- 该篇文章来自于 SIGMOD19: X-Engine: An Optimized Storage Engine for Large-scale E-commerce Transaction Processing
X-Engine
Abstract
- X-Engine,这是在阿里巴巴构建的 POLARDB 的一个写优化存储引擎,它使用了带有 LSM 树(日志结构的合并树)的分层存储架构,利用 FPGA 加速压缩等硬件加速,以及一套优化,包括事务中的异步写、多级流水线和压缩期间的增量缓存替换。评估结果表明,X-Engine 在事务性工作负载下的性能优于其他存储引擎。
- 简单概括:
- 大量的优化都是通过利用多核来异步并发执行一些操作,并使用流水线的相关技术来争取把 CPU 和磁盘打满,并一定程度上进行协同。但开启大量线程的代价就是极高的 CPU 占用,所以后面又提出了使用 FPGA 来加速 compaction,通过将 compaction 任务进行拆分,使得 FPGA 可以参与。
- 其他的几个优化在 RocksDB 上本身也已经得到了应用。
- L0 层内 compaction 来提高 L0 的有序性加速查询和 compaction
- 细粒度缓存 KV Cache 和 Block Cache 的协同;细粒度缓存效率对点查询的优化效率更高,粗粒度缓存在 compaction 过程中进行直接替换来代替缓存失效淘汰
- 元数据索引的多版本 CoW 更新来代替直接 Update 整个元数据
- 还有就是
- 并发内存跳表,跳表内热数据的多版本优化,数据按版本链式保存
- 事务的分阶段处理,流水线优化
- compaction 过程的数据重用,结合上面的元数据 CoW
- 内部各个操作的优先级调度,主要是对 compaction 调度
Introduction
- 下图是双 11 负载的变化情况,概括下来就是在特定时间点请求可能呈海啸式增长。
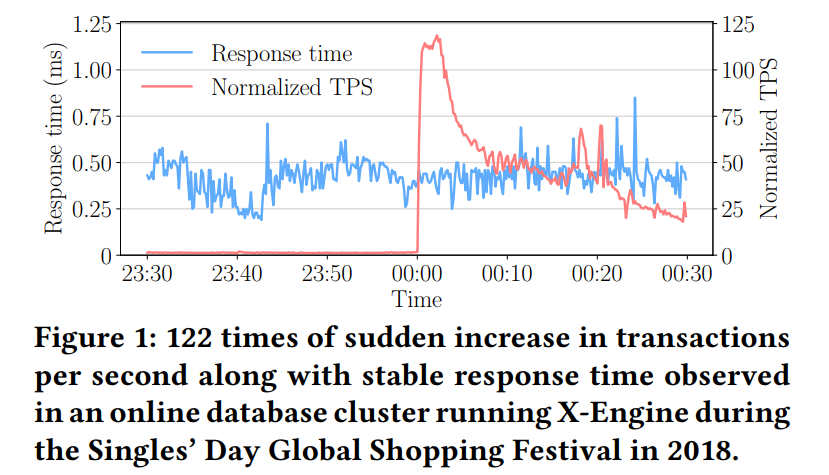
- 以前处理这种负载的方式为使用一个共享的架构,来在多个 DB 实例中进行分布式的事务处理,然后在峰值来临之前对 DB 实例进行扩展,但是这样由于需要大量实例,它需要大量的资金和工程成本。而本文提出的方法则是 提升单机的存储引擎容量来解决该问题,从而使得需要的实例数减少,给定固定成本的可实现吞吐量增加。
- 针对这种洪泛式的负载,需要快速将数据从内存移动到持久化存储,同时还需要处理高并发的电商事务处理。这种在线促销的负载主要表现为数个小时的事务陡增,包含大量的写入。即便内存大小不断增大,但是比起负载还是小很多,所以必须在 RAM/SSD/HDD 混和存储场景下来重复利用存储资源。X-Engine 根据数据的冷热来进行数据的分层放置,甚至使用 NVM。
- LSM 比较适合这种分层结构存储,除了 LSM 以外,还有一些加速写的数据结构,LSM、VLDB12 LogBase、以及优化的树结构,甚至混和结构 bLSM,但是对于我们的场景都不够高效;另一些则通过交换点和范围查询的性能来提高写的性能,因为写不适合混合读和写的电子商务工作负载。
- 大多数数据库负载,热记录都在一个稳定的时间内表现出了很强的空间局部性,记录的空间位置随时间变化很快。这是因为随着时间的推移,在不同的类别或记录上有不同的促销活动。例如,全天都有针对不同类别或品牌的秒杀促销活动(销售热门商品,你必须抓住它们可供购买的那一秒),以刺激需求,吸引顾客购买随时间变化的不同商品。这意味着数据库缓存中的热记录会不断变化,任何记录的温度都可能从冷/暖到热或从热到冷/暖。如果我们将数据库缓存视为一个储存库,而将底层(大型)数据库视为海洋,则这种现象将导致当前(即热记录vs .冷记录)在非常深的海洋中快速地向任何方向移动(例如,存储在X-Engine上的巨大数据库)。存储引擎需要确保新出现的热记录能够尽可能快地从深水中检索并有效缓存。
- Contributions
- 利用线程级别的并行在内存中处理大量请求,从事务中解耦写请求来异步执行,将长写路径分解为流水线中的多个阶段,以增加总体吞吐量
- 利用重定义的 LSM 结构来在分层存储器件上在不同的层次之间移动数据,并优化 compaction 算法
- 把 compaction offload 到 FPGA
- CoW 更新的多版本元数据索引来加速点查询,而不管数据的温度
System Overview
- 电商场景数据热度变化频繁,且包含大量的写请求,考虑使用 LSM,但是传统的 LSM 不适合该负载,所以我们做了大量的优化。X-Engine 可以部署在 POLARFS 上,POLARFS 使用了大量的新技术如 RDMA NVMe 等
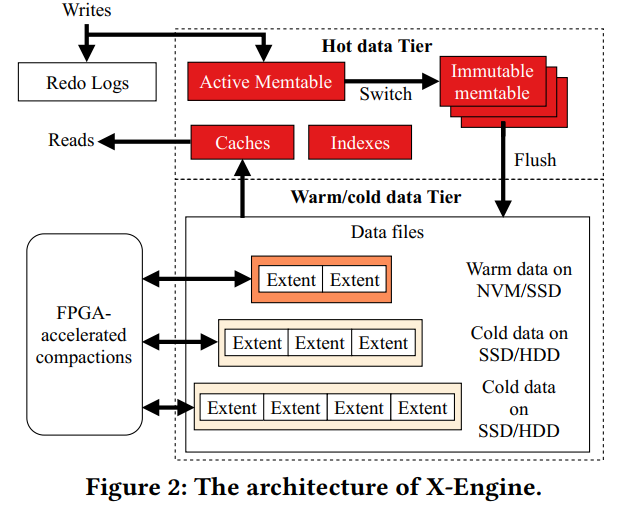
- 下图展示了 X-Engine 的架构,把每个 Table 分区到了多个子表,维护了一个 LSM 树,为每个子表关联 metasnapshot 和 索引,每个数据库实例有个 REDO LOG,每个 LSM 树由驻留在内存中的热数据层和 NVM/SSD/HDD 的 温/冷 数据层组成,之后会被分区到不同层。数据的热温冷代表着理想的访问频率,然后相应地被放到对应的层。热数据层包含一个 active memetable 和多个 immutable memtable,都是跳表,存储最近插入的数据,并缓冲热记录。温冷数据层组织数据在一个类似树的结构中,每一层的树存储有序的 extents,一个 extents 打包了对应的数据块、索引块和过滤器块,我们正在探索机器学习技术来识别适当的数据温度,这在附录C中有简要的讨论,它的全部细节超出了这项工作的范围。
- X-Engine 利用 redo logs、metasnapshots、和 index 来支持事务多版本并发控制,每一个 metasnapshot 有一个元数据索引来追踪所有的 memtables 和所有层次的 extents,树的一个或多个相邻层组成一个层,分别存储在NVM、SSD和HDD上。在X-Engine中,表被划分为几个子表。每个子表都有自己的热、热和冷数据层(即LSM树)。X-Engine 以面向行格式存储记录。我们设计了一个多版本memtables 来存储不同版本的记录,以支持MVCC(在第3.2.1节介绍)。在磁盘上,元数据索引跟踪存储在区段中的记录的所有版本。我们将在3.1节详细介绍数据结构。
- The read path: 读路径是从存储器中检索记录的过程。原来的lsm树设计没有很好的读取性能。查找首先搜索memtable。在memtable中,它必须一个一个地遍历每一层。在最坏的情况下,查找必须以扫描所有级别结束,直到最大级别得出查询记录不存在的结论。为了加速这一过程,提出了一个 manifest file 来定位包含查询键的目标SST。在每个 SST 内还应用了 Bloom 过滤器,以促进早期终止
- 为了为电子商务交易中常见的点查找获得良好的响应时间,我们优化了区段的设计,引入了跟踪所有 memtable 和区段的元数据索引,以及一组缓存以促进快速查找。我们还提出了压缩中的增量缓存替换方法,以减少压缩导致的不必要的缓存迁出。我们引入快照以确保查询读取记录的正确版本
- The write path: 写路径包括物理访问路径和在存储引擎中插入或更新记录的相关过程。在lsm树KV存储中,到达的键值对被附加或插入到活动memtable中。一旦完全填充,活动memtable就会切换为不可变的,等待刷新到磁盘。同时,创建一个新的空活动memtable。为了支持高并发事务处理,存储引擎需要通过在持久存储(例如SSD)中记录新记录,并将它们高速插入memtable。在这个过程中,我们区分了长延迟的磁盘 I/O 和低延迟的内存访问,并将它们组织在一个多级流水线中,以减少每个线程的空闲状态,提高总体吞吐量(章节3.2.3)。为了实现高水平的并发性,我们进一步将写的提交与事务处理分离开来,并分别优化它们的线程级并行性。
- Flush and Compaction: LSM 树依赖于刷新和压缩操作来合并数据,这些数据可能会淹没从memtable到磁盘的主内存,并保持合并数据的有序顺序。不可变memtable被刷新到Level0,在此期间记录被排序并打包到排序序列表(SSTs)中。每个SST都独占一个 Key 范围,因此一个级别可以包含多个SST。当 Level-i 的 sst 规模达到某一阈值时,与Leveli+1键值域重叠的sst合并。这个合并过程在某些系统中称为压缩,因为它还会删除标记为要删除的记录。最初的压缩算法从这两层读取 sst,合并它们,然后将合并后的结果写回 lsm 树。这个过程有几个缺点:它消耗大量的cpu和磁盘 I/O;同一条记录从LSMtree读取和写入多次,导致写入放大;它会使正在合并的记录的缓存内容无效,即使它们的值保持不变
- 在X-Engine中,我们首先优化不可变memtables的刷新。对于压缩,我们应用数据重用来减少要合并的区段数量,异步I/O与磁盘I/O重叠,以及FPGA加载来减少CPU消耗。

Detailed Design
- X-Engine 应用 MVCC 和两阶段锁来实现 Snapshot isolation 和 Read Commited 的隔离级别来保证 ACID,同一记录的不同版本被存储为具有自动递增版本 ID 的单独元组。X-Engine 将这些版本的最大值跟踪为 LSN (日志序列号)。每个传入事务使用它所看到的LSN 作为快照。事务只读取比它自己的 LSN 更小的最大版本的元组,并为它所写的每个元组添加行锁,以避免写冲突。
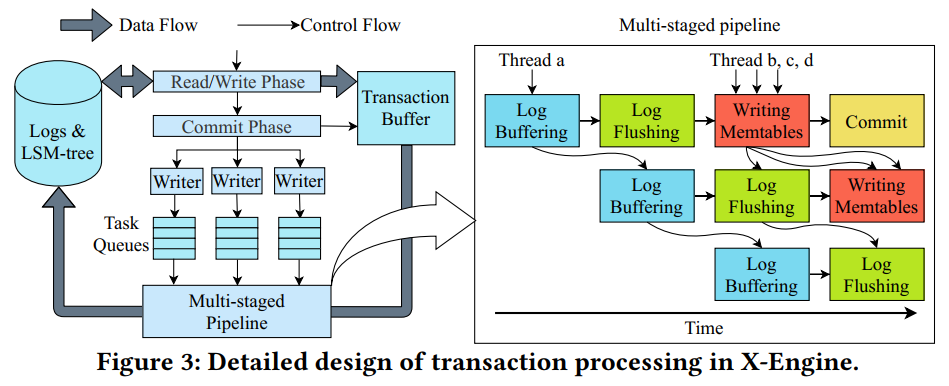
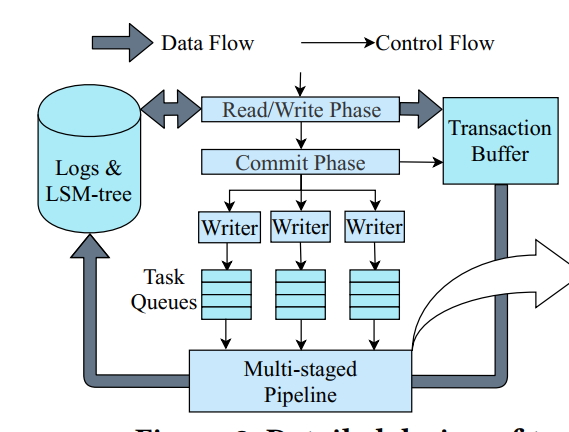
- 下图展示了事务处理的流程。这个过程包括一个读/写阶段和一个提交阶段。事务的所有读请求都是通过访问lsm树的读路径在读/写阶段提供的。在此阶段,将在事务中插入或更新的记录写入事务缓冲区。接下来,在提交阶段,将从事务缓冲区写入存储的任务记录分发到多个写任务队列。通过记录相应的记录并将它们插入到lsm树中,引入了一个多级流水线来处理所有这些写任务。下面我们将详细介绍X-Engine的数据结构、读路径、写路径、刷新和压缩
The read path
- 我们从数据结构的设计开始,包括区段、缓存和索引。对于每个数据结构,我们将介绍它如何促进读取路径中的快速查找。
Extent
- 图4显示了区段的布局,由数据块、元数据和块索引组成。记录以面向行的样式存储在数据块中。元数据 schema 跟踪每个列的类型。块索引保留每个数据块的偏移量。在生产系统的当前部署中,我们在 LSM 树的所有级别上将区段的总大小调优为2 MB。因为许多电子商务事务以高度倾斜的方式访问记录,所以保持这种大小的区段允许在压缩期间重用许多区段(详见第3.3.2节)。这种设计还有助于压缩期间的增量缓存替换(在3.1.4节中引入的优化)
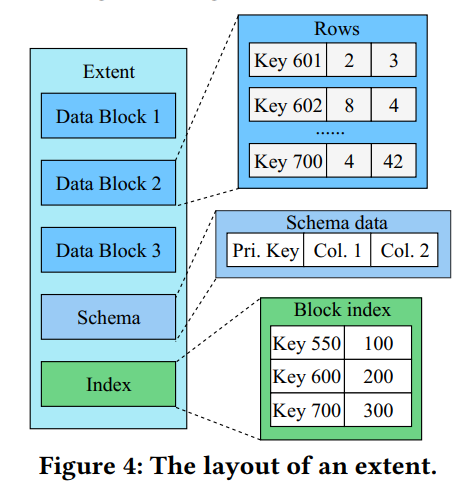
- 我们在每个区段中使用版本存储模式数据 schema,以加速 DDL(数据定义语言)操作。通过这种设计,当向表中添加新列时,我们只需要在新版本的新区段上强制执行这个新列,而不需要修改任何现有的区段。当查询读取带有不同版本模式的区段时,它将与最新版本保持一致,并将带有旧模式的记录的空属性的缺省值。这种快速 DDL 特性对于在线电子商务业务非常重要,因为在线电子商务业务经常根据需求的变化调整数据库模式的设计。
Cache
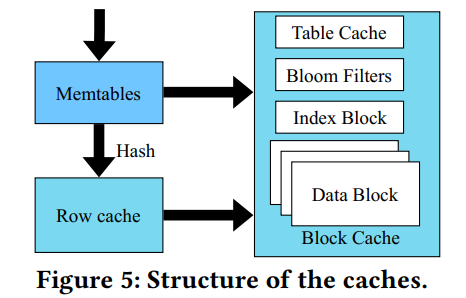
- 图5说明了XEngine中的数据库缓存。我们专门为点查找优化了行缓存,点查找是阿里巴巴电子商务交易中的大多数查询。行缓存使用LRU缓存替换策略缓存记录,而不管记录在 LSM 树中的哪个级别。 因此,即使是最大级别的记录也可以被缓存,只要查询访问它。一旦点查找错过了 memtables,查询的键就被散列到行缓存中相应的匹配槽中。因此,在点查询的行缓存中检索记录只需要 O(1)时间。当随机查找访问记录时,行缓存的影响较小。
- 我们在行缓存中只保存最新版本的记录,由于时间局部性,这些记录被访问的机会最大。为了实现这一点,我们在刷新期间用行缓存中的新记录替换旧版本的记录,从而减少因刷新而导致的缓存丢失
- 块缓存以数据块为单位缓冲数据。它为每个没有从行缓存c查询或范围查询请求提供服务。表缓存包含子表头的元数据信息,这些子表头通向相应的区段。找到区段后,我们使用Bloom筛选器筛选不匹配的键。然后,我们搜索索引块来定位记录,并最终从它的数据块中检索它。
- 这些缓存对于温度变化后减少记录缓存丢失非常重要。由于记录的空间局部性,行缓存中出现的热记录和已有的热记录可能来自相同的区段甚至相同的数据块。因此,表和块缓存有助于提高缓存未命中后的总体缓存命中率,并可能有助于减少行缓存中替换的延迟
Multi-version Metadata Index
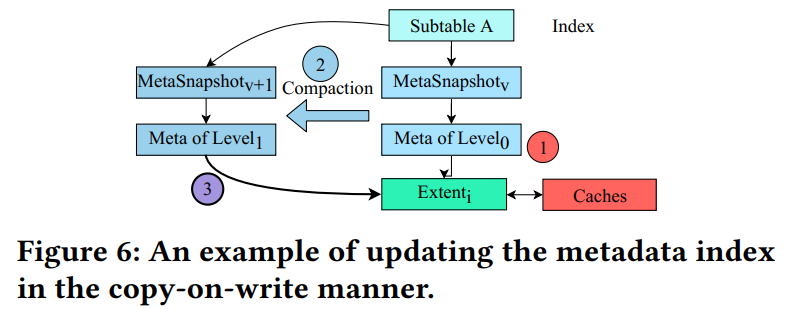
- 图 6 说明了 X-Engine 中多版本元数据索引的结构。每个子表的LSM 树都有其关联的元数据索引,该索引从表示子表的根节点开始。索引的每次修改都会创建一个新的元快照,它指向所有相关的级别和memtable,而不需要修改现有元快照的节点(即copy-on-write方法)。
- 在图6中, extent i 最初是 Level0 的一部分,且被缓存(用红色表示)。当重用此区段的压缩完成时,MetaSnapshot v 旁边会创建一个新的 MetaSnapshot v+1,链接到新合并的 Level1 (颜色较深)。Level1 的元数据只需要指向extent i,而不需要在磁盘中实际移动它(用紫色表示),从而保持所有缓存内容的完整性。利用这种写时复制方法,事务可以以只读方式访问它们想要的任何版本,而不需要在数据访问期间锁定索引。我们使用垃圾收集来删除过时的元快照。RocksDB 等其他存储引擎也探索过类似的设计。
Incremental cache replacement
- 在lsm树中,由于压缩合并了磁盘中的许多区段,它通常会导致大量缓存驱逐,降低了查找时的缓存命中率,并导致明显的性能下降和不稳定的响应时间。即使缓存记录的值没有改变,如果它们的区段与压缩中涉及的其他区段共享重叠的键范围,则它们可能已经在磁盘中移动了。
- 为了解决这个问题,我们建议在块缓存中进行增量替换,而不是从缓存中删除所有 compacted 区段。在压缩期间,我们检查要合并的区段的数据块是否被缓存。如果是这样,我们将缓存中的旧块替换为相同位置的新合并块,而不是简单地清除所有旧块。这种方法通过保持块缓存中一些块的更新和不移动来减少缓存丢失。
The write path
- 在本节中,我们从优化接收每个子表的 LSM 树的传入记录的memtable结构开始。接下来,我们介绍如何设计写任务队列和写路径中的多阶段流水线,它们由X-Engine中所有子表的 LSM 树共享。
Multi-version memtable
- 我们实现 memtable 作为一个无锁的skiplist,像许多其他系统一样,以实现良好的查找和插入性能[9]。然而,在查询热记录时,基于skiplist的memtable的最先进实现存在性能问题。对单个记录的频繁更新会生成多个版本。如果一个热记录与只关注最新版本的查询的谓词匹配,则查询可能必须扫描许多旧版本来定位所请求的版本。电子商务平台上的在线促销活动,在消费者下单购买热门商品时,放大了这些多余的访问。
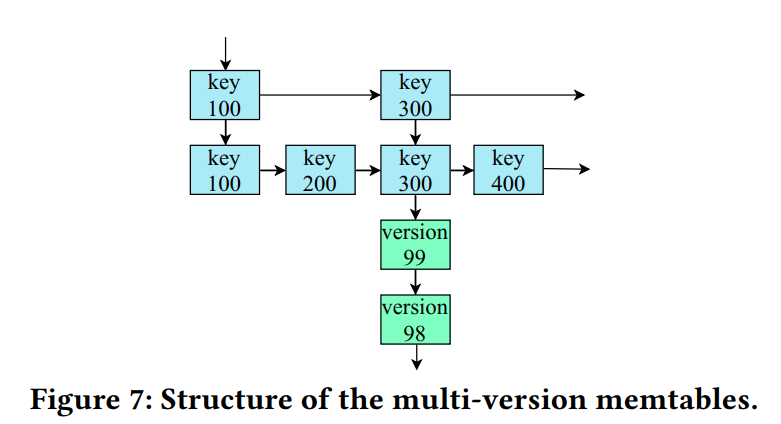
- 在X-Engine中,我们垂直地将相同记录的新版本附加到原始节点旁,形成一个新的链表。图7显示了提议的结构,其中蓝色节点存储具有不同键的记录,黄色节点存储同一记录的多个版本。不同的键被组织在一个跳表中,而每个键的多个版本存储在一个链表中。热记录上的更新会增加相应的链表节点。此外,通常被传入事务引用的新版本被保持在唯一键的skiplist的底层,如图7所示,其中版本99是最新的版本。该设计减少了扫描不必要的老版本的数据造成的开销。
Asynchronous writes in transactions
- 在InnoDB这样的存储引擎中,传统的一线程一事务方法在写效率上有很大的缺陷。在这种方法中,用户线程从头到尾执行事务。虽然这种方法很容易实现写的执行和事务的并发控制,而用户线程自己不写日志,线程必须等待磁盘IOs写日志的长延迟完成
- 在X-Engine中,我们选择了另一种方法,将写的提交与相应的事务解耦,并将它们分组以进行批处理。如图3所示,我们首先将写任务分配到多个无锁写任务队列中。在此之后,大多数线程可以异步返回来处理其他事务,这样在多级流水线(将在下面介绍)中,每个队列只留下一个线程来参与提交写任务。通过这种方式,事务中的写入是异步的。在高并发工作负载中,这种方法允许更多的线程处理来自并发事务的写任务。队列的最佳数量取决于机器中可用的I/O带宽,以及每个无锁队列上方的多个线程之间的争用。我们发现,在32核机器中,每个队列中有8个线程会使I/O带宽饱和,由于竞争,为每个队列分配更多的线程会降低吞吐量。此外,在解耦过程之后,我们将同一个队列中的写任务分组在一起,并批量处理它们。与单个事务提交相比,批处理提交可以显著提高I/O,从而提高吞吐量。在下面的讨论中,我们将优化批处理的效率
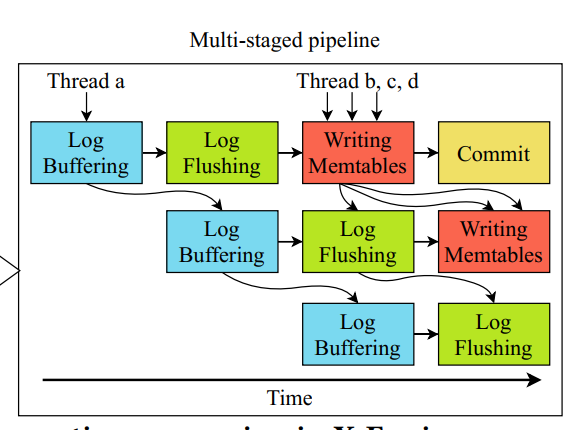
Multi-staged pipeline
- 写路径是访问主内存和磁盘的多个操作的一个长序列,在其执行过程中计算工作负载会发生变化。这使得通过计算隐藏内存访问和磁盘 I/O 具有挑战性
- 为了解决这个问题,我们将写路径分解为多个阶段。图3的右半部分显示了四阶段流水线的概述,其中各个阶段交替访问主内存和磁盘。
- 在第一阶段,日志缓冲,线程从事务缓冲区收集每个写请求的wal (write-ahead logs)到内存日志缓冲区,并计算它们相应的CRC32错误检测代码。这个阶段涉及重要的计算和仅访问主内存。
- 在第二阶段,日志刷回,线程将缓冲区中的日志刷新到磁盘。刷新日志后,日志序列号在日志文件中向前移动。然后,这些线程将已经写完日志的写任务推入下一阶段
- 写 memtable。在这里,多个线程并行地在活动 memtable 中追加记录。这个阶段只访问主内存。所有这样的写都可以在失败后从 WAL 中恢复。
- 最后一个阶段,提交,完成所有任务的事务最终由多个线程并行提交,并释放它们使用的资源(如锁)。
- 在这个流水线中,我们根据每个阶段的需求,分别为每个阶段调度线程,使每个阶段的吞吐量与其他阶段的吞吐量相匹配,以达到总吞吐量的最大化。虽然前三个阶段是内存密集型的,但第一和第二阶段访问主内存中的不同数据结构,而第二阶段写入磁盘。因此,重叠它们可以提高主存储器和磁盘的利用率。
- 此外,我们还分别限制了每个阶段的线程数。由于较强的数据依赖关系在前两个阶段,每个阶段我们只安排一个线程(例如,图3的线程 a),其他阶段,我们分配多个线程并行处理(例如,线程b, c, d,如图3所示)。所有线程从阶段拉取任务进行处理。从前两个阶段提取任务的操作是先发制人的,只允许第一个到达的线程处理该阶段。其他阶段则是理想并行,允许多个线程并行工作。
Flush and Compaction
Fast flush of warm extents in Level0
- 依赖 flush 来避免 OOM,在即将到来的交易高峰时,风险是很大的。在 X-engine中,每个刷新操作将其不可变的memtable转换为extent,将它们追加到Level0,并离开,而不与现有记录合并。然而,这个过程会留下一组未排序的区段。查询现在必须访问所有的区段来寻找潜在的匹配。这个过程中涉及的磁盘 I/O 开销很大。尽管Level0的大小可能不到整个存储空间的1%,但它包含的记录只比最近插入到memtable中的记录稍微老一点。由于电子商务工作负载中的强大时间局部性,传入查询很可能需要这些记录。因此,我们将 Level0 中的区段称为 warm extents
- 我们引入了 Level0 内部的压缩来积极地合并 Level0 中的暖区,而不将合并的区推入下一个 Level1。这种方法将温记录保存在lsm 树的第一级,防止查询深入树中检索这些记录。另一方面,由于 Level0 与其他级别相比规模较小,Level0 内部的压缩只需要访问一小部分区段,不像其他在更深级别中广泛合并区段的压缩。由于这种对 CPU 和 I/O 的轻量级消耗,可以频繁地执行level0内部的压缩。
Accelerating compactions
-
压缩涉及昂贵的合并操作。我们对压缩应用了三种优化: 数据重用、异步 I/O 和 FPGA 加载。
-
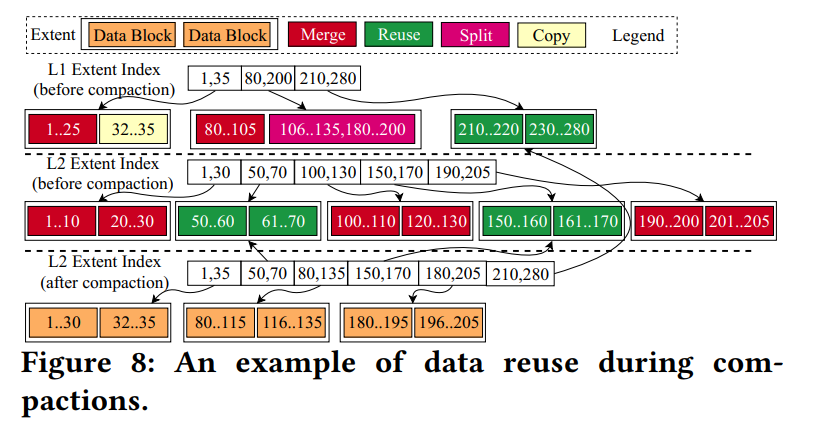
数据重用。我们在压缩过程中重用区段和数据块,以减少合并两个相邻级别(即Leveli和Leveli+1)所需的 I/O 数量。为了增加重用的机会并使其有效,我们将区段的大小减少到 2 MB,并进一步将区段划分为多个 16 KB 的数据块。如果压缩所涉及的一个区段的键范围与其他区段的键范围不重叠,则只需更新其相应的元数据索引(如第3.1.3节所介绍的)就可以重用它,而不需要在磁盘上实际移动它。我们在图8中展示了一个示例,其中Level1的3个区段(键范围为[1,35]、[80,200]和[210,280])被压缩为来自Level2的5个区段(键范围为[1,30]、[50,70]、[100,130]、[150,170]和[190,205])。下面我们列出了不同的重用情况:
- Level1 的 Extent[210,280]和Level2的Extent[50,70]被直接重用
- Level1 的 Extent[1,35] 与 Level2的extent[1,30]重叠。但前者只有一个数据块[1,25]与后者的数据块重叠。因此,数据块[32,35]被重用
- Level1 extent[80,200]与Level2中的多个extent重叠。它的第二个数据块与Level2中的三个区段重叠。然而,这个数据块中的键是稀疏的,因为在135到180之间没有键。因此,我们将其分为两个数据块 [106,135] 和[180,200],并分别将其与Level2的extent[100, 130]和[190,205]进行合并。Extent[150,170]被直接重用
-
Asynchronous I/O:在区段级别,压缩操作由三个不相交的阶段组成:
- (1)从存储器中检索两个输入区段,
- (2)合并它们,
- (3)将合并的区段(一个或多个)写回存储器。
-
第一和第三阶段是I/O阶段,而第二阶段是计算密集型阶段。我们在第一和第三阶段发出异步I/O请求。第二阶段实现为第一I/O阶段的回调函数。当多个压缩并行运行时,第二阶段的执行与其他阶段的执行重叠,以隐藏I/O
-
FPGA offloading:我们引入 FPGA 来加速压缩,并减少cpu上的资源消耗。通过上面介绍的两个优化,在cpu上运行的压缩仍然会消耗多个线程。因为压缩工作在lsm树的两个连续级别的独立区段对上,所以压缩任务在这些区段对的粒度上理论上能并行的。因此,它可以被分割成多个小任务。我们把这样小的任务放到 FPGA 上,并以流的方式处理它们。每个压缩区段都被传输回磁盘。通过这样的加载,CPU 线程从合并区段的沉重负担中得到释放。因此,我们能够分配更多的线程来处理并发事务。这种基于 FPGA 的压实加速的细节超出了本文的范围,将另行探讨。
Scheduling compactions
- LSM 树依赖于压缩来按已排序的顺序保存记录,并从存储中删除标记为要删除的记录。如果不及时删除已删除的记录,查找查询可能不得不遍历存储中的许多无效记录,从而严重损害读性能。压缩还有助于合并Level0中的子级别,以降低该级别的查找成本。在X-Engine中,我们引入了基于规则的压缩调度,以利用这些好处。我们根据压实操作的层次来区分压实:
- intra-Level0 压缩(合并Level0中的子层)
- minor 压缩(合并两个相邻的层,除了最大的层)
- major 压缩(合并最大的层和它上面的层)
- self-major 压缩(合并最大的层以减少碎片和删除记录)。
- 当一个级别的总大小或区段总数达到预定义的阈值时,就会触发压缩。所有触发的压缩作业都被放入一个优先队列。确定优先级的规则对配置是开放的,这进一步取决于数据库之上的不同应用程序的需求。
- 下面,我们将展示一个为阿里巴巴的一个在线应用程序量身定制的配置示例。在这个应用程序中,有频繁的删除。当应该删除的记录数量达到其阈值时,就会触发压缩以删除这些记录,并且这种压缩具有最高优先级,以防止存储空间的浪费。删除之后,Level0 内部的压缩被优先排序,以帮助加速查找 Level0 中最近插入的记录。Minor、major 和 self-major compaction 分别按此顺序排列:
- (1) Compactions for deletions.
- (2) Intra-Level0 compactions.
- (3) Minor compaction.
- (4) Major compaction.
- (5) Self-major compactions.
- 可以对不同子表以及不同 LSM 树的压缩进行并发执行调度。这种并行性是理想的,因为子表之间的数据独立。在每个子表中,一次只执行一个压缩。虽然可以对同一lsm -树执行多个压缩,而不会损坏数据或导致任何数据竞争,但我们有足够的机会在子表级别进行并发压缩,以提高性能。
