- 该篇文章来自于 FAST2019 - GearDB: A GC-free Key-Value Store on HM-SMR Drives with Gear Compaction
- 该篇文章来自于 FAST2019 - GearDB: A GC-free Key-Value Store on HM-SMR Drives with Gear Compaction
- 本文主要针对 HW-SMR 上的 KV 存储引擎的 GC 存在的问题进行了分析并进行了针对性的优化
- 由于场景相对单一,没有深入阅读,大致理解思想即可
Abstract
- HM-SMR 磁盘的出现顺应了数据爆炸增长的趋势,其主要优点就在于容量大,成本低,性能可预测,因此很适合顺序写、随机读的应用,如 LSM-tree。但是 LSM-tree 的 compaction 和 HM-SMR 的垃圾回收在数据清理过程中是有一定的冗余的,为了消除磁盘内部的 GC 开销并提升 compaction 的效率,我们提出了 GearDB,为 HM-SMR 定制的无 GC KV 存储。主要提出了三种技术:
- 提出了一种新的磁盘布局
- compation windows
- 一种新的压缩算法 gear compaction
- 我们在真实的 HM-SMR Drive 上实现并运行了基于 LevelDB 的 GearDB。在性能和空间效率上表现均较好。
Introduction & Background
SMR
- 通过增大磁盘表面密度来增大容量,相同的面积下,进行类似于瓦片的交叠技术来增大盘面密度。
- HM-SMR 随机写性能较差,因为需要将重叠部分的数据拷贝到空白区域之后修改才能保证不影响别的数据。因此这种顺序的要求使得 LSM-tree 成为比较好的存储引擎选择,但也是也就引入了垃圾回收的问题。GC 通过迁移有效数据来为新的写操作生成空区域,从而回收磁盘空间。GC的数据迁移开销严重降低了系统性能。
- SMR 根据随机写的复杂性处理的位置被分为三种类型:(其中 HM-SMR 因为较大的容量、可预测的性能以及较低的成本应用尤为广泛,特别是针对顺序写随机读比较显著的负载)
- drive-managed(DM-SMR:在固件中实现了一个转换层,以适应顺序和随机写操作)主要为了替代现有的 HDD,但是性能较差且不可预测。
- host-managed(HM-SMR:要求主机端软件修改来利用对应器件的优势,它只允许顺序写操作,并通过公开内部驱动器状态来提供可预测的性能)
- host-aware(HA-SMR:介于 HM-SMR 和 DM-SMR 之间,然而,它是最复杂的,并获得最大的好处和可预测性)
- 许多生产中的 HA/HM SMR 被分成了 256MB 大小的 Zones,每个区域通过维护一个写指针来恢复后续的写操作来适应严格的顺序写操作。两个相邻的 Zones 被 guard 分开。没有有效数据的区域可以通过将该区域的写指针重设到该区域的第一个块来重用为空区域。所有复杂的 HM-SMR 都通过一个新的命令集 T10 Zone Block Commands 暴露给软件
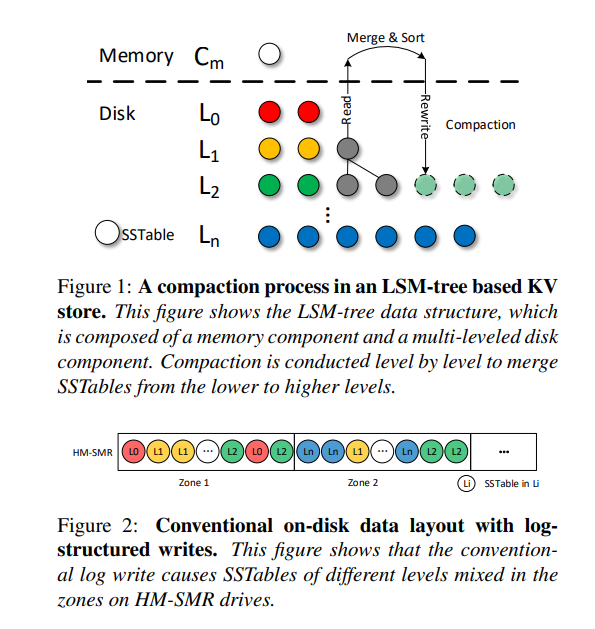
- 为了遵守 SMR 顺序写限制,应用程序或操作系统需要以日志结构的方式写数据。但是,log-structured 布局以垃圾收集(GC)的形式增加了额外的开销。并且由于实时数据迁移,GC 会阻塞前台请求并降低系统性能。
LSM-Tree
- LSM-Tree 的介绍此处省略。
- KV 存储容量的需求促进了基于 HM-SMR 构建 KV 存储的想法产生。现有的方案有 希捷的 Kinetic,华为的 SMR-based KV Store,Netapp 的 SMORE 等等。
- 但是在 HM-SMR 上构建 KV Store 的挑战主要表现在重复的数据清理过程对性能产生的严重影响。LSM 树中,压缩操作清理无效数据并排序。在 HM-SMR 驱动器中,由于应用程序使数据失效,具有日志结构数据布局的区域被分割。因此需要在 HM-SMR 上执行垃圾回收。HM-SMR 驱动器上的现有应用程序要么没有解决垃圾收集问题,要么使用简单的贪婪策略从部分空的区域迁移实时数据。冗余清理过程,特别是存储设备的垃圾收集,会显著降低系统性能。
- 为了演示磁盘上垃圾收集的影响,我们实现了一种成本较低和贪婪垃圾收集策略,类似于日志结构文件系统和 SSD 中的空闲空间管理,结果表明垃圾回收不仅仅带来系统延迟上很大的开销,也会对 HM-SMR 空间利用率产生影响。传统的 KV 存储在 HM-SMR 驱动器上面临困境:要么在性能差的情况下获得较高的空间效率,要么在空间利用率差的情况下获得良好的性能。(空间利用率定义为磁盘上有效数据卷与分配的磁盘空间之间的比率)
Motivation
- HM-SMR驱动器所需的日志结构写方式可能导致磁盘碎片过多,因此需要进行开销较大的垃圾收集来处理它们。具体而言,在基于 HM-SMR 的 LSM KV 存储中,压缩操作常常清理无效的 KV 项但是在磁盘上会留下无效的 SSTables。特别地,对常规日志的任意顺序写操作会导致 在一个 Zone 中来自多个层级的 SSTables 拥有不同的压缩频率。如图所示。
- 因为压缩操作在 LSM 的生命周期中持续地在进行,HM-SMR 的碎片将遍布到各个 Zones,就需要大量的片段 GC 操作。因为严峻的写放大系数(大于12x)以及压缩造成的大量的分散的碎片,被动的 GCs 变得不可避免。当空闲的磁盘空间低于阈值 20% 时候将触发 GC,GC 将先在 Zone 之间迁移有效数据,然后清理对应的 Zone。
- 为了证明上述的 HM-SMR 上的 LSM KV 存储在垃圾回收过程中的问题,我们在真实的 HM-SMR 实现了 LevelDB,实现了贪婪和利于成本的 GC 策略来管理 HM-SMR 空间。
- 贪婪 GC 通过将无效数据迁移到其他区域来清除无效数据最多的区域。
- Cost-benefit GC 考虑区域的年龄和空间利用度(u),使用如下公式选择区域。
- Zone Age:将 SSTables 的 Level 进行求和,因为 SSTable 在更底层也就意味着存在的时间更长,就有着更小的压缩频率
- n 是该 Zone 中 SSTables 的个数
- Li 即为一个 SSTable 的层数
- 开销包括读一个 Zone 然后写回 u 的有效数据的开销
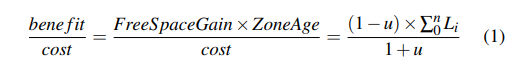
- 通过实现,我们有如下发现:
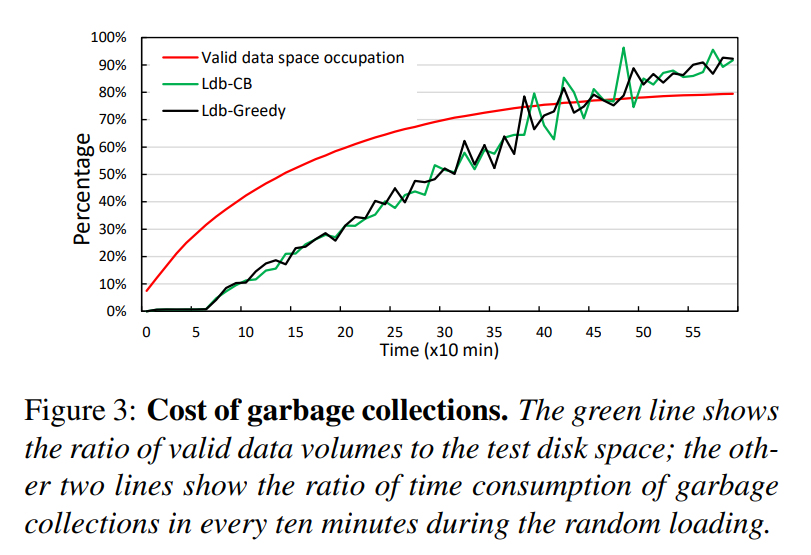
- 发现1:在加载过程中,我们每十分钟计算一次有效数据量和GC时间。当有效数据增长到大约磁盘空间的 70% 时,十分钟的采样周期中有超过一半的时间都被用于 GC,当有效数据的比例增长到 76% 的时候,GC 执行时间占据了超过 80%。测试结果表明,垃圾收集占用了总执行时间的很大一部分,从而显著降低了系统性能。
- 解释:因为来自一个区域中不同级别的sstable是混合的,多个区域在 Cost-benefit GC 策略中显示相似的年龄。相似的区域年龄使得贪婪策略和 Cost-benefit GC 策略表现出几乎相同的性能,因为它们都倾向于回收使用最多无效数据的区域
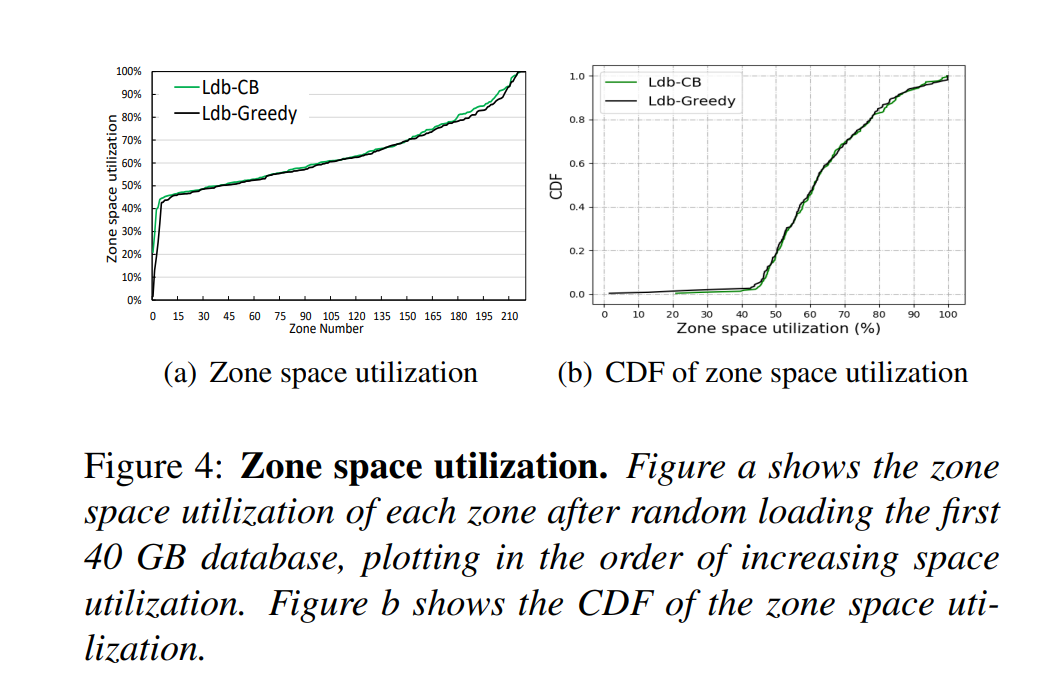
- 发现2:我们在 HM-SMR 驱动器上记录了加载 1000 万KV项后每个占区的空间利用情况,图 a 显示了有效数据在每个 Zone 中的比例,图 b 显示了 Zone 空间利用率的累计分布函数。两种 GC 策略平均空间效率达不到 60%,更具体地讲,85% 的 Zones 的空间利用率大约在 45% 到 80%。我们认为,正如上面所讨论的,这种空间利用率分布导致大量时间花费在GC上。
- 解释: 迁移的区域中的实时数据越多,清理所需的磁盘带宽就越多,而写入新数据则无法使用磁盘带宽。更好、更友好的空间利用方式是双峰分布,其中大多数区域几乎都已满,少数区域为空,而cleaner始终可以处理空区域,从而消除GC的开销。既可以实现高磁盘空间利用率,又可以消除磁盘上的垃圾收集开销。
 、
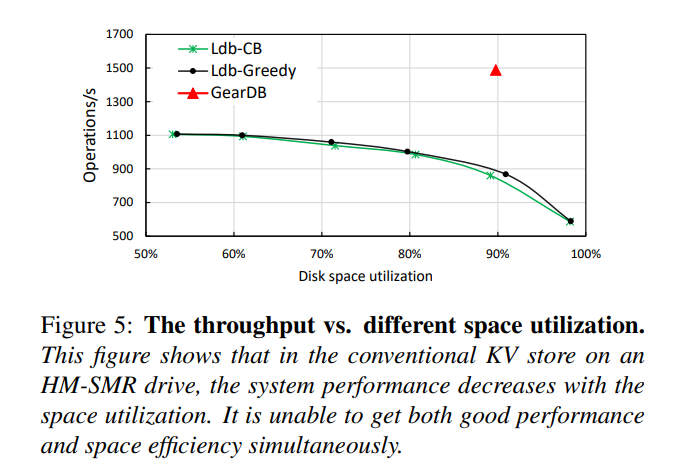
、 - 发现3:通过将GC的阈值从100%更改为50%)的110 GB限制磁盘容量,我们测试了6组80 GB的随机写操作,以显示性能随磁盘空间利用率的变化。磁盘空间利用率或空间效率定义为磁盘上有效数据卷与分配的磁盘空间的比率,如下图所示,系统性能随空间利用率而降低。
- 解释:在HM-SMR驱动器上运行的LevelDB面临着一个困境,即它只能在性能和空间利用率之间折衷,我们的设计 GearDB 旨在同时实现更高的性能和更好的空间效率。
Design
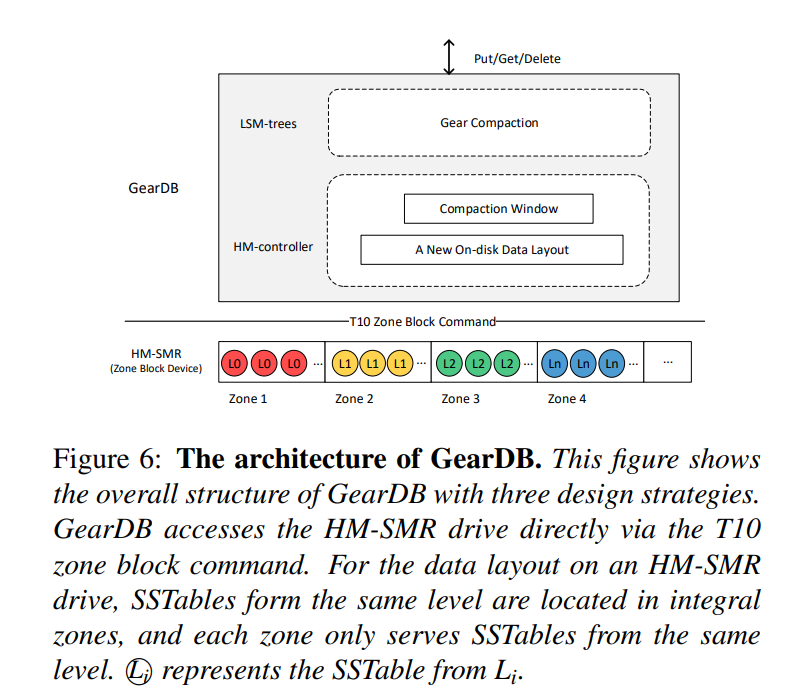
- 一个新的磁盘布局,为 HM-SMR 驱动器提供特定于应用程序的数据管理。一个 Zone 只服务于来自于同一个 Level 的 SSTable 来避免不同 Level 的数据混合分布导致大量分散的碎片。
- 基于新的磁盘布局,为每一个 LSM-trees Level 设计了一个压缩窗口。只有在压缩窗口中,压错操作才会被执行,从而讲碎片限制在了压缩窗口中
- 提出了一个新的压缩算法,gear compaction,基于上述两种设计,该算法将每次压缩合并了的数据分成三部分,并在下一级的压缩窗口中与重叠的数据进一步压缩。通过让压缩窗口中的 SSTables 全部无效实现了自动地清空 SMR Zones,从而不需要额外的垃圾回收操作。
A New On-disk Data Layout
- 初始的时候,每一个 Level 被关联到一个 Zone,随着一个 Level 的数据量的增长,其他的 Zones 也会被分配给这个 Level,即 Zone 和 Level 的关系是多对一的关系。
- 一旦一个 Zone 关联到了一个 level,该 Zone 就只能存储来自 Li 层的顺序写入的 SSTables,直到该 Zone 被作为一个 Empty Zone 释放。
- 每一层对应的多个 Zone 之间,只有一个 Zone 接受进来的写入,被称之为 Writing Zone,每个 Zone 的顺序写入严格遵循 HM-SMR 驱动器的重叠约束。
- 因为一个 Zone 都属于同一个 Level,所以对应的压缩频率也就相同,这样的数据布局就能减少碎片化的磁盘空间并为后面的设计提供便利,可能导致期望的双峰分布,从而使我们以低成本获得高系统性能。除此以外,读的性能也能因为空间局部性的原因而有所提升。
Compaction Windows
- 为了进一步减少碎片,为每一层提出了 Compaction Window,一个 Compaction Window 就是由一组属于该 Level 的 Zones 组成的。构建该窗口的时候,以旋转的方式从属于该级别的区域中挑选一定数量的区域,每一层对应的窗口大小常常使用如下方式计算:即每一层的 1/K,因此随着容量的增大每一层的窗口也就相应地增大,默认的 K 为 4,需要注意的是,在我们的研究中,L0 和 L1 的窗口大小就为整个 Level 的大小,因为这两层不够占据一个 Zone。
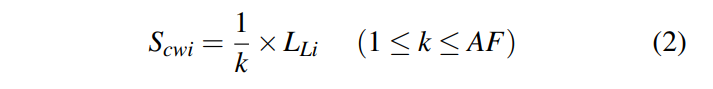
- 压缩窗口不是直接设计成用于提高系统性能,而是在压缩窗口中限制压缩过程,相应的碎片也就被限制在压缩窗口中而不是整个磁盘上进行分布。因为一个全是无效数据的 Zone 可以直接被置空然后进行重用,那么充满了无效 SSTables 数据的压缩窗口也就可以直接被释放从而让一组空的 Zone 直接服务于未来的写操作。当压缩窗口对应的 Zones 被释放,另外一组 Zones 被选出来形成新的压缩窗口,层内的不同区域旋转构成压缩窗口,保证各层均匀参与压缩。
- 如下所示为 Zone 的状态转换图:
-
- 一旦 writing zone 被写满了就成为了 Full Zone
- 2.3. writing zone 和 full zone 可以直接通过旋转被添加到压缩窗口中
-
- 当在压缩窗口中的所有 SSTables 经过 gear compaction 之后变为无效,则转换为 Empty
-
- 等待服务写请求,而不用触发设备级的垃圾回收
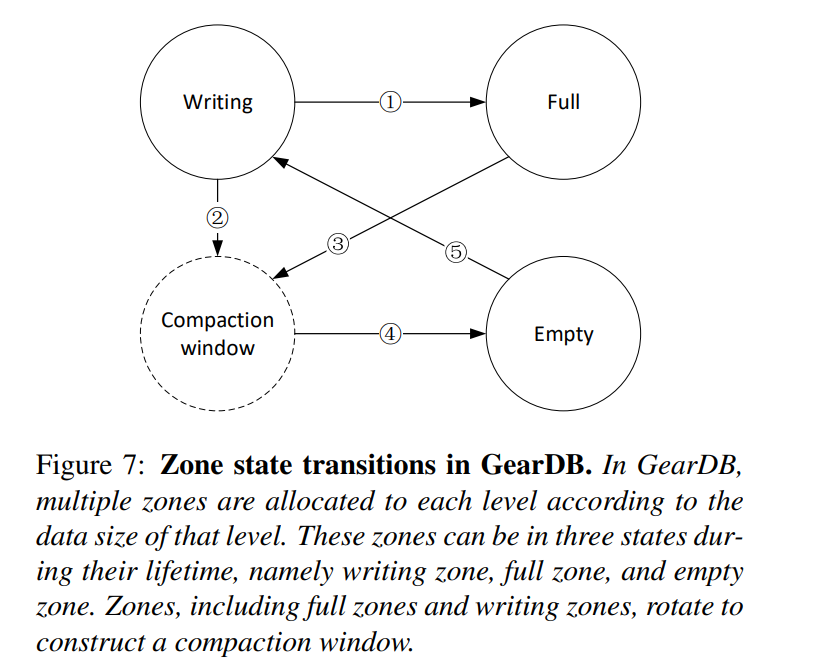
- 等待服务写请求,而不用触发设备级的垃圾回收
-
Gear Compaction
- 该算法首先压缩 L0 和 L1,称之为 Active Compaction,Active Compaction 触发连续的被动 Compaction,压缩从较低的级别进展到较高的级别。LevelDB 中两层压缩之后的结果将直接写入更大的一层,然而对于该算法而言,压缩后的数据会根据 Key 的范围被分成三个部分。假设压缩的层级是 和 ,将分成
- 压缩窗口以外的部分
- 键范围以外的部分
- 压缩窗口以内的部分
- 合并数据的这三个部分不会保存在内存中,而是分别
- 写到 ,
- dump 到 (能够减小写放大)
- 或者被处理成被动压缩(例如和 的 CW 中重叠的 SSTable 进行压缩)
- 为了避免数据直接被压缩到最高层,可以让 只有在 到达大小限制且 到达压缩窗口的大小的时候才加入 gear compaction。因为 GearDB 还保证了时间局部性,更新的数据仍然保留在更低的层次。
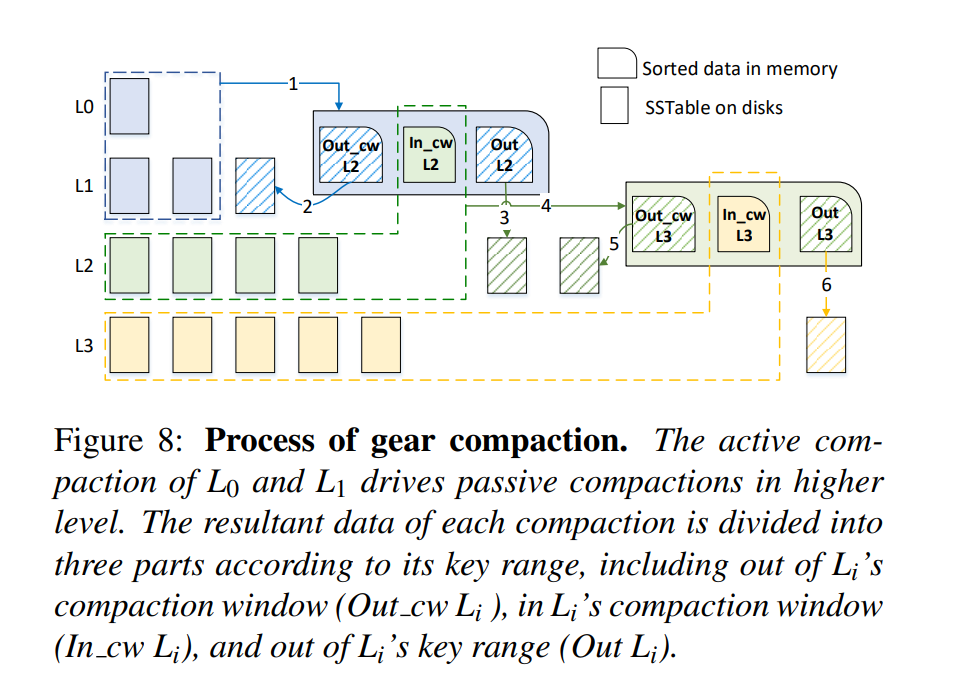
- 下图描述了整个过程:(该过程递归执行,一层一层地执行,直到最高层或者新生成的数据不再和下一层的压缩窗口重叠)
- Step1. 执行 和 的 active compaction,生成的数据分成三个部分
- Step2. 压缩窗口以外的部分写回
- Step3. 压缩窗口以内的部分 dump 到 ,避免后续的压缩引入的写放大
- Step4. 压缩窗口以外的部分保留在内存中以便于后续和 的压缩窗口一起进行压缩
- 该算法伪代码描述如下:

- 针对于根据键范围进行划分的操作进行了一定的优化,将每个级别划分为大粒度的键范围。具体而言,针对 CW 范围内和范围外的 SSTable 单独处理,如果 SSTables 之间的键范围差距不与该级别的其他 SSTables 重叠,我们将键范围合并成一个大的连续范围,因此,有序的数据只需要和该范围的最大最小值进行比较就能进行区分。
- 举例说明, 有两个 SSTables,键范围分别为 a-b,c-d,我们检查 中的其他 SSTables,看是否有和 b-c 范围重叠的,如果没有,那么就可以修正 的压缩窗口的范围为 a-d 从而减少键的比较。
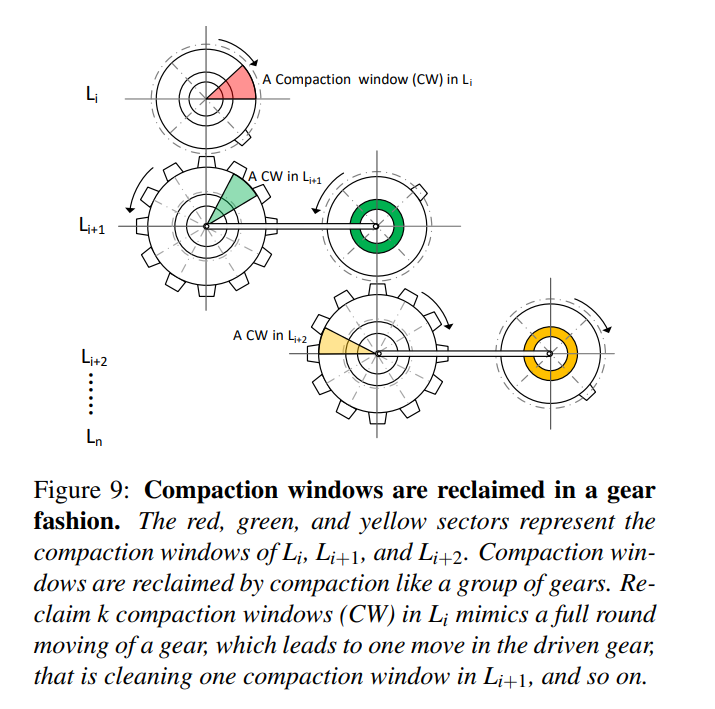
- 如何回收压缩窗口?当 CW 中的数据都无效时直接置空该 CW 就能进行垃圾回收,为了让 CW 为空, 层的 SSTables 中和 的 CW 具有重叠键范围的就必须进行 gear compaction。一旦所有的Li区域旋转地加入压缩窗口,我们在 Li 中得到这些 SSTable。当 的所有 CWs 被回收了, 才被回收,如下图所示。当 清理了 K 个 CWs, 才清理一个 CW。该过程意味着,释放 CWs 的机制就像齿轮一样。