- ATC21 Differentiated Key-Value Storage Management for Balanced I/O Performance
- https://www.cse.cuhk.edu.hk/~pclee/www/pubs/atc21diffkv.pdf
Abstract
- KV 存储读写放大严峻,现有设计都是在做 trade-off,不能同时实现高性能的读写以及 scan。所以提出了 DiffKV,在 KV 分离的基础上构建并仔细管理 Key Value 的顺序。Key 沿用 LSM-Tree,保持全序,同时以协调的方式管理部分有序的 Value,以保持高扫描性能。进一步提出细粒度 KV 分离,以大小区分 KV 对,实现混合工作负载下的均衡性能。
Introduction
- 为了减小 compaction 开销,现有方案大致有几个方向。
- 放松全局有序的要求来缓解 compaction 开销。但常伴随着 scan 性能的下降
- Dostoevsky
- PebblesDB
- SlimDB
- 基于 KV 分离,Key 有序,专门的存储区管理 Value。一是更适用于大 KV,二是还是有 scan 的性能损失(毕竟 Value 的顺序不保证了就导致随机读),三是还引入了垃圾回收的开销
- WiscKey
- HashKV
- BadgerDB
- Atlas
- An Efficient Memory-Mapped Key-Value Store for Flash Storage
- Titan
- UniKV
- 简而言之,现有的LSM-tree优化仍然受到读写和扫描之间紧密的性能紧张关系的限制,包括:
- (i) 键和值的有序程度
- (ii) 不同大小的KV对的管理。
Background and Motivation
- LSM-tree KV Store 基础结构此处省略。
现有优化方案
- 主要还是分为两类:
- Relaxing fully-sorted ordering
- KV separation
Relaxing fully-sorted ordering
- 以 PebblesDB 为例实现了分段 LSM。将一个 Level 分为了几个不相交的 Guards,每个 Guard 里的 SSTables 可以范围重叠。那么你会问了:为啥这样就能减小 compaction 开销呢? 因为 PebblesDB 只是读取了某一层中的 group 的 SSTables,然后进行了排序创建了新的 SSTables 写到下一层,compaction 过程不需要读取下一层的 SSTables 从而减小 compaction 开销和写放大。但是因为每个 Group 里的 SSTable 是重叠的,所以牺牲了一部分 scan 性能,虽然可以利用多线程来并行读,但是就导致了更多的 CPU 开销,所以提升也是有限的。
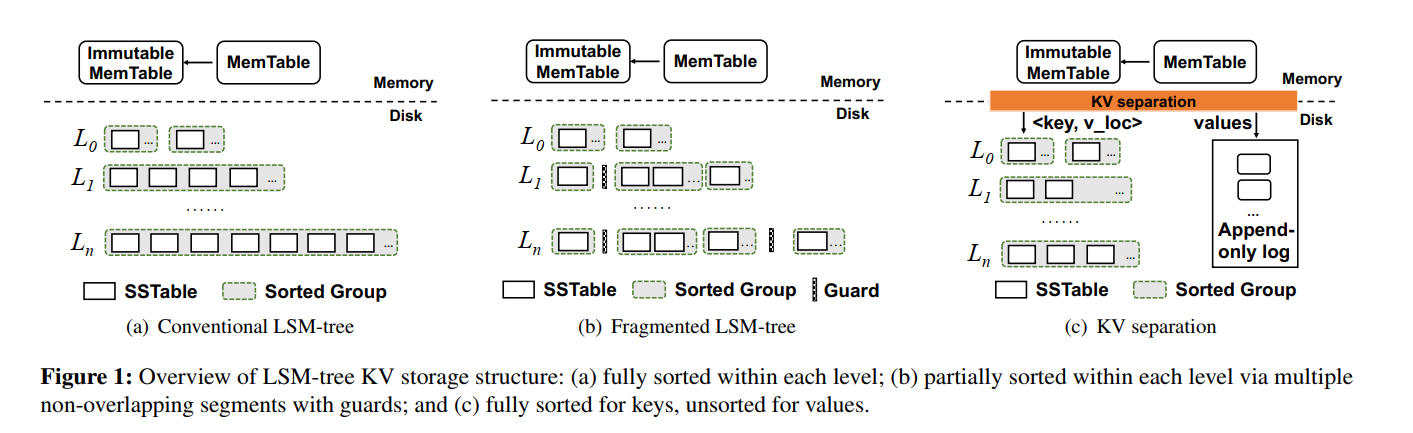
KV separation
- KV 分离则是将 Key 和 Location 信息存储在 LSM-tree,Value 单独地存储在一个日志里,Titan 中以多个 blob 文件形式来组织 Value。对于中大型 Value,因为 Key 和 Location 有着远小于 Value 的大小,在 LSM-tree 里存储的数据量就比较小,compaction 开销和写放大也相应比较小。除此以外,小的 LSM-tree 也减小了读放大,可以提升读性能。
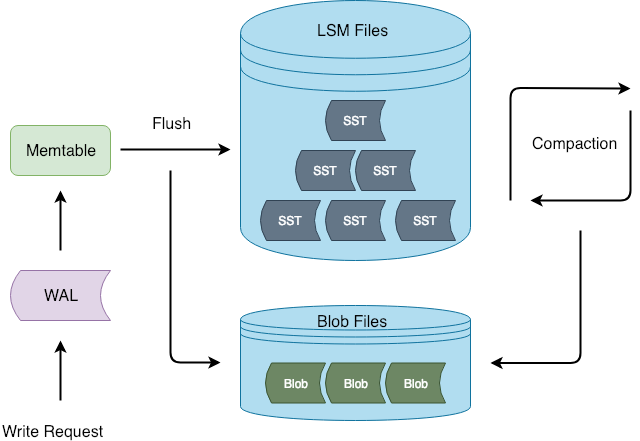
- 然而,由于 KV 分离将值写入一个附加日志,一个连续范围的键值现在分散在日志的不同位置。scan 操作也就会导致随机读取,因此导致比较差的 scan 性能,特别是小到中型 Value(OLTP 应用超过 90% 的 value 小于 1KB),除此以外,KV 分离还需要 GC 来回收空间,频繁的 GC 操作会导致额外的 I/O 开销。
Trade-off Analysis
- 性能测试之前,先大概讲一下 Titan
- Titan 基于 KV 分离实现,此外,采用了多个小的 Blob Files 来代替大的只追加写的日志对 Value 进行管理,使用多线程来减小 GC 开销。
- 数据组织形式如下:
- LSM-tree: Key - index(BlobFileID:offset:ValueSize)
- BlobFile: Value (Value 的存储类似于原本 SSTable 的结构)
- 每条 BlobRecord 冗余存储了 Value 对应的 Key 以便反向索引,但也引入了写放大
- KeyValue 有序存放,为了提升 scan 性能,甚至进行预取
- 支持 BlobRecord 粒度的 compression,支持多种算法
- GC:
- 监听 LSM-tree 的 compaction 来统计每个 BlobFile 的 discardable 数据大小,触发的 GC 则选择对应 discardable 最大的 File 来作为 candidate
- GC 选择了一些 candidates,当 discardable size 达到一定比例之后再 GC。使用 Sample 算法,随机取 BlobFile 中的一段数据 A,计其大小为 a,然后遍历 A 中的 key,累加过期的 key 所在的 blob record 的 size 计为 d,最后计算得出 d 占 a 比值 为 r,如果 r >= discardable_ratio 则对该 BlobFile 进行 GC,否则不对其进行 GC。如果 discardable size 占整个 BlobFile 数据大小的比值已经大于或等于 discardable_ratio 则不需要对其进行 Sample
- Write performance:加载 100GB 数据库,不同 value 大小(128B - 16KB),两种优化方案都能降低写放大,随着 value 大小的增加,写放大降低的越多,相应的写吞吐也就很大提升。证明以往的两种优化方向都是可以改善写放大并提升写性能的,特别是对于大 Value。
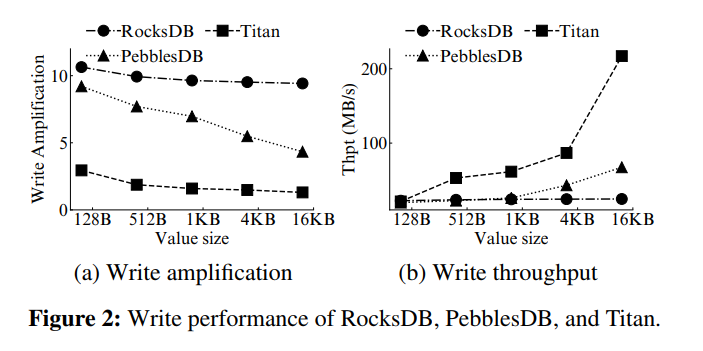
- Read and scan performance:放松全局有序的要求导致查询性能出现了降级,而 KV 分离因为显著减小了 LSM-tree 的大小,读吞吐比 RocksDB 高很多。而对于 scan 两种方案都比 RocksDB 差很多,做了延迟分解,发现大部分扫描时间花在了 iteratively reading values,随着 value 的增大,scan 延迟的差距变小,因为访问更大的 Value 对应了更小的随机读开销。对于那些小 KV 为主的负载,两种优化方案都会受到很大限制。
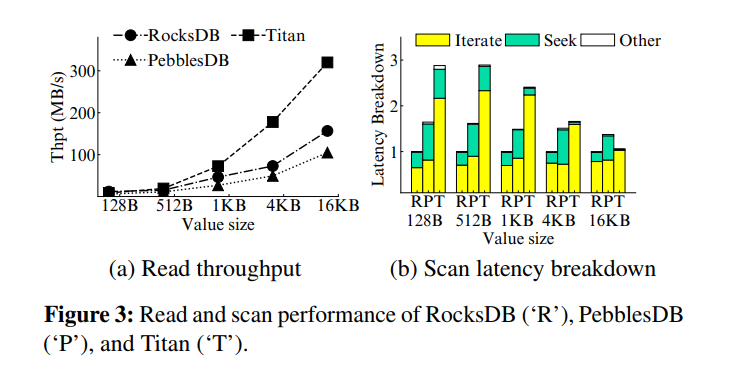
- 总结一下,现有的优化方案其实都是在做 reads/writes 的 trade-off,两种优化方向的本质都是在降低 Value 的有序程度来减小写放大并提升吞吐量,但相应地牺牲了 scan 的性能,特别是对于小到中型的 KV 对。
Design
System Overview
- DiffKV 利用了一个类似于 LSM-tree 的结构 vTree 来组织 Value 保证 Value 的部分有序,也是由多个 Level 组成,每个 level 只能以追加的方式写入,和 LSM-Tree 的不同在于,vTree 只存储那些在每一层中不一定按键完全排序的 Value,即允许部分有序来保证 scan 性能。
- 为了实现部分有序,vTree 也需要类似 compaction 的操作,称之为 merge,为了减小 merge 的开销,DiffKV 让 LSM-tree 的 compaction 和 vTree 的 merge 协调地执行来减少总体开销。
- 为了让 DiffKV 和现有设计兼容,内存组件和 WAL 都和原生 LSM 一样,流程是一样的。
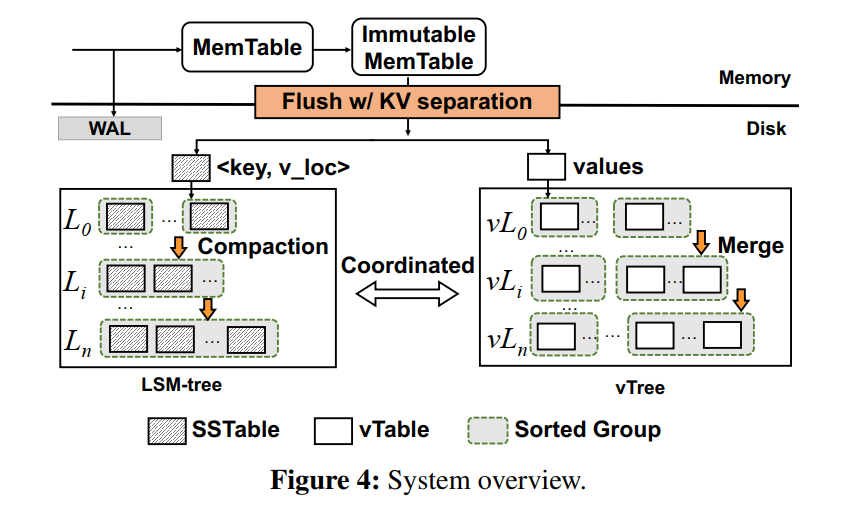
Data Orgaization
- vTree 分层组织,每层由 sorted groups 组成,每个 group 由很多 vTables 组成。(这里仿佛就跟 PebblesDB 的设计是类似的了)
vTable
- 大小固定,8MB 默认。一个 immutable Memtable 的 flush 可以生成很多个 vTables,取决于 value size 和 Memtable Size。
- vTable 组成部分:
- data area: 基于 Key 的顺序存储 values
- metedata area: 记录必要的元数据,比如 vTable 的数据大小,该 table 中最小最大 Value(和 SSTable 不同的是不要求 BloomFilter,因为直接查索引就能知道)。元数据较小,存储开销也较小。
Sorted Group
- 所有的 vTables 在 Group 中也是有序的。也就是无重叠范围,LSM-tree 的 SSTables 组成的集合也相当于一个 Sorted Group。DiffKV 一次 flush 对应生成一个 Sorted Group,从而保留每个 immutable Memtable 里顺序性,对应 Groups 数量表示了 vTree 的有序程度,Groups 数量增加,有序性相应下降,在一个极端情况下,如果所有的 sstable/vtable组成一个 Group,那么有序程度最大,因为所有的 KV 对都是完全排序的。
- (埋个坑:这里直接用 Groups 数量来表示有序程度会不会有些草率,其实有序与否更多是看重叠范围大小,当然 Groups 越多重叠的概率可能越大,但不确定这个有序程度是不是会对后面造成影响,拭目以待)
vTree
- vTree --- 1:N --- levels --- 1:N --- groups --- 1:N --- vTables --- 1:N --- values
- 全局有序的最小单元是 group,level 就可能存在具有重叠键范围的 groups 了,merge 操作不需要对 vTree 中连续两层中的所有值进行排序;与 lsm-tree 中的 compaction 相比,这减轻了I/O开销
Compaction-Triggered Merge
- 首先,为什么要 merge? 其实就是为了保证部分有序,或者说维持有序性,这样才可能加速 scan。
- Merge 会读取一定数量的 vTables,通过查询 LSM-tree 中存储的最新位置信息来检查哪些 value 是有效的,每个 merge 还要更新最新的 location 信息到 LSM-tree 中
- 为了限制 vTree 中的合并开销,vTree 中的合并操作不是独立执行的,而是和 LSM-tree 中的压缩操作以协调的方式触发的。所以称该操作为 compaction-triggered merge
- 举例说明: 假设 LSM tree 的 level 和 vTree 的 level 是关联的。
- 当 LSM-tree 发生 Level i -> i+1 的 compaction 的时候,相应地触发 vTree 上相应的 value 从 vLi 到 vLi+1 的 merge。
- Merge 有两个主要问题:
- 选哪些 value 进行 merge?选择那些参加了 compaction 的 keys 对应的 value 进行 merge,称之为 compaction-related value
- 如何把这些 value 写回到 vLi+1?把这些 value 组织起来生成新的 vTables 并把这些 vTables 以追加写的形式写到下一层。如下图所示的棕色就是这些需要 merge 的 values,V33, V13, V45 在排序后追加写入到下一层。
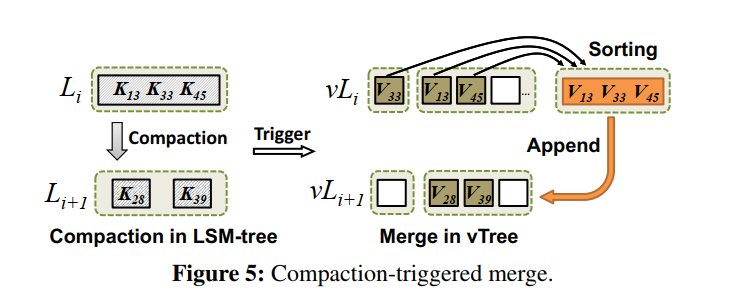
- 生成的 vTables 中的所有数据都是有序的,也就是说 Merge 产生的 vTables 形成了一个单独的 sorted group。但是,我们要指出的是,合并操作并不需要重新组织 vTree 中 vLi 和 vLi+1 两级的所有vtable。追加写的形式来表面重写,从而减小写放大,老的 vTables 也不会在 merge 过程中删除,因为可能还是包含一些有效的 value,交给 GC 来判断处理。
- compaction-triggered merge 带来的好处表现在两个方面:(协同设计的核心)
- 只合并与 compaction 相关的值可以非常有效地识别哪些值仍然有效,因为在 compaction 期间本身就需要从 lsm-tree 中读出相应的键。相反如果 vTree 的 merge 独立执行,那就需要查询 LSM-tree 并比较 location 信息来判断有效性了,增加了较大的查询开销。
- merge 操作过程中新生成的 vTables 伴随着有效 value 的位置信息的变化,LSM-tree 需要被更新来维护对应的最新的 value location 信息,因为只有 compaction-related values 被合并,更新 LSM 树中的值位置可以通过直接更新参与 compaction 的 KV 对来执行。因此,更新值位置的开销可以隐藏在 compaction 操作中,因为 compaction 本身需要重写 lsm 树中的 KV 对
Merge Optimizations
- Compaction-triggered merge 引入了有限的合并开销,该开销又主要是检查 value 的有效性并写回 value location 信息造成的。但是如果让每一次 compaction 操作都触发 merge 的话可能造成频繁的 merge,比如 vTree 中的每个级别只与 LSM-tree 中的一个级别相关,那么每个 compaction 操作都必须在 vTree 中触发合并操作,为了减小 merge 开销,提出了两个优化方案。
Lazy merge
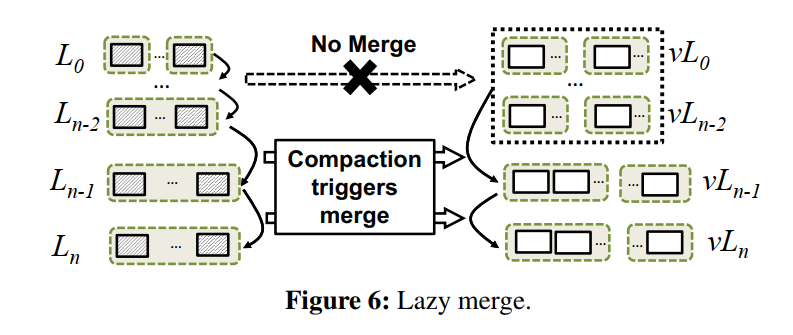
- 该策略用于限制 merge 频率和开销。核心思想是聚合多个 lower vTree levels 为单个 level,关联地聚合 LSM-tree 的多个 levels,如下图所示。聚合 vTree 的 0,...,n-2 为一个单独的 level,相应地聚合 LSM Tree 的 0,...,n-2 levels,因此任何发生在 0,...,n-2 之间的 compaction 都不会触发 merge,也就是说 vTree 的 0,...,n-2 Level Merge 操作被延迟到除非需要合并到 vLn−1 的时候才会执行。
- 该策略显著减少合并次数和合并数据量,但是牺牲了较低层次的 value 的有序程度,然而,我们认为这种牺牲对扫描性能的影响是有限的。因为 LSM 中的大部分数据都是保存在最后几层,不同层次的数据分布不均匀意味着大多数值实际上是从 vTree 的最后两层进行扫描的,所以最后两层的值的有序程度才会更多地影响 scan 性能。也就是说,low level 对 scan 性能影响很小,频繁的在 low level 的合并操作不会对 scan 性能的提升有什么帮助但却引入了较大的 merge 开销。
Scan-optimized merge
- 该策略用于调整 value 的有序程度,来保证较高的 scan 性能。原本的合并策略中,上层的 value 被重新组织写入到下层,下层的 value 其实是没有参与 merge 的。这种策略减小了写放大,但是导致了太多的 sorted group,即可能重叠的现象更严峻。因此我们的核心思想是找到和其他 vTables 有重叠范围的 vTables,让这些 vTables 参与 merge 而不管其位于哪一层。这样就能保证有序的程度较高。
- 下图描述了核心思想,在普通的 compaction-triggered merge 之后,首先在下层检查包含 compaction-related values 的 vTables,目标是找出满足如下两个条件的 vTables 集合:
- 集合中至少一个 vTable 有重叠的键范围
- vTables 的数量,也就是 set size,大于预先定义的阈值,max_sorted_run
- 如果存在上述的 SET,scan 性能势必会降低,因为这些 vTable 没有被排序。所以添加一个 scan optimization tag 给这些 tables,所以他们将能总是参与到下一次 Merge 并增加有序性。
- 为了找到这样的一组 vTables,首先遍历每个包含 compaction-related values 的 vTable 的起始和终止 Key,对于每个检查的 vTable,统计有重叠键范围的 vTables 的数量,可以通过扫描排序后的键字符串来完成。如下图所示,考虑一个检查过的 vTable 【26-38】,扫描排序后的字符串,可以统计出在 Key 38 之前起始 keys 的个数,本例中有五个,然后结束 Key 在 26 之前的只有一个,然后相减,得到和 【26-38】 重叠的 tables 有四个,也就是该集合的 size 为 4,如果超过了阈值,那么就会给这些 tables 添加 tag,并在下一次合并中对他们进行合并。同时这个 tag 会被持久化到 mainfest file 中,持久化开销可忽略不计。
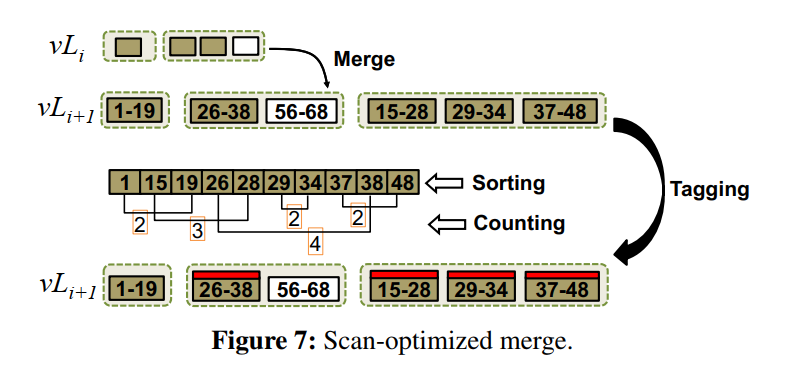
- Scan-optimized merge 该策略是一个原始策略上的 enhancement。原策略只是简单做追加写,而该策略进一步包含了下一层中确定的 tables 来进行合并,从而增加有序性。注意该策略引入了有限的合并开销,有两个原因:
- 允许每一层有多个 sorted groups(一整层不是全局有序的) (这里有点奇怪)
- 不是标记了的 table 中的所有 values 都会参与 merge,而只是 compaction-related values 会参与。
GC
- 为了减小 GC 开销,又提出了基于无效 value 数量的 state-aware lazy approach
State awareness
- DiffKV 在一个哈希表中记录每个 vTable 的无效 KV 的数量,每次当 vTable 参与一个 Merge 的时候,DiffKV 记录从 vTable 中检索到的值的数量,并在哈希表中更新旧 vTable中无效值的数量。它还为哈希表中任何新的 vTable 插入一个条目。对哈希表的更新是在合并操作期间执行的,因此开销是有限的。另外,哈希表中的每个条目只占用几个字节,所以哈希表的内存开销是有限的。
Lazy GC
- 如果 vTable 有一定比例的无效 Values 且超过阈值 gc_threshold 的时候被选为 GC candidate,需要注意的是 DiffKV 不能立马回收候选的 vTables,相反只是标记一个 GC tag,延迟 GC 到下一次合并。具体的,如果带有 GC tag 的 vTable 被包含到一次合并中,那么该 table 包含的 values 将总是被重写到下一个 level。
- 该策略避免了查询 LSM 检查有效性的额外开销,也避免了更新 LSM 新的地址信息的开销,被延迟到和合并一起执行,所以查询和更新的开销可以被合并操作给隐藏。
Discussion
- Optimizing compaction at L0:提出一个简单的优化 selective compaction 来聚合 Level 0 中小的 SSTables,具体而言,我们会触发内部 compaction,简单地在 L0 处合并多个小 sstable 来生成一个新的大的,而不与 L1 处的 sstable 合并,这样的话,L0 中的 SSTables 的大小将和 L1 中的相当,且没有额外的 compaction 开销引入。
- Crash consistency:DiffKV 基于 Titan 实现,一致性保证和 Titan 以及 RocskDB 一样,使用了 WAL。同时 DiffKV 还未记录无效数据的 HASHTable 提供了一致性保证,随着 HashTable 在 compaction 之后被更新,DiffKV 将更新信息追加到 manifest 文件中。
Fine-grained KV Separation
- 对于大KV对,KV分离的好处是显著的,但对于小KV对就不是这样了。然而,不同值大小的混合工作负载也很常见;例如,在广义帕累托分布下,值的大小可能变化很大。在本节中,我们通过 value 大小来区分KV对,通过细粒度的KV分离来进一步增强DiffKV,从而实现混合工作负载下的均衡性能。
Differentiated Value Management
- 使用两个参数分为三组,small medium large 。小 value 直接写 LSM,中 Value 写 vTree,大 value 写 vLog。
- 大 value 的在写 Memtable 之前就先分离了 KV,这样做的好处有两个方面:
- 直接将大 value 刷回到 vLog,并保留小的 Key 和地址信息在 Memtable,可以节省内存消耗,同时因为大的顺序 I/O 保证了较高的写性能。
- 因为大 value 被写回到了 disk,就不用再写 WAL 了,减小了 I/O 的次数
- 需要注意的是,对于中小型KV对,以及大型KV对的键和值位置,仍然需要写入WAL中,以保证一致性。
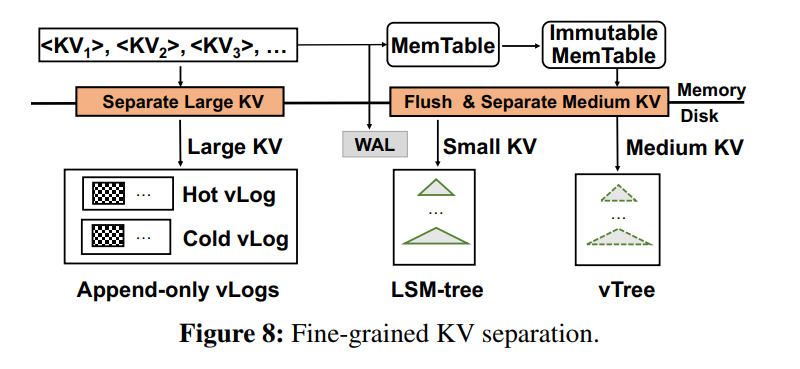
Hotness-aware vLogs
Structure of vLogs
- 就是一个简单的环形只允许追加的日志,由一组无序的 vTables 组成,vTable 和前面提到的 vTable 格式相同,唯一的不同是 value 是追加写入到无序的 vTables 的,所以在每个 table 内也是无序的,我们这样做的原因是因为 KV 分离对于大型 KV 对执行写入MemTable 之前,大型 KV 被立即刷新到磁盘,以免写 WAL,所以没有办法排序每个 table 中的 values。事实上也不需要,因为他们本身就能从大 I/O 中获益了而不用批量写入。
GC for vLogs
- 为了减小 GC 开销,使用了一个热点感知的设计,采用一种简单而有效的无参数冷热分离方案。如下图所示,使用两个 vLogs,分别对应冷热 vLogs,存储了对应的冷热数据,每个vLog 都有自己的写边界,我们分别称它们为 写头 和 GC 头。为了实现冷热分离,用户写入的数据被追加到 hot vLog 的 write head,而来自于 GC 写的数据(比如有效数据需要在 GC 过程中进行写入)被追加写到 cold vLog 的 GC head。其基本原理是,GC 回收的值通常比最近写入的用户数据访问频率更低,因此可以将它们视为冷数据,这种设计的一个好处是实现简单,因为实现冷热识别不需要参数。显然,我们还可以应用其他的热点感知分类方案。
- DiffKV 使用了一个贪心的算法来减小 GC 开销,思想是回收有最大数量的无效值的无序的 vTables。具体的,DiffKV 在 compaction 中监控了每个无序 vTables 的无效数据比例,并维护了一个内存中的 GC 队列来追踪所有候选的 vTables,候选条件即为无效值比例大于阈值。需要注意的是 GC 队列只维护每个无序 vTable 的元数据,它根据无效值的比率按降序进行维护。GC 触发的时候,DiffKV 简单地选择队列头的无序 vTables,如图 9 中的 t1 t2,然后将有效的 values 追加到 cold vLog 的 GC 头。出于性能考虑,DiffKV 使用后台进程多线程来实现 GC。
Evaluation
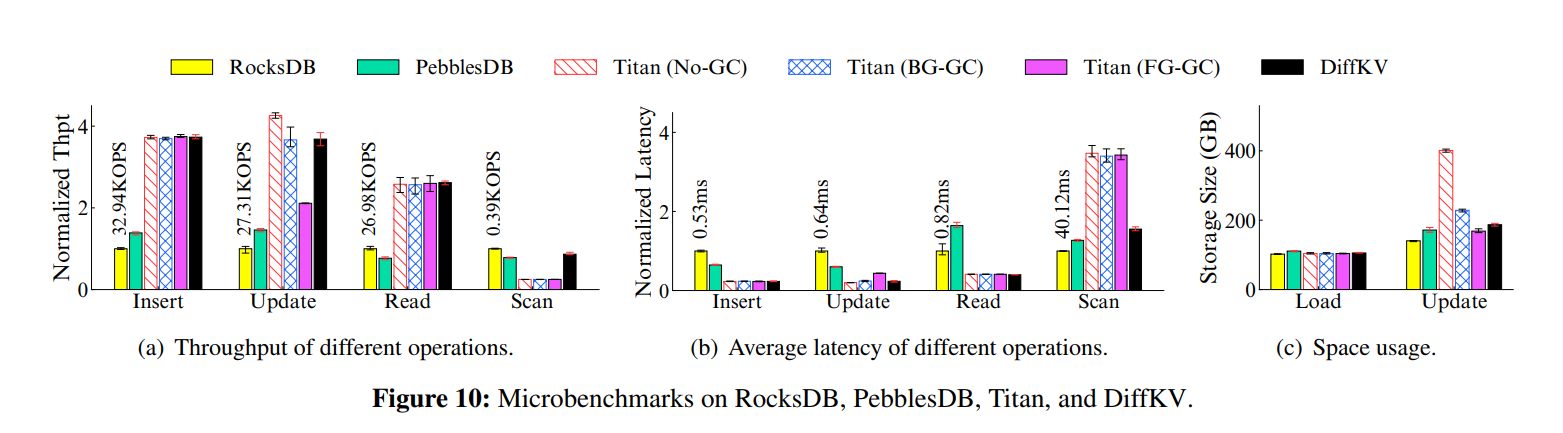
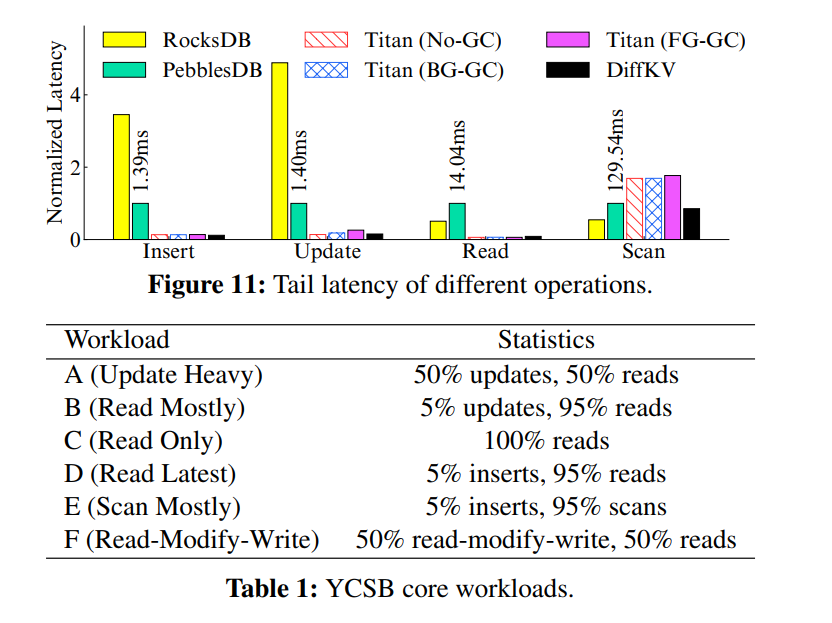
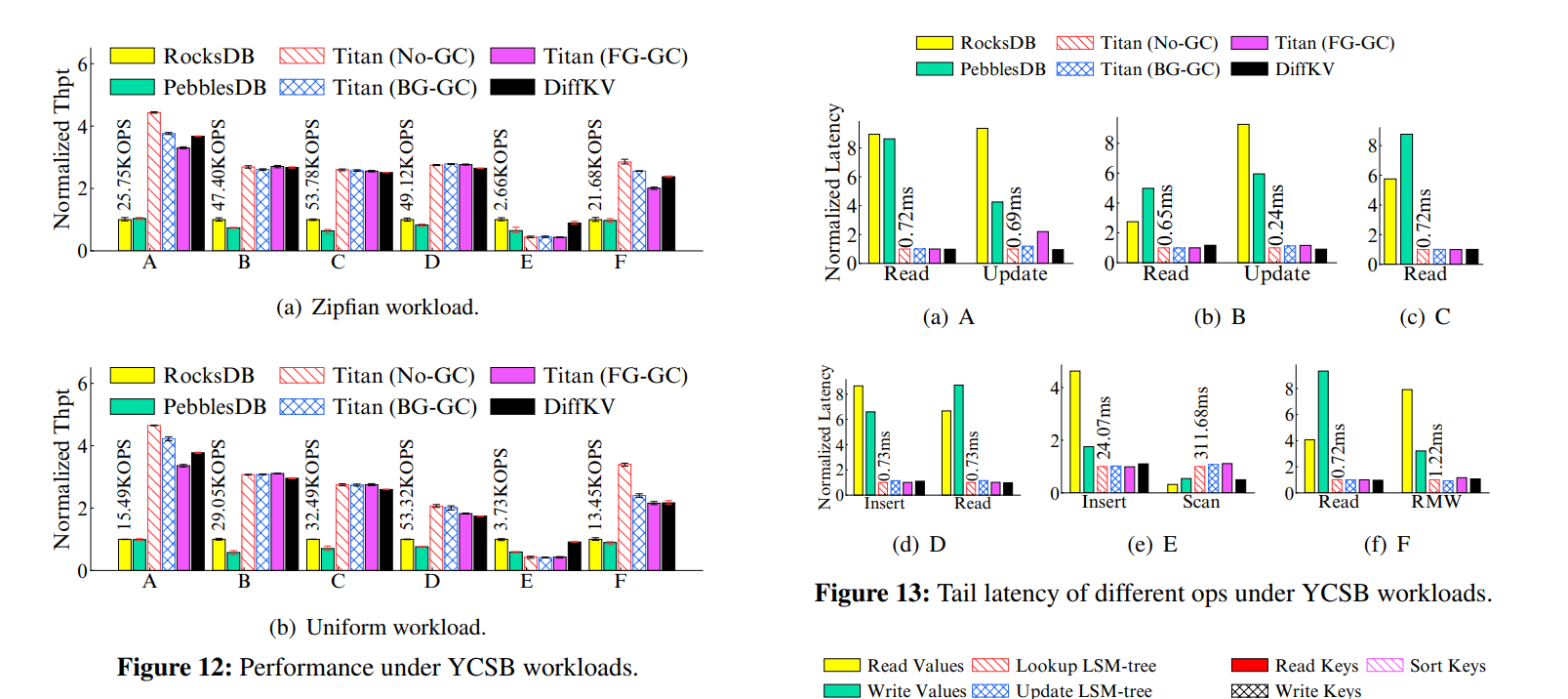
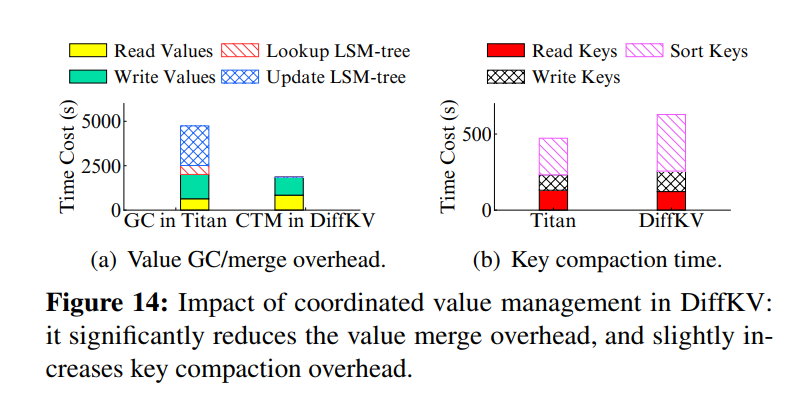
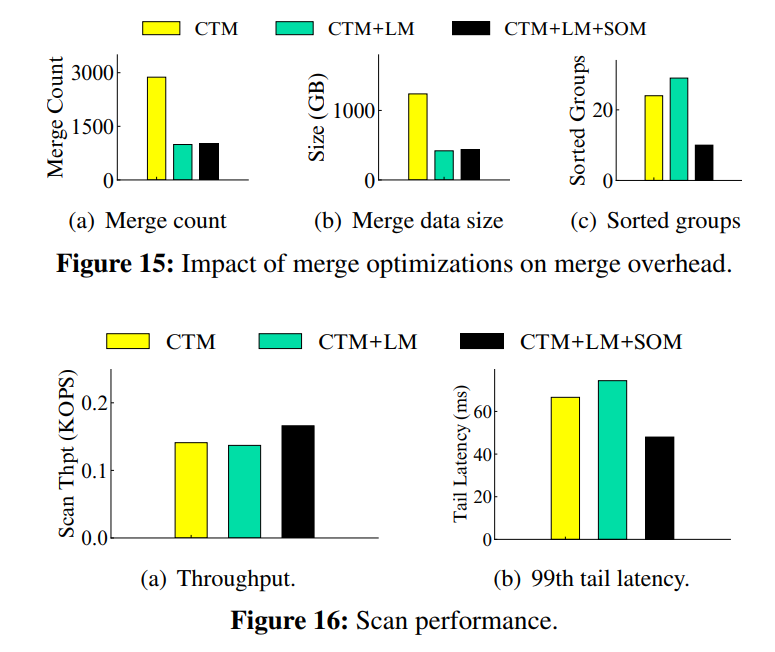
x
感谢您的支持,我会继续努力的!
扫码打赏,你说多少就多少
