- 一个项目测试使用到了 CephFS,故简要整理 CephFS 资料和相关文档
CephFS
Overview
- CephFS 应用相比于 RBD/RGW 不够广泛主要是因为文件系统采用树状结构管理数据(文件和目录)、基于查表寻址的设计理念与 Ceph 扁平化的数据管理方式、基于计算进行寻址的设计理念有些违背;其次文件系统的支持常常需要集中的元数据管理服务器来作为树状结构的统一入口,这又与 Ceph 去中心化、追求近乎无限的横向扩展能力的设计思想冲突。
- 由于分布式文件系统的需求仍旧很大,应用场景尤为广泛,在 Ceph 不断的版本迭代中,CephFS 也取得了越来越好的支持。
背景
- 要想实现分布式文件系统,那么就必须实现分布式文件系统的特点,即具有良好的横向扩展性,性能能够随着存储规模呈线性增长,为了实现这样的目标则需要对文件系统命名空间分而治之,即实现相应的负荷分担和负载均衡,采用相应的数据路由算法。
文件系统数据负载均衡分区
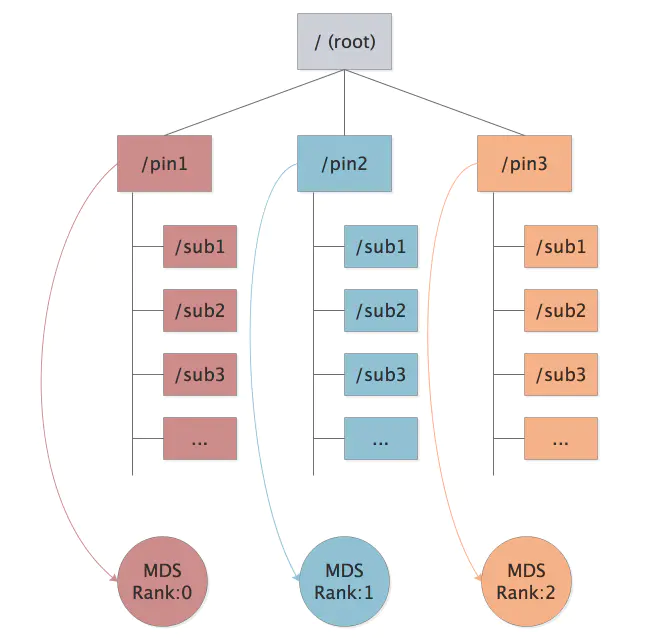
静态子树分区
- 手工分区,数据直接分配到某个固定的服务节点,负载不均衡时再手动调整。
HASH 计算分区
- HASH 计算数据的存储位置,保证了数据分布的均衡,但如果环境变化(集群规模变化)此时需要固定原有的数据分区而减少数据的迁移,或者根据元数据的访问频率,要想保证 MDS 负载均衡,需要重新决定元数据的分布,此时则不适合使用 HASH
动态子树分区
- 通过实时监控集群节点的负载,动态调整子树分布于不同的节点。这种方式适合各种异常场景,能根据负载的情况,动态的调整数据分布,不过如果大量数据的迁移肯定会导致业务抖动,影响性能。在元数据存储、流量控制和灵活的资源利用策略方面,动态分区比其他技术有许多优势。
- https://ceph.com/wp-content/uploads/2016/08/weil-mds-sc04.pdf
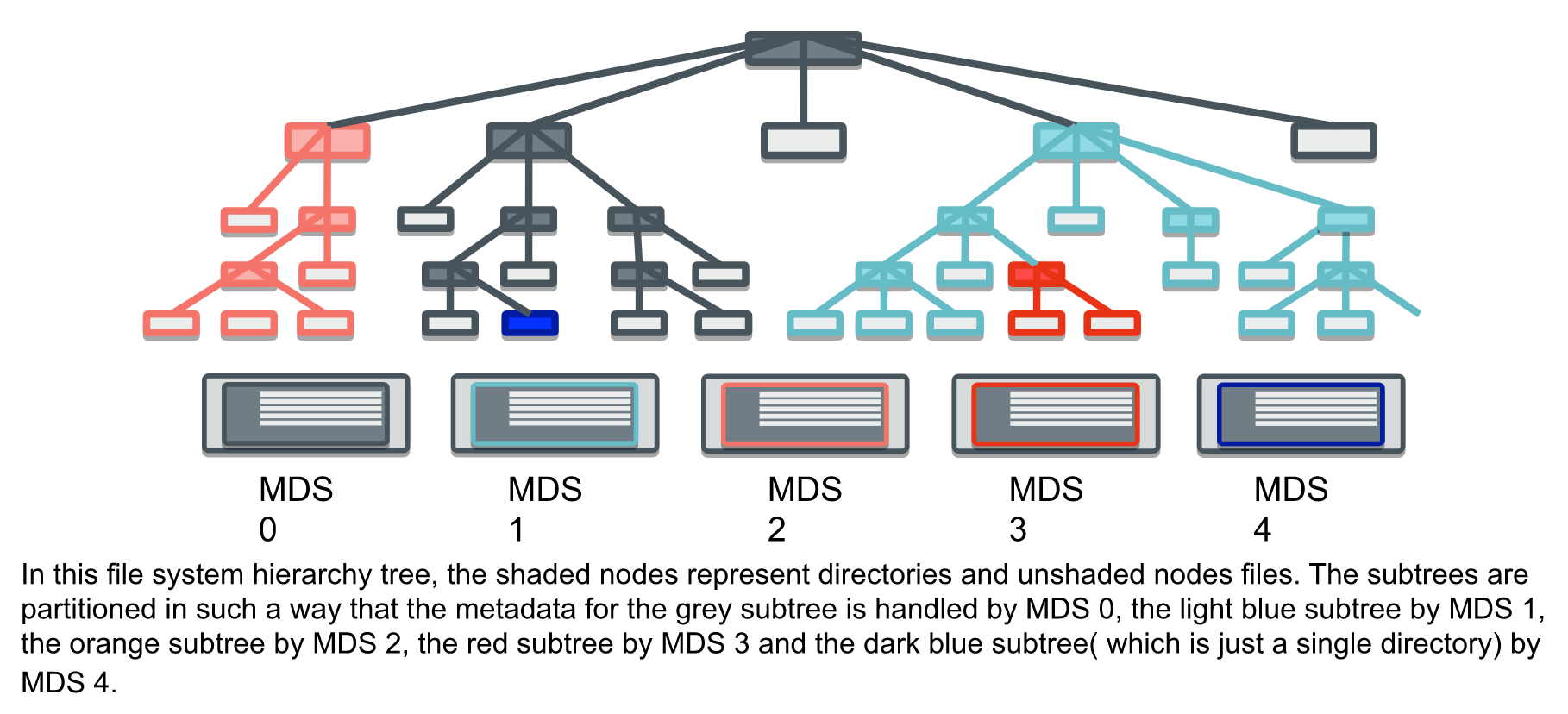
- 动态子树分区方法的核心是将文件系统作为层次结构处理。通过将层次结构的子树的权限委托给不同的元数据服务器,对文件系统进行分区。委托可以嵌套:例如,/usr可以分配给一个MDS,而/usr/local可以分配给另一个MDS。但是,在没有显式分配子树的情况下,嵌套在某个点下的整个目录树被假定驻留在同一台服务器上。
- 这个结构中隐含着层次结构遍历的过程,以便找到并打开嵌套的索引节点,以便随后下降到文件层次结构中。这样的路径遍历对于验证POSIX语义所要求的嵌套项的用户访问权限也是必要的,对于在目录层次结构深处定位一个文件来说,这个过程可能代价很高。
- 为了允许有效地处理客户机请求(以及正确响应它们所需的路径遍历),每个MDS都缓存缓存中所有项的前缀索引节点,以便在任何时候缓存的层次结构子集仍然是树结构。也就是说,只有叶子项可以从缓存中过期;在目录中包含的项首先过期之前,不能删除目录。这允许对所有已知项进行权限验证,而不需要任何额外的I/O成本,并保持层次一致性。
- 为了适应文件系统发展和工作负载变化的要求,MDS集群必须调整目录分区,以保持工作负载的最佳分布。动态分布是必要的,因为层次结构部分的大小和流行度都以一种不均匀和不可预测的方式随时间变化。通过允许MDS节点传输目录层次结构的子树的权限,元数据分区会随着时间的推移进行修改。MDS节点定期交换心跳消息,其中包括对其当前负载级别的描述。此时,忙碌的节点可以识别层次结构中适当流行的部分,并发起一个双重提交事务,将权限传递给非繁忙节点。在此交换过程中,所有活动状态和缓存的元数据都被转移到新的权威节点,这既是为了保持一致性,也是为了避免磁盘I/O,否则,新权威节点将需要磁盘I/O来重新读取它,而磁盘I/O会慢上几个数量级。
CephFS MDS 特点
- 采用多实例消除性能瓶颈并提升可靠性
- 采用大型日志文件和延迟删除日志机制提升元数据读写性能
- 讲 Inode 内嵌至 Dentry 中来提升文件索引率
- 采用目录分片重新定义命名空间层次结构,并且目录分片可以在 MDS 实例之间动态迁移,从而实现细粒度的流控和负载均衡机制
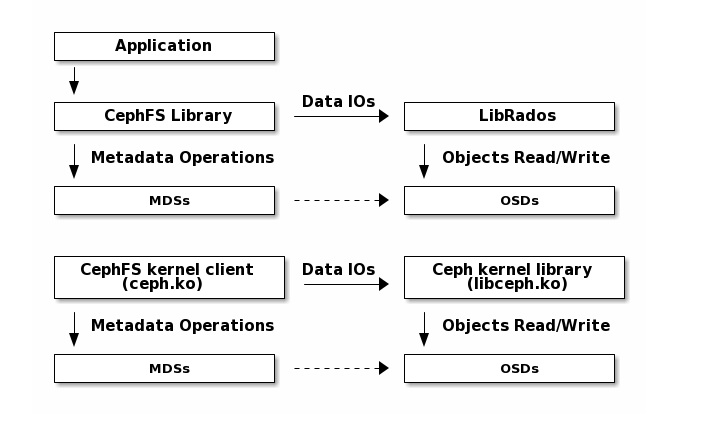
架构
-
虽然 Ceph 文件系统中的 inode 数据存储在 RADOS 中并由客户端直接访问,但是 inode 元数据和目录信息由Ceph metadata server (MDS)管理。MDS 充当所有与元数据相关的活动的中介,将结果信息存储在与文件数据不同的RADOS 池中。
-
CephFS中的所有文件数据都存储为RADOS对象。CephFS客户端可以直接访问RADOS对文件数据进行操作。MDS只处理元数据操作。
-
要读/写CephFS文件,客户端需要有相应inode的“文件读/写”功能。如果客户端没有需要的功能 caps,它发送一个“cap消息”给MDS,告诉MDS它想要什么。MDS将在可能的情况下向客户发布功能 caps。一旦客户端有了“文件读/写”功能,它就可以直接访问 RADOS 来读/写文件数据。文件数据以
,
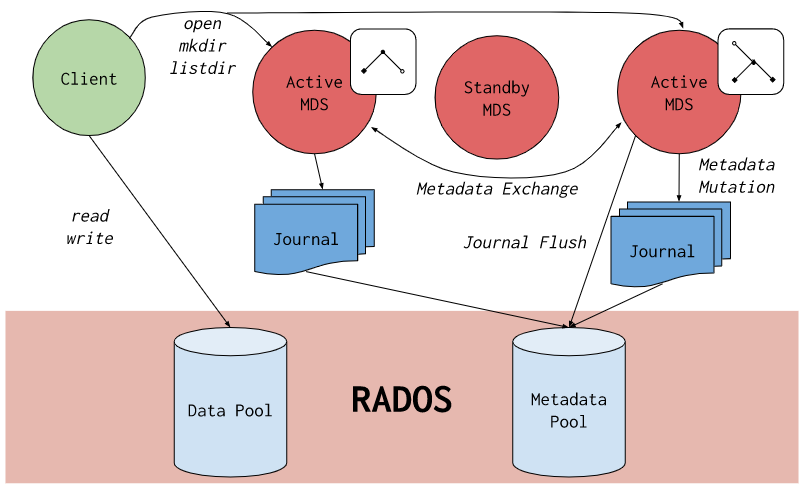
CepgFS Client 访问示例
- Client 发送 open file 请求给 MDS
- MDS 返回 file node, file size, capability 和 stripe 信息
- Client 直接 READ/WRITE 数据到 OSDs(如果无 caps 信息需要先向 MDS 请求 caps)
- MDS 管理 Client 对该 file 的 capabilities
- Client 发送 close file 请求给 MDS,释放 file 的 capabilities,更新 file 的详细信息
MDS 文件锁
- 当客户机希望在 inode 上操作时,它将以各种方式查询 MDS,然后授予客户机一组功能。它们授予客户端以各种方式操作 inode 的权限。与其他网络文件系统(例如 NFS 或 SMB)的主要区别之一是,所授予的功能非常细粒度,多个客户机可能在同一个 inode 上拥有不同的功能。
- CephFS 客户机可以请求MDS代表它获取或更改 inode 元数据,但是MDS还可以为每个 inode 授予客户机功能 (caps)
/* generic cap bits */
#define CEPH_CAP_GSHARED 1 /* client can reads (s) */
#define CEPH_CAP_GEXCL 2 /* client can read and update (x) */
#define CEPH_CAP_GCACHE 4 /* (file) client can cache reads (c) */
#define CEPH_CAP_GRD 8 /* (file) client can read (r) */
#define CEPH_CAP_GWR 16 /* (file) client can write (w) */
#define CEPH_CAP_GBUFFER 32 /* (file) client can buffer writes (b) */
#define CEPH_CAP_GWREXTEND 64 /* (file) client can extend EOF (a) */
#define CEPH_CAP_GLAZYIO 128 /* (file) client can perform lazy io (l) */
- 然后通过特定数量的位进行移位。这些表示 inode 的数据或元数据的一部分,在这些数据或元数据上被授予能力:
/* per-lock shift */
#define CEPH_CAP_SAUTH 2 /* A */
#define CEPH_CAP_SLINK 4 /* L */
#define CEPH_CAP_SXATTR 6 /* X */
#define CEPH_CAP_SFILE 8 /* F */
- 一个 Cap 授予客户端 缓存和操作与 inode 关联的部分数据或元数据的能力。当另一个客户机需要访问相同的信息时,MDS 将撤销该 cap,而客户机最终将返回该功能,以及 inode 元数据的更新版本(如果它在保留功能时对其进行了更改)。
- 客户机可以请求 cap,并且通常会获得这些 cap,但是当 MDS 面临竞争访问或内存压力时,这些 cap 可能会被 revoke。当一个 cap 被 revoke 时,客户端负责尽快返回它。未能及时这样做的客户端可能最终被阻塞并无法与集群通信。
- 由于缓存是分布式的,所以 MDS 必须非常小心,以确保没有客户机拥有可能与其他客户机的 cap 或它自己执行的操作发生冲突的 cap。这使得 cephfs 客户机比 NFS 这样的文件系统依赖于更大的缓存一致性,在 NFS 中,客户机可以缓存数据和元数据,而这些数据和元数据在服务器上已经更改了。
- 基于 caps,构建了 ceph 的分布式文件锁,分布式文件锁保证了多个客户端并发且细粒度访问同一文件、目录、文件系统,同时保证一致性、可靠性。ceph 实现的分布式文件系统锁,客户端可见部分是 caps,服务端可见部分包括 caps和各种 lock,每个类型的 lock 又有多种状态,根据客户端的请求、持有、释放情况,lock 转换自身状态,并和客户端同步 caps 信息。最终实现分布式锁的访问。
