- NSDI 2020 的文章 FileMR: Rethinking RDMA Networking for Scalable Persistent Memory
- 这篇论文主要结合了 RDMA 和 NVM,针对各自的特性进行了整合重组,修改相应的协议实现
Abstract
- 问题:NVM 和 RDMA 看起来天作之合。大容量持久性内存 + 远程内存访问。但实际上现有的 NVMM-aware 的文件系统使用文件来管理 NVM,RDMA 而是以 Memory Regions 的形式进行组织访问。因此要想构建 可使用 RDMA 访问的 NVMM 则需要实现代价较高的转换层,代价高是因为会有大量重复的工作需要做,从权限、到命名,再到地址转换。
- 贡献:在现有的 RDMA 协议基础上引入了两个变化:FileMR (file memory region) 和 range-based address translation。这两个优化点将内存区域和文件结合起来实现了内存抽象,即一个客户端可以通过 RDMA 直接访问一个由 NVMM 作为后端存储设备支持的文件,通过文件偏移进行内容寻址。通过消除重复的地址转换,减小了在网卡上完成的地址转换的数量,减小了网卡中的地址转换缓存的负载,提升了命中率约 3.8x - 340x,应用性能相应提升了 1.8x - 2.0x
Introduction
- 可伸缩计算机系统存储和访问数据的方式近年来变化迅速,而这些变化的部分原因是传统独立的系统组件之间的界限越来越模糊。NVM 模糊了内存和存储之间的界限,RDMA 模糊了本地和远端内存之间的界限。NVM+RDMA 仿佛组合起来就能整合内存、存储、网络来提供一个大规模的稳定的字节寻址的网络直连的内存。不幸的是,用于管理这些技术的现有系统同时存在重叠和不兼容的情况。
- NVMMs 合并内存和存储。该技术允许应用程序使用 load/store 指令访问持久数据,避免了传统存储系统使用的基于块的接口。而 NVMM 通常被一个基于 NVMM 的文件系统来管理,文件系统来负责对存储设备的访问,应用只需要使用文件系统的相关接口即可。应用程序可以将一个文件映射到它们的地址空间,然后使用 load 和 store 指令访问它,这大大减少了访问持久性数据的延迟。
- RDMA 合并了本地和远端的内存。RDMA 允许客户端直接访问远程服务器上的内存。一旦远程服务器决定允许传入访问,它将其地址空间的一部分注册为 RDMA 内存区域,并向客户机发送访问该区域的密钥。使用密钥,客户端可以利用服务器的 RDMA 网络接口(RNIC) 绕过 CPU 直接读写服务器的内存。RDMA之所以流行,是因为它将大部分网络栈转移到硬件上,并提供了接近硬件的抽象,与 TCP/IP 协议相比,它表现出更好的延迟。
- 基于 NVM 的文件系统和 RDMA 在设计之初没有考虑过两者的结合,所有如果将他们直接结合起来就会出现很多重复的工作。虽然只有 RDMA 提供网络数据传输和只有 NVMM 文件系统提供持久内存元数据,但两个系统都实现了保护、地址转换、命名和跨不同内存抽象的分配,RDMA 基于 Memory Region,NVMM Filesystem 基于 File。天真地同时使用RDMA 和 NVMM 文件系统会导致重复工作和它们抽象之间的低效转换层。这些转换层代价极高,特别是因为 RNIC 只能为有限的内存提供转换,而 NVM 的容量可以非常大。
- 所以我们提出了 FileMR,通过实现新的内存区域类型,它将 RDMA 需要的大多数与内存管理相关的任务卸载到 NVM 文件系统,从而实现这一目标;文件系统从而有效地成为 RDMA 的控制平面。FileMR 直接以文件代替 RDMA 访问过程中的 Memory Region,读写直接通过文件系统被定向到文件,并使用文件偏移来进行寻址。文件偏移和物理内存地址之间的转换则还是由 NVMM 文件系统来保证。对文件的访问还是由 NVM 文件系统来管理,使用原生的 ACL 来实现访问保护。为了进一步优化地址转换,我们将基于范围的转换系统集成到 RNIC 中,该系统使用地址范围(而不是页面 pages)进行转换,从而减少了地址转换所需的空间 space,并解决了 RDMA 和 NVMM 文件系统之间的内存抽象不匹配问题。
- 该方案相比于原生的 RDMA+NVMM 的组合,带来了以下好处:
- NIC 上完成的地址转换数量降低,从而减轻了 NIC 的地址转换缓存的负载,提升缓存命中率 3.8x - 340x
- 使用现有的文件系统 ACL 机制来替代了 RDMA 的 ad-hoc memory keys,从而简化了内存保护机制
- 通过使用持久性的文件代替了短暂的内存区域 IDs,从而简化了连接的管理
- 允许在不撤消权限或关闭连接的情况下移动或扩展网络可访问内存,从而使文件系统能够整理碎片并向文件追加内容。
RDMA Networking
- RDMA 硬件支持一组操作,如单边原语 read/write,无需远程 CPU 的参与就可直接访问远端内存,事实上是完全绕过了远端 CPU。还有双边原语,要求两台机器发起匹配的请求,比如 send/receive,通过本地发送方和接收方应用程序选择的地址在已注册的缓冲区之间传输数据。
- 为了建立 RDMA 连接,应用程序注册一个或多个内存区域(MRs),授权本地 RNIC 访问本地地址空间的,MR 既是一个命名空间又是一个安全域:为了让客户访问一个区域,本地 RNIC 提供 MR 的虚拟地址、内存大小和一个特殊的 32 位 “rkey”。Rkeys 在任何单边原语发送过程中就被发送,并允许接收端 RNIC 验证客户端是否有直接访问该区域的权限。对于双边原语,send/recv 操作要求发送方和接收方都发布匹配的请求,每个请求都附加到某个本地的、预先注册的内存区域,从而消除对 rkey 的需求。
- 为了管理未完成的请求,RDMA 使用来自虚拟接口体系结构(VIA)的工作队列,应用在建立连接之后,可以通过本地 RNIC 发布工作队列项 WQEs 来初始化一个 RDMA 原语。这些项被写入到一组队列中,也就是所谓的 QP,一个 Queue 用于 send/write 请求,一个 Queue 用于 read/receive 请求。一旦 WQE 被写到 QP 中,RNIC 将执行 RDMA 原语并访问远程机器。一旦原语完成,RNIC 将通过放置一个 completion 标志在 completion queue (CQ) 中来确认原语成功处理。应用程序可以从完成队列轮询完成,以接收谓词成功完成的通知。
参考链接
NVM
- NVMM 是持久性的存储介质,需要管理软件提供 naming, allocation 以及 protection 等功能,NVMM 通常由文件系统来管理,但和之前基于较慢的块设备构建的文件系统有一些不一样,支持 NVMM 的文件系统在提供高效的 NVMM 访问过程中扮演了重要的角色,接近 DRAM 延迟的 NVMM 意味着软件开销将显著影响整体的性能,因此支持 NVMM 的文件系统在关键路径上尽可能减小软件开销的方式大致有两种:
- 支持直接访问 mmap() (DAX-mmap)功能。DAX-mmap 允许应用将 NVMM 文件直接映射到他们自己的地址空间,并通过简单的 load/stores 指令来执行数据的访问。该模式允许应用对于大多数数据访问可以直接绕过内核和文件系统,显著提高了文件访问的性能。
- NVMM 驻留在内存层次结构中,这可能会导致并发症,因为缓存不是持久的,但可以保存应用程序希望持久保存的数据。为了让数据持久化,对 NVMM 的缓存写操作之后必须执行缓存行刷新或清理指令,以确保实际将数据写回 NVMM,而 ntstore 操作可以完全绕过 CPU 缓存。store fence 可以强制保证执行写操作的顺序,并保证数据在断电时仍然有效。
Managing RDMA and NVMM
- 用户空间 RDMA 访问和 NVMM mmapped-DAX 访问共享一个关键功能:它们允许直接访问内存,而不涉及内核。一般来说,我们可以将 NVMM 文件系统和 RDMA 划分为访问内存的数据平面和管理向用户应用程序公开的内存的控制平面。两者的数据平面实际上是相同的:它由直接的对内存的 load 和 store 组成。相比之下,不同系统之间的控制平面差别很大。
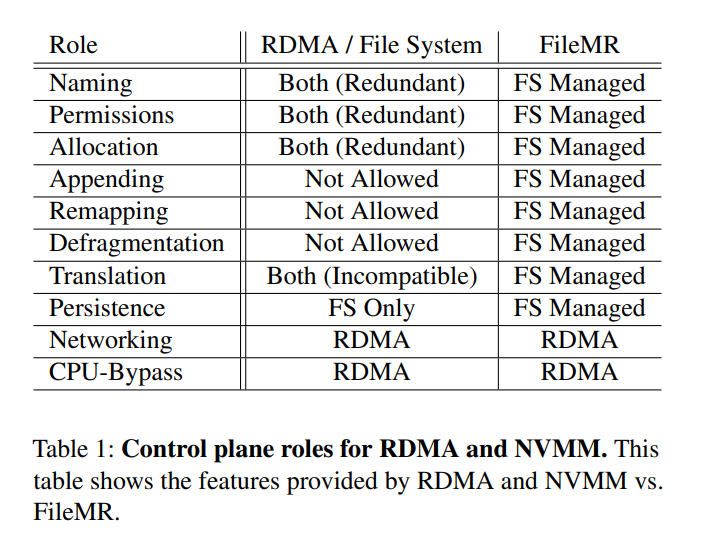
- 对于 RDMA 和 NVMM 文件系统,控制平面必须为内存管理提供四种服务。
- naming: 确保应用程序能够找到要直接访问的适当内存区域
- access control: 阻止应用程序访问它不应该访问的数据
- allocation: 提供一种机制来分配和释放资源,扩大或缩小为应用程序可用内存
- translation: 必须在应用程序级名称(例如,虚拟地址,或内存和文件偏移量)与物理内存地址之间进行转换.意味着 RDMA 和 NVMM 文件系统必须与虚拟内存子系统紧密合作
- 下表展示了 RDMA 和 NVMM Filesystem 已经提供的功能,总结了控制平面需要支持的元数据操作。但是内存管理功能被关联到了 RDMA 和 NVMM FS 不同的内存抽象上,RDMA 使用了 Memory Region 或者 Memory Windows,而 NVMM FS 使用了文件。
Naming
- Naming 提供了一种独立于硬件的方式来引用物理内存,在 RDMA 应用中,memory region 的虚拟地址是和其主机地址一起的,如 IP or GID,从而作为一个全局的有意义的物理内存区域的命名。这些命名的生命周期是短暂的,因为当创建该命名的应用退出的时候命名也就失效了;命名同时也不够灵活,因为它们防止 RDMA 公开的页面在可访问时更改其虚拟地址到物理地址的映射。为了与希望通过读和写直接访问名称的客户机共享 Naming,主机提供 MR 的元数据,对于双边原语(例如,发送/接收),Naming 是特别的:接收方必须使用带外通道来决定将接收到的数据放在哪里。
- 基于 NVMM 的文件系统使用文件名来命名主机上的内存区域,由于文件的寿命比应用程序长,因此文件系统独立于应用程序管理命名,并为命名内存区域提供更复杂的管理(例如分层目录和基于文本的名称)。为了访问一个文件,客户端和应用必须通过文件来访问
Permission
- 权限决定哪个进程有权限访问哪一块内存。在 RDMA 中,RDMA上下文是隔离的,权限通过两种方式执行:
- 为了授予客户端对内存位置的直接读/写访问权,主机共享内存区域特定的 “rkey”。rkey 是一个和所有的单边原语关联的 32 位的 key,会被 RNIC 验证是否有权限访问对应地址的内存区域。对于每一个注册了的区域,RNIC 驱动都会维护一个 rkey,和其他 RDMA 元数据一起在 DRAM 的硬件可访问数据结构中提供隔离和保护。
- 当两个节点之间建立起了 RDMA 连接的时候,Permissions 也被建立,由应用程序代码在建立连接的时候授权,权限不会比进程的寿命长,如果系统重启也会丢失。保护双边原语是由接收应用程序以一种特别的方式执行:接收方使用一个带外信道来决定发送方有哪些权限。
- NVMM 的访问控制使用传统的文件系统设计,权限被关联到每一个文件,并针对每个用户或者用户组单独设计。与 RDMA 内存区域和它们的 rkey 不同,权限是底层数据的一个属性,并且在进程和系统重启后仍然存在。
- 文件系统主要使用了 Permission Bits 和 Access Control Lists 来进行访问控制。延伸阅读 Series Three of Basic of Persistence - Files and Directories
Allocation
- RDMA 原语和 NVMM 文件都直接访问内存,所以可用内存的分配和扩充对于两者都是一个重要的元数据操作。
- NVMM 文件系统中维护了一个空闲物理页的列表,可以用于创建或者扩展文件。文件的创建涉及到编组适当的资源,并将新页面链接到现有的文件层次结构中,类似地,可以将空闲页面链接到现有文件或将其与现有文件分离,以扩大或缩小文件。通过调用 fallocate 和 mremap,也可以很容易地更改 DAX-mmap 文件的大小。
- 创建一个新的 RDMA 内存区域包括分配所需的内存资源、固定它们的页面和生成 rkey。需要注意的是尽管许多 RNICs 可以处理物理地址,但是内存区域的物理地址经常不受程序员控制(关键取决于 malloc 的实现方式),页面一旦被固定到了注册的区域,就将导致物理地址空间的碎片。
- 除此之外,改变内存区域的映射开销很大。例如,为了提升内存区域的大小,主机端的服务器通常需要先解除内存区域的注册,然后重新注册一个更大的区域,再将相应的变化发送给客户端。
rereg_mr原语包括了解除注册和重新注册的步骤,但是仍然会有很大的开销。带公共内存池的 MPI 应用使用了内存窗口在内存区域的上层来提供动态的访问控制。这种方法不能与 NVMM 文件系统混合使用,因为它仍然需要底层内存区域的静态映射。 - 程序员也可以把其他内存与添加到当前连接或者保护域中,由于内存区域需要不可忽略的元数据,并且 RDMA 不支持多区域访问,因此这种解决方案显著增加了复杂性。
- 这种固定的大小限制还阻碍了常见的文件系统操作和优化,例如附加到文件、重新映射文件内容和碎片整理
Address Translation
- 如下图所示,RDMA 通过将虚拟地址固定到物理地址来解决地址转换的问题,也就是说,只要注册了一个内存区域,它的虚拟地址和物理地址就不能改变。一旦这个映射被固定,RNIC 就能够直接处理在虚拟地址范围上注册的内存区域:RNIC 为传入的 RDMA 原语从虚拟地址转换为物理地址。为了完成这个转换,NIC 维护了一个内存转换表 memory
translation table(MTT),它保存了系统页表的一部分。 - MTT 将 RDMA 可访问的页面相关的地址转换条目扁平化,且可以缓存在 RNIC 的板载 SRAM 来加速这个映射的查找。pin-down 缓存对于 RDMA 获得良好性能至关重要,该缓存通常很小,几个 MB,如果缓存不命中开销将会很大,因为其对应的地址转换机制,大多数 RNICs 要求一个 region 的所有页都得是相同的大小,为了回避这些限制,研究者们做了大量的工作试图尽可能地利用缓存来寻址大内存。尽管存在复杂的解决方案,但最常见的建议是减少所需的地址转换数量,例如使用大页面或物理地址来寻址大型连续内存区域来减少地址转换的次数。
- NVMM 文件系统处理地址转换有两种方式,都和 RDMA 有所不同。
- 对于常规的读和写操作,文件系统使用偏移量来将文件名转换成物理地址,地址转换在内核中由系统调用完成。
- 对于映射内存的访问,mmap 从用户空间直接向 NVMM 上的文件内容建立了虚拟到物理地址的映射。只有在用户和物理地址之间缺少转换时,文件系统才会发起缺页中断,在正常的数据访问中,文件系统被绕过。
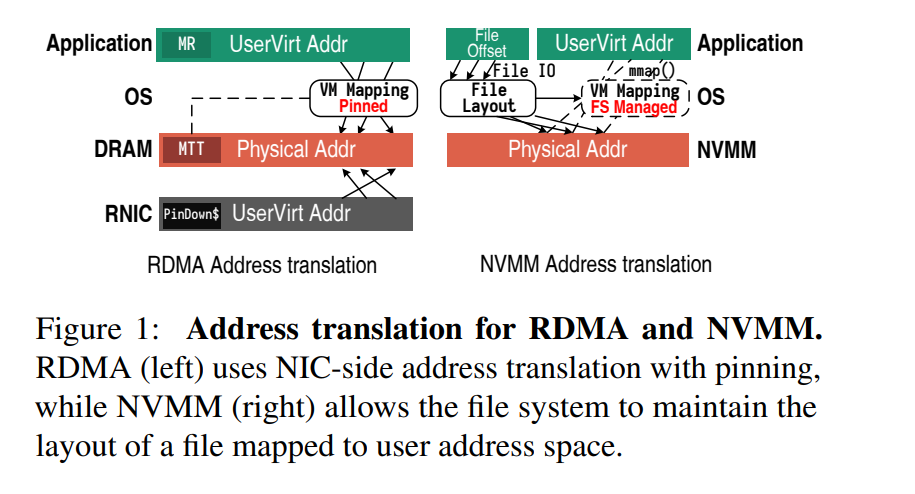
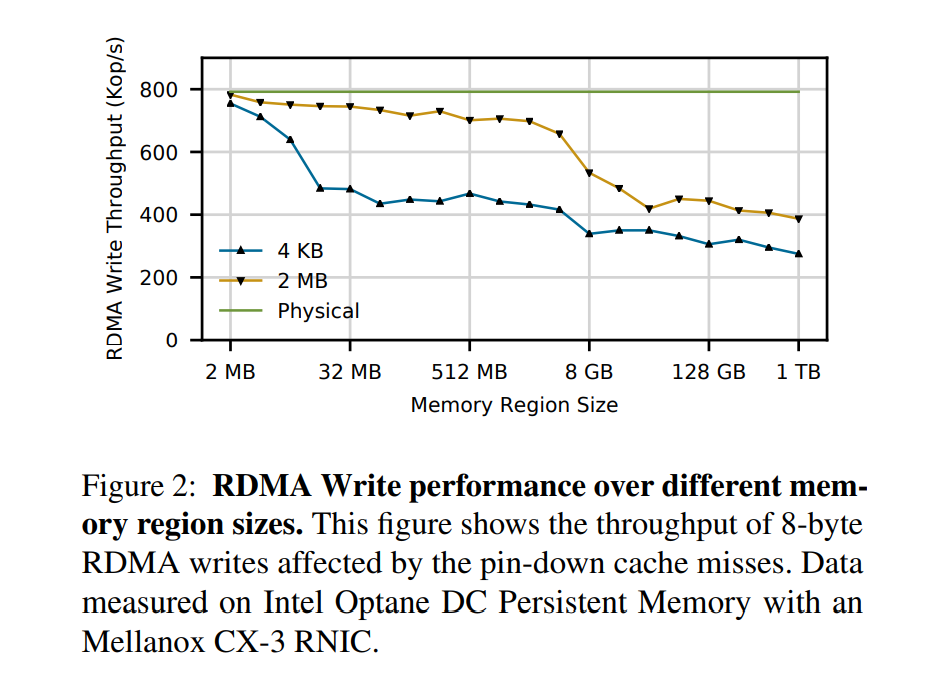
- 不同的转换方案相互干扰,从而产生性能问题。如果一个页通过 RDMA 访问,那么该页将被固定到了一个特定的物理地址,除此以外,内存区域内的每个页的大小还必须相同,因此文件系统不能更新打开的了的文件的数据布局(譬如对文件进行碎片整理或扩容)。 由于 RDMA 阻碍文件的碎片整理,并且禁止在 RDMA 可访问内存中混合页面大小(使用不同的页面大小),由文件支持的内存区域必须使用许多小页面来寻址较大的区域,撑满了 pin-down 缓存并削弱了 RDMA 性能。
- 下图展示了 pin-down cache 不命中对 RDMA 写吞吐量的影响。每个工作请求向随机的 8 字节对齐偏移量写入 8 字节。当内存区域大小为 16 MB 时,使用 4kB 可以达到基准性能的 61.1%(发送物理地址、没有 TLB 或 pin-down cache 缓存丢失),而使用 2 MB 的大页面时有95.2%。当区域大小达到 16 GB 时,即使是 2 MB 的页面也不够——只能达到 61.2% 的性能。
Design
- FileMR 是一种扩展了 RDMA 协议的内存区域新类型,提供针对 NVMM 的基于文件的内存抽象。它需要对现有的 RDMA 协议进行较小的更改,并且不依赖于任何特定的文件系统设计,FileMR 可以与传统的 RDMA 内存区域共存,确保向后兼容性。
- FileMR 通过一些创新解决了 RDMA 和 NVMM 文件系统之间的冲突,这些冲突会导致不必要的限制和性能下降。
- Merged control plane:客户端使用文件偏移来寻址内存,代替虚拟或物理地址,FileMR 还利用文件系统的命名、寻址和权限来流水线化 RDMA 访问。
- Range-based address translation:FileMR 利用文件系统的高效、基于区段的布局描述机制来减少 NIC 需要保留的状态数量。由于文件已经被组织成连续的区段,我们将这种寻址机制扩展到 RNIC,允许 RNIC 的 pin-down 缓存使用空间高效转换方案来寻址大量的 RDMA 可访问内存
Assumptions and Definitions
- FileMR 作为跨用户空间应用程序、系统软件和 RDMA 网络堆栈的高效和协调的内存管理层。本文假设 NVMM 是由系统软件主动管理的,我们将其描述为一个文件系统。注意,文件系统的概念是松散定义的:FileMR 可以与内核文件系统、用户空间文件系统或用户空间访问原始 NVMM(也称为device-DAX)并提供命名的 NVMM 库集成,其中文件映射到对应的实体。
- 本文假设 NVMM 在其整个生命周期中映射到应用程序地址空间:NVMM 最突出的特点是以非常低的成本获得细粒度的持久性。FileMR 的设计目标是支持远程 NVMM 访问,同时保持本地 NVMM 访问的简单性和效率。另一种方法是构建管理这两种存储的整体系统 (NVMM) 和网络 (RDMA)
FileMR
- 新的内存抽象 FileMR 既是一个 RDMA 内存区域,又是一个 NVMM 文件,这允许 RDMA 和 NVMM 控制平面以实现顺畅的交互操作。对FileMR 的 RDMA 访问是通过文件偏移来寻址的,文件系统管理底层文件的访问权限、命名和分配,就像管理任何文件一样。NVMM 文件始终由文件系统管理的物理页面支持,因此,在使用 FileMR 时,RDMA 子系统可以简单地重用文件系统元数据中已经可用的转换、权限和命名信息,以便进行适当的检查和寻址。
- 如下图所示描述了 FileMR 中的元数据和数据访问。
- 对于元数据,初始化内存区域的流程如下
- step1. 在创建 FileMR 之前,应用带着对应的权限去打开对应的后端文件
- step2. 应用创建 FileMR (File Memory Region)
- step3. 将对应的 region 绑定到文件上,将 FileMR 绑定到文件会产生一个类似于 rkey 的 filekey,远程客户端可以使用它来访问 FileMR
- step4. 创建了 FileMR 并将其绑定到后端文件之后,文件系统将使文件的寻址信息与 RNIC 保持同步
- 对于数据:对于远程 FileMR 及其后端 NVMM 文件的数据访问,应用程序使用 FileMR (带有 filekey 来证明其权限)和文件偏移量来访问,RNIC 使用由文件系统提供的地址转换信息来在文件偏移和物理内存之间转换。除了对 FileMR 的 read/write 单边原语以外,引入了一个新的单边原语 append,来增大对应的内存区域。当发送一个 append 原语的时候,客户端不包含远程地址,服务端处理该原语类似于处理对地址等于当前 FileMR 大小的写原语,然后更新 FileMR 的大小并通知文件系统。一个优化点,为了防止在每个 append 消息上出错,文件系统可以预先分配超出文件大小的地址转换项,即使在通过 FileMR 打开并访问后端我文件时,本地应用程序仍然可以使用普通的文件系统调用或映射的地址继续访问它,对文件元数据的任何更改都将传播到 RNIC。
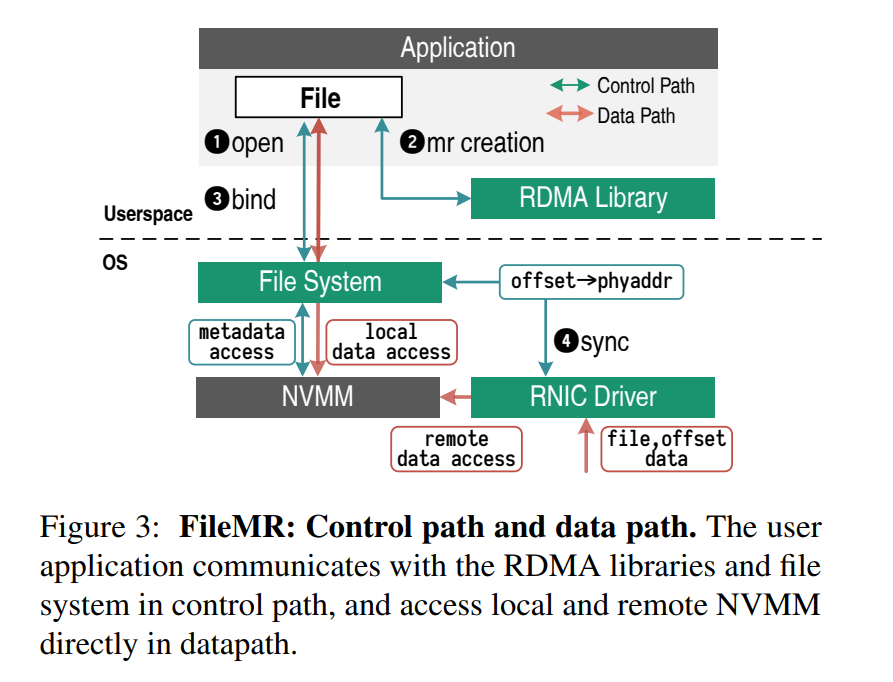
- 对于元数据,初始化内存区域的流程如下
Range-based Address Translation
- NVMM 文件系统尝试在 NVMM 中以大的线性区段存储文件数据。FileMR 在 MTT 和 pin-down cache 中分别使用基于范围的地址转换 RangeMTT, range pin-down cache。这一变化与传统 RDMA 基于页的寻址方式有很大的不同。基于页面的转换使用一组固定大小的页面将虚拟地址转换为物理地址,而基于范围的转换(在cpu端转换中探索和使用)不同于基于页面的转换,它将可变大小的虚拟地址范围映射为物理地址。当寻址很大的线性内存区域的时候,基于范围的地址缓缓就十分有用,并且能够利用已经存在的基于 extent 的文件组织。
- 对于 FileMR,基于范围的地址转换有两个主要的好处,存储映射所需的空间和 用可变大小的区段数量(而不是固定大小的页面数量)注册映射比例所需的时间。在 MTT 和 pin-down cache 中注册一个页大概需要花费 5 微妙,该过程需要对内存描述符加锁,而且很难并行化。因此,单核只能注册 4KB 的页以 770MB/s 的速度。如果是 TB 级的 NVMM,结果注册时间会长到无法接受的程度。
Design Overview
- 下图灰色部分展示了原生 RDMA 堆栈,绿色部分则是在 FileMR 中做的一些必要的改变。
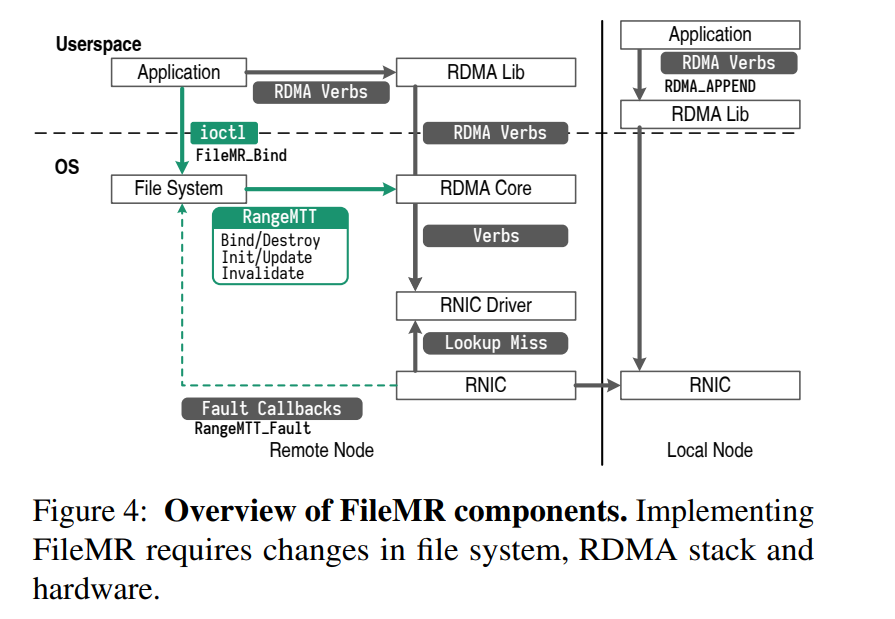
- 为了支持 FileMR 的抽象,文件系统要求实现
bind()函数来关联一个 FileMR 和一个 File,在必要时,当绑定文件的元数据通过回调发生变化时通知 RDMA 堆栈(最终是 RNIC 的 RangeMTT 和 pin-down 缓存)。这些回调允许 RNIC 为传入的 RDMA 请求维护正确的基于范围的物理地址映射 - 可选地,文件系统还可以注册一组回调函数,当 RNIC 无法找到传入地址的转换项时触发。这个过程类似于按需分页,需要它来支持新的 append ,它既修改文件布局,又写入文件

- 支持 FileMR 抽象还需要更改 RNIC 硬件。在我们提出的 RangeMTT 中,RNIC 硬件和驱动程序需要在 MTT 和pin-down 缓存中采用基于范围的寻址。基于范围的硬件寻址方案可以用来实现基于范围的地址查找。我们使用了软件 RNIC 进行模拟测试。
- FileMR 还向 RDMA 接口本身添加了增量的、向后兼容的更改。如下表所示,它为内存区域创建添加了一个新的访问标志,以标识 FileMR 的创建,创建后,FileMR 被标记为处于未配置状态。对文件系统的后续
bind()调用将在RangeMTT 中分配 FileMR 的转换条目(通过来自文件系统的cm_bind回调)。bind()方法可以通过ioctl()(用于内核级文件系统)或库调用(用于用户级文件系统)实现。FileMR 还添加了新的 RDMA 单边原语 Append。将现有应用程序转换为使用 FileMRs 很容易,因为应用程序只需要更改其区域创建代码

Implementation
- 为了实现 RangeMTT,我们遵循了冗余内存映射中引入的设计:每个 FileMR 指向存储了偏移量和长度的b树,我们使用这些偏移量作为索引。所有 RangeMTT 条目都是页面对齐的地址,因为 OS 只能以页面粒度管理虚拟内存
- 与页面对齐的 RangeMTT 不同,FileMR 支持任意大小并允许子页面文件/对象。每个 RangeMTT 条目由一个页面地址、一个长度字段和必要的位组成。这些条目没有重叠,对于稀疏的文件可能会有间隙。
- 为了支持 append 原语,FileMR 允许超出其大小的地址转换项。Append 是单边原语,不会在 WR 具体指定远程服务器的地址。在服务器端,RNIC 总是尝试 DMA 到当前的大小 FileMR,并在成功时增加其大小。当地址转换 missing,当IOMMU可用时,服务端可能会发起一个 IO 缺页中断,并且将调用文件系统例程来完成中断条目的处理。或者,如果这种支持不可用,服务器将通过类似于接收端未就绪(RNR)错误的消息向客户端发送信号。
- Soft-RoCE 将 MTT 条目管理为一个 64 位物理地址的平面数组,查找复杂度为O(1)。我们发现在硬件 RNIC 驱动程序如 mlx4 中也实现了类似的设计。对于具有范围 pin-down 缓存缺失的 FileMR,条目查找将以更高的时间复杂度遍历已注册的数据结构(O(log(n)))
- 由于映射是在 DRAM 中,Soft-RoCE 不具有 pin-down 缓存。为了模拟 RangeMTT,我们构建了一个
4096 项 4 路关联缓存用于模拟传统的定位缓存,以及用于 FileMR 的 4096 项 4 路关联范围定位缓存。每个范围转换条目由一个 32 位的页面地址和一个 32 位的长度组成,这允许最大的 FileMR 大小为 16TB (4 kB页)或 8PB (2 MB页)。 - 我们适配了两个应用程序来使用 FileMR。对于内核文件系统,我们的实现基于NOVA,这是一个成熟的内核空间 nvmm感知文件系统,具有良好的性能。我们还将 FileMR 修改为 libpmemlog (pmdk 的一部分,pmdk 是一个管理本地持久对象的用户级库),以构建可远程访问的持久日志。
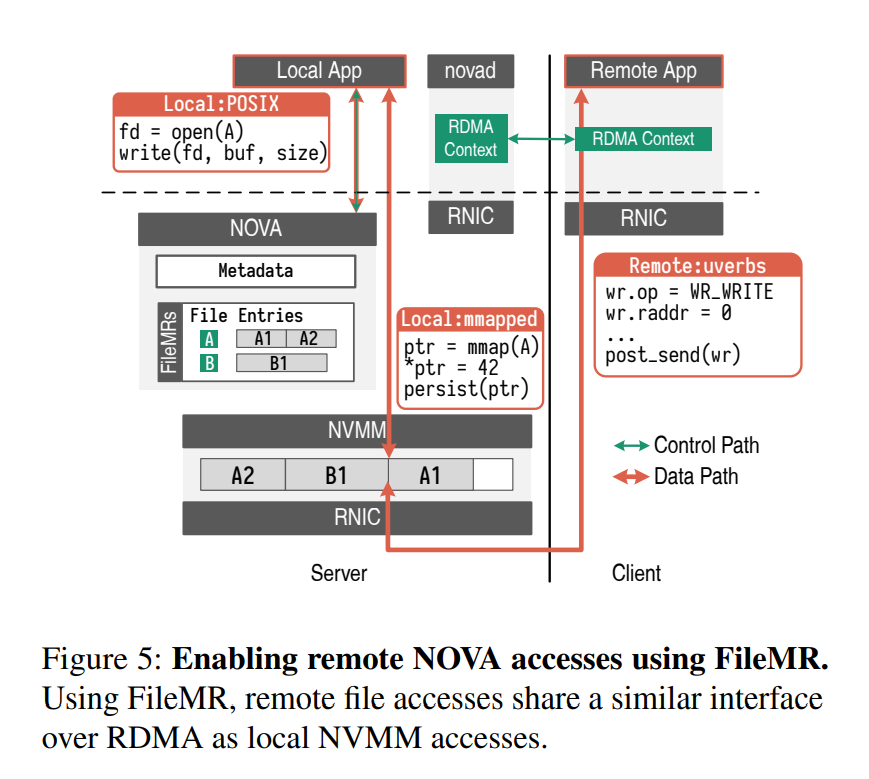
Remote File Access in NOVA
- NOVA 是一种符合 posix 的日志结构本地 NVMM 文件系统。在 NOVA 中,每个文件都组织为一个持久日志,其中包含大小不一的区段,这些区段驻留在持久内存中。文件数据由文件系统通过每个 cpu 空闲列表分配,并作为合并条目进行维护。
- 为了处理远程文件系统上的元数据操作,我们添加了一个用户级守护进程 novad,该进程打开文件以建立 FileMR,并接收来自远程应用程序的任何元数据更新(譬如目录创建),并将这些应用到本地文件系统上。
- 在客户端,应用程序通过与 novad 通信并接收 filekey 来远程打开文件。然后它可以发送单方面的 RDMA 原语来直接远程访问 NVMM。同时,本地运行的应用程序仍然可以使用传统的 POSIX IO 接口访问文件,或者将文件映射到它的地址空间,并发出加载和存储指令。
- 我们的组合系统也可以轻松处理数据复制。通过使用几个 FileMRs,我们可以简单地复制一个原语(具有相同或不同的filekey,具体取决于文件系统实现)并发送到多个主机,而无需考虑文件的物理地址(只要它们的名称相等)。
Remote NVMM Log with libpmemlog
- FileMR 抽象只要求后端的“文件系统”适当地实现
bind()方法,RNIC 回调,并可以访问原始 NVMM。例如,可以由能够访问原始 NVMM 设备的应用程序创建 FileMR。在本节中,我们将利用这种灵活性并基于 libpmemlog 构建远程 NVMM 日志 - 我们修改 libpmemlog 的分配器以使用必要的 FileMR 回调。也就是说,每当为日志分配或释放内存时,RNIC 的RangeMTT 都会更新。客户端使用新的 append 谓词追加到日志。在服务器端,当 FileMR 大小在映射的 RangeMTT 范围内时, RNIC 绕过服务器应用程序时可以进行地址转换。如果没有,则发生范围故障,并且库通过分配和映射额外的内存来扩展该区域
Evaluation
- DRAM 模拟 PM
- 2 Intel Xeon (Broadwell) CPUs with 10 cores and 256 GB of DRAM(64 GB configured as an emulated NVMM device)
- Soft-RoCE, Intel X710 10GbE NIC
Registration Overhead
Allocated Regions
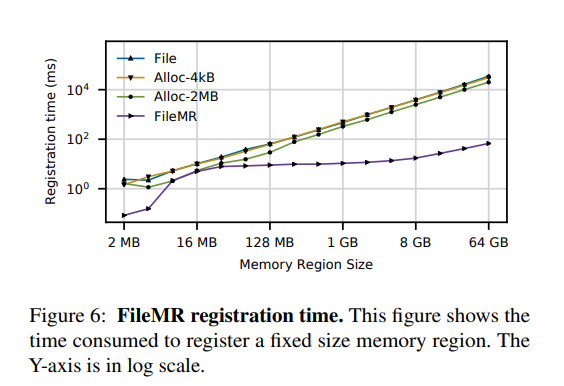
- 这个实验演示了当应用程序直接分配和映射文件而不更新其元数据时的用例。对于 FileMR,我们还包含了从 NOVA 日志中生成范围条目的时间,这在应用程序第一次打开文件时发生。
- 结果表明 注册一个大的内存区域会消耗大量的时间。主要是由于文件系统分配器的内部碎片。它花费 30 秒注册一个64gb 的持久性(文件)和易失性的具有 4 kB页面的(Alloc-4K)内存区域。使用 hugepages (alloc-2M)将注册成本降低到 20秒,而 FileMR 只需要67毫秒(低3个数量级)。
- 对于小文件,NOVA 只为文件创建一个或两个区段,而传统的 MRs 仍然与操作系统的虚拟内存例程交互,从而造成开销
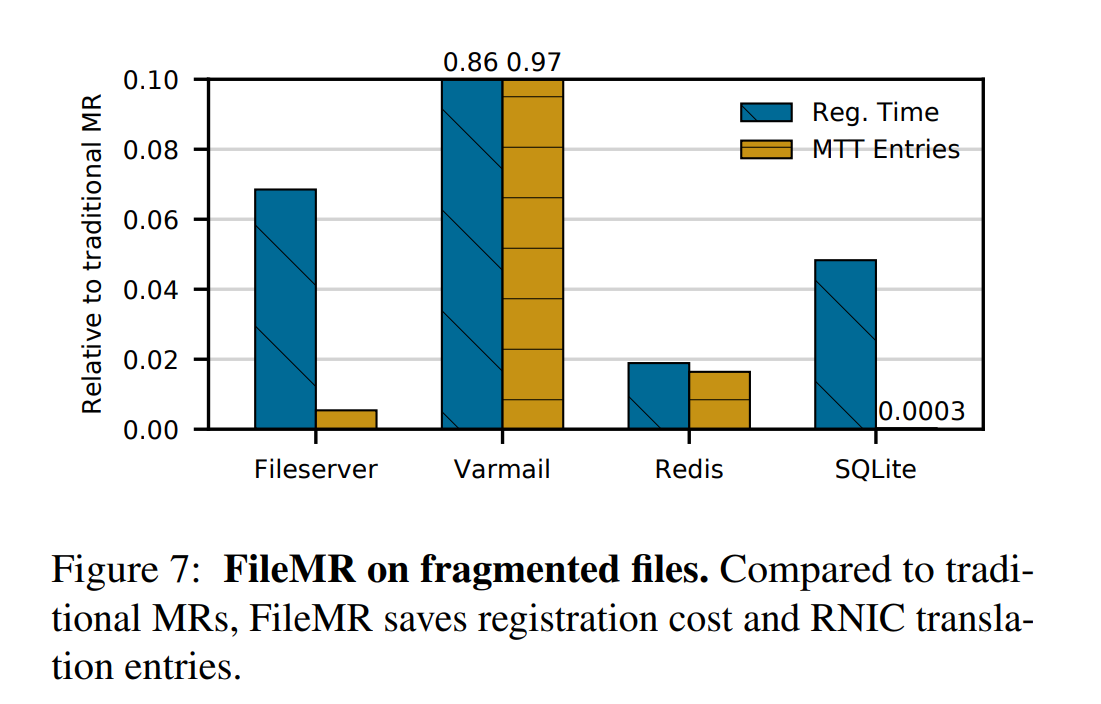
Data Fragmentation
- FileMR 得益于文件数据的连续性。文件系统的内部碎片可能有两个原因:文件系统老化和使用频繁更改文件布局的POSIX IO。为了测试 FileMR 在碎片化的文件系统上的性能,我们先使用了四个敏感的发起 POSIX IO 操作的负载来让文件系统产生碎片。完成之后,我们再在所有的 NVMM 文件上创建内存区域。使用了如下负载:
- 结果如下所示:在碎片化的文件上运行 FileMR 仍然显示了显著的的改善,在 region 注册时间和内存消耗 MTT 条目上。
- Fileserver 演示了许多文件的情况,其中FileMR 只创建传统内存区域条目的 0.5%,并且只需要 6.8% 的注册时间
- Metadata heavy 工作负载(Varmail), FileMR 条目的数量只减少了 3%(由于严重的内部碎片和小文件大小), 但它仍然可以节约 20% 的注册时间,因为它拥有索引节点锁,减少争用
- Redis 是一个键值存储,它在 IO 路径上持久化一个附加文件,并异步刷新数据库——少量的内部碎片意味着它只需要传统内存区域 2% 的空间和时间。
- 类似地,SQLite 也使用日志记录,这导致很少的碎片,并且极大地节省了空间和时间。
Translation Cache Effectiveness
- RDMA 在大型 NVMM 上的性能下降主要是由于 pin-down 缓存丢失造成的。由于 Soft-RoCE 在 UDP 中封装 RDMA 消息,并在 DRAM 中访问所有 RDMA 状态,因此我们不能通过端到端性能来衡量缓存的有效性。
- 相反,我们为 FileMR 测量模拟的向下缓存和范围向下缓存的缓存命中率。我们收集对表5中描述的工作负载的POSIX IO 系统调用的跟踪,并使用单向 RDMA 原语对远程主机 replay 它们。
- 下图展示了测试结果,range-based 的 pin-down cache 远好于 page-based pin-down cache。对于比较大的分配的文件,也就意味着更少的地址转换表项,range-based pin-down cache 的命中率接近达到了 100%

Accessing Remote Files
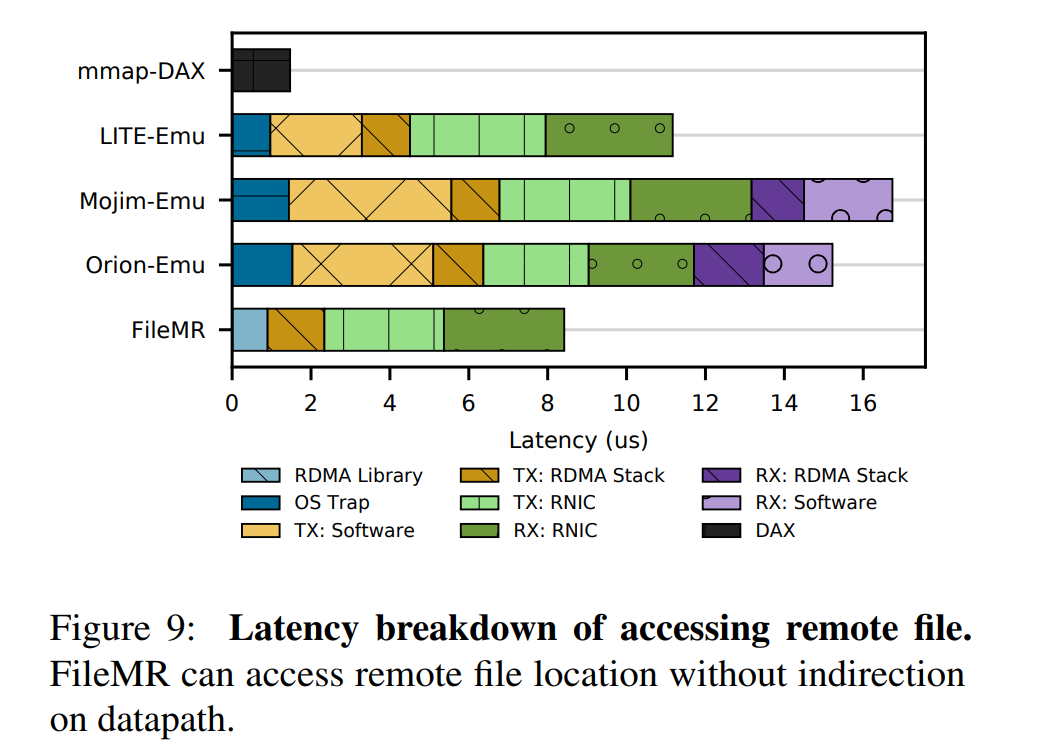
- 为了测试数据路径上的性能,我们让客户端访问运行 novad 的远程服务器上的文件。客户机使用 RDMA 写谓词发出随机的 1KB 写操作,我们测量客户机应用程序发出谓词和远程 RNIC DMAs 到目标内存地址(memcopy for Soft-RoCE)之间的延迟。我们将 FileMR 与映射本地访问和其他提供分布式存储访问的分布式系统进行了比较。所有这些系统都通过在链路上上发送物理地址来避免转换开销。
- 如下所示,延迟分解结果如下。注意,所有系统的延迟都比典型的 RDMA NIC 要高,因为 Soft-RoCE 比真正的 RNIC效率低。此外,我们省略了 UDP 包封装和交付的延迟,这控制了端到端延迟。它只需要1.5 微妙就可以将 4kB 的数据存储并持久化到本地 NVMM。FileMR 延迟更低,因为它消除了任何间接层的需要(Mojim 需要系统调用 msync,LITE 需要共享内存写入,Orion 需要进行 POSIX 写 )
Accessing Remote NVMM logs
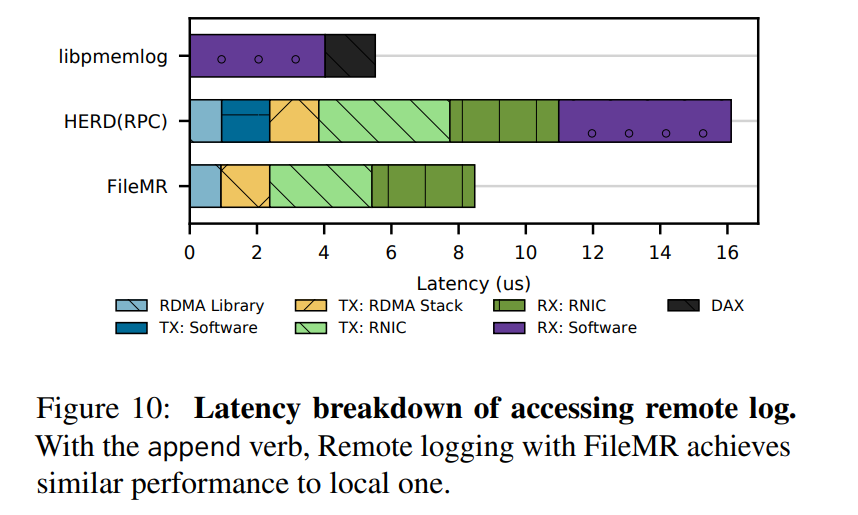
- 我们使用引入的远程日志实现来评估引入的新 append 谓词。我们比较基线 libpmemlog 使用本地NVMM(绕过网络),以及日志的 HERD RPC RDMA library。
- 如下所示了创建 64 字节日志项的延迟分解。使用 libpmemlog 花费大概 5.5 微妙来在本地进行日志记录。FileMR为远程日志和本地日志增加了 53% 的开销,HERD RPC-based 增加了 192% 的开销
Discussion
- 本章节讨论了软件模拟和实际硬件的差距,即该方案如果要像应用在实际的物理硬件上会有哪些问题与挑战,感兴趣请阅读原文。
Related Work
- 该章节介绍了大量的实验对比对象,以及一些思想的起源。
Conclusion
- NVMM 和 RDMA 系统之间元数据管理的冲突会导致昂贵的转换开销,并阻止文件系统更改其布局。这项工作引入了对现有RDMA协议的两个修改::基于FileMR和范围的转换,从而提供了一种结合内存区域和文件的抽象。它通过消除无关的转换提高了 RDMA 可访问 NVMMs 的性能,同时为 RDMA 提供了其他好处,包括更有效的访问权限和更简单的连接管理。
