Chapter Index
Motivation
- 内存容量不断变大:随着内存的变大,更多的数据可以被缓存在内存中,随着更多的数据被缓存,磁盘通信越来越多地由写组成,因为读是由缓存提供的。因此,文件系统性能在很大程度上取决于它的写性能。
- 随机 I/O 性能和顺序 I/O 性能之间存在很大的差距:硬盘传输带宽在过去几年里增加了很多,当更多的位被压缩到驱动器表面时,访问的带宽增加,然而,Seek 和旋转延迟成本已经缓慢下降,要让廉价的小型马达更快地旋转磁盘或更快地移动磁盘臂,这是一个挑战。所以 seek 和旋转操作相对较少的顺序读写会比随机读写性能好很多。
- 现有的文件系统在许多常见工作负载上执行得很差:FFS 会执行大量的写操作来创建一个大小为一个块的新文件(一次写 new inode,一次更新 inode bitmap,一次写该文件所在的目录对应的数据块,一次写目录对应的 inode,一次写文件的新数据块,一次更新数据块对应的位图)。因此,尽管FFS将所有这些块放在同一个块组中,但FFS会导致许多短寻和随后的旋转延迟,因此性能远远低于连续带宽的峰值
- 文件系统无法感知 RAID:RAID-4 RAID-5 都会有小写问题,逻辑上的一个对一个块的写操作会造成物理上四个实际的 I/O 发生,现有的文件系统无法避免 RAID 下的最坏的写情况。
- 因此理想的文件系统需要更加关注写性能,同时不仅需要支持较好的数据写,还要支持元数据的更新操作也比较高效。对于单盘和 RAID 都应该表现得比较好。所以出现了 LFS,LFS 首先将写操作缓冲到一个内存段 segment 中,当 segment 满了之后,顺序地将该段写入磁盘。LFS 从不更新已经存在得数据,及永远都是追加写的方式,所以每次都是将段写到磁盘的新位置,因为段很大,所以磁盘或 RAID 能够更加接近本身的带宽性能。
LSF
- CRUX: 如何让所有的写变成顺序写?对于读操作,因为可能读取磁盘的任何位置,所以要求读操作顺序很难,但写操作是可以保证顺序的。
Writing To Disk Sequentially
如何将所有对文件系统状态的更新转换为一系列对磁盘的连续写操作?
- 例如写入数据块 D 到磁盘上的地址 A0

- 写数据的同时,还会有元数据的写入,譬如写入 inode 数据,inode 数据指向数据块。即顺序写入是想将对应的数据块和元数据都顺序地写入到磁盘。

Writing Sequentially And Effectively
- 直接顺序写入到磁盘并不能保证高效。例如,假设我们写入了一个单独的数据块到地址 A,在时刻 T,等了一段时间之后,需要顺序写到磁盘的 A+1,这时候的时刻为 T + t。在第一次写和第二次之间,磁盘旋转了,当发起第二次写操作的时候,在真正写入之前坑需要等待一个完整的旋转周期(具体的等待时间为 t - 旋转周期)。因此简单的顺序写入到磁盘是无法解决性能较差的问题的,所以必须发起一连串的连续的读写操作或者一个大的写操作,才能实现比较好的性能。
- 为了实现上述的连续写操作或者一个较大的写操作,LFS 引入了一个古老的技术 写缓冲(write buffering)。在写入磁盘之前,LFS 在内存中追踪对应的写操作,当到达一定数量的更新操作之后,再一次性地将这些写操作写入磁盘,从而保证写入磁盘的高效性。
- 而 LFS 中批量写入的单位就是所谓的 segment,即 LFS 将一些要写入到磁盘中的写操作首先缓冲到内存的 segement 中,然后一次性地写入该段到磁盘。如果这个段足够大,那么磁盘的写入也将足够高效。
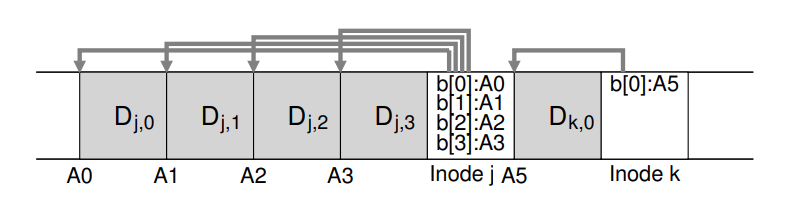
- 如图所示例子中,LFS 将两组更新操作合并到一个小段中,实际的段可能比图中更大,以 MB 为单位。第一组更新为写数据到文件 j 的四个块,第二组操作是向文件 k 中新写入一个块,LFS 然后把这七个块一次性写入磁盘,磁盘上的数据结构如图所示:
How Much To Buffer?
- LFS 在写入磁盘之前需要缓冲多少写操作?取决于磁盘本身,主要由磁盘的定位开销和传输速率决定。假设 seek 开销 Tposition,磁盘传输速率 Rpeak MB/S,写入数据 D MB,那么写入该数据块的总时间 Twrite 为 $$T_{write}=T_{position}+ \frac {D}{R_{peak}}$$ 因此写入效率 Reffective 即为 $$R_{effective} = \frac {D}{T_{write}}= \frac {D}{T_{position}+ \frac {D}{R_{peak}}}$$ 我们想要实现的是 Reffective 尽可能地接近 peak rate,假设我们使用系数 F 来表示,Reffective=F∗Rpeak,所以我们可以推导出 $$D = \frac{F}{1-F} * R_{peak} * T_{position}$$
- 假设 Tposition 为 10ms,peak transfer 为 100MB/S,假设我们想实现原设备的百分之九十的带宽,F = 0.9,计算出 D = 9MB。为了实现 95% 的带宽,对应需要缓冲 19MB,99% 的带宽需要 99MB
Problem: Finding Inodes
- 以前的文件系统中将 inode 数据组织成了数组并存放在了磁盘上固定的位置,可以通过起始地址和对应的inode 号计算得出 inode 的具体位置,FFS 通过在每个 group 中也能计算得出,但是 LFS 中寻找到 inode 很困难。
Solution Through Indirection: The Inode Map
- 引入数据结构 inode map,inode number 作为输入 key,value 输出则为对应的最新的 inode 地址。因此,可以想象它通常被实现为一个简单的数组,每个条目有4个字节(一个磁盘指针)。每当一个inode被写到磁盘时,imap就会更新它的新位置。
- imap 需要持久化来保证磁盘崩溃后的恢复也能正常进行,因此产生新的问题:持久化到磁盘的什么位置?如果持久化到磁盘的一个固定位置,因为 imap 可能会被频繁更新,性能上可能会严重下降。
- 因此 LFS 将 imap 放在了写入的所有新数据的最右侧,因此在向文件 k 中追加写入一个数据块时,LFS 实际会写入新的数据块、其对应的 inode 和 imap 的一部分数据到磁盘上。imap 告诉 LFS inode k 在对应的地址 A1 上,而 inode k 告诉 LFS 数据块 D 在对应的地址 A0 上。
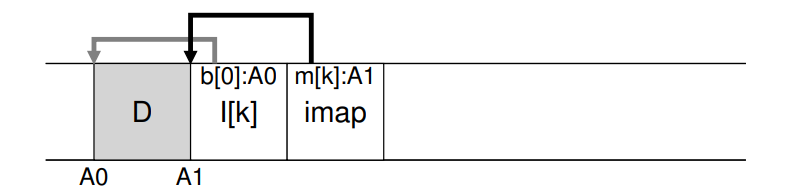
Completing The Solution: The Checkpoint Region
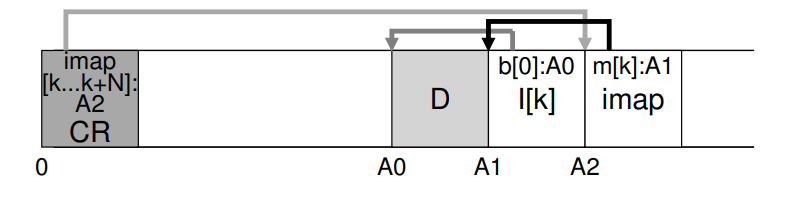
- 尽管已经将 imap 持久化散布到了磁盘的各个部分,但是文件系统还是不知道如何去查询 imap 找到对应的文件。LFS 因此设置了一个确定的位置 checkpoint region (CR),该区域包含 inode map 最近的部分,因此 inode map 可以通过首先读取 CR 查询到 inode map,CR 定期更新,大约 30s 更新一次,因此性能上不会有太大的影响。因此整个磁盘的结构将如图所示:
Reading A File From Disk: A Recap
- 假设内存中无任何缓存数据,读操作的步骤大致如下:
- 首先读取 CR,从而获取到整个 inode map,将其缓存在内存中
- 根据文件的 inode 号和缓存的 inode map,很容易读取到对应的文件 inode 地址信息,需要读取到最新版本的地址
- 读取到文件的 inode 之后,和原有的文件系统一样,使用 inode 中存储的数据块指针对应地读取数据块
- LFS 和普通的文件系统读取磁盘上的文件的开销应该是大致一样的,因为整个 imap 都会被缓存,因此 LFS 在读取期间所做的额外工作就是在 imap 中查找 inode 的地址。
What About Directories?
- 目录结构基本上与经典的 UNIX 文件系统相同,其中目录只是(名称、inode编号)映射的集合。例如创建一个文件时,LFS 需要写 inode,data,以及目录的 inode 和 data,结构大致如下,创建 /home/remzi/foo
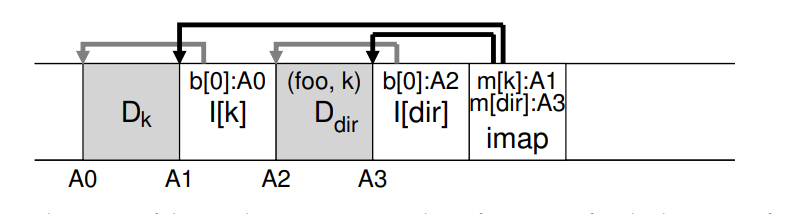
- 最右边的 imap 将同时包含文件和目录的映射信息,因此访问文件 foo 时,首先查询缓存到内存中的 imap,找到目录对应 inode A3,从而找到目录对应的数据块 A2,读取数据发现 foo 对应了 inode number 为 k,再去 imap 中查询 k 对应的 inode A1,再找到数据块 A0,从而得到 foo 的数据。
- inode map 还解决了递归更新问题,该问题存在于所有异地更新的文件系统中。因为每当 inode 更新,通常都是需要写入到一个新的位置,可能会导致对应的目录也发生更新,更严重的直接递归到根目录。使用了 inode map 就能避免这个问题,inode 的地址可能发生改变,但是改变不会反映到对应的目录中,当目录保持相同的名称到 inode-number映射时,会更新 imap 结构,而不会级联更新。
A New Problem: Garbage Collection
- 异地更新的策略会将最新版本的数据写入到新的位置,但是原本位置的老数据仍然分布在磁盘中,但此时已经是垃圾数据,假设现在有一个 inmuber 为 k 的文件,指向了单一的数据块 D0,现在更新数据块 D0,将会生成一个新的数据块 D0 和 inode,磁盘布局如下所示,省略了 imap
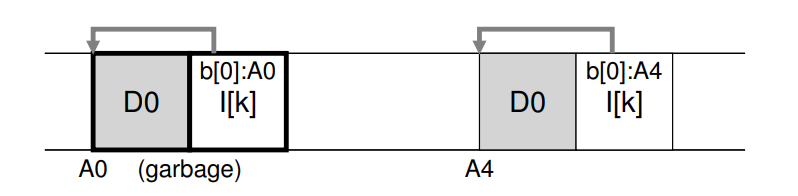
- 如果在原有的文件的基础上进行追加的方式写入新版本数据,布局如下:(version file system)
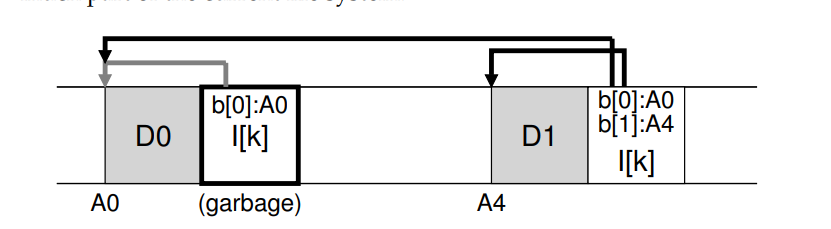
- LFS只保存文件的最新活动版本;因此(在后台),LFS 必须定期查找这些文件数据、索引节点和其他结构的旧版本,并清除它们。回收操作可以让磁盘上的数据块再一次 free,并用于之后顺序的读写。前面我们讨论了段的重要性,因为它们是LFS中支持对磁盘进行大规模写操作的机制,事实证明,它们也是有效清洁不可或缺的一部分。在磁盘上分配的空间之间混合了一些空闲孔的文件系统。写性能会显著下降,因为LFS将无法找到一个大的连续区域以高性能顺序写入磁盘。
- LFS 回收器是逐段工作的,从而为后续的写入清理大块空间。基本的回收过程如下
- LFS 回收器定期读入许多旧的(部分使用的)段,确定这些段中活动的块,
- 然后写出一组新的段,其中只有活动块,释放旧的用于编写。希望读入 M 个现有片段,将其内容压缩为 N 个新片段(其中N < M),然后把这 N 段写到磁盘的新位置。
- 然后释放旧的 M 段,供文件系统用于后续的写操作。
- LFS 如何分辨段中哪些块是活动的,哪些是老旧无效的?以及多久清理一次?
Determining Block Liveness
- LFS 在每一个段中添加了一些额外的数据信息,用于描述数据块,LFS 包含每个数据块的 inode number(属于哪个文件) 和偏移(属于该文件的哪个块),这部分数据信息位于段头,称之为 Segment Summary Block。
- 例如地址 A 上的数据块 D,查看 segment summary block 并找到对应的 inode number N 和偏移量 T。查询 imap 发现 N 对应的文件 inode 的实际地址,并将该 inode 读取上来。最后使用偏移量 T 看这个 inode 中对应 T 位置的数据块的地址,如果该地址等于 A,那说明该块在使用中,如果不等于,则说明该块已经是垃圾数据。伪代码如下:
(N, T) = SegmentSummary[A];
inode = Read(imap[N]);
if (inode[T] == A)
// block D is alive
else
// block D is garbage
- 如图所示:summray block 标识为 ss,记录了地址 A0 对应的 inode number 为 K,偏移量为 0,查询 imap 找 K 对应的地址,为 A1,读取 A1 对应的 inode,查看偏移量 0 对应的数据块地址,判断是否等于 A0
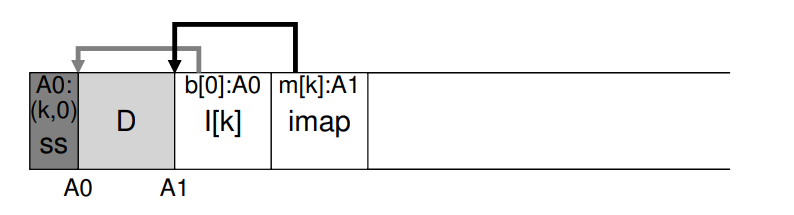
- LFS 可以采用一些捷径来更有效地确定数据块的活性,比如当一个文件被标记为删除,LFS 增加对应的版本号并记录最新的版本号到 imap 中,通过比较磁盘上的版本号和imap中的版本号,LFS可以缩短上述较长的检查,从而避免额外的读取。
A Policy Question: Which Blocks To Clean, And When?
- 清理哪些块是许多学术研究重点讨论的问题。原始的 LFS Paper 中描述了一种方式来区分段的冷热,经常被覆盖写的段被称为热数据段,对于热段,最好的策略就是等待一段时间之后再进行清理,因为越来越多的块被覆盖写从而就可以被释放用于新的写。冷数据段是指还有少量的垃圾数据块,但是其他数据块还很稳定,因此作者建议更早地清理冷数据段,更晚地清理热数据段。但是该方法不够完美。
- 对于何时清理,大概有两种思路。一种是定期清理,一种是在达到一定的阈值之后磁盘必须这样做。
Crash Recovery And The Log
- 当 LFS 往磁盘上写的时候发生了系统故障如何处理?在正常的操作中,LFS 缓存了写操作到段中,然后将段刷入到磁盘。这些写操作都是以日志的形式组织的,例如段中的 CR 区域指向了段的头部和尾部,每一个段指向了下一个段。LFS 周期性地更新 CR 区域的数据,故障可能发生在写段的操作或者写 CR 区域的操作中。
- 为了保证 CR 区域的原子更新,LFS 实际上保存了两个 CR 区域,分别在磁盘的两端,交替地对他们进行写操作。LFS 还设计了一个协议用于指向 inode 映射和其他信息的最新指针更新 CR 操作。具体表现为:首先写 header,带时间戳,然后写 CR 的 body,最后写最后一个数据块的时候也带上时间戳。如果在写 CR 过程中系统挂掉了,LFS 可以检查对应的前后时间戳是否一致来判断是否发生了故障,LFS 将选择使用带一致的时间戳的 CR,从而实现 CR 的一致性更新。
- 因为 LFS 大约每 30s 写一次 CR,所以出现不一致的时候可能 CR 中的数据已经很老了,重启的时候,将会读取 CR 中一致的那一部分数据,从而进行恢复,但自一致状态之后的写操作将会丢失。为了改善该现象,LSF 通过使用数据库领域中常用的 roll forward 技术,基本思想是从最后一个检查点区域开始,找到日志的末端(包含在CR中),然后使用它读取下一个片段,看看其中是否有任何有效的更新,如果对应的更新有效则相应的更新文件系统,从而恢复自上一个检查点以来写入的大量数据和元数据。Redo Log
