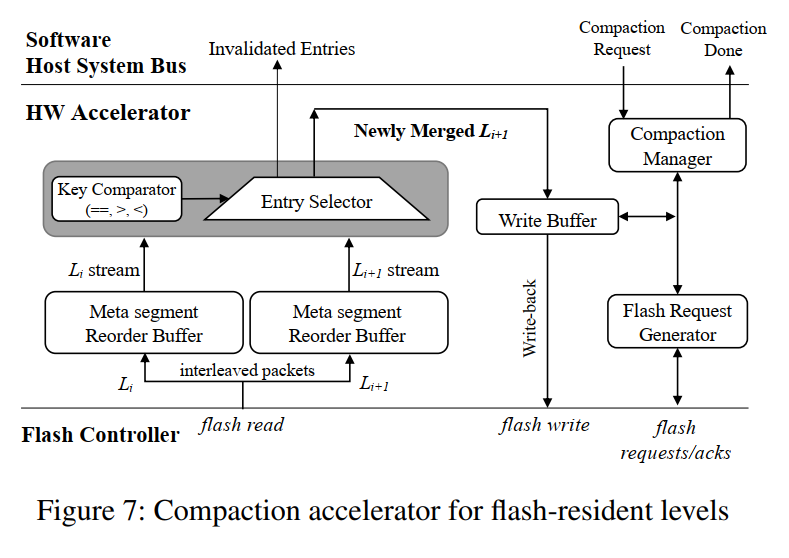
Speeding up Compaction
虽然减少了压缩对应的 I/O 次数,但是在压缩过程中的排序操作仍然需要计算资源的开销。考虑使用 HW accelerator (硬件加速)来缓解主机端的压力。HW 加速器放置在闪存和主机数据总线之间,可以很容易地合并两个位于闪存的 level,因为两个 level 的 meta segment 能够从 flash 中以速度较快的流的形式进行传输。该加速器写合并后的 meta segments 时不需要 CPU 的介入。硬件加速器的引入不仅减小了计算的开销,同时提高了 I/O 总线的利用率,因为不再需要以前那样的 等待合并的以及合并后的数据传输。
如图所示工作流程,PinK 软件首先请求加速器来执行压缩,并提供两个 level 的 meta segments 地址以及合并后写回的 mete segements 地址。flash request generator 会进行调度等待多个读请求以便充分利用 flash 带宽,由于不同 flash 通道的数据包是交错的,我们需要为每个 level 使用每个通道的 reorder buffer 来序列化 meta segment。序列化之后送入 compaction engine,本质是个比较器进行归并排序,将比较后的更小的数据以输出流的形式,使用了小的 write buffer,最终输出到写回地址中,当两个 key 相等的时候,上层对应的数据因为最新将取代另外的数据。操作完成后,将使用了的 meta segments 页号返回,从而由上层决定回收哪些未使用的空间。
对于 pinned levels 的合并是有一个类似的机制,只是使用了 DMA 代替 flash request generator,以及交互的不是 flash 而是 DRAM。
Optimizing Garbage Collection
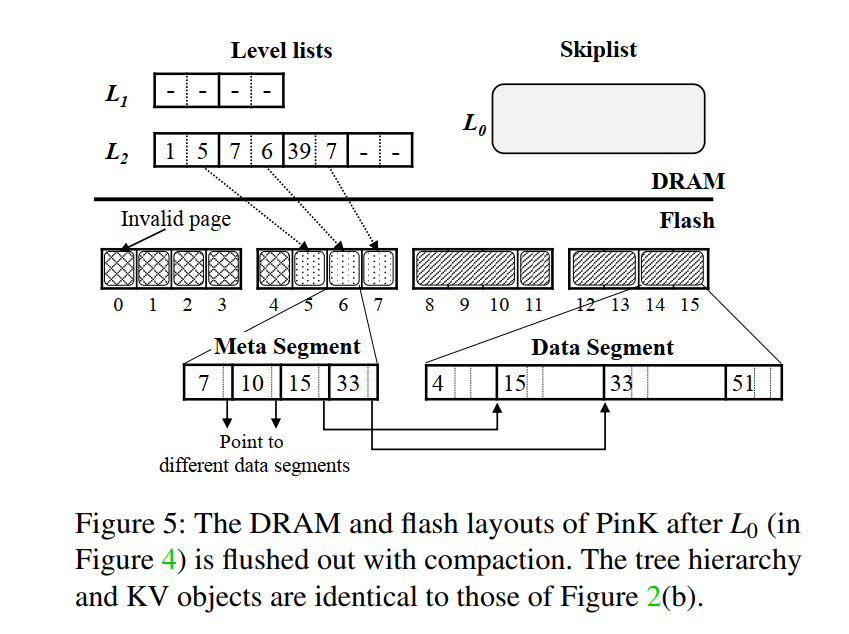
压缩会产生两种垃圾数据:
一种是老旧的 meta segment,当执行压缩时,PinK 写新的 meta segments 数据来替代老旧的数据,如下图所示的 pages 0,1,2。
另一种是过期的 KV 对象,该对象被更新了或者被客户端删除了都变成过期对象,过期对象的索引在压缩过程中会被直接丢弃,所以将没有 meta segments 指向。但是数据部分仍然存储在 data segments 中。
为了擦除老旧的数据,PinK 将在空间接近枯竭的时候触发 GC,选择一个 flash block,将其中的有效数据拷贝到空闲空间,然后擦除整个块。因为冷热分离的原因,meta segment 通常和 data segment 位于不同的块,PinK 通常针对不同块类型采用不同的 GC 策略。
读取页对应的起始键,然后查询 level list 中是否有 entry 指向该键,如果没有则说明是老旧的 segment,直接跳过,如果有则需要将该页迁移到空闲页,然后对该 entry 的更新也将定位到新的页。清理 meta segment 的开销较小,因为只涉及到有效页的拷贝以及 DRAM 中对 level list 的更新。
GC for Data Segment
从选出来的块中扫描一个 data segments,需要将 value 对应的键提取出来,利用 key 才能查询到 level lists 并找到 meta segments,才能检查该 value 的有效性,如果一个 meta segment 没有被 pin 到 DRAM 中,就必须从 flash 中去读,从而可以收集到很多的有效 values。
最简单的方法就是 WiscKey 的垃圾回收思想,收集有效的然后拷贝,然后整块擦除,对应 value 的 meta segment 也需要更新并刷回,从而指向新的位置。如果被 pin 到 DRAM 里了,则不需要写 flash。这种方法会造成会多对 flash 上的元数据更新,其次就是对于一些很久以前写的数据,压缩之后,很有可能一个 meta segment 中包含的对象不在同一个 value segement 或者 block 中,即可能只有很少的 value 被拷贝,但是却要更新对应的 meta segment。
所以 PinK 采用了延迟写的方式,把有效的 KV 再写到 L0,然后擦除整块。垃圾数据静待回收,但是对原有有效数据的访问将被更高 level 处理,即不进行元数据的更新,全部交给 GC,虽然增加了 compaction 开销,但是减少了 mete segment 的更新,因为有效的 KV 对应的元数据被重新整合到了一个 meta segment 中。
GC 过程中会把有的数据放在 L0 层会一定程度上地影响读延迟。
Durability and Scalability Issues
Durability with Limited Capacitor
前面我们默认了使用 SSD 里的电容来保证 SSD DRAM 里的数据不丢,但其实很多 SSD 没有足够的电容来保证 DRAM 里的所有元数据,此时就会有持久性的问题。可以通过将 DRAM 中的数据结构写入 flash 中来解决。L0 的数据可以在处理请求之前写入日志,即写前日志;在执行压缩之后,level list 和 pinned levels 会变成脏数据,需要被持久化到 flash。
无论是写前日志还是脏数据刷回,在 HASH-KV-SSD 中一样需要处理,但是在 LSM-tree-KV-SSD 中可能刷回操作的开销更小,因为写性能 LSM-tree 更好。
DRAM Scalability
我们一开始就假设了 SSD 的 DRAM 容量会随着 flash 的容量的增加而增加,但是 DRAM 的容量增长速度比 flash 要慢,所以可能就没把所有的 levels 给 pin 在 DRAM 中,即只能 pin 部分 levels,相应地也就会增加最坏情况下的查询开销,但即便是最坏情况下,也比使用 HASH 的 KV-SSD 或者使用通用 LSM-tree 的 KV-SSD 表现要好。
另外可以考虑减小树的高度,即让除了最后一层以外的上层结构都放在 DRAM 中,虽然会因为压缩开销的增大一定程度上牺牲写性能,但是能在最坏的情况下将查询复杂度限制在 O ( 1 ) O(1) O ( 1 )
Evaluation
器件:FPGA-based SSD platform with quad-core ARM Cortex-A53 (Xilinx ZCU102)。即使用 FPGA 做硬件加速
负载:YCSB
对比:HASH-KV-SSD, LightStore-KV-SSD, W/O HW PinK
分析
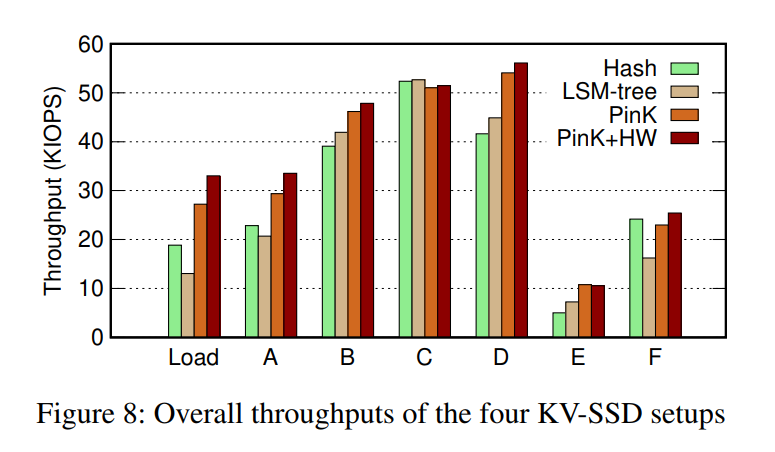
吞吐量显然 PinK 更高,以及 HW 的引入相应地带来了提升。对于有很多写操作的工作负载,PinK 的这些好处是显而易见的,对于读比较多的,就没什么提升。纯粹的 LSM-tree 相比于 HASH 在写敏感负载下表现更差,反而在读上表现更好。
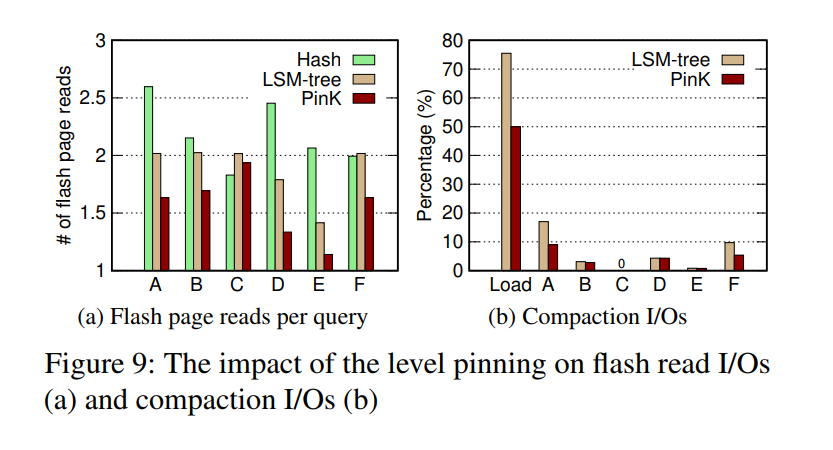
PinK 大幅减小了 flash 的读次数,压缩对应的 I/O 次数也比原始的 LSM-tree 小了很多
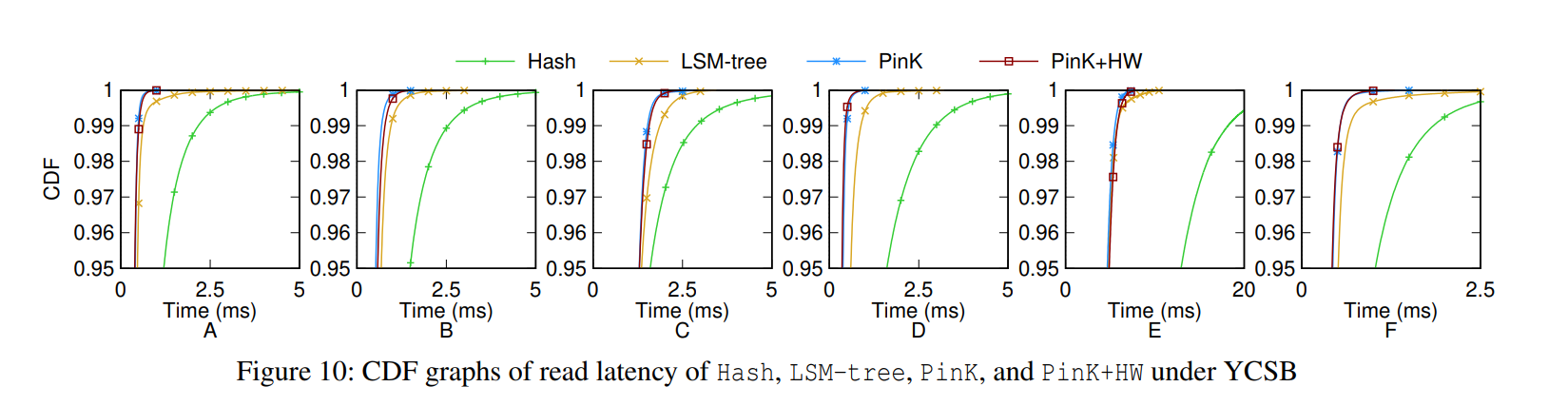
延迟测试情况
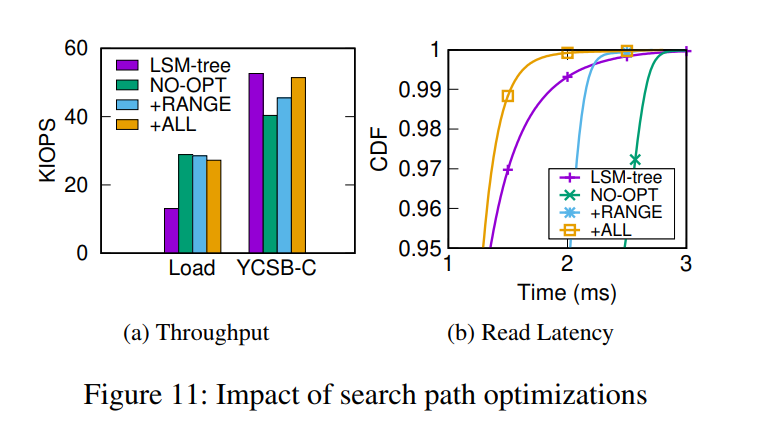
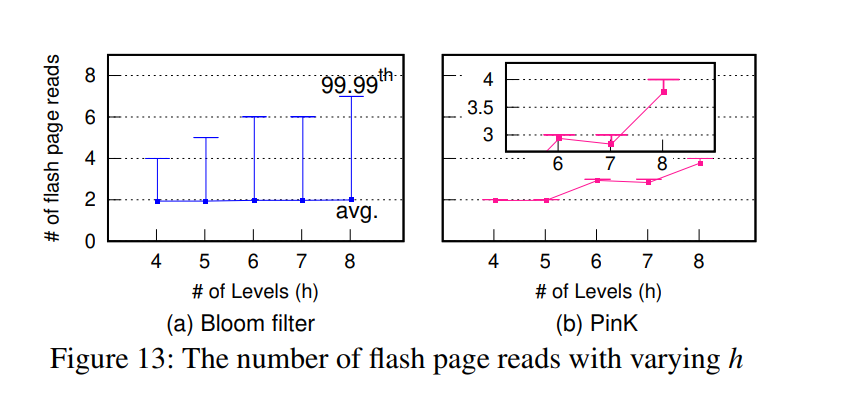
查询优化效果,ALL 是指既包含 range 指针又包含前缀匹配。效果比未优化的 PinK 肯定好很多,但比起 LSM-tree 其实只有尾延迟有一些改善。
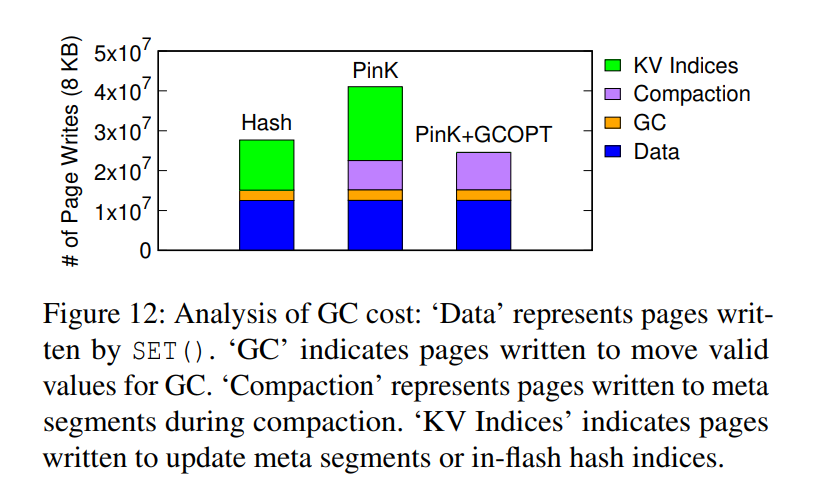
垃圾回收:优化之后效果比 PinK 好很多,甚至比 HASH 还要好
写延迟和高度的关系:PinK 的读延迟更稳定
Conclusion
PinK: 基于 LSM-tree 的 KV-SSD
pinning top level indices 改善了读延迟
使用 HW accelerate 显著减少了压缩的 I/O 次数
未来考虑在 RocksDB 这种通用的 KVS 中贯彻 pinned levels 思想,但可能需要借助 Persistent Memory 来保证主机端的持久性。
References
x
感谢您的支持,我会继续努力的!
扫码打赏,你说多少就多少