- 本篇主要总结 RADOS 底层的读写流程,并结合源码进行分析
- 考虑基于现有的强一致性模型的读写流程是否有可以优化的点,提升 Ceph 的 IO 性能
OSD 读写流程
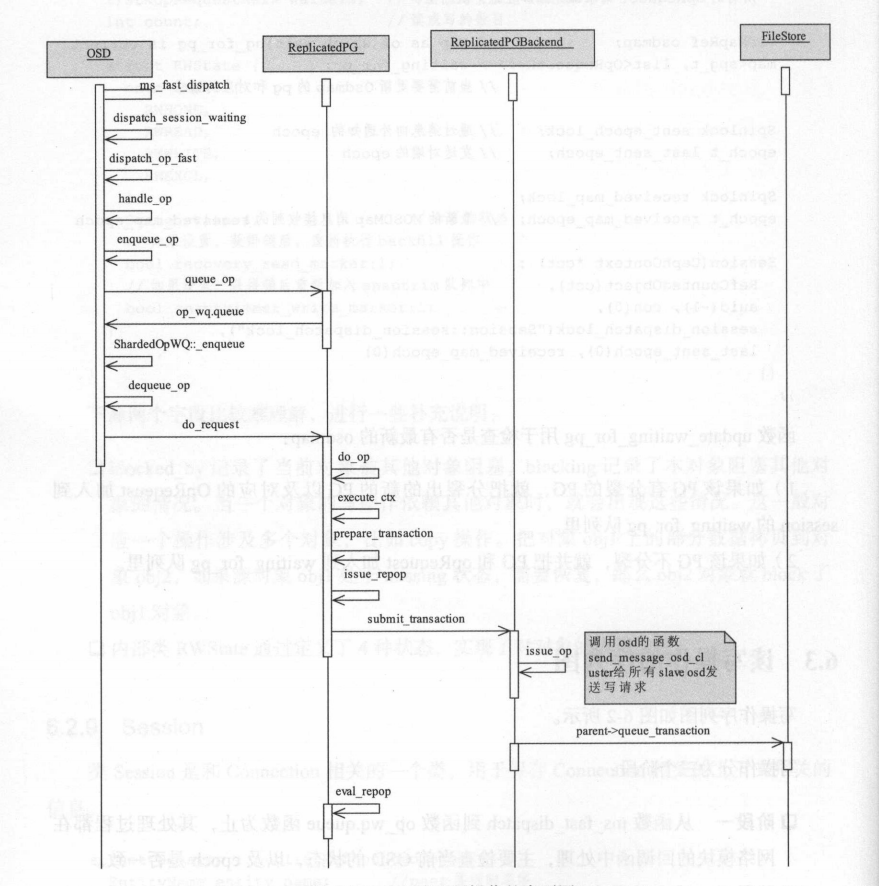
- 大致分为三个阶段:
- 接受请求:主要是网络模块相关
- OSD 的 op_wq 处理:在工作队列 op_wq 的线程池中处理,检查 PG 状态,封装请求为事务
- PGBackend 的处理:仍然在 op_wq 的线程池中处理,将事务进行分发,由对应的 PGBackend 来实现本地事务处理
PG
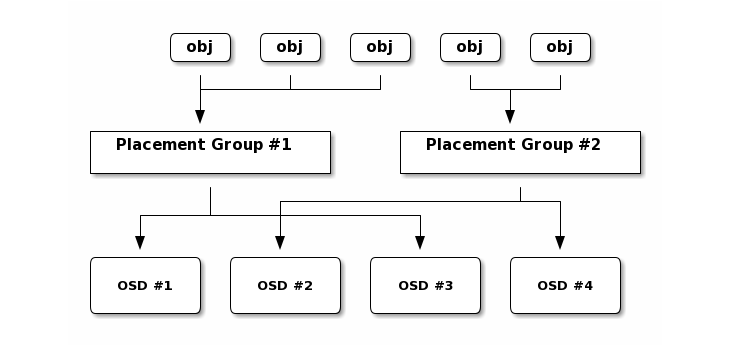
- Placement Group (PG),是一些对象的集合,对象和 PG 的对应关系其实就是对象标识 HASH 之后取模得到对应的 pg_id(模值为对应存储池对应的 PG 数目)。
locator = object_name
obj_hash = hash(locator)
pg = obj_hash % num_pg
OSDs_for_pg = crush(pg) # returns a list of OSDs
primary = osds_for_pg[0]
replicas = osds_for_pg[1:]
- 以 PG 为单位进行组织的目的是为了使用有限的、可控数目的 PG 来管理无限扩张的对象数据,并控制节点资源的分配。
- PG 是数据备份、同步、迁移等操作的基本单位。
常见的 PG 级别的操作
Peering
- 指(当前或者过去曾经)归属于同一个 PG 所有的 PG 实例就本 PG 所存储的全部对象及对象相关的元数据进行协商并最终达成一致的过程。
- Peering 基于 Info 和 Log 进行。Log 是指权威日志,作为数据同步的依据。Info 是指 PG 的基本元数据信息,在 Peering 过程中通过交换 Info,可以由 Primary 选举得到权威日志。
- 此处说的一致,并不意味着每个 PG 实例都实时拥有每个对象的最新内容
- Golden Rule: 对任何 PG 的写操作只有在该 PG 的操作集的所有成员都持久化后,才会向客户端确认,且在 Peering 期间不能进行任何 IO 操作,且不能做 Recovery
涉及的其他概念
- Acting Set:负责特定 PG 的(或在某些 epoch 时) OSD 的有序列表。列表第一个 OSD 为主 OSD,其余为 Replica OSD
- Up Set:通常情况下和 Acting Set 相同,出现 PG temp 时有所不同。Acting Set 完全由 CRUSH 决定,Up Set 会受到 PG temp 的影响
- PG temp:假设一个 PG 的 acting set 为 [0,1,2] 列表。此时如果 osd0 出现故障,导致 CRUSH 算法重新分配该 PG 的 acting set 为 [3,1,2]。此时 osd3 为该 PG 的主 OSD,但是 osd3 为新加入的 OSD,并不能负担该 PG 上的读操作。所以 PG 向 Monitor 申请一个临时的 PG,osd1 为临时的主 OSD,这时 up set 变为 [1,3,2],acting set 依然为 [3,1,2],导致 acting set 和 up set 不同。当 osd3 完成 Backfill 过程之后,临时 PG 被取消,该 PG 的 up set 修复为 acting set,此时 acting set 和 up set 都为 [3,1,2] 列表。
- Epoch:OSDMap 的版本号,Monitor 管理生成,单增。OSDMap 发生了变化,Epoch 相应地增加,但为了防止 Epoch 的剧烈变化和较快的消耗,一个特定时间段内的修改会被折叠进入一个 Epoch
- Interval:OSDMap 的一个连续 Epoch 间隔,该期间内的 PG 的 Active Set 和 Up Set 没有发生变化,也就意味着和 PG 是绑定的。每个 Interval 的起始 Epoch 称之为 same_interval_since
触发时机
- 系统初始化时,OSD 重新启动导致 PG 重新加载
- PG 新创建时,PG 会发起一次 Peering 的过程
- 当有 OSD 失效,OSD 的增加或者删除等导致 PG 的 acting set 发生了变化,该 PG 就会重新发起一次 Peering 过程
Recovery
- 当 PG 完成了 Peering 过程后,处于 Active 状态的 PG 就已经可以对外提供服务了。如果该 PG 的各个副本上有不一致的对象,就需要进行修复。Ceph 的修复过程有两种:Recovery 和 Backfill。本质是针对 PG 某些实例进行数据同步的过程,最终目标是将 PG 变成 Active+Clean 状态
过程
- Peering 过程产生关于缺失对象的信息,主副本和从副本对应的缺失对象信息有所不同,存储的位置不同。主 OSD 缺失的对象存储在权威日志 pg_log 的相关数据结构中,副本上缺失的对象存储在 OSD 对应的 peer_missing 的数据结构中。
- 对于主 OSD 缺失的对象,随机选择一个拥有该对象的 OSD,拉取数据(PULL)。(先修复主 OSD,再修复从 OSD)
- 对于 replica 数据缺失的情况,从主副本上把缺失的对象数据推送到副本上完成数据修复(PUSH)
- 快照对象有一些单独的处理
场景
- OSD 暂时下线,然后又上线
- OSD 硬件故障下线,更换硬盘重新上线
Pull/Push
- Recovery 由 Primary 主导进行,期间 Primary 通过 Pull 或者 Push 的方式进行对象间的数据同步
Backfill
- 是 Recovery 的一种特殊场景,指 Peering 完成后,如果基于当前权威日志无法对 Up Set 当中的某些 PG 实例实施增量同步(例如承载这些 PG 实例的 OSD 离线太久,或者是新的 OSD 加入集群导致的 PG 实例整体迁移),则通过完全拷贝当前 Primary 所有对象的方式进行全量同步。
Scrub
- Ceph 内部实现的数据一致性检查工具 Ceph Scrub。原理为:通过对比各个对象副本的数据和元数据完成副本的一致性检查。后台执行检查操作,可以设置相应的调度策略来触发 Scrub(立即启动/间隔一定的时间/定时)
- 主要包括scrub 和 deep-scrub。
- 其中 scrub 只对元数据信息进行扫描,相对比较快;
- 而 deep-scrub 不仅对元数据进行扫描,还会对存储的数据进行扫描,几乎要扫描磁盘上的所有数据并计算 crc32 校验值,相对比较慢。
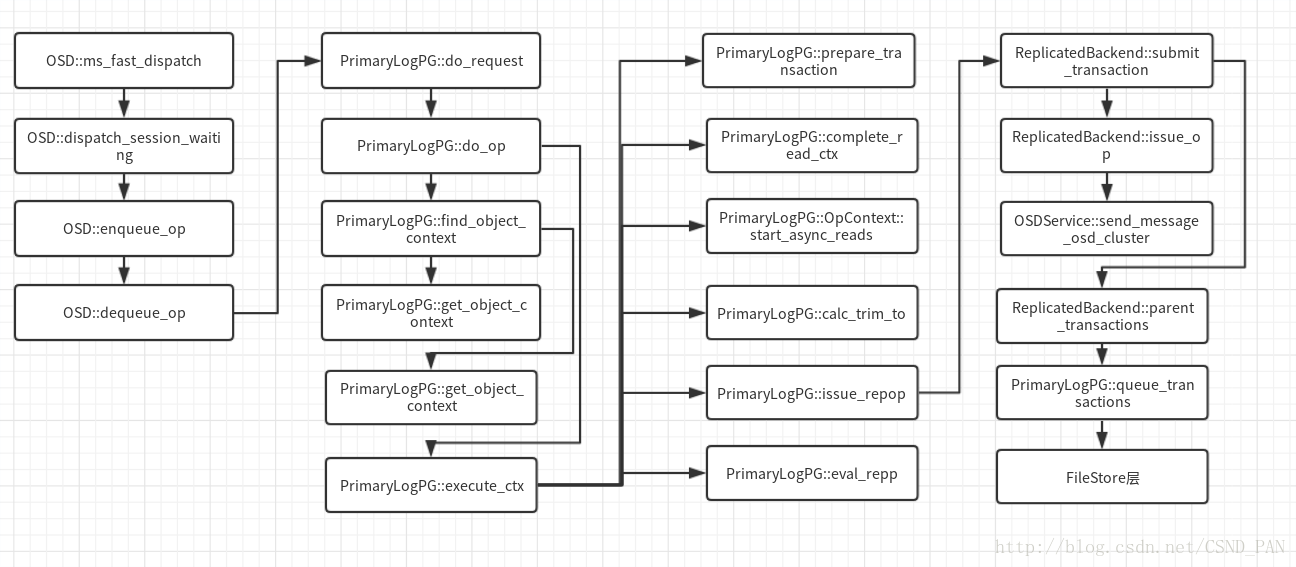
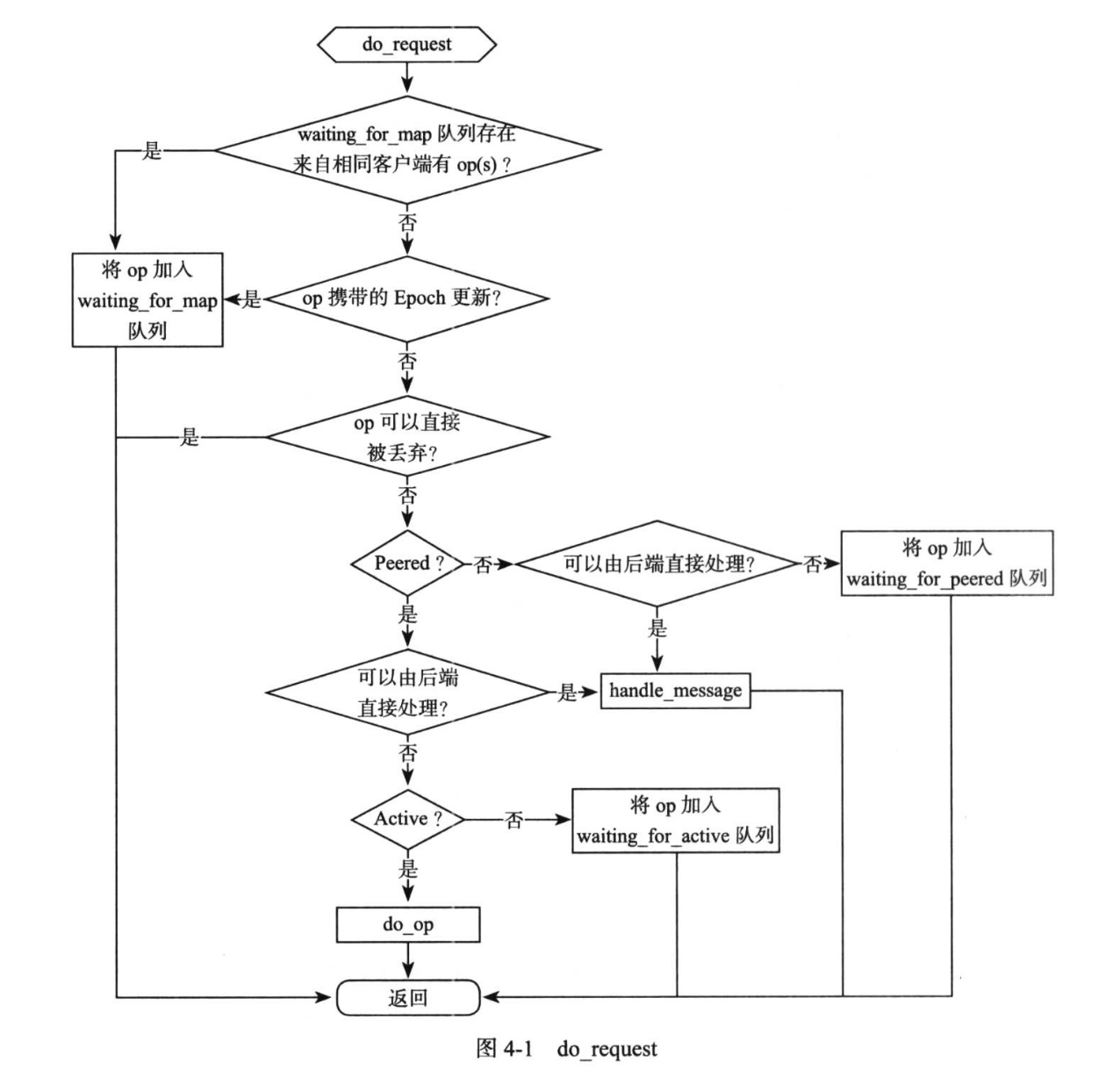
PrimaryLogPG::do_request
- 该步骤主要是做一些 PG 级别的检查,以及一些 PG 级别的操作的分发处理。
- 操作最终可能因为各种各样的原因被加入到响应队列推迟处理,对应了很多种重试队列,用于区分不同的场景。


- 为了保证 OP 之间不会乱序,上述队列均为 FIFO 队列,且队列之间也严格有序。当对应的限制接触后,PG 会触发关联的 OP 重新进入 op_shardedwq 队列排队,等候再次被 PG 执行
- 最终许多普通的操作都会进入 do_op 执行
void PrimaryLogPG::do_request(
OpRequestRef &op,
ThreadPool::TPHandle &handle)
{
// Trace 相关配置检查
if (op->osd_trace)
{
op->pg_trace.init("pg op", &trace_endpoint, &op->osd_trace);
op->pg_trace.event("do request");
}
// make sure we have a new enough map
// 判断 waiting_for_map 队列中是否有来自相同客户端的操作
auto p = waiting_for_map.find(op->get_source());
if (p != waiting_for_map.end())
{
// 有则将当前 Op 加入 waiting_for_map 队列,然后直接返回
// preserve ordering
dout(20) << __func__ << " waiting_for_map "
<< p->first << " not empty, queueing" << dendl;
p->second.push_back(op);
op->mark_delayed("waiting_for_map not empty");
return;
}
// 判断当前 op 携带的 Epoch 信息是否是最新的 op->min_epoch <= get_osdmap_epoch()
if (!have_same_or_newer_map(op->min_epoch))
{
// 如果 Op 携带的 epoch 更新,则将当前 Op 加入 waiting_for_map 队列,然后直接返回
dout(20) << __func__ << " min " << op->min_epoch
<< ", queue on waiting_for_map " << op->get_source() << dendl;
waiting_for_map[op->get_source()].push_back(op);
op->mark_delayed("op must wait for map");
osd->request_osdmap_update(op->min_epoch);
return;
}
// 判断是否可以丢弃掉该 op
// 1. op 对应的客户端链路断开
// 2. 收到 op 时,PG 当前已经切换到一个更新的 Interval (即 PG 此时的 same_interval_since 比 op 携带的 Epoch 要大,后续客户端会重发)
// 3. op 在 PG 分裂之前发送(后续客户端会进行重发)
// 4. ...
if (can_discard_request(op))
{
return;
}
// pg-wide backoffs
const Message *m = op->get_req();
int msg_type = m->get_type();
if (m->get_connection()->has_feature(CEPH_FEATURE_RADOS_BACKOFF))
{
auto session = ceph::ref_cast<Session>(m->get_connection()->get_priv());
if (!session)
return; // drop it.
if (msg_type == CEPH_MSG_OSD_OP)
{
if (session->check_backoff(cct, info.pgid,
info.pgid.pgid.get_hobj_start(), m))
{
return;
}
bool backoff =
is_down() ||
is_incomplete() ||
(!is_active() && is_peered());
if (g_conf()->osd_backoff_on_peering && !backoff)
{
if (is_peering())
{
backoff = true;
}
}
if (backoff)
{
add_pg_backoff(session);
return;
}
}
// pg backoff acks at pg-level
if (msg_type == CEPH_MSG_OSD_BACKOFF)
{
const MOSDBackoff *ba = static_cast<const MOSDBackoff *>(m);
if (ba->begin != ba->end)
{
handle_backoff(op);
return;
}
}
}
// PG 是否处于 Active 或者 Peer 状态?
if (!is_peered())
{
// 不处于上述状态,判断是否可以由后端直接处理。
// 1. ECBackend 该情况下不能处理
// 2. ReplicatedBackend 判断如果是 PULL 操作则可以进行处理
// Delay unless PGBackend says it's ok
if (pgbackend->can_handle_while_inactive(op))
{
bool handled = pgbackend->handle_message(op);
ceph_assert(handled);
return;
}
else
{
// 不能处理则加入 waiting_for_peered 队列,然后返回。
waiting_for_peered.push_back(op);
op->mark_delayed("waiting for peered");
return;
}
}
// PG 处于 Active 或者 Peer 状态,判断是否正在进行刷回
if (recovery_state.needs_flush())
{
// 正在刷回则将该 op 加入 waiting_for_flush 队列,并返回
dout(20) << "waiting for flush on " << op << dendl;
waiting_for_flush.push_back(op);
op->mark_delayed("waiting for flush");
return;
}
ceph_assert(is_peered() && !recovery_state.needs_flush());
// 由 PGBackend 直接处理然后返回,此处只处理以下操作
// 1. MSG_OSD_PG_RECOVERY_DELETE (Common)
// 2. MSG_OSD_PG_RECOVERY_DELETE_REPLY (Common)
// 3. MSG_OSD_PG_PUSH (副本)
// 4. MSG_OSD_PG_PULL (副本)
// 5. MSG_OSD_PG_PUSH_REPLY (副本)
// 6. MSG_OSD_REPOP (副本)
// 7. MSG_OSD_REPOPREPLY (副本)
// 8. MSG_OSD_EC_WRITE (EC)
// 9. MSG_OSD_EC_WRITE_REPLY (EC)
// 10. MSG_OSD_EC_READ (EC)
// 11. MSG_OSD_EC_READ_REPLY (EC)
// 12. MSG_OSD_PG_PUSH (EC)
// 13. MSG_OSD_PG_PUSH_REPLY (EC)
if (pgbackend->handle_message(op))
return;
// 其余操作如下处理:
switch (msg_type)
{
case CEPH_MSG_OSD_OP:
case CEPH_MSG_OSD_BACKOFF:
// 判断是否是 Active 状态
if (!is_active())
{
// 即 Peer 状态,加入 waiting_for_active 队列并返回
dout(20) << " peered, not active, waiting for active on " << op << dendl;
waiting_for_active.push_back(op);
op->mark_delayed("waiting for active");
return;
}
// 为 Active 状态
switch (msg_type)
{
// 处理 CEPH_MSG_OSD_OP
// 如果为 tier 相关直接报错,否则 do_op
case CEPH_MSG_OSD_OP:
// verify client features
if ((pool.info.has_tiers() || pool.info.is_tier()) &&
!op->has_feature(CEPH_FEATURE_OSD_CACHEPOOL))
{
osd->reply_op_error(op, -EOPNOTSUPP);
return;
}
do_op(op);
break;
// 处理 CEPH_MSG_OSD_BACKOFF
case CEPH_MSG_OSD_BACKOFF:
// object-level backoff acks handled in osdop context
handle_backoff(op);
break;
}
break;
// 其他操作的处理
case MSG_OSD_PG_SCAN:
do_scan(op, handle);
break;
case MSG_OSD_PG_BACKFILL:
do_backfill(op);
break;
case MSG_OSD_PG_BACKFILL_REMOVE:
do_backfill_remove(op);
break;
case MSG_OSD_SCRUB_RESERVE:
{
auto m = op->get_req<MOSDScrubReserve>();
switch (m->type)
{
case MOSDScrubReserve::REQUEST:
handle_scrub_reserve_request(op);
break;
case MOSDScrubReserve::GRANT:
handle_scrub_reserve_grant(op, m->from);
break;
case MOSDScrubReserve::REJECT:
handle_scrub_reserve_reject(op, m->from);
break;
case MOSDScrubReserve::RELEASE:
handle_scrub_reserve_release(op);
break;
}
}
break;
case MSG_OSD_REP_SCRUB:
replica_scrub(op, handle);
break;
case MSG_OSD_REP_SCRUBMAP:
do_replica_scrub_map(op);
break;
case MSG_OSD_PG_UPDATE_LOG_MISSING:
do_update_log_missing(op);
break;
case MSG_OSD_PG_UPDATE_LOG_MISSING_REPLY:
do_update_log_missing_reply(op);
break;
default:
ceph_abort_msg("bad message type in do_request");
}
}
PrimaryLogPG::do_op
/** do_op - do an op
* pg lock will be held (if multithreaded)
* osd_lock NOT held.
*/
void PrimaryLogPG::do_op(OpRequestRef &op)
{
FUNCTRACE(cct);
// 使用一个指针进行指向对应的请求,后续操作都使用该指针
// NOTE: take a non-const pointer here; we must be careful not to
// change anything that will break other reads on m (operator<<).
MOSDOp *m = static_cast<MOSDOp *>(op->get_nonconst_req());
// op 参数校验
ceph_assert(m->get_type() == CEPH_MSG_OSD_OP);
// decode 请求解码状态判断,从 bufferlist 中解析数据
if (m->finish_decode())
{
op->reset_desc(); // for TrackedOp
m->clear_payload();
}
dout(20) << __func__ << ": op " << *m << dendl;
const hobject_t head = m->get_hobj().get_head();
// 【PG 参数检查】判断是否包含 op 所携带的对象
if (!info.pgid.pgid.contains(
info.pgid.pgid.get_split_bits(pool.info.get_pg_num()), head))
{
derr << __func__ << " " << info.pgid.pgid << " does not contain "
<< head << " pg_num " << pool.info.get_pg_num() << " hash "
<< std::hex << head.get_hash() << std::dec << dendl;
osd->clog->warn() << info.pgid.pgid << " does not contain " << head
<< " op " << *m;
ceph_assert(!cct->_conf->osd_debug_misdirected_ops);
return;
}
bool can_backoff =
m->get_connection()->has_feature(CEPH_FEATURE_RADOS_BACKOFF);
ceph::ref_t<Session> session;
if (can_backoff)
{
session = static_cast<Session *>(m->get_connection()->get_priv().get());
if (!session.get())
{
dout(10) << __func__ << " no session" << dendl;
return;
}
if (session->check_backoff(cct, info.pgid, head, m))
{
return;
}
}
// op 携带了 CEPH_OSD_FLAG_PARALLELEXEC 标志,指示可以并发执行
if (m->has_flag(CEPH_OSD_FLAG_PARALLELEXEC))
{
// not implemented.
dout(20) << __func__ << ": PARALLELEXEC not implemented " << *m << dendl;
osd->reply_op_error(op, -EINVAL);
return;
}
{
int r = op->maybe_init_op_info(*get_osdmap());
if (r)
{
osd->reply_op_error(op, r);
return;
}
}
// op 携带了 CEPH_OSD_FLAG_BALANCE_READS 或者 CEPH_OSD_FLAG_LOCALIZE_READS 标志,
// 指示可以读取别的 OSD 节点,不一定是主 OSD,或者执行本地读
// 注意:该 Flag 支持读操作,且不支持缓存
if ((m->get_flags() & (CEPH_OSD_FLAG_BALANCE_READS |
CEPH_OSD_FLAG_LOCALIZE_READS)) &&
op->may_read() &&
!(op->may_write() || op->may_cache()))
{
// 当前节点既不是主节点,也不是 replicated 节点时,譬如 Stray,则报错
// balanced reads; any replica will do
if (!(is_primary() || is_nonprimary()))
{
osd->handle_misdirected_op(this, op);
return;
}
}
else
{
// 正常操作的时候必须是主节点,否则报错
// normal case; must be primary
if (!is_primary())
{
osd->handle_misdirected_op(this, op);
return;
}
}
// 判断是否为 laggy 状态
// https://docs.ceph.com/en/latest/dev/osd_internals/stale_read/
if (!check_laggy(op))
{
return;
}
// 检查权限 caps
if (!op_has_sufficient_caps(op))
{
osd->reply_op_error(op, -EPERM);
return;
}
// 如果包含 includes_pg_op 操作(对 PG 的操作,主要是获取 PG 相关信息),则执行 do_pg_op
if (op->includes_pg_op())
{
return do_pg_op(op);
}
// 对象名称超过、key、命名空间等数据信息超过最大限制会影响存储后端
// 检查 oid 是否为空,检查对象 key
// object name too long?
if (m->get_oid().name.size() > cct->_conf->osd_max_object_name_len)
{
dout(4) << "do_op name is longer than "
<< cct->_conf->osd_max_object_name_len
<< " bytes" << dendl;
osd->reply_op_error(op, -ENAMETOOLONG);
return;
}
if (m->get_hobj().get_key().size() > cct->_conf->osd_max_object_name_len)
{
dout(4) << "do_op locator is longer than "
<< cct->_conf->osd_max_object_name_len
<< " bytes" << dendl;
osd->reply_op_error(op, -ENAMETOOLONG);
return;
}
if (m->get_hobj().nspace.size() > cct->_conf->osd_max_object_namespace_len)
{
dout(4) << "do_op namespace is longer than "
<< cct->_conf->osd_max_object_namespace_len
<< " bytes" << dendl;
osd->reply_op_error(op, -ENAMETOOLONG);
return;
}
if (m->get_hobj().oid.name.empty())
{
dout(4) << "do_op empty oid name is not allowed" << dendl;
osd->reply_op_error(op, -EINVAL);
return;
}
if (int r = osd->store->validate_hobject_key(head))
{
dout(4) << "do_op object " << head << " invalid for backing store: "
<< r << dendl;
osd->reply_op_error(op, r);
return;
}
// 客户端被禁止访问
// blocklisted?
if (get_osdmap()->is_blocklisted(m->get_source_addr()))
{
dout(10) << "do_op " << m->get_source_addr() << " is blocklisted" << dendl;
osd->reply_op_error(op, -EBLOCKLISTED);
return;
}
// order this op as a write?
bool write_ordered = op->rwordered();
// 检查集群是否已被标记为 FULL,并检查 op 是否有携带 CEPH_OSD_FLAG_FULL_TRY 和 CEPH_OSD_FLAG_FULL_FORCE 标志
// discard due to cluster full transition? (we discard any op that
// originates before the cluster or pool is marked full; the client
// will resend after the full flag is removed or if they expect the
// op to succeed despite being full). The except is FULL_FORCE and
// FULL_TRY ops, which there is no reason to discard because they
// bypass all full checks anyway. If this op isn't write or
// read-ordered, we skip.
// FIXME: we exclude mds writes for now.
if (write_ordered && !(m->get_source().is_mds() || m->has_flag(CEPH_OSD_FLAG_FULL_TRY) || m->has_flag(CEPH_OSD_FLAG_FULL_FORCE)) &&
info.history.last_epoch_marked_full > m->get_map_epoch())
{
dout(10) << __func__ << " discarding op sent before full " << m << " "
<< *m << dendl;
return;
}
// 检查 PG 所在 OSD 可用存储空间情况
// mds should have stopped writing before this point.
// We can't allow OSD to become non-startable even if mds
// could be writing as part of file removals.
if (write_ordered && osd->check_failsafe_full(get_dpp()) &&
!m->has_flag(CEPH_OSD_FLAG_FULL_TRY))
{
dout(10) << __func__ << " fail-safe full check failed, dropping request." << dendl;
return;
}
int64_t poolid = get_pgid().pool();
// 判断 op 是否为写操作
if (op->may_write())
{
// 获取对应的 pool 并检查
const pg_pool_t *pi = get_osdmap()->get_pg_pool(poolid);
if (!pi)
{
return;
}
// invalid?
// 判断是否访问快照对象,若访问则报错,快照不允许写
if (m->get_snapid() != CEPH_NOSNAP)
{
dout(20) << __func__ << ": write to clone not valid " << *m << dendl;
osd->reply_op_error(op, -EINVAL);
return;
}
// too big?
// 判断写入的数据大小并校验,osd_max_write_size
if (cct->_conf->osd_max_write_size &&
m->get_data_len() > cct->_conf->osd_max_write_size << 20)
{
// journal can't hold commit!
derr << "do_op msg data len " << m->get_data_len()
<< " > osd_max_write_size " << (cct->_conf->osd_max_write_size << 20)
<< " on " << *m << dendl;
osd->reply_op_error(op, -OSD_WRITETOOBIG);
return;
}
}
dout(10) << "do_op " << *m
<< (op->may_write() ? " may_write" : "")
<< (op->may_read() ? " may_read" : "")
<< (op->may_cache() ? " may_cache" : "")
<< " -> " << (write_ordered ? "write-ordered" : "read-ordered")
<< " flags " << ceph_osd_flag_string(m->get_flags())
<< dendl;
// missing object?
// 检查对象是否不可读,
// 1. 如果对象在 missing 列表(恢复过程中检查 PGLog 构建的 missing 列表)中,不可读
// 2. 数据修复过程中,在当前 acting set 对应的多个 OSD 上该对象不可读
// bool is_unreadable_object(const hobject_t &oid) const
// {
// return is_missing_object(oid) ||
// !recovery_state.get_missing_loc().readable_with_acting(
// oid, get_actingset());
// }
if (is_unreadable_object(head))
{
// 不是主节点 报错
if (!is_primary())
{
osd->reply_op_error(op, -EAGAIN);
return;
}
// 是主节点相应地判断 OSD backoff 状态
if (can_backoff &&
(g_conf()->osd_backoff_on_degraded ||
(g_conf()->osd_backoff_on_unfound &&
recovery_state.get_missing_loc().is_unfound(head))))
{
add_backoff(session, head, head);
maybe_kick_recovery(head);
}
else
{
// 等待对象恢复完成
wait_for_unreadable_object(head, op);
}
return;
}
// 顺序写
if (write_ordered)
{
// 对象处于降级状态(恢复状态)
// degraded object?
if (is_degraded_or_backfilling_object(head))
{
if (can_backoff && g_conf()->osd_backoff_on_degraded)
{
// 尝试启动 recovery
add_backoff(session, head, head);
maybe_kick_recovery(head);
}
else
{
wait_for_degraded_object(head, op);
}
return;
}
// 对象正在被 scrub,加入相应的队列 waiting_for_scrub
if (scrubber.is_chunky_scrub_active() && write_blocked_by_scrub(head))
{
dout(20) << __func__ << ": waiting for scrub" << dendl;
waiting_for_scrub.push_back(op);
op->mark_delayed("waiting for scrub");
return;
}
if (!check_laggy_requeue(op))
{
return;
}
// 对象被 snap
// objects_blocked_on_degraded_snap 保存了 head 对象则需要等待
// head 对象在 rollback 到某个版本的快照时,该版本的 snap 对象处于确实状态,则需要等待 snap 对象恢复
// blocked on snap?
if (auto blocked_iter = objects_blocked_on_degraded_snap.find(head);
blocked_iter != std::end(objects_blocked_on_degraded_snap))
{
hobject_t to_wait_on(head);
to_wait_on.snap = blocked_iter->second;
wait_for_degraded_object(to_wait_on, op);
return;
}
// objects_blocked_on_snap_promotion 里的对象表示 head 对象 rollback 到某个版本的快照时
// 该版本的快照对象在 cache pool 层中没有,需要到 data pool 层获取
if (auto blocked_snap_promote_iter = objects_blocked_on_snap_promotion.find(head);
blocked_snap_promote_iter != std::end(objects_blocked_on_snap_promotion))
{
wait_for_blocked_object(blocked_snap_promote_iter->second->obs.oi.soid, op);
return;
}
// objects_blocked_on_cache_full 该队列中的对象因为 cache pool 层空间满而阻塞了写操作
if (objects_blocked_on_cache_full.count(head))
{
block_write_on_full_cache(head, op);
return;
}
}
// 检查 op 是否为重发
// dup/resent?
if (op->may_write() || op->may_cache())
{
// warning: we will get back *a* request for this reqid, but not
// necessarily the most recent. this happens with flush and
// promote ops, but we can't possible have both in our log where
// the original request is still not stable on disk, so for our
// purposes here it doesn't matter which one we get.
eversion_t version;
version_t user_version;
int return_code = 0;
vector<pg_log_op_return_item_t> op_returns;
bool got = check_in_progress_op(
m->get_reqid(), &version, &user_version, &return_code, &op_returns);
if (got)
{
dout(3) << __func__ << " dup " << m->get_reqid()
<< " version " << version << dendl;
if (already_complete(version))
{
osd->reply_op_error(op, return_code, version, user_version, op_returns);
}
else
{
dout(10) << " waiting for " << version << " to commit" << dendl;
// always queue ondisk waiters, so that we can requeue if needed
waiting_for_ondisk[version].emplace_back(op, user_version, return_code,
op_returns);
op->mark_delayed("waiting for ondisk");
}
return;
}
}
ObjectContextRef obc;
bool can_create = op->may_write();
hobject_t missing_oid;
// kludge around the fact that LIST_SNAPS sets CEPH_SNAPDIR for LIST_SNAPS
const hobject_t &oid =
m->get_snapid() == CEPH_SNAPDIR ? head : m->get_hobj();
// make sure LIST_SNAPS is on CEPH_SNAPDIR and nothing else
for (vector<OSDOp>::iterator p = m->ops.begin(); p != m->ops.end(); ++p)
{
OSDOp &osd_op = *p;
if (osd_op.op.op == CEPH_OSD_OP_LIST_SNAPS)
{
if (m->get_snapid() != CEPH_SNAPDIR)
{
dout(10) << "LIST_SNAPS with incorrect context" << dendl;
osd->reply_op_error(op, -EINVAL);
return;
}
}
else
{
if (m->get_snapid() == CEPH_SNAPDIR)
{
dout(10) << "non-LIST_SNAPS on snapdir" << dendl;
osd->reply_op_error(op, -EINVAL);
return;
}
}
}
// io blocked on obc?
if (!m->has_flag(CEPH_OSD_FLAG_FLUSH) &&
maybe_await_blocked_head(oid, op))
{
return;
}
// 当前节点不是主节点
if (!is_primary())
{
// 判断当前状态下是否能处理副本节点的读请求
if (!recovery_state.can_serve_replica_read(oid))
{
dout(20) << __func__
<< ": unstable write on replica, bouncing to primary "
<< *m << dendl;
osd->reply_op_error(op, -EAGAIN);
return;
}
dout(20) << __func__ << ": serving replica read on oid " << oid
<< dendl;
}
int r = find_object_context(
oid, &obc, can_create,
m->has_flag(CEPH_OSD_FLAG_MAP_SNAP_CLONE),
&missing_oid);
// LIST_SNAPS needs the ssc too
if (obc &&
m->get_snapid() == CEPH_SNAPDIR &&
!obc->ssc)
{
obc->ssc = get_snapset_context(oid, true);
}
if (r == -EAGAIN)
{
// If we're not the primary of this OSD, we just return -EAGAIN. Otherwise,
// we have to wait for the object.
if (is_primary())
{
// missing the specific snap we need; requeue and wait.
ceph_assert(!op->may_write()); // only happens on a read/cache
wait_for_unreadable_object(missing_oid, op);
return;
}
}
else if (r == 0)
{
// 检查 snapdir 对象是否可读
if (is_unreadable_object(obc->obs.oi.soid))
{
dout(10) << __func__ << ": clone " << obc->obs.oi.soid
<< " is unreadable, waiting" << dendl;
wait_for_unreadable_object(obc->obs.oi.soid, op);
return;
}
// 如果是写操作需要检查 snapdir 对象是否缺失
// degraded object? (the check above was for head; this could be a clone)
if (write_ordered &&
obc->obs.oi.soid.snap != CEPH_NOSNAP &&
is_degraded_or_backfilling_object(obc->obs.oi.soid))
{
dout(10) << __func__ << ": clone " << obc->obs.oi.soid
<< " is degraded, waiting" << dendl;
wait_for_degraded_object(obc->obs.oi.soid, op);
return;
}
}
bool in_hit_set = false;
// hitset 不为空,进入 cache tiering 流程
if (hit_set)
{
if (obc.get())
{
if (obc->obs.oi.soid != hobject_t() && hit_set->contains(obc->obs.oi.soid))
in_hit_set = true;
}
else
{
if (missing_oid != hobject_t() && hit_set->contains(missing_oid))
in_hit_set = true;
}
if (!op->hitset_inserted)
{
hit_set->insert(oid);
op->hitset_inserted = true;
if (hit_set->is_full() ||
hit_set_start_stamp + pool.info.hit_set_period <= m->get_recv_stamp())
{
hit_set_persist();
}
}
}
if (agent_state)
{
if (agent_choose_mode(false, op))
return;
}
if (obc.get() && obc->obs.exists && obc->obs.oi.has_manifest())
{
if (maybe_handle_manifest(op,
write_ordered,
obc))
return;
}
if (maybe_handle_cache(op,
write_ordered,
obc,
r,
missing_oid,
false,
in_hit_set))
return;
if (r && (r != -ENOENT || !obc))
{
// copy the reqids for copy get on ENOENT
if (r == -ENOENT &&
(m->ops[0].op.op == CEPH_OSD_OP_COPY_GET))
{
fill_in_copy_get_noent(op, oid, m->ops[0]);
return;
}
dout(20) << __func__ << ": find_object_context got error " << r << dendl;
if (op->may_write() &&
get_osdmap()->require_osd_release >= ceph_release_t::kraken)
{
record_write_error(op, oid, nullptr, r);
}
else
{
osd->reply_op_error(op, r);
}
return;
}
// 验证 object_locator 和 msg 中的是否相同
// make sure locator is consistent
object_locator_t oloc(obc->obs.oi.soid);
if (m->get_object_locator() != oloc)
{
dout(10) << " provided locator " << m->get_object_locator()
<< " != object's " << obc->obs.oi.soid << dendl;
osd->clog->warn() << "bad locator " << m->get_object_locator()
<< " on object " << oloc
<< " op " << *m;
}
// 检查该对象是否被阻塞
// io blocked on obc?
if (obc->is_blocked() &&
!m->has_flag(CEPH_OSD_FLAG_FLUSH))
{
wait_for_blocked_object(obc->obs.oi.soid, op);
return;
}
dout(25) << __func__ << " oi " << obc->obs.oi << dendl;
// 获取对象上下文,创建 OpContext 对 op 进行跟踪
OpContext *ctx = new OpContext(op, m->get_reqid(), &m->ops, obc, this);
// 根据对应的 flag 决定锁的处理方式
if (m->has_flag(CEPH_OSD_FLAG_SKIPRWLOCKS))
{
dout(20) << __func__ << ": skipping rw locks" << dendl;
}
else if (m->get_flags() & CEPH_OSD_FLAG_FLUSH)
{
dout(20) << __func__ << ": part of flush, will ignore write lock" << dendl;
// verify there is in fact a flush in progress
// FIXME: we could make this a stronger test.
map<hobject_t, FlushOpRef>::iterator p = flush_ops.find(obc->obs.oi.soid);
if (p == flush_ops.end())
{
dout(10) << __func__ << " no flush in progress, aborting" << dendl;
reply_ctx(ctx, -EINVAL);
return;
}
}
else if (!get_rw_locks(write_ordered, ctx))
{
dout(20) << __func__ << " waiting for rw locks " << dendl;
op->mark_delayed("waiting for rw locks");
close_op_ctx(ctx);
return;
}
dout(20) << __func__ << " obc " << *obc << dendl;
if (r)
{
dout(20) << __func__ << " returned an error: " << r << dendl;
if (op->may_write() &&
get_osdmap()->require_osd_release >= ceph_release_t::kraken)
{
record_write_error(op, oid, nullptr, r,
ctx->op->allows_returnvec() ? ctx : nullptr);
}
else
{
osd->reply_op_error(op, r);
}
close_op_ctx(ctx);
return;
}
if (m->has_flag(CEPH_OSD_FLAG_IGNORE_CACHE))
{
ctx->ignore_cache = true;
}
if ((op->may_read()) && (obc->obs.oi.is_lost()))
{
// This object is lost. Reading from it returns an error.
dout(20) << __func__ << ": object " << obc->obs.oi.soid
<< " is lost" << dendl;
reply_ctx(ctx, -ENFILE);
return;
}
if (!op->may_write() &&
!op->may_cache() &&
(!obc->obs.exists ||
((m->get_snapid() != CEPH_SNAPDIR) &&
obc->obs.oi.is_whiteout())))
{
// copy the reqids for copy get on ENOENT
if (m->ops[0].op.op == CEPH_OSD_OP_COPY_GET)
{
fill_in_copy_get_noent(op, oid, m->ops[0]);
close_op_ctx(ctx);
return;
}
reply_ctx(ctx, -ENOENT);
return;
}
op->mark_started();
// 真正开始执行 op
execute_ctx(ctx);
utime_t prepare_latency = ceph_clock_now();
prepare_latency -= op->get_dequeued_time();
osd->logger->tinc(l_osd_op_prepare_lat, prepare_latency);
if (op->may_read() && op->may_write())
{
osd->logger->tinc(l_osd_op_rw_prepare_lat, prepare_latency);
}
else if (op->may_read())
{
osd->logger->tinc(l_osd_op_r_prepare_lat, prepare_latency);
}
else if (op->may_write() || op->may_cache())
{
osd->logger->tinc(l_osd_op_w_prepare_lat, prepare_latency);
}
// force recovery of the oldest missing object if too many logs
maybe_force_recovery();
}
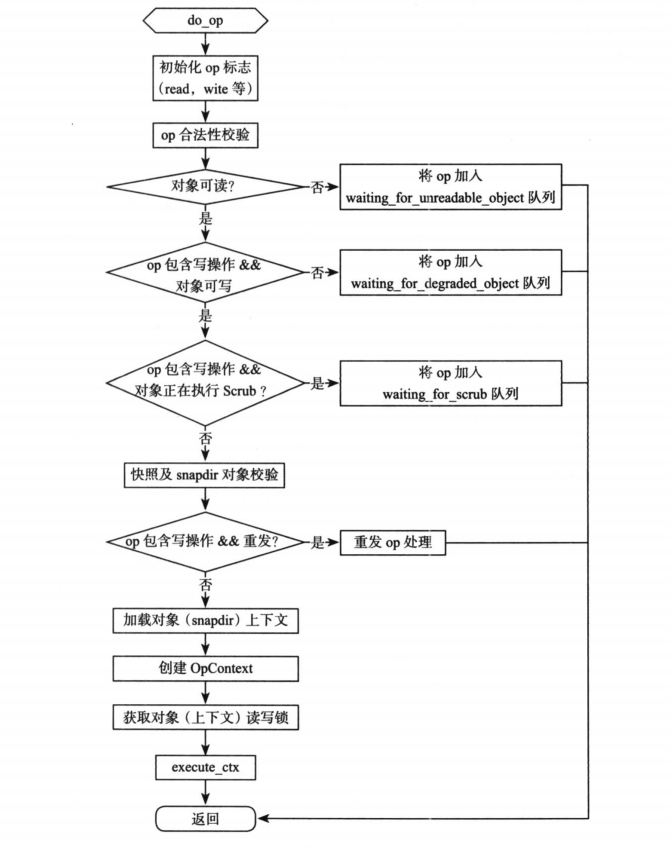
execute_ctx
void PrimaryLogPG::execute_ctx(OpContext *ctx)
{
FUNCTRACE(cct);
dout(10) << __func__ << " " << ctx << dendl;
ctx->reset_obs(ctx->obc);
ctx->update_log_only = false; // reset in case finish_copyfrom() is re-running execute_ctx
OpRequestRef op = ctx->op;
auto m = op->get_req<MOSDOp>();
ObjectContextRef obc = ctx->obc;
const hobject_t &soid = obc->obs.oi.soid;
// this method must be idempotent since we may call it several times
// before we finally apply the resulting transaction.
ctx->op_t.reset(new PGTransaction);
// 写操作
if (op->may_write() || op->may_cache())
{
// snap
// 对于快照进行一些处理
if (!(m->has_flag(CEPH_OSD_FLAG_ENFORCE_SNAPC)) &&
pool.info.is_pool_snaps_mode())
{
// 更新 ctx->snapc,该值保存了该操作的客户端附带的快照相关信息
// use pool's snapc
ctx->snapc = pool.snapc;
}
else
{
// 用户特定快照,通常为 RBD 快照,此时设置为消息中携带的信息
// client specified snapc
ctx->snapc.seq = m->get_snap_seq();
ctx->snapc.snaps = m->get_snaps();
filter_snapc(ctx->snapc.snaps);
}
// 比较 SNAP_SEQ,如果客户端的更小则报错
if ((m->has_flag(CEPH_OSD_FLAG_ORDERSNAP)) &&
ctx->snapc.seq < obc->ssc->snapset.seq)
{
dout(10) << " ORDERSNAP flag set and snapc seq " << ctx->snapc.seq
<< " < snapset seq " << obc->ssc->snapset.seq
<< " on " << obc->obs.oi.soid << dendl;
reply_ctx(ctx, -EOLDSNAPC);
return;
}
// 更新 OpContext 版本号
// version
ctx->at_version = get_next_version();
ctx->mtime = m->get_mtime();
dout(10) << __func__ << " " << soid << " " << *ctx->ops
<< " ov " << obc->obs.oi.version << " av " << ctx->at_version
<< " snapc " << ctx->snapc
<< " snapset " << obc->ssc->snapset
<< dendl;
}
else
{
dout(10) << __func__ << " " << soid << " " << *ctx->ops
<< " ov " << obc->obs.oi.version
<< dendl;
}
if (!ctx->user_at_version)
ctx->user_at_version = obc->obs.oi.user_version;
dout(30) << __func__ << " user_at_version " << ctx->user_at_version << dendl;
{
#ifdef WITH_LTTNG
osd_reqid_t reqid = ctx->op->get_reqid();
#endif
tracepoint(osd, prepare_tx_enter, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc);
}
// 准备事务
// 1. 通过 do_osd_ops 生成原始 op 对应的 PG 事务
// 2. 如果 op 针对 head 对象进行操作,通过 make_writable 检查是否需要预先执行克隆操作
// 3. 通过 finish_ctx 检查是否需要创建或者删除 snapdir 对象,生成日志,并更新对象的 OI(object_info_t) 和 SS(SnapSet) 属性
// 其中涉及了大量的对克隆和快照的处理
int result = prepare_transaction(ctx);
{
#ifdef WITH_LTTNG
osd_reqid_t reqid = ctx->op->get_reqid();
#endif
tracepoint(osd, prepare_tx_exit, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc);
}
// 异步读则将 op 加入 in_progress_async_reads 队列,完成之后再向客户端应答
bool pending_async_reads = !ctx->pending_async_reads.empty();
if (result == -EINPROGRESS || pending_async_reads)
{
// come back later.
if (pending_async_reads)
{
ceph_assert(pool.info.is_erasure());
in_progress_async_reads.push_back(make_pair(op, ctx));
// 完成异步读取
ctx->start_async_reads(this);
}
return;
}
if (result == -EAGAIN)
{
// clean up after the ctx
close_op_ctx(ctx);
return;
}
bool ignore_out_data = false;
if (!ctx->op_t->empty() &&
op->may_write() &&
result >= 0)
{
// successful update
if (ctx->op->allows_returnvec())
{
// enforce reasonable bound on the return buffer sizes
for (auto &i : *ctx->ops)
{
if (i.outdata.length() > cct->_conf->osd_max_write_op_reply_len)
{
dout(10) << __func__ << " op " << i << " outdata overflow" << dendl;
result = -EOVERFLOW; // overall result is overflow
i.rval = -EOVERFLOW;
i.outdata.clear();
}
}
}
else
{
// legacy behavior -- zero result and return data etc.
ignore_out_data = true;
result = 0;
}
}
// prepare the reply
ctx->reply = new MOSDOpReply(m, result, get_osdmap_epoch(), 0,
ignore_out_data);
dout(20) << __func__ << " alloc reply " << ctx->reply
<< " result " << result << dendl;
// 只包含读操作或者 失败,是则向客户端发送应答
// read or error?
if ((ctx->op_t->empty() || result < 0) && !ctx->update_log_only)
{
// finish side-effects
if (result >= 0)
do_osd_op_effects(ctx, m->get_connection());
// 同步读取调用以下方法完成读操作
complete_read_ctx(result, ctx);
return;
}
ctx->reply->set_reply_versions(ctx->at_version, ctx->user_at_version);
// 后续均为写操作
ceph_assert(op->may_write() || op->may_cache());
// trim log?
// 将旧的日志进行 trim
// calc_trim_to_aggressive()
// calc_trim_to()
recovery_state.update_trim_to();
// verify that we are doing this in order?
if (cct->_conf->osd_debug_op_order && m->get_source().is_client() &&
!pool.info.is_tier() && !pool.info.has_tiers())
{
map<client_t, ceph_tid_t> &cm = debug_op_order[obc->obs.oi.soid];
ceph_tid_t t = m->get_tid();
client_t n = m->get_source().num();
map<client_t, ceph_tid_t>::iterator p = cm.find(n);
if (p == cm.end())
{
dout(20) << " op order client." << n << " tid " << t << " (first)" << dendl;
cm[n] = t;
}
else
{
dout(20) << " op order client." << n << " tid " << t << " last was " << p->second << dendl;
if (p->second > t)
{
derr << "bad op order, already applied " << p->second << " > this " << t << dendl;
ceph_abort_msg("out of order op");
}
p->second = t;
}
}
if (ctx->update_log_only)
{
if (result >= 0)
do_osd_op_effects(ctx, m->get_connection());
dout(20) << __func__ << " update_log_only -- result=" << result << dendl;
// save just what we need from ctx
MOSDOpReply *reply = ctx->reply;
ctx->reply = nullptr;
reply->get_header().data_off = (ctx->data_off ? *ctx->data_off : 0);
if (result == -ENOENT)
{
reply->set_enoent_reply_versions(info.last_update,
info.last_user_version);
}
reply->add_flags(CEPH_OSD_FLAG_ACK | CEPH_OSD_FLAG_ONDISK);
// append to pg log for dup detection - don't save buffers for now
record_write_error(op, soid, reply, result,
ctx->op->allows_returnvec() ? ctx : nullptr);
close_op_ctx(ctx);
return;
}
// 写操作则注册如下的回调函数:按照如下顺序要求
// 1. on_commit: 执行时,向客户端发送写入完成应答
// 2. on_success: 执行时,进行 Watch/Notify 相关的处理
// 3. on_finish: 执行时,删除 OpContext
// no need to capture PG ref, repop cancel will handle that
// Can capture the ctx by pointer, it's owned by the repop
ctx->register_on_commit(
[m, ctx, this]() {
if (ctx->op)
log_op_stats(*ctx->op, ctx->bytes_written, ctx->bytes_read);
if (m && !ctx->sent_reply)
{
MOSDOpReply *reply = ctx->reply;
ctx->reply = nullptr;
reply->add_flags(CEPH_OSD_FLAG_ACK | CEPH_OSD_FLAG_ONDISK);
dout(10) << " sending reply on " << *m << " " << reply << dendl;
osd->send_message_osd_client(reply, m->get_connection());
ctx->sent_reply = true;
ctx->op->mark_commit_sent();
}
});
ctx->register_on_success(
[ctx, this]() {
do_osd_op_effects(
ctx,
ctx->op ? ctx->op->get_req()->get_connection() : ConnectionRef());
});
ctx->register_on_finish(
[ctx]() {
delete ctx;
});
// 事务准备完成,由 Primary 进行副本间的本地事务分发和整体同步
// issue replica writes
ceph_tid_t rep_tid = osd->get_tid();
// 创建一个 RepGather
RepGather *repop = new_repop(ctx, obc, rep_tid);
// 将 RepGather 提交到 PGBackend,由 PGBackend 负责将 PG 事务转为每个副本的本地事务,然后分发
// 即向各个副本发送同步操作请求
issue_repop(repop, ctx);
// 评估 RepGather 是否真正完成,真正完成后则依次执行 RepGather 中注册过的一系列回调函数,最后删除 RepGather
// 检查各个副本的同步操作是否已经 reply 成功
eval_repop(repop);
repop->put();
}
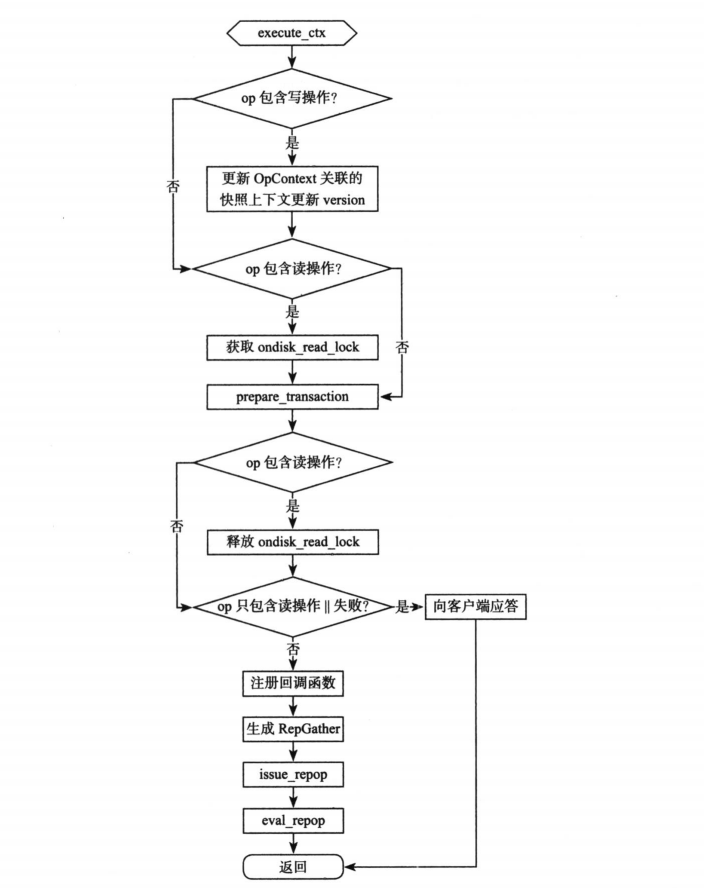
issue_repop
- 真正的分发逻辑,和 OSD 本地事务处理都封装在该方法中。回顾上述主流程中关于多副本写操作的处理:
// 写操作则注册如下的回调函数:按照如下顺序要求
// 1. on_commit: 执行时,向客户端发送写入完成应答
// 2. on_success: 执行时,进行 Watch/Notify 相关的处理
// 3. on_finish: 执行时,删除 OpContext
// no need to capture PG ref, repop cancel will handle that
// Can capture the ctx by pointer, it's owned by the repop
ctx->register_on_commit(
[m, ctx, this]() {
if (ctx->op)
log_op_stats(*ctx->op, ctx->bytes_written, ctx->bytes_read);
if (m && !ctx->sent_reply)
{
MOSDOpReply *reply = ctx->reply;
ctx->reply = nullptr;
reply->add_flags(CEPH_OSD_FLAG_ACK | CEPH_OSD_FLAG_ONDISK);
dout(10) << " sending reply on " << *m << " " << reply << dendl;
osd->send_message_osd_client(reply, m->get_connection());
ctx->sent_reply = true;
ctx->op->mark_commit_sent();
}
});
ctx->register_on_success(
[ctx, this]() {
do_osd_op_effects(
ctx,
ctx->op ? ctx->op->get_req()->get_connection() : ConnectionRef());
});
ctx->register_on_finish(
[ctx]() {
delete ctx;
});
// 事务准备完成,由 Primary 进行副本间的本地事务分发和整体同步
// issue replica writes
ceph_tid_t rep_tid = osd->get_tid();
// 创建一个 RepGather
RepGather *repop = new_repop(ctx, obc, rep_tid);
// 将 RepGather 提交到 PGBackend,由 PGBackend 负责将 PG 事务转为每个副本的本地事务,然后分发
// 即向各个副本发送同步操作请求
issue_repop(repop, ctx);
// 评估 RepGather 是否真正完成,真正完成后则依次执行 RepGather 中注册过的一系列回调函数,最后删除 RepGather
// 检查各个副本的同步操作是否已经 reply 成功
eval_repop(repop);
repop->put();
- 其中 issue_repopn 主要是调用了
submit_transaction让对应的 PGBackend 来执行事务
pgbackend->submit_transaction(
soid,
ctx->delta_stats,
ctx->at_version,
std::move(ctx->op_t),
recovery_state.get_pg_trim_to(),
recovery_state.get_min_last_complete_ondisk(),
std::move(ctx->log),
ctx->updated_hset_history,
on_all_commit,
repop->rep_tid,
ctx->reqid,
ctx->op);
}
submit_transaction
- 此处暂时只讨论 ReplicatedBackend,即多副本情况下的事务提交
- 副本方式:核心处理流程是把封装好的事务分发到该 PG 对应的其他从 OSD 上
- 纠删码方式:核心处理流程是为主 chunk 向各个分片 chunk 分发数据的过程
- 通过
issue_op分发消息到副本 OSD(异步),当前 OSD 相应地执行日志操作以及完成本地 OSD 请求的处理queue_transactions。
void ReplicatedBackend::submit_transaction(
const hobject_t &soid,
const object_stat_sum_t &delta_stats,
const eversion_t &at_version,
PGTransactionUPtr &&_t,
const eversion_t &trim_to,
const eversion_t &min_last_complete_ondisk,
vector<pg_log_entry_t> &&_log_entries,
std::optional<pg_hit_set_history_t> &hset_history,
Context *on_all_commit,
ceph_tid_t tid,
osd_reqid_t reqid,
OpRequestRef orig_op)
{
parent->apply_stats(
soid,
delta_stats);
vector<pg_log_entry_t> log_entries(_log_entries);
ObjectStore::Transaction op_t;
PGTransactionUPtr t(std::move(_t));
set<hobject_t> added, removed;
// 根据具体的操作类型生成相应的事务
generate_transaction(
t,
coll,
log_entries,
&op_t,
&added,
&removed,
get_osdmap()->require_osd_release);
ceph_assert(added.size() <= 1);
ceph_assert(removed.size() <= 1);
// 构建处理中的请求记录 in_progress_ops
auto insert_res = in_progress_ops.insert(
make_pair(
tid,
ceph::make_ref<InProgressOp>(
tid, on_all_commit,
orig_op, at_version)));
ceph_assert(insert_res.second);
InProgressOp &op = *insert_res.first->second;
// 统计 commit 的副本操作数量,等待副本操作完成回调时进行清除,使用该结构方便统计是不是所有的副本都完成了操作。
op.waiting_for_commit.insert(
parent->get_acting_recovery_backfill_shards().begin(),
parent->get_acting_recovery_backfill_shards().end());
// 把请求发送出去
issue_op(
soid,
at_version,
tid,
reqid,
trim_to,
min_last_complete_ondisk,
added.size() ? *(added.begin()) : hobject_t(),
removed.size() ? *(removed.begin()) : hobject_t(),
log_entries,
hset_history,
&op,
op_t);
add_temp_objs(added);
clear_temp_objs(removed);
//进行日志操作,开始记录本端操作 object 的 log
parent->log_operation(
std::move(log_entries),
hset_history,
trim_to,
at_version,
min_last_complete_ondisk,
true,
op_t);
// 开始注册本端的 commit 回调函数,这里回调后直接向上返回
op_t.register_on_commit(
parent->bless_context(
new C_OSD_OnOpCommit(this, &op)));
vector<ObjectStore::Transaction> tls;
tls.push_back(std::move(op_t));
// 完成本地 OSD 的请求处理
parent->queue_transactions(tls, op.op);
if (at_version != eversion_t())
{
parent->op_applied(at_version);
}
}
issue_op
- 该方法构造相应的写请求,以消息的方式发送到该主 OSD 对应的副本 OSD 上。
void ReplicatedBackend::issue_op(
const hobject_t &soid,
const eversion_t &at_version,
ceph_tid_t tid,
osd_reqid_t reqid,
eversion_t pg_trim_to,
eversion_t min_last_complete_ondisk,
hobject_t new_temp_oid,
hobject_t discard_temp_oid,
const vector<pg_log_entry_t> &log_entries,
std::optional<pg_hit_set_history_t> &hset_hist,
InProgressOp *op,
ObjectStore::Transaction &op_t)
{
// 副本节点数量 > 1
if (parent->get_acting_recovery_backfill_shards().size() > 1)
{
if (op->op)
{
op->op->pg_trace.event("issue replication ops");
ostringstream ss;
set<pg_shard_t> replicas = parent->get_acting_recovery_backfill_shards();
replicas.erase(parent->whoami_shard());
ss << "waiting for subops from " << replicas;
op->op->mark_sub_op_sent(ss.str());
}
// avoid doing the same work in generate_subop
bufferlist logs;
encode(log_entries, logs);
// 遍历所有的 replica OSDs
for (const auto &shard : get_parent()->get_acting_recovery_backfill_shards())
{
// 如果该节点是主节点,跳过
if (shard == parent->whoami_shard())
continue;
// 获取副本节点对应的 pg
const pg_info_t &pinfo = parent->get_shard_info().find(shard)->second;
Message *wr;
// 使用相应的参数构造 REPOP 请求
wr = generate_subop(
soid,
at_version,
tid,
reqid,
pg_trim_to,
min_last_complete_ondisk,
new_temp_oid,
discard_temp_oid,
logs,
hset_hist,
op_t,
shard,
pinfo);
if (op->op && op->op->pg_trace)
wr->trace.init("replicated op", nullptr, &op->op->pg_trace);
// 将消息发送出去到整个集群
// void OSDService::send_message_osd_cluster(int peer, Message *m, epoch_t from_epoch)
// 写操作的消息发送给对应副本节点对应的 osd
get_parent()->send_message_osd_cluster(
shard.osd, wr, get_osdmap_epoch());
}
}
}
do_repop
- 相应的副本 OSD 收到消息时,继续上述流程,从头到尾,直到执行对应的
do_request方法。在do_request方法中曾介绍有对部分请求的处理,截取如下:
// 由 PGBackend 直接处理然后返回,此处只处理以下操作
// 1. MSG_OSD_PG_RECOVERY_DELETE (Common)
// 2. MSG_OSD_PG_RECOVERY_DELETE_REPLY (Common)
// 3. MSG_OSD_PG_PUSH (副本)
// 4. MSG_OSD_PG_PULL (副本)
// 5. MSG_OSD_PG_PUSH_REPLY (副本)
// 6. MSG_OSD_REPOP (副本)
// 7. MSG_OSD_REPOPREPLY (副本)
// 8. MSG_OSD_EC_WRITE (EC)
// 9. MSG_OSD_EC_WRITE_REPLY (EC)
// 10. MSG_OSD_EC_READ (EC)
// 11. MSG_OSD_EC_READ_REPLY (EC)
// 12. MSG_OSD_PG_PUSH (EC)
// 13. MSG_OSD_PG_PUSH_REPLY (EC)
if (pgbackend->handle_message(op))
return;
- 其中就包含 MSG_OSD_REPOP 和 MSG_OSD_REPOPREPLY 的处理(针对多副本)。又相应地调用了
do_repop和do_repop_reply方法
bool ReplicatedBackend::_handle_message(
OpRequestRef op)
{
dout(10) << __func__ << ": " << op << dendl;
switch (op->get_req()->get_type())
{
case MSG_OSD_PG_PUSH:
do_push(op);
return true;
case MSG_OSD_PG_PULL:
do_pull(op);
return true;
case MSG_OSD_PG_PUSH_REPLY:
do_push_reply(op);
return true;
case MSG_OSD_REPOP:
{
do_repop(op);
return true;
}
case MSG_OSD_REPOPREPLY:
{
do_repop_reply(op);
return true;
}
default:
break;
}
return false;
}
do_repop用于处理 repop 类型的 msg,相应地检查参数和当前 OSD 对应的状态,记录日志,注册回调函数,并执行本地事务更新。
// sub op modify
void ReplicatedBackend::do_repop(OpRequestRef op)
{
static_cast<MOSDRepOp *>(op->get_nonconst_req())->finish_decode();
// 获取当前消息
auto m = op->get_req<MOSDRepOp>();
// 检查消息类型
int msg_type = m->get_type();
ceph_assert(MSG_OSD_REPOP == msg_type);
const hobject_t &soid = m->poid;
dout(10) << __func__ << " " << soid
<< " v " << m->version
<< (m->logbl.length() ? " (transaction)" : " (parallel exec")
<< " " << m->logbl.length()
<< dendl;
// 检查版本号和 interval
// sanity checks
ceph_assert(m->map_epoch >= get_info().history.same_interval_since);
// 检查该副本节点是否在进行 scrub 操作
dout(30) << __func__ << " missing before " << get_parent()->get_log().get_missing().get_items() << dendl;
parent->maybe_preempt_replica_scrub(soid);
// 获取消息来源
int ackerosd = m->get_source().num();
// 标记当前操作开始,设置相关参数
op->mark_started();
RepModifyRef rm(std::make_shared<RepModify>());
rm->op = op;
rm->ackerosd = ackerosd;
rm->last_complete = get_info().last_complete;
rm->epoch_started = get_osdmap_epoch();
ceph_assert(m->logbl.length());
// shipped transaction and log entries
vector<pg_log_entry_t> log;
auto p = const_cast<bufferlist &>(m->get_data()).cbegin();
decode(rm->opt, p);
if (m->new_temp_oid != hobject_t())
{
dout(20) << __func__ << " start tracking temp " << m->new_temp_oid << dendl;
add_temp_obj(m->new_temp_oid);
}
if (m->discard_temp_oid != hobject_t())
{
dout(20) << __func__ << " stop tracking temp " << m->discard_temp_oid << dendl;
if (rm->opt.empty())
{
dout(10) << __func__ << ": removing object " << m->discard_temp_oid
<< " since we won't get the transaction" << dendl;
rm->localt.remove(coll, ghobject_t(m->discard_temp_oid));
}
clear_temp_obj(m->discard_temp_oid);
}
p = const_cast<bufferlist &>(m->logbl).begin();
decode(log, p);
rm->opt.set_fadvise_flag(CEPH_OSD_OP_FLAG_FADVISE_DONTNEED);
bool update_snaps = false;
if (!rm->opt.empty())
{
// If the opt is non-empty, we infer we are before
// last_backfill (according to the primary, not our
// not-quite-accurate value), and should update the
// collections now. Otherwise, we do it later on push.
update_snaps = true;
}
// flag set to true during async recovery
bool async = false;
pg_missing_tracker_t pmissing = get_parent()->get_local_missing();
if (pmissing.is_missing(soid))
{
async = true;
dout(30) << __func__ << " is_missing " << pmissing.is_missing(soid) << dendl;
for (auto &&e : log)
{
dout(30) << " add_next_event entry " << e << dendl;
get_parent()->add_local_next_event(e);
dout(30) << " entry is_delete " << e.is_delete() << dendl;
}
}
parent->update_stats(m->pg_stats);
// 更新日志
parent->log_operation(
std::move(log),
m->updated_hit_set_history,
m->pg_trim_to,
m->version, /* Replicated PGs don't have rollback info */
m->min_last_complete_ondisk,
update_snaps,
rm->localt,
async);
// 注册回调函数 C_OSD_RepModifyCommit,回调完成后调用 pg->repop_commit(rm)
// C_OSD_RepModifyCommit(ReplicatedBackend *pg, RepModifyRef r)
// : pg(pg), rm(r) {}
// void finish(int r) override
// {
// pg->repop_commit(rm);
// }
rm->opt.register_on_commit(
parent->bless_context(
new C_OSD_RepModifyCommit(this, rm)));
vector<ObjectStore::Transaction> tls;
tls.reserve(2);
tls.push_back(std::move(rm->localt));
tls.push_back(std::move(rm->opt));
// 本地事务更新
parent->queue_transactions(tls, op);
// op is cleaned up by oncommit/onapply when both are executed
dout(30) << __func__ << " missing after" << get_parent()->get_log().get_missing().get_items() << dendl;
}
queue_transactions
- 无论是一开始的主节点还是后面描述的副本节点执行写操作都调用了
queue_transactions该方法,该方法是ObjectStore 层的统一入口,KVStore、MemStore、FileStore、BlueStore都相应的实现了这个接口。 - 该方法相应地创建事务上下文并进行保序,并执行事务状态机,事务提交后相应地执行上文注册的一系列回调函数。
// ---------------------------
// transactions
int BlueStore::queue_transactions(
CollectionHandle &ch,
vector<Transaction> &tls,
TrackedOpRef op,
ThreadPool::TPHandle *handle)
{
FUNCTRACE(cct);
// on_commoit: 事务提交完成之后的回调函数
// on_applied_sync: 同步调用执行,事务应用完成之后的回调函数
// on_applied: 在 Finisher 线程里异步调用执行,事务应用完成之后的回调函数
list<Context *> on_applied, on_commit, on_applied_sync;
ObjectStore::Transaction::collect_contexts(
tls, &on_applied, &on_commit, &on_applied_sync);
// 计时开始
auto start = mono_clock::now();
Collection *c = static_cast<Collection *>(ch.get());
// 获取操作序列号,用于保序。
// 会判断 PG 是否已经关联 OpSeq,未关联则新建并关联 PG
OpSequencer *osr = c->osr.get();
dout(10) << __func__ << " ch " << c << " " << c->cid << dendl;
// 创建 TransContext,并关联回调函数 on_commit
// prepare
TransContext *txc = _txc_create(static_cast<Collection *>(ch.get()), osr,
&on_commit, op);
// With HM-SMR drives (and ZNS SSDs) we want the I/O allocation and I/O
// submission to happen atomically because if I/O submission happens in a
// different order than I/O allocation, we end up issuing non-sequential
// writes to the drive. This is a temporary solution until ZONE APPEND
// support matures in the kernel. For more information please see:
// https://www.usenix.org/conference/vault20/presentation/bjorling
if (bdev->is_smr())
{
atomic_alloc_and_submit_lock.lock();
}
// 将所有的写操作添加到 TransContext,并记录操作字节数
for (vector<Transaction>::iterator p = tls.begin(); p != tls.end(); ++p)
{
txc->bytes += (*p).get_num_bytes();
_txc_add_transaction(txc, &(*p));
}
// 计算开销
_txc_calc_cost(txc);
// 更新 ONodes, shared_blobs
_txc_write_nodes(txc, txc->t);
// journal deferred items
if (txc->deferred_txn)
{
txc->deferred_txn->seq = ++deferred_seq;
bufferlist bl;
encode(*txc->deferred_txn, bl);
string key;
get_deferred_key(txc->deferred_txn->seq, &key);
txc->t->set(PREFIX_DEFERRED, key, bl);
}
_txc_finalize_kv(txc, txc->t);
#ifdef WITH_BLKIN
if (txc->trace)
{
txc->trace.event("txc encode finished");
}
#endif
if (handle)
handle->suspend_tp_timeout();
// 记录 throttle 开始的时间
auto tstart = mono_clock::now();
// 事务提交到 Throttle (内部流控机制)
if (!throttle.try_start_transaction(
*db,
*txc,
tstart))
{
// ensure we do not block here because of deferred writes
dout(10) << __func__ << " failed get throttle_deferred_bytes, aggressive"
<< dendl;
++deferred_aggressive;
deferred_try_submit();
{
// wake up any previously finished deferred events
std::lock_guard l(kv_lock);
if (!kv_sync_in_progress)
{
kv_sync_in_progress = true;
kv_cond.notify_one();
}
}
throttle.finish_start_transaction(*db, *txc, tstart);
--deferred_aggressive;
}
// 记录 throttle 完成时间
auto tend = mono_clock::now();
if (handle)
handle->reset_tp_timeout();
logger->inc(l_bluestore_txc);
// 处理事务状态,执行状态机,将 IO 请求交给块设备执行
// 该方法中为一系列事务状态机的转换,最终写操作完成后会执行 oncommit 的回调
// execute (start)
_txc_state_proc(txc);
if (bdev->is_smr())
{
atomic_alloc_and_submit_lock.unlock();
}
// 针对写完日志之后的回调操作,也就是所谓的 on_readable
// BliueStore 只会产生少量 WAL 到 RocksDB,所以写日志先于写数据完成
// we're immediately readable (unlike FileStore)
for (auto c : on_applied_sync)
{
c->complete(0);
}
if (!on_applied.empty())
{
if (c->commit_queue)
{
c->commit_queue->queue(on_applied);
}
else
{
finisher.queue(on_applied);
}
}
#ifdef WITH_BLKIN
if (txc->trace)
{
txc->trace.event("txc applied");
}
#endif
log_latency("submit_transact",
l_bluestore_submit_lat,
mono_clock::now() - start,
cct->_conf->bluestore_log_op_age);
log_latency("throttle_transact",
l_bluestore_throttle_lat,
tend - tstart,
cct->_conf->bluestore_log_op_age);
return 0;
}
repop_commit
- 在写完成后的回调函数中对应地执行
repop_commit,相应地构造 MOSDRepOpReply,再发送到集群。
void ReplicatedBackend::repop_commit(RepModifyRef rm)
{
rm->op->mark_commit_sent();
rm->op->pg_trace.event("sup_op_commit");
rm->committed = true;
// send commit.
auto m = rm->op->get_req<MOSDRepOp>();
ceph_assert(m->get_type() == MSG_OSD_REPOP);
dout(10) << __func__ << " on op " << *m
<< ", sending commit to osd." << rm->ackerosd
<< dendl;
ceph_assert(get_osdmap()->is_up(rm->ackerosd));
get_parent()->update_last_complete_ondisk(rm->last_complete);
MOSDRepOpReply *reply = new MOSDRepOpReply(
m,
get_parent()->whoami_shard(),
0, get_osdmap_epoch(), m->get_min_epoch(), CEPH_OSD_FLAG_ONDISK);
reply->set_last_complete_ondisk(rm->last_complete);
reply->set_priority(CEPH_MSG_PRIO_HIGH); // this better match ack priority!
reply->trace = rm->op->pg_trace;
get_parent()->send_message_osd_cluster(
rm->ackerosd, reply, get_osdmap_epoch());
log_subop_stats(get_parent()->get_logger(), rm->op, l_osd_sop_w);
}
do_repop_reply
- MSG_OSD_REPOPREPLY 消息发送到了集群,又开始从头到尾的消息处理逻辑,在 _handle_message 中对该类型的消息进行处理,相应地执行
do_repop_reply
void ReplicatedBackend::do_repop_reply(OpRequestRef op)
{
static_cast<MOSDRepOpReply *>(op->get_nonconst_req())->finish_decode();
// 获取上文构造的 Reply Msg
auto r = op->get_req<MOSDRepOpReply>();
ceph_assert(r->get_header().type == MSG_OSD_REPOPREPLY);
op->mark_started();
// must be replication.
ceph_tid_t rep_tid = r->get_tid();
pg_shard_t from = r->from;
auto iter = in_progress_ops.find(rep_tid);
if (iter != in_progress_ops.end())
{
// 获取副本节点上正在处理的 op InProgressOp
InProgressOp &ip_op = *iter->second;
const MOSDOp *m = nullptr;
if (ip_op.op)
m = ip_op.op->get_req<MOSDOp>();
if (m)
dout(7) << __func__ << ": tid " << ip_op.tid << " op " //<< *m
<< " ack_type " << (int)r->ack_type
<< " from " << from
<< dendl;
else
dout(7) << __func__ << ": tid " << ip_op.tid << " (no op) "
<< " ack_type " << (int)r->ack_type
<< " from " << from
<< dendl;
// oh, good.
// 检查响应消息中的 ACK 类型
if (r->ack_type & CEPH_OSD_FLAG_ONDISK)
{
ceph_assert(ip_op.waiting_for_commit.count(from));
ip_op.waiting_for_commit.erase(from);
if (ip_op.op)
{
ip_op.op->mark_event("sub_op_commit_rec");
ip_op.op->pg_trace.event("sub_op_commit_rec");
}
}
else
{
// legacy peer; ignore
}
parent->update_peer_last_complete_ondisk(
from,
r->get_last_complete_ondisk());
// 检查 waiting_for_commit 是否为空
// 如果为空,继续向上回调。C_OSD_RepopCommit
// C_OSD_RepopCommit(PrimaryLogPG *pg, PrimaryLogPG::RepGather *repop)
// : pg(pg), repop(repop) {}
// void finish(int) override
// {
// pg->repop_all_committed(repop.get());
// }
// };
if (ip_op.waiting_for_commit.empty() &&
ip_op.on_commit)
{
ip_op.on_commit->complete(0);
ip_op.on_commit = 0;
in_progress_ops.erase(iter);
}
}
}
repop_all_committed
PrimaryLogPG::repop_all_committed准备于客户端进行交互,调用eval_repop
void PrimaryLogPG::repop_all_committed(RepGather *repop)
{
dout(10) << __func__ << ": repop tid " << repop->rep_tid << " all committed "
<< dendl;
repop->all_committed = true;
if (!repop->rep_aborted)
{
if (repop->v != eversion_t())
{
recovery_state.complete_write(repop->v, repop->pg_local_last_complete);
}
eval_repop(repop);
}
}
eval_repop
- 通过执行在
execute_ctx函数中注册的 commit 回调,从而向客户端发送应答消息。
void PrimaryLogPG::eval_repop(RepGather *repop)
{
dout(10) << "eval_repop " << *repop
<< (repop->op && repop->op->get_req<MOSDOp>() ? "" : " (no op)") << dendl;
// 所有副本应答写入磁盘完成
// ondisk?
if (repop->all_committed)
{
dout(10) << " commit: " << *repop << dendl;
for (auto p = repop->on_committed.begin();
p != repop->on_committed.end();
repop->on_committed.erase(p++))
{
// 执行回调
// ctx->register_on_commit(
// [m, ctx, this]() {
// if (ctx->op)
// log_op_stats(*ctx->op, ctx->bytes_written, ctx->bytes_read);
// if (m && !ctx->sent_reply)
// {
// MOSDOpReply *reply = ctx->reply;
// ctx->reply = nullptr;
// reply->add_flags(CEPH_OSD_FLAG_ACK | CEPH_OSD_FLAG_ONDISK);
// dout(10) << " sending reply on " << *m << " " << reply << dendl;
// osd->send_message_osd_client(reply, m->get_connection());
// ctx->sent_reply = true;
// ctx->op->mark_commit_sent();
// }
// });
(*p)();
}
// send dup commits, in order
auto it = waiting_for_ondisk.find(repop->v);
if (it != waiting_for_ondisk.end())
{
ceph_assert(waiting_for_ondisk.begin()->first == repop->v);
for (auto &i : it->second)
{
int return_code = repop->r;
if (return_code >= 0)
{
return_code = std::get<2>(i);
}
osd->reply_op_error(std::get<0>(i), return_code, repop->v,
std::get<1>(i), std::get<3>(i));
}
waiting_for_ondisk.erase(it);
}
publish_stats_to_osd();
dout(10) << " removing " << *repop << dendl;
ceph_assert(!repop_queue.empty());
dout(20) << " q front is " << *repop_queue.front() << dendl;
if (repop_queue.front() == repop)
{
RepGather *to_remove = nullptr;
while (!repop_queue.empty() &&
(to_remove = repop_queue.front())->all_committed)
{
repop_queue.pop_front();
for (auto p = to_remove->on_success.begin();
p != to_remove->on_success.end();
to_remove->on_success.erase(p++))
{
(*p)();
}
remove_repop(to_remove);
}
}
}
}
