- 本篇为持久化技术的基础篇系列第一篇(I/O 设备),即一些硬件设备基础知识以及基础的 IO 处理相关知识,可以结合之前的一篇博客 Flavor of IO。
Chapter Index
- Basic of Persistence
- File Systems Implementation
- Locality and The Fast File System
- Crash Consistency: FSCK and Journaling
- Log-structured File System
Basic of Persistence
Before Persistence
- 原书中的章前对话中对 Persistence 的概念举例进行了通俗的解释:假设我们摘了很多桃子,并且我们想这些桃子能够保存的更久一点,但是水果的保存总会受天气温度等环境因素的影响,我们通常可能会将桃子晒成果干,或者做成 PIE 一样的能够保存的更久一点的形式。
- 数据信息同理,我们想要持久地保存数据,以防出现计算机宕机/磁盘故障/掉电等其他事件破坏了我们的数据。
I/O Devices
- 问题1:I/O 如何集成到系统中?
- 问题2:I/O 机制是什么样的?
- 问题3:如何让 I/O 变得更加高效?
System Architecture
-
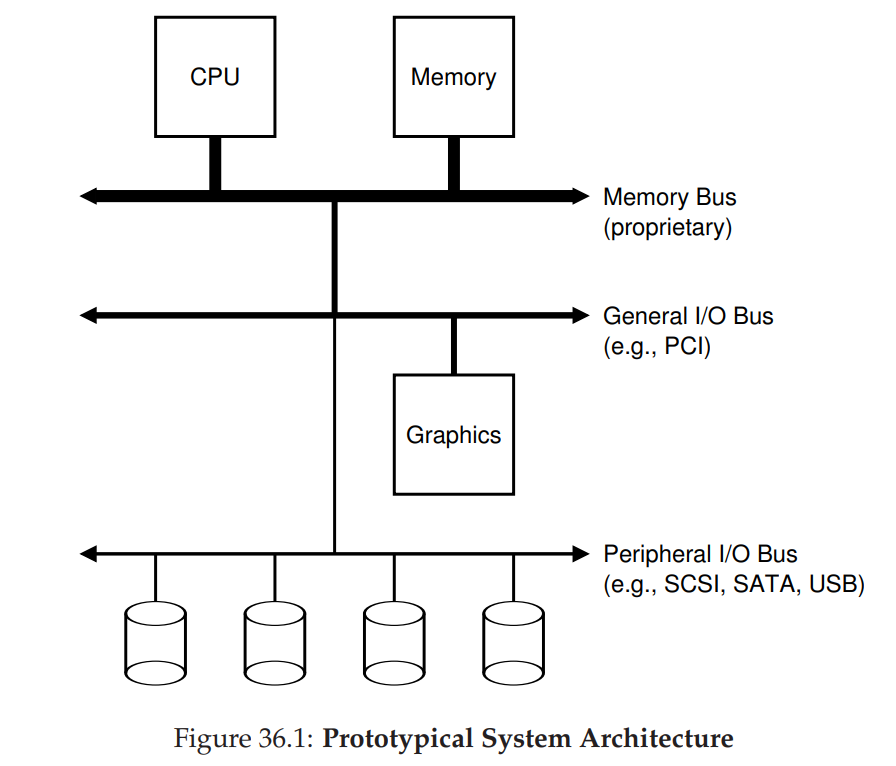
如图所示的 传统意义上的系统架构: (物理结构和成本 决定了架构)
- CPU 和 Memory 通过内存总线相连
- 部分外设(高性能 I/O 设备)通过通用的 I/O 总线(许多系统中为 PCI)和内存总线相连。eg. 显卡
- 其他外设则通过外围总线(SCSI, SATA, USB)相连,通常为 disk, mice, keyborads 等设备
-
思想:性能要求高的设备,离 CPU 更近,总线成本也更高,不适宜接入大量外设
-
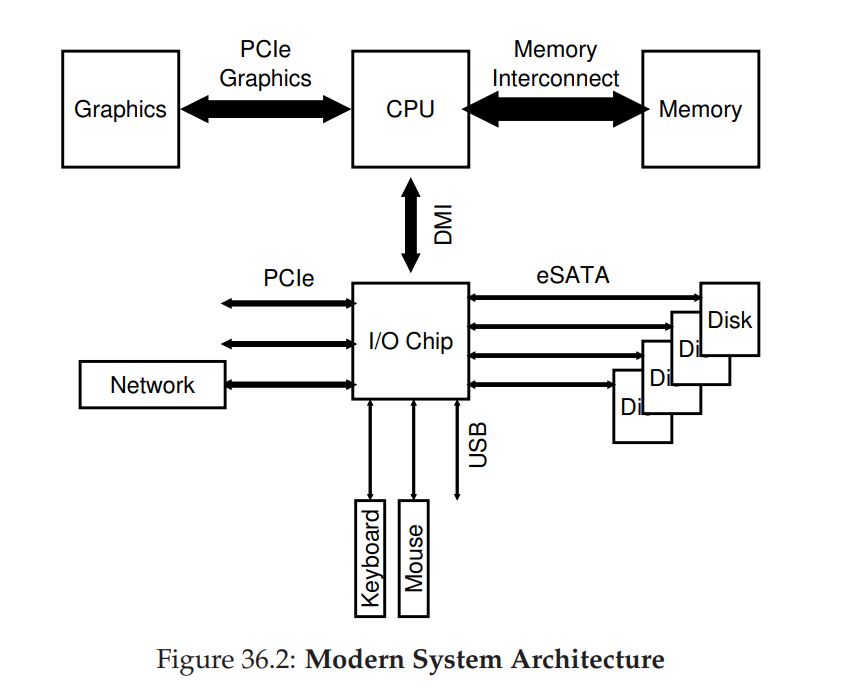
如图所示的 现代系统结构(Intel's Z270):现代系统越来越多地使用专用芯片组和更快的点对点互连来提高性能。
- CPU 同时直连 Memory 和 Graphics,保证其对高性能的需求
- CPU 通过 Intel 专有的 DMI (Direct Media Interface) 连接 I/O 芯片,其他外设再通过不同的接口连接到 I/O Chip
- Disk 通过 ATA / SATA / eSATA 连接;然后 USB 相关设备通过 USB 连接;网络接口(网卡)以及高性能存储设备(如 NVMe SSD)通过 PCIe 连接
A Canonical Device and The Canonical Protocol
Device
- 一个标准化的设备主要由两部分组成:硬件接口 和 内部结构
- 硬件接口:暴露给系统的其他部分,相当于一层对外提供了相应的程序接口的软件,需要借助硬件接口层控制硬件的具体操作。
- 内部结构:设备的这一部分是特定于实现的,负责实现设备呈现给系统的抽象。非常简单的设备将有一个或几个硬件芯片来实现其功能;更复杂的设备将包括一个简单的CPU、一些通用内存和其他特定于设备的芯片来完成它们的工作。如 RAID 控制器就由大量的 firmware 组成来实现相应的功能。

Protocol
- Interface 由三个寄存器组成:
- status:查看当前设备的状态
- command:告诉设备执行某项任务
- data:传递数据给设备,或者从设备中获取数据
- 交互过程示例如下:
- step 1: 通过重复地读取 STATUS 寄存器判断是否 Device 空闲,即轮询 Device
- step 2: 将此次需要处理的数据发送 DATA 寄存器,若当前设备为磁盘设备,大量的写操作需要传输数据块到数据寄存器中,倘若 CPU 参与了此次数据移动过程,此次过程被称为 PIO(Programmed I/O)
- step 3:将此次需要进行的指令发送到指令寄存器中,显示地告诉设备数据也已经准备就绪,可以开始执行对应的操作
- step 4:等待设备完成操作,再次对设备进行轮询,重复 step 1
While (STATUS == BUSY)
; // wait until device is not busy
Write data to DATA register
Write command to COMMAND register
(starts the device and executes the command)
While (STATUS == BUSY)
; // wait until device is done with your request
- 该协议的优点在于可以正常工作以及足够简单,但是不够高效。因为轮询机制的存在,需要花费大量的 CPU 时钟来等待设备完成前一个任务。
- CRUX:有什么比较好的方式可以检查设备状态,不用通过轮询,从而减小 CPU 开销?
Lowering CPU Overhead With Interrupts
- 使用中断机制代替轮询,当设备完成了相应任务之后,触发一个硬中断,CPU 再去对应地执行中断处理任务,等待任务完成的过程中,CPU 可以切换去处理其他任务。
- 中断机制允许计算和 I/O 操作同时进行,从而提升了利用率。如图所示,上图使用 polling 机制等待读取到存储在磁盘上的数据,下图所示则使用了中断机制,在等待上一个任务完成的过程中可以执行别的任务,上一个任务完成后再使用中断通知CPU,从而唤醒 Process 1 继续执行


- 但需要注意的是,中断机制不一定总是比轮询机制高效,因为中断机制引入了不同进程之间的切换操作,该操作也是有一定的开销的,针对通过比较短时间的轮询就能实现的操作往往会比中断机制更为高效。同时大量的中断操作可能导致操作系统出现活锁。
- 因此,
- 如果一个设备的处理速度比较快,通常轮询机制更为高效
- 如果处理速度较慢,通常中断机制更为高效
- 如果处理速度未知,时快时慢,通常使用混合机制来处理,即两阶段方式:轮询一段时间之后执行中断。
- 在网络传输过程中,也尽量不使用中断,因为针对那种大流量的数据传输,每一个数据包就进行一次中断,会出现活锁(即只处理中断,无法处理实际的操作和请求)。
- 另一个基于中断的优化是合并操作,在这种情况下,一个需要首先引起一个中断的设备在将中断发送给CPU之前会等待一点时间。在等待期间,其他请求可能很快就会完成,因此可以将多个中断合并为单个中断交付,从而降低中断处理的开销。当然,等待太久会增加请求的延迟。
More Efficient Data Movement With DMA
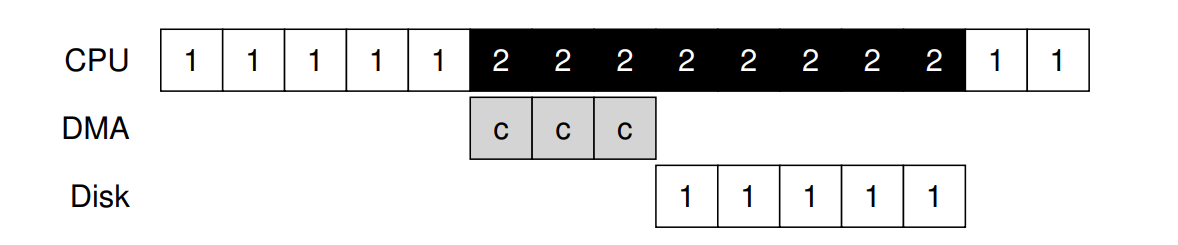
- 除了轮询机制占用 CPU 的资源以外,针对 PIO 过程,将大块数据传输到设备时,CPU又一次因一个相当琐碎的任务而负担过重。如图所示,Process 1 将要写部分数据到磁盘,发起 I/O 操作,首先将数据从内存拷贝到设备,如图中 c 所示,拷贝完成后开始向磁盘发起写。

- CRUX:如何降低 PIO 过程中设备上的数据寄存器的传输操作给 CPU 带来的开销?
Solution DMA
- Direct Memory Access (DMA):直接内存访问。DMA 引擎本质上是系统中的一个具体的设备,它可以在没有太多 CPU 干预的情况下协调设备和主内存之间的传输。
- DMA 的工作原理如下:为了将数据传输到设备,操作系统需要通过程序的方式告诉 DMA 引擎数据在内存中的位置、要复制多少数据以及要将数据发送到哪个设备。告诉 DMA 之后,操作系统的任务就完成了,就可以切换去执行其他任务。DMA 开始工作,当完成相应的数据传输以后,发起一个中断,此时 OS 就知道传输已经完成了,将会继续执行之前挂起的任务。
- 如图所示,相比于无 DMA 的方案,数据拷贝的过程主要由 DMA 来完成,此时 CPU 可以去执行别的任务来提高利用率。
Methods Of Device Interaction
- CRUX: 硬件与设备之间如何进行交互的?
I/O instructions
- 最古老的方法(被IBM大型机使用多年),显示的 I/O instructions。这些指令为操作系统指定了将数据发送到特定设备寄存器的方法,因此允许构建上述协议。
- 例如 x86 机器上就会用 in/out 指令和设备进行通信,比如发送数据到指定设备,caller 需要指定一个存储该数据的寄存器,以及具体的端口来表明是哪个设备,才能真正地执行对应的操作。
- I/O instructions 通常是高优先级的,因为通常是由 OS 发出相应的指令,因此 OS 也是唯一一个允许直接和设备通信的实体。假设所有程序都能读写磁盘,将会造成十分混乱的局面,每个程序都将能根据这个漏洞操纵整个机器。
Memory-mapped I/O
- 该方法让硬件寄存器能够如在内存中一样被直接访问。为了访问某一个寄存器,操作系统发起一个对相应地址的 load (to read) 或者 store (to write) 指令,然后硬件将相应的指令发送到对应的设备。
- 这两种方法都没有太大的优势。内存映射方法很好,因为不需要新的指令来支持它,但是这两种方法现在仍然在使用。
Fitting Into The OS: The Device Driver
- CRUX: 不同的设备可能使用了不同的接口,操作系统如何适配对应的设备,如何屏蔽设备指令的实现细节?
- 解决该问题的核心思想为 抽象。在操作系统的最底层,必须要有一层软件,知道和硬件交互的具体细节,我们称之为设备驱动,设备交互的任何细节都被封装在其中。
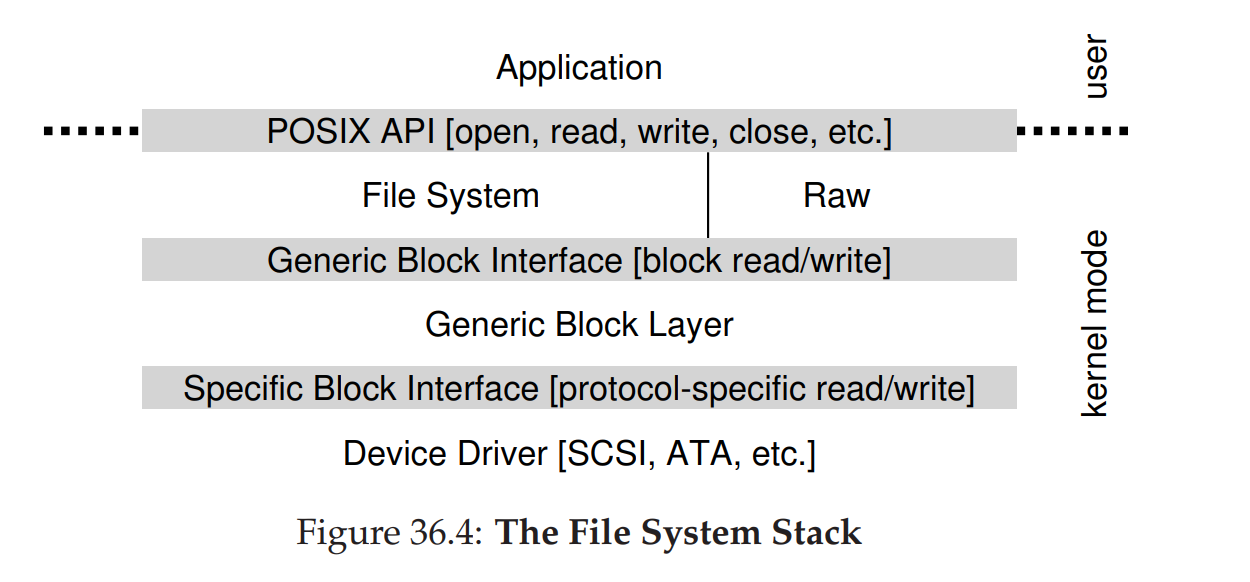
- 以文件系统软件栈为例,应文件系统完全不知道自己使用了哪种类型的磁盘,因为文件系统通常只对通用块层发起对块的读写,由通用块层将读写请求路由到合适的设备驱动,再由设备驱动处理具体请求。
- 图中还表示了裸设备接口,专门提供给一些特殊的应用,如 fsck 或者磁盘分区工具,从而不使用文件抽象直接读写块。大多数系统都提供了这种接口以供一些低级别的存储管理应用使用。
- 这种抽象/封装的方式也有一定的坏处。即当底层设备拥有大量的特性的时候,为了提供通用的接口,可能导致无法充分利用其特性。例如 SCSI 设备本身是支持了大量的错误处理的,相比于 ATA/IDE,但是在通用块层的实现只能报告为 EIO (generic IO error)
- 随着时间的的推移,设备驱动的代码占据了整个 Linux 代码的 70%,由于设备驱动的复杂性和多样性,很多设备驱动代码是由业余人士贡献的,往往可能导致 Linux 内核 crash。
Case Study: A Simple IDE Disk Driver
-
如图所示,IDE 磁盘暴露的接口主要由四个寄存器组成:(这些寄存器通过读写具体的 I/O 地址从而变得可用,使用 in/out 指令)
- 控制寄存器 control
- 命令块寄存器 command block
- 状态寄存器 status
- 错误寄存器 error
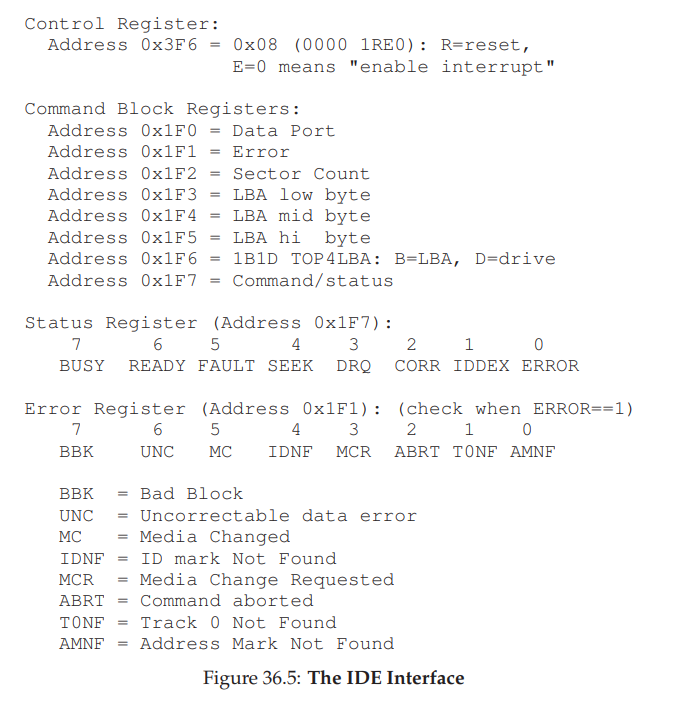
-
假设设备已经初始化,与设备交互的基本协议如下:
- 等待驱动器准备好:读取状态寄存器 0x1F7 (轮询直到 READY 或者 NOT BUSY)
- 向命令寄存器写入参数 (0x1F2-0x1F6):写入扇区计数(Sector Count),要访问的扇区对应的逻辑块地址(LBA of sectors to be accessed),驱动器编号(IDE 只允许两个设备,master = 0x00, slave = 0x10)
- 开始 I/O 操作 (0x1F7):向命令寄存器发起读写,直接将 READ/WRITE 命令写入到命令寄存器。
- 数据传输(写操作):直到驱动器 Status Ready 且驱动器请求数据,将数据写入写入到 Data Port.
- 处理中断:最简单的例子就是为每一个传输了的扇区处理一次中断,更为复杂的实现则是等整个传输过程结束之后处理中断。
- 错误处理:每一次操作之后,读取状态寄存器,如果为 ERROR 状态,对应地读取错误寄存器查看具体的错误原因。
-
该协议的大部分都可以 xv6 IDE Driver 的实现中找到。如下所示的代码中主要实现了四个功能:
ide_rw:如果有任务挂起,则将请求排队,或者ide_start_request直接发送到磁盘。都需要等待请求完成,调用线程进入休眠状态。ide start request: 发送请求到磁盘,in/out 指令被调用来对磁盘进行读写,一开始需要调用ide_wait_ready()ide_wait_ready:确保设备在接受请求之前处于就绪状态。ide_intr: 当中断发生时被调用,如果是读请求,则从设备中读取数据,并唤醒等待该 I/O 操作的进程继续执行。如果 I/O 队列中还有别的请求,则开始执行下一个ide_start_request()
static int ide_wait_ready() {
while (((int r = inb(0x1f7)) & IDE_BSY) || !(r & IDE_DRDY));
// loop until drive isn’t busy
}
static void ide_start_request(struct buf *b) {
ide_wait_ready();
outb(0x3f6, 0); // generate interrupt
outb(0x1f2, 1); // how many sectors?
outb(0x1f3, b->sector & 0xff); // LBA goes here ...
outb(0x1f4, (b->sector >> 8) & 0xff); // ... and here
outb(0x1f5, (b->sector >> 16) & 0xff); // ... and here!
outb(0x1f6, 0xe0 | ((b->dev&1)<<4) | ((b->sector>>24)&0x0f));
if(b->flags & B_DIRTY){
outb(0x1f7, IDE_CMD_WRITE); // this is a WRITE
outsl(0x1f0, b->data, 512/4); // transfer data too!
} else {
outb(0x1f7, IDE_CMD_READ); // this is a READ (no data)
}
}
void ide_rw(struct buf *b) {
acquire(&ide_lock);
for (struct buf **pp = &ide_queue; *pp; pp=&(*pp)->qnext);
// walk queue
*pp = b; // add request to end
if (ide_queue == b) // if q is empty
ide_start_request(b); // send req to disk
while ((b->flags & (B_VALID|B_DIRTY)) != B_VALID)
sleep(b, &ide_lock); // wait for completion
release(&ide_lock);
}
void ide_intr() {
struct buf *b;
acquire(&ide_lock);
if (!(b->flags & B_DIRTY) && ide_wait_ready() >= 0)
insl(0x1f0, b->data, 512/4); // if READ: get data
b->flags |= B_VALID;
b->flags &= ˜B_DIRTY;
wakeup(b); // wake waiting process
if ((ide_queue = b->qnext) != 0) // start next request
ide_start_request(ide_queue); // (if one exists)
release(&ide_lock);
}
