- FUSE-based file system backed by Amazon S3
- 基于对象存储的文件系统,国内有 aliyun/ossfs, huaweicloud/obsfs
- 本质是实现了将对象存储的 Bucket 挂载到了本地文件系统中,从而通过本地文件系统操作 OSS 上的对象
S3FS
Overfiew
- S3FS 是一个 FUSE 文件系统,它允许您将 Amazon S3 bucket 挂载为本地文件系统。它在 S3 中以自然和透明的方式存储文件。您可以使用其他程序来访问相同的文件)。s3fs 可以处理的对象的最大大小取决于 Amazon S3。例如,当使用单一 PUT API 时,可以达到 5GB。当使用多部分上传 API 时,最多支持 5TB。
- s3fs 是稳定的,并在许多生产环境中使用,例如,rsync 备份到 s3。
Dependency
FUSE
- FUSE: File System In User Space. 用户态文件系统,实现逻辑可以在用户态层面代码高度定制,相比于传统的内核文件系统如 Ext4 等,易用性更高,效率因为用户态和内核态的频繁切换相对较低。
- 内核必须支持 FUSE, 2.6.18-164 之前的内核可能不支持 FUSE。虚拟专用服务器(VPS)可能没有在其内核中编译 FUSE 支持。
- 黑客画家:什么是 FUSE?
S3 Standard Object Storage
- 由于是基于对象存储构建的存储系统,所以需要一个对象存储系统,S3FS 则是针对实现了 S3 标准的对象存储构建的本地文件系统。
Features
- 支持POSIX 文件系统的大部分功能,包括文件读写,目录,链接操作,权限, uid/gid,以及扩展属性(extended attributes)
- 支持随机写和追加写
- 大文件使用分片上传
- 通过在服务端拷贝实现 rename
- MD5 数据完整性校验
- 内存缓存元数据
- 本地磁盘数据缓存
- ...
Limitations
不能完全等价于内核态的文件系统,无论是性能还是语义支持方面都存在一定差距。
- 随机写和追加写可能导致整个文件的重写,可以使用分片上传进行优化
- 元数据的相关操作,例如枚举,性能较差,因为要访问对象存储
- 底层对象存储系统的最终一致性可能会使得 S3FS 暂时产生一些过时的数据
- 文件/文件夹的rename操作不是原子的。
- 多客户端挂载同一个 Bucket 时需要协调各个客户端的行为,避免对一个文件的不同客户端的并发写
- 不支持 hard link
- 不适合用在高并发读/写的场景,这样会让系统的 load 升高
原理
机制
1.读取文件
-
S3FS 对于文件的存储分为临时文件和缓存两种方式,用户可以在命令行中通过 use_cache 参数指定缓存目录来启动缓存方式。
-
用户通过 offset 和 size 来读取指定文件中的特定区域,如果本地没有相应的内容 S3FS 会通过网络请求 S3 上的相应内容,并且将对应的内容存储到本地的临时文件或者缓存中。
2.文件逻辑架构
- 不管是临时文件还是缓存文件,S3FS 都用同一个逻辑架构组织这个文件,S3FS 使用一个页的列表来代表一个文件,每页都是这个文件中的一部分:
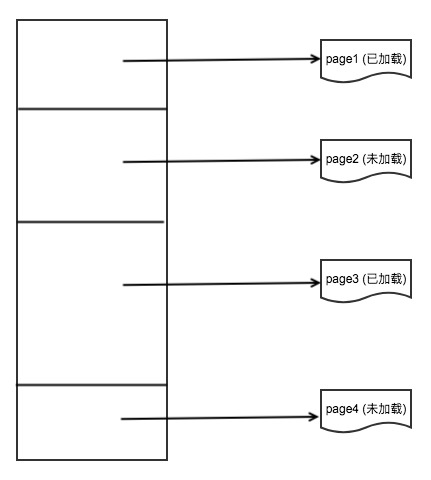
组成:
- FDPage: 代表了一个文件中的一页,即也是文件中的部分内容。
//------------------------------------------------
// fdpage & PageList
//------------------------------------------------
// page block information
struct fdpage
{
off_t offset; // 偏移量
off_t bytes; // 页的大小
bool loaded; // 是否加载到了本地
bool modified; // 是否修改
// 构造函数
fdpage(off_t start = 0, off_t size = 0, bool is_loaded = false, bool is_modified = false)
: offset(start), bytes(size), loaded(is_loaded), modified(is_modified) {}
// 获取下一页对应的偏移量
off_t next(void) const { return (offset + bytes); }
// 获取该页的末尾对应的偏移量
off_t end(void) const { return (0 < bytes ? offset + bytes - 1 : 0); }
};
// Page List
typedef std::list<struct fdpage> fdpage_list_t;
- PageList:代表一个本地文件,它是 FDPage 的一个链表。
class PageList
{
friend class FdEntity; // only one method access directly pages.
private:
fdpage_list_t pages;
public:
// 页状态枚举
enum page_status{
PAGE_NOT_LOAD_MODIFIED = 0,
PAGE_LOADED,
PAGE_MODIFIED,
PAGE_LOAD_MODIFIED
};
private:
void Clear(void);
bool Compress(bool force_modified = false);
bool Parse(off_t new_pos);
bool RawGetUnloadPageList(fdpage_list_t& dlpages, off_t offset, off_t size);
public:
static void FreeList(fdpage_list_t& list);
explicit PageList(off_t size = 0, bool is_loaded = false, bool is_modified = false);
explicit PageList(const PageList& other);
~PageList();
bool Init(off_t size, bool is_loaded, bool is_modified);
off_t Size(void) const;
bool Resize(off_t size, bool is_loaded, bool is_modified);
bool IsPageLoaded(off_t start = 0, off_t size = 0) const; // size=0 is checking to end of list
bool SetPageLoadedStatus(off_t start, off_t size, PageList::page_status pstatus = PAGE_LOADED, bool is_compress = true);
bool FindUnloadedPage(off_t start, off_t& resstart, off_t& ressize) const;
off_t GetTotalUnloadedPageSize(off_t start = 0, off_t size = 0) const; // size=0 is checking to end of list
int GetUnloadedPages(fdpage_list_t& unloaded_list, off_t start = 0, off_t size = 0) const; // size=0 is checking to end of list
bool GetLoadPageListForMultipartUpload(fdpage_list_t& dlpages);
bool GetMultipartSizeList(fdpage_list_t& mplist, off_t partsize) const;
bool IsModified(void) const;
bool ClearAllModified(void);
bool Serialize(CacheFileStat& file, bool is_output, ino_t inode);
void Dump(void);
};
- FdEntity:对一个文件的全面描述,包括页链表、本地文件描述符、文件路径等。
class FdEntity
{
private:
static bool mixmultipart; // whether multipart uploading can use copy api.
pthread_mutex_t fdent_lock;
bool is_lock_init;
int refcnt; // reference count 用于刷回
std::string path; // object path
int fd; // file descriptor(tmp file or cache file)
FILE* pfile; // file pointer(tmp file or cache file)
ino_t inode; // inode number for cache file
headers_t orgmeta; // original headers at opening
off_t size_orgmeta; // original file size in original headers
pthread_mutex_t fdent_data_lock;// protects the following members
PageList pagelist;
std::string upload_id; // for no cached multipart uploading when no disk space
etaglist_t etaglist; // for no cached multipart uploading when no disk space
off_t mp_start; // start position for no cached multipart(write method only)
off_t mp_size; // size for no cached multipart(write method only)
std::string cachepath; // local cache file path
// (if this is empty, does not load/save pagelist.)
std::string mirrorpath; // mirror file path to local cache file path
private:
static int FillFile(int fd, unsigned char byte, off_t size, off_t start);
static ino_t GetInode(int fd);
void Clear(void);
ino_t GetInode(void);
int OpenMirrorFile(void);
bool SetAllStatus(bool is_loaded); // [NOTE] not locking
//bool SetAllStatusLoaded(void) { return SetAllStatus(true); }
bool SetAllStatusUnloaded(void) { return SetAllStatus(false); }
public:
static bool SetNoMixMultipart(void);
explicit FdEntity(const char* tpath = NULL, const char* cpath = NULL);
~FdEntity();
void Close(void);
bool IsOpen(void) const { return (-1 != fd); }
int Open(headers_t* pmeta = NULL, off_t size = -1, time_t time = -1, bool no_fd_lock_wait = false);
bool OpenAndLoadAll(headers_t* pmeta = NULL, off_t* size = NULL, bool force_load = false);
int Dup(bool lock_already_held = false);
const char* GetPath(void) const { return path.c_str(); }
bool RenamePath(const std::string& newpath, std::string& fentmapkey);
int GetFd(void) const { return fd; }
bool IsModified(void) const { return pagelist.IsModified(); }
bool GetStats(struct stat& st, bool lock_already_held = false);
int SetCtime(time_t time);
int SetMtime(time_t time, bool lock_already_held = false);
bool UpdateCtime(void);
bool UpdateMtime(void);
bool GetSize(off_t& size);
bool SetMode(mode_t mode);
bool SetUId(uid_t uid);
bool SetGId(gid_t gid);
bool SetContentType(const char* path);
int Load(off_t start = 0, off_t size = 0, bool lock_already_held = false, bool is_modified_flag = false); // size=0 means loading to end
int NoCacheLoadAndPost(off_t start = 0, off_t size = 0); // size=0 means loading to end
int NoCachePreMultipartPost(void);
int NoCacheMultipartPost(int tgfd, off_t start, off_t size);
int NoCacheCompleteMultipartPost(void);
int RowFlush(const char* tpath, bool force_sync = false);
int Flush(bool force_sync = false) { return RowFlush(NULL, force_sync); }
ssize_t Read(char* bytes, off_t start, size_t size, bool force_load = false);
ssize_t Write(const char* bytes, off_t start, size_t size);
bool ReserveDiskSpace(off_t size);
};
typedef std::map<std::string, class FdEntity*> fdent_map_t; // key=path, value=FdEntity*
IO 流程
读取文件流程
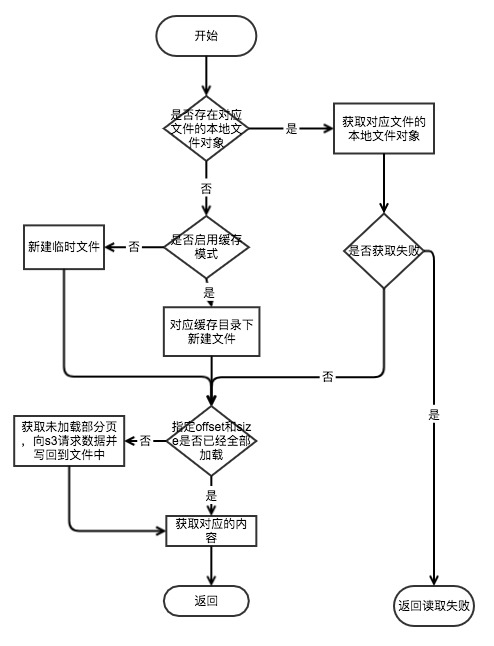
- 不启用缓存模式:不启用缓存模式下,S3FS 会在本地新建一个临时文件来存储网络传送过来的数据,读取结束后关闭相应的句柄,这样做得好处是如果多个进程同时读取同一个文件就不需要频繁的发起网络请求,当这个临时文件的所有句柄都关闭后这个临时文件也会删除。
if(0 == refcnt){
AutoLock auto_data_lock(&fdent_data_lock);
if(!cachepath.empty()){
// [NOTE]
// Compare the inode of the existing cache file with the inode of
// the cache file output by this object, and if they are the same,
// serialize the pagelist.
//
ino_t cur_inode = GetInode();
if(0 != cur_inode && cur_inode == inode){
CacheFileStat cfstat(path.c_str());
if(!pagelist.Serialize(cfstat, true, inode)){
S3FS_PRN_WARN("failed to save cache stat file(%s).", path.c_str());
}
}
}
if(pfile){
fclose(pfile);
pfile = NULL;
}
fd = -1;
inode = 0;
if(!mirrorpath.empty()){
if(-1 == unlink(mirrorpath.c_str())){
S3FS_PRN_WARN("failed to remove mirror cache file(%s) by errno(%d).", mirrorpath.c_str(), errno);
}
mirrorpath.erase();
}
- 启用缓存模式:启用缓存模式下,S3FS 会将 S3 的数据在本地缓存一份,如果磁盘空间不够,S3FS 会删除部分没有连接的文件来预留出磁盘空间。对于需要经常访问的文件,有一份在本地的缓存非常有必要。
Read OP
ssize_t FdEntity::Read(char* bytes, off_t start, size_t size, bool force_load)
{
S3FS_PRN_DBG("[path=%s][fd=%d][offset=%lld][size=%zu]", path.c_str(), fd, static_cast<long long int>(start), size);
if(-1 == fd){
return -EBADF;
}
AutoLock auto_lock(&fdent_data_lock);
if(force_load){
pagelist.SetPageLoadedStatus(start, size, PageList::PAGE_NOT_LOAD_MODIFIED);
}
ssize_t rsize;
// check disk space
if(0 < pagelist.GetTotalUnloadedPageSize(start, size)){
// load size(for prefetch)
size_t load_size = size;
if(start + static_cast<ssize_t>(size) < pagelist.Size()){
ssize_t prefetch_max_size = max(static_cast<off_t>(size), S3fsCurl::GetMultipartSize() * S3fsCurl::GetMaxParallelCount());
if(start + prefetch_max_size < pagelist.Size()){
load_size = prefetch_max_size;
}else{
load_size = pagelist.Size() - start;
}
}
if(!ReserveDiskSpace(load_size)){
S3FS_PRN_WARN("could not reserve disk space for pre-fetch download");
load_size = size;
if(!ReserveDiskSpace(load_size)){
S3FS_PRN_ERR("could not reserve disk space for pre-fetch download");
return -ENOSPC;
}
}
// Loading
int result = 0;
if(0 < size){
result = Load(start, load_size, /*lock_already_held=*/ true);
}
FdManager::FreeReservedDiskSpace(load_size);
if(0 != result){
S3FS_PRN_ERR("could not download. start(%lld), size(%zu), errno(%d)", static_cast<long long int>(start), size, result);
return -EIO;
}
}
// Reading
if(-1 == (rsize = pread(fd, bytes, size, start))){
S3FS_PRN_ERR("pread failed. errno(%d)", errno);
return -errno;
}
return rsize;
}
Write OP
ssize_t FdEntity::Write(const char* bytes, off_t start, size_t size)
{
S3FS_PRN_DBG("[path=%s][fd=%d][offset=%lld][size=%zu]", path.c_str(), fd, static_cast<long long int>(start), size);
if(-1 == fd){
return -EBADF;
}
// check if not enough disk space left BEFORE locking fd
if(FdManager::IsCacheDir() && !FdManager::IsSafeDiskSpace(NULL, size)){
FdManager::get()->CleanupCacheDir();
}
AutoLock auto_lock(&fdent_data_lock);
// check file size
if(pagelist.Size() < start){
// grow file size
if(-1 == ftruncate(fd, start)){
S3FS_PRN_ERR("failed to truncate temporary file(%d).", fd);
return -EIO;
}
// add new area
pagelist.SetPageLoadedStatus(pagelist.Size(), start - pagelist.Size(), PageList::PAGE_MODIFIED);
}
int result = 0;
ssize_t wsize;
if(0 == upload_id.length()){
// check disk space
off_t restsize = pagelist.GetTotalUnloadedPageSize(0, start) + size;
if(ReserveDiskSpace(restsize)){
// enough disk space
// Load uninitialized area which starts from 0 to (start + size) before writing.
if(!FdEntity::mixmultipart){
if(0 < start){
result = Load(0, start, /*lock_already_held=*/ true);
}
}
FdManager::FreeReservedDiskSpace(restsize);
if(0 != result){
S3FS_PRN_ERR("failed to load uninitialized area before writing(errno=%d)", result);
return static_cast<ssize_t>(result);
}
}else{
// no enough disk space
if(0 != (result = NoCachePreMultipartPost())){
S3FS_PRN_ERR("failed to switch multipart uploading with no cache(errno=%d)", result);
return static_cast<ssize_t>(result);
}
// start multipart uploading
if(0 != (result = NoCacheLoadAndPost(0, start))){
S3FS_PRN_ERR("failed to load uninitialized area and multipart uploading it(errno=%d)", result);
return static_cast<ssize_t>(result);
}
mp_start = start;
mp_size = 0;
}
}else{
// already start multipart uploading
}
// Writing
if(-1 == (wsize = pwrite(fd, bytes, size, start))){
S3FS_PRN_ERR("pwrite failed. errno(%d)", errno);
return -errno;
}
if(0 < wsize){
pagelist.SetPageLoadedStatus(start, wsize, PageList::PAGE_LOAD_MODIFIED);
}
// Load uninitialized area which starts from (start + size) to EOF after writing.
if(!FdEntity::mixmultipart){
if(pagelist.Size() > start + static_cast<off_t>(size)){
result = Load(start + size, pagelist.Size(), /*lock_already_held=*/ true);
if(0 != result){
S3FS_PRN_ERR("failed to load uninitialized area after writing(errno=%d)", result);
return static_cast<ssize_t>(result);
}
}
}
// check multipart uploading
if(0 < upload_id.length()){
mp_size += wsize;
if(S3fsCurl::GetMultipartSize() <= mp_size){
// over one multipart size
if(0 != (result = NoCacheMultipartPost(fd, mp_start, mp_size))){
S3FS_PRN_ERR("failed to multipart post(start=%lld, size=%lld) for file(%d).", static_cast<long long int>(mp_start), static_cast<long long int>(mp_size), fd);
return result;
}
// [NOTE]
// truncate file to zero and set length to part offset + size
// after this, file length is (offset + size), but file does not use any disk space.
//
if(-1 == ftruncate(fd, 0) || -1 == ftruncate(fd, (mp_start + mp_size))){
S3FS_PRN_ERR("failed to truncate file(%d).", fd);
return -EIO;
}
mp_start += mp_size;
mp_size = 0;
}
}
return wsize;
}
读取文件网络请求流程
- 通过网络请求 S3 的数据,S3FS 分为了两种,一种是单次请求,一种是多次请求,请求流程如下:
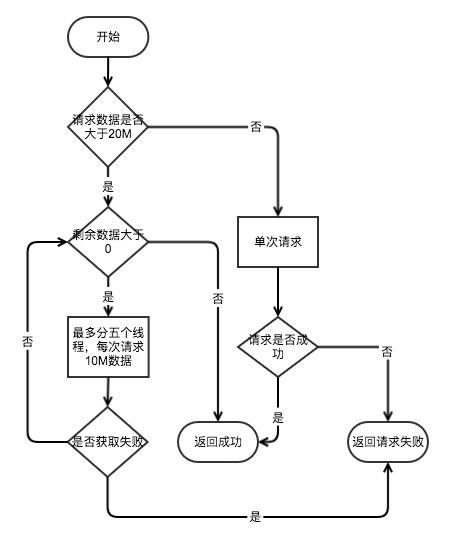
- 单次请求:默认情况下单次请求的大小在 20M 以下,S3FS 会通过单个请求完成数据的请求。
- 多次请求:默认情况下如果请求的数据在 20M 以上,S3FS 会切割数据进行多次请求,每次请求 10M 的数据,对单个文件的请求每次最多启动 5 个线程来进行数据的获取,并且是在 5 个线程都请求完成后才会启动下一轮请求。
请求 S3
int FdEntity::Load(off_t start, off_t size, bool lock_already_held, bool is_modified_flag)
{
AutoLock auto_lock(&fdent_lock, lock_already_held ? AutoLock::ALREADY_LOCKED : AutoLock::NONE);
S3FS_PRN_DBG("[path=%s][fd=%d][offset=%lld][size=%lld]", path.c_str(), fd, static_cast<long long int>(start), static_cast<long long int>(size));
if(-1 == fd){
return -EBADF;
}
AutoLock auto_data_lock(&fdent_data_lock, lock_already_held ? AutoLock::ALREADY_LOCKED : AutoLock::NONE);
int result = 0;
// check loaded area & load
fdpage_list_t unloaded_list;
if(0 < pagelist.GetUnloadedPages(unloaded_list, start, size)){
for(fdpage_list_t::iterator iter = unloaded_list.begin(); iter != unloaded_list.end(); ++iter){
if(0 != size && start + size <= iter->offset){
// reached end
break;
}
// check loading size
off_t need_load_size = 0;
if(iter->offset < size_orgmeta){
// original file size(on S3) is smaller than request.
need_load_size = (iter->next() <= size_orgmeta ? iter->bytes : (size_orgmeta - iter->offset));
}
// download
if(S3fsCurl::GetMultipartSize() <= need_load_size && !nomultipart){
// parallel request
result = S3fsCurl::ParallelGetObjectRequest(path.c_str(), fd, iter->offset, need_load_size);
}else{
// single request
if(0 < need_load_size){
S3fsCurl s3fscurl;
result = s3fscurl.GetObjectRequest(path.c_str(), fd, iter->offset, need_load_size);
}else{
result = 0;
}
}
if(0 != result){
break;
}
// Set loaded flag
pagelist.SetPageLoadedStatus(iter->offset, iter->bytes, (is_modified_flag ? PageList::PAGE_LOAD_MODIFIED : PageList::PAGE_LOADED));
}
PageList::FreeList(unloaded_list);
}
return result;
}
源码
原理概述:
- 代码层面 s3fs 的实现方法主要是:利用 fuse 库实现一个文件系统并挂载到本地文件系统的某个目录下,该文件系统的底层并不使用磁盘存储,而是使用 s3 os 存储(因为文件系统是自己实现的,用什么存储,怎么存储可以自己定);
代码结构
- s3fs 项目一共有 11 个头文件,除去一个测试代码文件,一共有10个文件系统实现相关的文件,分别是:
- curl.h:用于请求s3 os中的文件,多线程
- fdcache.h:缓存文件相关类,包括fdpage、pagelist、FdEntity、FdManager,主要用于os中文件分页缓存到本地以及缓存文件的相关管理(比如检查存在、创建、清除等) 注意,若文件句柄持有线程为0,则该文件缓存被清除;
- psemaphore.h:信号量机制实现类
- s3fs.h:s3文件系统实现类,用于利用s3 os 为存储介质,构造一个文件系统挂载到本地文件系统目录中
- s3fs_util.h:一些工具类
- s3fs_auth.h:用于s3 os的认证
- string_util.h:用于处理http协议的(header,body)
- cache.h:文件缓存,将已读取或加载的文件缓存到本地,以备以后使用(相当于cpu的三级缓存)
- common.h:主要用于日志记录
- add_head.h
同类产品
ossfs AliCloud
- 官方介绍
- Github Repo
- ossfs 能让您在Linux系统中,将对象存储OSS的存储空间(Bucket)挂载到本地文件系统中,您能够像操作本地文件一样操作OSS的对象(Object),实现数据的共享。
obsfs HuaweiCloud
- 官方介绍
- Github Repo
- Obsfs 是基于开源 s3fs 修改的。Obsfs 继承了 s3fs 的一些功能,并为华为云OBS服务开发了一些独特的功能。obsfs 允许 Linux 和 Mac OS X 通过 FUSE 挂载 S3 bucket。
References
- goofys - similar to s3fs but has better performance and less POSIX compatibility. Performance First, POSIX Second
- We can try to implement self-define backend object storage service. But we must use Go-Language to call functions given by our object operations sdk.
- s3acker - mount an S3 bucket as a single file
- S3Proxy - combine with s3fs to mount Backblaze B2, EMC Atmos, Microsoft Azure, and OpenStack Swift buckets.
- It is used as a S3 Proxy for other object storage service and implements S3 API.
- s3ql - similar to s3fs but uses its own object format
- YAS3FS - similar to s3fs but uses SNS to allow multiple clients to mount a bucket
