Cache Replacement Policies - Fine-Grained Reuse Distance
Fine-Grained Replacement Policies
细粒度策略在插入时区分高速缓存行,这种区分通常基于类似高速缓存行的前一个生存期的回收信息。例如,如果细粒度策略得知某一行在其之前的生命周期中没有被重用而被逐出,那么它可以以低优先级将该行插入到缓存中。相比之下,粗粒度策略(如LRU)只有在从MRU位置迁移到LRU位置后才会驱逐一行,所以该方案强制缓存行驻留在缓存很长一段时间,消耗宝贵的缓存空间来确定行应该驱逐。因此,通过学习以前缓存行的行为,细粒度策略可以更有效地使用缓存 。
根据用于预测插入优先级的指标,我们将细粒度策略分为三大类。
第一类(第4.1节) 包含预测传入行预期重用时间间隔 的解决方案。
第二类(第4.2节) 包含预测二分缓存决策 的解决方案 (缓存友好 vs. 缓存不友好 )。
第三类比其他两类要小得多,包括引入新的预测指标的策略 [Beckmann and Sanchez, 2017, Kharbutli and Solihin, 2005]。
细粒度解决方案有其他几个设计维度。首先,由于要记住跨多个缓存生存期的单个行的缓存行为可能很麻烦,所以这些策略学习一组行的缓存行为 。例如,许多解决方案根据加载行的指令的地址 (PC) 对行进行分组,因为由同一 PC 加载的行往往具有类似的缓存行为 。最近的解决方案着眼于更复杂的方法来分组缓存行 [Jiménez 和 Teran, 2017, Teran et al., 2016]。第二个设计维度是用于学习缓存行为的历史记录量。
细粒度替换策略起源于两个看起来不同的上下文中。
其中一个使用预测来识别死块(即在被移除之前不会被使用的块),然后就可以重新用于其他用途 。例如,识别死块的最早动机之一是将它们用作预取缓冲区 [Hu等人,2002,Lai等人,2001]。另一个动机是关闭已死的缓存行 [Abella等人,2005,Kaxiras等人,2001]。第二个工作推广了混合重引用间隔策略 [Jaleel et al., 2010b],使它们更有 learning 的基础 。
尽管它们的起源不同,这两种研究方向已经趋同为概念上相似的解决方案。
PC 程序计数器是计算机处理器中的寄存器,它包含当前正在执行的指令的地址(位置)。当每个指令被获取,程序计数器的存储地址加一。在每个指令被获取之后,程序计数器指向顺序中的下一个指令。当计算机重启或复位时,程序计数器通常恢复到零。
REUSE DISTANCE PREDICTION POLICIES
基于重用距离的策略预估块的重用距离,重用距离可以根据连续引用块之间的访问次数或循环次数来定义。对重用距离的完美预测足以模拟 Belady 的最优解决方案,但由于重用距离值的高变化,很难精确预测重用距离。因此,现实的解决方案估计重用距离分布或其他聚合的重用距离统计 。
EXPIRATION-BASED DEAD BLOCK PREDICTORS
许多死块预测器使用过去的驱逐信息 来估计平均重用距离统计数据,它们驱逐未在预期重用距离内重用的行 [Abella et al., 2005, Faldu和Grot, 2017, Hu et al., 2002, Kharbutli 和 Solihin, 2005, Liu et al., 2008, Takagi 和 Hiraki, 2004]。
Hu 等人了解了缓存块的存活时间,其中存活时间定义为一个块在缓存中保持存活的周期数 [Hu等人,2002]。当插入一个块时,它的生命周期预计与最近的一次的生命周期相近。如果块在缓存中停留了两倍的生命周期而没有收到缓存命中,则这样的块被定义为死亡块并将从缓存中移除。
Abella 等人使用了类似的死块预测策略来关闭 L2 高速缓存行,但他们没有使用周期数,而是根据连续引用之间的缓存访问次数来定义重用距离 [Abella等人,2005]。
Kharbutli 和 Solihin[2005] 使用计数器来跟踪每条缓存行的访问间隔,其中一行的访问间隔被定义为在对该行的后续访问之前被访问的其他缓存行的数量 。而且,如果访问间隔超过一定的阈值,它们就会预测一个缓存行是死的。该阈值由访问间隔预测器(AIP)预测,该预测器跟踪所有过去驱逐的访问间隔,并记住基于 PC 的表中所有此类间隔的最大值。
Faldu 和 Grot [2017] 展示了 Leeway 策略,该策略使用了 live distance 的概念,即在缓存行生命周期中观察到的最大栈距离,以识别死块 。缓存块的活动距离是从块的前几代学习的,当一个块超过它的活动距离时,它被预测为死块。使用每个 PC 的活距离预测表(LDPT)来保存前面的活距离。LDPT 为传入的块预测活动距离,任何在 LRU 堆栈中移动超过其预测活动距离的块都被预测为死块。为了避免跨生存期和跨同一 PC 访问的块的活动距离的高可变性,Leeway 部署了两个更新策略 ,它们控制基于工作负载特征调整 LDPT 中的活动距离值的速率。第一种策略是激进的,支持 bypassing;第二种策略是保守的,有利于缓存。Leeway 使用 Set Dueling [Qureshi et al., 2007] 来选择这两种策略。
REUSE DISTANCE ORDERING
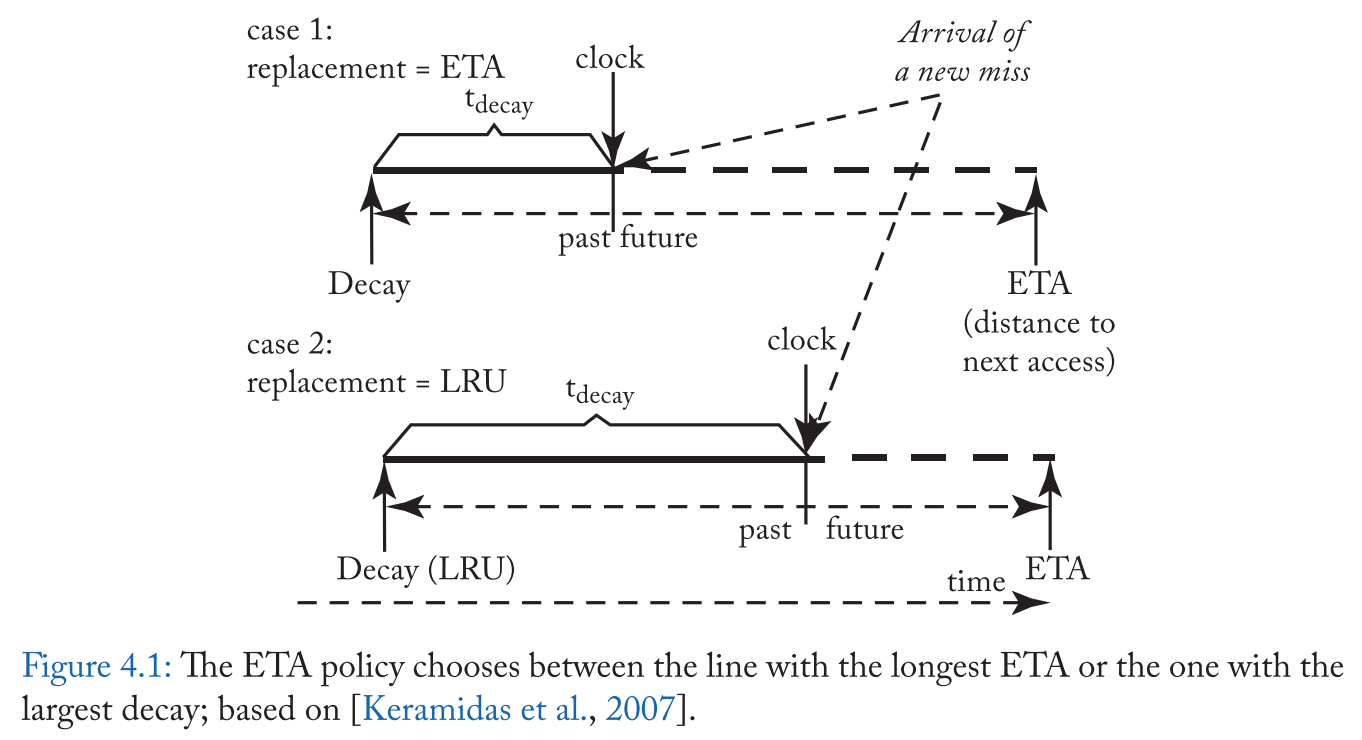
Keramidas 等人 [2007] 使用重用距离预测来代替驱逐预计在未来被重用最多的缓存行。他们的策略学习每个 LOAD 指令 (PC) 的重用距离,对于每个传入行,它计算一个估计的访问时间 (ETA),这是当前时间和预期的重用间隔的总和。然后,它根据 ETA 值来排序缓存行,并驱逐 ETA 值最大的行 。
为了防止 ETA 预测不可用的情况,该方案还跟踪行衰减,这是对一行在缓存中未被访问的时间的估计,如果该行的衰减间隔大于其 ETA,它将驱逐该行 。
更具体地说,图4.1显示了替换策略有两个候选行:
(1) ETA最大的行(ETA行);
(2) 衰减时间最大的行(LRU行)
选择两个值中最大的行进行驱逐。因此,该策略在有条件时依赖 ETA,否则转变回 LRU。
参考文献
基于重用距离的缓存策略的其他相关研究
x
感谢您的支持,我会继续努力的!
扫码打赏,你说多少就多少