- CPU 虚拟化被分为两篇,此篇是第二篇,Policy
- 今天阅读到项目代码时候,涉及到了 Python 协程的概念,由于才疏学浅一时半会儿未能参透协程的实际意义。查阅了很多资料,都是和线程、进程对照着一起阐述,理解起来实在有难度,有了比较浅薄的了解之后决定还是先继续了解进程这一块的知识。
- 威斯康辛州大学操作系统书籍《Operating Systems: Three Easy Pieces》读书笔记系列之 Virtulization(虚拟化)。本篇为虚拟化技术的基础篇系列第二篇(Mechanism and Policy),机制和策略。(结合第一篇给出的虚拟化两层实现)
- CPU 虚拟化被分为两篇,此篇是第二篇,Policy
Chapter Index
Scheduling: Introduction
Pre-Scheduling
Workload Assumptions
- 对操作系统中运行的进程(有时也叫工作/任务)做出如下的假设:
- 每一个工作运行相同的时间
- 所有的工作同时到达
- 一旦开始,每个工作保持运行直到完成
- 所有的工作只是用 CPU(即它们不执行 IO 操作)
- 每个工作的运行时间是已知的
Scheduling Metrics
- turnaround time 周转时间:$$T_{turnaround}=T_{completion}-T_{arrival}$$
- 因为我们假设了同时到达,Tarrival=0,所以 Tturnaround=Tcompletion
First In, First Out (FIFO)
- 先进先出,又称 First Come, First Served (FCFS)
- 优点:简单,易于实现;假设情况下,效果很好。
- 考虑两种情况:
- 假设 A B C 都需要运行 10s,但由于必须有一个先执行,周转时间即为 (10+20+30)/3 = 20s;
- A B C 执行时间不相等,A 100s,B 和 C 10s,周转时间变为(100 + 110 + 120)/ 3 = 110s
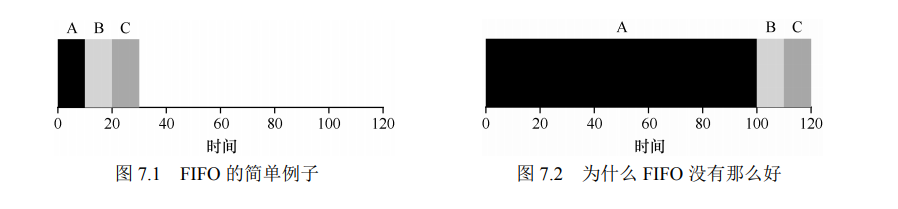
- 上述第二种情况对应的问题通常被称为 convoy effect,即一些耗时的任务排队在前造成了后面的任务等待时间较长。
Shortest Job First (SJF)
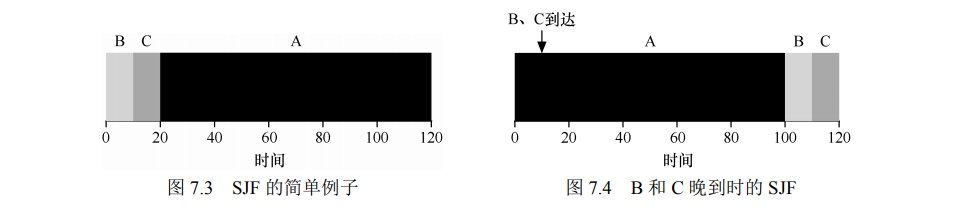
- 最短任务优先:耗时更短的先执行。
- 回到前面的例子,SJF 可以使得周转时间变为 (10+20+120)/3=50。
- 但此时如果考虑任务不是同时到达的,A 先到达,BC 在 10s 时刻到达,这时候的周转时间变为 (100+110-10+120-10)/3=103.33,即还是出现了上文提到的 convoy effect
Shortest Time-to-Completion First (STCF)
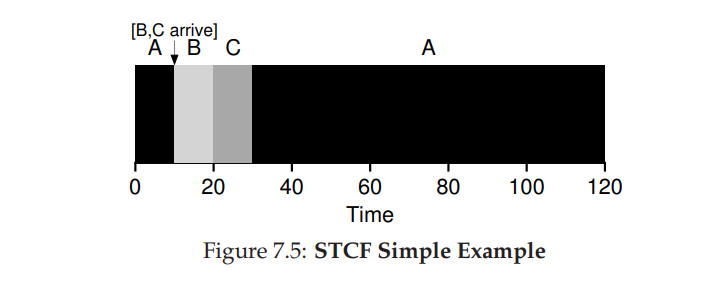
- 为了实现该策略,需要放宽任务必须一直执行直到完成的限制条件。
- SJF 策略本身是一种非抢占式的调度,如果我们向 SJF 中引入抢占的策略,也就是 STCF 或者叫 Preemptive Shortest Job First ,PSJF。每当新任务进入系统时,会确定剩余任务和新任务谁的时间消耗最少,然后执行调度。
- 在 SJF 的第二个例子中,周转时间将变为 (10+20+90+10+20)/3=50s,周转时间大幅降低
A New Metric: Response Time
- 如果我们知道任务长度,而且任务只使用 CPU,而我们唯一的衡量是周转时间,STCF 将是一个很好的策略。对于早期的批处理系统,这样的策略比较有效,但是分时系统的引入,产生了一个新的度量 响应时间(response time)
- 响应时间定义为从任务到达系统到首次运行的时间 $$T_{response}=T_{firstrun}-T_{arrival}$$
- 回到最初的例子,假设 A 最先到达,B 和 C 第10s到达,那么对应的响应时间为0,0,10。平均响应时间3.33
- STCF 和相关方法在响应时间上并不是很好。例如,如果 3 个工作同时到达,第三个工作必须等待前两个工作全部运行后才能运行。这种方法虽然有很好的周转时间,但对于响应时间和交互性是相当糟糕。
- 针对一些对响应时间特别敏感的任务就需要设计一种新的调度策略。
Round Robin
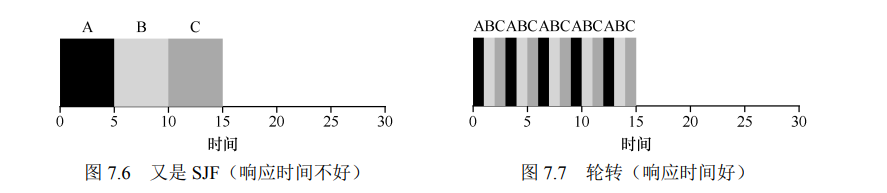
- Round Robin 轮转调度,RR 在一个时间片(time slice,有时称为调度量子,scheduling quantum)内运行一个工作,然后切换到运行队列中的下一个任务,而不是运行一个任务直到结束。它反复执行,直到所有任务完成。因此,RR 有时被称为时间切片(time-slicing)。时间片长度必须是时钟中断周期的倍数。
- 假设 ABC 同时到达,都希望运行 5s,SJF 调度程序必须运行完当前任务才可运行下一个任务,而 RR 可以快速地循环工作。平均响应时间分别为 SJF - 5,RR - 1。
- 时间片长度对于 RR 是至关重要的。越短,RR 在响应时间上表现越好。,时间片太短是有问题的:突然上下文切换的成本将影响整体性能。需要权衡时间片的长度,使其足够长,以便摊销(amortize)上下文切换成本,而又不会使系统不及时响应。
- 上下文切换的成本不仅仅来自保存和恢复少量寄存器的操作系统操作。程序运行时,它们在 CPU 高要缓存、TLB、分支预测器和其他片上硬件中建立了大量的状态。切换到另一个工作会导致此状态被刷新,且与当前运行的作业相关的新状态被引入,这可能导致显著的性能成本。
- 而对于周转时间,平均值变成了 14,这时候 RR 表现就很差。RR 所做的正是延伸每个工作,只运行每个工作一小段时间,就转向下一个工作。因为周转时间只关心作业何时完成,RR 几乎是最差的,在很多情况下甚至比简单的 FIFO 更差。
- 任何公平(fair)的政策(如 RR),即在小规模的时间内将 CPU 均匀分配到活动进程之间,在周转时间这类指标上表现不佳。事实上,这是固有的权衡:如果你愿意不公平,你可以运行较短的工作直到完成,但是要以响应时间为代价。如果你重视公平性,则响应时间会较短,但会以周转时间为代价。
- 第一种类型(SJF、STCF)优化周转时间,但对响应时间不利。第二种类型(RR)优化响应时间,但对周转时间不利。
Incorporating I/O
- 放宽假设 4:当然所有程序都执行 I/O。
- 调度程序显然要在工作发起 I/O 请求时做出决定,因为当前正在运行的作业在 I/O 期间不会使用 CPU,它被阻塞等待 I/O 完成。如果将 I/O 发送到硬盘驱动器,则进程可能会被阻塞几毫秒或更长时间,具体取决于驱动器当前的 I/O 负载。因此,这时调度程序应该在 CPU 上安排另一项工作。
- 调度程序还必须在 I/O 完成时做出决定。发生这种情况时,会产生中断,操作系统运行并将发出 I/O 的进程从阻塞状态移回就绪状态。当然,它甚至可以决定在那个时候运行该项工作。
- 假设任务 A 和 B,都需要 50ms CPU,但是 A 运行 10ms 后发起 I/O,假设 I/O 需要 10ms,而 B 不执行 I/O。先运行 A 再运行 B。STCF 将 A 分解成 5 个 10ms CPU 和 5 个 10ms I/Os,STCF 选择执行时间短的 A,执行完后执行 B,然后出现了 A 的新子任务抢占 B,从而重叠运行。一个进程在等待另一个进程的 I/O 完成时使用 CPU,系统因此得到更好的利用。
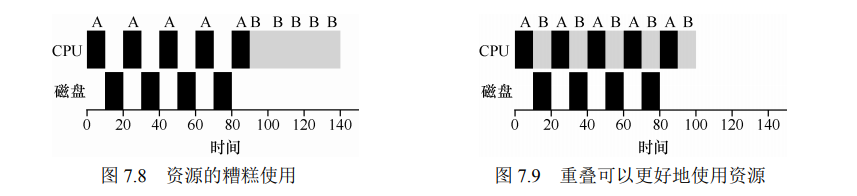
No More Oracle
- 放宽假设 4:不知道每个任务的执行时间。
- 实际上,在通用操作系统中(比如我们关心的那些),操作系统通常对每个作业的长度知之甚少。因此,在没有这种先验知识的情况下,我们如何构建行为类似于SJF/STCF的方法呢?此外,如何将我们在RR调度器中看到的一些思想结合起来,使响应时间也相当好呢? Multi-level Feedback Queue
Scheduling: The Multi-Level Feedback Queue
- 1962 年 Corbato 提出的多级反馈队列调度方法,应用到了兼容时分共享系统(CTSS),因此还获得了图灵奖。(mo大佬)多级反馈队列调度方法在这里提出,显然目标就是对上文提到的两个性能指标进行优化:周转时间和响应时间。SJF(或STCF)对周转时间比较友好,但需要知道任务所需时间,RR 对响应时间友好,但 RR 的粒度也很关键,同样需要任务所需时间来进行决策。所以引出了 CRUX:没有任务长度的先验知识,如何设计一个能同时减少响应时间和周转时间的调度程序?
- 开始之前,简单构思一下解决办法,大概率就是经验主义。即通过参考已经发生了的任务的一些数据来对后面的任务进行预测,在生活中最常见的例子就是中医,而在计算机系统中这个其实也应用的很广泛,譬如分支预测以及一些缓存算法(经常访问的多半之后还是会经常访问)
MLFQ: Basic Rules
- MLFQ 有很多实现,但核心思想大体相同。MLFQ 有很多独立的队列,每个队列又有相应的优先级(优先级队列),一个任务只能在一个队列中,更高优先级的队列中的任务首先被运行。而每个队列可能有多个任务,优先级相同,那么该队列里的任务则采用轮转的方式进行调度。简而言之:优先级队列 + 轮转
- Rule 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
- Rule 2:如果 A 的优先级 = B 的优先级,轮转运行 A 和 B
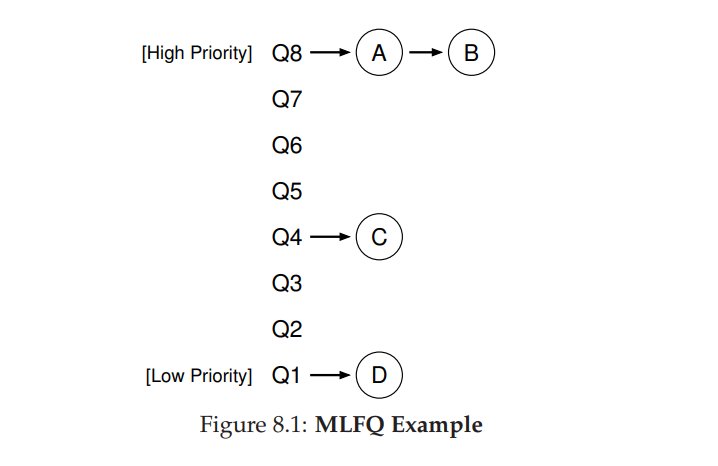
- 基本运行规则如上所述,但 MLFQ 的关键在于任务的优先级的设置,因为优先级决定了任务的分布。不会为每个任务设置固定的优先级,而是根据观察到的行为动态调整优先级。eg. 一个任务不断放弃 CPU 等待键盘 IO 输入,MLFQ 会给他高优先级,如果某个程序占用 CPU 时间特别长,则降低优先级。
Attempt #1: How To Change Priority
- 负载中既有运行时间很短、频繁放弃 CPU 的交互型工作,也有需要很多 CPU 时间、响应时间却不重要的长时间计算密集型工作。
- Rule 3:任务进入系统时放置在最高优先级队列
- Rule 4:
- a. 任务用完整个时间片后,降低其优先级,进入下一个队列
- b. 如果任务在时间片内主动放弃 CPU,优先级不变
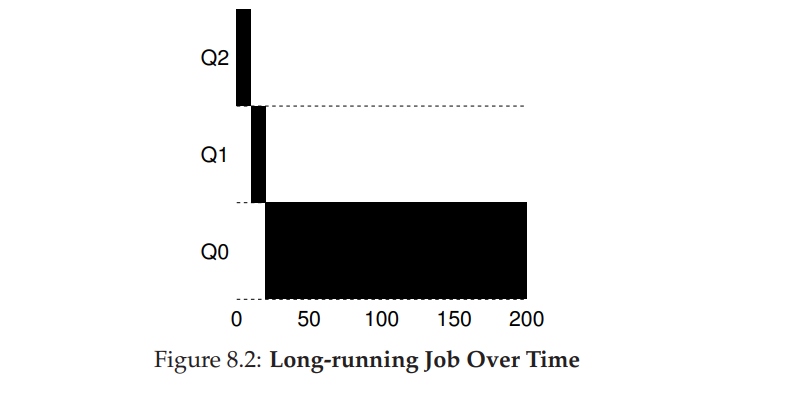
Example 1: A Single Long-Running Job
- 长时间任务不断被降级,直到最低优先级
Example 2: Along Came A Short Job
- 在实例 1 的基础上,T = 100 时来了一个短任务20ms。经过两个时间片,在被移入最低优先级队列之前,B 执行完毕。然后 A 继续运行(在低优先级)。
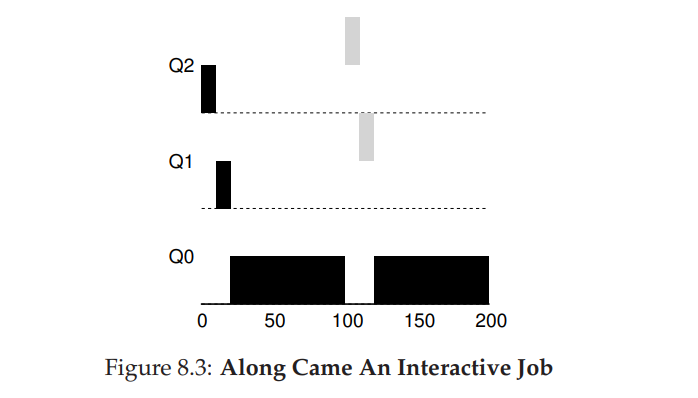
- 该算法的主要目标:假设一开始进入的任务是短任务,给予最高优先级,确实是短任务则很快执行完毕,否则被移动到更低优先就的队列中,也就被看成长任务了,通过该种方式使得 MLFQ 近似于 SJF
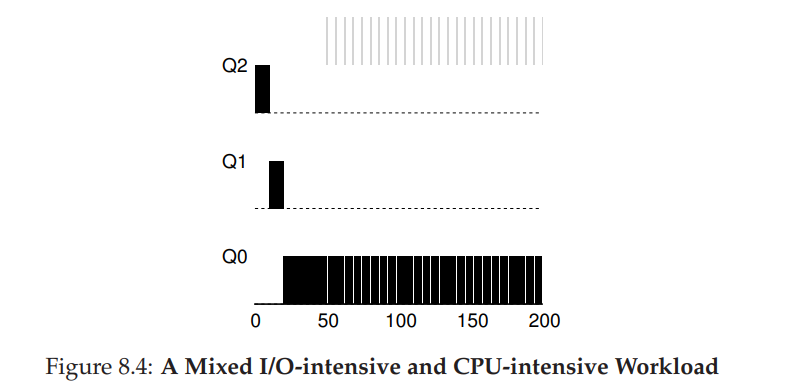
Example 3: What About I/O?
- 灰色所示则为需要大量进行交互的操作,与长时间任务黑色表示竞争 CPU,MLFQ 保持需要大量交互的操作为最高优先级,因为总是主动让出 CPU,对应地则实现了对响应时间敏感的进程的优化。
Problems With Our Current MLFQ
- starvation 大量的交互型任务会造成长任务无法得到 CPU,也就是饿死。需要让 CPU 密集型进程也能一定程度上的运行
- 用户设计操纵进程,在每一个时间片结束之前执行 I/O 来主动释放 CPU,保证自己的高优先级,占用更多的 CPU 时间。
- 无法处理程序行为变化的情况。譬如计算密集型变成交互型,目前没有对优先级进行提升。
Attempt #2: The Priority Boost
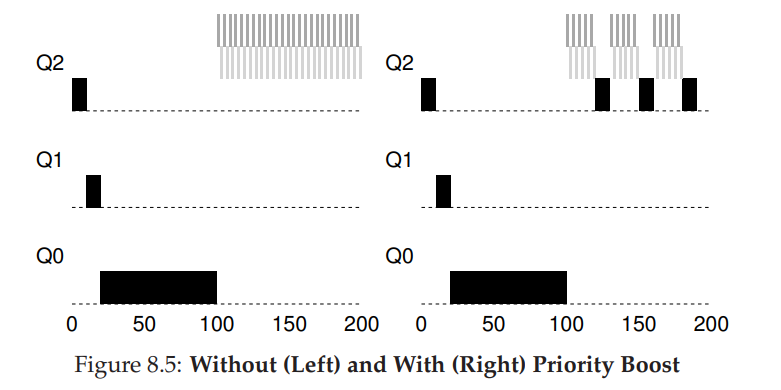
- 为了避免饿死现象,可以考虑周期性地提升所有任务的优先级。
- Rule 5:经过一段时间 S,就将系统中所有任务重新加入最高优先级队列。
- 该规则解决了饿死问题,使得提升优先级后的进程能够以轮转的方式共享 CPU;其次如果任务行为发生了变化,变成了IO密集型,优先级提升后也能得到正确的处理。
- 如下例子,长任务与两个交互型短任务竞争 CPU。左图无优先级提升,长任务在两个短任务进入之后饿死,右图每 50ms 进行提升,保证长任务能有一定的进展。但也就引入了新的问题,S 周期的设定。过长会导致饿死,过短导致交互型任务不能得到合适的 CPU 时间比例。也被称之为 voo-doo constants
Attempt #3: Better Accounting
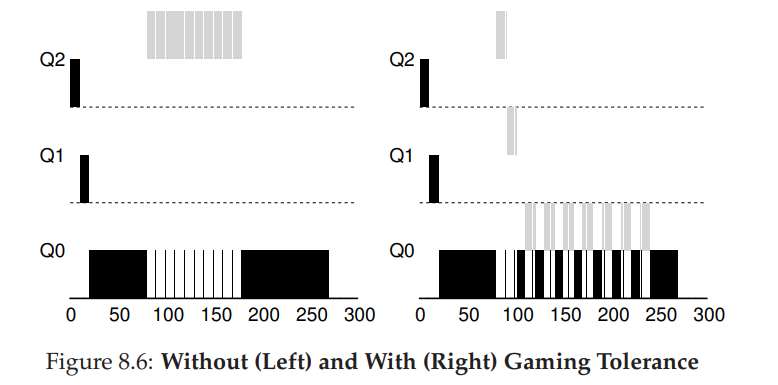
- 还有一个问题没解决,防止用户程序的故意行为欺骗。造成有机可乘的原因主要是 Rule 4,导致任务可以通过主动放弃 CPU 来保证自己的高优先级。
- 解决方案是为 MLFQ 的每层队列提供更完善的 CPU 计时方式(accounting)。即调度程序记录某一个进程在某一个队列中消耗的总时间,而不是每次调度之后重新计时,进程总时间配额用完之后进行降级。这样就能阻止用户进程肆无忌惮地花费时间片。改写规则 4
- Rule 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次 CPU),就降低其优先级(移入低一级队列)
- 如下例子对比了规则 4 修改前后的两种情况。没有规则 4 的保护时,进程可以在每个时间片结束前发起一次 I/O 操作,从而垄断 CPU 时间。有了这样的保护后,不论进程的 I/O 行为如何,都会慢慢地降低优先级,因而无法获得超过公平的 CPU 时间比例。
Tuning MLFQ And Other Issues
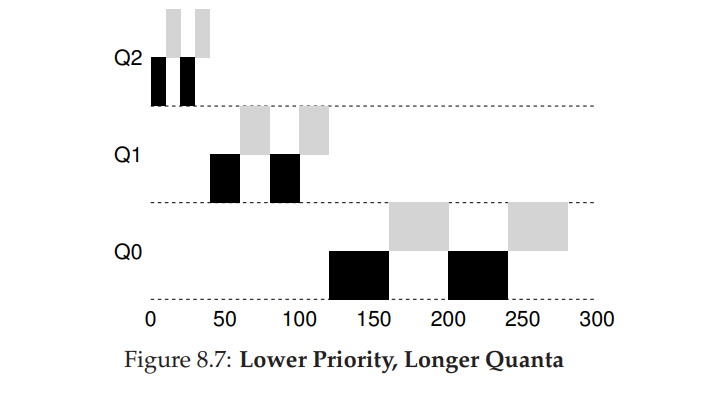
- MLFQ 调度算法涉及到了一些参数,这些参数的设置会影响在对应负载下的性能表现。主要有队列数量,队列时间片长度,提升优先级周期等。
- 大多数的 MLFQ 变体都支持不同队列可变的时间片长度。高优先级队列通常只有较短的时间片(比如 10ms 或者更少),因而这一层的交互工作可以更快地切换。相反,低优先级队列中更多的是 CPU 密集型工作,配置更长的时间片会取得更好的效果。如图所示
- Solaris 的 MLFQ 实现(时分调度类 TS)很容易配置。它提供了一组表来决定进程在其生命周期中如何调整优先级,每层的时间片多大,以及多久提升一个工作的优先级。管理员可以通过这些表,让调度程序的行为方式不同。该表默认有 60 层队列,时间片长度从 20ms(最高优先级),到几百 ms(最低优先级),每一秒左右提升一次进程的优先级。
- FreeBSD 调度程序(4.3 版本),会基于当前进程使用了多少 CPU,通过公式计算某个工作的当前优先级。另外,使用量会随时间衰减,这提供了期望的优先级提升,但与这里描述方式不同。
- 有些调度程序将最高优先级队列留给操作系统使用,因此通常的用户工作是无法得到系统的最高优先级的。有些系统
允许用户给出优先级设置的建议(advice),比如通过命令行工具 nice,可以增加或降低工作的优先级(稍微),从而增加或降低它在某个时刻运行的机会。
Summary
- MLFQ 有趣的原因是:它不需要对工作的运行方式有先验知识,而是通过观察工作的运行来给出对应的优先级。通过这种方式,MLFQ 可以同时满足各种工作的需求:对于短时间运行的交互型工作,获得类似于 SJF/STCF 的很好的全局性能,同时对长时间运行的CPU 密集型负载也可以公平地、不断地稳步向前。
Scheduling: Proportional Share
- 又称 fair-share,该调度程序的最终目标:确保每个工作获得一定比例的 CPU 时间,而不是优化周转时间和响应时间。有一个实际的例子 lottery scheduling:每隔一段时间,都会举行一次彩票抽奖,以确定接下来应该运行哪个进程。越是应该频繁运行的进程,越是应该拥有更多地赢得彩票的机会。
- CRUX:如何设计调度程序来按比例分配 CPU?其关键的机制是什么?效率如何?
Basic Concept: Tickets Represent Your Share
- 一个进程拥有的彩票数占总彩票数的百分比,就是它占有资源的份额。
- 假设有两个进程 A 和 B,A 拥有 75 张彩票,B 拥有 25 张。因此我们希望 A 占用 75%的 CPU 时间,而 B 占用 25%。通过不断定时地(比如,每个时间片)抽取彩票,彩票调度从概率上(但不是确定的)获得这种份额比例。调度程序知道总共的彩票数(在我们的例子中,有 100 张)。调度程序抽取中奖彩票,这是从 0 和 99①之间的一个数,拥有这个数对应的彩票的进程中奖。假设进程 A 拥有 0 到 74 共 75 张彩票,进程 B 拥有 75 到 99 的 25 张,中奖的彩票就决定了运行 A 或 B。调度程序然后加载中奖进程的状态,并运行它。
- 彩票调度中利用了随机性,这导致了从概率上满足期望的比例,但并不能确保。随着任务运行的时间越长,得到的 CPU 时间就越来越接近期望。
Ticket Mechanisms
- ticket currency:允许拥有一组彩票的用户以他们喜欢的某种货币,将彩票分给自己的不同工作。之后操作系统再自动将这种货币兑换为正确的全局彩票。简而言之就是按比例分配
- ticket transfer:通过转让,一个进程可以临时将自己的彩票交给另一个进程。这种机制在客户端/服务端交互的场景中尤其有用,在这种场景中,客户端进程向服务端发送消息,请求其按自己的需求执行工作,为了加速服务端的执行,
客户端可以将自己的彩票转让给服务端,从而尽可能加速服务端执行自己请求的速度。服务端执行结束后会将这部分彩票归还给客户端。
- ticket inflation:利用通胀,一个进程可以临时提升或降低自己拥有的彩票数量。当然在竞争环境中,进程之间互相不信任,这种机制就没什么意义。一个贪婪的进程可能给自己非常多的彩票,从而接管机器。但是,通胀可以用于进
程之间相互信任的环境。在这种情况下,如果一个进程知道它需要更多 CPU 时间,就可以增加自己的彩票,从而将自己的需求告知操作系统,这一切不需要与任何其他进程通信。
Implementation
- 只需要一个不错的随机数生成器来选择中奖彩票和一个记录系统中所有进程的数据结构(一个列表),以及所有彩票的总数。
- 假设如图所示 ABC 三个进程,每个进程有一定数目的彩票。

- 首先要从彩票总数 400 中选择一个随机数(中奖号码),假设选了 300,然后遍历链表,来寻找对应的中奖者。
1 // counter: used to track if we’ve found the winner yet
2 int counter = 0;
3
4 // winner: use some call to a random number generator to
5 // get a value, between 0 and the total # of tickets
6 int winner = getrandom(0, totaltickets);
7
8 // current: use this to walk through the list of jobs
9 node_t *current = head;
10 while (current) {
11 counter = counter + current->tickets;
12 if (counter > winner)
13 break; // found the winner
14 current = current->next;
15 }
16 // ’current’ is the winner: schedule it...
- 要让这个过程更有效率,建议将列表项按照彩票数递减排序。这个顺序并不会影响算法的正确性,但能保证用最小的迭代次数找到需要的节点,尤其当大多数彩票被少数进程掌握时。
An Example
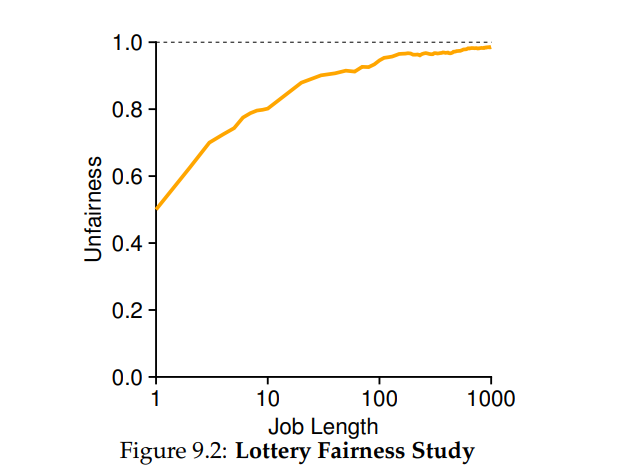
- 两个互相竞争的任务,每个任务都有 100 张彩票,以及相同的运行时间 R。
- 这种情况下,我们希望两个工作在大约同时完成,但由于彩票调度算法的随机性,有时一个工作会先于另一个完成。我们定义不公平指标 U 来量化这种区别,两个任务完成时刻相除为 U。比如 A 任务 10s 完成,B 任务 20s 时完成,那么 U=10/20=0.5。同时完成则 U 接近于 1,也就是我们的目标。
- 用模拟器测试了运行时间变化的情况下,30 次试验的平均 U 值。不难发现任务短时,不公平现象比较严峻,只有时间较长的任务才能达到近似理想的效果。
How To Assign Tickets?
- 系统的运行严重依赖于彩票的分配。假设用户自己知道如何分配,因此可以给每个用户一定量的彩票,由用户按照需要自主分配给自己的工作。然而这种方案似乎什么也没有解决——还是没有给出具体的分配策略。因此对于给定的一组工作,彩票分配的问题依然没有最佳答案。
Why Not Deterministic?
- 虽然随机方式可以使得调度程序的实现简单(且大致正确),但偶尔并不能产生正确的比例,尤其在工作运行时间很短的情况下。Waldspurger 提出了步长调度(stride scheduling),一个确定性的公平分配算法
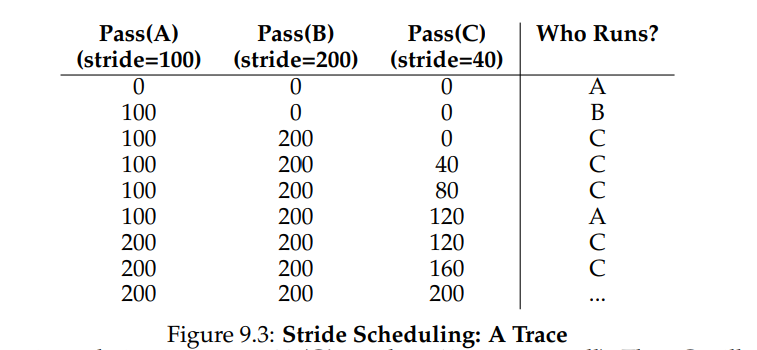
- 系统中的每个工作都有自己的步长,这个值与票数值成反比。在上面的例子中,A、B、C 这 3 个工作的票数分别是 100、50 和 250,我们通过用一个大数分别除以他们的票数来获得每个进程的步长。比如用 10000 除以这些票数值,得到了 3 个进程的步长分别为 100、200 和 40。我们称这个值为每个进程的步长(stride)。每次进程运行后,我们会让它的计数器 [称为行程(pass)值] 增加它的步长,记录它的总体进展。之后,调度程序使用进程的步长及行程值来确定调度哪个进程。基本思路很简单:当需要进行调度时,选择目前拥有最小行程值的进程,并且在运行之后将该进该进程的行程值增加一个步长。
current = remove_min(queue); // pick client with minimum pass
schedule(current); // use resource for quantum
current->pass += current->stride; // compute next pass using stride
insert(queue, current); // put back into the queue
- 如下表所示展示了例子中的进程调度情况。C 运行了 5 次、A 运行了 2 次,B 一次,正好是票数的比例——200、100 和 50。彩票调度算法只能一段时间后,在概率上实现比例,而步长调度算法可以在每个调度周期后做到完全正确。
- 彩票调度算法的优势在于不需要全局状态。假如一个新的进程在上面的步长调度执行过程中加入系统,应该怎么设置它的行程值呢?设置成 0 吗?这样的话,它就独占 CPU 了。而彩票调度算法不需要对每个进程记录全局状态,只需要用新进程的票数更新全局的总票数就可以了。因此彩票调度算法能够更合理地处理新加入的进程。
The Linux Completely Fair Scheduler (CFS)
- Linux 使用了另外一种方法实现了 fair-share 的目标。Completely Fair Scheduler (or CFS),以高效和可扩展的方式实现了 fair-share。
- CFS 的目标是花费很少的时间来制定调度决策,这是通过其固有的设计和它对非常适合该任务的数据结构的巧妙使用实现的。因为近年来的研究表明调度效率是非常重要的, Google datacenters, Kanev et al 表明即使在主动优化之后,调度也会使用大约 5% 的数据中心 CPU 时间。因此,尽可能减少这种开销是现代调度器体系结构的一个关键目标。
Basic Operation
- 目标:公平地将 CPU 划分给进程进行竞争。它通过一种称为虚拟运行时(vruntime)的简单的基于计数的技术来实现。
- 当每个进程运行时,它会累积 vruntime。在最基本的情况下,每个进程的 vruntime 以相同的速度增长,与物理(实时)时间成比例。当一个调度决策发生时,CFS 将选择 vruntime 最低的进程下一个运行。此时引入了一个问题:调度器如何知道何时停止当前进程开启另一个进程?如果 CFS 切换的太频繁,公平性就会增加,因为需要确保每个进程都能获得它的 CPU 份额,即使是在极短的时间内,当然也就引入了大量切换导致的性能开销。如果 CFS 切换更少,性能会提高(减少上下文切换),但会以近期的公平性为代价。
- CFS 引入了一些参数来控制:
- sched_latency:在考虑切换之前,一个进程应该运行多长时间?(有效地确定它的时间片,但以动态方式)。通常设置为 48ms,CFS 用这个值除以 CPU 上运行的进程数(n)来确定进程的时间片,从而确保在这段时间内,CFS 是完全公平的。
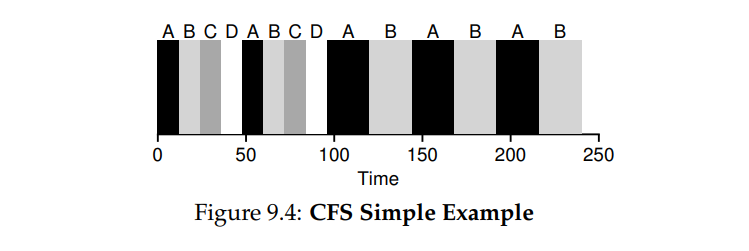
- eg. 4 个进程在运行,那么每个进程的时间片为 12ms,CFS 调度第一个任务并执行直到花光 12ms,这时候检查是否有更小的 vruntime,该例子中有那么执行切换,选择剩下三个中的一个,如下图所示。
- 图中四个任务都首先执行了两个时间片,然后 CD 结束了,AB 还未执行完,这时候时间片变为 24ms,然后 RR 轮转执行。
- 出现了新的问题,如果进程太多,那么时间片就会很小,就会造成频繁的上下文切换,性能就不太好
- min_granularity:为了解决上述问题出现了该参数,通常设置为 6ms,也就是说 CFS 设置的时间片大小不会低于该值,确保不会花费大量时间在调度上。
- eg. 10 个进程,时间片则为 4.8ms,但是因为设置了 min_granularity,那么时间片变成 6ms,尽管 CFS 在目标调度延迟(sched_latency)上不会(完全)公平,但也十分接近,仍然能实现较高的 CPU 效率。
- 请注意,CFS 使用了周期性的计时器中断,这意味着它只能在固定的时间间隔做出决策。这个中断经常发生(例如,每1毫秒),给 CFS 一个机会来唤醒并确定当前的作业是否已经到达它运行的终点。如果一个任务的时间片不是计时器中断间隔的完美倍数,那也没关系;CFS 精确地跟踪 vruntime,这意味着从长期来看,它最终将接近理想的 CPU 共享。
Weighting (Niceness)
- CFS 还支持对进程优先级的控制,使用户或管理员可以为某些进程提供更高的 CPU 份额。通过 UNIX 中的一种 nice level of process 机制来实现的。对于进程,nice 参数可以在 -20 到 +19 之间任意设置,默认值为 0。正 nice 值表示低优先级,负 nice 值表示高优先级; CFS将每个进程的 nice 值映射到一个权重
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
- 这些权重允许我们计算每个过程的有效时间片,但是现在引入了优先级,计算公式如下:$$timeSlice_{k}=\frac{weight_k}{\sum_{i=0}^{n-1}weight_k}* schedLatency$$
- 假设两个任务 A 和 B,A 的优先级 nice 值为 -5,B 为默认优先级 nice 值为 0,那么 weightA 即为 3121,weightB 即为 1024。公式计算时间片,A 的时间片大约为 schedLatency 的四分之三,36ms,B 的时间片大约为四分之一,12ms。
- 除了推广时间片计算,CFS 计算 vruntime 的方式也必须调整。会考虑到进程的实际运行时间 runtimei,与进程的权重成反比。在上述例子中,A 的 vruntime 的累积速度是 B 的三分之一。$$vruntime_i=vruntime_i+\frac{weight_0}{weight_i}*runtime_i$$
- 上面权重表构造的一个聪明之处在于,当 nice 值的差为常数时,该表保持了 CPU 比例比率。比如 A 的 nice 值为 5,B 的 nice 值为 10,因为对应的权重差值较小,CFS 会以与之前完全相同的方式安排它们。
Using Red-Black Trees
- CFS 调度算法重点关注效率,效率又涉及很多方面,而上文中描述的效率是指选择合适的进程来提升整体的效率。而对于如何快速地找到已经确定的下一个需要执行的任务的效率也是至关重要的。列表这样的简单数据结构是无法伸缩的,现代系统有时由1000个进程组成,因此每隔这么多毫秒就搜索一个长列表是很浪费的。
- CFS 采用了红黑树来解决这个问题。相比于二叉树,红黑树是一个平衡树,平衡树在降低树的深度上做了一些额外的工作,从而保证操作的时间复杂度是对数级别的,而不是线性的(二叉树在最坏的情况下可能退化成链表)
- CFS 不会在数据结构中保留所有的进程,仅仅保留部分运行中的进程,如果进程即将处于休眠状态,譬如等待 I/O 完成或者等待网络包到达,这样的线程将从红黑树中移除。
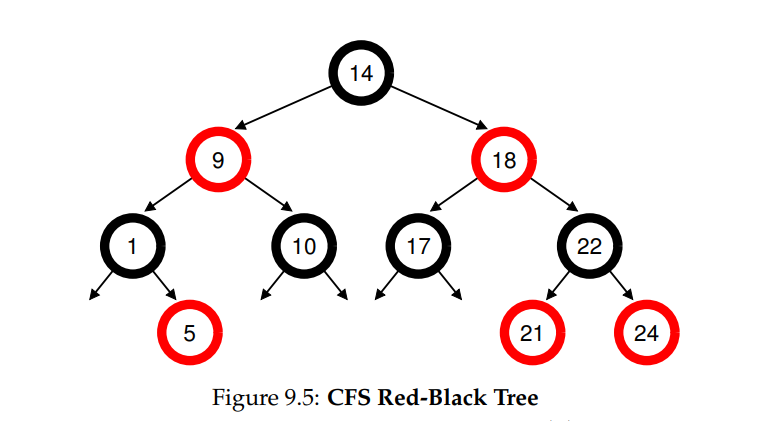
- 假设现在有 10 个任务,对应的 vruntime 分别为 1,5,9,10,14,18,17,21,22,24。如果使用有序列表保存这些任务,那么找到下一个执行的任务就很简单,直接从列表中取出第一个即可。但是当将任务放回列表中的时候,就必须扫描 list 里,因为需要找到正确的位置进行插入,时间复杂度对应地变为 O(n),在列表中任何搜索都是非常低效的,平均花费的时间也是线性的。
- 把对应的值保存在红黑树中可以让操作更为高效,如图所示,进程根据 vruntime 在树中也是有序的,大多数操作在时间复杂度上都为 O(log n)。当 n 特别大的时候,比如数以千计,红黑树就显得更为高效。
Dealing With I/O And Sleeping Processes
- 在选择最小的 vruntime 对应的进程时候存在另外一个问题:即任务已经休眠了很长一段时间。假设有任务 AB,其中一个(A)连续运行,另一个(B)已经休眠很长一段时间(比如,10秒)。当 B 被唤醒,它的 vruntime 会比 A 晚 10 秒(比 A 小 10s),因此(如果我们不小心的话),B 现在会在接下来的 10 秒内垄断 CPU,在它赶上 A 之前,这实际上是在饿死 A。
- CFS 通过在一个任务被唤醒时改变它的 vruntime 来处理这种情况,具体来说,CFS 将该任务的 vruntime 设置为树中找到的最小值(请记住,树只包含正在运行的任务)。通过这种方式,避免了饿死现象的发生,但也不是没有代价: 睡眠时间短的工作可能就经常不能公平地共享 CPU。
Summary
- 彩票调度通过随机值,聪明地做到了按比例分配。步长调度算法能够确定的获得需要的比例。虽然两者都很有趣,但由于一些原因,并没有作为 CPU 调度程序被广泛使用。一个原因是这两种方式都不能很好地适合 I/O,另一个原因是其中最难的票数分配问题并没有确定的解决方式,例如,如何知道浏览器进程应该拥有多少票数?通用调度程序(像前面讨论的 MLFQ 及其他类似的 Linux 调度程序)做得更好,因此得到了广泛的应用。
- 比例份额调度程序只有在这些问题可以相对容易解决的领域更有用(例如容易确定份额比例)。例如在虚拟(virtualized)数据中心中,你可能会希望分配 1/4 的 CPU 周期给 Windows 虚拟机,剩余的给 Linux 系统,比例分配的方式可以更简单高效。
- CFS 是本章中讨论的唯一的“真正的”调度器,它有点像带有动态时间片的加权轮询,但它的构建是为了在负载下扩展和执行良好;据我们所知,它是目前使用最广泛的公平共享调度器。
- 没有调度策略是万能的,都有一些各自的问题。一个问题就是这些方法并不能很好地与 I/O 结合,如上所述,偶尔执行 I/O 的任务可能无法获得公平的 CPU 份额。另一个问题是,它们留下了票或优先级分配的难题,比如你的应用的 nice 值到底设置为多少比较合适?其他通用调度器(如前面讨论的 MLFQ 和其他类似的 Linux 调度器)自动处理这些问题,因此可能更容易部署。
Multiprocessor Scheduling (Advanced)
- 前面章节更多地都是在介绍单个 CPU 上的调度,而现实中常常是多 CPU 协同工作的,那么多 CPU 的调度又是什么样的呢?
Background: Multiprocessor Architecture
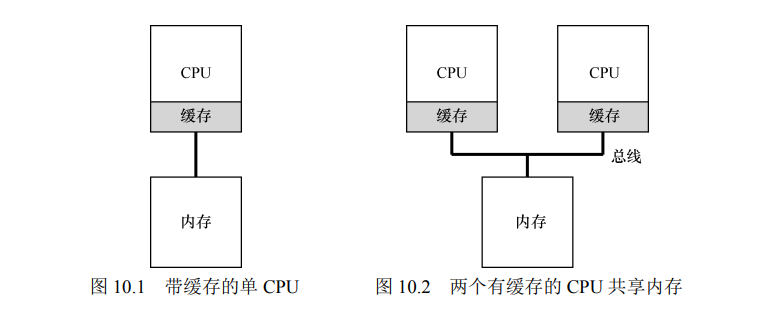
- 多 CPU 与单 CPU 的区别:核心在于对硬件缓存(cache)的使用,以及多处理器之间共享数据的方式。
- 在单 CPU 系统中,存在多级的硬件缓存(hardware cache),一般来说会让处理器更快地执行程序。缓存是很小但很快的存储设备,通常拥有内存中最热的数据的备份。相比之下,内存很大且拥有所有的数据,但访问速度较慢。通过将频繁访问的数据放在缓存中,系统似乎拥有又大又快的内存。
- 多 CPU 的情况下缓存要复杂得多。例如,假设一个运行在 CPU 1 上的程序从内存地址 A 读取数据。由于不在 CPU 1 的缓存中,所以系统直接访问内存,得到值 D。程序然后修改了地址 A 处的值,只是将它的缓存更新为新值 D'。将数据写回内存比较慢,因此系统(通常)会稍后再做。假设这时操作系统中断了该程序的运行,并将其交给 CPU 2,
重新读取地址 A 的数据,由于 CPU 2 的缓存中并没有该数据,所以会直接从内存中读取,得到了旧值 D,而不是正确的值 D'。这就是缓存一致性问题
- 硬件提供了这个问题的基本解决方案:通过监控内存访问,硬件可以保证获得正确的数据,并保证共享内存的唯一性。在基于总线的系统中,一种方式是使用总线窥探(bus snooping)。每个缓存都通过监听链接所有缓存和内存的总线,来发现内存访问。如果 CPU 发现对它放在缓存中的数据的更新,会作废(invalidate)本地副本(从缓存中移除),
或更新(update)它(修改为新值)。
Don’t Forget Synchronization
- 跨 CPU 访问(尤其是写入)共享数据或数据结构时,需要使用互斥原语(比如锁),能保证正确性(其他方法,如使用无锁(lock-free)数据结构,很复杂,偶尔才使用。例如,假设多 CPU 并发访问一个共享队列。如果没有锁,即使有底层一致性协议,并发地从队列增加或删除元素,依然不会得到预期结果。需要用锁来保证数据结构状态更新的原子性。
- 如下所示代码,用于删除共享链表的一个元素。假设两个 CPU 上的不同线程同时进入这个函数。如果线程 1 执行第一行,会将 head 的当前值存入它的 tmp 变量。如果线程 2 接着也执行第一行,它也会将同样的 head 值存入它自己的私有 tmp 变量(tmp 在栈上分配,因此每个线程都有自己的私有存储)。因此,两个线程会尝试删除同一个链表头,而不是每个线程移除一个元素,这导致了各种问题
1 typedef struct __Node_t {
2 int value;
3 struct __Node_t *next;
4 } Node_t;
5
6 int List_Pop() {
7 Node_t *tmp = head; // remember old head ...
8 int value = head->value; // ... and its value
9 head = head->next; // advance head to next pointer
10 free(tmp); // free old head
11 return value; // return value at head
12 }
- 让这类函数正确工作的方法是加锁(locking)。这里只需要一个互斥锁(即pthread_mutex_t m;),然后在函数开始时调用 lock(&m),在结束时调用 unlock(&m),确保代码的执行如预期。我们会看到,这里依然有问题,尤其是性能方面。具体来说,随着 CPU 数量的增加,访问同步共享的数据结构会变得很慢。
One Final Issue: Cache Affinity
- 在设计多处理器调度时遇到的最后一个问题,是所谓的缓存亲和度(cache affinity)。这个概念很简单:一个进程在某个 CPU 上运行时,会在该 CPU 的缓存中维护许多状态。下次该进程在相同 CPU 上运行时,由于缓存中的数据而执行得更快。相反,在不同的 CPU 上执行,会由于需要重新加载数据而很慢(好在硬件保证的缓存一致性可以保证正确执行)。因此多处理器调度应该考虑到这种缓存亲和性,并尽可能将进程保持在同一个 CPU 上。
Single-Queue Scheduling
- 最基本的方式是简单地复用单处理器调度的基本架构,将所有需要调度的工作放入一个单独的队列中,我们称之为单队列多处理器调度(Single Queue Multiprocessor Scheduling,SQMS)。这个方法最大的优点是简单。它不需要太多修改,就可以将原有的策略用于多个 CPU,选择最适合的工作来运行(例如,如果有两个 CPU,它可能选择两个最合适的工作)。
- 然而,SQMS 有几个明显的短板。第一个是缺乏可扩展性(scalability)。为了保证在多CPU 上正常运行,调度程序的开发者需要在代码中通过加锁(locking)来保证原子性,如上所述。在 SQMS 访问单个队列时(如寻找下一个运行的工作),锁确保得到正确的结果。锁可能带来巨大的性能损失,尤其是随着系统中的 CPU 数增加时。随着这种单个锁的争用增加,系统花费了越来越多的时间在锁的开销上,较少的时间用于系统应该完成的工作。
- SQMS 的第二个主要问题是缓存亲和性。比如,假设我们有 5 个工作(A、B、C、D、E)和 4 个处理器。调度队列如下:

- 一段时间后,假设每个工作依次执行一个时间片,然后选择另一个工作,下面是每个CPU 可能的调度序列:
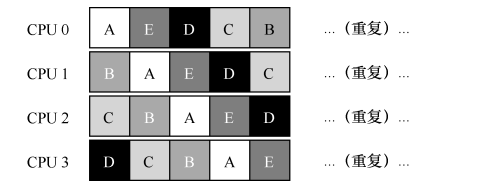
- 由于每个 CPU 都简单地从全局共享的队列中选取下一个工作执行,因此每个工作都不断在不同 CPU 之间转移,这与缓存亲和的目标背道而驰。为了解决这个问题,大多数 SQMS 调度程序都引入了一些亲和度机制,尽可能让进程在同一个 CPU 上运行。保持一些工作的亲和度的同时,可能需要牺牲其他工作的亲和度来实现负载均衡。例如,针对同样的 5 个工作的调度如下:
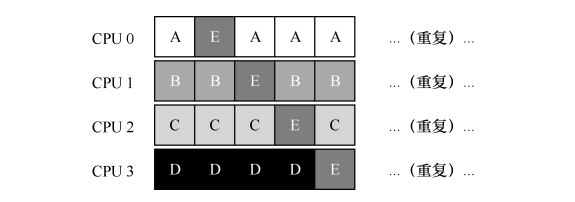
- 这种调度中,A、B、C、D 这 4 个工作都保持在同一个 CPU 上,只有工作 E 不断地来回迁移(migrating),从而尽可能多地获得缓存亲和度。为了公平起见,之后我们可以选择不同的工作来迁移。但实现这种策略可能很复杂。
- SQMS 调度方式有优势也有不足。优势是能够从单 CPU 调度程序很简单地发展而来,根据定义,它只有一个队列。然而,它的扩展性不好(由于同步开销有限),并且不能很好地保证缓存亲和度。
Multi-Queue Scheduling
- 在 MQMS 中,基本调度框架包含多个调度队列,每个队列可以使用不同的调度规则,比如轮转或其他任何可能的算法。当一个任务进入系统后,系统会依照一些启发性规则(如随机或选择较空的队列)将其放入某个调度队列。这样一来,每个 CPU 调度之间相互独立,就避免了单队列的方式中由于数据共享及同步带来的问题。
- 例如,假设系统中有两个 CPU(CPU 0 和 CPU 1)。这时一些工作进入系统:A、B、C和 D。由于每个 CPU 都有自己的调度队列,操作系统需要决定每个工作放入哪个队列。可能像下面这样做:
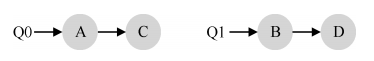
- 根据不同队列的调度策略,每个 CPU 从两个工作中选择,决定谁将运行。例如,利用轮转,调度结果可能如下所示:

- MQMS 比 SQMS 有明显的优势,它天生更具有可扩展性。队列的数量会随着 CPU 的增加而增加,因此锁和缓存争用的开销不是大问题。此外,MQMS 天生具有良好的缓存亲和度。所有工作都保持在固定的 CPU 上,因而可以很好地利用缓存数据。但是,如果稍加注意,你可能会发现有一个新问题(这在多队列的方法中是根本的),即负载不均(load imbalance)。假定和上面设定一样(4 个工作,2 个 CPU),但假设一个工作(如 C)这时执行完毕。现在调度队列如下:

- 如果对系统中每个队列都执行轮转调度策略,会获得如下调度结果:

- 从图中可以看出,A 获得了 B 和 D 两倍的 CPU 时间,这不是期望的结果。更糟的是,假设 A 和 C 都执行完毕,系统中只有 B 和 D。调度队列看起来如下:

- 为了解决负载不均的问题,考虑使用迁移的策略。通过工作的跨 CPU 迁移,可以真正实现负载均衡。
- 在图示这种情况下,期望的迁移很容易理解:操作系统应该将 B 或 D 迁移到 CPU0。这次工作迁移导致负载均衡
- 在图示情况下,单次迁移并不能解决问题。
- 不断地迁移一个或多个工作。一种可能的解决方案是不断切换工作,如下面的时间线所示。可以看到,开始的时候 A 独享 CPU 0,B 和 D 在 CPU 1。一些时间片后,B 迁移到 CPU 0 与 A 竞争,D 则独享 CPU 1 一段时间。这样就实现了负载均衡。

- 如何进行迁移? 一个基本的方法是采用一种技术,名为工作窃取(work stealing)。通过这种方法,工作量较少的(源)队列不定期地“偷看”其他(目标)队列是不是比自己的工作多。如果目标队列比源队列(显著地)更满,就从目标队列“窃取”一个或多个工作,实现负载均衡。但如果太频繁地检查其他队列,就会带来较高的开销,可扩展性不好,而这是多队列调度最初的全部目标!相反,如果检查间隔太长,又可能会带来严重的负载不均。
Linux Multiprocessor Schedulers
- 在构建多处理器调度程序方面,Linux 社区一直没有达成共识。存在 3 种不同的调度程序:
- O(1)调度程序:该调度器引入了每CPU的优先级队列组,每组队列包含 active 和 expire 两个队列,采用启发式算法动态调整优先级,尽可能的进行时间片补偿和惩罚等动态计算,多CPU之间的优先级队列负载均衡。
- 完全公平调度程序(CFS)
- BF 调度程序(BFS)
- O(1) CFS 采用多队列,而 BFS 采用单队列,这说明两种方法都可以成功。当然它们之间还有很多不同的细节。例如,O(1)调度程序是基于优先级的(类似于之前介绍的 MLFQ),随时间推移改变进程的优先级,然后调度最高优先级进程,来实现各种调度目标。交互性得到了特别关注。与之不同,CFS 是确定的比例调度方法(类似之前介绍的步长调度)。BFS 作为三个算法中唯一采用单队列的算法,也基于比例调度,但采用了更复杂的方案,称为最早最合适虚拟截止时间优先算法(EEVEF)
参考链接
