- 主要介绍 Ceph 缓存机制涉及到的相关参数
- 提供了一些参数的经验值参考
- 后续针对具体的IO设计更为细致的优化方案
Ceph Tiring 调优
- Ceph Tiring 功能需要仔细配置其各种参数以确保良好的性能。需要对工作负载I/O有基本的了解;只有当您的数据只有一小部分是热数据时,Tiring 才能很好地工作。均匀随机或涉及大量顺序访问模式的工作负载的情况下,要么没有任何改进,要么在某些情况下可能比无Tiring 更慢。
Flushing & Eviction
target_max_bytes / target_max_objects
- 该值设定了缓冲池中最大的数据字节数或对象个数,当缓冲池中数据大小或者对象个数到达该值时将根据缓存策略进行数据的刷回或者淘汰。
- 该值需要根据缓存池的容量大小以及副本个数来设置,以三副本为例,target_max_bytes 不应该超过容量的 1/3,如果实际的负载使得存储池中的数据大小达到了容量的 1/3,后续的 IO 将被阻塞,所以需要设置别的参数来避免池中的数据到达该阈值。
- 该类参数的设计目的:
- 作为刷回淘汰操作的触发条件,避免 OSD 被数据撑满。
- 为什么不直接使用存储池的容量作为该参数,是为了考虑另外一种场景,存在多个缓存池,使用相同的磁盘。
cache_target_full_ratio
- 该参数的设置是为了防止存储池中的数据大小达到 target_max_bytes/objects。
- 当数据到达 cache_target_full_ratio 时,将淘汰缓存池中的对象数据
- 淘汰数据本质就是删除数据,其开销相比于 flush/promote 小的多
- 需要注意的是,target_max_bytes 和 cache_target_full_ratio 虽然是对存储池的配置,但 Ceph 内部将这些参数用于每个 PG 的 limit 计算。
// 计算脏数据的比率和数据满的比率,单位为百万分之一
// get dirty, full ratios
uint64_t dirty_micro = 0;
uint64_t full_micro = 0;
// 如果设置了 target_max_bytes,就按照字节数算
if (pool.info.target_max_bytes && num_user_objects > 0) {
// 首先计算每个对象的平均大小 avg_size
uint64_t avg_size = num_user_bytes / num_user_objects;
// 脏数据率 = 100w * 脏数据对象数目 * 每个对象的平均大小 / 每个PG的平均字节数
dirty_micro =
num_dirty * avg_size * 1000000 /
std::max<uint64_t>(pool.info.target_max_bytes / divisor, 1);
// 满数据率 = 100w * 用户对象数目 * 每个对象的平均大小 / 每个PG的平均字节数
full_micro =
num_user_objects * avg_size * 1000000 /
std::max<uint64_t>(pool.info.target_max_bytes / divisor, 1);
}
// 如果设置了 target_max_objects,就按照对象个数算
if (pool.info.target_max_objects > 0) {
// 脏数据率 = 100w * 脏数据对象数目 / 每个 PG 的平均对象数目
uint64_t dirty_objects_micro =
num_dirty * 1000000 /
std::max<uint64_t>(pool.info.target_max_objects / divisor, 1);
// 取两种计算方式中的最大值
if (dirty_objects_micro > dirty_micro)
dirty_micro = dirty_objects_micro;
// 满数据率 = 100w * 用户对象数目 / 每个 PG 的平均对象数目
uint64_t full_objects_micro =
num_user_objects * 1000000 /
std::max<uint64_t>(pool.info.target_max_objects / divisor, 1);
if (full_objects_micro > full_micro)
full_micro = full_objects_micro;
}
dout(20) << __func__ << " dirty " << ((float)dirty_micro / 1000000.0)
<< " full " << ((float)full_micro / 1000000.0)
<< dendl;
- 每个 PG 计算出来的结果会因为该 PG 内的数据分布情况不一致,有的 PG 可能大于 full_ratio,有的可能小于 full_ratio,所以为了避免出现故障,不能将该数据设置为 1.
- 经验表明,不能将 cache_target_full_ratio 设置的太高,需要预留一定的空间,经验值 0.8 通常能够很好低保证系统运行。
cache_target_dirty_ratio / cache_target_high_dirty_ratio
- 这两个参数主要用于控制刷回操作的时机,区别在于刷回的速度不同
- 刷回操作是指 cache tier -> base tier 的数据写入过程,涉及到了一次完整的数据写入过程,开销相对较大。所以通常情况下,对象的刷回速度小于淘汰速度,因为淘汰操作开销更小
- 刷回操作是异步的,不直接影响客户端发来的 IO 请求处理
- 刷回速度不同的原因是刷回的并发线程数不同,高速刷回使用的并发线程更多。并发线程数一般由 OSD 的相关配置参数指定:osd_agent_max_ops, osd_agent_max_high_ops. 默认低速为 2 个线程,高速为 4 个线程
// flush mode
// 获取 flush_target 和 flush_high_target 参数,以及计算 flush_slop
uint64_t flush_target = pool.info.cache_target_dirty_ratio_micro;
uint64_t flush_high_target = pool.info.cache_target_dirty_high_ratio_micro;
uint64_t flush_slop = (float)flush_target * cct->_conf->osd_agent_slop;
// 根据传入的参数和 flush_mode 对 target 做修正
if (restart || agent_state->flush_mode == TierAgentState::FLUSH_MODE_IDLE) {
flush_target += flush_slop;
flush_high_target += flush_slop;
} else {
flush_target -= std::min(flush_target, flush_slop);
flush_high_target -= std::min(flush_high_target, flush_slop);
}
// 根据脏数据的比例,设置 flush_mode
if (dirty_micro > flush_high_target) {
flush_mode = TierAgentState::FLUSH_MODE_HIGH;
} else if (dirty_micro > flush_target || (!flush_target && num_dirty > 0)) {
flush_mode = TierAgentState::FLUSH_MODE_LOW;
}
...
skip_calc:
bool old_idle = agent_state->is_idle();
// 设置新的 flush_mode,并更新统计信息
if (flush_mode != agent_state->flush_mode) {
dout(5) << __func__ << " flush_mode "
<< TierAgentState::get_flush_mode_name(agent_state->flush_mode)
<< " -> "
<< TierAgentState::get_flush_mode_name(flush_mode)
<< dendl;
recovery_state.update_stats(
[=](auto &history, auto &stats) {
if (flush_mode == TierAgentState::FLUSH_MODE_HIGH) {
osd->agent_inc_high_count();
stats.stats.sum.num_flush_mode_high = 1;
} else if (flush_mode == TierAgentState::FLUSH_MODE_LOW) {
stats.stats.sum.num_flush_mode_low = 1;
}
if (agent_state->flush_mode == TierAgentState::FLUSH_MODE_HIGH) {
osd->agent_dec_high_count();
stats.stats.sum.num_flush_mode_high = 0;
} else if (agent_state->flush_mode == TierAgentState::FLUSH_MODE_LOW) {
stats.stats.sum.num_flush_mode_low = 0;
}
return false;
});
agent_state->flush_mode = flush_mode;
}
- 理论上,集群在正常的使用情况下,脏对象的百分比一般在低脏数据率的附近徘徊,部分对象数据将被刷回到存储层,使用的刷回线程较少,尽可能地减小集群的响应延迟;但写如果发生突增,脏数据的比例将会小幅度上升,但通常不会持续太长一段时间,后台线程仍然进行刷回。但如果出现了持续写,且速度大于低速刷回的速度,那么脏数据的比率将会持续上升,如果持续时间较短则保持低俗刷回,脏数据比例会逐渐下降;但如果持续时间较长,到达高速刷回的阈值,将开启更多的线程进行高速刷回,避免脏数据率进一步增长,一旦写流量减少,脏数据率又会重新回到低阈值。
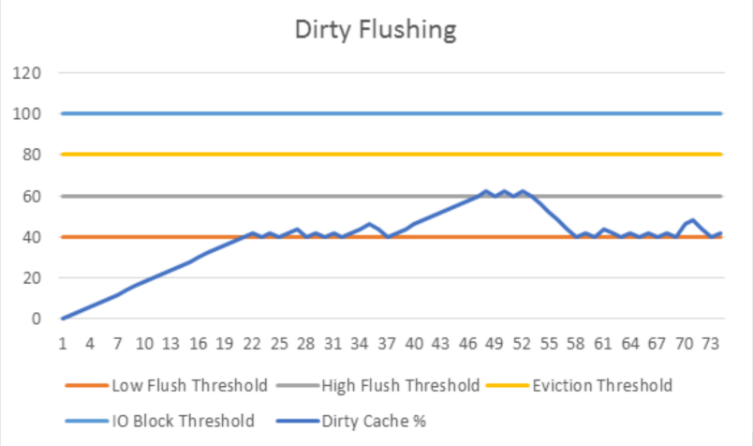
- 脏数据率的低阈值和高阈值之间需要存在一定的差距,从而才能够较好地吸收正常写操作,而不需要引入高阈值。高阈值应被视为一种紧急限制。经验值表明:一个好的初始值是低阈值为0.4,高阈值为0.6。
- osd_agent_max_ops 的配置,需要根据实际情况进行设置,以便在正常操作条件下,脏对象的数量在低脏比率上下浮动。该参数无准确的经验值,因为该值在很大程度上取决于顶层与底层的大小和性能之比。但是,首先将osd_agent_max_ops设置为1,然后根据需要增加,将 osd_agent_max_high_ops 设置为 osd_agent_max_ops 的至少两倍。
- Ceph Dashboard 可以观察刷回情况,如果正在进行高速刷新,可以考虑增加osd_agent_max_ops。如果发现缓存层被填满并阻塞了1/O,那么需要考虑降低 cache_target_dirty_high_ratio,或者增加osd agent_max_high_ops 线程数来阻止层被脏对象填满
hitset_count & hitset_period
- hitset_count 控制在最老的 hitset 开始被清除之前可以存在多少 hitset(即最多多少个 hitset)。hitset_period 控制创建 HitSet 的频率。
- 如果在实验室环境中测试分层,应该注意,为了创建 HitSet,需要对 PG 进行 I/O;在空闲集群上,不会创建或清除hitset。
- 拥有正确的数量并控制创建 hitset 的频率是能够可靠地控制何时提升对象的关键。
- hitset 只包含对象是否被访问过的数据,不包含访问对象的次数计数
- 如果 hitset_period 太大,那么即使访问相对较少的对象也会出现在大多数 hitset 中。例如,对于hitset_period为2分钟的情况,一个包含磁盘块的RBD对象(日志文件每分钟更新一次)与一个每秒访问100次的对象处于相同的hitset中
- 相反,如果 hitset_period 过短,即使是热数据对象也可能无法出现在足够多的 hitset 中,从而无法使热数据成为 Promote 的候选对象,则缓存层得不到充分利用。
- 通过找到正确的 HitSet 创建周期,就能够捕捉到 I/O 的对应视图,从而设置适当大小的热数据比例来优化 Promotion
- 这两个参数定义一个对象必须出现多少最近的 hitset 才能 Promote。
- 由于概率的影响,半热数据 与 recency 设定的关系不是线性的。一旦 recency 设置超过 3或4,需要 Promote 的对象的数量将指数级下降
- 虽然可以分别对读或写分别设置Promeote策略,但它们都引用相同的HitSet数据,因此无法确定访问是读还是写。
- 如果您将 recency 设置为高于 hitset_count 的值,那么它将永远不会 Promote。例如,可以通过将 min_write_recency_for_promote 设置为高于 hitset_count 的值来确保写 I/O 不会导致对象提升。
- Promotion 是一个开销较大的操作,所以尽量只在必须进行 Promote 的场景下进行该操作。
- 通常通过配置 HitSet 和 recency 来限制 Promote 操作,但为了限制 Promotion 带来的影响,有额外的参数来限制 Promotion 的速度。
- 默认限制是 4 Mbps 或每秒 5 个对象。虽然这些数字可能看起来很低,特别是与最新ssd的性能相比,他们的主要目标是尽量减少 Promote 对延迟的影响,所以需要根据实际的负载和硬件条件应该进行仔细的调优,以便在集群中找到更好的平衡值。
- 需要注意的是,这个值是根据每个OSD配置的,因此总的 Promote 速度将是所有 OSD 的总和。
hit_set_grade_search_last_n
- 该配置选项允许配置刷回对象的选择过程(即选择哪些对象进行刷回)
- 该参数控制多少个 hitset 被用于查询对象的访问热度,而对象的访问热度反映了访问它的频率。
- 经验值表明一般将该参数设置为 recency 对应的值
hit_set_grade_decay_rate
- 两个连续的hit_set之间的温度衰减率
- 该参数与 hit_set_grade_search_last_n 协同生效,Hitset 的相关结果会随着时间变得不太具有时效性,所以为了确保更频繁访问的对象没有被错误地刷新,比其他对象更频繁访问的对象具有更热的评级。
- 需要注意的是,min_flush 和 evict_age 的设置可能会覆盖被刷新或被驱逐对象的访问热度
cache_min_flush_age & cache_min_evict_age
- cache_min_evict_age 和 cache_min_flush_age 参数简单地定义了一个对象在允许被刷新或被驱逐之前必须多长时间没有被修改。
- 可以用来阻止那些仅仅不够 Promote 的对象,使它们不再陷入在层之间移动的循环中。
- 经验值将它们设置为10到30分钟,但是需要注意,在没有需要刷新或清除的对象的情况下,要保证缓存层不能被填满。
