- Distributed Storage System Basic Serie 1 - Flavor of IO.
- Distributed Storage System Basic Serie 1 - Flavor of IO.
- Here is the basic of linux io and try to compare io operations.
- The content is based on the On Disk IO - Flavors of IO and I will present my understanding.
- Only summary, not details.
Disk I/O
Flavors of I/O
- Syscalls: open, write, read, fsync, sync, close
- System I/O can be defined as any operation that writes data into the storage layers accessible only to the kernel's address space via the kernel's system call interface.
- Standard IO: fopen, fwrite, fread, fflush, fclose
- Usually provided by library
- Writes using these functions may not result in system calls, meaning that the data still lives in buffers in the application's address space after making such a function call.
- Vectored IO: writev, readv
- Memory mapped IO: open, mmap, msync, munmap
- similar to the system I/O
- Files are still opened and closed using the same interfaces, but access to the file data is performed by mapping that data into the process' address space, and then performing memory read and write operations as you would with any other application buffer.
I/O API
System I/O
- Open:
open(),creat() - Write:
write(),aio_write(),pwrite(),pwritev() - Sync:
fsync(),sync() - Close:
close()
Stream I/O
-
Open:
fopen(),fdopen(),freopen() -
Write:
fwrite(),fputc(),fputs(),putc(),putchar(),puts() -
Sync:
fflush(), followed byfsync()orsync()fflush()flush the data in library cache to the disk (actual page cache)fsync()flush the data in page cache to disks and metedata to disks. (Usually contains 2 operations: data and metedata)fdatasync()flush the data definitely and flush the metedata if necessary.(Such as the file size changed.)
-
Close:
fclose()
Memory mapped IO
- Open:
open(),creat() - Map:
mmap() - Write:
memcpy(),memmove(),read(), or any other routine that writes to application memory - Sync:
msync() - Unmap:
munmap() - Close:
close()
Sector/Block/Page
- Sector is the smallest unit of data transfer for block device. And size is always 512 bytes in most disk devices.
- The smallest addressable unit of File System is block. Block is a group of multiple adjacent sectors requested by a device driver. 512/1024/2048/4096 bytes.
- Virtual Memory works with pages, which map to filesystem blocks. Typical page size is 4096 bytes. (Usually IO is done through the Virtual Memory, which caches requested filesystem blocks in memory and serves as a buffer for intermediate operations)
- Virtual Memory pages map to Filesystem blocks, which map to Block Device sectors.
Standard IO
- When reading the data, Page Cache is addressed first. If the data is absent, the Page Fault is triggered and contents are paged in. (This means that reads, performed against the currently unmapped area will take longer)
- During writes, buffer contents are first written to Page Cache. ( This means that data does not reach the disk right away. The actual hardware write is done when Kernel decides it’s time to perform a writeback of the dirty page)
- Standard IO takes a user space buffer (Byte Buffer) and then copies it’s content to the page cache. When the O_DIRECT flag is used, the buffer is written directly to the block device. (It means O_DIRECT will not use page cache)
- Byte Buffer in Application is implemented by application to try to align with single page(4K) in Page Cache. (For example, in program, we usually create a buffer array to send/receive data)
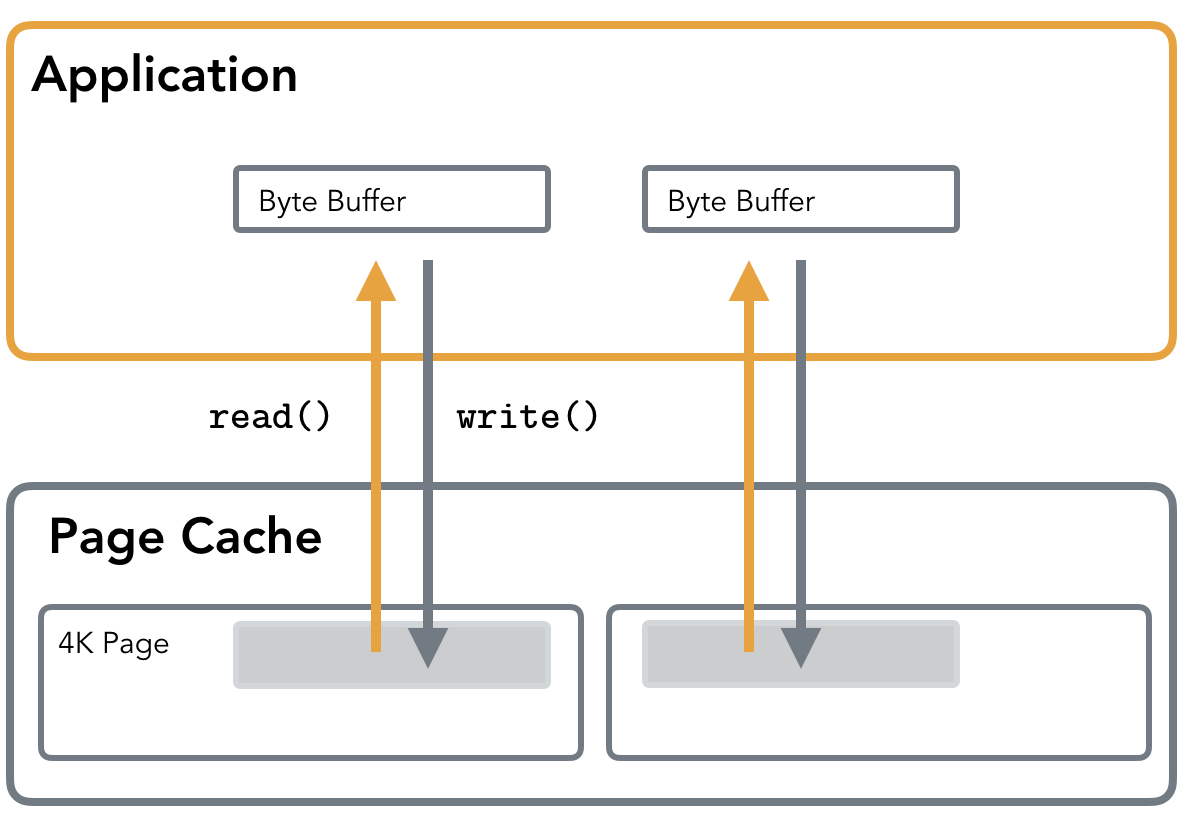
Page Cache
- Page Cache stores the recently accessed fragments of files that are more likely to be accessed in the nearest time.
- How Buffered IO works: Applications perform reads and writes through the Kernel Page Cache, which allows sharing pages processes, serving reads from cache and throttling writes to reduce IO.
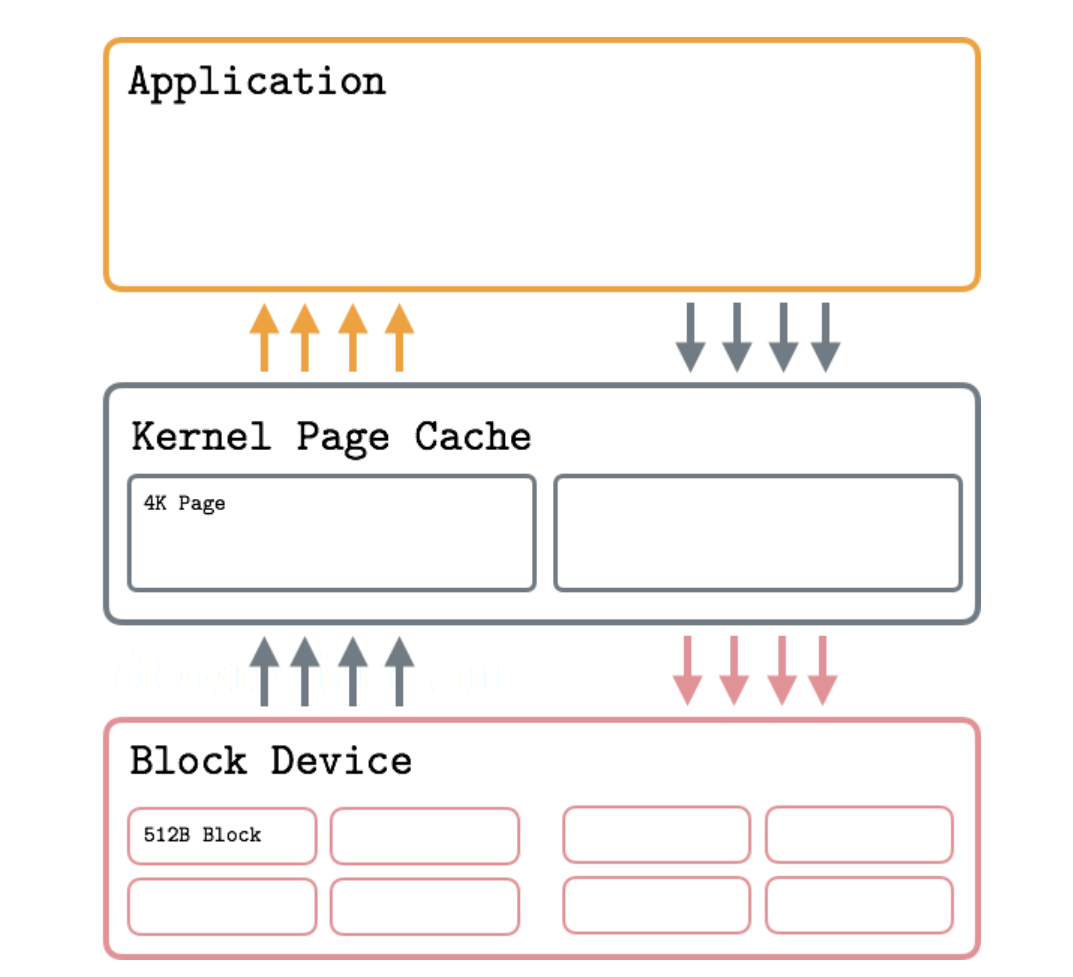
- Read OP:
- Cache Miss: block device -> kernel page cache -> application
- Cache Hit: kernel page cache -> application
- Cache evict/flush: LRU Pages (Least Recently Used)
- Write OP:
- application -> kernel page cache (Mark Page Dirty) -> (Wait Flush/Writeback) disk
- Flush/Writeback Strategy: thresholds of dirty page; period flush.
- Temporal locality principle (时间局部性原理): Recently accessed pages will be accessed again at some point in nearest future.
- Spatial Locality (空间局部性): implies that the elements physically located nearby have a good chance of being located close to each other. This principle is used in a process called “prefetch” that loads file contents ahead of time anticipating their access and amortizing some of the IO costs.
- Page Cache also improves IO performance by delaying writes and coalescing adjacent reads.
- Buffer cache is same as page cache in recent years.
Direct IO
- Direct IO: Bypass the Page Cache, and offer a fine-grained control over IO operations. Most used in systems which implement cache by self.
- PostgreSQL use direct io in WAL, since they are sure this log data will not be reused immediately.
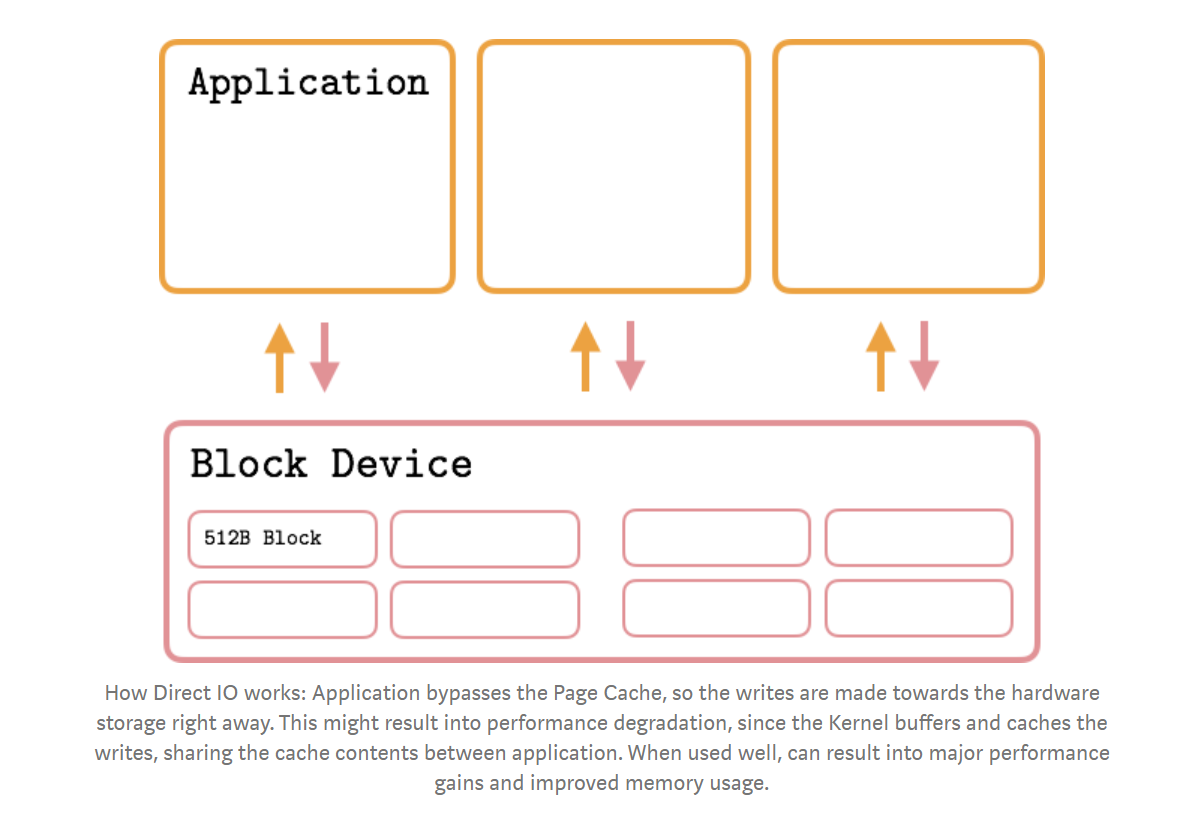
- Notice:
fsync()is still required for files opened with O_DIRECT in order to save the data to stable storage.- It is decided by specific file system and operations. Some file systems contain metadata cache, if you create a new file, you should write all data and metadata to disks, but
O_DIRECToption only can make sure the data be stored on the disk. The metadata stored in file system cache need other sync operations to be flushed to disks. - Some operations may not change the metadata, so O_DIRECT option can make sure data be flushed to disk right although without
fsync(). So in MySQL configuration, you can set different options forinnodb_flush_method, such asO_DIRECT,O_DIRECT_NO_FSYNC. You can view details by clicking https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_flush_method - You can refer Zhihu:使用O_DIRECT_NO_FSYNC来提升MySQL性能
- It is decided by specific file system and operations. Some file systems contain metadata cache, if you create a new file, you should write all data and metadata to disks, but
Block Alignment
- Unaligned writes.
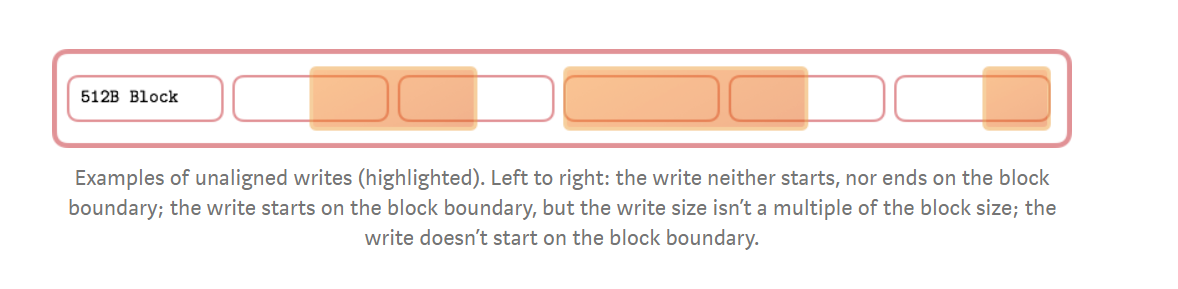
- Aligned writes.

- Whether or not O_DIRECT flag is used, it is always a good idea to make sure your reads and writes are block aligned. Although page cache will help to make sure write is aligned.
Nonblocking FileSystem IO
- There’s no true “nonblocking” Filesystem IO.
- Compared with sockets i/o, block device operations are considered non-blocking. Filesystem IO delays are not taken into account by the system. Possibly this decision was made because there’s a more or less hard time bound on operation completion.
- The NIO concept is always used in network.
Memory Mapping
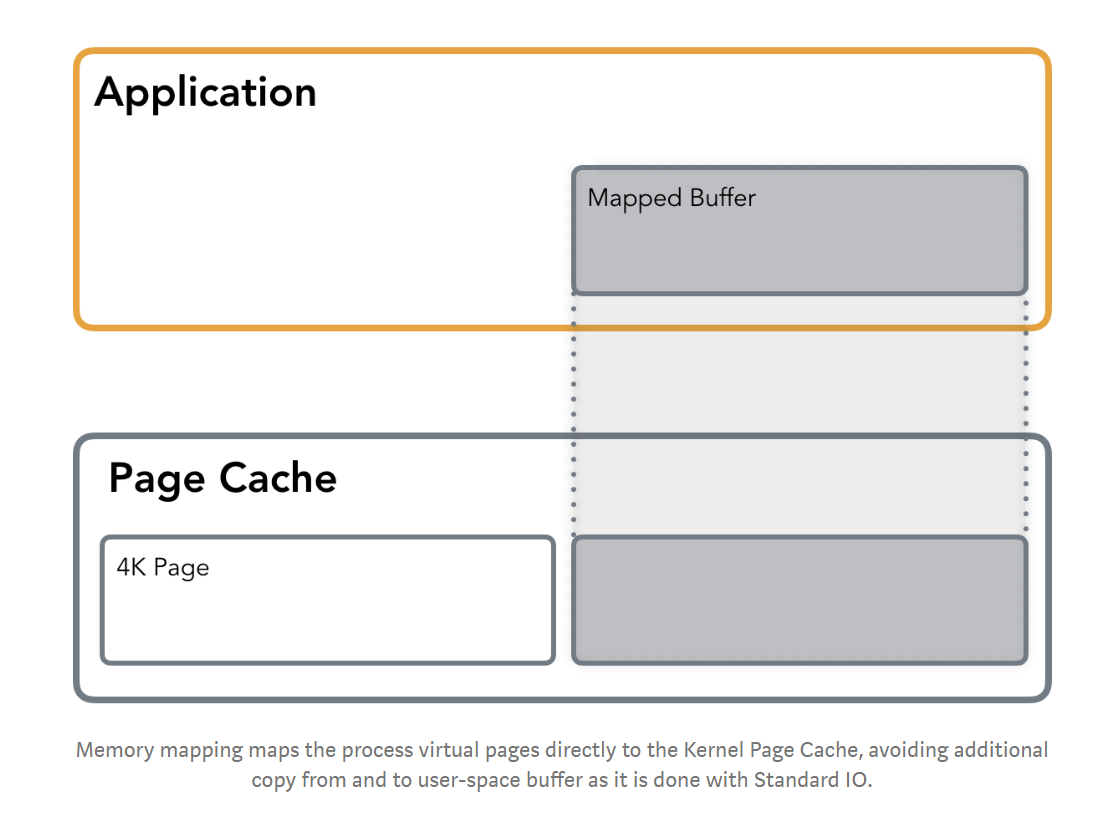
- Memory mapping (mmap) allows you to access a file as if it was loaded in memory entirely.
- Different mode:
- private mmap: write would trigger copy-on-write of the page in question in order to leave the original page intact and keep the changes private.
- shared mmap: the file mapping is shared with other processes so they can see updates to the mapped memory segment. Additionally, changes are carried through to the underlying file (precise control over which requires the use of msync).
- Memory Space Allocate: Lazy Manner. First I/O operation trigger a page fault and allocate the appropriate page.
- Adavantages and Disadvantages:
- Advantages:
- Avoid creating an extraneous copy of the buffer in memory
- Avoid system call (less subsequent context switch)
- Disadvatages:
- imposes overhead of the kernel data structures required for managing the memory mappings
- Memory-mapped file size limit: Most of the time, the kernel code is much more memory-friendly anyways and 64 bit architectures allow mapping larger files.
- Advantages:
- Usage: MongoDB default storage engine was mmap-backed.
Page cache optimization
- Page case is at the cost of control loss.
- One of the ways of informing the kernel about your intentions is using fadvise.
- FADV_SEQUENTIAL specifies that the file is read sequentially, from lower offsets to higher ones, so the kernel can make sure to fetch the pages in advance, before the actual read occurs.
- FADV_RANDOM disables read-ahead, evicting pages that are unlikely to be accessed any time soon from the page cache.
- FADV_WILLNEED notifies the OS that the page will be needed by the process in the near future. This gives the kernel an opportunity to cache the page ahead of time and, when the read operation occurs, to serve it from the page cache instead of page-faulting.
- FADV_DONTNEED advises the kernel that it can free the cache for the corresponding pages (making sure that the data is synchronised with the disk beforehand).
- There’s one more flag (FADV_NOREUSE), but on Linux it has no effect.
- Just as the name suggests, fadvise is only acting advisory. The kernel is not obligated to do exactly as fadvise suggests.
- Usage: RocksDB
- call mlock: It allows you to force pages to be held in memory. This means that once the page is loaded into memory, all subsequent operations will be served from the page cache.
AIO
- Asynchronous IO (AIO). AIO is an interface allowing to initiate multiple IO operations and register callbacks that will be triggered on their completion.
io_submit
- allows passing one or multiple commands, holding a buffer, offset and an operation that has to be performed.
io_getevents
- Completions can be queried by using
io_getevents, a call that allows to collect result events for corresponding commands.
Others
- Linux AIO has several shortcomings:
- the syscalls API isn’t exposed by the glibc and requires a library for wiring them up (libaio seems to be the most popular)
- Despite several attempts to fix that, only file descriptors with O_DIRECT flag are supported, so buffered asynchronous operations won’t work. Besides, some operations, such as stat, fsync, open and some others aren’t fully asynchronou
- Differences between Linux AIO and POSIX AIO
- The Posix AIO implementation on Linux is implemented completely in user space and does not use this Linux-specific AIO subsystem at all.
Vectored IO
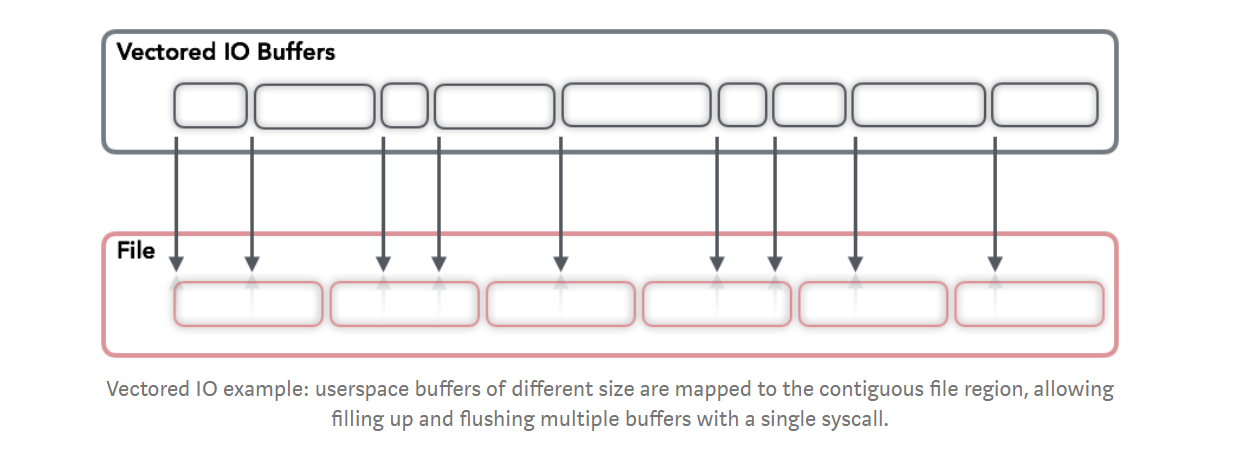
- One, possibly less popular, method of performing IO operations is Vectored IO (also known as Scatter/Gather). It is called this way because it operates on a vector of buffers and allows reading and writing data to/from disk using multiple buffers per system call.
Advantages
- Such an approach can help by allowing reading smaller chunks (therefore avoiding allocation of large memory areas for contiguous blocks).
- Reduce the amount of system calls required to fill up all these buffers with data from disk
- Reads and writes are atomic: The kernel prevents other processes from performing IO on the same descriptor during read and write operations, guaranteeing data integrity.
Usage
- A few databases use the Vectored IO. This might be because general purpose databases work with a bunch of files simultaneously, trying to guarantee liveness for each running operation and reduce their latencies, so and data is accessed and cached block-wise.
- Vectored IO is more useful for analytics workloads and/or columnar databases, where the data is stored on disk contiguously, and its processing can be done in parallel in sparse blocks. One of the examples is Apache Arrow.
Reference
- Ensuring data reaches disk: https://lwn.net/Articles/457667/
