- InfiniFS: An Efficient Metadata Service for Large-Scale Distributed Filesystems
InfiniFS: An Efficient Metadata Service for Large-Scale Distributed Filesystems
摘要
- 现代数据中心更喜欢一个文件系统实例,它跨越整个数据中心并支持数十亿个文件。在这样的场景中,文件系统元数据的维护面临着独特的挑战,包括在保持局部性的同时实现负载平衡、长路径解析和接近根的热点。
- 为了解决这些挑战,我们提出了INFINIFS,这是一种针对大规模分布式文件系统的高效元数据服务。它包括三个关键技术。
- 首先,INFINIFS 解耦了目录的访问和内容元数据,因此可以通过元数据位置和负载均衡对目录树进行分区。
- 其次,INFINIFS 设计了预测路径解析,以并行遍历路径,这大大减少了元数据操作的延迟。
- 第三,INFINIFS 在客户端引入乐观访问元数据缓存,缓解了近根热点问题,有效提高了元数据操作的吞吐量。
- 广泛的评估表明,INFINIFS在延迟和吞吐量方面都优于最先进的分布式文件系统元数据服务,并为多达1000亿个文件的大规模目录树提供稳定的性能。
Introduction
- 数据中心文件数量很多,很容易达到当前分布式文件系统单个实例的容量,所以一个数据中心一般分成很多个集群,每个集群跑一个分布式文件系统实例。但是如果整个数据中心只跑一个文件系统实例,这样做是比较理想的,因为提供了全局的数据共享,提高了资源利用,以及很低的操作复杂度。
- 例如,Facebook 引入了 Tectonic 分布式文件系统,将小型存储集群整合到一个包含数十亿个文件的单一实例中
- 现代数据中心元数据量很大, 数以百亿甚至数千亿的文件,用一个大规模的文件系统来管理所有的文件元数据就会遇到挑战
- 目录树分区很难实现局部性和负载均衡的 tradeoff
- 路径解析的延迟可能很高,因为文件深度可能很深
- 客户端元数据缓存一致性的开销将因为并发客户端数目较多变得很大
- 本文的方案
- 访问数据和内容数据解耦的元数据分区方法,来兼顾局部性和负载均衡
- 访问信息 name, ID, and permissions
- 内容信息 entry list and timestamps
- 细粒度分区
- 内部分区(高局部性)
- 访问元数据和其父目录 分区在一起
- 内容元数据和孩子节点数据分布在一起
- 细粒度分组使用对于 directory id 的一致性哈希来分布(负载均衡)
- 内部分区(高局部性)
- 预测路径解析来并行遍历目录树,减小了元数据操作的延迟
- 每个目录分配一个 predictable id,客户端可以通过计算预测出中间目录的 ID
- 多个组件的路径执行并行查询
- 乐观访问元数据缓存来缓解近根节点的热点问题,实现可扩展的路径解析
- 客户端缓存目录的访问元数据信息,来吸收近根节点的查询压力
- 低开销的惰性缓存失效策略。
- 即针对访问元数据信息的修改操作,将发送一个失效通知给元数据服务器,而不是通知客户端
- 每个服务器可以在处理客户端请求的时候验证对应的缓存的状态(惰性)
- 访问数据和内容数据解耦的元数据分区方法,来兼顾局部性和负载均衡
Background
Large-Scale Filesystem
- 文件系统一般都是用的层级结构,也就是目录树来组织文件
- 每个文件/目录都有元数据信息
- 元数据操作包含两步:
- 路径解析:定位对应的目标文件,检查用户是否有权限访问
- 元数据处理:文件系统执行元数据处理操作来原子更新对应的元数据对象
- 元数据服务可扩展性是大规模分布式存储系统的瓶颈,即单个实例相对的元数据处理能力有限,所以很多公司数据中心都使用了多个集群(实例)来实现
- 但是其实使用一个集群实例比使用多个更好
- 全局数据共享:
- 全局的namespace,跨数据中心的数据共享更好实现
- 对比:专门的数据防止策略,数据迁移策略,计算服务逻辑也变复杂,因为需要进行数据的切分
- 高资源利用
- 消除多个集群的重复数据,提升磁盘空间利用,实现更好的资源共享
- 对比:单个集群的空闲资源没法释放给其他集群
- 操作符复杂度低:
- 只需要维护一个系统和维护多个系统的区别,劳动密集,出错概率高
- 全局数据共享:
Challenges of Scalable Metadata
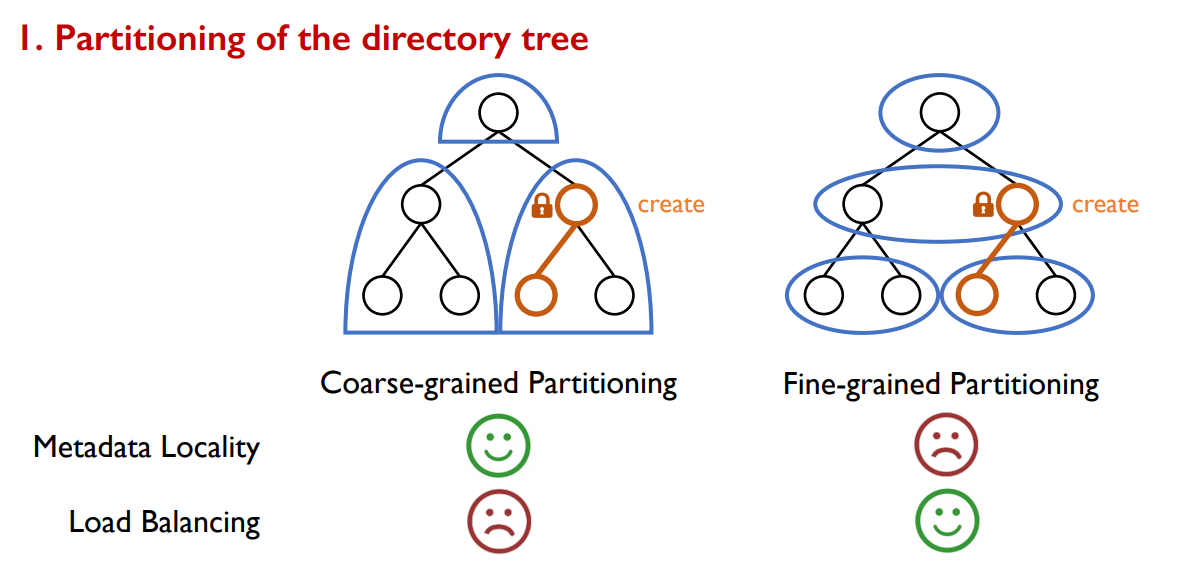
目录树分区
- 目录树分区很难同时实现高元数据局部性和负载均衡,特别是在目录树扩张以及负载变化的情况下
- 局部性:文件系统操作经常都需要同时处理多个元数据对象。分布式文件系统中有了局部性,就可以避免分布式锁和分布式事务,从而实现低延迟和高吞吐
- 文件创建操作首先加锁父目录,以保证和目录 list 的串行,然后原子更新三个元数据对象(目录的 entry list,新建的文件元数据,目录时间戳)
- 负载均衡:目录树中的元数据操作通常导致不均衡。
- 真实的数据中心负载经常把相关文件分组到一个子树,连续子树中的文件和目录可能在短时间内被大量访问,导致存储该子树的元数据服务器出现性能瓶颈
- 局部性:文件系统操作经常都需要同时处理多个元数据对象。分布式文件系统中有了局部性,就可以避免分布式锁和分布式事务,从而实现低延迟和高吞吐
- 现有分区方案很难兼顾两个特性。管理数据中心中的所有文件可以使目录树在深度和广度上迅速扩展。而且文件系统面对的负载特征经常变化
- 细粒度的分区策略
- 哈希分区,虽然可以实现负载均衡,但是局部性缺失了,造成频繁的分布式锁和事务,引入了开销较大的协调操作,高延迟低性能
- 粗粒度的分区策略
- 子树分区,将一个连续的子树分组到同一个服务器上,保持局部性并避免跨服务器操作。但易受负载偏置的影响,导致负载不平衡。
- 细粒度的分区策略
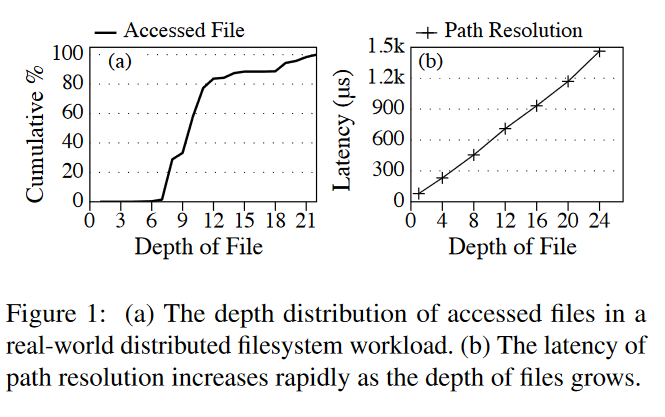
路径解析延迟
- 路径解析的延迟可能很高,因为在极其大规模的文件系统中,文件深度非常深
- 超过一半的访问对应的深度大于了 10
- 基于 Tectonic 的机制实现了原生的路径解析,发现随着深度增加,延迟也几乎线性增加
- Tectonic 将目录分区到不同元数据服务器,基于对应的目录 ID,解析深度为 N 的路径需要解析 N−1 个中间目录,从而导致 N−1 个顺序的网络请求
客户端元数据缓存开销
-
客户端元数据缓存一致性维护的开销变得非常大,因为非常大规模的文件系统通常需要为大量并发的客户端服务
-
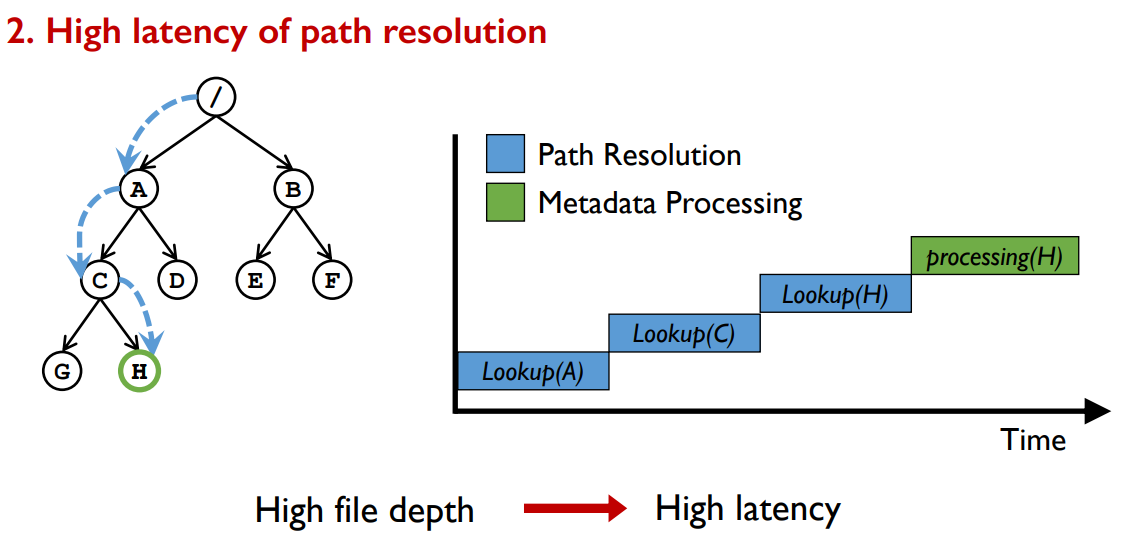
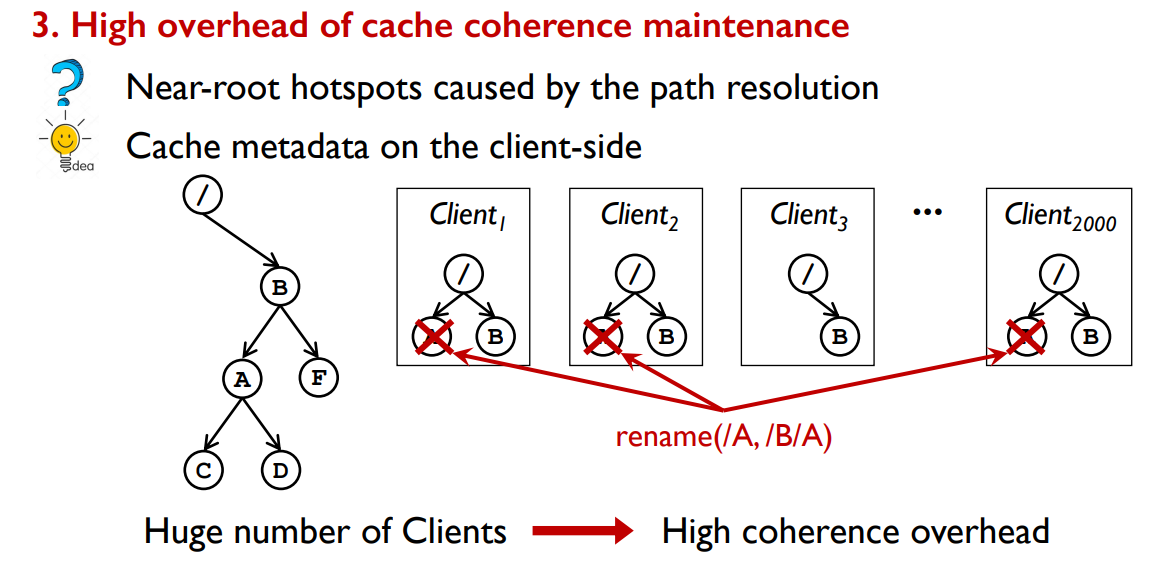
路径解析需要从根遍历目录树,并依次检查路径中所有中间目录的权限。这将导致大量读取接近根目录,即使是为了平衡元数据操作工作负载。文件系统的吞吐量将受到存储近根目录的服务器的限制。在本文中,我们称之为近根热点。许多分布式文件系统依赖于客户端元数据缓存来缓解接近根的热点
-
我们发现,以前的客户端缓存机制在大量客户端的大规模场景中不能很好地工作。
- 例如,基于租约的机制为每个在固定期限后将过期的缓存条目授予租约。当租期到期时,相应的缓存条目将自动失效。在NFS v4、PVFS、LocoFS和IndexFS中广泛使用。
- 然而,由于近根目录的缓存更新,租约机制存在负载失衡的问题。
- 这是因为所有客户端都必须反复更新它们的近根目录的缓存条目,以进行路径解析。随着客户端数量的增加,这种近根目录上的负载不平衡最终将成为性能瓶颈,并削弱总体吞吐量
负载特征
- 阿里云负载,Pangu 文件系统

Design And Implementation
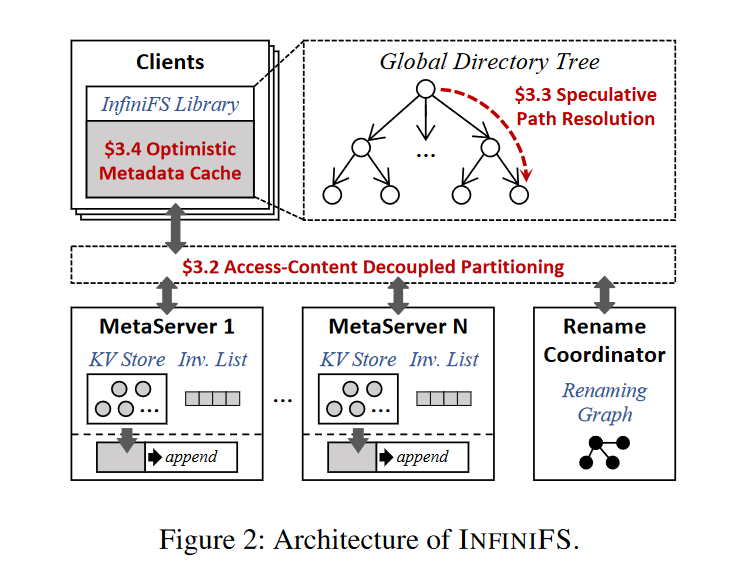
Overview
- 客户端:
- 全局文件系统目录树视图,客户端用用户态的库或者 FUSE 来通信
- 通过使用预测路径解析来遍历目录树
- 路径解析过程中使用乐观元数据缓存来减少近根热点读
- 元数据服务器:
- 目录树分布在多个元数据服务节点
- 使用 访问信息和内容信息解耦的方式,同时实现高局部性和负载均衡
- 每个服务器在本地管理 KV 存储中存储元数据对象,在内存会缓存元数据,也会在 NVMe SSD 中使用日志记录更新操作
- 元数据服务器使用 失效列表 来惰性验证客户端元数据请求
- 重命名协调器
- 中心化的 rename 协调器,处理目录 rename 和 目录的 set_premission 操作
- 使用 renaming graph 检查并发的目录 rename 操作避免循环
- 广播修改信息到元数据服务器的失效列表
Access-Content Decoupled Partitioning
问题理论分析
- 以前方案无法兼顾局部性和负载均衡的根本原因:把目录元数据当作了一个整体
- 使用分区目录树的时候,不得不把目录和他们的父节点或者子节点给分区到不同的服务器,也就不经意地打破了相关元数据的局部性
元数据原机制分析
- 元数据的组成:
- 访问元数据:包含目录名,ID,权限。用于访问目录树的信息
- 内容元数据:entry list,时间戳等,和子节点更相关的数据信息
- 元数据操作分类:
- 仅处理目标文件/目录元数据的操作,如 open、close、stat 等。
- 文件 stat 将只读取目标文件的元数据
- 处理目标文件/目录及其父文件/目录元数据的操作,如 create、delete、readdir等。
- 例如,文件创建将首先插入文件元数据,然后锁定和更新父目录的 entry list 和时间戳。
- rename 操作是特殊的,因为它处理两个文件/目录及其父文件的元数据。
- 仅处理目标文件/目录元数据的操作,如 open、close、stat 等。
- 第一类和第二类为大部分操作,需要在元数据处理过程中获取对应目标文件/目录的元数据。
解决思路
局部性的考虑
- 所以我们就是如下图 c 所示的,把每个目录的内容元数据(蓝色)和对应子目录的访问元数据(红色)分组在一起。
- 这样目录树就被分成独立的每个目录组。同时保证了目录操作 readdire 以及文件操作 create/delete/open/close/stat/ set_permission 的局部性
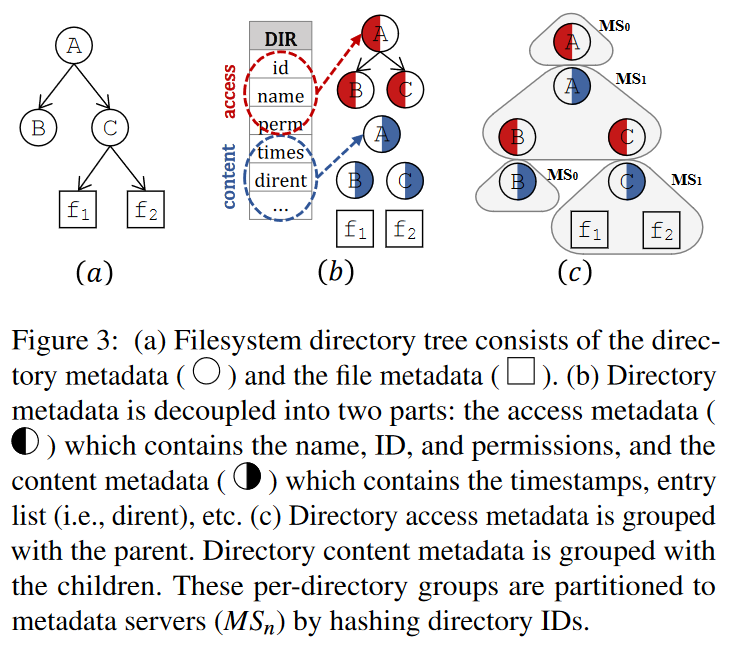
负载均衡的考虑
- 根据局部性进行了分组以后,得到了很多个独立的 per-directory groups。
- 使用基于 directory id 的哈希,把这些分组分区到不同的元数据服务器,从而实现负载均衡
- 还是上图 c 所示,得到了四个组,包含了 C 的内容元数据和 f1 f2 的组被分区到服务器 1,那么在 C 目录下的文件创建操作就只需要在 MS1 上进行,因为只需要创建一个新的文件元数据,然后更新对应 C 的时间戳和 entry list
- 对于目录 C 的 readdir 操作也只涉及到 MS1,首先出于隔离性的考虑加锁 entry list,然后从 entry list 中读取到对应的文件名
- INFINIFS 利用了一致性哈希 GIGA+ 来映射细粒度的元数据分组到服务器,从而减小集群规模变化过程中的数据迁移
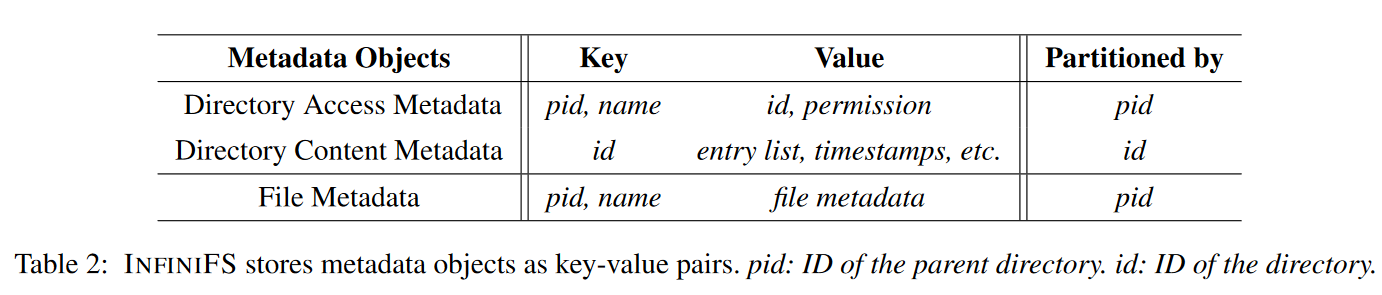
数据的存储
- KV 存储来存储元数据,存储格式如下表所示,包含了三种类型的数据
- 目录访问元数据
- 目录内容元数据
- 文件元数据
- 例子:访问 /A/B/file,假设 / A B对应的 ID 分别为 0,1,2
- 首先查询 <0, A> 得到 A 的访问信息,然后知道了 A 的 ID 为 1
- 查询 <1, B> 得到 B 的访问信息,知道了 B 的 ID 为 2
- 查询 <2> 得到了 B 的内容元数据信息,以及 <2, file> 得到了目标文件的元数据
Speculative Path Resolution
Predictable Directory ID
-
INFINIFS 如何生成并维护 可以在未来根据 pathname 预测的目录 ID
-
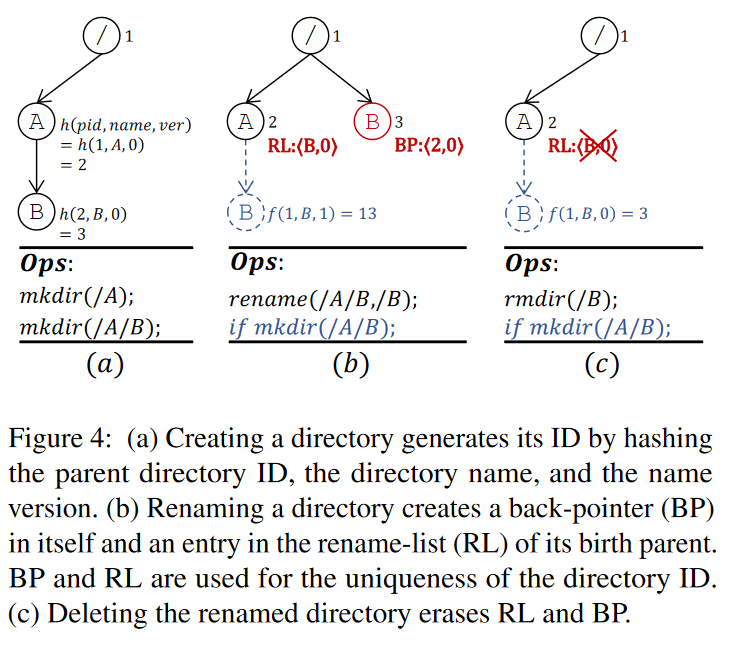
Creating:
- 创建一个新目录,生成对应目录 ID(根据 parentID, directory name,以及 name version),如下图 a 所示
- 创建目录的父目录被称为目录的 birth parent,用一个版本号来保证 birth triple 的唯一性
-
Renaming:
- 更改一个目录名称只需要修改对应的访问元数据信息,内容元数据和对应的 ID 是不会变得,因此,目录下的所有后代元数据都保持不变
- 当一个目录自创建以来第一次被重命名时,
- 它的父目录将记录一个重命名列表(RL):每一项就是一个二元组 <directory name, name version>
- 然后目录本身会记录一个 back-pointer,<birth parent’s ID, name version>,目录的 RL 记录的就是其对应原生子目录的,但是可能现在已经迁移到了别处了
- 重命名目录的 BP 指向的是原来他所在的父节点 birth parent 目录,我们在创建目录时使用父目录的 RL 确定 name version
- 举个例子:下图 b 所示即为 /A/B rename 到 /B
- 如果 B 是第一次 rename,
- 那么 B 的访问元数据信息将从 2:B 改成 1:B (2和1分别为父目录的 ID),B 的 ID 是不会发生改变的
- A 将记录从其中迁出的数据在 RL 中,记录一条 <B, 0>,作为 A 的内容元数据
- B 会记录一条 BP 信息 <2, 0> 在 B 的访问元数据中,因为其原生父目录为 2
- 这时候如果在 /A 下创建一个新的 B
- 那么对应的 name version 就变成了 1,因为 RL 表明了以前这儿有一个 B 目录被 rename 了
- 为什么需要更新版本号,因为 hash 计算如果不变版本号,就会算出一个相同的 directory id,就无法区分两个目录 B 了
- 如果 B 不是第一次 rename 了
- 那么只需要更新对应的访问元数据,对应的内容元数据 BP,以及原生父目录的 RL 都不会变化
- 当删除一个 renamed 目录的 birth parent 目录时,对应的访问信息和内容信息都会被擦除,但是其 RL 会被保留,只有当重命名的目录被删除时,RL 才会通过 BP 删除
- 如果 B 是第一次 rename,
- Deleting
- 删除一个重命名目录,使用对应的 BP 定位到原来的父目录,然后擦除对应的 RL
- 这时候创建一个新的该目录下的 /B,版本号就可以重置回 0 了
ID 唯一性
- 目录 ID 是根据对应的三元组算出来的,三元组只要一个不同,那么算出来的 directory id 也就不同,除非哈希冲突
- 文件系统语义要求同一父目录中的两个目录在任何时候都不能有相同的名称。如果没有 rename 操作,那么二元组 <birth parent’s ID, directory name> 就够了,但是因为 rename 存在 ,所以一个目录下可能在 rename 前后拥有相同 name 的但是两个完全不同的目录,所以得用三元组
- 用加密哈希来生成 ID,比如 SHA-256,冲突的概率比较低,在目录创建的过程中也很容易检测到哈希冲突,直接使用版本号,RL,BP 来解决冲突
- 在 INFINIFS 中,冲突和重命名情况对后续的目录创建具有相同的影响,可以通过 RL 条目格式进行区分
并行路径解析
- 基于前面可预测的目录 ID,客户端可以并行执行路径解析,如下两步
- 预测目录 IDs
- 客户端根据对应的路径的 rootID 预测所有中间目录的 IDs,它首先以 0 作为版本号重建 birth 三元组,然后重新计算哈希结果。
- 使用推测的目录 id,客户端为所有路径组成部分重建键。
- 并行查询:
- 客户端并行发送查询请求查询中间目录,每个查询请求首先检查访问权限
- 然后比较推测的 ID 和存储在元数据服务器中的 ID
- 如果推测的 ID 不匹配,查询请求将返回真实的 ID 给客户端
- 上面两个步骤不断重复直到解析完成
- 预测目录 IDs
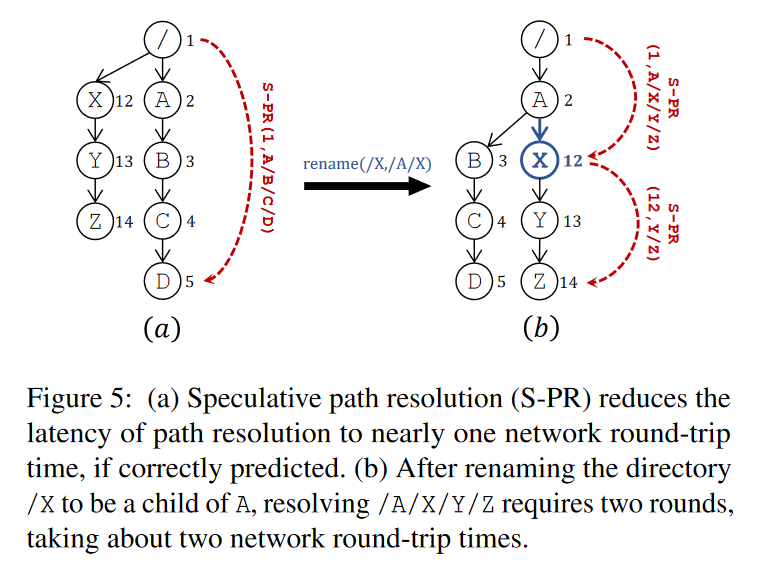
- 下图展示了预测路径解析的机制
- 如果一个中间目录一旦被 rename 了,rename 的预测 ID 就会出错,即计算 /A/X 的 ID 的时候,发现 h(2,X,0) ≠ 12,因为 h(1,X,0) = 12,12 是根据原来的父节点算出来的。
- 但是查询请求可以使用 <2:X> 找到 X 的访问信息,然后得到正确的 ID 返回给客户端,有了正确的 ID,就可以继续解析 X 的子路径了。
Optimistic Access Metadata Cache
缓存机制
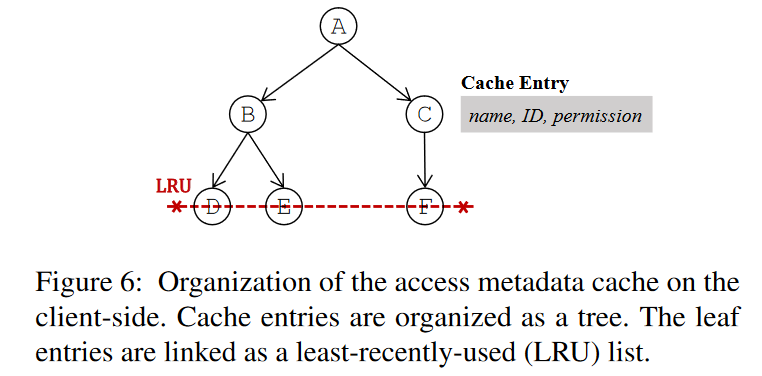
- 本文的客户端缓存只缓存访问元数据,缓存命中将消除对近根目录的查找请求,从而避免根目录附近的热点,并确保可伸缩的路径解析。
- 缓存项还是基于文件系统的层次来组织,把叶子节点链接在了一起组成一个 LRU,来进行叶子节点的淘汰,近根目录将一直被缓存
惰性缓存失效
- rename 操作以及 set_permission 操作可能让大量客户端缓存失效,在每个目录重命名操作期间,使所有关联客户端的陈旧缓存条目无效是不切实际的。因为客户端的成员很难管理,而且客户端的数量可能非常大,远远超过元数据服务器的数量。所以有了惰性缓存失效机制
- 该机制广播失效信息给元数据服务器,每个元数据服务器可以在执行对应的元数据请求的时候惰性地检查数据的有效性
- rename 操作会联系中心化的 rename 协调器,避免陷入循环,然后广播对应的 rename 信息,一个中心化的 rename 协调器就够了,因为 rename 操作很少
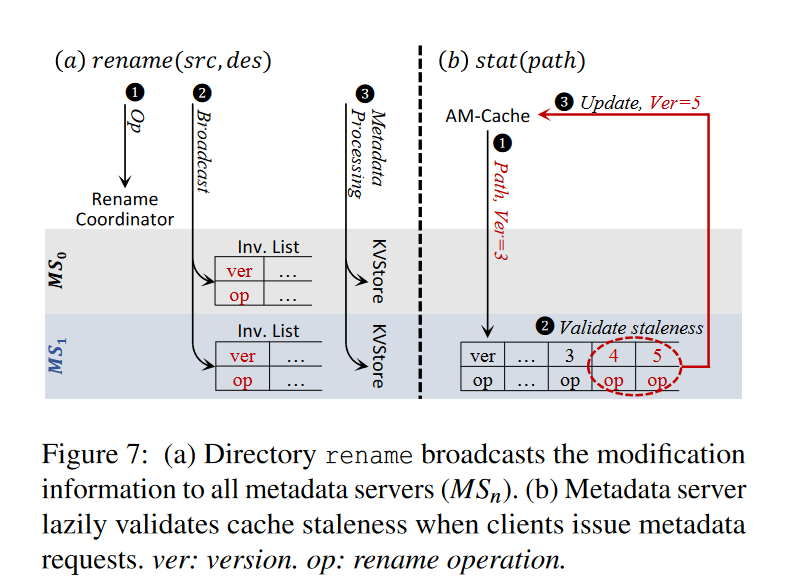
- 所以 rename 的完整步骤如下:如下图 a 所示
- 发送 rename 操作给协调器,检查这个目录的 rename 是否和当前已有的操作发生 orphaned loops,然后协调器给每个 rename 操作分配一个自增的版本号
- 将 rename 操作和其他操作通过锁定目标目录来是进行串行化,所以新的访问需要阻塞等待 rename 结束。然后并行广播带版本号的 rename 信息给元数据服务器,等待确认。
- 元数据服务器维护一个失效队列并根据版本号排序来记录 rename 信息
- 然后把目录的访问信息从 source server 移动到 dest server,并更新对应的 RL,BP 信息。
- 惰性检查缓存是否失效的步骤如下:下图b
- 客户端不知道是否过时,并在路径解析期间乐观地利用本地缓存条目。
- 每个客户端都有一个本地版本,这表明在此版本之前,它的缓存已经通过重命名操作进行了更新。
- 当客户端与元数据服务器联系时,它会将请求连同路径名和版本一起发送出去
- 元数据服务器通过比较无效列表中的路径名和重命名操作来验证是否过时。
- 只需要比较请求版本和失效列表中的最新版本之间的操作。如果服务器发现请求的路径名是有效的,则请求被成功处理并返回。
- 如果服务器发现请求无效,它将中止请求并返回这些新的重命名操作的信息。然后客户机更新缓存和版本
- 客户端不知道是否过时,并在路径解析期间乐观地利用本地缓存条目。
一致性
Orphaned Loop
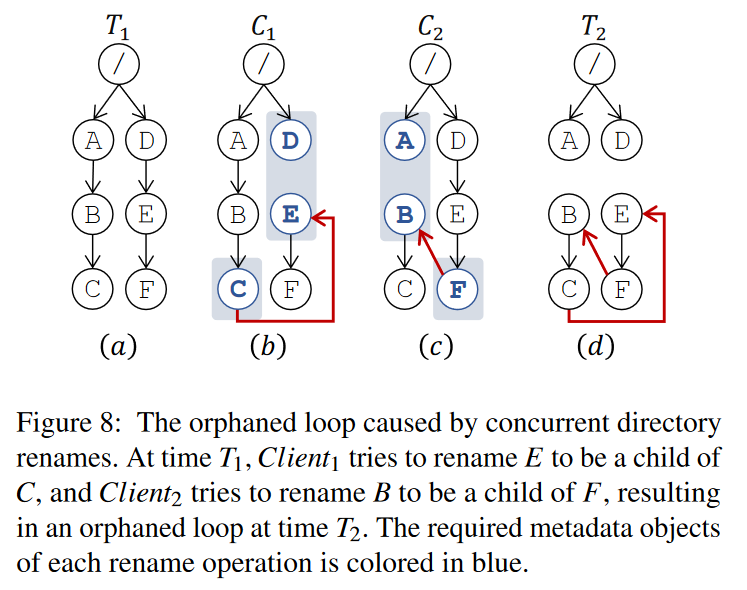
- 什么是 Orphaned Loop?
- 并发的 rename 操作可能导致该现象
- 下图展示了由两个 rename 操作造成的 Orphaned Loop
- 图 a 表明了正常的文件目录树应该是一个有向无环图
- 图 b 的客户端 1 尝试 rename E 到 C 目录下,即 /D/E 变成 /A/B/C/E,修改的元数据 DEC
- 图 c 的客户端 2 尝试 rename B 到 F 目录下,即 /A/B 到 /D/E/F/B,修改的元数据 ABF
- 两个重命名所需的元数据对象彼此完全独立,因此允许并行执行。
- 但是它们会导致 Orphaned Loop,破坏目录树,如图8(d)所示。没有客户端可以访问 Orphaned Loop 中的任何文件
- 如何解决?
- 中心化的 rename 协调器,来在 rename 执行前检查
- 协调器维护了一个 rename graph,它跟踪正在运行的目录 rename 的源路径和目标路径。
- 在允许进行新的目录 rename 操作之前,协调器首先验证它是否会导致带有正在进行中的操作的 Orphaned Loop
- 在整个 rename 过程中,目录 rename 操作的源路径和目标路径都保存在重命名图中,并在重命名操作完成后删除
事务性的元数据操作
- 操作可以进行如下分类
- 单个服务器上的操作:readdir,create/delete/open/close/stat/ set_permission。直接利用 KV 的事务机制来实现
- 当元数据服务器在崩溃后重新启动时,它恢复元数据操作的事务,并告诉重命名协调器以更新其无效列表
- 两个服务器上的操作:mkdir/rmdir/statdir,文件 rename
- 两阶段提交协议的分布式事务
- 由于客户机不可靠且难以跟踪,因此选择两个元数据服务器中的一个作为事务中的协调器。
- 为了从失败中恢复,协调器和参与者都使用预写日志记录事务的部分状态
- 目录 rename: 目录重命名和目录set_permission
- 很少发生。
- 这些操作被委托给 rename 协调器,它检测 Orphaned Loop,将修改广播到所有元数据服务器,并跨两个服务器处理目标目录元数据。
- 这些操作是通过类似于双服务器操作的分布式事务来实现的,不同之处在于它们在事务中选择 rename 协调器作为协调器,并在提交阶段开始时广播修改。如果 rename 协调器在广播期间崩溃,它将重新启动并恢复事务,方法是重新启动广播,以确保修改至少被发送到所有服务器一次。
- 单个服务器上的操作:readdir,create/delete/open/close/stat/ set_permission。直接利用 KV 的事务机制来实现
测试
- 注意用的是 RAMDisk 测试,因为元数据大多都是缓存在内存里的
- 实现:
- RPC: Thrift
- KV Store: RocksDB
整体性能
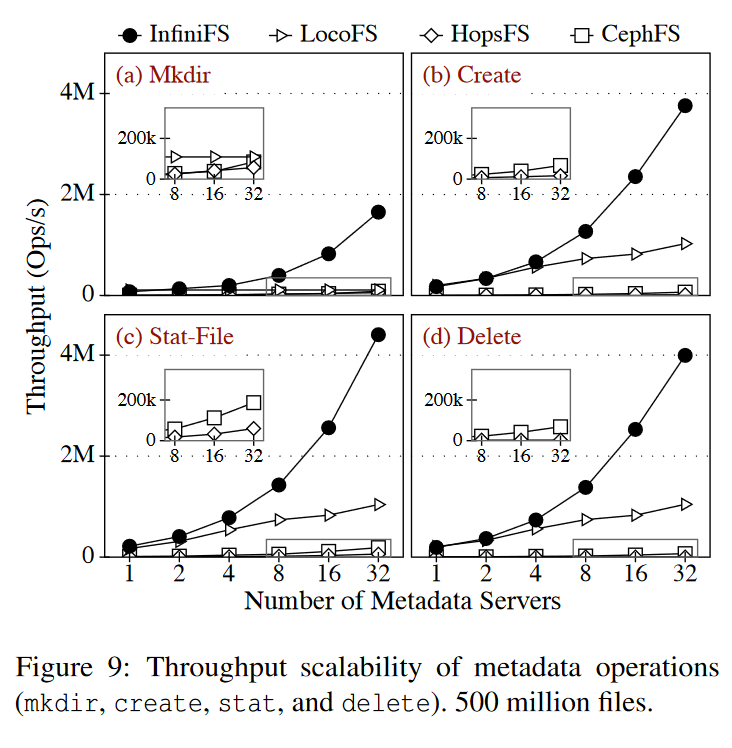
- INFINIFS在 mkdir、create、stat和delete元数据操作中呈现近乎线性的吞吐量可伸缩性,元数据服务器的数量从1扩展到32
- 对于路径解析,INFINIFS在客户端缓存近根访问元数据,以吸收近根目录上的读负载,因此路径解析导致的近根热点不会影响可伸缩性。此外,INFINIFS通过散列目录id在元数据服务器上划分文件/目录元数据。细粒度哈希分区策略有效地平衡了元数据访问,实现了高可伸缩性
- 对于元数据处理,INFINIFS解耦目录元数据,然后将目录访问元数据与父节点分组,将目录内容元数据与子节点分组。通过这种方式,create、stat 和 delete 的元数据处理只访问单个服务器,不需要跨服务器协调,因此具有可伸缩性。目录 mkdir 的元数据处理需要与两台服务器协调原子性,这也可以很好地扩展到更多的服务器。
- mkdir 操作的吞吐量远低于 INFINIFS 中create操作的吞吐量。这是因为文件创建是使用本地事务协议实现的,不需要跨服务器协调,而目录创建需要两阶段锁定和两阶段提交协议。这些分布式协议需要在服务器之间进行昂贵的协调,从而降低了吞吐量。
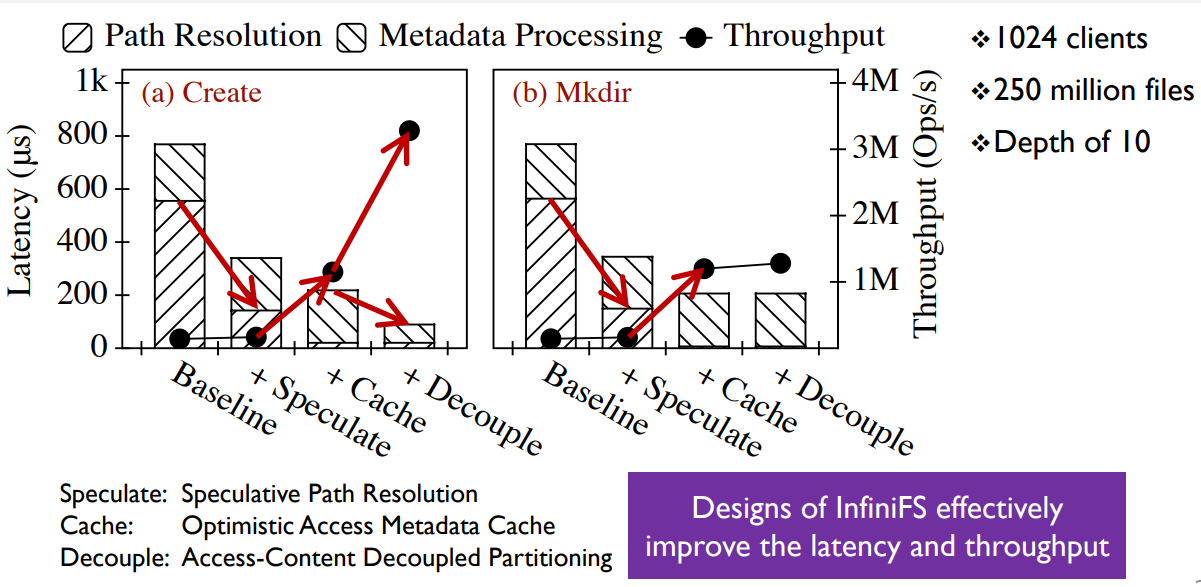
优化分解
其他测试
- 参见原文
