- 本篇为智能缓存相关的研究调研,可能涉及 AI for System 以及相关缓存策略的设计
Smart SSD Cache
- 智能缓存顾名思义为不同的负载下提供相应的缓存策略来保证缓存的高效,主要包含多种缓存策略执行和 IO 负载的捕捉两个方面,同时可能结合不同的缓存层级需要进行动态调整。
- 缓存策略本身很难有普适的,现有做法和方案常常需要根据 IO 负载来进行决策,而对于 IO 负载的建模往往采用统计或者机器学习的方法
OceanStor V5 系列 V500R007 SmartCache
- 参考 https://support.huawei.com/enterprise/zh/doc/EDOC1000181455/1064ba78
定义
- 华为技术有限公司开发的 SmartCache 特性又叫智能数据缓存特性。
- 缓存池化:利用 SSD 盘对随机小I/O读取速度快的特点,将 SSD 盘组成智能缓存池,将访问频率高的随机小I/O读热点数据从传统的机械硬盘移动到由 SSD 盘组成的高速智能缓存池中。由于 SSD 盘的数据读取速度远远高于机械硬盘,所以 SmartCache 特性可以缩短热点数据的响应时间,从而提升系统的性能。
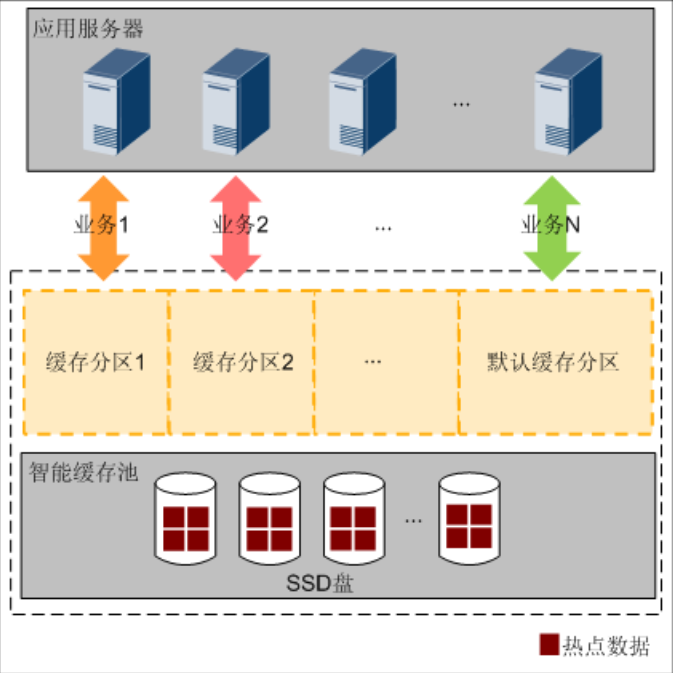
- 多粒度:SmartCache 将智能缓存池划分成多个分区,为业务提供细粒度的SSD缓存资源,不同的业务可以共享同一个分区,也可以分别使用不同的分区,各个分区之间互不影响。从而向关键应用提供更多的缓存资源,保障关键应用的性能。
场景
- SmartCache特性对LUN(块业务)和文件系统(文件业务)均有效。
- SmartCache特性可以提高业务的读性能。尤其是存在热点数据,且读操作多于写操作的随机小I/O业务场景。例如:OLTP(Online Transaction Processing )应用、数据库、Web服务、文件服务应用等。
原理
- SmartCache特性在对SSD盘资源进行管理上,分为智能缓存池和SmartCache分区两部分。
智能缓存池
- 智能缓存池管理本控制器的所有SSD盘,用以保证每个智能缓存分区的资源来自不同SSD盘,从而避免不同SSD盘负载不均衡。
- 存储系统默认在每个控制器上生成一个智能缓存池。
读流程
- SSD Cache 缓存命中
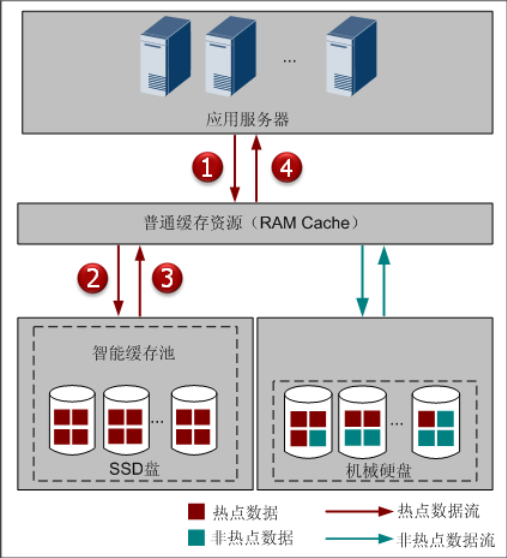
- SmartCache读未命中
- 当从 HDD 读取到 RAM Cache 后,RAM Cache 将数据返回给应用服务器,同时 RAM Cache 将该数据同步到智能缓存池中。当智能缓存池容量不够时,则智能缓存池根据时间顺序释放旧数据,释放数据内存,完成旧数据的淘汰。
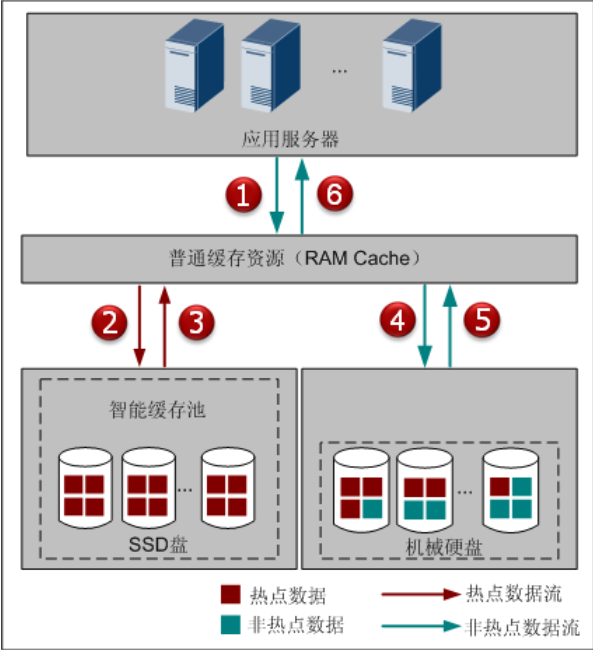
SmartCache分区
- SmartCache分区负责为业务提供细粒度(4KB、8KB、16KB、32KB、64KB、128KB,与前端I/O自适应,即根据前端下发的I/O大小申请不同粒度的SSD缓存资源)的SSD缓存资源。
- 每两个控制器创建一个默认的SmartCache分区。除了默认分区外,每两个控制器最多支持创建8个用户自定义分区。
- 通过SmartCache分区调控,各业务独立使用所分配的SmartCache分区,避免不同类型应用之间的相互影响,保障存储系统整体的服务质量。可以通过设置SmartCache大小,实现不同业务与性能的最佳匹配。通过限制非关键应用的缓存资源,向关键应用提供更多的缓存资源,保障关键应用的性能。
- SmartCache分区负责为业务提供细粒度的SSD盘缓存资源,不同的业务可以共享同一个分区,也可以分别使用不同的分区,各个分区之间互不影响。
Machine Learning
DATE20 - A Machine Learning Based Write Policy for SSD Cache in Cloud Block Storage
- 发现:作者在腾讯云的云存储环境中(主要是块存储系统),测试统计发现大约有 47.9% 的写操作是 write-only 的,即在某一个确定的时间窗口内所写的这些块不会再次被访问。那么这些 write-only 的写操作对应的数据放置在缓存中其实并不会带来性能的提升,反而会占据缓存容量,影响其他真正需要缓存的数据来进行缓存。
- 问题:现有的写策略大致分为两种:
- 将所有要写的数据加载到缓存中(write-back 和 write through)
- write-back:在数据更新时只写入缓存Cache。只在数据被替换出缓存时,被修改的缓存数据才会被写到后端存储。此模式的优点是数据写入速度快,因为不需要写存储;缺点是一旦更新后的数据未被写入存储时出现系统掉电的情况,数据将无法找回。
- Write-through(直写模式)在数据更新时,同时写入缓存Cache和后端存储。此模式的优点是操作简单;缺点是因为数据修改需要同时写入存储,数据写入速度较慢。
- 不加载数据到缓存,直接写存储设备 (write-around)
- 将所有要写的数据加载到缓存中(write-back 和 write through)
- 方案:提出了一种基于机器学习的方法来识别 write-only 数据和 normal 数据,针对不同类型的数据动态应用不同的写策略。最大的挑战是怎么样才能够实时地区分数据类型
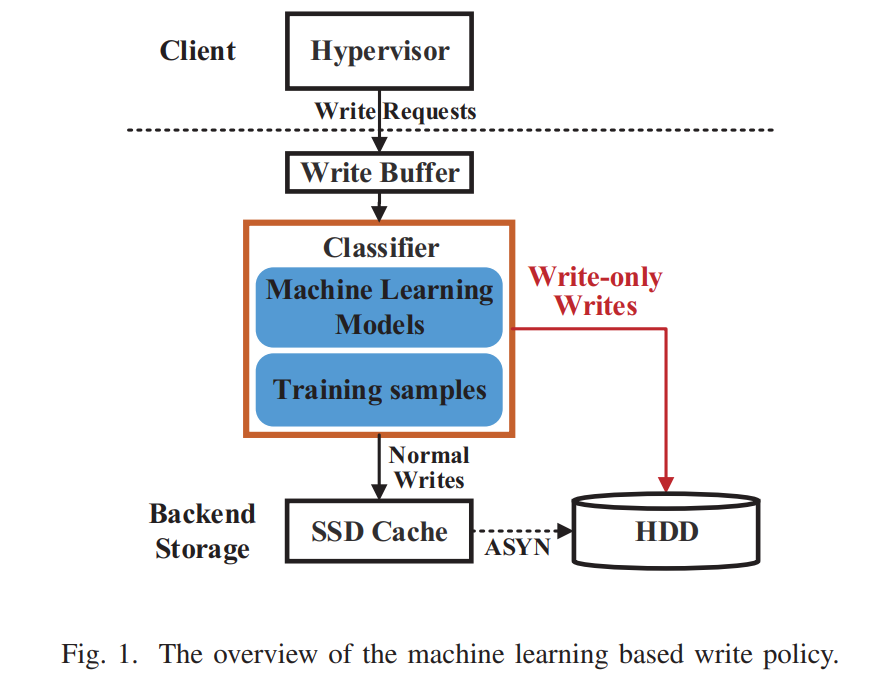
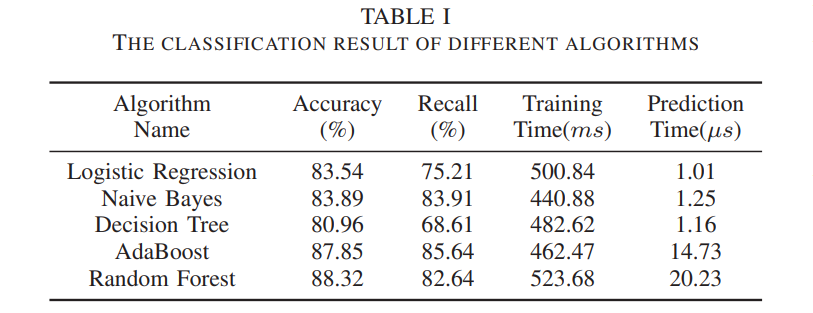
- 使用了五种监督学习方法:Naive Bayes, Logistic Regression, Decision Tree, AdaBoost, and Random Forest。随机森林准确率最高,但是耗时最长,不满足实时性,朴素贝叶斯在准确率、召回率和预测时间上基本做到了 trade-off,所以最终选择了朴素贝叶斯。
- 数据指标的选择:不同于在文件级别或者片上系统的基于机器学习的优化,在块级系统中部署机器学习算法来分类不同的数据面临很大的障碍,因为块级能提供的信息是有限的,常用的信息包括时间特征和空间特征(如最近访问时间和最近访问的地址)。本文中我们扩展了数据指标到 IO 请求,收集了如 average write size, write request ratio 等,这是由于具有类似请求级别的数据往往表现出类似的访问特征
- Temporal features:这些特性包括数据块的访问近因和时间间隔。
- Last Access Timestamp 在本文中被定义成了当前时间和最近访问该块的时间间隔。
- Average Re-access Time Difference:对一个数据块进行两个相邻访问的时间间隔
- Spatial features:这些特性包含地址信息,例如卷 ID、偏移量等
- 因为地址会随着时间不断变化,对算法的效果会有显著影响,在作者实现的算法中其实没有使用空间特征。
- Request-level features
- Average Request Size 平均请求大小,单位 KB,上界为 100KB
- Big Request Ratio 大请求比例,请求大小大于 64KB 即为大请求
- Small Request Ratio 小请求比例,请求小于 8KB 即为小请求
- Write Request Ratio 写请求的比例
- Temporal features:这些特性包括数据块的访问近因和时间间隔。
- 统计粒度: 块设备的最小粒度为一个块,假设一个块为 8KB,如果我们为每一个块都统计对应的数据特征,因为块设备容量很大,那么统计这些特征就会造成巨大的开销,同时太大可能影响算法的准确率,所以实际应用过程中,作者采用了 1MB 为统计粒度(称之为 tablet),1MB 连续的数据块中所包含的最小物理块对应的数据特征相同,从而减少统计的开销。
- 整个模型的工作流程如下:
- 写请求的所有数据被首先被写入到内存中并顺序地记录在日志文件中,然后当脏数据的比例达到阈值则刷回到后端存储服务器,当在内存写缓冲中要执行对应的刷回操作时,进行下一步
- 分类器获取最近刷回的数据块的 tablet 特征并预测其写请求类型,如果是 write-only 跳转到下一步,如果不是(即为 normal data)跳转到第四步
- 如果该数据位于 SSD Cache 中且为脏数据,那么首先将该脏数据刷回到 HDD。对应的数据块将直接在 HDD 上进行写
- 数据块首先写入到 SSD 缓存然后使用 write-back 的策略异步刷回 HDD
- 分类器每天训练一次用于第二天的预测,系统运行过程中收集样本数据,当 SSD cache 发生 eviction 的时候将增加一个样本,如果 evicted-data 有一次或者多次读命中,该样本将被设置为 0,也就是 normal data,否则设置为 1,write-only data。在作者的想法中,真实的实现里,write-only 的数据块是指一个在从缓存中 evict 之前不会被读的块
- 效果:实验结果表明,与业界广泛部署的回写策略相比,ML-WP 减少了对 SSD 缓存的写流量 41.52%,同时提高了 2.61% 的命中率,降低了 37.52% 的平均读延迟
Related Work
-
写策略优化
- ATC15 - Request-oriented durable write caching for application performance
- 分析IO工作负载(判断是否会发生争用),然后部署最合适的写策略,使用了固定的写策略
- ATC15 - Request-oriented durable write caching for application performance
-
Cache Optimization Based on Machine Learning:
- MICRO16 Perceptron learning for reuse prediction
- 感知器学习用于判断 last-level cache 的重用预测 (神经网络做预测)
- 通过使用多个能够展示程序和存储器行为的特征(七个参数化特征)来从多个视角对LLC中的缓存块的未来重用进行预测。利用预测的结果,设计三种cache的管理策略:block placement,replacement,bypass
- PC, address, reference count, etc
- ICPP18 Efficient ssd caching by avoiding unnecessary writes using machine learning
- 使用机器学习(决策树)来进行一次访问排除,能够准确地识别和过滤一次访问的照片,并阻止它们写入cache,提高社交网络照片缓存服务的效率。更多的使用照片的相关数据以及用户的登录请求数据来作为数据集
- 使用 reaccess distance 来定义是否为只访问一次的图像,被定义为从该图像进入cache 开始到下一次被访问之间的总的图像访问量
- 命中率提高了17%,缓存写操作降低了79%,平均访问延迟降低了 7.5%
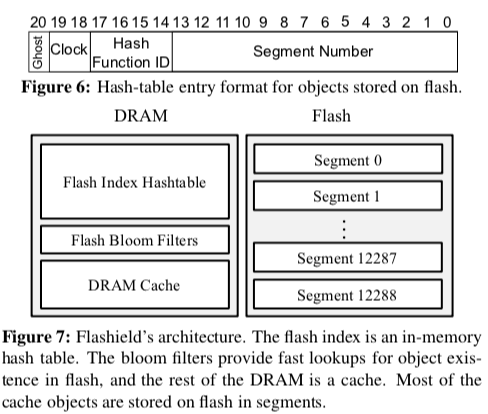
- NSDI19 Flashield: a hybrid key-value cache that controls flash write amplification
- 由于键值更新会对 SSD 造成严重的有害的小随机I/O写操作,因此使用机器学习(支持向量机 SVM)的方法来选择期望读取频率更高的对象
- Flashield这里引入了Flashiness的概念,作为一个对象被Cache价值的一个评价指标,一个高Cache价值的对象要满足两点条件
- 一个对象在访问之后会在不远的将来访问n次(及以上),这里的n作为参数定义,
- 在将来的一段时间内不会被修改
- MICRO16 Perceptron learning for reuse prediction
New Cache Policy
TPDS20 - Efficient SSD Cache for Cloud Block Storage via Leveraging Block Reuse Distances
-
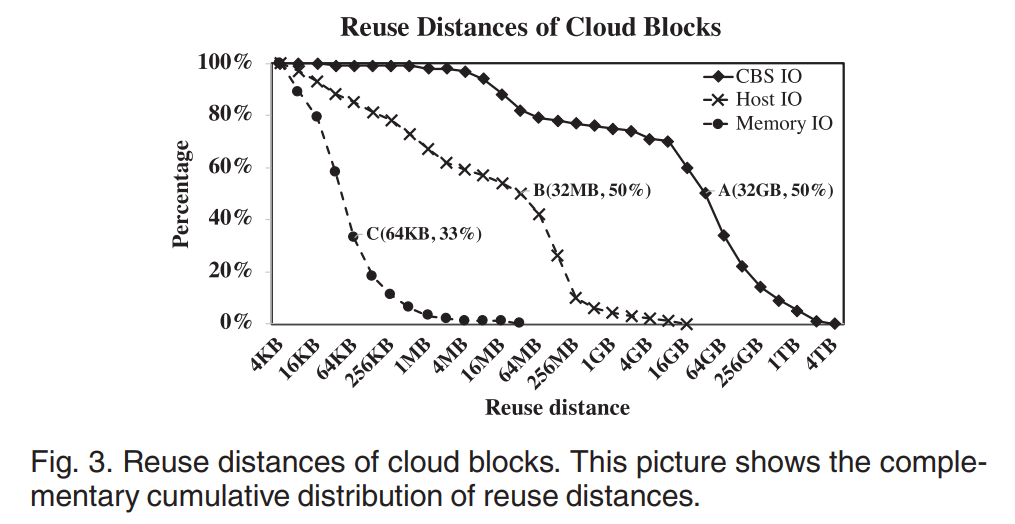
发现:我们在一个典型云块存储的服务器端发现了这一点,有很大比例的块具有很大的重用距离,这意味着很多块只有在遥远的将来才会被重新引用。在这样的场景中,如果在每次 miss 时进行简单的替换,新访问的块会污染缓存,而不会给命中率带来任何好处,从而降低缓存效率。现有的缓存算法在存在较大的重用距离时,缓存效率往往不理想
- 如下图所示,A 点意味着 CBS 访问中,有大约 50% 的块的重用距离大于 32GB,而对于内存和主机上的 IO 则要小得多
- 因此,如果我们使用像LRU这样的缓存算法,当缓存大小等于或小于 32gb 时,50% 的重用块不会被命中
-
现象分析:
- 多数具有小重用距离的数据块已经被客户端缓存设备缓存和过滤。
- 单个云磁盘的容量可以达到几十TB,这比传统磁盘高出几个数量级。因此,数据规模较大的云应用程序可能导致更大的重用距离
- 在多租户共享云环境中,来自不同租户的访问会混合在一起,导致重用距离增加
-
贡献:我们提出了一种新的缓存算法,专为 CBS 和其他类似场景设计的 LEA,LEA在缓存未命中时默认不进行替换,除非满足某些(惰性)条件。条件包含两个方面:新访问块的频率 和 缓存中的候选逐出块的值(该值是指该块对缓存的重要性或有用性)。这样,块的缓存持续时间可以大大延长。更重要的是,可以大大减少对 SSD 的写操作,延长 SSD 的生命周期
-
Reuse Distance:数据块的重用距离定义为对同一块的两个连续引用之间的唯一数据量。例如 1-2-4-5-4-3-3-2 的块访问序列中,Block 2 的 reuse distance 就是三个块的大小,在有的研究中,Block 2 的 reuse distance 为 5 个块的大小。本文采用了第二种定义。
-
传统的 LRU 当缓存空间满时,对每次miss进行替换,主要遵循时间局部性原则,这些缓存替换算法的主要目标是保留重用距离较小的块,驱逐重用距离较大的块。当大部分数据重用距离小于缓存大小时,这些算法可以有效地工作。
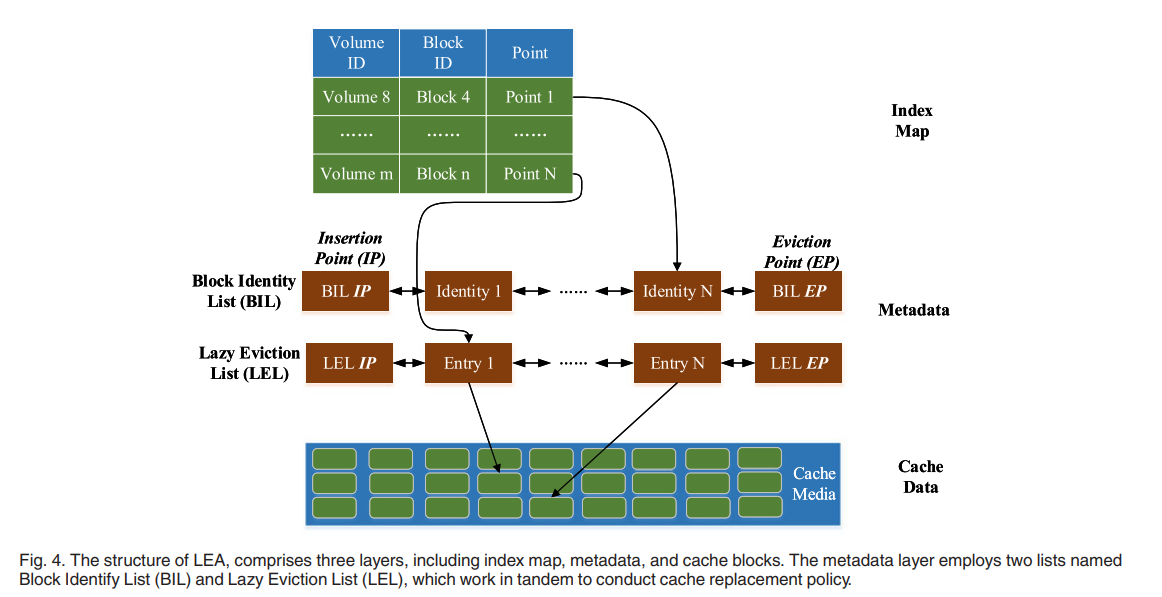
LEA Algorithm
- 维护两个队列,Lazy Eviction List (LEL) 和 Block Identity List (BIL)。每个队列有两个端点 Insertion Point (IP) 和 Eviction Point (EP)
- 标识只包括块的卷号和地址信息(偏移量)。一个条目包含额外的块信息,如 last_access, reuse_distance, age, flag,等等。条目中的信息用于计算条目块的值。
- age 表示块的当前时间和最后一次访问时间(last_access)之间的时间差,如果 age 小于 reuse_distance,它表明该块对缓存具有较高的价值。这里的时间是逻辑时间,当一个新的块请求到来时,逻辑时间增加1。这里,重用距离是最后两次访问之间的时间(而不是访问之间的平均时间)。
- flag 也用来判断块的值,当块在 LEL 列表中命中时增加 1,当块被视为块驱逐候选,但由于懒惰替换还没有被驱逐时减少一半,如果 flag 大于 0,它表明该块对于缓存是有价值的。
- 当发生缓存 miss 时,LEA 不进行替换,只在满足延迟条件时将丢失的块标识插入 BIL 列表,否则,它将执行替换并将丢失的块条目插入到 LEL 列表中。如果在 BIL 列表中命中了一个块,那么它进入LEL列表的概率更高。通过这样做,间接地考虑了访问频率
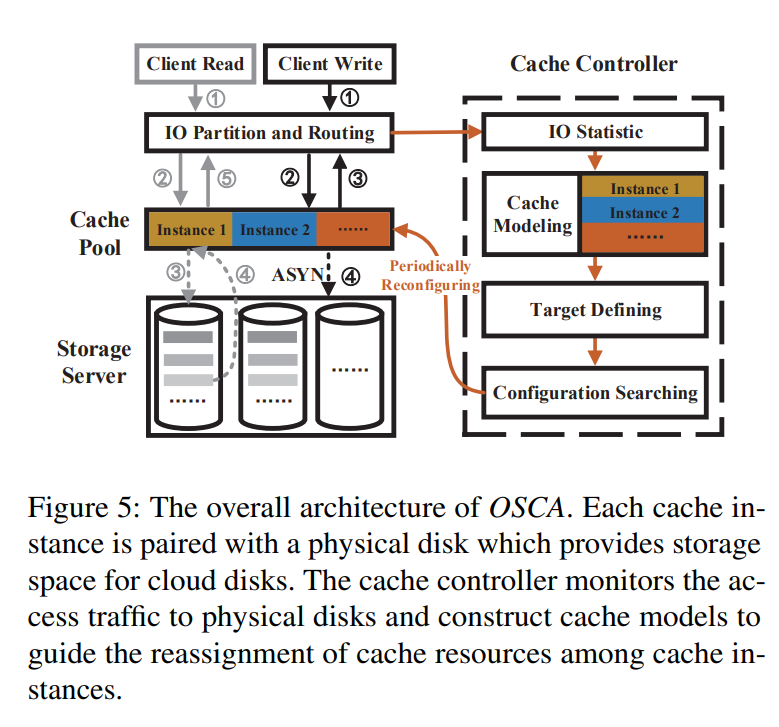
ATC20 - OSCA: An Online-Model Based Cache Allocation Scheme in Cloud Block Storage Systems
- OSCA 可以在非常低的复杂度下找到接近最佳的配置方案,从而提高缓存服务器的总体效率
- 部署了一个新的缓存模型来获得云基础设施块存储系统中每个存储节点的 miss ratio curve (MRC)。使用一种低开销的方法来获得一个时间窗口内从重新访问流量与总流量之比的数据重用距离。然后将得到的重用距离分布转化为 miss ratio curve (MRC)。
- 通过了解存储节点的缓存需求,将总命中流量指标定义为优化目标
- 使用动态规划方法搜索接近最优的配置,并基于此解进行缓存重新分配
- 在实际工作负载下的实验结果表明,模型达到了一个平均值绝对误差(MAE),可与现有的最先进的技术相媲美,但同时可以做到没有跟踪收集和处理的开销。由于命中率的提高,相对于在相同缓存内存的情况下对所有实例的等分配策略,OSCA 减少了到后端存储服务器的 IO 流量 13.2%