是否引入了新的读放大问题?存在,但较小的读放大带来的是整体性能的提升。由于 LSM Tree 中存储的数据量显著减少,相比于传统的从 LSM Tree 中读取 KV 对的数据信息,WiscKey 这种先读取 Key,再根据对应的地址去读 Value 对应的读取的速度在数据量相对较大的情况下是更快的。除此以外还可以针对数据量较小的 LSM Tree 使用内存缓存来加速对 Key 的检索。
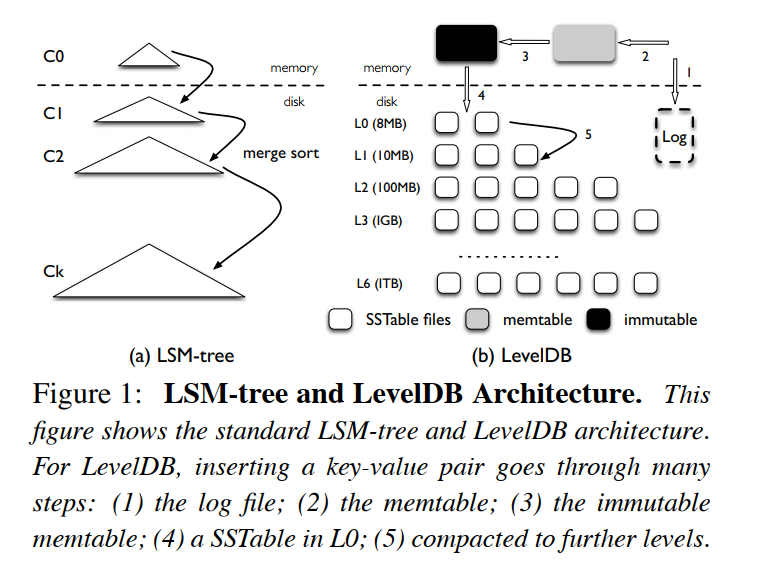
架构和流程
组成:
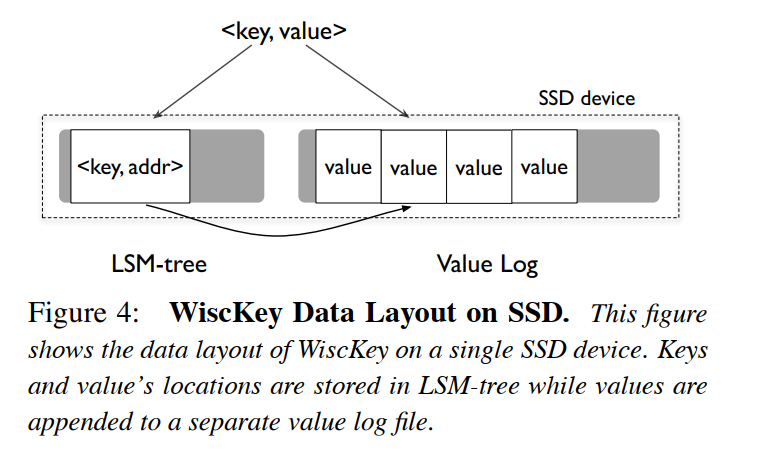
LSM Tree - 存储 <Key, Address>
Value Log File - 存储 Value
流程
Insert:首先将 Value 追加写到 Value Log 中,然后将 Key 和 Value 对应的地址信息(地址信息主要包含对应的偏移量 vlog-offset 和 Value 的数据大小 value-size)组成的键值对插入到 LSM Tree 中
Delete:直接在 LSM Tree 中删除对应的 Key,不涉及 Value Log,对应的 Value 由垃圾回收机制统一地进行处理。
Point/Range Query: 先去 LSM Tree 中检索对应的 Key,拿到其对应的 Value Address 信息后对应地从 Value Log File 中去读取对应的 Value。
KV 分离对应的挑战(存在的问题)
并行范围查询 Parallel Range Query
Range Query 的重要性以及应用场景不再赘述,简单介绍 LevelDB 为了实现 Range Qurey 对外提供的 API。
Seek(key), Next(), Prev(), Key(), Value()
首先 seek 到起始 Key,然后调用 Next 或者 Prev 一个接一个地检索 Key,真正需要获取该指针对应的 Key 时调用 Key(), Value 则调用 Value()
存在的问题
传统的 LSM Tree 如 LevelDB,在进行 Range Query 操作时,由于其 KV 对是顺序地保存在 LSM Tree 中的,故可以进行顺序的 IO 就可以读取出来;但是针对 WiscKey 将 KV 分离了的方案,不可避免地就造成了对 Value 的随机写问题。
实现方式:针对 Range Qurey 的操作, 一旦请求了一个连续的键-值对序列,WiscKey 就开始按顺序从 LSM 树中读取大量的后续键,将对应的 Key Address 信息插入到一个队列中,然后启动多线程去从该队列中获取地址信息再并发地去 Value Log File 中读取对应的 Value 信息。
垃圾回收机制的实现 Garbage Collection
传统的 LSM Tree 中垃圾回收的方式是针对要删除的数据或者过时的数据进行标记,在执行压缩过程中对垃圾数据进行回收。
由于 WiscKey 没有对 Value 的压缩过程,所以需要单独设计一套垃圾回收的机制对 Value 进行垃圾回收。
垃圾回收实现思路
最简单的方式(最直接的方式):扫描 LSM Tree 中存储的所有有效 Key 对应的有效地址信息,将 Value Log 文件中存储的无对应 Key 的 Value 标记为了垃圾数据,再进行回收
更高效的方式:调整 WiscKey 的数据布局。
实现方式
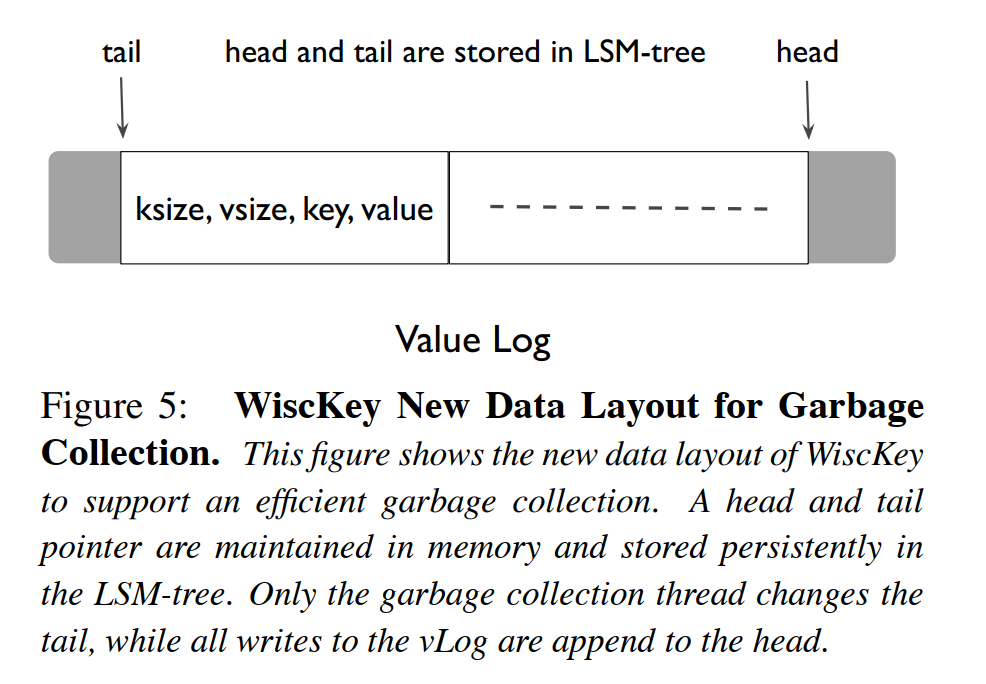
数据布局:在 Value Log 中除了存取 Value 对应的信息外,同时存取 Key 对应的数据信息。数据单元成为 Tuple,其中包含 key size, value size, key, value。
设置头尾指针来进行垃圾回收操作,尾指针只会在垃圾回收时被移动,头指针只会在有数据追加写入到 Value Log File 中时才会移动。
垃圾回收的过程:WiscKey 从尾指针指向的位置读取一个 Chunk 大小的 KV 键值对的集合,大约数 MB,通过查询 LSM Tree 中是否有该集合内的键信息来判断当前 Value 是否有被覆盖写或者删除。判断为有效状态的 Value 将追加写到头指针指向的位置,然后释放尾指针对应的一个 Chunk 的存储空间,并更新尾指针的位置。
垃圾回收过程中一致性的保证
为了避免出现数据丢失(如在垃圾回收过程中发生了故障),需要保证在释放对应的存储空间之前追加写入的新的有效 Value 和新的尾指针持久化到了设备上。
WiscKey 实现垃圾回收过程中的一致性的步骤:
追加写入新的 Value 值到 Value Log 中
调用 fsync(),将 Value Log File 进行同步
同步地将新的 Value 地址和尾指针地址写入到 LSM Tree 中。(尾指针的存储形式为 Key:tail - Value:tail-vlog-offset)
最后进行相应的垃圾回收,释放对应的空间
垃圾回收的时机
WiscKey 可以根据实际需求进行配置,主要有以下两种方式:
周期性地进行垃圾回收
到达一定阈值时触发垃圾回收
崩溃一致性的保证 Crash Consistency
传统的 LSM Tree 的崩溃一致性保证使用了 WAL 来保证 KV 对的原子性插入,恢复时也能严格按照插入的顺序进行恢复,但 LSM Tree 由于采用了 KV 分离的方式使得一致性的保证机制实现变得更为复杂。
WiscKey 一致性机制的实现利用了文件系统的一个特性:即一旦出现了系统故障,发生数据丢失时,针对顺序写入的数据序列 X1 X2 X3...,一旦 X1 丢失,那么 X1 之后的数据都将丢失。具体的讲解请参考 OSDI 14 的一篇文章 All File Systems Are Not Created Equal: On the Complexity of Crafting Crash-Consistent Applications。
实现方式/处理流程
由于数据造成的数据丢失,如果未能在 LSM Tree 中找到对应的丢失的 Key,那么处理方式和传统的 LSM Tree 一样,返回空或者 Key 不存在。(即便其 Value 已经写入到了 Vlog 文件中,会对其进行垃圾回收)
如果 LSM Tree 中存在要查找的 Key,那么将会比传统的 LSM Tree 多一次校验的操作,该校验操作主要校验从 LSM Tree 中查询到的 Value 地址信息是否在有效的 Vlog File 的范围内;其次校验该地址对应的 Value 上存取的 Key 和要查询的 Key 是否一致。如果校验失败,则对应地删除 LSM Tree 中的 Key,并返回给客户端 Key Not Found。
对 Vlog 上查询到的 Value 校验,可以利用对应的 Key 信息,也可以引入 Magic Number 或者校验和的机制让校验更简单。
当用户请求同步插入数据时,LSM Tree 还保证了键值对在系统崩溃后的持久性;而 WiscKey 也可以通过在向 LSM Tree 中同步插入对应的 Key 之前将 Vlog 上的数据同步刷回来实现同步的数据插入。
优化方案
KV 分离对应地引发了新的思考,关于 Value Log 的写操作和原有 LSM Tree Log 写操作,优化方案将主要针对提升相应的日志写的性能展开。
Value-Log Write Buffer
针对每次对 Value Log 的写入操作,都将进行系统调用 write(),对于某些插入敏感型的负载,会对文件系统发起大量的小写操作,针对不同的设备的带宽,选择合适大小的写入单元就显得十分必要。