- 主要介绍 Ceph 中的缓存机制和缓存相关实现
- 介绍 Tiring 的相关模式并结合部分代码
- 调研业界对于 Ceph 缓存的性能评价和优化方案
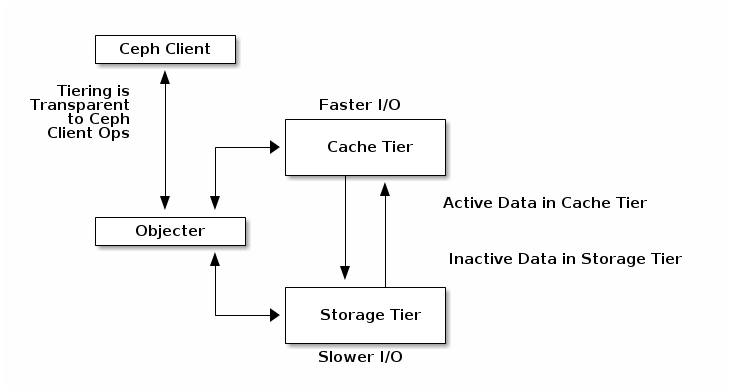
Cache Tiering
Architecture
Data Structure
struct pg_pool_t {
...
// cache_mode
typedef enum {
CACHEMODE_NONE = 0, ///< no caching
CACHEMODE_WRITEBACK = 1, ///< write to cache, flush later
CACHEMODE_FORWARD = 2, ///< forward if not in cache
CACHEMODE_READONLY = 3, ///< handle reads, forward writes [not strongly consistent]
CACHEMODE_READFORWARD = 4, ///< forward reads, write to cache flush later
CACHEMODE_READPROXY = 5, ///< proxy reads, write to cache flush later
CACHEMODE_PROXY = 6, ///< proxy if not in cache
} cache_mode_t;
...
// Tier cache : Base Storage = N : 1
// ceph osd tier add {data_pool} {cache pool}
std::set<uint64_t> tiers; ///< pools that are tiers of us
int64_t tier_of = -1; /// pool for which we are a tier(-1为没有tier)
// Note that write wins for read+write ops
// WriteBack mode, read_tier is same as write_tier. Both are cache pool.
// Diret mode. cache pool is read_tier, not write_tier.
// ceph osd tier set-overlay {data_pool} {cache_pool}
int64_t read_tier = -1; /// pool/tier for objecter to direct reads(-1为没有tier)
int64_t write_tier = -1; /// pool/tier for objecter to direct write(-1为没有tier)
// Set cache mode
// ceph osd tier cache-mode {cache-pool} {cache-mode}
cache_mode_t cache_mode = CACHEMODE_NONE; /// cache pool mode
// Cache pool max bytes and objects
uint64_t target_max_bytes = 0; ///< tiering: target max pool size
uint64_t target_max_objects = 0; ///< tiering: target max pool size
// 目标脏数据率:当脏数据比例达到这个值,后台 agent 开始 flush 数据
uint32_t cache_target_dirty_ratio_micro = 0; ///< cache: fraction of target to leave dirty
// 高目标脏数据率:当脏数据比例达到这个值,后台 agent 开始高速 flush 数据
uint32_t cache_target_dirty_high_ratio_micro = 0; ///< cache: fraction of target to flush with high speed
// 数据满的比率:当数据达到这个比例时,认为数据已满,需要进行缓存淘汰
uint32_t cache_target_full_ratio_micro = 0; ///< cache: fraction of target to fill before we evict in earnest
// 对象在 cache 中被刷入到 storage 层的最小时间
uint32_t cache_min_flush_age = 0; ///< minimum age (seconds) before we can flush
// 对象在 cache 中被淘汰的最小时间
uint32_t cache_min_evict_age = 0; ///< minimum age (seconds) before we can evict
// HitSet 相关参数
HitSet::Params hit_set_params; ///< The HitSet params to use on this pool
// 每间隔 hit_set_period 一段时间,系统重新产生一个新的 hit_set 对象来记录对象的h缓存统计信息
uint32_t hit_set_period = 0; ///< periodicity of HitSet segments (seconds)
// 记录系统保存最近的多少个 hit_set 记录
uint32_t hit_set_count = 0; ///< number of periods to retain
// hitset archive 对象的命名规则
bool use_gmt_hitset = true; ///< use gmt to name the hitset archive object
uint32_t min_read_recency_for_promote = 0; ///< minimum number of HitSet to check before promote on read
uint32_t min_write_recency_for_promote = 0; ///< minimum number of HitSet to check before promote on write
uint32_t hit_set_grade_decay_rate = 0; ///< current hit_set has highest priority on objects
///< temperature count,the follow hit_set's priority decay
///< by this params than pre hit_set
uint32_t hit_set_search_last_n = 0; ///< accumulate atmost N hit_sets for temperature
bool is_tier() const { return tier_of >= 0; }
bool has_tiers() const { return !tiers.empty(); }
void clear_tier() {
tier_of = -1;
clear_read_tier();
clear_write_tier();
clear_tier_tunables();
}
bool has_read_tier() const { return read_tier >= 0; }
void clear_read_tier() { read_tier = -1; }
bool has_write_tier() const { return write_tier >= 0; }
void clear_write_tier() { write_tier = -1; }
void clear_tier_tunables() {
if (cache_mode != CACHEMODE_NONE)
flags |= FLAG_INCOMPLETE_CLONES;
cache_mode = CACHEMODE_NONE;
target_max_bytes = 0;
target_max_objects = 0;
cache_target_dirty_ratio_micro = 0;
cache_target_dirty_high_ratio_micro = 0;
cache_target_full_ratio_micro = 0;
hit_set_params = HitSet::Params();
hit_set_period = 0;
hit_set_count = 0;
hit_set_grade_decay_rate = 0;
hit_set_search_last_n = 0;
grade_table.resize(0);
}
...
}
Cache Mode
Write Back
- Ceph客户端将数据写入缓存层并从缓存层接收ACK。随着时间的流逝,写入缓存层的数据将迁移到存储层,并从缓存层中清除。从概念上讲,缓存层覆盖在后备存储层的“前面”。当Ceph客户端需要驻留在存储层中的数据时,缓存分层代理在读取时将数据迁移到缓存层,然后将其发送到Ceph客户端。此后,Ceph客户端可以使用缓存层执行I / O,直到数据变为非活动状态为止。
- 该模式适合于大量修改数据的应用场景(例如,照片/视频编辑,交易数据等)。
Read Forward
- client 发起读请求,对象不在 cache pool 中,出现 cache miss 状态,就返回 redirect 信息给客户端,客户端再根据返回的信息再次直接向 base pool 发起读请求。

Read Proxy
- 此模式将使用缓存层中已经存在的任何对象,但是如果一个对象不在缓存中,则请求将代理到基层。这对于将writeback模式转换为禁用的缓存非常有用,因为它允许工作负载在缓存耗尽时正常工作,而不需要向缓存添加任何新对象。
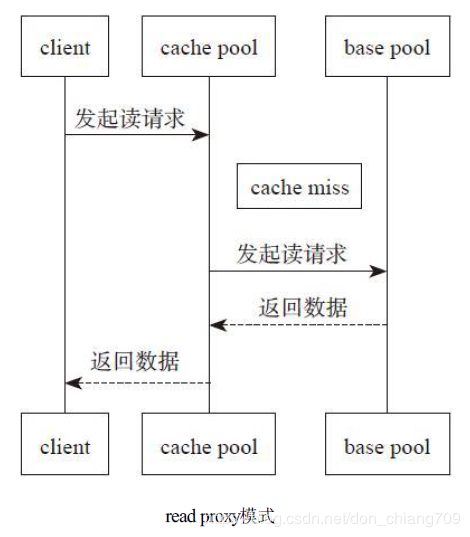
Proxy
- 针对读写请求都会执行proxy,也就是作为一个代理向后端存储池发起请求并返回给客户端,除非强制要求先进行promote操作。
Forward
- FORWARD模式表示所有到达cache tier存储池的请求都不会处理,直接将它的后端存储池的ID回复给请求方,并返回-ENOENT的错误号,具体实现比较简单。
- 该模式的用途是在删除WRITEBACK模式的cache tier时,需将其cache mode先设置为FORWARD,并主动调用cache tier的flush和evict操作,确保cache tier存储池的对象全部evict和flush到后端存储池,保证这个过程中不会有新的数据写入。
Read Only
- 仅在读取操作时将对象提升到缓存中;写操作被转发到基本层。该种模式下,cache pool 设置成单副本,极大减少缓存空间的占用,当cache pool层失效时,也不会有数据丢失。
- 此模式适用于不需要存储系统强制一致性的只读工作负载。适合一次写入多次读取的场景(警告:当基本层中的对象更新时,Ceph不会尝试将这些更新同步到缓存中的相应对象。因为这种模式被认为是实验性的,所以必须通过一个yes-i-really-mean-it的选项来启用它。)
HitSet
- 在 write back/read forward/read proxy 模式下需要 HitSet 来记录缓存命中。read only 不需要
- HitSet 用于跟踪和统计对象的访问行为,记录对象是否存在缓存中。定义了一个缓存查找到抽象接口,目前提供了三种实现方式:ExplicitHashHitSet,ExplicitObjectHitSet,BloomHitSet
- ceph/src/osd/HitSet.h 定义了抽象接口,同时该头文件中包含了具体的 HitSet 实现
...
/// abstract interface for a HitSet implementation
class Impl {
public:
virtual impl_type_t get_type() const = 0;
virtual bool is_full() const = 0;
virtual void insert(const hobject_t& o) = 0;
virtual bool contains(const hobject_t& o) const = 0;
virtual unsigned insert_count() const = 0;
virtual unsigned approx_unique_insert_count() const = 0;
virtual void encode(ceph::buffer::list &bl) const = 0;
virtual void decode(ceph::buffer::list::const_iterator& p) = 0;
virtual void dump(ceph::Formatter *f) const = 0;
virtual Impl* clone() const = 0;
virtual void seal() {}
virtual ~Impl() {}
};
...
ExplicitHashHitSet
/**
* explicitly enumerate hash hits in the set
*/
class ExplicitHashHitSet : public HitSet::Impl {
uint64_t count;
// Data Structure
ceph::unordered_set<uint32_t> hits;
public:
class Params : public HitSet::Params::Impl {
public:
HitSet::impl_type_t get_type() const override {
return HitSet::TYPE_EXPLICIT_HASH;
}
HitSet::Impl *get_new_impl() const override {
return new ExplicitHashHitSet;
}
static void generate_test_instances(std::list<Params*>& o) {
o.push_back(new Params);
}
};
ExplicitHashHitSet() : count(0) {}
explicit ExplicitHashHitSet(const ExplicitHashHitSet::Params *p) : count(0) {}
ExplicitHashHitSet(const ExplicitHashHitSet &o) : count(o.count),
hits(o.hits) {}
HitSet::Impl *clone() const override {
return new ExplicitHashHitSet(*this);
}
HitSet::impl_type_t get_type() const override {
return HitSet::TYPE_EXPLICIT_HASH;
}
bool is_full() const override {
return false;
}
void insert(const hobject_t& o) override {
hits.insert(o.get_hash());
++count;
}
bool contains(const hobject_t& o) const override {
return hits.count(o.get_hash());
}
unsigned insert_count() const override {
return count;
}
unsigned approx_unique_insert_count() const override {
return hits.size();
}
void encode(ceph::buffer::list &bl) const override {
ENCODE_START(1, 1, bl);
encode(count, bl);
encode(hits, bl);
ENCODE_FINISH(bl);
}
void decode(ceph::buffer::list::const_iterator &bl) override {
DECODE_START(1, bl);
decode(count, bl);
decode(hits, bl);
DECODE_FINISH(bl);
}
void dump(ceph::Formatter *f) const override;
static void generate_test_instances(std::list<ExplicitHashHitSet*>& o) {
o.push_back(new ExplicitHashHitSet);
o.push_back(new ExplicitHashHitSet);
o.back()->insert(hobject_t());
o.back()->insert(hobject_t("asdf", "", CEPH_NOSNAP, 123, 1, ""));
o.back()->insert(hobject_t("qwer", "", CEPH_NOSNAP, 456, 1, ""));
}
};
WRITE_CLASS_ENCODER(ExplicitHashHitSet)
ExplicitObjectHitSet
struct hobject_t {
...
public:
object_t oid;
snapid_t snap;
private:
uint32_t hash;
bool max;
uint32_t nibblewise_key_cache;
uint32_t hash_reverse_bits;
public:
int64_t pool;
std::string nspace;
private:
std::string key;
class hobject_t_max {};
...
- 使用内存中缓存数据结构来进行判断带来的优点就是实现相对简单直观,但占用的内存空间相对较大。
/**
* explicitly enumerate objects in the set
*/
class ExplicitObjectHitSet : public HitSet::Impl {
uint64_t count;
// Data Structure
ceph::unordered_set<hobject_t> hits;
public:
class Params : public HitSet::Params::Impl {
public:
HitSet::impl_type_t get_type() const override {
return HitSet::TYPE_EXPLICIT_OBJECT;
}
HitSet::Impl *get_new_impl() const override {
return new ExplicitObjectHitSet;
}
static void generate_test_instances(std::list<Params*>& o) {
o.push_back(new Params);
}
};
ExplicitObjectHitSet() : count(0) {}
explicit ExplicitObjectHitSet(const ExplicitObjectHitSet::Params *p) : count(0) {}
ExplicitObjectHitSet(const ExplicitObjectHitSet &o) : count(o.count),
hits(o.hits) {}
HitSet::Impl *clone() const override {
return new ExplicitObjectHitSet(*this);
}
HitSet::impl_type_t get_type() const override {
return HitSet::TYPE_EXPLICIT_OBJECT;
}
bool is_full() const override {
return false;
}
void insert(const hobject_t& o) override {
hits.insert(o);
++count;
}
bool contains(const hobject_t& o) const override {
return hits.count(o);
}
unsigned insert_count() const override {
return count;
}
unsigned approx_unique_insert_count() const override {
return hits.size();
}
void encode(ceph::buffer::list &bl) const override {
ENCODE_START(1, 1, bl);
encode(count, bl);
encode(hits, bl);
ENCODE_FINISH(bl);
}
void decode(ceph::buffer::list::const_iterator& bl) override {
DECODE_START(1, bl);
decode(count, bl);
decode(hits, bl);
DECODE_FINISH(bl);
}
void dump(ceph::Formatter *f) const override;
static void generate_test_instances(std::list<ExplicitObjectHitSet*>& o) {
o.push_back(new ExplicitObjectHitSet);
o.push_back(new ExplicitObjectHitSet);
o.back()->insert(hobject_t());
o.back()->insert(hobject_t("asdf", "", CEPH_NOSNAP, 123, 1, ""));
o.back()->insert(hobject_t("qwer", "", CEPH_NOSNAP, 456, 1, ""));
}
};
WRITE_CLASS_ENCODER(ExplicitObjectHitSet)
BloomHitSet
/**
* use a bloom_filter to track hits to the set
*/
class BloomHitSet : public HitSet::Impl {
compressible_bloom_filter bloom;
public:
HitSet::impl_type_t get_type() const override {
return HitSet::TYPE_BLOOM;
}
class Params : public HitSet::Params::Impl {
public:
HitSet::impl_type_t get_type() const override {
return HitSet::TYPE_BLOOM;
}
HitSet::Impl *get_new_impl() const override {
return new BloomHitSet;
}
uint32_t fpp_micro; ///< false positive probability / 1M
uint64_t target_size; ///< number of unique insertions we expect to this HitSet
uint64_t seed; ///< seed to use when initializing the bloom filter
Params() : fpp_micro(0), target_size(0), seed(0) {}
Params(double fpp, uint64_t t, uint64_t s) : fpp_micro(fpp * 1000000.0), target_size(t), seed(s) {}
Params(const Params &o) : fpp_micro(o.fpp_micro), target_size(o.target_size), seed(o.seed) {}
~Params() override {}
double get_fpp() const {
return (double)fpp_micro / 1000000.0;
}
void set_fpp(double f) {
fpp_micro = (unsigned)(llrintl(f * 1000000.0));
}
void encode(ceph::buffer::list& bl) const override {
ENCODE_START(1, 1, bl);
encode(fpp_micro, bl);
encode(target_size, bl);
encode(seed, bl);
ENCODE_FINISH(bl);
}
void decode(ceph::buffer::list::const_iterator& bl) override {
DECODE_START(1, bl);
decode(fpp_micro, bl);
decode(target_size, bl);
decode(seed, bl);
DECODE_FINISH(bl);
}
void dump(ceph::Formatter *f) const override;
void dump_stream(std::ostream& o) const override {
o << "false_positive_probability: " << get_fpp() << ", target_size: " << target_size << ", seed: " << seed;
}
static void generate_test_instances(std::list<Params*>& o) {
o.push_back(new Params);
o.push_back(new Params);
(*o.rbegin())->fpp_micro = 123456;
(*o.rbegin())->target_size = 300;
(*o.rbegin())->seed = 99;
}
};
BloomHitSet() {}
BloomHitSet(unsigned inserts, double fpp, int seed)
: bloom(inserts, fpp, seed)
{}
explicit BloomHitSet(const BloomHitSet::Params *p) : bloom(p->target_size, p->get_fpp(), p->seed){}
BloomHitSet(const BloomHitSet &o) {
// oh god
ceph::buffer::list bl;
o.encode(bl);
auto bli = std::cbegin(bl);
this->decode(bli);
}
HitSet::Impl *clone() const override {
return new BloomHitSet(*this);
}
bool is_full() const override {
return bloom.is_full();
}
void insert(const hobject_t& o) override {
bloom.insert(o.get_hash());
}
bool contains(const hobject_t& o) const override {
return bloom.contains(o.get_hash());
}
unsigned insert_count() const override {
return bloom.element_count();
}
unsigned approx_unique_insert_count() const override {
return bloom.approx_unique_element_count();
}
void seal() override {
// aim for a density of .5 (50% of bit set)
double pc = bloom.density() * 2.0;
if (pc < 1.0)
bloom.compress(pc);
}
void encode(ceph::buffer::list &bl) const override {
ENCODE_START(1, 1, bl);
encode(bloom, bl);
ENCODE_FINISH(bl);
}
void decode(ceph::buffer::list::const_iterator& bl) override {
DECODE_START(1, bl);
decode(bloom, bl);
DECODE_FINISH(bl);
}
void dump(ceph::Formatter *f) const override;
static void generate_test_instances(std::list<BloomHitSet*>& o) {
o.push_back(new BloomHitSet);
o.push_back(new BloomHitSet(10, .1, 1));
o.back()->insert(hobject_t());
o.back()->insert(hobject_t("asdf", "", CEPH_NOSNAP, 123, 1, ""));
o.back()->insert(hobject_t("qwer", "", CEPH_NOSNAP, 456, 1, ""));
}
};
WRITE_CLASS_ENCODER(BloomHitSet)
HitSet::HitSet(const HitSet::Params& params)
: sealed(false)
{
switch (params.get_type()) {
case TYPE_BLOOM:
{
BloomHitSet::Params *p =
static_cast<BloomHitSet::Params*>(params.impl.get());
impl.reset(new BloomHitSet(p));
}
break;
case TYPE_EXPLICIT_HASH:
impl.reset(new ExplicitHashHitSet(static_cast<ExplicitHashHitSet::Params*>(params.impl.get())));
break;
case TYPE_EXPLICIT_OBJECT:
impl.reset(new ExplicitObjectHitSet(static_cast<ExplicitObjectHitSet::Params*>(params.impl.get())));
break;
default:
assert (0 == "unknown HitSet type");
}
}
IO
Add Cache
else if (prefix == "osd tier add-cache") {
...
// go
// 分别获取 base_pool 和 cache_pool 信息
pg_pool_t *np = pending_inc.get_new_pool(pool_id, p);
pg_pool_t *ntp = pending_inc.get_new_pool(tierpool_id, tp);
// 检查 Pool 之间的 Tier 关系
if (np->tiers.count(tierpool_id) || ntp->is_tier()) {
wait_for_finished_proposal(op, new C_RetryMessage(this, op));
return true;
}
// 将缓存 Pool 添加到 base_pool 的 tiers 中去
np->tiers.insert(tierpool_id);
// 设置 read_tier/write_tier = cache_tire
np->read_tier = np->write_tier = tierpool_id;
np->set_snap_epoch(pending_inc.epoch); // tier will update to our snap info
np->set_last_force_op_resend(pending_inc.epoch);
ntp->set_last_force_op_resend(pending_inc.epoch);
ntp->tier_of = pool_id;
// 设置缓存策略,默认 write-back
ntp->cache_mode = mode;
// 设置 flush evict 相关参数
ntp->hit_set_count = g_conf().get_val<uint64_t>("osd_tier_default_cache_hit_set_count");
ntp->hit_set_period = g_conf().get_val<uint64_t>("osd_tier_default_cache_hit_set_period");
ntp->min_read_recency_for_promote = g_conf().get_val<uint64_t>("osd_tier_default_cache_min_read_recency_for_promote");
ntp->min_write_recency_for_promote = g_conf().get_val<uint64_t>("osd_tier_default_cache_min_write_recency_for_promote");
ntp->hit_set_grade_decay_rate = g_conf().get_val<uint64_t>("osd_tier_default_cache_hit_set_grade_decay_rate");
ntp->hit_set_search_last_n = g_conf().get_val<uint64_t>("osd_tier_default_cache_hit_set_search_last_n");
ntp->hit_set_params = hsp;
ntp->target_max_bytes = size;
ss << "pool '" << tierpoolstr << "' is now (or already was) a cache tier of '" << poolstr << "'";
wait_for_finished_proposal(op, new Monitor::C_Command(mon, op, 0, ss.str(), get_last_committed() + 1));
return true;
}
选择 Cache Pool
int Objecter::_calc_target(op_target_t *t, Connection *con, bool any_change)
{
...
// 根据读写操作,分别设置需要操作的 tier
// apply tiering
t->target_oid = t->base_oid;
t->target_oloc = t->base_oloc;
if ((t->flags & CEPH_OSD_FLAG_IGNORE_OVERLAY) == 0) {
if (is_read && pi->has_read_tier())
t->target_oloc.pool = pi->read_tier;
if (is_write && pi->has_write_tier())
t->target_oloc.pool = pi->write_tier;
pi = osdmap->get_pg_pool(t->target_oloc.pool);
if (!pi) {
t->osd = -1;
return RECALC_OP_TARGET_POOL_DNE;
}
}
}
Cache Pool 请求处理
- Cache 的相关请求处理可以通过主流程进行梳理。
- 主流程中主要包含了
agent_choose_mode 和 maybe_handle_cache_detail 两个主要方法。
主流程
/** do_op - do an op
* pg lock will be held (if multithreaded)
* osd_lock NOT held.
*/
void PrimaryLogPG::do_op(OpRequestRef& op)
{
...
// 预处理
ObjectContextRef obc;
bool can_create = op->may_write();
hobject_t missing_oid;
// kludge around the fact that LIST_SNAPS sets CEPH_SNAPDIR for LIST_SNAPS
const hobject_t& oid = m->get_snapid() == CEPH_SNAPDIR ? head : m->get_hobj();
...
// io blocked on obc?
if (!m->has_flag(CEPH_OSD_FLAG_FLUSH) &&
maybe_await_blocked_head(oid, op)) {
return;
}
// 获取上下文信息 obc
int r = find_object_context(oid, &obc, can_create, m->has_flag(CEPH_OSD_FLAG_MAP_SNAP_CLONE), &missing_oid);
//
bool in_hit_set = false;
// 如果有 hit_set
if (hit_set) {
if (obc.get()) {
if (obc->obs.oi.soid != hobject_t() && hit_set->contains(obc->obs.oi.soid))
in_hit_set = true;
} else {
// 如果是读操作,且要读的object在当前的cachepool中不存在,但是在hit_set中记录了该object 刚被访问过。
if (missing_oid != hobject_t() && hit_set->contains(missing_oid))
in_hit_set = true;
}
if (!op->hitset_inserted) {
// hitset 统计这次访问 object 的操作
hit_set->insert(oid);
op->hitset_inserted = true;
// 如果这hit_set 满了,或者时间间隔到了,则需要持久化这个hit_set信息。
if (hit_set->is_full() || hit_set_start_stamp + pool.info.hit_set_period <= m->get_recv_stamp()) {
// 持久化 hit_set
hit_set_persist();
}
}
}
// 如果这个pg存在agent_state
if (agent_state) {
// 对相应的 PG 设置 flush 模式和 evict 模式
if (agent_choose_mode(false, op))
return;
}
if (obc.get() && obc->obs.exists && obc->obs.oi.has_manifest()) {
if (maybe_handle_manifest(op,
write_ordered,
obc))
return;
}
// 如果maybe_handle_cache 处理成功了则直接return,否则继续进行后面的操作。
if (maybe_handle_cache(op, write_ordered, obc, r, missing_oid, false, in_hit_set))
return;
...
// 如果读的话,则直接读本osd,如果写的话,就分发到其他replicate osd上
}
agent_choose_mode(bool restart, OpRequestRef op)
bool PrimaryLogPG::agent_choose_mode(bool restart, OpRequestRef op)
{
bool requeued = false;
// Let delay play out
if (agent_state->delaying) {
dout(20) << __func__ << " " << this << " delaying, ignored" << dendl;
return requeued;
}
TierAgentState::flush_mode_t flush_mode = TierAgentState::FLUSH_MODE_IDLE;
TierAgentState::evict_mode_t evict_mode = TierAgentState::EVICT_MODE_IDLE;
unsigned evict_effort = 0;
// 如果当前统计的信息无效,暂时跳过计算过程,暂时不计算 flush_mode 和 evic_mode 的值
if (info.stats.stats_invalid) {
// idle; stats can't be trusted until we scrub.
dout(20) << __func__ << " stats invalid (post-split), idle" << dendl;
goto skip_calc;
}
{
// 计算 divisor 的值, 也就是 cache_pool 中 PG 的数量
uint64_t divisor = pool.info.get_pg_num_divisor(info.pgid.pgid);
ceph_assert(divisor > 0);
// 基于 HitSet 对象的数量计算 unflushable,不能刷回的对象
// adjust (effective) user objects down based on the number
// of HitSet objects, which should not count toward our total since
// they cannot be flushed.
uint64_t unflushable = info.stats.stats.sum.num_objects_hit_set_archive;
// also exclude omap objects if ec backing pool
const pg_pool_t *base_pool = get_osdmap()->get_pg_pool(pool.info.tier_of);
ceph_assert(base_pool);
// 如果 base_pool 是 ec pool,不支持 omap,去掉所有需要 omap 支持的对象
if (!base_pool->supports_omap())
unflushable += info.stats.stats.sum.num_objects_omap;
// 计算 num_user_objects
uint64_t num_user_objects = info.stats.stats.sum.num_objects;
// 其值为统计的对象数目减去 unflushable 对象数
if (num_user_objects > unflushable)
num_user_objects -= unflushable;
else
num_user_objects = 0;
uint64_t num_user_bytes = info.stats.stats.sum.num_bytes;
uint64_t unflushable_bytes = info.stats.stats.sum.num_bytes_hit_set_archive;
// 计算 num_user_bytes,其值为统计信息的字节数减去 unflushable 字节数
num_user_bytes -= unflushable_bytes;
uint64_t num_overhead_bytes = osd->store->estimate_objects_overhead(num_user_objects);
num_user_bytes += num_overhead_bytes;
// 计算脏对象的数目 num_dirty 值
// also reduce the num_dirty by num_objects_omap
int64_t num_dirty = info.stats.stats.sum.num_objects_dirty;
// 如果 base_pool 不支持 omap,去掉带 omap 的对象
if (!base_pool->supports_omap()) {
if (num_dirty > info.stats.stats.sum.num_objects_omap)
num_dirty -= info.stats.stats.sum.num_objects_omap;
else
num_dirty = 0;
}
dout(10) << __func__
<< " flush_mode: "
<< TierAgentState::get_flush_mode_name(agent_state->flush_mode)
<< " evict_mode: "
<< TierAgentState::get_evict_mode_name(agent_state->evict_mode)
<< " num_objects: " << info.stats.stats.sum.num_objects
<< " num_bytes: " << info.stats.stats.sum.num_bytes
<< " num_objects_dirty: " << info.stats.stats.sum.num_objects_dirty
<< " num_objects_omap: " << info.stats.stats.sum.num_objects_omap
<< " num_dirty: " << num_dirty
<< " num_user_objects: " << num_user_objects
<< " num_user_bytes: " << num_user_bytes
<< " num_overhead_bytes: " << num_overhead_bytes
<< " pool.info.target_max_bytes: " << pool.info.target_max_bytes
<< " pool.info.target_max_objects: " << pool.info.target_max_objects
<< dendl;
// 计算脏数据的比率和数据满的比率,单位为百万分之一
// get dirty, full ratios
uint64_t dirty_micro = 0;
uint64_t full_micro = 0;
// 如果设置了 target_max_bytes,就按照字节数算
if (pool.info.target_max_bytes && num_user_objects > 0) {
// 首先计算每个对象的平均大小 avg_size
uint64_t avg_size = num_user_bytes / num_user_objects;
// 脏数据率 = 100w * 脏数据对象数目 * 每个对象的平均大小 / 每个PG的平均字节数
dirty_micro =
num_dirty * avg_size * 1000000 /
std::max<uint64_t>(pool.info.target_max_bytes / divisor, 1);
// 满数据率 = 100w * 用户对象数目 * 每个对象的平均大小 / 每个PG的平均字节数
full_micro =
num_user_objects * avg_size * 1000000 /
std::max<uint64_t>(pool.info.target_max_bytes / divisor, 1);
}
// 如果设置了 target_max_objects,就按照对象个数算
if (pool.info.target_max_objects > 0) {
// 脏数据率 = 100w * 脏数据对象数目 / 每个 PG 的平均对象数目
uint64_t dirty_objects_micro =
num_dirty * 1000000 /
std::max<uint64_t>(pool.info.target_max_objects / divisor, 1);
// 取两种计算方式中的最大值
if (dirty_objects_micro > dirty_micro)
dirty_micro = dirty_objects_micro;
// 满数据率 = 100w * 用户对象数目 / 每个 PG 的平均对象数目
uint64_t full_objects_micro =
num_user_objects * 1000000 /
std::max<uint64_t>(pool.info.target_max_objects / divisor, 1);
if (full_objects_micro > full_micro)
full_micro = full_objects_micro;
}
dout(20) << __func__ << " dirty " << ((float)dirty_micro / 1000000.0)
<< " full " << ((float)full_micro / 1000000.0)
<< dendl;
// flush mode
// 获取 flush_target 和 flush_high_target 参数,以及计算 flush_slop
uint64_t flush_target = pool.info.cache_target_dirty_ratio_micro;
uint64_t flush_high_target = pool.info.cache_target_dirty_high_ratio_micro;
uint64_t flush_slop = (float)flush_target * cct->_conf->osd_agent_slop;
// 根据传入的参数和 flush_mode 对 target 做修正
if (restart || agent_state->flush_mode == TierAgentState::FLUSH_MODE_IDLE) {
flush_target += flush_slop;
flush_high_target += flush_slop;
} else {
flush_target -= std::min(flush_target, flush_slop);
flush_high_target -= std::min(flush_high_target, flush_slop);
}
// 根据脏数据的比例,设置 flush_mode
if (dirty_micro > flush_high_target) {
flush_mode = TierAgentState::FLUSH_MODE_HIGH;
} else if (dirty_micro > flush_target || (!flush_target && num_dirty > 0)) {
flush_mode = TierAgentState::FLUSH_MODE_LOW;
}
// evict mode
// 获取 evict_target 的值,用 evict_slop 做修正
uint64_t evict_target = pool.info.cache_target_full_ratio_micro;
uint64_t evict_slop = (float)evict_target * cct->_conf->osd_agent_slop;
if (restart || agent_state->evict_mode == TierAgentState::EVICT_MODE_IDLE)
evict_target += evict_slop;
else
evict_target -= std::min(evict_target, evict_slop);
// 判定缓存满
// 如果 full_micro > 100w,设置为EVICT_MODE_FULL,evict_effort为100w
if (full_micro > 1000000) {
// evict anything clean
evict_mode = TierAgentState::EVICT_MODE_FULL;
evict_effort = 1000000;
} else if (full_micro > evict_target) {
// 设置为 EVICT_MODE_SOME,部分满,需要计算 evic_effort(PG 在 agent 队列中的优先级 )
// set effort in [0..1] range based on where we are between
evict_mode = TierAgentState::EVICT_MODE_SOME;
uint64_t over = full_micro - evict_target;
uint64_t span = 1000000 - evict_target;
evict_effort = std::max(over * 1000000 / span,
uint64_t(1000000.0 *
cct->_conf->osd_agent_min_evict_effort));
// 通过 osd_agent_quantize_effort 进行修正,使得优先级级别不会太多
// quantize effort to avoid too much reordering in the agent_queue.
uint64_t inc = cct->_conf->osd_agent_quantize_effort * 1000000;
ceph_assert(inc > 0);
uint64_t was = evict_effort;
evict_effort -= evict_effort % inc;
if (evict_effort < inc)
evict_effort = inc;
ceph_assert(evict_effort >= inc && evict_effort <= 1000000);
dout(30) << __func__ << " evict_effort " << was << " quantized by " << inc << " to " << evict_effort << dendl;
}
}
skip_calc:
bool old_idle = agent_state->is_idle();
// 设置新的 flush_mode,并更新统计信息
if (flush_mode != agent_state->flush_mode) {
dout(5) << __func__ << " flush_mode "
<< TierAgentState::get_flush_mode_name(agent_state->flush_mode)
<< " -> "
<< TierAgentState::get_flush_mode_name(flush_mode)
<< dendl;
recovery_state.update_stats(
[=](auto &history, auto &stats) {
if (flush_mode == TierAgentState::FLUSH_MODE_HIGH) {
osd->agent_inc_high_count();
stats.stats.sum.num_flush_mode_high = 1;
} else if (flush_mode == TierAgentState::FLUSH_MODE_LOW) {
stats.stats.sum.num_flush_mode_low = 1;
}
if (agent_state->flush_mode == TierAgentState::FLUSH_MODE_HIGH) {
osd->agent_dec_high_count();
stats.stats.sum.num_flush_mode_high = 0;
} else if (agent_state->flush_mode == TierAgentState::FLUSH_MODE_LOW) {
stats.stats.sum.num_flush_mode_low = 0;
}
return false;
});
agent_state->flush_mode = flush_mode;
}
// 设置新的 evict_mode
if (evict_mode != agent_state->evict_mode) {
dout(5) << __func__ << " evict_mode "
<< TierAgentState::get_evict_mode_name(agent_state->evict_mode)
<< " -> "
<< TierAgentState::get_evict_mode_name(evict_mode)
<< dendl;
// 如果evict_mode由 FULL 变为其他类型,并且 PG 的状态 Active,需要把当前的 op 以及因 cache full 而等待的操作都重新加入请求队列,设置返回值为 true
if (agent_state->evict_mode == TierAgentState::EVICT_MODE_FULL && is_active()) {
// 把当前的 op 以及因 cache full 而等待的操作都重新加入请求队列
if (op)
requeue_op(op);
// 各个操作的等待队列
requeue_ops(waiting_for_flush);
requeue_ops(waiting_for_active);
requeue_ops(waiting_for_readable);
requeue_ops(waiting_for_scrub);
requeue_ops(waiting_for_cache_not_full);
objects_blocked_on_cache_full.clear();
// 设置返回值为 true
requeued = true;
}
recovery_state.update_stats(
[=](auto &history, auto &stats) {
if (evict_mode == TierAgentState::EVICT_MODE_SOME) {
stats.stats.sum.num_evict_mode_some = 1;
} else if (evict_mode == TierAgentState::EVICT_MODE_FULL) {
stats.stats.sum.num_evict_mode_full = 1;
}
if (agent_state->evict_mode == TierAgentState::EVICT_MODE_SOME) {
stats.stats.sum.num_evict_mode_some = 0;
} else if (agent_state->evict_mode == TierAgentState::EVICT_MODE_FULL) {
stats.stats.sum.num_evict_mode_full = 0;
}
return false;
});
agent_state->evict_mode = evict_mode;
}
uint64_t old_effort = agent_state->evict_effort;
if (evict_effort != agent_state->evict_effort) {
dout(5) << __func__ << " evict_effort "
<< ((float)agent_state->evict_effort / 1000000.0)
<< " -> "
<< ((float)evict_effort / 1000000.0)
<< dendl;
agent_state->evict_effort = evict_effort;
}
// 根据 MODE 做相应的处理
// NOTE: we are using evict_effort as a proxy for *all* agent effort
// (including flush). This is probably fine (they should be
// correlated) but it is not precisely correct.
if (agent_state->is_idle()) {
if (!restart && !old_idle) {
// 把该 PG 从 agent_queue 中删除
osd->agent_disable_pg(this, old_effort);
}
} else {
if (restart || old_idle) {
// 把该 PG 重新加入 agent_queue 处理队列
osd->agent_enable_pg(this, agent_state->evict_effort);
} else if (old_effort != agent_state->evict_effort) {
// 已经存在与队列中,调整 evict_effort 队列中的优先级
osd->agent_adjust_pg(this, old_effort, agent_state->evict_effort);
}
}
return requeued;
}
maybe_handle_cache_detail
PrimaryLogPG::cache_result_t PrimaryLogPG::maybe_handle_cache_detail(
OpRequestRef op,
bool write_ordered,
ObjectContextRef obc,
int r, hobject_t missing_oid,
bool must_promote,
bool in_hit_set,
ObjectContextRef *promote_obc)
{
// return quickly if caching is not enabled
if (pool.info.cache_mode == pg_pool_t::CACHEMODE_NONE)
return cache_result_t::NOOP;
if (op &&
op->get_req() &&
op->get_req()->get_type() == CEPH_MSG_OSD_OP &&
(op->get_req<MOSDOp>()->get_flags() &
CEPH_OSD_FLAG_IGNORE_CACHE)) {
dout(20) << __func__ << ": ignoring cache due to flag" << dendl;
return cache_result_t::NOOP;
}
must_promote = must_promote || op->need_promote();
if (obc)
dout(25) << __func__ << " " << obc->obs.oi << " "
<< (obc->obs.exists ? "exists" : "DNE")
<< " missing_oid " << missing_oid
<< " must_promote " << (int)must_promote
<< " in_hit_set " << (int)in_hit_set
<< dendl;
else
dout(25) << __func__ << " (no obc)"
<< " missing_oid " << missing_oid
<< " must_promote " << (int)must_promote
<< " in_hit_set " << (int)in_hit_set
<< dendl;
// if it is write-ordered and blocked, stop now
if (obc.get() && obc->is_blocked() && write_ordered) {
// we're already doing something with this object
dout(20) << __func__ << " blocked on " << obc->obs.oi.soid << dendl;
return cache_result_t::NOOP;
}
if (r == -ENOENT && missing_oid == hobject_t()) {
// we know this object is logically absent (e.g., an undefined clone)
return cache_result_t::NOOP;
}
// 判断该object是否在cache pool中是否命中。如果在cachepool中命中,则直接return false,然后在do_op中会直接操作cache pool后面的流程。
if (obc.get() && obc->obs.exists) {
osd->logger->inc(l_osd_op_cache_hit);
return cache_result_t::NOOP;
}
if (!is_primary()) {
dout(20) << __func__ << " cache miss; ask the primary" << dendl;
osd->reply_op_error(op, -EAGAIN);
return cache_result_t::REPLIED_WITH_EAGAIN;
}
// 如果缓存未能命中,则获取对应的 oid 信息
if (missing_oid == hobject_t() && obc.get()) {
missing_oid = obc->obs.oi.soid;
}
auto m = op->get_req<MOSDOp>();
const object_locator_t oloc = m->get_object_locator();
if (op->need_skip_handle_cache()) {
return cache_result_t::NOOP;
}
OpRequestRef promote_op;
// 根据不同的缓存策略分别处理
switch (pool.info.cache_mode) {
// Write Back 策略
case pg_pool_t::CACHEMODE_WRITEBACK:
// Cache 满
if (agent_state &&
agent_state->evict_mode == TierAgentState::EVICT_MODE_FULL) {
// 读操作 Proxy Read
if (!op->may_write() && !op->may_cache() && !write_ordered && !must_promote) {
dout(20) << __func__ << " cache pool full, proxying read" << dendl;
do_proxy_read(op);
return cache_result_t::HANDLED_PROXY;
}
// 写操作,等待缓存淘汰
dout(20) << __func__ << " cache pool full, waiting" << dendl;
block_write_on_full_cache(missing_oid, op);
return cache_result_t::BLOCKED_FULL;
}
// Cache 未满
if (must_promote || (!hit_set && !op->need_skip_promote())) {
promote_object(obc, missing_oid, oloc, op, promote_obc);
return cache_result_t::BLOCKED_PROMOTE;
}
// 写操作 代理写
if (op->may_write() || op->may_cache()) {
do_proxy_write(op);
// Promote too? 判断是否需要从 Base 层取数据到 Cache
if (!op->need_skip_promote() && maybe_promote(obc, missing_oid, oloc, in_hit_set, pool.info.min_write_recency_for_promote, OpRequestRef(), promote_obc)) {
return cache_result_t::BLOCKED_PROMOTE;
}
return cache_result_t::HANDLED_PROXY;
} else {
// 读操作 代理读
do_proxy_read(op);
// Avoid duplicate promotion
if (obc.get() && obc->is_blocked()) {
if (promote_obc)
*promote_obc = obc;
return cache_result_t::BLOCKED_PROMOTE;
}
// Promote too?
if (!op->need_skip_promote()) {
(void)maybe_promote(obc, missing_oid, oloc, in_hit_set,
pool.info.min_read_recency_for_promote,
promote_op, promote_obc);
}
return cache_result_t::HANDLED_PROXY;
}
// 异常信息输出
ceph_abort_msg("unreachable");
return cache_result_t::NOOP;
// Read Only 策略
case pg_pool_t::CACHEMODE_READONLY:
// TODO: clean this case up
// 缓存中无该对象,对应地去从 Base 层 Promote 对象
if (!obc.get() && r == -ENOENT) {
// we don't have the object and op's a read
promote_object(obc, missing_oid, oloc, op, promote_obc);
return cache_result_t::BLOCKED_PROMOTE;
}
// 非读操作 - 写操作 重定向写操作
if (!r) { // it must be a write
do_cache_redirect(op);
return cache_result_t::HANDLED_REDIRECT;
}
// 异常处理
// crap, there was a failure of some kind
return cache_result_t::NOOP;
// Forward 策略 已过期,由 Proxy 取代
case pg_pool_t::CACHEMODE_FORWARD:
// this mode is deprecated; proxy instead
// Proxy 策略
case pg_pool_t::CACHEMODE_PROXY:
// 可以不从 Base 层 Promote 的情况
if (!must_promote) {
if (op->may_write() || op->may_cache() || write_ordered) {
// 写操作 - 代理写
do_proxy_write(op);
return cache_result_t::HANDLED_PROXY;
} else {
// 读操作 - 代理读
do_proxy_read(op);
return cache_result_t::HANDLED_PROXY;
}
}
// ugh, we're forced to promote.
// 写操作 缓存已满 进入等待队列
if (agent_state && agent_state->evict_mode == TierAgentState::EVICT_MODE_FULL) {
dout(20) << __func__ << " cache pool full, waiting" << dendl;
block_write_on_full_cache(missing_oid, op);
return cache_result_t::BLOCKED_FULL;
}
// 缓存未满,进行 Promote
promote_object(obc, missing_oid, oloc, op, promote_obc);
return cache_result_t::BLOCKED_PROMOTE;
// READ-FORWARD 模式,已过期,由 Proxy 模式处理
case pg_pool_t::CACHEMODE_READFORWARD:
// this mode is deprecated; proxy instead
// READ-PROXY 模式
case pg_pool_t::CACHEMODE_READPROXY:
// Do writeback to the cache tier for writes
if (op->may_write() || write_ordered || must_promote) {
if (agent_state && agent_state->evict_mode == TierAgentState::EVICT_MODE_FULL) {
dout(20) << __func__ << " cache pool full, waiting" << dendl;
block_write_on_full_cache(missing_oid, op);
return cache_result_t::BLOCKED_FULL;
}
promote_object(obc, missing_oid, oloc, op, promote_obc);
return cache_result_t::BLOCKED_PROMOTE;
}
// If it is a read, we can read, we need to proxy it
do_proxy_read(op);
return cache_result_t::HANDLED_PROXY;
default:
ceph_abort_msg("unrecognized cache_mode");
}
return cache_result_t::NOOP;
}
图解缓存策略
- 将以上缓存策略的处理流程转换为流程图如下所示(注:流程细节随着Ceph版本的迭代已经有锁改变,此处重点关注最终的调用):
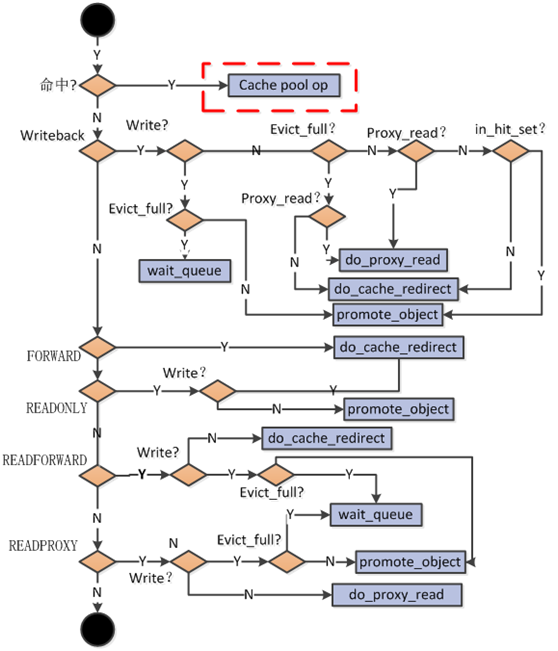
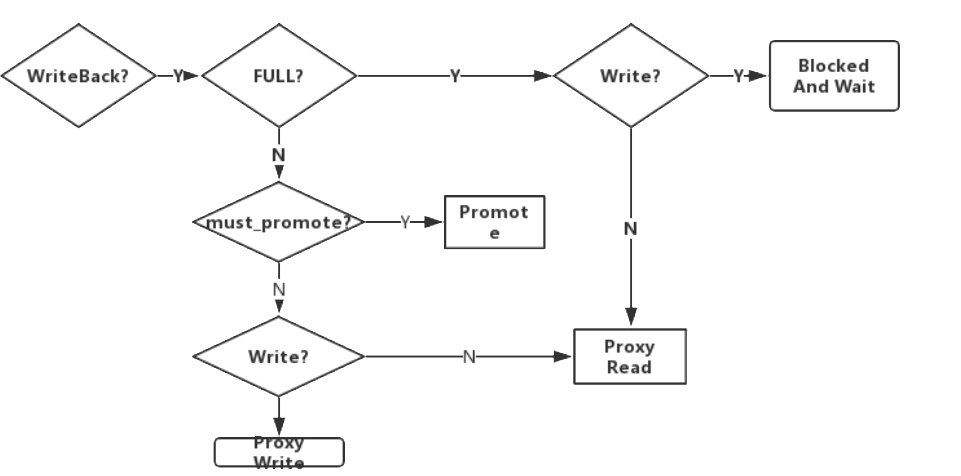
- 针对其中涉及到的几个封装好的方法的操作: do_cache_redirect, do_proxy_read, do_proxy_write, promote_object
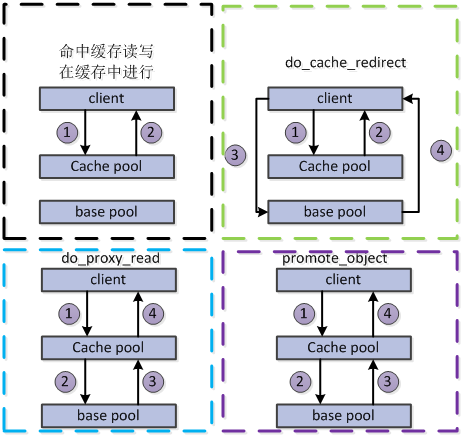
- do_cache_redirect :客户端请求cache pool,cache pool告诉客户端你应该去base pool中请求,客户端收到应答后,再次发送请求到base pool中请求数据,由base pool告诉客户端请求完成。
void PrimaryLogPG::do_cache_redirect(OpRequestRef op)
{
// Cast the request to MOSDOp
auto m = op->get_req<MOSDOp>();
int flags = m->get_flags() & (CEPH_OSD_FLAG_ACK|CEPH_OSD_FLAG_ONDISK);
// 构造 MOSDOpReply 对象
MOSDOpReply *reply = new MOSDOpReply(m, -ENOENT, get_osdmap_epoch(), flags, false);
// 将请求重定向到指定的存储池 Pool
request_redirect_t redir(m->get_object_locator(), pool.info.tier_of);
reply->set_redirect(redir);
dout(10) << "sending redirect to pool " << pool.info.tier_of << " for op "
<< op << dendl;
// 发送响应信息(包含重定向目标存储池的信息和对象的相关信息)
m->get_connection()->send_message(reply);
return;
}
- do_proxy_read:客户端发送读请求到cache pool,但是未命中,则cache pool自己会发送请求到base pool中,获取数据后,由cache pool将数据发送给客户端,完成读请求。但是值得注意的是,虽然cache pool读取到了该object,但不会保存在cache pool中,下次请求仍然需要重新向basepool请求。
void PrimaryLogPG::do_proxy_read(OpRequestRef op, ObjectContextRef obc)
{
// NOTE: non-const here because the ProxyReadOp needs mutable refs to
// stash the result in the request's OSDOp vector
MOSDOp *m = static_cast<MOSDOp*>(op->get_nonconst_req());
object_locator_t oloc;
hobject_t soid;
/* extensible tier */
// 获取对应的需要查询的对象的信息
// 判断是否包含 manifest
if (obc && obc->obs.exists && obc->obs.oi.has_manifest()) {
switch (obc->obs.oi.manifest.type) {
// 如果为 redirect 类型,获取对应的重定向 Target
case object_manifest_t::TYPE_REDIRECT:
oloc = object_locator_t(obc->obs.oi.manifest.redirect_target);
// 获取重定向 target 对应的信息
soid = obc->obs.oi.manifest.redirect_target;
break;
default:
ceph_abort_msg("unrecognized manifest type");
}
} else {
// 不包含 manifest
/* proxy */
soid = m->get_hobj();
oloc = object_locator_t(m->get_object_locator());
oloc.pool = pool.info.tier_of;
}
unsigned flags = CEPH_OSD_FLAG_IGNORE_CACHE | CEPH_OSD_FLAG_IGNORE_OVERLAY;
// pass through some original flags that make sense.
// - leave out redirection and balancing flags since we are
// already proxying through the primary
// - leave off read/write/exec flags that are derived from the op
flags |= m->get_flags() & (CEPH_OSD_FLAG_RWORDERED |
CEPH_OSD_FLAG_ORDERSNAP |
CEPH_OSD_FLAG_ENFORCE_SNAPC |
CEPH_OSD_FLAG_MAP_SNAP_CLONE);
dout(10) << __func__ << " Start proxy read for " << *m << dendl;
ProxyReadOpRef prdop(std::make_shared<ProxyReadOp>(op, soid, m->ops));
ObjectOperation obj_op;
obj_op.dup(prdop->ops);
// 判断 Cache Mode 和 缓存是否已满
if (pool.info.cache_mode == pg_pool_t::CACHEMODE_WRITEBACK &&
(agent_state && agent_state->evict_mode != TierAgentState::EVICT_MODE_FULL)) {
for (unsigned i = 0; i < obj_op.ops.size(); i++) {
ceph_osd_op op = obj_op.ops[i].op;
switch (op.op) {
case CEPH_OSD_OP_READ:
case CEPH_OSD_OP_SYNC_READ:
case CEPH_OSD_OP_SPARSE_READ:
case CEPH_OSD_OP_CHECKSUM:
case CEPH_OSD_OP_CMPEXT:
op.flags = (op.flags | CEPH_OSD_OP_FLAG_FADVISE_SEQUENTIAL) &
~(CEPH_OSD_OP_FLAG_FADVISE_DONTNEED | CEPH_OSD_OP_FLAG_FADVISE_NOCACHE);
}
}
}
C_ProxyRead *fin = new C_ProxyRead(this, soid, get_last_peering_reset(),
prdop);
unsigned n = info.pgid.hash_to_shard(osd->m_objecter_finishers);
// 调用 objecter read 方法读取对象数据
ceph_tid_t tid = osd->objecter->read(
soid.oid, oloc, obj_op,
m->get_snapid(), NULL,
flags, new C_OnFinisher(fin, osd->objecter_finishers[n]),
&prdop->user_version,
&prdop->data_offset,
m->get_features());
fin->tid = tid;
prdop->objecter_tid = tid;
proxyread_ops[tid] = prdop;
in_progress_proxy_ops[soid].push_back(op);
}
- do_proxy_write:类似于 do_proxy_read
void PrimaryLogPG::do_proxy_write(OpRequestRef op, ObjectContextRef obc)
{
// NOTE: non-const because ProxyWriteOp takes a mutable ref
MOSDOp *m = static_cast<MOSDOp*>(op->get_nonconst_req());
object_locator_t oloc;
SnapContext snapc(m->get_snap_seq(), m->get_snaps());
hobject_t soid;
/* extensible tier */
if (obc && obc->obs.exists && obc->obs.oi.has_manifest()) {
switch (obc->obs.oi.manifest.type) {
case object_manifest_t::TYPE_REDIRECT:
oloc = object_locator_t(obc->obs.oi.manifest.redirect_target);
soid = obc->obs.oi.manifest.redirect_target;
break;
default:
ceph_abort_msg("unrecognized manifest type");
}
} else {
/* proxy */
soid = m->get_hobj();
oloc = object_locator_t(m->get_object_locator());
oloc.pool = pool.info.tier_of;
}
unsigned flags = CEPH_OSD_FLAG_IGNORE_CACHE | CEPH_OSD_FLAG_IGNORE_OVERLAY;
if (!(op->may_write() || op->may_cache())) {
flags |= CEPH_OSD_FLAG_RWORDERED;
}
if (op->allows_returnvec()) {
flags |= CEPH_OSD_FLAG_RETURNVEC;
}
dout(10) << __func__ << " Start proxy write for " << *m << dendl;
ProxyWriteOpRef pwop(std::make_shared<ProxyWriteOp>(op, soid, m->ops, m->get_reqid()));
pwop->ctx = new OpContext(op, m->get_reqid(), &pwop->ops, this);
pwop->mtime = m->get_mtime();
ObjectOperation obj_op;
obj_op.dup(pwop->ops);
C_ProxyWrite_Commit *fin = new C_ProxyWrite_Commit(
this, soid, get_last_peering_reset(), pwop);
unsigned n = info.pgid.hash_to_shard(osd->m_objecter_finishers);
ceph_tid_t tid = osd->objecter->mutate(
soid.oid, oloc, obj_op, snapc,
ceph::real_clock::from_ceph_timespec(pwop->mtime),
flags, new C_OnFinisher(fin, osd->objecter_finishers[n]),
&pwop->user_version, pwop->reqid);
fin->tid = tid;
pwop->objecter_tid = tid;
proxywrite_ops[tid] = pwop;
in_progress_proxy_ops[soid].push_back(op);
}
- promote_object:当客户端发送请求到cache pool中,但是cache pool未命中,cache pool会选择将该object从base pool中提升到cache pool中,然后在cache pool进行读写操作,操作完成后告知客户端请求完成,在cache pool会缓存该object,下次直接在cache中处理,和proxy_read存在的区别。
void PrimaryLogPG::promote_object(ObjectContextRef obc,
const hobject_t& missing_oid,
const object_locator_t& oloc,
OpRequestRef op,
ObjectContextRef *promote_obc)
{
hobject_t hoid = obc ? obc->obs.oi.soid : missing_oid;
ceph_assert(hoid != hobject_t());
// 等待 Scrub 操作完成
if (write_blocked_by_scrub(hoid)) {
dout(10) << __func__ << " " << hoid
<< " blocked by scrub" << dendl;
if (op) {
waiting_for_scrub.push_back(op);
op->mark_delayed("waiting for scrub");
dout(10) << __func__ << " " << hoid
<< " placing op in waiting_for_scrub" << dendl;
} else {
dout(10) << __func__ << " " << hoid
<< " no op, dropping on the floor" << dendl;
}
return;
}
if (op && !check_laggy_requeue(op)) {
return;
}
// Context为空创建一个新的Context
if (!obc) { // we need to create an ObjectContext
ceph_assert(missing_oid != hobject_t());
obc = get_object_context(missing_oid, true);
}
if (promote_obc)
*promote_obc = obc;
/*
* Before promote complete, if there are proxy-reads for the object,
* for this case we don't use DONTNEED.
*/
unsigned src_fadvise_flags = LIBRADOS_OP_FLAG_FADVISE_SEQUENTIAL;
// 获取该对象对应的 proxy_read 等待队列的遍历器
map<hobject_t, list<OpRequestRef>>::iterator q = in_progress_proxy_ops.find(obc->obs.oi.soid);
if (q == in_progress_proxy_ops.end()) {
src_fadvise_flags |= LIBRADOS_OP_FLAG_FADVISE_DONTNEED;
}
// 构造 PromoteCallback
CopyCallback *cb;
object_locator_t my_oloc;
hobject_t src_hoid;
// 判断是否有 manifest
if (!obc->obs.oi.has_manifest()) {
my_oloc = oloc;
my_oloc.pool = pool.info.tier_of;
src_hoid = obc->obs.oi.soid;
cb = new PromoteCallback(obc, this);
} else {
// 有manifest,判断类型是否为 chunk_data
if (obc->obs.oi.manifest.is_chunked()) {
src_hoid = obc->obs.oi.soid;
cb = new PromoteManifestCallback(obc, this);
} else if (obc->obs.oi.manifest.is_redirect()) {
// mainfest 类型为 redirect
object_locator_t src_oloc(obc->obs.oi.manifest.redirect_target);
my_oloc = src_oloc;
src_hoid = obc->obs.oi.manifest.redirect_target;
cb = new PromoteCallback(obc, this);
} else {
ceph_abort_msg("unrecognized manifest type");
}
}
unsigned flags = CEPH_OSD_COPY_FROM_FLAG_IGNORE_OVERLAY |
CEPH_OSD_COPY_FROM_FLAG_IGNORE_CACHE |
CEPH_OSD_COPY_FROM_FLAG_MAP_SNAP_CLONE |
CEPH_OSD_COPY_FROM_FLAG_RWORDERED;
// 复制对象数据
start_copy(cb, obc, src_hoid, my_oloc, 0, flags,
obc->obs.oi.soid.snap == CEPH_NOSNAP,
src_fadvise_flags, 0);
ceph_assert(obc->is_blocked());
if (op)
wait_for_blocked_object(obc->obs.oi.soid, op);
recovery_state.update_stats(
[](auto &history, auto &stats) {
stats.stats.sum.num_promote++;
return false;
});
}
void PrimaryLogPG::start_copy(CopyCallback *cb, ObjectContextRef obc,
hobject_t src, object_locator_t oloc,
version_t version, unsigned flags,
bool mirror_snapset,
unsigned src_obj_fadvise_flags,
unsigned dest_obj_fadvise_flags)
{
const hobject_t& dest = obc->obs.oi.soid;
dout(10) << __func__ << " " << dest
<< " from " << src << " " << oloc << " v" << version
<< " flags " << flags
<< (mirror_snapset ? " mirror_snapset" : "")
<< dendl;
ceph_assert(!mirror_snapset || src.snap == CEPH_NOSNAP);
// cancel a previous in-progress copy?
if (copy_ops.count(dest)) {
// FIXME: if the src etc match, we could avoid restarting from the
// beginning.
CopyOpRef cop = copy_ops[dest];
vector<ceph_tid_t> tids;
cancel_copy(cop, false, &tids);
osd->objecter->op_cancel(tids, -ECANCELED);
}
// 封装 cop 对象
CopyOpRef cop(std::make_shared<CopyOp>(cb, obc, src, oloc, version, flags,
mirror_snapset, src_obj_fadvise_flags,
dest_obj_fadvise_flags));
copy_ops[dest] = cop;
obc->start_block();
if (!obc->obs.oi.has_manifest()) {
// 执行实际的 copy 操作
_copy_some(obc, cop);
} else {
if (obc->obs.oi.manifest.is_redirect()) {
_copy_some(obc, cop);
} else if (obc->obs.oi.manifest.is_chunked()) {
auto p = obc->obs.oi.manifest.chunk_map.begin();
_copy_some_manifest(obc, cop, p->first);
} else {
ceph_abort_msg("unrecognized manifest type");
}
}
}
void PrimaryLogPG::_copy_some(ObjectContextRef obc, CopyOpRef cop)
{
dout(10) << __func__ << " " << *obc << " " << cop << dendl;
unsigned flags = 0;
if (cop->flags & CEPH_OSD_COPY_FROM_FLAG_FLUSH)
flags |= CEPH_OSD_FLAG_FLUSH;
if (cop->flags & CEPH_OSD_COPY_FROM_FLAG_IGNORE_CACHE)
flags |= CEPH_OSD_FLAG_IGNORE_CACHE;
if (cop->flags & CEPH_OSD_COPY_FROM_FLAG_IGNORE_OVERLAY)
flags |= CEPH_OSD_FLAG_IGNORE_OVERLAY;
if (cop->flags & CEPH_OSD_COPY_FROM_FLAG_MAP_SNAP_CLONE)
flags |= CEPH_OSD_FLAG_MAP_SNAP_CLONE;
if (cop->flags & CEPH_OSD_COPY_FROM_FLAG_RWORDERED)
flags |= CEPH_OSD_FLAG_RWORDERED;
C_GatherBuilder gather(cct);
if (cop->cursor.is_initial() && cop->mirror_snapset) {
// list snaps too.
ceph_assert(cop->src.snap == CEPH_NOSNAP);
ObjectOperation op;
op.list_snaps(&cop->results.snapset, NULL);
ceph_tid_t tid = osd->objecter->read(cop->src.oid, cop->oloc, op,
CEPH_SNAPDIR, NULL,
flags, gather.new_sub(), NULL);
cop->objecter_tid2 = tid;
}
ObjectOperation op;
if (cop->results.user_version) {
op.assert_version(cop->results.user_version);
} else {
// we should learn the version after the first chunk, if we didn't know
// it already!
ceph_assert(cop->cursor.is_initial());
}
op.copy_get(&cop->cursor, get_copy_chunk_size(),
&cop->results.object_size, &cop->results.mtime,
&cop->attrs, &cop->data, &cop->omap_header, &cop->omap_data,
&cop->results.snaps, &cop->results.snap_seq,
&cop->results.flags,
&cop->results.source_data_digest,
&cop->results.source_omap_digest,
&cop->results.reqids,
&cop->results.reqid_return_codes,
&cop->results.truncate_seq,
&cop->results.truncate_size,
&cop->rval);
op.set_last_op_flags(cop->src_obj_fadvise_flags);
C_Copyfrom *fin = new C_Copyfrom(this, obc->obs.oi.soid,
get_last_peering_reset(), cop);
unsigned n = info.pgid.hash_to_shard(osd->m_objecter_finishers);
gather.set_finisher(new C_OnFinisher(fin,
osd->objecter_finishers[n]));
// 调用 objecter->read方法进行读取
ceph_tid_t tid = osd->objecter->read(cop->src.oid, cop->oloc, op,
cop->src.snap, NULL,
flags,
gather.new_sub(),
// discover the object version if we don't know it yet
cop->results.user_version ? NULL : &cop->results.user_version);
fin->tid = tid;
cop->objecter_tid = tid;
gather.activate();
}
- 无论是 Proxy Read 还是 Promote Object 操作最终都是调用了 objecter 的 read 方法来从base storage层读取对象数据
Cache flush & evict
flush
- cache pool 空间不够时,需要选择一些对象回刷到数据层
evict
- 将一些 clean 对象从缓存层中剔除。以释放更多的缓存空间
Data Structure
- OSDServices :定义了 AgentThread 线程,用于完成 flush 和 evict 操作
class OSDService {
....
// -- agent shared state --
// agent 线程锁,保护下面所有数据结构
ceph::mutex agent_lock = ceph::make_mutex("OSDService::agent_lock");
// 线程相应的条件变量
ceph::condition_variable agent_cond;
// 所有淘汰或者回刷所需的 PG 集合,根据 PG 集合的优先级,保存在不同的 map 中
map<uint64_t, set<PGRef> > agent_queue;
// 当前在扫描的 PG 集合的一个位置,只有 agent_valid_iterator 为 true 时,这个指针才有效,否则从集合的起始处开始扫描
set<PGRef>::iterator agent_queue_pos;
bool agent_valid_iterator;
// 所有正在进行的回刷和淘汰操作
int agent_ops;
// once have one pg with FLUSH_MODE_HIGH then flush objects with high speed
int flush_mode_high_count;
// 所有正在进行的 agent 操作(回刷或者淘汰)的对象
set<hobject_t> agent_oids;
// agent 是否有效
bool agent_active;
// agent 线程
struct AgentThread : public Thread {
OSDService *osd;
explicit AgentThread(OSDService *o) : osd(o) {}
void *entry() override {
osd->agent_entry();
return NULL;
}
} agent_thread;
// agent 停止的标志
bool agent_stop_flag;
ceph::mutex agent_timer_lock = ceph::make_mutex("OSDService::agent_timer_lock");
// agent 相关定时器:当扫描一个 PG 对象时,该对象既没有剔除操作,也没有回刷操作,就停止 PG 的扫描,把该 PG 加入到定时器中,5S 后继续
SafeTimer agent_timer;
}
- TierAgentState:用于保存 PG 相关的 agent 信息
flush/evict 执行入口
- agent_entry:agent_entry 是 agent_thread 的入口函数,它在后台完成 flush 操作和 evict 操作
void OSDService::agent_entry()
{
dout(10) << __func__ << " start" << dendl;
// 加锁,保护相关字段
std::unique_lock agent_locker{agent_lock};
while (!agent_stop_flag) {
if (agent_queue.empty()) {
// 扫描 agent_queue 队列,如果为空则在 agent_cond 上等待
dout(20) << __func__ << " empty queue" << dendl;
agent_cond.wait(agent_locker);
continue;
}
uint64_t level = agent_queue.rbegin()->first;
// 从队列中取出优先级最高的 PG 的集合 top
set<PGRef>& top = agent_queue.rbegin()->second;
dout(10) << __func__
<< " tiers " << agent_queue.size()
<< ", top is " << level
<< " with pgs " << top.size()
<< ", ops " << agent_ops << "/"
<< cct->_conf->osd_agent_max_ops
<< (agent_active ? " active" : " NOT ACTIVE")
<< dendl;
dout(20) << __func__ << " oids " << agent_oids << dendl;
// 获取 agent 操作的最大数目 max 值和 agent_flush_quota
int max = cct->_conf->osd_agent_max_ops - agent_ops;
int agent_flush_quota = max;
if (!flush_mode_high_count)
agent_flush_quota = cct->_conf->osd_agent_max_low_ops - agent_ops;
if (agent_flush_quota <= 0 || top.empty() || !agent_active) {
agent_cond.wait(agent_locker);
continue;
}
// 迭代器获取 PG
if (!agent_valid_iterator || agent_queue_pos == top.end()) {
agent_queue_pos = top.begin();
agent_valid_iterator = true;
}
PGRef pg = *agent_queue_pos;
dout(10) << "high_count " << flush_mode_high_count
<< " agent_ops " << agent_ops
<< " flush_quota " << agent_flush_quota << dendl;
agent_locker.unlock();
// 调用 pg->agent_work(),正常返回 true,若返回 false,则处于 delay,需要加入定时器
if (!pg->agent_work(max, agent_flush_quota)) {
dout(10) << __func__ << " " << pg->pg_id
<< " no agent_work, delay for " << cct->_conf->osd_agent_delay_time
<< " seconds" << dendl;
osd->logger->inc(l_osd_tier_delay);
// Queue a timer to call agent_choose_mode for this pg in 5 seconds
std::lock_guard timer_locker{agent_timer_lock};
Context *cb = new AgentTimeoutCB(pg);
agent_timer.add_event_after(cct->_conf->osd_agent_delay_time, cb);
}
agent_locker.lock();
}
dout(10) << __func__ << " finish" << dendl;
}
- agent_work:完成一个 PG 内的 evict 操作和 flush 操作
bool PrimaryLogPG::agent_work(int start_max, int agent_flush_quota)
{
// 加锁
std::scoped_lock locker{*this};
if (!agent_state) {
dout(10) << __func__ << " no agent state, stopping" << dendl;
return true;
}
ceph_assert(!recovery_state.is_deleting());
if (agent_state->is_idle()) {
dout(10) << __func__ << " idle, stopping" << dendl;
return true;
}
osd->logger->inc(l_osd_agent_wake);
dout(10) << __func__
<< " max " << start_max
<< ", flush " << agent_state->get_flush_mode_name()
<< ", evict " << agent_state->get_evict_mode_name()
<< ", pos " << agent_state->position
<< dendl;
ceph_assert(is_primary());
ceph_assert(is_active());
// 加载 hit_set 历史对象到内存
agent_load_hit_sets();
const pg_pool_t *base_pool = get_osdmap()->get_pg_pool(pool.info.tier_of);
ceph_assert(base_pool);
int ls_min = 1;
int ls_max = cct->_conf->osd_pool_default_cache_max_evict_check_size;
// list some objects. this conveniently lists clones (oldest to
// newest) before heads... the same order we want to flush in.
//
// NOTE: do not flush the Sequencer. we will assume that the
// listing we get back is imprecise.
vector<hobject_t> ls;
hobject_t next;
// 扫描本 PG 的对象,从 agent_state->position 开始扫描,结果保存在 ls 中
int r = pgbackend->objects_list_partial(agent_state->position, ls_min, ls_max, &ls, &next);
ceph_assert(r >= 0);
dout(20) << __func__ << " got " << ls.size() << " objects" << dendl;
int started = 0;
// 对扫描的 ls 对象做相应的检查
for (vector<hobject_t>::iterator p = ls.begin();
p != ls.end();
++p) {
// 跳过 hitset
if (p->nspace == cct->_conf->osd_hit_set_namespace) {
dout(20) << __func__ << " skip (hit set) " << *p << dendl;
osd->logger->inc(l_osd_agent_skip);
continue;
}
// 跳过 degraded 对象
if (is_degraded_or_backfilling_object(*p)) {
dout(20) << __func__ << " skip (degraded) " << *p << dendl;
osd->logger->inc(l_osd_agent_skip);
continue;
}
// 跳过 missing 对象
if (is_missing_object(p->get_head())) {
dout(20) << __func__ << " skip (missing head) " << *p << dendl;
osd->logger->inc(l_osd_agent_skip);
continue;
}
// 跳过 object_context 不存在的对象
ObjectContextRef obc = get_object_context(*p, false, NULL);
if (!obc) {
// we didn't flush; we may miss something here.
dout(20) << __func__ << " skip (no obc) " << *p << dendl;
osd->logger->inc(l_osd_agent_skip);
continue;
}
// 跳过对象的 obs
if (!obc->obs.exists) {
dout(20) << __func__ << " skip (dne) " << obc->obs.oi.soid << dendl;
osd->logger->inc(l_osd_agent_skip);
continue;
}
// 跳过正在进行 scrub 操作的对象
if (range_intersects_scrub(obc->obs.oi.soid,
obc->obs.oi.soid.get_head())) {
dout(20) << __func__ << " skip (scrubbing) " << obc->obs.oi << dendl;
osd->logger->inc(l_osd_agent_skip);
continue;
}
// 跳过已经被阻塞的对象
if (obc->is_blocked()) {
dout(20) << __func__ << " skip (blocked) " << obc->obs.oi << dendl;
osd->logger->inc(l_osd_agent_skip);
continue;
}
// 跳过有正在读写请求的对象
if (obc->is_request_pending()) {
dout(20) << __func__ << " skip (request pending) " << obc->obs.oi << dendl;
osd->logger->inc(l_osd_agent_skip);
continue;
}
// 如果不支持 omap,跳过有 omap 的对象
// be careful flushing omap to an EC pool.
if (!base_pool->supports_omap() &&
obc->obs.oi.is_omap()) {
dout(20) << __func__ << " skip (omap to EC) " << obc->obs.oi << dendl;
osd->logger->inc(l_osd_agent_skip);
continue;
}
// agent_maybe_evict 完成对象的 evict 操作
if (agent_state->evict_mode != TierAgentState::EVICT_MODE_IDLE &&
agent_maybe_evict(obc, false))
++started;
// agent_maybe_flush 完成一个对象的 flush 操作
else if (agent_state->flush_mode != TierAgentState::FLUSH_MODE_IDLE &&
agent_flush_quota > 0 && agent_maybe_flush(obc)) {
++started;
--agent_flush_quota;
}
if (started >= start_max) {
// If finishing early, set "next" to the next object
if (++p != ls.end())
next = *p;
break;
}
}
if (++agent_state->hist_age > cct->_conf->osd_agent_hist_halflife) {
dout(20) << __func__ << " resetting atime and temp histograms" << dendl;
agent_state->hist_age = 0;
agent_state->temp_hist.decay();
}
// Total objects operated on so far
int total_started = agent_state->started + started;
bool need_delay = false;
dout(20) << __func__ << " start pos " << agent_state->position
<< " next start pos " << next
<< " started " << total_started << dendl;
// See if we've made a full pass over the object hash space
// This might check at most ls_max objects a second time to notice that
// we've checked every objects at least once.
if (agent_state->position < agent_state->start &&
next >= agent_state->start) {
dout(20) << __func__ << " wrap around " << agent_state->start << dendl;
if (total_started == 0)
need_delay = true;
else
total_started = 0;
agent_state->start = next;
}
agent_state->started = total_started;
// See if we are starting from beginning
if (next.is_max())
agent_state->position = hobject_t();
else
agent_state->position = next;
// Discard old in memory HitSets
hit_set_in_memory_trim(pool.info.hit_set_count);
if (need_delay) {
ceph_assert(agent_state->delaying == false);
agent_delay();
return false;
}
// 重新计算 agent 的 evict 和 flush 值
agent_choose_mode();
return true;
}
真正执行操作的方法
bool PrimaryLogPG::agent_maybe_evict(ObjectContextRef& obc, bool after_flush)
{
const hobject_t& soid = obc->obs.oi.soid;
// 检查对象的状态
if (!after_flush && obc->obs.oi.is_dirty()) {
dout(20) << __func__ << " skip (dirty) " << obc->obs.oi << dendl;
return false;
}
// This is already checked by agent_work() which passes after_flush = false
if (after_flush && range_intersects_scrub(soid, soid.get_head())) {
dout(20) << __func__ << " skip (scrubbing) " << obc->obs.oi << dendl;
return false;
}
if (!obc->obs.oi.watchers.empty()) {
dout(20) << __func__ << " skip (watchers) " << obc->obs.oi << dendl;
return false;
}
if (obc->is_blocked()) {
dout(20) << __func__ << " skip (blocked) " << obc->obs.oi << dendl;
return false;
}
if (obc->obs.oi.is_cache_pinned()) {
dout(20) << __func__ << " skip (cache_pinned) " << obc->obs.oi << dendl;
return false;
}
if (soid.snap == CEPH_NOSNAP) {
int result = _verify_no_head_clones(soid, obc->ssc->snapset);
if (result < 0) {
dout(20) << __func__ << " skip (clones) " << obc->obs.oi << dendl;
return false;
}
}
// 检查 evict 模式是否为 EVICT_MODE_SOME 模式
if (agent_state->evict_mode != TierAgentState::EVICT_MODE_FULL) {
// 检查 clean 的时间是否大于设置的最小淘汰时间
// is this object old than cache_min_evict_age?
utime_t now = ceph_clock_now();
utime_t ob_local_mtime;
if (obc->obs.oi.local_mtime != utime_t()) {
ob_local_mtime = obc->obs.oi.local_mtime;
} else {
ob_local_mtime = obc->obs.oi.mtime;
}
if (ob_local_mtime + utime_t(pool.info.cache_min_evict_age, 0) > now) {
dout(20) << __func__ << " skip (too young) " << obc->obs.oi << dendl;
osd->logger->inc(l_osd_agent_skip);
return false;
}
// 计算对象的热度值
// is this object old and/or cold enough?
int temp = 0;
uint64_t temp_upper = 0, temp_lower = 0;
if (hit_set)
agent_estimate_temp(soid, &temp);
agent_state->temp_hist.add(temp);
agent_state->temp_hist.get_position_micro(temp, &temp_lower, &temp_upper);
dout(20) << __func__
<< " temp " << temp
<< " pos " << temp_lower << "-" << temp_upper
<< ", evict_effort " << agent_state->evict_effort
<< dendl;
dout(30) << "agent_state:\n";
Formatter *f = Formatter::create("");
f->open_object_section("agent_state");
agent_state->dump(f);
f->close_section();
f->flush(*_dout);
delete f;
*_dout << dendl;
if (1000000 - temp_upper >= agent_state->evict_effort)
return false;
}
// evict_mode 为 FULL 模式,调用函数 _delete_oid 删除该对象
dout(10) << __func__ << " evicting " << obc->obs.oi << dendl;
OpContextUPtr ctx = simple_opc_create(obc);
auto null_op_req = OpRequestRef();
if (!ctx->lock_manager.get_lock_type(
ObjectContext::RWState::RWWRITE,
obc->obs.oi.soid,
obc,
null_op_req)) {
close_op_ctx(ctx.release());
dout(20) << __func__ << " skip (cannot get lock) " << obc->obs.oi << dendl;
return false;
}
osd->agent_start_evict_op();
ctx->register_on_finish(
[this]() {
osd->agent_finish_evict_op();
});
ctx->at_version = get_next_version();
ceph_assert(ctx->new_obs.exists);
// 删除该对象
int r = _delete_oid(ctx.get(), true, false);
if (obc->obs.oi.is_omap())
ctx->delta_stats.num_objects_omap--;
ctx->delta_stats.num_evict++;
ctx->delta_stats.num_evict_kb += shift_round_up(obc->obs.oi.size, 10);
if (obc->obs.oi.is_dirty())
--ctx->delta_stats.num_objects_dirty;
ceph_assert(r == 0);
finish_ctx(ctx.get(), pg_log_entry_t::DELETE);
// 发起实际的删除请求
simple_opc_submit(std::move(ctx));
osd->logger->inc(l_osd_tier_evict);
osd->logger->inc(l_osd_agent_evict);
return true;
}
- flush:该方法完成一个对象的 flush 操作(非最底层的实现)
bool PrimaryLogPG::agent_maybe_flush(ObjectContextRef& obc)
{
// 检查对象是否为脏数据
if (!obc->obs.oi.is_dirty()) {
dout(20) << __func__ << " skip (clean) " << obc->obs.oi << dendl;
osd->logger->inc(l_osd_agent_skip);
return false;
}
// 检查对象是否为 cache_pinned 状态
if (obc->obs.oi.is_cache_pinned()) {
dout(20) << __func__ << " skip (cache_pinned) " << obc->obs.oi << dendl;
osd->logger->inc(l_osd_agent_skip);
return false;
}
// 统计时间
utime_t now = ceph_clock_now();
utime_t ob_local_mtime;
if (obc->obs.oi.local_mtime != utime_t()) {
ob_local_mtime = obc->obs.oi.local_mtime;
} else {
ob_local_mtime = obc->obs.oi.mtime;
}
// 判断当前 evict 状态是否为 full
bool evict_mode_full =
(agent_state->evict_mode == TierAgentState::EVICT_MODE_FULL);
// 未满则检查该对象作为脏数据的时间,和最短刷回时间进行对比
if (!evict_mode_full &&
obc->obs.oi.soid.snap == CEPH_NOSNAP && // snaps immutable; don't delay
(ob_local_mtime + utime_t(pool.info.cache_min_flush_age, 0) > now)) {
dout(20) << __func__ << " skip (too young) " << obc->obs.oi << dendl;
osd->logger->inc(l_osd_agent_skip);
return false;
}
// 检查对象是否处于 activate 状态
if (osd->agent_is_active_oid(obc->obs.oi.soid)) {
dout(20) << __func__ << " skip (flushing) " << obc->obs.oi << dendl;
osd->logger->inc(l_osd_agent_skip);
return false;
}
dout(10) << __func__ << " flushing " << obc->obs.oi << dendl;
// FIXME: flush anything dirty, regardless of what distribution of
// ages we expect.
hobject_t oid = obc->obs.oi.soid;
osd->agent_start_op(oid);
// no need to capture a pg ref, can't outlive fop or ctx
std::function<void()> on_flush = [this, oid]() {
osd->agent_finish_op(oid);
};
// 调用函数 start_flush 完成对象的刷回操作
int result = start_flush(
OpRequestRef(), obc, false, NULL,
on_flush);
if (result != -EINPROGRESS) {
on_flush();
dout(10) << __func__ << " start_flush() failed " << obc->obs.oi
<< " with " << result << dendl;
osd->logger->inc(l_osd_agent_skip);
return false;
}
osd->logger->inc(l_osd_agent_flush);
return true;
}
- start_flush:该函数完成实际的 flush 操作
int PrimaryLogPG::start_flush(
OpRequestRef op, ObjectContextRef obc,
bool blocking, hobject_t *pmissing,
std::optional<std::function<void()>> &&on_flush)
{
const object_info_t& oi = obc->obs.oi;
const hobject_t& soid = oi.soid;
dout(10) << __func__ << " " << soid
<< " v" << oi.version
<< " uv" << oi.user_version
<< " " << (blocking ? "blocking" : "non-blocking/best-effort")
<< dendl;
bool preoctopus_compat =
get_osdmap()->require_osd_release < ceph_release_t::octopus;
SnapSet snapset;
if (preoctopus_compat) {
// 过滤掉已经删除的 snap 对象
// for pre-octopus compatibility, filter SnapSet::snaps. not
// certain we need this, but let's be conservative.
snapset = obc->ssc->snapset.get_filtered(pool.info);
} else {
// NOTE: change this to a const ref when we remove this compat code
snapset = obc->ssc->snapset;
}
// 检查比当前 clone 对象更早版本的克隆对象
// verify there are no (older) check for dirty clones
{
dout(20) << " snapset " << snapset << dendl;
vector<snapid_t>::reverse_iterator p = snapset.clones.rbegin();
while (p != snapset.clones.rend() && *p >= soid.snap)
++p;
if (p != snapset.clones.rend()) {
hobject_t next = soid;
next.snap = *p;
ceph_assert(next.snap < soid.snap);
if (recovery_state.get_pg_log().get_missing().is_missing(next)) {
dout(10) << __func__ << " missing clone is " << next << dendl;
if (pmissing)
*pmissing = next;
return -ENOENT;
}
ObjectContextRef older_obc = get_object_context(next, false);
if (older_obc) {
dout(20) << __func__ << " next oldest clone is " << older_obc->obs.oi
<< dendl;
if (older_obc->obs.oi.is_dirty()) {
dout(10) << __func__ << " next oldest clone is dirty: "
<< older_obc->obs.oi << dendl;
return -EBUSY;
}
} else {
dout(20) << __func__ << " next oldest clone " << next
<< " is not present; implicitly clean" << dendl;
}
} else {
dout(20) << __func__ << " no older clones" << dendl;
}
}
// 设置对应的对象为 blocked 状态
if (blocking)
obc->start_block();
// 检查该对象是否在 flush_ops 中,也就是该对象是否已经在 flush
map<hobject_t,FlushOpRef>::iterator p = flush_ops.find(soid);
if (p != flush_ops.end()) {
FlushOpRef fop = p->second;
if (fop->op == op) {
// we couldn't take the write lock on a cache-try-flush before;
// now we are trying again for the lock.
return try_flush_mark_clean(fop);
}
if (fop->flushed_version == obc->obs.oi.user_version &&
(fop->blocking || !blocking)) {
// nonblocking can join anything
// blocking can only join a blocking flush
dout(20) << __func__ << " piggybacking on existing flush " << dendl;
if (op)
fop->dup_ops.push_back(op);
return -EAGAIN; // clean up this ctx; op will retry later
}
// cancel current flush since it will fail anyway, or because we
// are blocking and the existing flush is nonblocking.
dout(20) << __func__ << " canceling previous flush; it will fail" << dendl;
if (fop->op)
osd->reply_op_error(fop->op, -EBUSY);
while (!fop->dup_ops.empty()) {
osd->reply_op_error(fop->dup_ops.front(), -EBUSY);
fop->dup_ops.pop_front();
}
vector<ceph_tid_t> tids;
cancel_flush(fop, false, &tids);
osd->objecter->op_cancel(tids, -ECANCELED);
}
if (obc->obs.oi.has_manifest() && obc->obs.oi.manifest.is_chunked()) {
// 执行对应的 flush 操作
int r = start_manifest_flush(op, obc, blocking, std::move(on_flush));
if (r != -EINPROGRESS) {
if (blocking)
obc->stop_block();
}
return r;
}
- start_manifest_flush:真正刷回数据之前的数据准备
int PrimaryLogPG::start_manifest_flush(OpRequestRef op, ObjectContextRef obc, bool blocking,
std::optional<std::function<void()>> &&on_flush)
{
auto p = obc->obs.oi.manifest.chunk_map.begin();
FlushOpRef manifest_fop(std::make_shared<FlushOp>());
manifest_fop->op = op;
manifest_fop->obc = obc;
manifest_fop->flushed_version = obc->obs.oi.user_version;
manifest_fop->blocking = blocking;
manifest_fop->on_flush = std::move(on_flush);
int r = do_manifest_flush(op, obc, manifest_fop, p->first, blocking);
if (r < 0) {
return r;
}
flush_ops[obc->obs.oi.soid] = manifest_fop;
return -EINPROGRESS;
}
- do_manifest_flush:真正刷回数据的过程
int PrimaryLogPG::do_manifest_flush(OpRequestRef op, ObjectContextRef obc, FlushOpRef manifest_fop,
uint64_t start_offset, bool block)
{
// 获取 manifest 和 实际的对象数据
struct object_manifest_t &manifest = obc->obs.oi.manifest;
hobject_t soid = obc->obs.oi.soid;
ceph_tid_t tid;
SnapContext snapc;
uint64_t max_copy_size = 0, last_offset = 0;
// 遍历 manifest 统计要复制刷回的数据大小
map<uint64_t, chunk_info_t>::iterator iter = manifest.chunk_map.find(start_offset);
ceph_assert(iter != manifest.chunk_map.end());
for (;iter != manifest.chunk_map.end(); ++iter) {
if (iter->second.is_dirty()) {
last_offset = iter->first;
max_copy_size += iter->second.length;
}
if (get_copy_chunk_size() < max_copy_size) {
break;
}
}
iter = manifest.chunk_map.find(start_offset);
for (;iter != manifest.chunk_map.end(); ++iter) {
// 如果数据 clean 则跳过
if (!iter->second.is_dirty()) {
continue;
}
uint64_t tgt_length = iter->second.length;
uint64_t tgt_offset= iter->second.offset;
hobject_t tgt_soid = iter->second.oid;
object_locator_t oloc(tgt_soid);
ObjectOperation obj_op;
bufferlist chunk_data;
// 先读取数据到 chunk_data 中
int r = pgbackend->objects_read_sync(soid, iter->first, tgt_length, 0, &chunk_data);
if (r < 0) {
dout(0) << __func__ << " read fail " << " offset: " << tgt_offset
<< " len: " << tgt_length << " r: " << r << dendl;
return r;
}
if (!chunk_data.length()) {
return -ENODATA;
}
// 判断刷回的模式
unsigned flags = CEPH_OSD_FLAG_IGNORE_CACHE | CEPH_OSD_FLAG_IGNORE_OVERLAY |
CEPH_OSD_FLAG_RWORDERED;
tgt_length = chunk_data.length();
// 根据不同的存储池指纹信息,选择对应的摘要算法获取 chunk_data 对应的 hash 值
if (pg_pool_t::fingerprint_t fp_algo = pool.info.get_fingerprint_type(); iter->second.has_reference() && fp_algo != pg_pool_t::TYPE_FINGERPRINT_NONE) {
object_t fp_oid = [fp_algo, &chunk_data]() -> string {
switch (fp_algo) {
case pg_pool_t::TYPE_FINGERPRINT_SHA1:
return crypto::digest<crypto::SHA1>(chunk_data).to_str();
case pg_pool_t::TYPE_FINGERPRINT_SHA256:
return crypto::digest<crypto::SHA256>(chunk_data).to_str();
case pg_pool_t::TYPE_FINGERPRINT_SHA512:
return crypto::digest<crypto::SHA512>(chunk_data).to_str();
default:
assert(0 == "unrecognized fingerprint type");
return {};
}}();
bufferlist in;
// 如果 oid 不一致
if (fp_oid != tgt_soid.oid) {
// 减小旧块的引用计数
// decrement old chunk's reference count
ObjectOperation dec_op;
cls_chunk_refcount_put_op put_call;
put_call.source = soid;
::encode(put_call, in);
// 对 chunk 的计数执行修改 PUT 操作
dec_op.call("cas", "chunk_put", in);
// 执行 objecter_mutate 方法会将请求转化为 Op 请求,再进行请求的提交,写入到后端存储池 dec_op chunk_put
// we don't care dec_op's completion. scrub for dedup will fix this.
tid = osd->objecter->mutate(
tgt_soid.oid, oloc, dec_op, snapc,
ceph::real_clock::from_ceph_timespec(obc->obs.oi.mtime),
flags, NULL);
in.clear();
}
tgt_soid.oid = fp_oid;
iter->second.oid = tgt_soid;
// 编码实际操作的关键数据(偏移量和数据长度)
// add data op
ceph_osd_op osd_op;
osd_op.extent.offset = 0;
osd_op.extent.length = chunk_data.length();
// 将数据编码
encode(osd_op, in);
encode(soid, in);
in.append(chunk_data);
obj_op.call("cas", "cas_write_or_get", in);
} else {
obj_op.add_data(CEPH_OSD_OP_WRITE, tgt_offset, tgt_length, chunk_data);
}
C_ManifestFlush *fin = new C_ManifestFlush(this, soid, get_last_peering_reset());
fin->offset = iter->first;
fin->last_offset = last_offset;
manifest_fop->chunks++;
unsigned n = info.pgid.hash_to_shard(osd->m_objecter_finishers);
// 封装写请求写入到后端存储池 obj_op cas_write_or_get
tid = osd->objecter->mutate(
tgt_soid.oid, oloc, obj_op, snapc,
ceph::real_clock::from_ceph_timespec(obc->obs.oi.mtime),
flags, new C_OnFinisher(fin, osd->objecter_finishers[n]));
fin->tid = tid;
manifest_fop->io_tids[iter->first] = tid;
dout(20) << __func__ << " offset: " << tgt_offset << " len: " << tgt_length
<< " oid: " << tgt_soid.oid << " ori oid: " << soid.oid.name
<< " tid: " << tid << dendl;
if (last_offset < iter->first) {
break;
}
}
return 0;
}
- 通过源码分析我们不难看出,flush 操作最终是以 Op 请求的方式传递到底层存储层的,也就意味着需要再执行一次 Ceph 存储池写数据的相关逻辑。
Command
ceph osd tier add {data_pool} {cache pool} // Bind cache pool to storage poolceph osd tier cache-mode {cache-pool} {cache-mode} // Set cache mode for cache poolceph osd tier cache-mode {cache-pool} {cache-mode} // Set read tier/write tier according to the cache mode
References
