- 该篇文章来自于 OSDI2004,Google 当年率先提出的 MapReduce 框架,开启了分布式和大数据的纪元。
Before Beginning
- 为什么要读这篇论文呢?其实这篇文章之前也已经简单看过了,只是最近开始刷 MIT6.824,本来是想直接做相关 Lab 的,但是发现还是有整理不清楚的思路,觉得还是有必要回顾一下,那就多花点时间继续研读吧~
- 网上关于 6.824 以及 MapReduce 的资料很多了,我在这里只是做一些简单的记录,如果有发现其他大佬做的比较好的笔记,也会贴在这里,以供膜拜学习。我的 6.824 系列的的博客介绍大抵都是如此。
- 话不多说,学习开始~
Abstract
- 大致流程: 用户指定一个 map 函数来处理键/值对以生成一组中间键/值对,以及一个 reduce 函数来合并与同一中间键相关的所有中间值
- 为什么这么做? 是想充分利用不同机器的并行性来处理大量的数据,分别执行 map 和 reduce 任务来完成大数据任务,提高每个 host 的利用率。(也就是分布式系统的原型)
- 需要解决的问题:
- 数据输入的切分
- 不同机器上执行的任务的调度
- 机器故障处理
- 机器间通信的管理
Introduction
- 根本矛盾:少数据量时单机能够直接运行简单的任务来完成相关计算,但面对大数据量的情况下,引入多计算实例组成的系统的复杂性和本身计算任务的简单性之间的矛盾。
- 思想起源:来自于 Lisp 语言的函数式编程思想中的 map/reduce 函数。
- 在 lisp 语言中,map 作为一个输入函数接受一个序列,然后处理每个序列中 value 值,然后 reduce 将最终的 map 计算出来的结果整理成最终程序输出。
Programming Model
- MapReduce 本质是一种编程模型
- Map: 由用户编写,接受一个输入对并生成一组中间键/值对
// map (k1,v1) → list(k2,v2)
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
- Reduce: 也由用户编写,接受一个中间键和该键的一组值。它将这些值合并在一起,形成一个可能更小的值集
// reduce (k2,list(v2)) → list(v2)
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
- 应用实例:
- Distributed Grep
- Count of URL Access Frequency:map <URL, 1>, reduce <URL, total count>
- Reverse Web-Link Graph: map <target, source>, reduce <target, list(source)>
- Term-Vector per Host
- Inverted Index: map <word, document ID>, reduce <word, list(document ID)>
- Distributed Sort
Implementation
- Map 函数分布在多个机器上,相应地自动将输入数据划分为 M 份,然后可以由分布了 Map 函数的机器并行处理这些数据。而对于 Reduce 则是将中间数据划分为 R 份,通常需要使用一个分割函数,常见的就是
hash(key) mod R 来将中间 Key 进行区分。
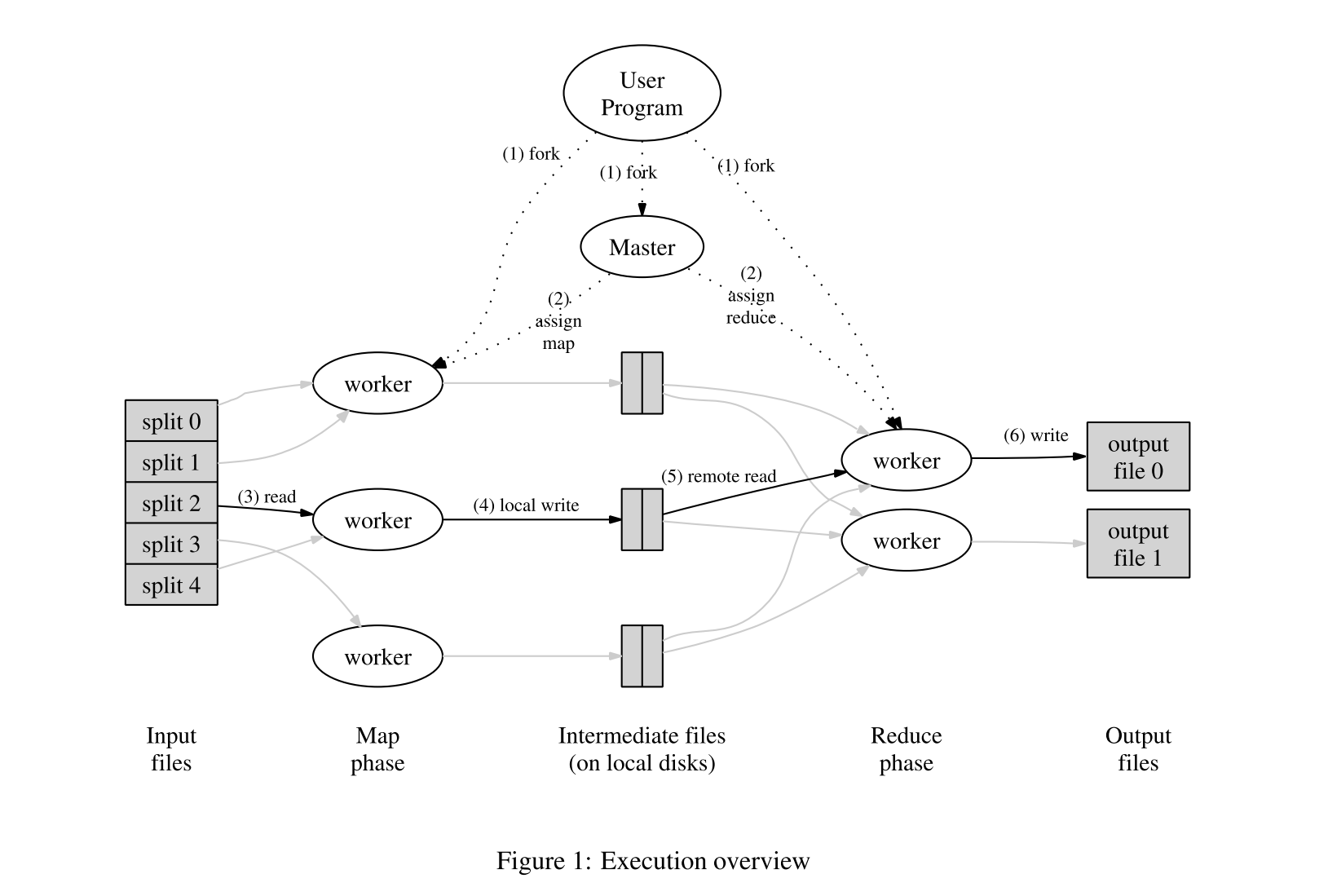
- 下图演示了整个 MapReduce 的流程,当用户程序调用 MapReduce 函数时将按照以下顺序执行:
-
- MapReduce Library 首先将输入文件划分为 M 个分片,每个分片大小通常为 16MB or 64MB,可以由用户控制,然后开始将程序拷贝到各个机器上,也就是图中的 fork 过程
-
- fork 的过程中会有一个特殊的情况,即 master 节点上运行的程序。剩下的 worker 对应执行的任务都是由 master 分配的,有 M 个 map task 和 R 个 reduce task 需要分配,master 选择空闲的 worker 来执行 map 或者 reduce task。
-
- 被分配到 map task 的 worker 首先读取分片的数据内容,它从输入数据中解析键/值对,并将每对键/值传递给用户定义的 Map 函数,然后由 Map 产生的中间键值对将被缓冲在内存中;
-
- 缓冲在内存中的中间数据将定期执行刷回操作写到磁盘,然后再由用户定义的分割函数执行将中间数据分割为 R 个区域,这些原本缓冲在内存中的数据持久化到磁盘之后的地址将传递给 master,然后 master 负责告诉 reduce task worker 这些数据在哪里。
-
- 执行 reduce task 的 worker 在接收到来自 master 的数据地址的通知之后,使用 RPC 来从 map worker 的本地磁盘中读取数据,当一个 reducer 读取到了所有的中间数据之后,就可以根据中间键对它进行排序,以便将所有出现的相同键组合在一起。之所以需要排序,是因为通常有许多不同的键映射到同一个reduce任务。如果中间数据量太大,无法装入内存,则使用外部排序。
-
- reduce worker 迭代已排序的中间数据,对于遇到的每个惟一的中间键,它将键和相应的中间值集传递给用户的 reduce 函数。Reduce 函数的输出被追加到这个 Reduce 分区的最终输出文件中;
-
- 所有的 map 任务和 reduce 任务都完成后,master 唤醒用户程序。此时,用户程序中的MapReduce 调用返回到用户程序。
Master Data Structures
- master 节点保存了几个数据结构:
- 对于每个 map 和 reduce task,它存储了 task 对应的状态(idle, in-progress, completed)
- worker machine 的标识(非空闲任务运行所在的机器)
- master 是一个管道,通过它将中间文件区域的位置从 map task 传播到 reduce task。因此,对于每个完成的 map task,master 存储了 map task 产生的 R 个中间文件区域的位置和大小,当 map task 完成时,master 将接收对该位置和大小信息的更新。信息被递增地推送给正在进行 reduce task 的 worker。
Fault Tolerance
- 由于 MapReduce 库被设计用来帮助处理使用成百上千台机器的大量数据,所以这个库必须能够优雅地容忍机器故障。
Worker Failure
- master 周期地 ping 每个 worker,如果在确定时间内未收到对应的响应,则认为该 worker 宕机,标记该 worker 为 failed,由 worker 已经完成的任何 map task 都将被重置回初始的空闲 idle 状态,因此有资格对其他 worker 进行重新调度,类似地,在一个失败的 worker 上正在进行的任何 map task 或reduce task 也会被重置为空闲,并可以重新调度。
- 在发生故障时,完成的 map task 将被重新执行,因为它们的输出存储在故障机器的本地磁盘上,因此无法访问。已完成的 reduce 任务不需要重新执行,因为它们的输出存储在全局文件系统中。
- 假设一个 map task A 一开始由 A 执行,之后由 B 执行(因为 A failed),所有正在执行 reduce task 的 workers 将被通知重新执行,任何尚未从 worker A 读取数据的 reduce task 都将从 worker B 读取数据。
Master Failure
- 让 master 定期对上面描述的 master 节点存取的数据结构做 checkpoint 很容易。如果 master task 失效,可以从最后一个检查点状态启动一个新的副本。然而,考虑到只有一个主机,它的失败是不太多见,因此,如果 master 失败,我们当前的实现将终止 MapReduce 计算。客户端可以检查这种情况,如果他们愿意,可以重试 MapReduce 操作。
Semantics in the Presence of Failures
- 当用户提供的 map 和 reduce 操作符是其输入值的确定性函数时,我们的分布式实现产生的输出与整个程序的非故障顺序执行产生的输出相同。
- 我们依赖 map 和 reduce task 输出的原子提交来实现该属性。每个正在进行的任务都将其输出写入私有临时文件。一个 reduce task 生成一个这样的文件,map task 生成 R 个这样的文件(每个 reduce task 一个)。当 map task 完成时,worker 向 master 发送一条消息,并在消息中包含 R 临时文件的名称,如果 master 接收到一个已经完成的 map task 的完成消息,它将忽略该消息。否则,它将在主数据结构中记录 R 文件的名称。
- 当一个 reduce task 完成之后,reduce worker 自动地将其临时输出文件重命名为最终输出文件。如果在多台机器上执行相同的 reduce 任务,那么将对相同的最终输出文件执行多个 rename 调用。我们依赖于底层文件系统提供的原子重命名操作,以确保最终文件系统状态只包含一次执行 reduce 任务所产生的数据。
- 我们的 map 和 reduce 操作符绝大多数都是确定性的,在这种情况下,我们的语义等价于顺序执行,这使得程序员可以很容易地推断他们的程序行为。当 map 或 reduce 操作符是不确定的时,我们提供较弱但仍然合理的语义。在存在非确定性操作符的情况下,特定 reduce 任务 R1 的输出等价于由非确定性程序的顺序执行产生的 R1 的输出。然而,不同 reduce 任务 R2 的输出可能对应于非确定性程序的不同顺序执行产生的 R2 输出。
- 考虑 map 任务 M 和 reduce 任务 R1 和 R2。设 e(Ri) 是所承诺的 Ri 的执行(只有一个这样的执行)。由于 e(R1) 可能读取了 M 的一次执行产生的输出,而 e(R2) 可能读取了 M 的另一次执行产生的输出,所以语义较弱。
Locality
- 在我们的计算环境中,网络带宽是一个相对稀缺的资源。通过利用输入数据(由 GFS 管理)存储在组成集群的机器的本地磁盘这一事实,我们节约了网络带宽。GFS 将每个文件划分为64 MB的块,并在不同的机器上存储每个块的多个副本(通常是3个副本),MapReduce master 将输入文件的位置信息考虑在内,并尝试在包含相应输入数据副本的机器上调度map任务。如果失败,它将尝试调度靠近该任务输入数据副本的 map 任务(例如,在与包含数据的机器在同一网络交换机上的工作机器上)。当在集群中相当一部分 worker 上运行大型MapReduce 操作时,大部分输入数据都是在本地读取的,不会消耗网络带宽
Task Granularity
- 如上所述,我们将 map 阶段细分为 M 个部分,将 reduce 阶段细分为 R 个部分。理想情况下,M 和 R 应该远远大于工作机器的数量。让每个 worker 执行许多不同的任务可以改善动态负载平衡,并在 worker 失败时加快恢复速度:它完成的许多 map 任务可以分散到所有其他 worker 机器上。
- 在我们的实现中,M 和 R 的大小最多有多大是有实际限制的,因为如上所述,master 必须做出 O(M + R) 调度决策,并在内存中保持 O(M*R) 状态。(内存使用的常量是很小的:状态的 O(M∗R) 部分由每个 map任务/reduce任务对大约一个字节的数据组成。)
- 此外,R 常常受到用户的限制,因为每个 reduce 任务的输出都以单独的输出文件结束。在实践中,我们倾向于选择 M,以便每个单独的任务大约有 16MB 到 64MB 的输入数据(以便上面描述的局部性优化最有效),并且我们将 R 设为预期使用的工作机器数量的小倍数。我们经常使用 2000 台 worker 机器进行 M = 200000 和 R = 5000 的 MapReduce 计算。
Backup Tasks
- 导致 MapReduce 操作总时间延长的一个常见原因是“掉线”(straggler)。一种需要异常长时间才能完成计算过程中最后几个 map 或 reduce 任务之一的机器。掉队者出现的原因有很多。例如,磁盘有问题的机器可能会经常出现可纠正错误,导致读性能从 30MB/s 降至 1MB/s。集群调度系统可能已经调度了机器上的其他任务,由于 CPU、内存、本地磁盘或网络带宽的竞争,导致它执行 MapReduce 代码的速度变慢。我们最近遇到的一个问题是,机器初始化代码中的一个bug导致了处理器缓存被禁用:受影响机器的计算速度降低了 100 倍以上。
- 我们有一个一般性的机制来缓解掉队者的问题。当 MapReduce 操作接近完成时,master 会对剩余的正在执行的任务进行备份。只要主执行或备份执行完成,任务就被标记为完成。我们已经调优了这种机制,因此它通常不会增加操作使用的计算资源超过几个百分点。我们发现,这大大减少了完成大型 MapReduce 操作的时间。以5.3中所述的排序程序为例,关闭备份机制后,排序程序完成的时间会增加 44%。
Refinements
Partitioning Function
- MapReduce 的用户指定他们想要的 reduce 任务/输出文件的数量(R),使用中间键上的分区函数在这些任务之间对数据进行分区。提供了一个默认的分区函数,使用哈希(例如" hash(key) mod R ")。这往往会导致相当平衡的分区。然而,在某些情况下,通过键的其他函数来分区数据是有用的。例如,有时输出键是url,我们希望单个主机的所有条目都在同一个输出文件中结束。为了支持这种情况,MapReduce 库的用户可以提供一个特殊的分区函数。例如,使用" hash(Hostname(urlkey)) mod R "作为分区函数会导致来自同一主机的所有 url 最终出现在同一个输出文件中。
Ordering Guarantees
- 我们保证在给定的分区中,中间键/值对按键的递增顺序进行处理。这种排序保证使得为每个分区生成有序的输出文件变得很容易,当输出文件格式需要支持按键进行有效的随机访问查找,或者输出的用户发现对数据进行排序很方便时,这很有用。
Combiner Function
- 在某些情况下,每个 map 任务产生的中间键有显著的重复,并且用户指定的 Reduce 函数是可交换的和关联的。单词计数示例就是一个很好的例子。由于单词频率倾向于遵循 Zipf 分布,每个 map 任务将产生数百或数千个 <the, 1> 形式的记录。所有这些计数将通过网络发送到一个 reduce 任务,然后由 reduce 函数相加产生一个数字。我们允许用户指定一个可选的Combiner函数,该函数在通过网络发送数据之前对数据进行部分合并。
- Combiner 函数在每一个执行 map task 上的机器执行,通常使用相同的代码来实现 combiner 和 reduce 函数,reduce 函数和 combiner 函数之间的唯一区别是 MapReduce 库如何处理函数的输出。reduce 函数的输出被写入最终的输出文件。combiner 函数的输出被写入一个中间文件,该文件将被发送到reduce 任务。
- 部分 Combine 大大加快了 MapReduce 操作的某些类。
- MapReduce 库支持以几种不同的格式读取输入数据。text 模式的输入将每一行视为键/值对:键是文件中的偏移量,值是行内容。另一种常见的支持格式存储按键排序的键/值对序列。每个输入类型实现都知道如何将自己分割成有意义的范围,以便作为单独的 map 任务进行处理(例如,文本模式的范围分割确保范围分割只发生在行边界)。用户可以通过提供一个简单的 reader 接口的实现来添加对新输入类型的支持,尽管大多数用户只使用少数预定义输入类型中的一种。
- reader 并不一定需要提供从文件中读取的数据。例如,很容易定义从数据库或映射在内存中的数据结构中读取记录的 reader。
- 以类似的方式,我们支持一组输出类型来生成不同格式的数据,并且用户代码很容易添加对新输出类型的支持。
Side-effects
- 在某些情况下,MapReduce 的用户发现从他们的 map 或 reduce 操作生成辅助文件作为额外的输出是很方便的。我们依靠应用程序 writer 使这些副作用具有原子性和幂等性。通常,应用程序会写入一个临时文件,并在完全生成该文件后自动重命名该文件。
- 我们不支持单个任务生成的多个输出文件的原子两阶段提交。因此,产生具有跨文件一致性要求的多个输出文件的任务应该是确定的。这种限制在实践中从来就不是问题。
Skipping Bad Records
- 有时,用户代码中的错误会导致 Map 或 Reduce 函数在特定记录上崩溃。此类 bug 会导致 MapReduce 操作无法完成。通常的做法是修复 bug,但有时这是不可行的;这个 bug 可能存在于源代码不可用的第三方库中。此外,有时忽略一些记录是可以接受的,例如在对一个大数据集进行统计分析时。我们提供了一个可选的执行模式,MapReduce 库会检测哪些记录导致确定性崩溃,并跳过这些记录以便继续前进。
- 每个工作进程都安装一个信号处理程序来捕获分割违规和总线错误。在调用 Map 或 Reduce 操作之前,MapReduce 库会将参数的序号存储在全局变量中。如果用户代码产生信号,信号处理器发送一个包含序列号的“最后一口气” UDP 包给 MapReduce master。当主服务器在一个特定的记录上看到多个失败时,它指示在下一次重新执行对应的 Map 或 Reduce 任务时应该跳过该记录。
Local Execution
- 在 Map 或 Reduce 函数中调试问题可能会很棘手,因为实际的计算发生在分布式系统中,通常在几千台机器上,由 master 动态地做出工作分配决策。为了方便调试、分析和小规模测试,我们开发了 MapReduce 库的替代实现,在本地机器上顺序执行 MapReduce 操作的所有工作。控件提供给用户,以便计算可以限制到特定的映射任务。用户可以用一个特殊的标志来调用他们的程序,然后可以很容易地使用任何他们认为有用的调试或测试工具(例如gdb)。
- 主服务器运行一个内部HTTP服务器,并导出一组状态页面供人们使用。状态页面显示了计算的进度,例如有多少任务已经完成,有多少任务正在进行,输入字节数,中间数据字节数,输出字节数,处理速率等。这些页面还包含指向每个任务生成的标准错误和标准输出文件的链接。用户可以使用这些数据来预测计算将花费多长时间,以及是否应该向计算中添加更多的资源。这些页面还可以用于计算何时会比预期的慢得多。
- 此外,顶级状态页面显示哪些 worker 失败了,以及当他们失败时正在处理哪些 map 和 reduce 任务。当试图诊断用户代码中的错误时,此信息非常有用。
Counters
- MapReduce 库提供了一个计数器来计算各种事件的发生次数。例如,用户代码可能需要计算已处理的字的总数或索引的德文文档的数量,等等。
- 要使用这个功能,用户代码创建一个命名的计数器对象,然后在 Map 或 Reduce 函数中适当地增加计数器。例如:
Counter* uppercase;
uppercase = GetCounter("uppercase");
map(String name, String contents):
for each word w in contents:
if (IsCapitalized(w)):
uppercase->Increment();
EmitIntermediate(w, "1");
- 来自各个 worker 机器的计数器值定期传播到 master (在 ping 响应中附带)。master 聚合成功的 map 和 reduce 任务的计数器值,并在 MapReduce 操作完成时将它们返回给用户代码。当前计数器值也显示在 master 状态页面上,以便人们可以观看实时计算的进度。在聚合计数器值时,master 消除了重复执行同一个 map 或 reduce 任务的影响,以避免重复计算。(重复执行可能是由于我们使用了备份任务以及由于失败而重新执行任务引起的。)
- 一些计数器值由 MapReduce 库自动维护,例如处理的输入键/值对的数量和产生的输出键/值对的数量。
- 用户已经发现 counter 工具对于检查 MapReduce 操作的行为是非常有用的。例如,在一些 MapReduce 操作中,用户代码可能希望确保生成的输出对的数量恰好等于处理的输入对的数量,或者确保处理的德文文档的比例在处理的文档总数的某个可容忍的比例内。
Conclusion
- MapReduce编程模型已经在谷歌上成功地用于许多不同的目的。我们认为这种成功有几个原因。首先,该模型易于使用,即使对于没有并行和分布式系统经验的程序员也是如此,因为它隐藏了并行化、容错、局部性优化和负载平衡的细节。其次,大量的问题可以通过MapReduce计算很容易地表达出来。例如,MapReduce被用于谷歌生产web搜索服务的数据生成、排序、数据挖掘、机器学习以及许多其他系统。第三,我们开发了一个MapReduce的实现,它可以扩展到由数千台机器组成的大型机器集群。该实现有效地利用了这些机器资源,因此适合用于在谷歌中遇到的许多大型计算问题。
- 我们从这项工作中学到了一些东西。首先,对编程模型的限制使得并行化和分布式计算变得容易,并使这些计算具有容错性。其次,网络带宽是一种稀缺资源。因此,我们系统中的许多优化都旨在减少通过网络发送的数据量:局部性优化允许我们从本地磁盘读取数据,将中间数据的单个副本写入本地磁盘可以节省网络带宽。第三,冗余执行可以用来减少慢速机器的影响,并处理机器故障和数据丢失。
#include "mapreduce/mapreduce.h"
// 用户实现map函数
class WordCounter : public Mapper {
public:
virtual void Map(const MapInput& input) {
const string& text = input.value();
const int n = text.size();
for (int i = 0; i < n; ) {
// 跳过前导空格
while ((i < n) && isspace(text[i]))
i++;
// 查找单词的结束位置
int start = i;
while ((i < n) && !isspace(text[i]))
i++;
if (start < i)
Emit(text.substr(start,i-start),"1");
}
}
};
REGISTER_MAPPER(WordCounter);
// 用户实现reduce函数
class Adder : public Reducer {
virtual void Reduce(ReduceInput* input) {
// 迭代具有相同key的所有条目,并且累加它们的value
int64 value = 0;
while (!input->done()) {
value += StringToInt(input->value());
input->NextValue();
}
// 提交这个输入key的综合
Emit(IntToString(value));
}
};
REGISTER_REDUCER(Adder);
int main(int argc, char** argv) {
ParseCommandLineFlags(argc, argv);
MapReduceSpecification spec;
// 把输入文件列表存入"spec"
for (int i = 1; i < argc; i++) {
MapReduceInput* input = spec.add_input();
input->set_format("text");
input->set_filepattern(argv[i]);
input->set_mapper_class("WordCounter");
}
//指定输出文件:
// /gfs/test/freq-00000-of-00100
// /gfs/test/freq-00001-of-00100
// ...
MapReduceOutput* out = spec.output();
out->set_filebase("/gfs/test/freq");
out->set_num_tasks(100);
out->set_format("text");
out->set_reducer_class("Adder");
// 可选操作:在map任务中做部分累加工作,以便节省带宽
out->set_combiner_class("Adder");
// 调整参数: 使用2000台机器,每个任务100MB内存
spec.set_machines(2000);
spec.set_map_megabytes(100);
spec.set_reduce_megabytes(100);
// 运行它
MapReduceResult result;
if (!MapReduce(spec, &result)) abort();
// 完成: 'result'结构包含计数,花费时间,和使用机器的信息
return 0;
- 论文的部分到此结束,后面展开讲一下 MapReduce 的其他东西。
Other
- MapReduce 最重要的贡献:MR takes care of, and hides, all aspects of distribution!
Problems
- What if the master gives two workers the same Map() task?
- Perhaps the master incorrectly thinks one worker died. it will tell Reduce workers about only one of them.
- What if the master gives two workers the same Reduce() task?
- they will both try to write the same output file on GFS! atomic GFS rename prevents mixing; one complete file will be visible.
- What if a single worker is very slow -- a "straggler"?
- perhaps due to flakey hardware. master starts a second copy of last few tasks.
- What if a worker computes incorrect output, due to broken h/w or s/w?
- too bad! MR assumes "fail-stop" CPUs and software.
Current status
- Hugely influential (Hadoop, Spark, &c).
- Probably no longer in use at Google.
- Replaced by Flume / FlumeJava (see paper by Chambers et al).
- GFS replaced by Colossus (no good description), and BigTable.
Conclusion
- MapReduce single-handedly made big cluster computation popular.
- -Not the most efficient or flexible.
- +Scales well.
- +Easy to program -- failures and data movement are hidden.
