- 该篇文章来自于 ASPLOS20 - FlatStore: An Efficient Log-Structured Key-Value Storage Engine for Persistent Memory
- 要解决的主要问题是现阶段的 PM 上的 KV 存储都没能充分利用 NVM 的带宽,出发点其实也是发现生产环境中的 KV 负载大多是小 KV
- 整个方案还是比较清晰的,涉及到的方方面面也在论文中有所阐述,基于 NVM 的数据结构的设计,流水线优化,RDMA 实现优化,值得一读。
Abstract
- 问题:新型技术 PM 和高速 NIC 的出现使得高效的键值存储系统能够得以构建。但是我们观察发现现有的 KV 存储系统中小 IO 的访问模式和 PM 的持久性保证粒度不匹配,没有充分利用 PM 的带宽。
- What we do: 提出了 FlatStore,一个基于 PM 的高效 KV 存储引擎。具体而言,该引擎将 KV 存储给解耦成了一个持久的日志结构(实现高效存储)和一个易失的索引(实现快速索引)。在此基础上,FlatStore 进一步结合了两种技术:
- 压缩的日志格式,以最大限度的批处理的机会在日志
- 在创建批处理时,通过流水线水平批处理从其他内核窃取日志条目,从而提供低延迟和高吞吐量的性能
- 实现和测试:使用了 Hash Table 和 Masstree 构建易失的索引,在 Optane DC PM 上进行了部署测试,单服务器节点可以达到 35Mop/s,比现有的系统快 2.5-6.3 倍。
Introduction
- 关键问题:如何设计高效的键值存储来处理写密集型和小规模的工作负载?
- 业界的解决方式和问题:运用新型技术,诸如新型存储介质(PCM, ReRAM, Optane DC PM)以及 InfiniBand 网络技术。通过分析大量的学术界中现有的对于基于 PM 的 KV 存储研究发现,其访问模式都没能匹配 PM 的访问粒度。
- KV 存储本身的特点:
- KV 存储生成大量的小型写操作(例如,在生产工作负载中,很大一部分KV对只包含几个或几十个字节),大多数更新操作其实只会导致一个或几个指针的更新
- 此外,KV 存储中的索引结构会导致写操作的放大。
- 基于 HASH 的索引往往需要进行重映射来解决 HASH 冲突,或者因为 HASH 表大小的变化而进行重映射
- 基于 Tree 的索引需要频繁地移动每个树节点中的索引条目,以保持它们的顺序,并合并/拆分树节点,以保持树的平衡
- 对于故障原子性,需要使用额外的刷新指令显式地持久化更新后的数据。(clflushopt/clwb)但是 CPU 刷新数据是以 cache line 为粒度的,在 AMD 和 x86 平台粒度对应的为 64B,PM 可能有更粗的内部块大小,比如 Optane DC PM 通常为 256B,在绝大多数场景下都比写的粒度要大,所以严重地浪费了硬件带宽。
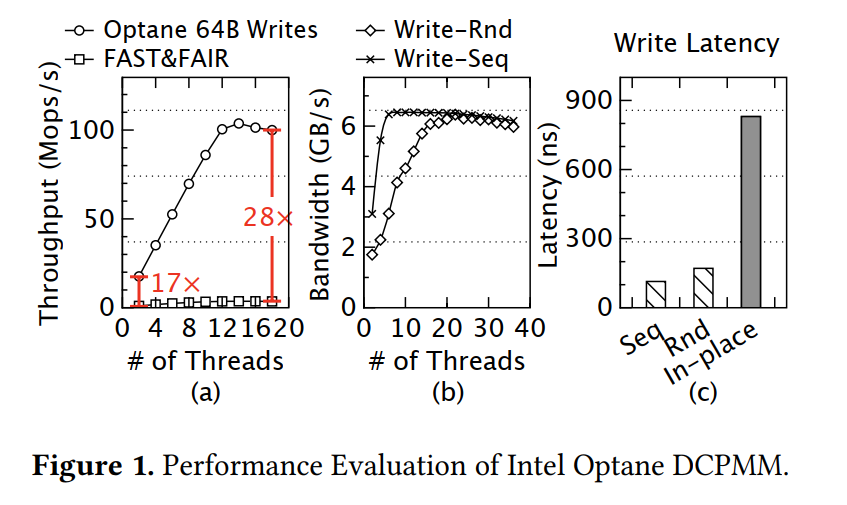
- 简单测试:部署了 FAST&FAIR,发现该方案实现了 PUT 操作 3.5 Mops/s,仅仅只达到了 Optane PM 的裸带宽的 6%
- 解决问题的通用思路:使用日志结构来管理 KV 存储,通过将批量的写请求进行聚合成大块的顺序读写,从而将写开销分摊到每个请求,但是这种方法受限于可以同时进行的更新的数量,在顺序 IO 友好的存储器如 HDD SSD 上效果较好。但是在 NVM 上进行构建时将会存在一些问题:
- 随着 I/O 大小大于 PM 最小的 I/O 单元 256B 之后,且有足够的线程数并发地执行 I/O,此时对于 Optane 的顺序和随机写的性能十分相近,此时聚合写的好处将体现不出来。PM 有更细的访问粒度(即64 B刷新大小和256 B块大小),如果我们简单地在日志中记录每个内存更新,那么它只能容纳非常有限的日志条目
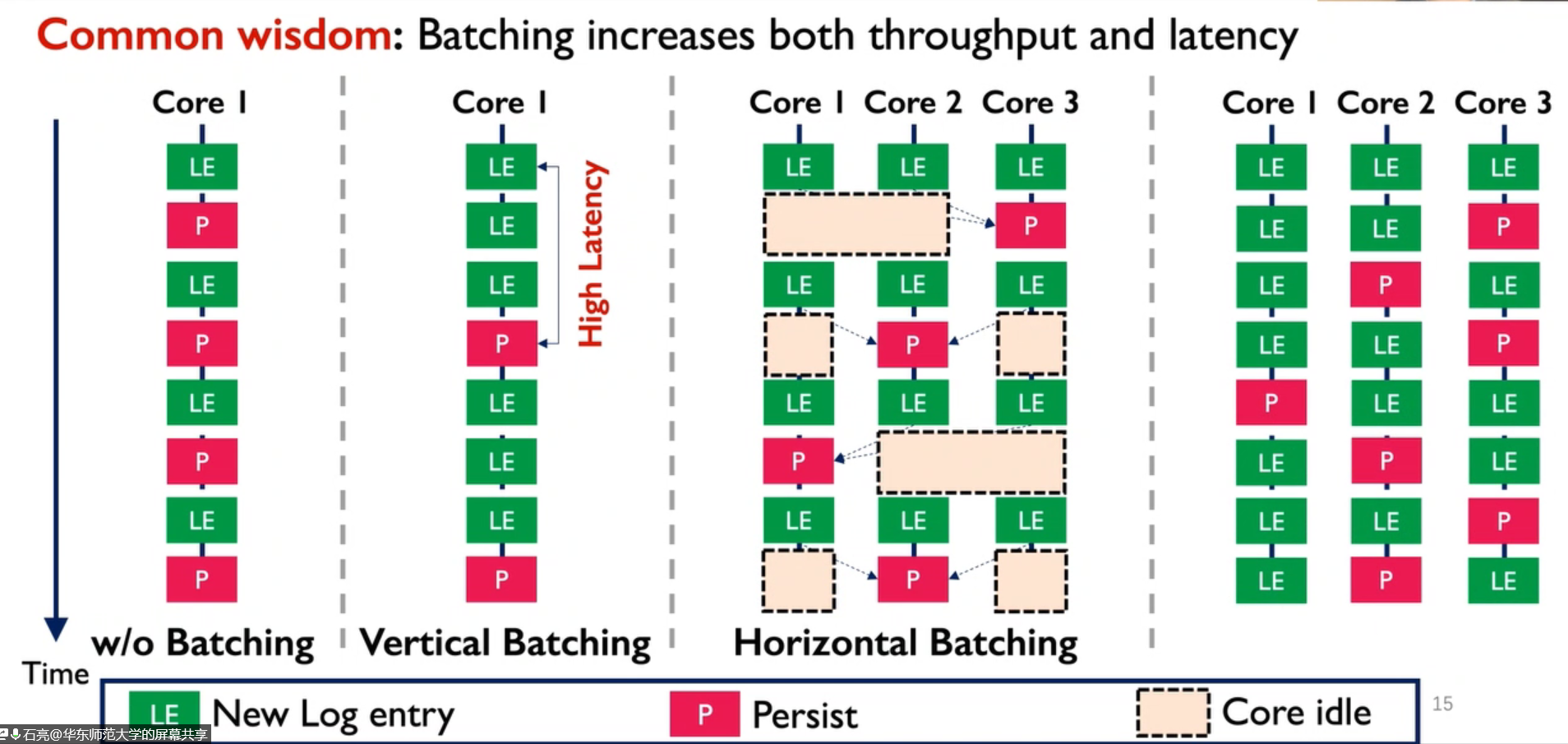
- 批处理不可避免地增加了延迟,阻碍了它在新兴的PMs和高速 NIC 中的应用,因为低延迟是对应硬件的最大好处之一。
- 现有方案的主要问题:已经有一些研究(ATC17 Log-structured non-volatile main memory 和 FAST16 的 NOVA) 将日志结构化的数据结构应用到基于 PM 的存储系统上,主要是为了利用日志结构的故障原子性保证或者减少内存的碎片,但都没有考虑使用批处理来分摊持久化的开销。
- 本文的方案: 目的是为了解决上述问题,实现 高吞吐、低延迟、多核扩展。核心思想是解耦成两个部分,一个是易失的索引结构,一个是存储在 PM 上的高效日志结构。还包括以下技术点:
- Compact log format:FlatStore 只存储索引元数据和小 KVs 到持久化的日志中。大 KVs 通过使用 NVM allocator 单独存储,因为日志结构对于大 IO 没有那么好的效果。而在日志结构上的数据组织方式,采用了 operation log technique 的方式,即简单描述每一个操作,而不是记录每个索引更新操作,从而减小索引元数据对于空间的占用,
- Pipelined Horizontal Batching:允许一个核在创建一个批量任务的时候可以收集来自别的核的日志项,该方法减少了积累指定数目的日志项的时间,为了缓和核与核之间的争用:
- 在不影响正确性的前提下,调度核提前释放锁
- 将核心组织成组,以平衡争用开销和批处理机会
- 内存的索引结构使用了两种, hash table (FlatStore-H) 和 Masstree (FlatStore-M)
Background And Motivation
-
现有的研究都是基于模拟器实现,所以存在一定的假设,和实际的物理器件的具体表现其实有一定的差异,甚至相反的结果。

-
生产环境的 KV 负载:数据中心的数据统计表示 KV 存储大多都是小粒度的,读为主的访问模式也逐渐转变成为了写为主的访问模式
-
细粒度更新和持久化的粒度不匹配:主要分析了现有的持久性内存上的 KV 存储,由持久化的索引和实际需要存储的 KV 对两部分组成。KV 记录通常都保存在 NVM 上,但是索引的存储方式略有不同。CDDS-Tree、wB+-Tree、FAST&FAIR、CCEH、Level-Hashing 都是把整个索引放在 NVM 上,FPTree、NV-Tree 是把索引结构的叶子节点放在 NVM 上(其他节点放在 DRAM 上),Bullet、HiKV 则是采用了容灾的策略(DRAM 上和 NVM 上都存,使用后台线程进行同步),这些设计中一个 PUT 操作通常都会引入很多对 NVM 的更新操作,就包括:
- 对实际的 KV 的更新(生产环境通常都是小 IO)
- 对 allocator 内部的元数据更新
- 对于索引结构的多次更新(可能造成严峻的写放大)
- CPU Cache 到 NVM 常常会以 CacheLine 的粒度进行刷回,64B,与 PM 的 256B 的块大小不匹配,浪费了 PM 的带宽
-
Optane DCPMM:在一些测试的基础上,我们有一些新的发现
- 高并发情况下顺序访问和随机访问的带宽相近。
- 对同一 cacheline 重复刷新会被显著延迟。
- 可能的原因一:clwb 异步发起,后续的 clwb 被阻塞,直到前一个完成或者超时
- 原因二:Optane 自带片上的负载均衡功能,当访问同一个 CacheLine 时阻塞后续的 flush 操作
-
挑战:
- 日志结构存储在PM中有较少的批处理机会。PM 粒度更小,顺序随机访问性能接近,日志结构化数据结构的更新常常伴随严峻的写放大。
- 批处理增加延迟。器件本身就是低延迟特性,批处理的设计与器件特性背道而驰
Design
Overview
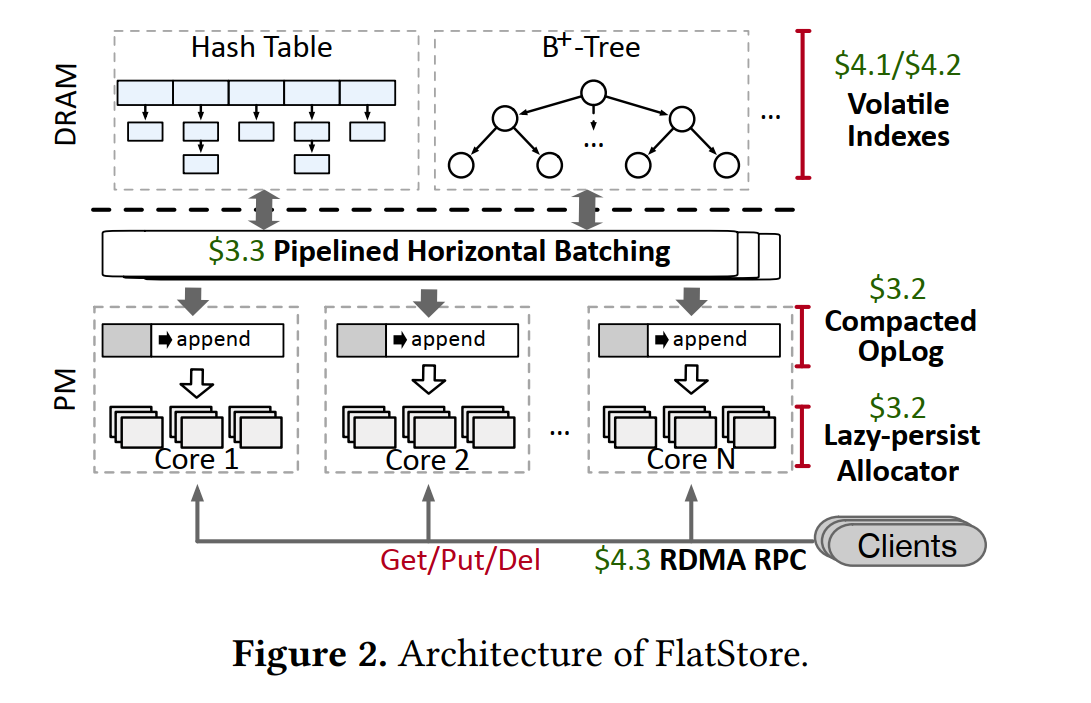
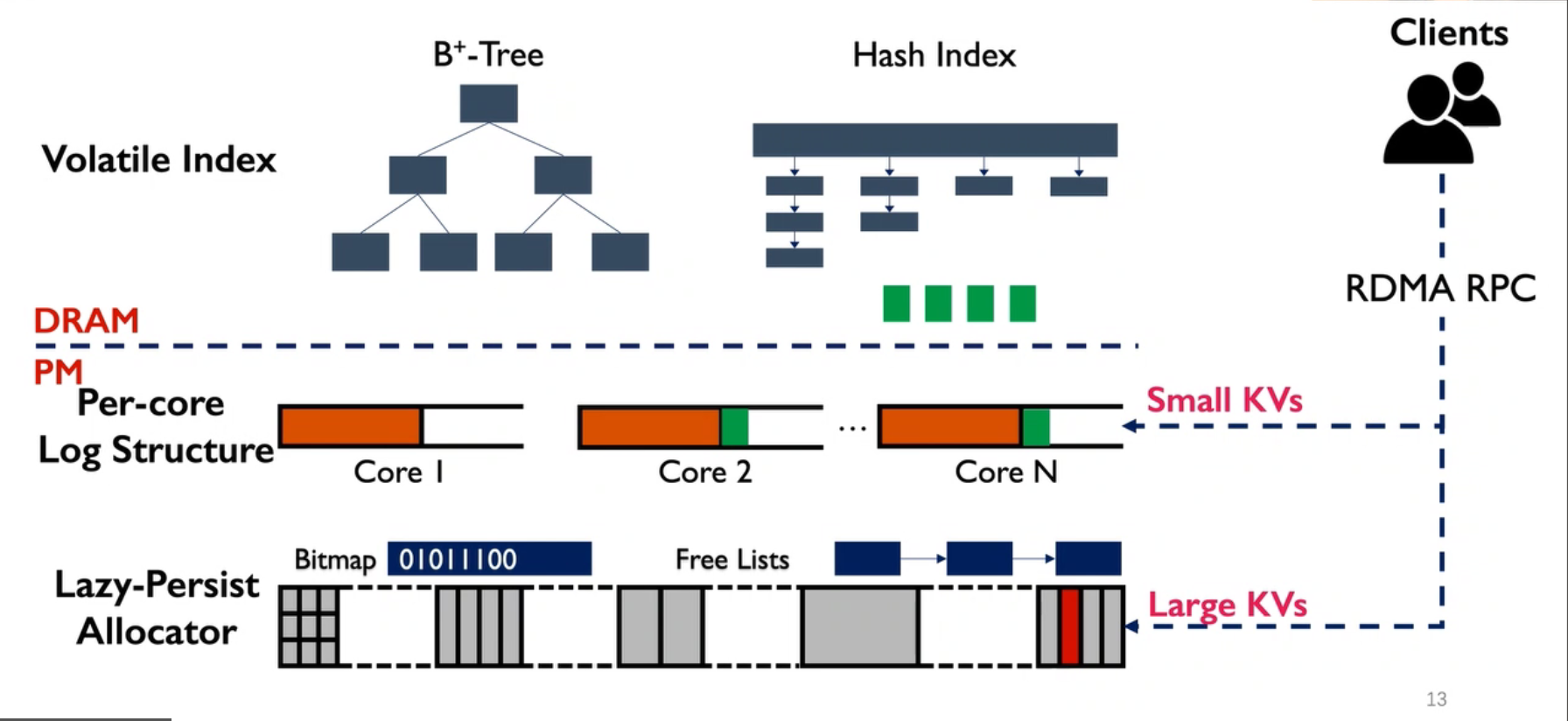
- 结构组成主要分为三个部分:
- Volatile Indexes
- Compacted OpLog
- Lazy-Persistent Allocator
- 优化主要体现以下两个个方面:
- Compacted OpLog
- (Pipelined) Horizontal Batching
Compacted OpLog
- 组成:日志项会尽可能地设计得比较小以更好地支持批量操作,以便在一个 FLUSH 操作里持久化更多的日志项,所以 OpLog 中的日志项只会保存索引元数据和特别小的 KV 数据。
- 压缩日志项:使用 operation log technique,日志项不会记录内存的每一次更新,而是只包含描述每个操作的最少信息,如图所示,每个日志项包含五个部分:
- Op:操作类型
- Emd: 该 KV 对是否放在日志项的末尾,用于日志类型的区分
- Version: 版本用于保证日志清理的正确性
- Key:8byte key。
- Ptr-based:
- FlatStore 支持更大的 Key 存在 OpLog 之外,和 Value 一样,然后使用指针 Ptr 指向实际的存储位置。- 为了最小化日志大小,只给 Ptr 40bits,40+8 位能索引 128TB 的 NVM 空间。
- 每个日志项的大小被限制在 16 字节,因此可以同时刷入 16 个日志项,和刷入一个日志项开销相等。
- Ptr-based:
- Value:较小的 KV 会把 value size 和 Value 一同放在日志项末尾
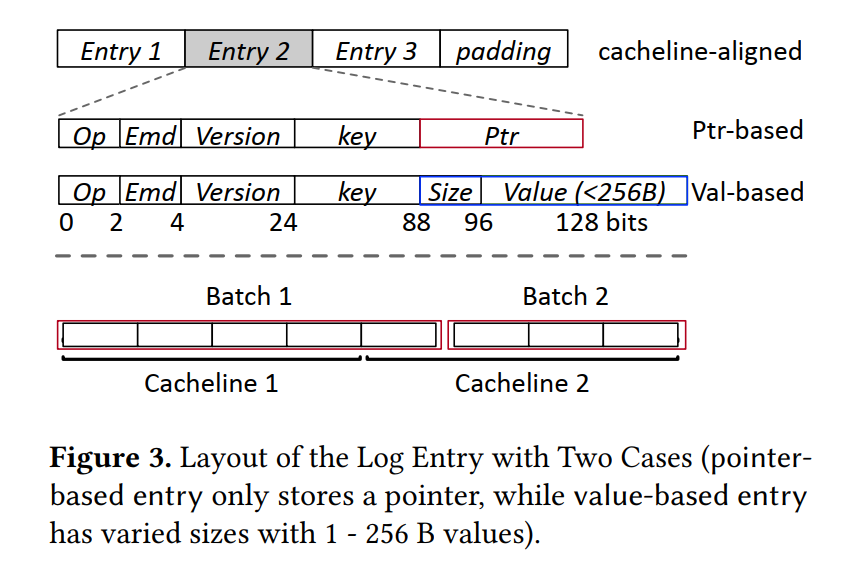
- Padding:前文提到对同一 cache line 的刷回会有性能问题,在我们对应的日志刷回过程中,也可能存在两个 Batch 使用同一个 cache line 的情况,如上图所示,Batch 1 和 Batch 2 同时使用了 Cacheline2,batch2 会被延迟,所以我们为了解决这个问题,采用填充的方式,即在每一个 Batch 后进行填充,直到填满 Cacheline,从而避免多个 Batch 使用一个 Cacheline 的情况。但是这种方式对于就地更新的存储系统较为复杂,特别是在一些倾斜负载的情况下。
Lazy-persist Allocator
- 思路来源:NVM 分配器需要仔细维护 NVM 元数据,即追踪哪些地址已经被使用,哪些地址仍然空闲。但是我们发现在日志项和分配元数据有一定的重复:一旦数据被插入成功,日志中的 Ptr 指针总是指向一个分配了的数据块,因此我们可以惰性地持久化分配元数据,并且可以在系统故障之后利用该重复数据进行恢复。主要的挑战是如何在恢复期间在每个日志条目中使用 Ptr 来反向定位分配元数据,因为分配器需要支持可变长度分配。
- 核心思想:我们提出了 Lazy-persist Allocator,将 NVM 切分成 4MB 的 chunks,然后这些 4MB 的 chunks 又被划分成不同种类的数据块,相同 chunk 里的数据块对应的数据大小相等。在每个 NVM 块准备分配时会记录对应的切分数据大小,记录在 head 中,同时还会存储一个位图,来标识未使用的 data blocks。在这种设计中,每个块的起始地址都是 4MB 对齐的,每个块的分配粒度在其头部指定,因此一个已经分配的 NVM block 在 chunk 内的偏移量可以直接通过 Ptr 计算出来,从而就能系统崩溃后恢复出对应的 bitmap。考虑到扩展性问题,这些 4MB 的 NVM chunks 被分分区到不同的 cores。一旦收到分配请求,分配器首先选择一个合适的 NVM chunk,然后分配一个空闲的数据块,修改相应的位图。对于大小大于 4MB 的分配,虽然在 KV 存储中几乎不太可能,我们也可以直接分配一个或多个连续的 chunks 来解决。
- 完整流程(PUT 操作):
- Lazy-persist Allocator 分配一个数据块,拷贝数据到该数据块,格式位 (v_len, value) 并持久化。(小 KV 会跳过该步骤)
- 初始化一个日志项,并填充日志项中的数据
- 如果该记录放在 OpLog 之外的位置,Ptr 指向步骤一分配的数据块
- 如果该数据块已经存在的话,相应的版本号加一
- 追加日志项到日志中并进行持久化
- 最终更新尾指针指向日志的末尾,并持久化
- 更新项对应的易失的索引结构来指向该日志项
- 对于崩溃一致性,如果记录存在的话我们需要进行异地更新,因此除了上述步骤以外,一旦插入完成,我们还需要释放老的数据块。释放之后的空闲块可以立即被重新使用,因为 FlatStore 中不存在 删后读 异常,因为 KV 被根据 keyhash 被转发到对应的核,相同 Key 操作对应的核也相同,会使用一个冲突队列来串行化操作。只有步骤二之后,即数据被写入到日志中并持久化才认为此次操作完成,但如果此时发生了故障,FlatStore 可以通过重放 OpLog 来重建索引和分配位图,删除操作则使用一个标识。
- 开销分析:FlatStore 包含三个刷回操作,KV record、日志项和尾指针。因为小 KV 直接放在了日志中,刷回的次数大大减少,选择性地将 KV 记录放在 OpLog 和分配器中,也使得垃圾回收更加高效。FlatStore 需要周期性地回收陈旧的日志项占用的 NVM 空间,因为日志项很小所以其压缩过程也不会占用太多的 CPU 资源。
Horizontal Batching
-
为了更好地支持 batching,服务器的 core 可以接受多个客户端请求并统一处理。假设 N 个 PUT 请求到达,FlatStore 为每个请求首先分配数据块并持久化 KV 项,然后合并日志项并一起刷回到 OpLog 中,最后更新内存中的索引。因为使用了 Batching,PM 写的次数从 3N 减小到了 N+2:
- 因为使用了只能追加写的 OpLog,来自不同请求的日志条目有机会被刷新在一起
- OpLog 尾指针的更新从每请求一次到每批处理一次
- 小 KV 直接存储在日志中,持久化操作进一步减少
-
因为上述批处理策略只会批处理每一个核各自收到的请求,称之为 Vertical Batching。该方式减小了持久化的开销,但是引入了更高的延迟,因为减少了跨核的 Batching,每个核不得不等足够的请求到了之后才能 Batch。如下图所示 a 和 b 的对比,Vertical Batching 相比于无 batching 的情况显著增加了响应延迟。亚微妙级别的硬件如 NVM,RDMA 驱使我们实现更小的延迟,于是设计了 Horizontal Batching,允许 steal 其他核的请求。
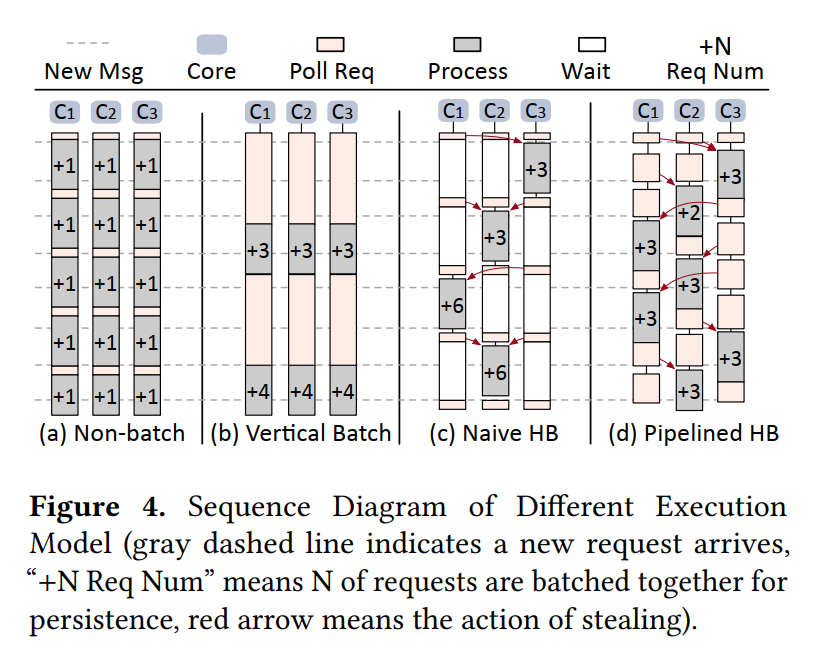
-
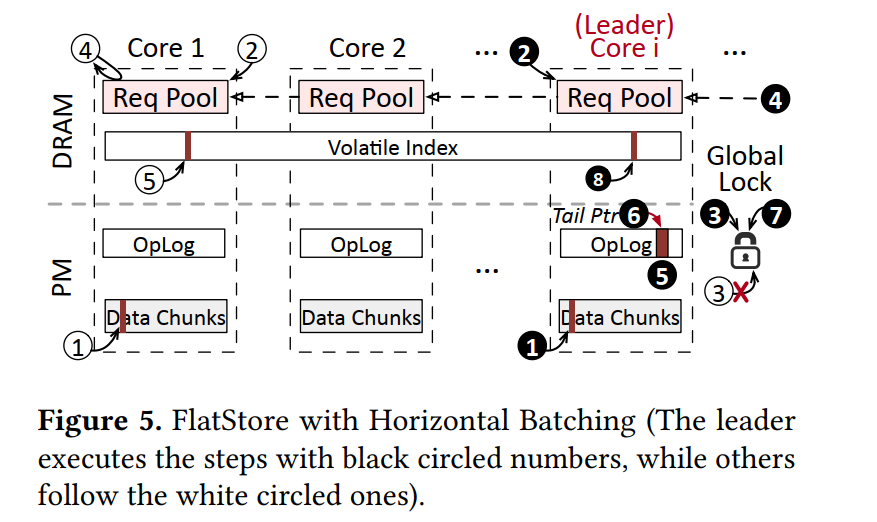
在 Pipelined Horizontal Batching (Pipelined HB) 之前首先介绍什么是 Horizontal Batching:如下图所示,为了实现日志项的跨核,我们设计了:
- 一个用于同步所有核的全局锁
- 用于核之间的通信请求池,每个核对应一个池
-
PUT 操作被解耦成三个阶段:
- l-persist:空间分配并持久化 KV 对
- g-persist:持久化日志项
- volatile:更新易失索引
-
步骤如图所示:
- 空间分配并持久化 KV 对 ❶/➀
- 每个 CPU core 将需要持久化的日志项对应的地址放在本地的请求池中 ❷/➁
- 试图请求全局锁 ❸/➂
- 拿到锁的 core 成为 leader,其他的 core 成为 followers,followers 等待提交了的请求完成 ➃
- leader core 从其他核那里抓取日志项 ❹。(这里通过让 leader core 扫描所有其他 cores 来抓取所有存在的日志项,而不是使用其他复杂的策略,来减少延迟)
- 收集到的日志项被合并到一起然后追加到 OpLog 中,以批量的形式 ❺ and ❻
- 完成后释放全局锁,并通知其他核心持久化操作已经完成 ❼
- 最后 leader 和 followers 都更新内存索引结构并向客户端发送响应消息 ❽/➄
-
使用这种方式其实次优的。因为这三个阶段的处理是严格有序的,而且大多数 CPU 周期都花在等待日志持久化完成上。于是提出了 Pipelined HB 交叉执行每个阶段:
- 一旦核获取锁失败,core 转而轮询下一个请求的到达,并执行第二个水平批处理的逻辑
- followers 仅异步地等待来自之前 leader 的完成消息
- leader 在从其他 core 收集了日志条目之后,就会释放全局锁,因此日志持久化开销就不会在锁的逻辑里
-
如下图 C D 所示的效果
-
但是 Pipelined HB 也存在一定的问题。Pipelined HB 可能对客户端的请求重排序:一个 core 处理一组请求,后面的 Get 操作可能无法看到前面的 PUT 操作相同 Key 带来的实质影响。这样的例子发生在 PUT 仍然在被 leader 处理时,follower core 切换了开始处理下一个请求。为了解决这个问题,每个 core 会维护一个独占的冲突队列来追踪正在被服务的请求,如果 Key 冲突的话后续请求相应地都会被滞后。
-
Pipelined HB 和 work stealing 的不同:work stealing 通过让空闲的线程窃取繁忙的线程的任务。重新平衡了负载;Pipelined HB 依赖 work stealing,但是是以相反的方式让一个 core 获得所有的请求从而减小 Batching 的延迟。
-
Pipelined HB with Grouping:在 multi-socket 平台上,由于大量的 cores 都需要请求全局锁会导致严峻的同步开销,为了解决这个问题,cores 通常会被分区成不同的 groups 来执行 Pipelined HB。因此,一个合适的分组大小和 batch 大小能够较好地平衡全局同步开销。分组太小,虽然锁开销更小,但是也就意味着 batch size 变小。基于我们的实验结果,通过将一个 socket 对应的所有核安排在一个组就能提供较优的性能。
Log Cleaning
- FlatStore 中每一个 core 维护了一个内存中的 table 来追踪正在处理普通的 PUT 和 DELETE 请求时 OpLog 中每个 4MB chunk 的使用情况。一个 block 何时被插入到回收列表中取决于该块中有效 KV 对的比例和总共空闲的 chunks 数。每一个 HB group 启用一个后台线程来清理日志,因此日志的回收操作是在不同的组并行进行的,cleaner 线程是周期执行的,周期地扫描回收列表。
- 为了回收 NVM chunk,cleaner 线程首先扫描该 chunk 来判断每个日志项的活性,通过比较日志项的版本号和内存索引中存储的最新的版本号,所有仍然有效的日志项将被拷贝到新分配的 NVM chunk 中。对 tombstones (对于Del)的活性进行识别则更为复杂,只有在回收了与此KV项相关的所有日志项之后,才能安全地回收它。之后,cleaner 更新内存中索引中的对应项,以使用原子 CAS 指向它们的新位置。最后,通过将旧块放回分配器来释放它。当新的NVM chunk 被填满时,它将该块链接到相应的 OpLog。还需要跟踪新的 NVM 块的地址,以防止在系统故障时丢失它。我们把这样的地址记录在日志区域上上(PM中的预保护区域),可以在恢复期间重新读取。
Recovery
- Recovery after a normal shutdown:正常关闭之前,会将内存中的索引拷贝到 NVM 上的一块预定义的区域中,将每一个 NVM chunk 的 bitmap 进行刷回,最后,写一个 shutdown 的标志来表明是一次正常的关机。在重启的时候,Flatstore 首先检查这个标志的状态并进行重置,如果是正常关机则相应地加载索引数据到内存。
- Recovery after a system failure:如果标志位检查发现不是正常关机,则需要重建索引和位图,需要从头到尾地扫描 OpLogs。日志项的 key 将被用于在内存索引中定位一个 slot,如果没有相应的 slot 则在索引中执行插入操作。否则,它通过进一步比较版本号来判断是否更新该索引项的指针。使用 Ptr 项也能重建出分配元数据。实验表明恢复 10 亿个 KV 只需要花费 40s,这样的恢复时间是容许的:
- 许多生产环境中的负载有更多不同大小的 KV 分布,因此在大多数场景下需要恢复的索引数较少
- 为了缩短恢复时间,FlatStore 也支持使用 Checkpoint 方式在 CPU 不是特别繁忙的时候周期地将索引数据写入 PM
Implementation
FlatStore-H: FlatStore with Hash Table
- 索引结构使用了 CCEH 的方案,CCEH 被用单独的键散列划分为多个范围,每个核都拥有一个CCEH 实例。因此多核可以无锁开销地修改 HashTable。因为索引的持久性已经被 OpLog 来保证,所以直接将 CCEH 放在 DRAM 中且移除了他的刷回操作。客户端直接放请求发送到具体的负责该 Key 的核,每个核将只负责更新他自己的索引,但仍然需要使用 pipelined HB 持久化日志项。
- 每一个 Bucket 包含多个 index slots,包括
- 一组 keys 和相应的 version
- 一组指针指向在 OpLog 中对应的日志项
- 分区的设计可能会导致在倾斜负载下的负载不均衡,然而,水平批处理能够在很大程度上减轻这种不平衡:它将最耗时的持久化日志操作的负载分散在各个核之间。
FlatStore-M: FlatStore with Masstree
- 因为现有的持久化 KV 存储常常使用树来作为索引从而之支持顺序和范围查询,所以我们也使用了 Masstree 来实现。Masstree 本身就是基于多核扩展性和高效设计的,为了支持范围查询,一个全局的 Masstree 实例在启动的时候创建,也被所有的 cores 共享。Keys,Versions 和指针都被存储在叶子节点中,和 FlatStore-H 类似,客户端发送的请求也会先经过 HASH 找到一个具体的 core,同时也就减少了 Masstree 更新时的冲突。
RDMA-based FlatRPC
- RDMA 本身的相关介绍此处不做赘述
- RDMA-based FlatRPC 让客户端直接写 core 的 message buffer,但 reply 被委托给 agent core 来发送。当一个客户端连接到每个 server node,只会在它和 agent core 之间常见一个 QP,agent core 随机选择离 NIC 近的 socket。每个 core 也会预分配一个 message buffer 给客户端来存储收到的消息,但是共享一个 QP。
- 如下图所示,为了发送一个消息,
- 客户端首先将消息内容跟直接写到一个具体的核对应的 message buffer 中
- 每个服务器核心都会轮询消息缓冲区以提取新消息并处理它
- 然后按照响应的规则准备 response 并发送:
- 如果当前 core 恰好是 agent core,直接使用 MMIO 发送 write 原语
- 不是 agent core,通过共享内存将原语委托给代理核心
- NIC 收到原语,将获取对应的消息内容并发送到客户端
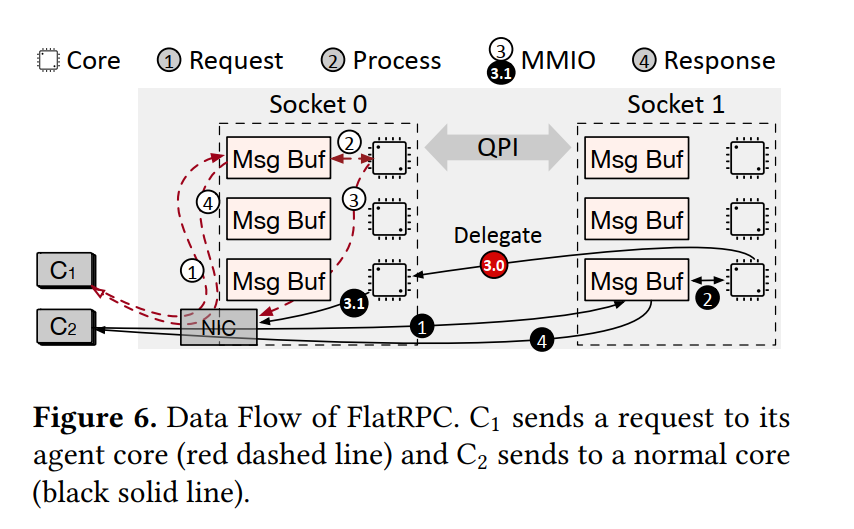
- FlatRPC 将 QP 的数量减少到 ,即客户端的数量,但是引入了额外的核与核之间的委托开销,但我们发现这样做是值得的:
- 原语命令是轻量级的,只有几个字节,同时 agent core 可以使用预取指令来加速委托过程
- 委托阶段收集了所有的离当前 NIC 较近的 Socket 的原语命令,从而减小了 MMIO 的开销。
- 后文有实验整明我们的 FlatRPC 相比于全连接方式有 1.5 倍的吞吐量提升。
- RDMA offloading:有的研究建议使用单边原语,例如 READ,来 offload 对客户端 GET 请求的处理,从而减轻服务器 CPU 的负担。在我们的系统中,我们实验发现 RDMA read 原语对应的吞吐量相比双边原语有一定的下降。因为我们有大量的读操作。因此在 FlatStore 中 GET 和 PUT 请求在服务端都是通过 RPC 原语来处理的。
Evaluation
Env
- 节点数目:1 server,12 clients
- 服务器:
- 内存:
- Optane DCPMM 1TB in total,每个 256GB
- 128 GB DRAM
- CPU:two 2.6GHz Intel Xeon Gold 6240M CPUs (36 cores in total)
- OS:Ubuntu 18.04
- 内存:
- 客户端:
- 内存:128GB DRAM
- CPU: two 2.2GHz Intel Xeon E5-2650 v4 CPUs (24 cores in total)
- OS:CentOS 7.4
- 服务器:
- 网络:Mellanox MSB7790-ES2F switch,MCX555AECAT ConnectX-5 EDR HCAs,100Gbps IB
- 参数:默认 batch_size 8
Compare
- 下表所示四种持久性索引,使用默认配置,具体参见原论文

Results
YCSB
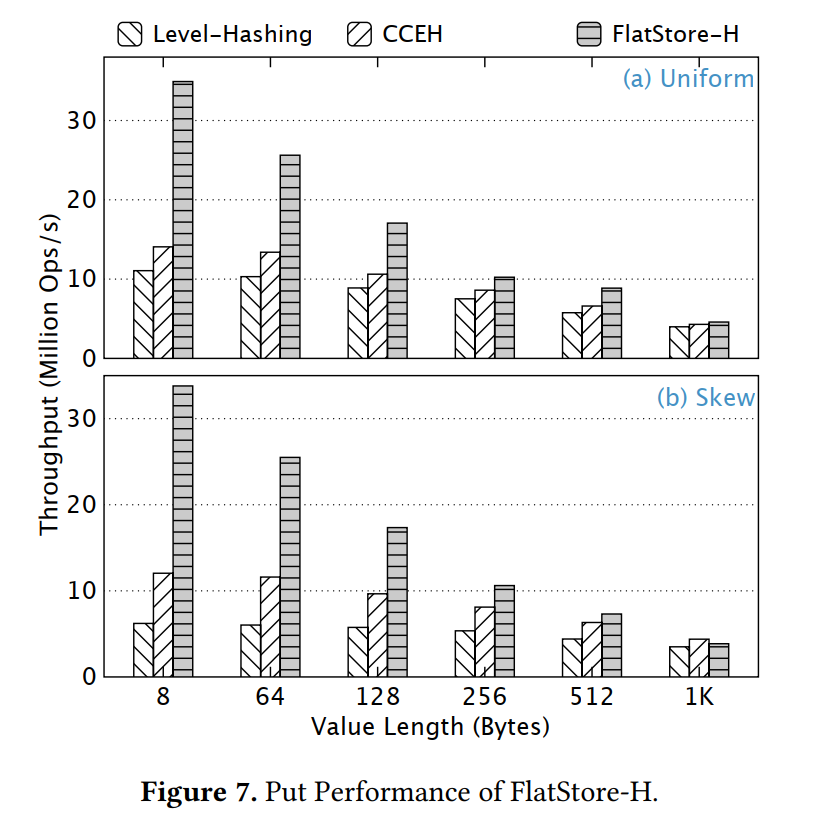
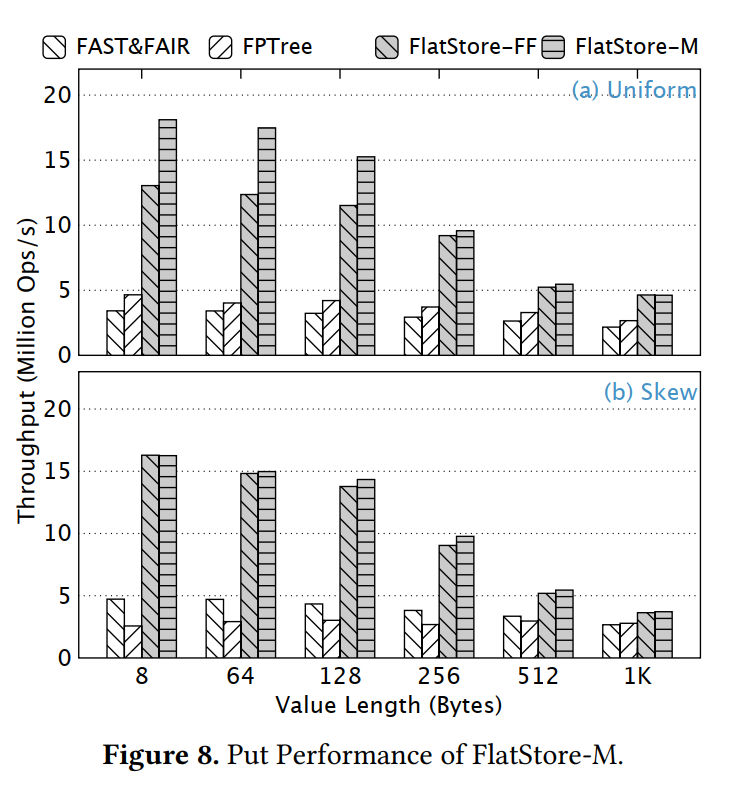
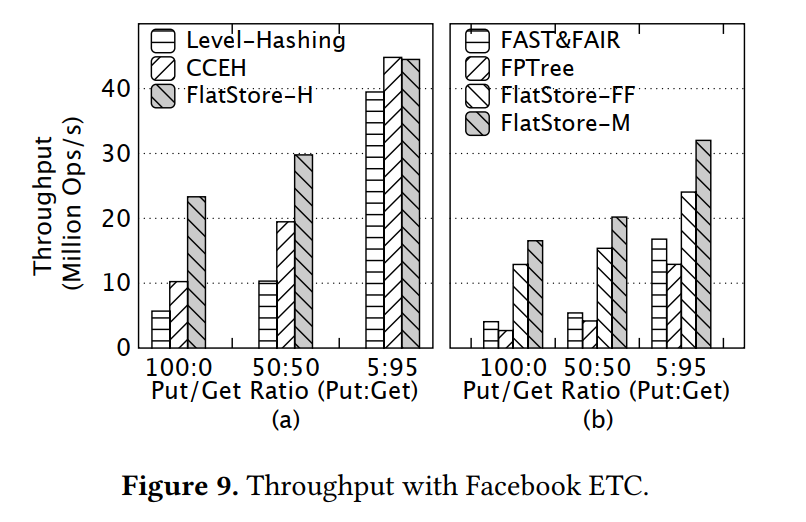
Facebook ETC Pool - Production Workload
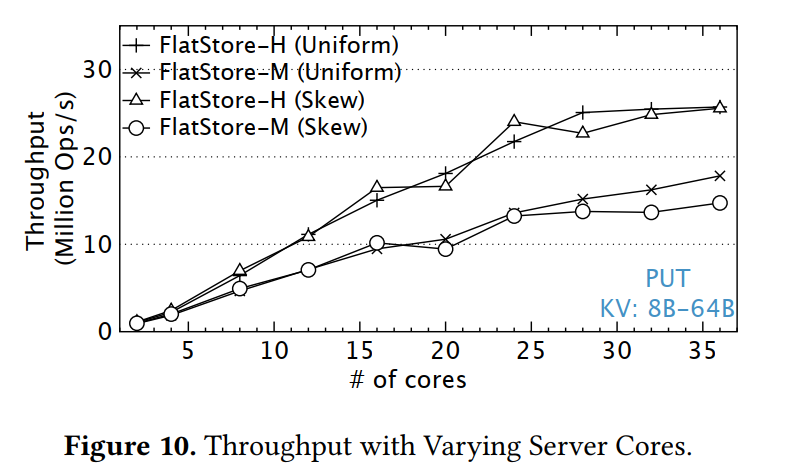
Multicore Scalability
Internal Function Performance Evaluations
- 对于每个优化点带来的性能提升,原文也有测试来体现,还对日志回收机制的效率进行了测试,具体细节请查看原文。
Related Work
- NVM-based KV stores:
- Hash Based: HiKV, Bullet
- Tree Based: NV-Tree, FP-Tree, wB+Tree, CDDS-Tree
- Log-structured Persistent Memory: LSNVMM, NOVA
- RDMA and Persistent Memory: Octopus, Hotpot, AsymNVM
