Cache Replacement Policies - Coarse-Grained Recency
粗粒度缓存
缓存替换文献跨越了50年,首先是在操作系统页面替换的上下文中,然后是在硬件缓存的上下文中。在此期间,大多数研究都集中在更智能的粗粒度策略的开发上,这可能可以用这些策略的简单性来解释:每个缓存行都与少量的替换状态相关联,对所有新插入的行进行统一初始化,然后在重用这些行时使用简单的操作进行操作。
在本章中,我们将讨论粗粒度策略的关键进展。我们将粗粒度策略划分为三个类,根据它们在插入到缓存后区分行的方式。
第一类包括绝大多数粗粒度策略,使用最近信息来排序行(基于最近的策略)。
第二个类使用频率来排序行(基于频率的策略)。
最后,第三类(混合策略)动态地选择不同的粗粒度替换策略。
粗粒度策略设计中的一个运行主题是识别三种常见的缓存访问模式,即最近友好访问、抖动访问[Denning, 1968]和扫描[Jaleel et al., 2010b]。当应用程序的工作集小到足以容纳缓存时,就会出现最近友好访问,这样大多数内存引用的重用距离小于缓存的大小。相比之下,当应用程序的工作集超过缓存的大小时,就会发生抖动访问,这样大多数内存引用的重用距离都大于缓存的大小。最后,扫描是一个永不重复的流访问序列 。正如我们将在本章中看到的,几乎所有粗粒度替换策略都专门针对这些访问模式或这三种访问模式的混合进行了优化。
RECENCY-BASED POLICIES
基于最近的策略根据最近的信息对行进行优先排序。LRU策略[Mattson et al., 1970]是这些策略中最简单和最广泛使用的。在缓存回收中,LRU策略只是从一组给定的候选缓存行中删除最老的行。为了找到最老的行,LRU策略在概念上维护一个最近栈,其中栈的顶部代表 MRU 行,堆栈的底部代表 LRU 行。通过为每一行关联一个计数器并更新它,可以精确地或近似地维护这个最近堆栈,如表3.1所示
当引用存在时间局域性时,即最近使用的数据可能在不久的将来被重用时,LRU的性能很好。但是对于两种类型的访问模式,它的性能很差。
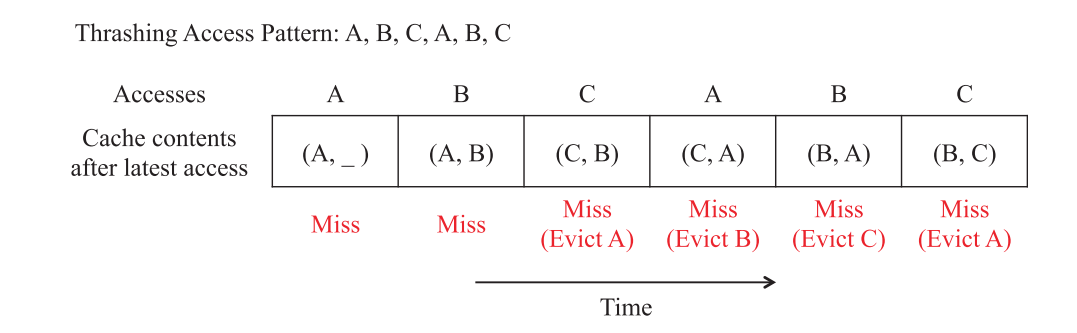
首先,当应用程序的工作集大小超过缓存大小时,它可能是悲观的,导致一种称为抖动的现象[Denning, 1968] (见图3.1)。
其次,LRU在有扫描的情况下表现很差,因为它缓存了最近使用的扫描,代价是更有可能被重用的旧行。
VARIANTS OF LRU
我们现在描述一些显著的 LRU 变体,用于检测和容纳抖动或流访问。
Most Recently Used (MRU)
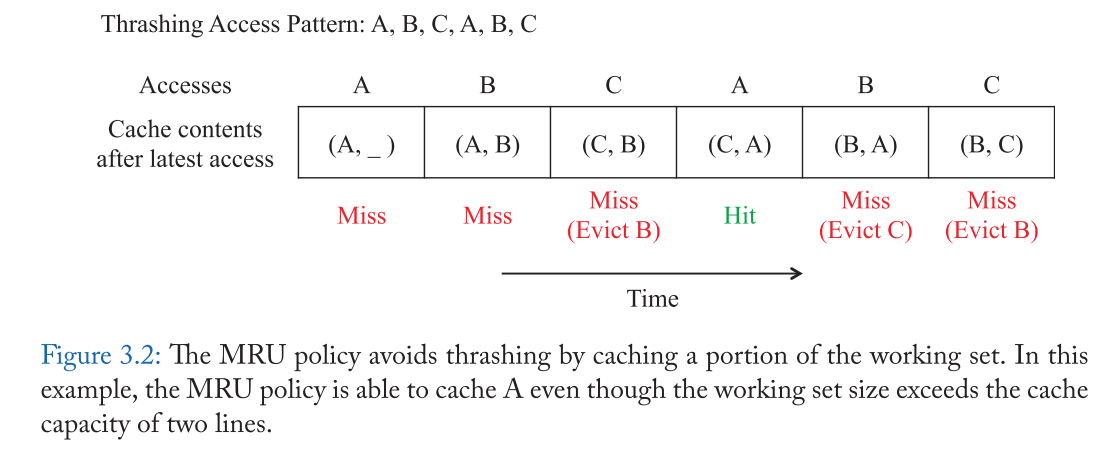
MRU 策略通过取消新行以保留旧行来解决问题。因此,当工作集大于缓存时,它能够保留工作集的一部分。例如, 图3.2显示了抖动, 访问模式如图3.1所示,系统提高了 LRU 年代缓存命中率的一小部分工作集在这个例子中没有驱逐行a .表3.2显示, MRU 和 LRU的系统最新政策是相同的,除了 MRU 就清除系统的缓存行最新位置而不是LRU的位置。
然而 MRU 对于抖动访问是理想的,但它在最近友好访问出现时表现很差,而且它对应用程序工作集的变化适应性很差,因为它不太可能缓存来自新工作集的任何行 。
Early EvictionLRU(EELRU)
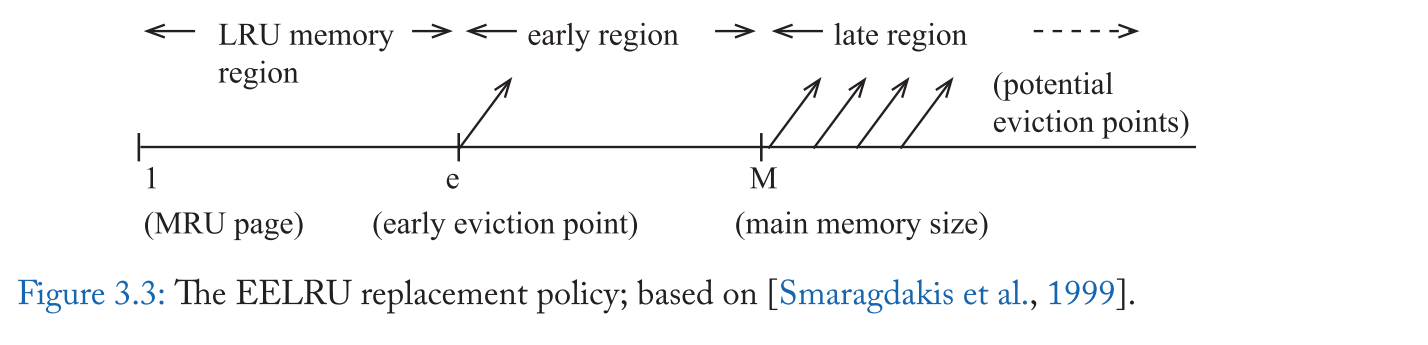
EELRU政策也避免了抖动[Smaragdakis等人,1999]。其主要思想是检测工作集大小超过缓存大小的情况,在这种情况下,有几行会提前被逐出。因此,早期驱逐会丢弃一些随机选择的行,这样剩余的行就可以通过 LRU 策略进行有效管理 。更具体地说,当工作集与缓存匹配时,EELRU 会收回 LRU 行,但当它观察到在一个比主内存大的粗略循环模式中接触了太多行时,它会驱逐 e t h e^{th} e t h
图 3.3 显示了EELRU在最近轴的三个区域之间的区别。最近轴的左端点表示MRU线,右端点表示LRU线。LRU内存区域由最近使用的行组成,位置e和M分别表示早期驱逐区域和晚期驱逐区域的开始。在 miss 时,EELRU 策略要么淘汰最近最少使用的位置(晚区域)的行,要么淘汰 e t h e^{th} e t h
为了决定是使用早期驱逐还是 LRU 驱逐,EELRU 跟踪每个地区收到的命中次数。如果该分布是单调递减的,则 EELRU 假设没有振荡,并将 LRU 行逐出 。但是,如果分布显示晚期区域比早期区域的命中次数更多,那么 EELRU 将从早期区域删除,这使得晚期区域的行在缓存中保留的时间更长。表3.3总结了 EELRU 的操作。
Segmented LRU (Seg-LRU)
分段 LRU 通过优先保留至少访问过两次的行来处理扫描访问 [Karedla et al., 1994]。Seg-LRU将LRU堆栈划分为两个逻辑段(见图3.4),即适用段段和受保护段 。新进来的缓存行被添加到试用段,当他们收到再次命中,被提升到保护段。因此,受保护段中的行至少被访问了两次,而扫描访问永远不会提升到受保护段。在驱逐中,从试用部分中选择最近使用最少的一行。
表 3.4 总结了 seg-lru 的操作。在预备段的 MRU 位置插入新的行,在缓存命中时,行被提升到保护段的 MRU 位置。因为受保护的部分是有限的,提升到受保护的部分可能会迫使受保护部分的 LRU 线迁移到试用部分的 MRU 末端,使这一行在从试用部分被驱逐之前有另一个机会获得 hit。因此,Seg-LRU 可以适应工作集的变化,因为老的缓存行最终被降级到试用段。
Seg-LRU 策略的一个变体赢得了第一次缓存替换锦标赛[Gao和Wilkerson, 2010]。
Qureshi 等人[2007]观察到,通过修改插入策略,同时保持驱逐策略不变(将缓存行逐出LRU位置),可以实现基于最近的策略的变体。例如,可以使用 LRU Insertion policy (LIP) [Qureshi et al., 2007] 来模拟 MRU (表3.2),该策略在 LRU 位置插入新行,而不是 MRU 位置(见表3.5)。
这种见解促进了使用新的插入和 promotion 策略的替换策略的设计。通过以不同的方式解释最近的信息,这些策略可以处理比 LRU 更广泛的访问模式类。在本节中,我们将讨论这方面的一些值得注意的解决方案。由于应用程序通常由许多不同的访问模式组成,这些策略本身都不够,通常被用作混合解决方案的一部分,我们将在3.3节中讨论。
Bimodal Insertion Policy (BIP)
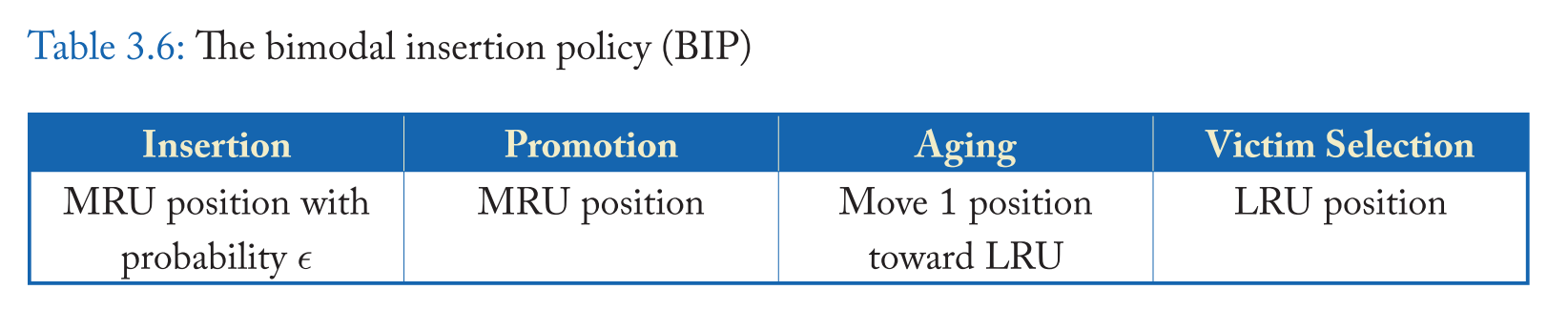
由于像 LIP(和MRU) 这样的抗抖动策略不能适应在阶段变化期间工作集的变化,BIP [Qureshi等人,2007] 修改LIP,使缓存行偶尔(以低概率)插入到 MRU 位置 。BIP 保持 LIP 的抗抖动,因为它在大多数时间插入 LRU 位置,但它也可以通过偶尔保留较新的行来适应阶段变化。表3.6显示,BIP 插入到 MRU 位置的概率为 e,设为 1/32 或 1/64。e 取值为 1 表示在 MRU 位置插入(模拟 LRU 插入策略),e 取值为 0 表示在 LRU 位置插入(模拟LIP插入策略)。因此,从实现的角度来看,BIP 的参数统一了 LRU 和 MRU 插入光谱中不同位置的所有插入策略 。
Static Re-Reference Interval Prediction (SRRIP)
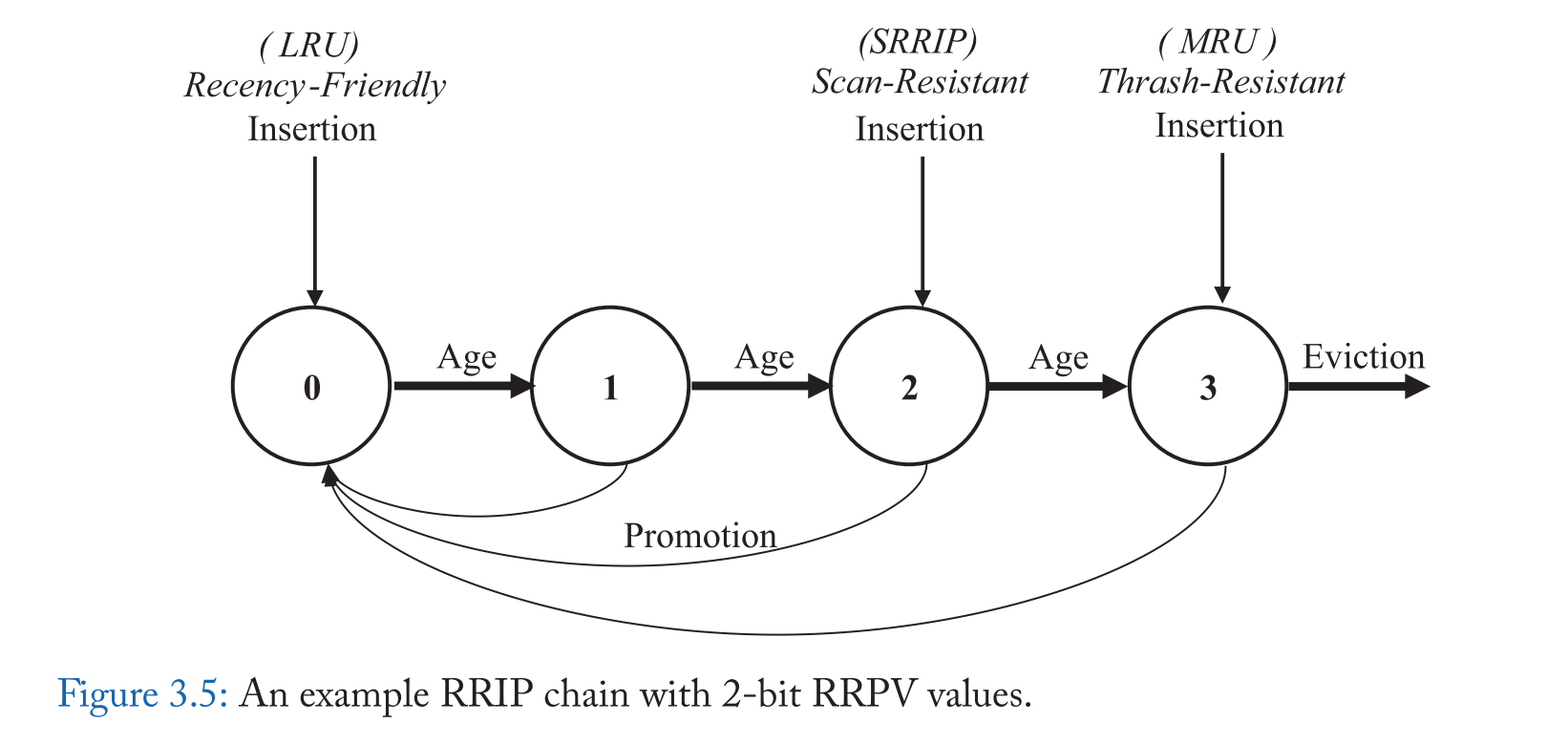
Jaleel等人[2010b]认为缓存替换可以被认为是一个重新引用区间预测 (RRIP) 问题 ,传统的 LRU 链可以被认为是一个 RRIP 链; LRU 链上一行的位置代表了自上次使用以来的时间,而 RRIP 链上一行的位置代表了它被预测重新引用的顺序[Jaleel et al., 2010b]。特别是,预测在 RRIP 链首的行将被最快的重新引用(最短的重新引用间隔),而在 RRIP 链尾的行将被最远的重新引用(最大的重新引用间隔)。当缓存丢失时,位于 RRIP 链尾部的行将被替换。
在这个视图中,我们可以看到,LRU策略预计,新的缓存行将有 near immediate re-reference 间隔(插入在 RRIP 链的头),而 thrash-resistant LIP 策略预测,新行将有一个遥远的 re-reference 间隔(插入在 RRIP 的尾部)。图 3.5 用一个 2bit 重引用预测值(RRPV)表示的RRIP 链说明了这一点:00 对应最近的重参考区间预测,11 对应遥远的重参考区间预测。
Jaleel等人[2010b]表明,与预测位于 RRIP 链末端的重新引用间隔不同,预测中间的重新引用间隔有很大的好处,它允许替换策略适应不同访问模式的混合 。特别是,扫描对未重用数据的引用会破坏最近友好策略(如 LRU),因为它们会丢弃应用程序的工作集,而不会产生任何缓存命中。为了适应最近友好访问和扫描的混合,Jaleel等人[2010b] 提出了SRRIP ,它给进入的行一个中间的重新引用间隔 ,然后如果它们被重用,将它们提升到链首。因此,SRRIP 为最近友好的策略增加了抗扫描的能力,因为它防止具有远重引用间隔的行(扫描)驱逐具有近重引用间隔的行。
在大多数情况下,SRRIP 为每个缓存块关联一个 m 位值来存储它的 Re-Reference Prediction value (RRPV),但是 Jaleel 等人[2010b] 发现一个 2 位的RRPV值就足以提供抗扫描能力。表 3.7 总结了2位 RPRV 值对SRRIP的操作。
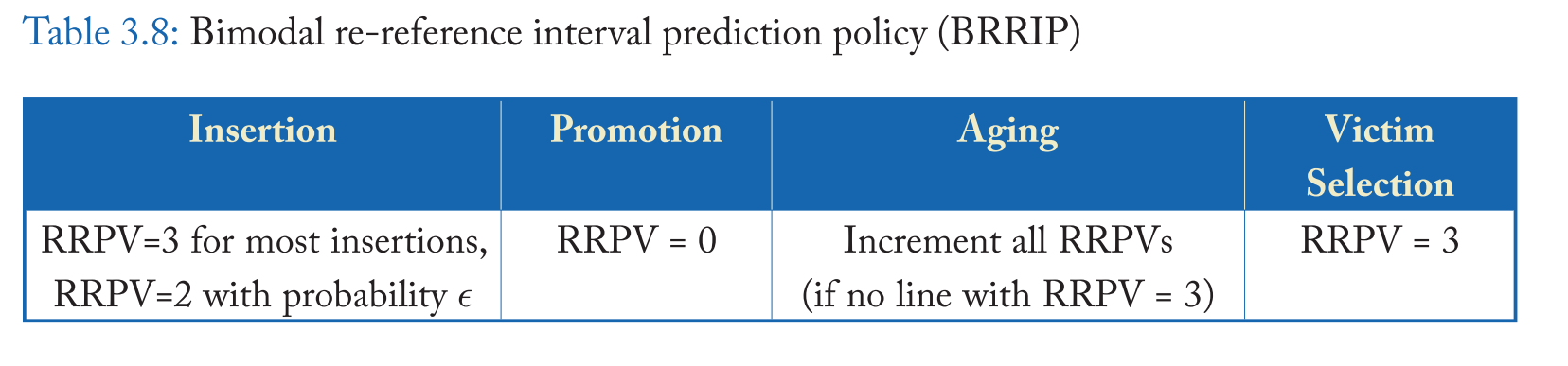
和 LRU 一样,当所有块的重引用间隔大于可用缓存时,SRRIP会对缓存进行震荡。 为了添加 thrash-resistance scan-resistant 策略),Jaleel et al. [2010b] 提出 BimodalRRIP (BRRIP) , BIP[Qureshi et al., 2007] 的一个变种,大多数缓存块都插入了一个远端重引用间隔预测(即 RRPV 为 3),它很少插入一个中间重引用间隔预测(即 RRPV 为 2 )的缓存块。. BRRIP 业务的 RRPV 汇总于表 3.8。由于应用程序可以在最近友好型和抖动型工作集之间交替使用,因此 SRRIP 和 BRRIP 本身都是不够的。在3.3节中,我们将讨论可以解决所有三种常见访问模式(最近友好、抖动和扫描)的 SRRIP 和 BRRIP 的混合版本,为许多应用程序带来性能改进。
Protecting Distance-Based Policy (PDP)
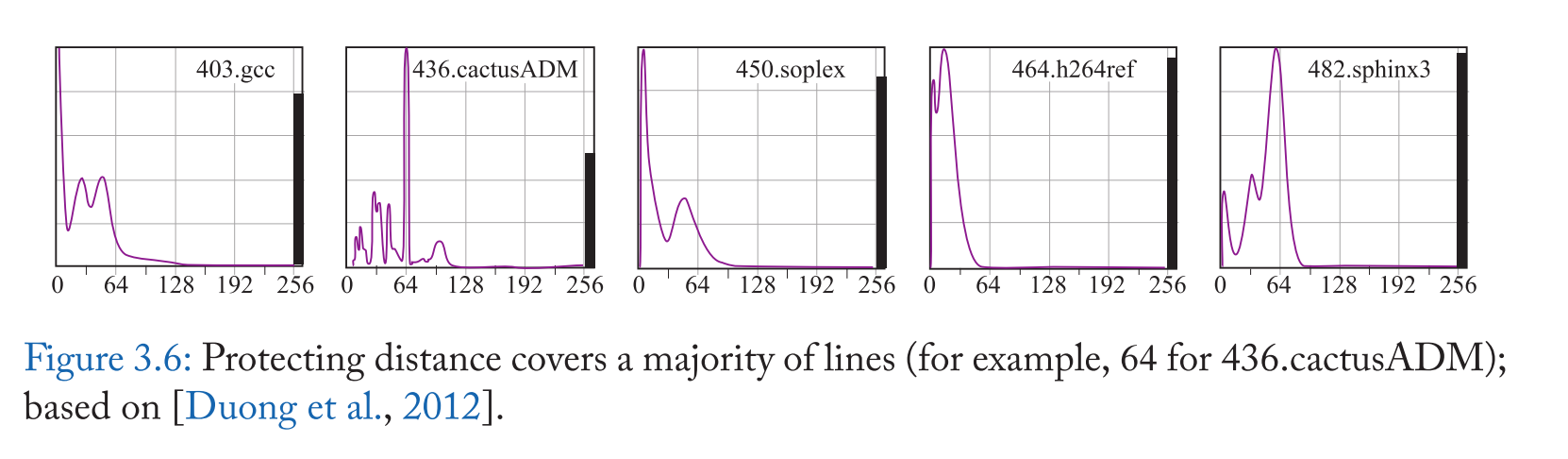
PDP 策略[Duong et al., 2012]是 RRIP 的一种推广,因为它动态估计保护距离(PD),所有的缓存行在 PD 访问时都受到保护,然后才能被驱逐。PD 是一个单独的值,用于插入到缓存中的所有行,但它会根据应用程序的动态行为不断更新 。为了估计 PD, PDP 计算重用距离分布(RDD),这是在程序执行的最近间隔内观察到的重用距离分布。使用 RDD, PD 被定义为覆盖缓存中大多数行的重用距离 ,这样大多数行在 PD 或更小的距离被重用。例如,图 3.6 显示了 436.cactusADM 的 RDD。这里 PD 设置为 64。使用小型专用处理器很少重新计算 PD。
更具体地说,在插入或提升时,每条缓存行都被赋一个值来表示其剩余的 PD (RPD),即它仍然受到保护的访问的次数;这个值被初始化为 PD。每次访问一个集合后,该集合中每一行的 RPD 值都是通过递减的 RPD 值 (在0处饱和) 来老化的。只有当该行的 RPD 大于 0 时,该行才会受到保护。未受保护的行被选为受害者进行逐出。
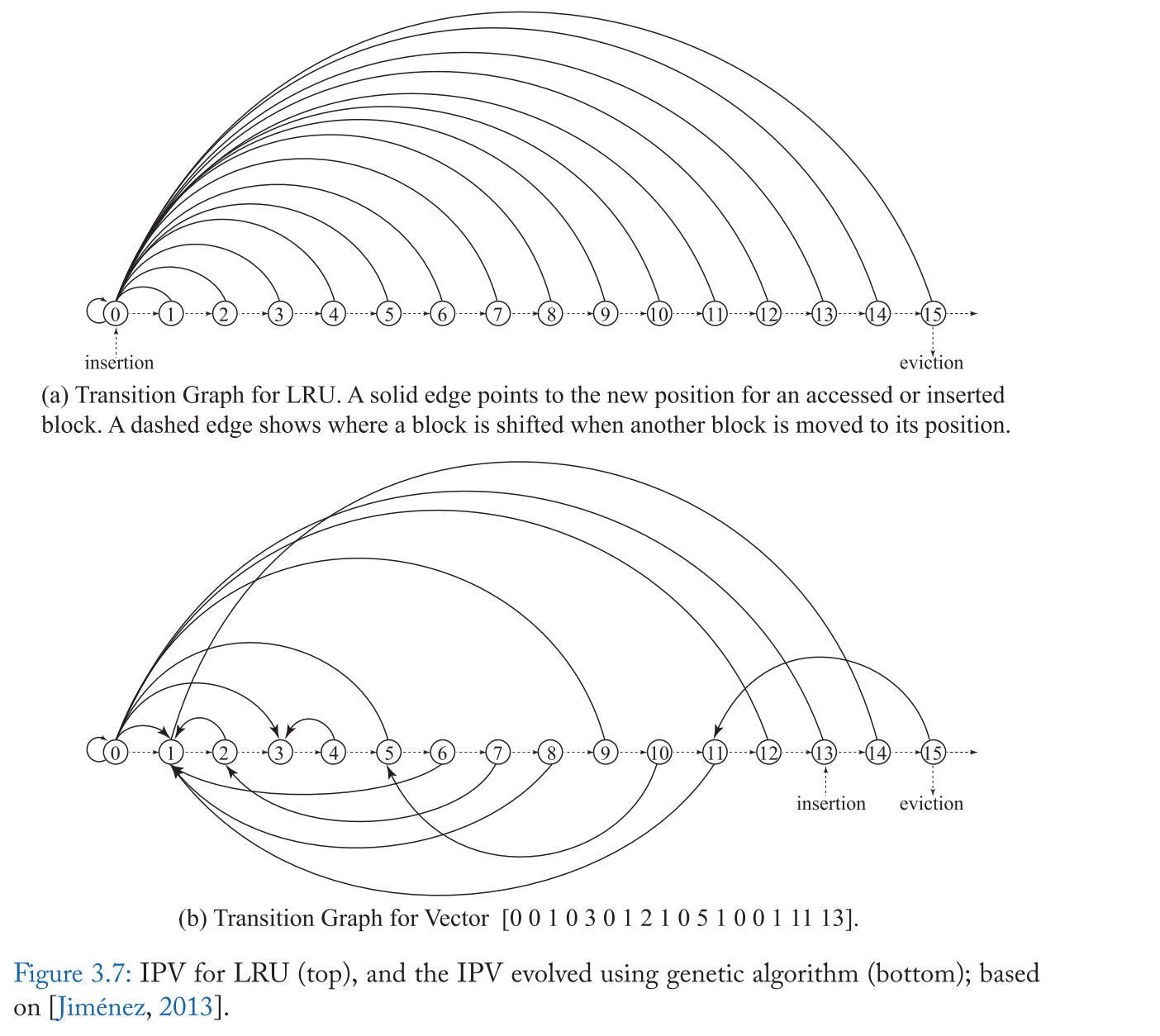
受 RRIP 的启发,Jiménez[2013] 观察到在插入和 Promote 的选择上有很多自由度,因此他们使用 插入/Promote 向量(IPV) 的概念概括了插入和 Promote 策略的修改。当块被插入到缓存中,或者从最近栈的不同位置提升时,IPV 则指示块在最近栈中的新位置。特别是,k 路 set-associative 缓存,IPV 是一个 k+1 个项组成的向量的,其中每个项的整数从 0 到 k-1,其中第 I 个位置的值表示位置 I 的块在被重新引用时应该提升到的新位置 。IPV 中的第 k 个项表示应该插入一个新的传入块的位置。如果最近堆栈中的新位置小于旧位置,则块向下移动以腾出空间;否则,块会向上移动以腾出空间。
图3.7显示了两个样本IPVs,第一个代表LRU,第二个代表更复杂的插入和提升策略。
虽然 IPVs 的广义概念非常强大,但可能的 IPVs 数量呈指数增长,(k-way 缓存的可能的 IPVs 有 k k + 1 k^{k+1} k k + 1
正如不存在适用于所有工作负载的单一插入策略或 RRIP 策略一样,每个工作负载的最佳 IPV 也是不同的。因此,Jiménez[2013] 提出了一种混合解决方案,使用 set dueling (见章节3.3) 来考虑多个 IPVs。
EXTENDED LIFETIME RECENCY-BASED POLICIES
延长生存期策略是基于最近的策略的一个特殊类,它通过将一些缓存行存储在辅助缓冲区或受害缓存中人为地延长它们的生存期。这里的关键动机是将驱逐决定推迟到更晚的时候,以便做出更明智的决定 。此策略允许粗粒度策略稍微增大缓存命中的重用窗口,使其大于缓存的大小 。
Shepherd Cache
Shepherd Cache (SC) 模仿了 Belady 的最优策略 [Rajan and Govindarajan, 2007]。由于 Belady 的策略需要未来访问的知识,Rajan 和 Govindarajan 在一个叫做 Shepherd Cache 的辅助缓存的帮助下模拟了这个未来的前瞻性。特别地,缓存在逻辑上分为两个组件,模拟最佳替换的主缓存(MC)和 使用简单的FIFO替换策略的 SC 。SC 通过提供一个前视窗口来支持 MC 的最佳替换。新行最初在 SC 中进行缓冲,直到新行离开 SC 时,才从 MC 决定替换受害者。当新行在 SC 中时,将收集关于替换候选人在 MC 中重用顺序的信息。
例如,由于 Belady 的策略驱逐了在未来被重用最多的行,所以早期被重用的行就不太可能被驱逐。当从 SC 中移除新行(由于 SC 中的其他插入)时,将通过从前瞻性窗口中尚未重用的 MC 中选择一个候选者或最后重用的候选者来选择一个替换候选者; 如果 MC 中的所有行在 SC 行重用之前被重用,那么 SC 行将替换自己。尽管 SC 和 MC 在逻辑上是分离的,Rajan 和 Govindarajan[2007] 通过组织缓存避免了数据从一个组件到另一个组件的任何移动,这样两个逻辑组件可以被组织为一个单一的物理结构。
因此,SC 通过在 SC的帮助下延长 MC 缓存中的行的生命周期,模拟了一种更好的替换方案, SC 的权衡是 MC 中的替换以高 lookahead 接近真正的最优,而更高的 lookahead 是以降低 MC 容量为代价的。不幸的是,Jain 和 Lin[2016] 的后续工作表明,为了接近 belady 的最优策略的行为,该策略需要提前 8x 缓存的大小。
x
感谢您的支持,我会继续努力的!
扫码打赏,你说多少就多少