- RBD 是 Ceph 分布式存储系统中提供的块存储服务
- 该篇主要针对 RBD 中的整体架构以及 IO 流程进行介绍
- 针对 librbd 中提供的接口进行简单介绍,后续将在此基础上进行实战
Ceph RBD
- RBD:RADOS Block Devices. Ceph block devices are thin-provisioned, resizable and store data striped over multiple OSDs in a Ceph cluster.
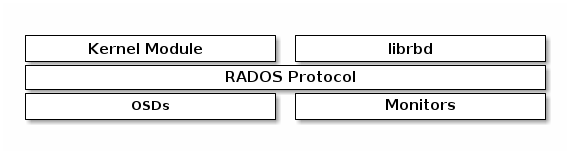
整体介绍
- Ceph RBD 模块主要提供了两种对外接口:
- 一种是基于 librados 的用户态接口库 librbd,支持 C/C++ 接口以及 Python 等高级语言的绑定;
- 另外一种是通过 kernel Module 的方式(一个叫 krbd 的内核模块),通过用户态的 rbd 命令行工具,将 RBD 块设备映射为本地的一个块设备文件。
- RDB 的块设备由于元数据信息少而且访问不频繁,故 RBD 在 Ceph 集群中不需要单独的守护进程讲元数据加载到内存进行元数据访问加速,所有的元数据和数据操作直接与集群中的 Monitor 服务和 OSD 服务进行交互。
RBD IO 流
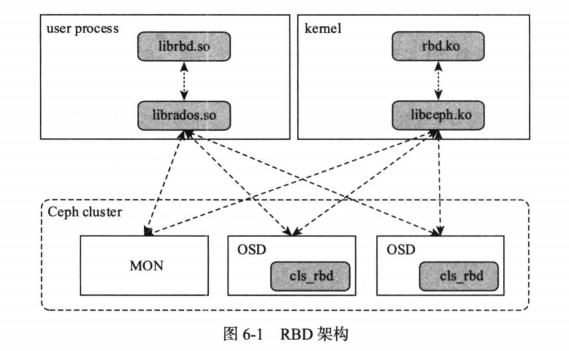
- RBD 模块 IO 流图

几个重要的存储组织
- Pool:存储资源池。IO 之前,需要先创建一个存储池,存储池统一地对逻辑存储单元进行管理,并对其进行初始化。同时指定一个 Pool 中的 PG 数量。是 Ceph 存储数据时的逻辑分区,类似于 HDFS 中的 namespace
ceph osd pool create rbd 32
rbd pool init rbd
- RBD:块设备镜像。在创建好 Pool 的基础之上,对应的创建块设备镜像并和存储池进行映射绑定
- Object:按照数据切片的大小,将所有数据切片为一个个对象,进行相应的对象存储操作。其中 Key 需要根据序号进行生成从而进行区分。
rbd create --size {megabytes} {pool-name}/{image-name}
rbd create --size 1024 swimmingpool/bar
- PG:Placement Group,用于放置标准大小的 Object 的载体。其数量的计算公式:
Total PGs = (Total_number_of_OSD * 100) / max_replication_count再对结果向上取 2 的 N 次方作为最终的数量。PG 同时作为数据均衡和迁移的最小单位,PG 也有相应的主从之分。 - OSD:OSD 是负责物理存储的进程,也可以理解为最终的对象存储节点。一般情况下,一块磁盘启动一个 OSD 进程,一组 PG (多副本)分布在不同的 OSD 上。
IO 流程
- 客户端创建对应的存储池 Pool,指定相应的 PG 个数以及 PGP 个数(用于 PG 中的数据均衡)
- 创建 pool/image rbd设备进行挂载
- 用户写入的数据进行切块,每个块有默认大小,并且每个块都有一个 Key,Key 就是 object+序号
- 将每个 object 通过 pg 进行副本位置的分配
- PG 根据 cursh 算法会寻找指定个数的 osd(主从个数),把这个 object 分别保存在这些 osd 上
- osd 上实际是把底层的 disk 进行了格式化操作,一般部署工具会将它格式化为 xfs 文件系统
- object 的存储就变成了存储一个文件 rbd0.object1.file
RBD IO 框架

客户端写数据osd过程:
- 采用的是 librbd 的形式,使用 librbd 创建一个块设备,向这个块设备中写入数据
- 在客户端本地同过调用 librados 接口,然后经过 pool,rbd,object,pg 进行层层映射(CRUSH 算法),在 PG 这一层中,可以知道数据保存在哪几个 OSD 上,这几个 OSD 分为主从的关系
- 客户端与 primary OSD 建立 SOCKET 通信,将要写入的数据传给 primary OSD,由 primary OSD 再将数据发送给其他 replica OSD 数据节点。
librbd
- librbd 到 OSD 的数据流向如下:

模块介绍
- librbd:Librbd 是Ceph提供的块存储接口的抽象,它提供C/C++、Python等多种接口。对于C++,最主要的两个类就是RBD 和 Image。 RBD 主要负责创建、删除、克隆映像等操作,而Image 类负责映像的读写等操作。
- cls_rbd:cls_rbd是Cls的一个扩展模块,Cls允许用户自定义对象的操作接口和实现方法,为用户提供了一种比较直接的接口扩展方式。通过动态链接的形式加入 osd 中,在 osd 上直接执行。
- librados:librados 提供客户端访问 Ceph 集群的原生态统一接口。其它接口或者命令行工具都基于该动态库实现。在 librados 中实现了 Crush 算法和网络通信等公共功能,数据请求操作在 librados 计算完成后可以直接与对应的 OSD 交互进行数据传输。
- OSDC:该模块是客户端模块比较底层的模块,用于封装操作数据,计算对象的地址、发送请求和处理超时。
- OSD:部署在每一个硬盘上的 OSD 进程,主要功能是存储数据、复制数据、平衡数据、恢复数据等,与其它OSD间进行心跳检查等,并将一些变化情况上报给Ceph Monitor
- OS:操作系统,在此处则主要是 OSD 的 IO 请求下发到对应的硬盘上的文件系统,由文件系统来完成后续的 IO 操作。
librbd 详细介绍
功能模块
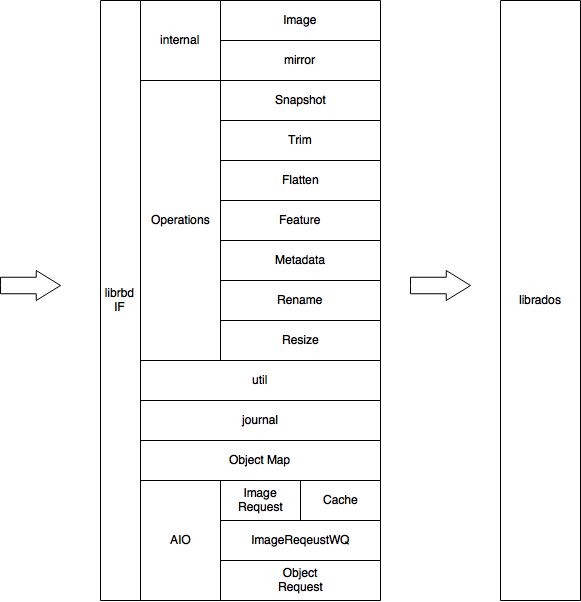
核心机制
-
librbd 是一个将 block io ([off, len])转换成 rados object io ([oid, off, len])的中间层。为了支持高性能 io 处理,其内部维护了一个 io 队列,一个异步回调队列,以及对这两个队列中的请求进行处理的线程池,如下图所示。
-
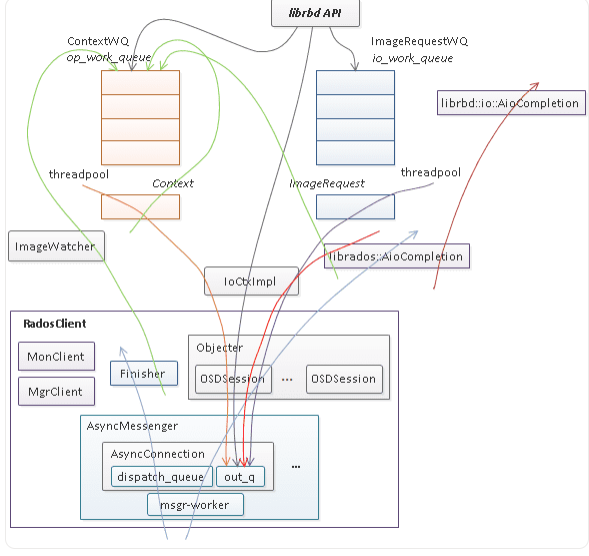
IO 时序图
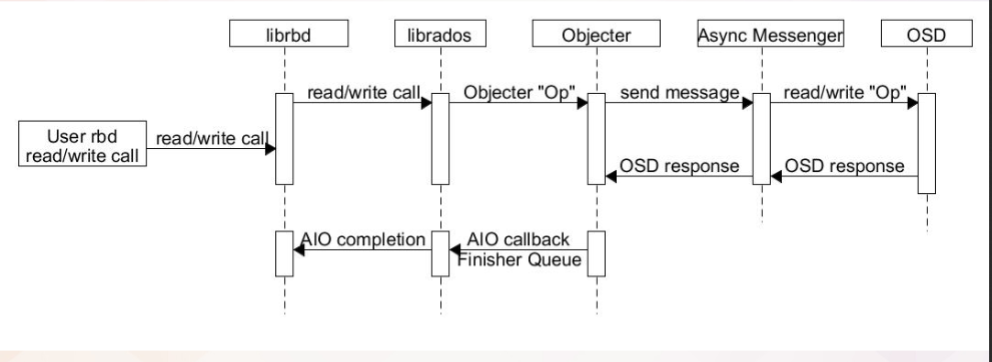
-
librbd 提供了针对 image 的数据读写和管理操作两种访问接口,其中数据读写请求入
io_work_queue,然后由线程池中的线程将 io 请求以 object 粒度切分并分别调用 rados 层的 aio 接口(IoCtxImpl)下发,当所有的 object 请求完成时,调用 librbd io 回调(librbd::io::AioCompletion)完成用户层的数据 io。而对 image 的管理操作通常需要涉及单个或多个对象的多次访问以及对内部状态的多次更新,其第一次访问将从用户线程调用至 rados 层 aio 接口或更新状态后入op_work_queue队列进行异步调用,当 rados aio 层回调或 Context 完成时再根据实现逻辑调用新的 rados aio 或构造 Context 回调,如此反复,最后调用应用层的回调完成管理操作请求。 -
此外为了支持多客户端共享访问 image,librbd 提供了构建于 rados watch/notify 之上的通知、远程执行以及 exclusive lock 分布式锁机制。每个 librbd 客户端在打开 image 时(以非只读方式打开)都会 watch image 的 header 对象,从远程发往本地客户端的通知消息或者内部的 watch 错误消息会通过 RadosClient 的 Finisher 线程入 op_work_queue 队列进行异步处理。
组成元素
- image 主要由
rbd_header元数据 rados 对象及rbd_data数据 rados 对象组成,随着特性的增加会增加其它一些元数据对象,但 librbd 内部的运行机制并不会有大的变化,一切都以异步 io、事件(请求)驱动为基础。
相关接口声明
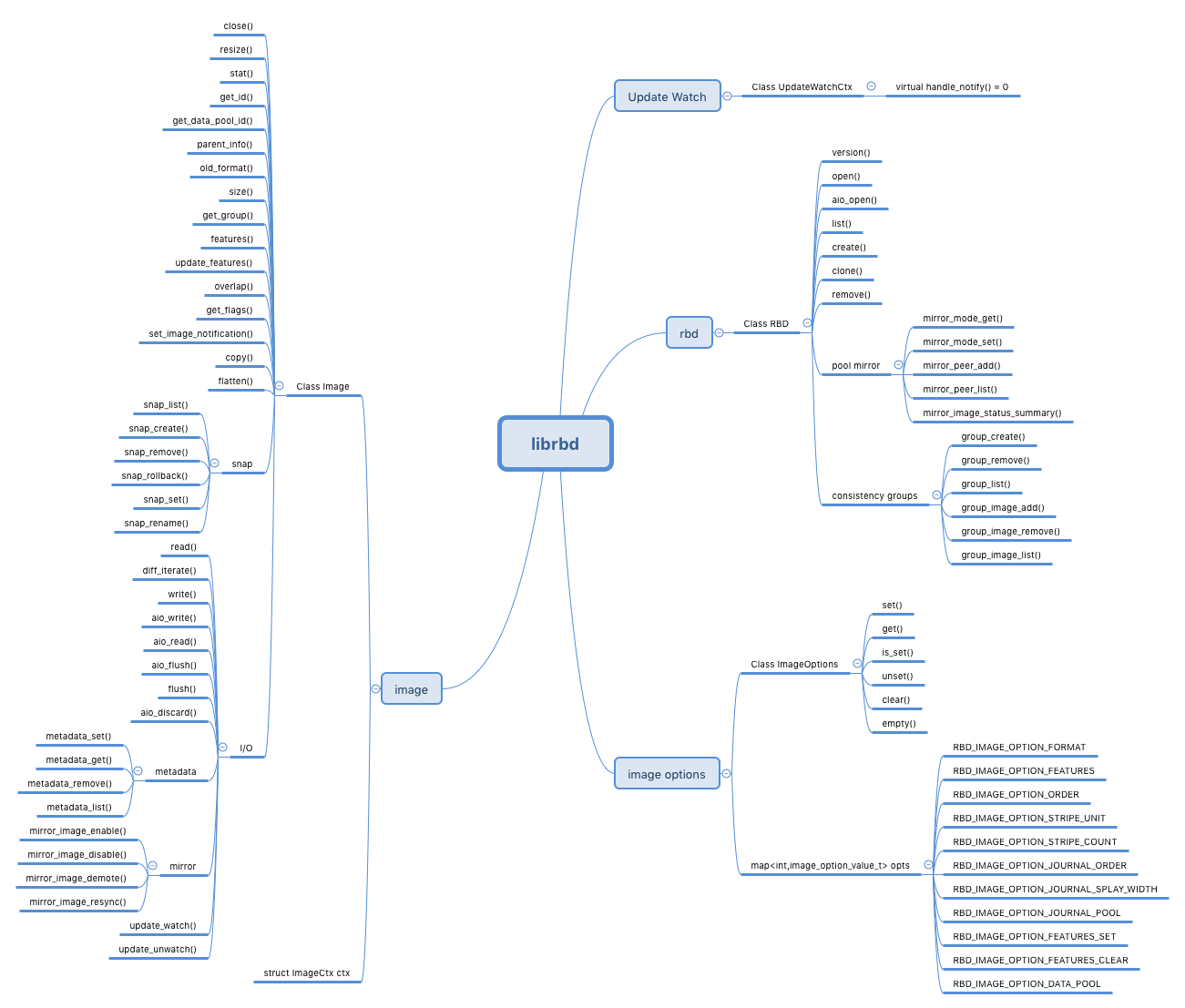
- 此处以 librbd 的 C++ 库 librbd.hpp 为例对 librbd 提供的相关功能 API 进行介绍(除此以外还提供了 C 语言的相关库 librbd.h)
- librbd 提供的接口导图如下:
namespace librbd { // 库在librbd名字空间中
using librados::IoCtx; // librados 库对外提供的接口
class Image;
class ImageOptions;
class PoolStats;
typedef void *image_ctx_t;
typedef void *completion_t;
typedef void (*callback_t)(completion_t cb, void *arg); // 异步操作回调接口
...
class CEPH_RBD_API RBD
{
public:
RBD();
~RBD();
// This must be dynamically allocated with new, and
// must be released with release().
// Do not use delete.
struct AioCompletion {
void *pc;
AioCompletion(void *cb_arg, callback_t complete_cb);
bool is_complete();
int wait_for_complete();
ssize_t get_return_value();
void release();
};
// 接下来一些API: open/create/clone/remove/rename/list/migration 等
// RBD groups support functions create/remove/list/rename
private:
/* We don't allow assignment or copying */
RBD(const RBD& rhs);
const RBD& operator=(const RBD& rhs);
};
// Image 参数设置
class CEPH_RBD_API ImageOptions {
public:
ImageOptions();
ImageOptions(rbd_image_options_t opts);
ImageOptions(const ImageOptions &imgopts);
~ImageOptions();
int set(int optname, const std::string& optval);
int set(int optname, uint64_t optval);
int get(int optname, std::string* optval) const;
int get(int optname, uint64_t* optval) const;
int is_set(int optname, bool* is_set);
int unset(int optname);
void clear();
bool empty() const;
private:
friend class RBD;
friend class Image;
rbd_image_options_t opts;
};
// 存储池 Pool 状态
class CEPH_RBD_API PoolStats {
public:
PoolStats();
~PoolStats();
PoolStats(const PoolStats&) = delete;
PoolStats& operator=(const PoolStats&) = delete;
int add(rbd_pool_stat_option_t option, uint64_t* opt_val);
private:
friend class RBD;
rbd_pool_stats_t pool_stats;
};
class CEPH_RBD_API UpdateWatchCtx {
public:
virtual ~UpdateWatchCtx() {}
/**
* Callback activated when we receive a notify event.
*/
virtual void handle_notify() = 0;
};
class CEPH_RBD_API Image
{
public:
Image();
~Image();
// 镜像的读写,flatten,trim等操作
private:
friend class RBD;
Image(const Image& rhs);
const Image& operator=(const Image& rhs);
image_ctx_t ctx; // viod*, 实际指向具体实现的类
};
}
class CEPH_RBD_API RBD
- RBD 主要负责 Image 的创建、删除、重命名、克隆映像等操作,包括对存储池的元数据的管理
- 针对部分操作提供异步接口
class CEPH_RBD_API RBD
{
public:
RBD();
~RBD();
// This must be dynamically allocated with new, and
// must be released with release().
// Do not use delete.
struct AioCompletion {
void *pc;
AioCompletion(void *cb_arg, callback_t complete_cb);
bool is_complete();
int wait_for_complete();
ssize_t get_return_value();
void *get_arg();
void release();
};
void version(int *major, int *minor, int *extra);
int open(IoCtx& io_ctx, Image& image, const char *name);
int open(IoCtx& io_ctx, Image& image, const char *name, const char *snapname);
int open_by_id(IoCtx& io_ctx, Image& image, const char *id);
int open_by_id(IoCtx& io_ctx, Image& image, const char *id, const char *snapname);
int aio_open(IoCtx& io_ctx, Image& image, const char *name,
const char *snapname, RBD::AioCompletion *c);
int aio_open_by_id(IoCtx& io_ctx, Image& image, const char *id,
const char *snapname, RBD::AioCompletion *c);
// see librbd.h
int open_read_only(IoCtx& io_ctx, Image& image, const char *name,
const char *snapname);
int open_by_id_read_only(IoCtx& io_ctx, Image& image, const char *id,
const char *snapname);
int aio_open_read_only(IoCtx& io_ctx, Image& image, const char *name,
const char *snapname, RBD::AioCompletion *c);
int aio_open_by_id_read_only(IoCtx& io_ctx, Image& image, const char *id,
const char *snapname, RBD::AioCompletion *c);
int list(IoCtx& io_ctx, std::vector<std::string>& names)
__attribute__((deprecated));
int list2(IoCtx& io_ctx, std::vector<image_spec_t>* images);
int create(IoCtx& io_ctx, const char *name, uint64_t size, int *order);
int create2(IoCtx& io_ctx, const char *name, uint64_t size,
uint64_t features, int *order);
int create3(IoCtx& io_ctx, const char *name, uint64_t size,
uint64_t features, int *order,
uint64_t stripe_unit, uint64_t stripe_count);
int create4(IoCtx& io_ctx, const char *name, uint64_t size,
ImageOptions& opts);
int clone(IoCtx& p_ioctx, const char *p_name, const char *p_snapname,
IoCtx& c_ioctx, const char *c_name, uint64_t features,
int *c_order);
int clone2(IoCtx& p_ioctx, const char *p_name, const char *p_snapname,
IoCtx& c_ioctx, const char *c_name, uint64_t features,
int *c_order, uint64_t stripe_unit, int stripe_count);
int clone3(IoCtx& p_ioctx, const char *p_name, const char *p_snapname,
IoCtx& c_ioctx, const char *c_name, ImageOptions& opts);
int remove(IoCtx& io_ctx, const char *name);
int remove_with_progress(IoCtx& io_ctx, const char *name, ProgressContext& pctx);
int rename(IoCtx& src_io_ctx, const char *srcname, const char *destname);
int trash_move(IoCtx &io_ctx, const char *name, uint64_t delay);
int trash_get(IoCtx &io_ctx, const char *id, trash_image_info_t *info);
int trash_list(IoCtx &io_ctx, std::vector<trash_image_info_t> &entries);
int trash_purge(IoCtx &io_ctx, time_t expire_ts, float threshold);
int trash_purge_with_progress(IoCtx &io_ctx, time_t expire_ts, float threshold,
ProgressContext &pctx);
int trash_remove(IoCtx &io_ctx, const char *image_id, bool force);
int trash_remove_with_progress(IoCtx &io_ctx, const char *image_id,
bool force, ProgressContext &pctx);
int trash_restore(IoCtx &io_ctx, const char *id, const char *name);
// Migration
int migration_prepare(IoCtx& io_ctx, const char *image_name,
IoCtx& dest_io_ctx, const char *dest_image_name,
ImageOptions& opts);
int migration_execute(IoCtx& io_ctx, const char *image_name);
int migration_execute_with_progress(IoCtx& io_ctx, const char *image_name,
ProgressContext &prog_ctx);
int migration_abort(IoCtx& io_ctx, const char *image_name);
int migration_abort_with_progress(IoCtx& io_ctx, const char *image_name,
ProgressContext &prog_ctx);
int migration_commit(IoCtx& io_ctx, const char *image_name);
int migration_commit_with_progress(IoCtx& io_ctx, const char *image_name,
ProgressContext &prog_ctx);
int migration_status(IoCtx& io_ctx, const char *image_name,
image_migration_status_t *status, size_t status_size);
// RBD pool mirroring support functions
int mirror_mode_get(IoCtx& io_ctx, rbd_mirror_mode_t *mirror_mode);
int mirror_mode_set(IoCtx& io_ctx, rbd_mirror_mode_t mirror_mode);
int mirror_peer_add(IoCtx& io_ctx, std::string *uuid,
const std::string &cluster_name,
const std::string &client_name);
int mirror_peer_remove(IoCtx& io_ctx, const std::string &uuid);
int mirror_peer_list(IoCtx& io_ctx, std::vector<mirror_peer_t> *peers);
int mirror_peer_set_client(IoCtx& io_ctx, const std::string &uuid,
const std::string &client_name);
int mirror_peer_set_cluster(IoCtx& io_ctx, const std::string &uuid,
const std::string &cluster_name);
int mirror_peer_get_attributes(
IoCtx& io_ctx, const std::string &uuid,
std::map<std::string, std::string> *key_vals);
int mirror_peer_set_attributes(
IoCtx& io_ctx, const std::string &uuid,
const std::map<std::string, std::string>& key_vals);
int mirror_image_status_list(IoCtx& io_ctx, const std::string &start_id,
size_t max, std::map<std::string, mirror_image_status_t> *images);
int mirror_image_status_summary(IoCtx& io_ctx,
std::map<mirror_image_status_state_t, int> *states);
int mirror_image_instance_id_list(IoCtx& io_ctx, const std::string &start_id,
size_t max, std::map<std::string, std::string> *sevice_ids);
// RBD groups support functions
int group_create(IoCtx& io_ctx, const char *group_name);
int group_remove(IoCtx& io_ctx, const char *group_name);
int group_list(IoCtx& io_ctx, std::vector<std::string> *names);
int group_rename(IoCtx& io_ctx, const char *src_group_name,
const char *dest_group_name);
int group_image_add(IoCtx& io_ctx, const char *group_name,
IoCtx& image_io_ctx, const char *image_name);
int group_image_remove(IoCtx& io_ctx, const char *group_name,
IoCtx& image_io_ctx, const char *image_name);
int group_image_remove_by_id(IoCtx& io_ctx, const char *group_name,
IoCtx& image_io_ctx, const char *image_id);
int group_image_list(IoCtx& io_ctx, const char *group_name,
std::vector<group_image_info_t> *images,
size_t group_image_info_size);
int group_snap_create(IoCtx& io_ctx, const char *group_name,
const char *snap_name);
int group_snap_remove(IoCtx& io_ctx, const char *group_name,
const char *snap_name);
int group_snap_rename(IoCtx& group_ioctx, const char *group_name,
const char *old_snap_name, const char *new_snap_name);
int group_snap_list(IoCtx& group_ioctx, const char *group_name,
std::vector<group_snap_info_t> *snaps,
size_t group_snap_info_size);
int group_snap_rollback(IoCtx& io_ctx, const char *group_name,
const char *snap_name);
int group_snap_rollback_with_progress(IoCtx& io_ctx, const char *group_name,
const char *snap_name,
ProgressContext& pctx);
int namespace_create(IoCtx& ioctx, const char *namespace_name);
int namespace_remove(IoCtx& ioctx, const char *namespace_name);
int namespace_list(IoCtx& io_ctx, std::vector<std::string>* namespace_names);
int namespace_exists(IoCtx& io_ctx, const char *namespace_name, bool *exists);
int pool_init(IoCtx& io_ctx, bool force);
int pool_stats_get(IoCtx& io_ctx, PoolStats *pool_stats);
int pool_metadata_get(IoCtx &io_ctx, const std::string &key,
std::string *value);
int pool_metadata_set(IoCtx &io_ctx, const std::string &key,
const std::string &value);
int pool_metadata_remove(IoCtx &io_ctx, const std::string &key);
int pool_metadata_list(IoCtx &io_ctx, const std::string &start, uint64_t max,
std::map<std::string, ceph::bufferlist> *pairs);
int config_list(IoCtx& io_ctx, std::vector<config_option_t> *options);
private:
/* We don't allow assignment or copying */
RBD(const RBD& rhs);
const RBD& operator=(const RBD& rhs);
};
class CEPH_RBD_API Image
- Image 类负责镜像的读写(read/write),以及快照相关的操作等等。
- 同时提供了相关异步操作的接口。
class CEPH_RBD_API Image
{
public:
Image();
~Image();
// 镜像的读写,resize, flush, flatten,trim等操作
int close();
int aio_close(RBD::AioCompletion *c);
int resize(uint64_t size);
int resize2(uint64_t size, bool allow_shrink, ProgressContext& pctx);
int resize_with_progress(uint64_t size, ProgressContext& pctx);
int stat(image_info_t &info, size_t infosize);
int get_name(std::string *name);
int get_id(std::string *id);
std::string get_block_name_prefix();
int64_t get_data_pool_id();
int parent_info(std::string *parent_poolname, std::string *parent_name,
std::string *parent_snapname)
__attribute__((deprecated));
int parent_info2(std::string *parent_poolname, std::string *parent_name,
std::string *parent_id, std::string *parent_snapname)
__attribute__((deprecated));
int get_parent(linked_image_spec_t *parent_image, snap_spec_t *parent_snap);
int old_format(uint8_t *old);
int size(uint64_t *size);
int get_group(group_info_t *group_info, size_t group_info_size);
int features(uint64_t *features);
int update_features(uint64_t features, bool enabled);
int get_op_features(uint64_t *op_features);
int overlap(uint64_t *overlap);
int get_flags(uint64_t *flags);
int set_image_notification(int fd, int type);
/* exclusive lock feature */
int is_exclusive_lock_owner(bool *is_owner);
int lock_acquire(rbd_lock_mode_t lock_mode);
int lock_release();
int lock_get_owners(rbd_lock_mode_t *lock_mode,
std::list<std::string> *lock_owners);
int lock_break(rbd_lock_mode_t lock_mode, const std::string &lock_owner);
/* object map feature */
int rebuild_object_map(ProgressContext &prog_ctx);
int check_object_map(ProgressContext &prog_ctx);
int copy(IoCtx& dest_io_ctx, const char *destname);
int copy2(Image& dest);
int copy3(IoCtx& dest_io_ctx, const char *destname, ImageOptions& opts);
int copy4(IoCtx& dest_io_ctx, const char *destname, ImageOptions& opts,
size_t sparse_size);
int copy_with_progress(IoCtx& dest_io_ctx, const char *destname,
ProgressContext &prog_ctx);
int copy_with_progress2(Image& dest, ProgressContext &prog_ctx);
int copy_with_progress3(IoCtx& dest_io_ctx, const char *destname,
ImageOptions& opts, ProgressContext &prog_ctx);
int copy_with_progress4(IoCtx& dest_io_ctx, const char *destname,
ImageOptions& opts, ProgressContext &prog_ctx,
size_t sparse_size);
/* deep copy */
int deep_copy(IoCtx& dest_io_ctx, const char *destname, ImageOptions& opts);
int deep_copy_with_progress(IoCtx& dest_io_ctx, const char *destname,
ImageOptions& opts, ProgressContext &prog_ctx);
/* striping */
uint64_t get_stripe_unit() const;
uint64_t get_stripe_count() const;
int get_create_timestamp(struct timespec *timestamp);
int get_access_timestamp(struct timespec *timestamp);
int get_modify_timestamp(struct timespec *timestamp);
int flatten();
int flatten_with_progress(ProgressContext &prog_ctx);
int sparsify(size_t sparse_size);
int sparsify_with_progress(size_t sparse_size, ProgressContext &prog_ctx);
/**
* Returns a pair of poolname, imagename for each clone
* of this image at the currently set snapshot.
*/
int list_children(std::set<std::pair<std::string, std::string> > *children)
__attribute__((deprecated));
/**
* Returns a structure of poolname, imagename, imageid and trash flag
* for each clone of this image at the currently set snapshot.
*/
int list_children2(std::vector<librbd::child_info_t> *children)
__attribute__((deprecated));
int list_children3(std::vector<linked_image_spec_t> *images);
int list_descendants(std::vector<linked_image_spec_t> *images);
/* advisory locking (see librbd.h for details) */
int list_lockers(std::list<locker_t> *lockers,
bool *exclusive, std::string *tag);
int lock_exclusive(const std::string& cookie);
int lock_shared(const std::string& cookie, const std::string& tag);
int unlock(const std::string& cookie);
int break_lock(const std::string& client, const std::string& cookie);
/* snapshots */
int snap_list(std::vector<snap_info_t>& snaps);
/* DEPRECATED; use snap_exists2 */
bool snap_exists(const char *snapname) __attribute__ ((deprecated));
int snap_exists2(const char *snapname, bool *exists);
int snap_create(const char *snapname);
int snap_remove(const char *snapname);
int snap_remove2(const char *snapname, uint32_t flags, ProgressContext& pctx);
int snap_remove_by_id(uint64_t snap_id);
int snap_rollback(const char *snap_name);
int snap_rollback_with_progress(const char *snap_name, ProgressContext& pctx);
int snap_protect(const char *snap_name);
int snap_unprotect(const char *snap_name);
int snap_is_protected(const char *snap_name, bool *is_protected);
int snap_set(const char *snap_name);
int snap_set_by_id(uint64_t snap_id);
int snap_rename(const char *srcname, const char *dstname);
int snap_get_limit(uint64_t *limit);
int snap_set_limit(uint64_t limit);
int snap_get_timestamp(uint64_t snap_id, struct timespec *timestamp);
int snap_get_namespace_type(uint64_t snap_id,
snap_namespace_type_t *namespace_type);
int snap_get_group_namespace(uint64_t snap_id,
snap_group_namespace_t *group_namespace,
size_t snap_group_namespace_size);
int snap_get_trash_namespace(uint64_t snap_id, std::string* original_name);
/* I/O */
ssize_t read(uint64_t ofs, size_t len, ceph::bufferlist& bl);
/* @param op_flags see librados.h constants beginning with LIBRADOS_OP_FLAG */
ssize_t read2(uint64_t ofs, size_t len, ceph::bufferlist& bl, int op_flags);
int64_t read_iterate(uint64_t ofs, size_t len,
int (*cb)(uint64_t, size_t, const char *, void *), void *arg);
int read_iterate2(uint64_t ofs, uint64_t len,
int (*cb)(uint64_t, size_t, const char *, void *), void *arg);
/**
* get difference between two versions of an image
*
* This will return the differences between two versions of an image
* via a callback, which gets the offset and length and a flag
* indicating whether the extent exists (1), or is known/defined to
* be zeros (a hole, 0). If the source snapshot name is NULL, we
* interpret that as the beginning of time and return all allocated
* regions of the image. The end version is whatever is currently
* selected for the image handle (either a snapshot or the writeable
* head).
*
* @param fromsnapname start snapshot name, or NULL
* @param ofs start offset
* @param len len in bytes of region to report on
* @param include_parent true if full history diff should include parent
* @param whole_object 1 if diff extents should cover whole object
* @param cb callback to call for each allocated region
* @param arg argument to pass to the callback
* @returns 0 on success, or negative error code on error
*/
int diff_iterate(const char *fromsnapname,
uint64_t ofs, uint64_t len,
int (*cb)(uint64_t, size_t, int, void *), void *arg);
int diff_iterate2(const char *fromsnapname,
uint64_t ofs, uint64_t len,
bool include_parent, bool whole_object,
int (*cb)(uint64_t, size_t, int, void *), void *arg);
ssize_t write(uint64_t ofs, size_t len, ceph::bufferlist& bl);
/* @param op_flags see librados.h constants beginning with LIBRADOS_OP_FLAG */
ssize_t write2(uint64_t ofs, size_t len, ceph::bufferlist& bl, int op_flags);
int discard(uint64_t ofs, uint64_t len);
ssize_t writesame(uint64_t ofs, size_t len, ceph::bufferlist &bl, int op_flags);
ssize_t compare_and_write(uint64_t ofs, size_t len, ceph::bufferlist &cmp_bl,
ceph::bufferlist& bl, uint64_t *mismatch_off, int op_flags);
int aio_write(uint64_t off, size_t len, ceph::bufferlist& bl, RBD::AioCompletion *c);
/* @param op_flags see librados.h constants beginning with LIBRADOS_OP_FLAG */
int aio_write2(uint64_t off, size_t len, ceph::bufferlist& bl,
RBD::AioCompletion *c, int op_flags);
int aio_writesame(uint64_t off, size_t len, ceph::bufferlist& bl,
RBD::AioCompletion *c, int op_flags);
int aio_compare_and_write(uint64_t off, size_t len, ceph::bufferlist& cmp_bl,
ceph::bufferlist& bl, RBD::AioCompletion *c,
uint64_t *mismatch_off, int op_flags);
/**
* read async from image
*
* The target bufferlist is populated with references to buffers
* that contain the data for the given extent of the image.
*
* NOTE: If caching is enabled, the bufferlist will directly
* reference buffers in the cache to avoid an unnecessary data copy.
* As a result, if the user intends to modify the buffer contents
* directly, they should make a copy first (unconditionally, or when
* the reference count on ther underlying buffer is more than 1).
*
* @param off offset in image
* @param len length of read
* @param bl bufferlist to read into
* @param c aio completion to notify when read is complete
*/
int aio_read(uint64_t off, size_t len, ceph::bufferlist& bl, RBD::AioCompletion *c);
/* @param op_flags see librados.h constants beginning with LIBRADOS_OP_FLAG */
int aio_read2(uint64_t off, size_t len, ceph::bufferlist& bl,
RBD::AioCompletion *c, int op_flags);
int aio_discard(uint64_t off, uint64_t len, RBD::AioCompletion *c);
int flush();
/**
* Start a flush if caching is enabled. Get a callback when
* the currently pending writes are on disk.
*
* @param image the image to flush writes to
* @param c what to call when flushing is complete
* @returns 0 on success, negative error code on failure
*/
int aio_flush(RBD::AioCompletion *c);
/**
* Drop any cached data for this image
*
* @returns 0 on success, negative error code on failure
*/
int invalidate_cache();
int poll_io_events(RBD::AioCompletion **comps, int numcomp);
int metadata_get(const std::string &key, std::string *value);
int metadata_set(const std::string &key, const std::string &value);
int metadata_remove(const std::string &key);
/**
* Returns a pair of key/value for this image
*/
int metadata_list(const std::string &start, uint64_t max, std::map<std::string, ceph::bufferlist> *pairs);
// RBD image mirroring support functions
int mirror_image_enable();
int mirror_image_disable(bool force);
int mirror_image_promote(bool force);
int mirror_image_demote();
int mirror_image_resync();
int mirror_image_get_info(mirror_image_info_t *mirror_image_info,
size_t info_size);
int mirror_image_get_status(mirror_image_status_t *mirror_image_status,
size_t status_size);
int mirror_image_get_instance_id(std::string *instance_id);
int aio_mirror_image_promote(bool force, RBD::AioCompletion *c);
int aio_mirror_image_demote(RBD::AioCompletion *c);
int aio_mirror_image_get_info(mirror_image_info_t *mirror_image_info,
size_t info_size, RBD::AioCompletion *c);
int aio_mirror_image_get_status(mirror_image_status_t *mirror_image_status,
size_t status_size, RBD::AioCompletion *c);
int update_watch(UpdateWatchCtx *ctx, uint64_t *handle);
int update_unwatch(uint64_t handle);
int list_watchers(std::list<image_watcher_t> &watchers);
int config_list(std::vector<config_option_t> *options);
private:
friend class RBD;
Image(const Image& rhs);
const Image& operator=(const Image& rhs);
image_ctx_t ctx; // void*, 实际指向具体实现的类
};
具体实现
- librbd.cc 主要实现了 I/O 相关接口 read/write。
- internal.cc 主要实现了定义在头文件中的相关函数接口
Cls
- cls_rbd是Cls的一个扩展模块,Cls允许用户自定义对象的操作接口和实现方法,为用户提供了一种比较直接的接口扩展方式。通过动态链接的形式加入 osd 中,在 osd 上直接执行。
Client
- cls_rbd_client.h/cc 该文件中主要定义了客户端上运行的接口,将函数参数封装后发送给服务端 OSD ,然后做后续处理.
cls_rbd_client.h/cc定义了通过客户端访问osd注册的cls函数的方法。以snapshot_add函数和create_image函数为例,这个函数将参数封装进 bufferlist ,通过 ioctx->exec 方法,把操作发送给osd处理。
void snapshot_add(librados::ObjectWriteOperation *op, snapid_t snap_id,
const std::string &snap_name, const cls::rbd::SnapshotNamespace &snap_namespace)
{
bufferlist bl;
::encode(snap_name, bl);
::encode(snap_id, bl);
::encode(cls::rbd::SnapshotNamespaceOnDisk(snap_namespace), bl);
op->exec("rbd", "snapshot_add", bl);
}
void create_image(librados::ObjectWriteOperation *op, uint64_t size,
uint8_t order, uint64_t features,
const std::string &object_prefix, int64_t data_pool_id)
{
bufferlist bl;
::encode(size, bl);
::encode(order, bl);
::encode(features, bl);
::encode(object_prefix, bl);
::encode(data_pool_id, bl);
op->exec("rbd", "create", bl);
}
int create_image(librados::IoCtx *ioctx, const std::string &oid,
uint64_t size, uint8_t order, uint64_t features,
const std::string &object_prefix, int64_t data_pool_id)
{
librados::ObjectWriteOperation op;
create_image(&op, size, order, features, object_prefix, data_pool_id);
return ioctx->operate(oid, &op);
}
Server
- cls_rbd.h/cc 该类中主要定义了服务端上(OSD)执行的函数,响应客户端的请求。在
cls_rbd.cc函数中,对函数进行定义和注册。 - 例如,下面的代码注册了rbd模块,以及
snapshot_add和create函数。
cls_register("rbd", &h_class);
cls_register_cxx_method(h_class, "snapshot_add",
CLS_METHOD_RD | CLS_METHOD_WR,
snapshot_add, &h_snapshot_add);
cls_register_cxx_method(h_class, "create",
CLS_METHOD_RD | CLS_METHOD_WR,
create, &h_create);
- cls_rbd.cc定义了方法在服务端的实现,其一般流程是:从bufferlist将客户端传入的参数解析出来,调用对应的方法实现,然后将结果返回客户端。
/**
* Adds a snapshot to an rbd header. Ensures the id and name are unique.
*/
int snapshot_add(cls_method_context_t hctx, bufferlist *in, bufferlist *out)
{
bufferlist snap_namebl, snap_idbl;
cls_rbd_snap snap_meta;
uint64_t snap_limit;
// 从bl中解析参数
try {
bufferlist::iterator iter = in->begin();
::decode(snap_meta.name, iter);
::decode(snap_meta.id, iter);
if (!iter.end()) {
::decode(snap_meta.snapshot_namespace, iter);
}
} catch (const buffer::error &err) {
return -EINVAL;
}
// 判断参数合法性,略
......
// 完成操作,在rbd_header对象中增加新的snapshot元数据,并更新sanp_seq。
map<string, bufferlist> vals;
vals["snap_seq"] = snap_seqbl;
vals[snapshot_key] = snap_metabl;
r = cls_cxx_map_set_vals(hctx, &vals);
if (r < 0) {
CLS_ERR("error writing snapshot metadata: %s", cpp_strerror(r).c_str());
return r;
}
return 0;
}
/**
* Initialize the header with basic metadata.
* Extra features may initialize more fields in the future.
* Everything is stored as key/value pairs as omaps in the header object.
*
* If features the OSD does not understand are requested, -ENOSYS is
* returned.
*
* Input:
* @param size number of bytes in the image (uint64_t)
* @param order bits to shift to determine the size of data objects (uint8_t)
* @param features what optional things this image will use (uint64_t)
* @param object_prefix a prefix for all the data objects
* @param data_pool_id pool id where data objects is stored (int64_t)
*
* Output:
* @return 0 on success, negative error code on failure
*/
int create(cls_method_context_t hctx, bufferlist *in, bufferlist *out)
{
string object_prefix;
uint64_t features, size;
uint8_t order;
int64_t data_pool_id = -1;
// 从 buffer 里解析参数
try {
auto iter = in->cbegin();
decode(size, iter);
decode(order, iter);
decode(features, iter);
decode(object_prefix, iter);
if (!iter.end()) {
decode(data_pool_id, iter);
}
} catch (const buffer::error &err) {
return -EINVAL;
}
CLS_LOG(20, "create object_prefix=%s size=%llu order=%u features=%llu",
object_prefix.c_str(), (unsigned long long)size, order,
(unsigned long long)features);
if (features & ~RBD_FEATURES_ALL) {
return -ENOSYS;
}
if (!object_prefix.size()) {
return -EINVAL;
}
bufferlist stored_prefixbl;
// 从 cls context 里获取 object_prefix
int r = cls_cxx_map_get_val(hctx, "object_prefix", &stored_prefixbl);
if (r != -ENOENT) {
CLS_ERR("reading object_prefix returned %d", r);
return -EEXIST;
}
bufferlist sizebl;
bufferlist orderbl;
bufferlist featuresbl;
bufferlist object_prefixbl;
bufferlist snap_seqbl;
bufferlist timestampbl;
uint64_t snap_seq = 0;
utime_t timestamp = ceph_clock_now();
encode(size, sizebl);
encode(order, orderbl);
encode(features, featuresbl);
encode(object_prefix, object_prefixbl);
encode(snap_seq, snap_seqbl);
encode(timestamp, timestampbl);
// 更新 rbd_header omap
map<string, bufferlist> omap_vals;
omap_vals["size"] = sizebl;
omap_vals["order"] = orderbl;
omap_vals["features"] = featuresbl;
omap_vals["object_prefix"] = object_prefixbl;
omap_vals["snap_seq"] = snap_seqbl;
omap_vals["create_timestamp"] = timestampbl;
omap_vals["access_timestamp"] = timestampbl;
omap_vals["modify_timestamp"] = timestampbl;
if ((features & RBD_FEATURE_OPERATIONS) != 0ULL) {
CLS_ERR("Attempting to set internal feature: operations");
return -EINVAL;
}
if (features & RBD_FEATURE_DATA_POOL) {
if (data_pool_id == -1) {
CLS_ERR("data pool not provided with feature enabled");
return -EINVAL;
}
bufferlist data_pool_id_bl;
encode(data_pool_id, data_pool_id_bl);
omap_vals["data_pool_id"] = data_pool_id_bl;
} else if (data_pool_id != -1) {
CLS_ERR("data pool provided with feature disabled");
return -EINVAL;
}
// 更新 OMAP
r = cls_cxx_map_set_vals(hctx, &omap_vals);
if (r < 0)
return r;
return 0;
}
Others

分片 Striper
- Ceph RBD 默认分片到了许多对象上,这些对象最终会存储在 RADOS 中,对 RBD Image 的读写请求会分布在集群中的很多个节点上,从而避免当 RBD Image 特别大或者繁忙的时候,单个节点不会成为瓶颈。
- Ceph RBD 的分片由三个参数控制
- object-size,代码中常常简写为 os,通常为 2 的幂指数,默认的对象大小是4 MB,最小的是4K,最大的是32M
- stripe_unit,代码中常常简写为 su,一个对象中存储了连续该大小的分片。默认和对象大小相等。
- stripe_count,代码中常常简写为 sc,在向 [stripe_count] 对象写入 [stripe_unit] 字节后,循环到初始对象并写入另一个条带,直到对象达到其最大大小。此时,将继续处理下一个 [stripe_count] 对象。
- 分片的组织形式类似于 RAID0,看一个来自官网的 例子。此处只举例一个 Object Set,对象大小在如下图示中即为纵向的一个对象大小,由整数个分片单元组成,而一个分片是指指定 stripe_count 个 stripe_unit,图示中的 stripe_count 即为 5,假设 stripe_unit 为 64KB,那么对应的分片大小即为 320KB,对象大小如果设置为 64GB,那么一个对象对应的就会有 64GB/64KB = 1048576 个 stripe_unit.
_________ _________ _________ _________ _________
/object 0\ /object 1\ /object 2\ /object 3\ /object 4\
+=========+ +=========+ +=========+ +=========+ +=========+
| stripe | | stripe | | stripe | | stripe | | stripe |
o | unit | | unit | | unit | | unit | | unit | stripe 0
b | 0 | | 1 | | 2 | | 3 | | 4 |
j |---------| |---------| |---------| |---------| |---------|
e | stripe | | stripe | | stripe | | stripe | | stripe |
c | unit | | unit | | unit | | unit | | unit | stripe 1
t | 5 | | 6 | | 7 | | 8 | | 9 |
|---------| |---------| |---------| |---------| |---------|
s | . | | . | | . | | . | | . |
e . . . . .
t | . | | . | | . | | . | | . |
|---------| |---------| |---------| |---------| |---------|
0 | stripe | | stripe | | stripe | | stripe | | stripe | stripe
| unit | | unit | | unit | | unit | | unit | 1048575
| 5242875 | | 5242876 | | 5242877 | | 5242878 | | 5242879 |
\=========/ \=========/ \=========/ \=========/ \=========/
class Striper {
public:
static void file_to_extents(
CephContext *cct, const file_layout_t *layout, uint64_t offset,
uint64_t len, uint64_t trunc_size, uint64_t buffer_offset,
striper::LightweightObjectExtents* object_extents);
/*
* std::map (ino, layout, offset, len) to a (list of) ObjectExtents (byte
* ranges in objects on (primary) osds)
*/
static void file_to_extents(CephContext *cct, const char *object_format,
const file_layout_t *layout,
uint64_t offset, uint64_t len,
uint64_t trunc_size,
std::map<object_t, std::vector<ObjectExtent> >& extents,
uint64_t buffer_offset=0);
...
- 分片大小对应的数据结构:
struct file_layout_t {
// file -> object mapping
uint32_t stripe_unit; ///< stripe unit, in bytes,
uint32_t stripe_count; ///< over this many objects
uint32_t object_size; ///< until objects are this big
int64_t pool_id; ///< rados pool id
std::string pool_ns; ///< rados pool namespace
file_layout_t(uint32_t su=0, uint32_t sc=0, uint32_t os=0)
: stripe_unit(su),
stripe_count(sc),
object_size(os),
pool_id(-1) {
}
// 默认分片大小 4MB
static file_layout_t get_default() {
return file_layout_t(1<<22, 1, 1<<22);
}
uint64_t get_period() const {
return static_cast<uint64_t>(stripe_count) * object_size;
}
void from_legacy(const ceph_file_layout& fl);
void to_legacy(ceph_file_layout *fl) const;
bool is_valid() const;
void encode(ceph::buffer::list& bl, uint64_t features) const;
void decode(ceph::buffer::list::const_iterator& p);
void dump(ceph::Formatter *f) const;
void decode_json(JSONObj *obj);
static void generate_test_instances(std::list<file_layout_t*>& o);
};
- 查看分片类对应的实现:ceph/src/osdc/Striper.cc
void Striper::file_to_extents(CephContext *cct, const char *object_format,
const file_layout_t *layout,
uint64_t offset, uint64_t len,
uint64_t trunc_size,
std::vector<ObjectExtent>& extents,
uint64_t buffer_offset)
{
striper::LightweightObjectExtents lightweight_object_extents;
file_to_extents(cct, layout, offset, len, trunc_size, buffer_offset,
&lightweight_object_extents);
// convert lightweight object extents to heavyweight version
extents.reserve(lightweight_object_extents.size());
for (auto& lightweight_object_extent : lightweight_object_extents) {
auto& object_extent = extents.emplace_back(
object_t(format_oid(object_format, lightweight_object_extent.object_no)),
lightweight_object_extent.object_no,
lightweight_object_extent.offset, lightweight_object_extent.length,
lightweight_object_extent.truncate_size);
object_extent.oloc = OSDMap::file_to_object_locator(*layout);
object_extent.buffer_extents.reserve(
lightweight_object_extent.buffer_extents.size());
object_extent.buffer_extents.insert(
object_extent.buffer_extents.end(),
lightweight_object_extent.buffer_extents.begin(),
lightweight_object_extent.buffer_extents.end());
}
}
void Striper::file_to_extents(
CephContext *cct, const file_layout_t *layout, uint64_t offset,
uint64_t len, uint64_t trunc_size, uint64_t buffer_offset,
striper::LightweightObjectExtents* object_extents) {
ldout(cct, 10) << "file_to_extents " << offset << "~" << len << dendl;
ceph_assert(len > 0);
/*
* we want only one extent per object! this means that each extent
* we read may map into different bits of the final read
* buffer.. hence buffer_extents
*/
__u32 object_size = layout->object_size;
__u32 su = layout->stripe_unit;
__u32 stripe_count = layout->stripe_count;
ceph_assert(object_size >= su);
if (stripe_count == 1) {
ldout(cct, 20) << " sc is one, reset su to os" << dendl;
su = object_size;
}
uint64_t stripes_per_object = object_size / su;
ldout(cct, 20) << " su " << su << " sc " << stripe_count << " os "
<< object_size << " stripes_per_object " << stripes_per_object
<< dendl;
uint64_t cur = offset;
uint64_t left = len;
while (left > 0) {
// layout into objects
uint64_t blockno = cur / su; // which block
// which horizontal stripe (Y)
uint64_t stripeno = blockno / stripe_count;
// which object in the object set (X)
uint64_t stripepos = blockno % stripe_count;
// which object set
uint64_t objectsetno = stripeno / stripes_per_object;
// object id
uint64_t objectno = objectsetno * stripe_count + stripepos;
// map range into object
uint64_t block_start = (stripeno % stripes_per_object) * su;
uint64_t block_off = cur % su;
uint64_t max = su - block_off;
uint64_t x_offset = block_start + block_off;
uint64_t x_len;
if (left > max)
x_len = max;
else
x_len = left;
ldout(cct, 20) << " off " << cur << " blockno " << blockno << " stripeno "
<< stripeno << " stripepos " << stripepos << " objectsetno "
<< objectsetno << " objectno " << objectno
<< " block_start " << block_start << " block_off "
<< block_off << " " << x_offset << "~" << x_len
<< dendl;
striper::LightweightObjectExtent* ex = nullptr;
auto it = std::upper_bound(object_extents->begin(), object_extents->end(),
objectno, OrderByObject());
striper::LightweightObjectExtents::reverse_iterator rev_it(it);
if (rev_it == object_extents->rend() ||
rev_it->object_no != objectno ||
rev_it->offset + rev_it->length != x_offset) {
// expect up to "stripe-width - 1" vector shifts in the worst-case
ex = &(*object_extents->emplace(
it, objectno, x_offset, x_len,
object_truncate_size(cct, layout, objectno, trunc_size)));
ldout(cct, 20) << " added new " << *ex << dendl;
} else {
ex = &(*rev_it);
ceph_assert(ex->offset + ex->length == x_offset);
ldout(cct, 20) << " adding in to " << *ex << dendl;
ex->length += x_len;
}
ex->buffer_extents.emplace_back(cur - offset + buffer_offset, x_len);
ldout(cct, 15) << "file_to_extents " << *ex << dendl;
// ldout(cct, 0) << "map: ino " << ino << " oid " << ex.oid << " osd "
// << ex.osd << " offset " << ex.offset << " len " << ex.len
// << " ... left " << left << dendl;
left -= x_len;
cur += x_len;
}
}
数据 IO
- 主要对应于
ImageCtx::io_work_queue成员变量。librbd::io::ImageRequestWQ派生自ThreadPool::PointerWQ<ImageRequest>(<= Luminous) / ThreadPool::PointerWQ<ImageDispatchSpec>(>= Mimic)。 - librbd 支持两种类型的 aio,一种是普通的 aio,一种是非阻塞 aio。前者的行为相对简单,直接在用户线程的上下文进行 io 处理,而后者将用户的 io 直接入
io_work_queue队列,然后 io 由队列的工作线程出队并在工作线程上下文进行后续的处理。这两种 aio 的行为由配置参数rbd_non_blocking_aio决定,默认为 true,因此默认为非阻塞 aio,但需要注意的是,即使默认不是非阻塞 aio,在某些场景下 aio 仍然会需要入io_work_queue队列,总结如下:
read
ImageRequestWQ::writes_blocked()为 true,即已调用ImageRequestWQ::block_writes,当前已禁止 write io 下发至 rados 层;ImageRequestWQ::writes_empty()为 false,即前面已经有 write io 入了io_work_queue队列;ImageRequestWQ::require_lock_on_read()为 true,这里的 lock 是指 exclusive lock,表示当前还未拿到,在启用 exclusive lock 特性的前提下,一旦开启克隆 COR (copy on read) 或者启用 journaling 特性,处理 read io 也要求拿锁;
write
ImageRequestWQ::writes_blocked()为 true,即已调用ImageRequestWQ::block_writes,当前已禁止 write io 下发至 rados 层;- 对于 write 而言,并没有类似
ImageRequestWQ::require_lock_on_write的接口,这是因为一旦启用 exclusive lock 特性,在初始化 exclusive lock 时会调用ImageRequestWQ::block_writes(参考 ExclusiveLock::init),直至拿到锁(参考ExclusiveLock::handle_post_acquired_lock),因此增加ImageRequestWQ::require_lock_on_write接口并没有必要。 - 需要注意的是,ImageRequestWQ::block_writes 并不只是简单的设置禁止标志,还需要 flush 已下发的 rados io,即等待所有已下发的 rados io 结束才返回。
- 从上面对 read、write 的分析,似乎
ImageRequestWQ::writes_blocked改成ImageRequestWQ::io_blocked似乎更合理,但实际上这里并没有真的禁止 read io 下发至 rados 层,只是让 read io 先入io_work_queue队列。
TCMU-RBD
static void tcmu_rbd_image_close(struct tcmu_device *dev)
{
struct tcmu_rbd_state *state = tcmur_dev_get_private(dev);
rbd_close(state->image);
rados_ioctx_destroy(state->io_ctx);
rados_shutdown(state->cluster);
state->cluster = NULL;
state->io_ctx = NULL;
state->image = NULL;
}
static int tcmu_rbd_image_open(struct tcmu_device *dev)
{
struct tcmu_rbd_state *state = tcmur_dev_get_private(dev);
int ret;
ret = rados_create(&state->cluster, state->id);
if (ret < 0) {
tcmu_dev_err(dev, "Could not create cluster. (Err %d)\n", ret);
return ret;
}
/* Try default location when conf_path=NULL, but ignore failure */
ret = rados_conf_read_file(state->cluster, state->conf_path);
if (state->conf_path && ret < 0) {
tcmu_dev_err(dev, "Could not read config %s (Err %d)",
state->conf_path, ret);
goto rados_shutdown;
}
rados_conf_set(state->cluster, "rbd_cache", "false");
ret = timer_check_and_set_def(dev);
if (ret)
tcmu_dev_warn(dev,
"Could not set rados osd op timeout to %s (Err %d. Failover may be delayed.)\n",
state->osd_op_timeout, ret);
ret = rados_connect(state->cluster);
if (ret < 0) {
tcmu_dev_err(dev, "Could not connect to cluster. (Err %d)\n",
ret);
goto rados_shutdown;
}
tcmu_rbd_detect_device_class(dev);
ret = rados_ioctx_create(state->cluster, state->pool_name,
&state->io_ctx);
if (ret < 0) {
tcmu_dev_err(dev, "Could not create ioctx for pool %s. (Err %d)\n",
state->pool_name, ret);
goto rados_shutdown;
}
ret = rbd_open(state->io_ctx, state->image_name, &state->image, NULL);
if (ret < 0) {
tcmu_dev_err(dev, "Could not open image %s. (Err %d)\n",
state->image_name, ret);
goto rados_destroy;
}
ret = tcmu_rbd_service_register(dev);
if (ret < 0)
goto rbd_close;
return 0;
rbd_close:
rbd_close(state->image);
state->image = NULL;
rados_destroy:
rados_ioctx_destroy(state->io_ctx);
state->io_ctx = NULL;
rados_shutdown:
rados_shutdown(state->cluster);
state->cluster = NULL;
return ret;
}
static int tcmu_rbd_open(struct tcmu_device *dev, bool reopen)
{
rbd_image_info_t image_info;
char *pool, *name, *next_opt;
char *config, *dev_cfg_dup;
struct tcmu_rbd_state *state;
uint32_t max_blocks;
int ret;
state = calloc(1, sizeof(*state));
if (!state)
return -ENOMEM;
tcmur_dev_set_private(dev, state);
dev_cfg_dup = strdup(tcmu_dev_get_cfgstring(dev));
config = dev_cfg_dup;
if (!config) {
ret = -ENOMEM;
goto free_state;
}
tcmu_dev_dbg(dev, "tcmu_rbd_open config %s block size %u num lbas %" PRIu64 ".\n",
config, tcmu_dev_get_block_size(dev),
tcmu_dev_get_num_lbas(dev));
config = strchr(config, '/');
if (!config) {
tcmu_dev_err(dev, "no configuration found in cfgstring\n");
ret = -EINVAL;
goto free_config;
}
config += 1; /* get past '/' */
pool = strtok(config, "/");
if (!pool) {
tcmu_dev_err(dev, "Could not get pool name\n");
ret = -EINVAL;
goto free_config;
}
state->pool_name = strdup(pool);
if (!state->pool_name) {
ret = -ENOMEM;
tcmu_dev_err(dev, "Could not copy pool name\n");
goto free_config;
}
name = strtok(NULL, ";");
if (!name) {
tcmu_dev_err(dev, "Could not get image name\n");
ret = -EINVAL;
goto free_config;
}
state->image_name = strdup(name);
if (!state->image_name) {
ret = -ENOMEM;
tcmu_dev_err(dev, "Could not copy image name\n");
goto free_config;
}
/* The next options are optional */
next_opt = strtok(NULL, ";");
while (next_opt) {
if (!strncmp(next_opt, "osd_op_timeout=", 15)) {
state->osd_op_timeout = strdup(next_opt + 15);
if (!state->osd_op_timeout ||
!strlen(state->osd_op_timeout)) {
ret = -ENOMEM;
tcmu_dev_err(dev, "Could not copy osd op timeout.\n");
goto free_config;
}
} else if (!strncmp(next_opt, "conf=", 5)) {
state->conf_path = strdup(next_opt + 5);
if (!state->conf_path || !strlen(state->conf_path)) {
ret = -ENOMEM;
tcmu_dev_err(dev, "Could not copy conf path.\n");
goto free_config;
}
} else if (!strncmp(next_opt, "id=", 3)) {
state->id = strdup(next_opt + 3);
if (!state->id || !strlen(state->id)) {
ret = -ENOMEM;
tcmu_dev_err(dev, "Could not copy id.\n");
goto free_config;
}
}
next_opt = strtok(NULL, ";");
}
ret = tcmu_rbd_image_open(dev);
if (ret < 0) {
goto free_config;
}
tcmu_rbd_check_excl_lock_enabled(dev);
ret = tcmu_rbd_check_image_size(dev, tcmu_dev_get_block_size(dev) *
tcmu_dev_get_num_lbas(dev));
if (ret) {
goto stop_image;
}
ret = rbd_stat(state->image, &image_info, sizeof(image_info));
if (ret < 0) {
tcmu_dev_err(dev, "Could not stat image.\n");
goto stop_image;
}
/*
* librbd/ceph can better split and align unmaps and internal RWs, so
* just have runner pass the entire cmd to us. To try and balance
* overflowing the OSD/ceph side queues with discards/RWs limit it to
* up to 4.
*/
max_blocks = (image_info.obj_size * 4) / tcmu_dev_get_block_size(dev);
tcmu_dev_set_opt_xcopy_rw_len(dev, max_blocks);
tcmu_dev_set_max_unmap_len(dev, max_blocks);
tcmu_dev_set_opt_unmap_gran(dev, image_info.obj_size /
tcmu_dev_get_block_size(dev), false);
tcmu_dev_set_write_cache_enabled(dev, 0);
free(dev_cfg_dup);
return 0;
stop_image:
tcmu_rbd_image_close(dev);
free_config:
free(dev_cfg_dup);
free_state:
tcmu_rbd_state_free(state);
return ret;
}
static void tcmu_rbd_close(struct tcmu_device *dev)
{
struct tcmu_rbd_state *state = tcmur_dev_get_private(dev);
tcmu_rbd_image_close(dev);
tcmu_rbd_state_free(state);
}
static int tcmu_rbd_aio_read(struct tcmu_device *dev, struct rbd_aio_cb *aio_cb,
rbd_completion_t completion, struct iovec *iov,
size_t iov_cnt, size_t length, off_t offset)
{
struct tcmu_rbd_state *state = tcmur_dev_get_private(dev);
int ret;
aio_cb->bounce_buffer = malloc(length);
if (!aio_cb->bounce_buffer) {
tcmu_dev_err(dev, "Could not allocate bounce buffer.\n");
return -ENOMEM;
}
ret = rbd_aio_read(state->image, offset, length, aio_cb->bounce_buffer,
completion);
if (ret < 0)
free(aio_cb->bounce_buffer);
return ret;
}
static int tcmu_rbd_aio_write(struct tcmu_device *dev, struct rbd_aio_cb *aio_cb,
rbd_completion_t completion, struct iovec *iov,
size_t iov_cnt, size_t length, off_t offset)
{
struct tcmu_rbd_state *state = tcmur_dev_get_private(dev);
int ret;
aio_cb->bounce_buffer = malloc(length);
if (!aio_cb->bounce_buffer) {
tcmu_dev_err(dev, "Failed to allocate bounce buffer.\n");
return -ENOMEM;;
}
tcmu_memcpy_from_iovec(aio_cb->bounce_buffer, length, iov, iov_cnt);
ret = rbd_aio_write(state->image, offset, length, aio_cb->bounce_buffer,
completion);
if (ret < 0)
free(aio_cb->bounce_buffer);
return ret;
}
static int tcmu_rbd_read(struct tcmu_device *dev, struct tcmulib_cmd *cmd,
struct iovec *iov, size_t iov_cnt, size_t length,
off_t offset)
{
struct rbd_aio_cb *aio_cb;
rbd_completion_t completion;
ssize_t ret;
aio_cb = calloc(1, sizeof(*aio_cb));
if (!aio_cb) {
tcmu_dev_err(dev, "Could not allocate aio_cb.\n");
goto out;
}
aio_cb->dev = dev;
aio_cb->type = RBD_AIO_TYPE_READ;
aio_cb->read.length = length;
aio_cb->tcmulib_cmd = cmd;
aio_cb->iov = iov;
aio_cb->iov_cnt = iov_cnt;
ret = rbd_aio_create_completion
(aio_cb, (rbd_callback_t) rbd_finish_aio_generic, &completion);
if (ret < 0) {
goto out_free_aio_cb;
}
ret = tcmu_rbd_aio_read(dev, aio_cb, completion, iov, iov_cnt,
length, offset);
if (ret < 0)
goto out_release_tracked_aio;
return TCMU_STS_OK;
out_release_tracked_aio:
rbd_aio_release(completion);
out_free_aio_cb:
free(aio_cb);
out:
return TCMU_STS_NO_RESOURCE;
}
static int tcmu_rbd_write(struct tcmu_device *dev, struct tcmulib_cmd *cmd,
struct iovec *iov, size_t iov_cnt, size_t length,
off_t offset)
{
struct rbd_aio_cb *aio_cb;
rbd_completion_t completion;
ssize_t ret;
aio_cb = calloc(1, sizeof(*aio_cb));
if (!aio_cb) {
tcmu_dev_err(dev, "Could not allocate aio_cb.\n");
goto out;
}
aio_cb->dev = dev;
aio_cb->type = RBD_AIO_TYPE_WRITE;
aio_cb->tcmulib_cmd = cmd;
ret = rbd_aio_create_completion
(aio_cb, (rbd_callback_t) rbd_finish_aio_generic, &completion);
if (ret < 0) {
goto out_free_aio_cb;
}
ret = tcmu_rbd_aio_write(dev, aio_cb, completion, iov, iov_cnt,
length, offset);
if (ret < 0) {
goto out_release_tracked_aio;
}
return TCMU_STS_OK;
out_release_tracked_aio:
rbd_aio_release(completion);
out_free_aio_cb:
free(aio_cb);
out:
return TCMU_STS_NO_RESOURCE;
}
参考链接
- [1] Ceph RDB 官方文档介绍
- [2] 简书 - ceph rbd:总览
- [3] 掘金 - Ceph介绍及原理架构分享
- [4] CSDN:Ceph学习——Librbd块存储库与RBD读写流程源码分析
- [5] CSDN:Ceph RBD编程接口Librbd(C++) -- 映像创建与数据读写
- [6] 腾讯云专栏:大话Ceph系列
- [7] runsisi.com - librbd 内部运行机制
- [8] CSDN:Ceph学习——Librados与Osdc实现源码解析
- [9] CSDN:librbd代码目录解读
- [10] Ceph: RBD 创建镜像过程以及源码分析
- [11] librbd 架构分析
