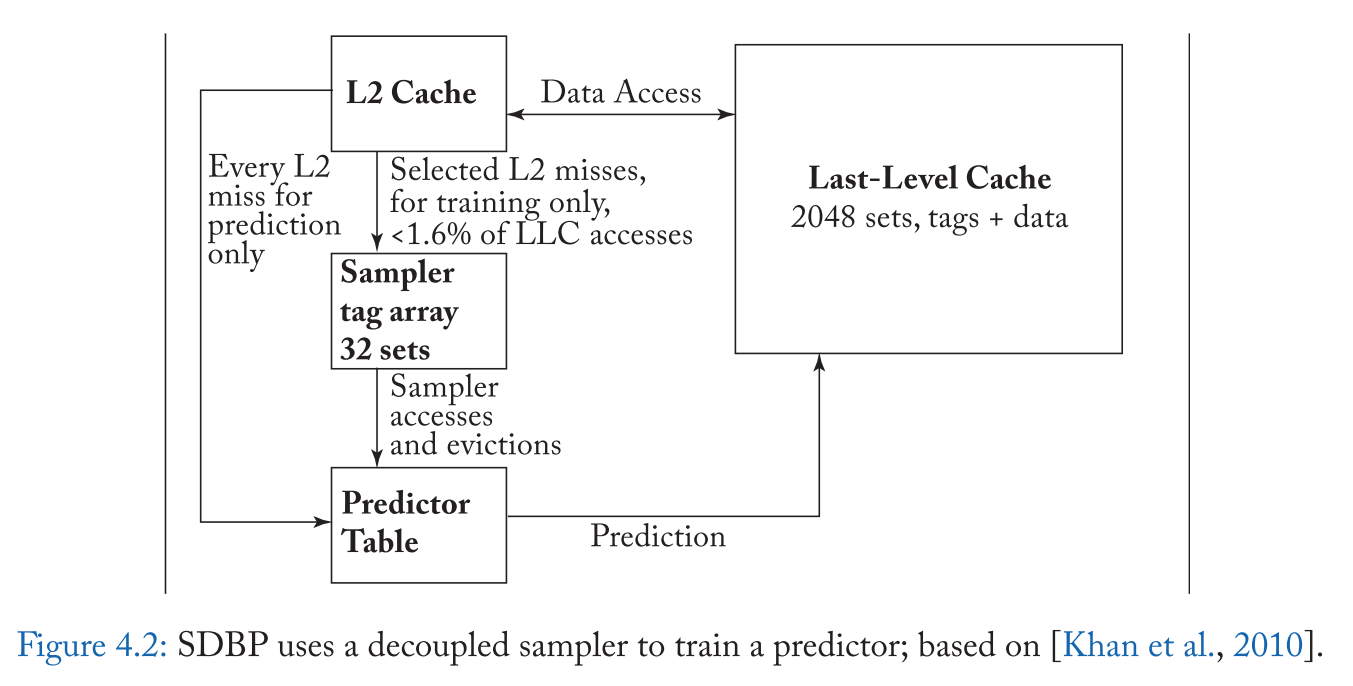
像 SDBP 一样,SHiP [Wu et al., 2011a] 学习了底层替换策略的淘汰行为,但 SHiP 背后的主要观点是,重用行为与将该行插入缓存的 PC 更紧密相关,而不是与最后访问该行的 PC。因此,在缓存淘汰时,SHiP 的预测器被 PC 训练,PC 首先在缓存丢失时插入该行,预测器只在缓存 MISS 时被咨询(在命中时,行被提升到最高优先级而不咨询预测器)。
(2) SHiP 使用基于 PC 的预测器,其中与一行相关联的 PC 就是插入一行缓存 miss 的 PC,其中每个 PC 与一个饱和计数器相关联。
(3) SHiP 依靠 RRIP 政策来老化所有行。
HAWKEYE
为了避免基于启发式的解决方案(如LRU)的病态,Hawkeye [Jain和Lin, 2016] 构建了 Belady 的 MIN 解[Belady, 1966],这是有趣的两个原因。
首先,Belady 的 MIN 对于任何引用序列都是最优的,因此基于 MIN 的解决方案可能适用于任何访问模式。
其次,Belady 的 MIN 算法是一种不切实际的算法,因为它替换了将来重复使用最多的行;因此,它依赖于未来的知识。
Hawkeye 的核心见解是,虽然无法预测未来,但可以将 Belady 的 MIN 算法应用到过去的内存引用中。此外,如果一个程序过去的行为是它未来行为的一个很好的预测器,那么通过学习过去的最优解,Hawkeye 可以训练一个预测器,它应该在未来访问中表现良好。
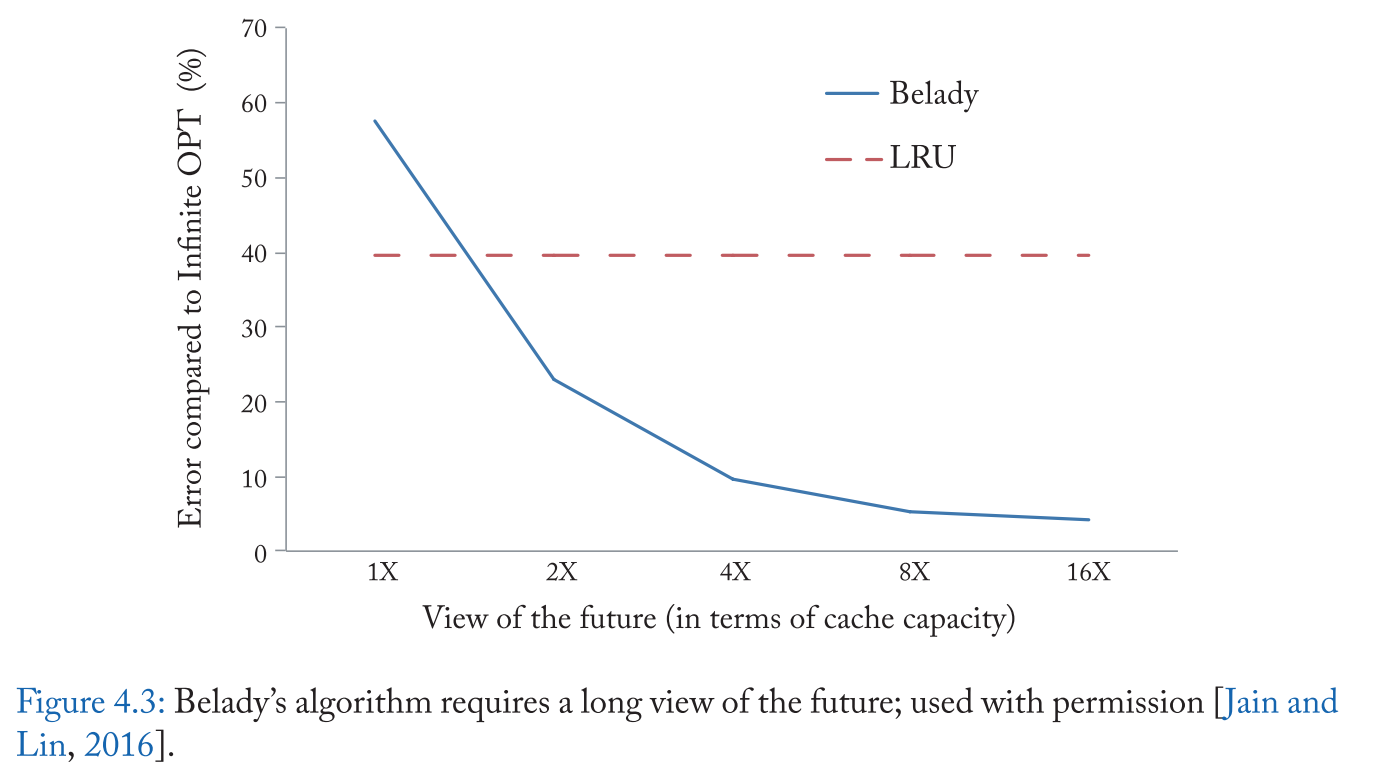
为了理解模拟过去事件的 MIN 需要多少历史信息,Jain 和 Lin[2016] 通过限制其未来的窗口来研究 MIN 的性能。图 4.3 显示,虽然 MIN 需要一个很长的窗口到未来(SPECint 2006的 8x 缓存大小),但它不需要一个无边界窗口。因此,要将 MIN 应用到过去的事件,我们需要一个缓存大小为 8x 的历史记录。
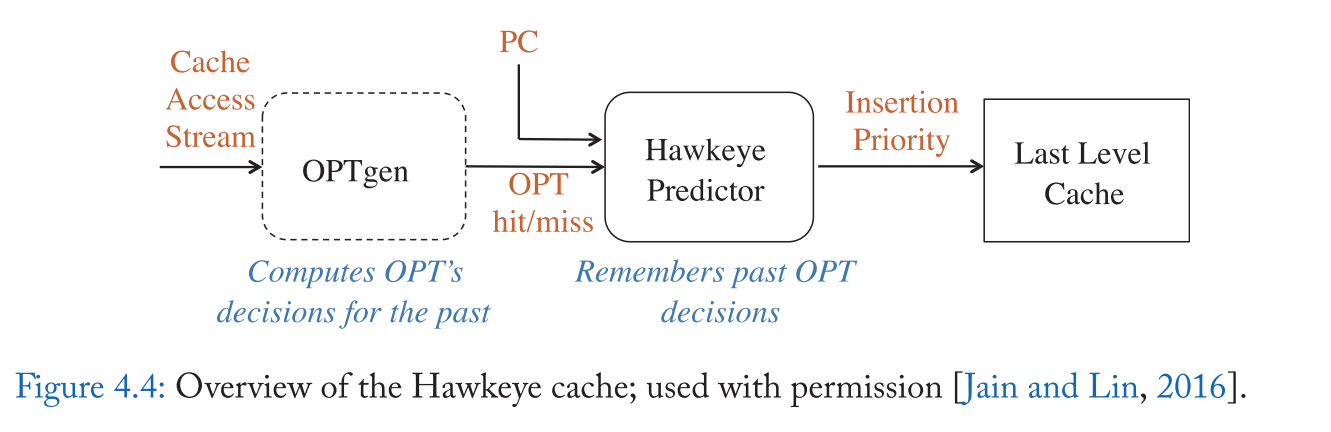
由于维持缓存大小 8x 的历史信息开销巨大,Hawkeye 只计算几个抽样集的最优解,并引入 OPTgen 算法,为这些抽样集计算与 Belady 的 MIN 策略相同的答案。OPTgen 确定如果使用 MIN 策略将被缓存的行。OPTgen 背后的关键观点是,当一行再次被重用时,可以准确地确定该行的最佳缓存决策。因此,在每次重用时,OPTgen 都会回答以下问题: 这一行是否会在 MIN 情况下是缓存命中还是缓存丢失?这种洞察力使得 OPTgen 能够使用少量的硬件预算和简单的硬件操作,以 O(n) 复杂性再现 Belady 的解决方案。
图4.4 显示了 Hawkeye 替换策略的总体设计。OPTgen 训练 Hawkeye 预测器,这是一种基于 PC 的预测器,它可以了解 PC 插入的行是倾向于缓存友好型还是缓存反对型。当 OPTgen 确定一条行将被 MIN 命中时,该行对应的 PC 被正训练,否则被负训练。每次使用传入行的 PC 进行缓存插入和提升时,都会参考预测器。被预测为缓存友好的行将以高优先级插入,而被预测为缓存厌恶的行将以低优先级插入(参见表4.3)。
回答本节开头的问题:
(1) Hawkeye 从最优缓存解决方案中学习,而不是从 LRU 或 SRRIP 中学习;
(2) Hawkeye 使用基于 PC 的预测器学习最优解;
(3) Hawkeye 还依赖于 RRIP 的老化机制,以高优先级插入 age line。为了纠正不准确的预测,Hawkeye 还对预测器进行负训练,当预测到不喜欢缓存的行被取消而没有被重用时。