源于分布式存储系统中对一致性的严格要求,该篇针对 CAP 理论中的一致性做简单总结。
源于分布式存储系统中对一致性的严格要求,该篇针对 CAP 理论中的一致性做简单总结。
结合行业中为了保证一致性所采用的方案进行实例讲解,诸如分布式数据库等产品
同 ACID 中的事务一致性进行对比总结,进一步理解分布式系统
一致性问题前情提要
并发性和一致性
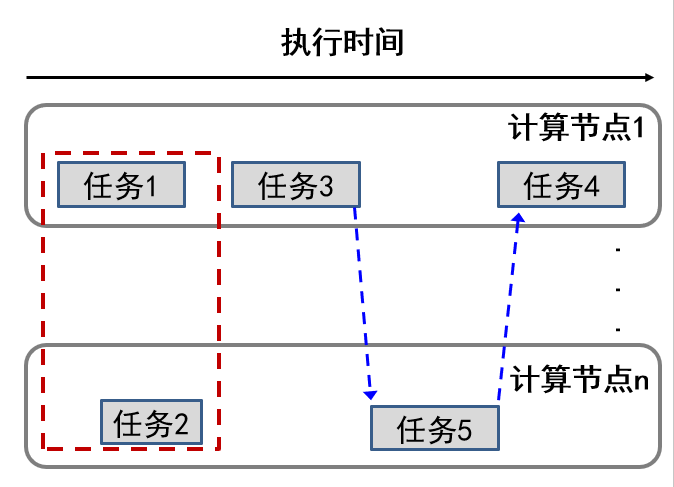
并发性:指同一个时间段内哪些任务可以同时执行,并且都没有执行结束。例如,任务1和任务2同时执行
一致性:确保执行完毕后每个计算节点(或用户)都能看到一致的数据视图。例如,任务3和任务5的不同执行顺序可能导致完全不同的计算结果
并发时序
分布式解决了单节点性能和容量的问题,但也带来了节点间时序关系的难题
时钟不一致 :分布式系统中没有一个绝对的全局时钟,各物理设备上的本地时钟也是不准确,即使设置了时间同步机制,也会存在毫秒级别的偏差,这在金融分布式事务中是不可接受的。在分布式事务中,不精确的并发时序关系可能会导致结果的不一致
Lamport逻辑时钟
与物理时钟的区别:在实际应用中,只要所有机器有相同的时间就够了,这个时间不一定要跟物理时间相同。 如果两个节点之间不进行交互,那么它们的时间甚至都不需要同步。因此问题的关键点在于节点间要在事件发生顺序上达成一致,而不是对时间达成一致
定义( Leslie Lamport 在1978年提出逻辑时钟的概念):逻辑时钟指的是分布式系统中用于区分事件发生顺序的时间机制。从某种意义上讲,现实世界中的物理时间其实是逻辑时钟的一个特例
机制
节点(或进程)ni维护一个逻辑时钟Li,由单调递增的软件计数器维护
逻辑时钟可用于为事件添加一个时间戳
事件时间戳大小可表示事件间的时序关系
向量时钟
设计目标:克服Lamport时钟不能进行因果推导的缺点
基本原理:每个事件维护一个向量时钟V(a)=[c1, c2, …, cn] 其中,ci为节点i中因果关系上发在事件e之间的事件数量
什么是一致性问题
背景 :今天的业务场景越来越复杂,规模越来越大。在面向大规模复杂任务场景时,单点的服务往往难以解决可扩展(Scalability)和容错(Fault-tolerance)两方面的需求,就需要多台服务器来组成集群系统,虚拟为更加强大和稳定的“超级服务器”。集群的规模越大,处理能力越强,管理的复杂度也就越高。目前在运行的大规模集群包括谷歌公司的搜索系统,通过数十万台服务器支持了对整个互联网内容的搜索服务。宏观层面:通常情况下,集群系统中的不同节点可能处于不同的状态,随时收到不同的请求,要时刻保持对外响应的“一致性”。
微观层面:针对某些具体的业务场景,往往需要多种业务操作按照一定的顺序在一个完整的事务中执行,要么全部成功要么全部失败,如简单数据库事务或者分布式数据库事务场景。或者在多个服务节点以相同的角色对外提供服务时,面对相同时间的相同请求需要确保该角色系统中每一个服务节点的执行情况一致,如主从节点之间的数据一致性。
产生一致性问题的原因
系统层面的原因:分布式系统的引入
分布式系统在带来了相应的处理性能优势(通过将计算资源和存储资源协同,从系统层面解决了数据的“海量”问题以及“快”响应的问题)以及架构上的优势(实现了软件工程领域中高内聚低耦合的思想)的同时,引入了多节点之间的协同工作,相比于单机情况下,也相应地引入了节点之间如何保持业务场景中分布式事务的一致性问题(节点协作),以及多个节点中的数据一致性问题(服务分治)。
根本原因
分布式事务场景:某个业务场景下的功能事务,往往涉及到跨库跨表的数据操作,跨库跨表则相应地依赖各项操作执行的结果,对应地受到所在节点的硬件条件和网络的影响。
主从数据一致性:分布式系统为了保证服务的高可用,往往提供了数据副本,而从主数据复制到副本则是产生不一致性的根本原因,复制操作的策对应地影响系统的一致性表现。
一致性基本概念
定义
一致性(Consistency) ,早期也叫(Agreement),在分布式系统领域中是指对于多个服务节点,给定一系列操作,在约定协议的保障下,使得它们对处理结果达成“某种程度”的协同。理想情况(不考虑节点故障)下,如果各个服务节点严格遵循相同的处理协议(即构成相同的状态机逻辑),则在给定相同的初始状态和输入序列时,可以确保处理过程中的每个步骤的执行结果都相同。因此,传统分布式系统中讨论一致性,往往是指在外部任意发起请求(如向多个节点发送不同请求)的情况下,确保系统内大部分节点实际处理请求序列的一致,即对请求进行全局排序。
一致性模型 :一致性模型本质上是进程与数据存储的约定:如果进程遵循某些规则,那么进程对数据的读写操作都是可预期的。其中数据存储是指在分布式系统中指分布式共享数据库、分布式文件系统等。
分类
一致性 在互联网与计算机领域中按照业务场景主要有两大分支:分布式系统中 CAP 理论所介绍的数据一致性 和 数据库事务 ACID 中所提及的一致性。
分布式事务一致性,指的是“操作序列在多个服务节点中执行的顺序是一致的”。
分布式数据一致性,指的是“数据在多份副本中存储时,各副本中的数据是一致的”。
一致性 根据不同的要求等级又可以划分为 强一致性 和 弱一致性 。套用一致性模型的定义的话,一致性模型 主要可以分为两类:能够保证所有进程对数据的读写顺序都保持一致的一致性模型称为 强一致性模型 ,而不能保证的一致性模型称为 弱一致性模型 。
强一致性(模型)
强一致性(模型)又可以分为 线性一致性(模型) 和 顺序一致性(模型) 。
线性一致性(模型)Linearizability Consistency
线性一致性 也叫 严格一致性 (Strict Consistency)或者 原子一致性 (Atomic Consistency)
Maurice P. Herlihy 与 Jeannette M. Wing 在 1990 年经典论文《Linearizability: A Correctness Condition for
具体要求
任何一次读都能读取到某个数据最近的一次写的数据。
所有进程看到的操作顺序都跟全局时钟下的顺序一致。
顺序一致性(模型)Sequential Consistency
Leslie Lamport 1979 年经典论文《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs》中提出,是一种比较强的约束,保证所有进程看到的全局执行顺序(total order)一致,并且每个进程看自身的执行顺序(local order)跟实际发生顺序一致。例如,某进程先执行 A,后执行 B,则实际得到的全局结果中就应该为 A 在 B 前面,而不能反过来。同时所有其它进程在全局上也应该看到这个顺序。顺序一致性实际上限制了各进程内指令的偏序关系,但不在进程间按照物理时间进行全局排序。
具体要求
任何一次读写操作都是按照某种特定的顺序。
所有进程看到的读写操作顺序都保持一致。
线性一致性和顺序一致性的对比
相同点
不同点
实现保证读写顺序一致的方式不同:
线性一致性的实现很简单,就按照全局时钟(可以简单理解为物理时钟)为参考系,所有进程都按照全局时钟的时间戳来区分事件的先后
顺序一致性使用的是 逻辑时钟 来作为分布式系统中的全局时钟,进而所有进程也有了一个统一的参考系对读写操作进行排序
和实际上发生的顺序的一致性不同:
顺序一致性虽然通过逻辑时钟保证所有进程保持一致的读写操作顺序,但这些读写操作的顺序跟实际上发生的顺序并不一定一致。
线性一致性是严格保证跟实际发生的顺序一致的。
弱一致性(模型)
弱一致性(模型)又可以分为 因果一致性 (Causal Consistency)、最终一致性 (Eventual Consistency)和以客户端为中心的一致性 (Client-centric Consistency)。
因果一致性 Causal Consistency
需要有因果关系的多种操作能够保持顺序一致,其本质是一种弱化的顺序一致性模型。
因果关系 是指操作之间存在一定的依赖关系,譬如自增操作中需要先读取对应的值,再进行自增,此时增加操作和读取操作就存在了因果关系。
具体要求
所有进程必须以相同的顺序看到具有因果关系的读写操作。
不同进程可以以不同的顺序看到并发的读写操作。
与顺序一致性的区别
顺序一致性虽然不保证事件发生的顺序跟实际发生的保持一致,但是它能够保证所有进程看到的读写操作顺序是一样的。而 因果一致性更进一步弱化了顺序一致性中对读写操作顺序的约束,仅保证有因果关系的读写操作有序,没有因果关系的读写操作(并发事件)则不做保证。 也就是说如果是无因果关系的数据操作不同进程看到的值是有可能是不一样,而有因果关系的数据操作不同进程看到的值保证是一样的。
最终一致性 Eventual Consistency
具体要求
“最终”到底是多久?通常来说,实际运行的系统需要能够保证提供一个有下限的时间范围。
多副本之间对数据更新采用什么样的策略?一段时间内可能数据可能多次更新,到底以哪个数据为准?一个常用的数据更新策略就是以时间戳最新的数据为准。
以客户端为中心的一致性 Client-centric Consistency
以客户端为中心的一致性为单一客户端提供一致性保证,保证该客户端对数据存储的访问的一致性,但是它不为不同客户端的并发访问提供任何一致性保证。
实现方式:客户端缓存。举个例子:客户端 A 在副本 M 上读取 x 的最新值为 1,假设副本 M 挂了,客户端 A 连接到副本 N 上,此时副本 N 上面的 x 值为旧版本的 0,那么一致性模型会保证客户端 A 读取到的 x 的值为 1,而不是旧版本的 0。一种可行的方案就是给数据 x 加版本标记,同时客户端 A 会缓存 x 的值,通过比较版本来识别数据的新旧,保证客户端不会读取到旧的值。
以客户端为中心的一致性包含了四种子模型: 单调读一致性(Monotonic-read Consistency),单调写一致性(Monotonic-write Consistency),读写一致性(Read-your-writes Consistency),写读一致性(Writes-follow-reads Consistency)
单调读一致性(Monotonic-read Consistency)
如果一个进程读取数据项 x 的值,那么该进程对于 x 后续的所有读操作要么读取到第一次读取的值要么读取到更新的值。即保证客户端不会读取到旧值。单调读比强一致性更弱,比最终一致性更强。
实现方式:确保每个用户总是从同一个节点进行读取(不同的用户可以从不同的节点读取),比如可以基于用户ID的哈希值来选择节点,而不是随机选择节点。
单调写一致性(Monotonic-write Consistency)
一个进程对数据项 x 的写操作必须在该进程对 x 执行任何后续写操作之前完成。即保证客户端的写操作是串行的。
读写一致性(Read-your-writes Consistency)
一个进程对数据项 x 执行一次写操作的结果总是会被该进程对 x 执行的后续读操作看见。即保证客户端能读到自己最新写入的值。
实现方式:
最简单的方案,对于某些特定的内容,都从主库读。举个例子,知乎个人主页信息只能由用户本人编辑,而不能由其他人编辑。因此,永远从主库读取用户自己的个人主页,从从库读取其他用户的个人主页。
客户端可以在本地记住最近一次写入的时间戳,发起请求时带着此时间戳。从库提供任何查询服务前,需确保该时间戳前的变更都已经同步到了本从库中。如果当前从库不够新,则可以从另一个从库读,或者等待从库追赶上来。
写读一致性(Writes-follow-reads Consistency)
同一个进程对数据项 x 执行的读操作之后的写操作,保证发生在与 x 读取值相同或比之更新的值上。即保证客户端对一个数据项的写操作是基于该客户端最新读取的值。
一致性的实现方式
基本实现思路
分布式事务的一致性
为了保证分布式事务的一致性,主要采用了 两阶段提交协议、三阶段提交协议和 TCC 补偿协议。
现如今也已有带事务功能的消息中间件来辅助实现分布式事务,如 RocketMQ
强一致性
强一致性的实现方式最主要分为两种:一种是主从同步复制,另外一种是多数派的方式。
主从同步复制
流程:主节点接收写请求,主节点复制日志到从节点,主节点等待,直到所有的库都返回相应的执行结果。
问题:一个节点失败, 主节点阻塞,导致整个主从节点对应的集群不可使用,保证了强一致性,但牺牲了可用性。
多数派
流程:每次写入保证写入大于N/2个节点,每次读保证从大于N/2个节点读。
问题:在并发环境下,无法保证系统的正确性,顺序很重要。
最终一致性
为了实现数据的最终一致性,往往需要结合共识算法 Paxos\Raft 等算法以及 Gossip 去中心化协议等来进行实现。
分布式存储系统中的实现
Azure Cosmos DB
Azure Cosmos DB 是一个支持多地部署的分布式NoSQL数据库服务。它提供了丰富的可配置的一致性级别。以下五种一致性级别,从前向后可以提供更低的读写延迟,更高的可用性,更好的读扩展性。
一致性级别
强一致性
保证读操作总是可以读到最新版本的数据(即可线性化)
写操作需要同步到多数派副本后才能成功提交。读操作需要多数派副本应答后才返回给客户端。读操作不会看到未提交的或者部分写操作的结果,并且总是可以读到最近的写操作的结果。
保证了全局的(会话间)单调读,读自己所写,单调写,读后写
有界旧一致性(bounded staleness)
保证读到的数据最多和最新版本差K个版本
通过维护一个滑动窗口,在窗口之外,有界旧一致性保证了操作的全局序。此外,在一个地域内,保证了单调读。
会话一致性
在一个会话内保证单调读,单调写,和读自己所写,会话之间不保证
会话一致性能够提供把读写操作的版本信息维护在客户端会话中,在多个副本之间传递
会话一致性的读写延迟都很低
前缀一致性
前缀一致保证,在没有更多写操作的情况下,所有的副本最终会一致
前缀一致保证,读操作不会看到乱序的写操作。例如,写操作执行的顺序是A, B, C,那么一个客户端只能看到A, A, B, 或者A, B, C,不会读到A, C,或者B, A, C等。
在每个会话内保证了单调读
最终一致性
最终一致性保证,在没有更多写操作的情况下,所有的副本最终会一致
最终一致性是很弱的一致性保证,客户端可以读到比之前发生的读更旧的数据
最终一致性可以提供最低的读写延迟和最高的可用性,因为它可以选择读取任意一个副本
Cassandra
Cassandra 是一个使用多数派协议的NoSQL存储系统,通过控制读写操作访问的副本数和副本的位置,可以实现不同的一致性级别。注意,作为NoSQL系统,Cassandra只提供单行操作的原子性,多行操作不是原子的。下面的读写操作,都是指单行操作。
对于NoSQL系统,一般支持的写操作叫做PUT(有些系统叫做UPSERT)。这个操作的含义是,如果这行存在(通过唯一主键查找),则修改它;如果这行不存在,则插入。这个语义,可以近似(在不考虑二级索引的时候)等价于关系数据库的INSERT ON DUPLICATE KEY UPDATE语句,类比于 MySQL 中的 REPLACE 原语。本文前面所讲的“写操作”也是泛指这种语义。这个语义有什么特殊之处呢? 第一, 它是幂等的 。所以PUT操作可以重复执行,不怕消息重传。第二, 它是覆盖(overwrite)语义 。所以,NoSQL系统的最终一致性,允许对于同一行数据的写操作可以乱序,只要写操作不断,最终各个副本会一致。而关系数据库的insert和update等修改语句,内部实现都是即需要读也需要写。所以,关系数据库的多副本一致性,假设简单地把SQL修改语句同步到多个副本的方式来实现,必须要以相同的顺序执行才能保证结果一致(当然,实际系统不能这么实现)。
写操作配置
写操作一致性配置定义了对于写操作在哪些副本上成功之后,才能返回给客户端。
ALL: 写操作需要同步到所有副本并应用到内存中。提供了最强的一致性保证,但是单点故障会引起写入失败,造成系统不可用。
EACH_QUORUM: 在每个机房(数据中心)中,写操作同步到多数派副本节点中。在多数据中心部署的集群中,可以在每个数据中心提供QUORUM一致性保证。
QUORUM: 写操作同步到多数派副本节点中。当少数副本宕机的时候,写操作可以持续服务。
LOCAL_QUORUM: 写操作必须同步到协调者节点所在数据中心的多数派副本中。这种模式可以避免多数据中心部署时,跨机房同步引起的高延迟。在单机房内,可以容忍少数派宕机。
ONE: 写操作必须写入最少一个副本中。
TWO: 写操作必须写入至少两个副本中。
THREE: 写操作必须写入至少三个副本中。
LOCAL_ONE: 写操作必须写入本地数据中心至少一个副本中。在多机房部署的集群中,可以达到和ONE相同的容灾效果,并且把写操作限制在本地机房。
读操作配置
每个读操作可以设定如下不同的一致性配置。
ALL: 读操作在全部副本节点应答后才返回给客户端。单点单机会引起写操作失败,造成系统不可用。
QUORUM: 在任何数据中心的一定数量的副本已响应后,返回记录。读操作在多数派副本返回应答后返回给客户端。
LOCAL_QUORUM: 读操作在本机房多数派副本返回应答后返回给客户端。可以避免跨机房访问的高延迟。
ONE: 最近的一个副本节点应答后即返回给客户端。可能返回旧数据。
TWO: 两个副本节点应答后即返回给客户端。
THREE: 三个副本节点应答后返回给客户端。
LOCAL_ONE: 本机房最近的一个副本节点应答后返回客户端。
系统一致性级别
从系统层面来看,Cassandra提供了强一致性和最终一致性两种一致性级别。不考虑多机房因素,通过设置上述读写操作的一致性配置,当写入副本数与读取副本数之和大于总副本数的时候,可以保证读操作总是可以读取最新被写入的数据,即强一致性保证。如果写入副本数与读取副本数之和小于总副本数的时候,读操作可能无法读到最新的数据,而且读操作可能读到比之前发生的读操作更旧的数据,所以这种情况下是最终一致性。
而副本位置是选择整个集群、每个机房还是本地机房等因素,是为了在不同的容灾场景下,对跨机房通讯引入的高延迟进行优化,固有的一致性级别并不受影响。例如,写操作用EACH_QUORUM,读操作用LOCAL_QUORUM,还是提供了强一致性保证,但是不同机房的读操作都变成本地的了,读延迟较低。但是,和写操作用QUORUM模式相比,某个机房发生了多数派宕机(总副本数还是少数派),就会导致写操作失败。再如,读写操作都用LOCAL_QUORUM,那么协调者节点所在机房内是强一致性的,与协调者节点不在一个机房的读操作则可能读到旧数据。
OceanBase
OceanBase是一个支持海量数据的高性能分布式数据库系统,实现了数千亿条记录、数百TB数据上的跨行跨表事务,由淘宝核心系统研发、运维、DBA、广告、应用研发等部门共同完成。在设计和实现OceanBase的时候暂时摒弃了不紧急的DBMS的功能,例如临时表,视图(view),研发团队把有限的资源集中到关键点上,当前 OceanBase主要解决数据更新一致性、高性能的跨表读事务、范围查询、join、数据全量及增量dump、批量数据导入。
一致性级别
强一致性:
OceanBase使用Multi-Paxos分布式共识算法在多个数据副本之间同步事务提交日志,每个修改事务,要在多数派副本应答以后才认为提交成功。多个副本之间,通过自主投票的机制,选出其中一个副本为主副本(leader),它负责所有修改语句的执行,特别的,达成多数派的事务提交日志要求包含主副本自己。在通常情况下,数据库需要保证强一致性语义(和单机数据库类比),我们的做法是,读写语句都在主副本上执行。当主副本宕机的时候,其余的多数派副本会选出新的主副本。此时,已经完成的每一个事务一定有至少一个副本记录了提交日志的。新的主副本通过和其他副本的通信可以获得所有已提交事务的日志,进而完成恢复,恢复以后继续提供服务。通过这种机制,OceanBase可以保证在少数派宕机的情况下不会丢失任何数据,而强一致性读写服务的宕机恢复时间小于一分钟。
如果一个语句的执行涉及到多个表的分区,在OceanBase中这些分区的主副本可能位于不同的服务节点上。严格的数据库隔离级别要求涉及多个分区的读请求看到的是一个“快照”,也就是说,不允许看到部分事务。这要求维护某种形式的全局读版本号,开销较大。如果应用允许,可以调整读一致性级别,系统保证读到最新写入的数据,但是不同分区上的数据不是一个快照。从一致性级别来看,这也是强一致性级别,但是打破了数据库事务的ACID属性。
最终一致性:在最弱的级别下,我们可以利用所有副本提供读服务。在OceanBase的实现中,多副本同步协议只保证日志落盘,并不要求日志在多数派副本上完成回放(写入存储引擎的memtable中)。所以,利用任意副本提供读服务时,即使对于同一个分区的多个副本,每个副本完成回放的数据版本也是不同的,这样可能会导致读操作读到比之前发生的读更旧的数据。也就是说,这种情况下提供的是最终一致性。当任意副本宕机的时候,客户端可以迅速重试其他副本,甚至当多数派副本宕机的时候还可以提供这种读服务。
前缀一致性:它可以在每个数据库连接内,保证单调读。这种模式,一般用于OceanBase集群内读库的访问,业务本身是读写分离的架构。
有界旧一致性:在多地部署OceanBase的时候,跨地域副本数据之间的延迟是固有的。比如,用户配置允许读到30秒内的数据,那么只要本地副本的延迟小于30秒,则读操作可以读取本地副本。如果不能满足要求,则读取主副本所在地的其他副本。如果还不能满足,则会读取主副本。这样的方式可以获得最小的读延迟,以及比强一致性读更好的可用性。这样,在同时保证会话级单调读的条件下,我们提供了有界旧一致性级别。
参考链接
x
感谢您的支持,我会继续努力的!
扫码打赏,你说多少就多少