- OSDI’22 ListDB: Union of Write-Ahead Logs and Persistent SkipLists for Incremental Checkpointing on Persistent Memory
OSDI’22 ListDB: Union of Write-Ahead Logs and Persistent SkipLists for Incremental Checkpointing on Persistent Memory
Abstract
- 由于 DRAM 和非易失性主存(NVMM)之间的延迟差异以及 DRAM 的有限容量,传入的写操作经常在基于 LSM 树的键值存储中停顿 stal。本文提出了一种为 NVMM 进行写优化的键值存储 ListDB,以克服 DRAM 和 NVMM 写延迟之间的差距,从而解决写停顿问题。L
- istDB 的贡献包括三种新的技术:
- (i) 字节寻址的 IndexUnified Logging,它增量地将预写日志转换为 SkipList;
- (ii) Braided SkipList,一个简单的 NUMA-aware SkipList,它有效地减少了 NVMM 的 NUMA 影响;
- (iii) Zipper Compaction,它不复制键值对象向下移动 LSM 树 levels,但是通过就地合并 SkipList 而不阻塞并发读取。
- 通过使用这三种技术,ListDB 使后台压缩足够快,足以解决臭名昭著的写停顿问题,并显示出比 PACTree 和 Intel Pmem-RocksDB 分别高 1.6 倍和 25 倍的写吞吐量。
Introduction
- NVM 延迟和 DRAM 相当,非易失,字节寻址,以内存总线速度来操作。
- NVM 中大数据集的定位和检索往往采用一个高效的持久化索引结构,并考虑 NVM 的器件特征。
- NVMM-only 的持久性索引:[11,13,24,35,45,49,56,63]
- VLDB’15 Persistent B+-Trees in Non-Volatile Main Memory
- ATC’20 Lock-free Concurrent Level Hashing for Persistent Memory
- FAST’18 Endurable Transient Inconsistency in Byte-Addressable Persistent B+-Tree
- aka. FAST and FAIR B+tree
- FAST’17 WORT: Write Optimal Radix Tree for Persistent Memory Storage Systems.
- FAST’19 Write-Optimized Dynamic Hashing for Persistent Memory.
- aka. CCEH
- SIGMOD’16 FPTree: A Hybrid SCM-DRAM Persistent and Concurrent B-Tree for Storage Class Memory
- FAST’11 Consistent and Durable Data Structures for Non-Volatile Byte-Addressable Memory.
- FAST’15 NV-Tree: Reducing Consistency Cost for NVM-based Single Level Systems.
- 混和 DRAM+NVM 持久性索引:[38, 40, 49, 63]
- VLDB’20 LB+Trees: Optimizing Persistent Index Performance on 3DXPoint Memory.
- VLDB’20 Dash: Scalable Hashing on Persistent Memory
- SIGMOD’16 FPTree: A Hybrid SCM-DRAM Persistent and Concurrent B-Tree for Storage Class Memory.
- FAST’15 NV-Tree: Reducing Consistency Const for NVM-based Single Level Systems.
- 还开发了一些使用这种持久索引和后台工作线程管理大型数据集的键值存储 [12, 29, 30, 57, 60]
- ASPLOS’20 FlatStore: An Efficient LogStructured Key-Value Storage Engine for Persistent Memory
- FAST’19 SLM-DB: SingleLevel Key-Value Store with Persistent Memory
- ATC’18 Redesigning LSMs for Nonvolatile Memory with NoveLSM
- OSDI’21 Nap: A Black-Box Approach to NUMA-Aware Persistent Memory Indexes
- ATC’17 HiKV: A Hybrid Index Key-Value Store for DRAMNVM Memory Systems
- NVMM-only 的持久性索引:[11,13,24,35,45,49,56,63]
- 针对 NVM 设计的索引结构,比如 FAST and FAIR, CCEH, PACTree,提供比基于磁盘的同类产品高数量级的性能。性能仍然低于 DRAM 索引。
- 因为 NVM 比 DRAM 性能要差,更高的延迟,更低的带宽,NUMA 效应更敏感,以及需要更大的数据访问粒度(256B XPLine).
- 混和 DRAM+NVM 索引以及键值存储,目的是为了发挥 DRAM 的优势,避免 NVM 的短板,所以把索引的复杂度给丢给了 DRAM。在这项工作中,我们质疑这种忽略字节寻址性、将整个索引保存在 DRAM 中、仅将 NVMM 用作日志空间的混合方法是否可取,因为它有两个主要限制:
- DRAM 容量比较小,如果数据集索引比较大,或者 DRAM 空间和其他进程共享,导致 DRAM 需要进行内存 Swapping,索引性能就会受到影响
- 易失的 DRAM 索引需要故障恢复之后重建,恢复时间很关键。周期性做 checkpoint 可以节省恢复时间,但是导致更高的写延迟,因为会阻塞并发写入
- 作者提出了一个异步增量 checkpoint 机制,后台合并小的、高性能的 DRAM 索引到一个持久性索引来加速数据恢复。ListDB 是一个写优化的 LSM 键值存储,实现了类似于 DRAM 索引的性能,并通过把 DRAM 索引刷回到 NVM 的方式来避免 DRAM 索引无限增长,同时实现了类似于 DRAM 索引的高性能。ListDB 缓冲了批量的插入到一个小的 DRAM 索引中,并运行后台压缩任务来增量地 Checkpointing 对于 NVMM 的缓冲写入,而不需要进行数据拷贝。ListDB 将日志条目重组为 SkipList,而不是将整个 volatile 索引刷新到 NVMM。同时,这样的 SkipLists 就地合并,减少了 NUMA 影响,而不会阻塞并发的读查询。
- 三个关键技术:
- 快速写缓冲刷回:ListDB 统一了 WAL 和跳表,使用 Index-Unified Logging (IUL),ListDB 只将每个键值对象作为日志条目写入 NVMM 一次。利用 NVMM 的字节可寻址性,IUL 以一种惰性的方式将日志条目转换为 SkipList 元素,这掩盖了日志记录和 MemTable flush 开销。因此,它使MemTable flush 吞吐量高于 DRAM 索引的写吞吐量,从而解决了写停顿问题。
- 减小 NUMA 效应:通过使上层指针只指向同一个 NUMA 节点上的 SkipList 元素,Braided SkipList 有效地减少了远程 NUMA 节点访问的数量
- 就地合并排序的快速 Compaction:Zippers Compaction 合并两个 Skiplist,不会阻塞读取操作。通过避免复制,Zipper Compaction 缓解了写放大的问题,并快速有效地减少 SkipLists 的数量,以提高读和恢复性能
- 我们的性能研究表明,ListDB 的写性能优于最先进的基于 NVMM 的键值存储。对于读性能,ListDB 依赖于经典的缓存技术。
Background and Motivation
Hybrid DRAM+NVMM Key-Value Store
- 基于 NVMM 的索引常常因为需要使用 memory fence 的相关指令来保证 cacheline 持久化,引入了较大的开销。为了避免这,NVTree 和 FPTree 在 DRAM 上存储内部节点,在 NVM 上存储叶子节点,内部节点在系统故障之后可以恢复出来,但是可以从持久的叶子节点中重建。基于此,对于内部节点的写入不需要保证 failure-atomic
- FlatStore 采用了一种相当激进的方法,即 NVMM 仅用作日志空间,其中键值对象以插入顺序而不是键顺序添加,而索引驻留在 DRAM 中。因此,FlatStore 必须在系统崩溃后从持久的日志条目重建一个不稳定的索引。为了减轻昂贵的恢复开销,FlatStore 建议定期在 NVMM 上 checkpoint DRAM索引。然而,一个简单的同步检查点(如FlatStore)在阻塞写入时获取全局快照,导致不可接受的高尾延迟。
LSM
- 更好的方法是异步增量 checkpoint,它只 checkpoints 当前检查点和最后一个检查点状态之间的差异。Log Structured Merge (LSM)树是一个经典的索引,它随着时间的推移合并检查点数据 [10, 17, 20, 33, 36, 48, 54].
基本操作
- 写过程不做介绍
- Compaction 不做介绍 [2, 9, 21, 29, 37, 41–43, 46, 53, 55]
- 读操作不做介绍,LSM 读比较慢,但是 LSM 比 B+tree 应用更广泛,因为读性能可以通过缓存很有效提升
Side Effect of Write Buffer: Write Stall
- 写 buffer 处理写入很快,但是在 LSM 里有一些人工调控限制了写 Buffer,导致很高的延迟。即 compaction 比较慢的时候会阻塞前台的 imm 刷回。相似的,如果 SST 没有很快被合并排序,重叠的 SST 也会增加,读性能下降。大部分 LSM 会阻塞客户端的写入,直到 compaction 完成以及有空间容纳新的 memtable。这就是写停顿,如果写停顿出现,这时候插入吞吐就受到持久存储性能的限制,而没法从 DRAM 中获益
写放大
多层和双层压缩
- 基于拷贝的 Compaction 允许并发的读查询访问旧的 SST,同时创建新的 SSTs。但是基于拷贝的 Compaction 要求重复拷贝相同的对象到新的 SSTs。一个键值对被拷贝到一个新文件的次数即为写放大,现有研究估计可能高达 40。如果使用 leveled compaction 的话,写放大会尤其严重,而且会有大量的 levels。因为 leveled compaction 限制了每层的 SSTables 数量,并且避免了单层里的数据重叠。
- 因为 NVM 字节寻址,因此可以考虑使用单层的持久化索引来替代多层 SSTs。SLM-DB 就使用了两层,一层 Memtable 和一个在 NVM 上的单层的 B+tree,使用两层设计,Memtable 缓冲了多个 KV 键值对然后插入到一个大的持久性索引,例如,对于多次写操作只遍历一次大型持久索引,并且它比单个持久索引产生更高的写吞吐量
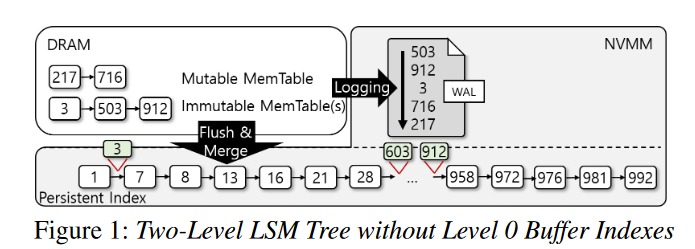
解耦归并排序和 Flush
- 双层设计的主要问题是持久性索引的大小影响合并易失索引到持久性索引的性能,也就无法让写性能独立于 NVMM 性能。因为 Memtable 不再是 flush 到底层,而是归并排序到大的慢的持久性索引。因为 NVMM 有更高的延迟,归并排序吞吐远低于易失索引的插入吞吐,特别是持久性索引比较大的时候
- 为了缓解这个问题,大多数键值存储采用了一个中间持久化 buffer level L0。即执行 flush 而不进行归并排序,下图展示了一个三层设计,通过分离归并排序和 flush,Memtable 可以刷回到 NVMM 更快,flush 的吞吐也就和数据库的大小独立开来
- 该设计的一个缺点就是导致了更多的重叠 SSTs,影响了查询性能。鉴于其较差的索引性能,中间持久缓冲区级别似乎与预写日志没有太大区别。另外,键值数据通常写到存储上至少两次,一次 WAL,一次 Memtable flush
- TRIAD, WiscKey, FlatStore 避免了重复写入。
- TRIAD 直接把 commit log 当作未排序的 L0 SST,为了高效检索 L0,TRIAD 为每个 L0 SST 维护了一个小的索引。索引不存储键值,只按键顺序存储每个对象的偏移。虽然 TRIAD 减少了 I/O,但每个 Memtable 刷回创建一个索引文件,然后调用开销较大的 fsync 来持久化。然而,考虑到 L0 SSTables 之间的高度重叠,以及 L0 SSTables 将很快合并到 L1 SSTables 的事实,是否应该以非常高的成本为每个 L0 SSTable 创建和持久化一个单独的索引文件是值得怀疑的
NUMA Effects
- 相比于 DRAM,NVM 因为其更低的带宽对 NUMA 效应更敏感。也就是因为这,CCEH, FAST and FAIR 这些索引的扩展性就比较一般,由于非常规的cacheline 访问和 NUMA 效应
- 有研究建议限制每个 Socket 的写线程为 4-6 个线程。
- SIGMOD’21 Maximizing Persistent Memory Bandwidth Utilization for OLAP Workloads.
- Nap 通过在 NVMM 常驻索引上覆盖一个 DRAM 索引来隐藏 NUMA 效果,这样 DRAM 索引就可以吸收远程 NUMA 节点访问。但是,存储在NVMM中的数据已经在内存地址空间中,而且 NVMM 的延迟与 DRAM 相当。因此,使用 DRAM 作为 NVMM 上的快速缓存层并在 DRAM 和 NVMM 之间来回复制数据可能会造成浪费。例如,EXT4-DAX 和 NOVA[61] 等 NVMM 文件系统不使用页面缓存,而是直接访问 NVMM
- 缓解 DRAM 上的 NUMA 效应有很多种方法,包括 基于哈希分片的 Delegation 和 Node Replication
- Delegation:指定的 worker 线程分配给一个具体的键范围,负责其所有操作。因此客户端线程需要和 worker 线程通信并使用消息传递来委派操作。因为消息传递的开销,Delegation 执行的性能不是最优的,特别是对于索引操作这样的轻量级任务 [4, 6, 7, 44]
- ATC’11 A Case for NUMAAware Contention Management on Multicore Systems.
- HotPar’13 Using Elimination and Delegation to Implement a Scalable NUMA-Friendly Stack
- ASPLOS’17 Black-Box Concurrent Data Structures for NUMA Architectures.
- PPoPP’12 CPHASH: A Cache-Partitioned Hash Table.
- Node Replication:实现了一个 NUMA 感知的共享日志,它用于对跨 NUMA 节点复制的数据结构重放相同的操作。但是,这将消耗内存来跨多个 NUMA 节点复制相同的数据结构。此外,由于 NUMA 节点数量增加,跨节点通信导致性能下降。考虑到 Optane DCPMM 的带宽远低于DRAM,复制会加剧低带宽问题
- ASPLOS’17 Black-Box Concurrent Data Structures for NUMA Architectures
- Delegation:指定的 worker 线程分配给一个具体的键范围,负责其所有操作。因此客户端线程需要和 worker 线程通信并使用消息传递来委派操作。因为消息传递的开销,Delegation 执行的性能不是最优的,特别是对于索引操作这样的轻量级任务 [4, 6, 7, 44]
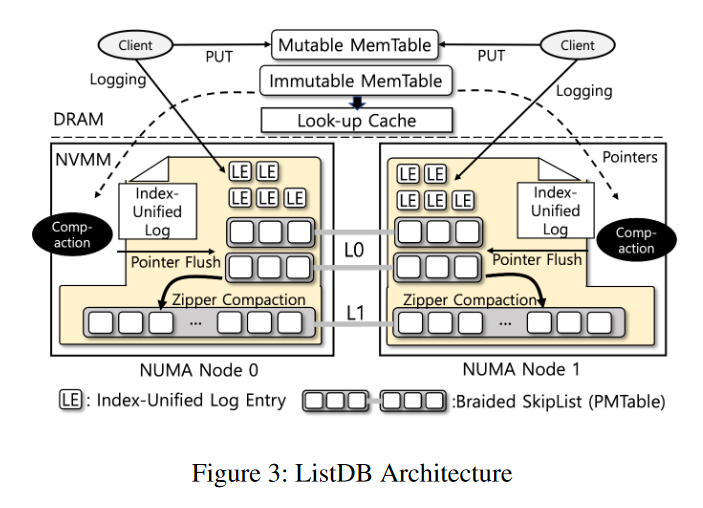
Design
Three-Level Architecture
- 三层:Memable,L0,L1 Persistent Memtables (PMTables)
- Memtable 和 PMTables 本质上是相同的跳表,但是 PMTable 有额外的元数据,因为是从 WAL 转换过来的
- ListDB使用 SkipList 作为所有级别的核心数据结构,因为它支持字节可寻址的就地合并排序,并避免了写放大问题[21,41,53]
- ListDB 在 NVMM 中使用一个中间持久缓冲区级别 L0 。对于 L0,MemTable 被 flush 到 NVMM 而不需要进行合并排序,这使得 flush 吞吐量与下一级持久索引大小无关。L0 积累的 MemTables (L0 PMTables)通过压缩逐渐合并到较大的 L1 PMTable 中。为了管理多个 PMTables, ListDB使用一个名为MANIFEST的元数据对象指向每个 SkipList 的开头。
Index-Unified Logging
- 目标就是将 Memtable 刷回到 NVMM 不需要拷贝简直对象
Conversion of IUL into SkipList
- Index-Unified Logging (IUL) 通过按照跳表元素的形式来分配和写入日志项,实现 WAL 和跳表的统一。图 4 展示了其中 Entry 的结构,同时作为日志项和跳表元素。当插入一个键值对到 Memtable,其对象和元数据(operation 以及 LSN)是已知的,对应的日志项被写入和持久化到 NVMM 上,对应的跳表指针初始化为 NULL。之后,一个 Compaction 线程把对应的 Memtable 刷回的时候,日志项被转换成跳表元素,重用日志项中对应的键值
- 但是跳表元素需要额外的信息,即键的顺序信息,该信息以跳表指针维护在 Memtable 中。当把日志转换成 PMTable 的时候,相应的 Memtable 元素的地址被简单的转换成 NVMM 的地址(通过偏移量转换)。跳表指针转换成 NVMM 地址之后,IUL 中的项也就变成了跳表元素
- 最后更新 MANIFEST 来让新的 L0 PMTable 生效,并让 Immutable Memtable 在一个 failure-atomic 事务中失效。
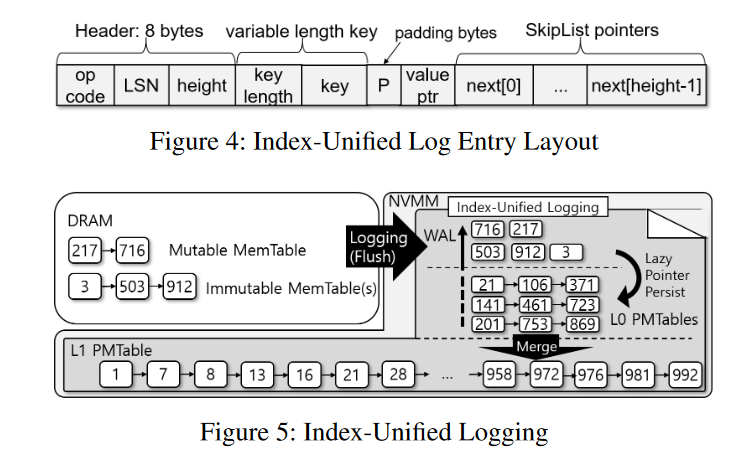
MemTable Flush without clflush
- 跳表指针写入到日志项时不需要 clflush,因为本身写入的只是顺序,不是数据,顺序完全可以恢复出来。
- 不需要显示 flush 也就是说利用 CPU 自己的缓存机制来管理数据的刷回,也就实现了对于相同 XPLine 的写入可以被缓冲,8B 小写也就不会转换成 256B 的 RMW,不仅延后了 RMW,也避免了后台 Compaction 线程受到 RMW 带来的延迟影响
Walk-Through Example
- 流程如上图 5 所示,假设插入的数据顺序为 503,921,3。每个客户端线程在它提交之前持久化对象、元数据和 NULL 指针到日志。然后后台线程标记 Memtable 为 immutable 并创建一个新的 Memtable。客户端线程再插入了 716 和 217。
- 后台 Compaction 线程刷回 Immutable Memtable,把相应的 Memtable 元素指针转换成 IUL 偏移量,然后替换掉对应的指针,从而成为跳表。
Checkpointing L0 PMTable
- 虽然日志条目现在被转换为 L0 PMTable 元素,但是日志空间和 L0 PMTable 空间之间的边界(如图6(a)中的粗虚线所示)没有移动,因为它不能保证新的 L0 PMTable 的指针是持久的。只有对更新的指针显示调用了 clflush 指令才会移动边界,在我们的实现中,后台线程批量地持久化 L0 PMTables 的脏cachelines。此操作称为 checkpointing。图6(b)显示了指针显式持久化后的NVMM布局。一旦PMTable被 checkpointing,就可以移动日志空间的边界以减少需要恢复的日志条目的数量,如图6(b)所示。
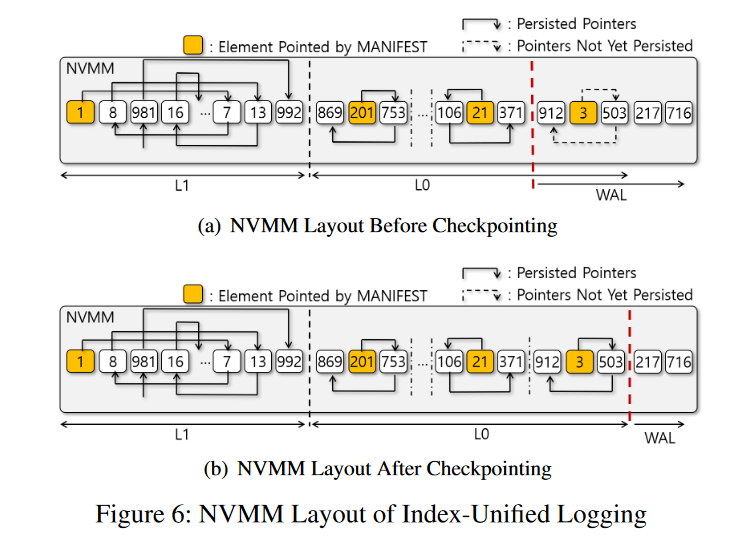
Lazy Group Checkpointing
- Checkpointing 目的是为了减少恢复时间。但是 ListDB 尽可能推迟 Checkpointing,因为调用 clflush 开销太大了,即便 L0 PMTables 没有被持久化,也不会影响崩溃一致性,因为会被当作日志来恢复。其顺序也可以重建
- 作者实现中,多个 L0 PMTables 被分组,脏的 cachelines 批量进行持久化。也就是所谓的 lazy group checkpointing。本身就是在日志大小、恢复时间以及 flush 吞吐量方面做妥协。checkpointing 越频繁,flush 越慢,日志大小越小,恢复越快。
- Zipper compaction 持久化指针很快,可以避免 L0 的表数量太多。即使 IUL 不持久化任何 L0 PMTable,当将 L0 PMTable 合并到 L1 PMTable 时,Zipper 压缩持久化指针的速度很快,而且 IUL 的恢复时间比同步检查点要短得多
NUMA Effects for SkipList
- ListDB 采用了 NUMA 感知的数据结构,与委托和节点复制相比,该结构在最小化 NUMA 互连争用方面更具可伸缩性和有效性
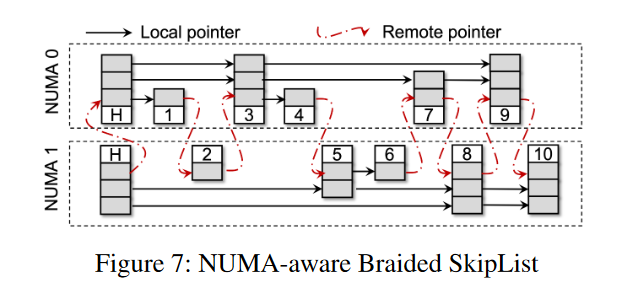
NUMA-aware Braided SkipList
- 跳表的一个特点:每一层的 list 必然是最底层 list 的有序子集。上层的指针是概率选择出来的,不影响查询的正确性。但是,上层不需要是下一层的子列表,只要是底层的子列表即可。即使搜索没有找到更接近上层搜索键的键,搜索也会回到更低的层,最终搜索到包含所有有序键的底层。
- Braided SkipList 就是利用这个特点来减小 NUMA 效应。上层指针忽略远程 NUMA 节点中的 SkipList 元素;例如,每个元素的上层指针指向同一个NUMA 节点中具有更大键的元素。与 NUMA-oblivious 传统的 SkipList 相比,Braided SkipList 把远程内存访问次数减少到 1/N,其中 N 是 NUMA 节点的数目
- 如下例子,为了便于显示,NUMA节点 1 中的上层颠倒了。
- NUMA 0 上的元素 3 指向了相同 NUMA 节点的元素 7,但是没有指向 NUMA 1 上的元素 5(原始的跳表就会指向 5)。
- 尽管如上维护指针,查询还是正确的。
- 比如在 NUMA 0 上的线程查询 5。首先找到 3 和 9,因为 9 更大,向下移动找到 3 和 7,继续下移,找到了 3 和 4。因为 5 大于 4,那么继续下移动,这时候检查 4 的下一个指针。也就找到了 NUMA 1 上的 5
- 在作者的 Braided SkipList 实现中,NUMA ID 被嵌入到 64 位虚拟地址的额外 16 位中,类似于 pointer swizzling 的操作,这样它就可以使用 8 字节的原子指令,而不是较重的 PMDK 事务。为了直接引用,Braided SkipList 通过 masking 额外的 16 位来恢复 SkipList 元素的虚拟内存地址。
Zipper Compaction
- Zipper Compaction 通过只修改指针来归并排序 L0 和 L1 的 PMTables,不会阻塞并发的读。就地归并排序避免了写放大,提升了 Compaction 吞吐
- 基于跳表的特性,部分研究提出了无锁的跳表。基于 Java 的 ConcurrentSkipListMap 在实践中表现良好。经典的无锁跳表避免对多个 Writers 加锁。相反,ListDB 不会并发写入。唯一的 writers 是 Compaction 线程,ListDB 会协调这些线程避免写写冲突。对于并行性,多个压缩线程写入不相交的分片。一个分片是 L1 PMTable 中一个高度最大的元素到下一个高度最大的元素之间的一个不相交的键范围。为了将 L0 元素合并到 L1 中,压缩线程必须获得对应分片上的锁。
- Zipper Compaction 分为两阶段:
- 从头到尾的 scan
- 从尾到头的 merge
- 为了保证正确的搜索结果而不阻塞并发读,L0 PMTable 元素由尾到头被合并到 L1 PMTable 中,同时并发读取操作从头到尾遍历它们。
Scan Phase
- 在前向扫描阶段,压缩线程从头到尾遍历 L0 和 L1 PMTable,并确定每个 L0 PMTable 元素应该插入 L1 PMTable 中的什么位置。但是,在这个阶段,它不会对 PMTables 进行任何更改,而是将必要的指针更新推送到堆栈上。后向合并阶段弹出堆栈以应用并持久化 L1 PMTable 中的更新。
- 扫描阶段沿着 L0 PMTable 的底层。对于每个 L0 元素,它会搜索 L1 PMTable,以找到插入 L0 元素的位置。为此,它跟踪每层中小于当前搜索键 (L0元素) 的最右边的元素,以避免重复遍历 L1 PMTable。因为两个 PMTable 中的键都是排序的,所以 L0 PMTable 中的下一个较大的键可以重用前面最右边的元素,并回溯到最右边的最顶层元素进行下一次搜索。因此,扫描阶段的复杂度为 O(n0 + logn1),其中 n0 和 n1 分别为 L0 和 L1 PMTables 的大小。
- 对于支持 NUMA 的 Braided SkipList, Zipper 压缩需要一个最右的二维数组 [numa_id][layer] 来保持每一层中最右的元素数量与 Braided SkipList 的 NUMA 节点数量相同。但是,请注意,Braided SkipList 元素不需要比传统的 SkipList 元素更多的指针,因为它在 8 字节地址中嵌入了 NUMA 节点 ID。
- 下图 a 展示了一个例子:假设所有跳表元素都在一个 NUMA 节点
- L0 的元素 A 需要放置到 L1 的第一个位置。因此 L1 头结点的 H0 和 H1 就是当前最右的指针,需要为 A 的合并来更新。压栈
- A0 和 A1 需要指向 B。但是该信息没有压栈 ,因为 B 是由当前已经压入堆栈的最右边的元素(L1.H0, L1.H1)指向的。每个 L0 元素被插入到两个 L1 元素之间,每层中只有前一个(即最右边的)元素需要被推入堆栈,因为从前一个元素中可以找到下一个元素。
- 接下来,扫描阶段访问 L0 中的第二个元素D,并搜索L1。插入D需要更新B2、C1和C0。同样,它们被压入堆栈。
- 最后,它访问L0中的最后一个元素E,并搜索L1。注意L1 PMTable没有改变,当前最右边的指针仍然是B2、C1和C0。因此,扫描阶段将C1和C0推入堆栈,使它们指向E。
- L0 的元素 A 需要放置到 L1 的第一个位置。因此 L1 头结点的 H0 和 H1 就是当前最右的指针,需要为 A 的合并来更新。压栈
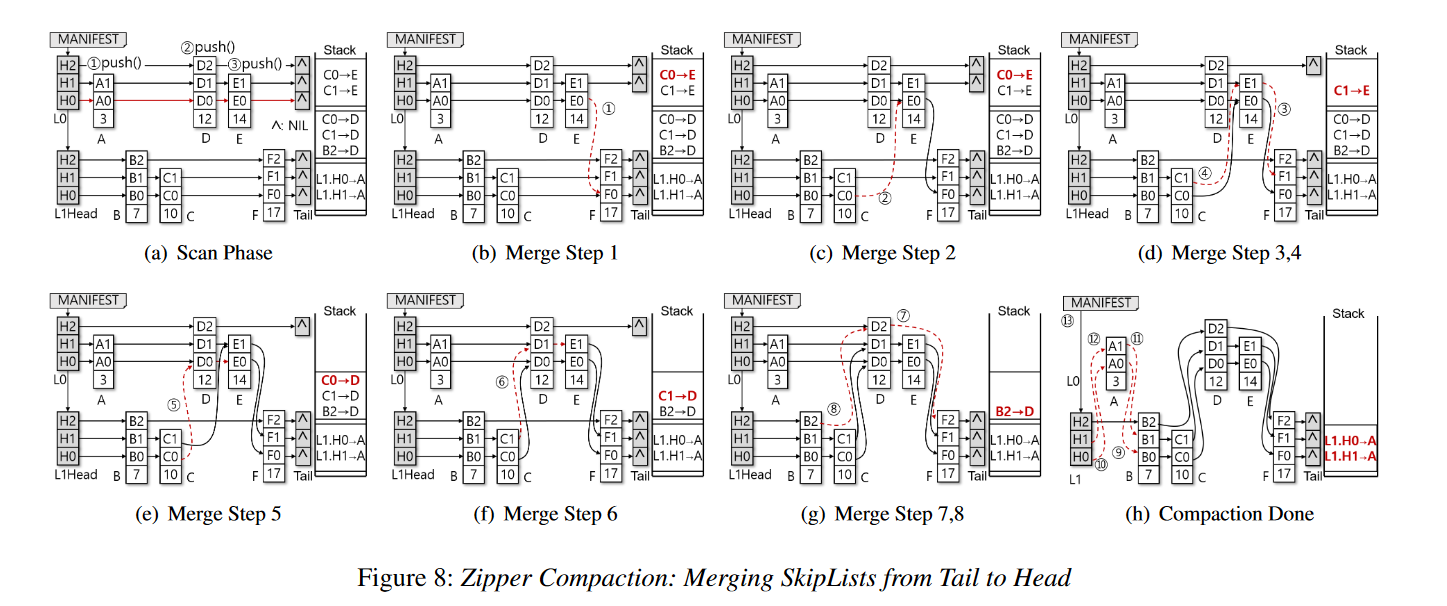
Merge Phase
- 合并阶段将指针更新从尾部应用到头部。当压缩线程从栈中弹出一个更新 → 的指针时,将 Y 元素中的第 N 层指针更新为 的当前值,然后将 设置为 Y 的地址。
- 如上图所示:
- Compaction 线程出栈 C0→E
- 图8b,因为 C0 当前指向了 F0,所以合并的时候就需要把 E0 指向 F0。但是 E1 这时候没有指向,但无伤大雅,不影响查询的正确性。
- 图8c,把 C0 指向 E0,好结束
- 出栈 C1→E
- 图 8d,设置 E1 指向原来 C1 指向的位置 F1,然后让 C1 指向 E1
- 后续操作同理
- Compaction 线程出栈 C0→E
- Zipper 压缩假定 8 字节指针更新是原子的。为了保证指针更新 failure-atomic,它使用内存 fence 和 cacheline 刷新指令立即持久化每个底层更新。在最后一步中,压缩线程从 MANIFEST 对象中删除 L0 PMTable 的头元素,从而完成压缩。
Lock-Free Search
- Zipper 压缩不会违反并发搜索的正确性,也就是说,一个读线程不会在不获取锁的情况下错过它的目标 SkipList 元素。这是因为读线程从头到尾、从L0到L1访问PMTables,而压缩线程则从尾到头合并它们。在 Zipper 压缩期间,每个元素都保证是指向至少一个 head(即肯定是能追溯到的)。考虑图 8 所示的示例,它显示了一个原子存储指令序列如何合并两个示例 skiplist。即使并发读线程以图 8 所示的任何状态访问 PMTables,它也会返回正确的结果。
- 即使在压缩线程修改 SkipLists 的过程中读取线程挂起,该算法仍然是正确的。例如,假设读取在访问 L0 元素时挂起。当它恢复时,元素可能已经合并到 L1 中。当读线程醒来时,如果没有找到搜索键,它将继续遍历到尾部。一旦到达尾部,它就结束了 L0,并开始搜索 L1,L0 的元素已经合并到 L1 中。因此,读线程可能会多次访问相同的元素,但它永远不会错过它正在搜索的元素。多次访问可能会影响搜索性能。为了避免这种情况,如果读操作检测到当前元素的级别是 L1,它将停止搜索 L0。
Updates and Deletes
- LSM 树中的更新会重复相同的键,因为写操作会缓冲到 MemTables 中,并逐渐刷新到最后一层。ListDB 不会主动删除 L1 中的旧版本。相反,当压缩线程扫描 L0 和 L1 级别以进行 Zipper 压缩时,它将标记 L1 中的旧版本过时。类似地,ListDB 中的删除并不会物理地删除对象,而是将一个 key-delete 对象插入到 MemTable 中。如果 LSM 树从 MemTables 或 L0 PMTables 中物理删除密钥的最新版本,则旧版本的密钥将恢复使用。Zipper 压缩将较新的键值或键删除对象放在其对应的旧对象之前。因此,读查询总是在旧对象之前访问最近的对象,从而返回正确的搜索结果。
Fragmentation and Garbage Collection
- 通过使用 libpmemobj库,ListDB为PMDK的故障原子事务中的多个 IUL 条目分配和释放一个内存块(例如,8 MB),从而可以减少对昂贵的PMDK事务的调用数量。如果一个内存块中的所有元素都被标记为过时或删除,则 ListDB 将释放该内存块。注意,ListDB 不会重新定位 SkipList 元素以进行垃圾收集。为了解决持久的碎片问题,压缩线程可以执行基于 CoW 的垃圾收集。作者把这个优化留给以后的工作。
- 无锁数据结构的内存管理是一个困难的问题,因为没有简单的方法来检测被释放的内存空间是否仍然被并发读取访问。ListDB 使用简单的基于 epoch 的回收;ListDB 不会立即释放内存块,但会等待足够长的时间,让短期的读查询完成对释放内存块的访问。如果内存块中的所有对象都被废弃或删除,后台垃圾收集线程会定期检查并回收内存块。对于过时的对象,垃圾收集线程检查其新版本的 LSN。如果它也足够老,它认为过时的对象没有被任何读取访问,从 L1 PMTable 中删除它们,并物理地释放内存块。
Look-up Cache
- ListDB 要求读查询至少访问两个索引,即一个可变的 MemTable 和 L1 PMTable。因此,ListDB 的读吞吐量明显低于高度优化的持久 B+ 树。
- ListDB 引入了查询缓存,Flush MemTable 将每个元素散列到一个固定大小的静态散列表中。与基于磁盘的设计不同,查找缓存不会复制其中的元素,而只存储它的 NVMM 地址,因为 NVMM 中的元素已经在内存地址空间中,而且它的地址永远不会改变。因此,无论 PMTable 元素出现在哪个级别,查找缓存都可以定位到 PMTable 元素。ListDB 中的压缩线程经常更新 SkipList 指针,但是通过缓存不可变的地址,而不是可变的内容,查找缓存可以避免频繁的缓存失效。如果一个桶发生哈希冲突,旧的地址将被覆盖(即FIFO替换策略)。
- ListDB 在 DRAM 中构造一个SkipList,作为从哈希表中移除的高元素的二级查找缓存。第二级查找缓存的目的是加速 PMTable 搜索。即使在第二级查找缓存中没有找到一个键,查询也可以从缓存中找到的最近的 PMTable 元素开始搜索。假设读操作查找键 100,但是发现元素 85 是 L1 中最近的更小的元素。然后,从 L1 PMTable 中的 85 号元素继续搜索,而不是 L1 的开头。ListDB 不使用第二级查找缓存进行 L0 搜索,因为小的 L0 PMTables 很快被合并到 L1 中,L0元素大部分缓存在查找哈希表中,第二级查找缓存使用 SIZE 替换策略[58],即比较高度并剔除高度较短的元素。
Recovery
- 当 L0 和 L1 PMTables 被 Zipper 压缩合并时,系统可能会崩溃。为了从这样的故障中恢复,压缩线程执行微日志记录来跟踪哪个 L0 PMTable 被合并到L1 PMTable中。当系统重新启动时,ListDB 检查压缩日志以重做未完成的压缩。对于重做操作,由于 L0 PMTable 尾部的许多条目可以与 L1 PMTable 共享,因此 Zipper compaction 需要检查重复的条目。
- ListDB的恢复算法,与传统LSM树的恢复算法类似。首先,恢复进程定位WAL的边界,该边界由压缩线程记录在压缩日志中。然后,它对日志条目进行排序并恢复L0 PMTables。此时,系统返回到正常执行模式并开始处理客户端查询。L0和L1之间的压缩将在后台正常进行。
- 对于查找缓存,ListDB 可以在不恢复缓存的情况下处理客户端查询,尽管在填充缓存之前搜索性能会很差。通过避免 DRAM 缓存和索引的重构,ListDB的恢复性能优于同步检查点
Evaluation
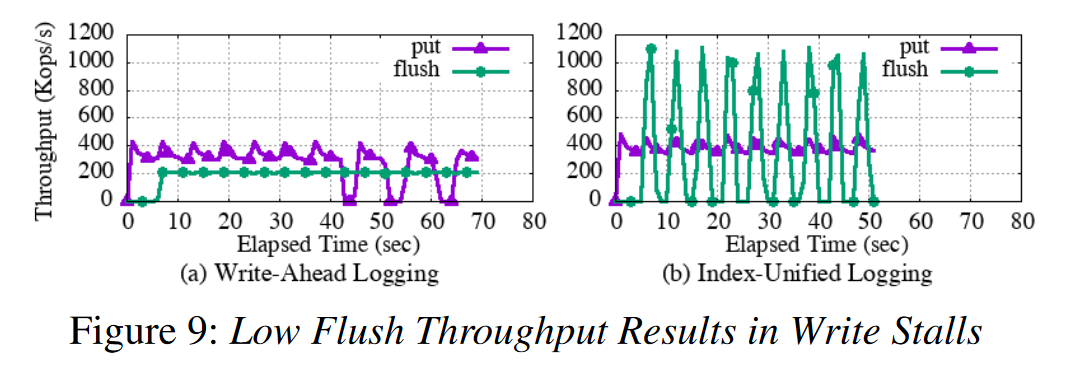
测试 Index-Unified Logging
flush and put
- 关闭 Zipper Compaction,WAL 中 put 比 WAL 好因为内存写入比 内存拷贝到 NVMM 更快,put 的性能抖动尖刺代表的就是新的空的 Memtable 创建储来,5s 填充一个 Memtable,40s 达到 Memtable 的阈值限制,阻塞后续写。如果提高阈值,stall 也只是时间长短的问题,因为 flush 比写慢。
- IUL 的 flush 比 写快,但是 flush 波动,每个 flush 花的时间比 put 少,但是 compaction 线程可能挂起空闲了,所以波动。flush 吞吐高因为 IUL 不从 DRAM 拷贝数据到 NVM,不调用 cacheline flush 指令,因此,写入停顿不会发生,压缩线程通常会变得空闲,从而允许 CPU 执行其他工作。
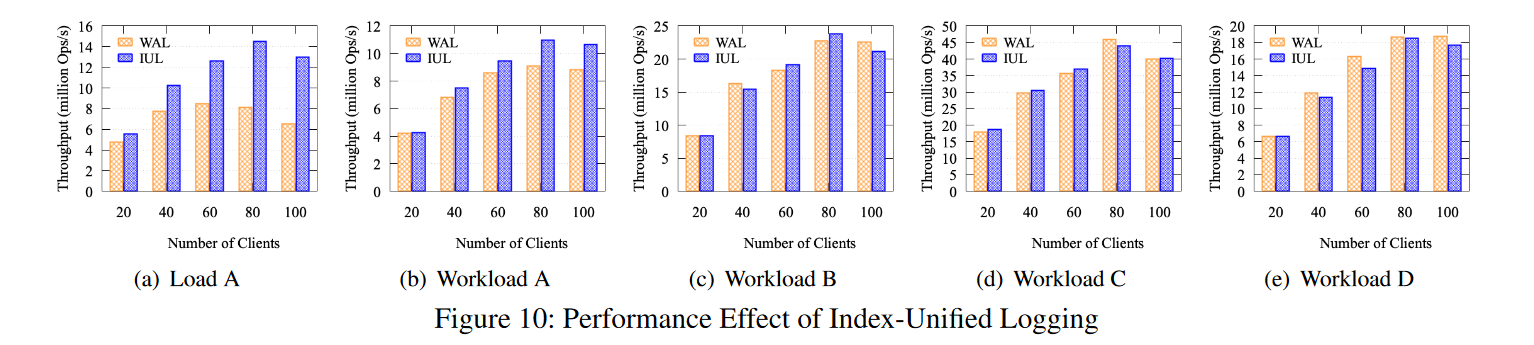
YCSB
- 不同线程,后台 Compaction 线程设置为前台客户端现成的一半,开启了 Zipper Compaction。
- 80线程之前,两种 log 方式性能都有提升,但是,当客户机线程的数量超过逻辑核心的数量时,由于过高的超额使用速率,吞吐量会下降。也就是说,100 个客户机线程和 50 个后台压缩线程竞争 80 个逻辑核。然而,IUL 的吞吐量比WAL高 99%。
- YCSB-B C D 两种方式性能差不多,有时候甚至WAL更好,因为WAL执行copy-on-write 操作以按键升序存储记录,而读操作得益于比 IUL 更高的内存访问局部性。但在工作负载 A (50:50 Read:Write) 中,IUL 的写性能优于 WAL。
测试 Braided SkipList
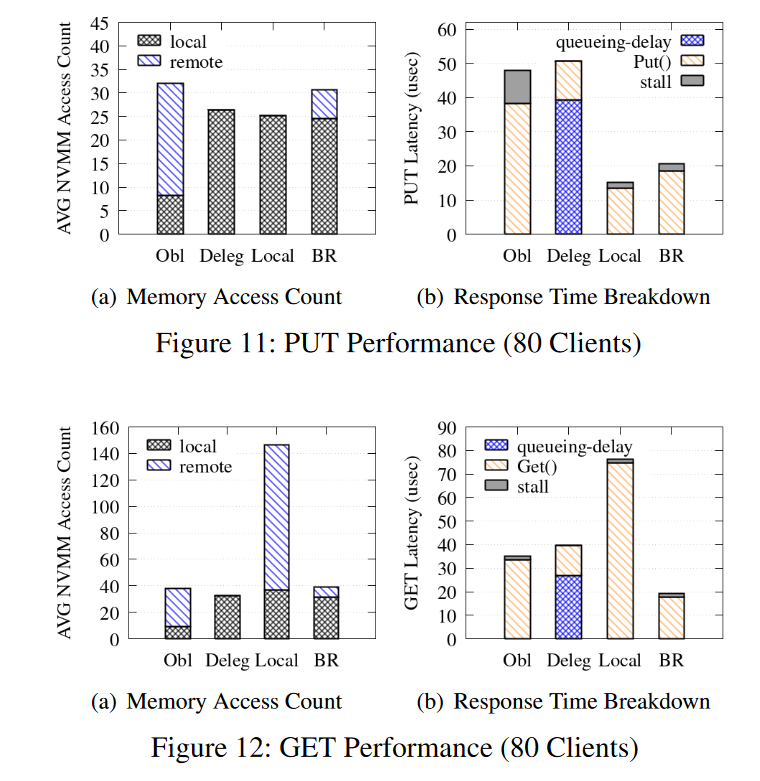
- 对比 不考虑 NUMA 的 Obl, Delegating 方案 Deleg,写优化的本地跳表 Local。
- BR 和 Obl 管理一个大的 PMTable,而 Deleg 和 Local 创建四个小的PMTable。根据散列键删除分区键值记录,但是 Local 允许写客户端在其本地 NUMA节点上插入数据到 SkipList,而不考虑键。因此,一个读查询必须搜索所有四个 skiplist。即使在本地索引中找到了一个键,它也必须搜索远程索引,因为远程索引可能有最近的更新。因此,当有 n 个NUMA节点时,本地访问的比例始终为 1/n。
- 写操作 Local 最好,因为总是写入到本地跳表,几乎消除了远程 NUMA 访问。BR 差一点,因为访问到底层的数据指针的时候需要访问远端节点,Deleg也完全删除了远程NVMM访问,但是由于委托开销,写响应时间要高得多。也就是说,线程使用缓慢的原子指令来访问共享队列,并为查询和结果复制内存。图11(b)显示,队列延迟占80个客户机线程的查询响应时间的77.1%。因为在无锁索引上的 put/get 操作是非常轻量级的,委托引起的同步开销占据了总体响应时间。
- 读操作:图12(a)显示BR对于读查询的响应时间比其他方法要低。虽然Local在写方面优于BR,但Local的读响应时间大约是BR的4倍,因为Local必须搜索所有4个pmtable。尽管BR避免了访问跟随远程元素的更有效的搜索路径,但图11(a)和12(a)表明它对遍历长度几乎没有影响。Deleg显示最少的内存访问。但是由于同步开销,它的查询响应时间比BR高出约2倍,性能甚至低于Obl。
整个系统测试
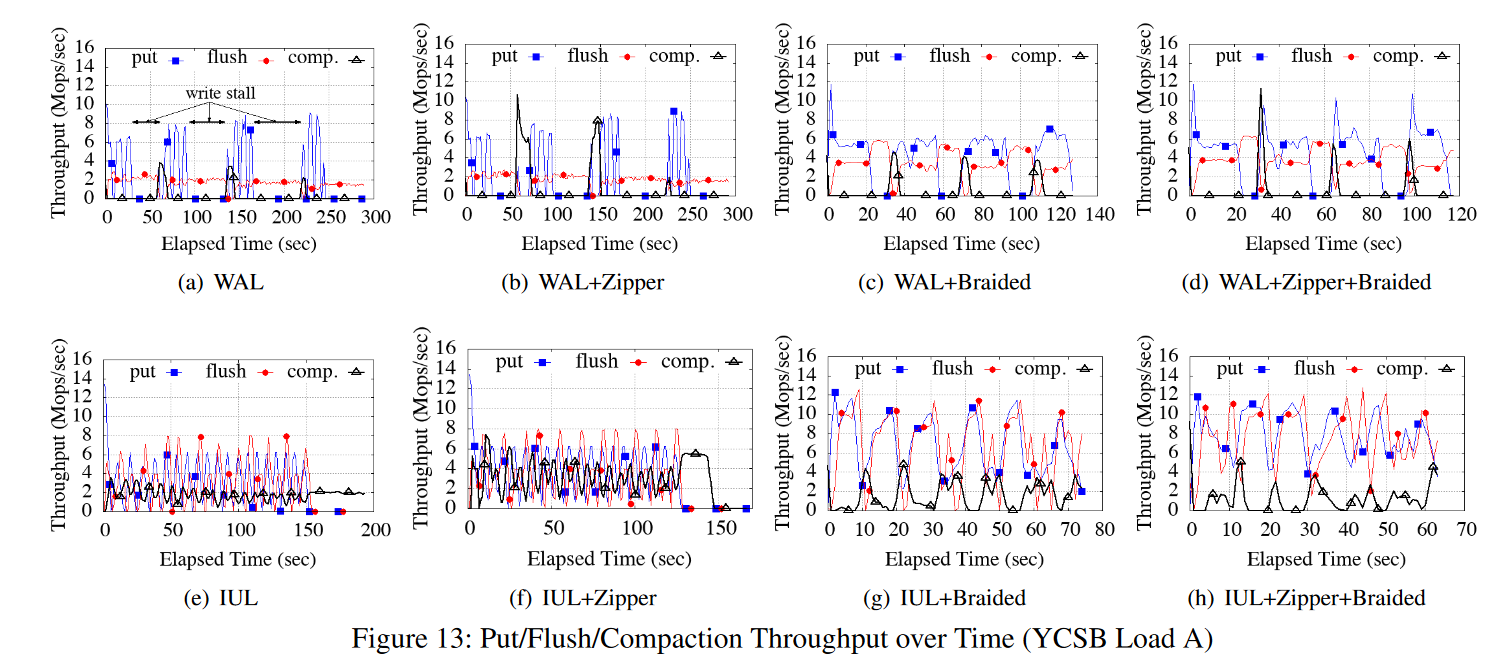
- 图13给出了ListDB的因子分析。我们启用和禁用ListDB的每个设计特性,并随着时间的推移测量写吞吐量(表示为put)、刷新吞吐量(MemTable L0 → PMTable,表示为 flush)和Compaction吞吐量(L0→L1 PMTable,表示comp)。我们为YCSB Load A运行了80个客户机线程和40个后台压缩线程,插入5亿个8字节的键和8字节的值。
- 图13(a)显示禁用所有三种优化会导致客户端线程暂停超过50秒。如图13(b)所示,启用Zipper压缩可以提高 L0→L1压缩吞吐量,但是由于刷新MemTable的内存拷贝开销,仍然会出现写停顿问题。如果使用了Braided SkipList,则可以避免在刷新MemTable时访问远程NUMA节点。因此,刷新吞吐量增加了一倍,从而降低了写停顿的频率,如图13(c)所示。同时启用Zipper压缩和Braided SkipList可以缩短写暂停时间,工作负载在120秒内完成(图13(d))
- 如果使用IUL而不是WAL,则刷新吞吐量与 PUT 吞吐量相当,如图13(e)所示。通过避免昂贵的内存拷贝,写停顿的频率比WAL要低。但是,请注意,压缩吞吐量比刷新吞吐量低得多。这会增加L0 PMTables的数量,降低搜索性能。如图13(f)所示,如果另外启用了IUL和Zipper压缩,那么NVMM带宽会通过减少内存副本的数量来提高。因此,它提高了压缩和刷新吞吐量。如图13(g)所示,启用IUL和Braided SkipList可以避免NUMA效应,从而提高压缩和刷新吞吐量。最后,启用所有三个优化后,工作负载在65秒内完成,几乎没有写入停顿(图13(h)),而图13(a)中的时间为300秒。
故障恢复
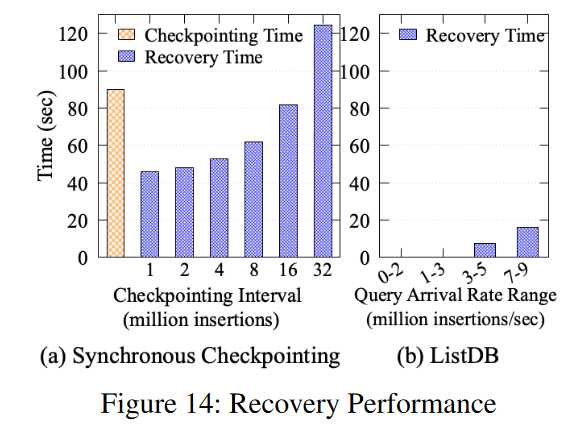
- 我们评估了针对ListDB的异步增量检查点和周期性同步检查点的恢复性能。使用Facebook基准测试,我们用1亿个对象填充数据库,并使用检查点和提前写日志条目测量恢复的时间。尽管使用相同的工作负载,同步检查点的恢复性能受检查点间隔的影响,而异步检查点只受查询到达率的影响。这是因为日志条目的数量随异步检查点而变化,而后台压缩线程还没有合并到 L1中。如果查询到达率高于 Zipper 压缩吞吐量,IUL 条目的数量会增加,恢复过程必须创建一个更大的 L0 PMTable,其中包含更多的日志条目。
- 图14显示了一个同步检查点使用Boost库中的 binary_oarchive 类序列化和刷新内存中的B+树大约需要90秒。这将导致并发查询在检查点执行期间阻塞90秒,导致不可接受的高尾延迟。为了缓解这个问题,可以降低检查点的执行频率,但是随着日志条目的增加,恢复时间会增加(即,恢复检查点索引并向其插入日志条目的时间)。
- 相反,图14 (b)显示,如果写查询到达率低于300万次/秒,ListDB就会立即恢复。如果查询到达率在700万到900万插入/秒之间变化,ListDB需要大约19秒来恢复。查询到达率越高,ListDB的恢复时间就越长。
对比其他设计
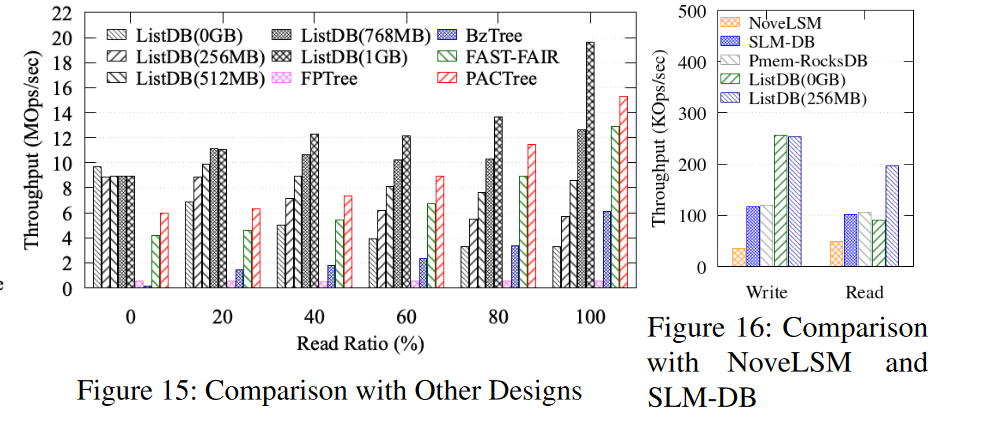
- 图15所示的实验比较了ListDB与最先进的持久索引的性能;即BzTree [1], FP-tree [49], FAST and FAIR B+tree[24],和PACTree[32],我们在一个双套接字机器上运行实验,因为PACTree是硬编码的两个套接字。采用Intel Xeon Gold 5215处理器(共40个逻辑核)、128gb DRAM (8 * 16GB)、1tb DCPMM (8 * 128gb)。数据库预加载了1亿条键值记录,然后40个客户端提交1000万个查询,这些查询具有不同的读写比率,分布均匀(由YCSB Workload A生成)。这些树结构索引没有针对(或不支持)大的可变长度字符串键和值进行优化。因此,我们为工作负载生成了8字节的数字键和8字节的指针值,这有利于具有较大扇出的树结构索引。
- 图 15 显示,对于写密集型工作负载,ListDB的性能优于树状结构的持久索引。对于只写工作负载,ListDB(0GB)的吞吐量分别比BzTree、FPTree、FAST和FAIR B+tree和PACTree高79倍、17倍、2.3倍和1.6倍。但是,对于只读工作负载,树结构索引受益于更快的搜索性能。特别是,FAST和FAIR B+树和PACTree显示的搜索吞吐量分别比ListDB(0GB)高3.88倍和4.61倍。在启用了查找缓存后,ListDB的性能优于树状结构的索引。图键中圆括号中的数字显示了查找缓存的大小。如果查找缓存大于768 MB, ListDB的性能优于PACTree,除非读比率高于80%。
- 这些结果证实了标准缓存技术可以很容易地提高读取性能。但是,索引键值记录位置的查找缓存不能用于PACTree、FAST FAIR B+tree、FPTree等,因为它们经常会因为树的再平衡操作而将键值记录重新定位到不同的树节点上。也就是说,为树状结构的持久索引使用DRAM缓存不像我们的仅地址查找缓存那么简单。例如,Nap[57]具有非常复杂的缓存机制。
- 虽然LSM树比树结构索引有更好的写性能,但它们有更高的写放大,这是块设备存储的一个关键限制[21,41,53]。为了比较写入放大,我们使用Intel PMwatch[25]来测量在图15所示的实验中访问的总字节数。所有的索引方法都存在写放大的问题。DCPMM的内部写合并缓冲区将一个小的写操作(8字节的键和8字节的值)转换为256字节的读-修改-写操作,导致至少16倍的写放大。在ListDB中,L0和L1 PMTables中的归并排序操作进一步放大了写操作。然而,ListDB(104.4)的写扩增比FAST和FAIR B+tree(126.789)低,与PACTree(91.5)相当,因为ListDB会对SkipLists进行合并排序。
- 图16显示了NoveLSM、SLM-DB、Pmem-RocksDB和ListDB的单线程读写吞吐量。这些实验运行一个单客户机线程(db_bench, 1亿个随机的8字节键和1 KB值),因为当多个线程并发访问数据库时,NoveLSM会崩溃。NoveLSM和SLM-DB被设计成使用NVMM作为块设备文件系统之上的中间层,但是我们的实验将所有sstable存储在使用EXT4-DAX格式化的NVMM中,以便进行公平的比较。
- NoveLSM表现出最差的性能,不是因为它的设计,而是因为它是在LevelDB之上实现的,众所周知,LevelDB的性能很差。SLM-DB也是在LevelDB之上实现的,但是性能更好,因为它使用FAST和FAIR B+树作为核心索引。由于SLM-DB还没有移植到使用PMDK,所以它没有运行时刷新或事务更新带来的开销,也就是说,它显示DRAM性能,并且不会在系统崩溃时存活下来。尽管如此,SLM-DB的性能并不比完全持久的键值存储Pmem-RocksDB更好。与Pmem-RocksDB相比,ListDB(0GB)的写吞吐量是Pmem-RocksDB的两倍,但读性能略差,除非启用了查找缓存。这是因为Pmem-RocksDB得益于内存位置,它以有序的顺序连续地将键存储在NVMM中,而ListDB不重新定位数据
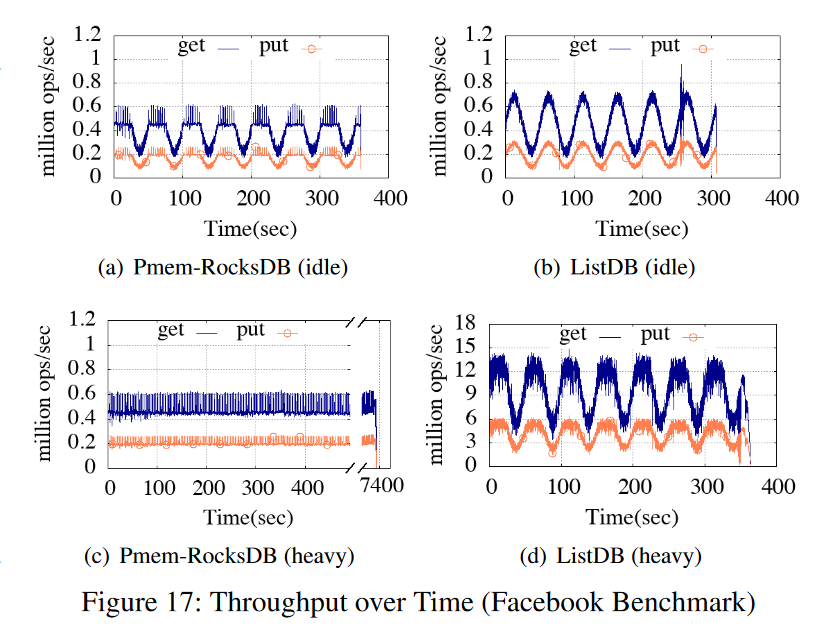
- 最后,我们在Facebook基准测试中使用Prefix Dist工作负载,比较ListDB和Intel的Pmem-RocksDB的性能。图17所示的实验运行了80个客户机线程,并使用基准的默认键和值大小(48字节字符串键和16字节到10 KB不等的可变长度值)。工作负载根据查询到达率(QPS参数)提交查询,该查询到达率遵循噪声因子为0.5的正弦分布。工作负载的put/get比率为3比7。
- 最后,我们在Facebook基准测试中使用Prefix Dist工作负载,比较ListDB和Intel的Pmem-RocksDB的性能。图17所示的实验运行了80个客户机线程,并使用基准的默认键和值大小(48字节字符串键和16字节到10 KB不等的可变长度值)。工作负载根据查询到达率(QPS参数)提交查询,该查询到达率遵循噪声因子为0.5的正弦分布。工作负载的put/get比率为3比7。
- 对于空闲工作负载,Pmem-RocksDB受到过多NVMM写入的影响,因此它的put吞吐量在200 Kops时饱和。对于Facebook基准测试,get查询必须等待它的前一个put查询提交。因此,实验中Pmem-RocksDB的get吞吐量在400 Kops处饱和。相反,图17(b)显示ListDB的吞吐量遵循正弦分布,即查询到达率,没有阻塞查询。
- 对于高负载,Pmem-RocksDB的吞吐量仍然处于饱和状态。另一方面,ListDB的put吞吐量比Pmem-RocksDB高25倍,即500万次。同样,ListDB的get吞吐量比Pmem-RocksDB高22倍(即1300万vs 60万)。因此,ListDB完成工作负载的速度比Pmem-RocksDB快19.4倍(即380比7400秒)。
Conclusion
- 在这项工作中,我们设计并实现了ListDB——一个利用字节寻址的键值存储,通过就地重构数据来避免数据复制,以及NVMM的高性能来减少写放大和避免写停滞。我们展示了ListDB通过异步增量检查点和就地压缩显著提高了写性能。通过它的三层结构,ListDB在写吞吐量方面优于最先进的持久索引和基于nvmm的键值存储。标准的查找缓存可以帮助缓解具有多个级别的问题。在未来的工作中,我们正在探索通过引入另一个层次,即L2 PMTable来提高搜索性能的可能性,以机会主义地重新排列L1 PMTable元素,用于空间局部性和垃圾收集
