- 源于最近的项目里涉及到的一致性问题,此处是指存储系统内部的数据一致性。
- 注意和 分布式系统中的一致性以及协同算法 进行区分,此处更多的是多层存储之间的一致性。
- 主要会先了解记录常见的存储系统中的数据一致性保证,如文件系统、数据库等;再分析项目中是否真正数据存在一致性问题。
文件系统中的一致性
前言
预备知识
- 知乎:计算机存储术语: 扇区,磁盘块,页
- ByteLiu:The differences between a chunk, page, block, sector and bytes/bits within storage systems?
问题
- Linux 系统中的 Page Cache 缓存文件数据,可能造成缓存数据和磁盘数据的不一致性。
一致性概念
- 操作系统中的文件 = 数据 + 元数据
- 文件一致性其实包含了两个方面:数据一致+元数据一致。
影响
- 不同的用户或者应用程序有不同的一致性需求,因为一致性往往是会对性能产生影响的。
- 例如,如果要求强一致性,一个IO操作处理之后,数据能够立马落盘,此时就需要跳过缓存直接同步写入磁盘。此时性能相比于有缓存的情况,将会有一定程度的下降。
需求
- 需要提供可由用户自定义的一致性方案,即向用户提供可控制一致性的接口。
- 系统内部自动保证一致性,某些用户或者应用程序对文件数据的一致性要求可能没有那么高,无需每次写入都实时调用相应的接口去保证文件缓存数据和磁盘上数据的一致性。
Linux 下的方案
-
- 提供特定接口,可调用接口来主动地保证文件一致性
-
- 系统中存在定期任务(表现形式为内核线程),周期性地同步文件系统中文件脏数据块
一致性实现
文件一致性接口
- fsync(int fd): 将fd代表的文件的脏数据和脏元数据全部刷新至磁盘中
- fdatasync(int fd): 将fd代表的文件的脏数据刷新至磁盘,同时对必要的元数据刷新至磁盘中,这里所说的必要的概念是指:对接下来访问文件有关键作用的信息,如文件大小,而文件修改时间等不属于必要信息
- sync(): 则是对系统中所有的脏的文件数据元数据刷新至磁盘中
fsync
- 函数流程:
fsync(int fd)(位于fs/sync.c中)
--->do_fsync(fd, 0)(位于fs/sync.c中)
--->vfs_fsync(file, datasync)(位于fs/sync.c中)
--->vfs_fsync_range(file, 0, LLONG_MAX, datasync)(位于fs/sync.c中)
--->filemap_write_and_wait_range(mapping,start, end)(位于mm/filemap.c中)
--->__filemap_fdatawrite_range(mapping,lstart, lend,WB_SYNC_ALL)(位于mm/filemap.c中)
--->filemap_fdatawait_range(mapping,lstart,lend)(位于mm/filemap.c中)
--->ext2_fsync(struct file*file, int datasync)(针对ext2文件系统,位于fs/ext2/file.c)
--->generic_file_fsync(file, datasync)(位于fs/libfs.c中)
- 大致流程:同步文件脏数据 -> inode 加锁 -> 同步文件元数据 -> 释放 inode 锁
fdatasync
- 函数流程:
fdatasync(intfd)(位于fs/sync.c中)
--->do_fsync(fd, 1)(位于fs/sync.c中)
--->vfs_fsync(file, datasync)(位于fs/sync.c中)
--->vfs_fsync_range(file, 0, LLONG_MAX, datasync)(位于fs/sync.c中)
--->filemap_write_and_wait_range(mapping, start, end)(位于mm/filemap.c中)
--->__filemap_fdatawrite_range(mapping,lstart, lend,WB_SYNC_ALL)(位于mm/filemap.c中)
--->filemap_fdatawait_range(mapping,lstart,lend)(位于mm/filemap.c中)
--->ext2_fsync(struct file*file, int datasync)(针对ext2文件系统,位于fs/ext2/file.c)
--->generic_file_fsync(file, datasync)(位于fs/libfs.c中)
- 与
fsync的区别在于 参数datasync. fsync将其设置为0,而fdatasync的实现中将其设置为1。在函数generic_file_fsync(file, datasync)中会对该参数的设置做出判断。-
- 若 inode 并没有被修改,即 I_DIRTY 没有被修改,此时无需同步inode;
-
- 若 inode 未被设置 I_DIRTY_DATASYNC 且 datasync 被设置,这意味着调用者只想在 I_DIRTY_DATASYNC 被设置时(inode 关键部分被修改,如文件大小信息)才去同步 inode,如果 I_DIRTY_DATASYNC 未被设置,也就意味着 inode 关键成员未作修改,此时无需同步,直接返回。
-
int generic_file_fsync(struct file *file,int datasync)
{
structwriteback_control wbc = {
.sync_mode= WB_SYNC_ALL,
.nr_to_write= 0, /* metadata-only; caller takes care of data */
};
struct inode*inode = file->f_mapping->host;
int err;
int ret;
ret = sync_mapping_buffers(inode->i_mapping);
if(!(inode->i_state & I_DIRTY))
return ret;
if (datasync&& !(inode->i_state & I_DIRTY_DATASYNC))
return ret;
err = sync_inode(inode, &wbc);
if (ret == 0)
ret = err;
return ret;
}
sync
被动一致性
被动一致性是指系统后台存在定期的任务刷新某些文件的脏数据以及元数据,且定期任务应该以内核线程的形式出现。
- 系统中存在一个管理线程和多个刷新线程(每个持久存储设备对应一个刷新线程)。
- 管理线程监控设备上的脏页面情况,若设备一段时间内没有产生脏页面,就销毁设备上的刷新线程;若监测到设备上有脏页面需要回写且尚未为该设备创建刷新线程,那么创建刷新线程处理脏页面回写
- 刷新线程:负责将设备中的脏页面回写至持久存储设备中。
管理线程
主要工作是监视工作线程的运行状况,根据设备上的脏页面状况调整工作线程的运行,如设备上无脏页面且设备的工作线程已经有一段时间未被激活那么就kill该设备的回写线程,如果设备上有回写页面但尚未创建回写线程,那么为设备创建回写线程并启动线程运行。
- 主要流程:
- 遍历系统中所有的设备,判断设备当前状态,如果设备脏inode链表不为空或者设备任务队列不为空且该设备当前尚未创建回写线程,那么为设备创建回写线程;
- 如果设备当前脏inode链表为空且设备的回写线程已经有较长一段时间未活跃,那么就需要kill该设备的回写线程
static int bdi_forker_thread(void *ptr)
{
struct bdi_writeback *me = ptr;
current->flags |= PF_FLUSHER | PF_SWAPWRITE;
set_freezable();
/*
* Our parent may run at a different priority, just set us to normal
*/
set_user_nice(current, 0);
//线程运行在一个大的循环之中
for (;;) {
struct task_struct *task = NULL;
struct backing_dev_info *bdi;
enum {
NO_ACTION, /* Nothing to do */
FORK_THREAD, /* Fork bdi thread */
KILL_THREAD, /* Kill inactive bdi thread */
} action = NO_ACTION;
/* 如果当前设备上也有脏的inode或者有回写任务,那么处理,但一般来说,控制线程对应的设备上并不会产生脏inode或者回写任务
*/
if (wb_has_dirty_io(me) || !list_empty(&me->bdi->work_list)) {
del_timer(&me->wakeup_timer);
wb_do_writeback(me, 0);
}
spin_lock_bh(&bdi_lock);
set_current_state(TASK_INTERRUPTIBLE);
list_for_each_entry(bdi, &bdi_list, bdi_list) {
bool have_dirty_io;
if (!bdi_cap_writeback_dirty(bdi) ||
bdi_cap_flush_forker(bdi))
continue;
WARN(!test_bit(BDI_registered, &bdi->state),"bdi %p/%s is not registered!\n", bdi, bdi->name);
have_dirty_io = !list_empty(&bdi->work_list) || wb_has_dirty_io(&bdi->wb);
/* 若设备上有任务需要回写并且尚未创建回写线程 */
if (!bdi->wb.task && have_dirty_io) {
/* 为设备设置Pending标志位,这样其他线程如果想要移除该设备,必须等在该标志位上 */
set_bit(BDI_pending, &bdi->state);
action = FORK_THREAD;
break;
}
spin_lock(&bdi->wb_lock);
/* 如果设备没有任务且长时间尚未处于活跃状态,那么Kill设备的回写线程,如果它存在的话
* 这里对设备加wb_lock是为了保证在此过程中没有其他的线程对向该设备发送回写任务并且唤醒该回写线程
*/
if (bdi->wb.task && !have_dirty_io && time_after(jiffies, bdi->wb.last_active + bdi_longest_inactive())) {
task = bdi->wb.task;
bdi->wb.task = NULL;
spin_unlock(&bdi->wb_lock);
set_bit(BDI_pending, &bdi->state);
action = KILL_THREAD;
break;
}
spin_unlock(&bdi->wb_lock);
}
spin_unlock_bh(&bdi_lock);
/* Keep working if default bdi still has things to do */
if (!list_empty(&me->bdi->work_list))
__set_current_state(TASK_RUNNING);
switch (action) {
case FORK_THREAD:
__set_current_state(TASK_RUNNING);
task = kthread_create(bdi_writeback_thread, &bdi->wb, "flush-%s", dev_name(bdi->dev));
if (IS_ERR(task)) {
/* 如果为设备创建回写线程失败,那么管理线程亲自操刀,回写设备上的任务 */
bdi_flush_io(bdi);
} else {
spin_lock_bh(&bdi->wb_lock);
bdi->wb.task = task;
spin_unlock_bh(&bdi->wb_lock);
wake_up_process(task);
}
break;
case KILL_THREAD:
__set_current_state(TASK_RUNNING);
kthread_stop(task);
break;
case NO_ACTION:
if (!wb_has_dirty_io(me) || !dirty_writeback_interval)
/* 如果对设备遍历了一圈发现没有设备上需要进行任何的处理,那么好吧,我们尽量睡眠更长的时间
* 这样可以更省电
*/
schedule_timeout(bdi_longest_inactive());
else
schedule_timeout(msecs_to_jiffies(dirty_writeback_interval * 10));
try_to_freeze();
/* Back to the main loop */
continue;
}
/* 任务做完以后,清除Pending标志位,这样其它想要移除该设备的线程便可以继续处理了 */
clear_bit(BDI_pending, &bdi->state);
smp_mb__after_clear_bit();
wake_up_bit(&bdi->state, BDI_pending);
}
return 0;
}
工作线程
- 每个设备保存脏文件链表,保存的是该设备上存储的脏文件的inode节点。所谓的回写文件脏页面即回写该inode链表上的某些文件的脏页面。
- 系统中存在多个回写时机:
- 应用程序主动调用回写接口(fsync,fdatasync以及sync等)
- 管理线程周期性地唤醒设备上的回写线程进行回写
- 某些应用程序/内核任务发现内存不足时要回收部分缓存页面而事先进行脏页面回写
- 系统为每个设备创建一个回写线程,而不是每个磁盘分区创建一个回写线程。
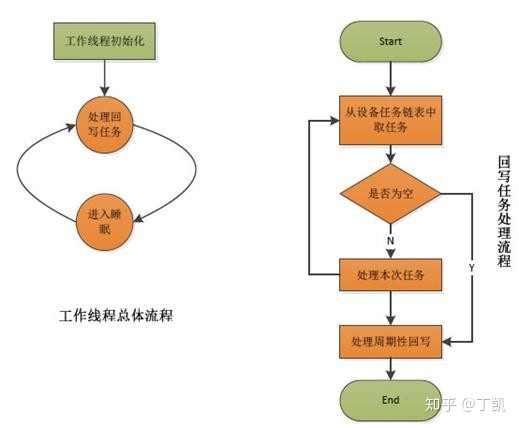
崩溃一致性
- 问题产生的本质原因是:文件系统对磁盘发出的更新操作通常是一个复合操作,即磁盘无法通过一次写入操作就能完成整个更新请求,相反,它需要依次更新多个相关数据结构,即多次写入磁盘才能顺利完成请求。在这多个依次写入的操作中间,系统发生了某种软件或硬件方面的错误(如突然断电power loss 或者系统崩溃 system crash),使得此次更新请求未能顺利完成,即只更新了部分数据结构,这就导致被更新的数据结构处于一个不一致的状态
- 可能导致很多问题,典型包括 space leak、garbage data 和 inconsistent data structures 三种 。
Example
- 以一个简单的标准文件系统为例,假设在如图所示的磁盘数据块布局中,已经存在如下的数据。
inode bitmap(8b). eg. 对应 inode 的 bit 00100000data bitmap(8b) eg. 对应 data 的 bit. 00001000inode(total 8 nodes, point to 4 blocks). eg. inode 号为 2 的 I[V1],V1 意为版本号为 1data block(total 8 blocks) eg. block 号为 4 的 Da
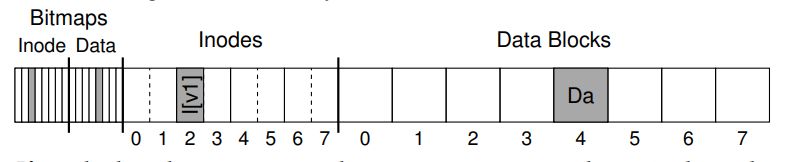
- I[V1] 中存储的元数据如下:
owner : remzi
permissions : read-write
size : 1 // 指向的 block 数量
pointer : 4 // 指向的第一个数据块
pointer : null
pointer : null
pointer : null
- 即将进行的操作为:追加写文件。(即向已存在的文件追加新的数据块)对应的会修改三个磁盘上的数据结构:
- inode:指向新的数据块,并重新统计大小 size
- data block:写入新的数据块,eg. Db
- data block bitmap:写入新的数据块对应的位图 eg. B[V2] = 00001100
- 更新后的元数据信息 I[V2] 为:
owner : remzi
permissions : read-write
size : 2
pointer : 4
pointer : 5
pointer : null
pointer : null
- 磁盘上的整体数据布局如图:

- 对应的三个数据结构的修改也就意味着文件系统需要和磁盘之间至少进行三次数据传输。由于页缓存的存在,数据结构对应的修改也不会立马持久化到磁盘,而是缓存在页缓存中,直到缓存刷新线程将数据刷回磁盘。在刷回磁盘之前,CRASH 导致这三个写操作中的其中一个或者两个操作成功,都将导致不一致的现象。
Crash Scenarios
- 主要分为一个操作失败和两个操作失败两种情况。
Single Write Success
- data block 写成功:没有对应 bitmap 和 inode,即该数据块会被文件系统当作是空闲的未使用的数据块,不会导致其他问题,只是下次写入会将该数据块原有的内容覆盖。
- inode I[V2] 写成功:inode 对应的指向了上图中的 data block 5,但是由于数据块未能成功写入,会导致读取该文件对应的第二个数据块时,读取到垃圾数据(即原本存在于 data block 5 上的数据,空数据或者旧数据)
- 除此以外,由于对应的 bitmap 也未写入,将出现 inode 指向了未分配的 data block 的情况,在文件系统的实际使用中,需要处理这种不一致的情况,来避免无效数据的访问。
- bitmap B[V2] 写成功:即分配了 data block 5,但无 inode 指向该数据块,因此又出现了上面提到的文件系统内部的不一致情况。如果不解决该问题,将会导致 data block 5 不再能被分配,即 space leak。
Two writes Success (Single failure)
- data block 写失败:即文件系统元数据是完整一致的,但是对应的数据块 5 仍为垃圾数据,即会导致读取到垃圾数据。
- bitmap B[V2] 写失败:即 inode 指向了未分配的数据区域,即便该数据区域里数据有效,但是都将导致未来不再能对该数据区域进行修改。
- inode I[V2] 写失败:仍为 inode 和 bitmap 之间的不一致,即便该数据块是真实有效且被分配管理,但是无法得知该数据块属于哪一个文件,因为没有对应的 inode 指向该数据块。
Summary
- 理想的效果是实现每一次写操作都是从一致的状态转变成另外一个一致的状态,且状态的转变过程是原子性的。但是往往写操作会涉及到很多个数据块(block)的操作,而磁盘只能保证一个扇区(sector - 512Bytes)的原子性,所以一次写操作过程中很容易产生崩溃一致性问题。crash-consistency problem / consistent-update problem
Solutions
Solution#1 The File System Checker (FSCK)
- 作为早期文件系统一种简单的解决崩溃一致性的方法:即允许产生不一致的情况,但是会在之后进行修复,比如 reboot 的时候。
- fsck 就是一种 UNIX 上的用于检测数据不一致并修复的工具,其他操作系统也有类似的工具。但这类工具不能解决所有问题,只能解决元数据内部的数据不一致情况,无法处理垃圾数据的情况。
- fsck 主要检测以下元数据信息:
- Superblock:主要是进行完整性检查,如果发现了已经损坏的超级块,则相应地使用超级块的副本
- Free blocks:通过遍历所有数据块临时性重构 d-bmap 以检验其同 inode 之间是否保持一致
- Inode State:检查每个 inode 是否损坏或其他问题。如确保每一个 inode 都有对应的有效类型(文件/目录/符号链接等)
- Inode links:检查 inode 引用计数,比较实际的引用数和 inode 中存储的计数,通常会修正 inode 中存储的计数。如果发现了一个分配了的 inode,但是没有目录引用该 inode,那么该 inode 将被移动到 lost+found 目录.
- Duplicates:检查重复指针。即两个不同的inode引用同一块的情况。如果一个 inode 明显是坏的,它可能被清除。另外,也可以复制指向的块,从而按需要为每个inode 提供自己的副本
- Bad Blocks:在扫描所有指针列表时,还会检查错误的块指针。错误的块指针往往可能执行超过有效范围的块,fsck 将删除 inode 中对应的块指针。
- Directory Checks:检查对应文件系统格式的目录,对每个目录的内容执行附加的完整性检查,以确保
.和..是第一个条目,每个 inode 在一个目录条目中引用的都被分配,确保在整个层次结构中没有哪个目录被链接超过一次。
- fsck 存在的问题很明显,除了不能解决 garbage data 的问题外,更让人不能接受的是,修复所耗费时间过长,这在文件系统日渐增长的情况下显得尤为突出。修复的时间会随着容量的增加变得更长。fsck 最为不科学的一点就是:部分数据的不一致现象可能需要整个磁盘执行故障恢复的操作。
Solution#2 Journaling (or WAL)
- 借鉴数据库管理系统(DBS)的一致性解决方案:WAL(写前日志)。在文件系统中通常将 WAL 称呼为 Journaling。大量的文件系统使用了该方法来保证崩溃一致性。如 ext3, ext4, reiserfs, IBM's JFS, SGI's XFS, Windows NTFS。
- Journaling 即在向磁盘写入实际的数据之前,先额外写一些数据(也被称为日志记录log)到磁盘指定区域,然后再更新磁盘写入实际数据。如此一来,若在磁盘更新的过程中发生了系统崩溃,则可读取之前写入到磁盘指定区域的log,以推断出被中断的更新操作的详细内容,然后针对性地重新执行更新操作。此种方案避免了对整个文件系统的全盘扫描,因此理论上提高了崩溃恢复效率。
- Ext3 就是在 Ext2 的基础上引入了 Journaling 机制


Data Journaling
- 即将完整的数据块信息和元数据信息均写入到 WAL 中。(即 Ext3 的 WAL 机制)
- 如图所示,以追加写 Db 为例。
- TxB 标志一条新的日志记录的开始 (包含一个事务号 transaction id 和 后续要写入的数据对应的地址信息)
- I[V2] 要写入的 Inode 数据
- B[V2] 要写入的数据块 bitmap
- Db 要写入的数据块
- TxE 标志日志记录的结束 (也包含对应的事务号 transaction id)

- 此种方式又被称之为物理日志 physical logging;对应地也有 logical logging,即不将数据放入 Journal 中。
- 故 data journaling 划分为两个阶段:
- Journal Write:写入事务开启标志、数据和元数据、事务结束标志到日志中,等待所有写操作完成
- Checkpoint:将数据与元数据写入到实际需要写入的地址上
- 存在问题:写入日志的过程中发生了崩溃将会造成不一致的情况。因为文件系统会缓存 I/O 请求以提升写性能(串行执行五个操作效率太低),即五部分数据可能会以任意顺序写入磁盘,则可能出现一种如图所示的情况,除开 Db 以外的数据均写入成功,在写 Db 的过程中发生了 Crash

- 在崩溃恢复阶段,当读入这条日志记录时,可能引起严重错误,因为 Db 的数据块内容是任意 garbage data。Ext4 引入了日志校验和机制,通过在日志记录的开始和末尾处增加数据块的校验和,来帮助故障恢复时对日志完整有效性的判断,从而提高恢复效率。
- 为了应对该问题,文件系统采用一种类似于“二阶段提交”的方式来写入日志:它先写入除TxE结构之外的日志部分,等到它们真正被写入磁盘后,再接着写入TxE结构到磁盘。
- 在写入第一部分的日志记录时发生了系统崩溃,那么此条日志记录是不完整的,在文件系统重启执行崩溃恢复时,会将此条日志记录视为非法,因此不会导致任何不一致的状态
- 考虑到 TxE 结构一般较小,不足一个扇区大小 sector (< 512 Bytes),因此其写入操作不会发生 torn write,换言之,日志记录的第二阶段的写入也是原子性的。
- 步骤:
- Journal write,同样先写日志,只不过先要确保除TxE结构之外的日志部分先写入到磁盘;

- Journal commit,进一步写入TxE,以确保整条日志记录写入的原子性;

- Checkpoint,最后才将需要追加或更新的文件数据内容真正地更新到磁盘对应的数据块中。
- Journal write,同样先写日志,只不过先要确保除TxE结构之外的日志部分先写入到磁盘;
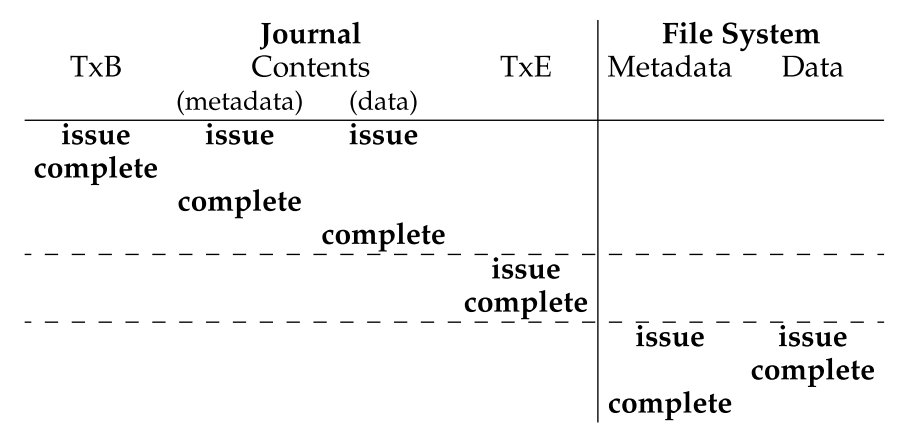
恢复
- 在顺利为每个更新操作写入data journaling日志记录后,一旦发生任何系统崩溃情况,则在文件系统恢复过程中:
- 一方面,若是在日志记录本身的写入过程中发生了系统崩溃,此时日志记录并不完整,因此恢复程序应当直接跳过,不会造成系统任何不一致现象
- 另一方面,若是在 checkpoint 阶段发生了系统崩溃,则只需要读取并解析对应日志内容,然后实施日志 replay 即可重新尝试将更新持久化到磁盘,这种日志类型在数据库管理系统中被称为 redo log。
data journaling 问题
data jounaling 模式能基本解决 crash consistency 问题,其不足之处在于日志记录包含了实际数据块,因此占用了较多额外空间。另外,恢复过程还会引入部分 redundant write。
redundant write (Batching Log Updates)
- 问题描述: 同一个目录下的两个文件 foo1 和 foo2 依次进行更新,更新目录下的一个文件,至少需要更新的磁盘数据结构包括 i-bmap、inode、目录所关联的 data block 以及目录的 inode,因此,这些信息全部需要作为日志内容写入到磁盘,那么 foo1 和 foo2 的更新则需要重复写入目录的 inode 及其关联的 data block,因此会导致较多写操作开销(考虑当更新同一个目录下的多个文件或目录的情况)
- ext3 文件系统采用 batch update 策略来解决。具体而言,它会先将文件的更新进行缓存,并标记对应的日志记录需要存盘,当发现同一目录中其它文件也需要更新时,会将对应的日志记录合并到前一文件所对应的日志记录的数据块中,最后当达到刷盘周期时,将包含多个文件更新的日志记录一次性写入磁盘。
Space
- 日志记录包含了数据块,占用了大量的空间,而且也会增加崩溃恢复过程的耗时。考虑优化日志记录来减小存储空间的使用。
- Making The Log Finite:回收已经持久化的数据对应的存储空间
- Metadata Journaling:日志记录中仅保留元数据减小日志
Making The Log Finite
- 通过日志循环写入(circular log)配合日志释放来解决。具体而言,将存储日志的磁盘区域作为一个环形数组即可,环形数组的首尾指针即为没有被释放的日志记录边界,为了方便,可以将这两个指针存储在journal superblock中。如下图所示。

- 为了实现circular log,需在每次成功文件更新的操作后,即时将日志区域中对应条目释放掉(即更新circular log的首尾指针)。通过引入circular log后,为了保证crash consistency,更新文件的整个过程可扩展为如下四个阶段:
- Journal write,写入除 TxB 结构之外的其它日志记录内容;
- Journal commit,进一步写入日志的 TxB 结构,至此,完成了日志记录的原子性写入;
- Checkpoint,将文件更新或追加的数据真正写入到磁盘;
- Free,释放掉步骤 1 和 2 中写入的日志记录,以备后续空间复用。
- 仍然存在的问题:每一个被更新的文件,其更新数据块需要被写入两次。
Metadata Journaling
- 数据双写(日志和Disk)问题严峻,严重影响磁盘实际使用带宽,在写入元数据和实际数据之间的寻道操作开销也较大,故考虑使用 metadata journaling (ordered journaling),如下所示:

- 如果仍保留原有的 data journaling 流程,只是去除日志中的数据块部分,将会产生垃圾数据,即日志记录写入完成,但实际数据写入过程可能发生错误。故需要调整此时的写入流程:(步骤1 和 2 无顺序依赖,可并发执行)
- Data write,将被更新的文件的数据块真正写入到磁盘;
- Journal metadata write,只将被更新的文件的元信息相关的数据块以及 TxB 构成的日志记录写入到磁盘;
- Journal commit,进一步将此日志记录的 TxE 结构写入磁盘;
- Checkpoint metadata,将被更新文件的元信息相关的数据块真正写入到磁盘;
- Free,释放掉步骤 2 和 3 中写入的日志记录,以备后续空间复用。

- 通过强制数据先写,文件系统可以保证指针永远不会指向垃圾数据。事实上,实现崩溃一致性的核心就是:“write the pointed-to object before the object that points to it。 即 在写入指向目标数据的访问信息(指针)之前,首先写入相应的数据 (取钱之前得先存钱)
- 元数据日志比全数据日志更为广泛被使用。Ext3 提供了多种日志模式,其中 ordered 即为元数据日志。NTFS,XFS 都有对应的元数据日志实现。
Tricky Case: Block Reuse
- 最为繁琐的操作——删除操作可能导致数据块重用的问题。如下图所示,foo 表示一个目录,当我们在目录 foo 下创建一个文件时,若采用metadata journaling模式,其磁盘数据块布局可简化如下。注意,因为目录所包含内容也被视为元数据,因此会被记录到日志中。

- 此时,用户删除目录中的所有内容和目录本身,释放出 Block 1000 以供重用,最后,用户创建一个新文件(比方说 bar),它重用了原来属于 foo 的相同 Block 1000。

- 现在假设发生了崩溃,所有这些信息仍然在日志中。在回放期间,恢复过程简单地回放日志中的所有内容,包括写块 1000 中的目录数据; 这时候恢复过程中的旧数据将会覆盖已经写入的 bar 数据,当用户读取 bar 对应的数据时,将出现不一致的情况。
- 一种比较简单的处理方式是在 checkpoint 日志删除释放 之前都不重用对应的 datablock
- ext3 文件系统的处理方式比较简单,它会将那些被删除文件或目录的日志记录标记成 revoke,且在崩溃恢复过程中,当扫描到包含 revoke 的日志记录时,不会对此日志记录执行 replay,因此避免了数据块覆盖的情况。
Solution#3 Other Approaches
Soft Updates
- 基本原理是将所有文件的更新操作请求进行严格排序,并且保证磁盘对应的数据结构不会处于不一致的状态,比如先写文件数据内容,再写文件元信息,以保证inode不会关联一个无效的数据块。
- 但是Soft Updates实现起来比较复杂,需要充分了解文件系统内部相关数据结构知识,因此增加了文件系统实现的复杂性
CoW Copy-On-Write
- 不直接更新文件包含的数据块,相反,它会创建一个完整的更新后的副本,当完成了若干个更新操作后,再一次性将更新后的数据块关联到被对应的被更新文件。
- ZFS 就同时使用 cow 和 journaling两种技术,LFS 也是 CoW 的一个早期例子
backpointer-based consistency
- FAST12 - Consistency Without Ordering
- 在写操作之间不强制排序,为了达到一致性,一个额外的反向指针被添加到系统中的每个块中,即每个数据块都有一个对它所属的inode的引用。
- 当访问一个文件时,文件系统可以通过检查正向指针(例如inode中的地址或直接块)是否指向指向它的块来确定该文件是否一致
- 通过向文件系统添加反向指针,可以获得一种新的延迟崩溃一致性
optimistic crash consistency
- SOSP13 - Optimistic crash consistency
- 这种新方法通过使用事务校验和的一般化形式,向磁盘发出尽可能多的写操作,还包括一些其他技术,可以在出现不一致时检测。对于某些工作负载,这些乐观技术可以将性能提高一个数量级。但是,要想真正正常工作,需要一个稍微不同的磁盘接口
- 主要用于优化磁盘写入日志记录的过程,以减少等待数据刷盘所导致的时间开销。
文件系统崩溃一致性测试
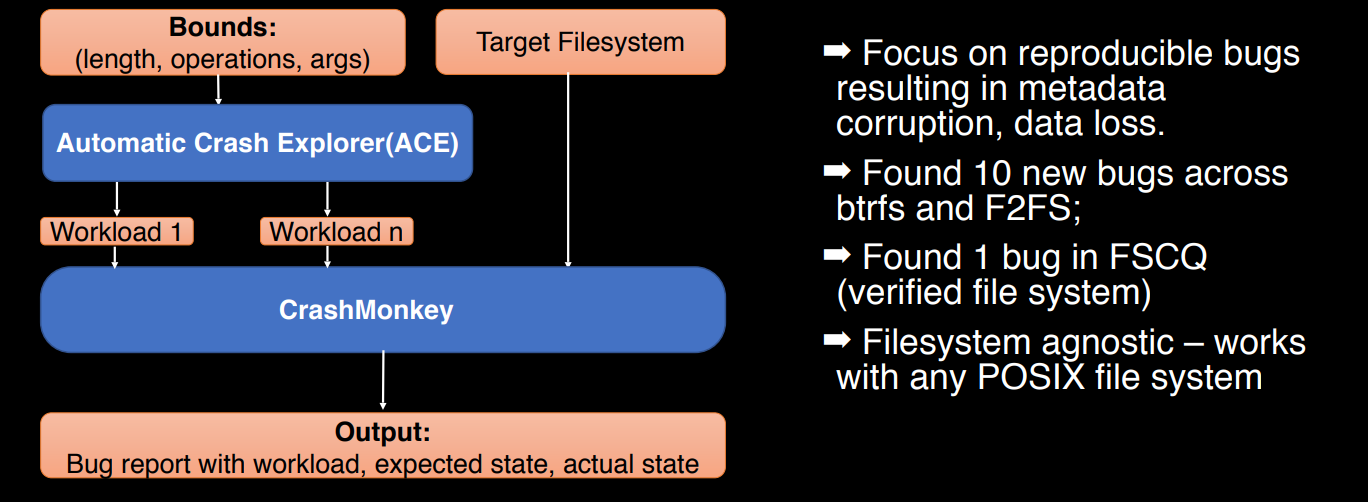
- OSDI18 - Finding Crash-Consistency Bugs with Bounded Black-Box Crash Testing
- Github Repo crashmonkey
参考文献
- [1] 知乎 - 丁凯:Linux文件一致性(一)
- [2] 知乎 - 丁凯:Linux文件一致性(二):脏文件回写之管理线程
- [3] 知乎 - 丁凯:Linux文件一致性(二):脏文件回写之工作线程
- [4] 一抹光辉油彩:简单文件系统的崩溃一致性和日志
- [5] 简书:文件系统天生就是不平等的 - 实现崩溃一致性应用的复杂性
- [6] 知乎 - 蒋炎岩:崩溃一致性:你的程序真的正确保存了数据吗?
- [7] JciX:存储系统的崩溃一致性问题 (Crash Consistency)
- [8] Arpaci-Dusseau R H, Arpaci-Dusseau A C. Operating systems: Three easy pieces[M]. Arpaci-Dusseau Books LLC, 2018
- [9] OSDI18 - Finding Crash-Consistency Bugs with Bounded Black-Box Crash Testing
