- Cache Replacement Policies - Taxonomy
缓存替换策略的分类
- 为了组织这本书和几十年来研究过的许多思想,我们提出了缓存替换问题的解决方案的分类。我们的分类法建立在这样一个观察之上:缓存替换策略解决了一个预测问题,其目标是预测是否应该允许任何给定的行留在缓存中。该决定在缓存行生命周期的多个点重新计算,从该行插入缓存时开始,到该行从缓存中删除时结束。
- 因此,在我们的分类法中,我们首先根据插入决策的粒度将缓存替换策略分为两大类。在第一类策略中,我们称之为粗粒度策略,当所有的行插入缓存时,它们被相同地对待,并且只根据它们在缓存中的行为来区分行。例如,由于一个缓存行驻留在缓存中,它的优先级可能会在每次重用时增加。相比之下,细粒度策略在插入到缓存时区分行(除了观察它们驻留在缓存中的行为)。为了在插入时进行区分,细粒度策略通常依赖于关于缓存访问行为的历史信息。例如,如果细粒度策略了解到某个特定指令加载的行在过去往往会被逐出而不会被重用,那么它可以以低优先级插入该行。
- 为了更好地理解我们的分类,了解替换策略通常是通过将少量替换状态与每个缓存行关联来实现的,这一点很有用。
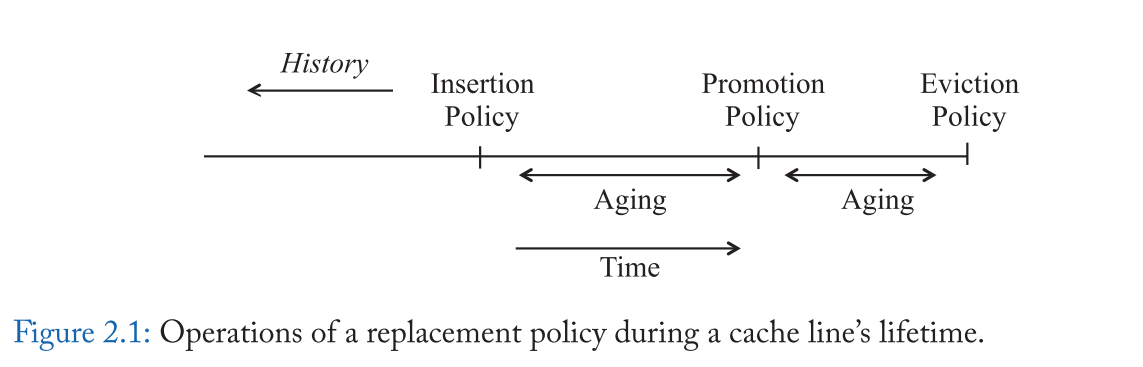
缓存生命周期中的相关概念
- Insertion Policy:当新行插入缓存时,替换策略如何初始化它的替换状态?
- Promotion Policy:当缓存行在缓存中命中的时候,替换策略如何更新该行的替换状态?
- Aging Policy:当插入或提升竞争行时,替换策略如何更新该行的替换状态?
- Eviction Policy:给定固定数量的选择,哪一行执行替换策略驱逐?
- 从缓存线的生命周期来看,我们可以看到粗粒度策略在插入时对所有缓存行的处理是相同的,所以它们主要依赖于聪明的老化和 promotion 策略来操作替换优先级。相反,细粒度策略使用更智能的插入策略。当然,细粒度策略还需要适当的老化和 promotion 来更新替换状态,因为在插入时并不能预测所有行为
粗粒度缓存
- 粗粒度策略在第一次插入缓存时对所有行的处理都是相同的,它们通过观察驻留在缓存中的行的重用行为来区分对缓存友好的行和对缓存不友好的行。根据用于区分缓存驻留行的指标,我们将粗粒度策略进一步划分为三个类。
- 第一个类包括绝大多数粗粒度策略,描述了基于最近访问时间对高速缓存行进行排序的策略。
- 第二个类包括基于访问频率对高速缓存行进行排序的策略。
- 最后,第三类中的策略随着时间的推移监视缓存行为,以便在给定的时间段内动态地选择最佳粗粒度策略。
Recency-Based Policies
- 基于最近的策略基于每一行在其生命周期内的最新引用来排序行。为了达到这个顺序,基于最近的策略维护了一个概念性的 recency stack,该栈提供了引用行的相对顺序。不同的政策以不同的方式利用最新信息。例如,常用的LRU(最近最少使用)策略(及其变体)优先驱逐最近最少使用的行,而MRU(最近最常使用)等策略优先驱逐最近使用的行;其他政策利用中间解决方案。
- 我们进一步划分基于最近行为的生命周期定义的基于最近行为的策略。
- 第一个类,包括绝大多数基于 recency-based 的策略,描述了当一行被从缓存中移除时结束该行生命周期的策略。我们认为这种策略有 固定的生命周期。
- 第二个类包括一些策略,这些策略通过引入一个临时结构来延长缓存行的生命周期,使其超越回收,该结构为具有较长重用距离的行提供第二次接收缓存命中的机会。我们说,这样的政策有一个延长的寿命。
Frequency-BasedPolicies
- 基于频率的策略维护频率计数器,以根据它们被引用的频率对行进行排序。不同的替换策略使用不同的策略来更新和解释这些频率计数器。例如,一些策略单调地增加计数器,而另一些策略则随着时间的推移使计数器老化(降低其值)。另一个例子是,一些策略驱逐频率最低的行,而另一些策略驱逐频率满足预定义标准的行
Hybrid Policies
- 由于不同的粗粒度策略适用于不同的缓存访问模式,因此混合策略可以在几个预先确定的粗粒度策略中动态选择,以适应程序执行中的阶段变化。特别是,混合策略在评估期间观察一些候选粗粒度策略的命中率,并使用此反馈来为未来访问选择最佳的粗粒度策略。自适应策略是有利的,因为它们有助于克服单个粗粒度策略的问题。在第三章中,我们将看到,最先进的混合政策调节粗粒度之间使用不同的插入优先的政策,我们注意到,尽管插入优先级的变化随着时间的推移,这些策略仍是粗粒度的,因为在一个时期,所有的处理是完全相同的。
细粒度缓存
- 细粒度策略在将行插入缓存时区分行。它们通过使用来自高速缓存行以前生命周期的信息来进行这些区分。例如,如果一行在过去没有收到命中,那么它可以以低优先级插入。由于记住所有缓存行的过去行为是不可行的,细粒度策略通常记住一组缓存行的行为。例如,许多策略组合成一组最后被相同的加载指令访问的缓存行。
- 当然,所有细粒度策略都需要考虑的一个问题是在插入时用于区分这些组的指标。基于使用的度量,我们将细粒度策略分为两大类:
- (1) 基于分类的策略与每一组可能的预测之一相关联,即缓存友好型和缓存厌恶型;
- (2) 基于重用距离的策略尝试预测每组缓存线的详细重用距离信息。
- 这两类定义了一个频谱的极端,频谱一端的策略只有两个可能的预测值,而频谱另一端的政策有许多可能的预测值;许多策略将会在四个或八个可能值中预测其中之一。最后,Beckmann 和 Sanchez 提出了新的度量标准 [Beckmann和Sanchez, 2017],我们将在第三类中讨论
Classification-Based Policies
- 基于分类的策略将传入的缓存行分为两类: 友好缓存行或反对缓存线。其主要思想是优先清除不支持缓存的行,以便为支持缓存的行留下更多的空间,因此,支持缓存的行会以比反对缓存的行更高的优先级插入。在缓存友好的行之间维护二级排序,通常基于最近次数。基于分类的策略被广泛认为是最先进的,因为 (1) 它们可以利用过去行为的长期历史来为未来做出更明智的决定,(2) 它们可以容纳所有类型的缓存访问模式。
Reuse Distance-Based Policies
- 基于重用距离的策略预测传入行的详细重用距离信息。超过预期重用距离而没有接收到命中的行将从缓存中删除。这些策略可以被视为基于最近的策略或基于频率的策略的预测变体,因为基于最近的和基于频率的策略都通过监视缓存线在缓存驻留时的重用行为隐式地估计重用距离(分别通过最近和频率)。利用历史信息对重用距离的显式预测有其独特的优点和缺点
设计考量
- 替换策略的主要目标是提高缓存命中率,许多设计因素有助于实现更高的命中率:
- 粒度: 在插入时,行的粒度是多少?是否所有的高速缓存行都被相同的处理,或者它们是否根据历史信息分配不同的优先级
- 历史: 替换策略在做决策时利用了多少历史信息?
- 访问模式: 替换策略对特定访问模式的专门化程度如何?它对访问模式的更改或不同访问模式的混合是否健壮?
- 图 2.2 总结了我们完整的分类,并显示了替换策略的不同类别是如何处理这些设计因素的。一般来说,当我们移到图的右侧(通常与更新的策略相对应)时,趋势是趋向于使用较长的历史记录并能够适应各种访问模式的更细粒度的解决方案。在细粒度预测缓存行为的重要性可以通过观察最近的cache Replacement Championship(2017)的前四个解决方案都是细粒度的来衡量。细粒度预测为最新的细粒度策略提供了两个优势。
- 首先,它们允许细粒度策略只将缓存空间专用于最有可能从缓存中受益的行;相比之下,粗粒度策略倾向于重复将缓存资源分配给没有产生任何命中的行。
- 其次,它们允许细粒度策略动态地确定不同组的行的访问模式;相比之下,粗粒度策略假设整个缓存遵循统一的缓存访问模式。
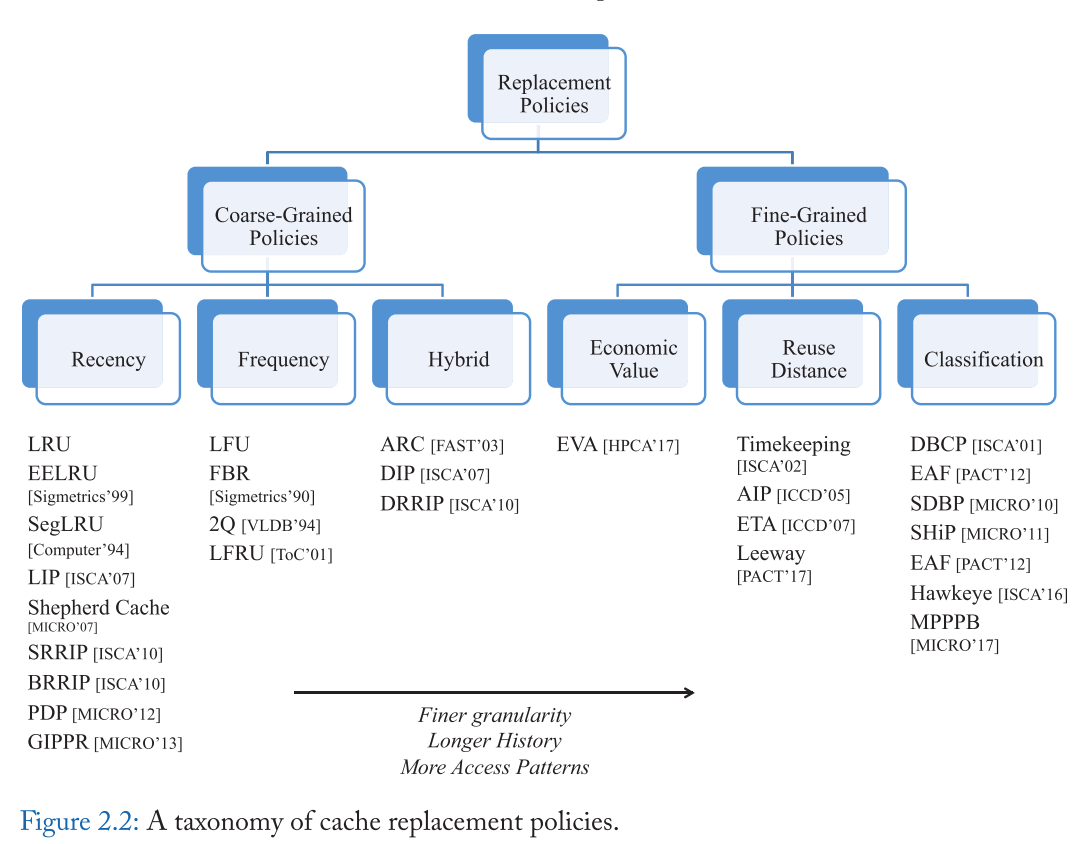
- 在细粒度的政策中,趋势是使用更长的历史作为state-ofthe-art细粒度策略(Jain and Lin, 2016)从历史是8样本信息缓存的大小(见第4章)。悠久的历史的应用让策略检测缓存友好长期重用行,否则就会被一长串厌恶缓存的中间访问所混淆。
x
感谢您的支持,我会继续努力的!
扫码打赏,你说多少就多少
