- Linux Storage Stack
Linux Storage Stack
References
- Wiki: Linux Storage Stack Diagram
- Develop PAPER: Linux Storage Stack Diagram
- Gitbook: deep-into-linux-and-beyond
- 知乎:浅谈Linux内核IO体系之磁盘IO
- INTRODUCTION TO THE LINUX VIRTUAL FILESYSTEM (VFS) -- PART I: A HIGH-LEVEL TOUR
- Linux虚拟文件系统
- 知乎:Linux 的IO栈
- Elvis Zhang: Flavor of IO
- 史明亚:浅谈分布式存储之sync详解
- CSDN: Linux内核中块层上的多队列
- CSDN:件IO - O_DIRECT和O_SYNC详解
概览
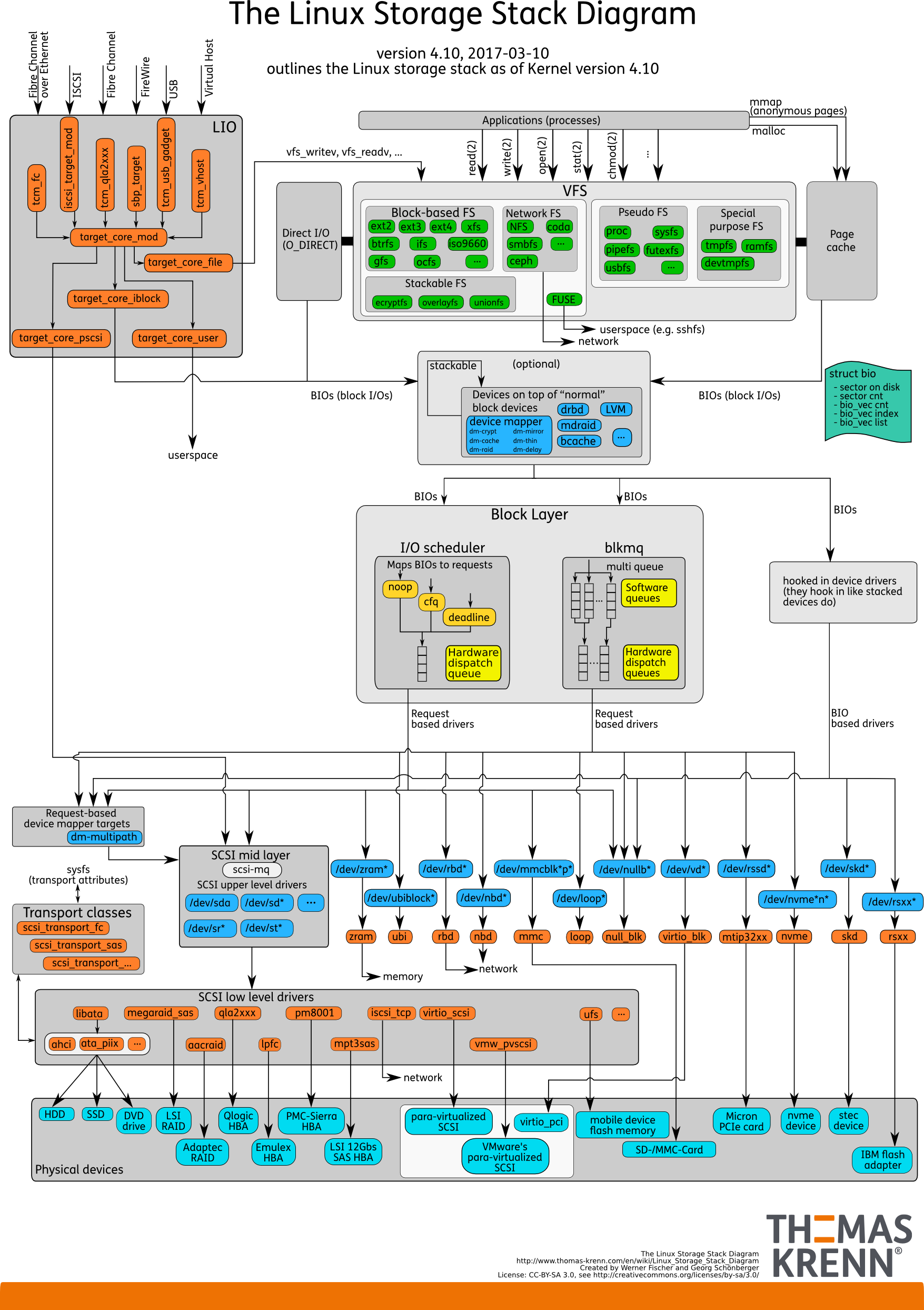
- 上图中使用了不同的颜色来区分组件(从下往上):
- 天蓝色:硬件存储设备
- 橙色:传输协议
- 蓝色:Linux系统中的设备文件
- 黄色:I/O 调度策略
- 绿色:Linux 中的文件系统
- 蓝绿色:Linux 存储操作基本数据结构 bio
- 上图也有简化版:
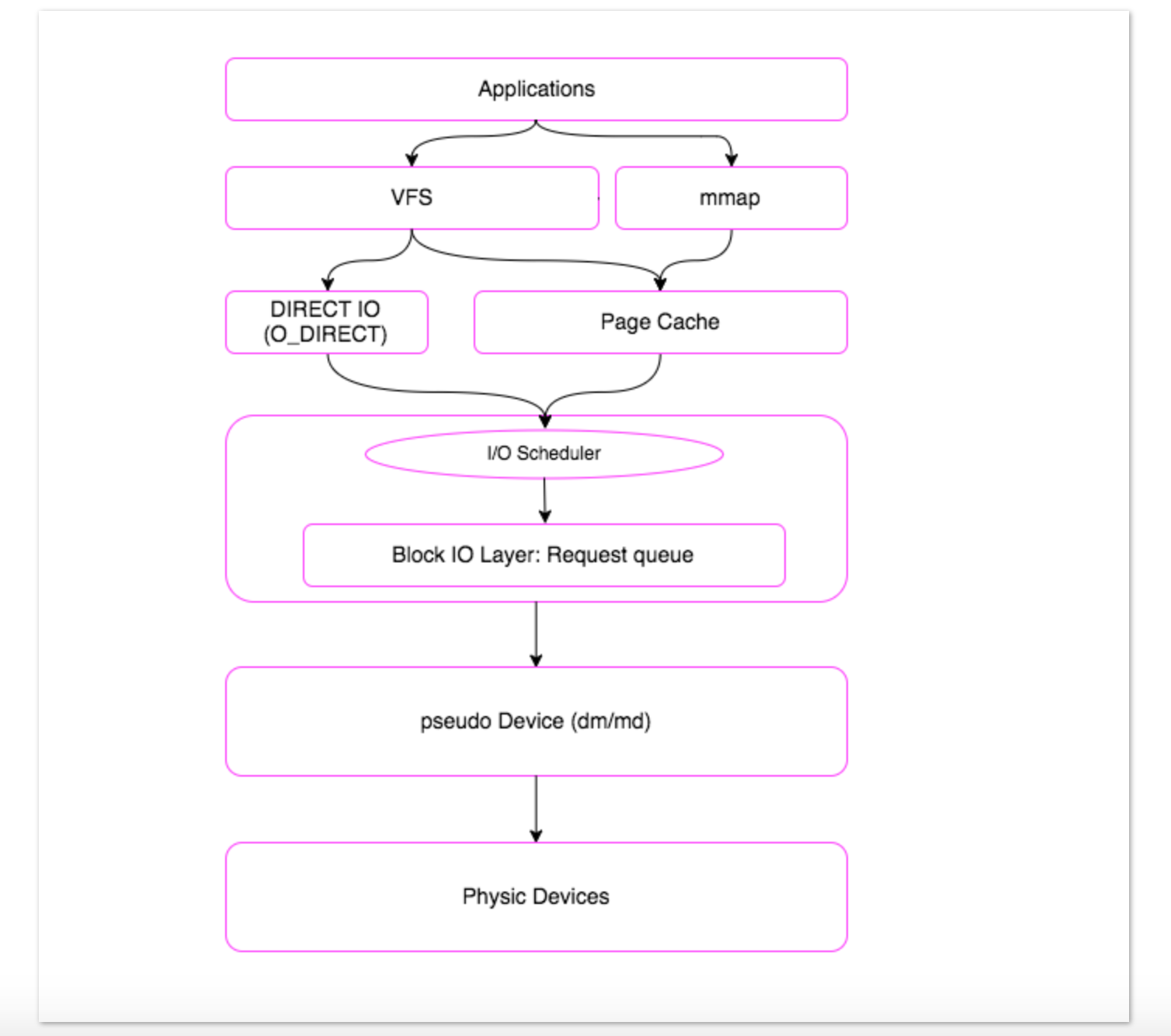
User's view
- 要开始处理文件,用户需要在存储设备上构建文件系统布局,也就是格式化文件系统(mkfs),然后将新创建的文件系统挂载到根文件系统层次结构中的某个位置(mount)。例如,/dev/sda 是表示系统中第一个SCSI磁盘的特殊块设备。
mkfs.ext4 /dev/sda
mkdir /mnt/disk2
mount /dev/sda1 /mnt/disk2
- 创建文件系统后,每个应用程序都可以访问、修改和创建文件和目录。这些操作可以使用一组由 Linux 内核公开的系统调用来执行。
open
close
read
write
unlink
mkdir
rmdir
readdir
VFS
概览
-
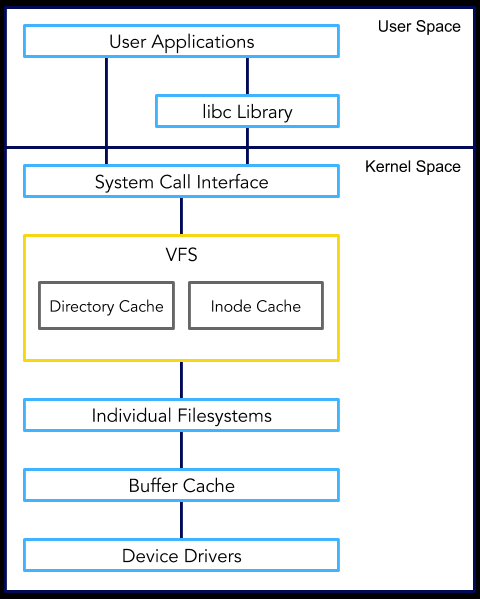
为了支持不同类型的文件系统,Linux引入了一个称为虚拟文件系统层(VFS)的公共层。这一层由一组对象和回调组成,任何新的文件系统都必须实现这些对象和回调。VFS层与Linux I/O堆栈挂钩,并将来自用户空间的任何I/O操作重定向到当前文件系统的特定实现中。I/O操作的实现操作VFS对象,并与块设备交互以读取和写入持久数据。
-
VFS被夹在两层之间:上层和下层。上层是系统调用层,在这个层中,用户空间进程进入内核请求服务(这通常通过libc包装器函数完成)——从而催化 VFS 进程。较低的一层是一组函数指针,每个文件系统实现一组,当VFS需要执行需要特定文件系统特定信息的操作时,它会调用该操作。换句话说,可以将VFS看作是用户空间应用程序对文件相关服务的请求与VFS根据需要调用的文件系统特定函数之间的粘合剂。从高层次的角度来看,这可以被建模为一个标准的抽象接口。
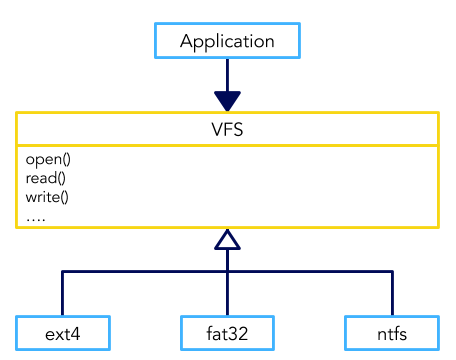
实现
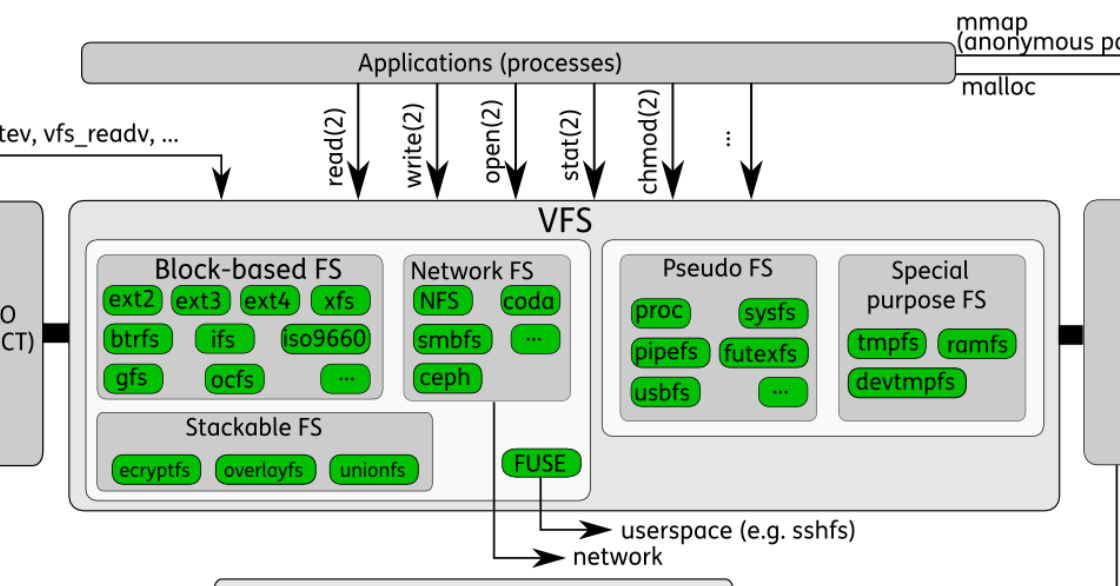
- VFS 层最重要的对象是 linux/include/linux/fs.h
- filesystem types: 文件系统类型
- superblock: 整个文件系统的元信息
- inode: 单个文件的元信息
- dentry: 目录项,一个文件目录对应一个dentry
- file: 进程打开的一个文件
Filesystem Types
- 如文章最开始的图中所示,VFS 后的文件系统实现具体有以下几种
- 基于块设备的文件系统(Block-based FS):ext2-4, btrfs, ifs, xfs, iso9660, gfs, ocfs, ...
- 基于物理存储设备的文件系统,用来管理设备的存储空间
- 网络文件系统(Network FS):NFS, coda, smbfs, ceph, ...
- 用于访问网络中其他设备上的文件。网络文件系统的目标是网络设备,所以它不会调用系统的Block层。
- 伪文件系统(Pseudo FS):proc, sysfs, pipefs, futexfs, usbfs, ...
- 因为并不管理真正的存储空间,所以被称为伪文件系统。它组织了一些虚拟的目录和文件,通过这些文件可以访问系统或硬件的数据。它不是用来存储数据的,而是把数据包装成文件用来访问,所以不能把伪文件系统当做存储空间来操作。
- 特殊文件系统(Special Purpose FS):tmpfs, ramfs, devtmpfs
- 特殊文件系统也是一种伪文件系统,它使用起来更像是一个磁盘文件系统,但读写通常是内存而不是磁盘设备。
- 堆栈式文件系统(Stackable FS):ecryptfs, overlayfs, unionfs, wrapfs
- 叠加在其他文件系统之上的一种文件系统,本身不存储数据,而是对下层文件的扩展。
- 用户空间文件系统(FUSE)
- 它提供一种方式可以让开发者在用户空间实现文件系统,而不需要修改内核。这种方式更加灵活,但效率会更低。FUSE 直接面向的是用户文件系统,也不会调用Block层。
- 基于块设备的文件系统(Block-based FS):ext2-4, btrfs, ifs, xfs, iso9660, gfs, ocfs, ...
- 代码:https://elixir.bootlin.com/linux/v5.7-rc4/source/include/linux/fs.h#L2234
struct file_system_type {
const char *name; // friendly name of the filesystem -- like 'ext2'
int fs_flags; // mostly obscure options
int (*init_fs_context)(struct fs_context *);
const struct fs_parameter_spec *parameters;
struct dentry *(*mount) (struct file_system_type *, int, const char *, void *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type *next; // 指向下一个已知的文件系统类型
struct hlist_head fs_supers; // 表示每个文件系统类型包含一个包含相同文件系统类型的所有超级块的哈希表
...
};
- struct file_system_type 维护与文件系统相关的数据,但不与任何特定的“文件系统实例”相关联,“文件系统实例”在这里是指挂载的文件系统。
- VFS维护已知文件系统类型的链表,可以通过执行
cat /proc/filesystems在用户空间中查看。使用数据结构中的 next 指针进行链接。 - 文件系统类型通过
include/linux/fs.h中的这些函数在内核中注册和取消注册:
int register_filesystem(struct file_system_type *);
int unregister_filesystem(struct file_system_type *);
- 一旦内核知道了文件系统类型,该类型的文件系统就可以被挂载到目录树的某个位置上。
Superblock
- 超级块是一个结构,它代表一个文件系统实例,也就是一个挂载的文件系统。超级块定义在
include/linux/fs中。 - 用 super_block 结构表示的superblock对象用来表示文件系统。它包括关于文件系统的元数据,比如文件系统的名称、大小和状态。此外,它还包含对存储文件系统的块设备的引用,以及对其他文件系统对象(inode、文件等等)列表的引用。大多数文件系统以冗余的方式将超级块存储在块设备上,以克服损坏。每当我们挂载文件系统,第一步是检索超块并在内存中构建它的表示。
struct super_block {
struct list_head s_list; // 指向相同文件系统类型的其他超级块的链表。
dev_t s_dev; // device associated with this mount
unsigned long s_blocksize;
loff_t s_maxbytes;
struct file_system_type *s_type; // struct describing the type of filesystem this mount represents
const struct super_operations *s_op; // 指向一个结构体,该结构体定义了一组函数,这些函数提供关于超级块的数据
uuid_t s_uuid; // unique ID of this mount
struct list_head s_inodes; // 这个文件系统挂载中的inodes列表
unsigned long s_magic; // magic number of this filesystem
struct dentry *s_root;
int s_count;
void *s_fs_info;
const struct dentry_operations *s_d_op;
...
};
- 超级块通常存储在存储设备本身,并在挂载时加载到内存中。
- super_opreations 其实是一组函数指针,它们是由文件系统的实现为每个文件系统类型提供的,从而使VFS与特定文件系统内部工作的细节无关
inode (Index Node)
- 索引节点表示文件系统中的一个对象。每个对象都有一个唯一的id。文件的inode包含指向包含文件内容的数据块的指针。目录索引节点包含指向存储名称-索引节点关联的块的指针。索引节点上的操作允许修改其属性和读取/写入其数据。
- 文件系统中的一个对象可以是:
- socket
- symbolic link
- regular file
- block device
- directory
- character device
- FIFO
- 对于所有文件系统对象类型,所有文件系统中的每个对象都存在一个inode(索引节点的缩写)。它在
include/linux/fs.h中定义。
struct inode {
umode_t i_mode; // access permissions, i.e., readable or writeable
kuid_t i_uid; // user id of owner
kgid_t i_gid; // group id of owner
unsigned int i_flags;
const struct inode_operations *i_op; // inode 文件元数据的函数操作
struct super_block *i_sb; //
struct address_space *i_mapping;
unsigned long i_ino; // unique number identifying this inode
const unsigned int i_nlink; // number of hard links
dev_t i_rdev;
loff_t i_size; // size of inode contents in bytes
struct timespec64 i_atime; // access time
struct timespec64 i_mtime; // modify time
struct timespec64 i_ctime; // creation time
unsigned short i_bytes; // bytes consumed
const struct file_operations *i_fop; // 文件数据的函数操作,open、write、read等
struct address_space i_data;
...
};
- struct inode_operations定义了一组在inode上操作的回调函数:(简而言之,为打开文件的每个实例创建一个struct文件)
- change permissions
- create files
- make symlinks
- make directories
- rename files
- 在设置inode的i_fop时候,会根据不同的inode类型设置不同的i_fop,以xfs为例:
- 如果inode类型为普通文件的话,那么设置XFS提供的xfs_file_operations。
- 如果inode类型为块设备文件的话,那么设置块设备默认提供的def_blk_fops。
dentry
- VFS实现以路径名作为参数的I/O系统调用。该路径名需要通过遍历路径组件并从块设备读取下一个组件节点信息来转换为特定的节点。为了减少将path组件转换到inode的开销,内核生成包含指向适当inode对象的指针的dentry对象。这些dentry存储在全局文件系统缓存中,可以非常快速地检索,而不需要从块设备读取额外的开销。
- dentry是目录项,由于每一个文件必定存在于某个目录内,我们通过路径查找一个文件时,最终肯定找到某个目录项。在Linux中,目录和普通文件一样,都是存放在磁盘的数据块中,在查找目录的时候就读出该目录所在的数据块,然后去寻找其中的某个目录项。
- dentry是目录条目的缩写,它通过将索引节点编号与文件名关联,将索引节点和文件粘合在一起。然而,在现实中,事情要复杂一些。
- 尽管文件系统中的每个对象都有一个inode,但struct inode本身并不包含该对象的名称或任何友好标识符。这样做的原因是一个inode可以被多个文件系统对象引用,每个对象都有自己唯一的名称(硬链接和符号链接)。因此,dentry将文件名映射到相应的inode。此外,dentry不仅适用于文件名,还适用于目录,从而适用于路径的每个组件。例如“/mnt/cdrom/foo”路径中包含“/”、“mnt”、“cdrom”和“foo”组件的dentry。
- dentry结构在include/linux/dcache.h中定义
struct dentry {
struct hlist_bl_node d_hash; // lookup hash list
struct dentry *d_parent; // parent directory
struct qstr d_name;
struct inode *d_inode; // where the name belongs to
unsigned char d_iname[DNAME_INLINE_LEN]; // small names
const struct dentry_operations *d_op;
void *d_fsdata; // fs-specific data
struct list_head d_child; // child of parent list, i.e., our siblings
struct list_head d_subdirs; // our children
...
};
- 我们可以看到,d_name 包含文件的名称,而 d_inode 指向其关联的inode。
- 使用dentry的另一个原因是优化:必须不断地比较字符串和查找文件系统路径,这在计算上是昂贵的。因此,在执行查找之后,内核将dentry缓存到适当命名的dentry缓存中。结果,文件访问速度显著提高。
- VFS把所有的dentry放在dentry_hashtable哈希表里面,使用LRU淘汰算法。
file
- 文件对象表示由用户空间进程打开的文件。它将文件连接到底层的inode,并引用文件操作的实现,如读、写、查找和关闭。用户空间进程持有一个整数描述符(出于隔离性的考虑,内核不会把file的地址返回,而是返回一个整形的fd),当执行文件系统调用时,内核将该描述符映射到实际的文件结构。
- file对象表示一个打开的文件,在
include/linux/fs.h中定义:
struct file {
struct path f_path; // a dentry and a mount point which locate this file
struct inode *f_inode; // the inode underlying this file
const struct file_operations *f_op; // callbacks to function which can operate on this file
spinlock_t f_lock;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos // offset in the file from which the next read or write shall commence
struct fown_struct f_owner;
void *private_data
struct address_space *f_mapping; // callbacks for memory mapping operations
...
};
- 我们要强调的是,这表示一个打开的文件,并包含诸如打开文件时使用的标志和进程可从其中读取或写入的偏移量等数据。当文件关闭时,这个数据结构将从内存中删除——诸如写数据之类的操作将被委托给相应的inode。
- file对象是由内核进程直接管理的。每个进程都有当前打开的文件列表,放在files_struct结构体中。
- fd_array数组存储了所有打开的file对象,用户程序拿到的文件描述符(fd)实际上是这个数组的索引。
IO 栈
-
我们经常使用的read、write系统调用实际上是对vfs_read、vfs_write的一个封装。然后 VFS 会根据具体的文件系统实现调用对应的 read/write。
-
对于通用的文件系统,Linux封装了很多基本的函数,很多文件系统的核心功能都是以这些基本的函数为基础,再封装一层。如 XFS 文件系统的 aio_read 和 aio_write 函数核心功能是构建在内核提供的 generic_file_aio_read/generic_perform_write 通用函数基础之上的,这些通用函数是基本上所有文件系统的核心逻辑。
-
generic_file_aio_read
- 根据文件偏移量计算出要读取数据在PageCache中的位置
- 如果命中PageCache则直接返回,否则触发磁盘读取任务,会有预读的操作,减少IO次数
- 数据读取到PageCache后,拷贝到用户态Buffer中
-
generic_perform_write
- 根据文件偏移量计算要写入的数据在PageCache中的位置
- 将用户态的Buffer拷贝到PageCache中
- 检查PageCache是否占用太多,如果是则将部分PageCache的数据刷回磁盘
-
使用Buffered IO时,VFS层的读写很大程度上是依赖于PageCache的,只有当Cache-Miss,Cache过满等才会涉及到磁盘的操作。
Page Cache
- 在HDD时代,由于内核和磁盘速度的巨大差异,Linux内核引入了页高速缓存(PageCache),把磁盘抽象成一个个固定大小的连续Page,通常为4K。对于VFS来说,只需要与PageCache交互,无需关注磁盘的空间分配以及是如何读写的。
- 当我们使用Buffered IO的时候便会用到PageCache层,与Direct IO相比,用户程序无需offset、length对齐。是因为通用块层处理IO都必须是块大小对齐的。
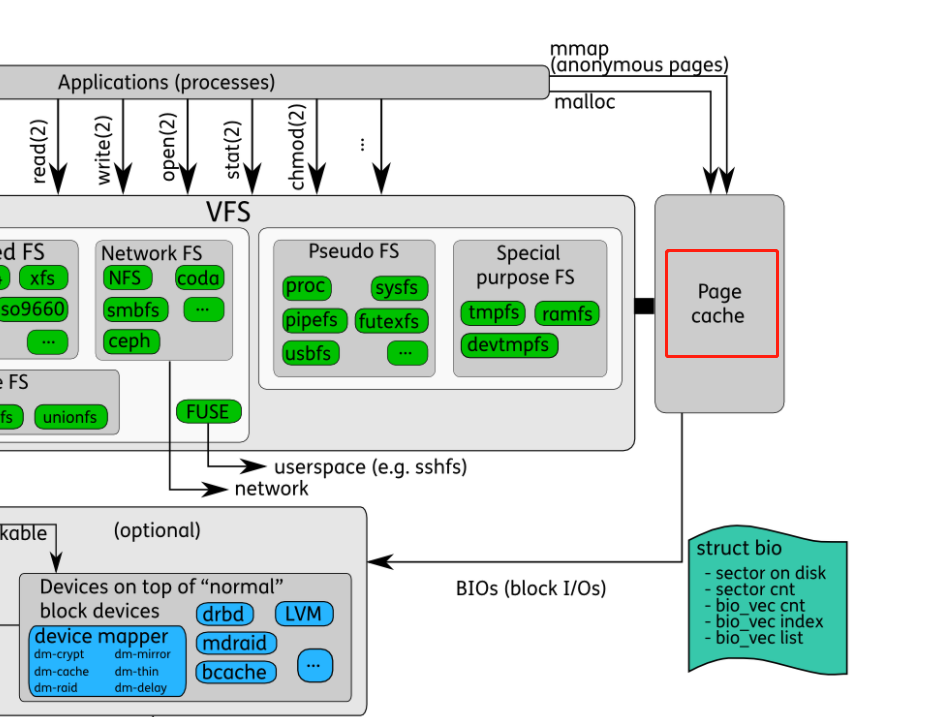
读写
- 读数据时,如果访问的页在Page cache中(命中),则直接返回页。然后执行页复制,Page Cache -> User Buffer,得到数据
- 读数据时,如果访问的页不在Page cache中(缺失),则产生缺页异常。系统会创建一个缓存页,将访问的地址对应的数据缓存到这个页中。上层会再次读取,发生cache命中。如果Page Cache已满,则刷新磁盘上最近最少使用的页,并从缓存中取出,以腾出空间用于新页。(LRU算法)
- 写数据时,如果cache命中,则将数据写到缓存页中。(User Buffer -> Page Cache)
- 写数据时,如果cache缺失,则产生缺页异常,系统创建缓存页。上层再次写入,发生cache命中。
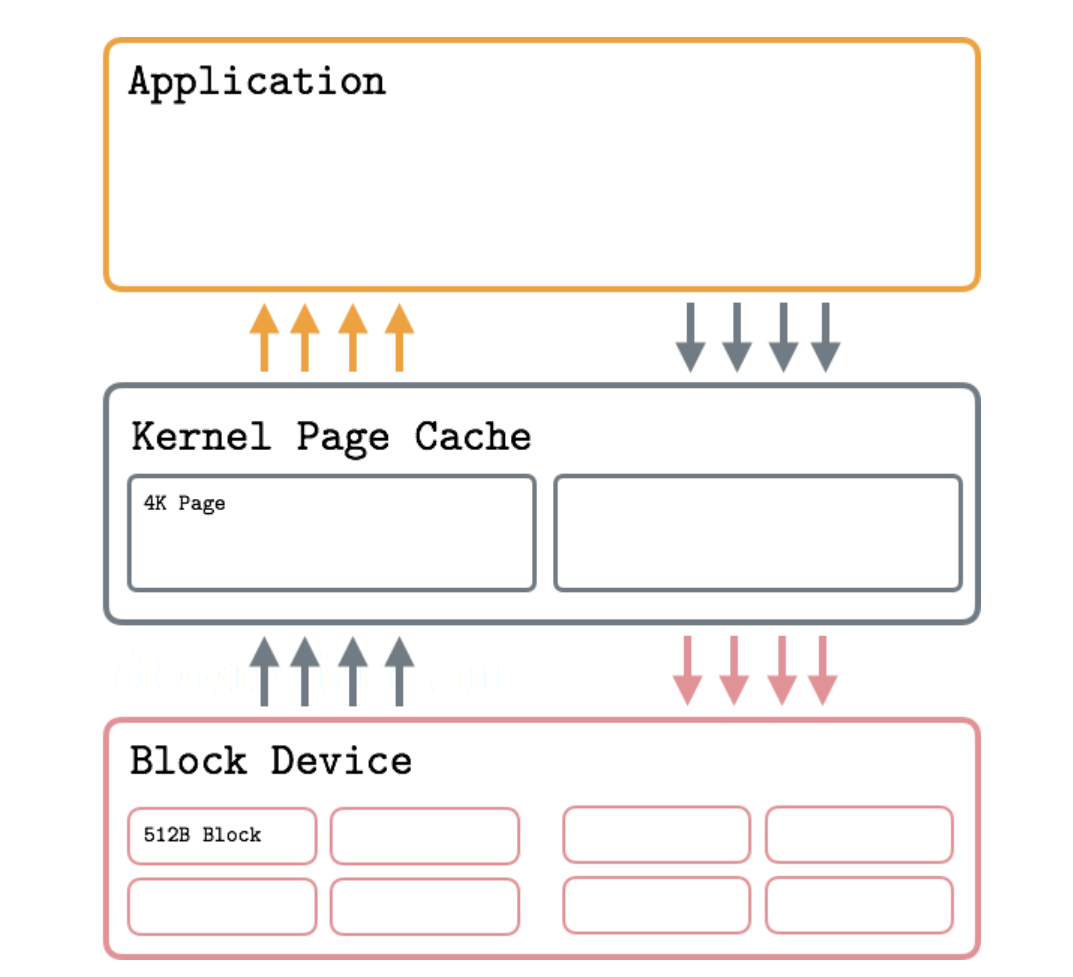
脏页刷盘
- Page Cache 的缓存策略本质是基于数据访问的 时间局部性
- 当Page cache中的一个缓存页被修改时,会标记为dirty。上层调用sync或pdflush进程会将脏页写回到磁盘中。
- 标记为dirty的页面将被刷新到磁盘,因为它们的缓存表示现在与磁盘上的不同。这个过程称为回写 writeback。回写可能有潜在的缺点,比如IO请求排队,所以有必要了解回写使用时使用的阈值和比率,并检查队列深度以确保可以避免节流和高延迟。Linux Kernel Documentation
- dirty_background_bytes
- dirty_background_ratio: 表示当pagecache占到了内存的百分之多少,就开始 异步 flushcache数据到disk
- dirty_bytes
- dirty_expire_centisecs
- dirty_ratio:这个参数是个硬限制,表示pagecache占到内存的百分之多少,阻塞IO进行 同步 flush cache数据到disk的操作
- dirtytime_expire_seconds:表示执行flush操作的进程起来之后,将多长时间的过期数据flush到disk。
- dirty_writeback_centisecs:表示多长时间 pdflush/flush/kdmflush 这些进程会起来一次,进行cache数据flush。
- ...
预取
- Page Cache 的预取策略本质是基于数据访问的 空间局部性
- 从VFS层我们知道写是异步的,写完PageCache便直接返回了;但是读是同步的,如果PageCache没有命中,需要从磁盘读取,很影响性能。如果是顺序读的话PageCache便可以进行预读策略,异步读取该Page之后的Page,等到用户程序再次发起读请求,数据已经在PageCache里,大幅度减少IO的次数,不用阻塞读系统调用,提升读的性能。
Direct I/O
- 在某些情况下,不希望使用内核页缓存来执行IO。在这种情况下,可以在打开文件时使用O_DIRECT标志。它指示操作系统绕过页面缓存,避免存储额外的数据副本,并直接对块设备执行IO操作。这意味着直接刷新磁盘上的缓冲区,而不是先将其内容复制到相应的缓存页面,然后等待内核触发回写。
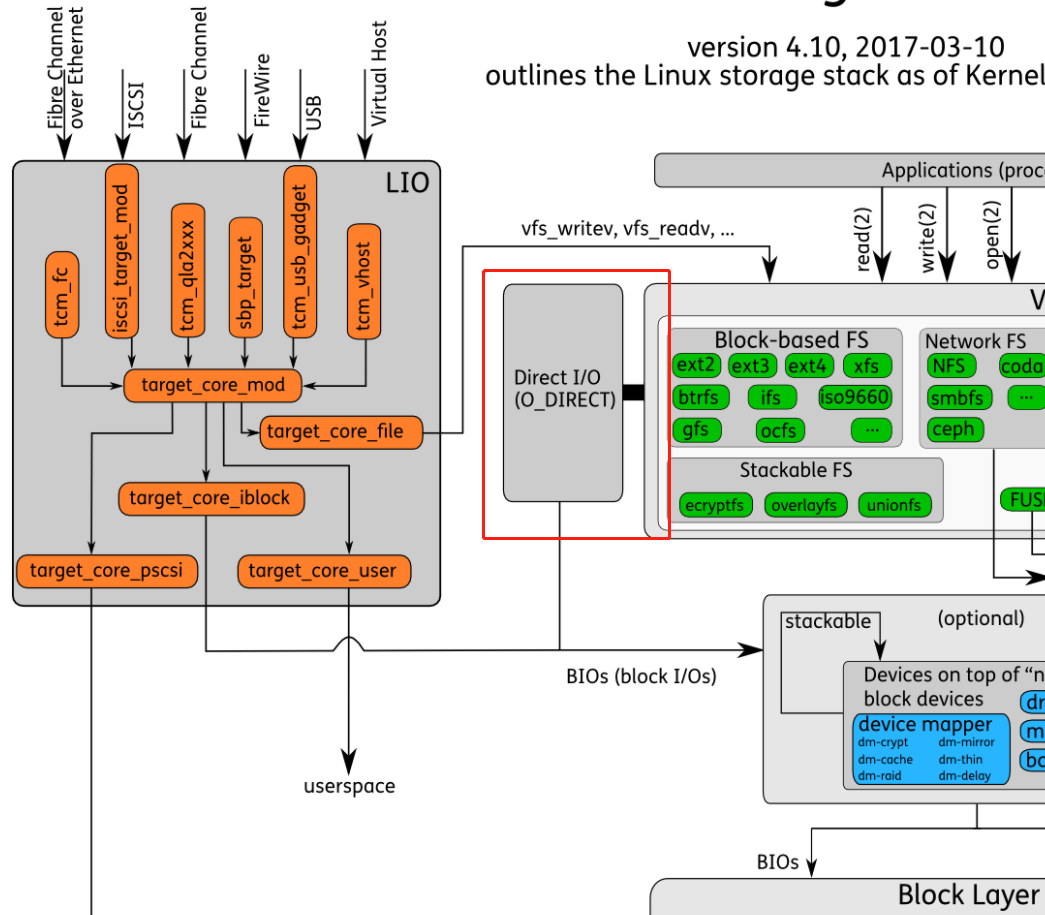
- 对于使用Direct IO的“传统”应用程序来说,它很可能导致性能下降而不是加速,但是如果使用得当,它可以帮助获得对IO操作的细粒度控制并提高性能。通常使用这种IO类型的应用程序实现它们自己的特定于应用程序的缓存层
- 注意: 使用O_DIRECT打开的文件仍然需要 fsync(),以便将数据保存到稳定的存储中。在 MySQL 中就存在一个选项可以设置 O_DIRECT_NO_FSYNC 策略。因为对于 DB 中的操作,O_DIRECT 只是保证了数据直接写盘,但是没有保证元数据落盘,元数据可能还位于 page cache 中。
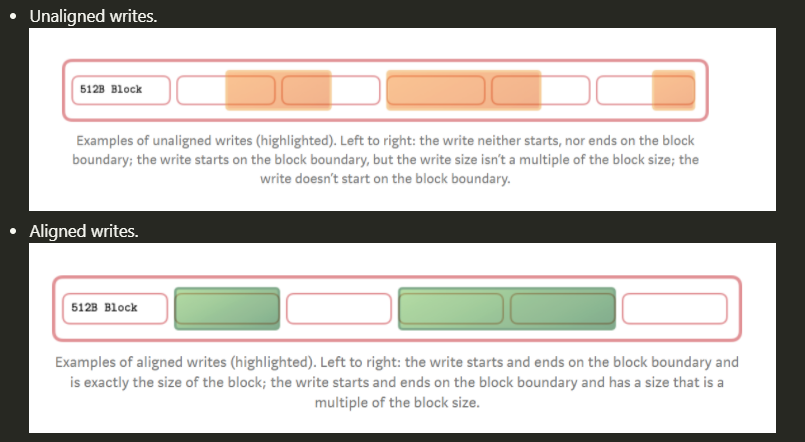
对齐
- Buffered IO中PageCache帮我们做了对齐的工作:如果我们修改文件的offset、length不是页大小对齐的,那么PageCache会执行RMW的操作,先把该页对应的磁盘的数据全部读上来,再和内存中的数据做Modify,最后再把修改后的数据写回磁盘。虽然是写操作,但是非对齐的写仍然会有读操作。
- Direct IO由于跳过了PageCache,直达通用块层,所以需要用户程序处理对齐的问题。
映射层
- 映射层是在PageCache之下的一层,由多个文件系统(Ext系列、XFS等,打开文件系统的文件)以及块设备文件(直接打开裸设备文件)组成,主要完成两个工作:
- 内核确定该文件所在文件系统或者块设备的块大小,并根据文件大小计算所请求数据的长度以及所在的逻辑块号。
- 根据逻辑块号确定所请求数据的物理块号,也即在在磁盘上的真正位置。
- 由于通用块层以及之后的的IO都必须是块大小对齐的,我们通过DIO打开文件时,略过了PageCache,所以必须要自己将IO数据的offset、length对齐到块大小。
- 我们使用的DIO+Libaio直接打开裸设备时,跳过了文件系统,少了文件系统的种种开销,然后进入通用块层,继续之后的处理。
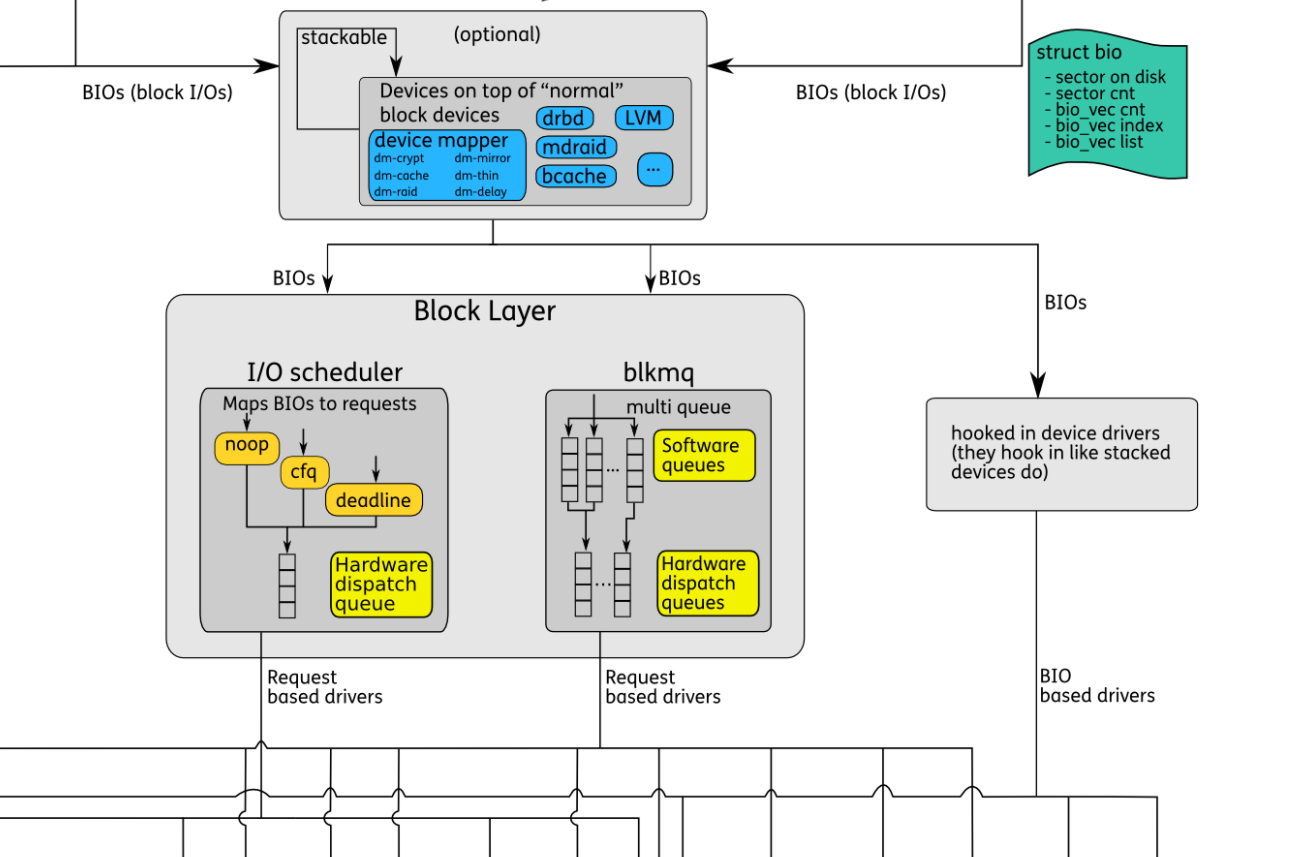
通用块层
- 页面缓存层需要从块设备写/读页面。为此目的,创建了一个叫做bio的特殊结构。该结构封装了一个条目数组,指向块设备需要读/写的各个内存页。
- Block Layer是Linux Storage系统中的中间层,连接着文件系统和块设备。它将上层文件系统的读写请求抽象为BIOs,通过调度策略将BIOs传输给设备。Block Layer包含图中的蓝绿色、黄色和中间BIOs传输过程。
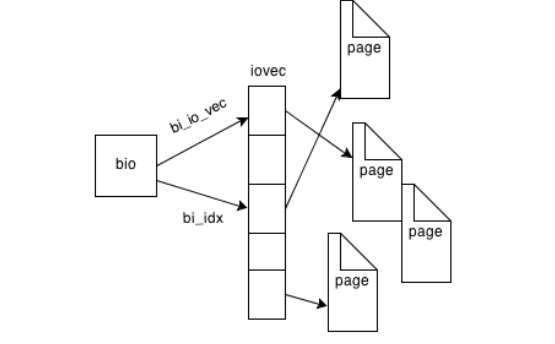
BIO
- BIO代表对Block设备的读写请求,在内核中使用一个结构体来描述。
struct bvec_iter {
sector_t bi_sector; // 设备地址,以扇区(512字节)为单位
unsigned int bi_size; // 传输数据的大小,byte
unsigned int bi_idx; // 当前在bvl_vec中的索引
unsigned int bi_bvec_done; // 当前bvec中已经完成的数据大小,byte
};
struct bio {
struct bio *bi_next; // request队列
struct block_device *bi_bdev; // 指向block设备
int bi_error;
unsigned int bi_opf; // request标签
unsigned short bi_flags; // 状态,命令
unsigned short bi_ioprio;
struct bvec_iter bi_iter;
unsigned int bi_phys_segments; // 物理地址合并后,BIO中段的数量
/*
* To keep track of the max segment size, we account for the
* sizes of the first and last mergeable segments in this bio.
*/
unsigned int bi_seg_front_size; // 第一个可合并段的大小
unsigned int bi_seg_back_size; // 最后一个可合并段的大小
atomic_t __bi_remaining;
bio_end_io_t *bi_end_io; // BIO结束时的回调函数,一般用于通知调用者该BIO的完成情况
......
unsigned short bi_vcnt; // bio_vec的计数
unsigned short bi_max_vecs; // bvl_vecs的最大数量
atomic_t __bi_cnt; // 使用计数
struct bio_vec *bi_io_vec; // vec list的指针 要提交到磁盘的多段数据
struct bio_set *bi_pool;
......
};
- 一个BIO构建完成后,就可以通过
generic_make_request()来创建传输Request,将Request加入到请求队列中。请求队列在内核中有结构体request_queue来描述,它包含一个双向请求链表以及相关控制信息。请求链表中每一项都是一个Request,Request由BIOs组成,BIO中又可能包含不同的Segment。因为一个BIO只能有连续的磁盘块,但一个Request可能不连续的磁盘块,所以一个Request可能包含一个或多个BIOs。尽管BIO中的磁盘块是连续的,但它们在内存中可能是不连续的,所以BIO中可能包含几个Segments。 - 所有到通用块层的IO,都要把数据封装成bio_vec的形式,放到bio结构体内。
- 在VFS层的读请求,是以Page为单位读取的,如果改Page不在PageCache内,那么便要调用文件系统定义的read_page函数从磁盘上读取数据。
const struct address_space_operations xfs_address_space_operations = {
......
.readpage = xfs_vm_readpage,
.readpages = xfs_vm_readpages,
.writepage = xfs_vm_writepage,
.writepages = xfs_vm_writepages,
......
};
Scheduler
- Linux调度层是Linux IO体系中的一个重要组件,介于通用块层和块设备驱动层之间。IO调度层主要是为了减少磁盘IO的次数,增大磁盘整体的吞吐量,会队列中的多个bio进行排序和合并,并且提供了多种IO调度算法,适应不同的场景。
- 读写数据组织成请求队列后,就是访问磁盘的过程,这个过程由IO调度完成。BIOs访问的指定的磁盘扇区,首先要进行寻址的操作。寻址就是定位磁盘磁头到特定块上的某个位置,这个过程相对来说很慢。为了优化寻址操作,内核既不会简单地按请求接收次序,也不会立即将其提交给磁盘,而是在提交前,先执行名为 合并与排序 的预操作,这种预操作可以极大地提高系统的整体性能。这就是IO调度需要完成的工作。
- Linux内核为每一个块设备维护了一个IO队列,item是struct request结构体,用来排队上层提交的IO请求。一个request包含了多个bio,一个IO队列queue了多个request。
struct request {
......
// total data len
unsigned int __data_len;
// sector cursor
sector_t __sector;
// first bio
struct bio *bio;
// last bio
struct bio *biotail;
......
}
- 上层提交的bio有可能分配一个新的request结构体去存放,也有可能合并到现有的request中。
- 当前内核中,支持两种模式的IO调度器:single-queue和multi-queue。single-queue在图中标识为“I/O Scheduler”,multi-queue标识为blkmq。二者应该都是Scheduler,只是请求的组织方式不同。
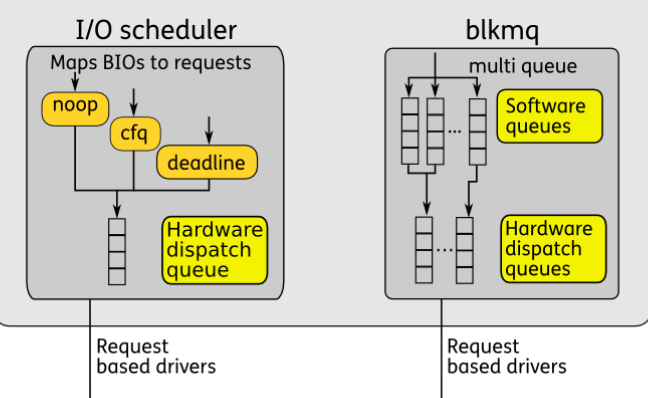
Single-queue (I/O Scheduler)
- single-queue 通过合并和排序来减少磁盘寻址时间。
- 合并指将多个连续请求合成一个更大的IO请求,以便充分发挥硬件性能。
- 排序使用电梯调度,将整个请求队列将按扇区增长方向有序排列。排列的目的不仅是为了缩短单独一次请求的寻址时间,更重要的优化在于,通过保持磁盘头以直线方向移动,缩短了所有请求的磁盘寻址的时间。
- 目前single-queue使用的调度策略包括:noop、deadline、cfq 等。
- Noop:IO调度器最简单的算法,将IO请求放入队列中并顺序的执行这些IO请求,对于连续的IO请求也会做相应的合并。
- Deadline:保证IO请求在一定时间内能够被服务,避免某个请求饥饿。
- CFQ:即绝对公平算法,试图为竞争块设备使用权的所有进程分配一个请求队列和一个时间片,在调度器分配给进程的时间片内,进程可以将其读写请求发送给底层块设备,当进程的时间片消耗完,进程的请求队列将被挂起,等待调度。
Multi-queue (blkmq)
- https://liyiping.cn/article/io-schedulers/
- 早先的内核只有single-queue,当时存储设备主要是HDD,HDD的随机寻址性能很差,single-queue就可以满足传输需求。当SSD发展起来后,它的随机寻址性能很好,传输的瓶颈就转移到请求队列上。结合多核CPU,multi-queue被设计出来。multi-queue为每个CPU core或socket配置一个Software queue,这也解决了single-queue中多核锁竞争的问题。如果存储设备支持并行多个Hardware dispatch queues,传输性能又会大幅度提升。目前multi-queue支持的调度策略包括:mq-deadline、bfq、kyber等。
- bfq (Budget Fair Queuing) (Multiqueue): 设计用于提供良好的交互响应,特别是对于较慢的I/O设备。这是一个复杂的I/O调度器,并且具有相对较高的每次操作开销,因此对于具有慢cpu或高吞吐量I/O设备的设备来说并不理想。公平共享基于请求的扇区数量和启发式,而不是时间片。桌面用户可能喜欢尝试这种I/O调度器,因为它在加载大型应用程序时很有优势。
- kyber (Multiqueue): 为快速多队列设备设计,相对简单。有两个请求队列: (对于发送到队列的请求操作的数量有严格的限制。从理论上讲,这限制了等待请求被分派的时间,因此应该为高优先级的请求提供快速完成时间)
- Synchronous requests (e.g. blocked reads)
- Asynchronous requests (e.g. writes)
- mq-deadline (Multiqueue):这是对deadline I/O调度器的改进,但专为多队列设备设计。一个良好的全能型,具有相当低的CPU开销。
- none (Multiqueue):多队列无操作I/O调度器。不重新排序请求,开销最小。理想的快速随机I/O设备,如NVME。
- blk_mq 的API实现了两级块层设计,该设计使用两组独立的请求队列。
- 软件暂存队列,按CPU分配
- 硬件调度队列,其数量通常与blcok设备支持的实际硬件队列数量匹配
Block Device
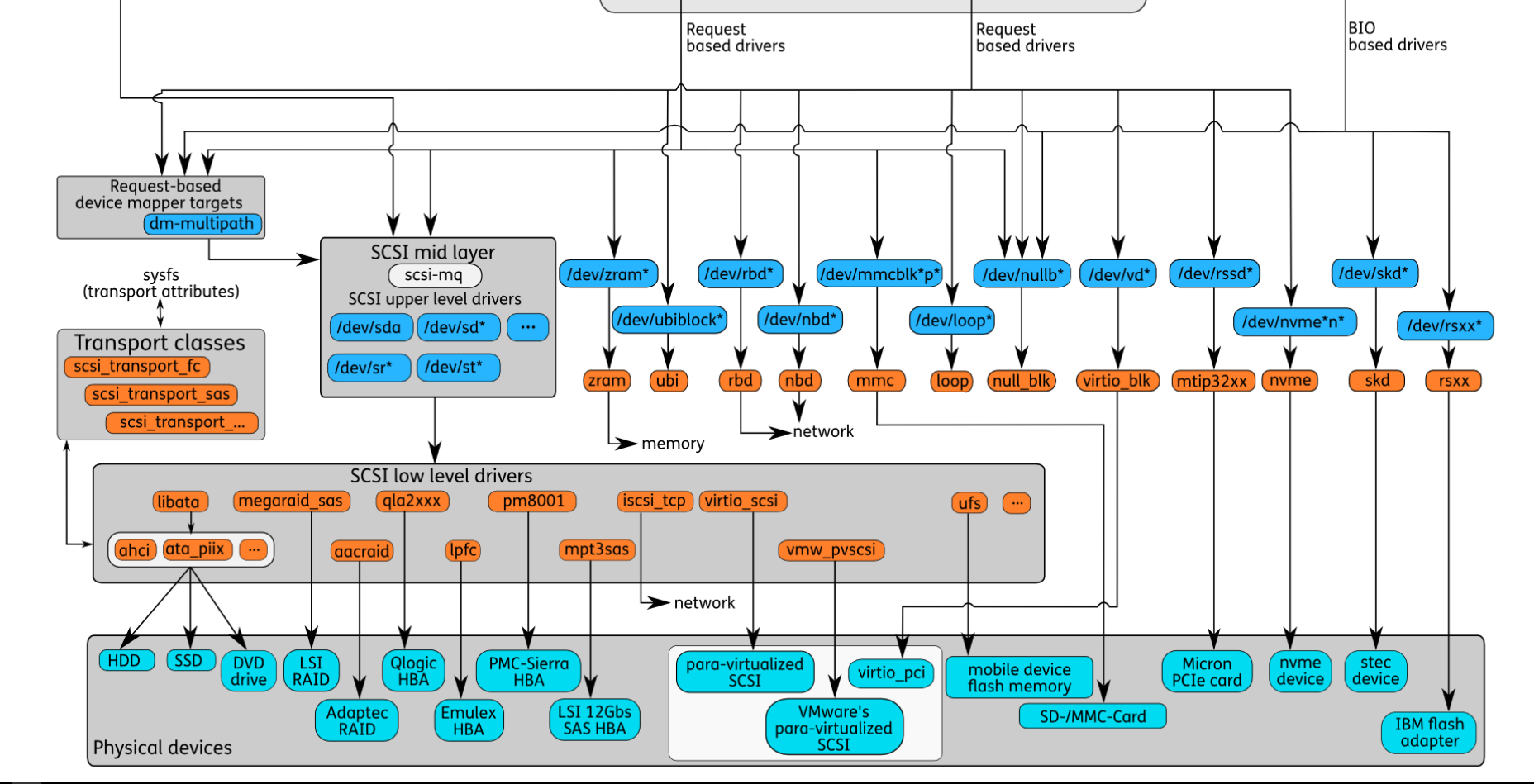
设备文件
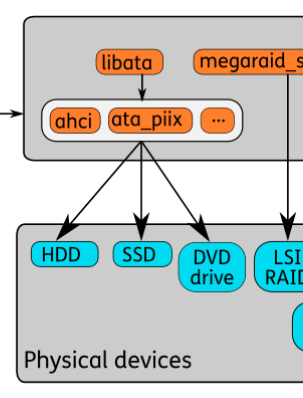
- 设备文件是Linux系统访问硬件设备的接口,驱动程序将硬件设备抽象为设备文件,以便应用程序访问。设备驱动加载时在/dev/下创建设备文件描述符,如果是Block设备,同时会创建一个软链接到/dev/block/下,并根据设备号来命名。图中将Block设备分为以下几类。
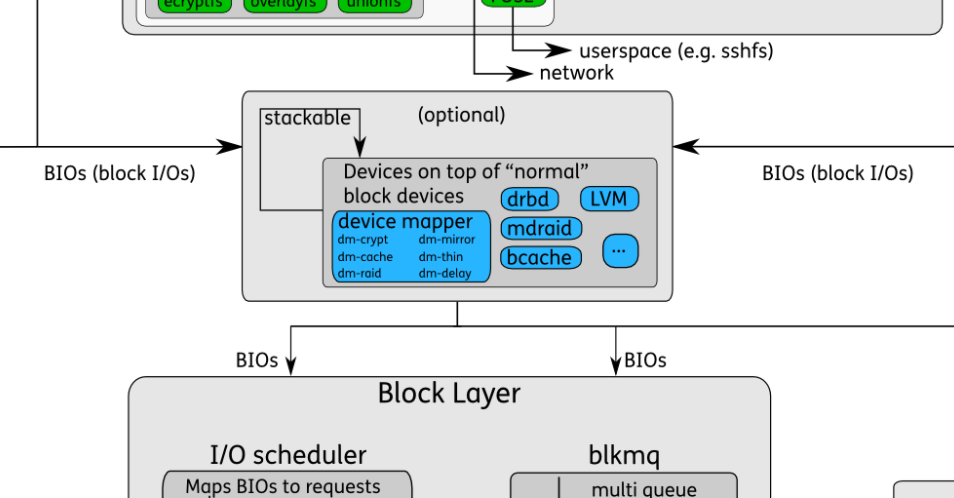
- 逻辑设备:图中的“Devices on top of "normal" block devices",使用Device Mapper将物理块设备进行映射。通过这种映射机制,可以根据需要实现对存储资源的管理。包括LVM、DM、bcache等。
- SCSI设备:使用SCSI标准的设备文件,包括sda(硬盘)、sr(光驱)等。
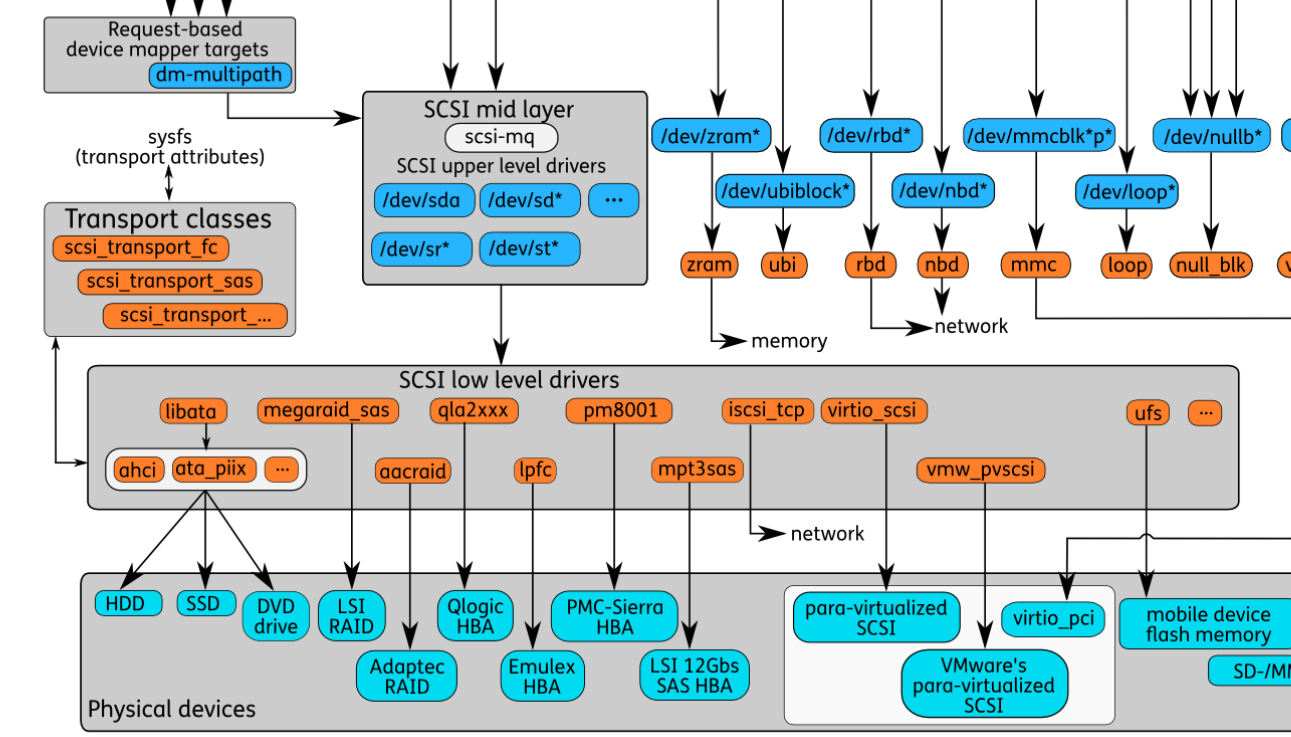
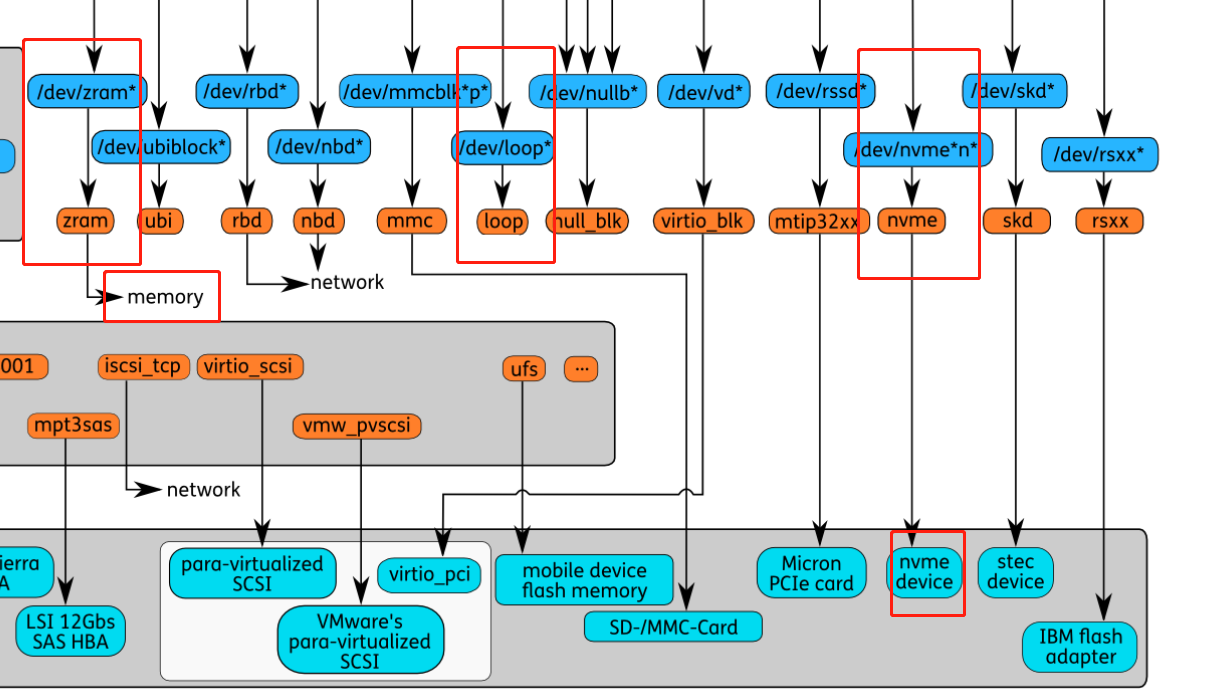
- 其他块设备:每一种块设备都有自己的传输协议。一类代表真正的硬件设备,如mmc、nvme等。另一类表示虚拟的块设备,如loop、zram等。
- 逻辑设备:图中的“Devices on top of "normal" block devices",使用Device Mapper将物理块设备进行映射。通过这种映射机制,可以根据需要实现对存储资源的管理。包括LVM、DM、bcache等。
传输协议
- 图中橙色部分表示了Block设备所依赖的技术实现,可能是硬件规范的软件实现,也可能是一种软件架构。图中把SCSI和LIO单独圈出来,因为这两部分相对比较复杂。SCSI包含的硬件规范很多,最常用的是通过 libata 来访问HDD和SSD。
SCSI Layer
- https://www.cnblogs.com/cobbliu/articles/11898787.html
- 放置在队列上的请求由块设备驱动程序处理。在现代版本的Linux中,负责几乎所有持久性存储控制器的块设备驱动程序是SCSI驱动程序。Linux中的SCSI层是一个大型子系统,负责与使用SCSI协议的存储设备(这意味着几乎所有的存储设备)进行通信。使用此层I/O请求将以SCSI命令的形式提交给物理设备。当一个设备完成一个请求的处理,它的控制器将发出一个中断请求。中断处理程序调用一个完成调用
- 在 LINUX 用户空间,有三种方式提交对 SCSI 设备的访问请求:
- 通过文件系统提供的文件访问接口进行访问。对建立在 SCSI 设备上的 LINUX 文件系统中的文件读写操作,就属于这种访问方式;
- RAW 设备访问方式。这种访问方式比较常见的应用就是dd命令。 RAW 设备访问方式和通过文件系统提供的文件访问接口进行访问的最大区别在于前者对 SCSI 设备直接进行线性地址访问,不需要由文件系统进行地址映射;
- SCSI PASSTHROUGH 方式。通过 LINUX 提供的 SG 进行访问,就属于这种方式,用户可以直接发 CDB 命令给 SCSI 设备。所以,通过该接口,用户可以做一些 SCSI 管理操作,如 SES 管理等
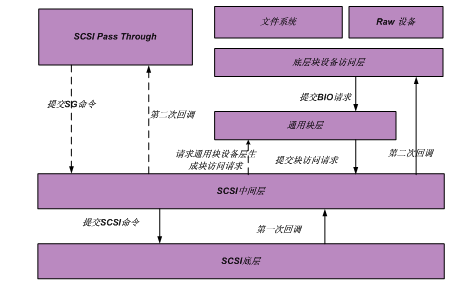
- 经由文件系统或 RAW 设备方式提交的请求,会通过底层块设备访问层(ll_rw_block()),由其生成块 IO 请求(BIO),并提交给通用块层 ;而通过 SG 接口提交的访问请求,会调用 SCSI 中间层提供的接口,将请求直接交由通用块层进行处理。
- SCSI(小型计算机系统接口)已经成为存储领域的主导协议。它由许多标准、接口和协议构成,这些标准、接口和协议规定了如何与广泛的设备通信。SCSI最常用于硬盘、磁盘阵列和磁带机。这个丰富的标准也支持许多其他类型的设备。Linux内核实现了一个复杂的SCSI子系统,并利用它来控制大多数可用的存储设备。
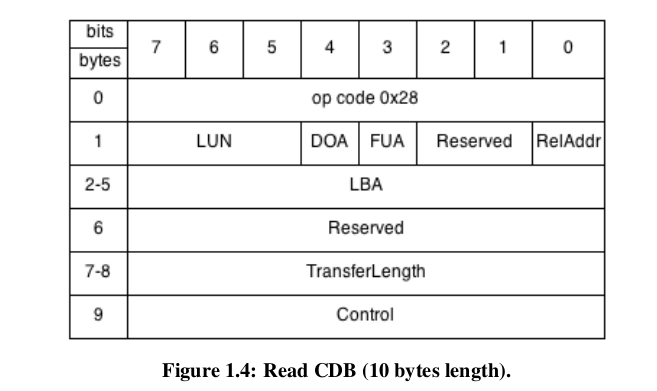
- Commands:
- SCSI命令及其参数被发送为一个称为命令描述块(CDB)的几个字节的块。每个CDB可以是6字节、10字节、12字节或16字节。SCSI标准的后续版本也支持可变长度的cdb,但是这种格式在存储系统中并不常用。CDB的第一个字节是操作码。它后面是LUN的第二字节的前三位、逻辑块地址(Logical Block Address, LBA)和传输长度字段(读写命令)或者其他参数。
- 在命令处理结束时,目标返回一个状态码字节(0x0 - SUCCESS, 0x2 - check CONDITION, 0x8 - BUSY等)。当目标返回一个Check Condition状态码时,启动器通常会发出一个SCSI Request Sense command,以获得指定失败原因的关键代码限定符 key code qualifier (KCQ)。
- SCSI命令根据数据传输方向的标准分为:非数据命令(N)、向目标命令写入数据(W)、从目标命令读取数据(R)和双向读写命令(B)。
- 另一种选择是根据它们适用的设备来分离SCSI命令:块命令(磁盘驱动器)、流命令(磁带驱动器)、媒体改变命令(点唱机)、多媒体命令(CD-ROM)、控制器命令(RAID)和基于对象的存储命令(OSD)。
- 受欢迎的命令的例子包括:REPORT LUNS ,返回lun公开的设备,TEST UNIT READY 查询设备是否准备好数据传输,INQUIRY 返回基本设备信息和请求,REQUEST SENSE 从上一个返回错误状态的命令返回任何错误代码。
- 层级结构:Linux内核中的SCSI子系统使用的是分层体系结构,有三个不同的层。
- 上层代表到几种设备(磁盘、磁带、cdrom和通用设备)的内核接口。
- 中间层用于封装SCSI错误处理,并将来自上层的内核请求转换为匹配的SCSI命令。
- 最后,最底层控制各种物理设备,并实现它们独特的物理接口,以允许与它们通信。
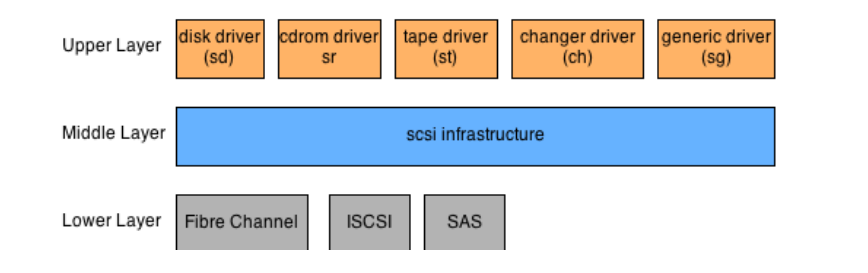
- The SCSI Upper Layer:SCSI上层的目的是公开高级接口,将不同的SCSI设备家族引入用户空间。通过这些接口(特殊设备文件),用户空间应用程序可以将文件系统挂载到块设备上,或者通过使用特定的ioctl命令控制SCSI设备。该层中实现了5个主要模块。这些模块允许控制,磁盘,cdrom/dvd,磁带,媒体转换器和通用SCSI设备。
- Disk Block Device:SCSI磁盘驱动程序在drivers/ SCSI / sdc中实现。它将自己注册为内核驱动程序,它将处理内核检测到的任何SCSI磁盘。然后,当内核检测到现有或新的SCSI磁盘时,驱动程序将创建块设备(通常称为sda、sdb等等)。这个设备可以通过调用sd_prep_fn来读写磁盘,sd_prep_fn从设备队列中获取挂起的块请求,并从中构建SCSI请求。该请求将使用控制特定存储设备的底层驱动程序发送到目标设备。
- Cdrom/DVD Block Device:SCSI光驱在drivers/ SCSI /sr.c中实现。这也是块驱动程序,其工作方式与sdc磁盘驱动程序类似。这里,sr_prep_fn将把内核块请求转换为可以发送到cd-rom设备的scsi介质命令。
- Generic Char Device:通用SCSI设备驱动程序在drivers/ SCSI /sg.c中实现。这是一个 driver 合集。它为每个SCSI设备创建带有模式/dev/sgxx的char设备文件。然后,它允许使用ioctl系统调用和特殊设计的参数向底层SCSI设备发送原始SCSI命令。流行的sg3_utils包使用这个驱动程序来构建广泛的实用程序集,这些实用程序将SCSI命令发送到设备。
- The SCSI Middle Layer:SCSI中间层本质上是下层SCSI层和内核其余部分之间的分离层。它的主要作用是提供错误处理和允许低级的驱动程序注册。来自较高设备驱动程序的SCSI命令将被注册并分派到较低的层。稍后,当较低的层向设备发送命令并接收响应时,该层将把它传播回较高的设备驱动程序。如果命令出错,或者响应没有在某些可定制的超时内到达,中间层将采取重试和恢复步骤。这些步骤可能意味着要求重置设备或完全禁用它。
- The SCSI Lower Layer:在SCSI子系统的最低层,我们有一组驱动程序,它们直接与物理设备通信。所有这些设备的通用接口用于将它们连接到中间层。另一方面,与设备的交互是通过使用内存映射I/O (MMIO)、I/O CPU命令和中断机制来控制物理接口执行的。下层驱动程序家族包含由主要的光纤通道HBA卡供应商(Emulex, QLogic)提供的驱动程序。其他驱动控制raid(如LSI MegaRAID) SAS盘等。
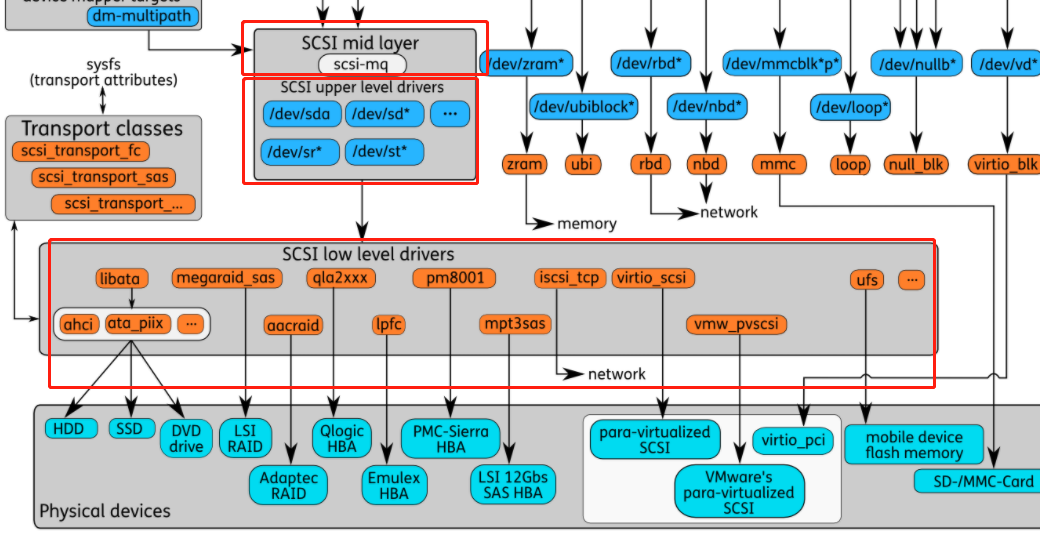
Linux SCSI Target Frameworks
- Linux内核对连接到各种SCSI设备有丰富的支持。在使用此类设备时,Linux需要实现SCSI架构的启动器角色。这些年来,越来越多的新的SCSI设备被引入到Linux内核中。这将导致支持SCSI启动器行为的层的快速改进。另一方面,SCSI客户机-服务器体系结构的另一端多年来一直被忽视。由于SCSI目标代码构建在物理设备(例如磁盘驱动器)中,因此没有特别的理由在Linux内核中实现这一层。
- 随着虚拟化技术的引入,情况开始发生变化。开发人员希望创建自定义SCSI设备,并通过SCSI协议在本地机器上公开现有的存储元素。这些需求导致创建几个具有独特设计和实现的SCSI目标框架。在这些框架中,最终选择了LIO,并在2011年1月将合并到内核主线中,有效地成为将SCSI目标支持引入Linux内核的官方框架。
- LIO
- LIO(Linux-IO)是基于SCSI engine,实现了SCSI体系模型(SAM)中描述的SCSI Target。LIO在linux 2.6.38后引入内核,其支持的SAN技术包括Fibre Channel、FCoE、iSCSI、iSER 、SRP、USB等,同时还能为本机生成模拟的SCSI设备,以及为虚拟机提供基于virtio的SCSI设备。LIO使用户能够使用相对廉价的Linux系统实现SCSI、SAN的各种功能,而不用购买昂贵的专业设备。可以看到LIO的前端是Fabric模块(Fibre Channel、FCoE、iSCSI等),用来访问模拟的SCSI设备。Fabric模块就是实现SCSI命令的传输协议,例如iSCSI技术就是把SCSI命令放在TCP/IP中传输,vhost技术就是把SCSI命令放在virtio队列中传输。LIO的后端实现了访问磁盘数据的方法。FILEIO通过Linux VFS来访问数据,IBLOCK访问Linux Block设备,PSCSI 直接访问SCSI设备,Memory Copy RAMDISK用来放访问模拟SCSI的ramdisk。
- 它包含在大多数Linux发行版中;QEMU/KVM、libvirt和OpenStack中对LIO的本机支持也使LIO成为云部署的存储选项。
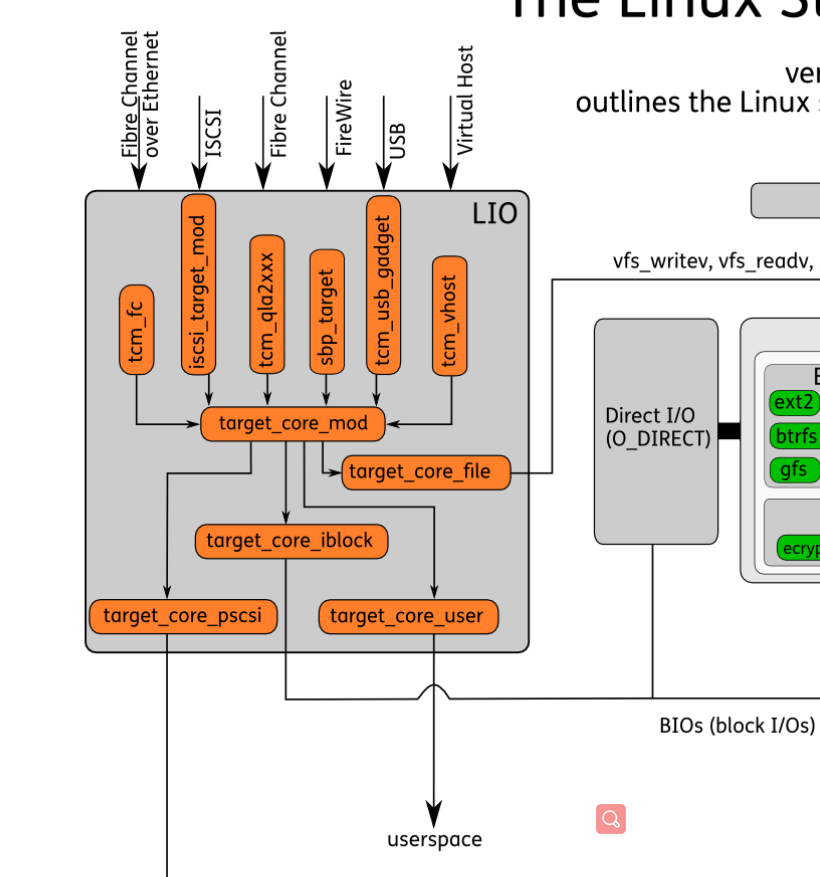
- LIO的架构由三个主要组件组成:
- SCSI target engine:实现SCSI目标的语义,不依赖于结构(传输层)或存储类型
- Backstores:后台存储实现SCSI目标设备的后端。它可以是实际的物理设备、块设备、文件或内存磁盘
- Fabric modules:Fabric模块实现了目标的前端。这是在传输层上与发起者通信的部分。在实现的fabric之间:iSCSI, Fibre Channel, iSER (iSCSI over infiniband)等等。
- 在内部,LIO不启动会话,而是提供一个或多个逻辑单元号(Logical Unit Numbers, lun),等待SCSI启动器的SCSI命令,并执行所需的输入/输出数据传输。
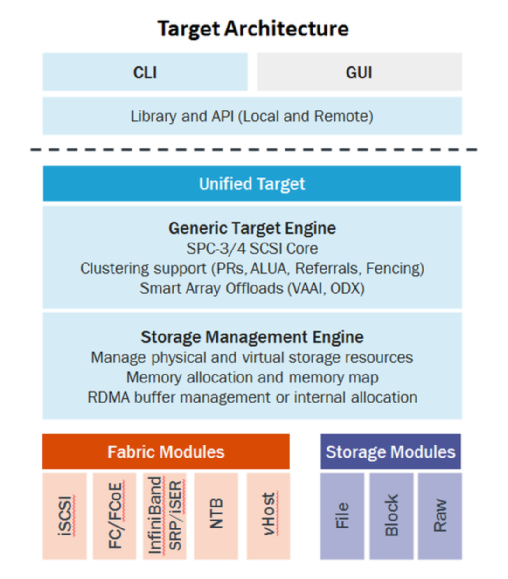
- 今天,LIO是内核主线中取代其他框架(SCST、TGT)的领先框架。尽管如此,该框架仍然需要一段时间才能成熟和稳定地用于日常使用。
硬件设备
- 图中天蓝色部分,就是实际的硬件存储设备。其中virtio_pci、para-virtualized SCSI、VMware's para-virtualized scsi是虚拟化的硬件设备。
fsync/direct/fdatasync
- 最后想在这里结合之前测试使用的一些参数讲解一下这几个参数的区别。
- 对于普通的 I/O 也就是常说的 Buffered I/O,其实数据 I/O 很多时候都是先在 PageCache 上完成的,一旦发生内核 crash 或者宕机,PageCache 中的数据就会丢失,所以就可能出现不一致的现象。所以很多应用都会显式地调用 fsync/fdatasync 来确保数据真正持久化到了磁盘上。
POSIX 接口
-
void sync(void);- 我们知道write系统调用只是写入到PageCache,脏页不会立刻写入到磁盘,而是由内核的flusher线程在满足一定阈值(一定时间间隔、脏页达到一定比例),调用sync函数将脏页同步到磁盘上(放入设备的IO请求队列)。
- POSIX语义要求sync系统调用只需将脏页提交到块设备IO队列就可以返回。所以我们看到sync函数返回值为void。同时sync函数返回后,并不等于写入磁盘结束,仍然会出现故障,此时sync函数是无法知晓的。对于可靠性要求比较高的应用,write提供的松散的异步语义是不够的,所以我们需要内核提供的同步IO来保证,常用fsync以及fdatasync。
- sync函数是针对整个PageCache的,对所有的文件更新产生的脏页都会flush。
-
int fsync(int fd);- fsync针对单个文件起作用,会阻塞等到PageCache的更新数据真正写入到了磁盘才会返回。fsync除了更新文件的数据外,还会更新文件的元数据(大小、修改时间等),适用于数据库这样的应用。
- 通常文件的数据和元数据是存储在磁盘不同位置的,因此fsync至少需要两次IO操作,一次数据、一次元数据。根据Wikipedia的数据,当前硬盘驱动的平均寻道时间(Average seek time)大约是3~15ms,7200RPM硬盘的平均旋转延迟(Average rotational latency)大约为4ms,因此一次IO操作的耗时大约为10ms左右。所以多一次IO操作时昂贵的。
-
int msync(void *addr, size_t length, int flags);- 如果采用内存映射文件的方式进行文件IO(mmap)也有类似的系统调用来确保修改的内容完全同步到硬盘之上。msync需要指定同步的地址区间,如此细粒度的控制似乎比fsync更加高效(因为应用程序通常知道自己的脏页位置),但实际上(Linux)kernel中有着十分高效的数据结构,能够很快地找出文件的脏页,使得fsync只会同步文件的修改内容,同时内核也提供了sync_file_range函数。
-
int fdatasync(int fd);- 上文提到fsync会同步数据以及元数据,增大延迟,因此POSIX定义了fdatasync,放宽了同步的语义,以提高性能。
- fdatasync的功能与fsync类似,但是仅仅在必要的情况下才会同步metadata,因此可以减少一次IO写操作。那么什么是“必要的情况”呢?举例来说,文件的尺寸(st_size)如果变化,是需要立即同步的,否则OS一旦崩溃,即使文件的数据部分已同步,由于metadata没有同步,依然读不到修改的内容。而最后访问时间(atime)/修改时间(mtime)是不需要每次都同步的,只要应用程序对这两个时间戳没有苛刻的要求,基本无伤大雅。
-
sync_file_range(int fd, off64_t offset, off64_t nbytes,unsigned int flags)- 可以将文件的部分范围作为目标,将对应范围内的脏页刷回磁盘,而不是整个文件的范围。好处是,当我们对大文件进行了修改时,如果修改了大量的数据块,我们最后fsync的时候,可能会很慢。即使fdatasync,也是有问题的,例如这个大文件的长度在我们的修改过程中发生了变化,那么fdatasync将同时写metadata,而对于文件系统来说,单个文件系统的写metadata 是串行的,这势必导致影响其他用户操作metadata(如创建文件)。
- sync_file_range是绝对不会写metadata的,所以用它非常合适,每次对文件做了小范围的修改时,立即调用sync_file_range,把对应的脏数据刷到磁盘,那么在结束对文件的修改后,再调用fdatasync (flush dirty data page)、fsync(flush dirty data+metadata page)都是很快的。
- 提供了几个flag:
SYNC_FILE_RANGE_WRIT:是异步的,可以结合fsync、fdatasync使用。SYNC_FILE_RANGE_WAIT_BEFORE:写前做一次全文件范围的sync_file_range。从而保证在调用fdatasync或fsync前,该文件的dirty page已经全部刷到磁盘。SYNC_FILE_RANGE_WAIT_AFTER:写后做一次全文件范围的sync_file_range。从而保证在调用fdatasync或fsync前,该文件的dirty page已经全部刷到磁盘。
flag
-
open 函数中指定的 flag
-
O_SYNC:使每次write操作阻塞等待磁盘IO完成,文件数据和文件属性都更新。 -
O_DSYNC:使每次write操作阻塞等待磁盘IO完成,但是如果该写操作并不影响读取刚写入的数据,则不需等待文件属性被更新。- 文件以O_DSYNC标志打开时,仅当文件属性需要更新以反映文件数据变化(例如,更新文件大小以反映文件中包含了更多数据)时,标志才影响文件属性。在重写其现有的部分内容时,文件时间属性不会同步更新。
- 文件以O_SYNC标志打开时,数据和属性总是同步更新。对于该文件的每一次write都将在write返回前更新文件时间,这与是否改写现有字节或追加文件无关。相对于fsync/fdatasync,这样的设置不够灵活,应该很少使用。
- 实际上:Linux对O_SYNC、O_DSYNC做了相同处理,没有满足POSIX的要求,而是都实现了fdatasync的语义
-
O_DIRECT:Linux允许应用程序在执行磁盘IO时绕过缓冲区高速缓存,从用户空间直接将数据传递到文件或磁盘设备,称为直接IO(direct IO)或者裸IO(raw IO)。- 注意可能发生的不一致性:若一进程以O_DIRECT标志打开某文件,而另一进程以普通(即使用了高速缓存缓冲区)打开同一文件,则由直接IO所读写的数据与缓冲区高速缓存中内容之间不存在一致性,应尽量避免这一场景。
- 使用直接IO需要遵守的一些限制:不遵守下述任一限制均将导致EINVAL错误。
- 用于传递数据的缓冲区,其内存边界必须对齐为块大小的整数倍
- 数据传输的开始点,即文件和设备的偏移量,必须是块大小的整数倍
- 待传递数据的长度必须是块大小的整数倍。
