- 本篇为持久化技术的基础篇系列第二篇(硬盘设备和磁盘阵列),即一些硬件设备基础知识以及基础的 IO 处理相关知识,可以结合之前的一篇博客 Flavor of IO。
Chapter Index
- Basic of Persistence
- File Systems Implementation
- Locality and The Fast File System
- Crash Consistency: FSCK and Journaling
- Log-structured File System
Hard Disk Drives
- CRUX:如何对磁盘进行数据的存储和访问操作?
- 现代硬盘驱动器如何存储数据?
- 接口是什么?
- 数据实际上是如何布局和访问的?
- 磁盘调度如何提高性能?
The Interface
- 磁盘驱动器通常由大量的扇区(512 字节大小的 block)组成,每一个扇区都能被读写,对应的被编号为 0 ~ n-1,编号本身就对应了扇区的地址。
- 支持多扇区操作。现代文件系统将一次读写 4KB 甚至更大的数据单元,然而,当更新磁盘时,驱动器制造商制造的唯一保证是一个 512 字节的写是原子的,所以如果写入过程中发生了故障,可能出现部分写成功。即 torn write.
- 磁盘驱动器中有一些不成文的规定或假设:通常可以假设访问驱动器地址空间中相邻的两个块比访问相隔很远的两个块要快,假设顺序访问驱动器的块比随机访问要快得多。后来大量的实验数据表明也确实如此。
Basic Geometry
- 关于机械硬盘的基本结构可以参考博客 [shunzi: 存储基本概念],此处不再赘述。
- 更详细的讲解也可以参考 bilibili-清华大学-陆游游-存储技术基础-P2 Disk Technologies
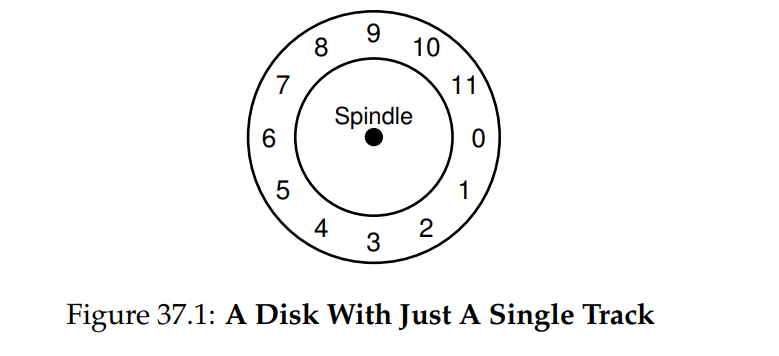
- Single-track Latency: The Rotational Delay:假设全旋转延迟为 R,那么磁盘需要承受大约 R/2 延迟,但最坏的情况即原本位于扇区 5,需要定位到扇区 6,则需要承受 R 延迟。

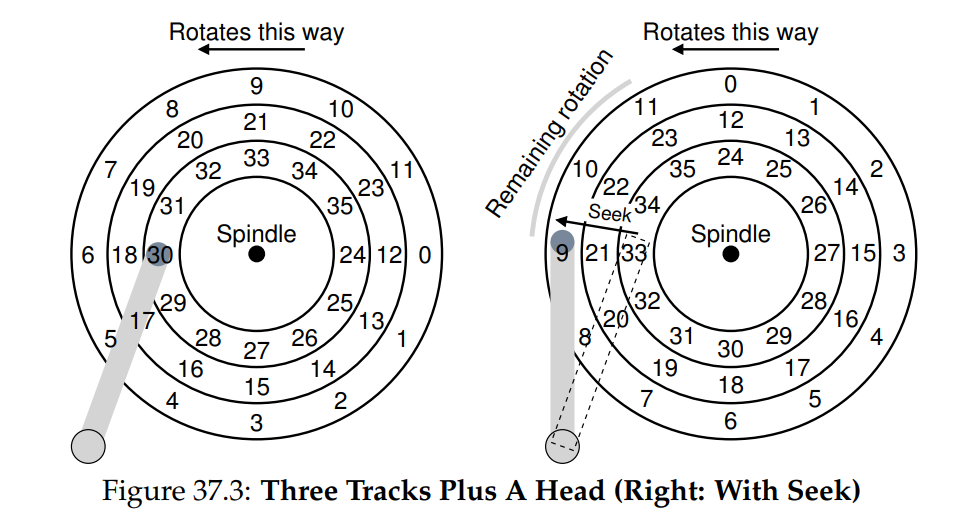
- Multiple Tracks: Seek Time:寻道时间。例如访问扇区 11,需要找到对应的磁道,也就是所谓的 seek 操作,同旋转一样,是开销最大的磁盘操作。Seek 又分为四个步骤:
- acceleration 加速移动阶段
- coasting 全速移动阶段
- deceleration 减速移动阶段
- settling 停止阶段,即到了正确的磁道,大约 0.5 - 2ms
- 通常旋转和寻道会同时进行,所以总的 I/O 时间: seek + rotational delay + transfer
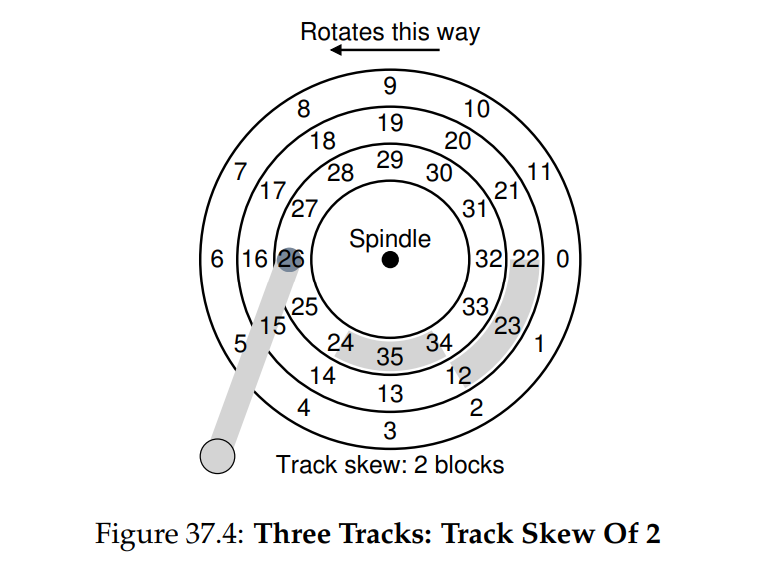
- track skew 用于减少顺序跨 track 边界读写的旋转时延。如图所示, block 23 和 24 之间间隔了两个扇区,即 track skew 为两个 blocks,为什么不直接 23 对应 24在不同轨道的同一位置呢?因为磁盘一直都在旋转,在 seek 的过程中,如果对应的话,24 已经旋转了,将会等待一圈完整的旋转时延,所以一般需要间隔一定的距离。
- 因为物理结构的原因,外部轨道的容量一般比内部轨道更大,称之为 multi-zoned disk drives。每一个轨道被划分为一组 zones,而外轨的 zone 包含的扇区数一般大于内轨的 zone。
- 现代磁盘驱动器都有对应的缓存。有时候也叫 track buffer。为小容量的内存,通常为 8-16MB。用于要存放到磁盘或者从磁盘读取的数据。
- 例如当读一个扇区时,驱动器可能会被对应磁道上的所有扇区的数据读取到缓存中,类似于预取。
- 对于写操作,驱动器可以选择:是否确认写操作已完成当数据写入到了磁盘缓存中?还是等磁盘完全写入磁盘之后再确认写入完成。前者称为 write-back; 后者成为 write-through. write-back 虽然性能更好效率更高,但是可能造成数据的丢失和不一致。
- 具体的延迟和性能计算请参考原文,此处不再赘述。
Disk Scheduling
- 由于 I/O 操作开销较大,如何组织发送到磁盘的 I/O 顺序就显得十分重要。和任务调度不同的是,I/O 调度可以预测的,即一个任务大致需要花多长时间,通过测量 seek 和旋转时延,就能计算出预计的 I/O 时延,然后通常选择时间花费最短的任务执行。
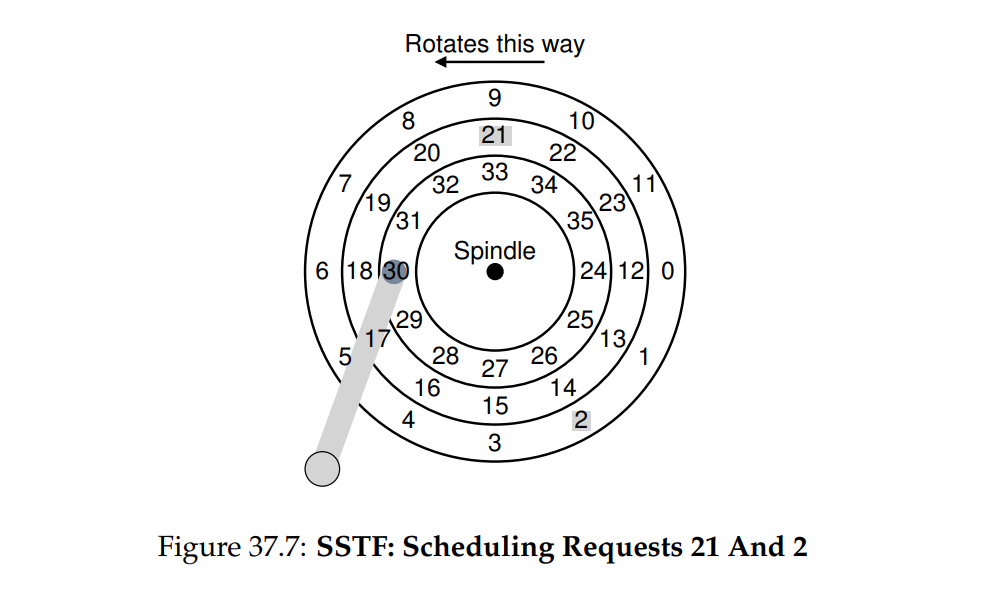
SSTF: Shortest Seek Time First
- 即选择离当前最近的磁道的 I/O 然后执行。如图所示,首先对 21 进行操作,然后再对 2 进行操作。对于操作系统而言,具体的磁盘组件是以块为单位呈现的,所以通常操作系统寻找最近的 block.
- 该方法很有可能造成 starvation 现象,即磁头一直在内部磁道移动,外部磁道很少被访问。
- CRUX:如何避免 starvation?
Elevator (a.k.a. SCAN or C-SCAN)
- 在磁盘上来回移动,按顺序在轨道上处理请求,一次从内到外或者从外到内的扫描过程我们称之为 sweep。如果要访问的块已经在这次 sweep 扫描过了,那么需要等待下一次 sweep 才能真正执行。
- F-SCAN:此操作将扫描期间传入的请求放置到一个队列中,以便稍后提供服务,这样做可以延迟更靠近的请求的服务,从而避免较远的请求的 starvation。
- C-SCAN:算法只从外到内扫描,然后在外轨道上重置,重新开始。这样做对内部和外部轨道更公平,因为纯粹的来回扫描有利于中间轨道
- SCAN 算法又称之为 电梯算法。
- CRUX:如何设计一个算法同时考虑 seek 时延和 旋转时延?
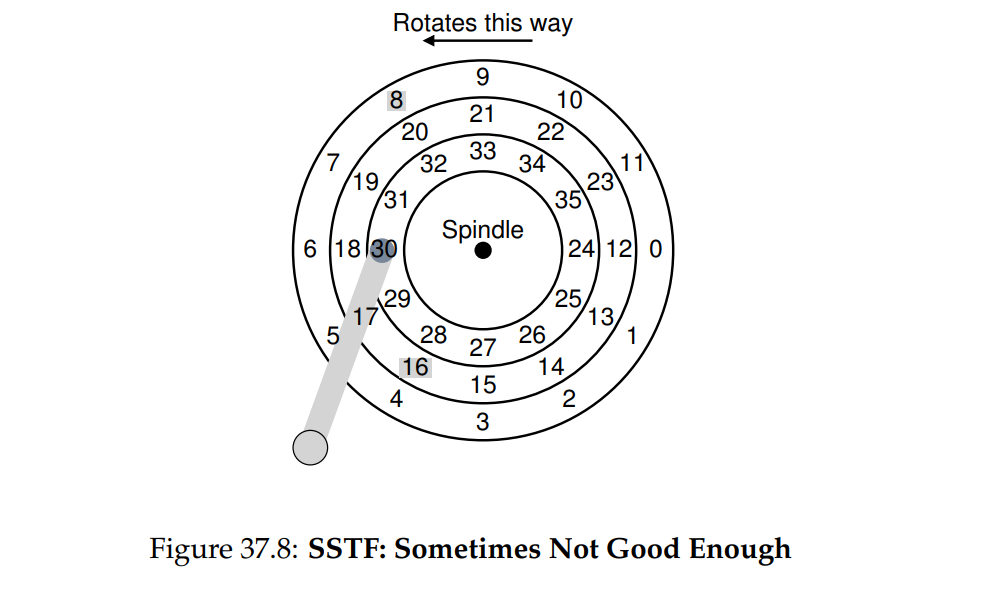
SPTF: Shortest Positioning Time First
- 如图所示,磁头位于 30,需要考虑先处理 8 还是先处理 16。需要判断时延主要由 seek 还是 rotation 决定。如果 seek 时间远大于 rotation,则 SSTF 更优,但如果 seek 小于 rotation,那么移动到 8 会是更好的选择,因为移动到 16 的话,由于旋转方向的原因,可能需要等待 rotation 更长的时间。
- 在现代磁盘驱动器中,seek 和 rotation 的时延相当,因此 SPTF 通常是更有效的,然而在系统中实现十分复杂,因为操作系统对于磁头的位置以及磁道的边界很难获取到对应的信息。所以 SPTF 通常在驱动器内部执行。
Other Scheduling issues
- 现代磁盘可以容纳多个未完成的请求,并且本身具有复杂的内部调度器(可以精确地实现 SPTF,在磁盘控制器内部,所有相关细节都是可见的,包括磁头的确切位置))。因此,OS调度器通常选择它认为最好的几个请求(比如16个),并将它们全部发送到磁盘; 磁盘然后使用其内部的头部位置和详细的轨道布局信息,以最好的(SPTF)顺序服务对应的请求。
- 磁盘调度器执行的另一个重要的相关任务是 I/O合并。假设一系列的请求读取块 33,8,34,磁盘调度器应该合并 33 和 34 为一个 两个块大小的数据请求,调度器执行的任何重新排序都将在合并后的请求上执行。合并在操作系统级别上特别重要,因为它可以减少发送到磁盘的请求数量,从而降低开销。
- 现代调度器解决的最后一个问题是:在向磁盘发出I/O之前,系统应该等待多长时间? 大致分为了两种方式:
- work-conserving:一有请求,磁盘就立即处理。即当存在请求的时候,磁盘从不会空闲。
- non-work-conserving:一些预测磁盘调度的研究表明,有时候等待一段时间可能效率更高。因为可能会有后续的更好的请求,可以通过合并等方式优化整体的请求处理效率。但是等待多长时间,什么时候开始等待都是很棘手的问题。
Homework (Simulation)
- 编写 disk.py 来熟悉掌握磁盘是如何工作的。
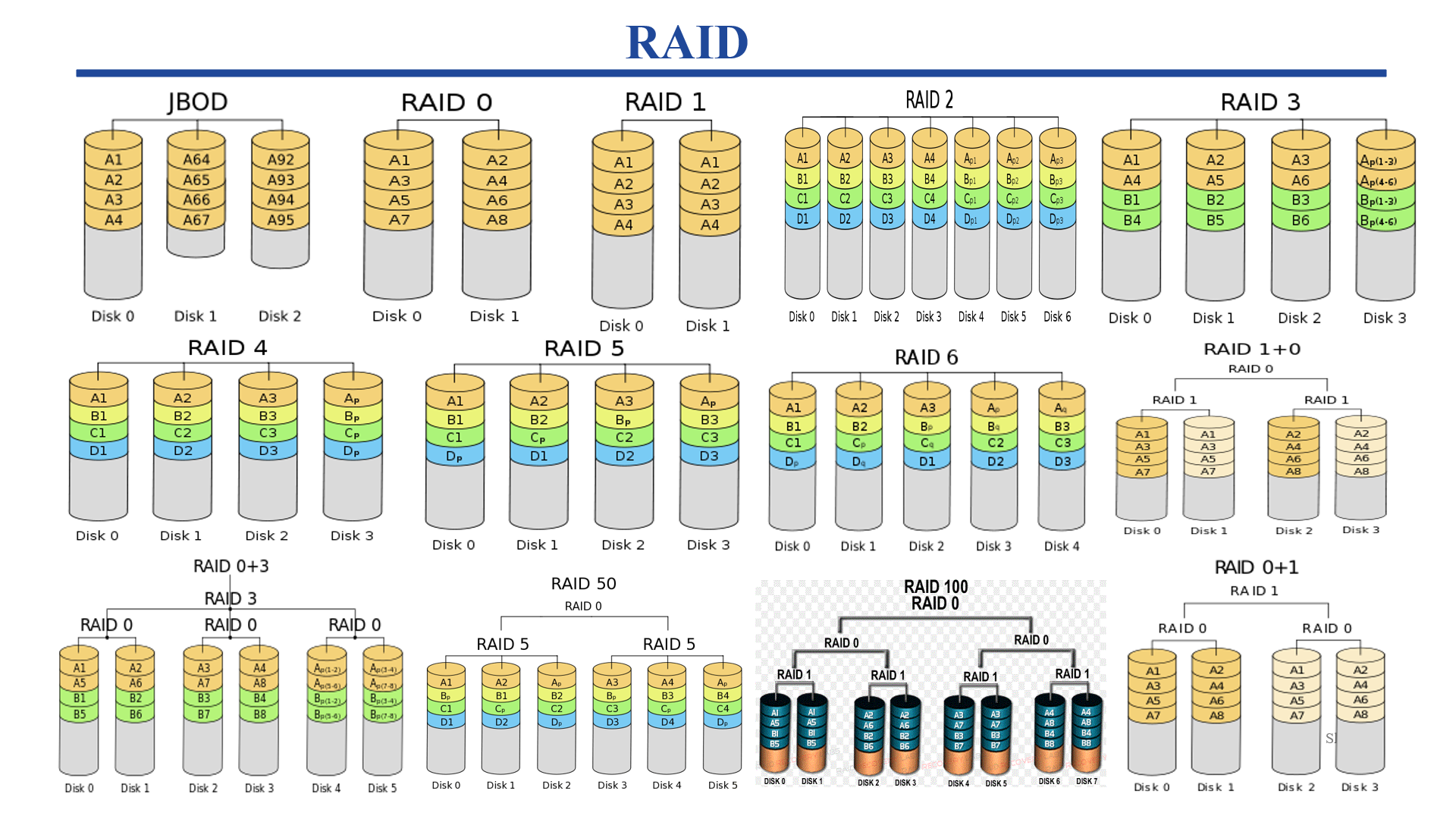
Redundant Arrays of Inexpensive Disks (RAIDs)
- CRUX:How can we make a large, fast, and reliable storage system?
- RAID:使用多个磁盘构建存储系统,实现 large/fast/reliable 的需求。对外像是一个单独的磁盘或者可以读写的数据块,内部实现复杂,有多个磁盘,内存和多个处理器组成。
Interface And RAID Internals
- 当文件系统向 RAID 发起读写的时候,RAID 必须计算出访问哪一个磁盘,然后再在对应的磁盘上完成实际的请求处理。
- RAID 系统通常构建为一个独立的硬件盒,使用标准接口连接主机(如SCSI或SATA)
- RAID 相当复杂,
- 一个微控制器,它运行固件来指导 RAID 的操作
- 易失内存 DRAM,在读取和写入数据块时缓冲数据块
- (可选)非易失内存,用于缓冲区安全写入,甚至可能是执行奇偶校验计算的专门逻辑
Fault Model
- RAID 的目的是检测和恢复某些类型的磁盘故障,因此,准确地知道预期会出现哪些错误对于实现工作设计是至关重要的:
- fail-stop:一个磁盘只会处于两个状态的其中一个:working/failed。该模型下我们假设 RAID 控制器能够很快检测到故障磁盘。
How To Evaluate A RAID
- capacity:N 个 disks, 每个 disk 有 B 个 blocks。如果没有冗余配置,那么对于客户端而言容量应该为 N * B;但是如果使用了两副本,即镜像组,容量将变为 N * B / 2
- reliability:即设计中能给容忍的磁盘错误是多少
- performance:性能取决于 RAID 的工作负载