- Ceph OSD 后端存储实现架构和源码分析
- 结合 Ceph 已经实现的存储引擎,考虑实现新的后端存储
- 理解 ObjectStore 和 Ceph IO 流的调用关系
Review
- 源码目录结构
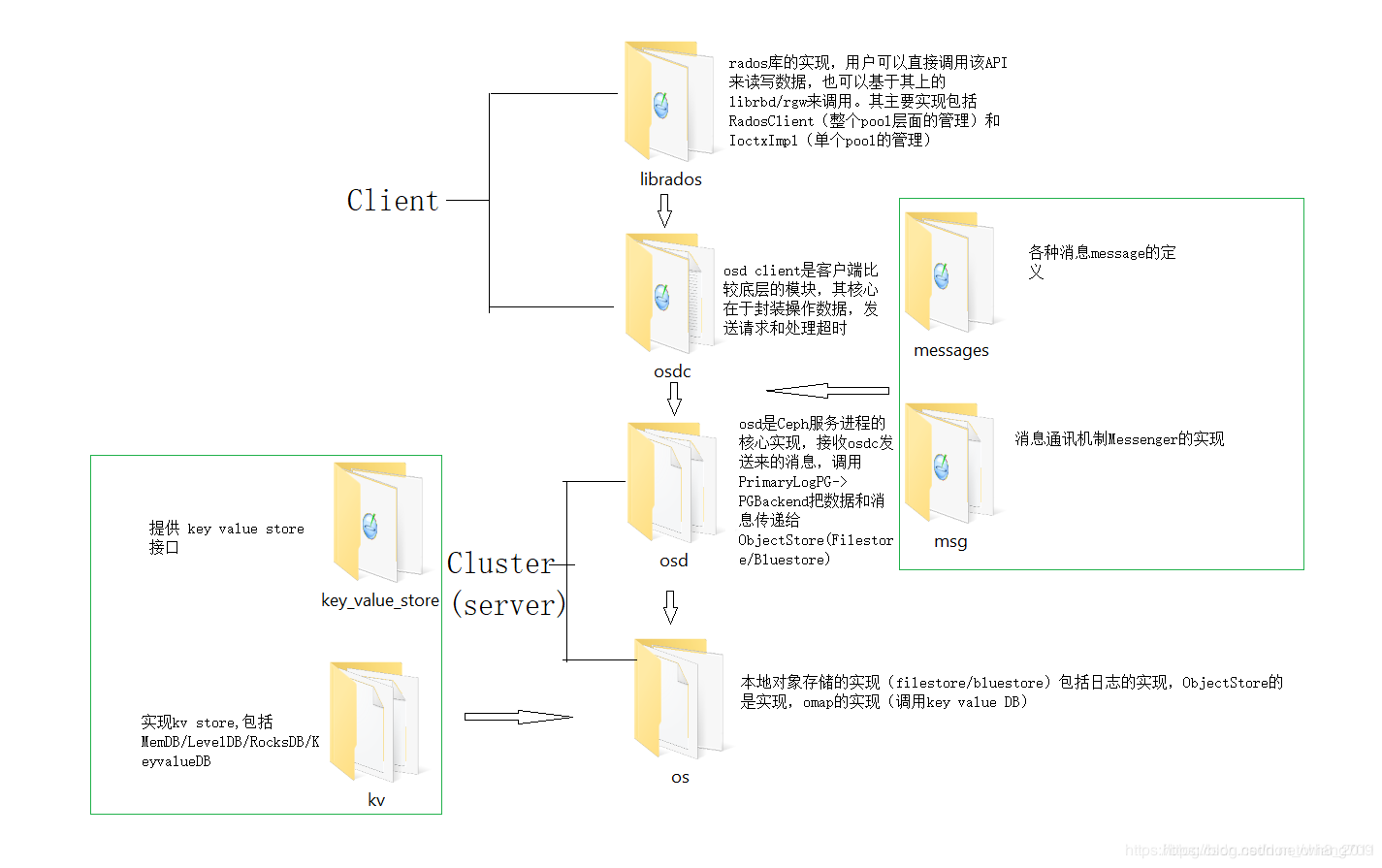
IO 流
- librados -> OSDC -> OSD -> OS -> ObjectStore
- PrimayLogPG 中使用 Objecter 发送 Operation 消息来执行对应的操作
- PrimaryLogPG 执行构造函数时创建了相应的 PGBackend.
PrimaryLogPG::PrimaryLogPG(OSDService *o, OSDMapRef curmap,
const PGPool &_pool,
const map<string,string>& ec_profile, spg_t p) :
PG(o, curmap, _pool, p),
pgbackend(
PGBackend::build_pg_backend(
_pool.info, ec_profile, this, coll_t(p), ch, o->store, cct)),
object_contexts(o->cct, o->cct->_conf->osd_pg_object_context_cache_count),
new_backfill(false),
temp_seq(0),
snap_trimmer_machine(this)
{
recovery_state.set_backend_predicates(
pgbackend->get_is_readable_predicate(),
pgbackend->get_is_recoverable_predicate());
snap_trimmer_machine.initiate();
}
- 构建 PGBackend 时会根据系统配置的后端存储类型,进行相应的实例化。Ceph 中的后端存储又主要分成 ECBackend 和 ReplicatedBackend,分别使用了纠删码和多副本来保证数据的一致性。在构造 PGBackend 时又相应地指定了 ObjectStore 的存储类型。此处以 ReplicatedBackend 为例。
- 读操作直接执行相关函数调用,写操作相应地使用事务进行封装提交
int ReplicatedBackend::objects_read_sync(
const hobject_t &hoid,
uint64_t off,
uint64_t len,
uint32_t op_flags,
bufferlist *bl)
{
return store->read(ch, ghobject_t(hoid), off, len, *bl, op_flags);
}
int ReplicatedBackend::objects_readv_sync(
const hobject_t &hoid,
map<uint64_t, uint64_t>&& m,
uint32_t op_flags,
bufferlist *bl)
{
interval_set<uint64_t> im(std::move(m));
auto r = store->readv(ch, ghobject_t(hoid), im, *bl, op_flags);
if (r >= 0) {
m = std::move(im).detach();
}
return r;
}
void ReplicatedBackend::submit_transaction(
const hobject_t &soid,
const object_stat_sum_t &delta_stats,
const eversion_t &at_version,
PGTransactionUPtr &&_t,
const eversion_t &trim_to,
const eversion_t &min_last_complete_ondisk,
const vector<pg_log_entry_t> &_log_entries,
std::optional<pg_hit_set_history_t> &hset_history,
Context *on_all_commit,
ceph_tid_t tid,
osd_reqid_t reqid,
OpRequestRef orig_op)
{
parent->apply_stats(
soid,
delta_stats);
vector<pg_log_entry_t> log_entries(_log_entries);
ObjectStore::Transaction op_t;
PGTransactionUPtr t(std::move(_t));
set<hobject_t> added, removed;
generate_transaction(
t,
coll,
log_entries,
&op_t,
&added,
&removed,
get_osdmap()->require_osd_release);
ceph_assert(added.size() <= 1);
ceph_assert(removed.size() <= 1);
auto insert_res = in_progress_ops.insert(
make_pair(
tid,
ceph::make_ref<InProgressOp>(
tid, on_all_commit,
orig_op, at_version)
)
);
ceph_assert(insert_res.second);
InProgressOp &op = *insert_res.first->second;
op.waiting_for_commit.insert(
parent->get_acting_recovery_backfill_shards().begin(),
parent->get_acting_recovery_backfill_shards().end());
issue_op(
soid,
at_version,
tid,
reqid,
trim_to,
min_last_complete_ondisk,
added.size() ? *(added.begin()) : hobject_t(),
removed.size() ? *(removed.begin()) : hobject_t(),
log_entries,
hset_history,
&op,
op_t);
add_temp_objs(added);
clear_temp_objs(removed);
parent->log_operation(
log_entries,
hset_history,
trim_to,
at_version,
min_last_complete_ondisk,
true,
op_t);
op_t.register_on_commit(
parent->bless_context(
new C_OSD_OnOpCommit(this, &op)));
vector<ObjectStore::Transaction> tls;
tls.push_back(std::move(op_t));
parent->queue_transactions(tls, op.op);
if (at_version != eversion_t()) {
parent->op_applied(at_version);
}
}
Architecture
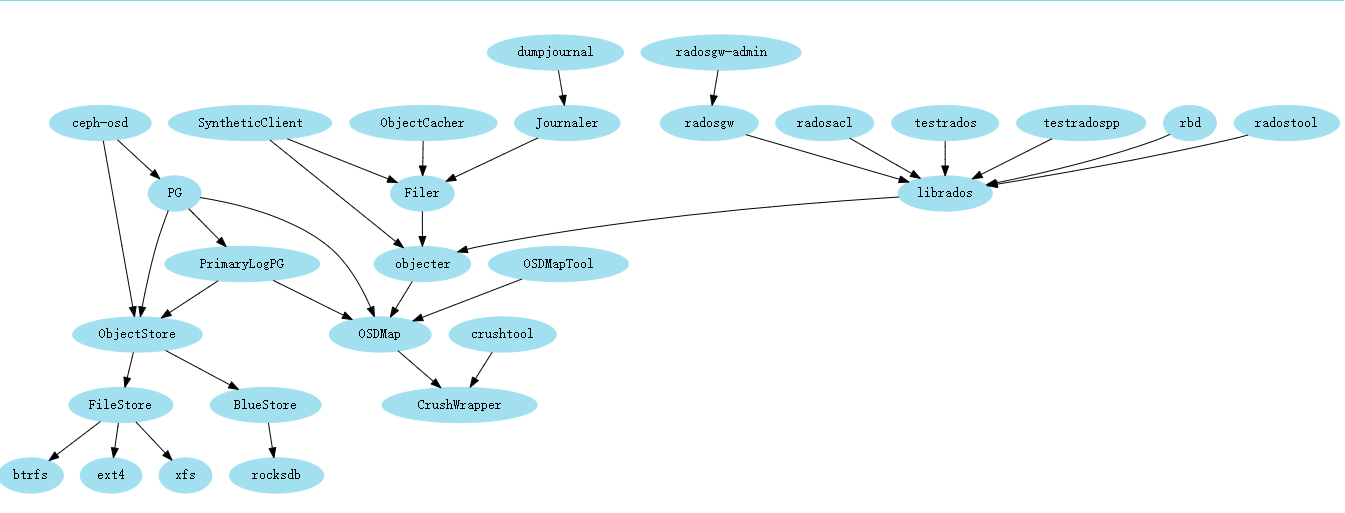
- 无论是哪种后端存储,都主要是通过实现 ObjectStore 所定义的相关接口来实现 IO
- ObjectStore 在现阶段的 Ceph 中主要有两种实现:FileStore,BlueStore
- 其中 FileStore 又主要提供了三种文件系统的实现:btrfs,ext4,xfs,(zfs)
- 其中 BlueStore 的主要实现又包括 RocksDB 和 BlueFS
ObjectStore
ObjectStore.h中定义了相关方法,具体的实现由具体的存储引擎来决定,主要涉及到的方法如下:read、readv、queue_transactions (其中我们将重点关注 read、queue_transactions)
class ObjectStore {
protected:
std::string path;
public:
using Transaction = ceph::os::Transaction;
CephContext* cct;
/**
* create - create an ObjectStore instance.
* This is invoked once at initialization time.
* @param type type of store. This is a std::string from the configuration file.
* @param data path (or other descriptor) for data
* @param journal path (or other descriptor) for journal (optional)
* @param flags which filestores should check if applicable
*/
static ObjectStore *create(CephContext *cct,
const std::string& type,
const std::string& data,
const std::string& journal,
osflagbits_t flags = 0);
/**
* probe a block device to learn the uuid of the owning OSD
* @param cct cct
* @param path path to device
* @param fsid [out] osd uuid
*/
static int probe_block_device_fsid(
CephContext *cct,
const std::string& path,
uuid_d *fsid);
//...
// Transactions Collections.
// Transactions in one collection will be applied in sequence.
// Transactions in different collections will be applied in parallel.
struct CollectionImpl : public RefCountedObject {
const coll_t cid;
virtual void flush() = 0;
virtual bool flush_commit(Context *c) = 0;
//...
}
int queue_transaction(CollectionHandle& ch,
Transaction&& t,
TrackedOpRef op = TrackedOpRef(),
ThreadPool::TPHandle *handle = NULL) {
std::vector<Transaction> tls;
tls.push_back(std::move(t));
return queue_transactions(ch, tls, op, handle);
}
virtual int queue_transactions(
CollectionHandle& ch, std::vector<Transaction>& tls,
TrackedOpRef op = TrackedOpRef(),
ThreadPool::TPHandle *handle = NULL) = 0;
/**
* read_meta - read a simple configuration key out-of-band
*
* Read a simple key value to an unopened/mounted store.
*
* Trailing whitespace is stripped off.
*
* @param key key name
* @param value pointer to value std::string
* @returns 0 for success, or an error code
*/
virtual int read_meta(const std::string& key,
std::string *value);
/**
* read -- read a byte range of data from an object
*
* Note: if reading from an offset past the end of the object, we
* return 0 (not, say, -EINVAL).
*
* @param cid collection for object
* @param oid oid of object
* @param offset location offset of first byte to be read
* @param len number of bytes to be read
* @param bl output ceph::buffer::list
* @param op_flags is CEPH_OSD_OP_FLAG_*
* @returns number of bytes read on success, or negative error code on failure.
*/
virtual int read(
CollectionHandle &c,
const ghobject_t& oid,
uint64_t offset,
size_t len,
ceph::buffer::list& bl,
uint32_t op_flags = 0) = 0;
/**
* readv -- read specfic intervals from an object;
* caller must call fiemap to fill in the extent-map first.
*
* Note: if reading from an offset past the end of the object, we
* return 0 (not, say, -EINVAL). Also the default version of readv
* reads each extent separately synchronously, which can become horribly
* inefficient if the physical layout of the pushing object get massively
* fragmented and hence should be overridden by any real os that
* cares about the performance..
*
* @param cid collection for object
* @param oid oid of object
* @param m intervals to be read
* @param bl output ceph::buffer::list
* @param op_flags is CEPH_OSD_OP_FLAG_*
* @returns number of bytes read on success, or negative error code on failure.
*/
virtual int readv(
CollectionHandle &c,
const ghobject_t& oid,
interval_set<uint64_t>& m,
ceph::buffer::list& bl,
uint32_t op_flags = 0) {
int total = 0;
for (auto p = m.begin(); p != m.end(); p++) {
bufferlist t;
int r = read(c, oid, p.get_start(), p.get_len(), t, op_flags);
if (r < 0)
return r;
total += r;
// prune fiemap, if necessary
if (p.get_len() != t.length()) {
auto save = p++;
if (t.length() == 0) {
m.erase(save); // Remove this empty interval
} else {
save.set_len(t.length()); // fix interval length
bl.claim_append(t);
}
// Remove any other follow-up intervals present too
while (p != m.end()) {
save = p++;
m.erase(save);
}
break;
}
bl.claim_append(t);
}
return total;
}
FileStore
- PGBackend 端的操作同 BlueStore 一样,区别只在于 FileStore 对相关读写方法实现的区别。
- FileStore 由于支持了多种文件系统作为存储后端,所以又提供了 FileStoreBackend 相关接口,便于各种文件系统提供基于该接口的实现。
写操作
- 写操作流程:
FileStore::queue_transactions
do_transactions(tls, op);
_op_journal_transactions(tbl, orig_len, op, ondisk, osd_op);
FileStore::_do_transaction
_write(cid, oid, off, len, bl, fadvise_flags);
lfn_open(cid, oid, true, &fd);
bl.write_fd(**fd, offset);
lfn_close(fd);
- 写操作实现:
int FileStore::queue_transactions(CollectionHandle& ch, vector<Transaction>& tls,
TrackedOpRef osd_op,
ThreadPool::TPHandle *handle)
{
Context *onreadable;
Context *ondisk;
Context *onreadable_sync;
ObjectStore::Transaction::collect_contexts(
tls, &onreadable, &ondisk, &onreadable_sync);
if (cct->_conf->objectstore_blackhole) {
dout(0) << __FUNC__ << ": objectstore_blackhole = TRUE, dropping transaction"
<< dendl;
delete ondisk;
ondisk = nullptr;
delete onreadable;
onreadable = nullptr;
delete onreadable_sync;
onreadable_sync = nullptr;
return 0;
}
utime_t start = ceph_clock_now();
OpSequencer *osr = static_cast<OpSequencer*>(ch.get());
dout(5) << __FUNC__ << ": osr " << osr << " " << *osr << dendl;
ZTracer::Trace trace;
if (osd_op && osd_op->pg_trace) {
osd_op->store_trace.init("filestore op", &trace_endpoint, &osd_op->pg_trace);
trace = osd_op->store_trace;
}
if (journal && journal->is_writeable() && !m_filestore_journal_trailing) {
Op *o = build_op(tls, onreadable, onreadable_sync, osd_op);
//prepare and encode transactions data out of lock
bufferlist tbl;
int orig_len = journal->prepare_entry(o->tls, &tbl);
if (handle)
handle->suspend_tp_timeout();
op_queue_reserve_throttle(o);
journal->reserve_throttle_and_backoff(tbl.length());
if (handle)
handle->reset_tp_timeout();
uint64_t op_num = submit_manager.op_submit_start();
o->op = op_num;
trace.keyval("opnum", op_num);
if (m_filestore_do_dump)
dump_transactions(o->tls, o->op, osr);
if (m_filestore_journal_parallel) {
dout(5) << __FUNC__ << ": (parallel) " << o->op << " " << o->tls << dendl;
trace.keyval("journal mode", "parallel");
trace.event("journal started");
_op_journal_transactions(tbl, orig_len, o->op, ondisk, osd_op);
// queue inside submit_manager op submission lock
queue_op(osr, o);
trace.event("op queued");
} else if (m_filestore_journal_writeahead) {
dout(5) << __FUNC__ << ": (writeahead) " << o->op << " " << o->tls << dendl;
osr->queue_journal(o);
trace.keyval("journal mode", "writeahead");
trace.event("journal started");
_op_journal_transactions(tbl, orig_len, o->op,
new C_JournaledAhead(this, osr, o, ondisk),
osd_op);
} else {
ceph_abort();
}
submit_manager.op_submit_finish(op_num);
utime_t end = ceph_clock_now();
logger->tinc(l_filestore_queue_transaction_latency_avg, end - start);
return 0;
}
if (!journal) {
Op *o = build_op(tls, onreadable, onreadable_sync, osd_op);
dout(5) << __FUNC__ << ": (no journal) " << o << " " << tls << dendl;
if (handle)
handle->suspend_tp_timeout();
op_queue_reserve_throttle(o);
if (handle)
handle->reset_tp_timeout();
uint64_t op_num = submit_manager.op_submit_start();
o->op = op_num;
if (m_filestore_do_dump)
dump_transactions(o->tls, o->op, osr);
queue_op(osr, o);
trace.keyval("opnum", op_num);
trace.keyval("journal mode", "none");
trace.event("op queued");
if (ondisk)
apply_manager.add_waiter(op_num, ondisk);
submit_manager.op_submit_finish(op_num);
utime_t end = ceph_clock_now();
logger->tinc(l_filestore_queue_transaction_latency_avg, end - start);
return 0;
}
ceph_assert(journal);
//prepare and encode transactions data out of lock
bufferlist tbl;
int orig_len = -1;
if (journal->is_writeable()) {
orig_len = journal->prepare_entry(tls, &tbl);
}
uint64_t op = submit_manager.op_submit_start();
dout(5) << __FUNC__ << ": (trailing journal) " << op << " " << tls << dendl;
if (m_filestore_do_dump)
dump_transactions(tls, op, osr);
trace.event("op_apply_start");
trace.keyval("opnum", op);
trace.keyval("journal mode", "trailing");
apply_manager.op_apply_start(op);
trace.event("do_transactions");
int r = do_transactions(tls, op);
if (r >= 0) {
trace.event("journal started");
_op_journal_transactions(tbl, orig_len, op, ondisk, osd_op);
} else {
delete ondisk;
ondisk = nullptr;
}
// start on_readable finisher after we queue journal item, as on_readable callback
// is allowed to delete the Transaction
if (onreadable_sync) {
onreadable_sync->complete(r);
}
apply_finishers[osr->id % m_apply_finisher_num]->queue(onreadable, r);
submit_manager.op_submit_finish(op);
trace.event("op_apply_finish");
apply_manager.op_apply_finish(op);
utime_t end = ceph_clock_now();
logger->tinc(l_filestore_queue_transaction_latency_avg, end - start);
return r;
}
读操作
- 读操作流程:
FileStore::read
lfn_open(cid, oid, false, &fd);
safe_pread(**fd, bptr.c_str(), len, offset);
lfn_close(fd);
- Read 函数实现如下:其中 lfnopen 是从文件句柄缓冲池中拿句柄信息,对应 POSIX 接口中的 open 系统调用,safe_pread 则是对 pread 系统调用的封装。
int FileStore::read(
CollectionHandle& ch,
const ghobject_t& oid,
uint64_t offset,
size_t len,
bufferlist& bl,
uint32_t op_flags)
{
int got;
tracepoint(objectstore, read_enter, ch->cid.c_str(), offset, len);
const coll_t& cid = !_need_temp_object_collection(ch->cid, oid) ? ch->cid : ch->cid.get_temp();
dout(15) << __FUNC__ << ": " << cid << "/" << oid << " " << offset << "~" << len << dendl;
auto osr = static_cast<OpSequencer*>(ch.get());
osr->wait_for_apply(oid);
FDRef fd;
int r = lfn_open(cid, oid, false, &fd);
if (r < 0) {
dout(10) << __FUNC__ << ": (" << cid << "/" << oid << ") open error: "
<< cpp_strerror(r) << dendl;
return r;
}
if (offset == 0 && len == 0) {
struct stat st;
memset(&st, 0, sizeof(struct stat));
int r = ::fstat(**fd, &st);
ceph_assert(r == 0);
len = st.st_size;
}
#ifdef HAVE_POSIX_FADVISE
if (op_flags & CEPH_OSD_OP_FLAG_FADVISE_RANDOM)
posix_fadvise(**fd, offset, len, POSIX_FADV_RANDOM);
if (op_flags & CEPH_OSD_OP_FLAG_FADVISE_SEQUENTIAL)
posix_fadvise(**fd, offset, len, POSIX_FADV_SEQUENTIAL);
#endif
bufferptr bptr(len); // prealloc space for entire read
got = safe_pread(**fd, bptr.c_str(), len, offset);
if (got < 0) {
dout(10) << __FUNC__ << ": (" << cid << "/" << oid << ") pread error: " << cpp_strerror(got) << dendl;
lfn_close(fd);
return got;
}
bptr.set_length(got); // properly size the buffer
bl.clear();
bl.push_back(std::move(bptr)); // put it in the target bufferlist
#ifdef HAVE_POSIX_FADVISE
if (op_flags & CEPH_OSD_OP_FLAG_FADVISE_DONTNEED)
posix_fadvise(**fd, offset, len, POSIX_FADV_DONTNEED);
if (op_flags & (CEPH_OSD_OP_FLAG_FADVISE_RANDOM | CEPH_OSD_OP_FLAG_FADVISE_SEQUENTIAL))
posix_fadvise(**fd, offset, len, POSIX_FADV_NORMAL);
#endif
if (m_filestore_sloppy_crc && (!replaying || backend->can_checkpoint())) {
ostringstream ss;
int errors = backend->_crc_verify_read(**fd, offset, got, bl, &ss);
if (errors != 0) {
dout(0) << __FUNC__ << ": " << cid << "/" << oid << " " << offset << "~"
<< got << " ... BAD CRC:\n" << ss.str() << dendl;
ceph_abort_msg("bad crc on read");
}
}
lfn_close(fd);
dout(10) << __FUNC__ << ": " << cid << "/" << oid << " " << offset << "~"
<< got << "/" << len << dendl;
if (cct->_conf->filestore_debug_inject_read_err &&
debug_data_eio(oid)) {
return -EIO;
} else if (oid.hobj.pool > 0 && /* FIXME, see #23029 */
cct->_conf->filestore_debug_random_read_err &&
(rand() % (int)(cct->_conf->filestore_debug_random_read_err *
100.0)) == 0) {
dout(0) << __func__ << ": inject random EIO" << dendl;
return -EIO;
} else {
tracepoint(objectstore, read_exit, got);
return got;
}
}
BlueStore
MSST17 测试数据
- 硬件环境:
- Admin Server x1
- CPU:Intel® Xeon® CPU E5-2640 v3
- Mem:128GB
- OSD Server x4
- CPU:Intel® Xeon® CPU E5-2640 v3
- Mem:32 GB
- Storage:
- HGST UCTSSC600 600 GB x4
- Samsung PM1633 960 GB x4
- Intel® 750 series 400 GB x2
- Admin Server x1
- 软件环境:Linux 4.4.43 kernel,Ceph Jewel LTS version (v10.2.5)
- 工具:ftrace(可能引入开销导致 Ceph 性能下降),或者修改内核记录写入的扇区数来测试写放大
- 负载解释
- Microbenchmark
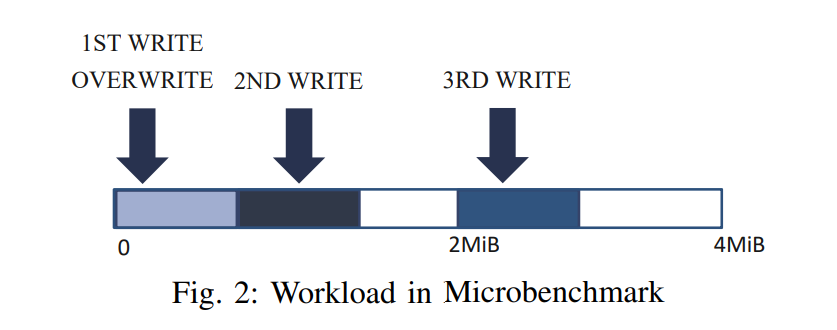
- 首先,我们分析在不同情况下,当我们向RBD发出一个写请求时,WAF如何变化。在默认情况下,整个RBD空间被划分为一组4MiB对象。
- 1st write:there is a write to an empty object
- 2nd write:there is a write next to the 1ST WRITE
- 3rd write:there is a write to the middle of the object leaving a hole between the 2ND WRITE and the current write。(即从 2MB 的位置开始写)
- overwrite:there is an overwrite to the location written by the 1ST WRITE
- 通过将请求大小从4KiB翻倍到4KiB来重复相同的实验
- 首先,我们分析在不同情况下,当我们向RBD发出一个写请求时,WAF如何变化。在默认情况下,整个RBD空间被划分为一组4MiB对象。
- Long-Term EXPERIMENT
- 使用 FIO 生成随机 4K 写到 RBD,周期性地测试 IOPS 和 WAF,对于每个存储后端,我们将所有写请求分类为几个类别,并计算每个类别的 WAF,因为 RBD 常用于虚拟桌面基础设施 VDI,所以写请求通常是随机的,大小从 4K 到 8K 不等,所以我们测试了 4K 写,我们修改内核来记录写入的扇区数来测试写放大
- step1. 安装 ceph,创建 64GB 的 krbd
- step2. 删除页面缓存,调用同步并等待600秒将所有脏数据刷新到磁盘
- step3. 执行 4KiB 随机写操作,队列深度为 128 (QD=128)对 krbd 分区使用 fio,直到总写量达到容量的 90%(即 57.6GB)
- 使用 FIO 生成随机 4K 写到 RBD,周期性地测试 IOPS 和 WAF,对于每个存储后端,我们将所有写请求分类为几个类别,并计算每个类别的 WAF,因为 RBD 常用于虚拟桌面基础设施 VDI,所以写请求通常是随机的,大小从 4K 到 8K 不等,所以我们测试了 4K 写,我们修改内核来记录写入的扇区数来测试写放大
- Microbenchmark
- 注意:所有的实验都是先使用 16 HDDs 测试,然后使用 16 SSDs 测试,对于 HDD 队列深度设置为 128 ,使用单个写线程即可让 OSD 饱和,但是对于 SSD 不行,所以使用了 2 个写线程和 128 的队列深度。
测试结果
MicroBenchmark
- 基于 XFS 的 FileStore,CephJournal 放在 NVMe SSD 上,数据被分类为:
- Ceph data
- Ceph metadata:因为 Ceph data 和 Ceph metadata 不好区分,所以这里采用的方式是写入 XFS 之前的数据总量减去 Ceph data 的数量(Ceph data 的数量则是在客户端处统计 * 副本数),所以此处的 Ceph metadata 包括了写入 LevelDB 的数据量(即 Metadata Attributes)
- Ceph journal
- File system metadata
- File system journal
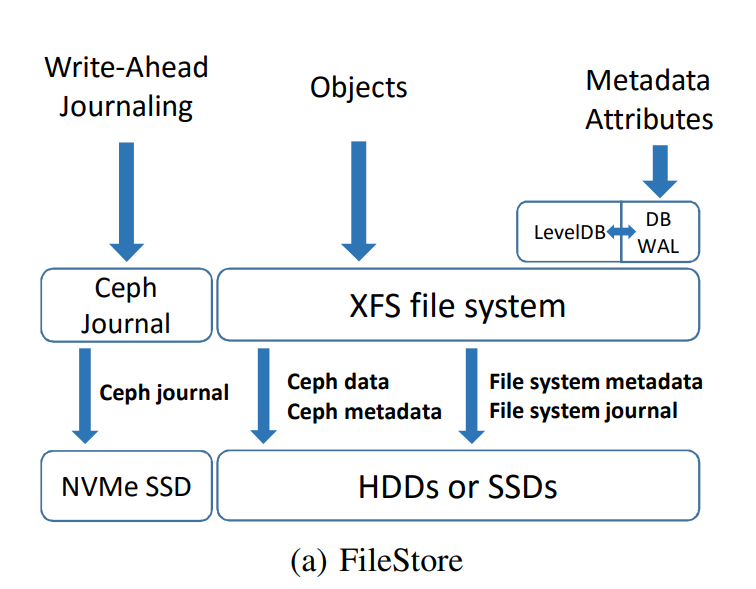
- 随着请求大小的增大,WAF 下降明显,因为对象的元数据、KV 对、文件系统日志和元数据相对于写入的数据变得更小了,到 4MB 的时候收敛到了大约 6 倍,6 则主要是 3 副本和写前日志 Ceph Journal 引入的双写叠加起来的。
- 下表所示的 2nd write 和 3rd write 对应在 2M 和 4M 大小的统计 WAF 系数为空
- 是因为对于单个请求大小为 2M 时,1st 写入就已经写入了 2M,2nd 写入和 3rd 写入是等价的,所以此处只记录了 3rd 从 2MB 开始写入。
- 而对于单个请求大小为 4MB 时,1st 就已经写满了 4MB 的 RBD 对象大小,所以 2nd 和 3rd 写入无法继续进行,故统计为空。
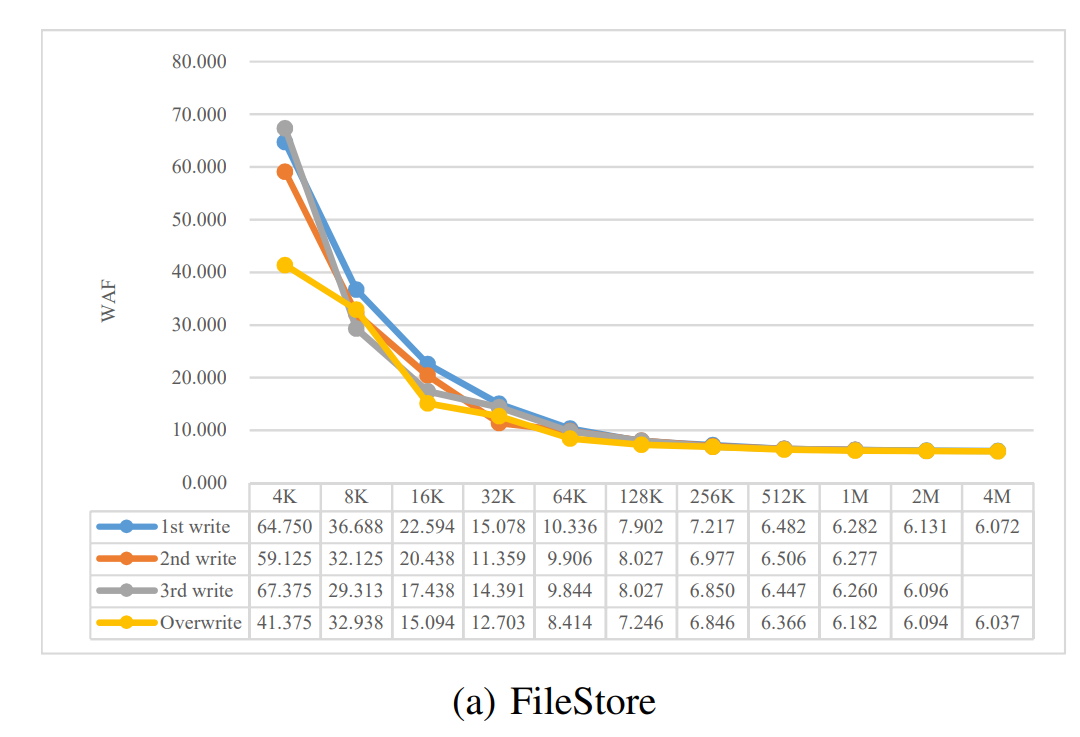
- 下表所示的 2nd write 和 3rd write 对应在 2M 和 4M 大小的统计 WAF 系数为空
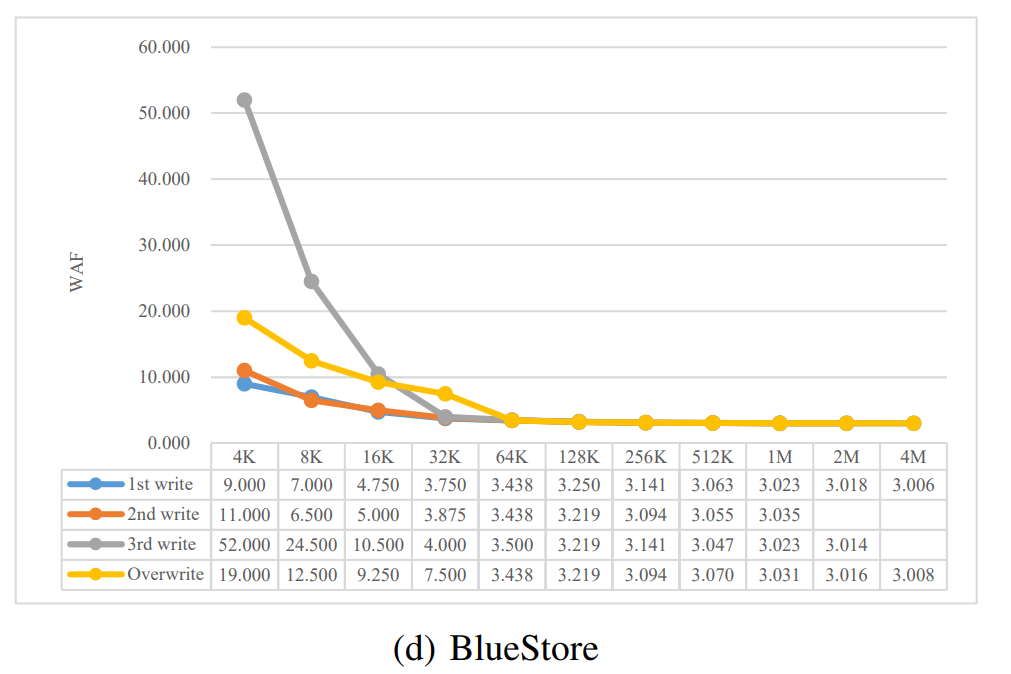
- BlueStore 数据被划分为以下类型:
- Ceph data
- Ceph metadata:写到 RocksDB 以及 RocksDB WAL 的数据
- Compaction:RocksDB Compaction 引入的写入
- Zero-filled data:Data filled with zeroes by Ceph OSD daemons。即当写入的 chunk 小于最小分配大小,chunk 中会有空白的部分也就是所说的 holes,使用 0 填充
- 3rd write 相比另外两种写操作的写放大更为严重,特别是在小 IO 的时候(小于16KB),因为 BlueStore 默认的最小分配 chunk 大小设置为了 64KB,小 IO 的话对应就需要进行填充(1st 和 2nd 小 IO 之后进行 3rd IO 需要填充前两次 IO 对应的 chunk),当请求大小达到 32KB 的时候,整个 chunk 因为第一次和第二次写入就已经被写满了(32+32),所以就不需要填充数据了,此时填充带来的写放大影响就是最小的。
- 当请求大小小于 64KB 的时候,overwrite 的写放大比 1st write 要严重,这是因为如果请求需要部分覆盖现有块,BlueStore 会尝试通过将数据写入 WAL 设备来维护数据一致性,以防止突然断电,如果直接对现有块执行部分覆盖,在写操作被中断的情况下,我们将无法恢复原始数据。
- BlueStore 相比于其他存储后端的写放大表现相对更好是因为没有使用本地文件系统来存储对象数据,减少了写流量,和其他存储后端不一样的是,只要不是部分覆盖写操作的话 BlueStore 就不会有双写的问题,当请求大小大于或等于块(chunk)大小时,这使得 BlueStore 中的 WAF 收敛为3。
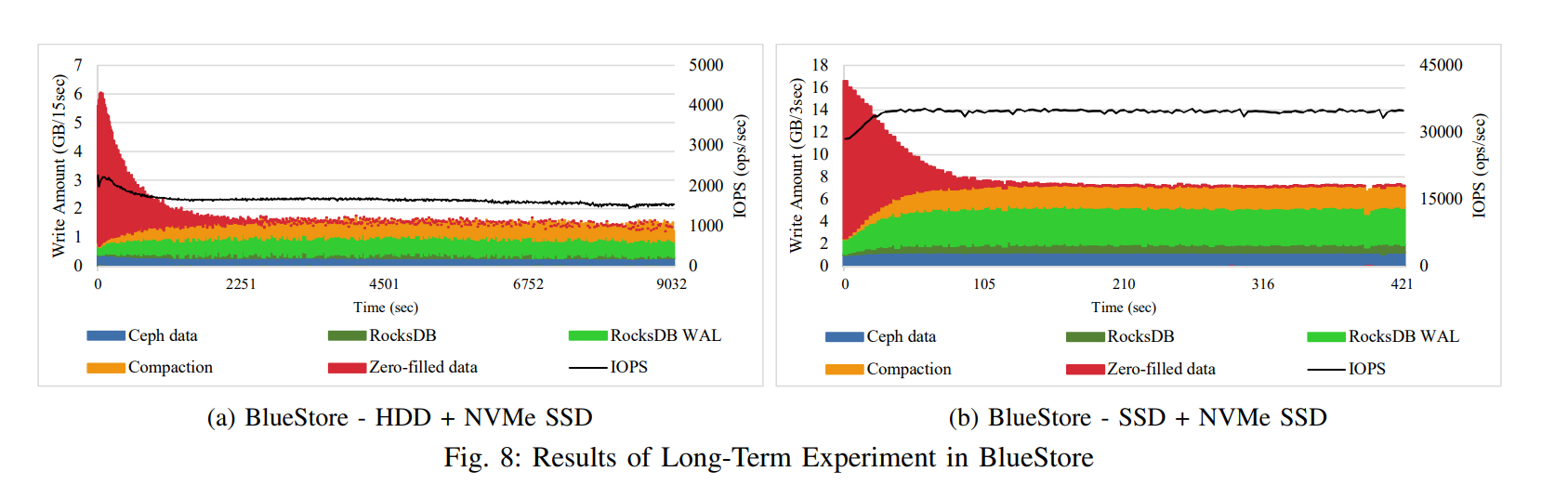
Long-Term EXPERIMENT
-
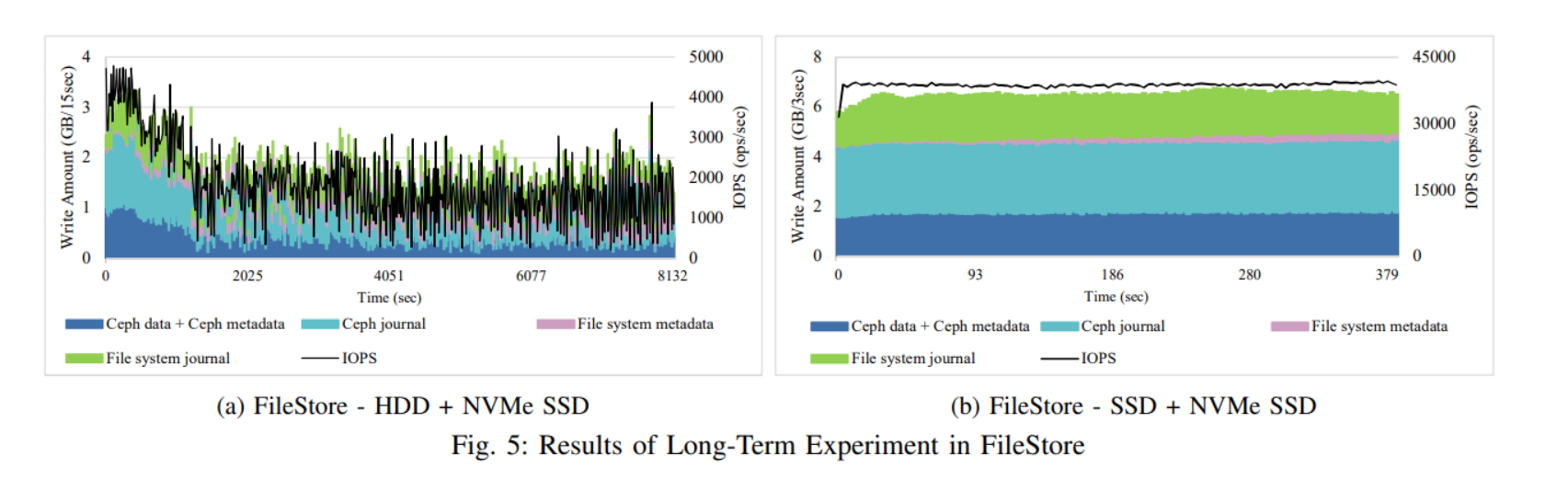
FileStore 的 IOPS 曲线和 Ceph Journal 的写流量是比较相近的,因为对于 FIleStore 下的客户端而言,需要等待三个写入请求都被封装成事务写入到日志中才会确认该请求成功写入。
-
HDD 和 SSD 的表现完全不同,HDD 下,IOPS 保持在接近 4000 ops/秒,持续约 1000 秒,但之后会降到 3000 ops/秒以下,直到实验结束。这种性能下降主要是由于 HDD 的速度较慢和文件存储中使用的节流(throttling)机制,开始写入的时候,无其他数据,Ceph 日志首先吸收传入的写事务,所以能够很快确认写入完成,由于 FileStore 一直以只追加的方式将 Ceph 日志写入NVMe SSD,所以对 HDD 的重写速度赶不上 Ceph 日志的速度,为了防止延迟骤降,FileStore 会检查日志项中还未刷入 HDD 的数量是否达到阈值然后来决定是否限制来自上层的事务写入(journal_throttle_low_threshold, journal_throttle_high_threshold),当向 HDD 写入了一定的事务之后,取消限制,高性能 Ceph 日志再次快速吸收写请求,直到它又达到阈值,所以会产生周期性的性能波动,写事务经常被限制,IOPS 曲线也会波动。
-
SSD 下的性能表现就相对稳定,实验开始时所写的Ceph日志与实验结束时所写的基本相同,在整个实验过程中,在数量上几乎没有变化。这意味着,装载 XFS 文件系统的底层 SSD 处理排队事务的速度与 Ceph 日志写入的速度一样快
-
BlueStore 与 FileStore 的一个显著区别是,在实验开始时,会有大量零填充的数据流量。当前 chunk 大小小于最小分配的单元大小时就需要进行填充,零填充的数据量会随着时间的推移而减少,因为对每个块只执行一次零填充操作。
-
因为 BlueStore 按顺序将块分配给原始块设备,在实验开始时零填充的数据将会很快写入完成,即便是在较慢的 HDD 上。但是对于已经分配好的 chunk 进行连续的 4KiB 随机写操作会导致对 HDD 的随机访问,就会让 HDD 的 IOPS 降低,但是相比于 FileStore,IOPS 表现更为稳定。当在 SSD 上运行的时候,实验开始阶段 IOPS 还略有上升,这是因为不像 HDD 那样,初始阶段之后的随机写不会成为 SSD 的瓶颈,因为 SSD 有更好的随机写性能相比于 HDD,IOPS 会随着由零填充数据引起的额外写操作的减少而增加一点
-
当使用 SAS SSD 作为 BlueStore 的主存储时,我们发现作为 RocksDB 和 RocksDB WAL 使用的 NVMe SSD 设备可能会出现瓶颈,因为 SAS SSD 和 NVMe SSD 的性能差异不显著。其中 RocksDB WAL 尤为明显,因为大部分随机的 4K 写将被转换成对于现有的存在的 chunk 的部分覆盖写,此时就需要 BlueStore 将数据保存在 RocksDB WAL 中来保证数据的一致性。
-
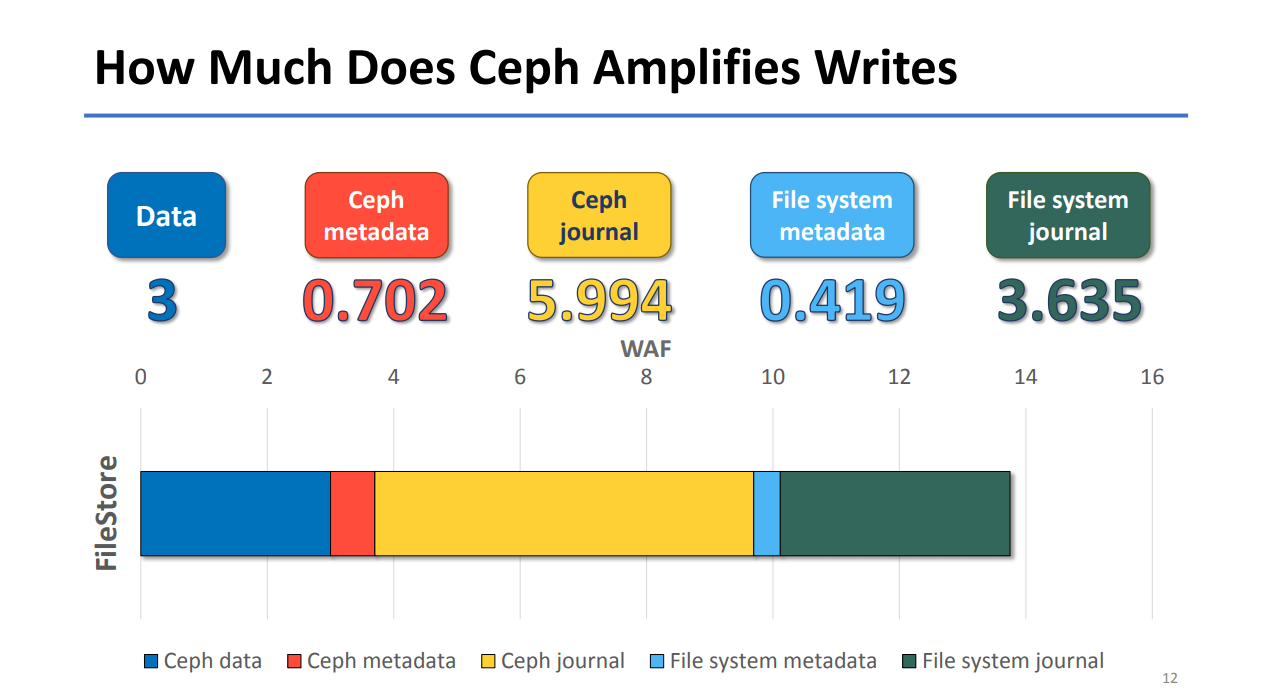
由于 FileStore 依赖于外部 Ceph 日志记录,传统的看法是,由于冗余的数据写入 Ceph 日志,它会使 WAF 翻倍,但是下表所示无论是 HDD 还是 SSD,不只是翻倍,而是三倍,这是因为 FileStore 不仅将数据写入日志,还把元数据和其他属性写入了日志。除此以外还会有 journaling of journal 问题,写放大增加了约 4 倍,这意味着文件系统元数据和文件系统日志的数量甚至大于每个OSD服务器中的实际数据大小。
-
对于 BlueStore 无论是 SSD 还是 HDD,由 RocksDB + RocksDB WAL + Compaction 造成的总流量很大,占据了写放大因子的 65.7~69.3%。
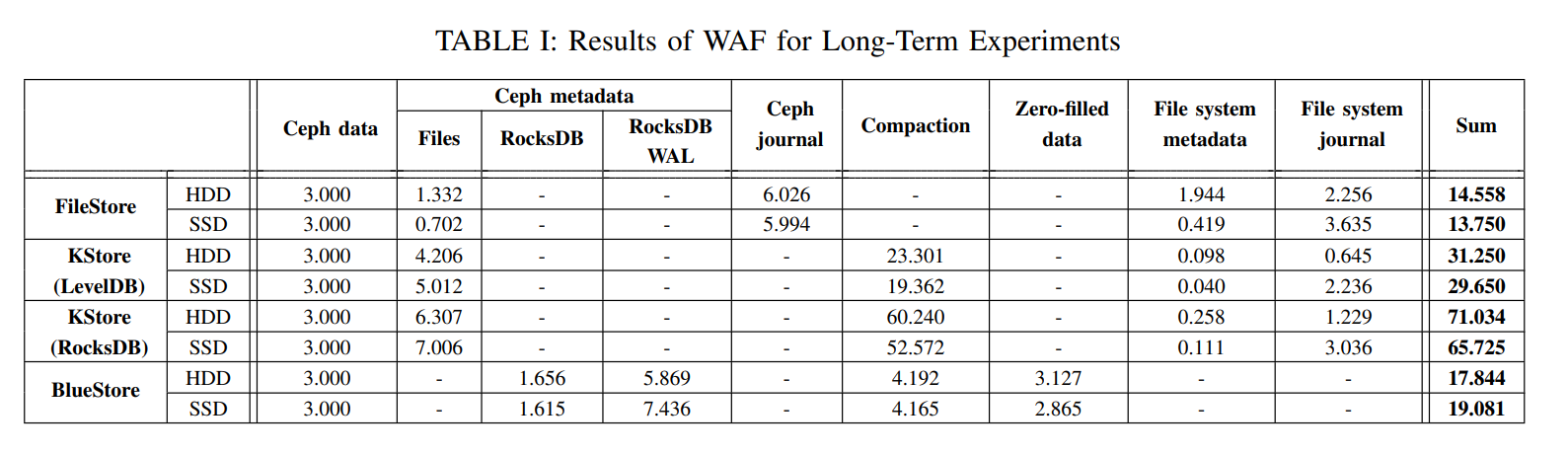
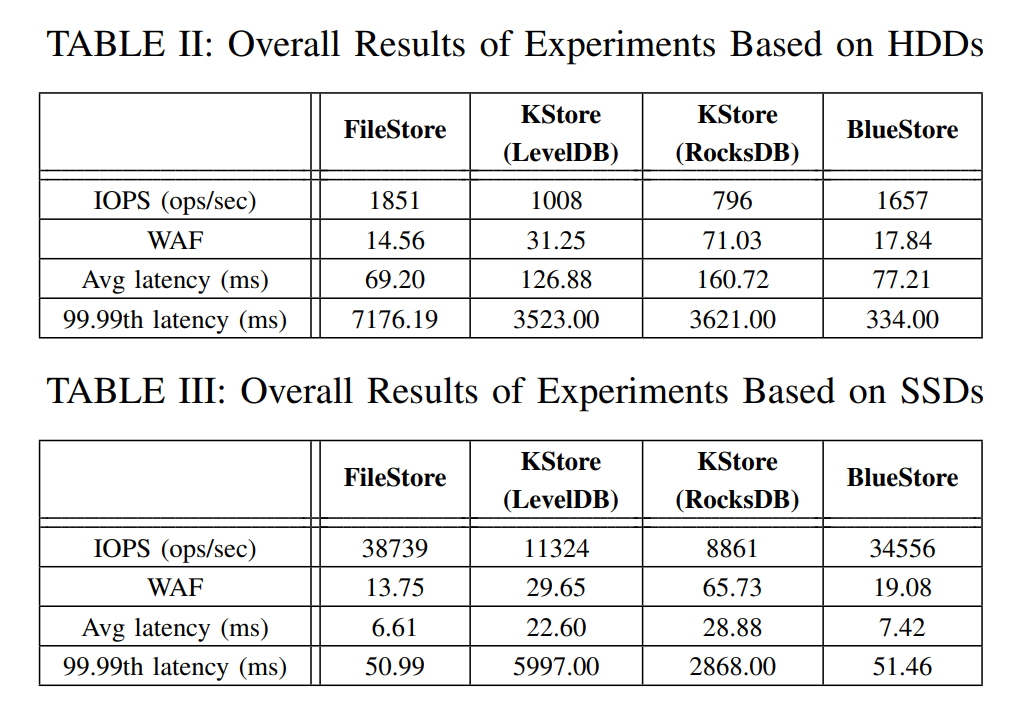
-
如下表所示,无论哪种存储后端,对于 HDD,Ceph 的 WAF 很高,从 14.56 到 71.03,考虑到使用了三副本,对于单个 4KB 的写入实质放大为 4.85x ∼ 23.68x,其中 FileStore 的 IOPS 和平均延迟上表现最好,但是尾延迟最差,但 BlueStore 的尾延迟最低,BlueStore 的写放大更大是因为虽然避免了 Ceph Journal 但还是需要对小写进行写前日志的操作来保证一致性。
-
SSD 上 FileStore 仍然表现最好,尾延迟也是如此,主要是因为主要存储变成 SSD 后速度也足够快能够赶上 Ceph Journal 的写入速度,大多数场景下,客户端在写入 Ceph Journal 后就能确认当前操作完成,也一定程度上减小了延迟。
-
BlueStore 似乎是在延迟敏感情况下最有前途的存储后端,特别是在 HDD 用作主存储介质时。SSD 上仍然是 FileStore 表现更好,但是 BlueStore 差距也不大。
SOSP19 测试数据
- 硬件环境:
- 16-node Ceph cluster
- 16-core Intel E5-2698Bv3 Xeon 2GHz CPU
- 64GiB RAM
- 400GB Intel P3600 NVMe SSD
- 4TB 7200RPM Seagate ST4000NM0023 HDD
- 软件环境:
- Linux kernel 4.15 on Ubuntu 18.04
- Ceph Luminous release (v12.2.11)
测试结果
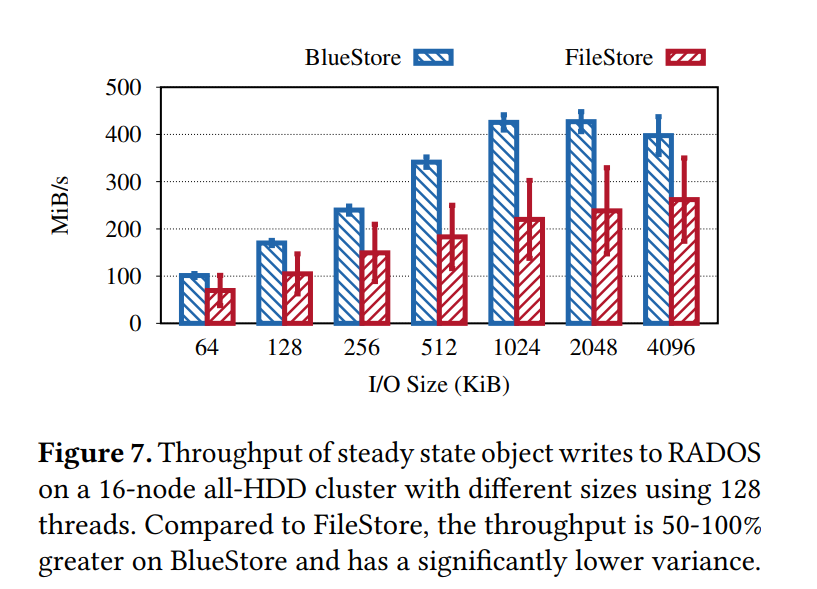
Bare RADOS Benchmarks
- 如图所示以队列深度 128 写入的不同对象大小的吞吐量。在稳定状态下,BlueStore的吞吐量比FileStore大50-100%,因为 BlueStore 避免了双写和一致性开销
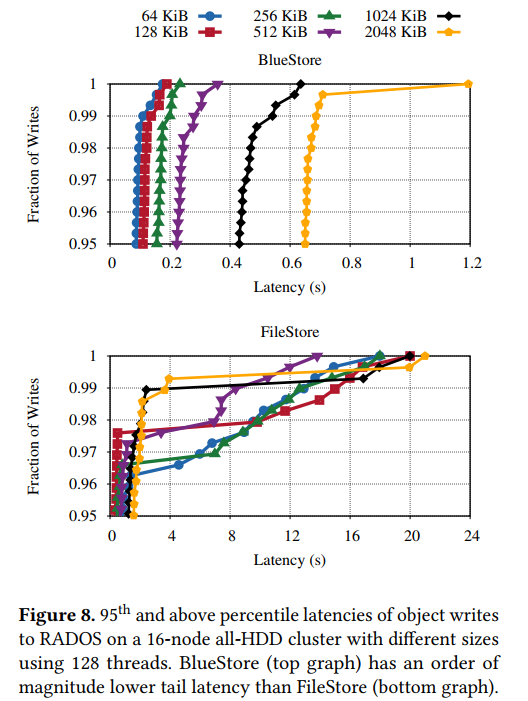
- 如图显示了对象写入RADOS的95%以上的延迟。BlueStore 的尾部延迟比 FileStore 低一个数量级。此外,正如预期的那样,使用 BlueStore 时,尾部延迟会随着对象大小的增加而增加,而使用 FileStore 时,即使是很小的对象写操作也可能有很高的尾部延迟,这是由于缺乏对写操作的控制
- 读取性能在 BlueStore(没有显示)是类似或更好的相比于 FileStore 当 I/O 大小大于 128 KiB;对于较小的 I/O大小,FileStore 更好,因为内核提前读取,BlueStore 无意实现预读。预期在RADOS上实现的应用程序将执行它们自己的预读。
RADOS Block Device Benchmarks
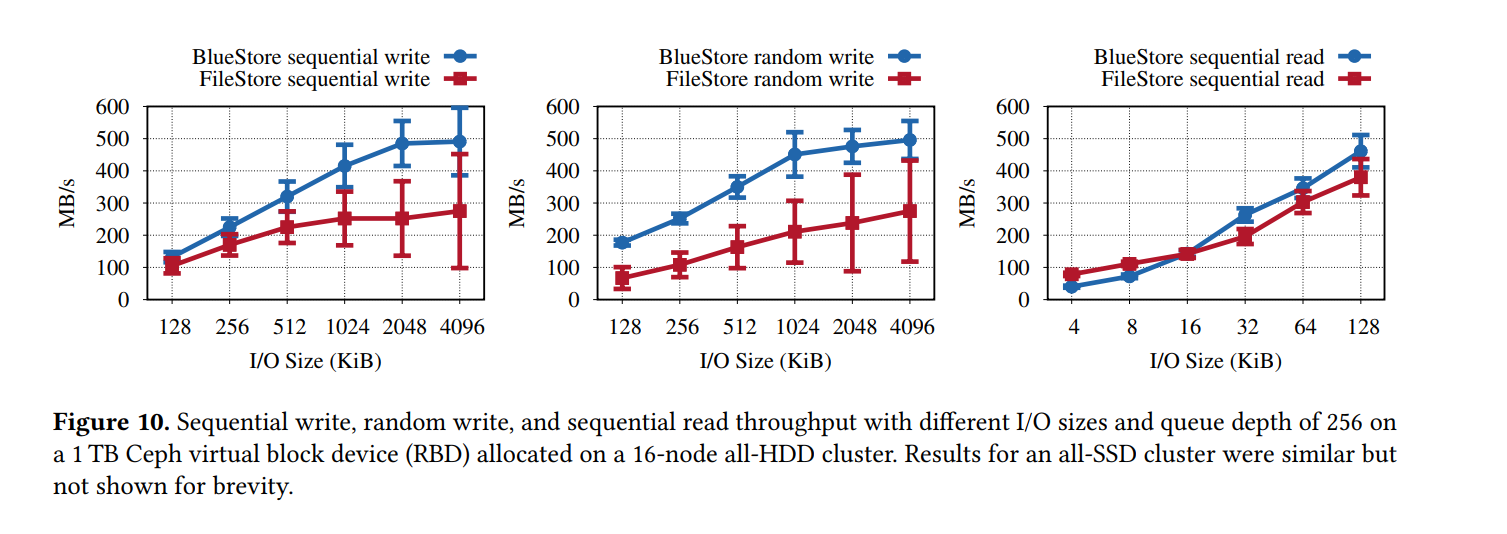
- 对于 I/O 大小大于 BlueStore 的 512 KiB、顺序写和随机写吞吐量平均分别高出 1.7 倍和 2 倍,同样主要是由于避免了重复写,BlueStore 还显示了一个显著更低的吞吐量差异,因为它可以确定地将数据推送到磁盘,另一方面,在 FileStore 中,任意触发的回写与前台对 WAL 的写入冲突,并引入了长请求延迟
- 对于中等 I/O 大小(128 512 KiB),顺序写操作的吞吐量差异会减小,因为XFS在文件存储中屏蔽了重复写操作的部分成本。对于中等 I/O 大小,对 WAL 的写操作不会完全利用磁盘,这样就留下了足够的带宽让另一个写入流通过,并且不会对前台对 WAL 的写入产生很大影响。将数据同步写入到 WAL 后,FileStore 再将其异步写入文件系统。XFS 缓冲这些异步写操作,并在将它们发送到磁盘之前将它们转换为一个大的顺序写操作。XFS 不能对随机写操作执行同样的操作,这就是为什么即使对于中等大小的随机写操作,高吞吐量的差异仍然存在。
- 对于小于 64KiB(未显示)的 I/O 大小,BlueStore 的吞吐量比 FileStore 高 20%。对于这些 I/O 大小,BlueStore 执行延迟写操作,首先将数据插入 RocksDB,然后异步覆盖对象数据以避免碎片。
为什么使用 BlueStore
- I/O 放大严峻:放大主要包括两个方面:在 FileStore 实现事务带来的放大 和 文件系统本身的放大
- 由于有的文件系统不支持事务,或者部分支持内部事务的文件系统如 btrfs(但实践表明事务中途发生故障的时候可能出现事务部分提交的情况),故 FileStore 需要实现一套 WAL 机制来实现事务(FileJournal),相应地也就引入了放大
- 许多文件系统后端本身就是日志文件系统,内部保证数据一致性也实现了写前日志,因此也存在一定的写放大
- 本地文件系统的元数据性能可能严重影响分布式系统的整体性能:Ceph 面对的一个很大的挑战就是“如何快速地枚举文件夹中数百万项的内容,如何保证返回的结果有序”。基于 Btrfs 和 XFS 的后端存储往往都会有这样的问题,同时用于分配元数据负载的目录分割操作与系统策略其实是有一定冲突的,整个系统的性能会受到元数据性能的影响。
- 新型存储器件向文件系统提出了挑战:文件系统日趋成熟带来的影响就是显得更加的保守和死板,不能较好地适配现在很多摒弃了块接口的新型存储器件。面向数据中心的新型存储器件往往都需要在原有应用程序接口层面做较大的修改。诸如为了提升容量, HDD 正在向 SMR 过渡,同时支持 Zone Interface;为了减小 SSD 中由于 FTL 造成的 IO 尾延迟,引入了 Zoned Namespace SSD 技术,支持 Zone Interface;云计算和云存储供应商也在调整他们的软件栈来适配 Zone 设备。分布式文件系统在这方面目前缺乏较好的支持。
架构
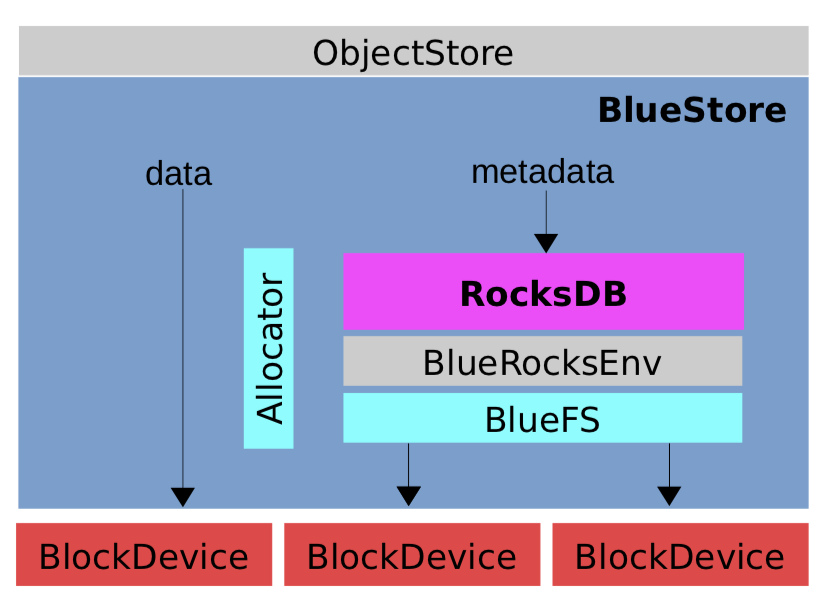
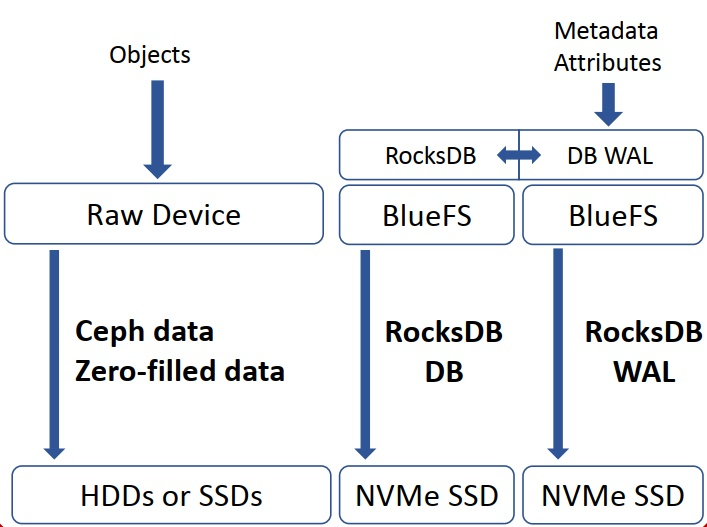
- BlueStore 整体架构分为三个部分:BlockDevice、BlueFS 和 RocksDB
- BlockDevice 为最底层的块设备,通常为 HDD 或者 SSD , BlueStore 直接操作块设备,抛弃了 XFS 等本地文件系统。 BlockDevice 在用户态直接以 linux 系统实现的 AIO 直接操作块设备,由于操作系统支持的 aio 操作只支持 directIO,所以对 BlockDevice 的写操作直接写入磁盘,并且需要按照 page 对齐。
- RocksDB 是 Facebook 在 leveldb 上开发并优化的 KV 存储系统。本身是基于文件系统的,不是直接操作裸设备。它将系统相关的处理抽象成 Env,用户可实现相应的接口。BlueFS 的主要的目的,就是支持 RocksDB Env 接口,保证 RocksDB 的正常运行。
- BlueFS 是一个小的文件系统,其文件系统的文件和目录的元数据都保存在全部缓存在内存中,持久化保存在文件系统的日志文件中, 当文件系统重新 mount 时,重新 replay 该日志文件中保存的操作,就可以加载所有的元数据到内存中。其数据和日志文件都直接保存在依赖底层的 BlockDevice 中。主要还实现了
RocksDB::Env所需要的接口。BlueFS 在设计上支持把.log和.sst分开存储,.log使用速度更快的存储介质(NVME等),从而提高 WAL 日志的性能。(即可以在 OSD 的配置中指定 wal/db path)
bluestore block db path =/dev/sdb2
bluestore block wal path =/dev/ram0
bluestore block path = /dev/sdb4
- BlueStore 是最终基于 RocksDB 和 BlockDevice 实现的 Ceph 的对象存储,其所有的元数据都保存在 RocksDB 这个KV存储系统中,包括对象的集合,对象,存储池的 omap 信息,磁盘空间分配记录等都保存 RocksDB 里, 其对象的数据直接保存在 BlockDevice 上,不使用本地文件系统,直接接管裸设备,并且只使用一个原始分区。
- Allocator: 最新的实现中有 AvlAllocator, BitmapAllocator, StupidAllocator, ZonedAllocator
BlueFS 数据结构
- BlueFS 会为每一个文件维护一个 inode,包括分配给该文件的区段列表也会维护相应的 inode。超级块存储在确定的物理地址上,且包含了日志的 inode 信息,其文件系统的文件和目录的元数据都保存在全部缓存在内存中,持久化保存在文件系统的日志文件中, 当文件系统重新 mount 时,重新 replay 该日志文件中保存的操作,就可以加载所有的元数据到内存中。当日志大小达到阈值时,日志文件将被压缩并写到一个新的日志文件中,同时将日志的新地址信息记录到超级块中
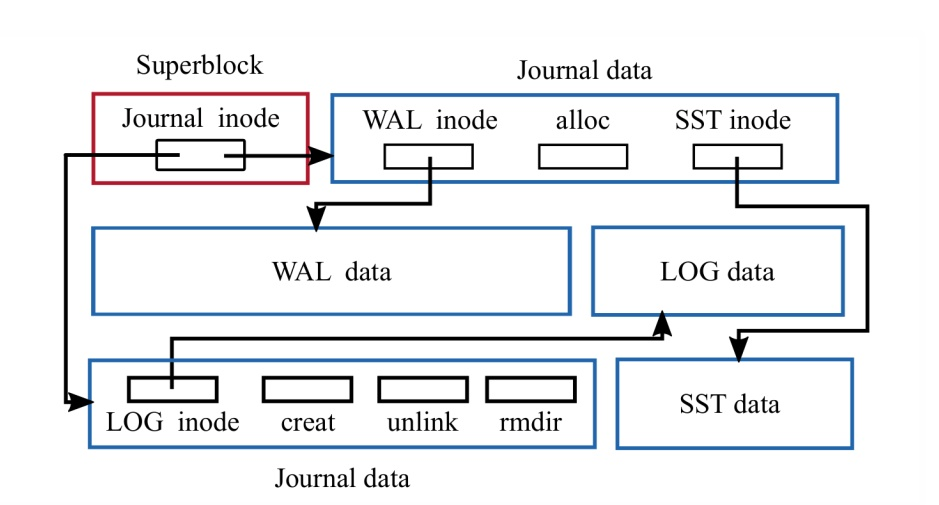
- WAL 对于提升RocksDB的性能至关重要,所以 BlueFS 在设计上支持把
.log和.sst分开存储,.log使用速度更快的存储介质(NVME等)。
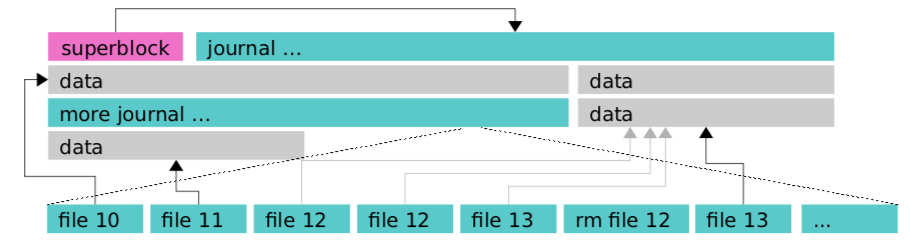
- BlueFS 与传统文件系统不同另外一个地方是并没有设计单独存储fnode的存储空间,而是将其存储在WAL(Write Ahead Log)日志当中。当文件系统挂载的时候通过回放该日志实现内存数据结构的构建。这样,在内存中就可以查到磁盘中的目录和文件信息,从而可以实现对文件的读写。BlueFS本身就是一个功能阉割的,迷你文件系统。BlueFS可以这么实现得益于其只服务于RocksDB,其文件数量非常有限,使用场景也非常有限。
class BlueFS {
public:
CephContext* cct;
// 支持不同种类的块设备
static constexpr unsigned MAX_BDEV = 5;
static constexpr unsigned BDEV_WAL = 0;
static constexpr unsigned BDEV_DB = 1;
static constexpr unsigned BDEV_SLOW = 2;
static constexpr unsigned BDEV_NEWWAL = 3;
static constexpr unsigned BDEV_NEWDB = 4;
enum {
WRITER_UNKNOWN,
WRITER_WAL, // RocksDB的log文件
WRITER_SST, // RocksDB的sst文件
};
// 文件
struct File : public RefCountedObject {
MEMPOOL_CLASS_HELPERS();
bluefs_fnode_t fnode; // 文件inode
int refs; // 引用计数
uint64_t dirty_seq; // dirty序列号
bool locked;
bool deleted;
boost::intrusive::list_member_hook<> dirty_item;
// 读写计数
std::atomic_int num_readers, num_writers;
std::atomic_int num_reading;
void* vselector_hint = nullptr;
...
写操作
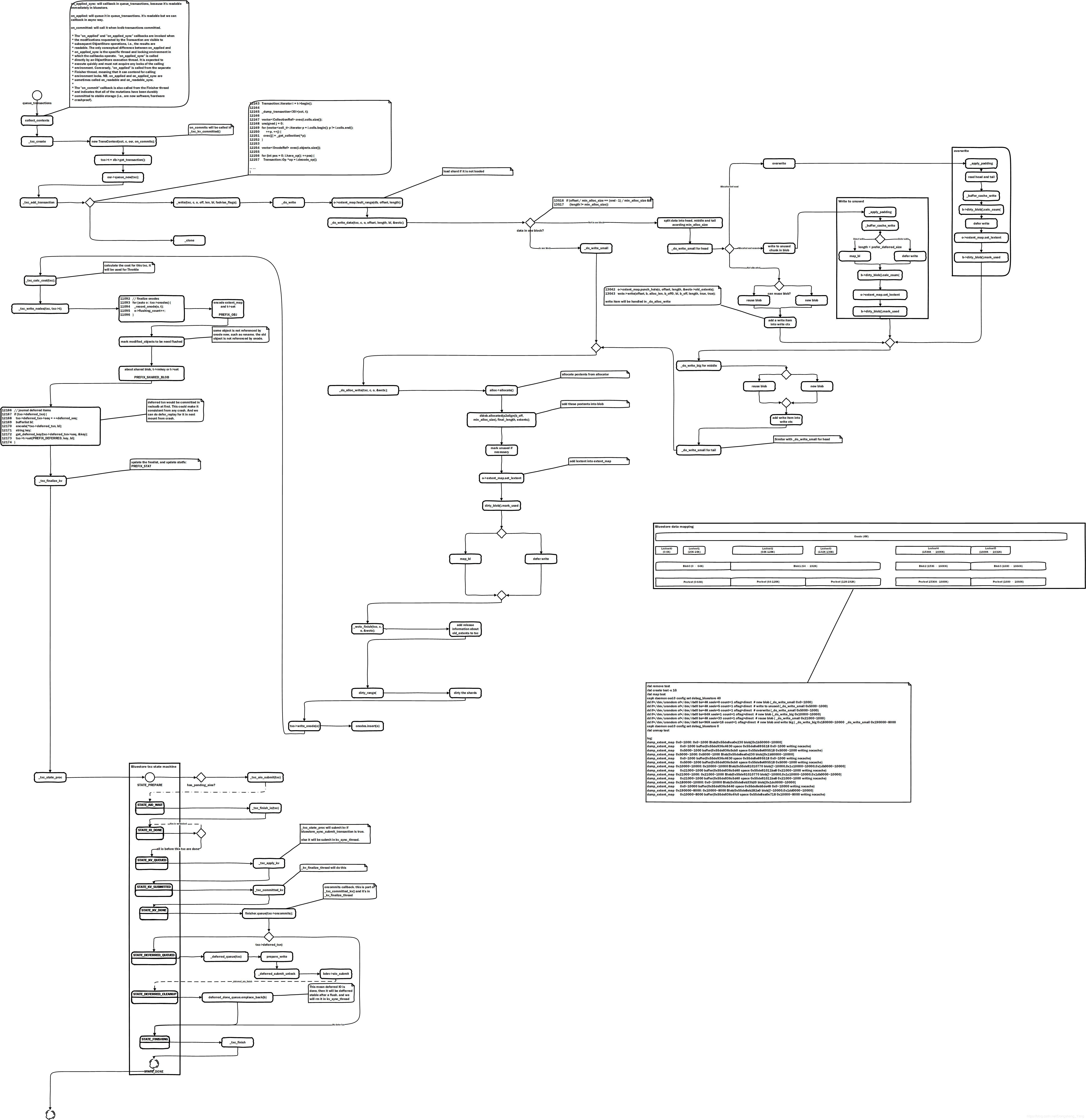
- 针对具体的存储引擎的实现,由于数据都是先写后读,此处将从写操作入手,再到读操作。
- 写操作的调用关系如下:
ReplicatedBackend::submit_transaction
parent->queue_transactions(tls, op.op); //调用PrimaryLogPG::queue_transactions
osd->store->queue_transactions(ch, tls, op, NULL); //调用BlueStore::queue_transactions
- 而在 BlueStore 中具体的 queue_transactions 中:
int BlueStore::queue_transactions(
CollectionHandle& ch,
vector<Transaction>& tls,
TrackedOpRef op,
ThreadPool::TPHandle *handle)
{
FUNCTRACE(cct);
/**
* Collect contexts
* on_applied: will queue it in queue transactions, it's readable but we can callback in async way
* on_applied_sync: will call back in queue_transactions, because it's readable immediately in bluestore.
* on_commit: will call it when kvdb transactions committed.
**/
list<Context *> on_applied, on_commit, on_applied_sync;
ObjectStore::Transaction::collect_contexts(
tls, &on_applied, &on_commit, &on_applied_sync);
auto start = mono_clock::now();
Collection *c = static_cast<Collection*>(ch.get());
OpSequencer *osr = c->osr.get();
dout(10) << __func__ << " ch " << c << " " << c->cid << dendl;
// Create transaction context
// 创建 KVDB 的事务同时获取PG对应的OpSequencer(每个PG有一个OpSequencer)用来保证PG上的IO串行执行
// prepare
TransContext *txc = _txc_create(static_cast<Collection*>(ch.get()), osr,
&on_commit);
// 遍历收集到的 list<Context *> 根据事务对应的操作码分别进行处理
// Collection Ops:remove_collection、create_collection、split_collection、merge_collection、collection hint objects
// Object Ops:OP_CREATE、OP_TOUCH(修改时间属性)、OP_WRITE、OP_ZERO、OP_TRUNCATE、OP_REMOVE、OP_SETATTR、OP_RMATTR(remove attributes)、OP_CLONE
// OMap Ops
for (vector<Transaction>::iterator p = tls.begin(); p != tls.end(); ++p) {
txc->bytes += (*p).get_num_bytes();
_txc_add_transaction(txc, &(*p));
}
// 计算事务开销
_txc_calc_cost(txc);
// 写 ONode 数据 (ONode 是常驻内存的数据结构,主要用于管理对象元数据)
// 持久化时,ONode 数据将被写入到 RocksDB 中
_txc_write_nodes(txc, txc->t);
// journal deferred items
if (txc->deferred_txn) {
txc->deferred_txn->seq = ++deferred_seq;
bufferlist bl;
encode(*txc->deferred_txn, bl);
string key;
get_deferred_key(txc->deferred_txn->seq, &key);
txc->t->set(PREFIX_DEFERRED, key, bl);
}
_txc_finalize_kv(txc, txc->t);
if (handle)
handle->suspend_tp_timeout();
auto tstart = mono_clock::now();
if (!throttle.try_start_transaction(
*db,
*txc,
tstart)) {
// ensure we do not block here because of deferred writes
dout(10) << __func__ << " failed get throttle_deferred_bytes, aggressive"
<< dendl;
++deferred_aggressive;
deferred_try_submit();
{
// wake up any previously finished deferred events
std::lock_guard l(kv_lock);
if (!kv_sync_in_progress) {
kv_sync_in_progress = true;
kv_cond.notify_one();
}
}
throttle.finish_start_transaction(*db, *txc, tstart);
--deferred_aggressive;
}
auto tend = mono_clock::now();
if (handle)
handle->reset_tp_timeout();
logger->inc(l_bluestore_txc);
// execute (start)
_txc_state_proc(txc);
// we're immediately readable (unlike FileStore)
for (auto c : on_applied_sync) {
c->complete(0);
}
if (!on_applied.empty()) {
if (c->commit_queue) {
c->commit_queue->queue(on_applied);
} else {
finisher.queue(on_applied);
}
}
log_latency("submit_transact",
l_bluestore_submit_lat,
mono_clock::now() - start,
cct->_conf->bluestore_log_op_age);
log_latency("throttle_transact",
l_bluestore_throttle_lat,
tend - tstart,
cct->_conf->bluestore_log_op_age);
return 0;
}
- 写操作调用关系:
BlueStore::queue_transactions
_txc_add_transaction(txc, &(*p)); //调用
BlueStore::_txc_add_transaction(TransContext *txc, Transaction *t)
_write(txc, c, o, off, len, bl, fadvise_flags); //调用BlueStore::_write
_do_write(txc, c, o, offset, length, bl, fadvise_flags);
txc->write_onode(o);
BlueStore::_do_write
_choose_write_options(c, o, fadvise_flags, &wctx);
o->extent_map.fault_range(db, offset, length);
_do_write_data(txc, c, o, offset, length, bl, &wctx);
r = _do_alloc_write(txc, c, o, &wctx);
- 写操作的函数流程:
int BlueStore::_write(TransContext *txc,
CollectionRef& c,
OnodeRef& o,
uint64_t offset, size_t length,
bufferlist& bl,
uint32_t fadvise_flags)
{
dout(15) << __func__ << " " << c->cid << " " << o->oid
<< " 0x" << std::hex << offset << "~" << length << std::dec
<< dendl;
int r = 0;
if (offset + length >= OBJECT_MAX_SIZE) {
r = -E2BIG;
} else {
_assign_nid(txc, o);
r = _do_write(txc, c, o, offset, length, bl, fadvise_flags);
txc->write_onode(o);
}
dout(10) << __func__ << " " << c->cid << " " << o->oid
<< " 0x" << std::hex << offset << "~" << length << std::dec
<< " = " << r << dendl;
return r;
}
int BlueStore::_do_write(
TransContext *txc,
CollectionRef& c,
OnodeRef o,
uint64_t offset,
uint64_t length,
bufferlist& bl,
uint32_t fadvise_flags)
{
int r = 0;
dout(20) << __func__
<< " " << o->oid
<< " 0x" << std::hex << offset << "~" << length
<< " - have 0x" << o->onode.size
<< " (" << std::dec << o->onode.size << ")"
<< " bytes"
<< " fadvise_flags 0x" << std::hex << fadvise_flags << std::dec
<< dendl;
_dump_onode<30>(cct, *o);
if (length == 0) {
return 0;
}
uint64_t end = offset + length;
GarbageCollector gc(c->store->cct);
int64_t benefit = 0;
auto dirty_start = offset;
auto dirty_end = end;
WriteContext wctx;
_choose_write_options(c, o, fadvise_flags, &wctx);
o->extent_map.fault_range(db, offset, length);
//*****************************************************
// 执行真正的数据写入的操作
_do_write_data(txc, c, o, offset, length, bl, &wctx);
//*****************************************************
r = _do_alloc_write(txc, c, o, &wctx);
if (r < 0) {
derr << __func__ << " _do_alloc_write failed with " << cpp_strerror(r)
<< dendl;
goto out;
}
if (wctx.extents_to_gc.empty() ||
wctx.extents_to_gc.range_start() > offset ||
wctx.extents_to_gc.range_end() < offset + length) {
benefit = gc.estimate(offset,
length,
o->extent_map,
wctx.old_extents,
min_alloc_size);
}
// NB: _wctx_finish() will empty old_extents
// so we must do gc estimation before that
_wctx_finish(txc, c, o, &wctx);
if (end > o->onode.size) {
dout(20) << __func__ << " extending size to 0x" << std::hex << end
<< std::dec << dendl;
o->onode.size = end;
}
if (benefit >= g_conf()->bluestore_gc_enable_total_threshold) {
wctx.extents_to_gc.union_of(gc.get_extents_to_collect());
dout(20) << __func__
<< " perform garbage collection for compressed extents, "
<< "expected benefit = " << benefit << " AUs" << dendl;
}
if (!wctx.extents_to_gc.empty()) {
dout(20) << __func__ << " perform garbage collection" << dendl;
r = _do_gc(txc, c, o,
wctx,
&dirty_start, &dirty_end);
if (r < 0) {
derr << __func__ << " _do_gc failed with " << cpp_strerror(r)
<< dendl;
goto out;
}
dout(20)<<__func__<<" gc range is " << std::hex << dirty_start
<< "~" << dirty_end - dirty_start << std::dec << dendl;
}
o->extent_map.compress_extent_map(dirty_start, dirty_end - dirty_start);
o->extent_map.dirty_range(dirty_start, dirty_end - dirty_start);
r = 0;
out:
return r;
}
- 真正执行数据写入的函数 _do_write_data:
void BlueStore::_do_write_data(
TransContext *txc,
CollectionRef& c,
OnodeRef o,
uint64_t offset,
uint64_t length,
bufferlist& bl,
WriteContext *wctx)
{
uint64_t end = offset + length;
bufferlist::iterator p = bl.begin();
// 判断写入的数据大小是否处于一个 min_alloc_size 大小中
// min_alloc_size 通常为 block_size 大小的整数倍
if (offset / min_alloc_size == (end - 1) / min_alloc_size &&
(length != min_alloc_size)) {
// 执行小写
// we fall within the same block
_do_write_small(txc, c, o, offset, length, p, wctx);
} else {
// 如果写入的数据大小超过 min_alloc_size,则会进行划分
// 一部分进行大写,一部分进行小写
uint64_t head_offset, head_length;
uint64_t middle_offset, middle_length;
uint64_t tail_offset, tail_length;
head_offset = offset;
head_length = p2nphase(offset, min_alloc_size);
tail_offset = p2align(end, min_alloc_size);
tail_length = p2phase(end, min_alloc_size);
middle_offset = head_offset + head_length;
middle_length = length - head_length - tail_length;
if (head_length) {
_do_write_small(txc, c, o, head_offset, head_length, p, wctx);
}
if (middle_length) {
// 执行大写
_do_write_big(txc, c, o, middle_offset, middle_length, p, wctx);
}
if (tail_length) {
_do_write_small(txc, c, o, tail_offset, tail_length, p, wctx);
}
}
}
- 当一个写请求按照min_alloc_size进行拆分后,就会分为对齐写,对应到do_write_big,非对齐写(即落到某一个min_alloc_size区间的写I/O(对应到do_write_small)
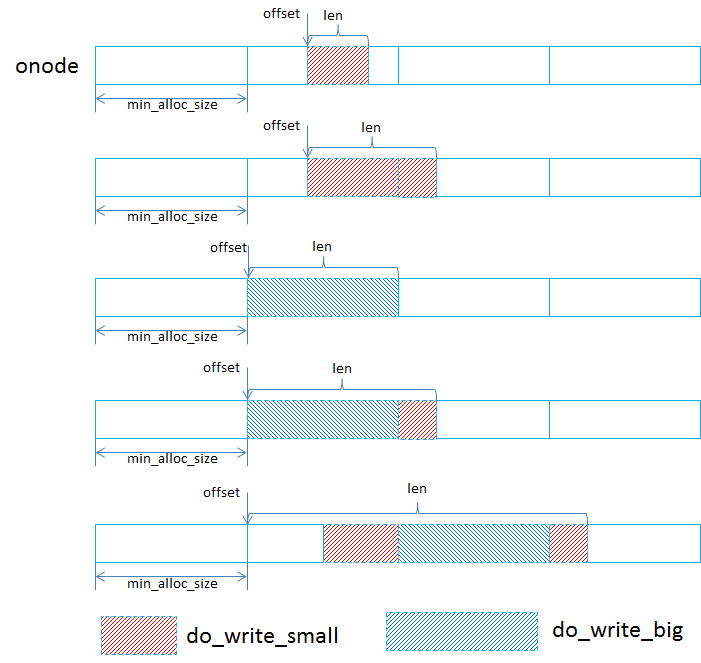
- do_write_big: 对齐到min_alloc_size的写请求处理起来比较简单,有可能是多个min_alloc_size的大小,在处理时会根据实际大小新生成lextent和blob,这个lextent跨越的区域是min_alloc_size的整数倍,如果这段区间是之前写过的,会将之前的lextent记录下来便于后续的空间回收。
- do_write_small: 在处理落到某个min_alloc_size区间的写请求时,会首先根据offset去查找有没有可以复用的blob,因为最小分配单元是min_alloc_size,默认64KB,如果一个4KB的写I/O就只会用到blob的一部分,blob里剩余的还能放其他的。
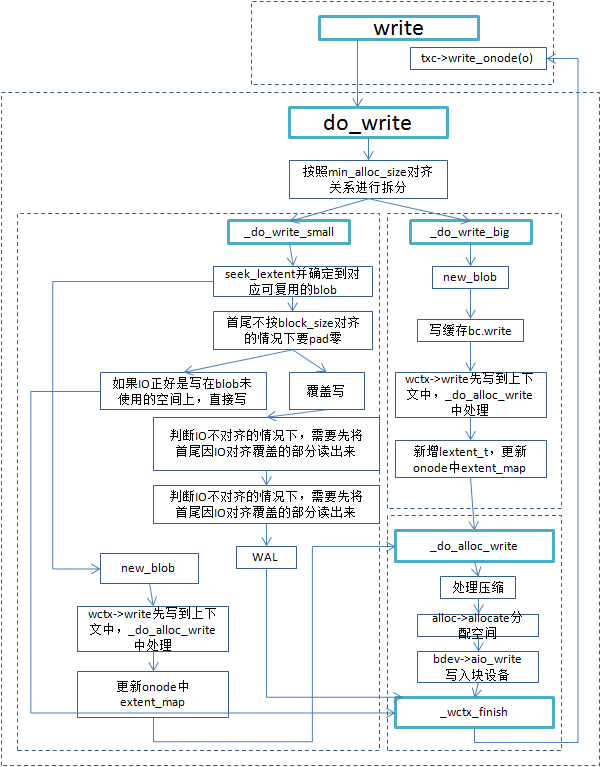
读操作
- 读操作的流程:
ReplicatedBackend::objects_read_sync
store->read(ch, ghobject_t(hoid), off, len, *bl, op_flags)
BlueStore::read
_do_read(c, o, offset, length, bl, op_flags);
BlueStore::_do_read
ReplicatedBackend::objects_readv_sync
store->readv(ch, ghobject_t(hoid), im, *bl, op_flags);
BlueStore::readv
_do_readv(c, o, m, bl, op_flags);
BlueStore::_do_readv
- 真正执行读操作的 _do_read 和 _do_readv
- 通过libaio的方式进行读写操作。实现的时候抽象出BlockDevice基类类型,统一管理各种类型的设备,如Kernel, NVME和NVRAM等,为裸盘的使用者(BlueFS/BlueStore)提供统一的操作接口
int BlueStore::_do_read(
Collection *c,
OnodeRef o,
uint64_t offset,
size_t length,
bufferlist& bl,
uint32_t op_flags,
uint64_t retry_count)
{
FUNCTRACE(cct);
int r = 0;
int read_cache_policy = 0; // do not bypass clean or dirty cache
dout(20) << __func__ << " 0x" << std::hex << offset << "~" << length
<< " size 0x" << o->onode.size << " (" << std::dec
<< o->onode.size << ")" << dendl;
bl.clear();
if (offset >= o->onode.size) {
return r;
}
// generally, don't buffer anything, unless the client explicitly requests
// it.
bool buffered = false;
if (op_flags & CEPH_OSD_OP_FLAG_FADVISE_WILLNEED) {
dout(20) << __func__ << " will do buffered read" << dendl;
buffered = true;
} else if (cct->_conf->bluestore_default_buffered_read &&
(op_flags & (CEPH_OSD_OP_FLAG_FADVISE_DONTNEED |
CEPH_OSD_OP_FLAG_FADVISE_NOCACHE)) == 0) {
dout(20) << __func__ << " defaulting to buffered read" << dendl;
buffered = true;
}
if (offset + length > o->onode.size) {
length = o->onode.size - offset;
}
auto start = mono_clock::now();
o->extent_map.fault_range(db, offset, length);
log_latency(__func__,
l_bluestore_read_onode_meta_lat,
mono_clock::now() - start,
cct->_conf->bluestore_log_op_age);
_dump_onode<30>(cct, *o);
// for deep-scrub, we only read dirty cache and bypass clean cache in
// order to read underlying block device in case there are silent disk errors.
if (op_flags & CEPH_OSD_OP_FLAG_BYPASS_CLEAN_CACHE) {
dout(20) << __func__ << " will bypass cache and do direct read" << dendl;
read_cache_policy = BufferSpace::BYPASS_CLEAN_CACHE;
}
// build blob-wise list to of stuff read (that isn't cached)
ready_regions_t ready_regions;
blobs2read_t blobs2read;
_read_cache(o, offset, length, read_cache_policy, ready_regions, blobs2read);
// read raw blob data.
start = mono_clock::now(); // for the sake of simplicity
// measure the whole block below.
// The error isn't that much...
vector<bufferlist> compressed_blob_bls;
IOContext ioc(cct, NULL, true); // allow EIO
r = _prepare_read_ioc(blobs2read, &compressed_blob_bls, &ioc);
// we always issue aio for reading, so errors other than EIO are not allowed
if (r < 0)
return r;
int64_t num_ios = length;
if (ioc.has_pending_aios()) {
num_ios = -ioc.get_num_ios();
bdev->aio_submit(&ioc);
dout(20) << __func__ << " waiting for aio" << dendl;
ioc.aio_wait();
r = ioc.get_return_value();
if (r < 0) {
ceph_assert(r == -EIO); // no other errors allowed
return -EIO;
}
}
log_latency_fn(__func__,
l_bluestore_read_wait_aio_lat,
mono_clock::now() - start,
cct->_conf->bluestore_log_op_age,
[&](auto lat) { return ", num_ios = " + stringify(num_ios); }
);
bool csum_error = false;
r = _generate_read_result_bl(o, offset, length, ready_regions,
compressed_blob_bls, blobs2read,
buffered, &csum_error, bl);
if (csum_error) {
// Handles spurious read errors caused by a kernel bug.
// We sometimes get all-zero pages as a result of the read under
// high memory pressure. Retrying the failing read succeeds in most
// cases.
// See also: http://tracker.ceph.com/issues/22464
if (retry_count >= cct->_conf->bluestore_retry_disk_reads) {
return -EIO;
}
return _do_read(c, o, offset, length, bl, op_flags, retry_count + 1);
}
r = bl.length();
if (retry_count) {
logger->inc(l_bluestore_reads_with_retries);
dout(5) << __func__ << " read at 0x" << std::hex << offset << "~" << length
<< " failed " << std::dec << retry_count << " times before succeeding" << dendl;
}
return r;
}
int BlueStore::_do_readv(
Collection *c,
OnodeRef o,
const interval_set<uint64_t>& m,
bufferlist& bl,
uint32_t op_flags,
uint64_t retry_count)
{
FUNCTRACE(cct);
int r = 0;
int read_cache_policy = 0; // do not bypass clean or dirty cache
dout(20) << __func__ << " fiemap " << m << std::hex
<< " size 0x" << o->onode.size << " (" << std::dec
<< o->onode.size << ")" << dendl;
// generally, don't buffer anything, unless the client explicitly requests
// it.
bool buffered = false;
if (op_flags & CEPH_OSD_OP_FLAG_FADVISE_WILLNEED) {
dout(20) << __func__ << " will do buffered read" << dendl;
buffered = true;
} else if (cct->_conf->bluestore_default_buffered_read &&
(op_flags & (CEPH_OSD_OP_FLAG_FADVISE_DONTNEED |
CEPH_OSD_OP_FLAG_FADVISE_NOCACHE)) == 0) {
dout(20) << __func__ << " defaulting to buffered read" << dendl;
buffered = true;
}
// this method must be idempotent since we may call it several times
// before we finally read the expected result.
bl.clear();
// call fiemap first!
ceph_assert(m.range_start() <= o->onode.size);
ceph_assert(m.range_end() <= o->onode.size);
auto start = mono_clock::now();
o->extent_map.fault_range(db, m.range_start(), m.range_end() - m.range_start());
log_latency(__func__,
l_bluestore_read_onode_meta_lat,
mono_clock::now() - start,
cct->_conf->bluestore_log_op_age);
_dump_onode<30>(cct, *o);
IOContext ioc(cct, NULL, true); // allow EIO
vector<std::tuple<ready_regions_t, vector<bufferlist>, blobs2read_t>> raw_results;
raw_results.reserve(m.num_intervals());
int i = 0;
for (auto p = m.begin(); p != m.end(); p++, i++) {
raw_results.push_back({});
_read_cache(o, p.get_start(), p.get_len(), read_cache_policy,
std::get<0>(raw_results[i]), std::get<2>(raw_results[i]));
r = _prepare_read_ioc(std::get<2>(raw_results[i]), &std::get<1>(raw_results[i]), &ioc);
// we always issue aio for reading, so errors other than EIO are not allowed
if (r < 0)
return r;
}
auto num_ios = m.size();
if (ioc.has_pending_aios()) {
num_ios = ioc.get_num_ios();
bdev->aio_submit(&ioc);
dout(20) << __func__ << " waiting for aio" << dendl;
ioc.aio_wait();
r = ioc.get_return_value();
if (r < 0) {
ceph_assert(r == -EIO); // no other errors allowed
return -EIO;
}
}
log_latency_fn(__func__,
l_bluestore_read_wait_aio_lat,
mono_clock::now() - start,
cct->_conf->bluestore_log_op_age,
[&](auto lat) { return ", num_ios = " + stringify(num_ios); }
);
ceph_assert(raw_results.size() == (size_t)m.num_intervals());
i = 0;
for (auto p = m.begin(); p != m.end(); p++, i++) {
bool csum_error = false;
bufferlist t;
r = _generate_read_result_bl(o, p.get_start(), p.get_len(),
std::get<0>(raw_results[i]),
std::get<1>(raw_results[i]),
std::get<2>(raw_results[i]),
buffered, &csum_error, t);
if (csum_error) {
// Handles spurious read errors caused by a kernel bug.
// We sometimes get all-zero pages as a result of the read under
// high memory pressure. Retrying the failing read succeeds in most
// cases.
// See also: http://tracker.ceph.com/issues/22464
if (retry_count >= cct->_conf->bluestore_retry_disk_reads) {
return -EIO;
}
return _do_readv(c, o, m, bl, op_flags, retry_count + 1);
}
bl.claim_append(t);
}
if (retry_count) {
logger->inc(l_bluestore_reads_with_retries);
dout(5) << __func__ << " read fiemap " << m
<< " failed " << retry_count << " times before succeeding"
<< dendl;
}
return bl.length();
}
参考链接
- [1] CSDN:Ceph 撸源码系列(三):Ceph OSDC源码分析 (1 of 2)
- [2] CSDN:Ceph 撸源码系列(一):Ceph开源项目源代码的关键目录介绍
- [3] CSDN:ceph bluestore 写操作源码分析(上)
- [4] CSDN:ceph bluestore 写操作源码分析(下)
- [5] Sysnote:ceph存储引擎bluestore解析
- [6] DieInADream - 分布式存储系统 Ceph 的后端存储引擎研究
- [7] tom-sun - BlueStore-先进的用户态文件系统《一》
- [8] Understanding Write Behaviors of Storage Backends in Ceph Object Store
- [9] 知乎 - 分布式存储
- [10] ceph存储引擎bluestore解析
