- 该篇文章来自于 SOSP2011: SILT: A Memory-Efficient, High-Performance Key-Value Store
Abstract
- SILT (Small Index Large Table) 是一个基于 flash storage 的内存高效、高性能的 KV 存储,可以在单个节点上扩展到数十亿个 KV 项,只要求每个数据项 0.7B 的 DRAM 开销,检索 KV 项时平均使用 1.01 次 flash read。SILT 结合了新的算法和系统技术来平衡内存、存储、计算资源的使用。
Introduction
- 存储发展更快,数据量上去了,内存开销变大了,瓶颈出现在了内存和 CPU。

- 有一些减少内存索引开销的方案,但是这些方案要求每个 KV 项在内存块中的索引超过几个 Bytes,或者以性能为代价只在内存中维护部分索引进一步导致更多磁盘操作。也就是所谓的读放大。
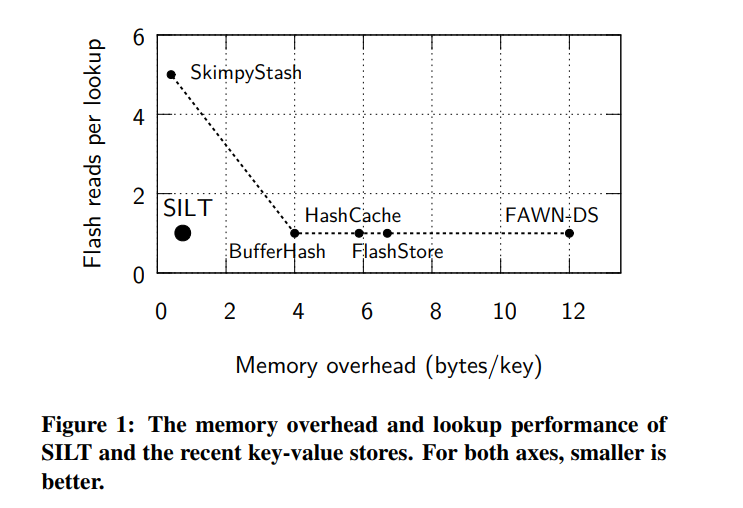
- SILT 很好地平衡了读放大和内存开销。SILT 可以使我们实验系统上的随机读 I/O 饱和,每秒对1024字节的键值项执行 46,000 次查找,并且在单个主机上可能扩展到数十亿个键值项。SILT 提供了几个旋钮来交换内存效率和性能,以匹配可用的硬件。
- Contributions:
- 实现了三个基础的 KV 存储设计,LogStore/HashStore/SortedStore,使用了新的快速的压缩索引的结构(部分键布谷鸟哈希和熵编码尝试),其中的每一个在内存效率和写友好方面都各有侧重。
- 将这三个基础 KV 存储集成在一个构成了 SILT
- 构建了分析模型来平衡内存、存储、计算资源,并给出系统性能、flash 寿命以及内存效率的准确预测。
SILT KEY-VALUE STORAGE SYSTEM
- 与其他键值系统一样, SILT 实现了一个简单的精确匹配散列表接口,包括PUT(将一个新的或现有的键映射到一个值)、GET(根据给定键检索值)和DELETE(删除给定键的映射)。为了简化假设 KEY 是 uniform 分布的 160 位的哈希值(使用 SHA-1 进行了预 HASH),数据是固定长度。在具有有损可压缩数据的系统中,例如图像存储,数据可以自适应地压缩到一个固定大小的槽中。键值系统还允许应用程序从多个键值存储中选择一个,每个键值存储都针对特定的值大小范围进行了优化,所以固定大小是可以接受的。
- SILT 目标:降低读放大、控制写放大并支持顺序写、内存高效的索引结构、CPU 高效的索引结构(索引应该足够快以利用 FLASH I/O)、高校的存储空间的利用。
- 在本节的其余部分中,我们首先探讨 SILT 的高级体系结构,我们将其称为多存储方法,并将其与更简单但效率较低的单一存储方法进行对比。然后,我们简要概述了组成 SILT 的各个存储类型的功能,并展示了 SILT 如何使用这些存储处理键值操作。
- 传统单一存储的办法:在 flash 上构建高性能 KV 存储的通用方法使用了三个组件:
- 内存 filter 在访问 FLASH 之前高效测试是否该 KEY 被存储在存储中;
- 内存索引用于定位 flash 上的数据
- flash 上的数据不错持久化地存储相应的 KV 数据
- 然而据我们所知没有存储系统能同时实现我们的目标,HashCache-Set 将磁盘上的 Keys 组织成了哈希表,忽略了内存索引,但是引起随机写入会降低插入速度。为了避免开销较大的随机写操作,FAWN-DS、FlashStore 和 SkimpyStash 这些系统将 Value 顺序地追加到 log 中,这些系统然后需要一个内存哈希表来将键映射到它在日志中的偏移量(通常每个条目需要 4 字节的 DRAM 或更多),或者在每次查找时使用多次随机读取将部分索引保存在flash上。
- Multi-Store Approach 如 BigTable、Anvil 和 BufferHash 把多种存储链接起来,每个都有不同的属性,比如高写性能或廉价的索引。多存储系统引入了两个挑战,一个是他们要求每个单独存储的高效的设计和实现:它们必须高效、组合良好,并且在存储类型之间转换数据必须高效。第二是当执行查询操作时必须很高效地查询多个存储。每个存储设计必须保持低读放大,不发出 flash 读取。一种常见的解决方案使用一个紧凑的内存 filter 来测试是否可以在特定的存储中找到给定的键,但是这个 filter 可能是内存密集型的。比如 BufferHash 每个项使用 4-6 字节。
- SILT’s multi-store design 使用一系列的基础 KV 存储,每个针对不同的目的进行优化。
- 键被插入到写优化的存储区中,并在其生命周期内流到内存效率越来越高的存储区中
- 大多数 KV 项被存储在内存高效的基础存储中,尽管这个存储之外的数据使用更少的内存效率索引(例如,优化写性能),每个键的平均索引成本仍然很低
- SILT 针对最差的情况下的性能进行了优化——查一下吧在最后一个且是最大的存储中进行查找,最终,SILT 在最后一级存储上可以避免使用内存的 filter,而让所有的查询无论成功与否都执行 1+e 次 flash reads。(e 是可配置的,而且很小)
- 图 2 描述了 SILT 的体系结构和基本存储(LogStore、HashStore和SortedStore)。
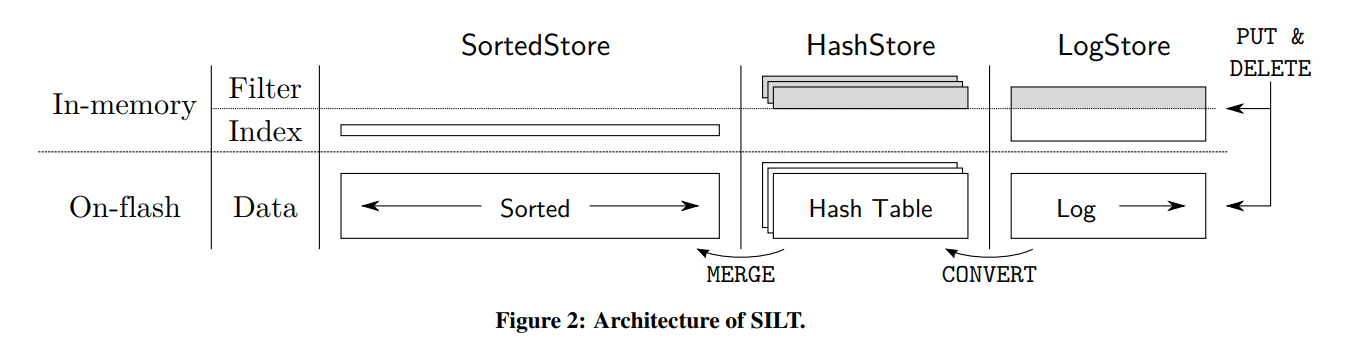
- 表 2 总结了这些存储的特征。

- LogStore 是一个写优化的 KV 存储,单独处理 PUT DELETE 请求,为了实现高性能,写被追加到 flash 的日志文件末尾,为了实现高性能,因为这些数据项是按照插入时间排序的,所以 LogStore 使用了一个内存 HASH 表来映射对应的 Key 和在日志文件上的偏移。这个表同时也是一个内存过滤器。SILT 使用了一个内存高效且高性能的基于 Cuckoo-Hash 的哈希表。partial-key cuckoo hashing 实现了使用非常低的计算开销和内存开销达到 93% occupancy,这是对早期系统(如FAWN-DS和BufferHash)的重大改进,这些系统仅占用了50%的哈希表。但是,与后面的两种只读存储类型相比,这个索引仍然是相对内存密集型的,因为它必须为每个键存储一个4字节的指针。因此, SILT 只使用 LogStore 的一个实例(除非在下文中描述的转换到HashStore期间),使用固定的容量来限制其内存消耗。
- 一旦 LogStore 满了将在后台被转换成不可变的 HashStore,HashStore的数据存储为一个闪存上的散列表,它不需要内存索引来定位条目。在将多个 hashstore 合并到下一个store类型之前,SILT 一次使用多个 hashstore。因此,每个 HashStore 使用一个有效的内存过滤器来拒绝对不存在的键的查询。
- SortedStore 维护了一个在 flash 上按照 Key 排序的 KV 数据,这使得一个非常紧凑的索引表示(例如,0.4 字节每个键) 使用一个新颖的设计和 entropycoded tries 实现。由于在排序数据中插入单个项的开销,SILT 周期性地将几个 hashstore 和一个旧版本的SortedStore 合并,并形成一个新的 SortedStore,在此过程中垃圾收集删除或覆盖的键。
- KV 操作:每个 PUT 操作插入了一个 KV 数据项在 LogStore 中,即使 Key 已经存在。DELETE 操作同样将一个 “DELETE” 条目附加到 LogStore 中。当 SILT 将 hashstore 合并到 SortedStore 时,删除或过时数据所占用的空间将被回收。这些延迟删除就是以闪存空间为代价以提高顺序写性能。GET 操作在 LogStore 中直接查询对应的 Key,然后查找 HashStore 和 SortedStore ,返回在最新的存储中找到的数据。如果找到了 DELETE 标识符,将停止搜索并返回 not found。
- Partitioning:最后,我们发现每个物理节点跑着多个 SILT 实例,主要负责不相交的 KEY RANGE,每个实例都有自己的三种存储。分区提升了负载均衡,在合并过程中减少了 flash 开销,促进系统范围的参数调优。
BASIC STORE DESIGN
LogStore
- LogStore按顺序将put、delete写入flash,实现高写吞吐量。它在内存中的部分键cuckoo哈希索引有效地将键映射到它们在flash日志中的位置,如图3所示。
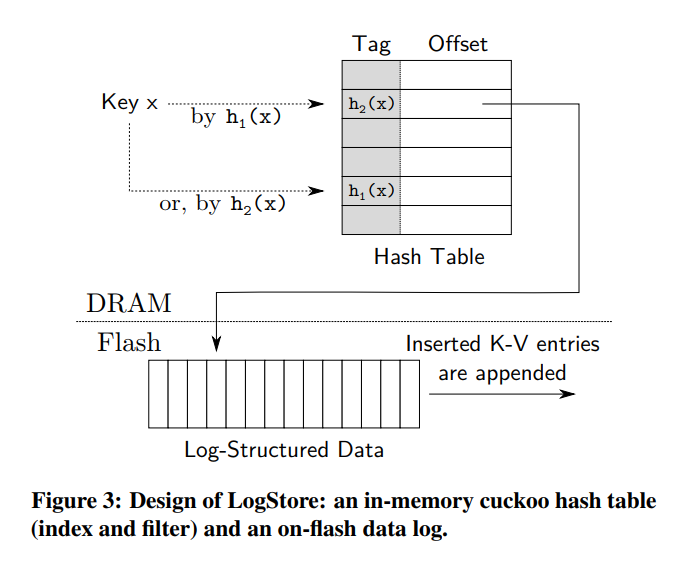
- Partial-Key Cuckoo Hashing:LogStore 基于 cuckoo hashing 使用一个新的哈希表,标准的布谷鸟HASH 使用了两个哈希函数,对应了两个候选的 Buckets,当插入一个新的 Key 时,如果候选的 Bucket 中的一个是空的,Key 就被插入到了这个空的槽中,如果 bucket 都不为空,新的 Key 将驱逐已经存在于这两个 bucket 中的某个 Key,被驱逐的这个 key 然后被插入到自己的可选的 bucket 中(可能会继续驱逐),插入算法一直重复直到找到了空的位置,或者到达了最大驱逐次数(我们的实现中使用了 128 次),如果没找到空的位置,就表明 HASH 表可能已经满了,所以 SILT 冻结 LogStore 并初始化一个新的LogStore,而无需代价高昂的重新散列。
- 为了使它紧凑,哈希表不存储整个键(例如,在 SILT 中存储 160 位),而只存储实际键的tag。只有当给定的键与标记匹配时,才进行 flash 查找,这可以防止对不存在的键进行大多数不必要的 flash 读取。如果标记匹配,则从 log on flash 中检索完整的键及其值,以验证它读取的键是否确实是正确的键
- 虽然只在哈希表中存储标签可以节省内存,但对于布谷鸟哈希来说,这是一个挑战:将一个键移动到它的替代桶中需要知道它的其他哈希值。然而,在这里,完整的键只存储在 flash 上,但是从 flash 中读取它太昂贵了。更糟糕的是,移动这个键到它的替代桶中,可能会替换另一个键;最终,布谷鸟哈希所需要的每一次位移都会导致额外的 flash 读取,只是为了插入一个键。
- 为了解决这个代价昂贵的位移问题,我们的部分键布谷鸟散列算法将备选桶的索引存储为标签;换句话说,部分键布谷鸟哈希使用标签来减少不存在的键查找的 flash 读取,以及指示一个替代桶索引来执行布谷鸟置换而不进行任何 flash 读取。例如,如果 x 是一个键分配给桶 h1 (x),其他的散列值 h2 (x) 将成为其标签,存储在存储桶 h1 (x) ,反之亦然(参见图3)。因此,当一个 key 从桶 a 中驱逐出来, SILT 读取这个桶中存储的标签(value:b), 那么移动 Key 到桶 b,而不需要从 flash 读取。然后它将桶 b 中的标记设置为 value a。
- 为了在表中找到键 x, SILT 检查 h1(x) 是否与存储在桶 h2(x) 中的标签匹配,或者 h2(x) 是否与桶 h1(x) 中的标签匹配。如果标记匹配,则从散列条目中指定的 flash 位置检索(键、值)对
- Associativity:标准的 Cuckoo hash 允许 50% 表项在不肯舍弃碰撞发生之前被占据。SILT 通过增加布谷鸟哈希表的 Associativity 提升 occupancy。每一个 Bucket 容量为 4,也就是说可以包含四个项,实验显示使用一个 4-way 集合关联散列表可以将表的空间利用率提高到约 93%,与已知的各种布谷鸟哈希方法的实验结果相吻合; 此外,4个条目/bucket仍然允许每个 bucket 适合一个 cacheline。
- Hash 函数:SILT 中的键是 100 位的哈希值,所以 LogStore 取键 x 的低阶位的两个不重叠切片来查找 h1(x) 和 h2(x)。默认 SILT 使用了 15 位的 key 片段作为标记。每个哈希表项是 6B,由一个 15 位的 tag,一个有效位,4B 的偏移量指针。假阳性检索的概率是0.024%。平均 4096 个 flash 检索中就有一个是不必要的。hash 桶(不是表项)的最大数量受键片段长度的限制。假定键片段为 15bits,那么哈希表就有 2^15 个桶,以及 4*2^15 个数据项。为了存储更多的 Keys,可以增加键分段的大小来拥有更多的桶,增加 Associativity 来将更多的条目打包到一个桶中,并/或将键空间分区到更小的区域,并将每个区域分配给一个带有 LogStore 的 SILT 实例
HashStore
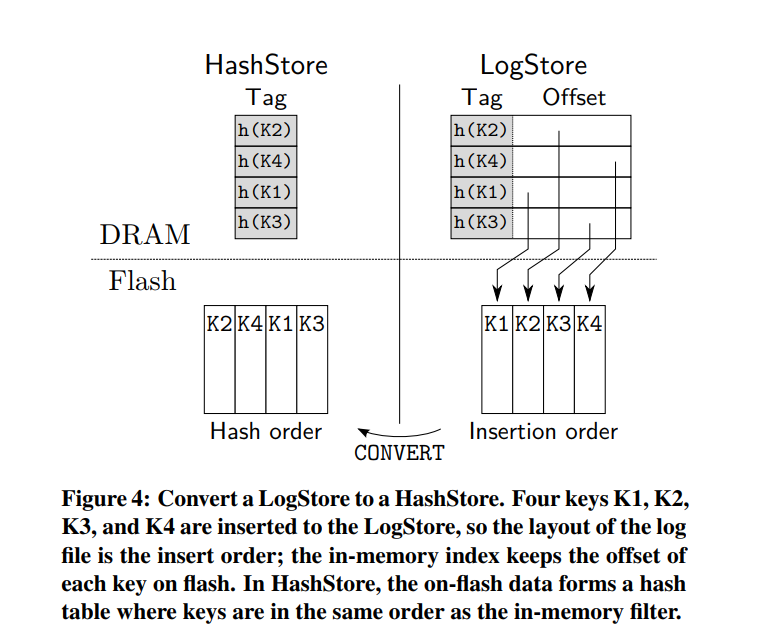
- 一旦 LogStore 满了之后(插入算法结束时,在哈希表中的最大位移数之后没有找到任何空槽),SILT 让 LogStore 保持不变,并将其转换成一个内存更高效的数据结构,直接对相对较小的 LogStore 进行排序并将其合并到更大的 SortedStore 中,需要重写大量的数据,从而导致高写入放大。另一方面,在合并之前保留大量的 LogStore 可能摊销重写的成本,但不必要地引起 LogStore 索引的高内存开销。为了弥补这一差距,SILT 首先将 LogStore 转换为具有更高内存效率的不可变 HashStore,一旦 SILT 累积可配置数量的 HashStore,它执行批量合并,将它们合并到 SortedStore 中。在 LogStore 到 HashStore 转换期间,旧的 LogStore 继续提供查找,而新的 LogStore 接收插入。
- HashStore 通过消除索引并将闪存上的(键、值)对从插入顺序重新排序为哈希顺序来节省内存。因此,HashStore 是一个 flash 上的布谷鸟散列表,其占用率(93%)与在LogStore中找到的内存版本相同。HashStores 也有一个内存组件,它是一个过滤器,用于概率地测试某个键是否存在于存储中,而不执行 flash 查找。
Memory-Efficient Hash Filter
- 虽然之前的方法使用Bloom过滤器进行概率隶属度测试,但 SILT 使用了基于部分键布谷鸟哈希的哈希过滤器。哈希过滤器比Bloom过滤器在低误报率下更内存高效地存储信息。给定一个 4 路集合关联布谷鸟哈希表中的 15 位标签,误阳性率为f = 2^(−12) = 0.024%,如第 3.1 节所计算。对于 93% 的表占用率,使用散列过滤器的每个键的有效位数是 15/0.93 = 16.12。相比之下,一个标准的 Bloom 过滤器通过设置哈希函数的数量来优化空间消耗,至少需要 1.44 log2(1/f) = 17.28 位内存才能实现相同的误报率。
- HashStore 的哈希过滤器也可以高效地创建:仅需按顺序从LogStore的哈希表中复制标记 tag,丢弃偏移量指针;相反,Bloom过滤器应该从头开始构建,再一次散列LogStore中的每一个条目。
SortedStore
- SortedStore 是一个静态的内存占用很小的 KV 存储,在 flash 上按照 Key 排序存储 KV 项,使用 entropy-coded trie 这种可以快速构建的结构来索引,平均每个 Key 使用 0.4B 的内存索引,且通过直接指向 flash 上的正确位置保证读放大很低为 1。
Using Sorted Data on Flash
- 由于这些理想的属性,SILT 将大多数键值条目保存在一个 SortedStore 中。然而,entropy-coded trie 不允许插入或删除;因此,要将 HashStore 条目合并到 SortedStore 中,SILT 必须生成一个新的 SortedStore。因此,SortedStore 的构建速度是影响 SILT 整体性能的一个重要因素。
- 排序提供了一种自然的方式来实现快速构建:
- 排序允许高效地批量插入新数据。可以对新数据进行排序,并按顺序合并到已排序的现有数据中。
- 排序研究。SILT 可以使用高度优化和测试的排序系统,如 Nsort
Indexing Sorted Data with a Trie
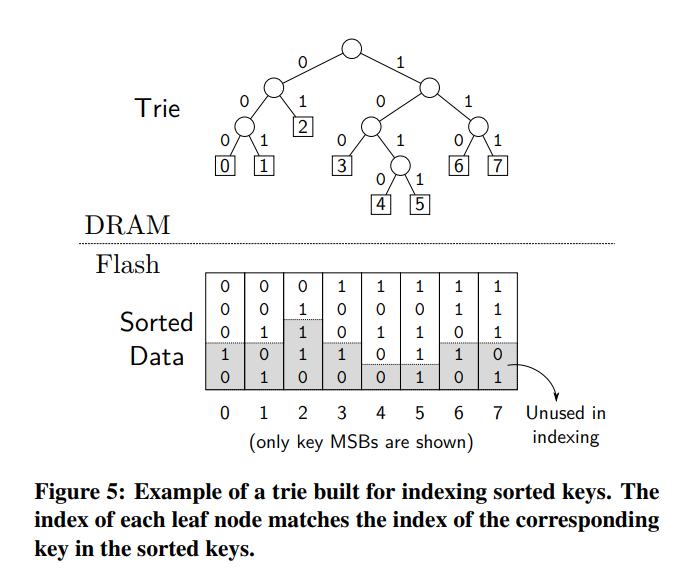
- trie 或前缀树是一种树数据结构,它存储一个键数组,其中每个叶节点表示数组中的一个键,每个内部节点表示其后代所表示的键的最长公共前缀。
- 当固定长度的键值条目在 flash 上按键排序时,trie 键的最短唯一前缀作为这些排序数据的索引。键的最短唯一前缀是键的最短前缀,它可以使键与其他键区分开来。在这样的 trie 中,查找键的某个前缀将我们引向一个叶节点,该叶节点具有查找键在 flash 上排序数据中的直接索引。
- 图 5 显示了一个 trie 索引排序数据的示例。没有阴影的键前缀是用于索引的最短唯一前缀。索引时忽略阴影部分,因为后缀部分的任何值都不会改变键的位置。对键(例如10010)的查找继续向下,直到表示100的叶节点。因为前面有3个叶节点,所以键的索引是3。对于flash上的固定长度键值对,数据的精确偏移量是获取的索引乘以键值对的大小(关于可变长度键值对的扩展,请参见第4节)。请注意,查找具有相同前缀100的类似键(例如,10000,10011)将返回相同的索引,即使它们不在数组中;trie保证对存储的键进行正确的索引查找,但没有说明是否存在查找键。
Representing a Trie
-
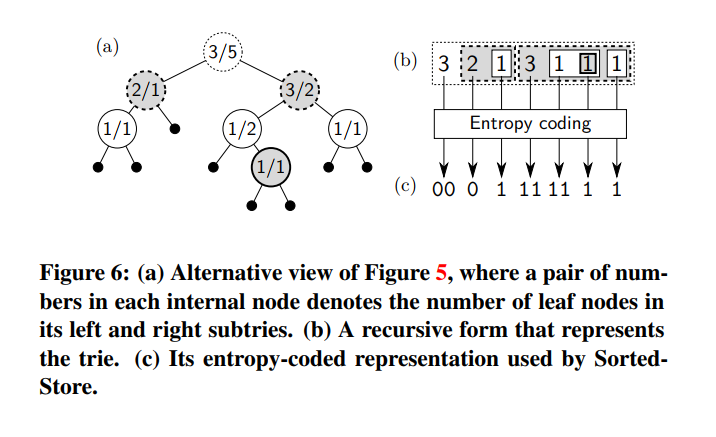
典型的树数据结构不适合 SILT,因为每个节点都需要昂贵的内存指针,每个指针长度为2到8字节。普通的 tries 表示,如级别压缩的 tries,如果它们使用指针也是不够的。SortedStore 使用紧凑的递归表示来消除指针。以 L 和 R 为左右子项的 T 的表示定义如下:$$Repr(T) := |L| Repr(L) Repr(R)$$
-
|L| 是指左边 subtrie 的叶子节点的数量,当 T 为空或者是叶子节点的时候,T 就用空的字符串表示,在简化的算法描述中,我们使用特殊标记(-1)代替空字符串,以保持简洁,但完整的算法不需要使用特殊标记。
-
下图表示了未压缩的图 5 中的 trie 的递归未压缩的表示。因为有三个 Key 是以 0 开始的,那么 |L| = 3,在对应的左子树中, |L|=2,因为有两个 Key 的第二位为 0,所以表示中的下一个数为 2,继续递归左子树,然后为 1。这里没有更多的非叶节点,所以它返回到根节点然后生成根的右子 trie 的表示,3 1 1 1
-
下图所示算法展示了构建该 trie 表示的简化版本。它类似于快速排序,它找到键的分区,然后递归到两个子集中。索引生成速度很快(在现代Intel台式机CPU上每秒7 M个键)

Looking up Keys
- key-lookup 通过递增读取 trie 表示(算法2)来工作。该函数提供了查找键和一个 trie 表示字符串。通过解码下一个编码的数字 thead, SortedStore 知道当前节点是否是一个内部节点,它可以递归到它的子 trie 中。如果查找键指向左子表,SortedStore 将递归到左子表,其表示紧跟在给定的 trie 表示之后;否则,SortedStore 递归地解码并丢弃整个左子项,然后递归到右子项。SortedStore 在递归到右子 trie 的每个节点上求和 thead ;如果查找键存在,则 thead 的总和就是存储查找键的偏移量。

- 例如,要查找 10010,SortedStore 首先从表示中获取3。然后,由于键的第一个位是 1,它会跳过下一个数字(2 1),也就是表示左子表的数字,然后它会继续执行右子表。在右边的子数组中,SortedStore读取下一个数字(3;不是叶子节点),检查键的第二位,并继续递归到它的左子表中。读取当前子trie(1)的下一个数字后,SortedStore通过取左子trie到达一个叶节点。在到达叶节点之前,它只在根节点处取一个右子trie;从根节点的n = 3开始,SortedStore 知道 10010 的数据偏移量是 flash 上的(3 x key-value-size)。
Compression
- 虽然上述未压缩表示平均每个键使用 3 个整数,但对于散列键,SortedStore 可以通过使用 entropy coding 压缩每个 |L| 值轻松地将平均表示大小减少到 0.4 字节/键 (图6 (c))。|L| 的值接近于 |L| 的一半(T中的叶节点数),因为固定长度的散列键均匀分布在键空间中,所以两个子元素存储键的概率相同。更正式的说法是|L| 服从 二项分布(|T|,1/2)。当|L|足够小(例如,小于等于16)时,SortedStore使用基于二项分布的静态全局共享Huffman表。如果|L|很大,SortedStore使用Elias gamma编码来编码|L|与其期望值(例如 |T|/2)之间的差值,以避免使用大型 Huffman 表填充 CPU 缓存。通过这种针对散列键值进行优化的熵编码,我们的熵编码的 trie 表示比之前的最佳递归树编码要紧凑两倍。
- 在处理压缩 trie 时,算法1和算法2被扩展为在每个递归步骤中跟踪叶节点的数量。这在表示中不需要任何附加信息,因为可以使用|T|= |L|+|R|递归计算叶节点的数量。这些算法在|T|的基础上,选择了一种熵编码器来编码len(L)和译码头。值得注意的是,特殊标记(-1)在熵编码时不占用空间,其熵为零
Ensuring Constant Time Index Lookups
- 如所述,查找可能必须对整个 trie 进行解压缩,因此查找的成本将随着键值存储中的条目数量的增加而增加(很大)。
- 为了限制查找时间,根据键的前k位将项划分为 2^k 个 bucket。每个 bucket 都有自己的 trie 索引。例如,使用 k = 10 来存储一个包含 2^16 项的键值存储,每个存储桶预期将包含 2^(16-10) = 2^6 项。由于bucket中所包含的条目不超过 28 个的概率很高,所以解压bucket的 trie 的时间既受一个常量的限制,也很小。
- 这个 bucket 需要在内存中存储额外的信息:(1) 指向每个 bucket 的 trie 表示的指针和(2) 每个bucket中的条目数。通过使用紧凑的 select 数据结构的更简单版本,即 semi-direct-16,SILT 保持这种桶信息的数量较小(小于1位/密钥)。使用 bucket,我们基于 trie 的索引属于一类被称为单调最小完美哈希的数据结构。
Further Space Optimizations for Small Key-Value Sizes
- 对于小的键值条目,SortedStore 可以通过应用稀疏索引来减小 trie 块大小。稀疏索引定位包含条目的块,而不是条目的精确偏移量。这种技术需要在块内进行扫描或二分搜索,但它减少了索引信息的数量。当存储介质有一个最小的可用块大小来读取时,它特别有用;例如,许多闪存设备在块大小下降时提供每秒不断增加的 I/O,但不会超过某个限制(例如512或4096字节)。当为键值大小配置为64字节或更小时,SILT 使用稀疏索引。
- SortedStore 通过修剪 trie 中的一些子元素来获得一个稀疏索引版本。当一个 trie 的子条目都在同一个块中时,trie 可以省略这些子条目的表示,因为省略的数据只给出了条目之间的块内偏移量信息。如果每个块包含 16 个或更多的键值项,则 Pruning 可以将每个键的 trie 大小减少到1位或更小。
Merging HashStores into SortedStore
- SortedStore是一个不可变的存储,不能被更改。因此,合并进程基于给定的hashstore和现有的SortedStore生成一个新的SortedStore。类似于从LogStore到HashStore的转换,HashStores和旧的SortedStore可以在合并期间提供查找
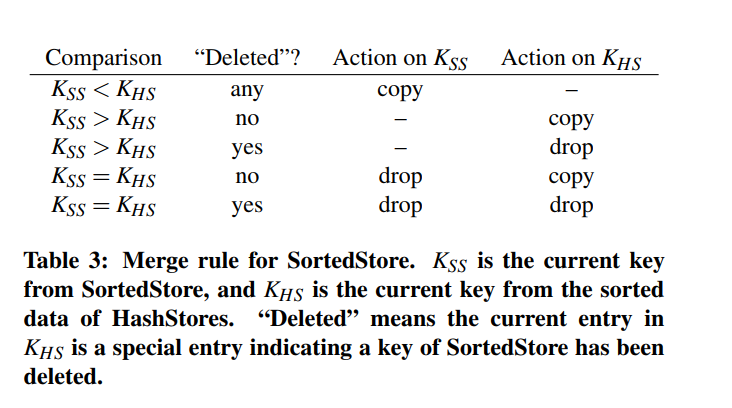
- 合并过程包括两个步骤:(1)排序HashStores和(2)顺序合并排序HashStores数据和SortedStore。首先,SILT 对hashstore中要合并的所有数据进行排序。该任务通过枚举hashstore中的每个条目并对这些条目进行排序来完成。然后,hashstore中的排序数据与SortedStore中已经排序的数据顺序合并。顺序合并选择最新的有效项,如表3所示。对键的复制或删除操作都会消耗键(例如,通过在相应的存储中移动merge指针),而如果没有对键应用操作,则当前键仍然可用,以便再次进行比较。在完成这两个步骤之后,旧的SortedStore将自动被新的SortedStore取代。在合并过程中,旧的SortedStore和新的SortedStore都存在于flash中;但是,通过同时在单个 SILT 实例上执行合并进程,临时使用两个 sorted store所带来的闪存空间开销会保持较小。
Application of False Positive Filters
- 由于 SILT 只为每个 SILT 实例维护一个 SortedStore,因此 SortedStore 不必使用假阳性过滤器来减少不必要的 I/O。然而,对 SILT 体系结构的扩展可能有多个 sortedstore。在这种情况下,trie 索引可以很容易地容纳 false positive filter;筛选器是通过从已排序的键中提取键片段来生成的。键片段可以存储在内存数组中,以便它们与flash上排序的数据具有相同的顺序。扩展的 SortedStore 可以在从 flash 中读取数据之前查阅键片段。
EXTENDING SILT FUNCTIONALITY
- 比起我们所描述的基本设计,SILT 可以支持更广泛的应用程序和工作负载。在本节中,我们将介绍扩展 SILT 功能的潜在技术。
Crash Tolerance
- SILT 确保其所有内存中的数据结构都备份到 flash 和/或在失败后容易地重新创建。LogStore 的所有更新都按时间顺序附加到闪存日志中;为了从故障停止崩溃中恢复,SILT 只是回放日志文件来构造内存中的索引和过滤器。对于静态的 HashStore 和 SortedStore,SILT 将它们的内存数据结构的副本保存在闪存上,可以在恢复期间重新读取。
- 然而,SILT 的当前设计并不为数据存储的新更新提供崩溃容忍度。这些写操作是异步处理的,因此对 SILT 的键插入/更新请求可能在将其数据持久地写入闪存之前完成。对于需要这种额外级别的崩溃容忍度的应用程序,SILT 将需要支持额外的同步写模式。例如,SILT 可以延迟从写调用返回,直到它确认所请求的写已完全刷新到 on-flash 日志。
Variable-Length Key-Values
- 为简单起见,我们目前提供的设计主要关注固定长度的键值数据。实际上,通过使用内联间接方式,SILT 可以很容易地支持变长键值数据。这个方案遵循现有的具有固定大小插槽的 SILT 设计,但是
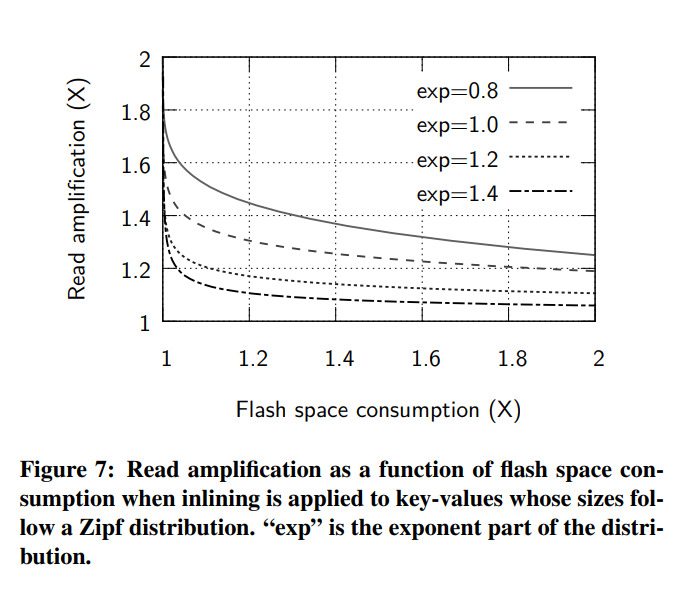
stores(offset, first part of (key, value))对,而不是 HashStores 和 SortedStores 中的实际(key, value)(LogStores可以本机处理变长数据)。这些偏移量指向存储在其他地方的键值数据的其余部分(例如,第二个闪存设备)。 - 如果整个项足够小,可以放入一个固定长度的槽,间接可以避免;因此,大数据需要额外的闪存读(或写),而小数据不产生额外的I/O成本。图7给出了不同插槽大小下该方案权衡的分析结果。它使用大小在 4B 到 1MiB 之间的键值对,并遵循 Zipf 分布,假设有4字节的头(键值长度)、4 字节的偏移指针和统一的访问模式
- 对于特定的应用,为了进一步提高效率,SILT 可以选择使用隔离存储。与简单隔离存储的思想类似,系统可以实例化几个不同的固定键值大小组合的 SILT 实例。应用程序可以选择一个具有最合适键值大小的实例,就像在 Dynamo 中所做的那样,或者 SILT 可以为一个新键选择最佳实例,并向应用程序返回一个包含实例ID的不透明键。由于每个实例都可以优化其自己的数据集的闪存空间开销和额外的闪存读取,因此使用隔离存储可以降低支持变长键值的成本,这接近于支持固定长度键值的水平。
Fail-Graceful Indexing
- 在高内存压力下,通过允许更高的读取放大(例如,每次查找超过2个flash读取),以避免由于内存不足而停机或崩溃,SILT 可能会暂时以降级的索引模式运行
- 删除内存中的索引和过滤器。HashStore过滤器和SortedStore索引存储在闪存上以保证崩溃,允许 SILT 从内存中删除它们。此选项节省内存,但代价是为 SortedStore 额外读取一次 flash,或为 HashStore 额外读取两次 flash。
- SortedStore 上的二分搜索。可以在没有索引的情况下搜索 SortedStore,因此可以删除内存中的 trie,甚至不需要在 flash 上存储副本,代价是从 flash 中额外读取log(n)。
- 这些技术还有助于加速 SILT 的启动。通过对 flash 索引文件进行内存映射或执行二分搜索,SILT 可以在将其索引后台加载到内存之前开始为请求提供服务
