- FAST19 Best Paper DistCache: Provable Load Balancing for LargeScale Storage Systems with Distributed Caching
- FAST19 Best Paper DistCache: Provable Load Balancing for LargeScale Storage Systems with Distributed Caching
- BestPaper 以及有很多大佬都对该文章有相应的解读,所以想看下原文,恰巧现阶段的项目中也有涉及分布式缓存的东西,学习一下相关思想。
- 主要设计了一个保证存储系统负载均衡的分布式缓存,并提供了相关理论证明
- 由于相关解读资料很多,此处只简单记录一些思想和关键点。也是一种新的阅读论文方式的尝试。
Abstract
- 负载均衡是大规模存储系统需要实现的功能,从而达到严苛的 SLO(service-level objectives)
- 实现负载均衡的方式通常为建立缓存系统,而传统的缓存系统方式往往会有缓存节点数据不均衡或者一致性开销较高的问题。
- 本文提出的 DistCache机制,使用 independent hash function 做 item partition,query 则受启发于 power-of-two-choices。
Introduction
- 大规模存储系统在 scale out 时一个最大的问题就是 负载均衡。具体表现则是,部分节点的数据被频繁访问,导致该节点可能出现过载,以及产生热点数据,从而过载的节点将成为整个系统的瓶颈,可能导致高尾延迟、低吞吐量。
- 负载均衡的解决方案通常都是使用缓存。而理论证明(SOCC2011 Small cache, big effect: Provable load balancing for randomly partitioned cluster services),n个存储节点,无论query是怎样的分布,缓存最热的O(nlogn)个对象即可均衡负载。即缓存大小只是和存储节点的数目相关,和存储节点上存储的对象数无关。相关论文有 SwitchKV(NSDI 2016),NetCache(SOSP 2017)
- 但是上面的小Cache解决热点的方案不能很好地scale out到多个集群,原因是一个集群一个Cache节点只能保证集群内的负载均衡,而集群间的负载均衡无法保证。为了保证集群间的负载均衡,最简单的方式则是再添加一个缓存节点来保证每个集群的负载均衡,但此时整个集群的吞吐量将受限于新添加的缓存节点,不足以支撑多个集群的吞吐,因此集群间需要一层分布式的Cache。而分布式Cache的难点在于如果简单地replicate热点数据到多个Cache节点会有一致性问题,而简单地按照hash partition又会造成Cache Node之间的负载不均衡导致吞吐受限于一个节点。所以关键就是避免Cache Node间的不均衡以及保证Cache一致性的开销。
- 提出了分布式缓存 DistCache。核心思想:使用独立的 HASH 函数在不同层的缓存节点之间对热数据进行分区,并将 The Power of Two Random Choices 应用到自适应的数据路由算法中。
参考链接
Background
- 同时保证集群内部和集群间负载均衡的方案:
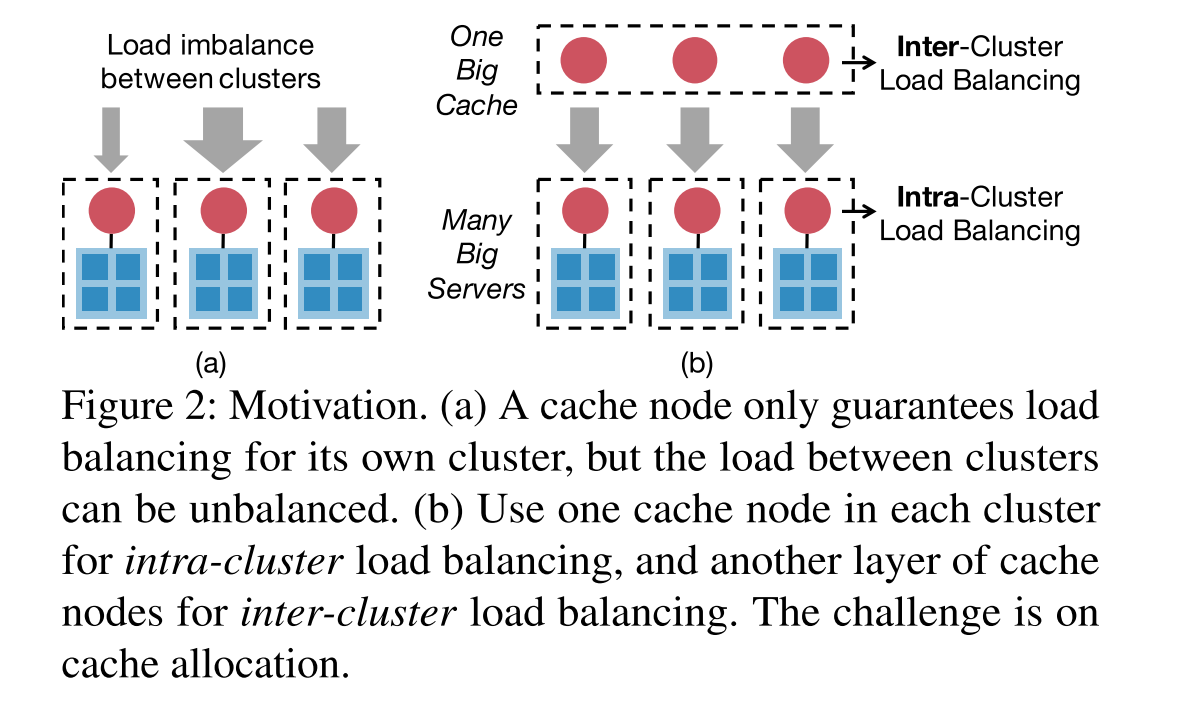
- 图b 关键问题:如何将热数据分配到分布式缓存层?
- 缓存分区:多个热数据可能被分区到同一个上层缓存节点上,导致上层缓存节点之间负载不均衡,使得缓存吞吐量不能线性增长,会受限于负载最高的节点。
- 缓存复制:虽然保证了负载均衡,但引入了较大的缓存一致性开销,需要更新上层缓存节点上所有副本。
- 故需要实现:避免上层缓存节点之间的负载不均现象,并减少缓存一致性的开销。
Design
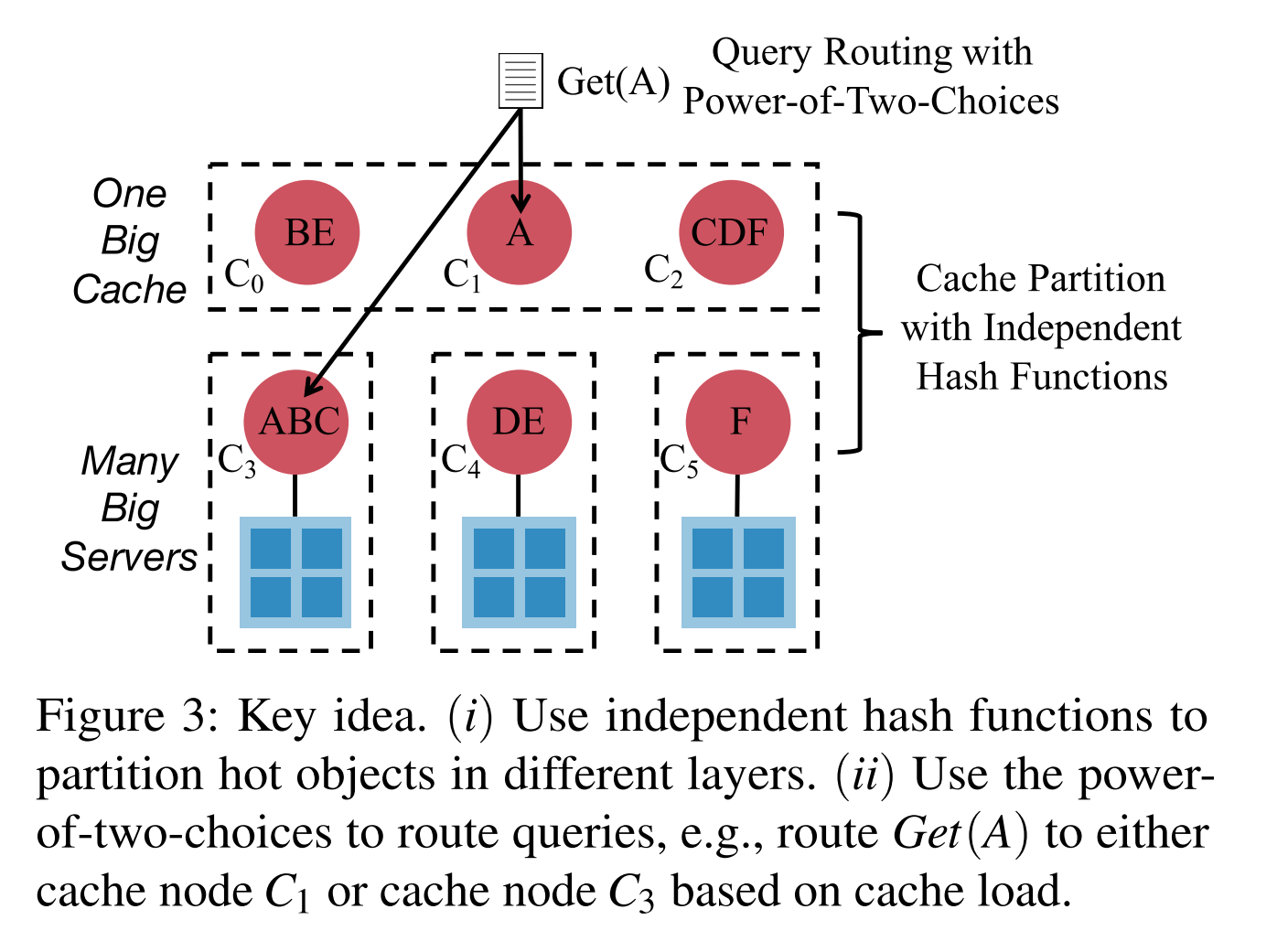
- 缓存分配时,上下两层采用不同的 HASH 算法,如图所示 C3 过载时,其热点数据将会均匀分布在上层缓存节点 C0,C1,C2,上层节点将主要吸收对于热点数据的 IO 操作。
- 缓存分配机制只是提供了一种负载均衡的方式,但未提供查询的分布方法。故 DistCache 方案采用了 The Power of Two Random Choices,如图所示,GET A 操作将被路由到 C1 或者 C3 节点,根据 C1 和 C3 的负载决定最终的选择。从而无需依赖中心节点来统计集群信息。
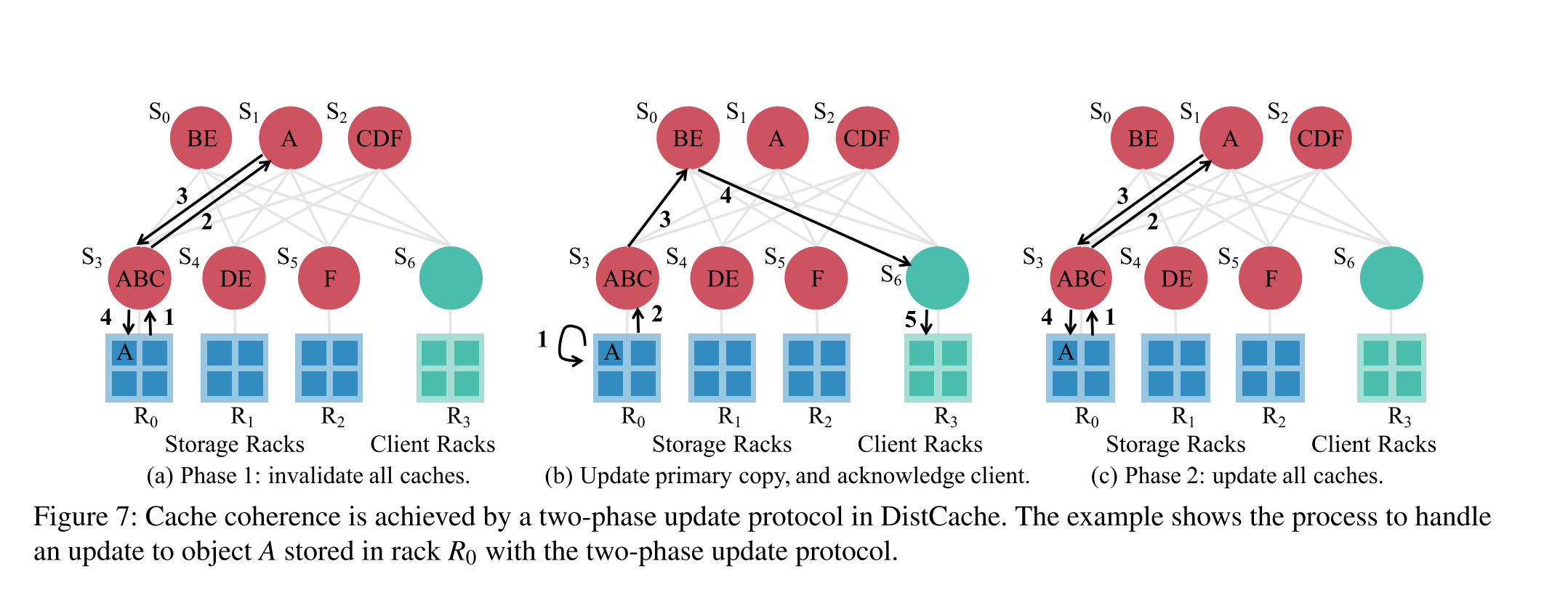
- 对于缓存的更新操作,则是保证缓存数据一致性的常用方案。DistCache 使用了两阶段更新协议,即在更新 Cache 数据之前,标记老数据无效,然后首先更新 server 上的数据,再更新 cache 数据。
理论证明推导
- 详见论文。
Instance
Switch-Based Caching
- 基于可编程的交换机缓存系统的设计
Architecture
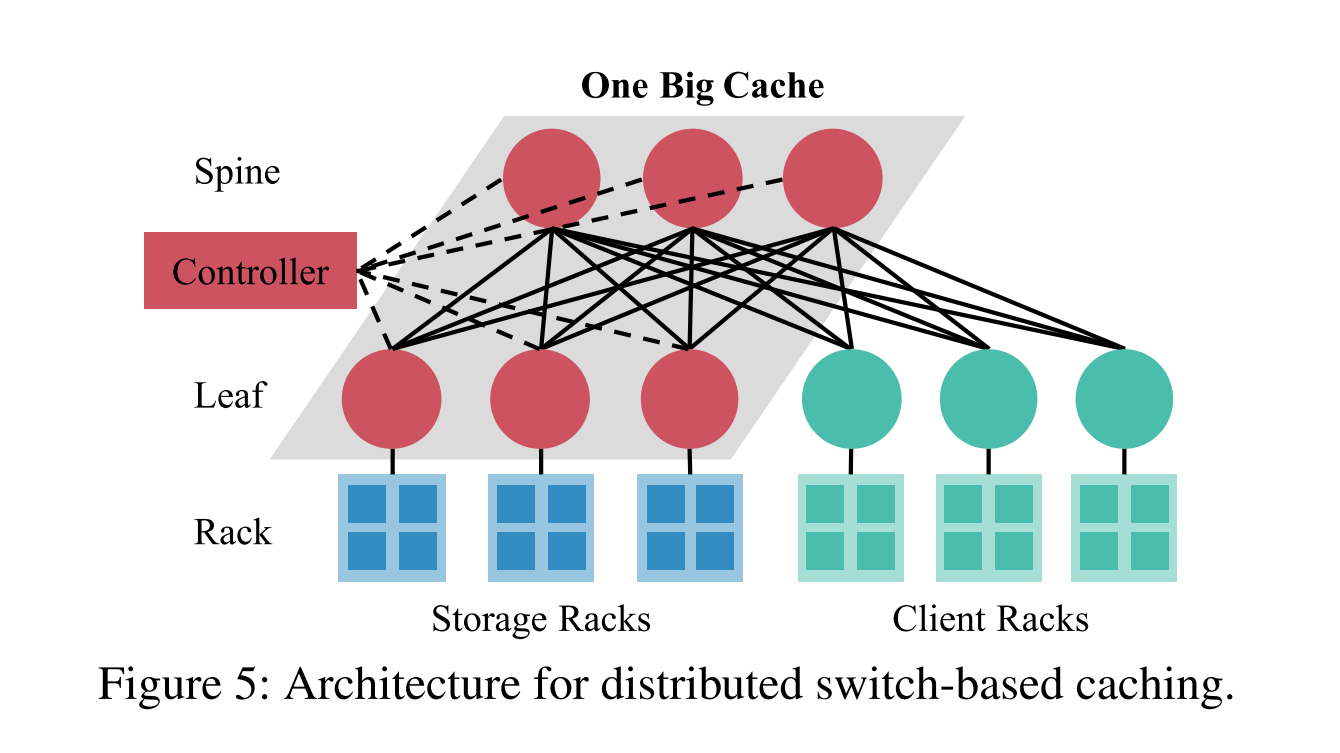
Component
- Controller:用于计算缓存分区,并通知缓存交换机。它更新系统重新配置下的缓存分配。
- Cache switches:
- 功能1:缓存热点数据
- 功能2:分发用于查询路由的交换机负载信息。
- ToR switches at client racks: 提供查询路由
- Storage servers:使用开源存储软件进行 KV 数据的存储,同时实现缓存数据一致性。
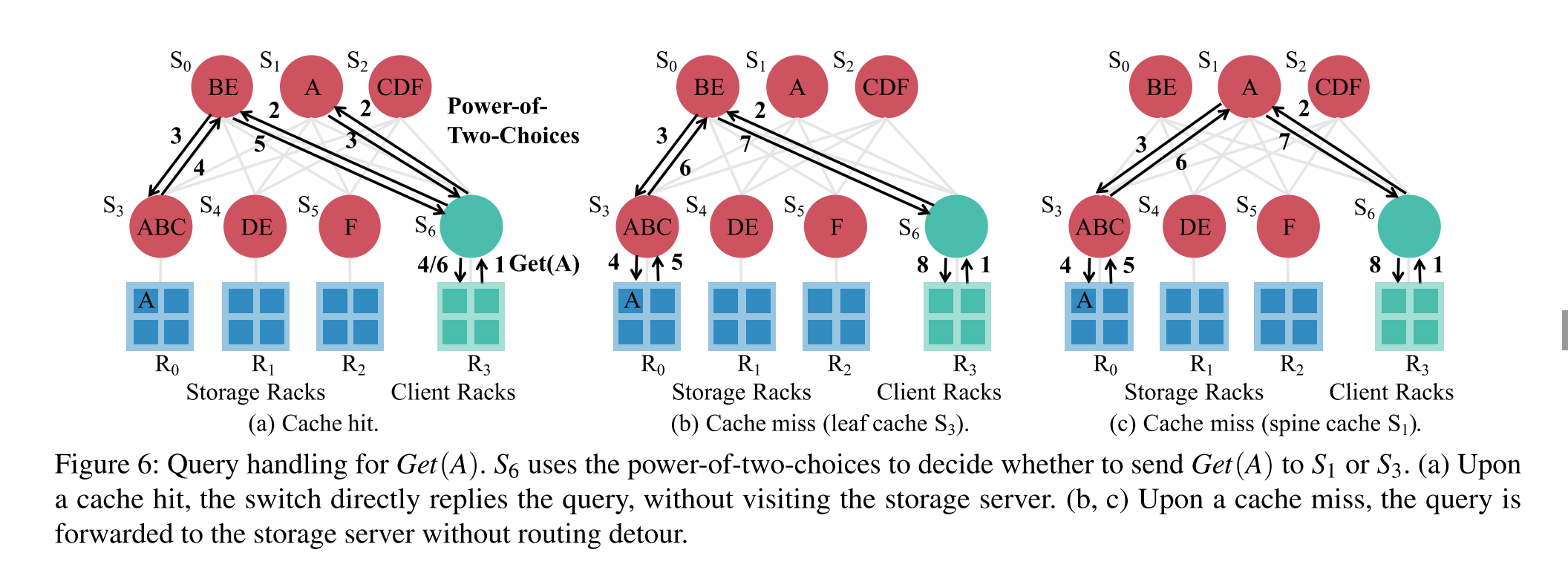
读流程
- R3 -> S6 -> Upper layer(S0, S1) -> S1 hit
- R3 -> S6 -> Upper layer(S0, S1) -> S0 -> S3 hit
写流程
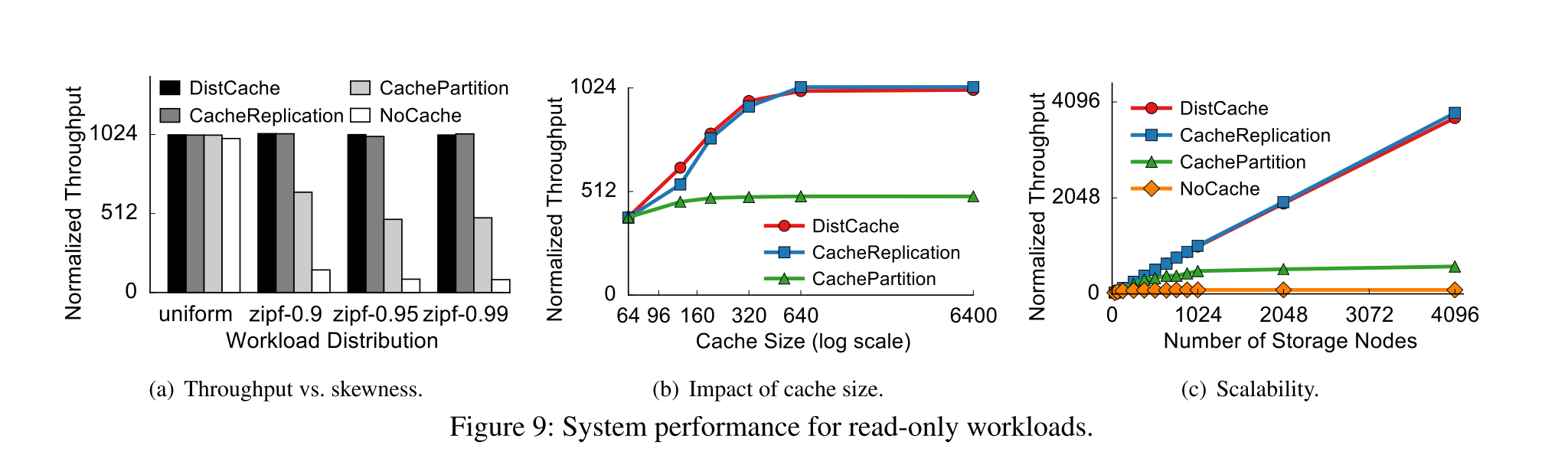
Evaluation
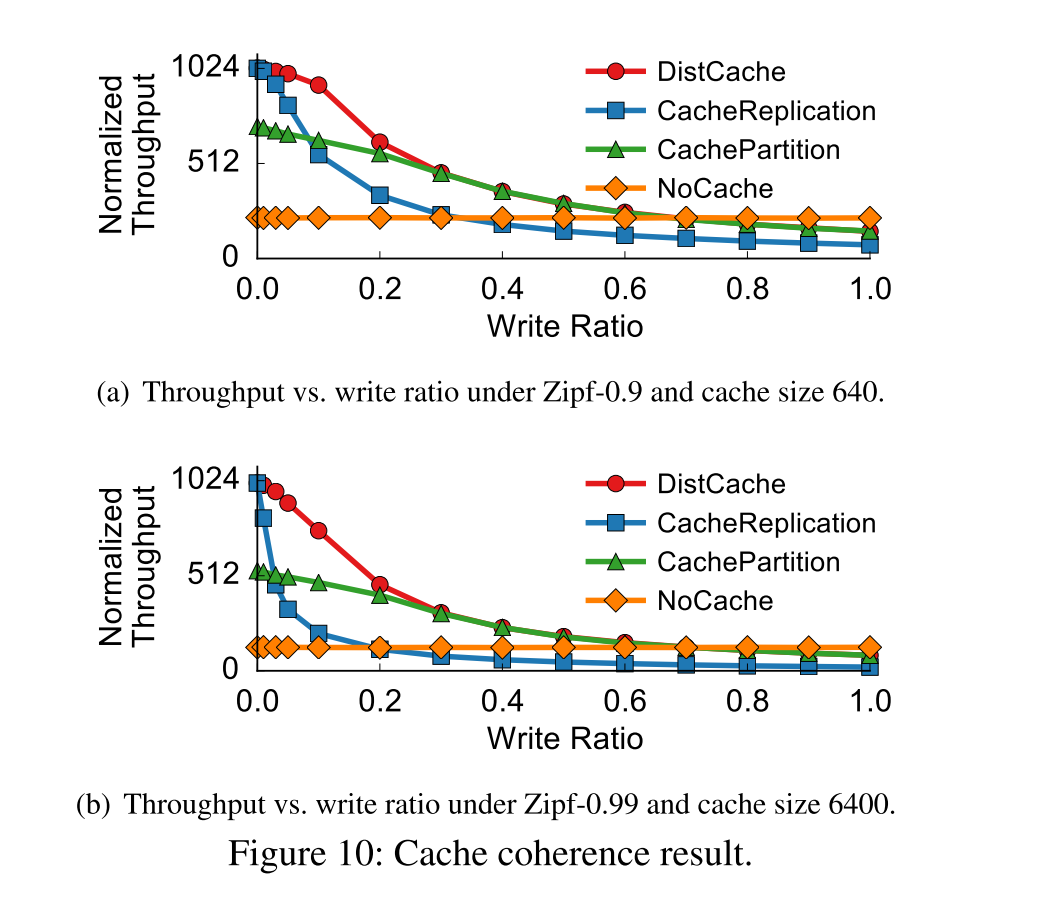
读性能
- 读性能表现 DistCache 与 Cache Replication 一样好
写性能
- DistCache 在写占比较低的时候能够保证高吞吐
- Cache Replication 一致性开销较大,随着写占比上升,吞吐量下降的较快。