- FAST21: Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience
Abstract
- RocksDB是一个针对大规模分布式系统的键值存储,并针对固态硬盘(ssd)进行了优化。本文描述了RocksDB在过去8年中开发重点的变化。这种演变是硬件发展趋势的结果,也是许多公司大规模生产RocksDB的丰富经验的结果。RocksDB在多个组织进行规模化生产。我们将描述RocksDB的资源优化目标是如何以及为什么从写放大、到空间放大、到CPU利用率迁移的。大规模应用的运行经验告诉我们,需要跨不同的RocksDB实例管理资源分配,数据格式需要保持向后和向前兼容,以允许增量软件上线,还需要对数据库复制和备份提供适当的支持。失败处理的教训告诉我们,需要更早地在系统的每一层检测到数据损坏错误。
Introduction
- RocksDB 起源于 LevelDB,针对 SSD 的一些特性进行了优化,以分布式应用程序为目标,同时也被设计成可以被嵌入到一些高级应用程序(如 Ceph)的 KV 库。每个RocksDB实例只管理单个节点上的数据,没有处理任何节点之间的操作(比如 replication、 loadbalancing),也不执行高级操作,比如 checkpoints,让上层应用来实现,底层只是提供一些支持。
- RocksDB 可以根据负载以及性能需求进行定制和调优,主要包括对 WAL 的处理、压缩策略的选择。
- RocksDB 应用广泛:
- Database: MySQL, Rocksandra, CockroachDB, MongoDB, TiDB
- Stream processing:Apache Flink, Kafka Stream, Samza, and Facebook’s Stylus.
- Logging/queuing services: Facebook’s LogDevice, Uber’s Cherami, Iron.io
- Index services: Facebook’s Dragon, Rockset
- Caching on SSD: Caching on SSD, Qihoo’s Pika, Redis
- 对不同应用特性进行了简单总结:
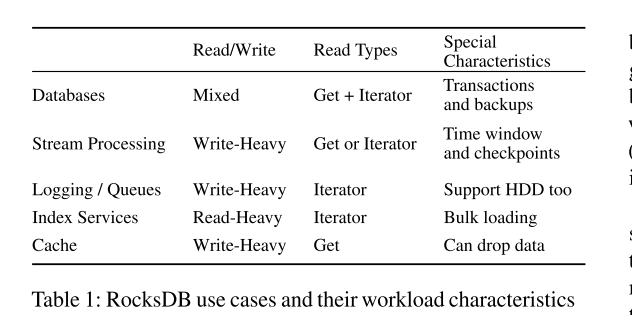
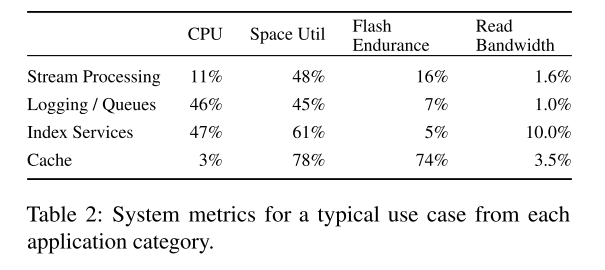
- FAST20 之前的一篇介绍 Facebook 实际的 RocksDB 负载特性也得出了一些数据信息:
- 使用如 RocksDB 这种公共的存储引擎有利有弊:
- 劣势在于每个系统需要基于 RocksDB 构建自己的子系统,那么就涉及到一系列复杂的崩溃一致性的保证操作(但比较好的公共存储引擎一般会 cover 这一点)
- 优势在于很多基础功能是可以复用的
- 其实就是因为 RocksDB 的应用广泛,以及一些硬件技术的发展,导致 RocksDB 的开发重点也在不断地变化。
Background
- flash的特性对RocksDB的设计产生了深刻的影响。读写性能的不对称和有限的寿命给数据结构和系统架构的设计带来了挑战和机遇。因此,RocksDB采用了flash友好的数据结构,并针对现代硬件进行了优化。
Embedded storage on flash based SSDs
- 低延迟高吞吐的高性能 SSD 的出现促进了相应设计的变化,在一些场景里,以往的 IO 瓶颈可能转移到了网络上,无论是吞吐量还是延迟。所以这时候数据存储到本地的 SSD 相比于存储到远端性能要好很多,这时候嵌入式的存储引擎的需求就增加了。
- RocksDB 就基于该场景产生了,并基于 LSM 开始了相关设计。
RocksDB architecture
- LSM 树是 RocksDB 存储数据的主要数据结构
主要操作
写
- 步骤:
- 首先写入到名为 MemTable 的内存 Buffer 和磁盘上的 WAL 中
- MemTable 基于跳表实现有序,插入和查询的复杂度均为 logN
- WAL 用于故障恢复,但其实不是强制的。
- 然后持续写入。一旦 MemTable 达到一定的大小(设定的阈值),当前 MemTable 和 WAL 就不可修改了
- 分配一个新的 MemTable 和 WAL 来接受后续的写入
- 不可修改的 Memtable 刷入到磁盘上的 SSTable 文件中
- 刷入后的 Memtable 和 WAL 相应地被丢弃
- 每个SSTable按排序顺序存储数据,并将其划分为大小相同的块。每个SSTable也有一个索引块,每个SSTable块有一个索引项用于二分查找。
Read
- 在读取路径中,在每个后续级别都进行键查找,直到找到键为止。它首先搜索所有memtable,然后搜索所有级别为0的sstable,然后依次搜索更高级别的sstable。在每一个级别上,都使用二分查找。Bloom过滤器用于消除SSTable文件中不必要的搜索。扫描要求搜索所有级别。
Compaction
- 最新的sstable由MemTable刷新创建,并放置在0级。高于0级的级别是由称为压缩的流程创建的。给定级别上sstable的大小受到配置参数的限制。当超过level-L的size目标时,选择level-L中的一些sstable与level-(L+1)中的重叠sstable合并。这样做,deleted 和 overwritten 的数据被删除,并优化表的读性能和空间效率。这个过程将写数据从0级逐渐迁移到最后一级。压缩I/O是高效的,因为它可以并行化,并且只涉及对整个文件的批量读写。
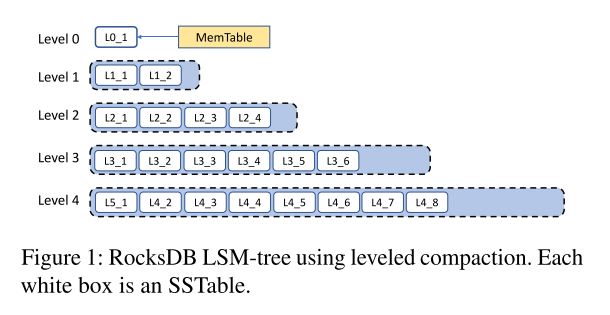
- Level-0 sstable有重叠的键范围,因为SSTable覆盖了完整的 sorted run。后面的每个级别只包含一个sorted run,因此这些级别中的sstable包含其级别 sorted run 的一个分区。
- RocksDB支持多种不同类型的压缩。
- Leveled Compaction 是从LevelDB继承的,然后进行了改进,如上图所示,Level 的 target 大小呈指数级增长
- Tiered Compaction (又称 Universal Compaction)是和 Cassandra 以及 HBase 使用的策略类似的。多个 sorted run 被延迟压缩在一起,或者当有太多的 sorted run,或者DB总大小与最大 sorted run 的大小之比超过了一个可配置的阈值。
- FIFO Compaction 当 DB 大小达到某个阈值限制时直接丢弃以前的文件并只执行轻量压缩,主要用于内存缓存应用。
- 通过使用不同的压缩策略,RocksDB 可以被配置为 读友好/写友好/对某些特殊缓存负载非常写友好。然而,应用程序所有者将需要考虑他们特定用例的不同指标之间的权衡。
- 一个 lazy 的压缩策略可以提升写吞吐量和写放大,但读性能将下降
- 虽然更积极的压缩会牺牲写性能,但允许更快的读取。
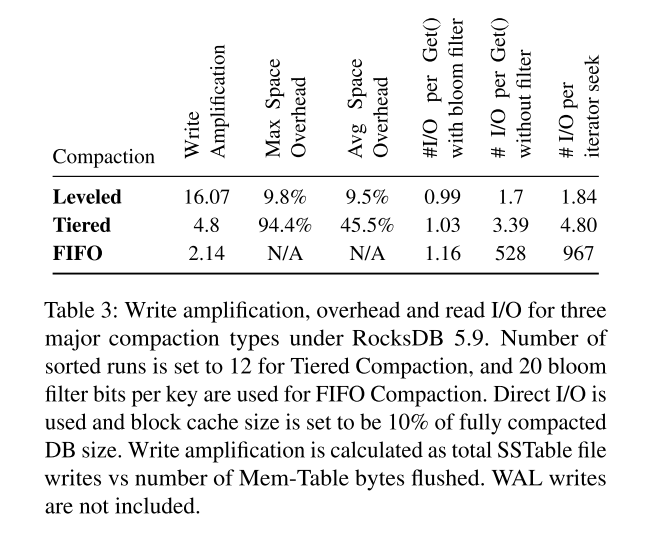
- 日志和流处理服务需要进行大量的写操作,而数据库应用更喜欢进行权衡。表3通过微基准测试结果描述了这种灵活性。
RocksDB History
Evolution of resource optimization targets
- 资源优化目标的转变过程:从写放大到空间放大再到 CPU 利用率
Write amplification
- 当初开发 RockDB 时主要关注节省 Flash 颗粒的擦除次数来减小 SSD 内部的写放大,这是当时社区的普遍看法,这个对于很多写密集型的应用确实是个极大的挑战,现在也仍然是个问题。
- 写放大实际出现在两个层次:
- SSD 本身的写放大,观察发现在 1.1 到 3 之间。
- 存储和数据库软件也会产生写放大,有时候甚至可能达到 100(比如当对小于100字节的更改写入整个4KB/8KB/16KB页时)
- Leveled Compaction 在 RocksDB 中通常显示出了 10-30 的写放大,在很多情况下,比使用 b 树要好好几倍。不过,10-30范围内的写放大对于写密集的应用程序来说还是太高了。
- Tiered Compaction 将写放大降低到了 4-10,但也降低了读性能。如下图以及上表所示的对比结果:
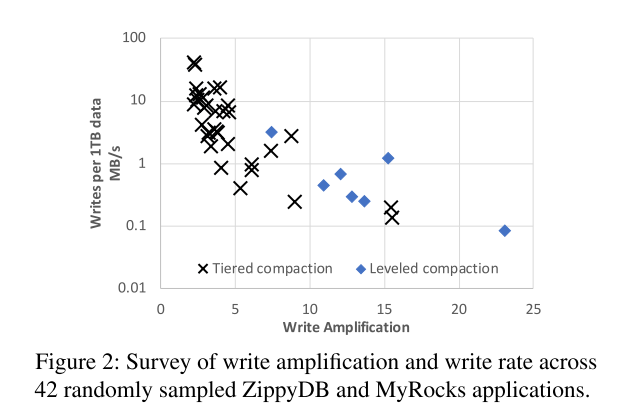
- RocksDB应用程序所有者通常会选择一种压缩方法,在写速率高的时候减少写放大,在写速率低的时候更积极地压缩,以实现空间效率和读性能的目标。
Space amplification
- 经历了几年的开发之后发现,考虑到闪存写周期和写开销都没有限制,Space amplification 比 Write amplification 更重要,实际生产环境中表现出的 IOPS 是要比 SSD 本身可以提供的性能要低的,因此,我们将资源优化目标转移到磁盘空间。
- 幸运的是,由于lsm -tree的非碎片数据布局,它在优化磁盘空间时也可以很好地工作。然而,我们看到了通过减少 LSM 树中的老数据(即删除和覆盖的数据)的数量来改进 Leveled Compaction 的机会,因此开发了 Dynamic Leveled Compaction,树中每个 Level 的大小会根据最后一个 Level 的实际大小自动调整(而不是静态地设置每个 Level 的大小)。该策略相比于 Leveled Compaction 实现了更好的以及更稳定的空间效率。
CPU utilization
- 很多人认为对于高速 SSD,已经足够快,性能瓶颈已经从 SSD 转移到了 CPU。基于我们的经验,我们并不认为这是一个问题,我们也不希望它成为未来基于 SSD 的 NAND 闪存的问题,原因有二。
- 只有少部分应用被 SSD 提供的 IOPS 给限制,大多数应用还是被空间给限制。
- 其次,我们发现任何具有高端 CPU 的服务器都有足够的计算能力来饱和一个高端 SSD,在我们的环境中,RocksDB在充分利用SSD性能方面从来没有遇到过问题。
- 当然,可以配置一个系统,使 CPU 变成一个瓶颈(比如一个 CPU,多个 SSD)。然而,高效的系统通常是那些配置为良好平衡的系统,这是今天的技术所允许的
- 密集的写为主导的工作负载也可能导致CPU成为瓶颈。对于某些情况,可以通过配置RocksDB使用更轻量级的压缩选项来缓解这种问题。
- 对于其他情况,工作负载可能根本不适合SSD,因为它将超过允许SSD持续2-5年的典型闪存耐久预算。
- 为了证实我们的观点,我们调查了生产中 ZippyDB 和 MyRocks 的 42 种不同部署,它们分别服务于不同的应用程序。下图测试结果表明 大多数工作负载都受到空间限制。有些主机的确CPU利用率很高,但是主机通常没有得到充分的利用,没有为增长和处理数据中心或区域级故障留出空间(或由于错误配置)。
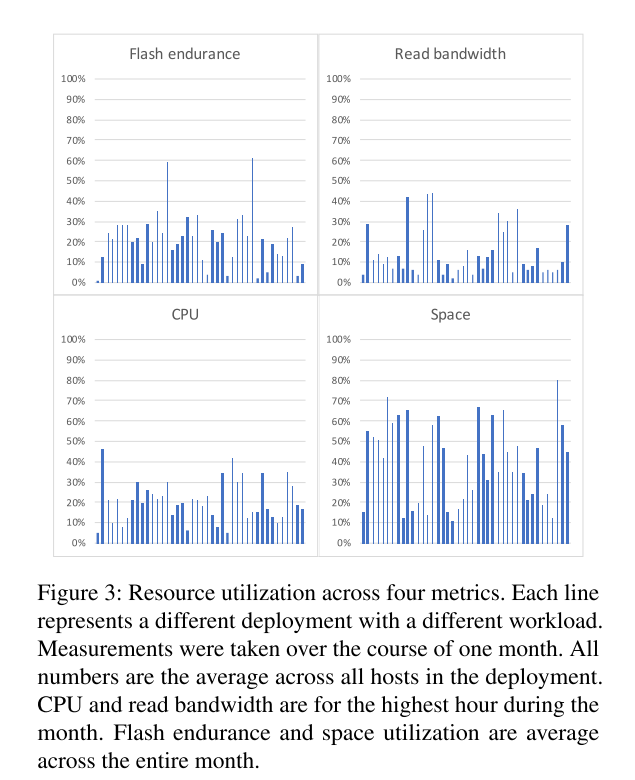
- 然而,减少 CPU 开销已经成为一个重要的优化目标,因为减少空间放大已经做的差不多了。减少CPU开销可以提高CPU确实受到限制的少数应用程序的性能,更重要的是,减少CPU开销的优化允许更经济有效的硬件配置,从成本的角度讲该优化也挺有必要的。
- 早期降低CPU开销的努力包括引入前缀bloom过滤器、在索引查找之前应用bloom过滤器,以及其他bloom过滤器改进。还有进一步改善的空间。
Adapting to newer technologies
- SSD 架构相关的改进可能很容易瓦解 RocksDB 的相关性,比如 OC-SSD,Multi-Stream SSD,ZNS 承诺改善查询延迟和节省flash擦除周期。然而,这些新技术只能使使用 RocksDB 的少数应用程序受益,因为大多数应用程序都受到空间限制,而没有消除周期或延迟限制。此外,如果让RocksDB直接使用这些技术,将会对RocksDB的经验构成挑战,一个可能的方法是将这些技术的适应能力委托给底层文件系统,也许RocksDB会给底层文件系统提供一定的额外的提示。
- 存储内计算可能会带来显著的收益,但目前还不清楚有多少RocksDB应用能从中受益。我们认为,RocksDB 要适应存储内计算将是一个挑战,可能需要对整个软件堆栈进行API更改,以充分利用。我们期待未来关于如何最好地做到这一点的研究。
- 分类(远程)存储似乎是一个更有趣的优化目标,并且是当前的优先级,到目前为止,我们的优化假设flash是本地连接的,因为我们的系统基础设施主要是这样配置的。然而,目前更快的网络可以提供更多的远程 I/O,因此在越来越多的应用程序中,使用远程存储运行RocksDB的性能是可行的。使用远程存储,可以更容易地同时充分利用 CPU 和 SSD 资源,因为它们可以根据需要分别提供(使用本地附加的SSD很难实现这一点),因此,优化 RocksDB 的远程闪存存储已成为当务之急。我们目前正在通过尝试合并和并行 I/O 来解决长 I/O 延迟的挑战。我们已经对RocksDB进行了改造,以处理瞬时故障,将QoS要求传递给底层系统,并报告分析信息。然而,还需要做更多的工作。
- 存储级内存(SCM)是一种很有前途的技术。我们正在研究如何最好地利用它。以下几种可能性值得考虑: (NVM) SCM介绍
- 使用 SCM 作为 DRAM 的延申,这就提出了这样的问题:如何用混合的 DRAM 和 SCM 来最好地实现关键数据结构(例如,块缓存或 memtable),以及在尝试利用所提供的持久性时会引入哪些开销
- 使用 SCM 作为数据库的主存储,但是我们注意到RocksDB往往会受到空间或CPU的瓶颈,而不是 I/O
- 为 WAL 使用 SCM,但是,这就提出了这样一个问题:考虑到我们只需要在转移到 SSD 之前的一小块 staging 区域,这个用例是否单独证明了 SCM 的成本是合理的。
Main Data Structure Revisited
- 我们不断地重新讨论lsm -tree是否仍然合适的问题,但仍然得出它们确实合适的结论。SSD的价格还没有下降到足以改变大多数用例的空间和闪存续航瓶颈的程度,用CPU或DRAM交换SSD的使用只对少数应用程序有意义,虽然主要结论是一致的,但我们经常听到用户对写放大的要求低于RocksDB所能提供的。然而,我们注意到,当对象大小很大时,可以通过分离键和值来减少写放大,比如 WiscKey 和 ForrestDB,所以在 RocksDB 中也添加了这种支持 BlobDB
Lessons on serving large-scale systems
- RocksDB是各种需求各异的大型分布式系统的基石。随着时间的推移,我们了解到需要在资源管理、WAL处理、批处理文件删除、数据格式兼容性和配置管理方面进行改进。
Resource management
- 分布式系统常常对数据进行分片,分片成 shards,shards 分布在多个服务器存储节点上,大小通常有限,因为要进行备份以及负载均衡,同时也会作为原子粒度进行一些一致性的保证。因此每个节点大概会有几十上百个 shards,一个 RocksDB 实例通常只服务于一个 shard,所以一个服务节点上可能通常会运行多个 RocksDB 实例。可能共享地址空间,也可能使用自己独立的地址空间。
- 一台主机可能会运行多个RocksDB实例,这对资源管理有一定影响。假设这些实例共享主机的资源,那么需要对资源进行全局(每个主机)和本地(每个实例)管理,以确保公平和有效地使用它们。当运行在单个进程模式下,拥有全局资源限制是很重要的,包括
- (1) 内存写入缓冲器和块缓存,
- (2) Compaction 的 I/O 带宽、
- (3) Compaction 线程数
- (4) 总磁盘使用情况
- (5) 文件删除率
- 还需要本地资源限制,例如,确保单个实例不能使用过多的任何资源。RocksDB允许应用程序为每种类型的资源创建一个或多个资源控制器(作为传递给不同DB对象的c++对象实现),也可以在每个实例的基础上这样做。同时需要支持一些优先级策略,来保证一些资源可以优先被分配给一些最需要该资源的实例。
- 在一个进程中运行多个实例时得到的另一个教训是:大量地生成非池线程可能会有问题,特别是当线程是长期存在的时候。拥有太多的线程会增加CPU的概率,导致过多的上下文切换开销,并使调试变得极其困难,导致I/O strike。如果一个RocksDB实例需要使用一个可能会休眠或等待某个条件的线程来执行一些工作,那么最好使用一个线程池,这样可以方便地限制线程的大小和资源使用。
- 考虑到每个shard只有本地信息,当RocksDB实例运行在单独的进程中时,全局(每台主机)资源管理变得更加具有挑战性。可以采用两种策略。
- 首先,将每个实例配置为谨慎地使用资源,而不是贪婪地使用资源。例如,使用压缩,每个实例可以启动比“正常”更少的压缩,只有在压缩落后时才会增加。这种策略的缺点是,全局资源可能无法得到充分利用,导致资源使用不理想。
- 第二种,在操作上更具挑战性的策略是让实例之间共享资源使用信息,并相应地进行调整,试图在更大范围内优化资源使用。RocksDB还需要更多的工作来改善主机范围内的资源管理。
WAL treatment
- 传统的数据库倾向于在每一个写操作上强制执行write-ahead-log (WAL),以确保持久性。相比之下,大型分布式存储系统通常为了性能和可用性复制数据,并且它们通过各种一致性保证来做到这一点。例如,当同一数据存在多个副本,其中一个副本损坏或无法访问时,存储系统会使用其他未受影响主机的有效副本重建故障主机的副本。对于这样的系统,RocksDB WAL 写的就不那么重要了。此外,分布式系统通常有自己的复制日志(例如Paxos日志),在这种情况下,根本不需要RocksDB WAL。
- 我们了解到,提供调优WAL同步行为的选项,以满足不同应用程序的需要是很有帮助的。具体来说,我们介绍了不同的WAL操作模式:(i)同步WAL写,(i)缓冲WAL写,和(i)根本没有WAL写。对于buffered WAL处理,为了不影响RocksDB的流量延迟,在后台定期将WAL以低优先级写入磁盘。
Rate-limited file deletions
- RocksDB通常通过文件系统与底层存储设备交互。这些文件系统支持是能识别出 SSD 的;例如,XFS。每当一个文件被删除,使用实时丢弃,可以发出修剪命令 TRIM 到 SSD。修剪命令通常被认为可以改善 SSD 性能和 Flash 寿命,这是经过我们的生产经验验证的。然而也会产生性能问题,TRIM 破坏性很大:除了更新地址映射(通常在SSD的内部内存中)之外,SSD固件还需要将这些更改写入flash中的FTL的日志,这反过来可能触发SSD的内部垃圾收集,导致相当大的数据迁移,并对前台IO延迟造成负面影响。为了避免 TRIM 活动 spike 和I/O延迟的相关增加,我们引入了文件删除的速率限制,以防止多个文件同时被删除(在压缩后发生)。
- 型分布式应用程序在许多主机上运行它们的服务,它们期望零停机时间。结果,软件升级在主机之间逐步推出;当出现问题时,更新将被回滚。由于持续部署,这些软件升级频繁发生;RocksDB每个月都会发布一个新版本。因此,磁盘上的数据在不同的软件版本之间保持向后和向前兼容是很重要的。新升级(或回滚)的RocksDB实例必须能够理解前一个实例存储在磁盘上的数据。此外,为了构建副本或平衡负载,可能需要在分布式实例之间复制RocksDB数据文件,而这些实例可能运行不同的版本。由于缺少前向兼容性保障,在一些部署中,RocksDB的操作出现了困难,因此我们增加了这一保障。
- RocksDB竭尽全力确保数据的前后兼容(除了新特性)。这在技术上和过程上都具有挑战性,但我们发现付出的努力是值得的。为了向后兼容,RocksDB必须能够理解之前写入磁盘的所有格式;这增加了软件和维护的复杂性。为了向前兼容,需要理解未来的数据格式,我们的目标是保持至少一年的向前兼容性。这可以通过使用通用技术部分实现,例如协议Buffer或Thrift所使用的技术。对于配置文件条目,RocksDB需要能够识别新的字段,并尽可能地猜测如何应用配置或何时放弃配置。我们不断地用不同版本的数据对不同版本的RocksDB进行测试。
Managing configurations
- RocksDB具有高度的可配置性,可以优化应用程序的工作负载。然而,我们发现配置管理是一个挑战。最初,RocksDB继承了LevelDB的参数配置方法,将参数选项直接嵌入到代码中。这造成了两个问题。
- 首先,参数选项通常与存储在磁盘上的数据绑定在一起,当使用一个选项创建的数据文件不能被新配置了另一个选项的RocksDB实例打开时,可能会产生兼容性问题。
- 其次,代码中没有明确指定的配置选项会自动设置为RocksDB的默认值。当RocksDB软件更新包括改变默认配置参数(例如,增加内存使用量或压缩并行度)时,应用程序有时会遇到意想不到的后果
- 为了解决这些问题,RocksDB首先引入了RocksDB实例使用包含配置选项的字符串参数打开数据库的能力。后来,RocksDB引入了对随数据库存储选项文件的可选支持。我们还引入了两个工具:(i)验证工具,验证打开数据库的选项是否与目标数据库兼容;(ii)迁移工具重写数据库以兼容所需的选项(尽管这个工具是有限的)
- RocksDB配置管理的一个更严重的问题是大量的配置选项。在RocksDB的早期,我们的设计选择是支持高度定制:我们引入了许多新的旋钮,并引入了可插拔组件的支持,所有这些都允许应用程序实现其性能潜力。这被证明是一种成功的策略,能够在早期获得最初的吸引力。然而,现在一个常见的抱怨是,选择太多了,很难理解它们的影响;也就是说,它变得非常困难
- 除了要调优许多配置参数之外,更令人生畏的是,最优配置不仅取决于嵌入了RocksDB的系统,还取决于上面应用程序产生的工作负载。以ZippyDB为例,ZippyDB是一个内部开发的大型分布式键值存储系统,在其节点上使用了RocksDB。ZippyDB服务于许多不同的应用程序,有时是单独的,有时是在多租户设置中。尽管在尽可能跨所有ZippyDB用例使用统一配置方面进行了大量努力,但不同用例的工作负载是如此不同,当性能很重要时,统一配置实际上是不可行的。表5显示了我们抽样的39个ZippyDB部署的25种不同配置

- 对于已交付给第三方的嵌入式RocksDB系统,调整配置参数也尤其具有挑战性。考虑第三方在其应用程序中使用MySQL或ZippyDB等数据库。第三方通常对RocksDB知之甚少,也不知道如何对其进行最佳调整。数据库所有者也不太愿意对客户的系统进行调优
- 这些真实的经验教训触发了我们配置支持策略的变化。我们在改进开箱即用性能和简化配置上花费了大量的精力。我们目前的重点是提供自动适应性,同时继续支持广泛的显式配置,考虑到RocksDB继续服务于专门的应用程序。我们注意到在追求自适应性的同时保持显式的可配置性会造成大量的代码维护开销,我们相信拥有一个统一的存储引擎的好处要大于代码的复杂性。
Replication and backup support
- RocksDB是一个单节点库。如果需要,使用RocksDB的应用程序将负责复制和备份。每个应用程序都以自己的方式实现这些函数(出于合理的原因),因此RocksDB对这些函数提供适当的支持是很重要的。
- 通过复制现有副本的所有数据来引导一个新的副本可以通过两种方式完成。
- 首先,可以从源副本读取所有键,然后将其写入目标副本(逻辑复制)。在源端,RocksDB支持数据扫描操作,能够最大限度地减少对并发在线查询的影响;例如,通过提供选项来不缓存这些操作的结果,从而防止缓存垃圾化。在目标端,支持散装装载,并针对此场景进行了优化。
- 第二,可以通过直接复制sstable和其他文件(物理复制)来引导一个新的副本。RocksDB通过识别当前时间点的现有数据库文件,并防止它们被删除或更改,从而帮助物理复制。支持物理复制是RocksDB将数据存储在底层文件系统上的一个重要原因,因为它允许每个应用程序使用自己的工具。我们认为,RocksDB直接使用块设备接口或与FTL进行深度集成所带来的潜在性能提升,不会超过上述所述的好处。
- 备份是大多数数据库和其他应用程序的重要特性。对于备份,应用程序具有与复制相同的逻辑与物理选择。备份和复制之间的一个区别是,应用程序通常需要管理多个备份。虽然大多数应用程序都实现了自己的备份(以满足自己的需求),但如果应用程序的备份需求很简单,RocksDB会提供一个备份引擎供其使用。
- 在这方面,我们看到有两个方面需要进一步改进,但都需要对key-value API进行更改;
- 第一个是在不同副本上以一致的顺序应用更新,这带来了性能挑战。
- 第二个问题涉及到每次发出一个写请求的性能问题,以及副本可能会落后,而应用程序可能希望这些副本能够更快地赶上
- 不同的应用程序实现了不同的解决方案来解决这些问题,但是它们都有局限性. 挑战在于,应用程序不能乱序写数据,也不能用它们自己的序列号读取快照,因为RocksDB目前不支持使用用户定义的时间戳进行多版本控制
Lessons on failure handling
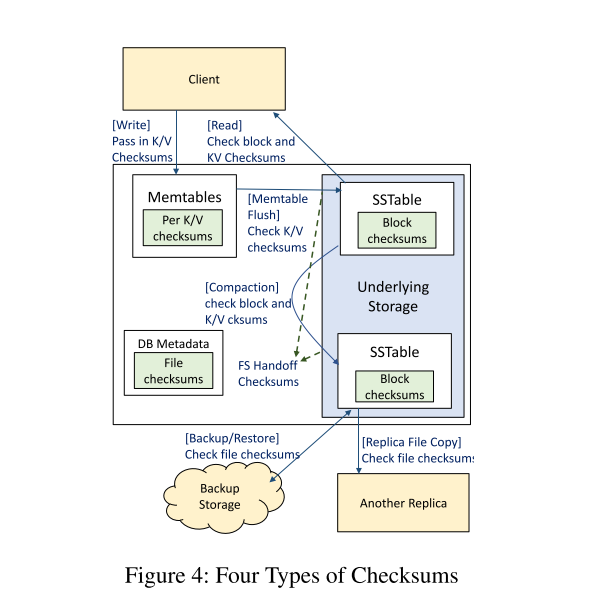
- 通过生产经验,我们学到了三个主要的教训,关于故障处理。首先,需要尽早检测数据损坏,以最小化数据不可用或丢失的风险,并通过这样做来查明错误的起源。其次,完整性保护必须覆盖整个系统,以防止静默的破坏暴露给RocksDB客户或传播到其他副本(见图4)。第三,错误需要以不同的方式处理.
Frequency of silent corruptions
- 由于性能原因,RocksDB用户通常不使用SSD(如DIF/DIX)的数据保护,存储介质损坏由RocksDB块校验和检测,这是所有成熟数据库的常规特性,因此我们在这里跳过分析。CPU/内存损坏很少发生,而且很难准确量化。使用RocksDB的应用程序通常会进行数据一致性检查,比较副本的完整性。这可以捕获错误,但这些错误可能是由RocksDB或客户端应用程序引入的(例如,在复制、备份或恢复数据时)。
- 我们发现,通过比较MyRocks数据库表中的主索引和二级索引,可以估计在RocksDB级别引入的损坏频率;任何不一致都可能在RocksDB级别上出现,包括CPU或内存损坏。根据我们的测量,大约每三个月,每100PB的数据就会出现一次RocksDB级别的故障。更糟糕的是,在这些案件中,有40%的损坏已经传播到其他副本。
- 在传输数据时也会发生数据损坏,通常是由于软件错误。例如,在处理网络故障时,底层存储系统中的错误导致我们在一段时间内看到,传输的每拍字节的物理数据大约有17个校验和不匹配。
Multi-layer protection
- 需要尽早检测到数据损坏,以减少停机时间和数据丢失。大多数RocksDB应用都将数据复制到多个主机上;当检测到校验和不匹配时,将丢弃损坏的副本,并用正确的副本替换。然而,只有在正确的副本仍然存在时,这才是可行的选择。
- 如今,RocksDB在多个层次上对文件数据进行校验和,以识别底层的损坏情况。这些以及计划的应用层校验和如图4所示。多层校验和是重要的,主要是因为它们有助于及早发现错误,也因为它们可以防止不同类型的威胁。从LevelDB继承的块校验和可以防止文件系统或文件系统以下的数据损坏暴露给客户端。文件校验和是在2020年增加的,用于防止底层存储系统传播到其他副本造成的损坏,以及防止在通过网络传输SSTable文件时造成的损坏。对于WAL文件,切换校验和能够在写时有效地早期检测损坏。
Block integrity
- 每个SSTable块或WAL片段都附加了一个校验和,在数据创建时生成。与仅在文件移动时才验证的文件校验和不同,这个校验和在每次读取数据时都要验证,因为它的作用域更小。这样做可以防止存储层损坏的数据暴露给RocksDB客户端。
File integrity
- 文件内容特别有可能在传输操作期间被破坏;例如,用于备份或分发SSTable文件。为了解决这个问题,sstable被它们自己的校验和保护,这些校验和是在创建表时生成的。SSTable的校验和记录在元数据的SSTable文件条目中,并在传输时使用SSTable文件进行验证。然而,我们注意到其他文件,如WAL文件,仍然没有采用这种方式保护。
Handoffintegrity
- 早期检测写损坏的一种已建立的技术是对将要写入底层文件系统的数据生成一个切换校验和,并将其与数据一起传递下去,由底层进行验证。我们希望使用这样的write API来保护WAL的写操作,因为与sstable不同的是,WAL可以从每次追加的增量验证中获益。不幸的是,本地文件系统很少支持这一点——但是,一些专门的堆栈,比如Oracle ASM就支持。
- 另一方面,在远程存储上运行时,write API可以更改为接受校验和,并与存储服务的内部ECC挂钩。RocksDB可以在现有的WAL片段校验和上使用校验和组合技术来高效地计算写切换校验和。由于我们的存储服务执行写时验证,我们希望将损坏检测延迟到读时的情况非常罕见。
End-to-end protection
- 虽然上面描述的保护层在许多情况下防止客户端暴露于损坏的数据,但它们并不全面。到目前为止提到的保护的一个不足是数据在文件I/O层以上是不受保护的;例如,MemTable中的数据和块缓存。在此级别损坏的数据将无法检测,因此最终将暴露给用户。此外,刷新或压缩操作可以持久化已损坏的数据,从而使损坏永久存在。
Key-value integrity
- 为了解决这个问题,我们目前正在实现每个键值校验和,以检测在文件I/O层之上发生的损坏。这个校验和将与键/值一起被复制,尽管我们将从已经存在替代完整性保护的文件数据中删除它。
Severity-based error handling
- RocksDB遇到的大多数错误是底层存储系统返回的错误。这些错误可能源于许多问题,从严重的问题(如只读文件系统)到短暂的问题(如全磁盘或访问远程存储的网络错误)。早期,RocksDB对此类问题的反应要么是简单地向客户端返回错误消息,要么是永久停止所有写操作。
- 今天,我们的目标是在错误不能在本地恢复的情况下中断RocksDB的操作;例如,临时网络错误不需要用户干预重启RocksDB实例。为了实现这一点,我们对RocksDB进行了改进,使其在遇到被归类为瞬态错误的错误后,能够周期性地重试恢复操作。因此,我们获得了运营上的优势,因为客户不需要为发生的大部分故障手动缓解RocksDB。
Lessons on the key-value interface
- 核心键值(KV)接口的用途惊人地多。几乎所有的存储工作负载都可以通过一个带有KV API的数据存储来提供;我们很少看到应用程序不能使用这个接口实现功能。这也许就是kv如此受欢迎的原因。KV接口是通用的。键和值都是可变长度的字节数组。应用程序在决定将哪些信息打包到每个键和值中方面具有很大的灵活性,而且它们可以从丰富的编码方案集中自由选择。因此,是应用程序负责解析和解释键和值。KV接口的另一个优点是可移植性。从一个键值系统迁移到另一个键值系统是相对容易的。然而,尽管许多用例通过这个简单的接口实现了最佳性能,但我们注意到它可能会限制一些应用程序的性能。
- 例如,在RocksDB之外构建并发控制是可能的,但很难提高效率,特别是在需要支持两阶段提交的情况下,在提交事务之前需要一些数据持久性。为此我们添加了事务支持,MyRocks (MySQL+RocksDB)使用了事务支持。我们会继续添加新功能;例如,gap/next 键锁定和大事务支持。
- 在其他情况下,这种限制是由key-value接口本身造成的。因此,我们已经开始研究基本键-值接口的可能扩展。其中一个扩展就是支持用户定义的时间戳
Versions and timestamps
- 在过去的几年里,我们已经认识到了数据版本控制的重要性。我们得出的结论是,版本信息应该成为RocksDB的头等公民,以适当地支持功能,如多版本并发控制(MVCC)和时间点读取。为了实现这一目标,RocksDB需要能够有效地访问不同的版本。
- 到目前为止,RocksDB内部一直在使用56位序列号来识别不同版本的kv -对。序列号由RocksDB生成,并在每次写入客户端时递增(因此,所有数据在逻辑上按排序顺序排列)。客户端应用程序不能影响序列号。然而,RocksDB允许应用程序对数据库进行快照,在此之后,RocksDB保证快照时存在的所有KV对将持续存在,直到应用程序显式地释放快照。因此,具有相同密钥的多个kv -对可能共存,并根据它们的序列号进行区分。
- 这种版本控制方法是不充分的,因为它并没有满足多种应用的要求。要从过去的状态读取数据,必须在前一个时间点已经拍摄了快照。RocksDB不支持对过去进行快照,因为没有API来指定时间点。此外,支持时间点读取是低效的。最后,每个RocksDB实例分配自己的序列号,并且只能根据每个实例获取快照。这使得具有多个(可能是复制的)分片(每个分片都是一个RocksDB实例)的应用程序的版本控制变得复杂。总之,创建提供跨分片一致读取的数据版本基本上是不可能的
- 应用程序可以通过在键或值中编码时间戳来绕开这些限制。但是,在这两种情况下,它们的性能都会下降。在键内进行编码会影响点查找的性能,而在值内进行编码会影响对相同键的无序写入的性能,并使读取旧版本的键变得复杂。我们相信应用程序指定的时间戳可以更好地解决这些限制,应用程序可以用可以全局理解的时间戳标记其数据,并且在键或值之外这样做
- 我们已经添加了对应用程序指定的时间戳的基本支持,并使用DB-Bench评估了这种方法。结果如表6所示。每个工作负载有两个步骤:第一步填充数据库,第二步测量性能。例如,在“fill_seq + read_random”中,我们通过按升序写一些键来填充初始数据库,在步骤2中执行随机读操作。相对于基线,应用程序将时间戳编码为密钥的一部分(对于RocksDB来说是透明的),应用程序指定的时间戳API可以带来1.2倍或更好的吞吐量增益。这些改进来自于将时间戳作为元数据与用户键分开处理,因为这样就可以使用点查找而不是迭代器来获取键的最新值,并且Bloom过滤器可以识别不包含该键的sstable。此外,SSTable覆盖的时间戳范围可以存储在其属性中,这可以用来排除只能包含陈旧值的SSTable。
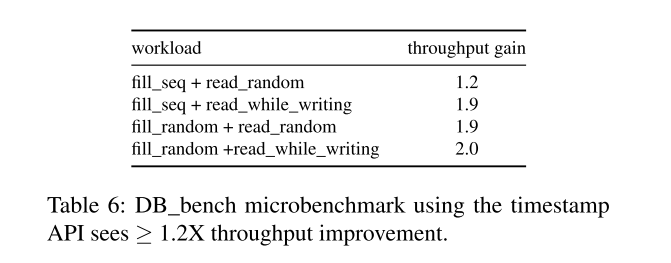
- 我们希望这个特性能够让用户更容易地在系统中实现单节点MVCC、分布式事务的多版本控制,或者解决多主复制中的冲突。然而,更复杂的API使用起来不那么简单,而且可能容易被误用。此外,与不存储时间戳相比,数据库将消耗更多的磁盘空间,而且对其他系统的可移植性也较差。
Storage Engine Libraries
- BerkeleyDB
- SQLite
- Hekaton
Key-value stores for SSDs
- SILT: 在内存效率、CPU和性能之间进行平衡的键值存储
- ForestDB: 使用 HB+ tree 在日志上建立索引
- TokuDB:和其他数据库使用 FractalTree/Bε 树。
- LOCS/NoFTL-KV/FlashKV 瞄准开放通道ssd以提高性能
LSM-tree improvements
- 一些系统也使用LSM树并改进了它们的性能。
- 写放大通常是最主要的优化目标:
- WiscKey
- PebblesDB
- IAM-tree
- TRIAD
- 这些系统在优化写放大方面比RocksDB做得更好,后者更关注不同指标之间的权衡。
- SlimDB 优化 LSM 树空间效率
- Monkey 试图在 DRAM 和 IOPs 之间实现平衡。
- bLSM/VT-tree/cLSM 优化LSM树的一般性能
Large-scale storage systems
Future Work and Open Questions
- 除了完成上面提到的改进,包括对分类聚合存储、键值分离、多层校验和和应用程序指定的时间戳的优化,我们计划统一 leveled 和 tiered 压缩并提高自适应能力。然而,一些开放的问题可以从进一步的研究中受益。
- How can we use SSD/HDD hybrid storage to improve efficiency?
- How can we mitigate the performance impact on readers when there are many consecutive deletion markers?
- How should we improve our write throttling algorithms?
- Can we develop an efficient way of comparing two replicas to ensure they contain the same data?
- How can we best exploit SCM? Should we still use LSM tree and how to organize storage hierarchy?
- Can there be a generic integrity API to handle data handoff between RocksDB and the file system layer?
Conclusion
- RocksDB已经从一个服务于小众应用的键值存储平台发展到目前广泛应用于众多工业大规模分布式应用的地位。作为主要数据结构的LSM树很好地服务于RocksDB,因为它表现出良好的写入和空间放大能力。然而,我们对业绩的看法是随着时间的推移而演变的。虽然写和空间放大仍然是主要关注的问题,但更多的焦点已经转移到CPU和DRAM效率,以及远程存储上。
- 运行大规模应用程序给我们带来了教训资源分配需要跨不同的RocksDB实例进行管理,数据格式需要保持向后和向前兼容,以允许增量软件部署,需要对数据库复制和备份提供适当的支持,配置管理需要简单且最好是自动化。失败处理的教训告诉我们,需要更早地在系统的每一层检测到数据损坏错误。key-value接口因其简单性和性能上的一些限制而广受欢迎。对界面进行一些简单的修改可能会产生更好的平衡。

x
感谢您的支持,我会继续努力的!
扫码打赏,你说多少就多少
