- FAST20 Overview
- 最近进入了一个怠惰期,一是苦于没有明确的研究方向,二是沉湎于琐碎小事,所以科研上很多事情都被搁置
- 遇到了问题就总得寻找解决的办法,所以决定还是好好看几篇论文,看看能不能找到感兴趣的点,再深入挖掘
- 最近也没太多新的会议,故还是先好好看看 FAST20 上的文章,对一些可能感兴趣的文章做些简单记录
FAST20
- 此次会议主要分为了 Cloud Storage、File Systems、HPC Storage、SSD and Reliability、Performance、Key Value Storage、Caching 和 Consistency and Reliability 几个 Topic。本篇文章不会对所有的 Topic 下的所有论文都进行总结记录,譬如 HPC Storage 由于缺乏一定的了解就没有在此处记录,针对每个 Topic 下的文章也只是选择了自己有一定的了解或者感兴趣的几篇来简单地记录。
- 有的文章会详细展开,有的因为受限于我自己的水平无法深入,故只能泛泛而谈,但会尽力尝试去理解所要解决的问题以及解决问题的方式。
- 本篇博文会持续记录更新,因为阅读量还挺大的,遇到比较好的感兴趣的论文会单独开一篇进行详细的理解记录。
Cloud Storage
- 云存储主题下 FAST20 有三篇:
- MAPX: Controlled Data Migration in the Expansion of Decentralized Object-Based Storage Systems
- Li Wang, Didi Chuxing; Yiming Zhang, NiceX Lab, NUDT; Jiawei Xu and Guangtao Xue, SJTU
- Lock-Free Collaboration Support for Cloud Storage Services with Operation Inference and Transformation
- Jian Chen, Minghao Zhao, and Zhenhua Li, Tsinghua University; Ennan Zhai, Alibaba Group Inc.; Feng Qian, University of Minnesota - Twin Cities; Hongyi Chen, Tsinghua University; Yunhao Liu, Michigan State University & Tsinghua University; Tianyin Xu, University of Illinois Urbana-Champaign
- POLARDB Meets Computational Storage: Efficiently Support Analytical Workloads in Cloud-Native Relational Database
- Wei Cao, Alibaba; Yang Liu, ScaleFlux; Zhushi Cheng, Alibaba; Ning Zheng, ScaleFlux; Wei Li and Wenjie Wu, Alibaba; Linqiang Ouyang, ScaleFlux; Peng Wang and Yijing Wang, Alibaba; Ray Kuan, ScaleFlux; Zhenjun Liu and Feng Zhu, Alibaba; Tong Zhang, ScaleFlux
- MAPX: Controlled Data Migration in the Expansion of Decentralized Object-Based Storage Systems
- 云存储主题下的文章被国内的企业和高校包揽,其实不难发现云存储还是更偏向于工业界的实际应用的,而国内的企业在相应的领域都有着各自丰富的积累,特别是在数据库领域更是百花齐放(POLARDB Meets Computational Storage);也有自己在运维相关存储系统时的经验总结以及对应的优化方案(MAPX);还有一个比较有意思的点就是近年来比较多的团队协作式的云存储(Lock-Free Collaboration Support for Cloud Storage),又恰逢疫情更是推动了云存储的普及。
MAPX: Controlled Data Migration in the Expansion of Decentralized Object-Based Storage Systems
- 这篇因为之前有针对全文的翻译和理解,此处不做过多的介绍,更详细的可以参考
简要介绍
- 问题:该文解决的问题其实是 CURSH 算法最大的问题——集群扩容或者添加中间逻辑结构(如PGs)时会造成不受控制的数据迁移,虽然迁移可以在扩展之后立即重新平衡整个系统的负载,但是在扩展规模较大时会导致显著的性能下降。(如以机架的规模进行扩容)
- 为什么会产生这样的问题? 设计 CRUSH 算法目的其实主要是为了去中心化,即不需要像 HDFS 等分布式存储系统依赖中心化的目录或元数据管理来寻址对应的数据,而是通过直接计算的方式来实现从而降低对中心化的元数据管理的耦合。但是 CRUSH 相比于中心化管理,中心化目录的存储系统可以保证原有的数据在扩容过程中不受影响,只把新的数据存储在新的存储节点上,CRUSH 由于缺少了关于集群扩容过程中带来的物理存储节点(OSD)的差异信息,在进行计算时都统一处理,由于相应的逻辑节点的权重发生了显著变化,CRUSH 计算结果发生了变化,就会导致大量的数据迁移。
解决方案
- 受中心化数据布局策略的启发,致力于实现扩容过程中数据迁移的可控,所以基于 CRUSH 设计实现了 MAPX,核心思想就是引入时间维度的映射机制来区分 新老 对象/OSD ,同时保留 CRUSH 算法随机和均匀的优点。
- 为了尽可能少地修改原有的 CRUSH 算法,在原本的 CRUSH 根节点下插入一个虚拟层,如图所示,每一个虚拟节点代表一次扩容。虚拟层对应的通过使用 MAPX 实现可控数据迁移,通过在执行原本的 CRUSH 算法之前将新的对象映射到新的 layer,因为新的 layer 不会影响原有 layer 的权重,原有对象的放置还是和以前一样,不会发生改变。
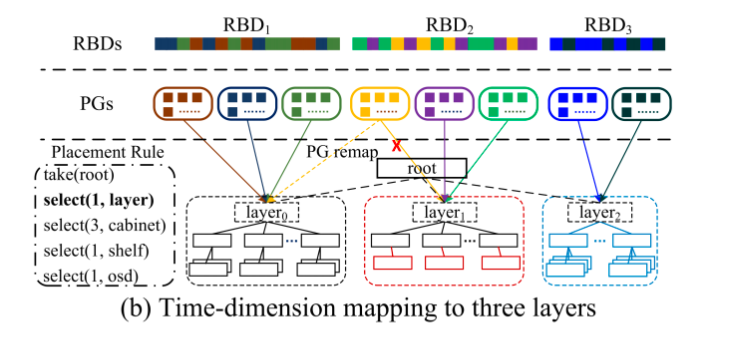
- MAPX 能保证每一层的负载均衡,主要是因为通用 CRUSH 算法的随机性和均匀性,随着时间的迁移,新的 layer 中的数据增多到和前一个 layer 时则实现了 layers 层面的负载均衡。但是一个 layer 的负载可能会因为 对象的删除、OSD 的宕机发生一些不可预测的负载变化。如图所示,当 layer1 中的负载跟原始集群 layer0 的负载一样高时,则可能会执行一次扩容产生 layer2,假设 layer1 中执行了大量的对象删除操作,则会造成不同 layers 之间的负载不均衡。
- 为了解决这个问题,MAPX 设计了三种灵活的策略来动态管理 MAPX 中的负载:
- PG 重映射:可以控制 PGs 到 Layer 的映射,来保证 layers 负载均衡
- 集群缩容:缩容时需要进行 PG 重映射调整负载,但也要保留部分元数据来保证映射关系不变
- layers 合并:使用时间戳来保证物理层的变化在逻辑层 layer 上保持相同以实现负载均衡
Lock-Free Collaboration Support for Cloud Storage Services with Operation Inference and Transformation
- 这篇文章呢其实主要是对现如今比较时髦的一个场景进行了综合性的分析,也提供了自己的方案。即针对共享文档的编辑时的版本管理和冲突解决的方式进行了深入探讨,结合了市面上现有的多种云存储的团队协作方案,分析之后他们提出了一种无锁的共享文档的编辑的方案,设计了一种比较智能的办法来减少冲突,且开源。
- 提出了问题同时也利用并设计了算法上的优化,难点主要在于对整个过程进行建模的过程。
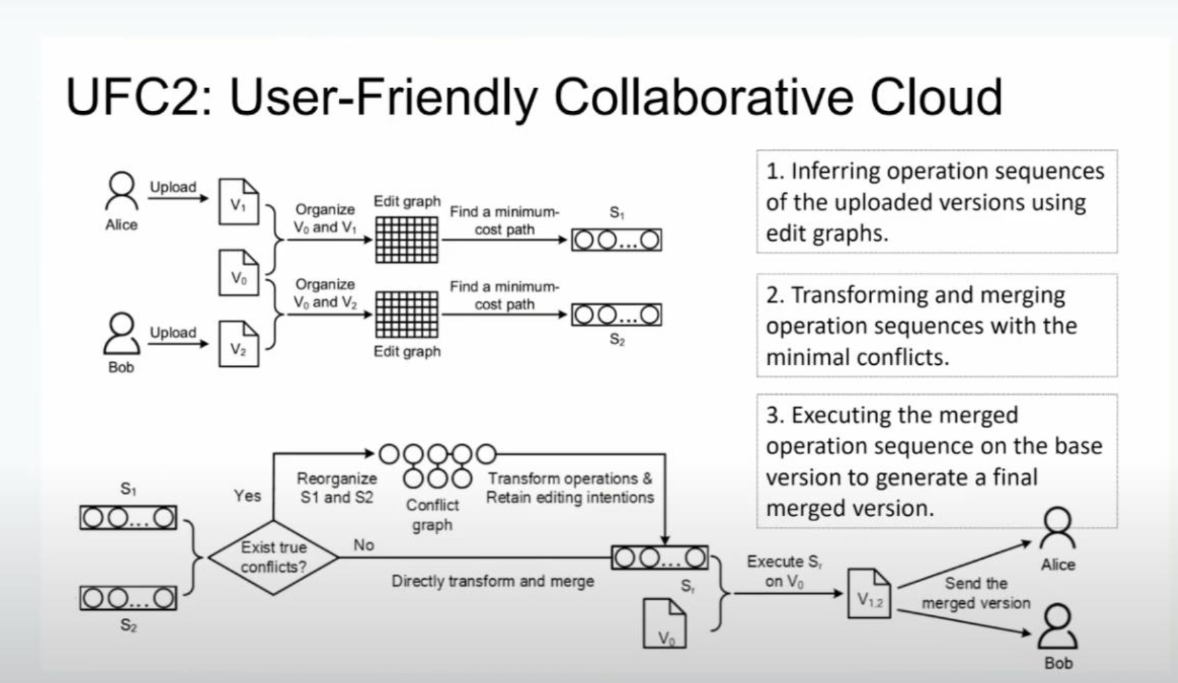
- 这篇文章还有的一个比较有意思的点在于,本文涉及到的别的云存储共享编辑的产品其本身是不开源的,所以在分析这些产品可能的实现方式的时候其实是个很复杂的过程,作者们通过抓包、解密网络流量、分析数据驱动的方法、阅读部分代码和文档的方式才渐渐分析出大致的实现原理
- 对共享文档的编辑或者云存储协作感兴趣的同学可以深入阅读,由于不涉及到自己更了解的存储系统领域,此处就不班门弄斧了。
POLARDB Meets Computational Storage: Efficiently Support Analytical Workloads in Cloud-Native Relational Database
- 开始之前先贴几篇讲解和总结(主要是不想重复造轮子hhhh)
简要介绍
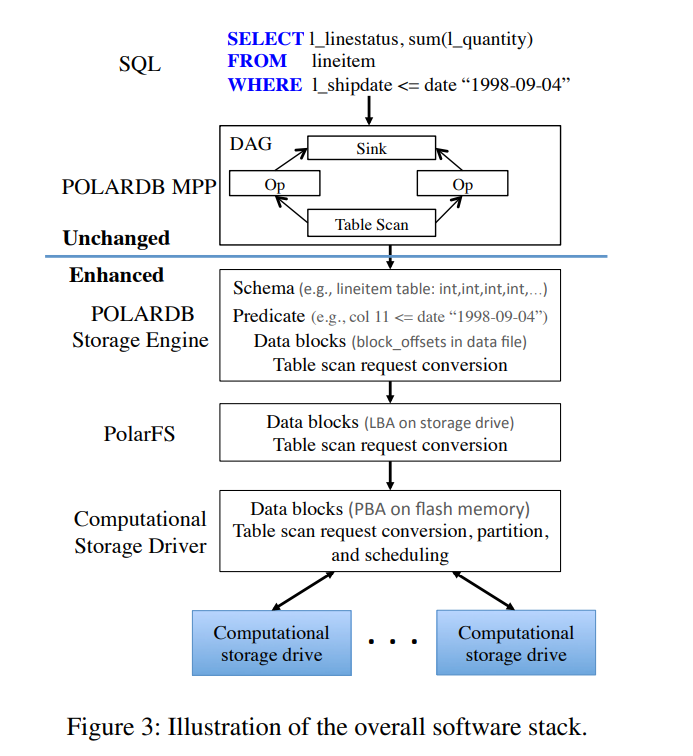
- PolarDB 整体架构
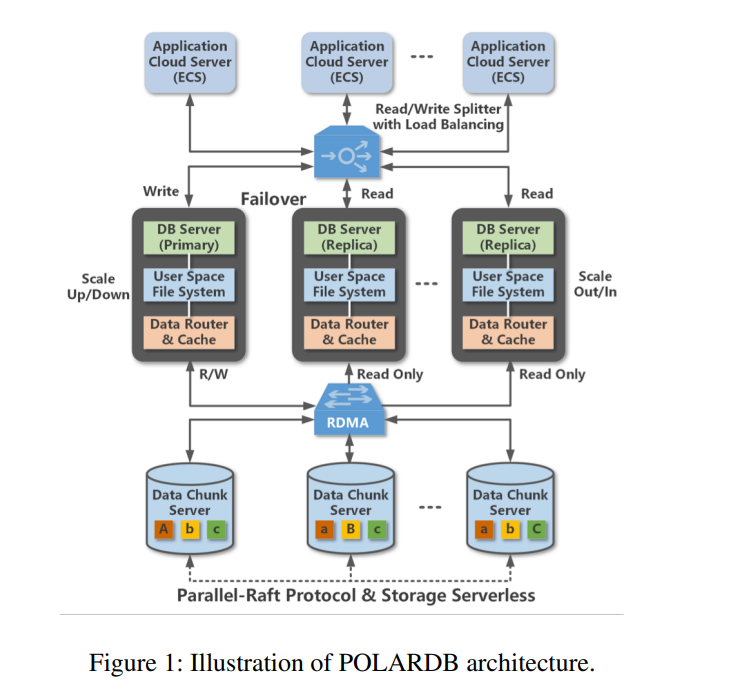
- 存算分离架构的背景下,云原生的关系型数据库需要把数据敏感型的任务(例如 table scan)从前端数据库给下发到后端存储节点,以便充分支持分析工作负载,减小存储节点和计算节点之间的链路传输,,但将该类任务转发到存储节点之后对于存储节点的效率则提出了挑战,新出现的 computational storage drives (也称存内计算或者计算型存储)使得上述想法成为可能。
- 要想使存储节点有足够的能力支持”计算下推”,通常有两个方案,一是scale-up存储节点的CPU能力;二是在存储节点上配备特殊硬件(比如GPU 或者FPGA)来用这些特殊硬件执行存储节点上的”计算下推“任务。第一个方案会较大增加存储节点的成本;第二个方案会引起存储节点内大量的数据迁移, 同时在拥有多块NVMe SSD的存储节点上很容易使特殊硬件成为热点,制约单个存储节点的对外能力。 论文提出了一个新的思路,直接将”计算下推“的工作offload到物理介质
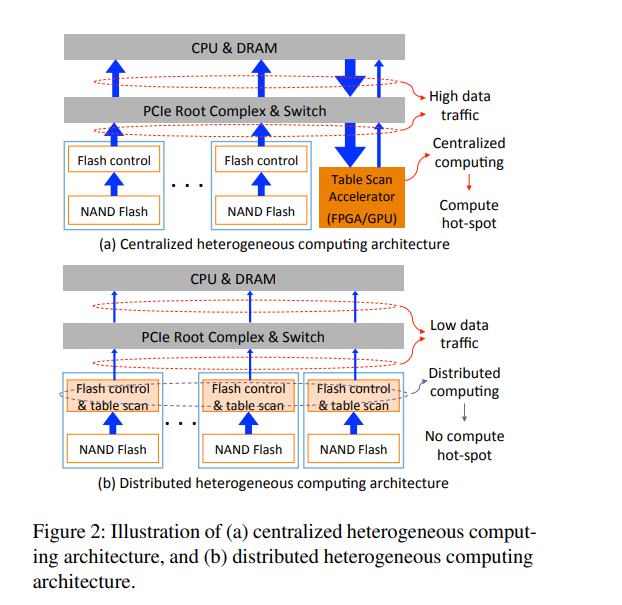
- 然而,异构计算实际可行的实现和实际部署仍然完全缺失,至少在开放文献中是这样。这主要是由于很难解决两个挑战:
- (1) 如何实际支持跨整个软件层次的表扫描 pushdown
- 由用户空间POLARDB存储引擎发起,该存储引擎通过指定文件中的偏移量来访问数据,而表扫描在物理上由计算存储驱动器提供,它作为原始块设备运行,并使用LBA(逻辑块地址)管理数据。整个存储I/O堆栈位于POLARDB存储引擎和计算存储驱动器之间。因此,我们必须内聚地增强/修改整个软件/驱动程序堆栈,以便创建一个支持表扫描叠加的路径
- 组成:
- 前端分析处理引擎 PolarDB MPP:该分析处理引擎与 MySQL 协议兼容,可以解析、优化和重写使用 AST(抽象语法树)的 SQL 和许多嵌入式优化规则,它将每个 SQL 查询转换为一个 DAG(有向无环图)执行计划,由操作符和数据流拓扑组成。该引擎原生就支持 pushdown
- 存储引擎 PolarDB Storage Engine:遵循了 LSM-tree 实现,数据被组织成了多个文件,每个文件包含很多块。
- 原有的实现中,存储引擎可以使用存储节点上的 CPU 来处理 table scan 请求,因此 table scan pushdown 将与底层的 IO 堆栈无关。
- 为了利用可计算型存储的特点,需要修改该引擎以便将 table scan 请求 pushdown 到 PolarFS 上。存储引擎根据文件中的偏移量访问数据块。每一个 table scan 请求包括:
- 要被扫描的数据的定位信息(文件内的偏移量);
- 应用表扫描的表的 schema;
- table scan condition。
- POLARDB 存储引擎分配一个内存缓冲区来存储从计算存储驱动器返回的数据,每个 table scan 请求都包含这个内存缓冲区的位置
- POLARDB部署在分布式文件系统PolarFS上,该文件系统管理跨所有存储节点的数据存储。computational storage drives 只能以 LBA 的形式定位数据,PolarFS 在收到来自 POLARDB存储引擎的每个表扫描请求后需要进行数据转换
- 计算存储驱动器完全由内核空间中的主机端驱动程序管理,该驱动程序将每个计算存储驱动器公开为块设备。当收到每个表扫描请求时,驱动程序执行以下操作
- 分析 scan conditions,可能对 conditions 重新进行组织以获得更好的性能
- 驱动程序进一步转换将被扫描数据的位置信息从LBA域到物理块地址(PBA)域,其中每个PBA与NAND闪存中的一个固定位置相关联。
- (2) 如何实现低成本的计算存储驱动器具有足够的表扫描处理能力
- 虽然基于FPGA的设计方法可以显著降低开发成本,但FPGA往往比较昂贵。此外,由于
FPGA通常仅工作在200 ~ 300MHz(与之相比,CPU时钟频率为2 ~ 4GHz),为了实现足够高的性能,我们必须使用大量的电路级实现并行性(因此需要更多的硅资源)。因此,我们必须在我们的实现中开发出能够使用低成本FPGA芯片的解决方案 - 为了解决计算存储驱动器实现成本的挑战,关键是最大化FPGA硬件资源的利用效率。为了实现这一目标,我们跨软件和硬件层进一步开发了以下技术。
- Hardware-Friendly Data Block Format
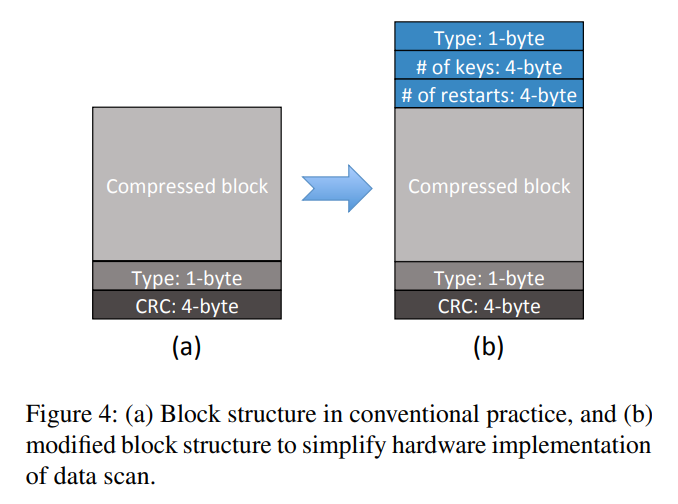
- Hardware-Friendly Data Block Format
- FPGA 并行化
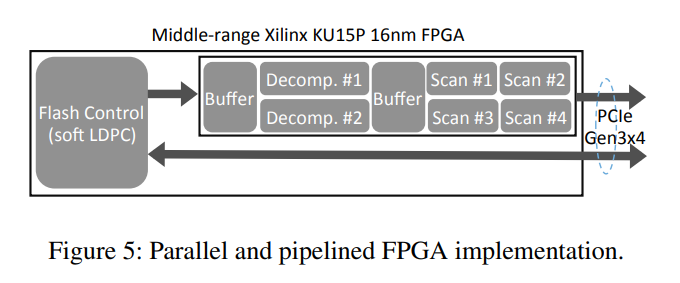
- 虽然基于FPGA的设计方法可以显著降低开发成本,但FPGA往往比较昂贵。此外,由于
- (1) 如何实际支持跨整个软件层次的表扫描 pushdown
个人见解
- 因为自己不是做数据库系统的,所以对于背景可能了解的不够,但这不妨碍对 PolarDB 整体结构的理解,个人感觉 PolarDB 对外提供的虽然是简单的关系型数据库服务,但是内部实现了大量的存储系统的工作。虽然本篇是基于 data-intensive 的负载 offload 到计算型存储的角度来组织的,但还是大体能看出 PolarDB 内部复杂的工作细节,以及各个组件都进行了各种软件栈上的优化。PolarDB 本身是一个很大的分布式存储系统,其中的很多小的创新点也基本都是能够组成一个 Paper Idea 的水准,且有工业界的实际实现,经得住实际负载的考验。
- 抛开本篇论文的主要内容不谈,PolarDB 本身就是一个十分出众的数据库,此处给一些 PolarDB 的整体介绍链接:
File Systems
- Read as Needed: Building WiSER, a Flash-Optimized Search Engine
- Jun He and Kan Wu, University of Wisconsin—Madison; Sudarsun Kannan, Rutgers University; Andrea Arpaci-Dusseau and Remzi Arpaci-Dusseau, University of Wisconsin—Madison
- How to Copy Files
- Yang Zhan, The University of North Carolina at Chapel Hill and Huawei; Alexander Conway, Rutgers University; Yizheng Jiao and Nirjhar Mukherjee, The University of North Carolina at Chapel Hill; Ian Groombridge, Pace University; Michael A. Bender, Stony Brook University; Martin Farach-Colton, Rutgers University; William Jannen, Williams College; Rob Johnson, VMWare Research; Donald E. Porter, The University of North Carolina at Chapel Hill; Jun Yuan, Pace University
Read as Needed: Building WiSER, a Flash-Optimized Search Engine
- 这篇文章是针对现有的搜索引擎进行设计和优化的(以前的研究中很少有针对搜索引擎这类上层应用进行优化的,但随着数据规模的增加,搜索引擎的应用也越来越广泛,尤其是在一些文本检索的领域),搜索引擎本身是一种计算密集型的应用,会有一些读取存储设备的操作,作为一种 "read as needed" 类型的负载,对于存储系统的要求和其他类型的应用负载稍有不同。本文则是实现了一个以相对较少的主存(main memory)提供高吞吐量和低延迟的搜索引擎。
简要介绍
背景
-
由于本身研究的点不同于以往,所以就按照惯例先介绍了一下这个问题有多关键。此处不表。
-
对于存储系统而言,不管你上层的应用是什么,在存储设备上本质都是数据结构的存取,而搜索引擎和数据库以及图等负载稍有不同,主要使用了倒排索引等结构,又随着 SSD 的普及,所以基于 SSD 的优化方案就比较有搞头。
-
需要注意的是搜索引擎对于存储系统的要求:
- low data latency:因为搜索引擎的交互性很强,常常需要较低的延迟来保证
- high data throughput:因为要处理和检索的数据很多,对于吞吐量的要求也较高
- high scalability:因为搜索引擎主要面型文本存储领域,数据规模会随着时间不断地变大,相应地就需要较好的扩展性来提供相应的支持。
-
以前的搜索引擎也会面对上述问题,但之前的解决方案都是利用内存作为一种存储介质,由于数据规模较大,为了保证低时延和吞吐量等特性,就常常需要把大量的数据放在内存中(虽然可能会丢,但重建肯定也是一个很大的开销)
-
作者觉得既然现在存储设备已经很快了现在,考虑到对大型数据集使用RAM的成本过高,那么是否可以重新构建一个搜索引擎,以更好地利用 SSD 来实现必要的性能目标,而使用比较少的内存。更明智的做法是重新组织传统的搜索数据结构,以创建和改进读流,从而利用现代 SSD 提供的带宽
-
针对 read as needed 的负载,作者提出了设计理念
- use small memory
- read data from SSDs as needed
- do not attempt to cache data in memory
- attempt to read data from SSDs efficiently
-
分析了现有的搜索引擎,其中 state-of-the-art 的 ElasticSearch。ES 不能实现高性能原因主要是因为读放大,因为 ES 将不同阶段的数据分组到多个位置,并将数据进行排列,使早期的数据项更小。其目的是缓存早期阶段的数据,因为早期阶段的数据要比后期阶段的数据访问得更频繁。然而,按阶段分组数据也可能导致比较大的读放大。
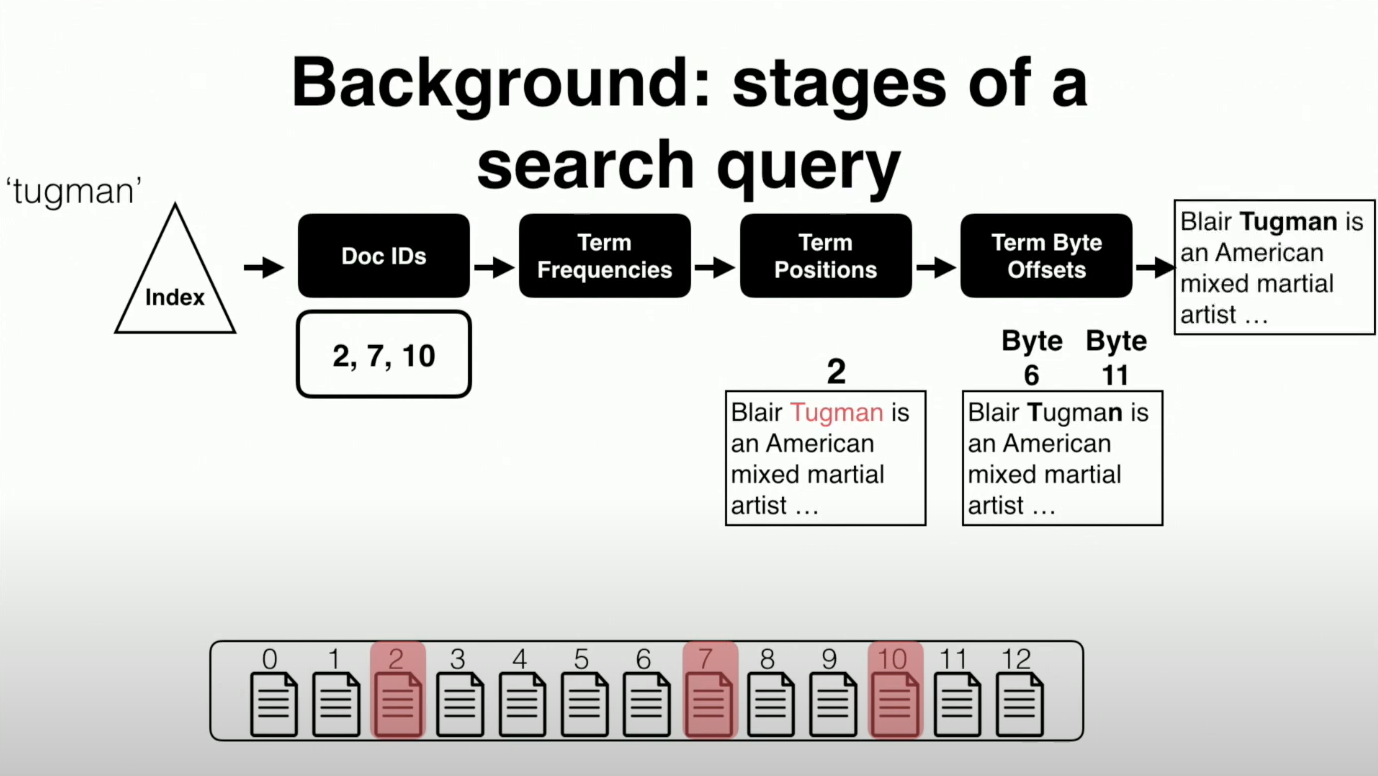

-
因为 SSD 本身的一些限制(有限的带宽、高延迟、大IO友好),以及在 ES 中发现的问题,为了实现上述的搜索引擎对于存储系统的要求,就需要
- reduce read amplification
- hide i/o latency
- use large request to improve device efficiency
Design
- 设计了四个关键技术
- Grouping data by term
- 即不再采用分阶段存取在不同的文件中的方式进行存储,而是使用连续的压缩的数据块来进行放置,从而将小的读请求转换成了大的读请求
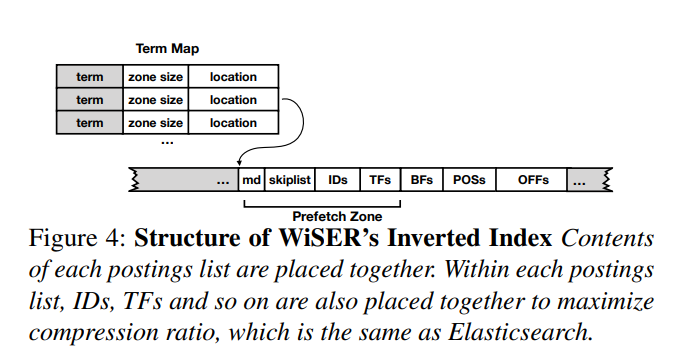

- 即不再采用分阶段存取在不同的文件中的方式进行存储,而是使用连续的压缩的数据块来进行放置,从而将小的读请求转换成了大的读请求
- Two-way Cost-aware Bloom Filters
- 针对于 phrase query 的场景,作者使用了两路布隆过滤器来帮助快速检索短语。
- 设置前后两路匹配的原因,是因为 before 和 after 的查询开销可能不一样,会尝试选择开销更小的那一路的布隆过滤器来进行匹配。但可能存在两路开销都很大的情况,这时候则直接使用默认的原有的短语匹配方式。这也就是所谓的 Cost-aware

- Adaptive Prefetching
- 为了获得最佳性能,预取应该适应查询和持久数据的结构。在倒排索引的所有数据中,最常被访问的数据包括元数据、跳跃表、文档id和词频,这些数据经常被一起顺序访问;
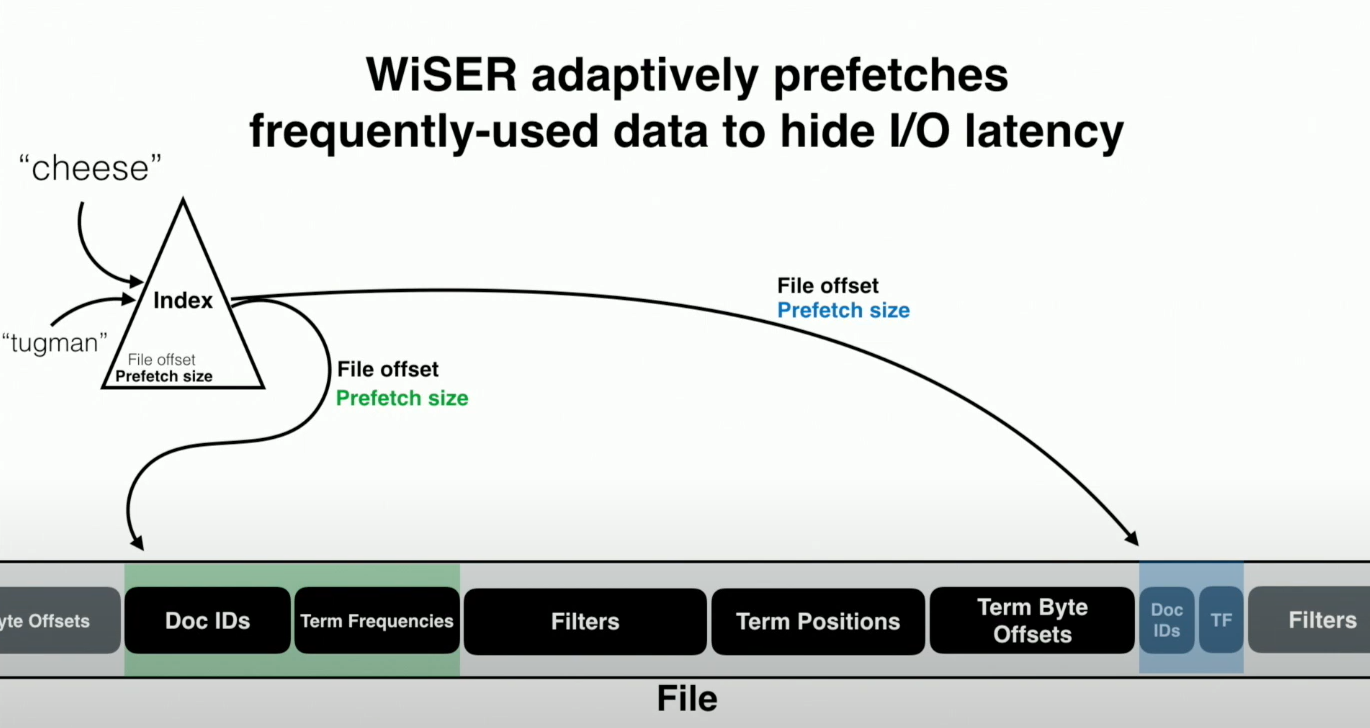
- 为了获得最佳性能,预取应该适应查询和持久数据的结构。在倒排索引的所有数据中,最常被访问的数据包括元数据、跳跃表、文档id和词频,这些数据经常被一起顺序访问;
- Trade Disk Space for I/O
- 压缩的粒度和 ES 不同,从而减小读放大,但其实做了 trade-off,压缩后的大小比 ES 压缩后的要大

- 压缩的粒度和 ES 不同,从而减小读放大,但其实做了 trade-off,压缩后的大小比 ES 压缩后的要大
- Grouping data by term
个人见解
- 这篇其实也不是个人所熟悉的领域,只是因为很早以前自己接触过 ElasticSearch 的应用(ELK 体系那一套),所以对 ES 还是比较感兴趣,这篇文章其实都是在和 ES 对比,可以理解为是对现有的 ES 上的优化,虽然作者指出可以延伸到按需读取场景下的其他负载,但本质还是在搜索引擎的这个领域下的优化。奈何才疏学浅,也就只能总结到这了。
How to Copy Files
- 先放几个链接:
- 文章从标题开始其实就很吸引眼球,毕竟是一个看着很简单的问题,但是作为论文标题就不禁想让我这种门外汉也要尝试着去看看作者在里面写了些啥我不知道的东西哈哈。走马观花看了看发现嗯自己确实不懂。。
- 本文其实是做的文件系统领域中关于复制或者克隆操作的优化,现有的很多克隆其实是基于 Copy-On-Write 实现的,但原生的 Copy-On-Write 启发算法有一定的问题,所以作者在这上边也下了很多功夫,提出了 copy-on-abundant-write,基于 BetrFS 实现,除此以外还做了一些别的针对性的优化,复制操作性能提升也比较明显。
简要介绍
背景
- 当然首先还是按惯例介绍这个问题多重要,所以就先介绍拷贝操作应用广泛,其实主要体现在备份、快照这些机制中,然后云计算领域中的容器、虚拟机等技术使用拷贝比较频繁。但拷贝本身其实可以分为逻辑拷贝和物理拷贝,从字面上也很好理解,物理拷贝肯定就是物理存储空间上进行完整的拷贝了,时间和空间的消耗可能会因为大文件而特别大,所以很多时候都用逻辑拷贝,也是 volume snapshots 中用的比较多的 Copy-On-Write 写时复制。CoW 可以对块设备进行,也可以在文件系统中对文件或者目录进行,取决于具体的产品实现。譬如 Linux 本身支持的 cp -reflink
- 引出主题 CoW 之后相应地指出现有的 CoW 的问题:标准的 CoW 本身其实是在写放大和局部性之间做了 trade-off。即 CoW 的粒度大小的设定将影响这两方面的表现。
- 如果粒度为文件的大小,那么对文件的小写操作带来的写放大就很严重,相应的写延迟也就增加了,空间也被浪费了(因为共享的数据被写操作给破坏了)
- 如果粒度很小,更新操作很快,但是容易产生碎片,顺序读副本的开销就变大了,因为局部性被破坏了。
- 想要实现的效果,也就是文中作者描述为 Nimble clones 的复制操作应该是这样的:(那肯定现有的文件系统里的 CoW 实现就不是 nimble 的,文中有测试)
- be fast to create
- have excellent read locality
- have fast writes
- conserve space
- 总结下来问题其实出在对克隆的写操作粒度与共享数据副本的粒度这两点,其实就是对于文件小写,不能直接就将源文件拷贝重写了,要设定一个相对大的 copy size 来保证局部性,即得 buffer 小写。所以就得把对克隆的写操作和副本的相关操作解耦。所以作者选了 BetrFS 来实现自己的方案。毕竟 BetrFS 以写见长,也有一些自己的 buffer 机制,当然主要还是测试出来的,文中的一个关于性能降级的测试。
Design
- 需要首先理解一下 btrfs 的原理和其中的数据结构 Bε-tree。
- btrfs 基于 KV 来管理文件系统中的数据,元数据 KV 存储的是 文件全路径 Full Path 到文件系统元数据的映射,数据 KV 存储的是 {fullpath + block number} 到 block的映射。
- Bε-tree 可以简单理解为一个带 buffer 缓冲的 B-tree,主要吸收随机小写。
- 在 Bε-tree 基础上实现逻辑拷贝,即 Bε-DAG。在树中增加新的边 edge,以使得在访问克隆后的文件夹时,能通过某种方法访问克隆前的数据(克隆后的数据在不修改内容前,都是完全共享的),通过使用 DAG (有向无环图)的思想来支持共享访问,对应地需要实现一层如图所示的转换 red->green
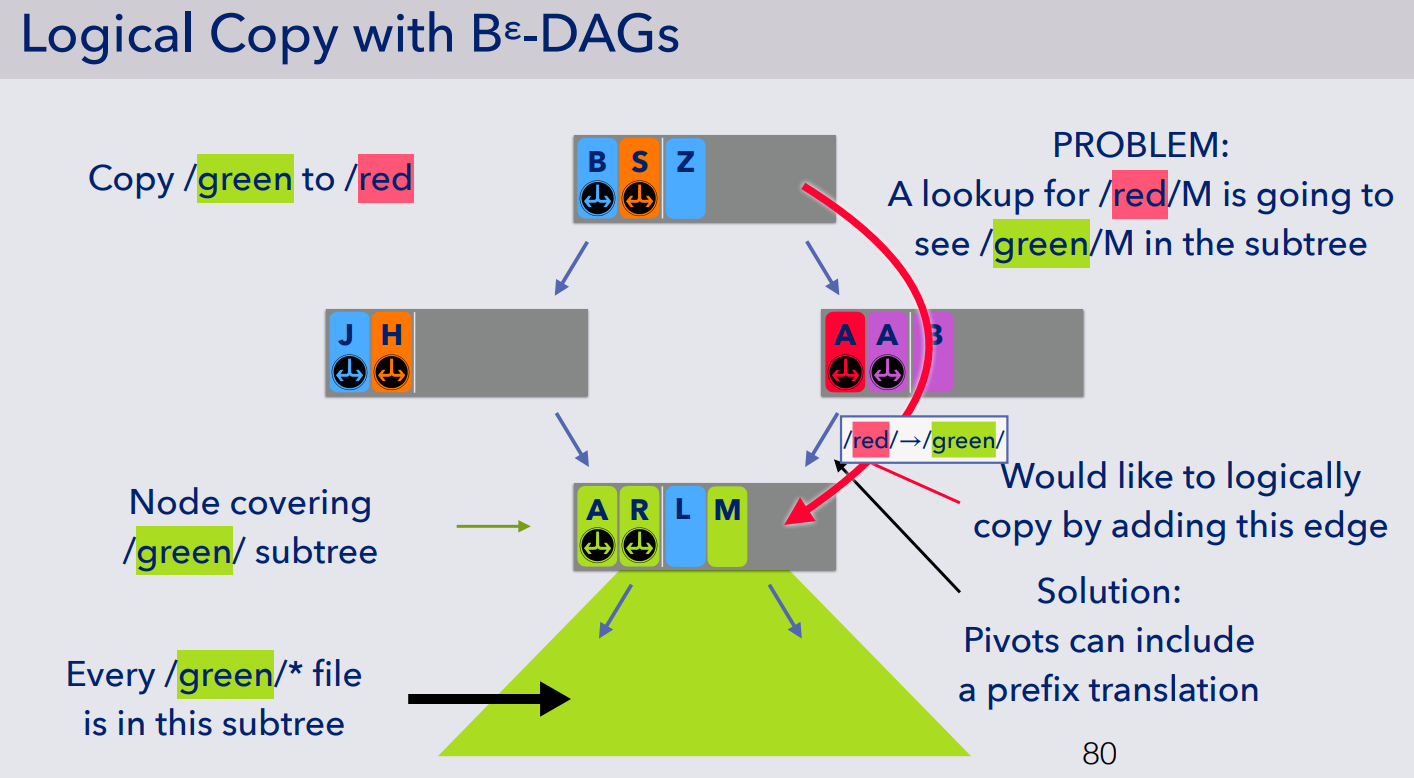
- 对于此时的写操作,则需要在 flush 的时候执行 copy-on-write,分为五个步骤执行: Copy-on-Abundant-Write
- 第一步,copy 该节点
- 第二步,转换文件对应的路径前缀(图中的 green->red)
- 第三步,删除无法到达的数据,图示中的蓝色 L,因为拷贝之后没有 blue 上层目录,即在该路径上该文件再也无法访问到,故可以删除
- 第四步,移动地址转换功能,即把原本的上一层的 red->green 移动到下一层(因为复制后的节点有一些数据为目录,如图中所示的 A 和 R,故需要指向底层文件,如果 flush 操作针对更底层的文件,那么再相应递归地执行 copy-on-write)
- 第五步,将数据刷入到复制后的节点中作为新的 buffer(即吸收小写)
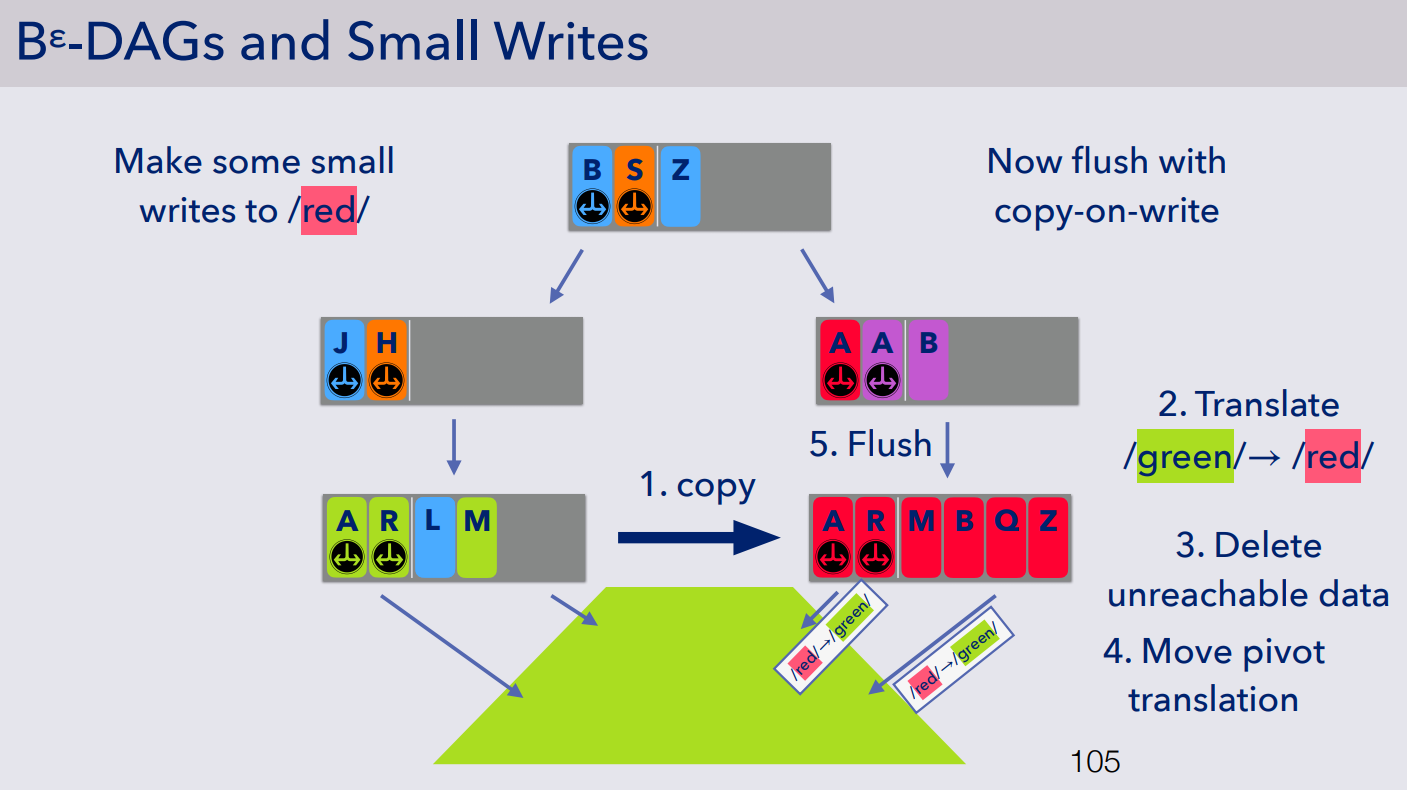
- 因为 Bε-DAG 中的节点本身比较大,即可以吸收小写,且局部性比较好,所以在读写上表现都很不错,又因为采用了新的上文描述的 Copy-on-Abundant-Write 在空间上的利用率也很高,但还有一个问题没有解决,即拷贝延迟
- 作者实现了一种称之为 GOTO Message 的机制,用于减小 Copy 操作的延迟。存储的数据大致如 (a,b) - height - dst_node,其中 (a,b)为拷贝操作覆盖的 key 空间/范围,height 表示要拷贝的目标节点的高度,dst_node 表示要拷贝的目标节点。
- 如果要进行拷贝操作,如图所示,拷贝 /green 到 /violet,那么相应地会先触发 green 的 flush,确保数据一致,然后插入一条 GOTO Message。
- 查询操作首先查询到了 GOTO Message,那么首先判断 key 是否在相应的区间中,如果在那么就要去 dst_node 处继续查找,相应地会进行前缀转换,直到找到该数据。
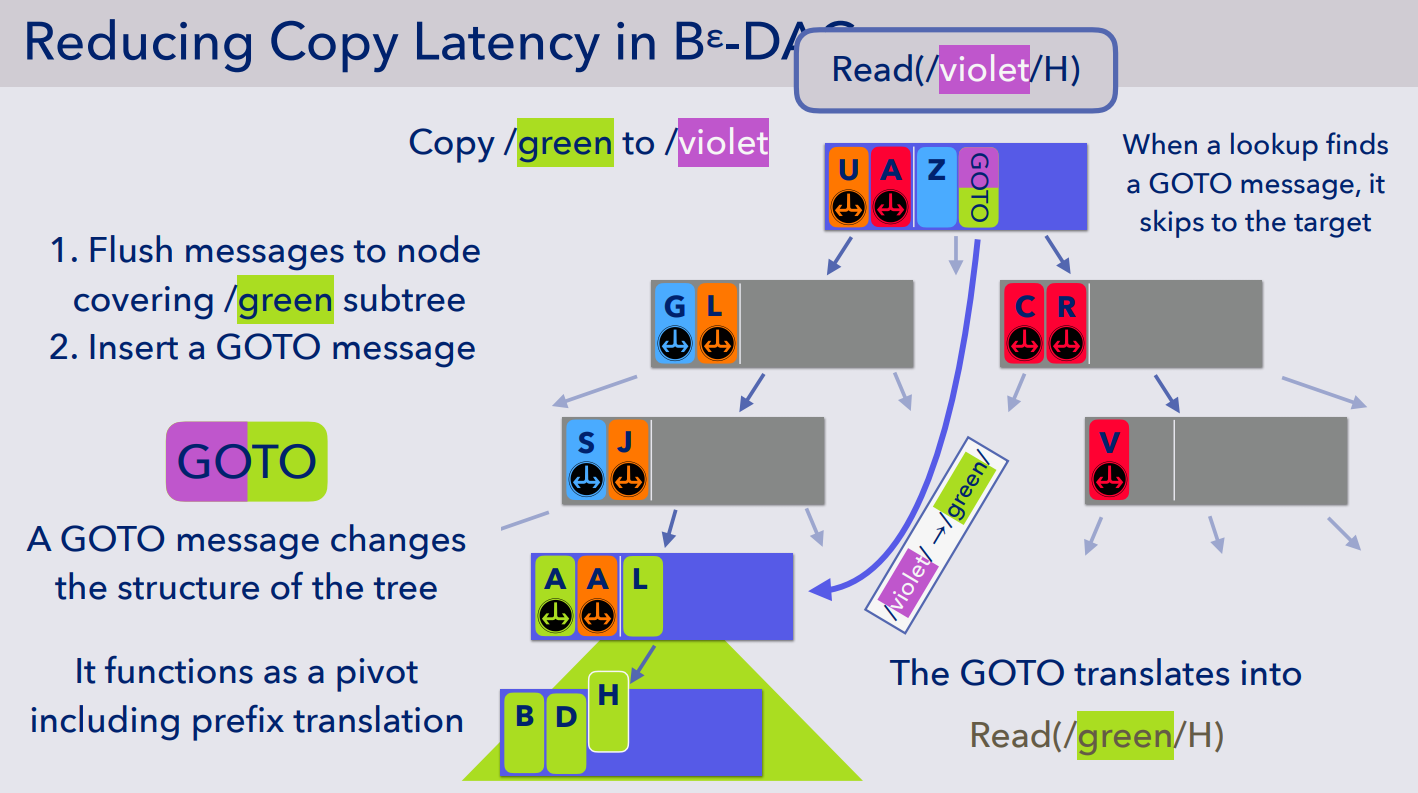
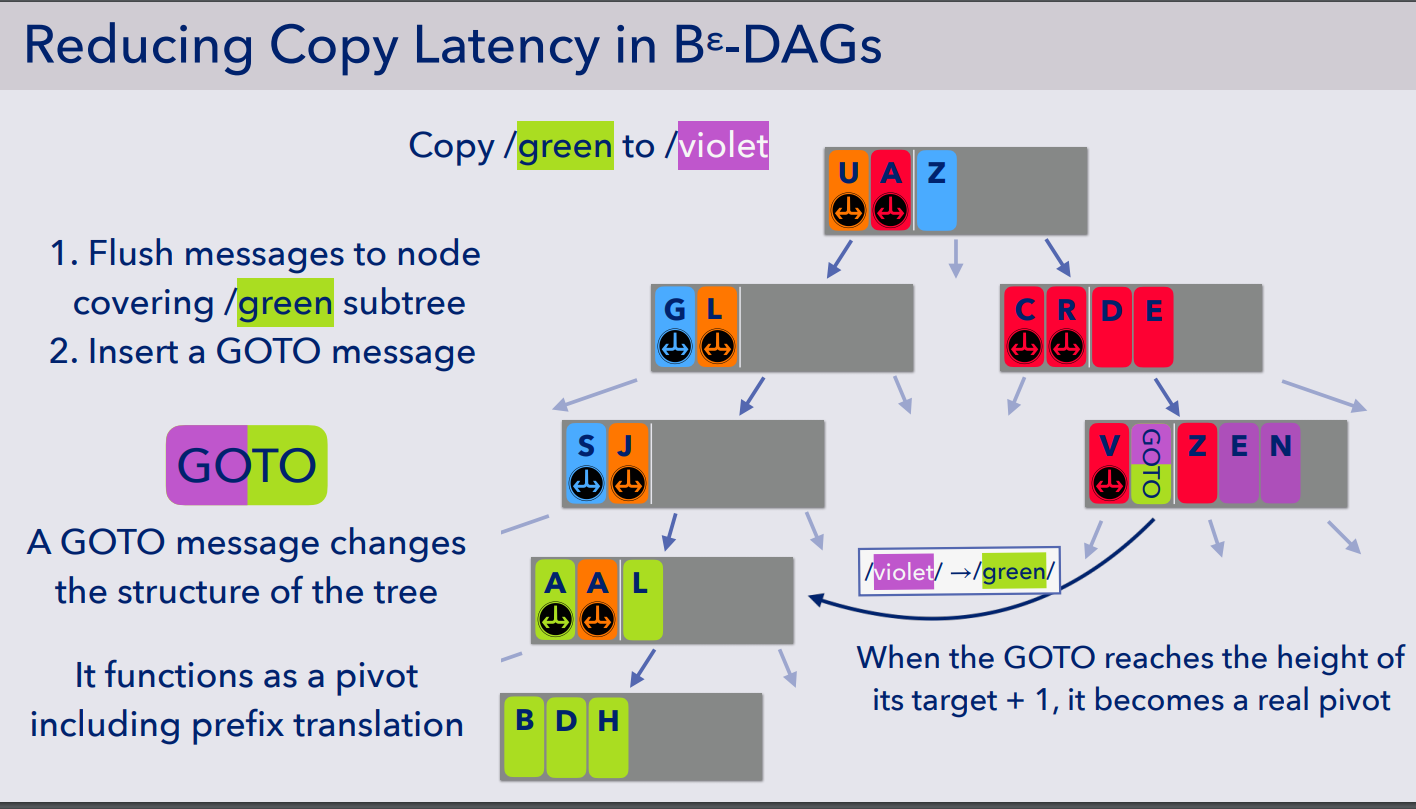
- 相应的 GOTO message 可以和其他数据一样,通过 flush 操作进入下一层,如下图所示,直到 GOTO Message 到达了目标节点高度 + 1 的层级的时候,GOTO Message 就此时可以成为一个真正的指向下一层的目录,也就是文中的 pivot,即 GOTO 将变成紫色的目录节点 /violet
- 这样子下来拷贝的时间复杂度完全取决于树的高度
个人见解
- 这篇呢个人也只是泛泛而谈,主要参考了 PPT 的动画解释,原文其实还涉及到了更为具体的实际的解释,由于重心不在这边所以没有细看,感兴趣的小伙伴可以再深入研究,但是在研究之前最好先大致看一下之前的 btrfs 的论文,至少了解到核心数据结构的设计和读写的流程,才有助于对本篇文章的理解。
- 想提一下的是,我发现 btrfs 相关的论文已经上了很多次 FAST 以及 TOS 了,而且本身这个文件系统提出来也没几年,FAST15 上提出来的,后续的一些对于该文件系统的迭代都直接被拿来作为了新的 idea,譬如本篇实现的 clone,其实做文件系统同学可以关注一下这个文件系统,我自己简单看了这个文件系统的数据结构之后理解为他其实是在利用 B-Tree 和 LSM-tree 各自的优势,当然主要还是解决 B-Tree 的写的问题,后续如果有相关的工作的话可能会关注一下。
SSD and Reliability
- A Study of SSD Reliability in Large Scale Enterprise Storage Deployments
- Stathis Maneas and Kaveh Mahdaviani, University of Toronto; Tim Emami, NetApp; Bianca Schroeder, University of Toronto
- Awarded Best Paper!
- Making Disk Failure Predictions SMARTer!
- Sidi Lu and Bing Luo, Wayne State University; Tirthak Patel, Northeastern University; Yongtao Yao, Wayne State University; Devesh Tiwari, Northeastern University; Weisong Shi, Wayne State University
A Study of SSD Reliability in Large Scale Enterprise Storage Deployments
- 虽然是 SSD 硬件相关的,但毕竟是 BestPaper,而且这篇其实更像是针对一些数据集的分析,不是具体的基于硬件或者协议的优化,想了想决定还是大概看看吧,万一之后有所涉及。
- 按照惯例放个链接:
- 本文首次对企业存储系统中基于 NAND 的 SSD 进行了大规模的现场研究(与分布式数据中心存储系统中的驱动器形成对比)。该研究基于一组非常全面的现场数据,涵盖了一家主要存储供应商(NetApp)的 140 万份 SSD。驱动器包括三个不同的制造商,18种不同的型号,12种不同的容量,和所有主要的闪存技术(SLC, cMLC - consumer-class, eMLC - enterprise-class, 3D-TLC)。这些数据使我们能够研究很多之前没有研究过的因素,包括固件版本的影响,TLC NAND的可靠性,以及RAID系统中驱动器之间的相关性(为这些驱动器收集的数据非常丰富,包括驱动器替换(包括替换的原因)、坏块、使用情况、驱动器年龄、固件版本、驱动器角色(例如,数据、奇偶校验或备用)等信息)。本文介绍了我们的分析,以及由此得出的一些实际影响。
简要介绍
背景
- 以前的存储设备的可靠性研究大多基于 HDD,近年来随着 SSD 的普及,对于 SSD 的可靠性研究才不断出现。现有的 SSD 可靠性研究除了在实验室的控制条件下的的相关研究以外,还有来自如 Facebook, Microsoft, Google, and Alibaba 等大型公司基于自己的数据中心中的数据对 SSD 可靠性的分析。但作者发现现有的研究中还是有一些 critical gap,所以本文就来填坑了:
- 没有研究关注企业级存储系统,这些系统中的驱动器、工作负载和可靠性机制可能与云数据中心中的非常不同。比如企业级存储系统中通常使用高端 SSD 并且可靠性通常由 RAID 来保障,而不是分布式存储中的那些副本的一些策略。
- 现有的研究没有涵盖构建现实的故障模型所需的一些最重要的故障特征,以便计算数据丢失的平均时间等指标,例如,这包括对驱动器替换原因的分析,包括底层问题的范围和相应的修复操作(RAID重建与耗尽驱动器),以及最重要的是对同一RAID组中驱动器之间的相关性的理解。
数据统计分析
- 采集的系统和数据对应的相关信息此处不表,直接看相关数据统计。
- 前六列描述了不同厂商对应不同系列的 SSD 的相关参数,包括匿名给出了制造商、容量、接口、闪存颗粒技术、光刻技术、PE 周期(寿命)
- 后四列描述了不同的 SSD 被用于了何种的环境,包括 OP 比例(用于垃圾回收的保留空间比例)、第一次部署使用该 SSD 的日期、SSD 通电的中位数年数(因为每类 SSD 对应了很多个实际的 SSD)、SSD 的额定使用寿命的平均值和中位数(SSD 所经历的 PE 循环数占其 PE 循环极限的百分比)
- 最后三列描述了三种不同的 SSD 健康性和可靠性的指标:空闲块的使用比例、坏的扇区的数量、每年的置换率
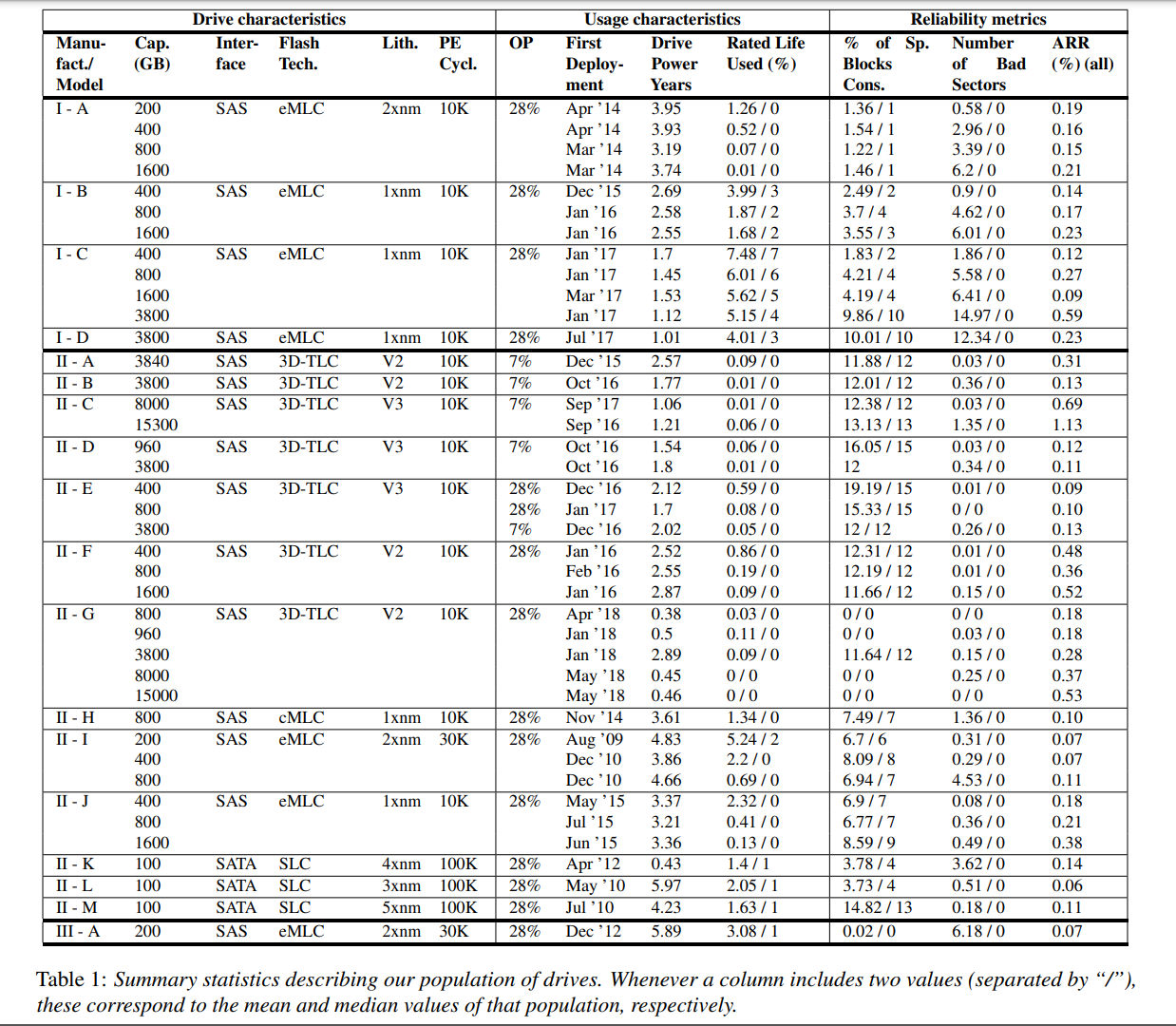
- 从上表中的相关数据统计得出以下结论:
- 平均 ARR 为 0.22%,在 0.07% 到 1.2% 之间波动,比数据中心中的故障率要低得多
- 即便是具有相同工艺的同厂商的 SSD,相似容量和相似使用期限,年故障率也非常不一样
- 为坏块保留的备用区域为典型的驱动器提供了大量的资源:即使对于已经在数据中心中存放了好几年的 SSD,使用的备用块的百分比平均也不到 15%。即便是第 99.9 和 第 99.99 使用空闲空间最多的盘都分别为 17% 和 33%
- 很多 SSD 都没达到 PE 限制,即便是使用了 2-3 年的 SSD,第 99.9 和 第 99.99 寿命消耗的也只消耗了 15% 和 33%,对于绝大多数 SSD 盘来说,因为达到最大可擦写次数而失效的可能性几乎为零。
原因分析
- 有不同的原因可以触发更换 SSD,存储层次结构中的不同子系统也可以检测具体触发更换 SSD 的原因。可能由 SSD 本身或者存储层或者文件系统报告相应的问题,如下表所示描述了可能触发更换 SSD 的原因,以及它们的频率,以及系统采取的恢复操作(例如,从要替换的 SSD 复制数据与使用 RAID 重新构建数据),以及问题的范围(例如,部分数据丢失的风险,完整驱动器丢失的风险,或者没有立即的问题)
- 原因被大致分为 4 类,分别以 ABCD 表示,严重程度递减。
- 最无关紧要的是 D 类,通常是由 SSD 内部或者更高的存储层在逻辑上触发的,即一些预测 SSD 未来故障的策略,基于之前发生的错误、超时以及磁盘的 SMART 统计信息等,但实际可能没坏。
- 最严重的是 A 类,通常是因为 SSD 变得完全无法响应,或者 SCSI 层检测到了 SSD 的问题严重到需要立即更换 SSD 并重建构建在当前 SSD 上的 RAID 时。
- B 类是指替换发生在当系统怀疑 SSD 丢失了写操作的时候,例如 SSD 根本没有执行写操作,或者将其写到错误的位置,或者以其他方式破坏了写操作,根本原因可能是 SSD 中的固件错误,尽管存储堆栈中的其他层也可能是原因。由于有许多潜在的原因,heuristic(启发式判断) 被用来决定是否触发替换;具体地说,如果一个 SSD 中出现了多个这样的错误,而其他 SSD 中没有错误,那么前一个 SSD 将被替换。
- C 类通常是因为命令被丢弃或者执行超时。
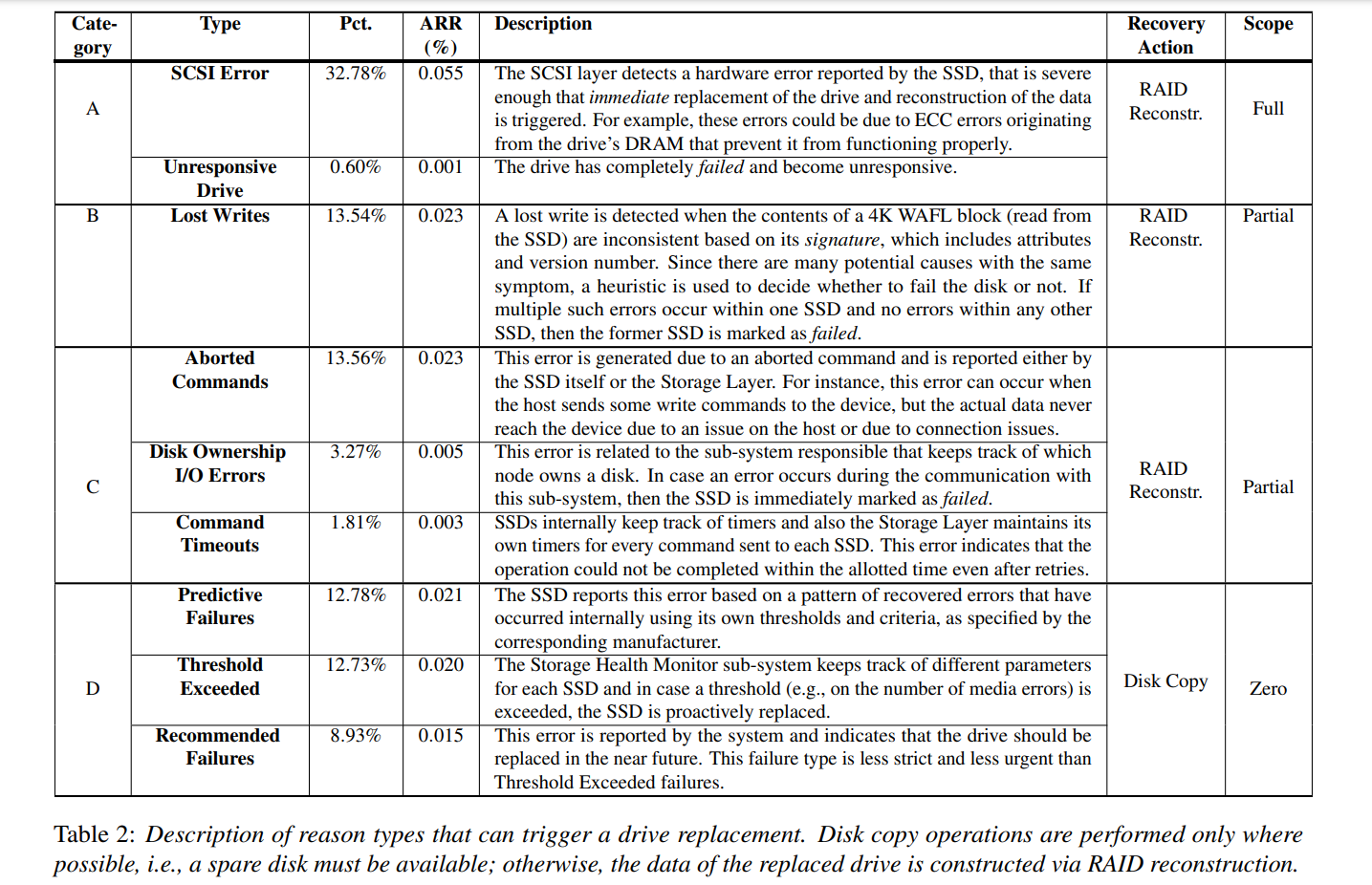
- 抛开所有的分类看具体的错误原因,我们不难发现最常见的错误是 SCSI errors,大约有 1/3 的替换都是因为 SCSI errors 发生,同时也是最严重的错误之一;还有大约 1/3 的替换仅仅是为了预防 SSD 故障才采取的,也就是 D 类错误,预测了磁盘故障可能带来的严重影响,预测性的替换通常是统计了超时次数判断是否达到了阈值
- 后续测试了不同的因素对 SSD 的 annual replacement rate 的影响,主要对 eMLC 和 3D-TLC SSD 进行了分析,得出了以下发现和结论:
- 盘在刚开始使用的 1 年内的 ARR 是 1 年后 ARR 的 2-3 倍,并且盘片的 ARR 并没有随着使用时间的增加而增加,部分原因可能是因为绝大部分盘片的擦写次数都远没达到总擦写次数。
- 3D-TLC SSD 比其他类型的有更高的 ARR,但是这个差别很小,SLC、MLC 和 TLC(不同 flash 和 drive) 对 ARR 的影响比使用率对 ARR 的影响更小。
- 大容量 SSD 不仅整体替换率更高,而且 A 类错误概率更高,可预测的错误概率更低。
- 更高密度的 SSD 并不总是看到更高的替代率 ARR。事实上,我们观察到,尽管更高密度的 eMLC SSD 有更高的替代率,但这一趋势在 TLC 中是相反的
- 早期的固件版本可能与较高的替换率相关,这就强调了固件更新的重要性。
- 具有非空缺陷列表的 SSD 被替换的几率更高,不仅是因为可预测的故障,还因为其他替换原因
- 更多地使用其 OP 空间的 SSD 很可能在将来被替换
- 虽然大型 RAID 组有更多的驱动器替换,但我们没有发现每个组的多次故障率(这可能导致数据丢失)与 RAID 组大小相关的证据。原因似乎是在第一次失败后出现后续失败的可能性与 RAID 组大小无关
- 最终作者总结了一下:
- 早期的固件版本可能与较高的故障率相关,所以得及时更新固件,要保证升级过程无痛且稳定
- RAID 组的大小对 SSD 盘的平均 ARR 没有明显的影响
- 单奇偶校验 RAID 配置(例如,RAID-5),可能容易发生数据丢失,而实际的数据丢失分析肯定必须考虑相关的故障。
- 具有非常大容量的驱动器总的故障率更高,出现更严重的故障。较高的故障率可能源于 SSD 上的更多 NAND 和die,这就强调了 SSD 及其系统能够处理部分驱动器故障(如 die 故障)的重要性,NetApp 正朝着这个方向努力,通过从 OP 区域来弥补部分故障的区域带来的容量损失
- 我们观察到,大容量的 SSD 预测失败率更小,这也提出了一个问题,即大容量 SSD 是否需要不同类型的故障预测器,以及是否需要更多来自 SSD 的内部问题(例如,坏死或 DRAM 问题)作为输入
- 随着 QLC NAND 的引入,人们重新开始关注 NAND SSD 的可靠性,其 PE 循环限制明显低于当前 TLC NAND。根据我们的数据,我们预测,对于绝大多数企业用户来说,向 QLC 的 PE 周期限制迈进不会带来任何风险,因为 99% 的系统最多使用其驱动器额定寿命的 15%
- 人们担心 NAND 有限的 PE 周期在 RAID 系统生命周期的后期,由于相关的磨损故障,SSD 可能会对数据的可靠性造成威胁,因为 RAID 组中的驱动器老化速度相同。相反,我们观察到,早期失效导致的相关失败可能是一个更大的威胁。例如,在我们的研究中,3D-TLC 驱动器,早期失效率高峰时的失败率比后期高出 2.5 倍
- 在选择 SSD 时,比起 flash type(比如 eMLC 还是 3D-TLC),工艺和容量更应该是首要的考量因素。
个人见解
- 这篇算是分析了 SSD 的一些物理特性和参数和 SSD 的故障之间的关系,以及 SSD 的替换策略的关系,但是文章开始的部分其实限定了场景为企业级存储,我个人对于企业级存储和如阿里等互联网企业的数据中心的存储这两种场景之间的差异其实不太具体理解,而且从 SSD 本身而言,这两种场景下,关于 SSD 的经验仿佛是通用的?这里有点一知半解
- 确实本篇文章有大量的数据支撑,最重要的其实都是文章总结出的那些发现,有的发现确实也一定程度上颠覆了以前大家对于 SSD 故障原因的一些固有认知,但可能缺少一些更为合理的解释?也可能是自己水平有限,对于相关成因的解释看的一知半解。
Making Disk Failure Predictions SMARTer!
- 这篇文章针对的领域是磁盘故障预测,之前有博客简要介绍过这篇文章,这篇文章的实验做的非常充分,整个行文也比较行云流水,照例贴一下链接:
- 磁盘驱动器是最常被替换的硬件组件之一,它继续对准确的故障预测提出挑战。在这项工作中,我们提出了一个最大的磁盘故障预测研究之一的分析和发现,涵盖了一个大型领先数据中心运营商的64个站点在两个月的时间里总共380,000个硬盘驱动器。我们提出的基于机器学习的模型在10天的预测周期内平均用0.95 F-measure和0.95 Matthews相关系数(MCC)预测磁盘故障
- 本篇文章就不展开介绍了,解决的其实就还是磁盘故障预测中的准确率低的问题和提前预警的时间较短的问题,而作者在磁盘故障预测的相关机器学习模型中引入了性能和物理位置条件的指标使得磁盘故障的预测模型更为准确,提前预警的时间也大约提升到了 10 天预警。
- 文章写的很清楚明朗,如果对磁盘故障预测感兴趣的同学,该文值得深入阅读。
Performance
- An Empirical Guide to the Behavior and Use of Scalable Persistent Memory
- Jian Yang, Juno Kim, and Morteza Hoseinzadeh, UC San Diego; Joseph Izraelevitz, University of Colorado, Boulder; Steve Swanson, UC San Diego
An Empirical Guide to the Behavior and Use of Scalable Persistent Memory
- 关于这篇就不再详细展开了,资料很多,贴几个典型的其他大佬的资料。做 NVM 的肯定是都会看的 8。
- 整体:
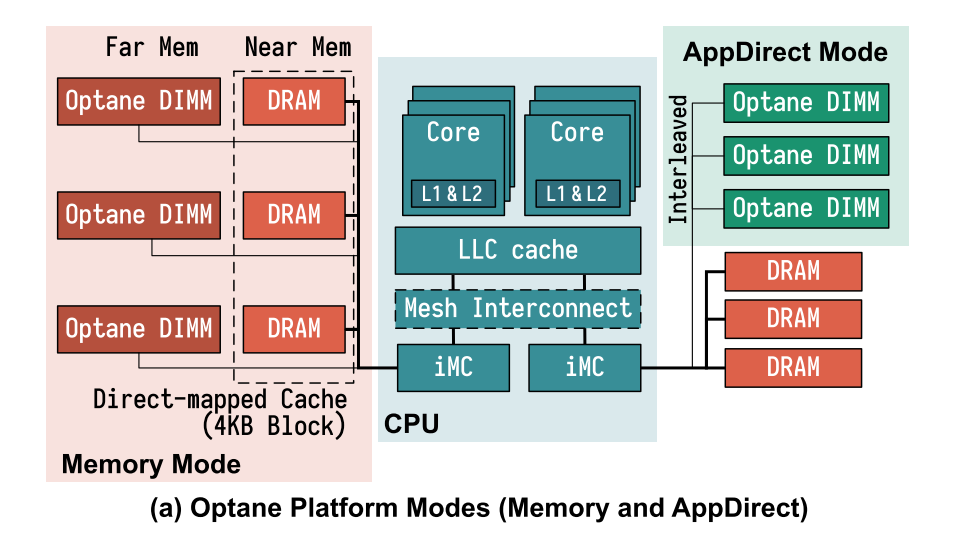
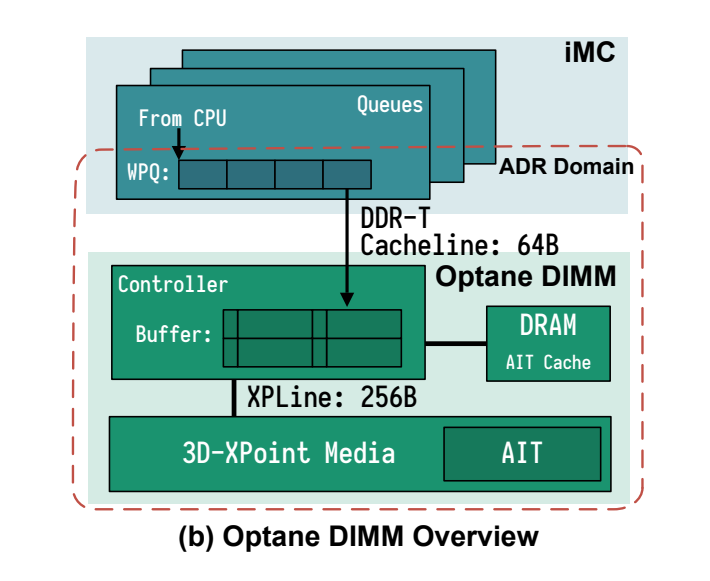
- 内存控制器和硬件交互细节: 对NVDIMM的访问首先到达DIMM上的控制器(本文中称为XPController),该控制器协调对Optane介质的访问。与SSD相似,Optane DIMM执行内部地址转换以实现损耗均衡和坏块管理,并为该转换维护AIT (address indirection table)。地址转换后,将实际访问存储介质。由于3D-XPoint物理介质的访问粒度为256B(文中称为XPLine),所以,XPController会将较小的请求转换为较大的256字节的访问以提升性能。然而,因为同样的原因,小数据量的存储会变为RMW(read-modify-write)操作而导致写放大。 XPController有一个小的写合并缓冲区(在本文中称为XPBuffer),用于合并地址相邻的写操作。 由于XPBuffer属于ADR域,因此到达XPBuffer的所有更新都是持久的。
- 文章通过介绍 Optane PM 以及做了相关的测试得出了几个 Best Practice
- 避免小于 256B 的随机读写;
- Optane 的数据更新,在内部介质会进行 read-modify-write 操作。若更新的数据量小于内部操作的数据粒度(256B),会带来写放大,而使得更新效率低。
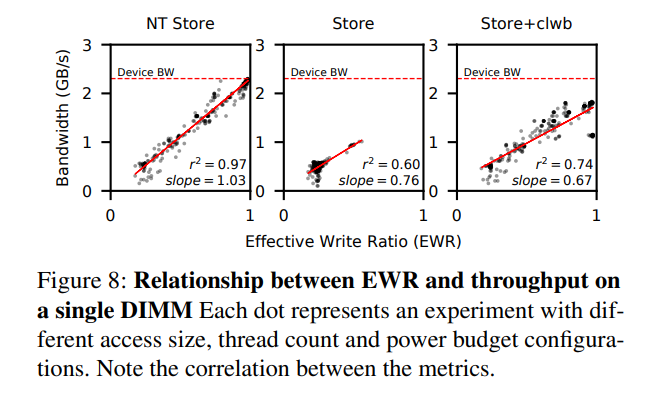
- EWR(Effective Write Ratio,由DIMM的硬件测量)的概念:其为iMC发出的字节数除以实际写入3D-XPoint介质的字节数,即为写放大的倒数。EWR小于1表示,Optane介质写效率低。EWR也可以大于1,此时表示XP-Buffer做了写合并(在内存模式中,因为DRAM的缓存作用,EWR也可以大于1)
- 展示了Optane DIMM的带宽(三种store命令)与EWR的正相关的关系。一般而言,小数据量的存储使得EWR小于1。 例如,当使用单个线程执行随机的ntstore时,对于64字节的写,EWR为0.25,对于256字节访问,其EWR为0.98。值得注意的是,虽然iMC仅以64B为单位访问DIMM,但是XPBuffer可以将多个64B的写进行缓存,并合并为256B的Optane内部写,所以256字节更新是高效的。由上可知,如果Optane DIMM的访问具有足够好的局部性,同样可以高效地进行小数据量的存储。
- 为了得到“怎样的局部性才足够”的命题结论,我们设计了一个实验来测量XPBuffer的大小。 首先,我们分配N个XPLine大小(256B)的连续区域。 在实验中,进行循环的写数据。首先,依次更新每个XPLine的前半部分(128 B), 然后再更新每个XPLine的后半部分。 我们测量每一轮后EWR的值。 图9显示: N 小于64(即16 kB的区域大小)时,EWR接近于1,其表明,后半部分的访问命中了XPBuffer。 N 大于64时,写放大进行了突变,其由XPBuffer miss急剧上升导致。这表明,XPBuffer的大小为16KB。进一步的实验表明,读操作也会占用XPBuffer中的空间从而造成竞争关系。
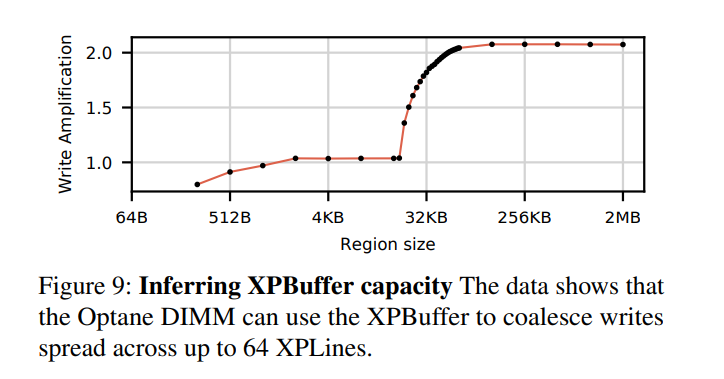
- 使用ntstore进行大数据(大于256B)写
- 一般通过下面操作进行数据写入:store操作后,程序员可以通过clflush/clflushopt操作进行高速缓存evict或通过clwb操作进行写回(write back),以将数据写入至ADR域并最终写至Optane DIMM;或者,通过ntstore指令绕过高速缓存直接写入Optane DIMM。在进行完上述某种操作后,再进行sfence操作可确保先前的evict,write back和ntstore操作的数据变成持久的。写数据时,采用上述何种操作对性能影响很大。
- 对于写超过 64B 的数据,每store 64B进行cache的flush操作(相比于不进行flush操作)获得的带宽会更大
- 对于超过 512B 的访问,ntstore的延迟比store + clwb更低
- 对于超过 256B 的访问,ntstore操作的带宽也最高
- 当写入的大小超过 8MB时,写入后再进行刷新操作会导致性能下降,因为其导致了高速缓存容量的失效,从而使得EWR升高
- 限制访问 Optane DIMM 的并发线程数
- XPBuffer的竞争。对XPBuffer中缓存空间的争用将导致逐出次数增加,触发写3D-XPoint介质,这将使EWR降低。
- iMC中的竞争。每个线程随机访问N个DIMM(线程间分布均匀)。随着N的增加,针对每个DIMM的写入次数会增加,但是每个DIMM的带宽会下降。
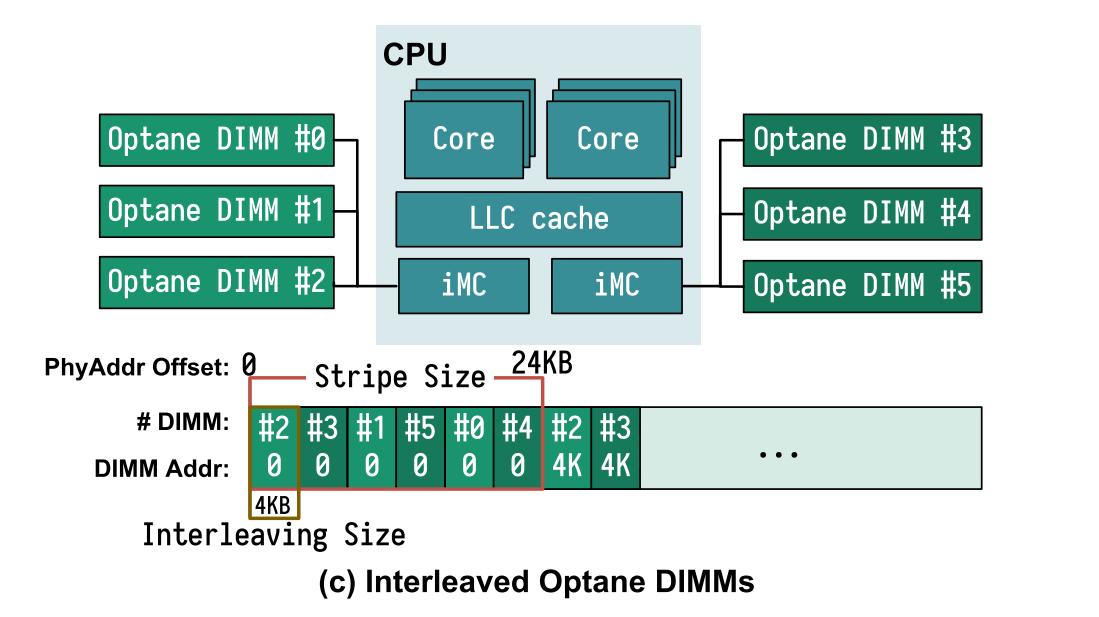
- 当对交错的Optane DIMM进行随机 4KB 访问时,Optane带宽急剧下降。当写入的数据大小为 24kB 和 48kB,出现了性能的小峰值,其访问在6个DIMM上完美分布。
- 避免 NUMA 访问(尤其对于是 read-modify-write 操作序列)。
- Optane的NUMA效应远大于DRAM,因此应更加努力地避免跨插槽的存储器通信。对于读写混合且包含多线程访问的情况,其成本特别高。
- 对于本地和远程访问,单线程带宽差距不大。而对于多线程访问,随着访问压力的提高,远程访问性能会更快下降,从而导致相对于本地访问而言性能较低。
- 避免小于 256B 的随机读写;
Key Value Storage
- Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook
- Zhichao Cao, University of Minnesota, Twin Cities, and Facebook; Siying Dong and Sagar Vemuri, Facebook; David H.C. Du, University of Minnesota, Twin Cities
- FPGA-Accelerated Compactions for LSM-based Key-Value Store
- Teng Zhang, Alibaba Group, Alibaba-Zhejiang University Joint Institute of Frontier Technologies, Zhejiang University; Jianying Wang, Xuntao Cheng, and Hao Xu, Alibaba Group; Nanlong Yu, Alibaba-Zhejiang University Joint Institute of Frontier Technologies, Zhejiang University; Gui Huang, Tieying Zhang, Dengcheng He, Feifei Li, and Wei Cao, Alibaba Group; Zhongdong Huang and Jianling Sun, Alibaba-Zhejiang University Joint Institute of Frontier Technologies, Zhejiang University
- HotRing: A Hotspot-Aware In-Memory Key-Value Store
- Jiqiang Chen, Liang Chen, Sheng Wang, Guoyun Zhu, Yuanyuan Sun, Huan Liu, and Feifei Li, Alibaba Group
Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook
- 这篇文章可能和其他文章都有所不同,主要做 Benchmarking 方面的工作,和 Facebook 合作完成,对 Facebook 中现有的 RocksDB 典型的应用场景进行了表征,同时提出了一种新的更接近实际生产环境负载的模型考虑来取代 YCSB。照例先贴几个链接:
- 持久化的键值存储是现代 IT 基础设施的基石,但是现有的表征 KV 存储的真是工作负载的研究有一定的局限,主要因为缺乏跟踪/分析工具以及在操作环境中收集跟踪的困难。本文对Facebook上三个典型的RocksDB生产用例的工作负载进行了详细表征:
- UDB:用于MySQL中用来存储社交图数据,使用RocksDB作为底层存储;
- ZippyDB:用于存储分布式对象存储的元数据的分布式KV;
- UP2X:用于存储AI/ML数据的分布式KV。
- 通过分析以上三种应用,有以下发现:
- 键和值大小的分布与用例/应用程序高度相关
- KV 对的访问具有良好的局部性,并遵循一定的特殊模式
- 收集的性能指标在 UDB 中显示强烈的昼夜变化模式,而其他两个没有
- 除此以外,作者表明现如今被广泛应用的 KV 负载 YCSB 尽管提供了各种工作负载的配置和 KV 对访问分布模型,但是忽视了键的空间局部性,和实际生产环境中的工作负载还是有一定的差距,于是本文提出了一种基于键范围的工作负载,并开发了一个可以更好地模拟真实键值存储的工作负载的基准。
简要介绍
Introduction & Background
- 首先描述工作的意义,主要是解决现如今提升 KV 存储的性能比较困难,原因主要表现在:
- 对KVstores的真实工作负载表征和分析的研究非常有限,KV-stores的性能与应用程序生成的工作负载高度相关
- 描述KV-store工作负载的分析方法与现有的块存储或文件系统的工作负载特性研究不同(语义不同)
- 在评估KV-store的底层存储系统时,我们不知道KV-store基准生成的工作负载是否能代表真实的KV-store工作负载
- 为了解决上面的问题,本文主要就做了三方面的事情:对 RocksDB 的 workload 进行 characterize, model, and benchmark
- 引入了一系列工具,可以在生产环境中应用,主要是收集 KV 层的查询 traces,replay traces 和分析 traces。且已开源:https://github.com/facebook/rocksdb/wiki/RocksDB-Trace%2C-Replay%2C-Analyzer%2C-and-Workload-Generation
- 为了更好地了解KV工作负载及其与应用程序之间的关系,分析了 UDB, ZippyDB,UP2X,有以下发现:
- UDB 和 ZippyDB 中的查询主要是 read,而 UP2X 中的主要查询类型是 read-modify-write (Merge)
- 由于上层应用程序的键组合设计,键大小通常较小且分布狭窄,大的值大小只在某些特殊情况下出现
- 大多数 KV 对是冷的(访问较少),只有一小部分 KV 对经常被访问
- Get, Put, and Iterator 都有很强的针对基于键的空间局部性(比如经常访问的 KV 对通常在空间的分布上也相对较近),与上层应用程序的请求局部性密切相关的一些键范围非常热(经常被访问)
- UDB 中的访问显式地表现为昼夜模式
- 发现尽管 YCSB 可以生成与 ZippyDB 工作负载类似的键值(KV)查询统计数据,但 RocksDB 存储 I/Os 可能会有很大的不同,这个问题主要是由 YCSB 生成的工作负载忽略键的空间局部性这一事实引起的。YCSB 中热的键值对可以在整个键空间中随机分配,也可以聚集在一起,这将导致存储中访问的数据块与与 KV 查询相关的数据块之间的 I/O 不匹配。在不考虑键空间局部性的情况下,基准测试生成的工作负载将导致 RocksDB 的读放大和写放大比实际工作负载大。于是作者提出了一种基于键范围的热度的工作负载建模方法。整个键空间被划分为较小的键范围,并且我们对这些较小的键范围的热度进行建模。在新的基准测试中,将根据键范围热度的分布将查询分配给键范围,并且在每个键范围中热键将被紧密地分配。
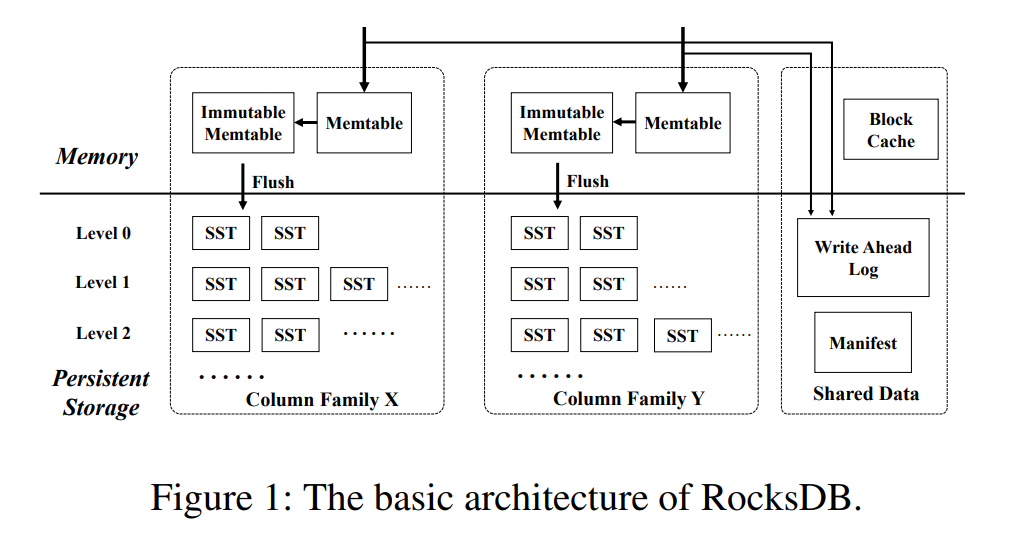
- RockDB 介绍:相比于普通的 LSM Tree 或 LevelDB,从架构上来看主要是多了一个 Column Family 的概念
- 三种应用场景介绍:
- UDB:Facebook 的社交图数据长期存储在UDB中,这是一个分片 MySQL 数据库层。UDB 依赖 MySQL 实例来处理所有的查询,查询会被 MyRocks 转换成对于 RocksDB 的查询。图数据主要被维护成点和边,相应地在 RocksDB 中使用了不同的列族来存储对应的数据。收集了 14 天的 traces,也单独分析了最后一天 24 小时的负载
- Object,Assoc,Assoc_count,Object_2ry,Assoc_2ry和Non_SG
- ZippyDB:基于 RocksDB 的分布式 KV 存储,使用 Paxos 来保证数据一致性和可靠性。KV 对被划分为切片,每个切片由一个 RocksDB 实例支持。选择一个副本作为主切片,其他副本作为次要切片。主切片处理对某个切片的所有写操作。如果读取需要强一致性,则读取请求(如 Get 和 Scan )仅由主切片处理。一个 ZippyDB 查询被转换为一组RocksDB 查询(一个或多个)。
- UP2X:Facebook 使用各种 AI/ML 服务支持社交网络,并使用大量动态变化的数据集(如用户活动统计计数器)进行AI/ML预测和推断。UP2X 是分布式的专门开发的 KV-store,用于将这种类型的数据存储为 KV 对。当用户使用 Facebook 服务时,UP2X 中的 KV 对会经常更新,例如计数器增加时。如果 UP2X 在每个 Put 之前调用 Get 来实现读-修改-写操作,由于随机 Get 的速度相对较慢,它将产生很高的开销。UP2X 利用 RocksDB Merge 接口避免在更新过程中获取 Gets。
- UDB:Facebook 的社交图数据长期存储在UDB中,这是一个分片 MySQL 数据库层。UDB 依赖 MySQL 实例来处理所有的查询,查询会被 MyRocks 转换成对于 RocksDB 的查询。图数据主要被维护成点和边,相应地在 RocksDB 中使用了不同的列族来存储对应的数据。收集了 14 天的 traces,也单独分析了最后一天 24 小时的负载
Methodology and Tool Set
- 开源的 RocksDB 负载分析和表征工具 https://github.com/facebook/rocksdb/wiki/RocksDB-Trace%2C-Replay%2C-Analyzer%2C-and-Workload-Generation
- Tracing:工具收集 RocksDB 对外暴露的开放接口对应的查询信息,并将信息记录在 trace files 中。主要包括 query type、CF ID、key、query specific data、timestamp。对于 Put 和 Merge,将值信息存储在特定于查询的数据中,对于 Seek 和 SeekForPrev 之类的迭代器查询,扫描长度(在 Seek 或 SeekForPrev 之后调用 Next 或 Prev 的次数)存储在特定于查询的数据中。为了在跟踪文件中记录每个查询的跟踪记录,需要使用锁来序列化所有查询,这可能会带来一些性能开销,但是,根据常规生产工作负载下的生产中的性能监视统计数据,我们没有观察到跟踪工具导致的吞吐量下降或延迟增加。
- Trace Replaying:回放工具根据跟踪记录信息向 RocksDB 发出查询,查询之间的时间间隔遵循跟踪中的时间戳,通过设置不同的快进和多线程参数,RocksDB 可以对不同强度的工作负载进行基准测试。但是,多线程不能保证查询顺序。Replayer 生成的工作负载可以看作是真实世界的工作负载。
- Trace Analyzing:由于工作负载跟踪的潜在性能开销,很难跟踪大规模和长时间的工作负载,此外,跟踪文件的内容对其用户/所有者来说是敏感和机密的,因此,RocksDB 用户很难与其他 RocksDB 开发人员或第三方公司的开发人员共享跟踪信息。为了解决这些限制,我们提出了一种分析 RocksDB 工作负载的方法,该方法根据跟踪中的信息来分析工作负载。
- 针对每一个 CF 中的 KV 对、query numbers、query types 的详细统计摘要
- key value 大小统计
- kv 对的流行度(热度)
- 键的空间局部性,它将访问的键与数据库中所有现有的键按排序顺序组合在一起
- 查询次数/秒 统计
- Modeling and Benchmarking:首先选定两个变量计算对应的相关系数,来确定变量相关性较低。通过这种方式,每个变量都可以单独建模,然后我们将收集到的工作负载匹配到不同的统计模型中,以找出哪一个具有最低的拟合误差,哪一个比总是将不同的工作负载匹配到相同的模型(如Zipfian)更精确。然后,该基准可以基于这些概率模型生成KV查询。
General Statistics of Workloads
- 我们将介绍每个用例的一般工作负载统计,包括每个 CF 中的查询组合,KV-pair 热度分布和每秒查询数。
- Query Composition:Get 是 UDB 和 ZippyDB 中最常用的查询类型,而 Merge 在 UP2X 查询中占主导地位。在不同的 CF 中查询组合可能都会有很大不同,
- 如下图所示 UDB 的统计
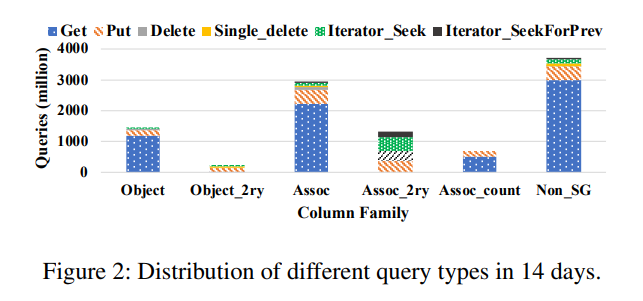
- ZippyDB 只有一个 CF,Get : Put : Delete : Iterator = 78 : 13 : 6 : 3
- UP2X Merge : Get : Put = 92.53 : 7.46 : 0.01
- 如下图所示 UDB 的统计
- KV-Pair Hotness Distribution:UDB 和 ZippyDB 中大部分 KV 数据是冷数据
- UDB 24 小时内访问的 key 最高不超过 3%,而 14 天内访问的 key 最高不超过 15%。如下为 UDB 的 Get 与 Put 操作的 KV 数据访问的 CDF 图。对于 Get,除了 Assoc 之外,其他 CF 的数据 60% 或者以上的数据都只被访问了一次。对于 Put,超过 75% 的数据都只被访问一次,Put 次数超过 10 的数据仅占不到2%,所以UDB中的KV数据大部分很少被Update。
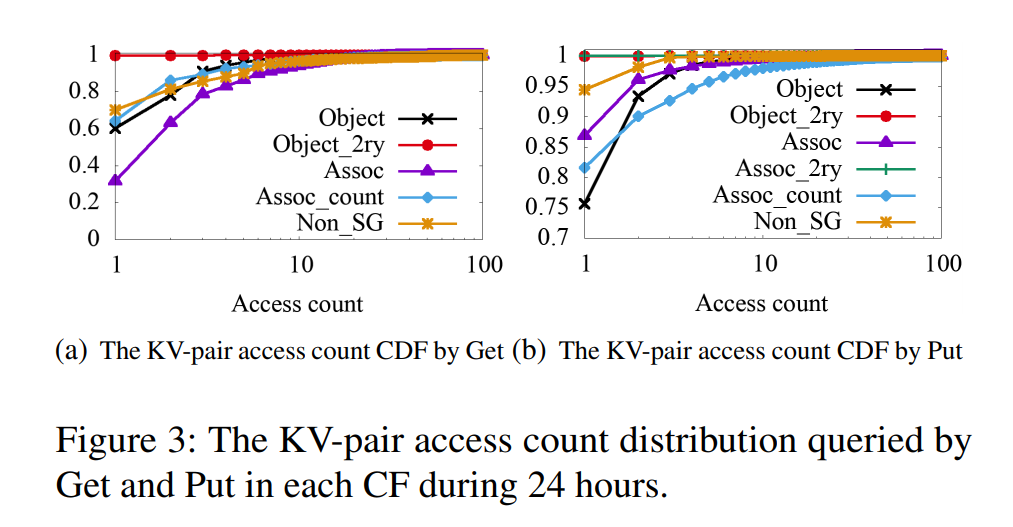
- 对于ZippyDB,大约80%的key只被访问一次,1%的key被访问超过100次,因此表现出较好的局部性。约73%的数据只被Put一次,访问次数超过10次的数据仅有0.001%,因此Put的局部性较差。
- UP2X:对于UP2X,Get与Merge的访问次数分布较广,并且访问次数高的数据占比比较大。
- UDB 24 小时内访问的 key 最高不超过 3%,而 14 天内访问的 key 最高不超过 15%。如下为 UDB 的 Get 与 Put 操作的 KV 数据访问的 CDF 图。对于 Get,除了 Assoc 之外,其他 CF 的数据 60% 或者以上的数据都只被访问了一次。对于 Put,超过 75% 的数据都只被访问一次,Put 次数超过 10 的数据仅占不到2%,所以UDB中的KV数据大部分很少被Update。
- QPS (Queries Per Second):UDB 的部分 CF 表现出较强的昼夜模式,这跟社交网络用户习惯相关(白天上 Facebook,晚上在睡觉),ZippyDB 和 UP2X 没有表现出这样的特征。
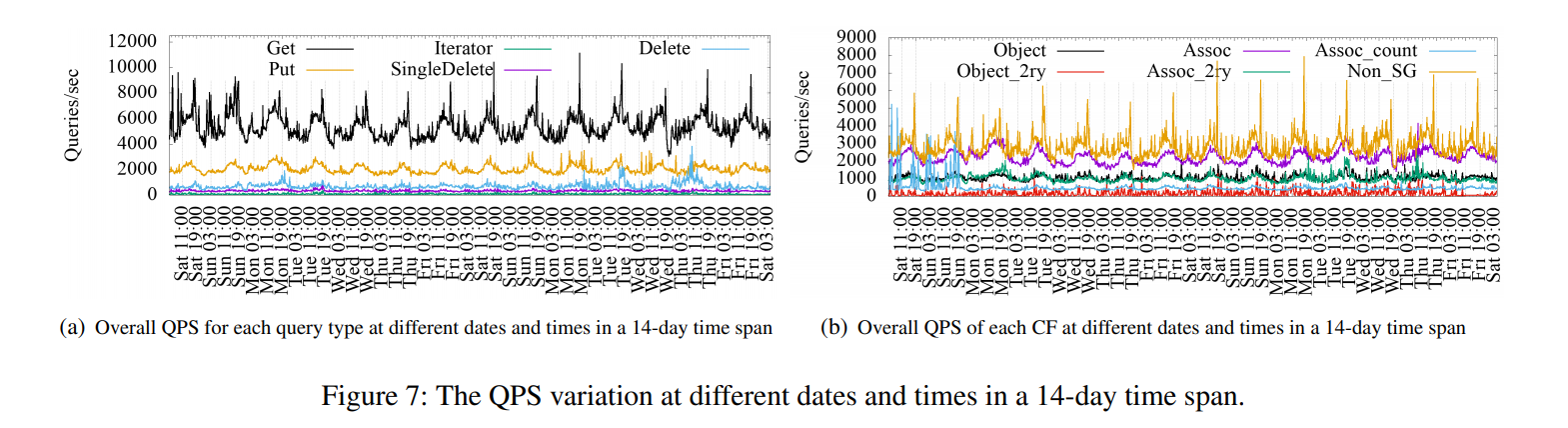
- Key and Value Sizes:key size通常比较小,value size的大小与具体数据类型有关,key size的标准差较小但是value size较大, UDB平均的value size比其他两个例子要大
- Key-Space and Temporal Patterns:统计方法:对key按递增顺序编号,然后统计每个key的访问次数绘制heat-map,统计key的访问时间绘制time-series。结论:heat-map可以看到三种DB的访问具有较强的key space locality,也就是热数据往往聚集分布在某些key space内。UDB的Delete/Single Delete以及UP2X的Merge的time-series表明其访问具有时间局部性
- UDB:KV数据访问并不会随机分布在整个key space,而是根据key-space进行区分,部分key-space访问热度较高,这部分数据占比较小,而部分基本没有访问。属于同一个MySQL table的数据物理上也相邻存储,部分SST和block具有较高的热度,可以考虑基于这个优化compaction以及cache。
- ZippyDB:ZippyDB的访问具有较为明显的key-space locality
- UP2X:UP2X的访问也表现出较强的key-space locality,只有后半段key被访问,而前半段key基本没有访问。merge的time-series表现出来merge每一段时间内会集中访问一个range内的key。
Modeling and Benchmarking
- 一些研究使用YCSB/db_bench + LevelDB/RocksDB来基准测试KV存储的存储性能。研究人员通常认为YCSB产生的工作量接近于实际工作量。对于实际的工作负载,YCSB可以针对给定的查询类型比率,KV对热度分布和值大小分布生成具有相似统计信息的查询。但是,尚不清楚它们在实际工作负载中生成的工作负载是否与基础存储系统的I/O相匹配。
- 为了对此进行调查,我们集中于存储I/O统计信息,例如由RocksDB中的perf_stat和io_stat收集的块读取,块缓存命中,读取字节和写入字节。为了排除可能影响存储I/O的其他因素,我们重放跟踪并在干净的服务器中收集统计信息。基准测试也在同一服务器中进行评估,以确保设置相同。为确保重放期间生成的RocksDB存储I/O与生产环境中的I/O相同,我们在收集跟踪的同一RocksDB的快照中重放跟踪。快照是在我们开始跟踪时创建的。YCSB是NoSQL应用程序的基准测试,而ZippyDB是典型的分布式KV存储。因此,预期YCSB生成的工作量接近ZippyDB的工作量,我们以ZippyDB为例进行调查。由于特殊的插件要求以及UDB和UP2X的工作量复杂性,我们没有分析这两个用例的存储统计信息。
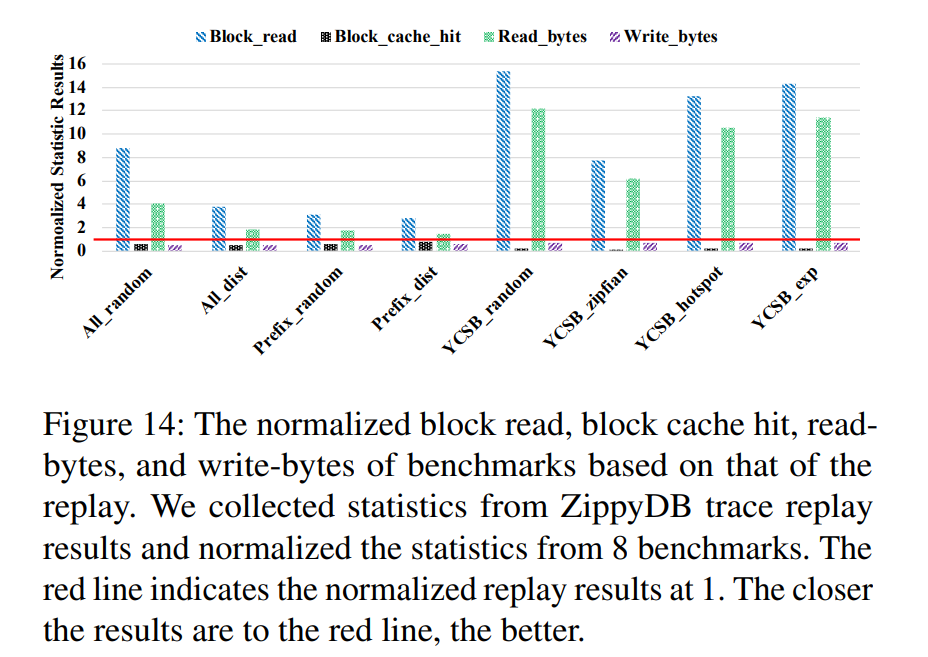
- 总的来说YCSB测workload相比于真实的trace会造成更大的读放大以及更小的写放大,同时cache命中率也更低。其中的主要原因在于忽略了真实workload的key space locality,YCSB中的热点数据随机分布在整个key范围内,访问这些key会造成大量的block读并且被缓存,而这些block可能仅包含较少的热数据,cache大小有限所以降低了cache命中率。对于put,随机的热点分布使得数据在前几层就被compaction掉,所以造成更小的写放大,update的数据具有key space locality,那么新数据会不断写入,就数据一直往下compact直到新数据遇到旧数据才会被处理掉。
- Key-Range Based Modeling:整个键空间被划分成几个较小的键范围。我们不再仅仅基于整个键空间统计数据对KV对访问进行建模,而是关注这些键范围的热度。实验发现 当键范围大小接近SST文件中KV对的平均数目时,它可以保留数据块级别和SST级别的局部性。因此,我们使用每个SST文件的平均KV对数作为键范围大小。 然后将key size,value size以及QPS套到模型里面去,再处理kv的访问次数,访问顺序以及每个range的平均访问次数,然后和原有的负载进行对比测试。
- Prefix_dist:基于建模构建的workload
- Prefix_random:随机将冷热数据分布到各个key-range
- All_random:热数据随机分布到整个key space
- All_dist:热数据集中放置
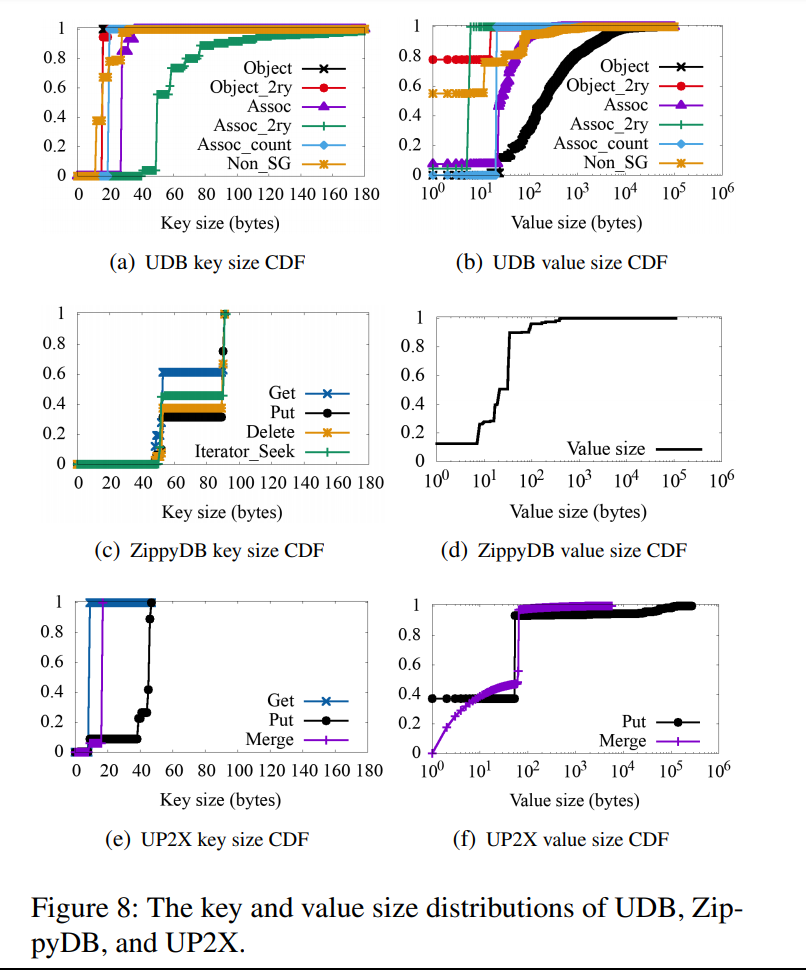
个人见解
- 做 Benchmarking 的工作今年来比较少,一般也只有相应的企业才能统计出相应的数据特征。Benchmarking 常常意味着一系列工具都需要去实现,如本文中的负载的 Trace 收集分析统计,意义很大,对于后续的 KV 存储研究提供了新的基准测试,也配套了相应的工具可以自己去收集相应的负载,且已开源。总之对于 KV 存储的研究,未来可能会成为新的测试基准。
FPGA-Accelerated Compactions for LSM-based Key-Value Store
- 本文主要还是解决 LSM Tree 中的压缩慢的问题,压缩慢还会因为资源的争用影响整个存储系统处理的性能,然后呢也是得出相同的结论,存储系统的瓶颈在往 CPU 转移,这个观点在之前看的 KVell (SOSP19)的那篇文章就已经充分说明。采用的解决办法呢其实就是替 CPU 减压,引入一个新的处理单元进来,FPGA,因为 compaction 操作其实本质就是归并排序,所以 FPGA 完全可以胜任,这个思路其实也不是很新奇,ATC20 的 Best Paper 的 PinK 其实也采用了这种方法。
- 其实问题和思路都不算是特别地别具一格(这里没有去追究前面文章里的具体的时间先后顺序),但是毕竟是经历了工业界的验证的,阿里巴巴自研的 X-Engine 的存储引擎就使用了本文描述的技术,所以也不妨深入读一读,看看有什么有意思的点。
- 照例贴链接:
- 本文主要提出的方法就是将压缩给下沉到 FPGA 来执行,从而加速压缩,减小 CPU 瓶颈。测试表明该方法加速压缩 2-5 倍,系统吞吐量提升了 23%,能源效率(每瓦特处理的事务数量)提升了 31.7%。
- BTW,X-Engine 的论文发表在 SIGMOD19
简要介绍
Introduction & Background
-
首先大致介绍了基于 LSM Tree 的 KV 的应用场景,以新零售为例做了简单介绍。除此以外,KV 主要还会和其他数据库一起作为缓存或者索引来提供服务,这也是 KV 存储的关键的一些应用。然后简单介绍 LSM Tree,LSM 这种数据组织形式通常迫使查询遍历多个级别,以合并分散的记录以获得完整的答案或查找记录,甚至使用索引。这样的操作会带来跳过标记为删除的无效记录的额外开销。为了控制这些 drawbacks,后台压缩操作被引入,在相邻的层之间合并键范围重叠的数据块,并删除已经标记为删除的记录,目的是保持 LSM 树在一个适当的分层形状。
-
引入了一个新的概念,WPI(write and point read-intensive)负载,在长时间的 WPI 负载下,因为 LSM Tree 本身数据结构维护的不好(比如出现过大的 levels),性能就会表现得越来越差。
-
作者总结发现在 LSM Tree 中有一个很困难的 trade-off,即分配给关键路径上查询操作和事务处理的资源 和 分配给后台压缩线程的资源(后台压缩操作需要消耗大量的计算资源和磁盘 I/O 资源,特别是对于既包含读又包含写的 WPI 负载),如果给 compactions 分配更多的软件线程,就会在降低 CPU 实际处理查询和事务的风险下,加大了对存储的后台维护。
-
如图 1 所示,描绘了在 WPI (75% 点查询、25% 写操作)的负载下吞吐量随着用于 Compaction 线程增加的变化情况。线程数小于 32 之前都是随着线程数单调递增,从而带来显著的性能优势。然而,随着更多的线程用于 Compactions,CPU 逐渐饱和,然后会产生 CPU 争用,因此系统吞吐量在 32 个线程之后下降。后文将有更详细的研究表明 32 线程压缩的时候仍然不够快,无法解决上述问题。
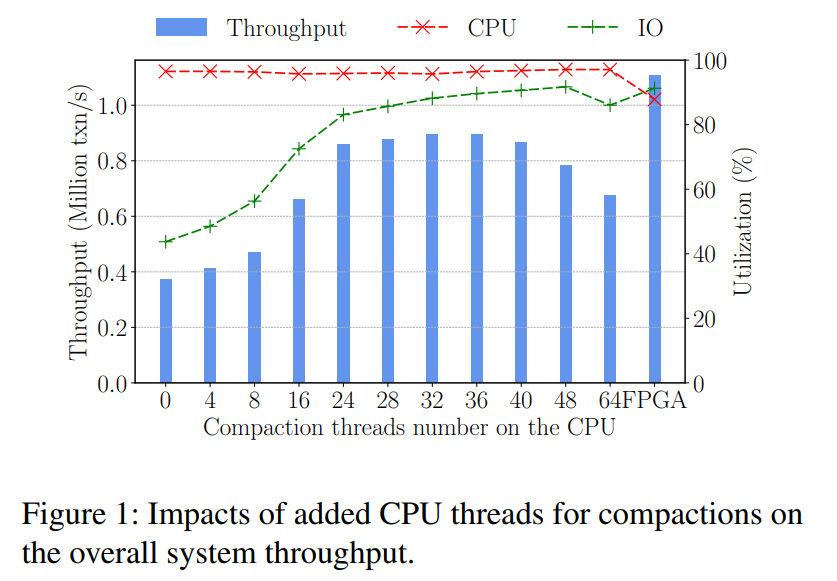
-
现有的优化 Compaction 的研究主要采用了两种方法:
- 一种是通过利用数据分布的特点(几乎是有序的,没有重叠的范围)来减小来减少每次压缩的负载,从而避免不必要的合并。如 X-engine(SIGMOD19),VT-Tree(FAST13)
- 或者通过将数据分割到多个分区,并在需要时分别为每个分区调度 Compaction 操作。The partitioned exponential file for database storage management(VLDBJ07)
- 另外一种方法是优化压缩的时机和选择哪些数据来压缩(when and where)。bLSM (SIGMOD12)。理想情况下,为了提高性能,压缩应该在最需要的时候完成,并且它的执行与系统中其他操作的资源竞争最小
- 但是上述的关于 when 和 where 的条件在 WPI 负载下经常都是会有冲突的,因为对compaction 的需求和对高吞吐量的需求经常同时达到峰值。因此,对于CPU和I/O,存储系统中的资源竞争仍然是一个挑战,通过增加 CPU 线程限制了压缩速度的可伸缩性,并留下了性能问题。
- 一种是通过利用数据分布的特点(几乎是有序的,没有重叠的范围)来减小来减少每次压缩的负载,从而避免不必要的合并。如 X-engine(SIGMOD19),VT-Tree(FAST13)
-
本文提出讲 Compaction 的压力从 CPU 向 FPGA 转移从而加速压缩的执行。理论角度上分析,
- offload compaction 一定程度上将 CPU 从 I/O 密集型应用中解放了出来,从而让存储系统使用更少的 CPU 或者在使用相等数量的 CPU 的情况下增加了吞吐量,在公有云的场景下都能降低成本开销。
- 相比于更喜欢进行 SIMD(单指令多数据流) 类型的计算的 GPU,FPGA 更符合加速压缩操作的需求,压缩任务本质是计算任务的 pipeline。我们还发现对于比较小的 KV 对的压缩合并往往会被计算资源给限制住,可能是因为现在磁盘的 I/O 带宽越来越高。
- 与其他方案相比,FPGA 的高能源效率在降低总拥有成本(TCO)方面具有竞争优势。KV 存储的用户对于成本其实很敏感,因为存储往往都意味着需要永久支出这笔成本。所以在云场景下,使用 FPGA 来 offload compaction 将能显著提升 LSM Tree 的经济效益。
-
在 FPGA 上,我们设计并实现了压缩操作,一个包含了三个阶段的流水线操作:
- decoding/encoding inputs/outputs
- merging data
- managing intermediate data in buffers
-
我们还实现了一个 FPGA 驱动程序和异步压缩任务调度器,以方便 offload 和提高效率,该方案被集成在 X-Engine 中,使用了不同的 WPI 负载来进行测试。效果显著。
-
以前的 LSM Tree 结构如图 a 所示,C0 满了之后合并到 C1,合并的开销会随着 C1 的大小的增加而增加,为了限制这样的开销,更好的选择是是把一个磁盘组件分成不同层级的多个组件,每个组件然后比前一层的组件大。但是会有写放大,因为一个 KV 对可能不得不合并很多次,同时也有读放大,因为查询不得不访问多个具有重叠键范围的组件。
-
为了限制读写放大,许多研究提出了如图 b 所示的分层存储结构。该结构具有优化的内存数据结构、多层磁盘组件,每一层由多个文件或细粒度的数据块组成。数据首先被插入到内存的 memtables 中(常用跳表来实现),一旦 memtables 满了之后转变成 immutable memtables,然后刷入到磁盘上的 L0 层,这里的 Lk 和以前的 LSM 树中的 Ck 是类似的,最大的区别是 Lk 是被分区成很多个文件(也就是 RocksDB 中的 SSTables)或者数据块(X-Engine 中的 extents),对应的合并策略有两种类型:
- 将其与目标级别中的现有数据合并,即所谓的 level 策略,这种方法以压缩速度为代价,将数据按良好的排序顺序保存在某个级别中
- 另外一种只需将数据追加到下一层,而不进行合并,这称为 tier 策略,压缩本身速度很快,但会牺牲某个级别内的排序顺序
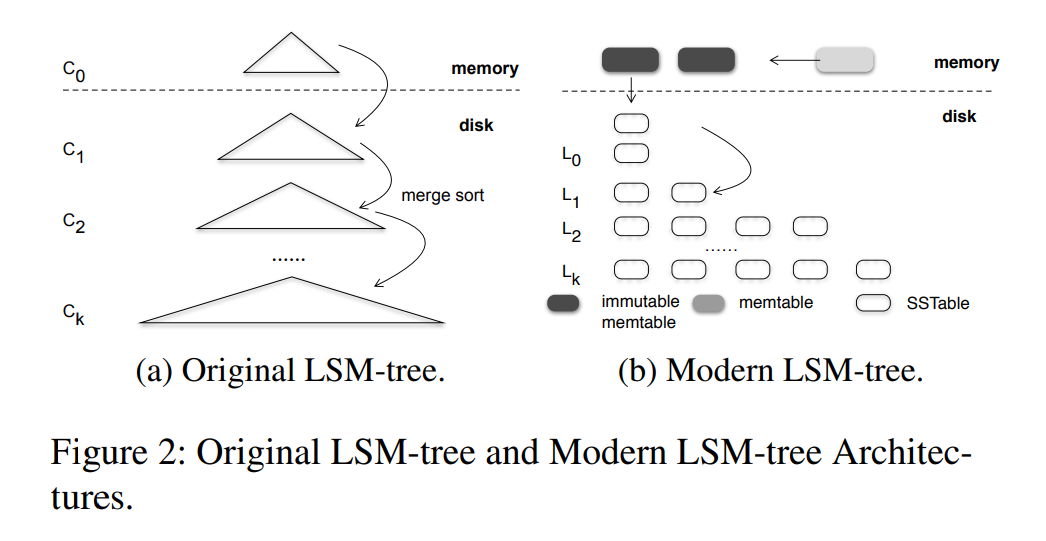
-
尽管上面介绍了最先进的优化,但我们发现,由于以下原因,压缩速度慢仍然会导致运行WPI 工作负载的 LSM-tree KV 存储的性能疲劳问题:
- Shattered L0:L0 层的数据块通常具有重叠的键范围,因为它们直接从主存中刷新而没有合并。除非压缩及时合并它们,否则点查找可能不得不检查多个块,以找到单个键,甚至索引也是如此。在这种压缩速度慢的情况下,随着时间的推移,L0 中存储的数据块会不断增加查找开销。这种破碎的 L0 对性能有重大影响,因为由于数据局部性,刷新到L0的记录仍然非常热(即很可能被访问)
- Shifting Bottlenecks:压缩操作自然由多个阶段组成:解码、合并和编码,因为KV记录通常是前缀编码的。为了确定这些阶段中的瓶颈,我们对 SSD 上由单个 CPU 线程执行的单个压缩任务进行概要分析。如图所示执行时间分解,随着 value 大小的增加,计算时间(解码、合并、编码)的百分比减少。而对于小 KV,计算占据整个压缩过程的 60% 的开销。当 value 大小达到 128 字节时,I/O 操作占用了大部分 CPU 时间。这个分解表明随着 KV 大小的增加,瓶颈从 CPU 转移到 I/O。这表明在合并小 KVs 时压缩以计算为限,在其他情况下压缩以 I/O 为限。
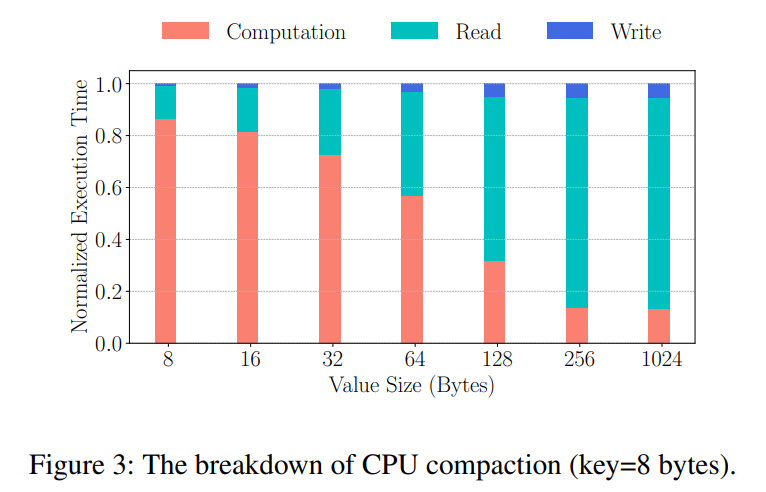
-
本文就是将上述的三个阶段给映射成 pipeline,并 offload 到专门的加速器。因为有了更快的压缩操作,L0 的数据块合并的更加频繁,因为 offloading,CPUs 从 heavy 的压缩操作中释放出来,从而腾出更多的资源用于事务和查询操作的处理。加速器选了 FPGA,因为 FPGA 它适合加速压缩等计算任务的 pipeline,且具有低 TCO 的低能耗,以及作为可插拔的 PCIe-attached 加速器的灵活性
-
原文还有一些关于 FPGA 本身的介绍,以及 FPGA 和 KV Store 结合的场景介绍。此处简单提及和 KVs 的结合问题,现有的研究大致有两种结合方式:
- bump-in-the-wire:将 FPGA 放在 CPU 和 disk 之间,该方法中,FPGA 类似于一个 data filter,在 FPGA 的片上 RAM 较小,只能临时保存数据流的一个 slice
- 随着片上 RAM 大小增加,FPGA 现在能像一个 co-processor 一样工作,所以可以把一些大数据量的处理任务给 offload 到 FPGA 上执行。这种方法适用于异步任务,在此期间,CPU 不会因为 offloaded 任务而 stall,本文就采用了这种方式,CPU 只用于任务的生成。Samsung 的 SmartSSD 也采用了这种方案实现计算型存储。
Design and Implementation
-
Overview:利用 Memtables 缓冲新插入的 KV 记录,利用缓存来缓冲热 KV 对和数据块,磁盘上的每一层包含多个 extents,每个 extent 依次用关联的索引和过滤器存储 KV 记录。X-Engine 在内存中还维护了一个全局索引用于加速查询。
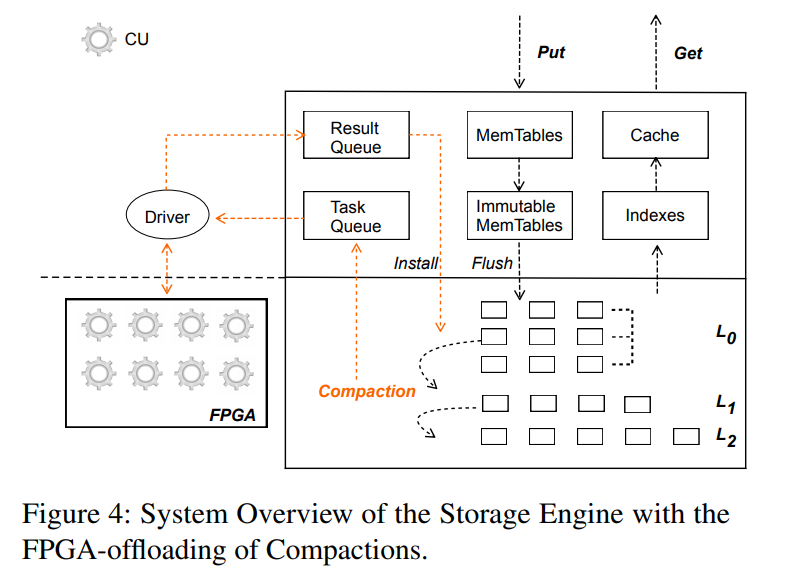
-
为了 offload compactions,首先设计了一个 Task Queue 来缓冲新触发的压缩任务,一个 Result Queue 缓冲在内存中的压缩过的 KV 记录。软件层面,引入了一个 Driver 来 offload compactions,包括管理从 host 到 FPGA 的数据传输过程,在 FPGA 上,设计并应用了多个 Compaction Units (CUs) 来负责合并 KV 对。
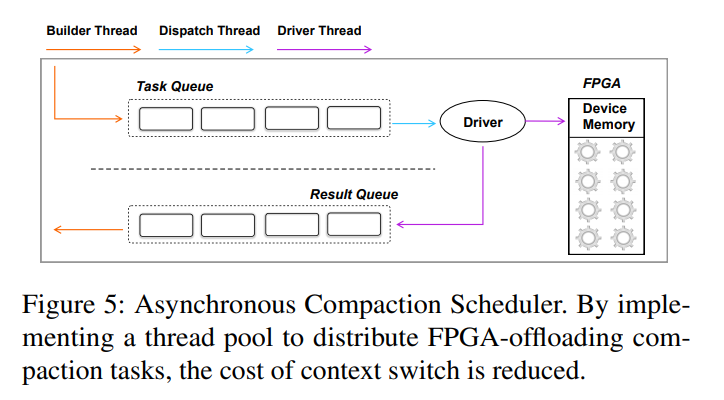
-
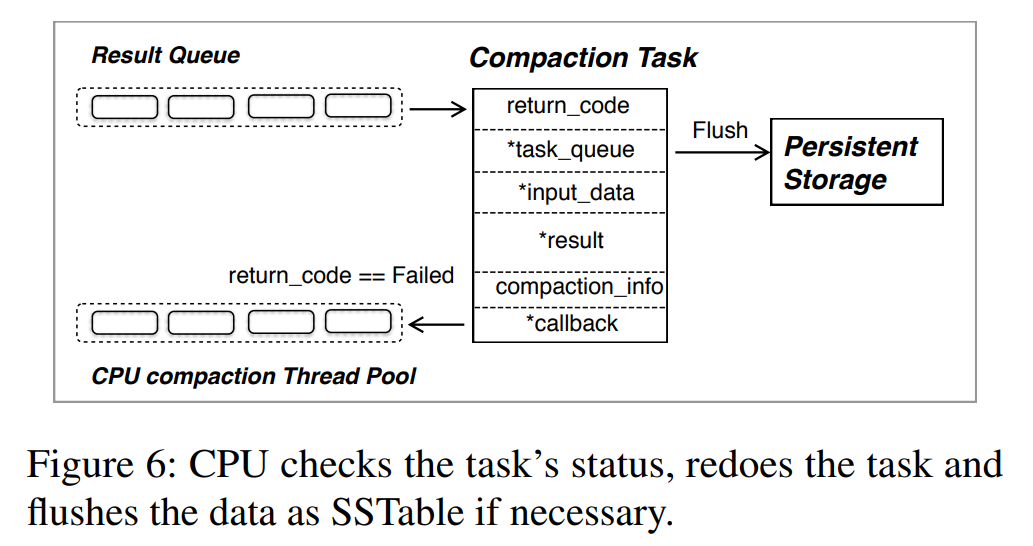
Managing Compaction Tasks:设计了三种线程,builder threads, dispatcher threads and driver threads 分别用于构建压缩任务、分发压缩任务到 FPGA 的 CU,install 压缩后的数据块到存储中。
- Builder thread:对于每个触发的压缩,Builder thread 将 extents 分区合并到多个大小相近的组中,每个组然后形成一个压缩任务,且将数据加载在内存中。FPGA 压缩任务。将构建一个 FPGA 压缩任务,其中包含所需的元数据,包括指向任务队列的指针、输入数据、结果和一个回调函数(将压缩后的数据块从FPGA传输到主存)、返回代码(指示任务是否成功完成)和压缩后任务的其他元数据。压缩任务会被推送到 task queue,等待被分发到 FPGA 的 CU 上,Builder Thread 也会检查 result queue 并把压缩后的数据块 install 回存储设备中(如果任务被成功处理的话),如果 FPGA 处理压缩任务失败了(比如 KV 的大小达到 FPGA 的容量),将重新启动一个 CPU 压缩线程来重新处理该任务。实践表明,offload 到 FPGA 上平均只有 0.03% 的任务处理失败。
- Dispatcher thread:dispatcher 消费任务队列,然后以 Round-Robin 的策略把任务分发到 FPGA 上所有的 CU。由于压缩任务大小相似,这种循环调度实现了 FPGA 上多个 CUs 之间的工作负载均衡分配。dispatcher 还会通知驱动线程将数据从设备内存传输到 FPGA。
- Driver thread:Driver thread 将输入数据和一个压缩任务一起传输到 FPGA 上的 device memory,然后通知对应的 CU 开始工作,当压缩任务完成之后,Driver thread 被中断以执行回调函数,回调函数将压缩后的数据块传输到宿主机 Memory,然后把完成后的任务推送到 result queue。
- 在这样的实现中,需要调整压缩任务的大小以为 compaction unit 提供充分的数据,在 CUs 之间保证负载均衡,同时也可以限制重试在 FPGA 上执行任务的开销。我们还会对 builder/dispatcher/installer 线程数单独进行调整,以实现比较稳定的吞吐量表现。
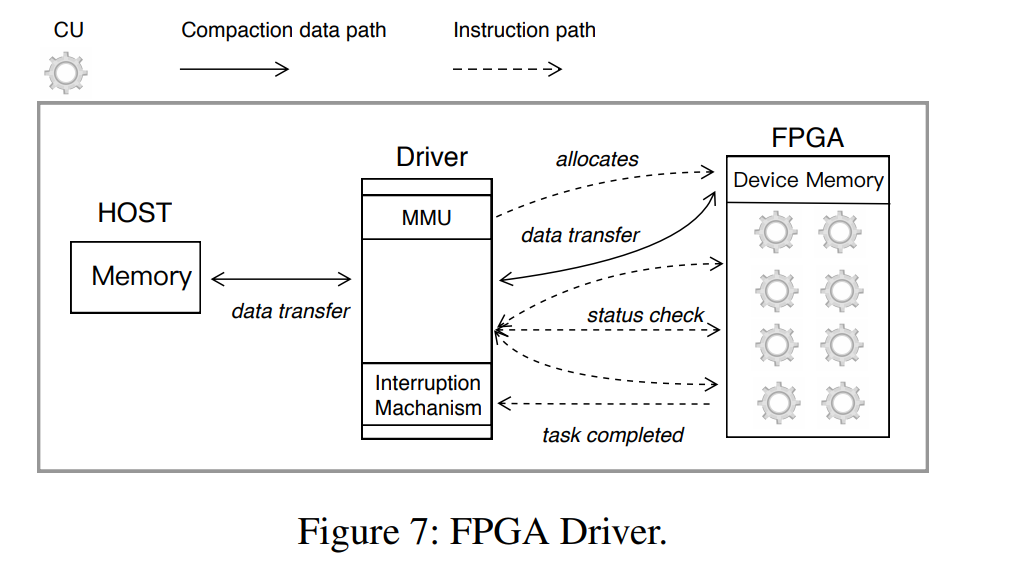
Instruction and Data Paths
- 为了驱动 FPGA 用于压缩,我们需要通过 PCIe 总线传输指令和数据,为了最大化传输效率,设计了 Instruction and Data Paths,还设计了 Interruption Mechanism 来通知 Installer Thread,Memory Management Unit (MMU) 来管理 FPGA 上的设备内存。
- Instruction Path:指令路径是为像 CU 可用性检查这样的小而频繁的数据传输而设计的
- Compaction Data Path:数据路径使用 DMA。要压缩的数据通过此路径传输。这样,CPU 就不参与数据传输过程了。
- Interruption Mechanism:当压缩任务完成时,将通过PCIe发送一个中断,然后在中断向量的帮助下将结果写回主机
- Memory Management Unit (MMU):MMU 在设备存储器上分配内存来存储从主机复制的输入数据
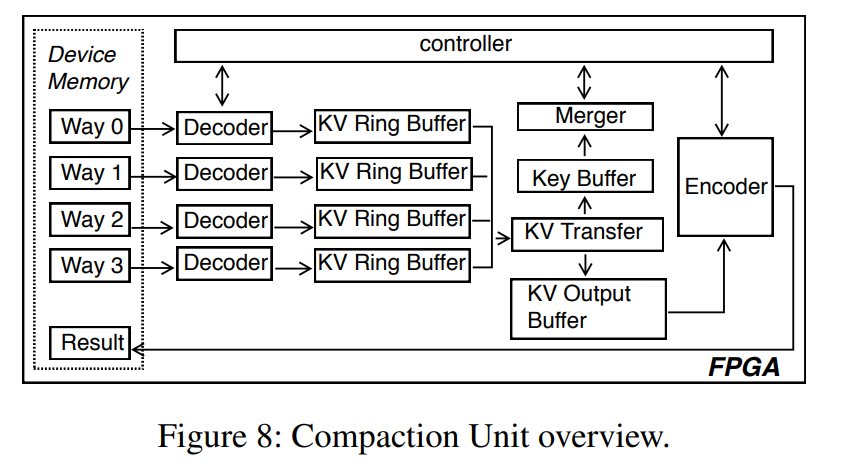
Compaction Unit
- 压缩单元(CU)是在FPGA上实现压缩操作的逻辑实现。很多个 CUs 被部署到同一个 FPGA 上,具体的数量取决于时机可用的资源。如下图所示了 CU 的设计,如下设计中,压缩任务由几个阶段共同组成:Decoder, Merger, KV Transfer, and Encoder。我们引入缓冲区
(即KV 环缓冲器、键缓冲器)在后续模块和控制器之间协调各模块的执行。- Decoder:KV 存储的 key 通常都是前缀编码的,为了节省空间,所以 Decoder 需要解码输入的 KV 记录。如果采用了 tiering compaction 策略,可能存在多种输入数据块的合并方式。而对于 levelling policy,只会有最多两个输入数据的方式,来自两个相邻的层。同时我们实际发现 tiering 最多也只有两个或四个输入方式,如果在一个 CU 里我们放置两个 decoders,每一个 decode 一种输入,那么我们需要构建三个 两路压缩 来实现一个 四路压缩,如果我们使用四个 decoder 会多消耗 40% 的硬件资源,而无需在 2-4 路压缩方式下执行额外的任务。因此我们在每个 CU 中放置了四个 decoders,decoder 将 解码后的 KV 对输送到了 KV Ring Buffers 中。
- KV Ring Buffer:KV Ring Buffer 缓存解码后的 KV 记录,我们在实践中观察到 KV 的大小很少超过 6KB,因此我们给每一个 KV Ring Buffer 配备了 32*8KB 的 slots,额外的 2KB 可以用于存储如 KV 长度这样的元数据信息。我们还设计了三种状态信号, FLAG_EMPTY, FLAG_HALF_FULL and FLAG_FULL 来表示 buffer 的空间情况。从一个空缓冲区开始,解码器持续解码并填充这个缓冲区,当处于 FLAG_HALF_FULL 时,下游的 Merger 将被允许独去缓冲区中填充的数据然后开始合并,在 Merger 工作的同时,decoder 持续地填充数据直到填满,我们匹配 merger 和解码器的速度,这样,通过填充一半的环形缓冲区,merger 将花费相同的时间来完成它的工作。通过这种方式可以有效地将 decoder 和 merger 流水线化。如果两个模块速度不匹配,Controller 将停止 decoder。我们为 merger 维护了一个读指针来标记从哪里读取的 KV 记录,并为解码器类似地维护了写指针。
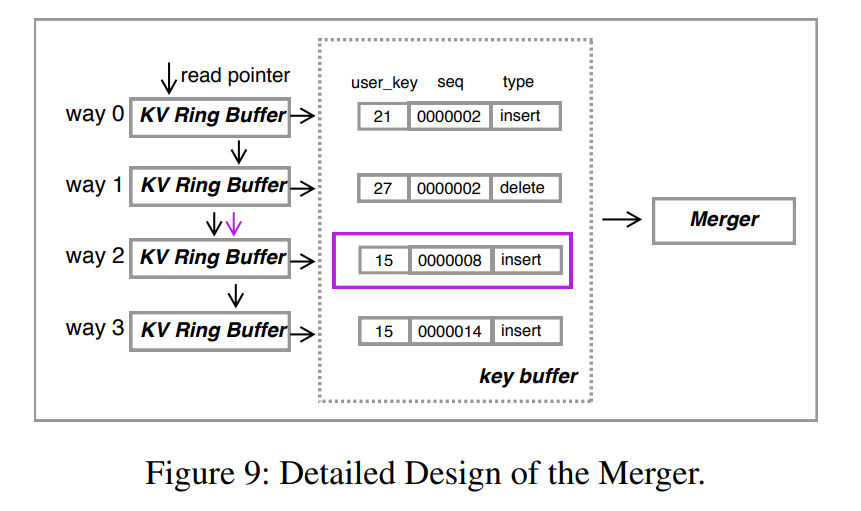
- KV Transfer, Key Buffer and Merger:只有 keys 被传输到了 Key Buffer,然后 Merger 进行比较。如果一个 key 被限定为一个输出,KV Transfer 模块将相应的 KV 记录从上游的 KV Ring Buffer 传输到 KV Output Buffer,数据结构和 Ring Buffer 完全相同。Controller 收到比较结果的通知后移动 ring buffer 中相应的 read pointer。如图 9 所示,如果 way 2 上的 KV 是最小的 KV,Controller 将会通知 KV Transfer 将该条记录传输,使用对应的读指针进行寻址,然后再移动到下一个位置来拉取用于下一轮比较的 entry。
- Encoder: 该模块编码合并后的 KV 记录,并放置到设备内存,因为这只有一种合并后的数据,所以每个 CU 只需要一个 encoder。
- Controller:Controller 在 CU 中更多地是作为一个协调者,管理 KV ring buffer 的读写指针(分别为 merger 和 decoder 管理),也需要给每一个信号传递开始或者停止的信号。
Analytical Model for CU:
- 由于采用流水线设计,因此匹配不同模块的吞吐量非常重要,以避免硬件资源的过度供应和浪费,但是,很难通过如此多的调优选项来确定每个组件的资源数量。因此提出了一种分析模型来指导资源分配。参数如下:
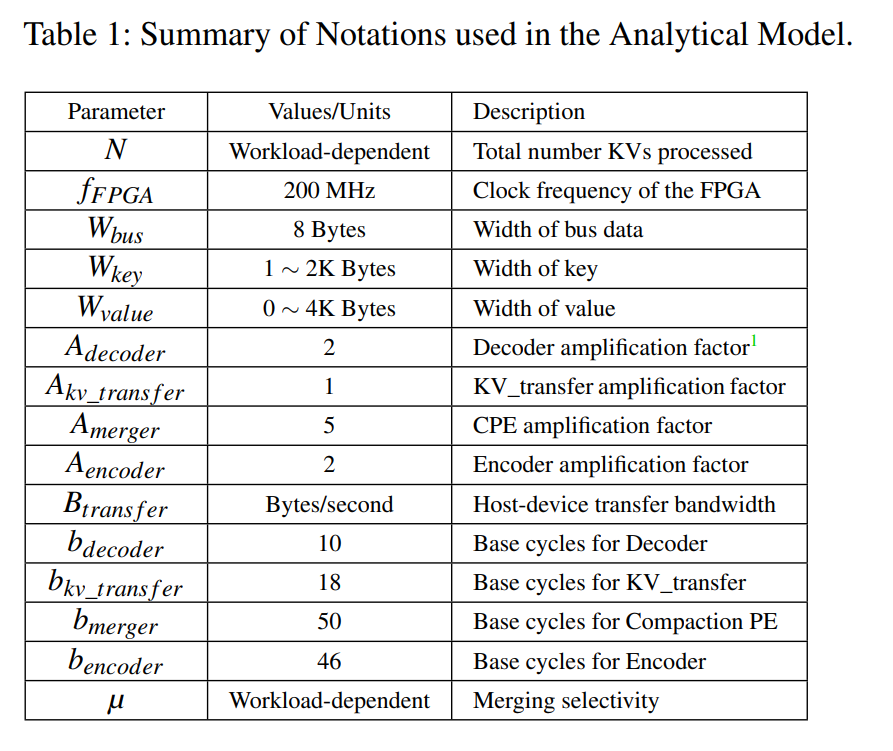
- CU 的吞吐量由最慢阶段的吞吐量来决定,只有一个例外 KV Transfer,当 KV Transfer 工作时,合并 KVs 的转移与其前一阶段的 Merger 串行执行,这种情况下,他们的开销应该合并起来计算。每一阶段的成本由其计算和内存开销组成,除了在启动此阶段时消耗的恒定数量的基本周期之外。
- 等式 2 3 4 5 都建模了每个 KV 对在对应组件内的开销,等式 6 建模了在 host 和 device 之间数据传输的吞吐量,主要受到 PCIe 带宽的限制。通过检查硬件实现和性能分析,我们使用表1中列出的数据初始化这些模型。例如一个 KV 对,8B key,32B value,每个 KV 在每个阶段消耗的周期为 16, 55, 23, 52(Decoder, Merger, KV ransfer, and Encoder stages)。整体的吞吐量为 3.6M records/s

Evaluation
-
Hardware:
- two Intel Xeon Platinum 8163 2.5 GHz 24-core CPUs with two-way hyperthreading
- a 768 GB Samsung DDR4-2666 main memory
- a RAID 0 consisting of 10 Samsung SSDs
- a Xilinx Virtex UltraScale+ VU9P FPGA board (running at 200MHz) with a 16 GB device memory to this server through a x16 PCIe Gen 3 interface
-
Software: Linux 4.9.79, X-Engine
-
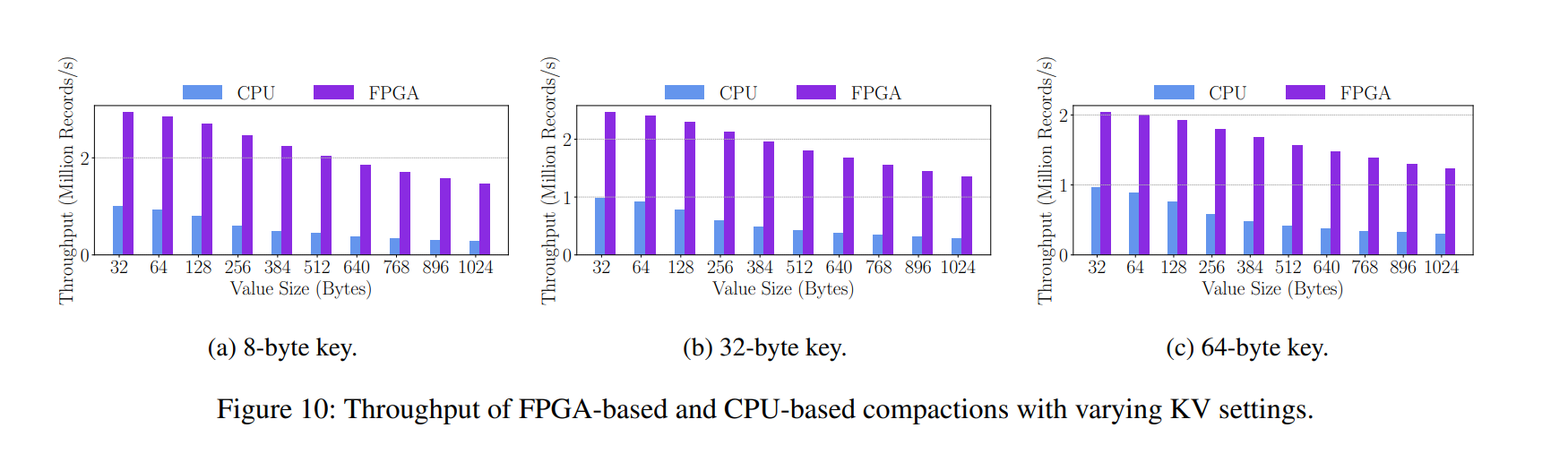
KV 对越小,更多的开销都是在 offload 过程,随着 KV 的增大,逐渐被稀释这部分开销,所以 KV 对越大,性能提升越明显
-
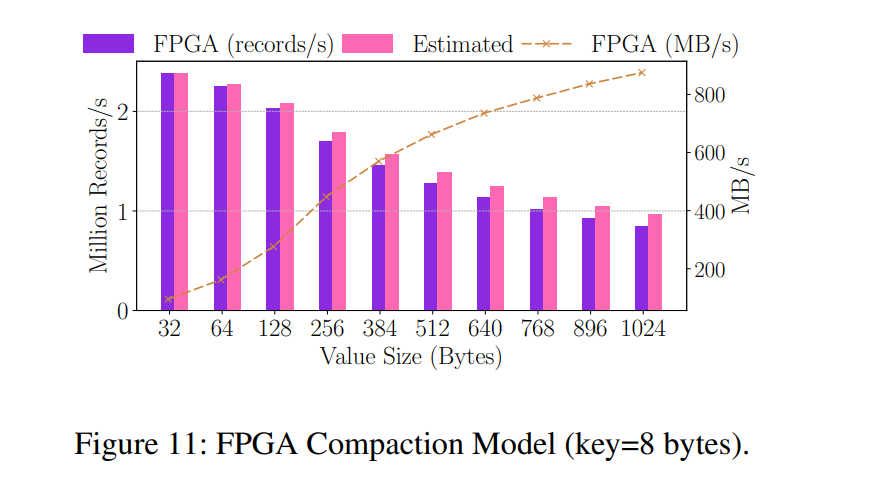
总吞吐量总是限制在合并和 KV 传输阶段的组合,既不不是对设备存储器的访问,也不是通过 PCIe 的数据传输
-
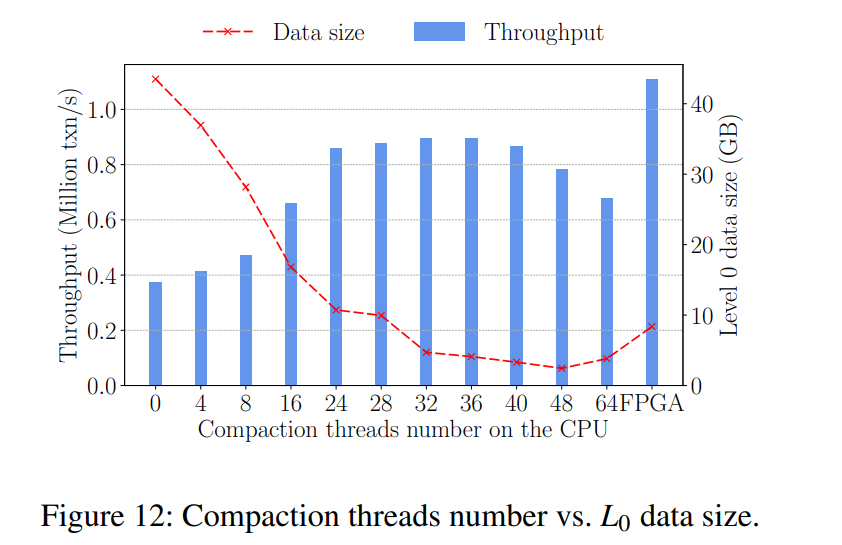
24 线程以前,压缩比 KV 存储的总写吞吐量要慢,因此它不能摄取lsm树中足够的新写数据。因此,使用更多线程加速压缩是有回报的。从24个线程到32个线程,吞吐量几乎没有变化。大于 32 个线程之后,随着线程的增加吞吐量下降。原因主要在于更多的线程也就引入了更多的资源争用,如前面图 1 所示整体的 CPU 利用率接近 100%,此时瓶颈在于 CPU。第二个原因是前面增加的线程已经让磁盘 I/O 饱和,持续增加线程只会造成更多的查询/事务处理和 compaction 之间的 I/O 争用。
-
FPGA-offloading 和 CPU-based 两种对比发现,FPGA-offloading 比最好的 CPU-based 的吞吐量都要高出 23%,因为不仅加速了压缩,还减少了 CPU 的争用。又因为 FPGA 上的压缩任务比较好的调度和分配,没有观察到对于内存的消耗上有太显著的区别,CPU-Only 的负载相对消耗更多的内存带宽。
-
吞吐量都有提升,延迟有所下降,尾延迟也有所下降,操作的响应时间也有降低,能源消耗也有所降低,整体的能源效率有所提高。

-
当读比例在 WPI 负载中下降到了 75% 时,也就是此时成为一个写密集的 WPI 负载,我们提出的卸载方法的性能优于基准,在所有情况下都减少了约 10% 的 CPU 消耗,并且由于其吞吐量高于 CPU,因此消耗的 I/Os 稍微多一些。
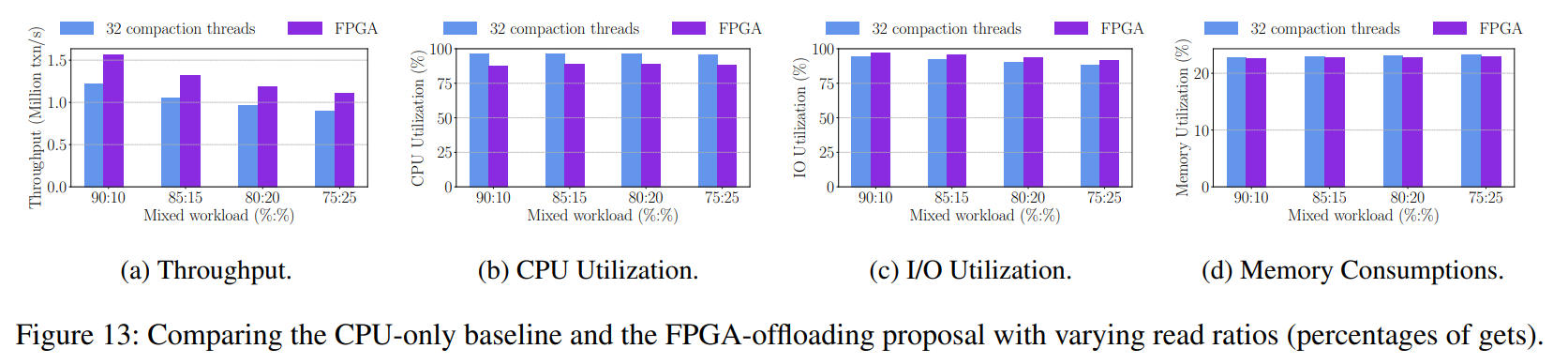
-
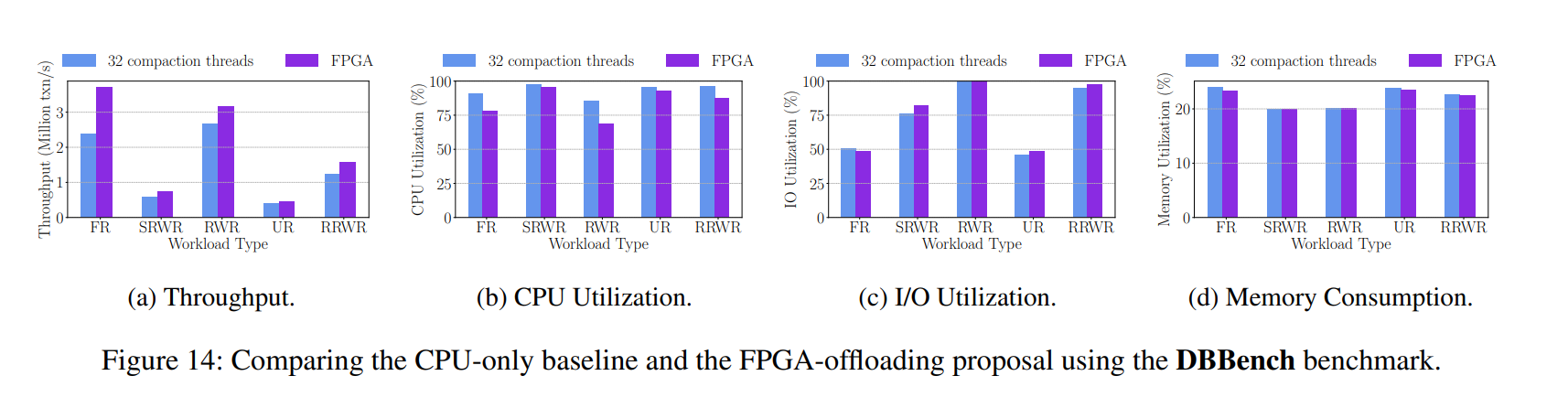
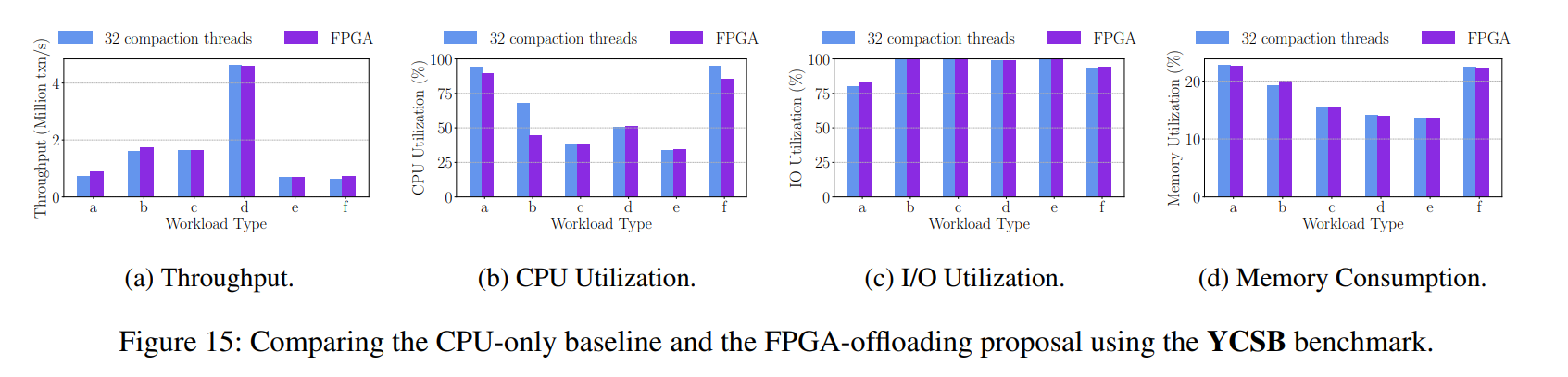
在 DBBench 和 YCSB 基准测试中,与读密集型的操作相比,当工作负载中有大量写操作时,提出的 FPGA-offload 压缩对 KV 存储的贡献更大,因为压缩在工作负载中 lsm 树只在写操作时触发
Related Work
Software Optimizations of Compactions
- FAST13 的 VT-tree 使用拼接技术来避免排序和不重叠的键范围的不必要的磁盘 I/Os,但是这种方法受数据分布的影响,可能导致碎片化,使范围扫描和压缩的性能变差。
- SIGMOD12 的 bLSM 和 VLDBJ07 的 PE 考虑了数据分布,都是将键范围分渠道多个键的子范围并限制比较热的键范围的数据压缩。
- IPDPS14 的 PCP 观察到压缩可以流水线化,使用多个 CPUs 和存储设备来充分利用 CPU 和 I/O 资源从而加速压缩过程。
- SIGMOD18 的 Better spacetime trade-offs for lsm-tree based key-value stores via adaptive removal of superfluous merging 通过合并尽可能少的内容来实现查找成本和空间的给定边界,从而提供了更丰富的时空权衡,并提出了一种混合压缩策略(即,对最大级别使用 levelling,对其余级别使用 tiering) 来减少写入放大
- SIGMOD19 的 X-engine 提出将 LSM-tree 中的数据分割成小数据块,并在压缩过程中广泛重用键范围不重叠的数据块,以减少写放大。
- 所有这些软件优化和我们提出的基于 FPGA 的优化是正交的,即可以一起作用来显著提升系统性能并降低能耗。
Hardware Accelerations in Databases
- 数据库领域早就在尝试使用各种其他类型的硬件来加速数据的读写。
个人见解
- 本文还是问题找的比较关键准确,所以后续的提升方案才能带来如此大的提升,而且这个问题也基本是学术界很多学者都已经发现了的问题,只是各自的解决方式不同,但大体思路其实是相通的,即借助其他处理器资源来减少 CPU 的争用问题。不同的是不同层级的优化,如很多做 KVSSD 的研究人员更多是在 SSD 那一层去做这样的优化,本文则更多地是从系统层面来做优化,一个好的点是可能很少人关注到引入新硬件后引入的成本和能耗问题,这个确实云厂商比较关注这方面的问题,所以在评价的角度上能够多出一环。
- 看完这篇文章的具体感受就是,处理器现在也是百家争鸣,具有各自鲜明特点的硬件单元堆积在板子上可能将会成为一个趋势,即把更专门的运算交给更专业的人去做,而不是像以前 CPU 一锅端。
HotRing: A Hotspot-Aware In-Memory Key-Value Store
- 本文主要针对的内存 KVs,最主要的应用还是作为 Cache,在大量的互联网场景中都有应用,作为 Cache 需要面对和解决的问题其实就是热点数据的访问。内存中的 KVs 最常见的数据结构就是 HASH,诸如像 Redis 这样的成熟的的内存 KVs,大多都是使用 HASH 来实现。而本文立足的场景也是阿里云淘宝这种并发高的电商场景,需要强劲的缓存支撑,淘宝的 Tair 也算是业界比较知名的数据库团队。
- 本文主要还是针对热点数据的优化,更多地是从数据结构本身出发,因为相关参考资料也已经讲的很多了,此处主要介绍问题和大致的方案。
- 贴几个链接:
- 本文主要探索针对内存索引结构的热点感知的相关设计,作者首先分析了理想的热点感知的索引的潜在收益,并讨论了有效利用热点感知可能面临的挑战(热点变化和并发访问问题), 基于此分析提出了可以热点感知的 KVs 设计 HotRing,针对一小部分 items 进行大规模并发访问而优化的。HotRing 基于有序的一个有序的环状 HASH 索引结构,通过移动 head 指针来快速访问热点数据。也会应用一个比较轻量的策略来检测运行时的热点变化。HotRing 在设计中采用了无锁的结构,所以并发操作能够更好地利用多核架构的性能。实验表明我们的方法相比于其他内存 KVs 在高度倾斜的负载下实现了 2.58x 的提升。
简要介绍
Introduction & Background
-
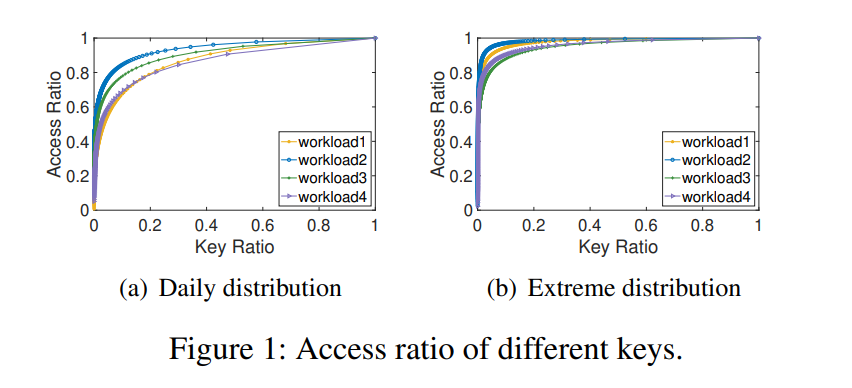
常见的内存 KVs,如 Memcached、Redis、SIGMOD18 的 FASTER(HASH)、NSDI13 的 MemC3(HASH)、NSDI14 的 MICA(HASH) 等。热点问题是一个广泛的问题,有一些集群层面上的热点问题的解决方案,如一致性 HASH、数据迁移、前端数据缓存等,同样单节点上的热点问题也需要被解决。比如计算机体系结构利用垂直的存储结构来缓存最常访问的数据在更低延迟的存储介质上。但是对于内存 KVs 内部的热点数据问题往往忽略了。作者从阿里巴巴的生产环境中收集了内存 KVs 的访问情况如图所示,可以发现 日常分布中的百分之五十和极端分布中的百分之九十的访问都只会访问到总的数据的 1%,这说明网络时代的热点问题空前严重。(具体的原因主要是在线应用的活跃用户数量持续增长,一些热门事件都会导致在短期内对于少部分数据的大量访问,所以对这些热点数据的快速访问是比较关键的,除此以外这些应用程序之下的基础设施变得复杂,一个小错误,例如由于软件错误或配置错误,可能导致(不可预测的)重复访问一个项,例如无休止地读取和返回一个错误消息。理想的效果是这些不可预测的热点不会导致整个系统崩溃或阻塞)
-
HASH 索引是最流行的内存 KV 数据结构,特别是针对于一些不需要范围查询的场景。下图展示了 HASH 索引的一种通用结构,bucket + list。HASH 值可以分为两部分,一部分用作 HASH 表的索引,一部分用作 list 种的比对,从而减少比较过程中的需要比较的对象数据的长度。
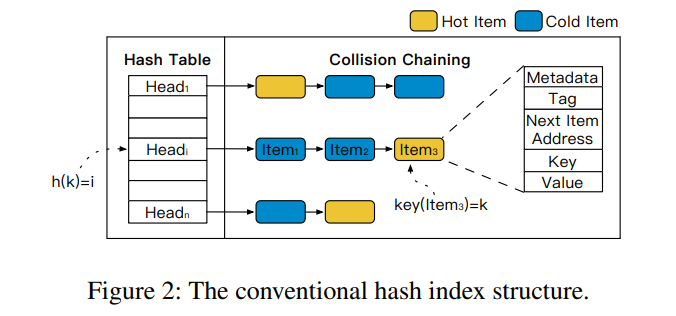
-
现有的内存 HASH 索引无法感知热点数据,即未对热点数据进行区分(如上图中的 热点数据 item3 位于冲突链的末尾,就会比之前多更多的内存访问次数,在一些倾斜负载的情况下热项访问成本的轻微增加可能导致整体性能的严重下降)
-
采用的相同的策略管理所有数据,但是理论分析表明查询热点数据的开销比理想的策略大得多,虽然存在一些减少内存访问的机制,但它们只能提供有限的效率。
- 比如 CPU 利用自己的缓存来加速吗,但是只有 32M 大小,完全不足以缓存热点数据,即便是有一些缓存友好的数据结构
- 可以扩大哈希表(即通过重新哈希),以减少冲突链的长度,从而查找一个热项所需的内存访问更少,Rehash 可以帮助减少冲突链的长度,但会显著增加内存占用。特别是当 HASH 表已经很大的时候,就不再推荐重 HASH。例如,对于两个连续的重哈希操作,第二个需要两倍的内存空间,但只带来一半的效率(就减少链长度而言)。
-
在本文中,我们提出了 HotRing,这是一种支持热点的内存 KVS,它利用 HASH 索引来优化对一小部分数据项(即热点)的大规模并发访问。最初的想法是让查找一个项所需的内存访问与它的热度负相关,即越热的项读取速度越快。但是需要解决两个问题:
- hotspot shif:热点项集不断变化,我们需要及时发现并适应这种变化
- 使用 ordered-ring 来解决,当热点变化时,bucket headers 可以直接重新指向热的数据项,而不会影响正确性
- 同时设计了一个轻量的机制来检测运行时的热点变化
- concurrent access:热点本质上是被大量并发请求访问的,我们需要为它们维持高并发性
- 基于现有的无锁数据结构(无锁链表)采用了一种无锁的设计,并扩展该数据结构以支持 HotRing 所需要的其他操作,包括热点变化检测、头指针移动以及有序环 rehash
- hotspot shif:热点项集不断变化,我们需要及时发现并适应这种变化
Design
-
HotRing 的 HASH 索引结构如下所示,将以往的传统的 HASH 冲突链表转变为冲突环,原本的链表最后的项将和链表的首项连接起来,当环中只有一项数据时,所有指针都指向自身。
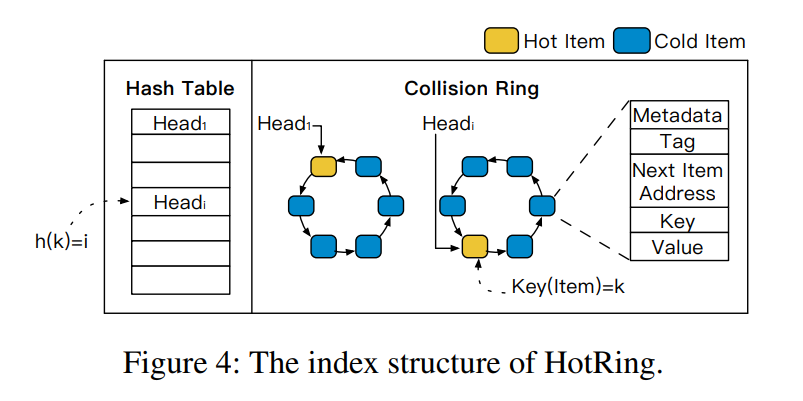
-
Ordered-Ring Hash Index:环状结构的问题就是没有遍历的终止条件(当对应 bucket 内无对应数据时),就需要一个机制来安全地终止查询过程。很直观的想法就是将 HEAD 指向的第一项标记为停止遍历的标识,但是对于并发请求时会有问题,比如删除了标记的项。所以本文提出了有序环结构来决定查询的过程,使用 Key 和 Tag 进行排序。(先按照 tag 排序,然后按照 key 排序),相比于以往的链式结构,平均查询次数减少到了 (n/2) + 1 次

-
Hotspot Shift Identification:此处讨论的都是 bucket 内的热点数据的变化,通常冲突链上有 5-10 个数据项,然后根据热点数据的比例 0.1 到 0.2 推断大约每个 Bucket 内有一个热点数据,可以直接把 HEAD 指针指向唯一的热点数据,从而避免数据的重新组织并减少内存开销。为了获取较好的性能,需要考虑两个因素:
- 热点识别的准确率:热点识别的准确性是通过识别热点所占的比例来衡量的
- 响应延迟:响应延迟是一个新的热点出现和我们成功检测到它之间的时间跨度。
-
基于上述两个因素提出了两种策略: random movement 和 statistical sampling strategy
- Random Movement:响应时间短,但是准确率低,其基本思想是,头指针从即时决策周期性地移动到潜在热点,而不记录任何历史元数据。每个线程维护一个 ThreadLocal 变量来记录该线程执行的请求数量,每 R 个请求后,线程决定是否执行头指针的移动操作。如果第 R 次访问是对热数据的访问,那么指针不移动,如果是对冷数据的访问,那么 HEAD 指针指向该冷数据,因为可能即将成为热数据。参数 R 将影响响应延迟和识别的准确率,如果 R 太小,为了实现稳定的性能的响应延迟会很低,但是将导致频繁的且低效的头指针移动。我们的场景中,数据负载是严重倾斜的,因此头指针的移动往往不频繁,根据经验,参数R默认设置为5,该参数可以提供较低的反应延迟和可忽略的性能影响。
- 如果负载的倾斜状况不是很明显,该策略将变得特别低效,最重要的是该策略无法处理一个冲突环中多个热点数据的问题,多个热点数据的时候,头指针频繁地移动,并不会加速对热点数据的访问反而会对正常操作产生不利影响。
- Statistical Sampling Strategy:为了实现更高的性能,我们设计了一种统计采样策略,旨在提供更准确的热点识别与稍高的反应延迟。
- 首先考虑数据格式:Head Pointer 和 Item。将同时记录 Ring 和 Item 级别的统计数据。
- Head Pointer 由三部分组成:
- Active bit: 用于控制该策略的 flag
- Total Counter: 对该冲突环的访问总次数
- Address: 为对应项的物理地址
- Item 由以下几部分组成:
- Rehash:用于控制 rehash 过程的 flag
- Occupied:用于保证并发时的准确性
- Counter:用于记录该项的访问次数
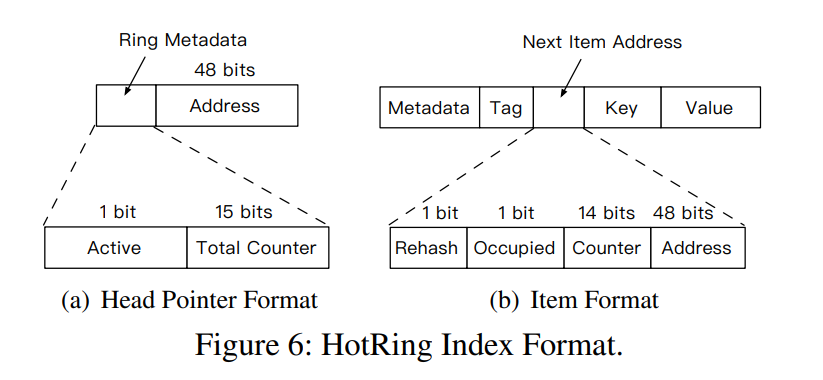
- Head Pointer 由三部分组成:
- Statistical Sampling:如何在这么大的 HASH 表中以一个低开销的方式动态识别出热点数据是一个极具挑战性的问题,关键是尽量减少开销,同时保持精度,这是通过周期采样在HotRing实现的。每个线程维护一个 ThreadLocal 变量用于计数已经处理了的请求数,每 R 个请求之后我们决定是否要开启新一轮的采样,通过改变 Active flag 的值来控制。如果第 R 个访问时热点数据,意味着当前的热点识别仍然是准确的,采样无需触发,如果是冷数据,意味着热点发生了变化,然后我们开始采样。R 默认还是设置为 5,当 Active 位被置为 1,后续对环的访问将被记录在 Total Counter 和对应的 Item 的 Counter 中。采样的策略要求额外的 CAS 操作,可能会导致临时的性能降级。为了减少这个时间,我们将样本的数量与每个环中的项目数量设置相等,我们认为这已经提供了足够的信息来派生新的热点。
- Hotspot Adjustment:采样完成后,最后一个访问线程负责频率计算和热点调整。该线程首先使用 CAS 原语 RESET Active BIt,这确保了只有一个线程将执行后续任务。然后,该线程计算环中每个项的访问频率(用于后续计算 income),对应项的 Counter 除以该环的 Total Counter,然后计算每个项被头指针指向的 income,即某个项被选中被头指针指向对应的平均内存访问次数。然后选择出 income 最小的项作为热数据从而确保热点最快被访问,头指针的移动也是 CAS 操作。对于多个热点数据的情况,可以计算出相对较优的位置从而避免热点数据之前的频繁移动。调整了热点数据之后,负责的线程重置所有的计数器便于下次采样。
- Write-Intensive Hotspot with RCU:对于更新操作,如果 value 小于 8 byte,那么可以就地更新。这个例子中,reading 和 updating 一个项被视作相同热度的操作,但是对于 value 比较大的项的更新操作就完全不同了。RCU(Read-Copy-Write)协议的情况下,前项的指针需要被修改因为在更新过程中指向了新的 item,如果HEAD 指针指向的写密集型热点被修改,整个冲突链将被遍历才能到达前项,也就是说一个写密集型的热数据也会造成他的前项数据变热,基于此我们稍微修改了统计采样策略。对于 RCU 更新,改为只对它的前一项的计数器加一。
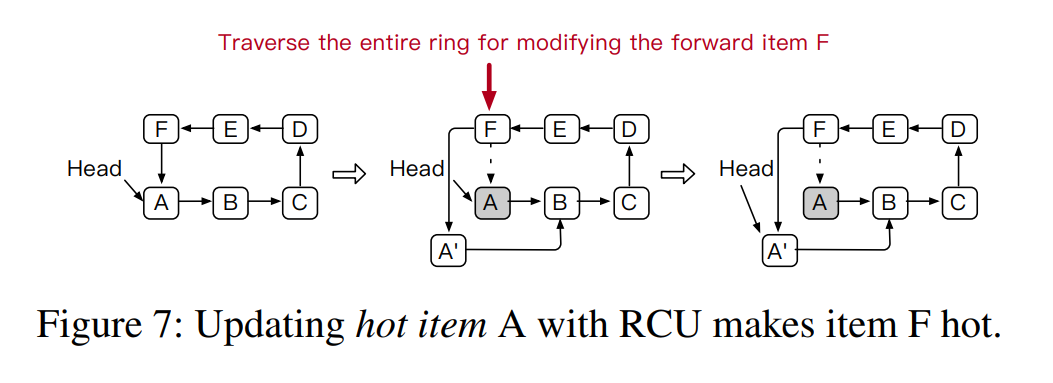
- Hotspot Inheritance:当对head项执行RCU更新或删除时,我们需要将head指针移动到另一个项。但是,如果头指针随机移动,它可能指向一个冷的数据,这将导致热点识别策略被频繁触发。此外,识别策略的频繁触发会严重影响系统的性能。如果环中就一个数据项,CAS 直接修改头指针来完成更新和删除操作,如果这有很多项,HotRing 使用现有的热点信息(头指针指向的位置)来继承对应的热度。针对RCU的更新和删除操作,我们设计了不同的头指针移动策略,以保证热点调整的有效性:
- 对于head项的RCU更新,由于访问的时间局部性,最近更新的项有很高的被立即访问的概率,因此头指针被移动到 head 的新版本
- 对于头项的删除,头指针只是移动到下一个项,这是一种简单而有效的解决方案
- 首先考虑数据格式:Head Pointer 和 Item。将同时记录 Ring 和 Item 级别的统计数据。
- Random Movement:响应时间短,但是准确率低,其基本思想是,头指针从即时决策周期性地移动到潜在热点,而不记录任何历史元数据。每个线程维护一个 ThreadLocal 变量来记录该线程执行的请求数量,每 R 个请求后,线程决定是否执行头指针的移动操作。如果第 R 次访问是对热数据的访问,那么指针不移动,如果是对冷数据的访问,那么 HEAD 指针指向该冷数据,因为可能即将成为热数据。参数 R 将影响响应延迟和识别的准确率,如果 R 太小,为了实现稳定的性能的响应延迟会很低,但是将导致频繁的且低效的头指针移动。我们的场景中,数据负载是严重倾斜的,因此头指针的移动往往不频繁,根据经验,参数R默认设置为5,该参数可以提供较低的反应延迟和可忽略的性能影响。
-
Concurrent Operations:HEAD 可移动导致并发控制更为复杂,但其实主要控制几个关键数据的原子操作即可。如 Next Item Address 后项指针需要使用 CAS 操作来保证原子性。
- Insert 操作如图 A 所示,需要保证只有一个修改后向指针的操作成功。
- Update 小于 8 byte 时无需额外的保证,对于 RCU 操作才需要进行控制。还是图 A 的例子,一个插入 C 的线程需要修改 B 的后向指针,一个线程需要更新 B 的数据为 B‘,这两个操作因为更新的是不同的数据指针其实都会成功,但是因为 B 对于环而言不可见了,即便 C 插入已经成功,所以后续对 B 的操作就会出错(C 的插入更新 B 的后向指针的操作),在图 b 中也有相同的问题,所以使用 Occupied 位来确保正确性,所以使用两个步骤来完成操作。对于 Update&Insert 操作,需要更新后向指针的 B 先把 Occupied 位置原子性第置为 1 ,一旦 Occupied 被置为 1,插入 C 的完整操作将会失败并需要重试。然后更新 A 的后项指针指向 B’,然后将 B‘ 的 Occupied 位重置。
- Delete:删除是通过将原本指向了已删除项的指针修改为下一个项来实现的。因此需要保证要删除的项的后向指针在操作过程中不被改变,还是借助 Occupied 位来实现。如图 C 所示
- Head Pointer Movement:
- 如何处理正常操作的和热点识别策略引起的头指针移动 形成的并发的情况? Occupied
- 如何处理头部指针移动,造成更新或删除头部项目? HotRing不仅需要 occupy 准备删除的项,还需要 occupy 下一个项。因为如果在删除操作期间下一项未被占用,则下一个节点可能已被更改,这使得头指针指向一个无效的项。

-
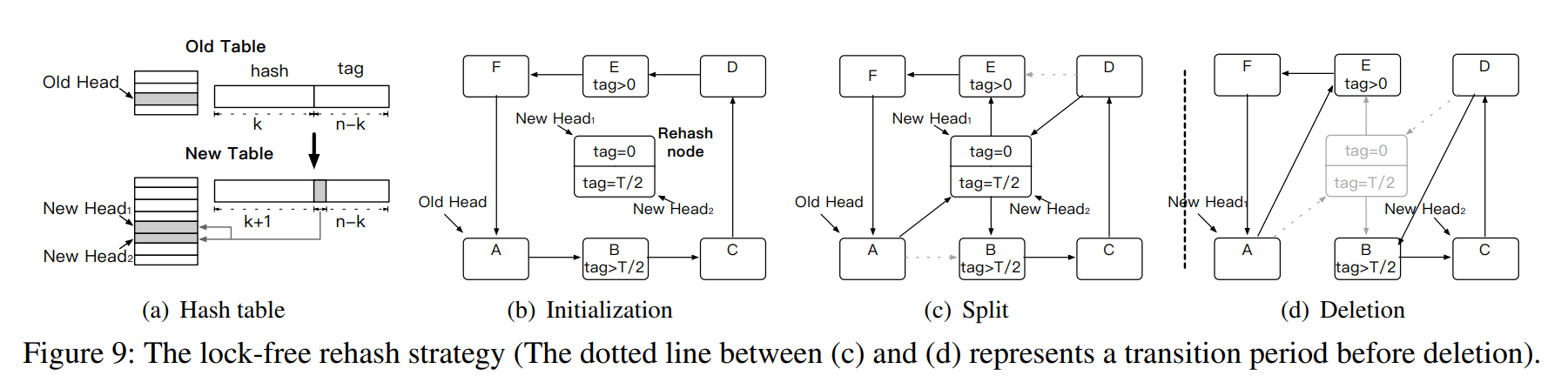
Lock-free Rehash:我们在HotRing中提出了一种无锁的重新哈希策略,允许在数据量增加时灵活地重新哈希。传统的重哈希策略是由哈希表的装载因子(即链的平均长度)触发的。但是,这没有考虑热点的影响,因此不适合HotRing。为了使索引适应热点项的增长,HotRing使用访问开销(即检索一个项的平均内存访问次数)来触发重新哈希。
- Initialization:创建一个后台 HASH 线程,线程通过共享 tag 的最高位来初始化新哈希表,新哈希表的大小是旧哈希表的两倍。如图 a 所示。同时,重哈希线程创建一个由两个子重哈希项组成的重哈希节点,这两个子重哈希项分别对应两个新的头指针。每个重哈希项的格式与数据项相同,只是没有存储有效的KV对。HotRing 通过每个项中的Rehash 位来标识重新散列项。在初始化阶段,两个子重散列项的标记设置不同。如图 b 所示,对应的重散列项分别将标签设置为0和T/2。
- Split: 重哈希线程通过向环中插入两个重哈希项来分割环。如图 C 所示,将重新哈希项分别插入到项B和项E的前面,作为标签范围的边界来划分环。当两个插入操作完成时,新建表被激活。之后,依次访问新表需要通过比较 tag 选择相应的头指针,而以前访问(从旧的表)通过 tag 重新散列节点继续。可以在不影响并发读和写的情况下正确地访问所有数据。到目前为止,对项的访问在逻辑上被划分为两条路径。
- Deletion: 如图 d 所示,在此之前,重散列线程必须维护一个过渡期,以确保从旧表发起的所有访问都已经完成,比如read-copy-update同步原语的过渡期。当所有访问结束时,重新哈希线程可以安全地删除旧表,然后重新哈希节点。注意,过渡期只阻塞重散列线程,而不阻塞访问线程。
个人见解
- 本文还是问题找的比较关键准确,当然主要是因为淘宝有对应的真实场景,冷热数据的访问影响极大,但相较于以往针对缓存算法中冷热数据的识别,本文将问题更多地聚焦在 HASH 冲突链内,所以方向性也就比较明确,个人觉得可以在缩小问题范围之前加一个测试来说明 HASH 冲突链内的热点问题的严重性,来进一步证明把这个大问题缩小范围的有效性和可行性。
- 本文设计的数据结构还是挺巧妙的,乍一看链变环仿佛没啥新东西,但其中蕴藏了很多有意思的问题,尤其是并发场景下的一些数据访问的问题,你使用了有序环的结构减少内存访问次数,但也就需要见招拆招地解决环结构本身的问题,对于并发访问的场景考虑的也很周全。
Caching
- BCW: Buffer-Controlled Writes to HDDs for SSD-HDD Hybrid Storage Server
- Shucheng Wang, Ziyi Lu, and Qiang Cao, Wuhan National Laboratory for Optoelectronics, Key Laboratory of Information Storage System; Hong Jiang, Department of Computer Science and Engineering, University of Texas at Arlington; Jie Yao, School of Computer Science and Technology, Huazhong University of Science and Technology; Yuanyuan Dong and Puyuan Yang, Alibaba Group
BCW: Buffer-Controlled Writes to HDDs for SSD-HDD Hybrid Storage Server
-
本文是隔壁实验室大佬发的,和 Alibaba 也有一些合作(盘古),有一些生产环境中的实际问题和数据可以借鉴。发现的问题也算是比较关键。
-
贴几个链接:
-
场景:本文主要针对混合存储(Hybrid Storage)场景,SSD 作为缓存为 HDD 加速。HDD 因为容量大、成本低在数据中心还是有着很多的应用,特别是对一些冷数据的存储,但对于当下对于存储设备的性能需求,HDD 又无法提供用户期待的性能,所以大多数公司会使用性能更好的 SSD 来为 HDD 加速,在保证大容量低成本的同时提供一定的性能保证。
-
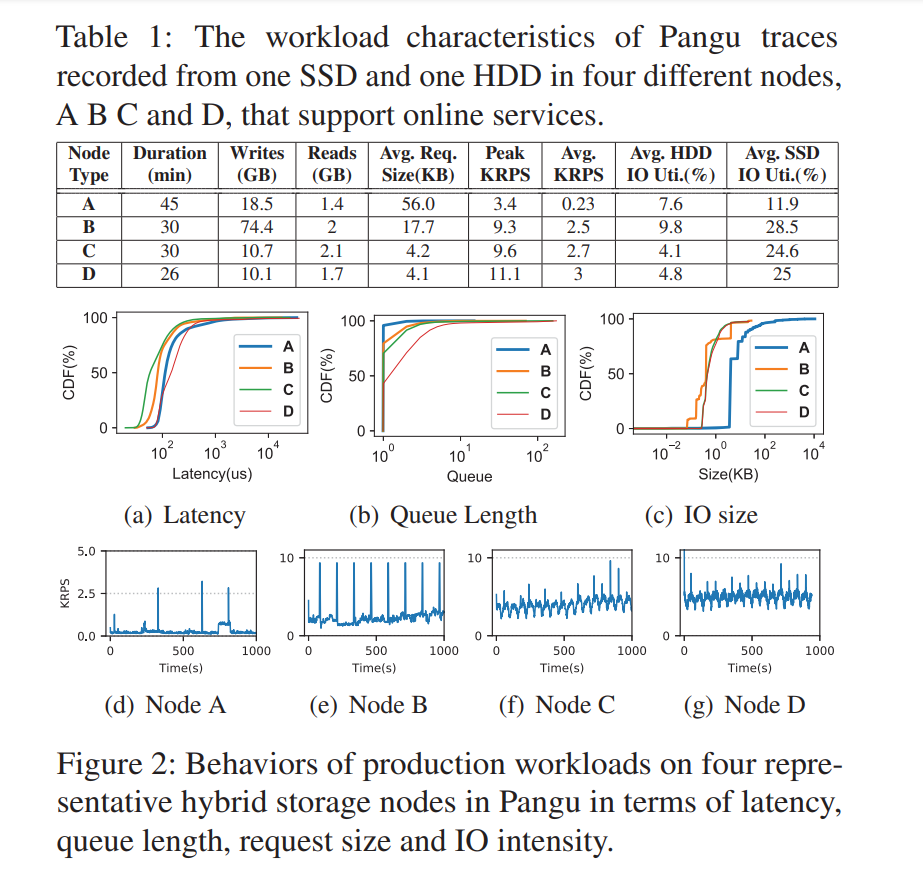
问题:在阿里的生产环境中发现(Pangu storage nodes A (Cloud Computing), B (Cloud Storage), C and D (Structured Storage)),这种混合存储的场景下有一个很严重的问题,就是对于 HDD 和 SSD 的使用严重不均衡,即对 SSD 过度使用,而 HDD 的利用率较低,如果负载是一些写密集型的负载,那么 SSD 磨损的情况更严重,而且因为 SSD 本身的机制的原因,写密集将导致频繁的 GC 从而增大 SSD 响应的尾延迟。
- 写入的数据量极大,每个 SSD 每天写入的数据有接近 3TB,接近于 DWPD (Drive Writes Per Day),严重影响 SSD 的可靠性(相当于每天满负荷运行) https://www.kingston.com/cn/ssd/dwpd
- 有很多突发 IO,SSD 需要处理这种突发的写密集型负载
- 写入到 SSD 和 HDD 的数据量差别较大,利用率有 10 个百分点的差距,而且 HDD 大多是转储 SSD 的数据,基本不直接服务用户请求
- 存在长尾延迟,因为队列阻塞。主要原因有两类:单个 IO 操作较大 1MB;频繁的垃圾回收
- 小 IO 占据了所有 IO 的很大一部分
-
以往的方案:以往解决上述问题的方案主要有两类,一类则简单粗暴直接增加 SSD,但成本开销巨大;另一类则是利用相对空闲的 HDD 来吸收部分写,也就是所谓的 SSD 写重定向 SSD-Write-Redirect (SWR) SoCC 2019,该方案可以一定程度上解决 SSD 队列的阻塞问题,HDD 上的延迟比 SSD 高 3-12 倍,对于大多数需要微妙级延迟的小型写操作来说,这即使不是不可接受的,也显然是不可取的。所以方案目标还是想降低 HDD 的延迟到 SSD 级别。
-
发现:除了上述问题以外,作者还有对于 HDD 新的发现,一系列连续的、顺序的对 HDD 的写操作呈现出周期性的、阶梯状的写延迟模式(低、中、高),原因主要是因为 HDD 控制器将写操作给缓冲了。这个发现也就意味着 HDD 本身是可以提供微妙级的 IO 写延迟的(如果进行了适当的写操作调度),这时候和 SSD 的写性能相近。这些观察结果促使作者有效地利用 HDD 的这种性能潜力来吸收尽可能多的写操作,从而避免 SSD 的过度使用而不会降低性能。
- 如图所示,无论是多大的 IO 操作,HDD 都表现出了低中高三种延迟模式,且具有很强的周期性,前两种可以视作微秒级的响应,因为写操作一旦被写到内置的控制器 buffer 中就已经认为该写操作完成了。
- 但是当写缓冲满了之后,host 写操作不得不被阻塞直到缓冲的数据被 flush 到磁盘,造成较慢的写操作,这一发现启发我们充分利用 HDD 的缓冲写提供的性能潜力,在 SSD 上提高性能的同时减少写损失。
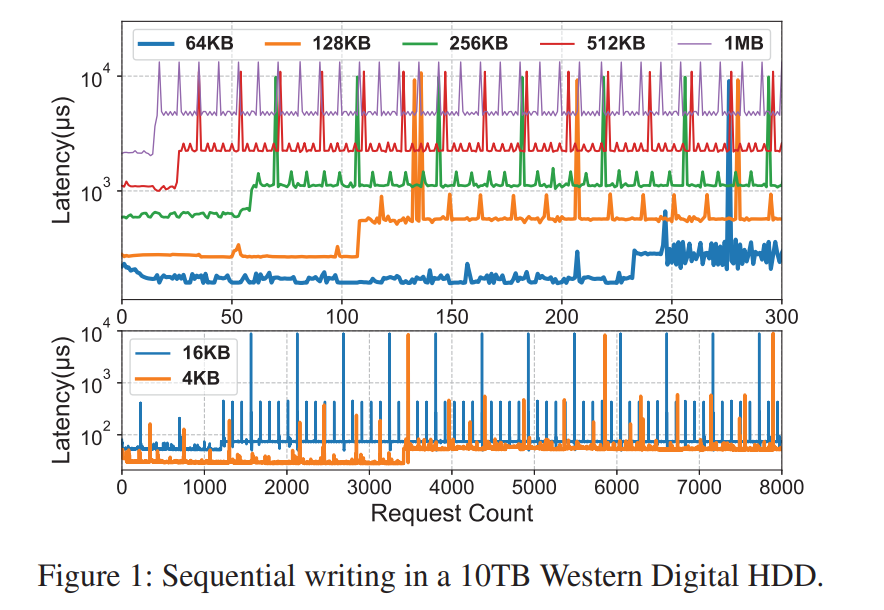
- 测试了不同品牌不同容量的 HDD,发现都有相同的规律,至于为什么有这样的规律,主要是因为 HDD 中有内建的 DRAM,但是 DRAM 中只有很少的一部分容量会被用于缓冲写 IO,剩下的大部分容量主要用于 read-ahead cache 预读缓存、ECC buffer、sector remapping buffer、prefetching buffer,然而,在 HDD 中使用此内置 DRAM 的具体策略(随HDD模型的不同而不同)通常仅为 HDD 制造商专有。幸运的是,写缓冲区的实际大小可以通过分析从外部测量。
- 成功缓冲写操作后,HDD会立即通知主机请求完成。当缓冲的数据到达阈值之后,HDD 将强制执行刷回,这期间将阻塞后续的写入直到 buffer 被释放。值得注意的是,在空闲一段时间后,由于将数据刷新到磁盘,HDD 缓冲区可能隐式变为空。但是,要显式清空缓冲区,我们可以主动调用
sync()来强制刷新。

-
贡献:本文基于上述问题和发现,对 HDD 的性能表现进行了建模,提出了一个预测模型来准确地决定下一个写延迟状态(因为 HDD 内置的控制器 Buffer 对于 HOST 而言是完全不可见的,主机只能根据当前的延迟状况判断状态,利用缓冲写周期和当前写状态信息,可以实现对下一次写状态的预测)。基于这个模型,提出了一种写方法, Buffer-Controlled Write approach, BCW 来主动和有效地控制缓冲写,所以在 HDD 的低延迟、中延迟阶段调度数据的写操作,而在高延迟阶段使用填充数据。基于 BCW,设计了一个混合的 IO 调度器(MIOS)来根据写模式、运行时队列长度和磁盘状态自适应地将传入数据引导到 SSD 和 HDD。在真实生产环境下的负载和 Benchmarks 都表明 MIOS 移除了写到 SSD 数据的 93%,减少了 65% 平均延迟和 85% 尾延迟。
Design
The HDD Buffered-Write Model
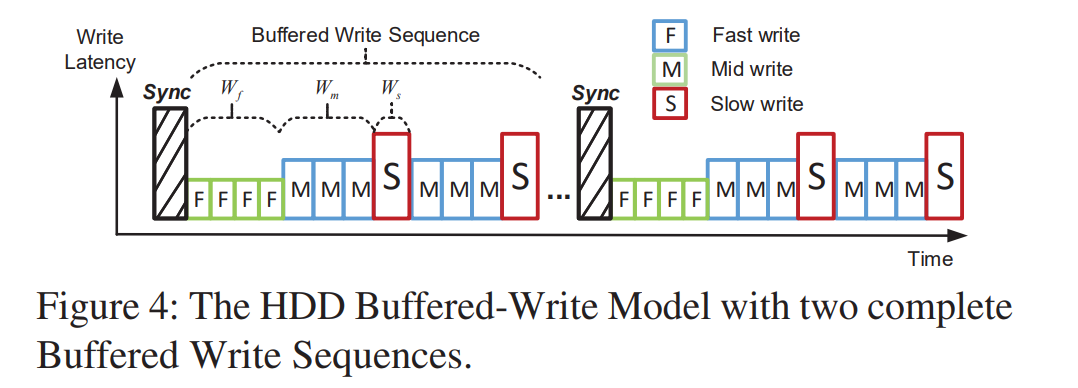
- 建模如下,每个时间序列都以 Sync 操作开始,F 表示可以完全缓冲写入到 HDD Buffer 的阶段,M 则是该 Buffer 越来越接近满的阶段,S 则是 Buffer 已满后续的写入都会被阻塞的阶段。
- Fast stage lasts for data written
- Mid stage lasts for data written
Write-state Predictor
- F/A : The current write state is F and the buffer is available. Next write state is most likely to be F.
- F/U : Although the current write state is F, the buffer is unavailable. Next write state is likely to change to S.
- M/A : The current write state is M and the buffer is available. Next write state is most likely to remain M.
- M/U : Although the current write state is M, the buffer is unavailable. Next write state should be S.
- S : The current write state is S. Next write state will be M with a high probability.
- The Sync operation will force the next write state and buffer state back to be F/A in all cases
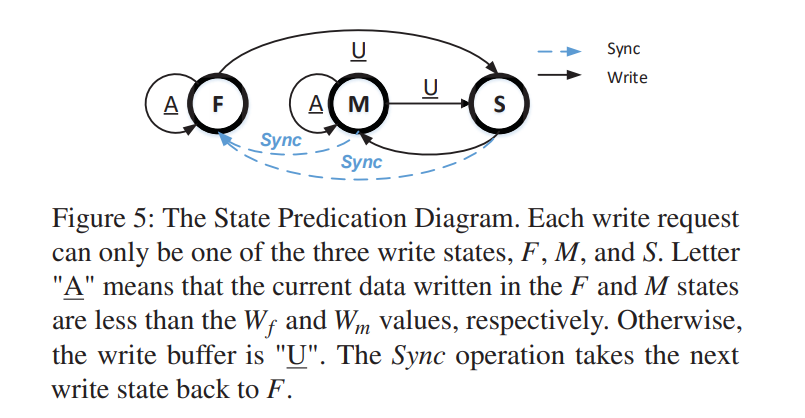
- 通过监视 IO 请求大小和延迟,并计算写缓冲区中的空闲空间确定了当前的写状态,F,M 或 S,也就是说,记录当前写状态(F 或 M)中的 ADW,并与 或 进行比较,以预测下一个写状态。
- 关于预测准确度的问题,实验表明对于 S 状态的预测相对较低,S 状态的低预测精度是由于当实际的 S 状态被错误地预测为另一种状态时,预测策略倾向于 S 状态以减少性能下降。
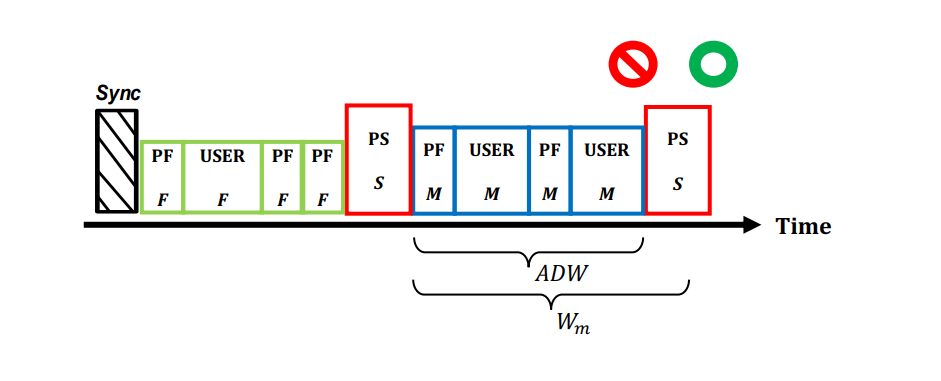
Buffer-Controlled Writes
- 缓冲区控制写(BCW)是一种 HDD 写方法,它确保用户使用 F 或 M 写状态进行写操作,并避免分配慢写操作。BCW 的核心思想是使缓冲写可控。
- 激活 BCW 后,将调用 sync() 操作来强制同步以主动清空缓冲区,如果预测处于 F 或 M 状态,BCW 将向 HDD 发送连续的用户写操作,否则,将非用户数据填充到 HDD,直到达到缓冲写的最大设置循环(或无限)序列。如果队列中有用户请求,BCW 按顺序写入它们。写完成后,BCW将它的写大小添加到 ADW,并相应地更新写状态。
- 在请求稀少的轻量级或空闲工作负载期间,HDD 请求队列将时不时为空,使写流不连续。为了确保按顺序和连续模式缓冲写操作的稳定性和确定性,BCW 将主动地将非用户数据填充到磁盘上写入。填充数据有两种类型:(即使对于每个填充写,BCW 仍然执行写状态预测算法)
- PF:用于用 4KB 的非用户数据填充 F 和 M 状态,小的 PF 可以尽量减少用户请求的等待时间
- PS:用更大的块大小填充 S 状态。例如 64KB 的非用户数据,大的 PS 帮助更快地触发慢写操作
- BCW 持续计算当前状态( F 或 M )的 ADW。当 ADW 接近 或 时,意味着硬盘驱动器缓冲写处于快速或中期阶段的末尾。S 写状态可能在多次写之后发生。此时,BCW 会通知调度程序,并使用 PS 主动触发慢写。为了避免用户写操作的长延迟,在这个阶段,所有传入的用户请求都必须被引导到其他存储设备,比如 SSD。S 状态的写完成之后,下一个写操作将为 M,然后 BCW 重新设置 ADW 并再次接受用户请求。
- 作者发现在 F 状态下 ADW 达到 之前没有必要主动地填充写操作。因为这时候物理磁盘操作尚未触发,缓冲区可以在此期间吸收用户请求,短时间之后达到该阈值,这意味着缓冲区将开始将数据刷新到磁盘,下一个写状态将更改为 S。另一方面,当 ADW 长时间小于 时,磁盘可以自动刷新缓冲过的数据,以便下一个写状态可能是 F。但是,它不会影响性能。
Mixed IO scheduler
- 调度器根据写状态预测器的结果和当前队列状态决定是否将用户写操作引导到 HDD 请求队列。
- 架构如下所示,MIOS 在运行时监控 SSD 和 HDD 的所有请求队列,明智地触发 BCW 进程,并确定是否应该将用户写操作定向到所选的 HDD 或 SSD。MIOS 在配置过程中在每个 HDD 中创建一个设备文件。设备文件以仅追加的方式存储BCW 写入。在 MIOS 调度之前,执行概要分析来确定写状态预测器的关键参数( 或 等)
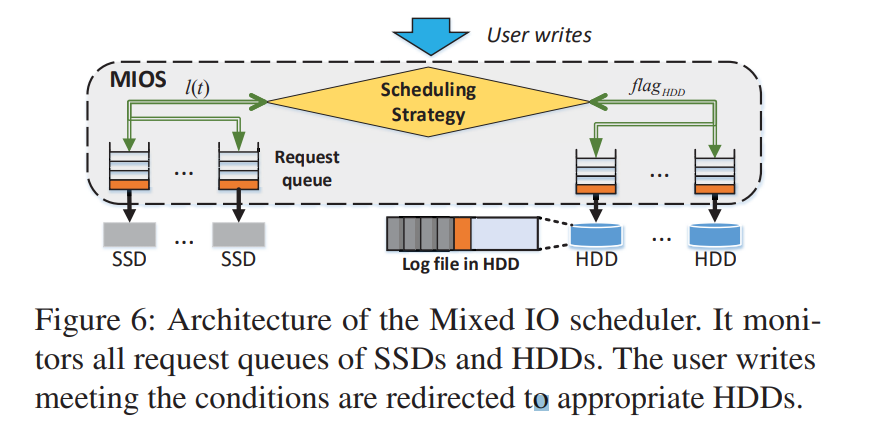
- 调度策略:SSD 在 t 时刻的请求队列长度 l(t) 是关键参数,当大于预定义的阈值 L,调度器通过预测用户的写状态是 F 或 M 来引导用户写到 HDD。阈值 L 是根据 SSD 上的实际性能测量值预先确定的。设定的标准是,我们测量不同 SSD 队列长度下的写延迟,如果队列长度为 l 的请求延迟大于在 M 状态下,我们只需设置阈值 L 为最小的 l 即可。其基本原理是,当 SSD 队列长度大于 L 时,SSD 写操作的延迟将与 BCW 的 F 或 M 写状态下 HDD 上的延迟相同。L 可以在运行时根据工作负载行为和存储设备配置实验性地确定和调整。此策略虽然不能避免,但可以缓解工作负载激增或繁重时的长尾延迟以及 SSD 上的垃圾回收,在这些情况下,SSD 请求队列长度可能是其平均长度的 8-10 倍。因此,重定向的 HDD 写操作不仅减轻了突发请求和重 gc 带来的 SSD 压力,抑制了长尾延迟,而且还降低了平均延迟。
- 另外,当SSD的队列长度小于 L 时,可选触发 BCW。在这种情况下,启用或禁用 BCW 分别表示为 MIOS_E 或MIOS_D。换句话说,当 SSD 的队列长度小于 L 时,MIOS_E 策略允许使用 BCW 重定向。MIOS_D 策略相反地可以在 SSD 队列长度小于 L 时关闭重定向。注意,在 M 写状态下的 HDD 的写延迟仍然比 SSD 的要高得多。重定向后的请求延迟可能会增加。因此,当 l(t) 小于 l 时,我们只重定向用户请求以利用 MIOS_E 中 HDD 的 F 写状态。
- 通常,一个典型的混合存储节点包含多个 SSD 和 HDD。我们把所有的磁盘分成独立的 SSD/HDD 对,每个对包含一个SSD 和一个或多个 HDD。每个 SSD/HDD 对都由一个独立的 MIOS 调度程序实例管理。
- 最后,MIOS 需要对 HDD 的完全控制。这意味着 BCW 中的 HDD 不会受到其他 IO 操作的干扰。当一个 HDD 正在执行 BCW 并且一个读请求到达时,MIOS 立即挂起 BCW 并提供这个读。此时,它将尝试将所有写操作重定向到其他空闲磁盘。对于以读为主的工作负载,可以禁用 BCW 以避免干扰读操作。
个人见解
- SSD/HDD 混合存储的场景其实在工业界的应用极为广泛,但仿佛很少有人关注这种场景下存在的问题,即便是考虑到对于 SSD 的磨损也大多是通过对单一的 SSD 层面上进行优化来减少磨损,而从整个混合存储系统的角度出发,屏蔽器件内部的技术细节,还是在 HDD/SSD 的写调度上发力来减少对 SSD 的消耗,当然关键主要还是对于 HDD 的测试发现了 HDD 本身的性能变化的规律,还是比较巧妙的。
- 本文的设计与实现其实在对于 HDD 的测试之后就已经呼之欲出了,但作者还是设计了很多细节上的东西来提供了更多实现方面的细节,包括一些具体调度策略的伪代码,使得该方案在工业界落地也成为可能,
Consistency and Reliability
-
CRaft: An Erasure-coding-supported Version of Raft for Reducing Storage Cost and Network Cost
- Zizhong Wang, Tongliang Li, Haixia Wang, Airan Shao, Yunren Bai, Shangming Cai, Zihan Xu, and Dongsheng Wang, Tsinghua University
-
Hybrid Data Reliability for Emerging Key-Value Storage Devices
- Rekha Pitchumani and Yang-suk Kee, Memory Solutions Lab, Samsung Semiconductor Inc.
-
Strong and Efficient Consistency with Consistency-Aware Durability
- Aishwarya Ganesan, Ramnatthan Alagappan, Andrea Arpaci-Dusseau, and Remzi Arpaci-Dusseau, University of Wisconsin–Madison
- Awarded Best Paper!
CRaft: An Erasure-coding-supported Version of Raft for Reducing Storage Cost and Network Cost
- 因为很久没单开分布式的文章的坑了,所以干脆拿这篇作为一个 Motivation,然后把 Raft、Paxos 也总结一下。虽然这篇文章跟 EC 有很大关系,但是更多的还是解决一致性的一些问题吧。
- 完成之后此处贴链接。
