NSDI 2019 的文章《Exploiting Commutativity For Practical Fast Replication》
NSDI 2019 的文章《Exploiting Commutativity For Practical Fast Replication》
这篇论文主要针对分布式系统中的主从复制场景提供了一种利用执行操作的可交换性快速同步的方案
恰好最近有在学习分布式系统中的一致性以及组会需要讲解论文,故细读了这篇 Paper 并进行总结
由于是研究生期间第一篇细读的论文,想以总结的形式顺便了解到学术论文的相关写作技巧和规范
结合组会交流过程中遇到的几个问题,进行仔细地思考和相关文献资料的查阅,未完待续~
摘要
传统的数据强一致性场景下的主从复制需要 2RTT(Round-Trip Time)来完成一次操作,而本文提出了一种新的方案 CURP (Consistent Unordered Replication Protocal)实现在 1RTT 内完成一次操作。通过在 Redis 和 RAMCloud 上进行测试:RAMCloud 性能有较大提升,写延迟从 14 微秒降低到 7.1微秒,吞吐量提升约为 4 倍; Redis 的持久化开销也相应地被减小。
编者注 :1RTT 只是针对少量场景能达到的最好效果,一般场景可能仍然需要 2RTT 甚至恶化到 3RTT,所以 1RTT 的说法稍有“标题党”的嫌疑。测试场景主要针对 K-V 型的存储,也是该方案的局限所在,后文具体介绍。
Introduction
背景
许多分布式系统,特别是分布式存储系统,对可用性和一致性要求都非常高。为了保证服务的高可用,业界往往采用了副本的方式来作为当前服务主节点的“备胎”,但针对部分一致性要求高的场景,需要尽量保证副本的数据和主节点上的数据保持一致。而为了保证一致性,常常都会采用复制的策略,但复制的策略又主体划分为:
1.树形复制,也称基于强 Leader 的数据一致性复制协议,诸如 Raft/Multi-Paxos
2.链式复制,链式复制也有相应的优化方案,可参考链接 Github:复制模型
3.分发复制:Client直接向各个节点直接进行分发写入,节点之间并不进行通信复制,只要写入多数节点成功,就判为写入成功。
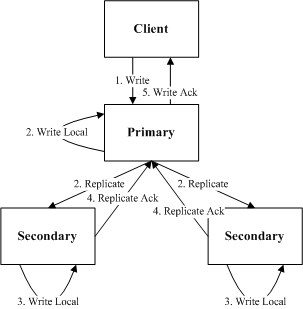
对比以上几种模型,树形复制作为吞吐量和延迟上的折中方案,被很多系统应用到了实际的生产环境中。树形复制流程如图所示,论文主要针对树形复制的 2RTT 进行优化,将其降低为 1RTT,在此基础上提出优化方案。
现有的一些方案
复制协议的核心思想 :
要保证操作执行顺序的一致性,特别是一些具有因果关系的操作。
需要提供相应的持久化功能,保证能够从故障情况中进行恢复。
主从复制 - 2RTT
传统意义上的主从复制方案,即上文提到的树形复制方案,实现了相应的核心思想,但产生了 2RTT 。
1RTT 来自于 Client 和 Master 之间的交互, 1RTT 来自于 Master 和 Backup 。
该方案中主要依赖 Master 节点对操作进行相应的排序和序列化。
Raft/Multi-Paxos 等基于强 Leader 的数据一致性复制协议,和普通的主从复制的区别仅仅在于复制过程中同步的数据有所不同,Raft/Multi-Paxos 主要针对操作日志进行同步复制。
Fast Paxos and Generalized Paxos - 1.5RTT
该类型方案中不是 Leader 节点来完成对应的序列化操作。
根据推测的执行顺序来进行推断,如果多数节点响应成功,则对应的执行操作。
1RTT 来自于客户端和主节点之间的交互, 0.5RTT 主要来自于等待多数节点同意该顺序。
编者注: 此处介绍的很抽象模糊,后续会针对这几种 Paxos 算法进行具体的分析比较。
Network-Ordered Paxos and Speculative Paxos - Near 1RTT
利用了特殊的网络硬件设施来保证操作的执行顺序。
由于硬件设施的复杂性以及延迟较高,该类型目前而言不太适用于实际生产环境。
CURP
Key Idea
Source of Idea :为了满足一致性复制协议的两个核心思想,性能上往往都差强人意。从需求方面而言,关于持久性的要求为了保证高可用不能做丝毫妥协,则只有在操作的执行顺序上下手进行优化。前有 multi-paxos 基于类似 pipeline 复制的乱序 commit,但是并不能乱序 apply,所以后来又有了 Parallel Raft 通过让 raft 协议感知具体应用而实现乱序 Apply,其实都是想在执行顺序上做些突破。CURP 采用了一种延迟确定顺序的方案,通过判断操作之间是否有顺序依赖,来区分可以乱序执行的操作和顺序执行的操作,从而实现 1RTT 的延迟。
Architecture
组成
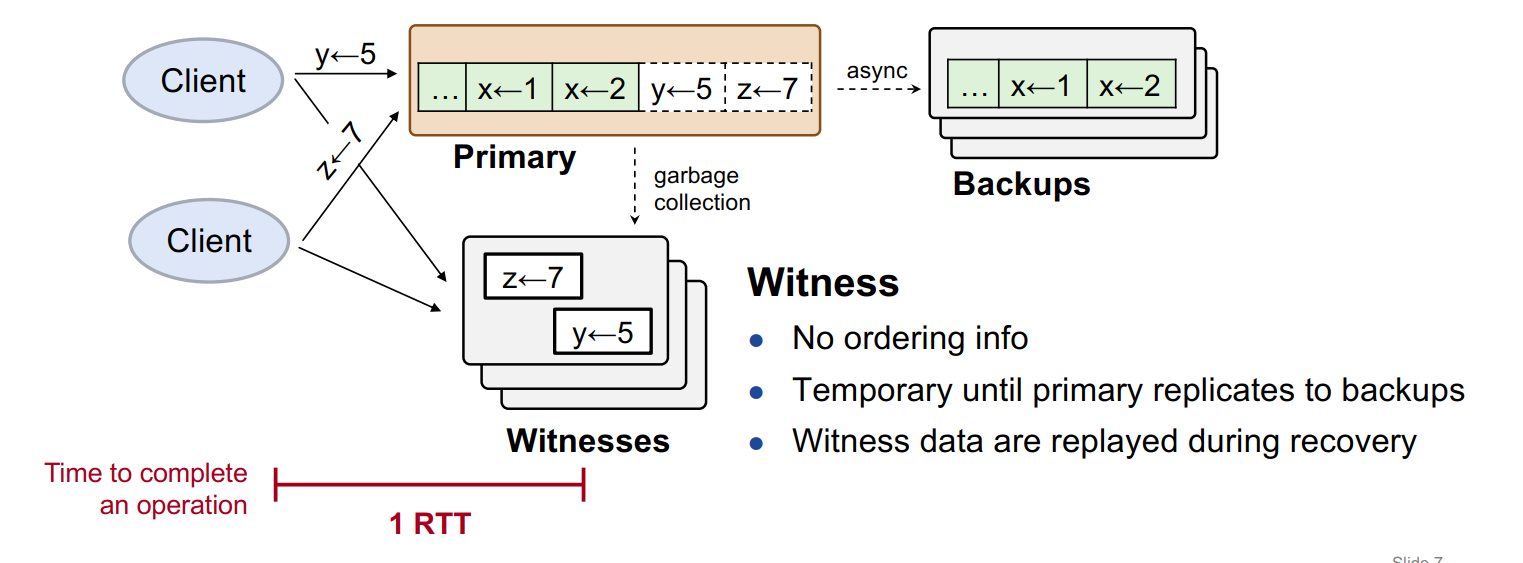
Client :并发地向 Primary 和 Witnesses 节点发送 op request,等到 Primary 和 Witnesses 都返回成功了,则认为该请求对应的执行成功。针对某些失败的操作,需要 Client 端针对返回的信息进行相应的处理,同时也有重试的机制。Primary :数据操作执行的主节点,也就是副本的 Leader 节点,主节点收到 op request,立马返回执行结果,然后异步地复制给 Backups。其中主节点把持久化的操作划分为了两个区域(或者以状态进行标识),同步区(Synced,图中绿色表示)和未同步区(Unsynced,图中白色表示),便于同步操作的执行。Backups :其他副本节点,主要接受来自 Primary 同步或者异步的复制操作。Witnesses :节点集群,接收客户端的 op request,将对接收到的请求和节点中已经持久化的 op request 进行交换律的验证,如果满足交换律,则对应的将该操作持久化到该节点中,否则返回 reject,由客户端处理该响应后向 Primary 节点发起 SYNC RPC,主动地触发 Primary 节点向 Backups 节点的复制,大多数副本节点返回成功后对应地向客户端返回成功。
Witnesses 集群
关于 Witness 节点数量的设置,取决于该模型中副本的个数(除去主副本),从而保证故障恢复情况下,整个系统能对应地表现出相应的容错率。在实际部署过程中,可以考虑 Witness 节点是否和 Backup 节点在一台物理机或者虚拟机上。
为了避免掉电时数据丢失, Witnesses 节点一般部署在 NVM 上,由于是临时数据,数据量不大,且对 IO 执行的速度有一定的要求(响应客户端的请求以及故障恢复时需要较快地读取数据进行恢复),故选择了 NVM 作为存储器件。
执行情况描述
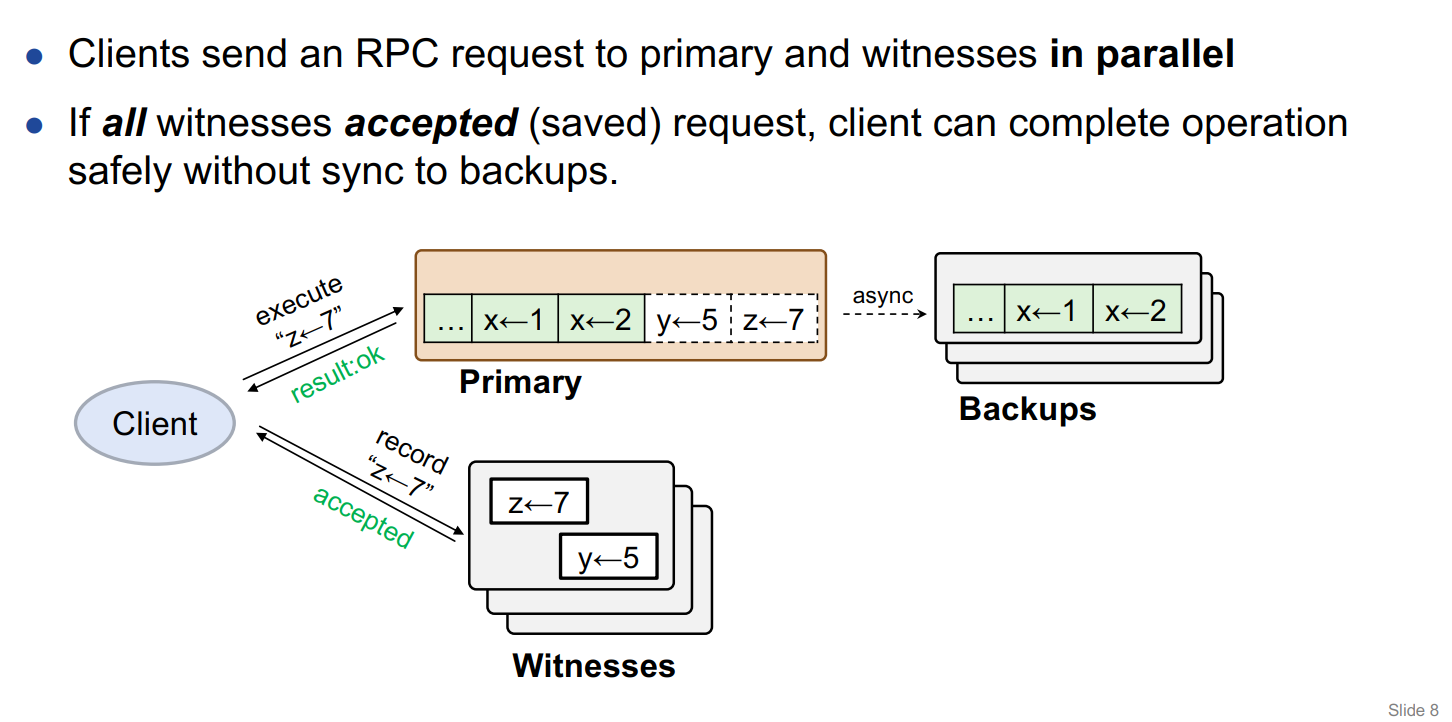
正常执行(可交换的操作执行):
Client 端的表现 :并发地发出请求,等待 Primary 和所有的 Witnesses 节点返回成功,则对应的确认该操作成功执行。这种机制也相应地带来了性能瓶颈:虽说是 1RTT 完成了操作的执行,但是具体的时间可能将取决于 Witenesses 以及 Primary 中最后执行成功的节点,同时还要考虑 Witnesses 节点部分执行成功的情况 。
如果 Witnesses 集群中仅有部分节点执行成功,则客户端需要向 Primary 中发起 SYNC RPC调用来进行同步。同接收到 Reject 的响应的结果一样。
Witnesses 节点的操作 :处理来自客户端的 Recored 请求,判断该请求和当前持久化在节点中的请求是否有冲突,没有则继续持久化到节点中,相应地返回 Accepted。Primary 节点的操作 :执行对应的操作,持久化到节点中,并发送执行成功的响应给客户端,异步地进行主从的复制,并修改该节点中每个操作的同步状态,定期地向 Witnesses 发送 GC 请求。
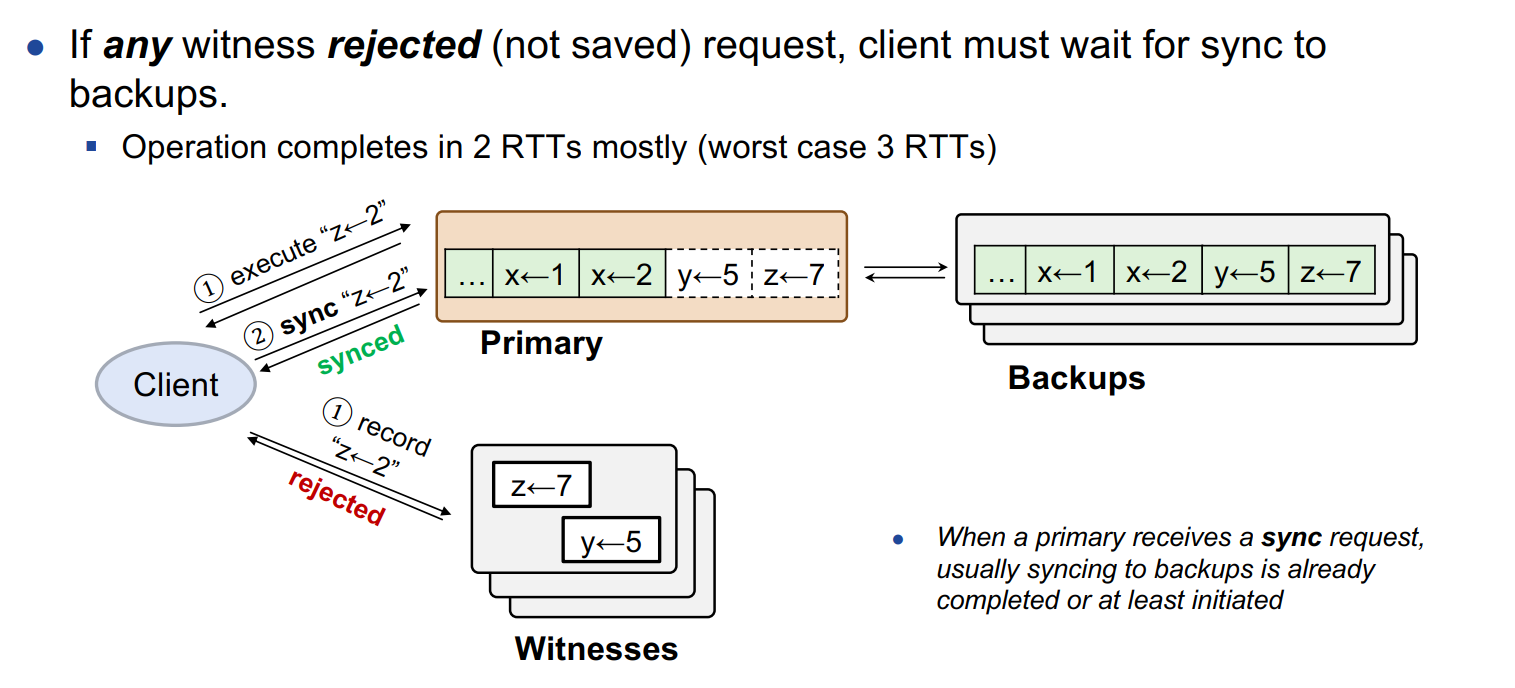
与之前的操作存在冲突时执行:
Client 端的表现 :在接收到来自 Witnesses 节点的 Reject 之后,发起 SYNC RPC,让 Primary 节点把其中 Unsynced 的操作进行对应的同步操作,并等待接收同步成功的请求。
在处理 Reject 的响应中,整个模型的流程将退化为 2RTT,因为多了一次主从之间的同步操作;但在最坏的场景(发送 SYNC RPC 之后发现 Primary 节点宕机)下可能恶化为 3RTT。
Witnesses 节点的操作 :在判断操作与现有的冲突之后,对应的发送 Reject 的响应,并等待 Primary 节点发起 GC 请求,把 Witnesses 中已经同步了的操作进行清除。Primary 节点的操作 :先执行对应的操作,持久化到节点中,并发送执行成功的响应给客户端,当收到来自客户端的 SYNC RPC 时,对应地将节点中 Unsynced 的数据同步到副本节点中,并向客户端发送 Synced 响应。
读操作的执行
读操作和写操作的流程大致相同,核心思想都是要先检查读操作和已有的未同步 Unsynced 操作之间是否存在冲突,如果存在则需要 Witnesses 拒绝掉 Record 请求,客户端发送 SYNC RPC来及时进行数据的同步。
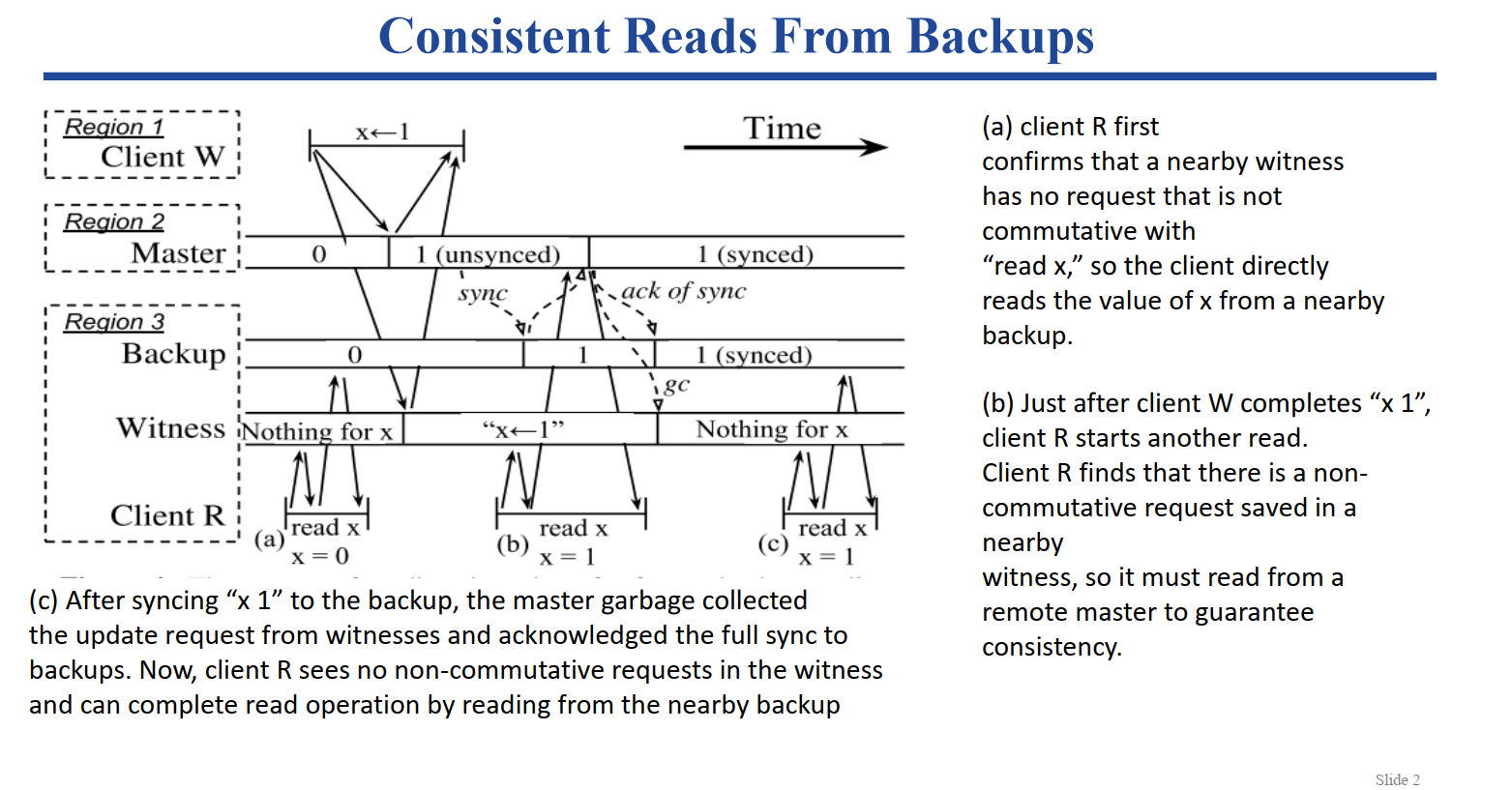
基于副本数据的一致读实现
背景 :主从复制的集群中,客户端的读操作往往都是在单节点上进行处理的,由主节点接管对应的读写请求来保证数据的一致性。但往往出于负载的考虑,部分分布式系统允许客户端从副本节点上去读取数据,从而缓解主节点上的压力,以及针对多数据中心的情况,一定程度上减少读取操作的开销,提升其响应操作。CURP 方案中的问题 :由于 CURP 方案为了提升读写操作的响应速度缩减到 1RTT,所以允许读写操作在完全同步到副本节点之间就完成。这样的机制虽然提高了响应速度,但与此同时也破坏了线性性。CURP方案中的实现 :为了避免客户端读取到老旧的数据,客户端利用了就近的 Witness 节点(一般为和副本节点在同一台物理机或者虚拟机上的 Witness 节点)来保证数据是最新的。大致流程 :
客户端向副本节点发起读操作之前,需要先向 Witness 节点发起请求询问是否和现有的 Unsynced 操作冲突;
如果不冲突,即此时副本节点上要读取的该数据是最新的,即可以直接向副本节点发起读请求;
如果冲突了,即存在最新的更新还未来得及同步到所有副本节点,故只能从主节点获取最新的数据。
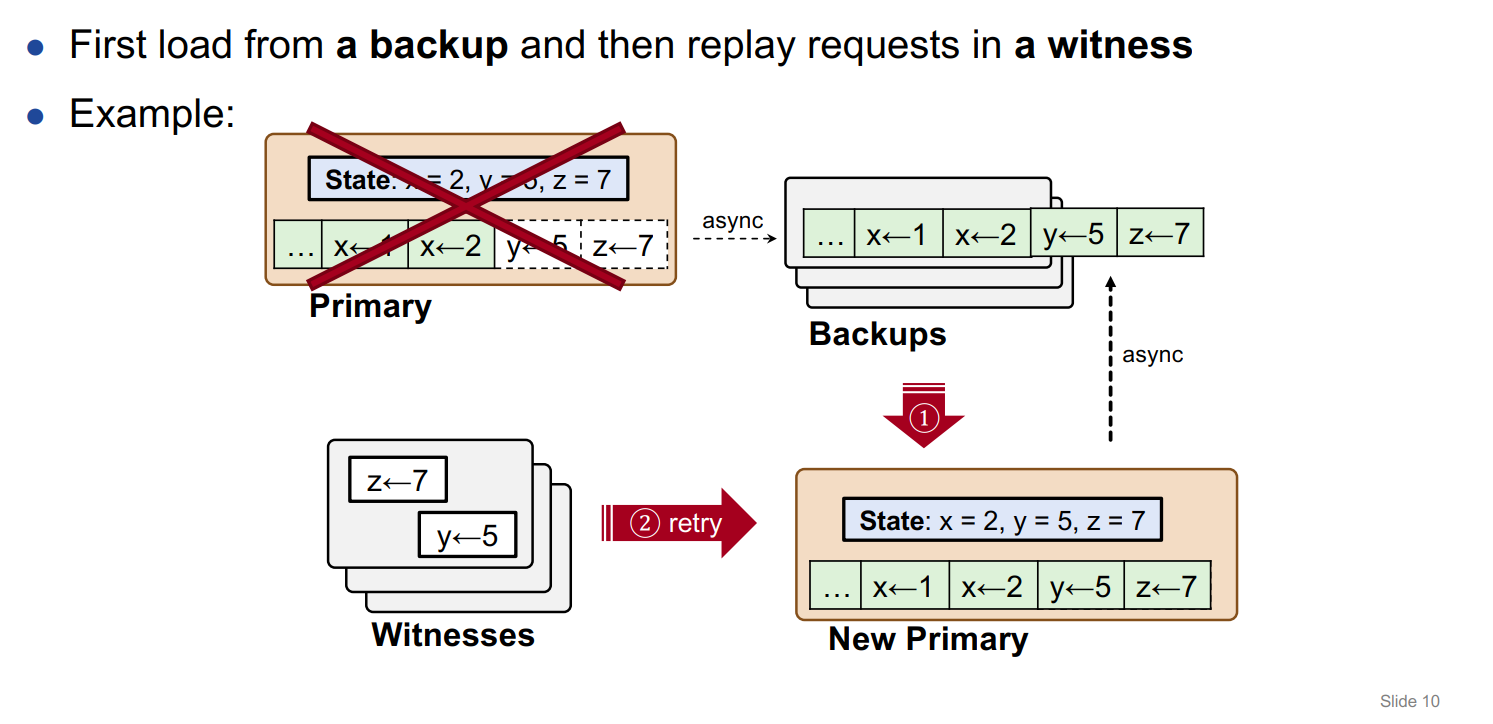
故障恢复流程
Primary 节点宕机
故障恢复大致可以分为三个阶段:
(1) restoration from backups:首先从 Backups 中选举出新的 Primary 节点,恢复对应的数据
(2) replay from witnesses:从 Witnesses 节点中选取一个节点,要求该节点停止接收客户端请求,进行相应操作的回放,保证数据的一致性
(3) Sync backups and reset witnesses:完成恢复以后,向其他副本节点异步地进行同步,同时重置当前这组 Witnesses 集群,或者要求管理节点分配一组新的 Witnesses 集群。
副本节点宕机
副本节点宕机和其他非 CURP 模型的处理方式一样,相应地需要将其踢出副本集群,并针对该节点执行后续的故障恢复操作。
Witnesses 节点宕机
Witness 节点宕机后,将由 系统管理节点 将该节点踢出集群,并分配一个新的 Witness 节点给节点数为 f-1 的 Witnesses 集群,对应的通知 Primary 节点更新其维护的所对应的 Witnesses 集群列表,Primary 节点将还未同步的数据同步到副本节点,相应地触发 GC,告知系统管理节点现在可以正常服务之后,恢复 Witnesses 节点的服务功能。
为了保证客户端维护的 Witnesses 集群信息缓存为最新,使用递增的版本号 WitnessListVersion 来进行控制。每次 Witnesses 集群信息发生改变时,相应地增加版本号,并通知到 Primary 节点。每次客户端向 Master 发起请求时,携带并发访问的 Witnesses 集群版本号,由 Primary 节点来判断是否为最新的 Witnesses 信息,如果不是最新,相应地返回客户端需要更新 Witnesses 集群信息的响应,再由客户端主动拉取 Witnesses 集群信息更新本地缓存。
数据迁移
出于负载均衡上的考虑,主节点可能将自己的数据拆分成两个分区上的数据,并把部分数据迁移到另外一个主节点上。
迁移的流程
在处理相关服务请求的同时z准备拷贝数据;
暂停该节点的相关服务进行数据迁移。
其他节点
为了简化数据迁移的场景以及减小数据迁移带来的不可靠因素的影响,在进行最后的数据迁移操作之前,主节点需要先将该节点上未同步的数据及时进行同步,确保副本节点上数据最新。
针对客户端可能访问到原有的主节点的情况,此时原主节点拒绝一切来自客户端的请求,并获取最新的主节点信息返回给客户端,告知其最新的集群信息,然后客户端向新的集群发起该次操作的重试。
核心操作的实现
Witnesses 节点如何判断操作之间是否有冲突?
本篇 Paper 提出的模型只能针对 能够进行顺序依赖判断的简单操作 进行优化,如 KV 型的 IO 操作,可以简单地通过比较每次操作的 KEY 是否相同来进行判断,使用简单的 HASH 函数即可实现。而针对部分需要先进行计算之后才能判断是否具有依赖关系的操作不能进行很好的判断。例如 SQL 语句使用了不同的限定条件(“UPDATE T SET
Witnesses 节点在出现数据不一致的情况下如何进行处理?
Client 需要等待所有的 Witnesses 节点 Record 成功之后才会进行下一步操作,如果其中接收到了任何一个 Reject 操作,都会调用 SYNC RPC 来进行主从同步复制。
在故障恢复过程中,只会从 Witenesses 节点中选择一个节点来进行操作的回放操作,所以也避免了不一致的情况。
故障恢复过程中如何避免操作重复执行?
CURP 利用了 RIFL 提供的保证只执行一次的机制。在 RIFL 中,客户端会为每一次 RPC 调用分配一个全局唯一标识 ID,在 Server 端对应的记录已经完成的 RPC 调用的 ID,从而便于之后恢复过程中对该操作是否执行过进行判断。
GC 垃圾回收的时机
Primary 节点会根据 Synced 的操作请求的 RPC ID,向 Witnesses 节点发起 GC 的请求,批量地进行垃圾回收以减小 Witnesses 中冲突的可能性。
在 NoSQL 中的实现
Witness 的生命周期和需要执行的操作
// CLIENT TO WITNESS:
record(masterID, list of keyHash, rpcId, request) -> ! {ACCEPTED or REJECTED}
// Saves the client request (with rpcId) of an update on keyHashes.
// Returns whether the witness could accomodate and save the request.
// MASTER TO WITNESS:
gc(list of {keyHash, rpcId}) -> list of request
// Drops the saved requests with the given keyHashes and rpcIds.
// Returns stale requests that haven’t been garbage collected for a long time.
getRecoveryData() -> list of request
// Returns all requests saved for a particular crashed master.
// CLUSTER COORDINATOR TO WITNESS:
start(masterId) -> {SUCCESS or FAIL}
// Start a witness instance for the given master, and return SUCCESS.
// If the server fails to create the instance, FAIL is returned.
end() -> NULL
// This witness is decommissioned. Destruct itself
Witness 的数据结构
Witness 的写入操作类似于缓存的级联操作,一次 Witness 的写入请求,会对应地将该请求中操纵的对象的主键进行 HASH(64位哈希值),然后根据哈希值计算当前 Witness 节点中是否已存在 Slot(比较哈希值),即是否存在操作同一个对象的请求。如果有说明操作冲突相应地拒绝掉该请求,没有则对应地写入该操作。
主节点上的操作可交换性检查(冲突检测)
由于 CURP 中的主节点存储的数据存在两种状态,SYNCED 和 UNSYNCED。故主节点可以通过判断操作的的数据对象的状态是否已同步来判断出该操作是否会冲突。
如果操作的对象的实际值是以日志的形式存储的,主节点可以通过比较日志中上次同步的位置和对象存储的值的现在的位置来比较。
如果操作的对象的实际值不是以日志的形式存储的,主节点可以利用单调递增的时间戳来进行比较判断。当主节点更新对象的值后,对应地更新一条元数据信息,类似于最近修改时间一样的时间戳属性,同时主节点也要记录最近一次同步的开始时间戳,通过比较这两个时间戳来判断是否已同步。
CURP 提高主节点的吞吐量方式
由于主从复制集群中,主节点往往是整个集群的性能瓶颈,故为了提高主节点的吞吐量,CURP 采用了以下几种方式:
进行批量同步操作
CURP 中采用了延迟同步的策略,所以不用每次操作之后都进行相应的同步操作。在无冲突异步复制的场景下,设定一个阈值,当主节点中 Unsynced 的数据个数达到该阈值时才对应地触发同步操作;在存在冲突主动复制的场景下,将此时主节点中未同步的数据全部进行同步(一般小于异步复制时设定的阈值)。
无论哪种场景,都采用了批量同步的情况,避免了频繁的 RPC 调用,从而提高了主节点的吞吐量。
注意 :异步复制时的阈值设定,对主节点吞吐量可能造成比较大的影响。当阈值较大时,每一次操作的冲突可能性越大,也就相应地增大了触发同步复制的可能性。所以需要根据具体的IO访问情况,进行阈值相关的测试,寻找到合适的阈值设定来保证主节点吞吐量最大化。
非阻塞IO
相比于其他主从同步的方案,主节点往往都需要等待复制完成后才进行后续的操作,而在CURP的方案中,主节点无需等待复制操作的完成就可以直接进行下一个请求的处理,一定程度上也提升了主节点的吞吐量。
GC 垃圾回收的实现
使用操作对象主键对应的 64 位哈希值和 RIFL 分配的 RpcID 来定位需要回收的垃圾数据,在收到对应的 GC 命令后,使用 keyHash 定位对象所属的 Slot,然后再根据 RpcID 来删除掉匹配的请求数据。
尽管简单的 GC 机制已经可以清除掉绝大多数垃圾,但是针对一些特殊情况如网络上的延迟以及客户端的一些宕机情况导致 Witness 节点存在未能正确清楚的垃圾数据,为了避免造成不一致问题,Witness 提供了相应的检测机制。
由于存在垃圾数据,故新请求被 Reject 的概率增大,如果发现针对某给对象的请求多次遇到冲突被拒绝,Witness 节点就将该对象标记为可能未正确回收的垃圾数据,在下一次主节点发送垃圾回收命令时相应地将这些未回收的数据信息返回给主节点,在下一次垃圾回收时,主节点将一并处理之前未回收的垃圾数据。
问题讨论
1. 可不可以让Witnesses 节点存储全量的数据,不区分操作是否冲突,直接异步地进行同步。
2. Witness 节点是以什么样的形式记录操作的?为何不合并相关写操作,记录最终的写数据?
3. 从设计角度来讲,CURP方案应该是有很大的尾延迟,为什么测试出来的尾延迟反而有提升?
4. 读过程是否可以进行优化,直接读取witness上的数据?
5. 多并发写相同数据时,系统的运行情况