- 虚拟化课程论文分享,文章来自 FAST17
- SSD 虚拟化相关,顺便补一下之前 SSD 的坑
- 主要解决云计算领域中虚拟化 SSD 设备中的隔离性问题
预备知识 闪存
参考链接
- [1] 知乎 - 老狼 - 杂说闪存一:关公战秦琼之 UFS VS NVMe
- [2] 知乎 - 老狼 - 杂谈闪存二:NOR和NAND Flash
- [3] 知乎 - 老狼 - 杂谈闪存三:FTL
- [4] 知乎 - 老狼 - 杂说闪存四:闪存硬盘接口大比拼
- [5] 存储产业技术创新战略联盟 SSD 相关培训资料
- [6] 阿里云云栖号:存储系统设计——NVMe SSD性能影响因素一探究竟
简单总结
- 此处简单总结 Paper 中可能将会使用到的一些术语和概念以及一些 SSD 相关的基本常识,结合该总结食用 Paper 更佳。
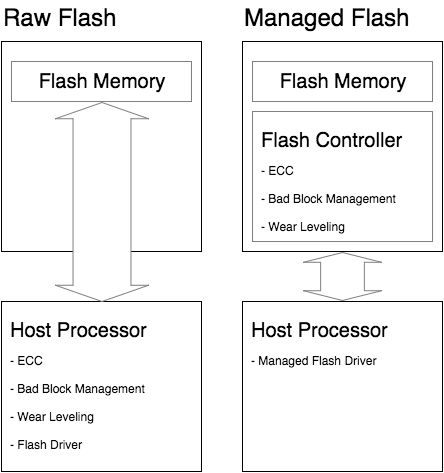
- SSD 基本结构:控制单元(主机接口,SSD控制器,DRAM),存储单元(NAND FLASH)
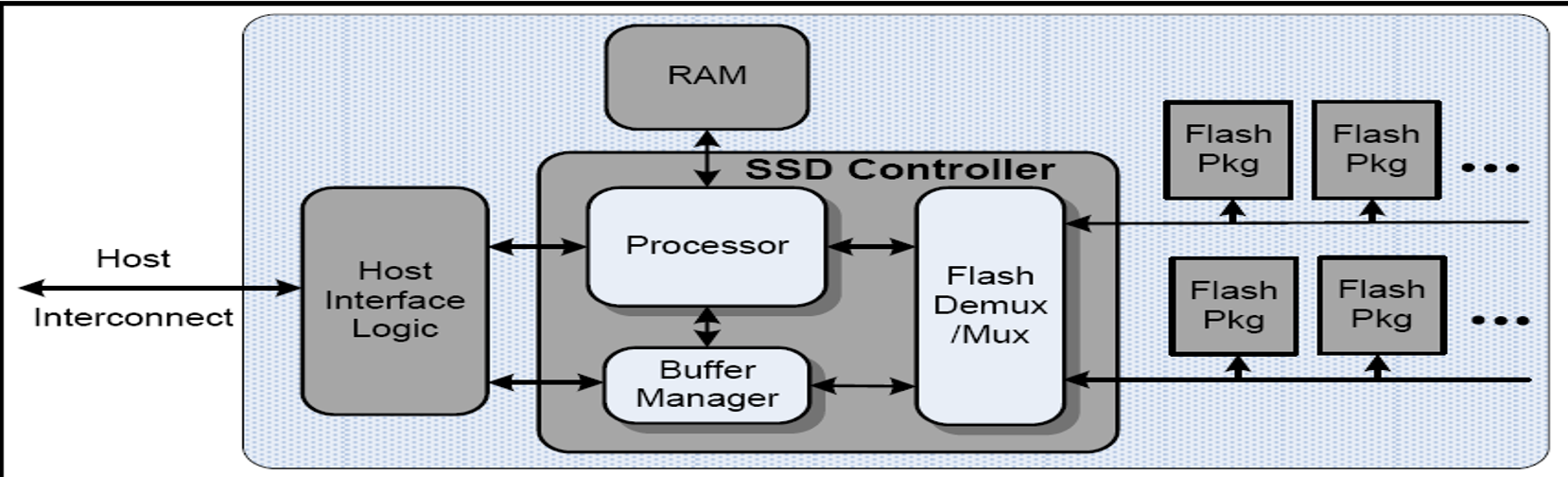
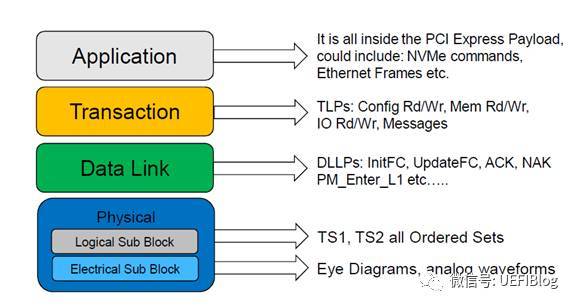
- NVMe 与 PCIe 的关系?:NVMe 的目标是取代传统的 SATA 接口,NVMe 本质是一种通信协议,在通信协议里属于应用层,使用PCIe 协议作为数据和链路层。
- NVMe 取代 SATA 的动力?:SATA接口采用AHCI规范,其已经成为制约SSD速度的瓶颈。AHCI只有1个命令队列,队列深度32;而NVMe可以有65535个队列,每个队列都可以深达65536个命令。NVMe也充分使用了MSI的2048个中断向量优势,延迟大大减小。
- NVMe 和 UFS 对比?:UFS 是为了取代 eMMC 嵌入式场景的协议,常用于手机;NVMe主要应用于计算机平台。UFS 通常使用 2 条 lane,NVMe 常使用 4 条 lane。UFS3.0,PCIe 4.0
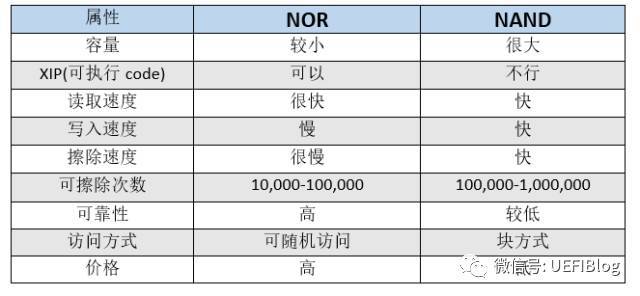
- NOR FLASH 和 NAND FLASH:NOR 常用于 BIOS,NAND 主要用于存储卡
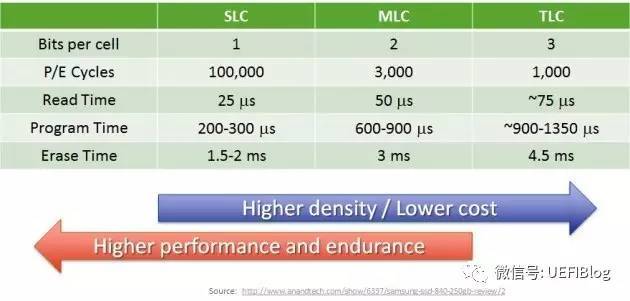
- NAND FLASH 颗粒:SLC/MLC/TLC/QLC
 -
- - FTL 产生的背景:NAND Flash相对NOR Flash更可能发生比特翻转,就必须采用错误探测/错误更正(EDC/ECC)算法,同时NAND Flash随着使用会渐渐产生坏块。如何才能平衡各块的擦写和为可能的坏块寻找替换呢?通常需要有一个特殊的软件层次,实现坏块管理、擦写均衡、ECC、垃圾回收等的功能,这一个软件层次称为 FTL(Flash Translation Layer)。编程可以让 FLASH 的 bit 从 1 变到 0,而从 0 到 1 只能进行擦除。写入的最小单元为 Page,擦除的最小单元为 Block,NAND flash的寿命是由其擦写次数决定的(P/E数 (Program/Erase Count)来衡量的),频繁的擦除慢慢的会产生坏块。需要一套机制ll来平衡整块 FLASH 的整体擦写次数
- NAND FLASH 结构
- Package: 也就是chip即Flash芯片,就是我们经常在M.2的SSD上看到的NAND flash颗粒。一个封装好的芯片就是一个chip。
- Die: 一个NAND颗粒是由一颗或者多颗Die封装在一起而成,这种封装可是平排的,也可以是层叠的。die内部可以通过3D 堆叠技术扩展容量,譬如三星的V-NAND每层容量都有128Gb(16GB),通过3D堆叠技术可以实现最多24层堆叠,这意味着24层堆叠的总容量将达到384GB!就像盖楼房一样。Die也是可以单独执行命令和返回状态的最小单位。
- Plane: 一个die可以包含几个Plane. 一个plane就是一个存储矩阵,包含若干个Block
- Block: 重要的概念,它是擦除操作的最小单位。
- Page:也很重要,它是写入动作的最小单位。读的最小单位也是 Page
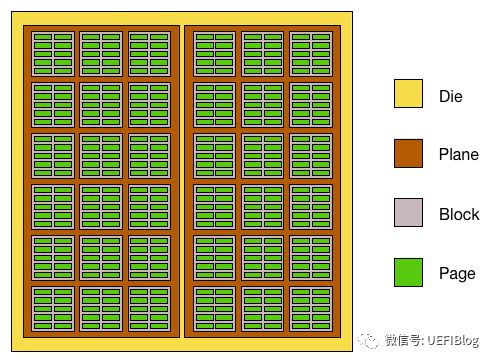
- Cell:每个16KB的Page页又是由大量的Cell单元构成。Cell是闪存的最小工作单位,执行数据存储的任务。闪存根据每个单元内可存储的数据量分成SLC(1bit/Cell)、MLC(2bit/Cell)、TLC(3bit/Cell)和QLC(4bit/Cell)
- NAND FLASH 存储原理:,其工作原理是利用 浮栅上是否储存有电荷或储存电荷的多少来改变晶体管 的阈值电压,通过读取到的晶体管阈值电压来实现数据 信息的表征。 写操作本质是向浮栅注入电荷,擦除操作是从浮栅挪走 电荷
- FTL原理:维护了一个逻辑Block地址(LBA,logical block addresses )和物理Block地址(PBA, physical block addresses)的对应关系,有了这层映射关系,我们需要修改时就不需要改动原来的物理块,只需要标记原块为废块,同时找一个没用的新物理块对应到原来的逻辑块上就好了
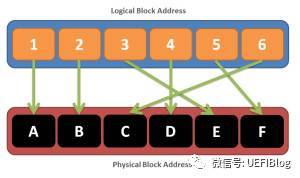
- 寿命均衡(Wear Levelling):LBA/PBA的映射本身会对寿命均衡产生正面影响。就如我们SD卡上的FAT文件系统,文件分配表会被经常修改,但由于修改的是逻辑块,我们可以让每次物理块不同而避免经常擦写相同的物理块,这本身就保证不会有物理块被经常擦写。但是有一种情况它没有办法处理,即冷的数据块(cold block),它们被写入后没有更改,就一直占据某些物理块,而这些物理块寿命还很长,而别的热的块却在飞速损耗中。这种情况怎么办呢?我们只有在合适的时机帮它们换个位置了,如何选择这个时机很重要,而且这个搬家动作本身也会损耗寿命本身。这些策略也是各个FTL算法的精华了。
- LBA/PBA表存储在哪里:在大部分的NAND Flash里,还有些空闲块,我们叫它OP(Over Provisioning)。这些空闲的块可以极大的帮助我们改善NAND flash的性能,它可以:
- A. 坏块处理。发现坏块,这些后备的可以立刻顶上,因为有映射机制,上层软件完全感受不到。
- B. 存储LBA/PBA表
- C. 给GC和Wear Levelling留下极大的腾挪空间。
- D. 减少写入放大(Write Amplification)
- 事实上,现在几乎所有主流SSD等NAND die上都有OP。譬如我们拿到标称容量240GB的SSD,实际空间可能有256GB甚至更高(一般>7.37%),只不过这些多余的空间我们用不到,感受不到,它完全被SSD固件藏做私用而已。
- SSD 关键概念:容量(用户容量)、接口类型、介质类型、顺序读/写、随机读/写、读/写延迟、典型功耗、可靠性、冗余空间、写放大系数、UBER(发生不可纠正ECC的几率)、数据保持里(Retention)、寿命(DWPD,每日整盘写入次数)
- SSD 技术趋势:新型接口 Ruler/M.3,新架构 OpenChannel/盘内计算,新介质QLC/SCM
- 新型接口 Ruler/M.3:存储服务器新型接口
- 新架构 OpenChannel/盘内计算: 数据库(Rocks DB,key-value),优化原有 SSD,提高性能/寿命
- 新介质QLC/SCM:QLC取代大容量硬盘,SCM用于内存数据库
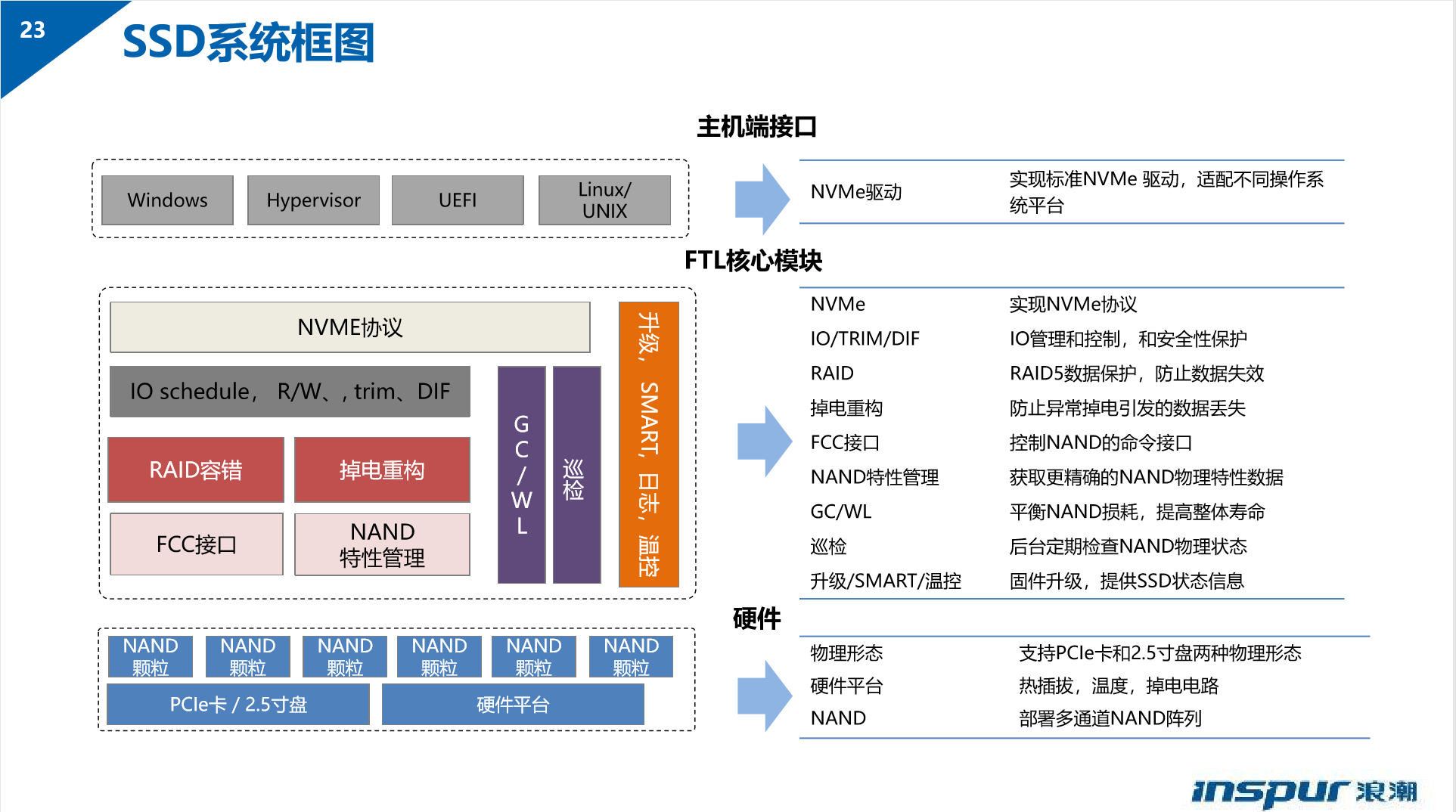
- 系统框图:
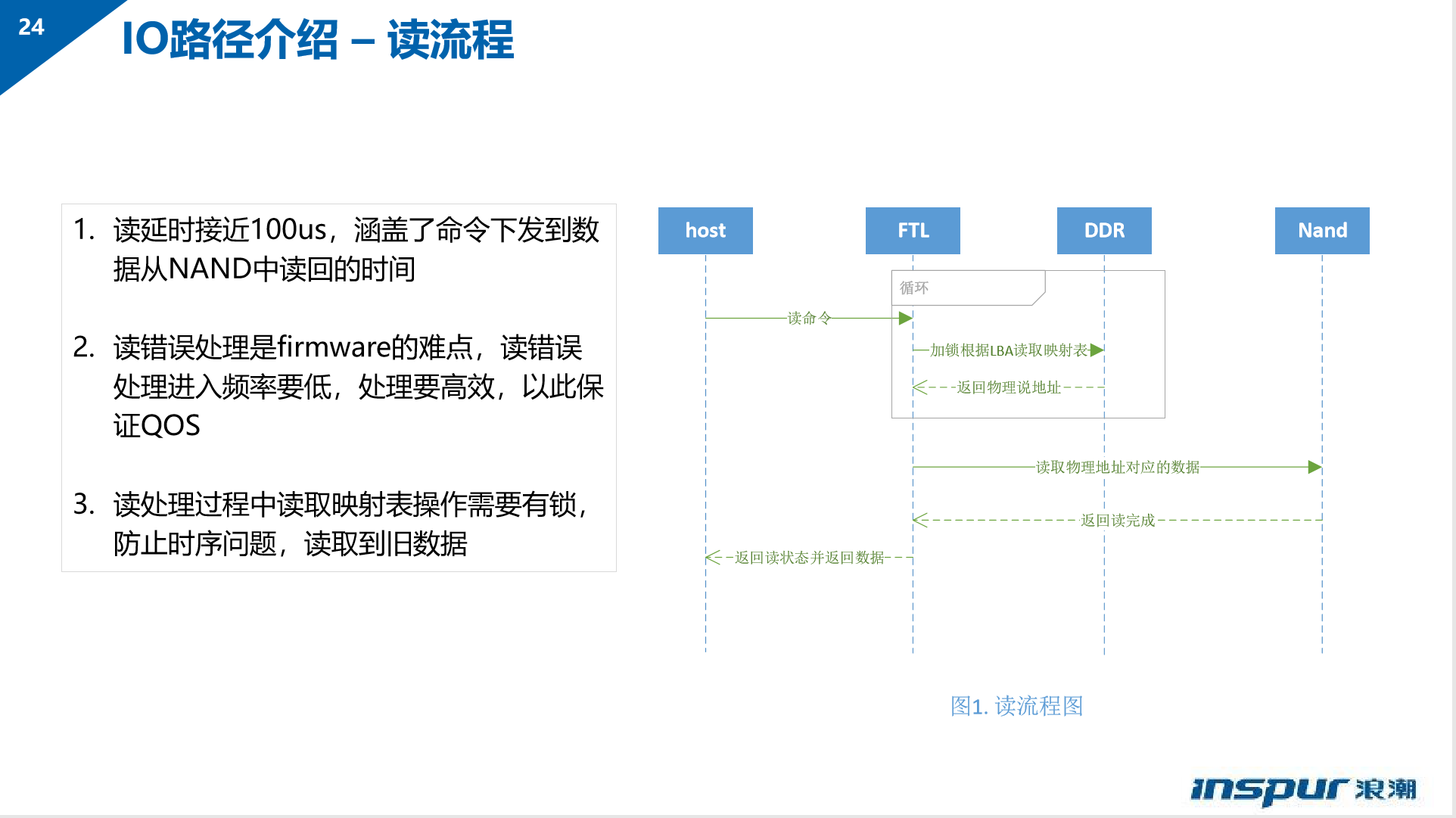
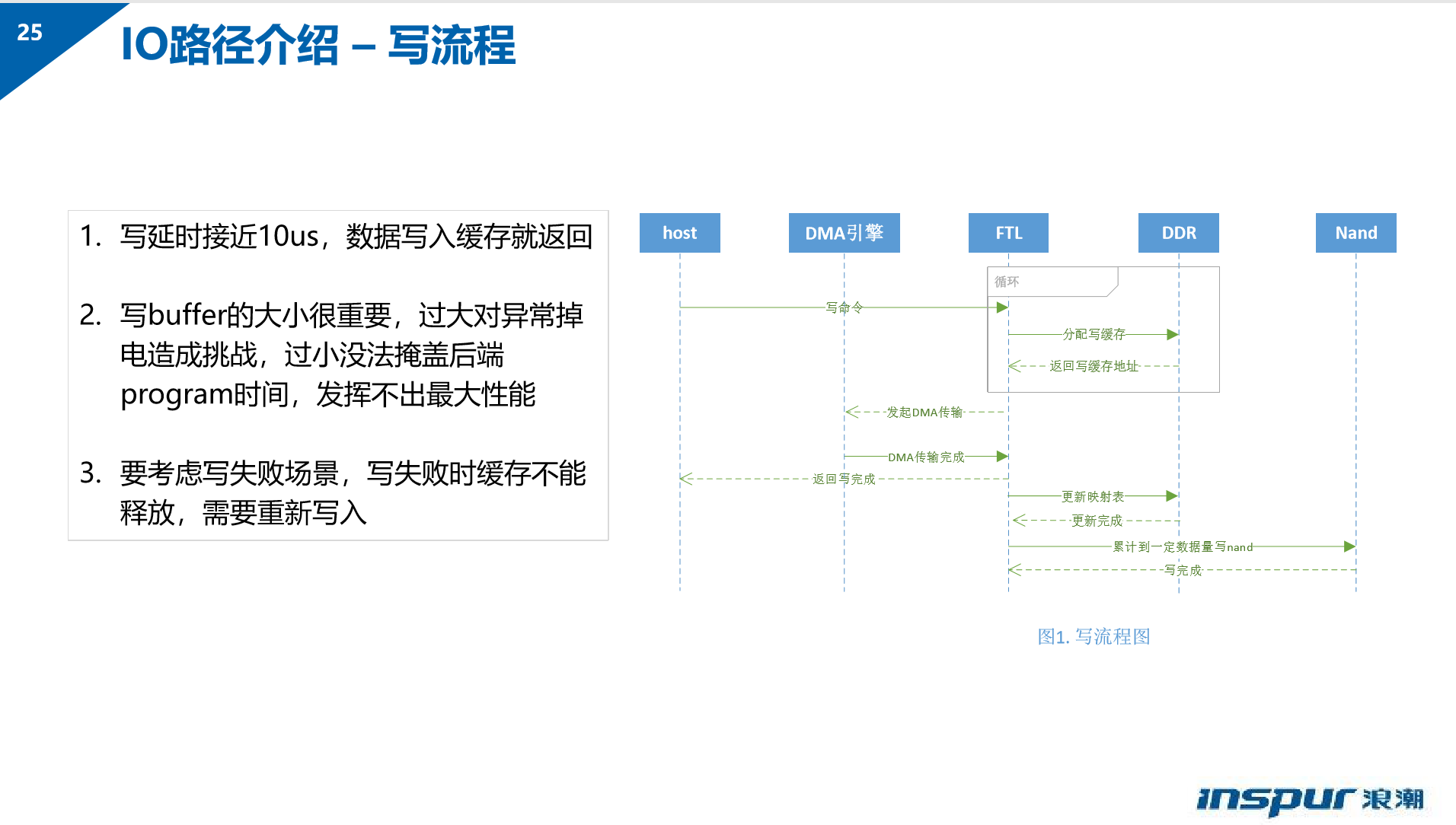
- SSD 读写流程:
Paper
- Course Requirements:motivation, idea, design, experiments and what you think.
Finial Report Request: Select one area, survey the area, and write a survey report, at least 3000 words, 30+ references. Finial report: Before May 30.
Abstract
-
SSD 虚拟化领域的一个长期目标是在共享SSD 存储设备的多个租户之间提供性能隔离。然而,由于资源隔离和设备寿命之间的根本冲突,虚拟化 SSD 在传统上一直是一个挑战——现有虚拟化 SSD 的目标是使SSD Flash 的所有区域一致老化(即负载均衡保证比较平均的使用寿命),但这不利于隔离。我们建议利用 SSD 的并行性来改善虚拟固态硬盘之间的隔离问题,方法则是在专用SSD通道和芯片上实现并行。除此以外,我们还提供了一个负载均衡的解决方案。我们提出了允许不同通道和 LUN 的负载在比较小的时间粒度上分散,从而支持隔离性并能在一个大的时间粒度上调控对应的负载。我们的实验表明,与软件隔离的虚拟固态硬盘相比,新的固态硬盘磨损均衡方案,在各种多租户设置下,存储操作的第99百分位延迟(尾延迟)减少了3.1倍。
-
Die也被称作LUN(逻辑单元),也是闪存内可执行命令并回报自身状态的最小独立单元。
Introduction
- 随着近年来的硬件技术的发展,SSD 的成本越发接近 HDD,但其性能表现远高于 HDD。所以 SSD 在云计算领域中得到了大量的应用,到如今已经显得不可或缺。对于 SSD 而言,硬件技术的发展使得可以通过增加芯片的数量来直接增加 SSD 的带宽和容量,大带宽大容量的出现则使得云计算领域考虑在 SSD 上虚拟化构建共享存储设备的可能性。但是由于 SSD 自身结构的原因(主要是指 SSD 的管理模块 FTL),屏蔽了大量的技术细节,特别是 SSD 的并行性并未在云计算的多租户场景下得到有效的利用。原有 SSD 在多租户场景下表现出来的瓶颈其中之一就是尾延迟,云计算场景下的云存储和数据库系统通常就构建在同一个 SSD 集群上,多个应用多租户的场景则加重了 SSD 尾延迟的问题。
- 从单个 SSD 的角度考虑尾延迟,造成尾延迟的根本原因是 SSD 控制器 FTL 中复杂的管理算法。管理算法从 SSD 发展开始至今,主要目标未发生过显著变化,主要是为了隐藏内部 FLASH 颗粒的相关特性,统一对外暴露出块接口,这些算法将 SSD 的磨损均衡(为了延长 SSD 的使用寿命)和 资源利用(利用并行性)合并在一起,导致在虚拟化 SSD 的场景下,常常引入了多租户之间的干扰。
- 【1】科普向 FTL 简书 - SSD之FTL技术
- 【2】科普向 FTL 老狼 - 杂谈闪存三:FTL
- 现有的优化方案中,主要有应用层面上通过利用物理涉设备的水平并行性来提升吞吐量,但并没有实际减少多租户共享 SSD 时的之间的干扰。这些租户不能有效地利用 flash 并行性来隔离它们,即使它们都分别是 flash 友好的,因为 FTL 隐藏了并行性。新的 SSD 接口提议将原始并行直接暴露给更高的层,这在为租户获得隔离方面提供了更大的灵活性,但是它们使跨不同并行单元的磨损均衡机制的实现复杂化 。
- 在这项工作中,我们建议利用当前SSD中固有的并行性来增强共享SSD的多个承租者之间的隔离,通过创建虚拟 SSD,根据租户的容量和性能需求,将其固定到特定数量的通道 channel 和 die 上,channel 和 die 可以一定程度上独立地运行工作,所以可以避免对彼此之间的性能产生影响。不同的工作负载可以以不同的比例和不同的读写模式运行,可能导致channel 和 die 不同程度上老化。例如固定在TPC-C数据库实例上的通道比固定在TPCE数据库实例上的通道耗损速度快12倍,从而显著降低了SSD的生存期。这种不一致的老化造成了不可预测的SSD生存期行为,这使数据中心集群的配置和负载平衡变得复杂
- 为了解决这个问题,我们提出了包含了两个部分的负载均衡模型,该模型使用不同的策略来平衡每个虚拟SSD内部和跨虚拟SSD之间的磨损。
- 对于每个虚拟 SSD 内部,利用了现存的 SSD 的负载均衡机制来管理,虚拟SSD内部的磨损是在粗粒度上平衡的,通过使用新的机制来减少干扰。
- 对于跨虚拟 SSD,使用一个数学模型来控制虚拟SSD之间的磨损不平衡,并证明了新的磨损平衡模型可以在几乎不影响租户的情况下确保SSD的接近理想寿命。
实际工作
- 提出了一个名为FlashBlox的系统,使用该系统,租户可以通过在专用通道上工作,以最小的干扰共享一个SSD。
- 提出了一种新的磨损平衡机制,允许测量磨损量的不平衡,以获得更好的性能隔离之间的租户
- 提出了一个分析模型和一个系统,控制channel 和 die 之间的磨损不平衡,使它们一致老化,对租户的干扰可以忽略不计
其他
- 我们设计并实现了FlashBlox及其新的耐磨调平机制在一个开放通道的SSD堆栈(Open Channel SSD),基于微软数据中心的多租户存储负载进行了测试评估,新的 SSD 显示出了原有 1.6 倍的吞吐量,99th 尾延迟减少了 3.1倍,我们实现的负载均衡机制保证了 SSD 寿命能够达到理想寿命的 95%,即便在同一个通道上进行写操作,其他通道进行写操作这样严重影响 SSD 寿命的负载。
SSD 虚拟化 - 机遇和挑战
- IaaS、PaaS 和 DaaS 中的存储服务为了达到对应的服务水平目标,常常需要使用性能远好于 HDD 的 SSD,而存储虚拟化则是帮助这些存储服务在多个客户和实例之间进行资源的分割,从而更高效地利用 SSD 的容量和性能。例如 DaaS 中的数据库存储服务容量需求大约为 10GB - 1TB,对应的服务器则需要拥有容量超过 20T 的 SSD。除此以外,存储虚拟化还常常需要使用诸如令牌桶算法之类的能够智能调控 IO 的技术来对带宽、IOPS等进行一定程度上的限制,实现定制化的需求。但是 SSD 虚拟化领域缺少一个类似的机制在实现 SSD 共享的同时保留 SSD 低延迟的特性,一个实例的延迟表现仍然取决于其他实例的前端负载和垃圾回收。
- 越来越有必要将不同的工作负载(例如延迟关键型应用程序和批处理作业)放在一起,以提高资源利用率,同时保持隔离,虚拟化和容器技术正在发展,以利用内存、CPU、缓存和网络的硬件隔离来支持这种场景。通过提供与硬件隔离的ssd,我们将这条研究线扩展到ssd,并提供了一个解决方案,以解决由于不同工作负载的租户之间的物理闪存分区而产生的磨损不平衡问题。
硬件隔离 VS 磨损均衡
- 此处比较两种硬件资源共享的方式:
- 第一种方法从所有flash通道(总共8个)的所有工作负载中提取数据,就像现有的ssd所做的那样。该方案为每个IO提供了最大的吞吐量,并使用Linux容器和Docker使用的软件速率限制器来实现资源的加权公平共享 。**注意,在软件隔离的情况下,实例不会与其他共区的实例共享物理flash块。**该方法消除了消除了其中一个实例垃圾回收对其他实例的读性能的影响。
- 第二种方使用我们提出的机制中的配置,通过为每个实例分配一定数量的通道来提供硬件隔离。
- 为了比较两种方法,我们使用了四种IO敏感型负载,这些负载分别请求 1/8,1/4,1/4,3/8 的共享存储资源,在第一种方法中将比例对应的设置为速率限制器的权重值,相应的方法二中则分配 1,2,2,3个通道。workloads 2 和 4 使用了 100% 的写,1 和 3 使用了 100% 的读,所有负载都使用 64KB 的 IO 大小。
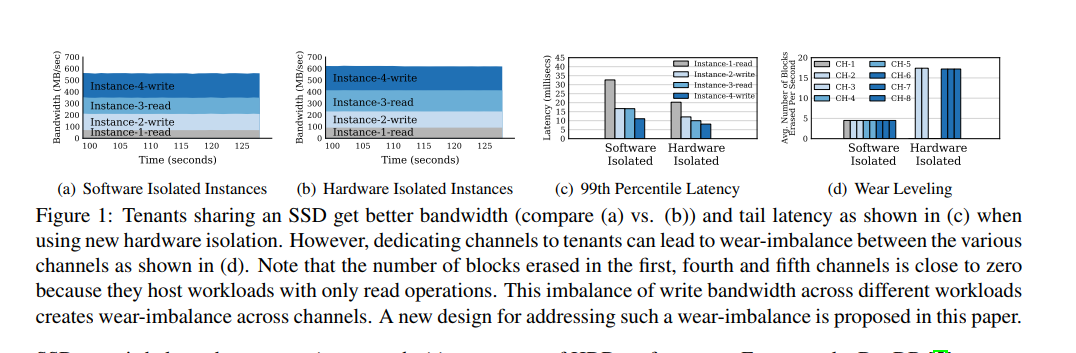
- 测试结果表明硬件隔离相比于软件隔离,延迟降低约 1.7 倍,吞吐量提升 10.8%,然而硬件隔离方案中的将通道固定到指定实例,阻止了硬件自动在多通道之间实现负载均衡的机制的运行,如图d 所示,我们夸大了写速率的差异,以便更好地解决由虚拟ssd的硬件隔离引起的损耗不平衡问题。为了进一步激发这个问题,我们必须首先探索SSD硬件中可用的并行性,以及在第一种方法中导致干扰的 FTLs 的各个方面
利用并行性保证隔离性
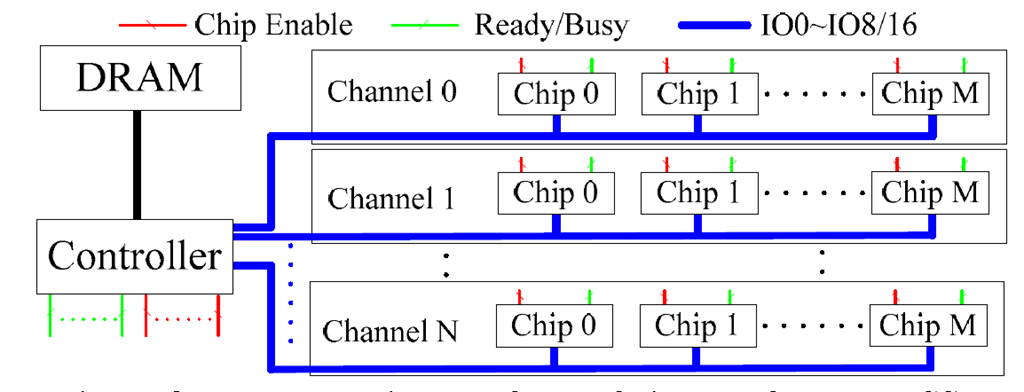
- 传统的 SSD 设备常常采用分层的结构来组织,从通道到 dies 到planes 到 blocks 到 pages,每两层之间都是一个一对多的关系,对应每一层的数量也会因为厂商的不同和产品的版本不同而不同,通常,一个 drive,8-32 个 channles,1 个 channel 约有 4-8 个 dies,一个 die 又有 2-4 个planes,每一个 planes 又有数千个 blocks,每一个 block 又包含 128 - 256 个 pages。该结构对定义隔离边界有很大的影响,通道(仅共享整个SSD的公共资源)提供了最强大的隔离,die以完全独立的方式执行它们的命令,但是它们必须与同一通道上的其他die共享一个总线,Planes 的隔离是有限的,因为die只包含一个地址缓冲区,控制器可以将数据隔离到不同的 planes,但是对这些数据的操作必须在不同的时间发生,或者在一个die中的每个 planes 上对相同的地址进行操作
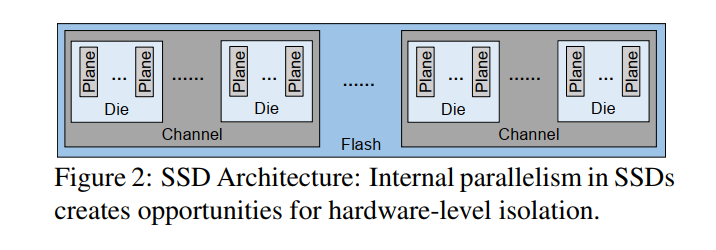
- 目前市面上流行的 SSD 设备,没有将这些内部组件的灵活性暴露给上层,相反,驱动器优化为一个单一的IO模式:非常大或连续的IO. FTL 逻辑上将所有的 planes 组合成一个大的单元,创造出的“super pages”和“super blocks”比它们的基本单元大上数百倍,例如,一个包含4MB块和256个planes的驱动器对应的有一个1GB的超级块。条带增加了连续的大型IOs的吞吐量,但是引入了共享驱动器的多个租户之间的干扰的负面影响,由于所有数据都是分段的,每个租户的读、写和擦除操作可能与其他租户的操作发生冲突。
- 以前的工作提出了新的技术来帮助租户放置他们的数据,这样底层的flash页面就可以从单独的块中分配。这有助于通过减少写放大因子来提高性能。缺少块共享有一个令人满意的副作用,那就是将垃圾聚集到更少的块中,从而提高垃圾收集(GC)的效率,从而减少ssd的延迟。然而,租户之间仍然存在显著的干扰,因为当数据被条带化时,每个租户使用每个通道、die和plane来存储数据,并且一个租户的存储操作可能会延迟其他租户,软件隔离技术相当于直接公平地分割了 SSD 资源,然而,当底层存在资源争用时,由于通道、dies 和 planes 等独立资源的强制共享,它们无法最大限度地利用flash并行性。
- OpenChannel SSD 则开放了内部组件给操作系统,通过使用专用通道,可以帮助共享SSD的租户避免这些陷阱,然而,不同租户以不同速度和比例写的 channel 之间的磨损不平衡问题仍然没有得到解决。我们提出了一个整体的方法来解决这个问题,通过暴露的flash channel 和 dies 作为虚拟ssd,而系统下磨损水平在粗糙的时间粒度上每个vSSD 的 channel 和 dies 保证负载均衡。FlashBlox 只关心在一个NVMe SSD内共享资源,公平共享机制,将PCIe总线带宽分割到多个 NVMe设备、网络接口卡、图形处理单元和其他PCIe设备超出了本工作的范围。
设计和实现
架构
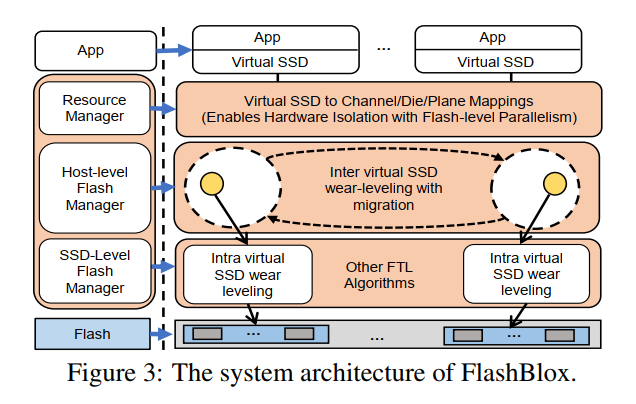
组成
- 资源管理器:允许租户分配和释放虚拟 SSD
- Host-Level 闪存管理器:通过在粗略的时间力度上平衡通道之间和 dies 之间的负载来实现实现虚拟 SSD 内部的负载均衡
- SSD-Level 闪存管理器:实现虚拟 SSD 内部的其他负载均衡,以及 FTL 的其他功能。
设计
- FlashBlox提供的一个关键的新抽象是虚拟SSD (vSSD),它可以减少尾部延迟,它使用专用的闪存硬件资源,如 channel 和 die,可以独立操作。并暴露创建 vSSD 的 API:isolationLevel, tputLevel, capacity 参数使得用户可以根据对隔离性和吞吐量的不同级别的要求来创建对应的 vSSD
vssd t AllocVirtualSSD(int isolationLevel, int tputLevel, size t capacity)

- 这些参数与性能和经济成本水平相兼容,如DaaS系统中宣传的,以简化使用和管理。租户可以通过创建支持大小的多个vssd来扩展容量,就像今天在DaaS系统中所做的那样。对应的解除 SSD 则使用:
void DeallocVirtualSSD(vssd t vSSD).
- channel 、die 和 plane 用于提供不同级别的性能隔离。这为多租户场景带来了显著的性能优势,因为它们可以相互独立运作。隔离级别越高,资源分配的粒度越大。因此,与 dies 粒度的分配相比,channel 粒度的分配具有更多的内部碎片。然而,由于几个原因,FlashBlox的设计不太关心这一点:
- 第一:一个典型的数据中心服务器可以容纳八个NVMe ssd,因此对应的支持的最大数量的 channel 隔离 和 die 隔离的数量分别为 128 和 1024(假设使用的是 16 通道 SSD),此外,根据我们与微软服务提供商的对话,拥有32个频道的ssd将使vssd的数量增加一倍,这应该足够了。
- 第二,DaaS系统提供的差异化存储允许租户从一定数量的性能和容量类中进行选择,这允许云提供商降低复杂性。在这样的应用程序中,动态更改容量和IOPS的灵活性是通过更改专用于应用程序的分区数量来实现的。FlashBlox的批量通道/die分配的设计与这种模型非常吻合。
- 第三,差异化的隔离级别与现有的云存储平台成本模型相匹配,在云存储平台中,更好的服务需要更高的定价,对于 FlashBlox 来说,这是一个自然的选择,因为在FlashBlox中,channe 比die更昂贵,性能也更好
channel 隔离的 vSSD
- 拥有16个通道的SSD的资源管理器可以承载最多16个与通道隔离的vSSD,每个vSSD包含一个或多个其他vSSD无法访问的通道

channel 的分配
- 吞吐量水平和目标容量决定分配给通道隔离的vSSD的通道数量。FlashBlox 允许数据中心/DaaS管理员实现
size t tputToChannel(int tputLevel)函数,该函数映射吞吐量级别和所需的通道数量。因此,分配给 vSSD 的信道数是tputToChannel(tputLevel)的最大值,capacity / capacityPerChannel向上取整。 - 在vSSD中,系统跨其分配的通道对数据进行条带处理,这与传统ssd类似,这通过在通道上并行操作来最大化峰值吞吐量。因此,图4中vSSD A的超级块大小是vSSD B的一半,超级块中的页面也跨通道条带化,类似于现有的物理ssd。通过硬件并行,通道之间的硬件级隔离允许一个vSSD上的读、编程和擦除操作在很大程度上不受其他vSSD上的操作的影响,这样的隔离使对延迟敏感的应用程序能够显著减少它们的尾延迟。
- 与跨所有通道从所有应用程序提取数据的SSD相比,vSSD(在较少的通道上)提供了SSD的部分全通道带宽。DaaS系统的客户通常按照固定的带宽/IOPS级别进行分配和收费,软件速率限制器积极地控制他们的消耗,因此,如果不为每个vSSD提供峰值带宽功能,就不会失去任何机会。
负载均衡的挑战
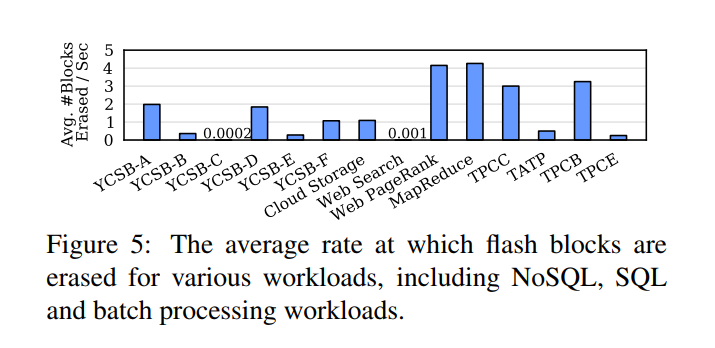
- 通道隔离的一个重要副作用是SSD中通道的不均匀老化风险,因为不同的vssd可能以不同的速率写入,图5显示了不同的存储工作负载如何以不同的速率擦除块,这表明如果不进行检查,被简单地固定到vssd上的通道将以不同的速率老化。这种不均匀的老化可能会在其他通道失效之前很久就耗尽一个通道的寿命,即使是单一信道的过早死亡也会造成严重的容量损失(> 6%在我们的SSD中),单个 channel 的过早死亡将导致一个机会的丧失,即永远无法为服务器生命周期的其余部分创建一个跨越所有16个通道的vSSD。考虑到服务器中的其他组件(如CPU、网络和内存)不会过早地丧失功能,服务器能力的这种不平衡意味着机会成本的损失,此外,功能中不可预测的变化也使负载平衡器的工作复杂化,负载平衡器通常采用统一的或可预测的非统一的(根据设计)功能,因此,有必要确保所有的通道以相同的速度老化。
通道内的磨损均衡
- 为了确保所有通道的均匀老化,FlashBlox使用了一个简单而有效的损耗均衡方案:到目前为止,已经引起最大磨损的通道定期与磨损率最小的通道交换。通道的磨损率是自最后一次交换通道以来擦除块的平均速率。这可以防止最老的通道出现高磨损率,从而直观地延长它们的寿命,以匹配系统中其他通道的寿命。
- 我们对来自Microsoft数据中心工作负载跟踪的实验表明,这种方法在实践中效果良好。通过这种机制,我们可以确保几乎完美的磨损平衡,并且每隔几周进行一次更换,此外,在15分钟的迁移期间,对尾部延迟的影响仍然很低,我们在§3.1.4中分析推导了最小必要频率,并在§3.1.5中给出了迁移机制的设计。
交换频率分析
- 设 si 为第 i 通道的磨损量(到日期为止所有块的擦除总数)。x= smax/savg 表示磨损不平衡不能超过1 + d; smax = Max (s1,:::; sN) savg = Avg (s1,:::; sN), N为通道总数,d为不平衡度。
- 当设备是新的,显然不可能确保x≤1 + d,因为没有交换通道。另一方面,必须在服务器生命周期的早期将其限制在一定范围内(通常为150-250周),以便所有通道在服务器的生命周期内尽可能多地可用。ssd配备了一个目标擦除工作负载,我们对相同的工作负载进行分析:假设每周擦除M个。我们用数学方法研究了磨损不平衡与迁移频率(f)之间的权衡关系。表明 f 的可管理值可以提供可接受的磨损不平衡,当 aL 周后x低于 1+d 时,a 在0到1之间。
- FlashBlox最坏的情况是所有的写操作都转移到一个通道,单个通道的带宽可以处理全部分配的带宽的假设对于现代ssd是有效的:大多数ssd配备了每个cell 3000 - 10000个擦除以维持使用150 - 250周。因此,为1TB SSD准备的擦除速率为M=21 - 116 MBPS,这低于通道擦除带宽(通常为64 - 128MBPS)
- 对于具有N通道的SSD,理想磨损水平的磨损不平衡为x = 1,而FlashBlox最坏情况下的工作负载为x = N:smax / savg = M∗time/(M∗time/N =N 在任何交换之前。分析了通过N个通道循环写工作负载的简单交换策略(每个通道的写工作负载花费1/ f周)。我们假设在经过K轮循环之后,KN / f≥aL成立
也就是说,已经过去了1周,x小于1 + d,并且继续保持不变,此时x = 1。因此,smax = MK, savg =
然后在下一次交换之后,smax = MK +M和savg = MK + M/N。为了保证不平衡总是有限的,我们需要:
x = smax/savg = (MK +M)/(MK +M/N) ≤ (1 + d )。这意味着 K ≥ (N−1−d)/(Nd),其上界为1/d。因此,要保证 x≤ (1+d),在 aL 个星期内,交换NK = N/d次就足够了。这意味着,在五年的时间里,如果a是0.9,那么必须每12天(= 1/ f)交换一次 d = 0.1 (N = 16)。表2显示了交换的频率如何随着通道的数量增加而增加(显示为减少的时间段)。但是,对于实际的工作负载,它们没有固定带宽的倾斜写模式,必须根据工作负载模式(见表5)自适应地执行交换,以减少交换的数量,同时保持平衡的磨损

自适应迁移机制
- 出于分析的目的,我们假设M的写速率是恒定的,但实际上,写的速度非常快。高写率必须触发频繁的交换,而在低写率期间可能不需要频繁地交换,为了实现这一点,FlashBlox为每个频道维护一个计数器,表示自上次交换以来每个通道中擦除的空间量(MB)。一旦其中一个计数器超过某个阈值g,就会执行交换,指针相应清零。如果通道在两次交换之间发生了最坏情况下的写工作负载,则将g设置为擦除的空间量。(M/ f)
- 这种机制背后的基本原理是,channel 必须始终以一种能够在最坏情况下赶上的方式进行定位。然后FlashBlox与smax和lmin交换通道,其中li表示第i个通道的磨损率,lmin = Min(l1;:::;lN)。FlashBlox使用原子块交换机制逐步将候选通道迁移到它们的新位置,而不涉及任何应用程序,该机制为每个vSSD使用一个擦除块粒度映射表(在§3.4中进行了描述),以一致和持久的方式进行维护。
- 迁移分为四个步骤:
- 首先,FlashBlox将停止并对与正在交换的两个擦除块相关的所有正在进行的读、编程和擦除操作进行排队。
- 其次,将擦除块读入内存缓冲区。
- 第三,擦除块被写入到它们的新位置。
- 第四,停止的操作将被退出队列继续执行。
- **注意,只有针对vSSD中的交换擦除块的IO操作才会排队并延迟。**对于其他块的IO请求仍然以更高的优先级发出,以减少迁移开销。
- 迁移会影响所涉及的vssd的吞吐量和延迟。但是,这种情况很少见(对于实际工作负载来说,一个月发生一次以下),而且只会发生15分钟就结束了。作为未来的优化,我们希望修改DaaS系统,以便在其他副本上执行读操作,以进一步减少影响,对于仅在主副本上执行读操作的系统,可以在副本集中执行迁移,以便当前正在进行vSSD迁移的副本(如果可能的话)首先转换为备份。这样的优化可以减少迁移对复制的应用程序中读操作的影响。
DIE 隔离的 vSSD
- 适用于能承受一定干扰的应用(即。,中等隔离),如免费的云数据库产品。vSSD 中的 dies 的数量的最大值为 tputToDie(tputLevel) (由管理员定义)和 capacity / capacityPerDie。它们的超级块和页面横跨vSSD中的所有模块,以最大化吞吐量。然而,这些vssd具有较弱的隔离保证,因为通道内的终端必须共享总线
- 因为是基于 DIE 隔离的,所以磨损均衡机制也必须基于 DIE 进行设计优化。因此,我们将FlashBlox中的磨损调平机制拆分为两个子机制:通道级和die级。通道级磨损平衡机制的工作是确保所有通道以大致相同的速度老化;DIE级磨损平衡机构的工作是确保通道内的所有 DIE 以大致相同的速度老化。
- 如§3.1.4所示,N通道SSD必须至少交换N/d次,以保证在目标时间段内x≤(1 + d),该数学分析同样适用于 DIE,对于今天的ssd,每个通道有4个die, FlashBlox必须在每个通道中交换die
在最坏的情况下,在SSD的整个生命周期中有40次,或者每个月一次。 - 作为一种优化,我们利用channel 级迁移,根据 dies 必须随着 channel 级迁移的事实,来是实现die 级磨损平衡的目标。在每个通道级别的迁移过程中,磨损最大的迁移通道中的 dir 与相应通道中写速率最低的 die 进行交换。实际工作负载的实验表明,这种简单的优化可以有效地为ssd提供满意的生存期。
软件隔离的 SSD
- 对于隔离要求更低的应用程序,比如Azure的基本数据库服务,使用 plane 级别的隔离的可能性也就出现了。但是 plane 相比于 channel 和 die 缺少足够的灵活性:每个 die 允许一次操作一个 plane 或在同一地址偏移处操作所有 plane。因此,我们使用一种方法,其中所有的 planes 同时操作,但他们的 带宽/IOPS 是使用软件来进行隔离。
- 默认情况下,每个die被划分为四个大小相等的区域,称为软平面。在FlashBlox中,每个软平面的大小为4gb(也支持其他配置),plane 本来是 DIE 中的物理结构,而软平面只是通过在 DIE 中所有 planes 上对数据进行条带化得到的,所以每一个 DIE 中的软平面都可以获得一个 DIE 中块总数的相等份额。他们也得到来自 DIE 的公平的带宽份额,这样做的原因是为了让数据中心/PaaS管理员更容易地将租户所需的吞吐量水平映射为量化的软平面数量。
- 使用软平面创建的vssd与使用软件速率限制器在多个承租者之间分割SSD的传统虚拟SSD是不可区分的。与这些设置类似,我们使用最先进的令牌桶速率限制器,它已被广泛用于Linux容器和Docker,同时提高了隔离性和利用率。我们的实际实施类似于之前工作中的加权公平分配机制,此外,使用单独的队列将请求排队到每个die。
- 用于创建这些vssd的软平面的数量与前面的情况类似:
tputToSoftPlane(tputLevel)和capacity / capacityPerSoftPlane。图4说明了vssd E和F,它们分别包含三个软平面。这种vSSD使用的超级块只是在vSSD使用的所有软平面上进行条带化,我们使用这些vssd作为比较通道和die隔离vssd的基线。
- 该软件机制允许对每个vSSD的flash块进行隔离裁剪,从而减少GC干扰。但是,它不能解决一个软平面上的擦除操作偶尔会阻塞共享die上其他软平面上的所有操作的情况。因此,这种vssd只能提供比 die 级隔离更低的软件隔离。
- 除了这些隔离的vSSD, FlashBlox还支持一个类似于软件隔离vSSD的非隔离vSSD模型。但是,并没有使用公平的共享机制来隔离这些vssd。为了保证当今云平台上的vssd之间的公平性,FlashBlox中默认启用了软件隔离的vssd,以满足较低的隔离要求。
- 对于软件隔离和非隔离的vssd,它们的磨损平衡策略保持不变,而不是交换软平面。这样做的理由是,模具的软平面之间的隔离是通过软件提供的,而不是通过将vssd固定到物理闪存plant上。因此,更传统的磨平机制是简单地在 DIE 的软平面之间旋转块,这就足以保证 DIR 内的软平面以大致相同的速度老化。
Intra Channel/Die Wear-Leveling
- 目标:相同速率老化。同时,通过避免多个间接层和跨这些层的冗余功能的缺陷,使应用程序能够有效地访问数据。
- 归功于 DIE 级别的磨损均衡机制和 DIE 内部的磨损均衡机制,FlashBlox也不可避免地实现了通道内部磨损均衡的目标:所有的 DIE 在每个通道和所有的块在每个 DIE 年龄均匀。
- 我们利用flash友好的应用程序或文件系统逻辑来执行GC和压缩,并简化设备级映射。我们还利用了驱动器的功能来管理坏块,而不必给应用程序带来纠错、检测和清除的负担,
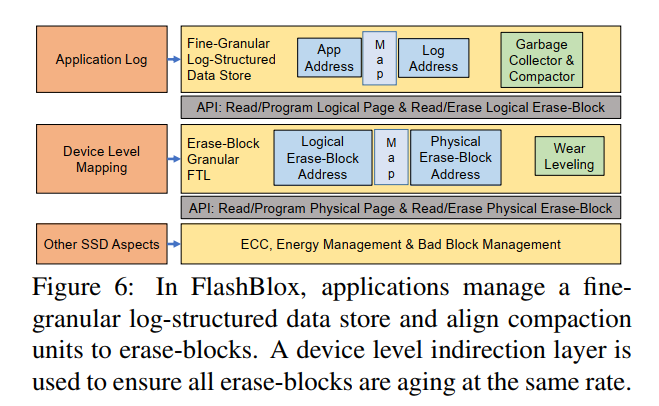
应用程序/文件系统级别的日志
- API 在设计时考虑了日志结构的系统,它所施加的惟一限制是,应用程序或文件系统执行日志压缩的粒度与底层vSSD的擦除粒度相同。当基于FlashBlox的日志结构应用程序或文件系统需要清除包含活动对象(比如O)的擦除块时:
- (1)首先通过AllocBlock分配一个新块;
- (2)通过ReadData读取O对象
- (3)通过WriteData将对象O写入新块;
- (4)修改索引以反映对象O的新位置
- (5)通过FreeBlock释放旧块。

- 注意,新分配的块仍然有许多可以写入的页面,这些页面可以用作日志的头部,用于从其他已清除的块写入活动数据或写入新数据。FlashBlox并不假设日志结构的系统以相同的速度释放所有分配的擦除块,这样的限制将迫使系统实现顺序日志清理器/压缩器,而不是考虑其他方面(如垃圾收集效率)的技术。相反,FlashBlox确保了较低级别的擦除块的均匀磨损。
设备级的映射
- 该层的主要目标:(1)一个die内所有的eraseblocks被按相同的比例擦除;(2)即将发生故障的擦除块将其数据迁移到另一个擦除块,而擦除块将对应用程序永久隐藏。两者都不需要更改应用程序
- 通过设备级映射,物理擦除块的地址不会暴露给应用程序,只有逻辑擦除块地址才会暴露给上层软件。也就是说,设备将每个die公开为使用块粒度FTL的单个SSD,而对于应用程序级别的日志,FlashBlox确保上层只发出块级别的分配和解除分配调用。间接开销很小,因为它们保持在擦除块粒度(每TB SSD需要8MB)。
- 与传统的ssd不同,在FlashBox中,租户不能共享预先擦除的块。虽然这样做的好处是租户可以控制自己的写放大因子、写和GC性能,但缺点是租户中的频繁写操作不能投机地从整个设备中使用预先擦除的块。在FlashBlox中,每个die都有自己的私有块粒度映射表,以及一个IO队列,该队列的默认深度为256(可配置),以支持基本的存储操作和软件隔离的vssd的软件速率限制器。每个块中的带外元数据(使用16个字节)用于记录物理擦除块的逻辑地址;这支持原子的、一致的和持久的操作。逻辑地址是一个惟一的全局8字节数,由die ID和die中的块ID组成。元数据的其他8个字节用于2字节擦除计数器和6字节擦除时间戳。FlashBlox在主机内存中缓存映射表和所有其他带外元数据。当系统崩溃时,FlashBlox利用反向映射和时间戳来恢复映射表
- 设备级映射层既可以在主机上实现,也可以在设备的固件本身中实现(如果设备的控制器没有充分利用资源),我们的方案中选了在 host 端实现。在FlashBlox中,错误检测、校正和掩蔽,以及其他低级别的flash管理系统仍然没有修改。
- 应用程序/文件系统级别的日志和设备级别的映射都需要过度提供,但原因不同。为了提高垃圾收集效率,日志需要过度配置。在这里,我们依赖于日志结构、flashaware应用程序和文件系统中的现有逻辑来执行它们自己的过度配置,以适应它们的工作负载。为了消除容易出错的擦除块,设备级映射需要自己的过度配置。在我们的实现中,我们根据之前工作中的错误率分析将其设置为1%。
实现细节
原型SSD
- 使用 CNEX SSD(它是一个开放通道的SSD,包含1 TB东芝A19闪存和一个开放控制器,允许从主机访问物理资源。)这个硬件提供了基本的I/O控制命令来对闪存执行读、写和擦除操作。我们使用CNEX固件/驱动程序堆栈的修改版本,它允许我们独立地将请求排队到每个die
原型应用程序和文件系统
- 我们能够修改LevelDB键值存储和ShoreMT数据库引擎,分别使用38和22个LoC修改来使用FlashBlox,同时使用了前文表三所列举的 API。此外,我们实现了一个基于FUSE的用户空间日志结构文件系统(vLFS),它有1,809个LoC(只有26个LoC来自FlashBlox API),用于不能修改的应用程序
资源分配
- 对于创建vSSD的每个调用,资源管理器对所有可用的通道、DIES 和 Soft Plane 进行线性搜索,以满足需求,相应地为此维护了一个空闲列表,在释放资源期间,资源管理器获取释放的通道、DIES 和 Soft Plane,并在可能的情况下合并它们。例如,如果通道的所有四个 DIES 都是空闲的,则资源管理器将这些 DIES 合并到一个通道中,并将该通道添加到空闲通道集。
测试
- 实验表明 :
- FlashBlox 的开销和 FTL 的基本相当(CPU 和写放大系数)。
- 利用flash并行可以实现不同级别的硬件隔离,并且它们的性能优于软件隔离
- 硬件隔离允许对延迟敏感的应用程序(如web搜索)与带宽密集型工作负载(如MapReduce作业)有效共享SSD
- 负载均衡造成的迁移对数据中心应用程序性能的影响较低
- FlashBlox的磨损水平接近理想
测试环境
- 工具: FIO Benchmark
- 负载:NoSQL YCSB A-F;DataBase ;DataCenter
- 测试运行的应用:基于 FlashBlox 修改的 LevelDB(KV) 和 Short-MT (Database)
- 参数:wear-imbalance : 1.1
Microbenchmarks
- 同 CNEX SSD 对照,测试写放大系数。2 vSSDS。FlashBlox 的写放大系数更小,因为 FlashBlox 基本上不会共享实际的物理闪存块。FlashBlox不同类型的vssd具有相似的WAFs,因为它们都使用单独的块,但是由于更高的隔离级别,它们提供了不同的吞吐量和尾延迟级别
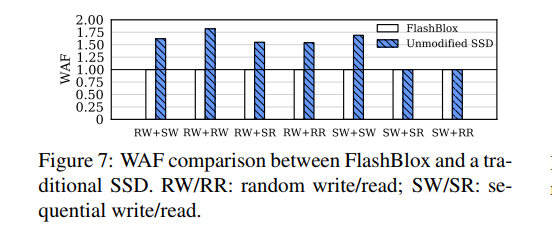
- 此外,与未修改的CNEX相比,FlashBlox的系统CPU总使用率最高可达6%。尽管通过使用FlashBlox api将文件系统的索引与FTL的索引合并,相比现有的openchannel 降低了延迟,但由于设备映射层会在每一个关键路径上都被访问到,引入了额外的 CPU 开销。
隔离级别 VS 尾延迟
- 记录最低线程数所获得的最大吞吐量,对于相同数量的线程,记录事务的平均延迟和尾部延迟。
硬件隔离 vs 软件隔离
- 2 个 LevelDB 实例,运行在两个 vSSD 上,使用三种配置,对应不同的隔离级别。1 channell, 4 dies, 16 soft-planes , 跑 YCSB 负载 32 GB,KV 1KB,50 million CRUD。选择数据库的大小和操作的数量,以便总是触发GC。
- channel 隔离,2 vSSDs 分配到 2 channels,die 隔离, vSSDs 共享 channel,channel 中的 dies 级别隔离。soft-plane 所有 vSSD 分片横跨所有 dies。
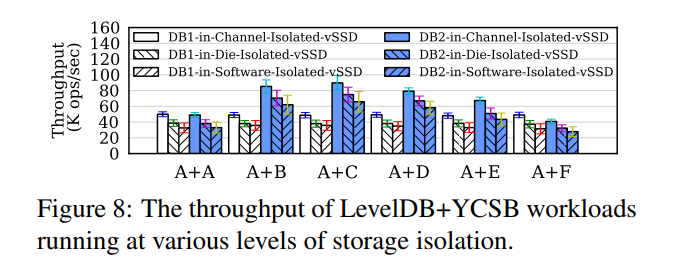
- 吞吐量:channel 级别比 dies 约好 1.3x,比 software 好 1.6x
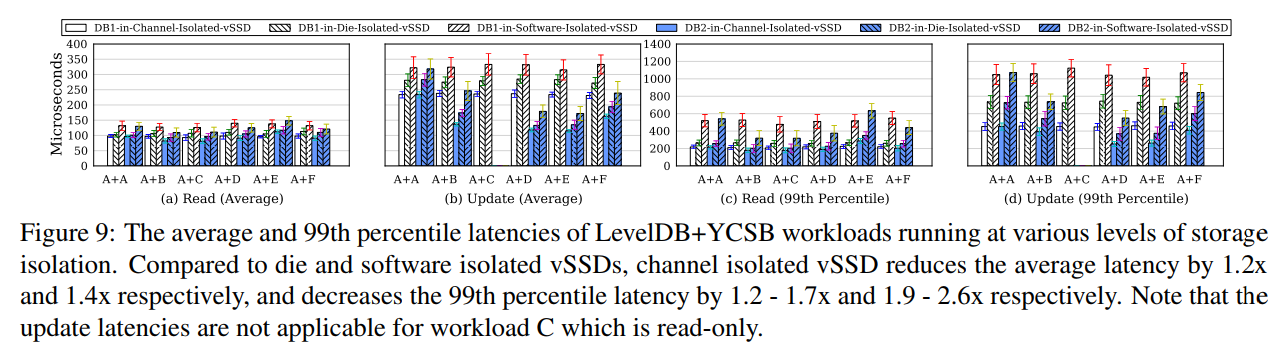
- 延迟:channel 级别比 dies 约好 1.7x,比 software 好 2.6x
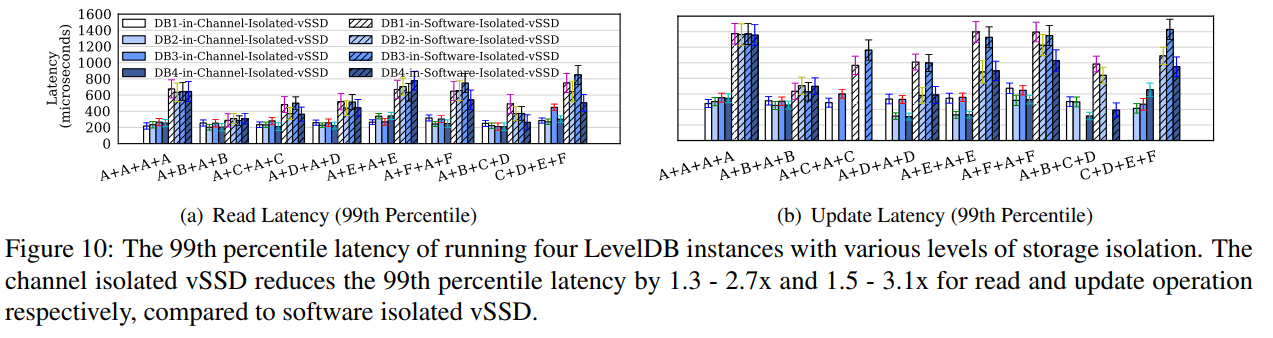
- 4 个 LevelDB 实例
延迟敏感型和带宽敏感型的应用之间的影响
- 此处采用了 WebSearch 和 MapReduce 共享 SSD 进行了测试。主要为了证明硬件隔离提供的优点。和软件隔离、未隔离之间进行对比。
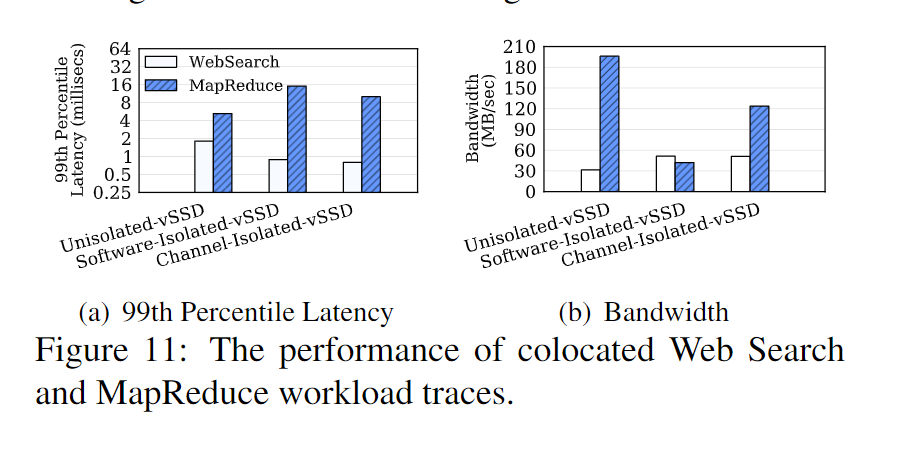
- 实验表明:
- 硬件隔离在带宽和延迟之间取得了最佳的折中。与未隔离的vSSD相比,MapReduce作业的带宽减少了36%,web搜索工作负载的尾部延迟减少了2倍以上。MapReduce的吞吐量下降是可以预料的,因为它只有非隔离情况下的一半,在这种情况下,由于缺乏任何隔离技术,它的大型sequentialIOs最终会不公平地消耗带宽
- 用于web搜索和MapReduce的软件隔离的vSSD可以将web搜索的尾部延迟降低到与通道隔离的情况相同的水平,但是与未隔离的vSSD相比,MapReduce作业的带宽减少了4倍多。这也是可以预见的,因为SSD可以执行的工作是IOPS和带宽的一个组合。当与MapReduce共享带宽时,Web搜索需要大量的小IOPS,这反过来又减少了MapReduce可用的总带宽
磨损均衡效率和开销测试
- FlashBlox 主要有两个层面的磨损均衡。所有DIE均匀老化,以及DIE中的所有块均匀老化。
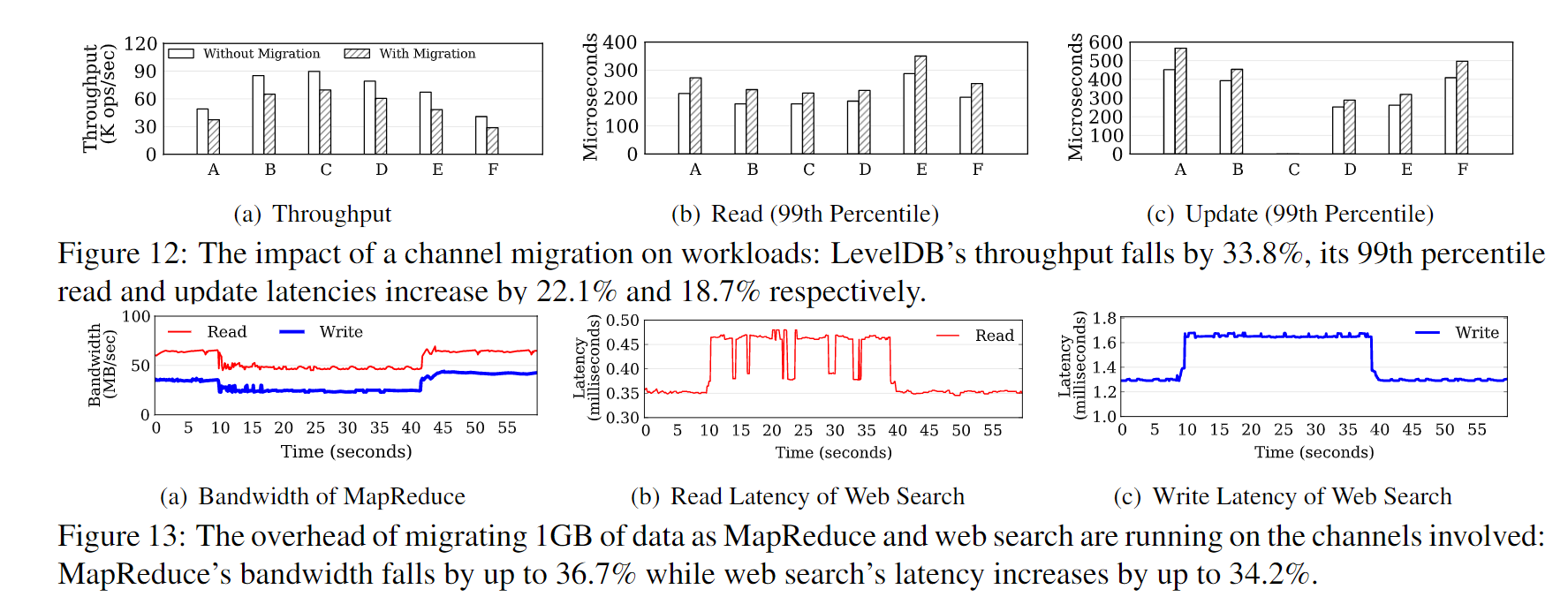
迁移开销
- 图12,LevelDB 迁移,迁移总共64GB通道中的1GB数据,单线程迁移,78.9MBPS,64GB全部迁移需要大概15分钟
- 图13,WebSearch 和 MapReduce 迁移
迁移频率分析测试
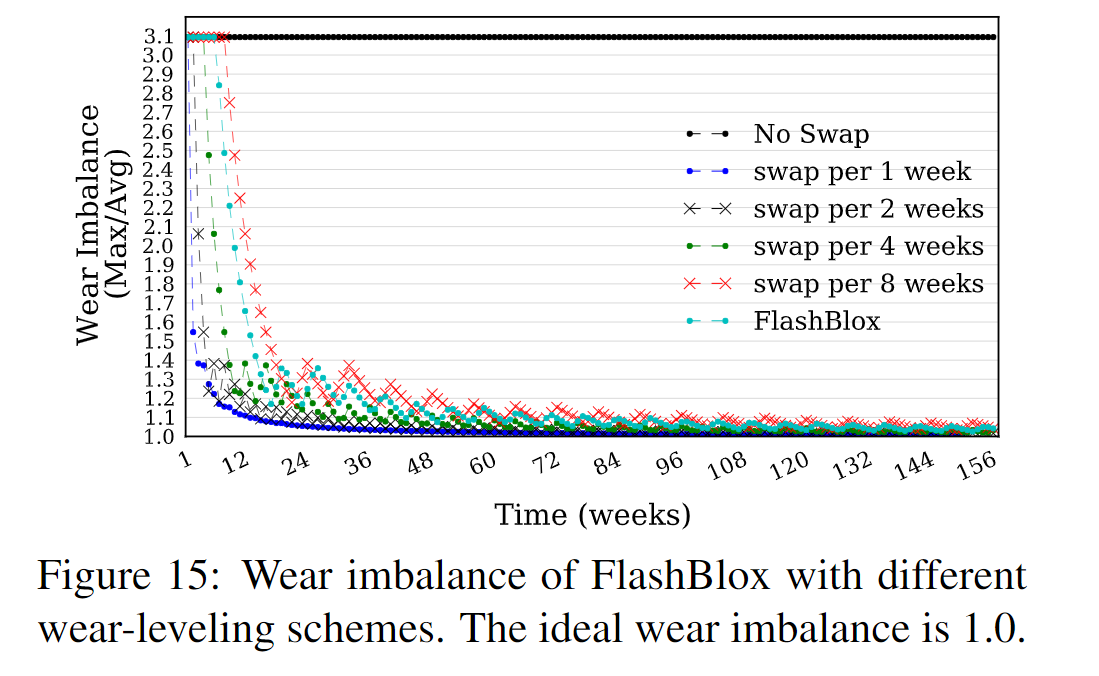
- 仿真实验,使用 vLFS 文件系统,基于 FlashBlox API,测试了一些极端情况下的负载,针对单个通道进行压力测试,其他通道用于读操作。图14显示了各种损耗均衡方案的SSD寿命。 如果不进行平均磨损(NoSwap 图14),SSD会在不到4个月的时间内死亡,而FlashBlox始终可以在通道和杀手级工作负载的迁移频率(≤4周一次)中保证95%的理想寿命。 FlashBlox中的自适应损耗均衡方案通过调整写入速率来自动迁移通道。
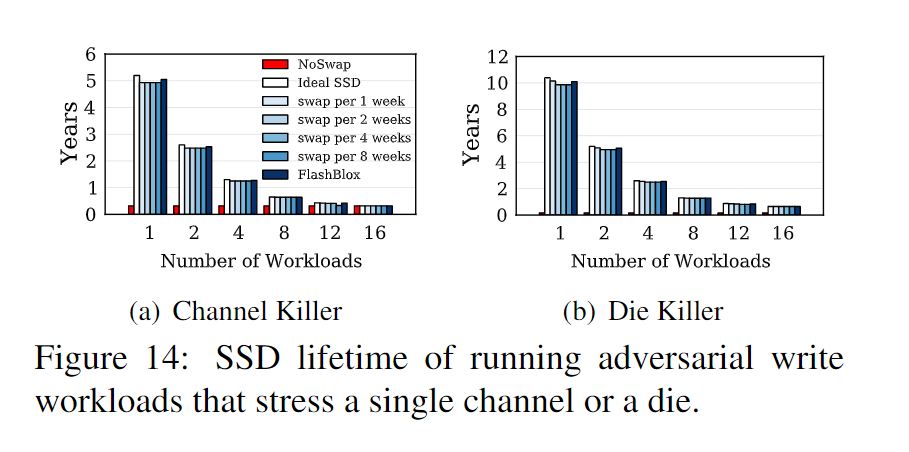
- 使用混合负载测试了相应的不平衡系数。
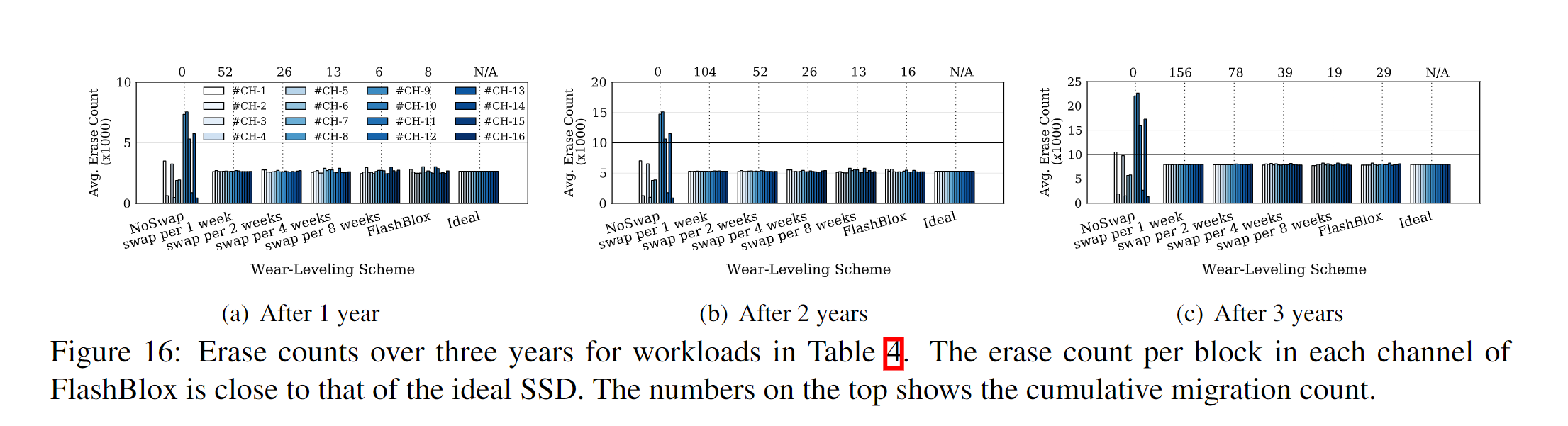
- 图16显示了通道的绝对擦除计数(包括迁移和gc所需的擦除)。与理想的损耗平衡相比,一周一次的交换频率基本就能达到理想效果。
相关工作
- 开放架构的 SSD,但缺少云计算领域多租户之间的性能影响的研究。
- SSD 层面的优化,大量研究致力于优化 FTL,本篇文章进行了扩展,在现有的优化基础上,将通道进行隔离,并使用新的负载均衡策略,内部闪存颗粒的管理沿用前人的有优化方案。
- SSD 接口,主要用于虚拟化场景下和应用程序之间的对接,FlashBlox 沿用了研究成果并设计了 FlashBlox API。
- 存储隔离
结论
- 利用SSD中存在的通道和DIE级并行来为共享SSD的延迟敏感应用程序提供隔离。此外,FlashBlox提供了近乎理想的生存期,尽管各个应用程序以不同的速度写入各自的通道和DIES。FlashBlox通过在粗糙时间粒度的通道和DIES之间迁移应用程序来实现这一点。
- 未来希望研究如何与虚拟硬盘驱动程序集成,以便虚拟机可以利用flashblox而无需修改。希望了解FlashBlox如何与多资源数据中心调度器集成,以帮助应用程序获得可预测的端到端性能
