该篇文章来自于 SOSP2019 的论文 KVell: the Design and Implementation of a Fast Persistent Key-Value Store
论文提到了一个比较犀利的观点:KV 存储不再像以往主要受限于存储设备,而是逐渐更多的受 CPU 的性能影响。即 storage device bound 转移到了 CPU bound
其实别的文章也略有提及现阶段 KV 存储存在的问题,但这篇文章更多是提出了新的设计范式来指导后续 KVS 的设计,值得一读。
Abstract
按块寻址的 NVMe SSD 相比以前的块设备提供了更高的带宽和更相近的随机和顺序读写的性能。持久化的 KV 存储是为早期的存储设备设计的,使用 LSM-tree 或者 B-tree,没有充分利用新型设备的优势。起初设计中为了避免随机访问的逻辑导致了保持磁盘上数据排序这样的开销巨大的操作以及同步操作,这些操作使得这些 KVs 在NVMe SSD 上受到 CPU 限制,成为新的瓶颈。
我们提出了一种新的持久性 KV 设计,与早期设计不同的是,不再追求顺序访问,数据存储在磁盘上时无序。采用无共享的理念来避免同步开销,与设备访问的批处理一起,这些设计决策使读写性能接近设备带宽,最后,在内存中维护一个开销较小的的部分有序可以产生足够的扫描性能。
我们设计了 KVell 作为第一个能充分利用现代 NVMe SSD 最大带宽的持久性 KV 存储系统。和最先进的 LSM-tree KV 和 B tree KV 进行了对比,KVell 在以读为主的工作负载上比其他类型的 KV 吞吐量至少高了 2x,以写为主的工作负载上高了 5x。对于以 scan 为主的负载,KVell 和其他类型相比性能接近甚至更好。KVell 的最大延迟也是最低的。
Introduction
KVS 应用广泛,缓存、元数据管理、消息通信、在线购物等场景。本文针对的是基于提供持久化保证的以块为单位寻址的存储设备上构建的 KVS,且数据集不能全部装在内存中的情况。
传统意义上,存储设备与 CPU 设备之间的速度差距是很大的,因此充分利用 CPU 周期来优化存储设备的访问是一个很有效的的 tradeoff。所以,一些 KV 存储包含了复杂的索引结构,如 B+ tree,LSM KV 强制顺序写,因为顺序写通常比随机写更高效。所有的 KV 一般都包含了某种形式的缓存,为了支持检索给定键范围内的所有项的高效扫描,KVs 在内存和磁盘上有序地维护了相应的索引。尽管所有这些优化都需要花费一些 CPU 周期,但存储设备仍然是瓶颈,而这些优化被证明是有益的,因为它们缓解了瓶颈。
当我们测量在按块寻地址的 NVMe SSD 设备上运行的最先进的 KVs 的性能时,我们发现 CPU 是瓶颈,而不再是存储设备,这证实了之前的定性观察。NVMe SSD 在随机和顺序访问方面表现出非常高的带宽和相当的性能,因此,许多为传统存储设备开发的优化不再有用,甚至可能适得其反,因为它们在 CPU 周期方面的成本加剧了 CPU 瓶颈。例如 LSM KV 现如今对于顺序写的要求的优化不再像以往那么带来特别大的好处,反而是一些维护过程的操作如压缩等加剧了 CPU 的资源使用,对性能产生了影响。一个更令人惊讶的例子是,在共享(内存中)数据结构上进行同步以进行缓存和维护顺序会导致 CPU 成为瓶颈。
我们的结论是 存储设备的特性的变化和发展迫使 KVs 的设计思想和范式必须发生转变,需要更多地聚焦在 CPU 的流水线式的使用上 。为此总结了四条设计原则:
Shared-nothing:所有的数据结构都在 CPU 核之间分区,这样每个 core 几乎可以完全独立运行而不需要任何同步。
Items 不在磁盘上排序。每个分区都维护一个内存中有序的索引,以便进行高效扫描。
不用强制顺序访问存储设备,但是 I/O 操作需要进行批处理来减小系统调用的次数。批处理同时为设备等待队列的提供了较好的控制,从而可以采用一些策略进行任务的调度来实现低延迟和高吞吐量。
无需 commit log:只有在更新操作被持久化到磁盘上的最终位置后,操作才相应地得到确认。
这些原则消除了很多复杂的维护过程,除了提高平均吞吐量以外,还实现了吞吐量和延迟的可预测性。一些设计决策也做了相应的权衡,比如 Shared-nothing 会有负载不均衡的风险;不保证有序会影响 scan 的性能。我们的测试结果显示,对于主要由大中型键值对组成的工作负载,精简的 CPU 操作带来的好处超过了这些缺点。我们和四种最先进的 KVs 做了对比:分别是 LSM tree 的代表 RocksDB 和 PebblesDB;B tree 的代表 TokuMX 和 WiredTiger。
Contributions:
对传统的 LSM 和 B 树型 KVs 进行了分析,指出 NVMe SSD 场景下的 CPU 瓶颈问题
持久 KVs 利用 NVMe SSD 的属性的新范例,重点关注 CPU 的流水线使用。
将 KVell 与最新的 LSM 和 B 树 KVs 在合成基准和生产工作负载上进行深入对比测试。
SSD 性能测试
Hardware :
Config-SSD :32-core 2.4GHz Intel Xeon,128GB of RAM, and a 480GB Intel DC S3500 SSD (2013).Config-Amazon-8NVMe :An AWS i3.metal instance, with 36 CPUs (72 cores) running at 2.3GHz, 488GB of RAM, and 8 NVMe SSD drives of 1.9TB each (brand unknown, 2016 technology).Config-Optane :A 4-core 4.2GHz Intel i7, 60GB of RAM, and a 480GB Intel Optane 905P (2018).
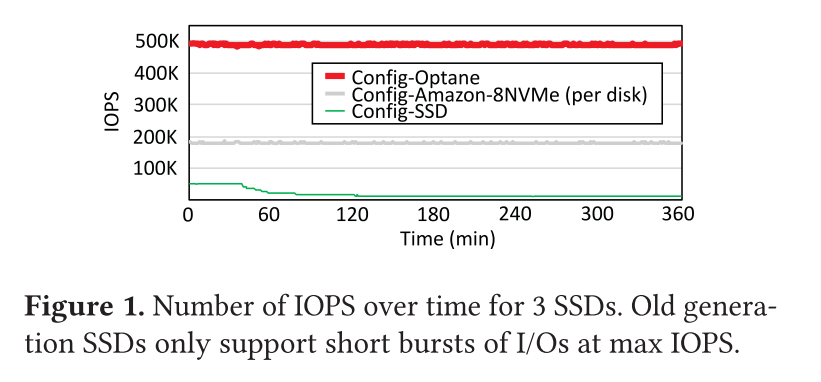
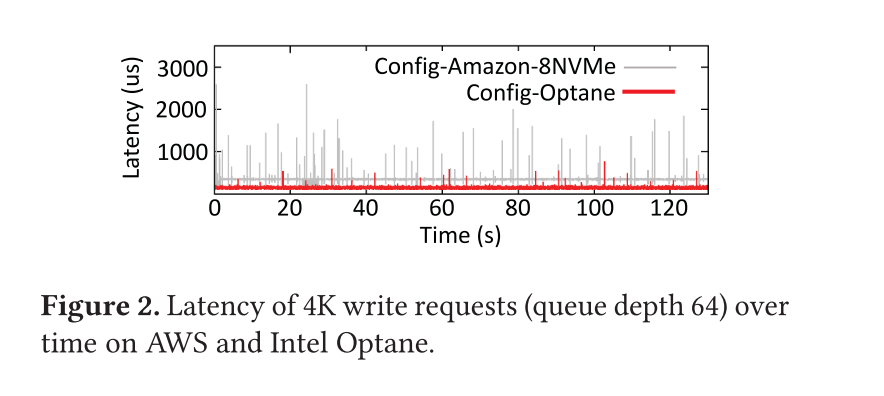
IOPS :表1 显示了这三种设备的最大读写 IOPS 数以及随机和顺序带宽。读写性能提升迅猛,顺序和随机之间的差距越来越小,混合随机读写不再会像老式设备那样导致性能低下Latency and bandwidth :表2 展示了三个设备的延迟和带宽测量值,它们是设备队列深度的函数,一个核心执行随机写操作。可以发现以前的存储设备只有在请求数较小的时候才能保证较低的延迟,新的存储设备因为并行性更好往往在较多请求情况下仍然能保证毫秒级别的延迟,通过和上面的测试数据对比,发现在请求数较少的时候但其实完全没有跑满存储设备的实际带宽。所以即便是在现代设备的应用中,也需要做一个请求等待处理时间(延迟)和并发处理请求数(充分利用带宽)之间的 tradeoff。(请求太少带宽有余,请求太多延迟较高)Throughput degradation :图 1 显示了这三种设备上的 IOPS 随时间的变化。Config-SSD 可以维持大约 40min 的 50K IOPS,随后性能下降到 11K IOPS,而新的存储设备基本不会有这个问题,可以进行长时间的持续的 IOLatency spikes :图 2 展示了 4K 写的延迟,队列深度为 64。在写密集的负载下,老一代的 SSD 常常受到 latency spike 的影响(正常写延迟通常为 1.5ms,五小时后延迟将变成 100ms)。Config-Amazon-8NVMe 驱动器也会受到周期性 Latency spikes 的影响。最大观察到的延迟是 15ms。在 Config-Optane 驱动器上,潜伏期峰值不规则地发生,它们的幅度通常小于1毫秒,最大可观测到3.6毫秒
NVMe SSD 上当前 KVs 的问题
在持久性 KV 存储中有两个主流的思想:
LSM KVs 被视为写密集负载的最好的解决方案,即对写更友好,如 RocksDB,Cassandra
B tree KVs 被视为读密集负载的最好的解决方案,即对读更友好,如 MongoDB
但其实这两种设计在 NVMe SSD 上都会逐渐变为 CPU 瓶颈,并遭受严重的性能波动。
CPU is the bottleneck
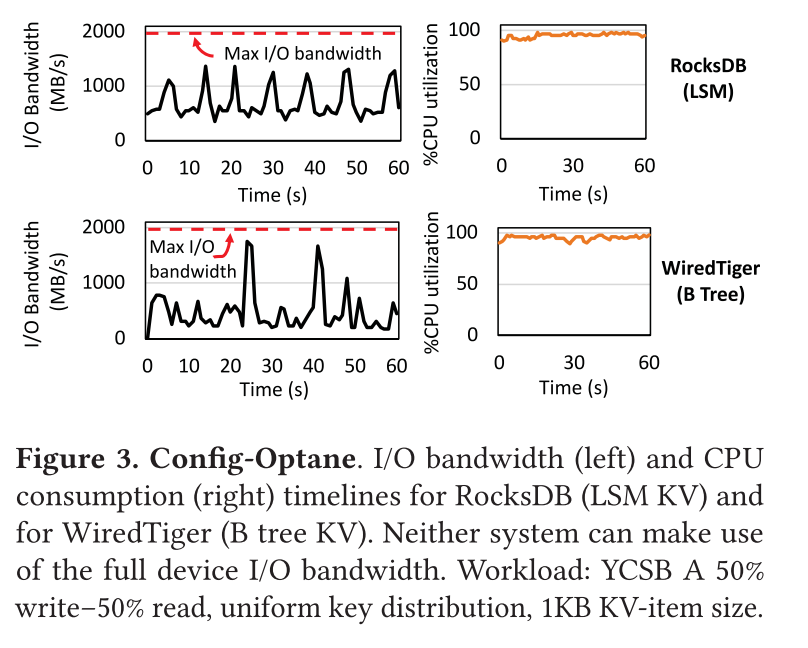
图 3 显示了在 Config-Optane 上构建的 RocksDB 和 Wired Tiger 在负载为 YCSB-A(写密集)请求分布为 uniform 下的磁盘利用率和 CPU 利用率。两种方案都几乎榨干了 CPU,但是都还是没有完全发挥出设备实际的最大带宽。
CPU is the bottleneck in LSM KVs
LSM KVs 通过使用内存缓冲区吸收更新操作,主要针对写密集型负载进行了优化。缓冲区满了之后,刷入到磁盘,然后由后台线程将刷回的数据维护在一个持久性存储设备中的树状结构中。磁盘上的数据结构包含了很多层,随着层数的增加,容量也在增加,每一层都包含多个 immutable sorted files,每一层中的每个 file 包含不同的键范围,除了第一层。为了维护这样的数据结构,LSM KVs 实现了压缩机制,该机制对 CPU 和 I/O 都比较敏感,即是比较占据 CPU 时钟周期和磁盘带宽的。
压缩操作在以前老的设备上主要是占据磁盘带宽,但是合并/索引/内核代码等也会占据一定的 CPU 时钟周期,但是在新设备上,CPU 成为了主要瓶颈。
研究分析表明 RocksDB 大概会占据 60% 的 CPU 时钟周期,其中 28% 数据合并,15% 索引构建,剩下的主要是数据传输过程(对磁盘进行数据的读写)中的 CPU 时钟周期占用。压缩需求源于 LSM 的设计要求,即顺序磁盘访问和在磁盘上保持数据排序,这种设计对于以前的存储设备是有益的,即在以往的存储设备上花费时钟周期来保证顺序执行提升存储设备的访问性能是值得的。
CPU is the bottleneck in LSM KVs
针对持久化存储的 B Tree 有两种变体 B+ tree 和 Bϵ tree。
B+ tree 在叶子节点中存储 KV 对,中间节点只包含用于路由的 Key,通常中间节点会被保存在内存中加速访问,叶子节点常常会被放在持久化的存储设备中。每一个叶子节点通常是以一个页的大小,存储了一个范围内的 KV 对。有的 B+ Tree 还会将每一个叶子节点使用指针链接起来,形成一个链表,从而提供较好的 scan 性能。WiredTiger 依赖内存缓存以实现更好的性能,更新操作首先写入到每一个线程对应的 commit log 中然后写入内存缓存,当更新的数据从缓存中被逐出时,树将使用新信息更新。更新使用序列号,这是扫描所必需的。读操作遍历缓存,只有在 KV 对未被缓存时才访问树。
将数据持久化到树中,主要有两种操作:checkpointing 和 eviction。
Checkpointing 周期性进行,或者当日志中数据大小到达一个阈值时就执行,从而确保日志文件不会过大。
Eviction 将脏数据从缓存写入到树中,当缓存中的脏数据达到一定的比例就执行 Eviction
Bϵ trees 是 B+ tree 的一个变种,增加缓冲区,临时存储每个节点上的键和值,最终,当缓冲区满了时,KV 对沿着树结构向下延伸,并被写入持久存储。
B 树的设计容易产生同步开销,根据对 WiredTiger 的分析发现花费总时间的大约 47% 等待日志中的 slots。这个问题源于不能足够快地推进序列号进行更新。在更新的主代码路径中,不包括内核所花费的时间,WiredTiger 只花费18% 的时间来执行客户端请求逻辑,其余时间用于等待。WiredTiger 还需要执行后台操作: 从页面缓存中清除脏数据占总时间的 12%,管理提交日志占总时间的 5%。内核中只有 25% 的时间用于读写调用,而其余的时间用于 futex 和 yield 函数。
Bϵ trees 也受同步性能开销的严重影响。因为 Bϵ trees 需要保证磁盘上的数据有序,工作线程最终会修改共享的数据结构,从而导致争用。对 TokuMX 的分析表明线程将 30% 的时间花费在锁或用于保护共享页面的原子操作上。缓冲也是 Bϵ trees 的一个比较大的开销来源, TokuMX 在工作负载为 YCSB-A 时花费了大约 20% 的时间从缓冲区向正确的叶子节点的正确位置传输数据。这些同步开销大大超过了其他开销。
在现代的 NVMe SSD 的条件下,为了避免与同步相关的 CPU 开销,尽可能减少共享是比较好的方式。以前用于提供快速持久性保证的日志最终成为主要的瓶颈,对内存中 KVs 的观察发现缓冲也引入了开销,对于持久性存储也是一样。
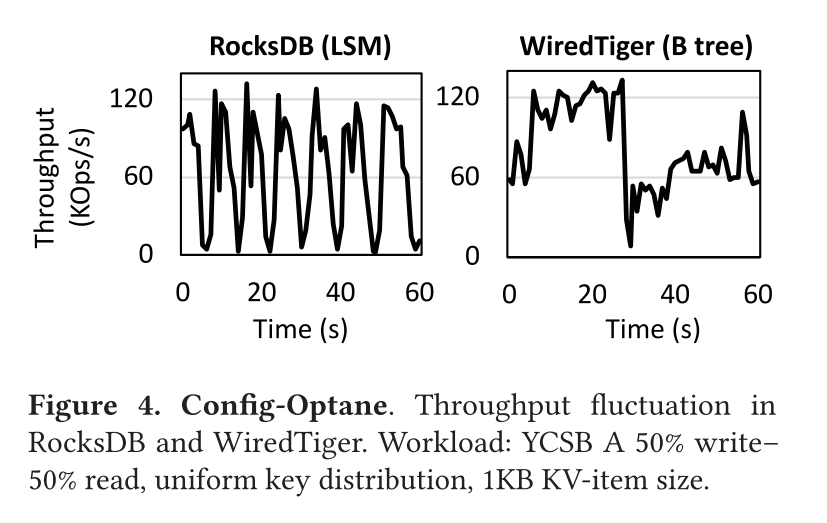
除了受制于 CPU 外,LSM 和 B树 KVs 都有显著的性能波动。如图所示,展示了性能波动的情况,每秒记录一次吞吐量,在 LSM RocksDB 和 B 树 WiredTiger KVs 中,基本问题是相似的: 客户端更新会因为数据结构的维护操作而停止
LSM KVs 中,吞吐量下降更多地是因为有时更新需要等待压缩完成。当 LSM tree 的第一层满了之后,更新需要等待,直到压缩后空间可用。但是,当 LSM KVs 在现代驱动器上运行时,压缩会遇到 CPU 瓶颈,随着时间的推移,吞吐量方面的性能差异会上升一个数量级,RocksDB 的平均请求数为 63K /s,但在写入停止时下降到 1.5K /s,分析显示,写线程大约有 22% 的时间被搁置,等待内存组件被刷回。因为压缩无法跟上更新的速度,所以内存组件的刷回被延迟。
为了减小压缩过程中对性能产生的影响,大致有延迟压缩(SOSP17-PebblesDB)或者在系统空闲的时候进行压缩(ATC19-SILK)两种方案,但是这两种方案都不适用于高端 SSD。例如 Optane 刷新内存组件的速度为 2GB/s,延迟压缩超过几秒钟会导致大量请求积压和空间浪费。
B tree 中性能也会受到用户负载的停顿的影响,因为 evictions 不能足够快地进行导致用户写入被延迟,Stalls 导致吞吐量下降了一个数量级,从 120 Kops/s 下降到 8.5 Kops/s。
我们的结论是,在这两种情况下,压缩和驱逐等数据结构的维护操作严重干扰用户的工作负载,造成的停顿可能会持续数几秒。因此,新的 KV 设计应避免数据结构的维护操作 。
KVell design principles
为了有效地利用现代的持久存储设备,KVs 现在需要重视 CPU 开销。如下原则将是在现代存储设备上实现高性能 KVs 的关键:
Share nothing.
在 KVell 中,是指支持并行性和最小化 KV 工作线程之间的共享状态,以减少 CPU 开销。
Do not sort on disk, but keep indexes in memory.
KVell 将未排序的数据保存在磁盘的最终位置,避免了昂贵的重新排序操作
Aim for fewer syscalls, not for sequential I/O.
KVell 的目标不再是追求顺序访问,因为顺序 IO 的优势不再明显,目标转变为通过批量执行 I/O 来最小化系统调用带来的 CPU 开销
No commit log.
KVell 不缓冲更新,因此不需要依赖于提交日志,避免了不必要的 I/O。
Share nothing
无论是读还是写,工作线程处理请求时无需和其他线程进行同步,每一个线程处理给定子集的键,并在线程中维护一个私有的数据集合对应管理该子集的键。键的数据结构:
一个轻量级的内存 B 树索引,用于跟踪键在持久存储中的位置
I/O 队列,负责高效地存储和检索来自持久化存储设备中的信息
空闲列表,部分在内存中的磁盘块列表,其中包含用于存储 items 的空闲位置
页缓存,KVell 使用自己的内部页面缓存,不依赖于 os 级结构。
Scan 是在内存中的 B 树索引上需要最小同步的唯一操作。
与传统 KV 设计相比,这种无共享方法是一个关键的区别,在传统 KV 设计中,所有或大多数主要数据结构都由所有工作线程共享,传统的方法需要对每个请求进行同步,这是 KVell 完全避免的。分区请求可能会导致负载不平衡,但我们发现,如果使用合适的分区,这种影响很小。
Do not sort on disk, but keep indexes in memory
KVell 不会对工作线程的工作集中的数据进行排序,因此可以直接将数据存储在磁盘上,且该位置不会发生改变。因为不要求有序,插入 KV 对的开销相对减小,因为不需要找到对应的位置来执行插入操作,同时能消除为了维护磁盘上的数据结构有序对应的开销,无序情况下,对写操作的性能优化效果很好,可以帮助实现较低的尾延迟。
在 scan 操作时,连续的 keys 可能不再位于同一个磁盘块中,scan 的性能似乎会有所下降。但实际上对于中等大小的键值对的负载,以及单个键值对大小较大的情况下,scan 的性能并未受到严重的影响。
Aim for fewer syscalls, not for sequential I/O
在 KVell 中所有操作包括 scan 都对磁盘执行随机访问,因为随机访问和顺序访问一样高效,KVell 不会浪费 CPU 周期来强制执行顺序 I/O。
和 LSM 相似的是,KVell 将请求批处理写到磁盘,不同的是 LSM KVs 批量执行 I/O 且把 KV 对排序是为了利用顺序的磁盘访问能力,而 KVell 批量执行 I/O 的目的是为了减少系统调用的次数,从而减少 CPU 开销。
批处理其实也是做了一种权衡,在 Introduction 部分中已经简单提及,磁盘需要长时间的保持运行忙碌的状态以实现最大的 IOPS,但是只有在硬件队列中包含的请求少于给定数量时,才会以亚毫秒级的延迟响应(如 Optane 要求 256 个 I/O 请求)。一个高效的系统需要把足够的请求发送给磁盘以充分利用磁盘的带宽,但是不能超过队列的最大服务请求数太多,否则可能将导致较高的尾延迟。
在具有多个磁盘的配置中,每个 worker 只在一个磁盘上存储文件,这种设计决策对于限制每个磁盘挂起的请求数量非常关键。事实上,因为 worker 彼此之间不会进行通信,所以他们不知道其他 workers 已经发送给磁盘多少个请求。如果 workers 都在一个磁盘上存储数据,然后一个磁盘对应的请求数量将被限制为 (batch size * 每个磁盘的 workers 数量)。如果 workers 可以访问所有磁盘,然后一个磁盘可能最多处理 (batch size * 所有 workers 的数量)
因为请求是根据它们的键分配给 worker 的,而且 worker 只访问一个磁盘,所以可以设计一个工作负载,主要访问一个磁盘上的数据,而让其他磁盘空闲。在表现出倾斜行为的工作负载中,数据倾斜被内部页面缓存吸收。因此,大多数负载不平衡不会导致磁盘I/O。
No commit log
KVell 只有在更新操作被持久化到磁盘上的最终位置才确认更新完成,而不依赖于 commit log。一旦更新被提交给工作线程,它将在下一个 I/O 批处理中持久化到磁盘上。移除 commit log 允许 KVell 仅将磁盘带宽用于有用的客户机请求处理。
KVell implementation
尽管 KVell 的设计看起来很简单粗暴,但其实实现起来还是很复杂的。
源码地址:https://github.com/BLepers/KVell
Client operations interface
实现了和 LSM KVs 一样的核心接口,
写 Update(k, v)。Value 和 Key 是组合在一起的,只有 Value 持久化到了磁盘上才会返回操作成功。
读 Get(k)
扫描(范围查询) scan(k1, k2)
On-disk data structures
为了避免碎片化,在相同大小范围内的 KV 对会被存储在相同的文件中,这些文件称之为 slab 。KVell 以块的粒度访问 slabs,在论文中的机器上使用 4KB 大小的页。
如果 KV 对比页小(即好几个 KV 对才能填充满一个页),KVell 用时间戳、键大小和值大小作为 slab 中的 KV 项的前缀。如果比页大,在磁盘上每个块的开头都有一个时间戳头。
对于小于页面大小的项,将在适当的位置进行就地更新。大于页面的项的更新,会把更新操作追加到 slab 然后写一个 tombstone 来标识原有的项所在的位置。当改变 KV 项的大小,KVell 首先将更新的项写入到新的 slab,然后删除旧的 slab 里对应的项。
In-memory data structures
Index
KVell 依赖于快速而轻量级的内存索引,这些索引具有可预测的插入和查找时间来查找磁盘上项的位置。KVell 为每个 worker 使用一个内存中的 B 树来存储磁盘上键值对的位置。Items 根据其键(前缀)建立索引。我们使用前缀而不是哈希来保持范围扫描的键的顺序。B-tree 在磁盘上存储比较大的 items 性能较差,但是如果 item 较小且数据大多都能装在内存中的话性能就很好。KVell 利用这个特性,就只使用 B 树存储查找信息(前缀和位置信息占13B)
KVell 树实现平均每个 KV 项大约使用 19B 的空间,存储对应的前缀/地址信息/B tree 结构,1.7G RAM 可以存储 100M 项。YCSB 负载(1KB 大小的项)下,索引大概占据数据库总大小的 1.7%,这样的比例是可以接受的。KVell 目前不显式地支持将 B 树的一部分刷回到磁盘,但是 B 树数据是从 mmap-ed 文件中分配的,可以由内核以页的形式置换出去。
Page Cache
KVell 维护自己的内部页面缓存,以避免从持久存储中获取频繁访问的页面。缓存的页面大小是一个系统参数。页面缓存会记住哪些页面缓存在索引中,并按照 LRU 顺序从缓存中回收页面。
确保索引中的查找和插入具有最小的 CPU 开销对于获得良好的性能至关重要。我们的第一个页面缓存实现使用快速uthash 哈希表作为索引。但是,当页面缓存很大时,散列中的插入可能会花费高达 100ms 的时间(增长散列表的时间),从而提高了尾部延迟。切换到 B 树可以消除这些延迟峰值。
Free list
当从一个 slab 中删除一个项时,它在该 slab 中的位置将插入到每个 slab 的内存堆栈中,我们称之为 slab 的空闲列表。然后在磁盘上的 item 位置写入一个 tombstone。为了限制内存的使用,内存中只保留最近 N 个空闲的位置,在本文的例子中 N 被设置为 64。其目标是限制内存使用,同时保持在不需要额外磁盘访问的情况下重用每批 I/O 的多个空闲 spots 的能力。
当第 N+1 项被释放了,KVell 使其磁盘 tombstone 指向第一个释放的位置,然后 KVell 从内存堆栈中删除第一个被释放的位置,并插入第 N + 1 个被释放的位置,当第 N + 2 个项被释放,磁盘 tombstone 指向第二个空闲位置。简而言之,KVell 维护 N 个独立的栈,这些栈的头驻留在内存中,剩余部分驻留在磁盘上。允许 KVell 重用每批 I/O 最多 N 个空闲点,如果只有一个栈,KVell 就必须从磁盘上依次读取 N 个 tombstone,以找到下一个被释放的 N 个位置。
KVell 依赖 Linux AIO 提供的异步 I/O API 来发送请求到磁盘,最多批量处理 64 requests。通过批处理,KVell 能平摊多个客户端请求对应的系统调用的开销。我们选择使用 Linux AIO 是因为其提供了在一个系统调用里执行多个 I/Os 的方法。我们估计,如果这样的调用在同步 I/O API中可用,性能将大致相同
我们没有采用两种常用的执行 I/O 的方法:
依赖于操作系统页缓存的 mmap (RocksDB 采用的)
通过 direct I/O 标识的读写系统调用来执行 (如 TokuMX 采用的)
这两种技术的效率都不如使用 AIO 接口, 如下表所示,展示了在 Optane 上的不同系统调用对应随机写 4K 的块(对设备 read-modify-write)的最大 IOPS,访问的数据集是 RAM 大小的三倍。
表中所示第一种方式依赖于操作系统级别的页缓存,在单线程的情况下,这种方法的性能不是最优的,因为当发生页中断时,它一次只能发出一个磁盘读取,此外,脏页只定期刷新到磁盘,这在大多数情况下会导致次优化的队列深度,然后是 I/Os 的爆发,当数据集不能完全装入内存时,内核就不得不从进程的虚拟地址空间中对置换出的页进行 map 和 unmap,将导致严峻的 CPU 开销。对于多线程,在刷新 LRU 时,页面缓存会受到 locking 开销以及系统使远程核的 TLB 项失效的速度的影响。实际上,当一个页面从虚拟地址空间中取消映射时,需要在所有访问过该页面的核上使虚拟到物理的映射失效,从而导致 IPI 通信的巨大开销。
第二种方式是使用 direct I/O。但是,当请求以同步方式完成时,direct I/O 读/写系统调用不会填满磁盘队列,因为没有必要处理复杂的从虚拟地址空间映射和取消映射页面的逻辑,该技术的性能优于 mmap 方法。
相反,批处理 I/O 每个批处理只需要一个系统调用,并允许 KVell 控制设备队列长度,以实现低延迟和高带宽。
尽管理论上 I/O 批处理技术可以应用于 LSM 和 B 树 KVs,但实现将需要很大的努力。在 B 树中,不同的操作可能会对 I/O 产生冲突的影响(例如,由插入引起的叶的分裂,然后是两个叶的合并)。此外,数据可能由于重新排序而在磁盘上移动,这也使得异步批处理请求难以实现。写请求的批处理已经通过内存组件在 LSM KVs 中实现,然而,批处理略微增加了读取路径的复杂性,因为 workers 必须确保所有要读的文件没有被压缩线程删除。
Client operation implementation
如图所示算法展示了单页 KV 对的处理。当一个请求访问该系统时,首先根据其 Key 分配给一个 worker。Worker 线程执行磁盘 I/O 并处理客户端请求的逻辑。
Get(k)
Get 操作主要包含从索引中读取到对应的磁盘上的地址和读取到对应的页。如果页已经被缓存,没有必要访问持久的存储,直接同步的返回对应的 value。如果未被缓存,则相应地由 worker 将请求入队到 I/O 请求队列中异步执行。
17 case GET :
18 if (!location || page. contains_data)
19 callback (..., page) // synchronous call
20 else
21 read_async (page , callback ) // enqueue I/O
22 break;
Update(k,v)
更新一个 KV 对的操作主要包含:首先读取到对应的页(即 key 存储在的页),修改值,然后将页写回磁盘。删除一个 KV 对其实就是将一个 tombstone 写入并将该项对应的位置添加到 slab 空闲列表中。当写入新的 KV 对时,空闲的位置得以重用,如果没有空闲位置则进行追加写。KVell 只在更新的项完全持久化到磁盘后确认更新已经完成(io_getevents 系统调用通知我们,与更新对应的磁盘写操作已经完成)脏数据会被立即刷新到磁盘,因为 KVell 的页面缓存不用于缓冲区更新,因此 KVell 比起其他 KVs 提供了更强的持久性保证。比如,RocksDB 只在 commit log 同步到磁盘的粒度上保证持久性,且通常同步操作只会在一定数量的更新之后才执行。
24 case UPDATE :
25 file = get_file_based_on_size ((k,v))
26 if (!location)
27 ... // asynchronously add item in file
28 else if(location. file != file) // size changed
29 ... // delete from old slab , add in new slab
30 else if (!page. contains_data) // page is not cached
31 // read data asynchronously first...
32 get ({ (k,v), UPDATE , callback });
33 else // ...then update & flush page asynchronously
34 update cached page
35 write_async (location , callback )
36
37 events = get processes I/O (io_getevents async I/O)
38 foreach ( e in events)
39 callback (..., e.page)
Scan(k1,k2)
范围查询操作只要包含:从索引中获取 keys 的位置,然后读取到对应的页。为了得到 keys list,需要扫描整个索引(线程依次锁定、扫描和解锁所有 workers 的索引,最后合并结果以获得一个要从 KV 读取的键列表)。读取到键后使用 Get() 命令直接根据索引中存储的物理位置访问磁盘进行查询。
范围查询是唯一要求线程间共享的操作,KVell 返回与扫描触及的每个键相关联的最新值。相比之下,RocksDB 和WiredTiger 都在 KV 快照上执行扫描。
Failure model and recovery
KVell 的当前实现为无故障操作进行了优化。当 crash 时,所有的 slabs 会被扫描并重建内存中的索引。即使扫描使顺序磁盘带宽最大化,在非常大的数据集上恢复仍然需要几分钟。
如果某一项在磁盘上出现了两次(故障发生在了将某个 KV 对从一个 slab 迁移到另一个 slab 时),只有最新的项被保存在了内存索引中,且另一项对应的位置也已经被插入到空闲列表中。如果该项大于块大小,KVell 使用时间戳来丢弃只被部分更新了的项。
KVell 是针对于可以支持 4KB 页的原子写入的设备设计的。通过避免对页面进行就地修改,在新页面中写入新值,然后在第一次写入操作完成后在 slab 的空闲列表中添加旧位置,可以解除该约束。
Evaluation
Goals
我们用各种生产和合成工作负载来评估 KVell,并将其与最先进的 KVs 进行比较。评估开始回答以下问题:
KVell 对比现有的运行在现代 SSD 上的 KVs 在读写以及是扫描的吞吐量、性能波动和尾延迟情况表现如何?
KVell 在大型数据库和生产环境中的工作负载下表现如何?
在超出其设计范围的工作负载中使用 KVell 的利弊和限制是什么(小型项目、内存限制极端的环境和较旧的驱动器)?
Experimental setting
Hardware :
Config-SSD :32-core 2.4GHz Intel Xeon,128GB of RAM, and a 480GB Intel DC S3500 SSD (2013).Config-Amazon-8NVMe :An AWS i3.metal instance, with 36 CPUs (72 cores) running at 2.3GHz, 488GB of RAM, and 8 NVMe SSD drives of 1.9TB each (brand unknown, 2016 technology).Config-Optane :A 4-core 4.2GHz Intel i7, 60GB of RAM, and a 480GB Intel Optane 905P (2018).
Workloads :
YCSB:测试使用了 uniform 和 zipfian 的请求分布。KV 项大小为 1024B,总的数据集大小分别为 100GB(小规模)和 5TB(大规模)
two production workloads from Nutanix:两个写敏感负载,write:read:scan 57:41:2,KV 项大小在 250B 到 1K 之间,中位数为 400B。数据集大小总的为 256GB,两个负载之间的区别在于数据的倾斜。Production Workload 1 更接近于 uniform 的分布, Production Workload 2 更倾斜。
Existing KVs :
LSM:RocksDB 和 PebblesDB
B+ tree: TokuMX 和 WiredTiger
System configuration :使用 cgroups 为所有的系统限制了相同大小的内存,即数据集大小的三分之一,确保从内存和持久存储同时为请求提供服务。当数据库大于 RAM 大小的三倍的时候,将不再使用 cgroups。
对于 B Tree,块大小设置为 4KB
LSM:5 levels 和两个 128MB 的内存组件,WAL Buffer 1MB
Results in the main experimental setting
Throughput
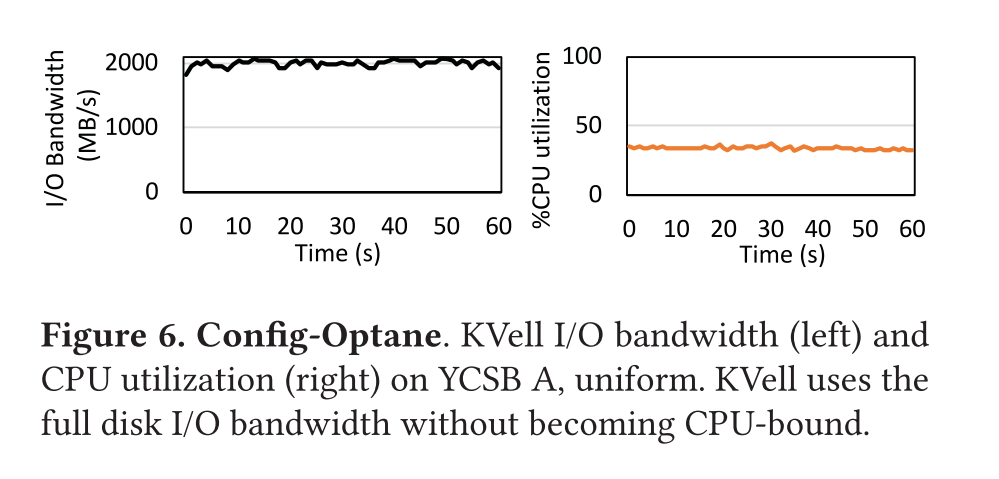
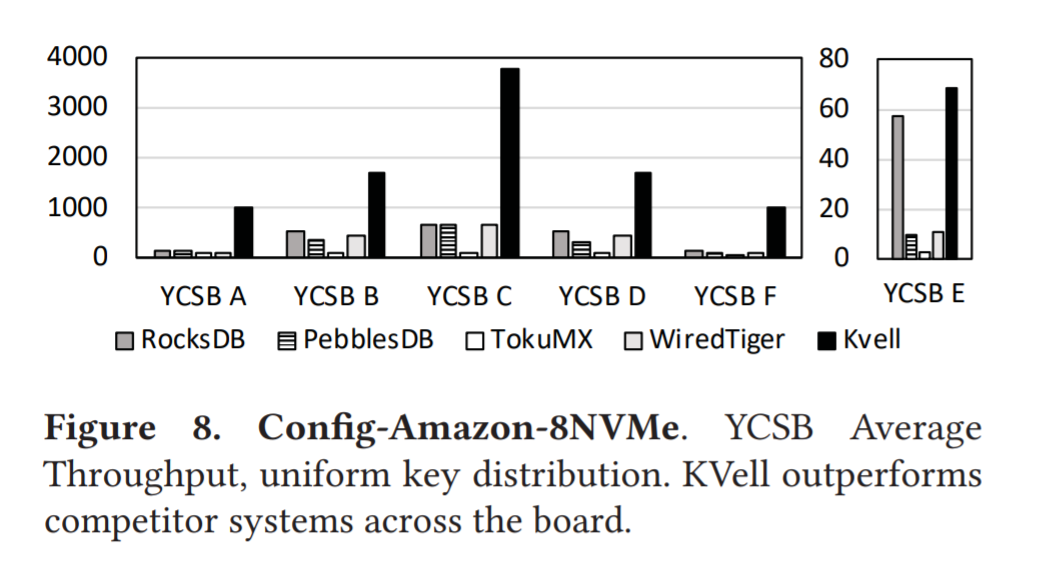
Write-intensive workload (YCSB A and F) :
TokuMX 15x WiredTiger and RocksDB by 8× and PebblesDB by 5.8× on the YCSB A workload。
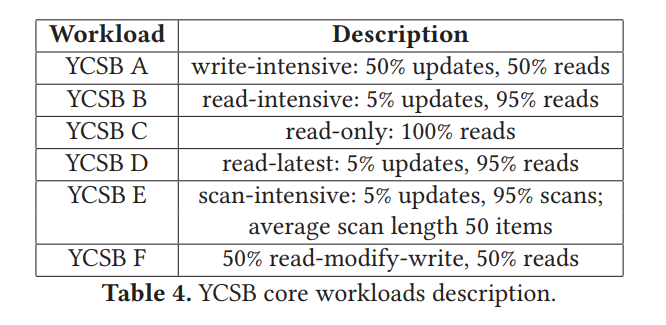
该负载下未缓存的 read 导致一次 I/O,缓存了的读导致 0 次 I/O,未缓存的写导致 2 次I/O(1 read + 1 write),缓存了的写导致一次 I/O。因为页缓存大约未数据集的 1/3,所以平均一次请求大约需要 1.17 I/Os,意味着最大理论吞吐量为 500K IOPS/1.17 = 428K requests/s。而 KVell 的平均吞吐量约为 420K,因此利用了纯设备带宽的 98%,且没有被 CPU 限制住。
在这个工作负载中,KVell 将 20% 的时间花在由页面缓存和内存中索引完成的 B树查找上,20% 的时间花在 I/O 函数上,60% 的时间花在等待上。
LSM KVs 被压缩的开销给限制住,WiredTiger 被日志的争用给限制住(大约消耗 50% 的时钟周期),TokuMX 被共享数据结构的争用和不必要的 buffering 给限制住(大约消耗 50% 的时钟周期)
Read-intensive workloads (YCSB B, C, D)
KVell outperforms existing KVs by 2.2× on YCSB B and 2.7× on YCSB C。接近完全利用磁盘的 IOPS。
YCSB-C KVell 花费 40% 的时间查询,20% 的时间执行 I/O,40% 的时间等待。
在这些工作负载中,现有 KVs 的执行不是最优的,因为它们共享缓存,或者因为它们没有将读请求批处理到磁盘(每个读一个系统调用)。例如,RocksDB 将 41% 的时间花费在 pread() 系统调用上,并且是受 CPU 限制的。
Scan workloads (YCSB E)
KVell 在扫描密集型工作负载中表现良好,在 uniform 和 Zipfian key 的分布中都是如此。注意,为了公平起见,我们修改了 YCSB 工作负载,以便它在 KVell 中以随机顺序插入键。默认情况下,YCSB 按顺序插入键。
Zipfian 下 KVell 领先至少 25%,因为负载是倾斜的,热数据被缓存在 KVell 的缓存中。shared-nothing 和低开销的缓存实现都给予了 KVell 优势。
uniform 下,KVell 由于 PebblesDB 5x,WiredTiger by 33%,和 RocksDB 相近。因为 KVell 数据在磁盘上并非有序,每个扫描项平均就要访问一个页面。相反 RocksDB 下数据有序存储,大概访问每页上的三个条目(页大小为 4K,每个 KV 项为 1024B)。因此,RocksDB 的最大吞吐量大约是 KVell 的三倍,如图 7 显示了吞吐量的时间线上的变化。RocksDB 最大吞吐量约为 55Kops/s,对比 KVell 的 18Kops/s。然而,RocksDB 的维护操作会干扰客户端负载,导致大的波动,而 KVell 的吞吐量保持稳定在 15Kops/s 左右。因此,平均而言,RocksDB 和 KVell 的表现相似。
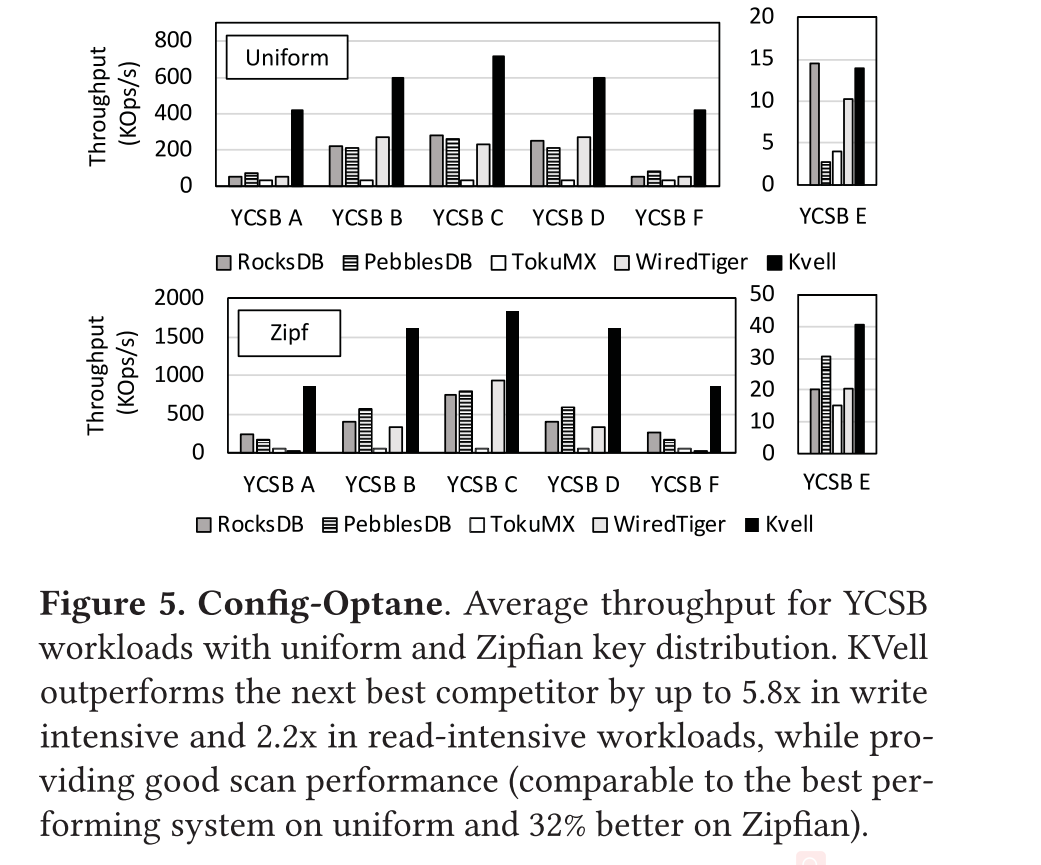
Throughput over time
下图展示了各种系统吞吐量随着时间的变化,每秒测一次吞吐量,KVell 除了提供更高的平均吞吐量以外,还不会遭受因为维护数据结构带来的性能波动。对于其他存储系统,性能下降的都很频繁。
相比之下,KVell 的性能在一个短暂的爬升阶段(页面缓存被填满的时间)之后保持不变。KVell 在 YCSB A 上至少保持 400K/s 的请求,在过渡阶段之后保持 15K/s 的扫描。
Tail latency
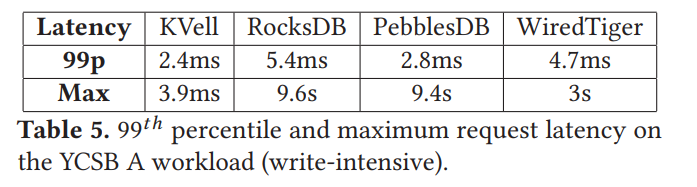
下表展示了最大 99th 尾延迟,LSM 最大尾延迟 9s,B Tree 3s,这是由于维护操作直接影响了LSM和B树KVs的尾部延迟。相比之下,KVell提供了较低的最大延迟(3.9ms),同时提供了强大的持久性保证。
Alternative configurations and workloads
下图展示了对于 uniform 负载下在 NVMe SSD 上的 YCSB 平均吞吐量,所有的系统都配备了一个 30G 的缓存,大约占 1/3 的数据库大小
KVell outperforms RocksDB by 6.7× and PebblesDB by 8×, TokuMX by 13× and WiredTiger by 9.3× on average on YCSB A
对于 YCSB-E,KVell 略优于 RocksDB,但比其他系统更快,虽然结果和 Optane 是类似的,但是我们可以看到 KVell 和竞争对手之间的性能差距是如何拉大的,因为与其他受 CPU 限制的系统相比,KVell能够更好地利用磁盘。
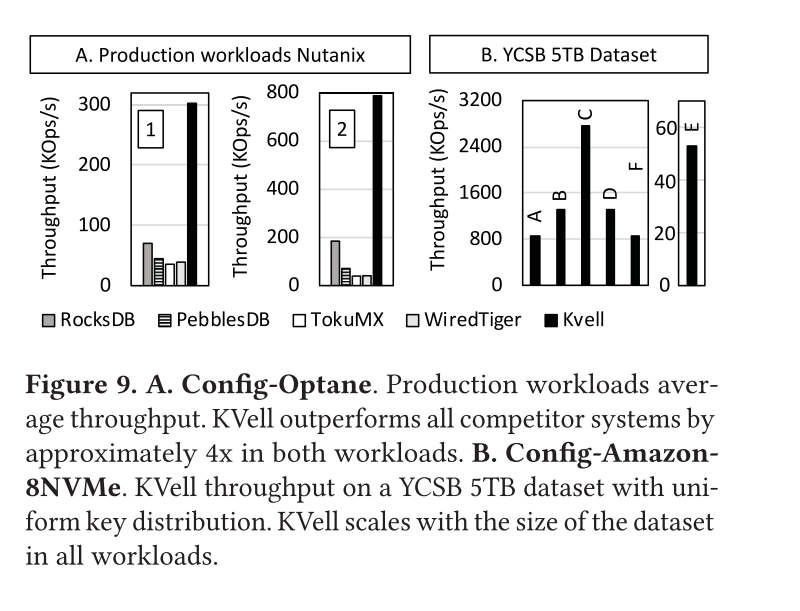
下图展示了两个生产环境中的真实负载下的性能表现,结果和 YCSB 其实都是类似的
图 B 显示了使用更大数据量的 YCSB 负载下的性能表现
Trade-offs and Limitations
Average latency
KVell 分批提交 I/O 请求。在饱和 IOPS(大批次)和最小化平均延迟(小批次)之间进行权衡。
Impact of item size
项的大小不会影响 Get() 和 Update()请求未缓存的项的性能。但是,对于保持条目有序的 KVs,条目大小会影响扫描速度。
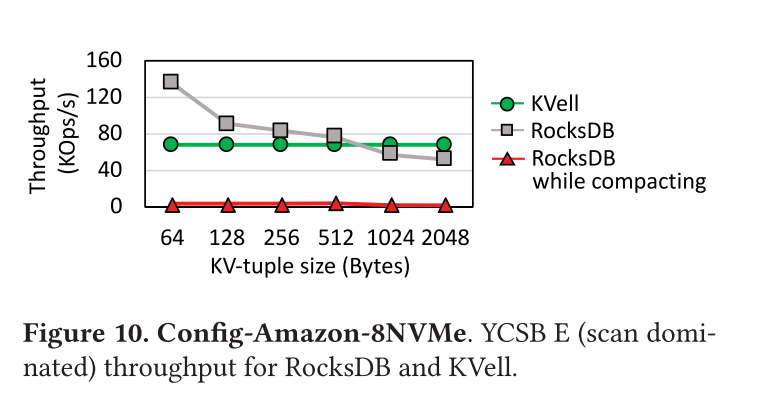
图10 显示了 RocksDB 的平均吞吐量,RocksDB 在执行压缩时,KVell 在 YCSB E 上改变项目大小(扫描为主)。
由于KVell不对磁盘上的项进行排序,因此无论项的大小如何,它平均为每个扫描项读取一个4KB的页面,并且性能稳定。对于小条目,RocksDB优于KVell,因为它读取的页面比KVell少(64B条目少64倍)。随着条目大小的增长,保持条目排序的好处就会减少。
在运行compactions时,对于所有的项大小,RocksDB只能维持其吞吐量的一小部分。KVell 没有专门针对小 KV 设计,在所有配置下提供了可预测的性能。
Memory size impact
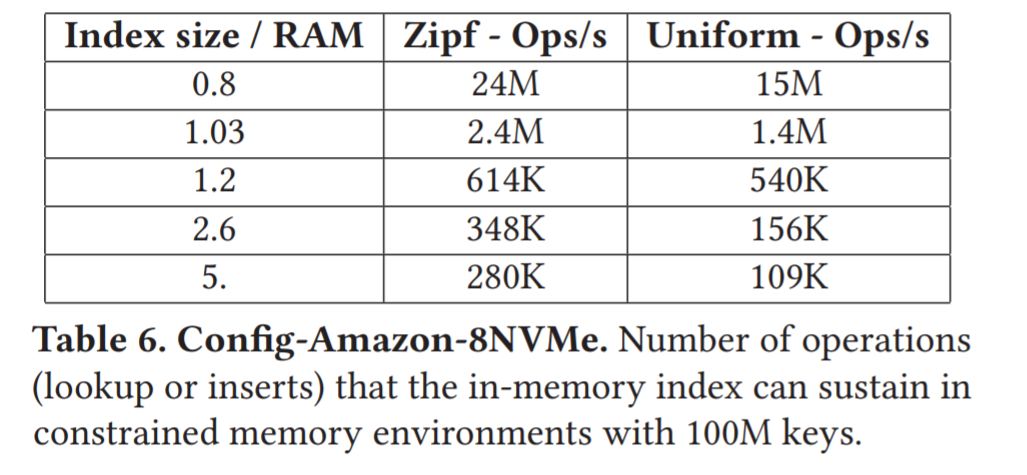
当索引无法装入RAM时,就会成为瓶颈
KVell只支持将索引部分刷新到磁盘,以避免索引超过可用RAM时崩溃,但没有优化到在这种情况下工作。在实践中,索引的内存开销非常低,因此它们可以在RAM中满足大多数工作负载(例如,对于YCSB来说,100GB数据集的索引为1.7GB)。
Older drives (Config-SSD)
在Config-SSD上,KVell在读写方面与LSM KVs相当,但是在扫描方面提供了相对较低的平均性能。在旧的驱动器上,花费用于优化磁盘访问的 CPU 周期平均来说是有益的,而且没有系统此时是受 CPU 限制的。压缩仍然会争夺磁盘资源,造成延迟峰值(18s以上)和吞吐量波动。KVell 的延迟仅受磁盘本身延迟的限制。因此,在旧的驱动器上使用KVell和LSM KVs是一种权衡:如果稳定性和延迟的可预测性很重要,那么KVell是比LSM更好的选择,但是对于扫描为主的工作负载,LSM KVs在旧驱动器上提供了更高的平均性能。
Recovery time
KVell的恢复时间取决于数据库的大小,而其他系统的恢复时间主要取决于提交日志的最大大小。对于所有系统,我们都使用默认的提交日志配置,并测量YCSB数据库上的恢复时间(100M Key,100GB)。我们通过在YCSB A工作负载中间终止数据库来模拟崩溃,并测量Config-Amazon-8NVMe上数据库的恢复时间。
KVell 需要 6.6 秒扫描数据库并从崩溃中恢复,最大限度地提高磁盘带宽。RocksDB和WiredTiger平均恢复时间分别为18s和24s。这两个系统主要花费时间回放来自提交日志的查询和重新构建索引。尽管KVell为无故障操作进行了优化,必须扫描整个数据库才能从崩溃中恢复,它的恢复时间比现有系统的恢复时间要短。
KVs for SSDs
WiscKey, HashKV
PebblesDB, TRIAD
SlimDB, NoveLSM, PapyrusKV, NVMRocks
BetrFS, TokuMX
SILT, Udepot, Tucana, Kreon
LOCS, BlueCache, NVMKV
KVs for byte-addressable persistent memory
KVs for in-memory data stores
MICA, Minos, Masstree, RAMCloud
Conclusion
现有的 KV 存储设计在老一代 SSD 上是有效的,但在现代 SSD 上执行不是最优的。我们已经展示了一种依赖于 share nothing 架构、磁盘上未排序的数据和随机 I/Os 批处理的流线化方法在快速驱动器上的性能优于现有的 KVs,甚至对于扫描工作负载也是如此。我们已经在 KVell 中建立了这些想法的原型。KVell 提供了高且可预测的性能和强大的延迟保证。