为了解决这一限制,Beckmann 和 Sanchez[2017] 提出了一个称为经济附加值(EVA)的新指标,将这两个因素合并为一个单一指标。EVA 被定义为候选对象可能产生的命中数与其在缓存中的平均占用率的比值。方程 (4.1) 表明 EVA 是对给定缓存行计算的。我们看到一个缓存行的 EVA 有两个组成部分。首先,该行将因其预期的未来命中次数而获得奖励(具有较高重用概率的该行将具有较高的EVA值)。其次,这一行会因为它所消耗的缓存空间而受到惩罚。这个惩罚是通过对每个候选对象在缓存中花费的时间进行收费来计算的,收费的速率是一行的平均命中率(缓存命中率除以其大小),这是消耗缓存空间的长期机会成本。因此,EVA 指标通过计算该行命中的几率是否值得它所消耗的缓存空间来获取缓存行的成本效益权衡。$$ EVA = Expected_hits - (Cache_hit_rate / Cache_size) * Expected_time$$
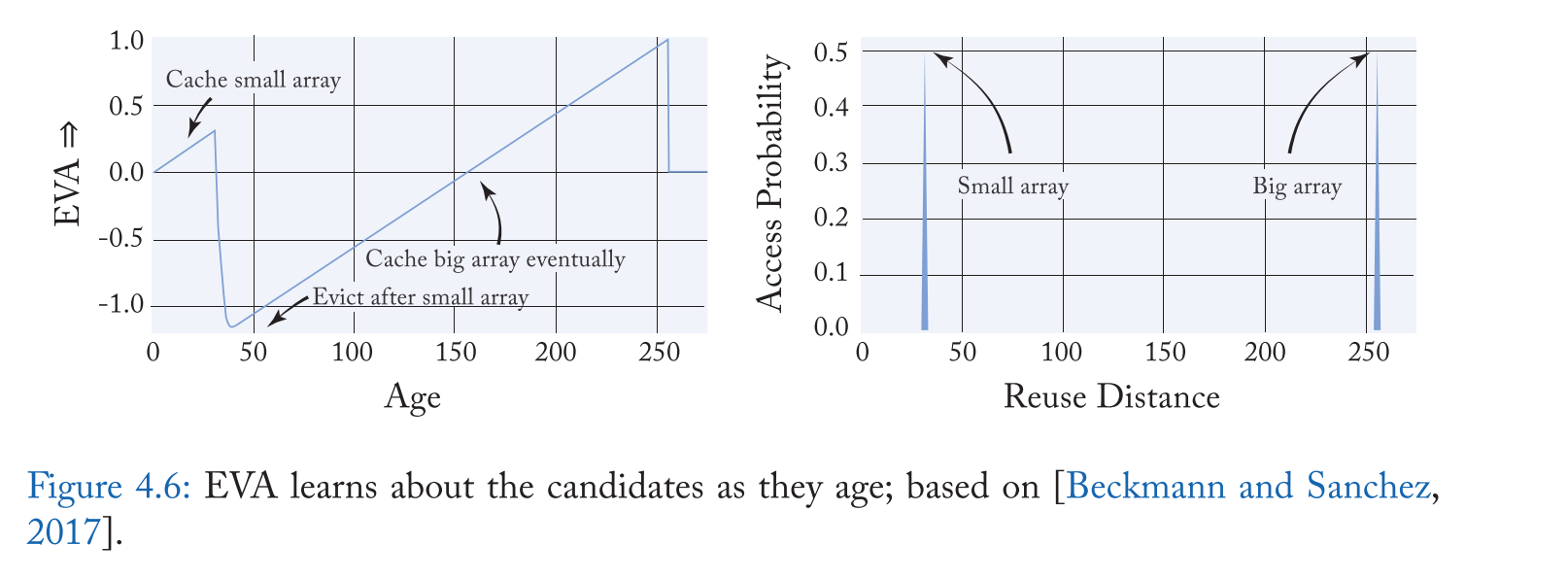
候选人的 EVA 是从他们的年龄推断出来的,并随着候选人的年龄进行修正。例如,左边的图4.6 显示了 EVA 是如何随着候选应用程序年龄的变化而变化的,该应用程序遍历一个小数组和一个大数组(右边显示了同一应用程序的重用距离分布)。首先,EVA 较高,因为访问很有可能来自一个小数组,这意味着替换策略可以赌候选者会很快命中。但是,当年龄超过短数组的长度时,EVA 急剧下降,因为从大数组缓存行的代价要高得多。此时,低 EVA 使大数组中的行很可能被逐出。缓存来自大数组的行所带来的代价随着行的老化和接近大数组的重用距离而降低。这种惩罚反映在年龄从 50 岁到 250 岁的 EVA 逐渐增加,在这一点上 EVA 替换策略保护缓存行免受大数组替代,即使它们是老的。因此,在面临不确定性时,EVA 替代策略会随着候选人年龄的增长而对他们有更多的了解。
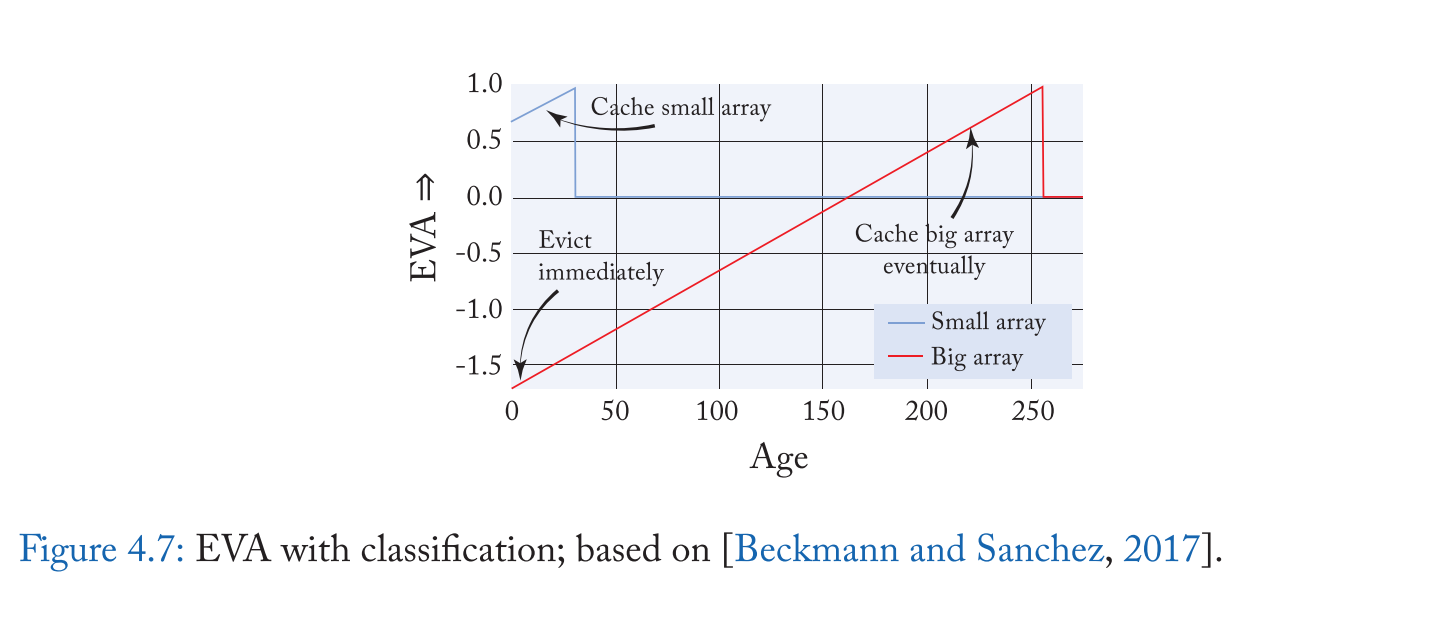
当然,另一种减少不确定性的方法是将缓存行分为不同的类别。例如,如果我们将小数组和大数组划分为不同的类别,图 4.7 显示了与年龄相关的 EVA,我们可以看到每个类别的 EVA 曲线要简单得多。理论上,可以扩展 EVA 以支持分类,但实现的复杂性将这种扩展限制在少数类。在下一节中,我们将讨论依赖于许多细粒度类的替换策略,但学习每个类的更简单的指标。相比之下,EVA 以细粒度对年龄进行排序,但这限制了 EVA 使用更少的类。
EVA 替换策略通过记录命中和驱逐的年龄分布并使用轻量级软件运行时处理有关这些驱逐的信息来计算 EVA 曲线。为了预测一条缓存行的 EVA,将其年龄作为索引,建立一个代表 EVA 曲线的驱逐优先级数组。