- 该篇文章原文是两年一届的 SOSP2019 《File Systems Unit as Distributed Storage:Lessons from 10 Years of Ceph Evolution》
- 该篇文章原文是两年一届的 SOSP2019 《File Systems Unit as Distributed Storage:Lessons from 10 Years of Ceph Evolution》
- 由于项目涉及到了 Ceph 相关,以及课程选择了分布式存储系统 Ceph 的后端存储引擎研究,故拜读了这篇 Paper
- 这篇讲主要总结 Ceph 后端存储引擎的发展历程,以及各种后端存储的优劣,得出如标题的结论
- 还将参考 MSST17 上的一篇文章 《Understanding Write Behaviors of Storage Backends in Ceph Object Store》
- 关于 Ceph 的其他组件和基础介绍,请参考 Ceph 相关博文,此处之总结后端存储引擎相关。
Abstract
- 过去十年,Ceph 同其他分布式存储系统一样,没能落俗,将本地文件系统作为分布式系统的后端存储,之所以文件存储能在分布式后端存储中大行其道,是因为文件系统的易用性以及技术和代码发展相对成熟。但从 Ceph 发展的经验来看,文件系统带来了极大的开销。
- 开发零开销的事务机制极具挑战性
- 元数据在本地级别的性能会显著提高!严重影响在分布式的层次的性能表现
- 支持新兴存储硬件的速度极其缓慢
- Ceph 开发了新的基于裸存储设备的后端存储引擎 BlueStore 来解决上述问题,BlueStore 现在也已经成了绝大多数用户的使用方案。BlueStore 在用户态运行并完全控制 IO 栈,让元数据更节省空间,并引入了数据校验和,实现了编码数据的快速覆盖写和内联压缩,降低了性能的多变性,避免了本地文件系统的性能缺陷,同时对新兴存储器件提供了较好的支持。
Introduction
文件系统的优劣
- 文件系统作为分布式存储系统的后端存储引擎的优势:
- 能够将数据持久性和数据块的分配等复杂问题委托给久经历练且性能较好的文件系统处理;
- 文件系统提供了类 POSIX 的接口和抽象(文件和目录)
- 文件系统支持一些标准工具的使用(ls,find),较好地查找磁盘上的内容
- 文件系统作为后端存储引擎的局限:
- 文件系统带来的性能损失;
- 文件系统对于现如今多样化的存储器件缺乏支持
BlueStore 诞生的原因
基于现有的文件系统难以实现高效的事务机制
- 虽然已经有大量工作致力于向文件系统中引入事务的机制,但往往由于其高额的开销或者功能的局限性或者接口本身以及实现的复杂度,导致这些方法很难投入实际应用。
- Ceph 采用了一种方式:利用文件系统有限的内部事务机制,在用户态实现 WAL;或者采用事务型的 KV 存储机制。但在性能上的表现都差强人意
本地文件系统的元数据性能可能严重影响分布式系统的整体性能
- Ceph 面对的一个很大的挑战就是“如何快速地枚举文件夹中数百万项的内容,如何保证返回的结果有序”。
- 基于 Btrfs 和 XFS 的后端存储往往都会有这样的问题,同时用于分配元数据负载的目录分割操作与系统策略其实是有一定冲突的,整个系统的性能会受到元数据性能的影响。
新型存储器件向文件系统提出了挑战
- 文件系统日趋成熟带来的影响就是显得更加的保守和死板,不能较好地适配现在很多摒弃了块接口的新型存储器件。面向数据中心的新型存储器件往往都需要在原有应用程序接口层面做较大的修改。
- 诸如为了提升容量, HDD 正在向 SMR 过渡,同时支持 Zone Interface;为了减小 SSD 中由于 FTL 造成的 IO 尾延迟,引入了 Zoned Namespace SSD 技术,支持 Zone Interface;云计算和云存储供应商也在调整他们的软件栈来适配 Zone 设备。分布式文件系统在这方面目前缺乏较好的支持。
BlueStore 的新特性
- 使用 KV 存储低级别的文件系统元数据(如bitmap),从而避免磁盘格式的变化,同时减小了实现的复杂度;
- 通过精细的接口设计,优化克隆操作并减小范围引用计数的开销;
- 引入自定义的 BlueFS 文件系统使 RocksDB 运行的更快,引入一个空间分配器,使得磁盘上每 1 TB 的数据只需要使用约 35MB 的内存;
Background
分布式存储系统后端存储概要
- 分布式存储系统对于后端存储的共同需求:
- 高效的事务机制
- 快速的元数据操作
- (可选)对新兴存储器件的支持
事务机制
- 后端存储支持事务相关的操作的话将会简化强一致性的实现过程
- 如果底层文件烯烃支持事务操作的话,作为后端存储也能无缝地提供事务的相关功能,但大多数文件系统实现了 POSIX 标准,就缺乏了事务的概念。
- 分布式文件系统的开发者只好采用低效或者复杂的机制来实现事务,例如在文件系统的基础上实现 WAL,或者利用文件系统内部的事务机制。
元数据管理
- 作为分布式文件系统中的一大痛点,主要表现为不能较好地枚举大目录中的内容或者无法较好地处理大规模的小文件,该类场景下对于无论是集中式还是分布式的元数据管理都严重影响性能上的表现。
- 为了解决这个问题,开发者采用了诸如 元数据缓存,使用 HASH 进行深度的目录层次结构排序,或者使用自定义开发的数据库来题文件系统进行管理。
新型硬件的支持
- SMR 提升 HDD 容量大于 25%,且预计 2023年将有超过半数的数据中心使用 SMR
- ZNS SSDs 摒弃了 FTL,不会再收到不可控的垃圾回收延迟的影响,减小了 IO 尾延迟。
Ceph 架构
- 不再赘述,请参考其他博文。
Ceph 后端存储的演变

FileStore
- Object Collection 对应的为 目录;Object Data 对应地存储在文件上;Object Attributes 一开始存储在 POSIX 扩展文件属性(xattrs)中,但如果超过xattrs的限制将移植到 LevelDB
- Btrfs 实现了事务机制,数据去重,校验和和透明压缩,但受到数据和元数据碎片的严重影响。
- XFS 具有更好的扩展性和更为高效的元数据管理,但仍然受元数据的碎片影响,且无法发挥硬件的最大性能,由于自身缺乏事务的支持,在用户态实现 WAL 又严重限制了 Ceph 的性能;除此以外,不支持 CoW,导致克隆操作被过度使用,也带了较大的开销。
NewStore
- 一开始是为了解决在文件系统作为后端过程中存在的元数据管理问题,NewStore 将对象元数据存储在 RocksDB(有序的KV存储) 中,对象数据依然保存在文件中。RocksDB 也被用于实现 WAL;
- 用文件的形式存储数据,并在日志文件系统上运行 RocksDB 也相应地引入了较高的一致性开销。
- 于是产生了 BlueStore。
Building Storage Backends on Local File Systems is Hard
- 文件系统不适用于作为分布式存储系统后端,文件系统面临以下几个方面的挑战:
高效的事务机制
- 事务的作用:通过将一系列操作封装成一个单独的原子工作单元来简化应用程序的开发。
- 基于文件系统实现事务的机制大致可以通过以下三种方式:
- 利用文件系统内部的事务机制
- 在用户态实现 WAL 机制
- 使用具有事务功能的 KV 数据库作为 WAL
文件系统内部的事务机制
- 许多文件系统实现了内核态的事务机制,以便原子性地执行复合操作。由于该种事务框架是为了保证内部文件系统的一致性的,功能上存在一定的限制,对于用户而言是不可用的,譬如缺乏回滚的机制,因为在文件系统内部为了保证一致性没有必要使用回滚机制。
- Btrfs 通过一组系统调用将操作原子性地从用户态的操作应用到文件系统内部的事务机制,从而向用户提供事务机制。起初基于 Btrfs 的 FileStore 引擎就依赖了这些系统调用,但仍然缺乏回滚的机制。对于一些在事务执行过程中的致命错误,如软件 CRASH 或者被 KILL,Btrfs将提交部分事务出现不一致的状态。
- Ceph 最终通过引入一个单独的系统调用(transaction system calls)来指定整个事务,并使用快照来实现回滚机制。但事实证明此种方式造成的开销很大,所以 Btrfs 的作者在后来决定标识该系统调用为过期。
- 经验表明,通过使用文件系统内部的事务机制来提供用户态的事务功能是很困难的。
用户态实现 WAL
- 通过在用户态实现逻辑上的 WAL 能够提供对应的事务机制,但同样也会引入以下几个重要的问题:
- Slow Read-Mddify-Write 缓慢的读-修改-写操作
- Non-Idempotent Operations 非幂等性操作
- Double Writes 双写问题
Slow Read-Modify-Write
- 首先明确什么是 Read-Modify-Write?RMW 操作在 Ceph 系统内的表现其实就是在准备生成一个事务的时候,往往需要依赖前一个事务,这时候需要读取前一个事务的数据,然后对应的修改当前的事务数据,再把修改过后的事务数据最终写入进行提交。
- 用户态的 WAL 的实现是如何提供事务机制的呢?首先,将事务的全部数据序列化并写入到 log 中去;然后调用 fsync 操作将事务提交到磁盘;最后将事务中执行的具体操作应用到文件系统中。
- 为什么RMW会比较慢?因为事务的机制表明了前一个事务在事务进行第三步操作之前是无法被后一个事务读取的,也就是说只有在前一个事务的操作真正应用到文件系统上之后才能读取该事务的数据。所以每一次 RMW 操作都需要等待一次完整的 WAL 提交,将受到 WAL 延迟的影响,无法进行高效的流水线操作。
Non-Idempotent Operations
- 幂等性操作是指在 WAL 的机制下,当系统 CRASH 之后需要重放 WAL 的记录来恢复数据,此时可能是非幂等操作。
- 由于 WAL 日志是定期进行修改的,那么就会存在一个时间窗口,该时间窗口内事务已经提交且应用到了文件系统中,但仍然保留在 WAL 日志中。
- 考虑以下场景:
- 事务A包含以下三个操作,如果第二个操作之后 CRASH,回放 WAL 日志,b 的值将会被错误地修改
1. clone a->b 2. updata a 3. update c- 事务B包含以下四个操作,如果 CRASH 发生在第三个操作完成之后,回放 WAL 将错误地修改 a
1. update b 2. rename b->c 3. rename a->b 4. update d - 为了解决非幂等性的问题。Btrfs FileStore 通过定期进行持久化快照操作,并在 WAL 日志中标记快照的时间;恢复时将基于最近的一次快照,然后将 WAL 日志中对应该快照的标记之后的操作进行回放。
- 使用 XFS 代替 Btrfs 之后,由于缺乏有效的快照机制,造成了两个问题:
- XFS 中只支持开销特别大的 sync 系统调用。会把所有文件系统数据同步到所有驱动设备上,后来出现了 syncfs 系统调用解决了该问题。
- XFS 不能将文件系统恢复到某一个具体的状态再回放 WAL 中的操作。所以需要引入 哨兵(序列号)机制来避免非幂等操作的,但验证序列号的正确性是一项非常复杂的操作。
Double Writes
- 使用 WAL 日志机制对应的引入了双写问题,一次需要写入 WAL ,后一次需要写入文件系统,平分了磁盘的带宽,该种方式又称作 Data Journaling。所以很多文件熊只是在 WAL 中记录元数据的变更信息,在 CRASH 时允许数据丢失,从而避免数据的双写问题,该种方式又称作 Metadata Journaling。
- Data Journaling 和 Metadata Journaling 的区别在于是否将 user data 的数据写入到日志文件中,以及 Metadata Journaling 的实现方式时先写入用户数据到文件系统,再写元数据日志,Data Journaling 是把所有数据先写入日志提交之后,再写入文件系统。
- 参考链接:日志文件系统是怎样工作的
使用键值存储作为 WAL
- NewStore 存储引擎中,元数据被保存在有序的键值存储 RocksDB 中,对象的数据仍然以文件的形式保存在文件系统中,因此元数据的相关操作可以原子性地执行,数据的覆盖些则是先记录到 RocksDB,然后执行写操作。
- KV 存储结局了逻辑 WAL 存在的三个问题,但也引入了新的一致性开销。
如何解决Logical WAL存在的问题
- KV 存储提供的接口允许读取对象的最新状态值,不用等待事务的提交。
- 避免了非幂等操作重放的问题,因为此类操作的读端是在事务准备时解决的。例如 clone a->b 操作的处理,如果对象较小,将被复制并插入到事务中,如果对象较大,将会使用 CoW 机制。
- 避免了新对象的双写问题,因为对象命名空间于文件系统状态实现了解耦。新对象的数据,先写入文件系统,然后创建一个对应的应用并原子性地添加到数据库中去。
键值存储带来的弊端
- RocksDB 和 日志文件系统的结合引入了较高的一致性开销,类似于 journaling of journal 问题。
- 在 NewStore 中创建一个对象的步骤:
- 1.数据写入到一个文件,调用 fsync
- 2.将对象元数据同步写入到 RocksDB,同样调用 fsync
- 因此对于 KV 存储,大约需要执行两次 fsync,而每一次 fsync 命令又会发起一次 FLUSH CACHE 的命令,但又因为是基于日志型文件系统的操作,每次 fsync 调用会额外触发一次对日志数据的 FLUSH CACHE命令。故一个对象的创建需要触发四次 FLUSH。
- 使用 Benchmark 模拟存储后端创建大量对象进行测试,循环创建 数据大小为0.5MiB,元数据大小为 500bytes 的对象,一种基于 XFS 进行创建,一种基于裸盘和基于裸盘和预先分配的WAL文件构建的RocksDB。
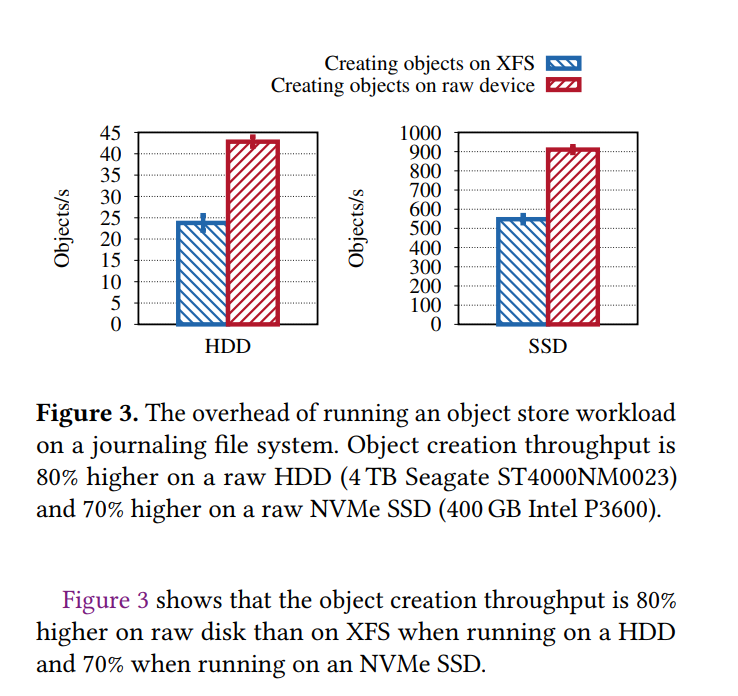
快速的元数据操作
- Ceph 使用 FileStore 作为后端面临的问题也包含了大目录结构的枚举操作较慢以及返回的结果无序。
存在的问题
什么时候进行枚举操作
- 针对 Ceph 中的 Scrubbing、Recovery 以及 RADOS 提供的 List 接口操作,都需要进行目录内容的枚举。
为什么结果无序
- RADOS中的对象根据其名称的散列映射到PG,并按散列顺序枚举。
FileStore 的解决方案
- FileStore遵循一种通常采用的解决慢枚举问题的解决方案:创建具有大扇出的目录层次结构,将对象分布在目录中,然后在读取后对所选目录的内容进行排序
- 为了快速地对它们进行排序,并限制潜在的stat调用的开销,在目录中的条目数量增长时对它们进行拆分,从而使目录保持较小(只有几百个条目)
拆分条目存在的问题
- 随着规模的的增大,拆分操作将会是一个高开销的操作
- 一次处理数百万个inode降低了dentry缓存的可靠性,导致许多小的I/Os到磁盘。
- XFS将子目录放在不同的分配组中,以确保有空间让将来的目录条目紧密地放在一起
- 随着对象数量的增长,目录内容会分散,由于查找而导致分割操作需要更长的时间。因此,当所有Ceph OSDs开始一致地分裂时,性能就会受到影响。
- 关于 Split 操作对磁盘吞吐量的影响的测试数据,请参见原文。
对新型存储器件的支持
- HDD 逐渐转向 SMR,为了利用额外的容量并同时实现可预测的性能,应该使用具有向后兼容 zone 接口的主机管理 SMR 驱动器。另一方面,zone接口将磁盘管理为256个必须按顺序写入的MiB区域的序列,这鼓励了一种 日志结构的、CoW 的设计,与大多数成熟的系统所遵循的 Overwrite 设计是完全相反的。
- SSD 也逐渐转变为 OpenChannel SSD,该类 SSD 省略了 FTL,直接由 host 来管理裸盘资源,但由于缺乏统一的标准,各大厂商分别做了自己的实现,为此,主流厂商引入了一种新的 NVMe 标准 ZNS(Zoned Namespaces),重新定定义了 OpenChannel SSD的标准。消除 FTL 带来了很多优势:减小了写放大问题,改善了延迟异常和吞吐量,一定程度上也减小了成本。
其他挑战
页缓存中的 Write-Back 机制
- 导致基于文件系统的存储后端出现高差异请求延迟的原因之一是操作系统页面缓存。大多数操作系统使用回写 write-back 策略来实现页面缓存,在这种策略中,一旦数据被存入内存,相应的页面被标记为脏,写操作就完成了。在几乎没有I/O活动的系统上,脏页定期写回磁盘,从而同步磁盘上和内存中的数据副本。另一方面,在繁忙的系统中,回写行为由一组复杂的策略控制,这些策略可以在任意时间触发写操作。
- 尽管写回策略为系统负载较轻的用户生成响应系统,但它会使繁忙的存储后端实现可预测的延迟变得复杂。即使定期使用fsync, FileStore也无法限制延迟的inode元数据回写的数量,从而导致性能不一致
无法利用 CoW 高效地实现一些操作
- 针对部分操作,例如快照,利用 CoW 可以十分高效地进行实现。不支持 CoW,导致在FileStore中快照和覆盖擦除编码数据的成本高得令人望而却步,因为需要对对象进行全量拷贝
- 但如果引入了 CoW 机制,文件系统也会存在其他缺陷,例如 Btrfs 的碎片问题。
BlueStore - 全新的后端存储引擎
- BlueStore 主要设计目的就是为了解决本地文件系统所面临的诸多问题。其中几个主要目标为:
- 快速的元数据操作
- 写入对象时无一致性开销
- 支持 CoW clone 操作
- 没有日志带来的双写问题
- 为 HDD 和 SSD 做 IO 整形优化
Architecture

- BlueStore 直接运行在裸设备上,其中由内置的 Space Allocator 决定新数据的存放位置,内部的元数据信息和对象的元数据信息存储在 RocksDB 中,RocksDB 又运行在定制化的小型文件系统 BlueFS 上。
BlueFS and RocksDB
- BlueStore 通过将元数据保存在 RocksDB 中来实现快速的元数据管理;通过直接将数据写入裸盘,实现只执行一次 FLUSH,重用 WAL 文件作为环形缓冲来构建 RocksDB 实现元数据写操作也只需执行一次 FLUSH。
BlueFS
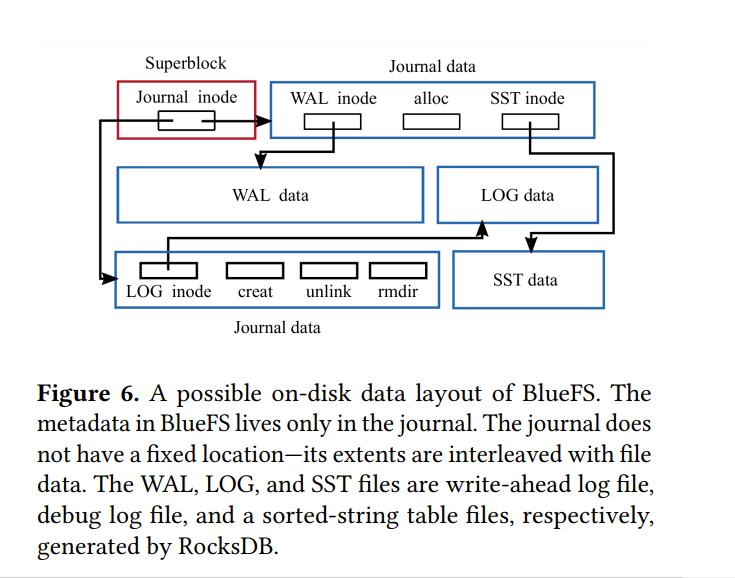
Metadata Organization
- RocksDB 中保留有多个 Namespaces,每一个 Namespace 存储不同种类的元数据。例如对象元数据存储在 O Namespace中,块分配元数据存储在 B Namespace中,集合元数据存储在 C Namespace中,每一个对象集合映射到 Ceph 中的一个 PG 并代表一个存储池 Namespace 的分片。集合名通常也包括存储池的标识符以及该集合中对象所共享的前缀字符串。
- 例如一个 KV 对 C12.e4-6 标识了在 12 号存储池中的 HASH 值以 e4 为起始的集合,使用 6 个有效位。故对象O12.e532属于该集合,对象O12.e832则不属于。可以通过调整有效位数来对集合进行拆分。
- 在Ceph的OSD集群中,往往需要进行数据均衡分布的操作。相比于 FileStore 基于目录 rename 的拆分,此种方式开销更小。
Data Path and Space Allocation
- BlueStore 支持 CoW 机制,针对写入的数据(大小大于最小分配的空间大小 HDD 64KiB,SSD 16KiB)先写入预先分配的区域,数据持久化之后,再向 RocksDB 中插入元数据信息。该机制提供了高效的克隆操作,也同时避免了双写问题,针对 HDD 和 SSD 分别进行了优化(最小分配空间大小的不同)
Space Allocator
- BlueStore 使用 FreeList Manager 和 Allocator 来进行空间分配。
FreeList Manager
- FreeList manager 负责表示磁盘中已经持久化的区域,同其他元数据一样保存在 RocksDB,Manager 有两种实现:
- 一种是 将磁盘中已经使用的区域以键值对的形式表示,同时存储偏移量和长度信息。该种方式实现的坏处是事务必须序列化:为了避免FreeList不一致的情况,在插入新的 Key 之前需要删除旧的 Key。
- 一种是基于位图进行实现,分配和回收操作都使用 RocksDB 合并操作来将相关数据块进行位翻转,消除排序的约束,且 RocksDB 的合并操作执行了一个延迟的原子读-修改-写操作,该操作不改变语义,并且避免了点查询的成本
Allocator
- Allocator 主要负责为新数据分配对应的空间,它将空闲列表的副本保存在内存中,并在进行分配时通知FreeList manager。
- Allocator 对应也有两种实现:
- 第一个实现是基于区段的,将空闲区段划分为两个power-of- size的区域。随着磁盘使用量的增加,这种设计容易产生碎片。
- 第二个实现使用索引层次结构来跟踪块的整个区域。通过分别查询较高和较低的索引,可以方便地找到较大和较小的区段。这个实现的单位内存使用为35MiB/TB
Cache
- 由于 BlueStore 实现在用户态,且以 Direct IO的模式访问磁盘,无法省略操作系统页缓存,所以 BlueStore 使用2Q算法实现了自己的写穿缓存
- 缓存实现被分片以实现并行。它使用与Ceph OSD相同的分片方案
它将请求分片到跨多个核心的集合。
BlueStore 引入的新特性
节省空间的校验和
为什么需要校验和?
- 尽管在 Ceph 中有 Scrub/Deep Scrub 操作来扫描副本间数据的一致性,当发现不一致时仍然很难判断哪一个副本被损坏了。因此,校验和就显得不可或缺了,特别是在分布式存储系统中处理经常发生位翻转的 PB 级别的数据时。
文件系统校验和
- 大多数文件系统不支持校验和,部分支持校验和的文件系统,如 Btrfs,每一个数据块计算出的校验和超过 4KiB,10TB 的数据校验和数据的大小将超过 10GB,此时将很难将校验和缓存在内存中进行快速的验证。
BlueStore 校验和
- 在分布式文件系统中的大多数数据位只读数据,所以可以以更大的规模去做校验和相关的操作。
- BlueStore 为每次写操作计算校验和,为每次读操作验证校验和,也支持多种校验和算法。CRC32c 由于其在 x86 和 ARM 架构上都有比较好的优化被用作默认校验和算法,在检测随机Bit位错误时也很高效。
- 由于BlueStore 完全控制了整个 IO 栈,BlueStore 可以根据 IO 的情况决定计算校验和的大小。
纠删码数据的覆盖写
- Ceph 支持使用纠删码存储池来保证数据的一致性,但是在 BlueStore 之前,EC pools 只是支持对象的追加写和删除操作,覆盖写操作效率太低可能导致系统不可用,所以只有 RGW 模块能够使用 EC 池,RBD 和 CephFS 都使用了多副本存储池
- 为了避免多步骤写可能造成的数据不一致问题,Ceph 在 EC 池中使用了两阶段提交算法来进行覆盖写。
- 所有存储EC对象块的osd都会复制该块,以便在发生故障时可以回滚。
- 在所有osd接收到新内容并覆盖其块之后,旧的副本将被丢弃
- 和 基于 XFS 的FileStore 的区别在于,BlueStore 的 CoW 机制避免了第一步全量物理拷贝,FileStore 需要做全量物理拷贝。
透明压缩
- 针对多副本场景,BlueStore 实现了数据被存储之前自动进行透明压缩。
- 当压缩的对象大大小超过 128KiB chunks 时压缩就能起到很好的效果,所以如果对象被完整地写入,压缩就能发挥很大的效益。
- 对于部分写操作,BlueStore 将新数据放置到一个单独的区域并更新元数据然后指向它,当该对象被多次覆盖写之后碎片化严重,BlueStore 通过读取和重写来压缩对象。
新型接口的支持
- 相比于传统的本地文件系统缺乏对新型存储器件的支持,BlueStore 不再拘泥于基于块进行设计,现有的 BlueStore 运行的 BlueFS 和 RocksDB 已经可以在 SMR 盘的基础上运行。同时也在位新型 NVMe 接口的设备开发新的存储引擎。
Evaluation
- 测试主要将 FileStore 和 BlueStore 进行性能上的对比。将比较 RADOS 的对象写的吞吐量,端对端的吞吐量(基于RBD的随机写、顺序写、顺序读)以及基于EC池构建的 RBD 的随机写吞吐量。
实验环境
- Cisco Nexus 3264-Q 64-port QSFP+ 40GbE
switch - 每个节点:
- 16-core Intel E5-2698Bv3 Xeon 2GHz CPU
- 64GiB RAM
- 400GB Intel P3600 NVMe SSD
- 4TB 7200RPM Seagate ST4000NM0023 HDD
- a Mellanox MCX314A-BCCT 40GbE NIC
- Linux Kernel 4.15 on Ubuntu 18.04
- Ceph Luminous(v12.2.11)
Bare RADOS Benchmark

RADOS Block Device Benchmarks

EC Pool RBD
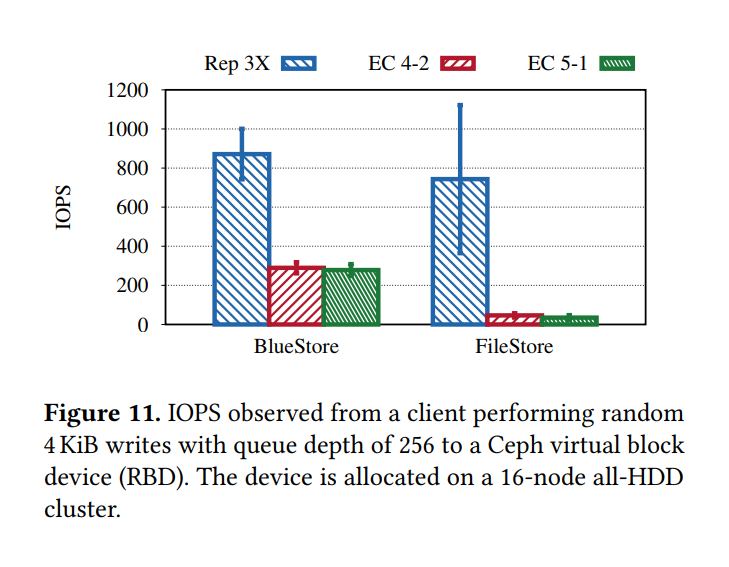
Challenges of Building Effcient Storage Backends on Raw Storage
缓存大小的调整和写回策略
- 文件系统继承了操作系统页缓存的优势,会根据应用程序的使用情况动态调整缓存的大小;而对于类似于 BlueStore 穿过内核的存储后端需要自己实现类似的机制。
- BlueStore 中需要自己手动设置缓存大小相关的参数,如何在用户态构建一个如操作系统页缓存动态调整大小的机制时很多存储系统都面临的问题,如 PostgreSQl,RocksDB。同时面对已经出现的 NVMe SSD,缓存需要更加高效,才能减小 SSD 的写负载,同时也是当前页缓存面临的问题。
KV 存储的效率问题
- Ceph 的经验表明把所有元数据给移植到有序的 KV 存储(如 RocksDB)上能够显著提高元数据操作的性能,然而同时也发现嵌入 RocksDB 带来的一些问题:
- 在 OSD 节点上使用 NVMe SSD 时,RocksDB 的压缩机制和严峻的写放大问题已经成为了主要的性能限制;
- 由于RockDB被视为一个黑盒,因此数据被序列化,并在其中来回复制,消耗数据 CPU 时间
- RocksDB 有自己的线程模型,这限制了自定义分片的能力。
CPU 和 内存的效率问题
- Ceph 中复杂的数据结构,且生命周期较长,采用默认的布局一定程度上会造成内存的浪费。因为现代编译器在内存中对齐和填充基本数据类型,这样CPU就可以方便地获取数据,从而提高了性能。跨越了内核的存储后端控制几乎机器的所有的内存。
- 如上提到的 KV 存储的问题,在使用 NVMe SSD 时,其工作负载会被 CPU 限制,涉及到大量的序列化和反序列化操作。故 Ceph 开发团队试图减小 CPU 的消耗,通过减小序列化和反序列化数据的大小,尝试使用 SeaStar 框架的共享模型来避免由于锁导致的上下文切换。
