- Alluxio 简单介绍,测试报告,然后会结合一些实际体验。
Alluxio
- Alluxio(之前名为 Tachyon),是一个开源的具有内存级速度的虚拟分布式存储系统, 使得应用程序可以以内存级速度与任何存储系统中的数据进行交互。
- 源码:https://github.com/Alluxio/alluxio
- 论文:https://www2.eecs.berkeley.edu/Pubs/TechRpts/2018/EECS-2018-29.pdf
架构
- 文档:https://docs.alluxio.io/os/user/stable/cn/Overview.html
- 初衷:建立底层存储和大数据计算框架之间的存储系统,为大数据应用提供一个数量级的加速,同时它还提供了通用的数据访问接口。
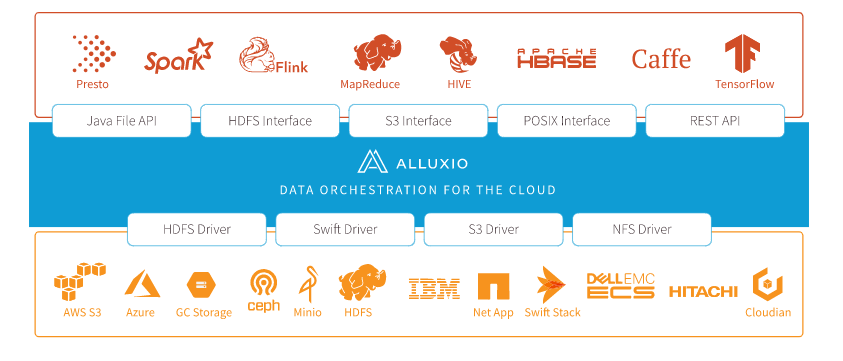
- 主要分为两层:UFS 和 Alluxio
- UFS:底层文件存储,该存储空间代表不受Alluxio管理的空间。
- UFS存储可能来自外部文件系统,包括如HDFS或S3。 Alluxio可能连接到一个或多个UFS并在一个命名空间中统一呈现这类底层存储。
- 通常,UFS存储旨在相当长一段时间持久存储大量数据。
- Alluxio 存储:
- Alluxio 做为一个分布式缓存来管理 Alluxio workers 本地存储,包括内存。这个在用户应用程序与各种底层存储之间的快速数据层带来的是显著提高的I/O性能。
- Alluxio存储主要用于存储热的、暂时的数据,而不关注长期的持久性。
- 要管理的每个Alluxio工作节点的存储数量和类型由用户配置决定。
- 即使数据当前不在Alluxio存储中,通过Alluxio连接的UFS中的文件仍然 对Alluxio客户可见。当客户端尝试读取仅可从UFS获得的文件时数据将被复制到Alluxio存储中。
- UFS:底层文件存储,该存储空间代表不受Alluxio管理的空间。
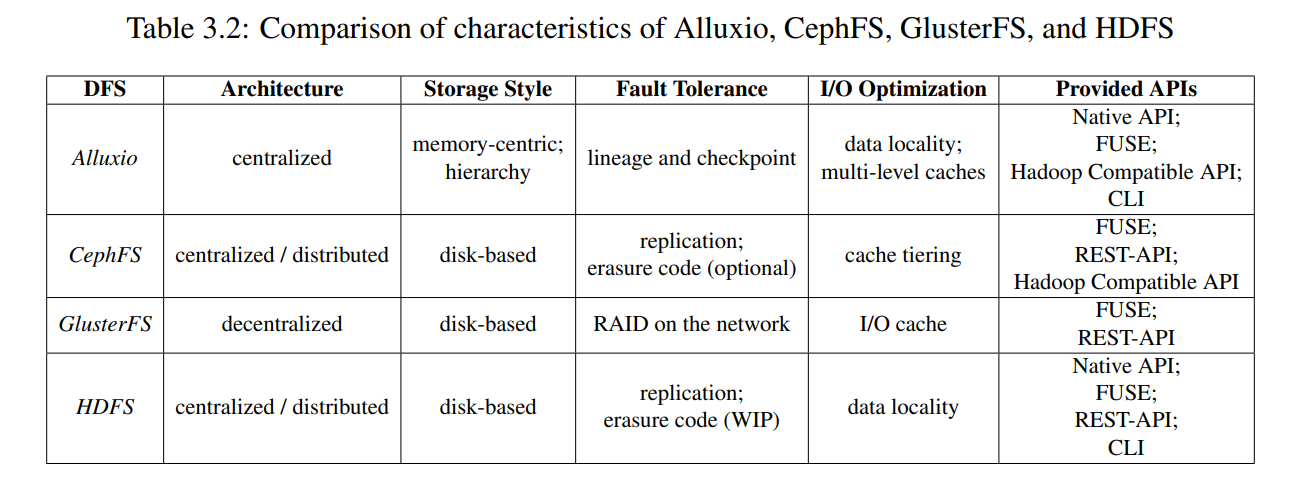
- 和其他常见的分布式文件系统对比:
角色
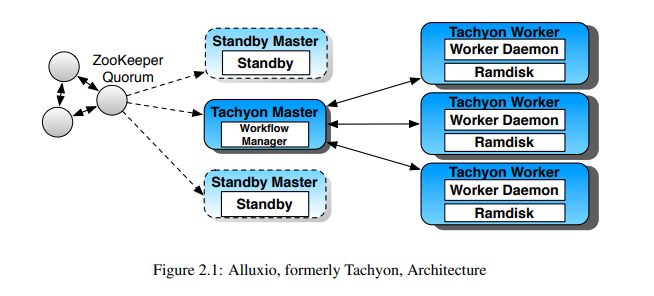
- Alluxio的设计使用了单Master和多Worker的架构。从高层的概念理解,Alluxio可以被分为三个部分,Master,Worker和Client。
- Master和Worker一起组成了Alluxio的服务端,它们是系统管理员维护和管理的组件。
- Client通常是应用程序,如Spark或MapReduce作业,或者Alluxio的命令行用户。
- 以前的版本需要借助 ZooKeeper 进行高可用选主,后续的 Alluxio 自己实现了高可用机制。(注:Tachyon 为 Alluxio 旧称)
Master
-
主从模式:主Master主要负责处理全局的系统元数据,从Master不断的读取并处理主Master写的日志。同时从Master会周期性的把所有的状态写入日志。从Master不处理任何请求。
- 主从之间心跳检测
- 主Master不会主动发起与其他组件的通信,它只是以回复请求的方式与其他组件进行通信。一个Alluxio集群只有一个主Master。
-
简单模式:最多只会有一个从Master,而且这个从Master不会被转换为主Maste。
-
高可用模式:可以有零个或者多个从Master。 当主Master异常的时候,系统会选一个从Master担任新的主Master。
Worker
- 类似于 OSD
- Alluxio的Worker负责管理分配给Alluxio的本地资源。这些资源可以是本地内存,SSD 或者硬盘,其可以由用户配置。
- Alluxio的Worker以块的形式存储数据,并通过读或创建数据块的方式处理来自Client读写数据的请求。但Worker只负责这些数据块上的数据;文件到块的实际映射只会存储在Master上。
Features
全局命名空间
- Alluxio通过使用透明的命名机制和挂载API来实现有效的跨不同底层存储系统的数据管理。
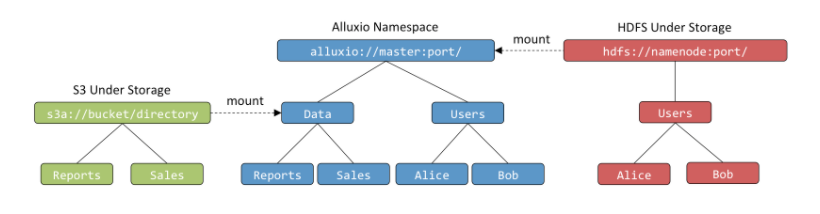
- https://www.alluxio.io/resources/whitepapers/unified-namespace-allowing-applications-to-access-data-anywhere/
智能多层级缓存
- Alluxio支持分层存储,以便管理内存之外的其它存储类型。目前Alluxio支持这些存储类型(存储层):MEM (内存),SSD (固态硬盘),HDD (硬盘驱动器)
- 单层/多层 区别?
单层存储
- 启动时默认分配一个 ramdisk,Alluxio将在每个worker节点上默认发放一个ramdisk并占用一定比例的系统的总内存。 此ramdisk将用作分配给每个Alluxio worker的唯一存储介质。
- 可以显示地设置每个 Worker 的 ramdisk 大小
alluxio.worker.ramdisk.size=16GB
- 可以指定多个存储介质共同组成一个 level,也可以自定义添加存储介质类型
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk,/mnt/ssd1,/mnt/ssd2
alluxio.worker.tieredstore.level0.dirs.mediumtype=MEM,SSD,SSD
- 所提供的路径应该指向安装适当存储介质的本地文件系统中的路径。要启用短路操作,这些路径的权限应该允许客户端用户对该路径进行读、写和执行。例如,启动Alluxio服务的同一用户组中的客户端用户需要770权限。
- 在更新存储媒体之后,我们需要指出为每个存储目录分配了多少存储空间。例如,如果我们想在ramdisk上使用 16GB,在每个 SSD 上使用 100GB:
alluxio.worker.tieredstore.level0.dirs.quota=16GB,100GB,100GB
多层存储
- 通常建议使用具有异构存储介质的单一存储层。在某些环境中,工作负载将受益于基于I/O速度的存储介质显式排序。Alluxio假设层是根据I/O性能从上到下排序的。例如,用户经常指定以下层:
- MEM
- SSD
- HDD
- 写策略:用户写新的数据块时,默认情况下会将其写入顶层存储。如果顶层没有足够的可用空间, 则会尝试下一层促成。如果在所有层上均未找到存储空间,因Alluxio的设计是易失性存储,Alluxio会释放空间来存储新写入的数据块。会基于 block annotation policies 尝试从 worker 中驱逐数据,如果不能释放出新的空间,那么该写入将会失败。
- eviction model 是同步的且是代表客户端来执行空间的释放的,主要是为要写入的客户端的数据腾出一块空闲空间,这种同步模式预计不会导致性能下降,因为在 block annotation policies 下有序的一组数据块通常都是可用的。
- 读策略:如果数据已经存在于Alluxio中,则客户端将简单地从已存储的数据块读取数据。 如果将Alluxio配置为多层,则不一定是从顶层读取数据块, 因为数据可能已经透明地挪到更低的存储层。有两种数据读取策略:
ReadType.CACHEandReadType.CACHE_PROMOTE。- 用
ReadType.CACHE_PROMOTE读取数据将在从worker读取数据前尝试首先将数据块挪到 顶层存储。也可以将其用作为一种数据管理策略 显式地将热数据移动到更高层存储读取。 ReadType.CACHEAlluxio将块缓存到有可用空间的最高层。因此,如果该块当前位于磁盘(SSD/HDD)上,您将以磁盘速度读取该缓存块。
- 用
# configure 2 tiers in Alluxio
alluxio.worker.tieredstore.levels=2
# the first (top) tier to be a memory tier
alluxio.worker.tieredstore.level0.alias=MEM
# defined `/mnt/ramdisk` to be the file path to the first tier
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
# defined MEM to be the medium type of the ramdisk directory
alluxio.worker.tieredstore.level0.dirs.mediumtype=MEM
# set the quota for the ramdisk to be `100GB`
alluxio.worker.tieredstore.level0.dirs.quota=100GB
# configure the second tier to be a hard disk tier
alluxio.worker.tieredstore.level1.alias=HDD
# configured 3 separate file paths for the second tier
alluxio.worker.tieredstore.level1.dirs.path=/mnt/hdd1,/mnt/hdd2,/mnt/hdd3
# defined HDD to be the medium type of the second tier
alluxio.worker.tieredstore.level1.dirs.mediumtype=HDD,HDD,HDD
# define the quota for each of the 3 file paths of the second tier
alluxio.worker.tieredstore.level1.dirs.quota=2TB,5TB,500GB
Block Allocation Policies
- Alluxio使用块分配策略来定义如何跨多个存储目录(在同一层或不同层中)分配新块。分配策略定义将新块分配到哪个存储目录中。这是通过 worker 属性
alluxio.worker.allocate.class配置的。MaxFreeAllocator:从 0 层开始尝试到最低层,尝试将块分配到当前最具有可用性的存储目录。这是默认行为。RoundRobinAllocator:从 0 层到最低层开始尝试。在每一层上,维护存储目录的循环顺序。尝试按照轮询顺序将新块分配到一个目录中,如果这不起作用,就转到下一层。GreedyAllocator:这是 Allocator 接口的一个示例实现。它从顶层循环到最低层,尝试将新块放入可以包含该块的第一个目录中。
[Experimental] Block Allocation Review Policies
- 这是在Alluxio 2.4.1中增加的一个实验特性。在未来的版本中,接口可能会发生变化。
- Alluxio 使用块分配审查策略来补充分配策略。与定义分配应该是什么样子的分配策略相比,分配审查过程验证分配决策,并防止那些不够好的分配决策。评审者与分配器一起工作
- 这是由worker属性
alluxio.worker.review.class配置的。ProbabilisticBufferReviewer:基于每个存储目录对应的可用的空间,概率性低拒绝把新的数据块写入对应目录的请求。这个概率由alluxio.worker.reviewer.probabilistic.hardlimit.bytes和alluxio.worker.reviewer.probabilistic.softlimit.bytes来决定。- 当可用空间低于 hardlimit,默认是 64MB,新的块将被拒绝
- 当可用空间大于 softlimit,默认 256MB,新的数据块将不会被拒绝
- 当可用空间介于上下限之间时,接受新的块的写入的概率将会随着可用容量的下降而线性低下降,我们选择在目录被填满之前尽早拒绝新的块,因为当我们读取块中的新数据时,目录中的现有块会扩大大小。在每个目录中留下缓冲区可以减少 eviction 的机会。
AcceptingReviewer:此审阅者接受每个块分配。和 v2.4.1 之前的行为完全一样
Block Annotation Policies
- Alluxio使用块注释策略(从v2.3开始)来保持存储中块的严格顺序。Annotation策略定义了跨层块的顺序,并在以下过程中被参考:
- Eviction
- Dynamic Block Placement.
- 与写操作一起发生的 Eviction 操作将尝试根据块注释策略执行的顺序删除块。按注释顺序排列的最后一个块是驱逐的第一个候选者,无论它位于哪一层。
- 可配置对应的 Anotator 类型,
alluxio.worker.block.annotator.class。有如下 annotation 实现:LRUAnnotator:根据最近最少使用的顺序注释块。这是Alluxio的默认注释器。LRFUAnnotator:使用可配置的权重,根据最近最不常用和最不常用的顺序注释块。- 如果权重完全偏向最近最少使用的,行为将与LRUAnnotator相同。
- 使用
alluxio.worker.block.annotator.lrfu.step.factor和alluxio.worker.block.annotator.lrfu.attenuation.factor来配置。
Managing Data Replication in Alluxio
Passive Replication
- 与许多分布式文件系统一样,Alluxio中的每个文件都包含一个或多个分布在集群中存储的存储块。默认情况下,Alluxio可以根据工作负载和存储容量自动调整不同块的复制级别。例如,当更多的客户以类型CACHE或CACHE_PROMOTE请求来读取此块时Alluxio可能会创建此特定块更多副本。当较少使用现有副本时,Alluxio可能会删除一些不常用现有副本 来为经常访问的数据征回空间(块注释策略)。 在同一文件中不同的块可能根据访问频率不同而具有不同数量副本。
- 默认情况下,此复制或征回决定以及相应的数据传输 对访问存储在Alluxio中数据的用户和应用程序完全透明。
Active Replication
- 除了动态复制调整之外,Alluxio还提供API和命令行 界面供用户明确设置文件的复制级别目标范围。 尤其是,用户可以在Alluxio中为文件配置以下两个属性:
alluxio.user.file.replication.min是此文件的最小副本数。 默认值为0,即在默认情况下,Alluxio可能会在文件变冷后从Alluxio管理空间完全删除该文件。 通过将此属性设置为正整数,Alluxio 将定期检查此文件中所有块的复制级别。当某些块 的复制数不足时,Alluxio不会删除这些块中的任何一个,而是主动创建更多 副本以恢复其复制级别。alluxio.user.file.replication.max是最大副本数。一旦文件该属性 设置为正整数,Alluxio将检查复制级别并删除多余的 副本。将此属性设置为-1为不设上限(默认情况),设置为0以防止 在Alluxio中存储此文件的任何数据。注意,alluxio.user.file.replication.max的值 必须不少于alluxio.user.file.replication.min。
Evaluation
Testing Alluxio for Memory Speed Computation on Ceph Objects
- https://blog.zhaw.ch/icclab/testing-alluxio-for-memory-speed-computation-on-ceph-objects/#more-12747
- 4th SEPTEMBER 2020
环境介绍
- 底层存储:Ceph mimic
- 6 OpenStack VMs
- one Ceph monitor
- three storage devices running Object Storage Devices (OSDs)
- one Ceph RADOS Gateway (RGW) node
- one administration node
- total storage size of 420GiB was spread over 7 OSD volumes attached to the three OSD nodes
- 6 OpenStack VMs
- Alluxio 2.3, Java8 (换成 Java11 即升级 Alluxio 后会有后续提升)
- Spark 3.0.0
- 两种模式:
- 单 VM 运行 Alluxio 和 Spark (16vCPU,40GB of memory)
- 集群模式:two additional Spark and Alluxio worker nodes are configured (with 16vCPUs and 40GB of memory).
- 对比测试:
- 直接访问 Ceph RGW 和 通过 Alluxio 访问
- 通过 Alluxio 访问时,第一次访问文件的话,Alluxio 会将文件上传到内存中,后续的文件访问将直接命中内存,从而带来显著的性能提升。
- 不同文件大小: 1GB, 5GB and 10GB,记录第一层和第二次访问文件需要的时间。
- 平均会运行超过 10 次
- 然后再次启动相同的应用程序,以再次测量相同的文件访问时间。这样做的目的是展示内存中的 Alluxio 缓存如何为以后访问相同数据的应用程序带来好处。
- 直接访问 Ceph RGW 和 通过 Alluxio 访问
测试结果:
- 如下为单节点测试测试结果,Ceph 上第二次访问该文件相比于 Alluxio 在 1GB,5GB,10GB 时的执行时间分别为 75x,111x,107x
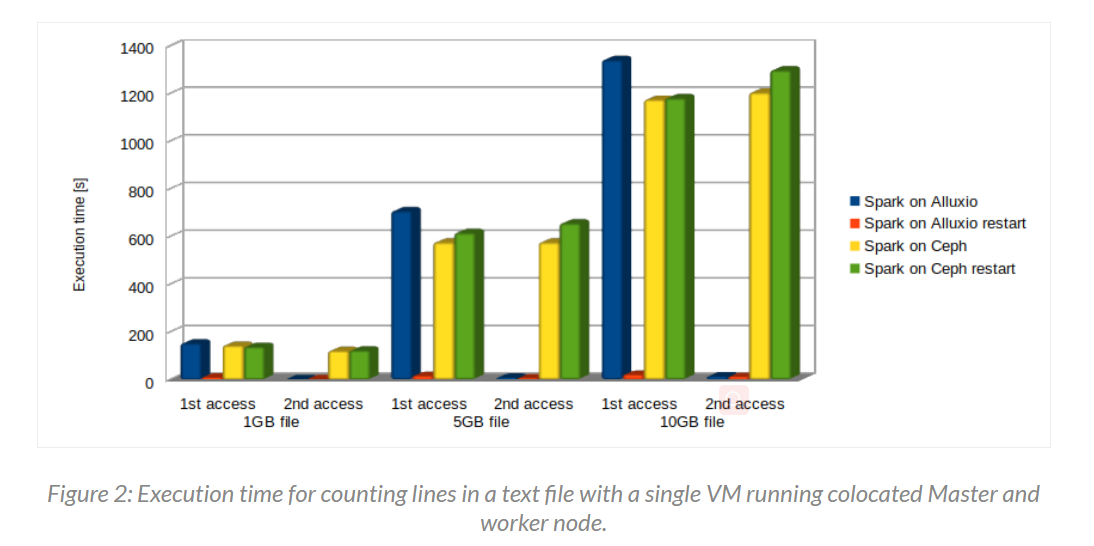
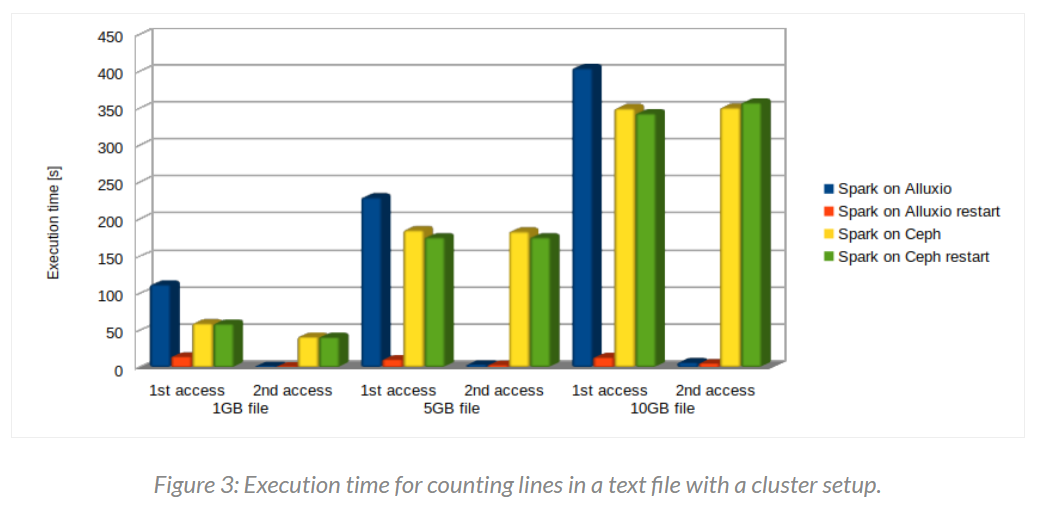
- 如下为集群模式下的测试结果,所有情况的整体时间比单机的时候少了很多,Ceph 相比于 Alluxio 的第二次访问时间为 35x, 57x, 65x
Accelerate And Scale Big Data AnAlytics with Alluxio And intel®optane™ persistent Memory
- https://www.alluxio.io/app/uploads/2020/05/Intel-Alluxio-DCPMM-Whitepaper-200507.pdf
Reliability Testing
- TODO
Install & Deploy
Single Server
Download
- Download Binary: https://www.alluxio.io/download/
- Choose Version. (eg. Alluxio 2.4.1 Release. 1.4GB)
- Tar file:
tar -xzf alluxio-2.4.1-bin.tar.gz
Initial Config
cd alluxio-2.4.1/conf && cp alluxio-site.properties.template alluxio-site.propertiesecho "alluxio.master.hostname=localhost" >> conf/alluxio-site.properties- [Optional] If use local file system, you can specific configuration in conf files like this:
echo "alluxio.master.mount.table.root.ufs=/root/shunzi/Alluxio/tmp" >> conf/alluxio-site.properties - Validate env:
./bin/alluxio validateEnv local
2 Errors:
ValidateRamDiskMountPrivilege
ValidateHdfsVersion
Start Alluxio
- Format journal and storage directory:
./bin/alluxio format- It may throw exceptions
java.nio.file.NoSuchFileException: /mnt/ramdisk/alluxioworkerinlog/task.log. So you need tomkdir -p /mnt/ramdisk/alluxioworker
- It may throw exceptions
- Start alluxio (with a master and a worker):
./bin/alluxio-start.sh local SudoMount - Stop local server:
./bin/alluxio-stop.sh local./bin/alluxio-stop.sh all
Verify
- Access website
http://localhost:19999to check the master server status. - Access website
http://localhost:30000to check the worker server status. - For internal network, you can use reverse proxy like this: (And you can access website master
http://114.116.234.136:19999and workerhttp://114.116.234.136:30000)autossh -M 1999 -fNR 19999:localhost:19999 [email protected]autossh -M 3000 -fNR 30000:localhost:30000 [email protected]
Run tests
- Verify run status and run test cases:
./bin/alluxio runTests - The runTests command runs end-to-end tests on an Alluxio cluster to provide a comprehensive sanity check.
- It will generate directory
/default_tests_filesand use different cache policy to upload files.- BASIC_CACHE_ASYNC_THROUGH
- BASIC_CACHE_CACHE_THROUGH
- BASIC_CACHE_MUST_CACHE
- BASIC_CACHE_PROMOTE_ASYNC_THROUGH
- BASIC_CACHE_PROMOTE_CACHE_THROUGH
- BASIC_CACHE_PROMOTE_MUST_CACHE
- BASIC_CACHE_PROMOTE_THROUGH
- BASIC_CACHE_THROUGH
- BASIC_NON_BYTE_BUFFER_CACHE_ASYNC_THROUGH
- BASIC_NON_BYTE_BUFFER_CACHE_CACHE_THROUGH
- BASIC_NON_BYTE_BUFFER_CACHE_MUST_CACHE
- BASIC_NON_BYTE_BUFFER_CACHE_PROMOTE_ASYNC_THROUGH
- BASIC_NON_BYTE_BUFFER_CACHE_PROMOTE_CACHE_THROUGH
- BASIC_NON_BYTE_BUFFER_CACHE_PROMOTE_MUST_CACHE
- BASIC_NON_BYTE_BUFFER_CACHE_PROMOTE_THROUGH
- BASIC_NON_BYTE_BUFFER_CACHE_THROUGH
- BASIC_NON_BYTE_BUFFER_NO_CACHE_ASYNC_THROUGH
- BASIC_NON_BYTE_BUFFER_NO_CACHE_CACHE_THROUGH
- BASIC_NON_BYTE_BUFFER_NO_CACHE_MUST_CACHE
- BASIC_NON_BYTE_BUFFER_NO_CACHE_THROUGH
- BASIC_NO_CACHE_ASYNC_THROUGH
- BASIC_NO_CACHE_CACHE_THROUGH
- BASIC_NO_CACHE_MUST_CACHE
- BASIC_NO_CACHE_THROUGH
Simple Example
Upload files from local server
- Show fs command help:
./bin/alluxio fs - List the files in Alluxio:
./bin/alluxio fs ls / - Copy files from local server:
./bin/alluxio fs copyFromLocal LICENSE /LICENSE - List again:
./bin/alluxio fs ls / - Cat the file:
./bin/alluxio fs cat /LICENSE
