- Cache Replacement Policies - Introduction
Abstract
- 这本书总结了CPU数据缓存的缓存替换策略。重点是算法问题,因此作者首先定义了一个分类法,将以前的策略分为两大类,他们称之为粗粒度策略和细粒度策略。然后每一类又分为三个子类,描述了解决缓存替换问题的不同方法,并总结了每一类的重要工作。然后探讨了更丰富的因素,包括优化缓存miss率之外的指标的解决方案、针对多核设置定制的解决方案、考虑与预取器的交互的解决方案以及考虑新的内存技术的解决方案。本书最后讨论了未来工作的趋势和挑战。这本书假定读者将对计算机架构和缓存有一个基本的了解,将对整个领域的学者和从业者有用。
Introduction
- 几十年来,移动数据的延迟大大超过了执行一条指令的延迟,所以缓存,既减少了内存延迟又减少了内存流量,是所有现代微处理器的重要组成部分。因为缓存的大小和延迟之间有一个一般的权衡,大多数微处理器维持一个缓存的层次结构,较小的低延迟缓存由较大的高延迟缓存提供下层支持,后者最终由 DRAM 提供。对于每一个缓存,有效性可以通过它的命中率来衡量,我们定义为 s/r,其中 s 是缓存服务的内存请求的数量,r 是向缓存发出的内存请求的总数。
- 有几种方法可以提高缓存命中率。一种方法是增加缓存的大小,通常以增加延迟为代价。第二种方法是增加缓存的关联性,这就增加了缓存行可以映射到的可能缓存位置的数量。在一种极端情况下,直接映射缓存(关联性为1)将每条缓存行映射到缓存中的单个位置。在另一个极端,完全关联缓存允许缓存线放置在缓存的任何位置。不幸的是,随着关联性的增加,功耗和硬件复杂度都会增加。第三种方法,也是本书的主题,是选择一个好的缓存替换策略,它回答了这样一个问题:当一个新行要插入到缓存中,哪一行应该被移除以为新行腾出空间?
- 写一本关于缓存替换的书似乎有些奇怪,因为Lazslo Belady在50多年前就提出了一个可证明的最优策略。但Belady的政策是不可实现的,因为它依赖于未来的知识,它抛弃了在未来会被重复使用最多的缓存行。因此,多年来,研究人员已经探索了几种不同的方法来解决缓存替换问题,通常依赖于考虑访问频率、访问近期和最近的预测技术的启发式方法。
- 此外,还有一个问题是缓存替换策略与死块预测器之间的关系,死块预测器试图预测缓存中不再需要的行。我们现在知道,缓存行的生命周期有多个决策点,从插入该行开始,随着时间的推移,直到最终退出该行,我们知道在这些不同的决策点执行操作有不同的技术。基于这个观点,我们认为死块预测器是缓存替换策略的一种特殊情况,我们发现缓存替换策略的空间非常丰富。
- 最后,缓存在软件系统中也很普遍。事实上,第一个替代策略是为操作系统的分页系统开发的,虽然软件缓存和硬件缓存之间存在技术上的差异,但我们希望本书中的一些想法也能对软件缓存的开发人员有用。
- Scope:本书主要介绍CPU数据缓存的硬件cache替换策略。虽然我们讨论的大多数研究都是在一级缓存的背景下进行的,智能缓存替换的好处是最明显的,但一般的想法通常适用于缓存层次结构的其他级别。
- Roadmap:在第2章中,我们首先定义一个二维分类法。主要维度描述替换决策的粒度。第二个维度描述了用于做出替换决策的度量。然后第3章和第4章使用我们的分类法来描述现有的替换策略。第5章介绍了使缓存替换复杂化的其他考虑因素,包括数据预取、共享缓存、可变丢失成本、压缩和新技术。在第六章中,我们总结了2017年举行的Cache replace锦标赛的结果,总结了最近的Cache replace趋势,然后后退一步,总结未来研究的更大趋势和挑战。
相关介绍
参考资料
概念理解延申
提高缓存命中率的方法二:增加缓存的关联性
什么是缓存的关联性
-
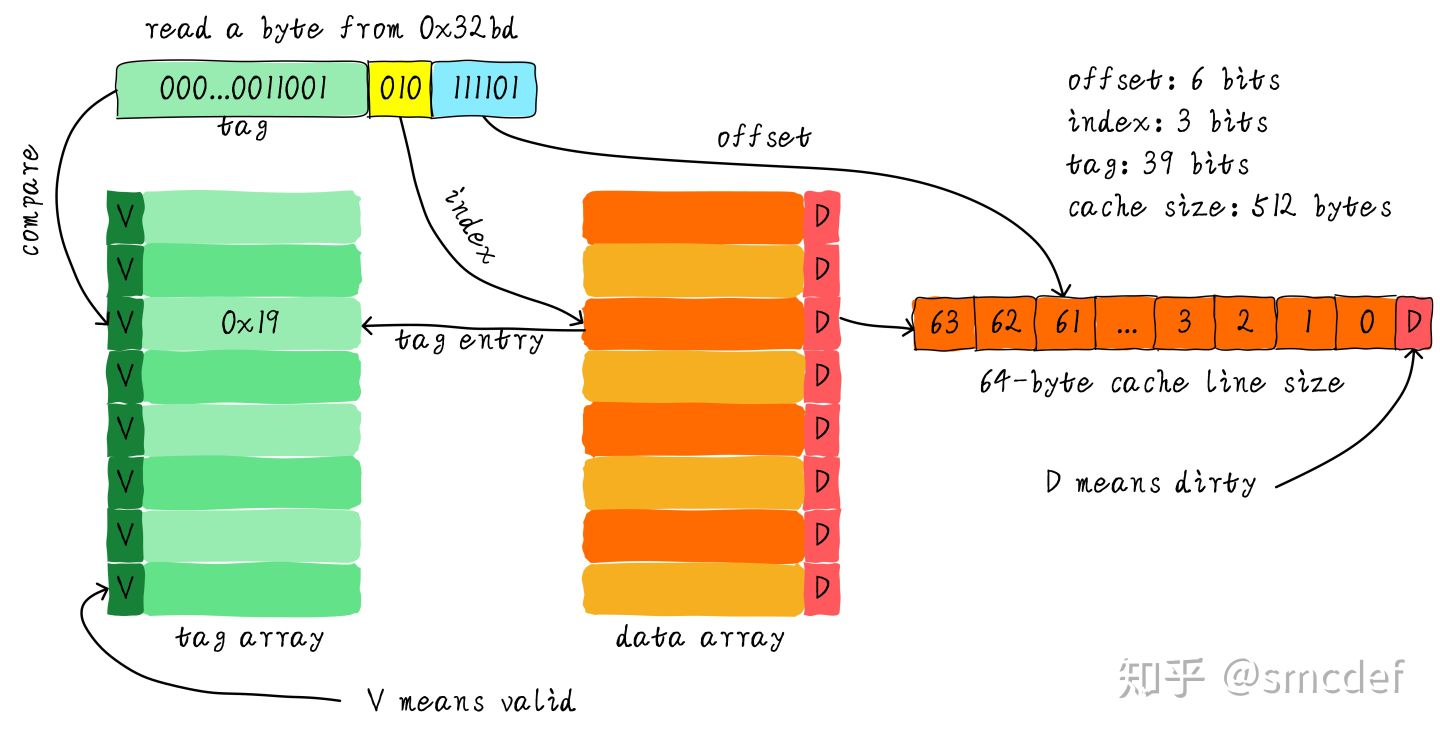
在Cache中,地址映射是指把主存地址空间映射到Cache地址空间,在将主存块复制到Cache中的时候遵循一定的映射规则,标志位为1时候,表示其Cache映射的主存块数据有效。(注意与地址变换的区别,地址变换是指CPU在访存的时候,将主存地址按照映射规则换算成Cache地址的过程 )。 地址映射有三种方式:直接映射,全相联映射,组相联映射
-
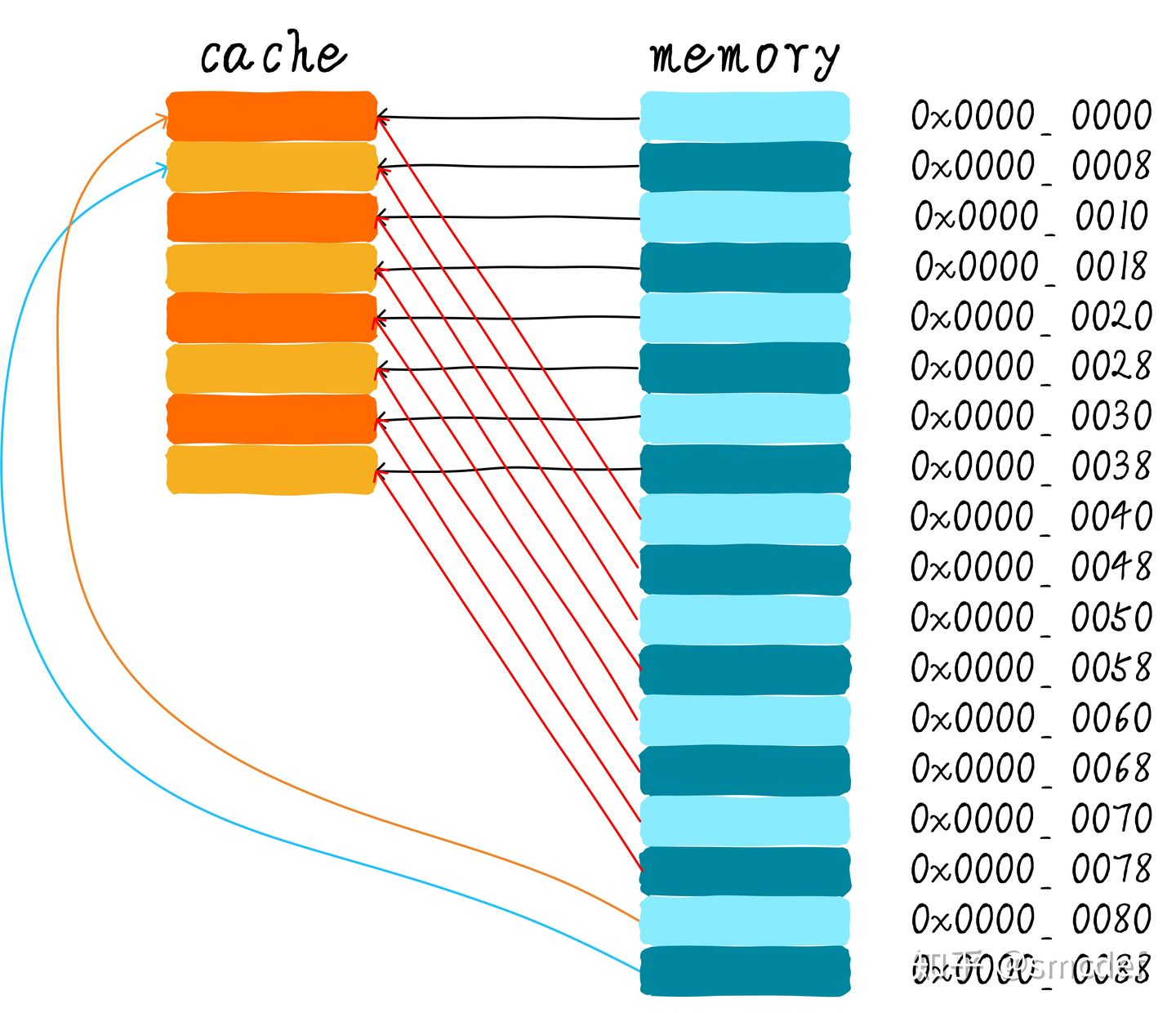
直接映射
- 优点:硬件设计上会更加简单,因此成本上也会较低
- 缺点:会出现 cache 颠簸(cache thrashing)
-
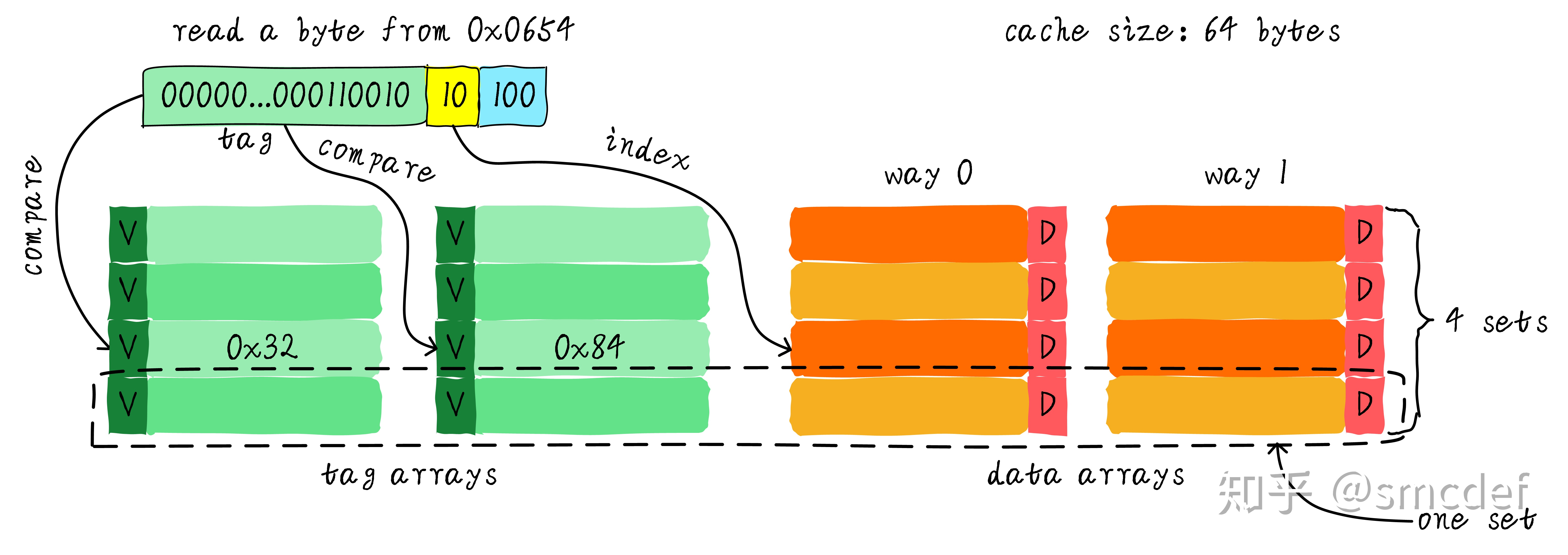
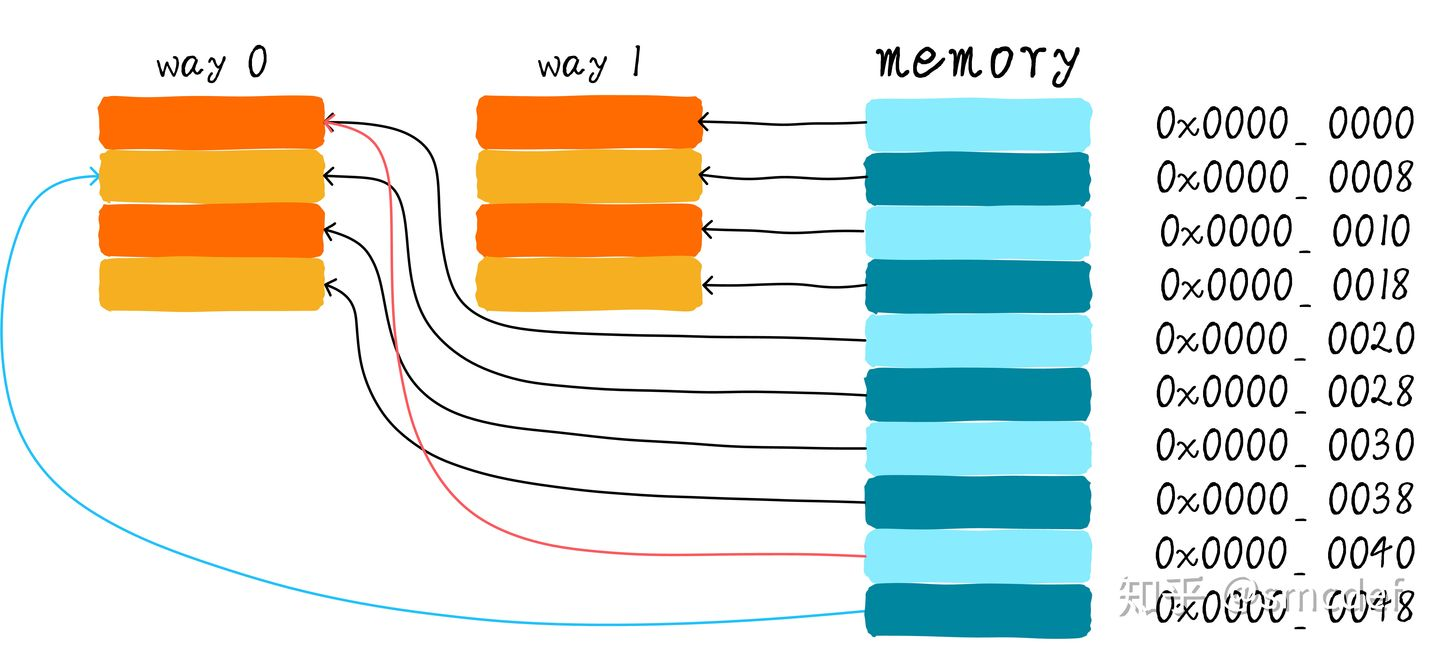
两路组相连:两路组相连缓存较直接映射缓存最大的差异就是:第一个地址对应的数据可以对应 2 个 cache line,而直接映射缓存一个地址只对应一个cache line。 组相联的本质就是组内是全相联,组间是直接相连
- 两路组相连缓存的硬件成本相对于直接映射缓存更高。因为其每次比较tag的时候需要比较多个cache line对应的tag(某些硬件可能还会做并行比较,增加比较速度,这就增加了硬件设计复杂度)
- 两路组相联缓存可以有助于降低 cache 颠簸可能性
-
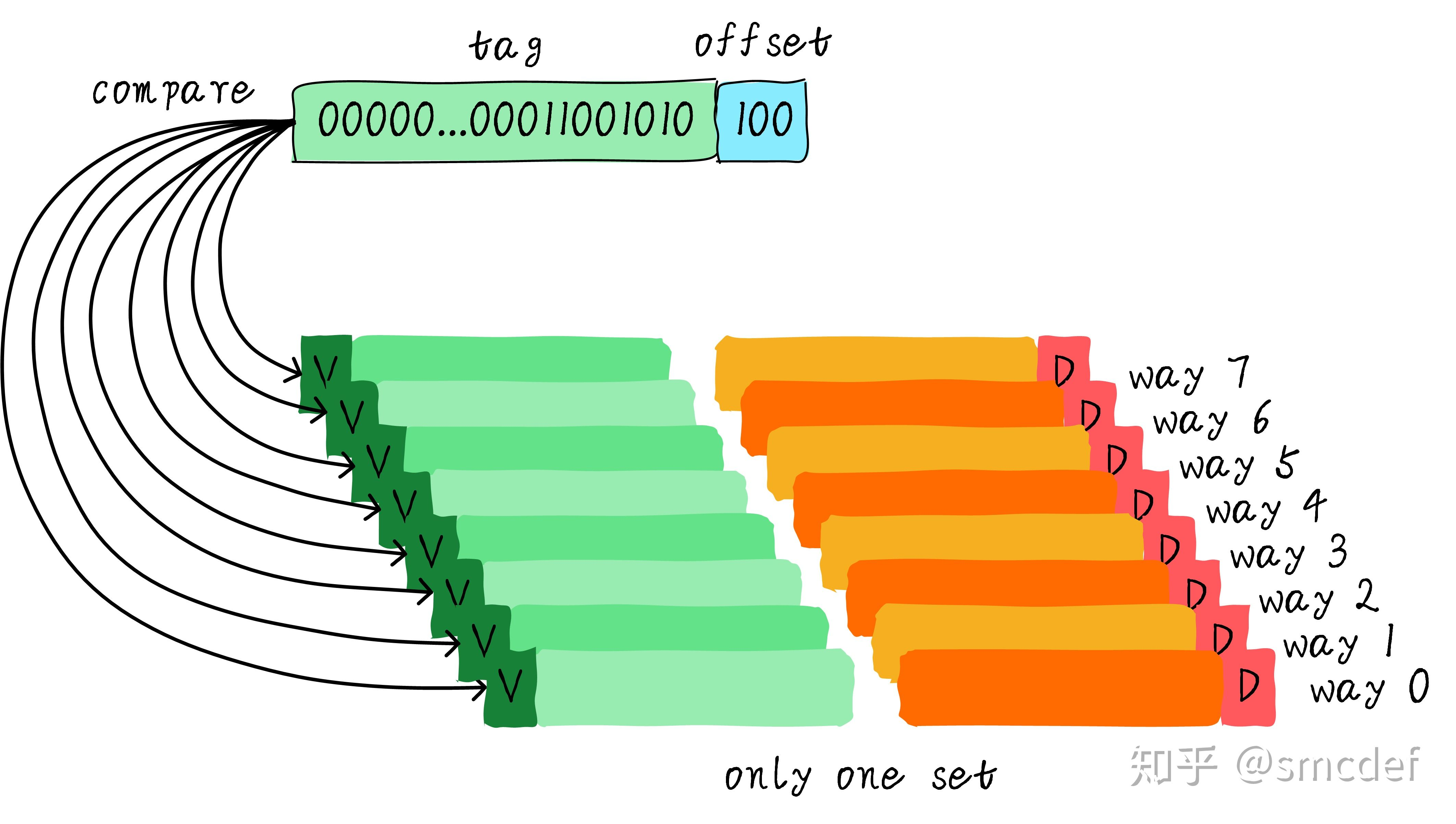
全相联:所有的cache line都在一个组内,因此地址中不需要set index部分。因为,只有一个组让你选择,间接来说就是你没得选。我们根据地址中的tag部分和所有的cache line对应的tag进行比较(硬件上可能并行比较也可能串行比较)。
- 在全相连缓存中,任意地址的数据可以缓存在任意的cache line中。所以,这可以最大程度的降低cache颠簸的频率。但是硬件成本上也是更高。
- 由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用。
缓存关联性如何影响缓存效率?
- 直接相连也就是对应的缓存关联性较差,对应的会造成缓存的频繁写入淘汰,因为映射关系固定,而增加了相联性之后,因为映射关系不再固定,缓存缺失的概率降低,命中率得到提升
Bélády's algorithm
- https://en.wikipedia.org/wiki/Cache_replacement_policies#B%C3%A9l%C3%A1dy's_algorithm
- 最有效的缓存算法是总是丢弃那些在未来很长一段时间内不需要的信息。这个最优结果被称为 Bélády 的最优算法/简单地说最优替换策略或千里眼算法。由于通常不可能预测未来需要多少信息,这在实践中通常是不可实现的。只有经过实验才能计算出实际的最小值,并且可以比较实际选择的缓存算法的有效性。
