- FAST 2021 的文章《SpanDB: A Fast, Cost-Effective LSM-tree Based KV Store on Hybrid Storage》
- SpanDB: A Fast, Cost-Effective LSM-tree Based KV Store on Hybrid Storage
- Elvis Zhang's Blog
Abstract
- 键值(KV)存储支持许多关键的应用程序和服务。它们在内存中执行的速度很快,但仍然经常受到I/O性能的限制。最近出现的高速商业NVMe ssd推动了利用其超低延迟和高带宽优势的新kv系统设计。与此同时,转换到全新的数据布局并将整个数据库扩展到高端 SSD 需要大量的投资。
- 作为一种折衷方案,我们提出了SpanDB,一种基于 LSM 树的 KV 存储,适应流行的RocksDB 系统,利用高速 SSD 选择性部署。SpanDB 允许用户将大量数据存储在更便宜、更大的SSD上,同时将预写日志(WAL)和 LSM 树的顶层重新定位到更小、更快的NVMe SSD上。为了更好地利用这个快速磁盘,SpanDB通过SPDK提供了高速、并行的WAL写入,并支持异步请求处理,以减轻线程间同步开销,并有效地使用基于轮询的I/O工作。我们的测试结果显示,SpanDB 同时将 RocksDB 的吞吐量提高了8.8x,并将延迟降低了9.5% - 58.3%。与专为高端 SSD 设计的 KVell 系统相比,SpanDB的吞吐量达到 96-140%,延迟 2.3-21.6x 更低,存储配置更便宜。
- Github Repo
Introduction
- LSM 树应用广泛,它仍然具有吸引力,因为生产KV环境经常被发现是写密集型的,特别是由于积极的内存缓存。正如最近的系统所证明的那样,最近快速的、商业NVMe SSD可以显著提高KV性能,如 KVell、KVSSD,通过丢弃为硬盘设计的LSM-tree数据结构或将KV数据管理卸载到专门的硬件,这些系统提供了高吞吐量和可伸缩性,整个数据集托管在高端设备上。
- 相反,这项工作的目标是将主流基于lsm树的KV设计适应于快速NVMe ssd和I/O接口,并特别关注在生产环境中具有成本效益的部署,因为我们发现当前基于 LSM 树的 KV 存储未能充分挖掘 NVMe SSD 的潜力(对比 NVMe SSD 和 SATA SSD),特别是,常见的KV存储设计的I/O路径严重地未充分利用超低延迟NVMe ssd,特别是对于小的写操作(对比 ext4 和 SPDK)
- 这对写前日志记录(WAL)尤为不利,WAL 它对数据持久性和事务原子性至关重要,位于写的关键路径上,是主要瓶颈。其次,现有的KV请求处理采用慢速设备,如果切换到快速的基于轮询的I/O,工作流设计将引入高软件开销或浪费CPU周期
- 此外,新的NVMe接口附带了访问约束(例如要求绑定整个设备以进行SPDK访问,或者建议将线程固定在core上)。这使得使用高端 SSD 来处理不同类型的KV I/O的KV设计变得复杂,并降低了当前的常见实践(如同步请求处理)的效率。
- 像Optane这样的顶级ssd对于大规模部署来说是昂贵的。由于大型的、写密集型的KV存储不可避免地拥有大量的冷数据,在这些相对较小和昂贵的设备上托管所有数据可能超出用户或云数据库服务提供商的预算。
- 针对这些挑战,我们提出了SpanDB,一个基于LSM tree的KV系统,采用高端NVMe ssd进行部分部署,对使用 SPDK I/O 的 KV 系统的瓶颈和挑战进行了全面分析。
- 它通过合并一个相对较小但速度较快的磁盘(SD)来扩大对最新数据的所有读写处理,同时将数据存储扩展到一个或多个更大、更便宜的磁盘(CD)上。
- 它可以通过SPDK实现快速并行访问,从而更好地利用SD,绕过Linux I/O堆栈,特别是允许高速WAL写入。(据作者描述,这是研究KV存储的SPDK支持的第一个工作。)
- 它设计了一个适合基于轮询的I/O的异步请求处理管道,它消除了不必要的同步,积极地将I/O等待与内存中处理重叠,并自适应地协调前台/后台I/O。
- 它根据实际的KV工作负载有策略地自适应地划分数据,积极地将CD的I/O资源,特别是带宽纳入其中,以帮助共享当代KV系统中常见的写放大
- SpanDB重新设计了RocksDB的KV请求处理、存储管理和组WAL写,利用快速SPDK接口,保留了RocksDB的lsm树组织、后台I/O机制、事务支持等数据结构和算法。 因此,它的设计与RocksDB的许多其他优化方案是互补的。添加SD后,可以将现有的RocksDB数据库迁移到SpanDB
- 我们使用YCSB和LinkBench进行的评估显示,SpanDB在所有测试用例中(吞吐量、平均延迟和尾部延迟)的性能都显著优于RocksDB,特别是在写密集型测试用例中。相对于最近设计用来利用高端ssd的KVell系统,SpanDB在大多数情况下提供了更高的吞吐量(只占KVell延迟的一小部分),而不牺牲事务支持。
Background & Motivation
LSM-tree based KV Stores
- 整体架构不再赘述。
- 几个观点:
- WAL 仍然是面向客户的数据库的一个组成部分,并且位于处理写请求的关键路径上
- 读操作可能会在 LSM 的很多层上产生随机数据访问,尽管有很多系统采用内存缓存来优化读性能,但是对于数据量较大的情况或者局部性较差的情况还是会产生 I/O 操作,严重增加了尾延迟,影响整体性能。
- flush 和 compaction 操作都会产生较大的顺序 I/O,它对前台请求处理的影响体现在 I/O 争用和写停滞(当用户写需要等待刷新以清空MemTable空间时)。
- RocksDB和LevelDB通过用户可配置的flush/compaction线程数量来控制后台I/O速率,当有后台I/O任务时,它们被激活,否则休眠。研究人员已经注意到后台线程设置对性能的影响,并提出了相关的优化 (SILK)。然而,现有的解决方案仍然保留了后台线程设计,假定I/O速度较慢和基于中断的同步,这在新的基于轮询的I/O接口(将在下面讨论)中不能很好地工作。
Group WAL Writes
-
当前写 WAL 的常见做法是分组日志记录(group logging),即对一次日志数据写入批量处理多个写请求。在很多常见的数据库系统中都使用了该技术,除了容错之外,组日志还通过促进顺序写操作,在速度较慢的存储设备(其中随机访问往往更慢)上提供了更好的写性能。
-
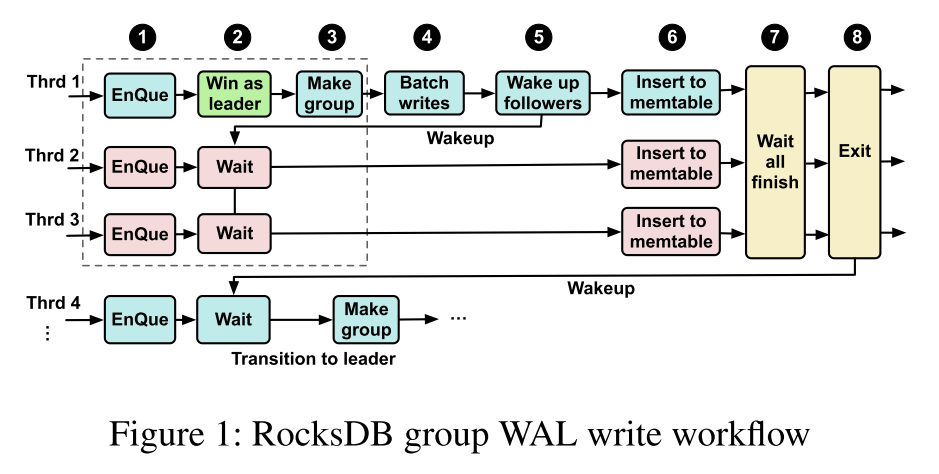
图 1 展示了批量写 WAL 的流程。WAL 的写入过程是顺序的,任何时候最多只有一个 group 在写 log。
- 当有一个正在进行中的写操作时,处理写请求的 workers 线程通过加入一个共享队列组成一个新的组,第一个进入队列的线程被指定为组的 leader。图示 1 - 3
- leader 从 peers 中收集日志项,直到前一个组的 leader (刚刚完成写入)通知它继续执行。这将关闭当前组的大门,随后到达的线程将启动一个新的组。
- leader 以单个同步 I/O 步骤(使用fsync/fdatasync, 4)将日志条目写入持久存储。然后,leader 唤醒组成员,启动 MemTables 中的更新,使这样的写入对后续的请求可见 5 - 6
- 通过将最后一个可见序列推进到其条目中的最新序列号来完成组提交 7
- 解散组 8,然后唤醒下一个 leader
-
使用高端 NVMe SSD 的话,上图中的步骤 4 的时间可以大幅减少。与此同时批处理写操作合并了小 IO。因此,同步组日志导致的软件开销增加,导致大多数线程将时间浪费在不同类型的等待上 (步骤 1-3 和 7)
-
例如,我们测量了RocksDB在通过ext4访问的SATA SSD上的这4个步骤上平均花费了68.1%的写请求处理时间,而在Optane上通过 SPDK 则增长到了81.0%。(因为总花费的时间减少了,等待的时间所占据的比重就增加了)
-
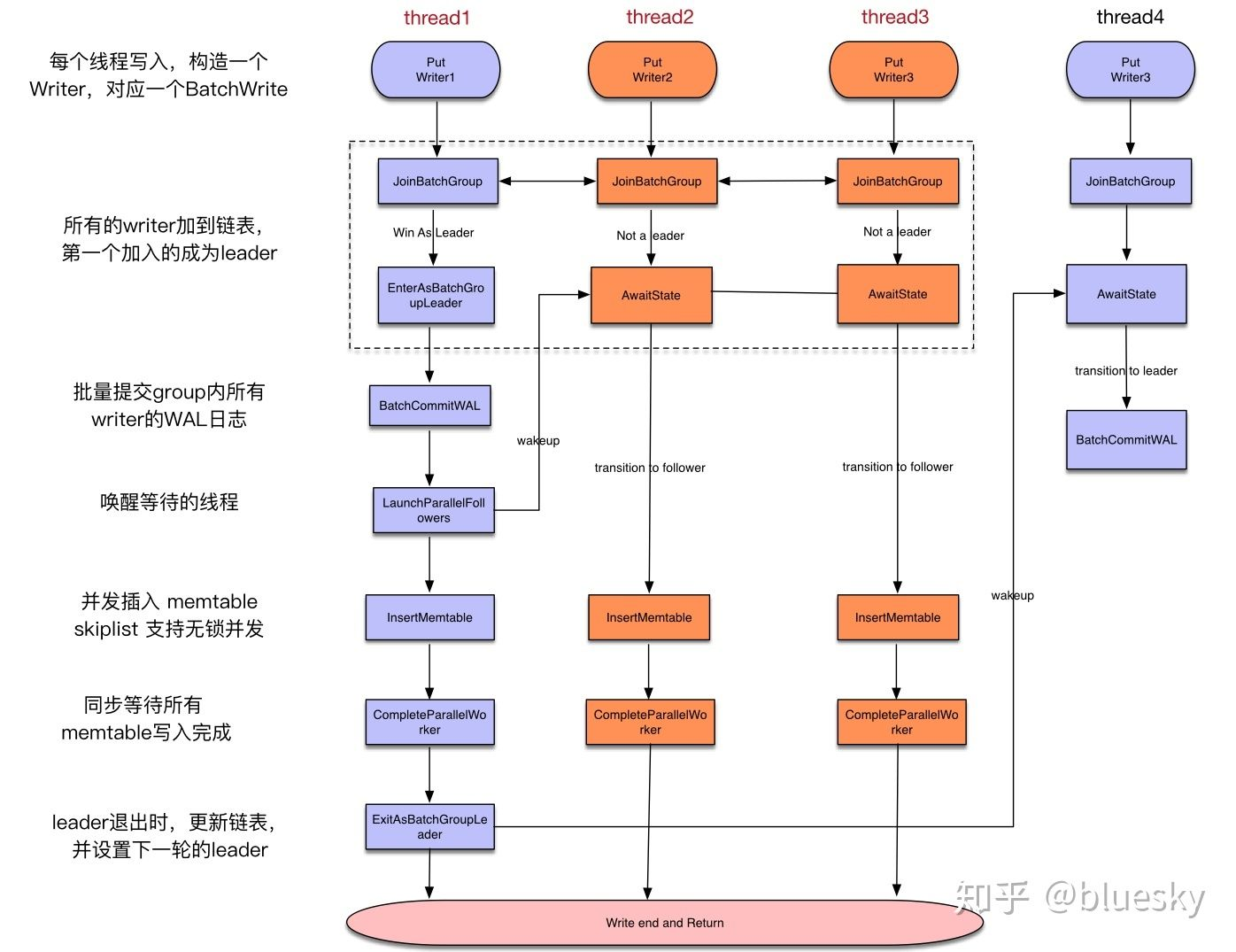
如果上面的 Group Logging 流程不够清晰,可以看下面这个图
High-Performance SSDs Interfaces
- 高性能 SSD Intel Optane、Toshiba XL-Flash、Samsung Z-SSD 提供了更低的延迟和更高的吞吐量。考虑到Linux内核I/O堆栈开销在总I/O延迟中不再是可以忽略的,Intel 开发了 SPDK,一组用户态的库/工具来访问高速的 NVMe 设备。SPDK 把驱动移动到了用户空间,避免了系统调用并支持了零拷贝访问。它轮询硬件完成,而不是使用中断,并避免I/O路径中的锁。在这里我们总结了在本研究中发现的与KV存储相关的SPDK性能行为和策略限制
SPDK 整体性能
- Intel Optane P4800X and P4610
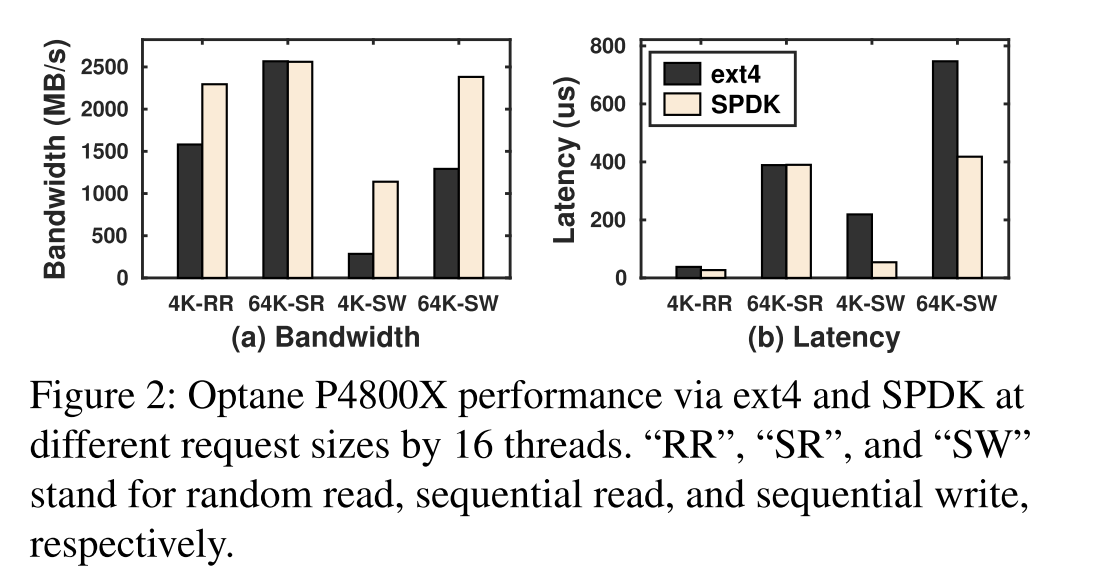
- 使用不同类型和不同大小的 IO 组合来模拟 I/O,下图展示了 P4800X 的结果,P4160 展示的测试结果趋势类似。ext4 使用了 write 调用,每一个都进行了 fdatasync,SPDK 使用了内建的 perf tool (spdk_nvme_perf)
- 结果表明:(此处无随机写测试)
- 顺序读下 ext4 和 SPDK 接近
- 通过ext4进行的4KB顺序写操作(WAL-style)只实现了硬件潜力的一小部分,延迟时间比SPDK高4.05x(IOPS相应降低)。
- 4KB的随机读和64KB的顺序写测试可以看到这两个极端之间的ext4-SPDK差距
- 这些结果突出表明,SPDK可以显著改善KV I/O,特别是日志和写密集型工作负载
SPDK concurrency
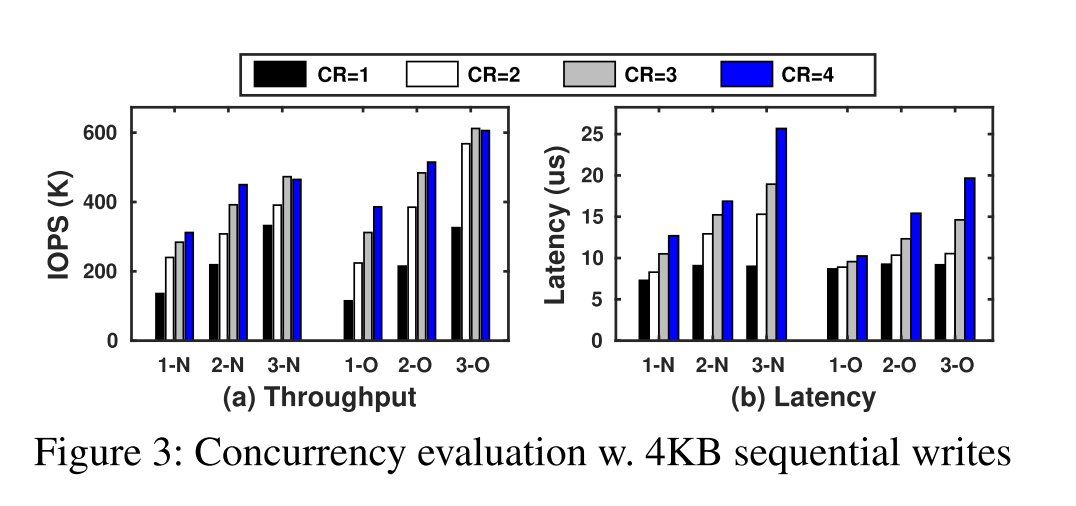
- 为了评估SPDK服务并发顺序写的能力,我们分析了各个SPDK请求,并发现7-8µs的单线程延迟中的大部分确实被busy-wait占用,由于争用下的I/O变慢,busy-wait随着并发写的线程增多而增加。
- 然后我们设计了一个 pipeline 方案,其中每个线程管理多个并发的SPDK请求。它允许“窃取”I/O等待时间来发出新请求,并检查未完成请求的完成状态(每个请求的完成时间低于1µs)。
- 图3 给出了Intel上的延迟和吞吐量结果P4610 (N)和Intel Optane (O) ssd硬盘。我们改变线程的数量(“3-N”有3个线程写入SSD N)和每个线程并发请求的上限(“CR=2”,每个线程最多发出2个请求)。NVMe ssd提供了目前RocksDB/LevelDB single-WAL-writer设计所没有的并行性。特别是,Optane (O)显示出比P4610 (N)更高的并发性,在更多的写入的情况下,具有更低的延迟和更快的吞吐量增长。然而,即使使用O,超过3个并发写入也不能提供更高的SPDK IOPS:使用3个loggers,每个CR=3似乎可以提供峰值的WAL速度,我们表示为3L3R。另一方面,N在2L4R处饱和。
SPDK access restrictions
- 快速使用spdk访问高端NVMe ssd带来的性能好处体现在:
- 一旦某个SSD被一个进程绑定到SPDK上,其他进程(无论是通过SPDK还是通过Linux I/O堆栈)都无法访问它。这简化了与用户级访问相关的工作负载间隔离,但也禁止将文件系统部分部署到通过SPDK访问的SSD上。
- 此外,建议用户将spdk access线程绑定到特定的内核。我们验证了不这样做会带来显著的I/O性能损失。这一点,再加上基于轮询的I/O模式,使得使用后台刷新/压缩线程的常见做法不适合SPDK访问:未绑定线程的I/O很慢,而绑定线程在空闲时不能轻松释放核心资源
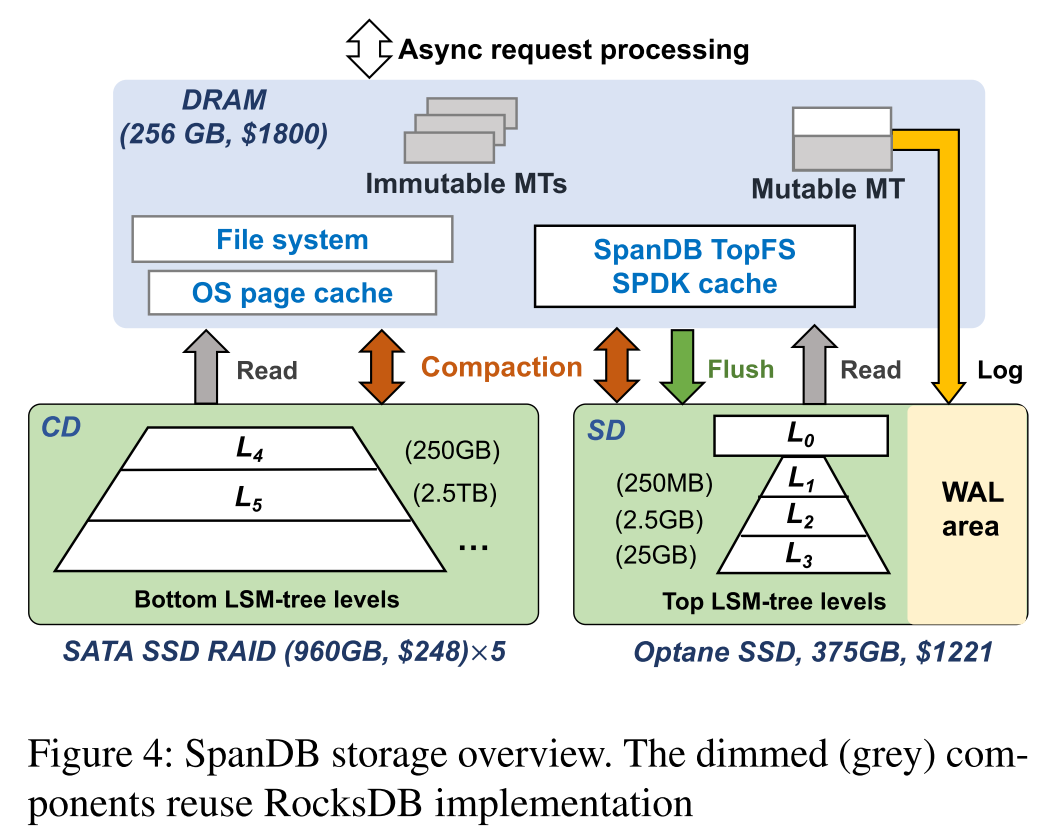
SpanDB Overview
Design rationale
- 我们提出了SpanDB,一个高性能,经济有效的基于lsm树的KV存储使用异构存储设备。SpanDB提倡使用小型、快速且通常更昂贵的NVMe SSD作为快速磁盘(SD),同时部署更大、更慢、更便宜的SSD(或此类设备的阵列)作为容量磁盘(CD)。SpanDB使用SD有两个目的:(1)对WAL进行写操作(2)存储RocksDB的LSM-tree的顶层。
- 由于WAL的处理成本是用户可见的,并且直接影响延迟,我们预留了足够的资源(内核和并发的SPDK请求,以及足够的SPDK队列),以最大化其性能。同时,WAL数据只需要维护到相应的flush操作,通常需要GBs的空间,而今天的“小型”高端ssd,如Optane,提供超过300GB的空间,这促使SpanDB将RocksDB的LSM-tree的顶层移至SD。这还会从CD上卸载大量的刷新/压缩流量,CD上驻留着大量较冷的数据
SpanDB architecture
- 下图展示了 SpanDB 的架构。在 DRAM 中保留了 RocksDB Memtable 的相关设计,使用一个可变和多个不可变memtable。SpanDB 几乎不会对 RocksDB 的 KV 数据结构、算法或者操作语义进行修改。这里的主要区别在于它的异步处理模型,以减少同步开销和自适应调度任务。
- 磁盘上的数据分布在 CD 和 SD 上,两个物理存储分区。
- SD 进一步被分区,一个小部分为 WAL 区域,另一个部分为数据区域。SpanDB 通过 SPDK 将 SD 当作裸设备管理并重新设计了 RocksDB 的 WAL 批量写入,以实现快速、并行的日志记录,将日志记录带宽提高 10x。为了最小化 RocksDB 的修改,SpanDB 实现了一个轻量级的自带缓存的文件系统 TopFS,允许简单和动态的 LSM levels 重定位。
- CD 分区同时存储了 tree stump,经常包含较冷的大部分数据。SpanDB 的管理还是与RocksDB一样,通过文件系统访问,并借助操作系统页面缓存进行辅助。
- 下图还对 SpanDB 不同类型的流量进行了区分。WAL 区域只进行 log 的操作,SD 的数据区域接受所有 flush 操作。此外,SD 数据区和 CD 都可以容纳用户读和压缩读/写,SpanDB 执行额外的优化,以支持在两个分区上同时进行压缩,并自动协调前台/后台任务。最后,SpanDB 能够基于对两个分区的实时带宽监控实现动态 tree level 布局。
Sources of performance benefits
- 通过采用一个通过SPDK访问的小而快的SD,它加快了WAL的速度,并行WAL写入。
- 通过将SD也用于数据存储,它优化了这种快速ssd的带宽利用率
- 通过启用工作负载自适应的SD-CD数据分发,它积极地聚合设备间可用的I/O资源(而不是仅仅将CD用作“溢出层”)。
- 虽然主要是通过将I/O卸载到SD来优化写,但它减少了读密集型工作负载的尾部延迟
- 通过减少同步和主动平衡前台/后台I/O需求,它利用了快速轮询I/O,同时节省CPU资源
Limitations
- 由于前面提到的SPDK访问约束,SD需要绑定到一个进程,这使得共享资源 SD 变得困难
- 对于全读的工作负载,SpanDB在异步处理中产生的速度提升很小,并带来轻微的开销。
Design and Implementation
Asynchronous Request Processing
- 很多 KV 系统都使用了嵌入式的 DB 处理,所有前端任务都被假设成客户端,每次同步处理一个KV请求。这样的处理通常是 I/O 限制(特别是WAL写),用户通常通过线程过度配置获得更高的总体吞吐量(每秒请求数),拥有比 cores 更多的客户端线程。具有快速NVMe ssd和SPDK等接口,线程同步(比如睡眠和唤醒)很容易花费比 I/O 请求更长的时间。在这种情况下,线程过度配置不仅增加了延迟,还会降低总体资源利用率,从而降低吞吐量。
- 此外,使用基于轮询的SPDK I/O,让线程在相同的 cores 上共存就失去了在 I/O 等待期间提高 CPU 利用率的吸引力。这也适用于使用后台线程管理LSM-tree刷新/压缩任务的常见实践。特别是,由于SPDK I/O的“fsync”涉及到忙等待,现有的 RocksDB 设计可能会释放许多后台线程,这会对其他线程造成巨大的破坏,并浪费 CPU 周期。
- 认识到这些,SpanDB采用异步请求处理。在 n 核机器上,用户将客户端线程的数量配置为N client,每个线程占用一个核。剩下的 个核心处理 SpanDB 内部服务线程,相应地被分为两个角色:loggers and workers。这些线程都被绑定到他们分配的核心上。 Loggers 主要执行 WAL 写入,Workers 处理后台任务处理(flush/compaction)以及一些非 I/O 任务,例如 Memtables 的写入和更新,WAL 日志项的准备,相关事务的加锁/同步。根据观察到的写强度,head-server 线程自动自适应地决定logger 的数量,这些 logger 被绑定到分配了 SPDK 队列的核上,从而保证 WAL 的写带宽
Asynchronous APIs
- SpanDB 提供了简单、直观的异步 api。对于现有的 RocksDB 同步 get 和 put 操作,它增加了异步对等对象A_get和A_put,再加上A_check来检查请求状态。类似的API扩展适用于扫描和删除。相应地,SpanDB扩展了RocksDB的 status 枚举。
- 如下代码示例大致描述了异步请求的流程。

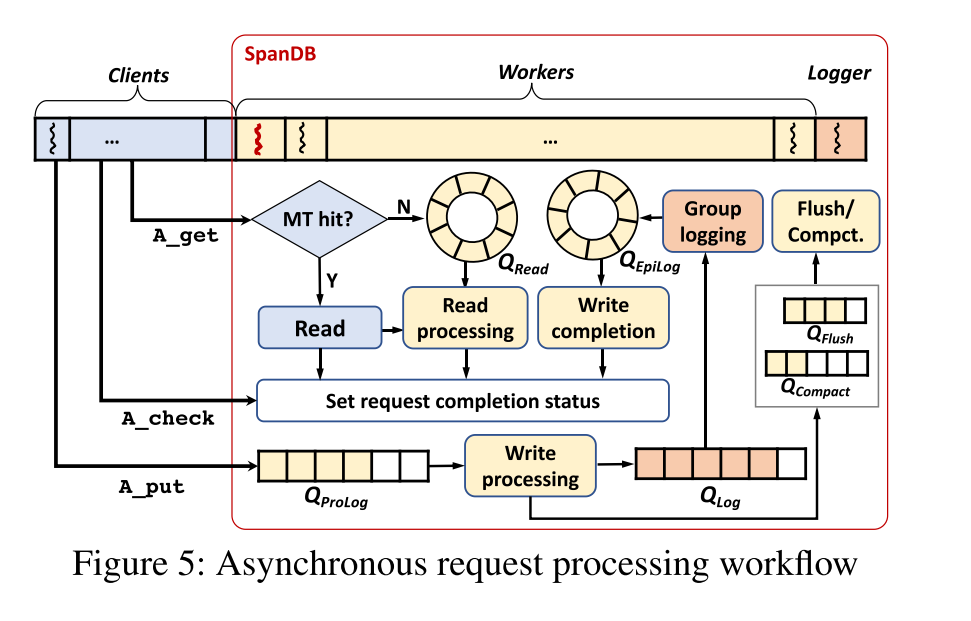
SpanDB request processing
- SpanDB管理前台请求处理的各个阶段,以及多个队列中的后台刷新/压缩任务。这些队列在线程之间传递子任务,还提供关于某个系统组件的压力级别的反馈。根据这些反馈,SpanDB可以调节客户端请求发出率(通过上述IsBusy接口),也可以动态调整内部 workers 的任务分配
- 图 5 描绘了 SpanDB 中的相关队列。flush 和 compaction 队列本身就是来自于 RocksDB 的设计,即便 SpanDB 修改了实际的操作来使用 SPDK I/O。SPDK 还额外加了四个队列,读队列、以及写相关的三个队列(ProLog、Log、EpiLog)
- 对于异步读,当请求不需要进行 I/O 时,SpanDB 保持了原有 RocksDB 的同步模型,在KV应用程序中,由于具有典型的局部性,许多读操作都是从MemTable中进行的,特别是在今天由 DRAM 支持的更大的 MemTable 的场景下。给定一个 Key,能够快速在检查 Memtables 是否命中,如果命中直接完成读请求。命中的情况下大概只花费 4-6 微秒,相反即使在争用的情况下从 Optane 上读取也只花费 30 微妙,相应地会把读请求插入到读请求等待队列中然后返回。之后会有 worker 从队列中取出该请求,完成剩下的和 RocksDB 相同的读任务并设置他的完成状态。
- 对于异步写,SpanDB 将处理过程划分成了三个部分。
-
- 客户端先将请求 dump 到 ProLog 队列中,由 worker 来处理。
-
- worker 相应地生成 WAL 日志项,按顺序传递到 Log 队列中。这两个队列都旨在促进批处理日志:一个 worker/logger 在这些队列中收集所有的日志项。除了批处理之外,logger 还将写日志流水线化,最大限度地提高了SPDK写并发性
-
- 当将一个组写入到了 SD 之后,logger 把相应的请求添加到 EpiLog 队列中,以便 worker 能够完成最终的处理。主要包括实际 MemTable 的更新。像读操作一样,这里的任务需要单独的注意力,不可能通过批量执行来加速。
-
- 如上图所示,ProLog 和 Log 队列都是 flat 的无锁队列,也就很容易地抓取所有请求进行出队。 Read、Epilog 都是环形队列,只在出队的时候要求加锁。
Task scheduling
- 上述SpanDB队列为调整内部资源分配提供了自然反馈。我们的SPDK基准测试结果表明 NVMe SSD 提供了并行性但是可能会被每个核心发出好几个并发请求使其饱和。因此 SpanDB 从一个 logger 开始,根据当前的写入强度在 1 到 3 之间增加和减少这个分配。
- 对于 Worker 因为需要处理所有其他的队列,所以比较灵活。在三个前端任务队列之间,SpanDB 根据队列的实际长度和每个任务的处理时间的加权来执行负载均衡。在前端队列和后端队列之间,SpanDB 以处理前台任务优先,使用一个合适的阈值来监控后台队列长度,从而主动执行清理,特别是在写密集型工作负载下。
Transaction support
- SpanDB 完整支持了事务并提供了一个异步提交接口
A_commit,对 RocksDB 做了一些小改动。注意在 RocksDB 的事务模式,写操作将在一个内部 Buffer 中生成 WAL 项,只会在提交的时候才会被写入。而 SpanDB 异步提交操作则是将相应的写任务插入到了 ProLog 队列。
High-speed Logging via SPDK
Enabling parallelism and pipelining
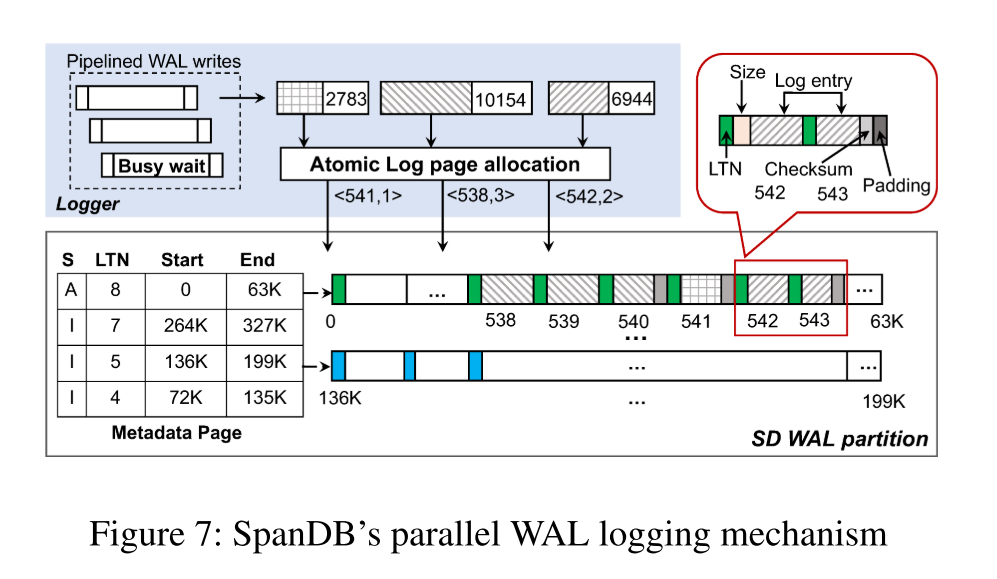
- SpanDB 保留了 group logging 机制,但也允许多个 WAL 流并发写入。它不是让一个客户端作为 leader (并迫使 follower 等待),而是使用专用的 logger,并发地发出批处理写操作。每个 logger 抓取它在 QLog 中看到的所有请求,并将这些 WAL 条目聚合为尽可能少的 4KB 块。它通过为一个请求窃取 SPDK 繁忙等待时间准备/检查其他请求来执行 pipeline。例如,对于 2L4R,有多达 8 个未完成的 WAL 写组
Log data management
- 并行的 WAL 写入让日志数据的管理变得复杂,特别是针对没有文件系统的裸设备。幸运的是,使用原子的 4KB SPDK 写操作,协调并发的 WAL 流只增加了很少的开销。
- SpanDB 首先在 SD 上分配可配置数量的 Pages 给相应的 WAL 区域(测试中分配了 10GB),每个都会有一个逻辑页号 LPN。这些页中的一个会被设置为元数据页,在任何时候只会有一个可变的 Memtable,其对应的日志文件会不断增大。我们会分配固定数量的逻辑页 groups,每个组会包含连续的页,而且足够大可以装下一个 Memtable 的日志数据。被使用了的日志页和对应的 Memtable 给组织在一起:SpanDB 重用了 RocksDB Memtable 的日志文件号 LFN 作为日志标签号 LTN,嵌入在所有日志页的开头以便进行故障恢复。
- 下图给了一个包含四个 Memtable 的例子,一个 mutable 三个 immutable,对应元数据页中的 Active 和 InActive 状态。
- 在一个 Memtable 被 flush 之后,日志页的整个分片将被回收,保证 Memtable 日志的连续性。对于每个 Immutable Memtable,元数据页都记录了对应日志页的起始和终止 LPN。假设典型的 KV 存储使用少量 memtable,一个页面就足够容纳这样的元数据了。
- Logger 发出并发请求,每个 Logger 提供一个 WAL 数据缓冲区和大小,唯一的同步点是日志页面的分配。我们使用比较和交换(CAS)操作实现了轻量级的原子页面分配。下图中的淡蓝色部分显示了三个请求的日志页分配过程,分别分配了 1,3,2 个页面,可以并行地进行分配。这些 WAL 写入不会修改元数据页,在元数据页中,只有当MemTable变得不可变时,per-MemTable end LPN 才会被追加。
- 在日志 Page 中,logger 首先记录当前 LTN,然后是一组日志条目,每个条目都有其大小的注释。图7中的放大部分描述了这种布局,包括每个条目的校验和(已经在RocksDB中计算过了)。
Correctness
- SpanDB的并行WAL写设计保留了RocksDB一致性语义。它不会改变用于协调和排序客户机请求的并发控制机制。因此,带有happened-before限制的事务在日志页面中不会出现顺序错误,如下面的简要解释。RocksDB 默认的隔离保证是 READ COMMITTED,也会检查写与写操作之间的冲突并序列化两个并发事务(假定两个更新相同 KV 项)。对于任何两个更新事务T1 和 T2,使用这两个隔离保证,READ COMMITTED 表明如果 T1 发生在 T2 之前,即 T2 看到了 T1 的效果,那么 T1 在 T2 开始执行之前必须提交。通过RocksDB group WAL写协议的设计,可以看出T1和T2的日志记录应该分两批出现,其中T1的批提交早于T2的批提交,在T2的批提交之前完成。当批量日志并行写入到 SpanDB 时,传递一个序列化的point 以便进行原子的页分配。因此 T1 的批任务仍然保证了比 T2 获得的序列号更小,后者就能看见前者的更新。相似的,从 WAL 中恢复的时候,SpanDB 总是按序列号升序执行 redo。
Log recovery
- 恢复操作首先读元数据页,检索出 log page groups 的数量以及相应的页地址范围。实际的从 log page group 恢复和从 RocksDB 的日志文件中恢复是一致的。同样,每个页面中的LTN号帮助标识 Active 日志 log group 的“结束”。
- 一个难点是 SpanDB 回收日志页 groups 时,有的 group 包含一些老的日志页,在恢复过程中 SpanDB 需要知道当前组中哪些页已经被重写了。RocksDB 依赖文件系统进行故障恢复:读取数据是否包含在活跃的 log file 中。没有文件系统,SpanDB 在回收之前可以持久化一个单独的元数据更新或者将老的日志页 wipe out(写 0)。会影响 SD 的 WAL 写带宽,降低到一半。而我们重用了每个 Memtable 的 LTN 作为日志页的 color。因为 SSD 可以保证 4K 原子写,LTN 通常又都是在页的开始写的,这些页已经暗含了最后一次成功写的位置信息了。元数据页维护了当前活跃的 LTN,在这个组中,具有过时LTN的页面还没有从当前MemTable中被覆盖写。
Offloading LSM-tree Levels to SD
- 为了 KV 服务器的持续均衡的运行,SpanDB将RocksDB的lsm树的顶层迁移到SD,为用户提供更多的硬件投资回报。下面我们讨论所涉及的主要挑战和解决办法
Data area storage organization
- 在NVMe SSD上使用SPDK的一个限制是,整个设备必须与本机内核驱动程序解除绑定,并且不能通过传统的I/O堆栈访问。因此不能对SD进行分区,只能使用SPDK将WAL写入一个区域,在另一个区域安装文件系统。
- SpanDB 实现的 TopFS,这是一个精简的文件系统,在SPDK I/O之上提供熟悉的文件接口包装器。SST 文件的仅追加和此后不可变的特性,加上它们的单 writer 访问模式,简化了TopFS设计。比如文件在创建的时候就知道了大小或者有有一个已知的大小限制。而且每个 SST 只会被单个线程写一次。大多数场景下,输入的数据不会被删除直到 SST 文件写入成功完成。此外,TopFS 保证了文件 close 时的数据的一致性。从而支持了每个文件连续的 LPN 范围分配,和前面提到的日志 groups 相似。元数据管理也比较简单:一个哈希表,按文件名进行索引,存储文件的起始和结束 LPN。TopFS 使用一个 LPN 空闲列表管理空闲空间,相应的连续的 LPN 范围被合并。
Ensuring WAL write priority
- flush/Compaction 操作是会影响前台负载的,但他们的延迟很多时候都对用户是透明的,因此 SD 可以完全更充分利用其带宽,比如在 WAL 写上,因为 WAL 的写入延迟用户时能感知到的。SPDK 提供了足够的 NVMe Queue Pairs,这允许对不同的请求类型进行单独管理。不幸的是,没有一个现有的通用 SSD 实现对这些队列的优先级管理。此外,这些队列提供的操作非常有限:用户只能发出请求和检查完成状态。
- 因此除了前后端任务在队列上的协调以外,SpanDB 还对 WAL 写请求赋予了优先级。我们发现他们的优先级可以有效地保护通过以下步骤:
- (1) 分配到每个日志请求 slot 专用队列(例如,8 个 L2R4 队列)
- (2) 减少 flush/compaction 的 I/O 请求的大小从 1MB 到 64KB 来减小有 WAL 时的 I/O 争用
- (3) 限制执行 flush/compaction 的 worker 线程数量
SpanDB SPDK cache
- SPDK bypass 了 OS page cache,如果无人看管,这会带来出色的原始 I/O,但会带来灾难性的应用程序 I/O 性能。为了克服这个问题,我们在 TopFS 上实现了 SpanDB 自己的缓存。注意,对于SPDK I/O,传递的所有数据缓冲区必须通过
spdk_dma_malloc()在固定内存中分配。SpanDB重用这样的缓冲区作为缓存,从而节省额外的内存复制。 - 在SpanDB初始化时,它在hugepage中分配一个大内存缓存(大小可配置)。在创建SST文件时,SpanDB在缓存中保留适当数量的连续64KB缓冲区(文件大小或大小限制是已知的)。SpanDB使用另一个哈希表来管理这个缓存,同样以RocksDB SST文件名作为键。value字段是一个数组,存储每个文件块的缓存项,如果块被缓存,则存储相应的内存地址,否则为空。块大小配置显然涉及到缓存数据粒度和元数据开销之间的权衡。我们的评估使用SpanDB默认块大小64KB,对100GB的数据库产生<500KB的元数据开销。
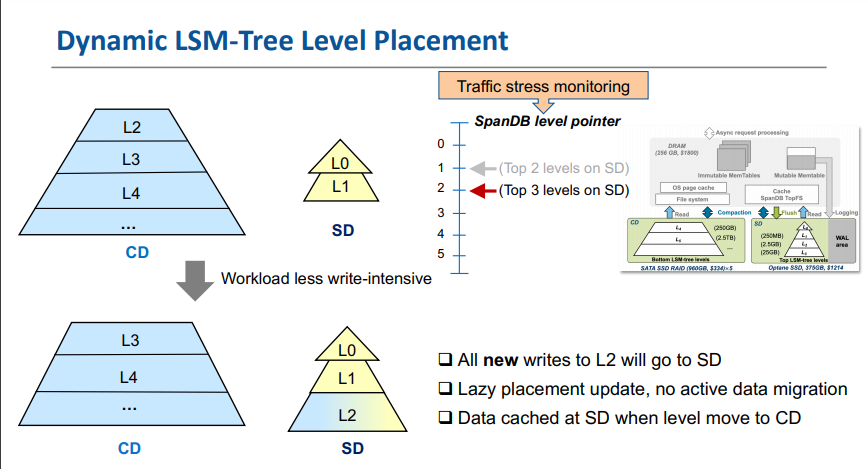
Dynamic level placement
- 通过上述所有机制,我们可以动态地调整SD上驻留的树级别的数量。最初,我们使用一个分析模型来直接计算最佳SD-CD级别分区,从而最大限度地提高整个系统的吞吐量。然而,我们无法找到与我们的测量结果一致的精确的 LSM-tree 写放大模型。特别是,最先进的工作在这前端的似乎没有考虑写速度和它的变化。我们的测试表明,这些因素会严重影响暂态的“树状结构”(最高层在不同程度上超出其大小限制),进而影响写/读放大级别。
- 因此,SpanDB 使用了临时的动态分区,通过观察 SD 和 CD 之间持续的资源利用率的不平衡,它的 head-server 线程监视 SD 带宽使用情况,并在低于 时触发SST文件重定位,直到达到 或 SD 满,其中 和 是两个可配置的阈值。
- 由于SST文件不断地进行合并,SpanDB并没有在SD和CD之间迁移数据,而是通过将文件创建重定向到不同的目标,逐步“提升”或“降级”整个级别。它有一个指针,指示当前哪些级别应该转到快速NVMe设备。例如,指针 3 覆盖了所有的前3个级别。然而,该指针仅确定新SST文件的目的地。因此,在SD上有一个新的L3文件,在CD上有一个旧的L2文件是可能的,尽管这种“倒置”是罕见的,因为顶层更小,他们的文件更新更频繁。
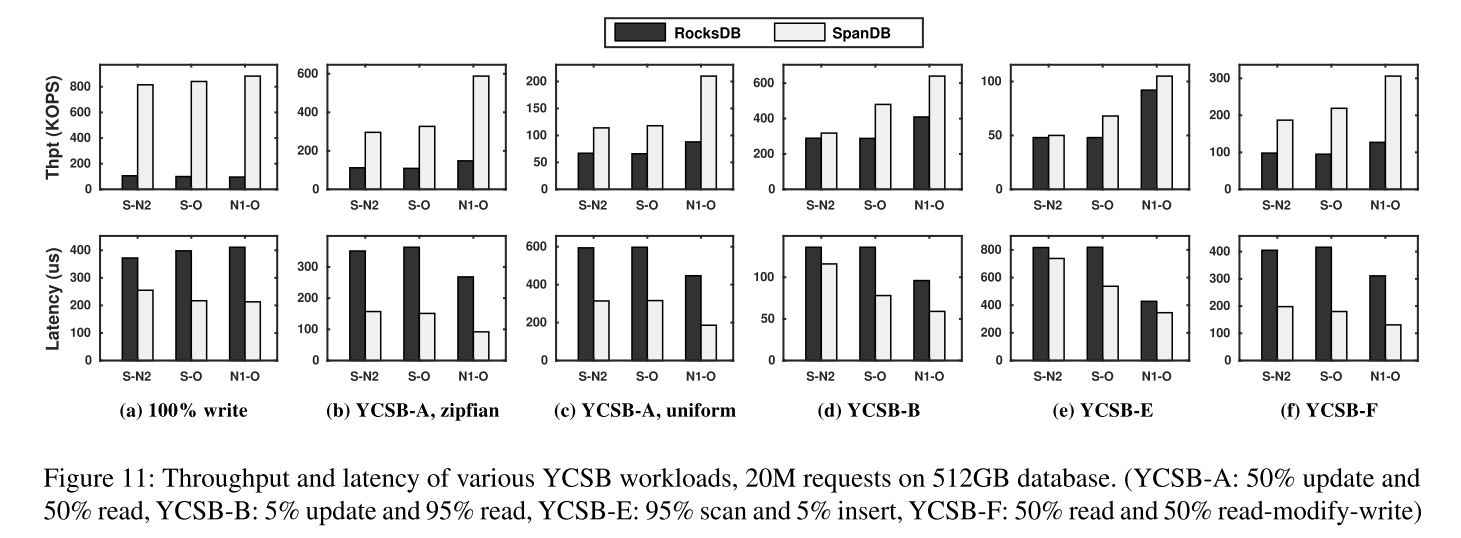
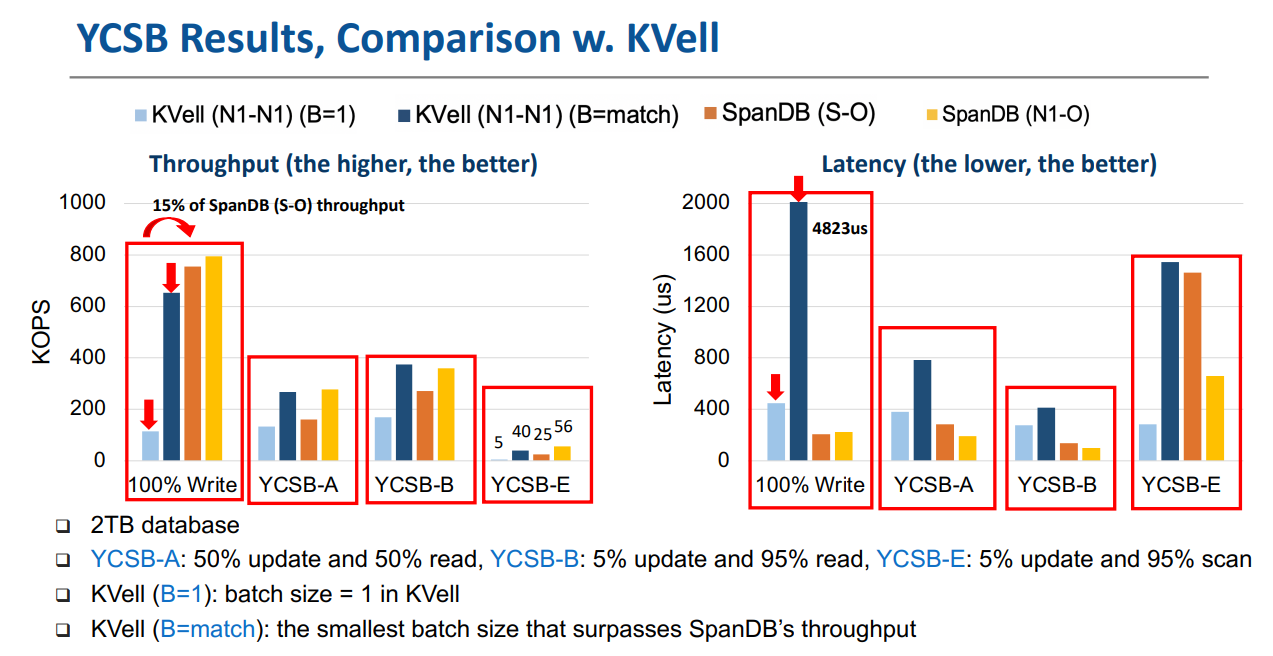
Evaluation
Related Work
Tiered storage
- NVMFS, Strata, Ziggurat: File system based on heterogeneous devices
- HiLSM, MatrixKV: Hybrid storage devices for KV
- Mutant: ranks SST files by popularity and places them on different cloud storage devices
- PrismDB: makes LSM-trees “read-aware” by pinning hot objects to fast devices.
KV stores optimizations for fast, homogeneous storage
homogeneous storage
- UniKV
- LSM-trie
- SlimDB
- FloDB
- PebblesDB
- KVell
- SplinterDB
FPGA
- X-Engine
- KVSSD
- ATC20 PinK
PM
- HiKV
- NoveLSM
- NVMRocks
- Bullet
- SLM-DB
- FlatStore
- MyNVM
- MyRocks
Logging optimizations
- NVLogging
- NVWAL
Other related work
- SILK
- Monkey
- ElasticBF
- TRIAD
- WiscKey
- HashKV
