- Ceph 作为分布式存储系统,在可用性和一致性方面有极高的要求。
- Ceph 区别于其他分布式数据库等产品,更多的是作为云计算基础设施提供服务。
- 本文主要介绍 Ceph 中的数据一致性的实现方案,以多副本为例,后续介绍纠删码。
Ceph IO
RBD IO
- 首先以 RBD 为例,回顾一下 Ceph RBD 的整个 IO 过程。

- 客户端创建对应的存储池 Pool,指定相应的 PG 个数以及 PGP 个数(用于 PG 中的数据均衡)
- 创建 pool/image rbd设备进行挂载
- 用户写入的数据进行切块,每个块有默认大小,并且每个块都有一个 Key,Key 就是 object+序号
- 将每个 object 通过 pg 进行副本位置的分配
- PG 根据 cursh 算法会寻找指定个数的 osd(主从个数),把这个 object 分别保存在这些 osd 上
- osd 上实际是把底层的 disk 进行了格式化操作,一般部署工具会将它格式化为 xfs 文件系统
- object 的存储就变成了存储一个文件 rbd0.object1.file
一致性实现方式
- Ceph 中的数据一致性实现主要依赖底层对象存储系统中的数据一致性保证。在 Ceph 中对应的则是 RADOS 在一致性上的实现,RADOS 作为 Ceph 存储的核心,主要提供了多副本和纠删码的方式来保证一致性,
主要分类
- 多副本一致性协议(以 PG 为逻辑存储单元的 OSD 多副本)
- EC 纠删码一致性协议
多副本一致性协议
- RADOS 提供的数据复制策略:主拷贝、链式复制、Splay树复制
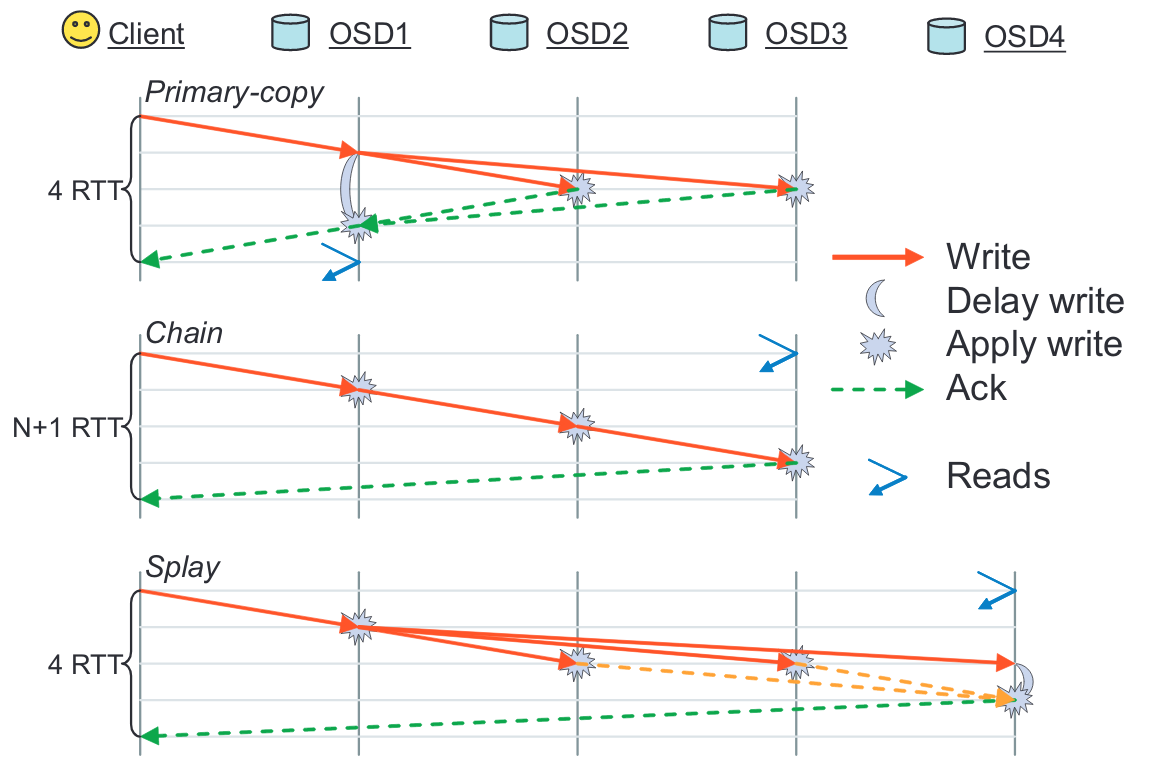
- 其中在 Ceph 中主要采用的为 主拷贝 方式。
主要流程
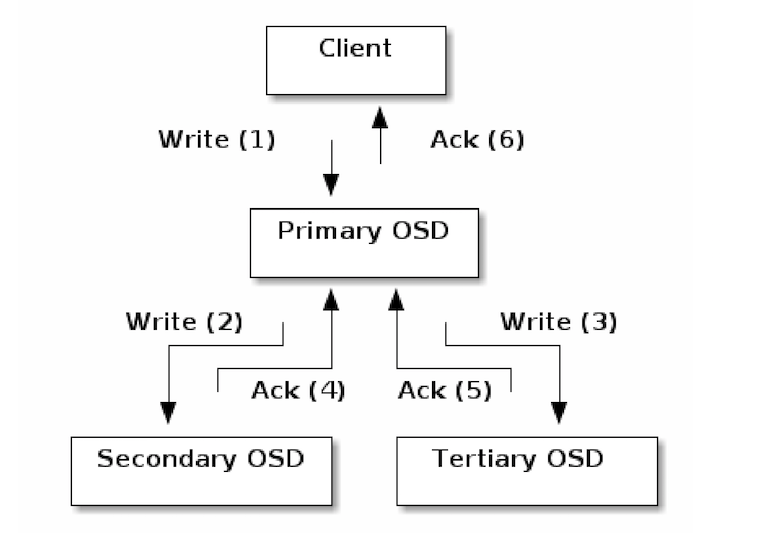
- librados 向主 OSD 写入分好块的二进制数据块 (先建立TCP/IP连接,然后发送消息给 OSD,OSD 接收后写入其磁盘)
- 主 OSD 负责同时向一个或者多个次 OSD 写入副本。注意这里是写到日志(Journal)就返回,因此,使用SSD作为Journal的话,可以提高响应速度,做到服务器端对客户端的快速同步返回写结果(ack)
- 当主次OSD都写入完成后,主 OSD 向客户端返回写入成功。
- 当一段时间(也许得几秒钟)后Journal 中的数据向磁盘写入成功后,Ceph通过事件通知客户端数据写入磁盘成功(commit),此时,客户端可以将写缓存中的数据彻底清除掉了。
- 默认地,Ceph 客户端会缓存写入的数据直到收到集群的commit通知。如果此阶段内(在写方法返回到收到commit通知之间)OSD 出故障导致数据写入文件系统失败,Ceph 将会允许客户端重做尚未提交的操作(replay)
实现方式
- Ceph 使用 PGLog 来保证多副本之间的一致性。PGLog是由PG来维护,记录了该PG的所有操作,其作用类似于数据库里的undo log。PGLog通常只保存近千条的操作记录(默认是3000条),但是当PG处于降级状态时,就会保存更多的日志(默认是10000条),这样就可以在故障的PG重现上线后用来恢复PG的数据。
数据结构
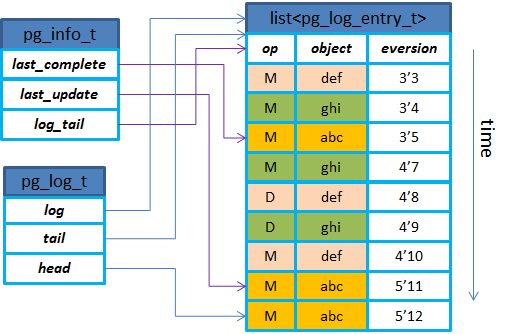
- pglog的示意图如下:pglog主要是用来记录做了什么操作,比如修改,删除等,而每一条记录里包含了对象信息,还有版本。
- ceph使用版本控制的方式来标记一个PG内的每一次更新,每个版本包括一个(epoch,version)来组成:其中epoch是osdmap的版本,每当有OSD状态变化如增加删除等时,epoch就递增;version是PG内每次更新操作的版本号,递增的,由PG内的Primary
- 属性:
- last_complete:在该指针之前的版本都已经在所有的OSD上完成更新(只表示内存更新完成);
- last_update:PG内最近一次更新的对象的版本,还没有在所有OSD上完成更新,在last_update与last_complete之间的操作表示该操作已在部分OSD上完成但是还没有全部完成;
- log_tail:指向pg log最老的那条记录;
- head:最新的pg log记录;
- tail:指向最老的pg log记录的前一个;
- log:存放实际的pglog记录的list;
存储方式
- 在ceph的实现里,对于写I/O的处理,都是先封装成一个transaction,然后将这个transaction写到journal里,在journal写完成后,触发回调流程,经过多个线程及回调的处理后再进行写数据到buffer cache的操作,从而完成整个写journal和写本地缓存的流程。
- 总体来说,PGLog也是封装到transaction中,在写journal的时候一起写到日志盘上,最后在写本地缓存的时候遍历transaction里的内容,将PGLog相关的东西写到Leveldb里,从而完成该OSD上PGLog的更新操作。
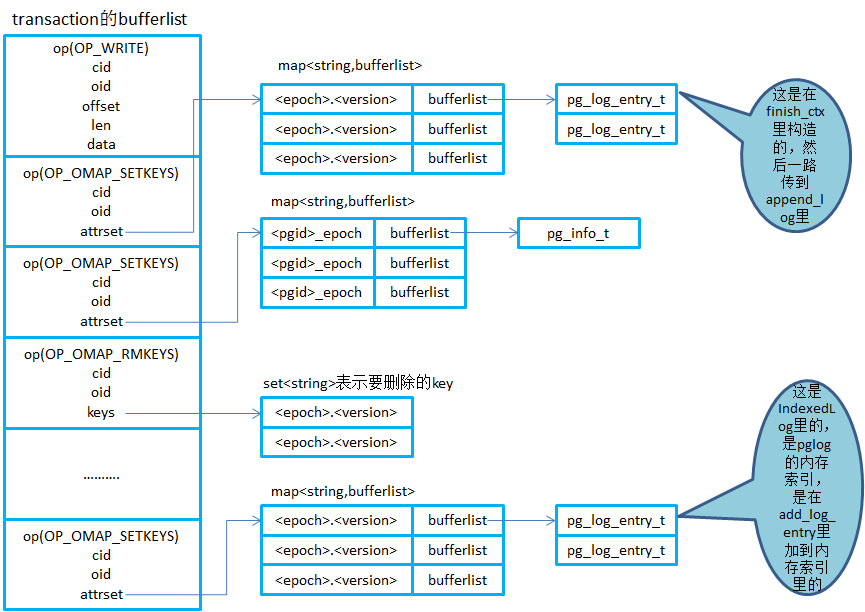
- 写I/O和PGLog都会序列化到transaction里的bufferlist里,这里就对这个bufferlist里的主要内容以图的形式展示出来。transaction的bufflist里就是按照操作类型op来序列化不同的内容,如OP_WRITE表示写I/O,而OP_OMAPSETKEYS就表示设置对象的omap,其中的attrset就是一个kv的map。 注意这里面的oid,对于pglog来说,每个pg在创建的时候就会生成一个logoid,会加上pglog构造的一个对象,对于pginfo来说,是pginfo_构造的一个对象,而对于真正的数据对象来说,attrset就是其属性。
流程细化
-
写流程:以 FileStore 后端存储为例
- 1)client把写请求发到Primary OSD上,Primary OSD上将写请求序列化到一个事务中(在内存里),然后构造一条pglog记录,也序列化到这个事务中,然后将这个事务以directIO的方式异步写入journal,同时Primary OSD把写请求和pglog(pglog_entry是由primary生成)发送到Replicas上;
- 2)在Primary OSD将事务写到journal上后,会通过一系列的线程和回调处理,然后将这个事务里的数据写入filesystem(只是写到文件系统的缓存里,会有线程定期刷数据),这个事务里的pglog记录(也包括pginfo的last_complete和last_update)会写到leveldb,还有一些扩展属性相关的也在这个事务里,在遍历这个事务时也会写到leveldb;
- 3)在Replicas上,也是进行类似于Primary的动作,先写journal,写成功会给Primary发送一个committed ack,然后将这个事务里的数据写到filesystem,pglog与pginfo写到leveldb里,写完后会给Primary发送另外一个applied ack;
- 4)Primary在自己完成journal的写入时,以及在收到Replica的committed ack时都会检查是否多个副本都写入journal成功了,如果是则向client端发送ack通知写完成;Primary在自己完成事务写到文件系统和leveldb后,以及在收到replica的applied ack时都会检查是否多个副本都写文件系统成功,如果是则向client端发送ack通知数据可读;
-
读流程:由于实现了强一致性,主节点和从节点的数据基本完全一致,故在读取时采用了随机的方式进行OSD的选取,然后读取对应的数据。
-
PGLog封装到transaction里面和journal一起写到盘上的好处:如果osd异常崩溃时,journal写完成了,但是数据有可能没有写到磁盘上,相应的pg log也没有写到leveldb里,这样在osd再启动起来时,就会进行journal replay,这样从journal里就能读出完整的transaction,然后再进行事务的处理,也就是将数据写到盘上,pglog写到leveldb里。
故障恢复
- 基于pglog的一致性协议包含两种恢复过程,一个是Primary挂掉后又起来的恢复,一种是Replica挂掉后又起来的恢复。
Primary 故障恢复

- 1)正常情况下,都是由Primary处理client端的I/O请求,这时,Primary和Replicas上的
last_update和last_complete都会指向pglog最新记录; - 2)当Primary挂掉后,会选出一个Replica作为“临时主”,这个“临时主”负责处理新的读写请求,并且这个时候“临时主”和剩下的Replicas上的
last_complete和last_update都更新到该副本上的pglog的最新记录; - 3)当原来的Primary又重启时,会从本地读出pginfo和pglog,当发现
last_complete<last_update时,last_complete和last_update之间就可能存在丢失的对象,遍历last_complete到last_update之间的pglog记录,对于每一条记录,从本地读出该记录里对象的属性(包含本地持久化过的版本),对比pglog记录里的对象版本与读出来的版本,如果读出来的对象版本小于pglog记录里的版本,说明该对象不是最新的,需要进行恢复,因此将该对象加到missing列表里; - 4)Primary发起peering过程,即“抢回原来的主”,选出权威日志,一般就是“临时主”的pglog,将该权威日志获取过来,与自己的pglog进行
merge_log的步骤,构建出missing列表,并且更新自己的last_update为最新的pglog记录(与各个副本一致),这个时候last_complete与last_update之间的就会加到missing列表,并且peering完成后会持久化last_complete和last_update; - 5)当有新的写入时,仍然是由Primary负责处理,会更新
last_update,副本上会同时更新last_complete,与此同时,Primary会进行恢复,就是从其他副本上拉取对象数据到自己这里进行恢复,每当恢复完一个时,就会更新自己的last_complete(会持久化的),当所有对象都恢复完成后,last_complete就会追上last_update了。 - 6)当恢复过程中,Primary又挂了再起来恢复时,先读出本地pglog时就会根据自己的
last_complete和last_update构建出missing列表,而在peering的时候对比权威日志和本地的pglog发现权威与自己的last_update都一样,peering的过程中就没有新的对象加到missing列表里,总的来说,missing列表就是由两个地方进行构建的:一个是osd启动的时候read_log里构建的,另一个是peering的时候对比权威日志构建的;
Replica 故障恢复
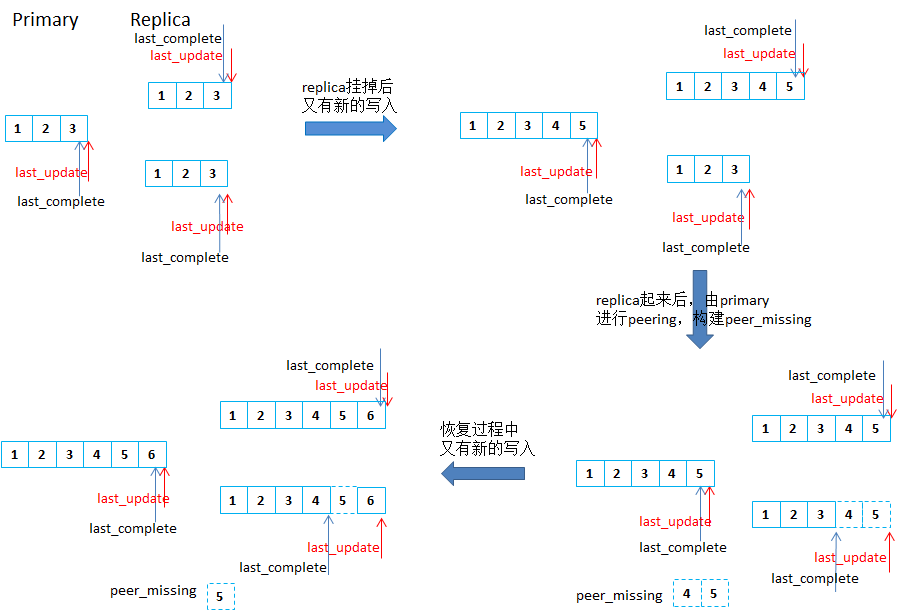
- 与Primary的恢复类似,peering都是由Primary发起的,Replica起来后也会根据pglog的
last_complete和last_update构建出replica自己的missing,然后Primary进行peering的时候对比权威日志(即自身)与故障replica的日志,结合replica的missing,构建出peer_missing,然后就遍历peer_missing来恢复对象。然后新的写入时会在各个副本上更新last_complete和last_update,其中故障replica上只更新last_update,恢复过程中,每恢复完一个对象,故障replica会更新last_complete,这样所有对象都恢复完成后,replica的last_complete就会追上last_update。
如果恢复过程中,故障replica又挂掉,然后重启后进行恢复的时候,也是先读出本地log,对比last_complete与last_update之间的pglog记录里的对象版本与本地读出来的该对象版本,如果本地不是最新的,就会加到missing列表里,然后Primary发起peering的时候发现replica的last_update是最新的,peering过程就没有新的对象加到peer_missing列表里,peer_missing里就是replica自己的missing里的对象。
