- HashKV: Enabling Efficient Updates in KV Storage via Hashing
- http://adslab.cse.cuhk.edu.hk/software/hashkv/
- ATC18 & TOS19
个人总结
Abstract
- 持久键值(KV)存储主要构建在日志结构的合并树(LSM)上,以获得较高的写性能,但是LSM树存在固有的较高的I/O放大问题。KV分离通过在LSM-tree中只存储键和在单独存储中的值来减轻I/O放大。然而,当前的KV分离设计在更新密集型工作负载下仍然是低效的,因为它在值存储方面的垃圾收集(GC)开销很大。我们提出了HashKV,它的目标是在更新密集型工作负载下,在KV分离的基础上提高更新性能。HashKV使用基于哈希的数据分组,它确定地将值映射到存储空间,从而提高更新和GC的效率。我们通过简单但有用的设计扩展进一步放宽了这种确定性映射的限制。通过大量的实验,我们将HashKV与最先进的KV存储进行了比较,并表明与当前的KV分离设计相比,HashKV实现了4.6×吞吐量和减少了53.4%的写流量。
Introduction
- 持久性 KV 存储应用广泛,用于存储海量结构化数据:Bigtable, Dynamo, Atlas。虽然现实中的KV存储工作负载主要是读密集型的(例如,在Facebook的Memcached工作负载中,Get/Update的比率可以达到30:1),但更新密集型的工作负载在许多存储场景中也占主导地位(例如,雅虎报告其低延迟工作负载越来越多地从读转移到写)
- 现代的针对写操作优化的 KV 存储大多是基于 LSM 树,思想源于最初的 LSF,LSM-tree设计不仅通过避免小的随机更新(这也有害于固态硬盘(SSD)的寿命)来提高写性能,而且通过在每个节点中保留已排序的KV对来提高范围扫描性能。但是写放大严重,读放大更严重。
- 已有方案:WiscKey 采用 KV 分离来减少 Compaction 操作带来的影响,但是我们发现 KV 分离还是无法在更新密集型工作负载下完全实现高性能。
- 根本原因在于用于值存储的循环日志需要频繁的垃圾收集(GC),以从被删除或被新更新取代的KV对中回收空间。然而,由于循环日志的两个限制,GC开销实际上是昂贵的。
- 首先,循环日志保持严格的GC顺序,因为它总是在日志的开始处执行GC,即最近写入的KV对所在的位置。这可能会导致大量不必要的数据重定位(例如,当最近写的KV对仍然有效时)。
- 其次,GC 操作需要查询LSM-tree,检查每个KV对的有效性。这些查询具有很高的延迟,特别是当LSM-tree在大工作负载下变得相当大时。
- 所以提出了 HashKV,为更新密集型工作负载量身定制的高性能KV存储。HashKV建立在KV分离的基础上,并使用一种新的基于哈希的数据分组设计来存储值。其思想是将值存储划分为固定大小的分区,并通过散列其键确定地将每个写入KV对的值映射到一个分区。基于哈希的数据分组支持基于确定性映射的轻量级更新。更重要的是,它显著地减轻了GC开销,因为每个GC操作不仅具有选择一个分区来回收空间的灵活性,而且还消除了为了检查KV对的有效性而对LSM-tree的查询。
- 另一方面,基于哈希的数据分组的确定性限制了KV对的存储位置。因此,我们提出了三种新的设计扩展来放松基于哈希的数据分组的限制:
- (i) 动态预留空间分配,在给定大小限制的情况下,动态分配预留空间给额外的写操作
- (ii) 热感知,受现有SSD设计的启发,将热KV和冷KV对的存储分开,以提高GC效率
- (iii) 有选择性的KV分离,在LSM-tree中保持较小的KV对的完整,以简化查找
- 基于 LevelDB 实现了 HashKV 的原型,通过测试实验表明,在更新密集型的工作负载下,HashKV 的吞吐量达到 4.6×,与 wisckey 中的循环日志设计相比,写流量减少了 53.4%。此外,在各种情况下,与现代KV存储(如LevelDB和RocksDB)相比,HashKV通常能够实现更高的吞吐量和更少的写流量。
- 我们的工作只是增加 KV 分离与一个新的Value管理设计的案例。虽然HashKV的密钥和元数据管理现在建立在LevelDB上,但它也可以采用带有新的LSM树设计的其他KV存储。在KV分离条件下,哈希KV如何影响各种基于lsm树的KV存储的性能是未来研究的重点。
Motivation
- 这一章节主要介绍 LevelDB 的读写放大问题,以及 WiscKey 这种 KV 分离方案带来的改善,同时分析普通的 KV 分离无法在写密集负载中实现高性能的原因。
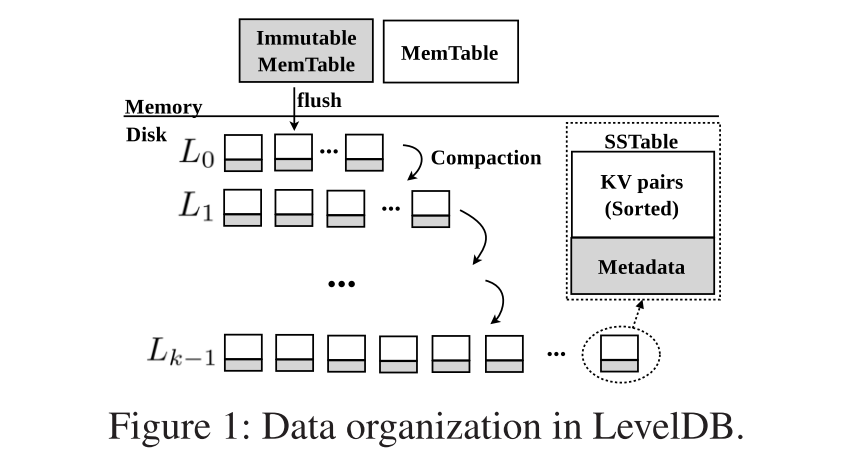
LevelDB
- 原理不过多介绍,重点是读写放大问题。
- 首先,压缩过程不可避免地产生额外的读写。在最坏的情况下,要将一个SSTable从Li−1合并到Li,它需要读取并排序10个SSTable,然后写回所有SSTable。先前的研究表明,LevelDB可以有至少50倍的总体写放大,因为在大的工作负载下,它可能会触发不止一次的压缩,将一个KV对向下移动多个级别。
- 查找操作可以在多个级别搜索一个KV对,并导致多个磁盘访问。原因是,每个级别的搜索都需要读取相关SSTable中的索引元数据和Bloom过滤器,虽然使用了Bloom过滤器,但它可能会引入误报。在这种情况下,即使KV对实际上不存在,仍然需要从磁盘读取SSTable。因此,每次查找通常会导致多次磁盘访问。这种读放大在大的工作负载下会进一步恶化,因为LSMtree会逐级累积。测量结果表明,在最坏的情况下,读放大可达300倍以上
KV Separation
WiscKey 原理
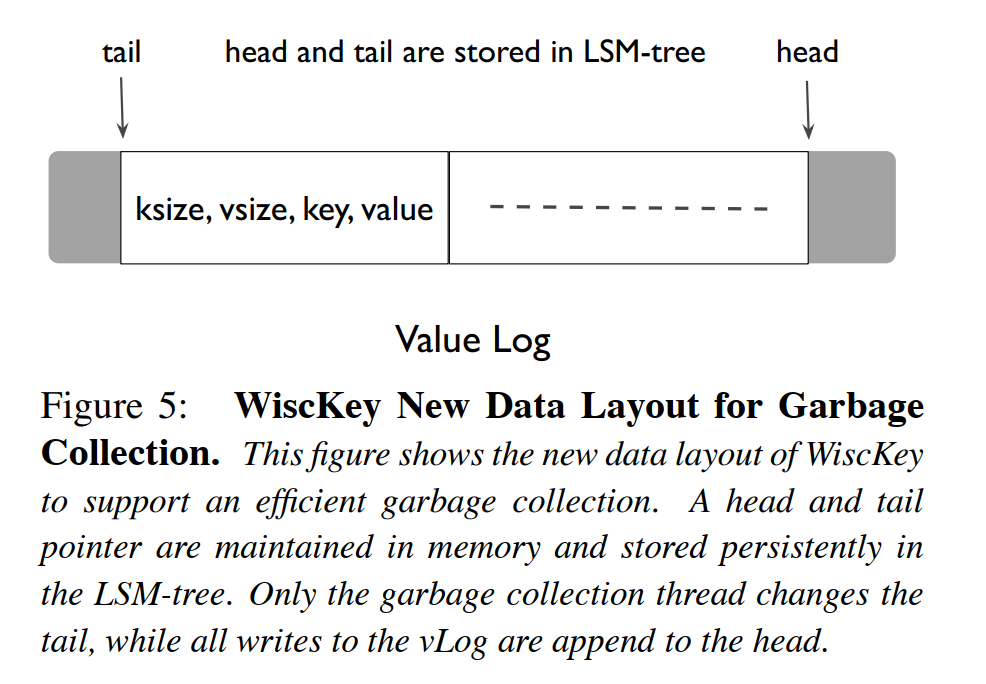
- KV分离,由 Wisckey 提出,对键和值的管理进行解耦,以减轻写和读的放大。其基本原理是,在 LSM-tree 中存储值对于索引来说是不必要的。因此,在LSM-tree中,wisckey 只存储键和元数据(例如键/值的大小、值的位置等),而将值存储在一个单独的仅追加的循环日志vLog 中。KV 分离有效地减轻了LevelDB的写和读放大,因为它显著地减少了 lsm 树的大小,从而同时减少了压缩和查找开销。
- 由于vLog遵循日志结构设计,KV分离在vLog中实现轻量级的垃圾收集(GC)是至关重要的,即在有限的开销下从无效值中回收空闲空间。具体来说,wisckey跟踪的是vLog头部和vLog尾部,分别对应于vLog的结束和开始。它总是向vLog头插入新的值。当它执行GC操作时,它从vLog尾部读取一大块KV对。它首先查询lsm树,查看每个KV对是否有效。然后丢弃无效KV对的值,并将有效值写回vLog头。它最后更新LSM-tree以获取有效值的最新位置。为了在GC期间支持有效的LSM-tree查询,wisckey还将相关的键和元数据与值一起存储在vLog中。请注意,vLog经常为减少GC开销而提供额外的预留空间。
Limitations
- 虽然KV分离降低了压缩和查找开销,但我们认为它受到了vLog中大量GC开销的影响。另外,如果预留空间有限,GC开销会变得更加严重。原因有两方面:
- 首先,由于它的循环日志设计,vLog只能从它的vLog尾部回收空间。这个约束可能会导致不必要的数据移动。特别是,真实世界的KV存储往往表现出很强的局部性,其中一小部分的热KV对经常更新,而其余的冷KV对只接收到很少甚至没有更新。在vLog中保持严格的顺序不可避免地会多次重新定位冷KV对,从而增加GC开销。
- 此外,每个GC操作都查询LSM-tree,以检查vLog尾部chunk中每个KV对的有效性。由于KV对的键可能分散在整个LSM-tree中,查询开销很高,并增加了GC操作的延迟。虽然KV分离已经减少了LSM-tree的大小,但是LSM-tree在大的工作负载下仍然是相当大的,这加剧了查询成本。
- 分别总结一下这两个问题:
- GC 过程中需要对有效数据进行拷贝,热数据进行 GC 是必须的,确保频繁更新的数据的老旧版本的空间能够及时回收,冷数据 GC 其实意义不大,反而因为 GC 过程中的数据迁移引入了开销。GC 最好的情况就是遇到需要删除和回收的数据,因为在 WiscKey 这样的设计背景下,无需进行回收的数据就肯定会进行数据的拷贝来回收对应的这一段空间(为了避免碎片或者说hole 的产生,因为碎片相应地容易引发随机 I/O)
- GC 操作每个都需要检查数据的有效性,需要去 LSM 树中进行查询,相当于 GC 操作引入了额外的查询开销,并增加了 GC 操作的延迟(这个是因为 LSM 树本身读的一部分原因,造成了读操作需要读很多层,延迟就比较高,本来 LSM 树读性能就不是特别好)
- 那 KV 分离为啥是用 LSM + Value Log 的方案,而不是 B tree + Value Log 呢?思想就是找一个小写读写性能比 LSM 相对更好的数据结构来代替 LSM 存储 Key。Key 大小甚至可以固定,使用一些定长编码的策略。换一个更高效的索引结构似乎就能解决查询延迟的问题?但仿佛又会牺牲写
实验验证
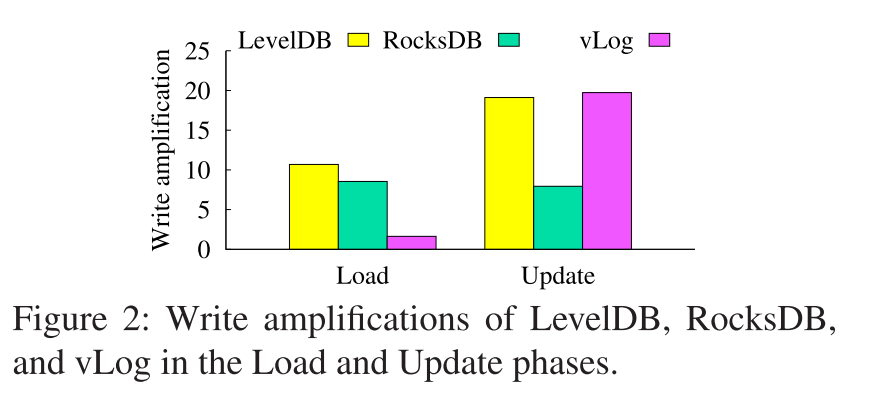
- 为了验证KV分离的局限性,我们实现了一个基于vLog的KV存储原型(见§3.8),并评估其写入放大。我们考虑两个阶段:加载和更新。在加载阶段,将40GiB的1-KiB KV对插入到初始为空的vLog中;在更新阶段,我们基于Zipf分布,Zipfian常数为0.99,发起了40GiB对现有KV对的更新。我们为视频日志提供40GiB的空间,并额外预留30% (12GiB)的空间。我们也在原型中禁用了写缓存(见§3.2)。图2显示了加载和更新阶段vLog的写放大结果,即由于插入或更新导致的总设备写大小与实际写大小的比例。
- 为了进行比较,我们还考虑两个现代KV存储,LevelDB和RocksDB,基于它们的默认参数。在 Load 阶段,vLog有足够的空间容纳所有KV对,不触发GC,由于KV分离,它的写入放大只有1.6×。但是,在更新阶段,更新会填满保留的空间并开始触发GC。我们可以看到,vLog的写放大倍数为19.7×,接近LevelDB (19.1×),高于RocksDB (7.9×)。
- 为了减轻vLog的GC开销,一种方法是将vLog划分成段,并根据成本-收益策略或其变体 [如下参考文献 ] 选择最佳的候选段来减少GC开销。但是,热KV和冷KV对仍然可以在vLog中混合在一起,所以为GC选择的段可能仍然包含冷KV对,并且不必要地移动。
- [SOSP1997 Improving the Performance of Log-Structured File Systems with Adaptive Methods]
- [TOCS1992 The Design and Implementation of a Log-structured File System]
- [FAST14 Logstructured Memory for DRAM-based Storage]
- 为了解决热数据和冷数据的混合问题,更好的方法是像SSD设计中那样执行热-冷数据分组,其中,我们将热KV和冷KV的存储分成两个区域,并分别对每个区域应用GC(更多的GC操作将应用于热KV的存储区域)。然而,直接实现热-冷数据分组不可避免地增加了KV分离过程中的更新延迟。由于KV对可能存储在热或冷数据区,每次更新都需要首先查询LSM-tree以获得KV对的确切存储位置。因此,我们工作的一个关键动机是在不使用 LSM 树查找的情况下启用热状态识别。
Design
- HashKV是一个持久的KV存储,专门针对更新密集型工作负载。在KV分离的基础上改进了 Value 存储的管理,实现了高更新性能。它支持标准的KV操作:PUT(即写入一个KV对)、GET(即检索一个键的值)、DELETE(即删除一个KV对)和SCAN(即检索一个键范围的值)。
Main Idea
- 在KV分离之上,HashKV引入了几个核心设计元素来实现高效的 Value 存储管理:
- Hash-based data grouping: 回想一下,vLog在值存储方面会招致大量的GC开销。相反,HashKV通过散列相关的键将值映射到值存储中固定大小的分区中。这种设计实现了:
- (i)分区隔离,在这种情况下,所有版本的值更新都必须被写入到相同的分区中,
- (ii)确定性分组,在这种情况下,一个值应该存储在哪个分区中是通过哈希来确定的。我们利用这种设计来实现灵活和轻量级的GC
- Dynamic reserved space allocation: 由于我们将值映射到固定大小的分区中,一个挑战是一个分区接收的更新可能多于它能容纳的更新。HashKV通过在值存储中分配部分保留空间,允许分区动态增长,超过其大小限制。
- Hotness awareness:由于确定性分组,分区可能会被来自热KV对和冷KV对的混合值填满,在这种情况下,GC操作会不必要地读取和回写冷KV对的值。HashKV使用标记方法将冷KV对的值重新定位到不同的存储区域,并将热KV对和冷KV对分开,这样我们就可以只对热KV对使用GC,避免重复复制冷KV对。
- Selective KV separation:HashKV通过其值大小来区分KV对,小的KV对可以直接存储在LSM-tree中,而不需要分离KV。这节省了访问小KV对的LSM-tree和值存储的开销,而在LSM-tree中存储小KV对的压缩开销是有限的。
- Hash-based data grouping: 回想一下,vLog在值存储方面会招致大量的GC开销。相反,HashKV通过散列相关的键将值映射到值存储中固定大小的分区中。这种设计实现了:
- HashKV维护一个单一的LSM-tree来进行索引(而不是像值存储中那样对LSM-tree进行哈希分区),以保持键的顺序和范围扫描性能。由于基于哈希的数据分组将KV对分散到值存储中,因此会导致随机写操作;相反,vLog使用日志结构的存储布局来维护顺序写入。我们的HashKV原型(见§3.8)利用多线程和批处理写来限制随机写开销。
Storage Management
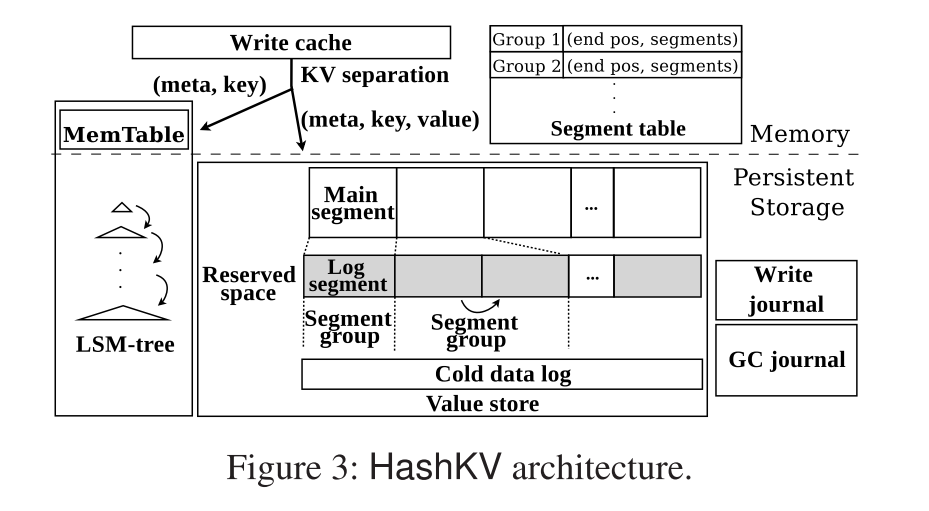
- 将 value store 的逻辑地址空间划分成固定大小的单元,称之为 main segments,此外,它还过度规定了保留空间的固定部分,将其再次划分为固定大小的单元,称为 log segments。注意,主段和日志段的大小可能不同;缺省情况下,分别设置为64MiB和1MiB。
- 对于每一个KV对的插入或更新,HashKV将其密钥散列到一个主要段中。如果主段没有被填满,HashKV会把这个值添加到主段的末尾,以一种日志结构的方式存储这个值;另一方面,如果主段已满,HashKV会动态分配一个空闲的日志段,以日志结构的方式存储额外的值。同样,如果当前日志段已满,它将进一步分配额外的空闲日志段。我们统称一个主段和它的所有关联的日志段为段组。
- 此外,HashKV更新LSM-tree以获得最新的值位置。为了跟踪段组和段的存储状态,HashKV使用一个内存中的全局段表来存储每个段组的当前结束位置,以供后续的插入或更新,以及与每个段组相关的日志段列表。我们的设计确保了每个插入或更新都可以直接映射到正确的写位置,而无需在写路径上执行LSM-tree查找(直接 HASH 得到对应的分区,然后在分区中进行追加写),从而实现了较高的写性能。另外,与同一个键相关联的值的更新必须转到同一个段组,这简化了GC。为了容错,HashKV checkpoints 段表到持久存储(内存中的段表数据恢复方式)。
- 为了便于GC, HashKV还存储键和元数据(例如,键/值大小),和 WiscKey 一样和值存储在一起(参见图3)。这使GC操作能够在 scan value store 时,快速识别关联到某一个值的键。然而,我们的GC设计与 WiscKey 使用的 vLog 有本质上的不同。
- 为了提高写性能,HashKV在内存中保存了一个写缓存,以降低可靠性为代价来存储最近写的KV对。如果在写缓存中找到了要写的新KV对的键,HashKV就直接就地更新缓存的键的值,而不用向LSM-tree和值存储区发出写操作。它还可以从写缓存中返回KV对用于读取。如果写缓存已满,HashKV将所有缓存的KV对刷新到lsm 树和值存储中。注意,写缓存是一个可选组件,可以出于可靠性考虑禁用它。
- HashKV 通过将冷值保存在单独的冷数据日志 cold data log 中来支持热感知(见§3.4)。它还通过在 write journal 和 GC journal 中跟踪更新来解决崩溃一致性问题(见3.7)。
Garbage Collection (GC)
- HashKV要求GC回收值存储中无效值所占用的空间。在HashKV中,GC以段组为单位进行操作,当保留空间中的空闲日志段用完时将触发GC。在较高的级别上,GC操作首先选择一个候选段组,并识别组中所有有效的KV对(即最新版本的KV对)。然后,它以日志结构的方式将所有有效的KV对写回主段,或者在需要时写到附加的日志段。它还释放任何未使用的日志段,这些日志段以后可以被其他段组使用。最后,它更新LSM-tree中最新的值位置。这里,GC操作需要解决两个问题:
- (i) 应该为GC选择哪个段组;
- (ii) GC操作如何快速识别所选段组中的有效KV对。
- 不同于vLog,它要求GC操作遵循严格的顺序,HashKV可以灵活地选择执行GC的段组。目前采用的是贪婪的方法,选择写量最大的段组。我们的基本原理是,所选的段组通常保存有许多更新,因此有大量写操作的hot KV对。因此,为GC选择这个段组可能会回收最多的空闲空间。为了实现贪婪的方法,HashKV跟踪内存段表中每个段组的写量(见§3.2),并使用堆 heap 来快速识别哪个段组收到的写量最大
- 为了检查所选段组中KV对的有效性,HashKV顺序扫描段组中的KV对,而不查询LSM-tree(注意,它还检查写缓存,以查找段组中最新的KV对)。由于KV对以日志结构的方式写入段组,所以必须按照更新的顺序依次放置KV对。对于一个有多个版本更新的KV对,最接近段组末尾的版本必须是最新的版本,并且对应于有效的KV对,而其他版本是无效的。因此,每个GC操作的运行时间只取决于需要扫描的段组的大小。相反,vLog中的GC操作从vLog尾部读取一大块KV对(见§2.2)。它查询LSM-tree(基于与值一起存储的键)以获取每个KV对的最新存储位置,以检查KV对是否为有效的。在大的工作负载下,查询LSM-tree的开销会变得很大。
- 在段组的GC操作期间,HashKV构造一个临时内存哈希表(按键索引)来缓冲在段组中找到的有效KV对的地址。由于键和地址的大小通常比较小,并且一个段组中的 KV 对数量有限,所以哈希表的大小有限,可以全部存储在内存中。
Hotness Awareness
- 冷热数据分离提高了日志结构存储中的GC性能。事实上,当前基于散列的数据分组设计实现了某种形式的冷热数据分离,因为对热KV对的更新必须散列到同一段组,而我们当前的GC策略总是选择可能存储热KV对的段组。然而,不可避免的是,一些冷KV对被散列到为GC选择的段组中,导致不必要的数据重写。因此,充分实现冷热数据分离,进一步提高GC性能是一个挑战。
- HashKV通过标记方法放松了基于哈希的数据分组的限制(见图4)。具体来说,当HashKV对一个段组执行GC操作时,它将段组中的每个KV对划分为热的或冷的。目前,我们将自最后一次插入以来至少更新过一次的KV对视为热的,否则是冷的(可以使用更精确的热-冷数据识别方法)
- 对于热KV对,HashKV仍然通过散列将它们的最新版本写回同一个段组。
- 对于冷KV对,它现在将它们的值写入一个单独的存储区域,并在段组中只保留它们的元数据(即没有值)。此外,它在每个冷KV对的元数据中添加一个标记,以表明它在段组中的存在。
- 因此,如果一个冷KV对后来被更新,我们直接从标签(不查询LSM-tree)知道冷KV对已经被存储,因此我们可以根据我们的分类策略将其视为热;标记的KV对也将失效。最后,在GC操作结束时,HashKV更新LSM-tree中最新的值位置,这样冷KV对的位置(LSM存储的地址)就指向单独的区域。
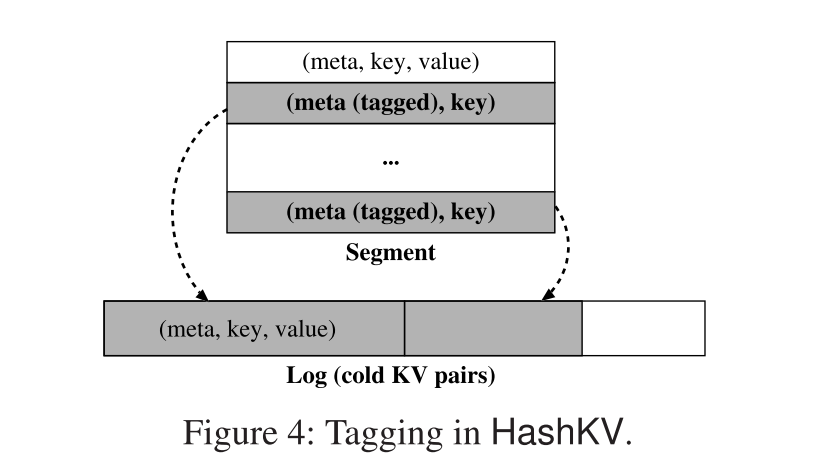
- 通过标记,HashKV避免了将冷KV对的值存储在段组中,并在GC期间重写它们。而且,标记只在GC期间触发,不会给写路径增加额外的开销。目前,我们为冷KV对实现了单独的存储区域,作为值存储中的一个仅追加的日志(称为冷数据日志),并像vLog一样对冷数据日志执行gc(这里就和 WiscKey 一样了)。如果冷KV对很少被访问,冷数据日志也可以放在容量更大的二级存储中(如硬盘)。
- 其实这里有三个问题:
- 热数据特别少,冷数据特别多的时候,空间分配会是个问题。
- 所有的数据第一次访问的时候都是冷数据,第二次访问就成了热数据了,要是冷数据变热数据之间的时间较长,中间进行了 GC,就会导致数据拷贝(至少一次 segment group 到 cold Value Log),然后再引入一次 Cold Value Log 中的 GC 操作,这时候就退化成了 WiscKey 的 GC,需要检查 LSM Tree。
- 这种过于简单的冷热数据识别,应对不了热数据变冷的问题,热数据变冷会一直在 segment group 中进行拷贝,还是会一直进行数据的拷贝,还是退化成了 WiscKey 的 GC。(这种简单的冷热数据识别只能对 只访问一次的冷数据为主要组成部分的负载 产生比较好的效果)
- 其实这里有三个问题:
- 本质是将冷数据只进行一次拷贝操作,减少了冷数据的数据迁移,同时验证冷数据的有效性直接通过 tag 验证,不用查询 LSM 树,热数据的有效性的话还是需要通过内存中临时内存哈希表来进行验证。
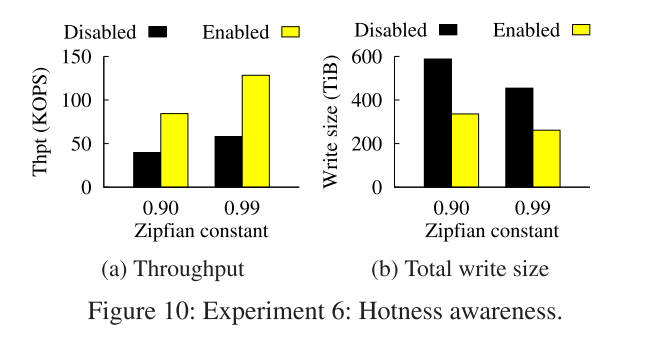
- 我们评估了热度感知对HashKV更新性能的影响。我们考虑两个Zipfian常量,0.9和0.99,以捕获工作负载中的不同偏度。图10显示了禁用和启用热感知功能时的结果。当启用热感知功能时,更新吞吐量增加了113.1%和121.3%,而对于Zipfian常数0.9和0.99,写大小分别减少了42.8%和42.5%。
Selective KV Separation
- HashKV支持具有一般值大小的工作负载。我们的理论基础是,KV分离降低了压缩开销,特别是对于大型KV对,但它对小型KV对的好处是有限的,而且它会导致访问 LSM 树和值存储的额外开销。因此,我们提出了选择KV分离的方法,即对较大值的KV对仍然采用KV分离,而较小值的KV对则全部存储在LSM-tree中。选择KV分离的一个关键挑战是选择区分小尺寸和大尺寸KV对的KV对大小阈值(假设键大小不变)。我们认为选择取决于部署环境。在实践中,我们可以对不同的值大小进行性能测试,看看什么时候选择性KV分离的吞吐量增益显著。
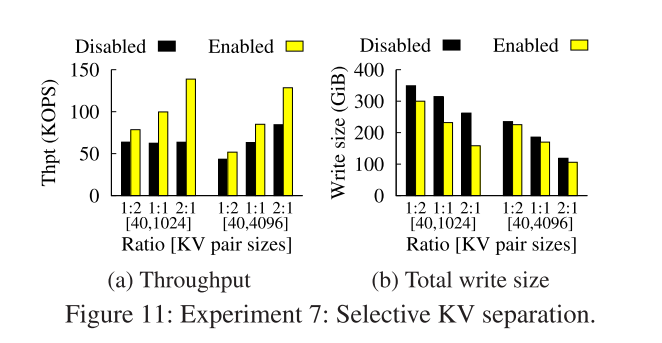
- 我们观察到,由于在KV分离下存储的小KV对的高更新开销,当小KV对的比例较高时,此时工作负载下,KV分离的性能增益更高。同时 40B-1KB 的组合相比于 40B-4KB 的组合优化效果更明显。
Range Scans
- 使用LSM-tree进行索引的一个关键原因是它对范围扫描的有效支持。由于LSMtree按键存储和排序KV对,因此它可以通过顺序读取返回一系列键的值。然而,KV分离现在将值存储在单独的存储空间中,因此它会招致额外的值读取。在HashKV中,这些值分散在不同的段组中,因此范围扫描将触发许多随机读取,从而降低性能。HashKV目前利用预读机制通过将值预取到页面缓存中来加速范围扫描。对于每个扫描请求,HashKV遍历LSM-tree中排序键的范围,并(通过posix fadvise)向每个值发出预读请求。然后读取所有值并返回排序的KV对。
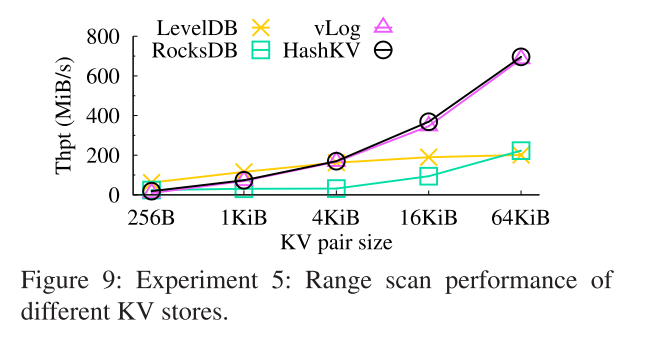
- 在KV对大小上,HashKV具有与vLog相似的扫描性能。然而,对于256-B和1-KiB KV对,HashKV的扫描吞吐量分别比LevelDB低70.0%和36.3%,主要是因为HashKV需要向LSM-tree和值存储发出读操作,而且通过随机读操作从值存储中检索小值的开销也很大。然而,对于4KiB或更大的KV对,HashKV的性能优于LevelDB,例如,4KiB KV对的性能为94.2%。
- 注意,预读机制(见§3.6)是使HashKV实现高范围扫描性能的关键。例如,与没有预读的情况相比,256-B KV对的HashKV的范围扫描吞吐量增加了81.0%
Crash Consistency
-
当HashKV问题写入持久性存储时,可能会发生崩溃。HashKV基于元数据日志记录解决崩溃一致性问题,主要关注两个方面:
- (i) 刷新写缓存
- (ii) GC操作。
-
刷新写缓存涉及将KV对写入值存储并更新LSM-tree中的元数据。HashKV维护一个写日志 write journal 来跟踪每次 flush 操作。它在刷新写缓存时执行以下步骤:
- (i) 将缓存的KV对刷新到值存储中;
- (ii) 在 write journal 中追加写入元数据更新;
- (iii) 在 journal end 写入一个提交记录;
- (iv) 更新 LSM-tree 中的 keys 和元数据;
- (v) 在日志中标记 flush 操作为 free 状态( free 的日志记录可以稍后回收)。
-
如果在步骤(iii)完成后发生崩溃,HashKV在写日志中回放更新,并确保LSMtree和值存储是一致的。
-
GC 操作中崩溃一致性的处理是不同的,因为它们可能会覆盖现有的有效 KV 对。因此,我们还需要保护现有的有效 KV 对,防止在GC 期间崩溃。HashKV 维护一个GC日志来跟踪每个GC操作。 在GC操作中识别出所有有效的KV对后,它将执行以下步骤:
- (i) 将被覆盖的有效KV对以及元数据更新一起添加到GC日志中;
- (ii) 将所有有效KV对写回段组;
- (iii) 更新LSM-tree中的元数据;
- (iv) 在日志中标记GC操作对应的记录为 free 状态。
-
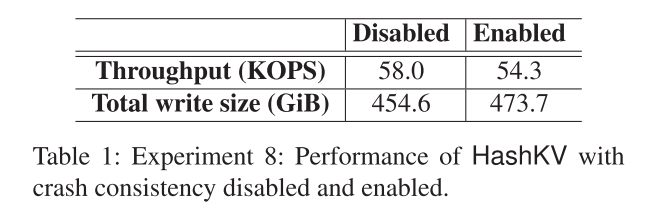
我们研究了崩溃一致性机制对HashKV性能的影响。表1显示了结果。当启用了崩溃一致性机制时,P3阶段的HashKV的更新吞吐量减少了6.5%,总写大小增加了4.2%,这表明崩溃一致性机制的影响仍然有限。请注意,我们在运行时通过代码注入和意外终止来使HashKV崩溃,从而验证崩溃一致性机制的正确性。
Implementation Details
- 基于 LevelDB v1.20 实现
- Storage organization: 我们目前将HashKV部署在具有多个ssd的RAID阵列上,以获得更高的I/O性能。我们使用 mdadm 创建一个软件RAID卷,并将RAID卷挂载为Ext4文件系统,在该文件系统上运行LevelDB和值存储。特别地,HashKV将值存储管理为一个大文件。它根据预先配置的段大小,将value store文件划分为两个区域,一个用于主段,另一个用于日志段。所有的段在value store文件中对齐,这样每个 main/log 段的起始偏移量是 main 段大小的倍数。如果启用了热感知功能(见§3.4),HashKV会在值存储文件中为冷数据日志添加一个单独的区域。此外,为了解决崩溃一致性(见3.7),HashKV使用单独的文件来存储写和GC日志。
- Multi-threading:HashKV通过线程池实现了多线程,当把写缓存中的KV对刷新到不同的段时(见§3.2),并且在GC(见§3.3)过程中从段组中并行检索段,从而提高I/O性能。
- 为了减轻确定性分组带来的随机写开销(见§3.1),HashKV实现了批量写。当HashKV在写缓存中刷新KV对时,它首先识别并缓冲一批被散列到同一个分段组中的KV对,然后(通过线程)发出一个顺序写来刷新批处理。更大的批处理大小减少了随机写开销,但它也降低了并行性。 目前,我们配置了一个批写入阈值,在批中添加KV对后,如果批大小达到或超过批大小阈值,批将被刷新;换句话说,如果一个KV对的大小大于批写阈值,HashKV就直接刷新它。
Evaluation
- 我们评估了LevelDB (LDB)、RocksDB (RDB)、HyperLevelDB (HDB)、PebblesDB (PDB)、vLog和HashKV (HKV)在更新密集型工作负载下的性能。我们首先比较LevelDB, RocksDB, vLog和HashKV;之后,我们还将HyperLevelDB和pebblesdb纳入比较中。
- 图5(a)显示了每个阶段的性能。对于vLog和HashKV,加载阶段的吞吐量比更新阶段的吞吐量高,因为更新阶段主要由GC开销控制。在 load 阶段,hashkv的吞吐量分别比LevelDB和RocksDB大17.1×和3.0×。HashKV的吞吐量比vLog慢7.9%,这是由于通过哈希来分发KV对而引入了随机写。在更新阶段,HashKV的吞吐量在LevelDB、RocksDB和vLog上分别为6.3-7.9×、1.3-1.4×和3.7-4.6×。由于压缩开销很大,LevelDB的吞吐量在所有KV存储中是最低的,而vLog的GC开销也很高。
- 图5(b)和5(c)显示了总写大小和所有加载和更新请求发出后,不同KV存储的大小。HashKV将LevelDB、RocksDB和vLog的总写大小分别减少了71.5%、66.7%和49.6%。而且,它们有非常相似的 KV 存储大小。
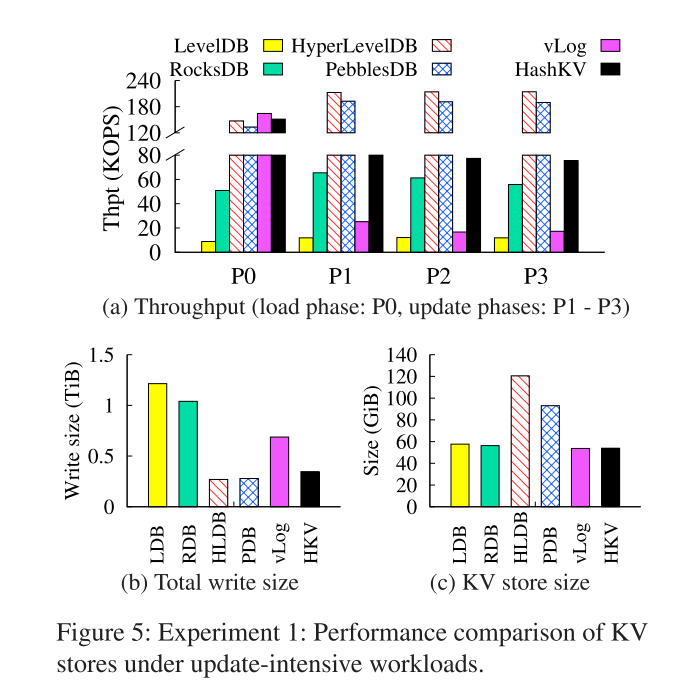
- 对于 HyperLevelDB 和 peblesdb,两者都是如此,由于压缩开销较低,因此具有较高的负载和更新吞吐量。例如,PebblesDB将sstable的片段从较高的级别添加到较低的级别,而不重写较低级别的sstable。HyperLevelDB和PebblesDB都至少实现了HashKV的两倍吞吐量,同时产生的写大小也小于HashKV。 另一方面,它们的存储开销很大,其最终KV存储大小分别为2.2× HashKV和1.7× HashKV。主要原因是HyperLevelDB和PebblesDB都只对选定范围的键进行压缩,以减少写放大,这样在压缩后可能仍然会有很多无效的KV对。它们触发压缩操作的频率也低于LevelDB。这两个因素都会导致较高的存储开销。 在接下来的实验中,我们关注LevelDB、RocksDB、vLog和HashKV,因为它们的存储开销相当。
- 写放大 PebblesDB/HyperLevelDB 做得更好,但空间放大 HASHKV 更好
Related Work
- General KV stores:
- DRAM: Redis, MemC3, NSDI13 Distributed Caching with Memcached, NSDI14 MICA
- SSDs: FlashStore, SIGMOD11 SkimpyStash, SOSP11 SILT, FAST16 WiscKey
- NVM: ATC15 NVMKV, ATC17 HiKV
- LSM-tree-based KV stores
- bLSM
- VT-tree
- LSM-trie
- LWC-store
- SkipStore
- PebblesDB
- KV separation
- WiscKey
- Atlas
- Cocytus
- Hash-based data organization
- Dynamo
- Kinesis
- Ceph
- NVMKV
Conclusion
- 本文提出了HashKV算法,它能够在更新密集型工作负载下对KV存储进行有效的更新。它的新颖之处在于利用基于哈希的数据分组进行确定性数据组织,从而减轻GC开销。我们通过几个扩展进一步增强了HashKV,包括动态预留空间分配、热度感知和选择性KV分离。试验台实验表明,HashKV实现了较高的更新吞吐量,并减少了总写大小。
