VLDB21: Viper: An Efficient Hybrid PMem-DRAM Key-Value Store
https://github.com/hpides/viper
Abstract
现有的 KV 存储,为了持久化直接将数据放置在二级存储上,就要求 KVS 使用各种技术来在下层介质上提升读写性能。新出现的持久性内存技术不仅提供了接近 DRAM 的速度,还提供了数据持久性,使它们成为传统的基于磁盘的存储的有前途的替代品。但是,简单地用PMem替换现有存储不会产生好的结果,因为基于块的访问在PMem中的行为与在磁盘上的不同,并且忽略了PMem的字节寻址能力、布局和独特的性能特征。
本文中,我们提出了三种特定于 PMem 的访问模式,并在一个 PMem-DRAM 混和的 KVS 中进行了实现,称之为 Viper。使用了一个基于 DRAM 的哈希索引,一个 PMem 感知的存储布局来利用 DRAM 的随机写速度以及 PMem 高效的顺序写性能。测试表明 Viper 在核心的 KV 操作方面表现得比现有的 KV 存储更好,且同时提供所有数据的持久性。此外,在写工作负载方面,Viper比现有的仅 Pmem-Only、hybrid 和 基于磁盘的kvs性能高出4 - 18倍,同时与它们的 get 性能相匹配或超过它们。
Introduction
持久键值存储(KVSs)已经成为传统关系数据库管理系统(RDBMS)之外广泛使用的替代数据存储类型。不同于 RDBMSs,KVS 存储可通过给定键检索的 schema-less 数据(value)。KVS 负载和传统的 RDBMS 负载不一样的点在于 KVS 写量大,几乎只对单个记录进行操作。这些工作负载特征允许使用各种KVS应用程序,从SQL系统中的存储引擎,到流处理引擎的状态存储,再到web应用程序的缓存。在很大程度上,这些用例都需要高性能和强持久性保证。
为了确保数据的持久化,现在 KVS 都是把数据写到 KVS,例如 SSD 或者 HDD,然而新出现的持久性内存提供了字节寻址的数据持久性,同时提供了接近 DRAM 的访问速度,因此在 KVS 利用 PMem 来移除磁盘访问在提升 KVS 性能方面有很大的潜力。同时支持存储任意数据结构,而不需要进行记录反/序列化,这在传统的基于字符串的 KVS 中是必需的。
为了提升写密集负载下的性能,KVS 如 RocksDB,LevelDB 采用日志结构树来现在内存中收集要写入的记录然后再写入到磁盘上,该方法需要现在磁盘上进行 WAL 写入来保证持久性,大多数基于磁盘的kvs需要字符串或字节键和值来存储任意数据。这使得每次访问的反/序列化成本很高,严重影响了整体性能。
以前的PMem研究要么集中在如何适应现有系统,要么开发新的系统来利用PMem的潜力。各种混合的PMem-DRAM数据结构已经被提出,利用DRAM的速度和PMem的持久性来获得更好的整体性能。大部分研究聚焦在索引结构上,B-Tree,LSM-Tree,甚至 hashmap。其他研究将PMem集成到更大的系统中,例如用于数据库缓冲区管理或恢复。还提出了一些 PMem KVSs的仿真。
以前基于 PMem 仿真的 KVS 研究当时提出的假设后来证明是错误的,这些错误的假设限制了所提出的解决方案作为最优利用 PMem 的有效性,需要了解底层存储访问模式和特征。现在的研究表明 Optane DIMM 和 DRAM 以及 SSD 表现完全不同,因此,简单地用相同的基于 PMems 的存储替换基于磁盘的存储并不能获得最佳性能。基准测试还表明,对 PMem 的顺序写延迟更接近于 DRAM 的性能,而随机读的代价比预期的要高,这打破了之前研究的主要假设:写很慢需要尽量避免,读很快且可以随机。
为了克服基于磁盘的 KVS 的核心性能问题以及之前研究中的不正确的假设,我们提出了三个特定于PMem的访问模式,用于高效的数据存储: 直接 PMem 写,内存对齐的存储段,以及线程到内存的统一分布 。我们在 Viper 中实现了这三种模式,Viper 是一个 DRAM-Pmem 混和的存储系统,持久性构建在 Pmem 上从而避免昂贵的磁盘访问,Viper 由易失索引和持久性数据组成,从而既在 DRAM 尽可能发挥随机的性能,同时优化对 PMem 的高效写入。
Contributions
我们提出了特定于 Pmem 的访问模式,以便在混合 PMem DRAM环境中有效地直接存储和检索数据
我们在 Viper 中实现了这些访问模式,Viper 是一种混合的PMem DRAM KVS,它将其数据直接保存在PMem中
我们对 Viper 与最先进的 KVS 进行了评估,并表明它在核心KVS操作方面优于它们。在写工作负载方面,Viper比现有的pmem-only、hybrid 和 基于磁盘的kvs高出4 - 18倍,同时与它们的get性能相匹配或超过它们。
Background
Persistent Memory
Optane PMem:密度更高、容量更大,速度接近 DRAM,字节寻址,持久性
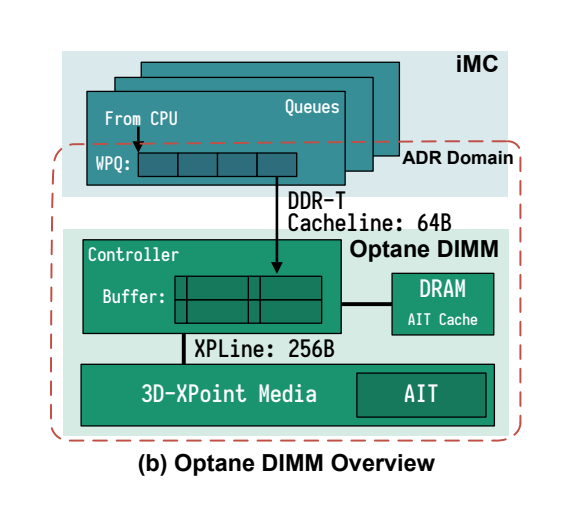
对于每个 DIMM,集成的内存控制器 iMC 维护了读写队列,RPQs, WPQs 来缓冲发送给 iMC 的请求。为了保证持久性,iMC 的 WPQs 是 ADR Domain(asynchronous DRAM refresh domain) 的一部分,数据到达了 WPQ 后就肯定能被刷回到 PMem,无论 CPU Cache 中的数据是否丢失。同时 iMC 和 DIMM 是以 64Byte 缓存行的粒度进行交互的,而物理介质的访问通常是以 256Bytes 为粒度的,因此一个 on-DIMM controller 在物理访问媒体之前,将较小的请求转换为256字节粒度,这会导致读写放大。为了减小该影响,控制器使用 write-combining buffer 来合并相邻的写入。
在 APP-Direct 模式下运行 PMem 可以让用户显式控制对PMem的访问,而内存模式使用 PMem 作为 DRAM 的易失扩展,其中 DRAM 充当“L4”缓存,数据不是持久的。为了保证 Viper 数据的持久性,我们使用了 App-Direct 模式并把 PMem 通过 mmap 映射到了我们应用程序的虚拟内存空间从而利用其字节寻址的特性。
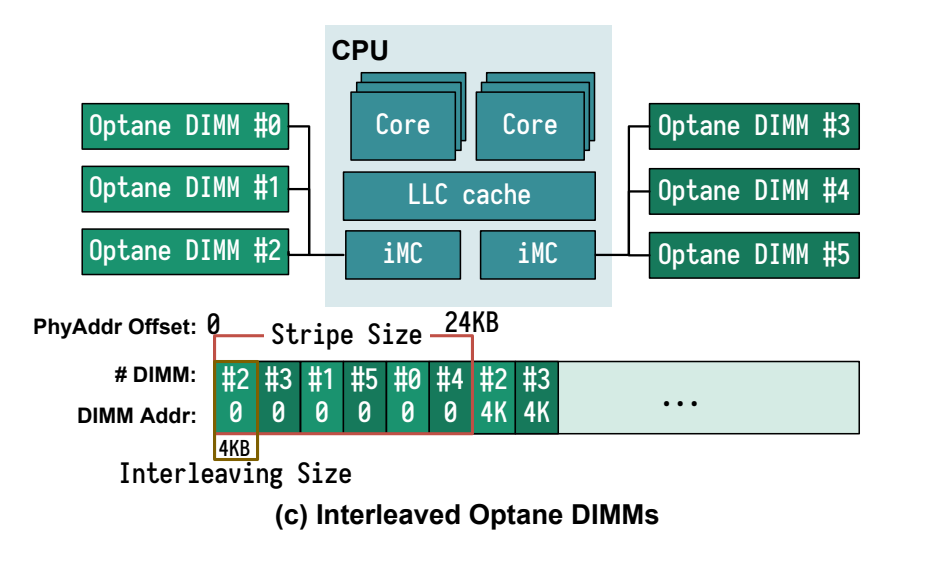
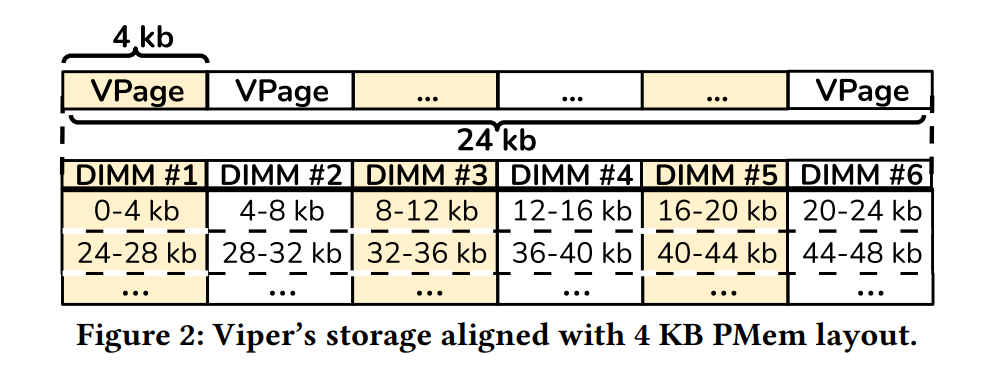
PMem 还支持内存条之间的交错数据。而非交错 PMem 将一个内存空间附加在另一个内存后面,交错的目的是通过将顺序数据访问分散到多个内存上来提高读写的总体吞吐量,也就是内存并行,类似于RAID 0。这允许更好的并行访问和更高的吞吐量。在 PMem 中,数据通常以 4KB 的块交织在一起,将每个连续的24 KB 块分布在所有6个可用内存上。在Viper中,我们假设是交错PMem存储。
为了保证 App-Direct 模式下的持久性,用户必须通过使用一些指令例如 clwb 来 flush 缓存行,因为编译器和操作系统可能会重排序指令,很有必要进行 sfence 的显式调用来避免重排序,保证写 PMem 能够完成,而不是重新排序后的。
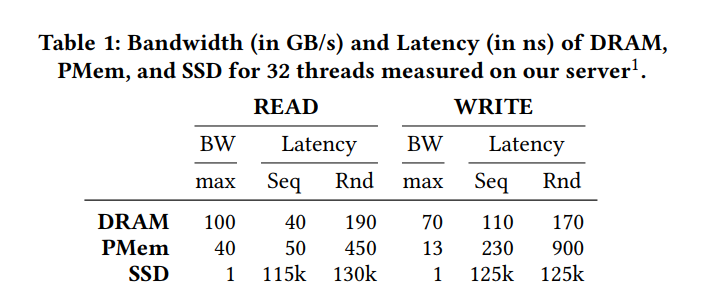
即便 PMem 性能假设和 DRAM 相近,但是其实是更慢的。最近的研究表明其性能差异显著,而且更难预测。我们使用32个线程执行高负载微基准测试,以在我们的服务器上为KVS工作负载获得准确的延迟和带宽数。如表1所示,随机读取的延迟是DRAM 的 2.5x,由访问媒体的较长延迟引起,但比SSD低三个数量级。同时,顺序持久化写的延迟几乎等同于DRAM,因为数据只需要到达要持久化的iMC中的WPQ。随机写会有5倍的延迟,并且会受到带宽的严重影响。因此,鼓励按顺序写PMem,而随机访问应该尽可能直接到DRAM。虽然PMem的峰值带宽低于DRAM,但读带宽仍达到40%,写带宽达到20%,明显高于SSD。
Key-Value Store
为了访问KVS,出现了两种设计,KVS服务器和嵌入式KVS。基于服务器的KVS存储和同步状态,这些状态可以被运行在不同机器上的多个应用程序全局访问。它通过网络 C/S API 通信,服务端 KVS 有诸如 Redis, Memcached。如果单个应用使用 KVS,嵌入式的 KVs 相比与服务端 KVs 提供了一个更轻量级的选择,应用通过对应的库函数来访问这些嵌入式的 KVs,比较流行的嵌入式 KVs 有 RocksDB 以及 FASTER 等。
服务端 KVs 的优势主要是他们是独立的系统。这为它们提供了完整的系统控制,也就是说,它们管理自己的线程、并发性和I/O队列。然而,这种控制需要抽象成本,例如基于网络的接口。另一方面,嵌入式 KVs 由应用程序内的用户控制,这与基于网络的访问相比减少了通信开销,并允许更多的微调。然而,这种控制带来了不正确使用的风险,这可能会影响正确性和性能。为了提供良好的性能和控制,嵌入式KVS必须将其接口设计得尽可能简单,而不要求用户在出现部分故障或系统重新启动时严格遵循模式或复杂的程序。在本工作中,我们着重于设计这样一个嵌入式KVS和简单的接口,以允许用户充分利用 PMem 而不需要高的网络开销。我们在Viper中提出了这样一个设计和实现
VIPER: A HYBRID KEY-VALUE STORE
Viper 通过将数据持久化在 PMem 上避免了昂贵的磁盘访问操作,同时维护了一个内存索引来利用 DRAM 的较低的随机访问延迟。
Hybrid Design
为了完全利用 DRAM 和 PMem 的特性,我们提出了一个混合存储方法。Viper 由一个易失的位于 DRAM 上的哈希索引以及位于 PMem 上的持久数据组成。Optane DIMMs 可以作为 SSD 的替代来实现数据持久性,以充分利用性能。我们需要理解它的存储布局和有益的访问模式。在 PMem 上的所有数据都是持久的,哈希索引只是引用了存储位置。
混和存储模型在很多前面基于索引的工作中就被提出过了,都是基于选择性地持久化的理念。在选择性持久化的背后的思想其实是只存储在持久内存中重建整个系统状态并在易失性内存中保持动态可恢复状态所需的数据。Viper 也被设计成了一种嵌入式的 KVS。
PMem Access Patterns
在真实的 PMem 上的研究显示出了其复杂的性能特征,经常会出现低带宽高延迟的情况。我们提出了三种专门针对 PMem 的访问模式来显著影响其性能表现。
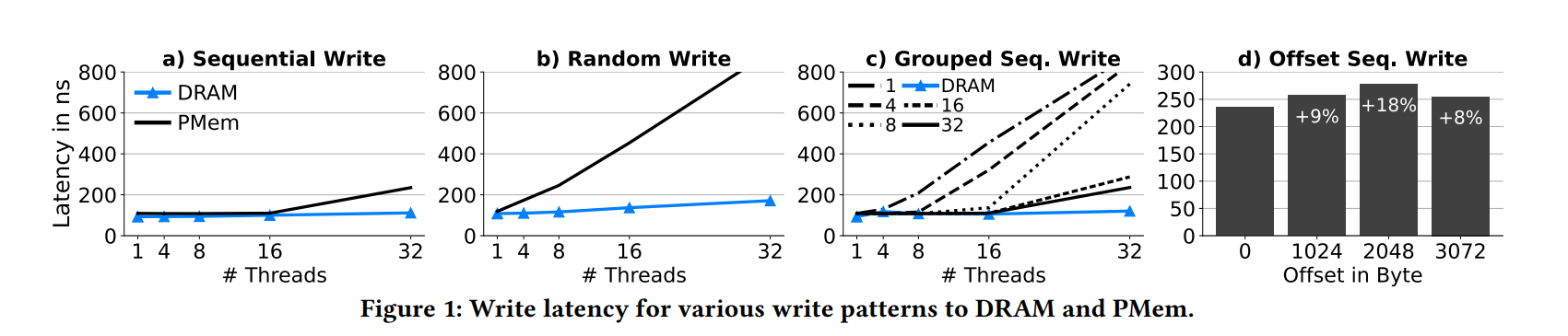
Direct PMem writes :因为顺序的 PMem 写入比前面模拟假设中提出的更快,所以 Viper 直接把所有数据写入到 PMem 而不用任何中间的 DRAM BufferUniform thread-to-DIMM distribution :Viper 通过将线程分配给不同的内存区域来最小化了插入过程中 thread-to-DIMM 的比例DIMM-aligned storage segments :Viper 将数据存储在DIMM boundary 对齐的 VPage 中,以平衡内存争用和并行性。较小的 VPage 会导致更多线程访问相同的内存,较大的 VPage 会导致单个线程访问多个内存,这两种情况都会导致更糟糕的线程/内存比率。下图证明了不同设计选择的影响。我们执行 64 个字节存储,然后在 PMem 和 DRAM 使用不同数量的线程执行 clwb 和 sfence。图 1a 和 图b 表明了顺序写延迟方面 PMem 和 DRAM 接近,最坏的情况下是 32 线程的达到了 2x,随机写方面,PMem 表现得更差,即便是在线程数较少的时候。这是因为 Optane 内部的写聚合缓冲,把相邻的写入进行了聚合从而减少了昂贵的 flush 开销,但是不能聚合小的随机写操作,造成了较高的写放大。从这个观察中,我们得到了 direct PMem writes 设计。
1c 表明了线程在所有内存上均匀分布的重要性。我们把线程分布到了 k 个内存区域,每个内存区域 1GB,代表日志文件,它们按顺序写入日志。使用 1 log fle(在图中表示为1),所有线程都写相邻的缓存行,即线程 1 写字节 0-63,线程 2 写字节 64-127,以此类推。当使用相同数量的线程和日志时,每个线程有自己对应的内存区域,如果有更多的日志,将很少有线程共享一个内存区域,并均匀地分布在内存上。1 log 性能差是因为所有线程都在一个 DIMM 上操作(32 × 64 Byte = 2048Byte),因此没有考虑到交错的 DIMM 内部的并行性。当使用更多的日志时,我们可以看到性能的提高,因为线程通过写入均匀分布在内存上的不同位置来提高PMem 的并行性。从这个观察,我们得出了 uniform thread-to-DIMM distribution 设计
最后 1d 表示了存储对齐的访问的影响。在这个基准测试中,我们让每个线程顺序写入 4KB,并改变写入的对齐方式。我们看到 4KB 对齐的写入(偏移量= 0)可以实现最低的延迟,而2 KB的偏移量会带来18%的延迟。这同样是由于需要访问两个内存来写入 4KB,而不是只写一个。从这个观察中,我们得出了 DIMM-aligned storage segments 设计
Volatile Index
我们实验表明真实的 PMem 器件随机操作比顺序操作的延迟要高很多,吞吐量也更低。因此,我们通过在 DRAM 中定位哈希索引来避免(可能很多)开销较大的随机操作。额外的,高效的 DRAM 中 HASHMap 的设计和实现也被广泛研究过,可以在我们的方案中得到应用,而对于持久的 HashMap 则是在近年来才有所研究,但通常都比 DRAM 中的设计性能更差。此外,由于映射中的每个操作都具有持久性,因此需要复杂的逻辑来避免并发性和内存问题,例如持久内存泄漏,无效指针,以及阻塞的持久锁。对于我们的实现,我们使用了 CCEH 并在 DRAM 中使用而不是 PMem,CCEH 使用了一个可扩展的哈希方法,因此允许动态 resizing 而不用进行昂贵的全表 rehash,因为我们使用了易失索引存储 PMem 上的 Location 的偏移量信息,我们在后文称之为 Offset Map
Persistent Data
因为我们的目标是持久化 Viper 中的所有数据,我们需要存储所有的 KV 对到一个持久的存储介质上。我们选择了 Intel Optane DC PMem 来实现。Viper 将所有记录直接写入到基于 PMem 的存储段上,也就是我们的设计1,Viper 的主要存储段被称之为 VPages,并且包含独立的 KV 记录和一些元数据。下图展示了我们如何将 VPages 与底层 PMem 内存的布局对齐(设计3)。
然而,Viper 可以被配置,来适应任何数量的 DIMMs,我们使用了 Optane DIMM 以交叉存取的模式来实现高度并行。在交叉存储模式下,数据被分片到横跨多个 DIMMs,以 4KB 页为单位,我们通过将 VPage 对齐到 4KB 的页边界大小来利用分片。这允许我们每个VPage 只能访问一个 DIMM,因此在并行访问过程中减少了 DIMMs 的争用。(对应了我们的设计2)
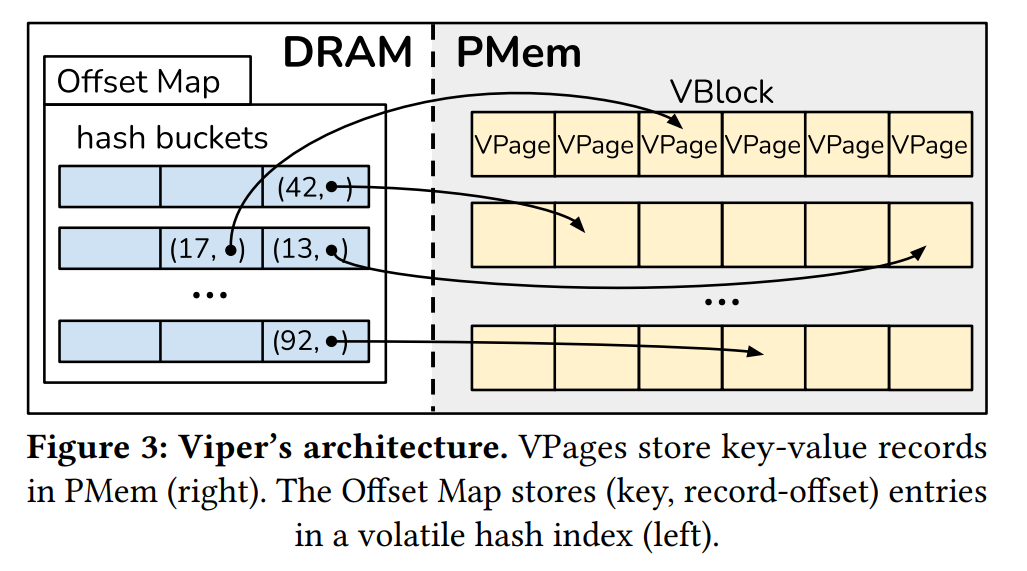
Architectures
Viper 由三个组件组成。持久的 VBlocks, VPages, 和内存中的 Offset Map。如下图所示。在右侧我们看见 Viper 的持久存储端(VPage)被分组成 VBlocks,位于 PMem 中。在左边,我们看到了 Offset Map,也就是索引,存储 Key 和每个记录对应在 PMem 的位置信息。
Common Components
在本节中,我们将介绍用于固定大小和可变大小记录的相同组件 VBlock 和偏移映射,以及 Viper 的元数据管理。
VBlock
Viper 中我们将 VBlock 对齐到底层交错内存集的边界,也就是 24KB,每个 VBlocks 包含固定数量的 VPages,一个 DIMM 一个 VPage,存储在一个就地的数组中以便高效访问。VBlocks 本身不包含逻辑只是以一组 VPage 的形式来减少统计开销。VPage 为 4KB,包含一些元数据和实际的存储在 slots 的 KV 记录。他们是实际的存储单元,为了支持更大的 KV 对,Viper 将 VPages 扩展到多个 4KB 甚至 VBlock 多个 24KB,确保是按照 4 或者 24KB 对齐的。
template <typename VPage, page_size_t num_pages>
struct alignas(PAGE_SIZE) ViperPageBlock {
/**
* Array to store all persistent ViperPages.
* Don't use a vector here because a ViperPage uses arrays and the whole struct would be moved on a vector resize,
* making all pointers invalid.
*/
std::array<VPage, num_pages> v_pages;
// 判断该 Block 是否被客户端持有
inline bool is_owned() const {
return IS_BIT_SET(v_pages[0].version_lock, CLIENT_BIT);
}
// 判断该 Block 是否被使用
inline bool is_unused() const {
return IS_BIT_SET(v_pages[0].version_lock, UNUSED_BIT);
}
};
Offset Map
Offset Map 是核心的易失索引,Viper用来追踪各条记录。在 Viper 中,Offset Map 是一个内存中的并发 HASHMap,当插入一条记录时,首先持久化到 VPage 然后记录的偏移量被存储在 Offset Map 中。offset 由三个部分组成,VBlock id, VPage ID, record position in the VPage。记录位置主要取决于记录的大小是固定的还是变长的。Viper 存储偏移量在一个 64位 Offset 对象中,其中最重要的45位表示块id,接着的3位表示页面id,接下来的16位用于记录位置。如果用户对预期的工作负载有特定的了解,例如非常大的记录或内存的数量变化显著,则可以修改位分配
类似于以前的工作,我们使用 fingerprinting 在偏移映射中存储大于8字节的键。Viper不是将实际的键存储在映射中,而是存储该键的散列,并仅在散列匹配时检查是否相等。这大大减少了与输入键进行代价昂贵的比较的次数
为了扩展,Viper在 PMem 上分配 Vblock,并通过 mmap 将它们映射到虚拟内存空间。为了追踪到虚拟地址的信息,Viper 存储了一个指针来执行每一个 VBlock,从而在 DRAM 中形成了一个 List。这样就可以方便地通过隐式id访问任意的VBlock,该id等于列表中的偏移量。一旦可用的 VBlock 达到一定的可配置的 filling degree,Viper 就可以分配额外的 Vblock 并将它们添加到列表中。Viper 支持 PMem 的分配通过 devdax 或者 fsdax 目录。数据以增加内存顺序(devdax) 或增加 file名称(fsdax)的方式分配,以保证顺序。从而在重启后维持 VBlock 顺序。为了减少内存分配的数量,会分配大的块(或chunk),默认情况下包含 43690个 VBlock (1GB)。元数据恢复和将所有数据映射回 Viper 的虚拟内存空间只需要几毫秒,因为它主要由 mmap 调用组成。
Fixed-Sized Records
固定大小的记录的布局如下图 a 所示。
VPage Data
Viper 在 VPage 中存储实际的 KV 记录。KV 被一起存储在一个单独的 slot 中,slot id 被用于作为 Offset Map Entry 的第三部分(也就是 record position)。每个 VPage 中的 slots 数量取决于记录的大小,更大的记录占据更大的空间因此,也就很少一部分能够容纳在 4KB 的空间中。Viper 使用几乎 4KB 的全部来存储数据,只有很少的一部分字节存储元数据。下面我们描述了使用元数据大小的槽的数量的计算。
VPage Metadata
元数据被存储在 VPage 的前几个字节中。主要包括一个 version lock byte 和一个 bitset 来表明哪些 slots 是空闲的或者被占据了。这样的思想在之前的 PMem 数据结构上也有应用,如树节点 VLDB20 uTree, SIGMOD16 FPTree,以及 HASH Bucket VLDB20 DASH。我们使用了一个 lock byte 来处理 VPage 的并发访问,只允许一个线程来并发修改数据。该锁通过原子的 CAS 操作来获取和释放,我们因此避免了比较重的 mutexes 的使用。尽管存在确保正确持久化语义的持久化CAS实现,但是 Viper 使用了开销更小的常规内存中CAS操作。锁只在活动使用期间被关联,并在崩溃后重置。
template <typename K, typename V>
struct alignas(PAGE_SIZE) ViperPage {
using VEntry = std::pair<K, V>;
static constexpr data_offset_size_t num_slots_per_page = get_num_slots_per_page<K, V>();
std::atomic<version_lock_t> version_lock; // 锁
std::bitset<num_slots_per_page> free_slots; // 位图
std::array<VEntry, num_slots_per_page> data;// 包含的数据数组
...
}
bitset 包含 K 位,每一个对应 VPage 的一个槽,一个被置位的 bit 表示了这个操是否被占据是否包含数据,未置位的 bit 则相反,表明该 slot 是空闲的。这允许 Viper 高效地删除一条记录,直接把对应的 bit 设置为 0。
template <typename K, typename V>
struct alignas(PAGE_SIZE) ViperPage {
...
void init() {
static constexpr size_t v_page_size = sizeof(*this);
static_assert(((v_page_size & (v_page_size - 1)) == 0), "VPage needs to be a power of 2!");
static_assert(PAGE_SIZE % alignof(*this) == 0, "VPage not page size conform!");
version_lock = 0; // lock 初始为 0, unlock
free_slots.set(); // 初始化为 0
}
...
}
VPage Slot Count and Metadata Size
元数据的实际大小取决于记录的大小,因为 Viper 要求每个 Slot 一个 Bit,为了计算元数据的大小,首先计算 slot 的数量,直接使用页大小除以记录的大小就能得到。相应地向下取整,为了避免 VPage 中 slot 的过度分配,我们需要检查是否元数据使用。元数据大小使用 slots 的数量除以 8 然后加上 1 来求得的。也就是 lock+bitset。向上取整 bit 大小,因为底层系统不能在单个位上工作,而是需要完整的字节。如果数据加上元数据对于 VPage 太大了的话,就必须减少 slots 的数量。VPage 最后没用的空间将进行 padding 来保证 4KB 对齐。
template <typename K, typename V>
constexpr data_offset_size_t get_num_slots_per_page() {
const uint32_t entry_size = sizeof(K) + sizeof(V); // 数据的实际长度
uint16_t current_page_size = PAGE_SIZE; // 页大小
// 页开销主要包括:lock 开销 + 1
const uint16_t page_overhead = sizeof(version_lock_t) + 1; // 页本身的开销
// 数据大于一个页的时候,再分配一个页。4K-24K
while (entry_size + page_overhead > current_page_size && current_page_size <= BLOCK_SIZE) {
current_page_size += PAGE_SIZE;
}
// 得到一个块对应的页个数
page_size_t num_pages_per_block = current_page_size / PAGE_SIZE;
// 往 24KB 对齐
if (num_pages_per_block == 4 || num_pages_per_block == 5) {
num_pages_per_block = 6;
current_page_size = BLOCK_SIZE;
}
// 页大小除以数据项的大小,得到 slot 数量,向下取整
// eg. 4KB/200B = 4096/200 = 20
// eg. 4KB/16B = 4096/16 = 256, Key-Value 各自最少为 8Bytes
uint16_t num_slots_per_page_large = current_page_size / entry_size;
// 其实就是针对 KV 为 16 字节时候,自减 1 来装元数据(但这其实在后面的代码中有逻辑来处理这种情况)
if (num_slots_per_page_large > 255) {
num_slots_per_page_large--;
}
data_offset_size_t num_slots_per_page = num_slots_per_page_large;
// 检查总开销是否超过了当前页大小,大了就减少 slot
// 总空间开销 = 数据的大小 + 页自身的开销 + 页对应的元数据开销(bitset)
// 页对应的元数据开销(bitset) 向上取整,因为最小操作单位为 byte
// eg.
// data_size 20*200B = 4000Bytes
// page_overhead = uint8_t + 1 = 2Bytes
// bitset_size = 20 / 8 = 3Bytes
while ((num_slots_per_page * entry_size) + page_overhead +
std::ceil((double) num_slots_per_page / 8) > current_page_size) {
num_slots_per_page--;
}
assert(num_slots_per_page > 0 && "Cannot fit KV pair into single page!");
return num_slots_per_page;
}
Variable-Sized Records
为了支持可变长度的记录,VPage 设计需要被修改,如下图 b 所示。
VPage data
记录不再存储在固定的 slots 中,因为大小事先不知道,因此使用 VPage 中的所有非元数据字节作为日志。每个记录被连续地写入到日志中,和对应的 Key 以及对应的 value length。大小被存储在一个 32bit 的值中,key 15位,value 16位,允许原子更新,剩下的一位来表明该记录被 set =1 还是被删除 =0,日志中的偏移量被用作 Offset Map Entry 的第三部分也就是 record position,对于大于 4KB 的 KV 对,Viper 动态地使用一整个 VBlock 作为一个单独的 VPage,对于更大的记录,Viper 就要横跨多个 VPages 并标记这些 Page 为 overflow pages。因此较大的记录不会影响 Viper 的设计,因为仍然对每个客户端还是有唯一的 VBlock,并且将客户端线程平均分配到 DIMM。
struct VarSizeEntry {
union {
uint32_t size_info;
struct {
bool is_set : 1;
uint16_t key_size : 15;
uint16_t value_size : 16;
};
};
char* data;
VarSizeEntry(const uint64_t keySize, const uint64_t valueSize)
: is_set{true}, key_size{static_cast<uint16_t>(keySize)}, value_size{static_cast<uint16_t>(valueSize)} {}
};
VPage Metadata
因为 VPage 不包含任何 slots,空闲的 slot bitset 被移除,相反,每个 VPage 包含一个指针指向它下一个插入的位置,例如日志的尾指针,然后一个 8bit 的整数来追踪大约删除了多少数据(i.e., metadata bit = 0),需要被 compacted。元数据大小是固定的 10 Bytes,因此每个 Page 允许 4086B 的记录。
template <>
struct alignas(PAGE_SIZE) ViperPage<std::string, std::string> {
// 元数据 - 指向下一个插入位置的指针
char* next_insert_pos;
// VPage 对应的 version_lock
std::atomic<version_lock_t> version_lock;
// 记录大约删除了多少数据
uint8_t modified_percentage;
// 元数据大小,1 + 1 + 8 = 10B
static constexpr size_t METADATA_SIZE = sizeof(version_lock) + sizeof(next_insert_pos) + sizeof(modified_percentage);
// 数据大小,4096 - 10 = 4086B
static constexpr uint16_t DATA_SIZE = PAGE_SIZE - METADATA_SIZE;
// 数据
std::array<char, DATA_SIZE> data;
void init() {
// 检查 VPage Size
static constexpr size_t v_page_size = sizeof(*this);
static_assert(((v_page_size & (v_page_size - 1)) == 0), "VPage needs to be a power of 2!");
static_assert(PAGE_SIZE % alignof(*this) == 0, "VPage not page size conform!");
static_assert(PAGE_SIZE == v_page_size, "VPage not 4096 Byte!");
// 初始化元数据
version_lock = 0;
next_insert_pos = nullptr;
modified_percentage = 0;
}
// 加锁访问 VPage
inline bool lock(const bool blocking = true) {
// atomic<uint8_t> load(std::memory_order_acquire)
// 加载原子对象中存入的值,等价与直接使用原子变量
// 初始状态下 version_lock = 0, 即 lock_value = 0
version_lock_t lock_value = version_lock.load(LOAD_ORDER);
// Compare and swap until we are the thread to set the lock bit
// lock_value &= 0b11111110 => lock_vakue = 0 即未加锁状态
lock_value &= UNLOCKED_BIT;
// CAS 操作
// b.compare_exchange_weak(expected, new_value);
// 比较原子变量值 b 和所提供的期望值 expected,如果二者相等,则存储提供的期望值 new_Value,
// 如果不等则将期望值更新为原子变量的实际值,更新成功则返回true反之则返回false
// eg. 比较 version_lock 和 lock_value,相等则 + 1
while (!version_lock.compare_exchange_weak(lock_value, lock_value + 1)) {
// Compare 发现不等,那么就不能 Swap
// 判断是否指定了要阻塞,如果 blocking = true,那么就在这循环等待
// 如果是非阻塞的,blocking = false,那么直接返回加锁失败
lock_value &= UNLOCKED_BIT;
if (!blocking) { return false; }
}
// 返回加锁的结果
return true;
}
// 解锁
inline void unlock() {
// 一样先加载对应的 version_lock 数据,假设此时为 1
const version_lock_t current_version = version_lock.load(LOAD_ORDER);
// 对应地将 version_lock + 1,增加一个版本,1 + 1 = 2
// current_version & 0b10000000,1 & 0b10000000 = 0b00000000
// 此时 new_version = 0b00000000 | 0b00000010 = 0b00000010
// current_version & CLIENT_BIT 判断是否客户端持有,如果持有
const version_lock_t new_version = (current_version + 1) | (current_version & CLIENT_BIT);
// 存储新版本到 version_lock,即 version_lock = 0b00000010
version_lock.store(new_version, STORE_ORDER);
}
};
KEY-VALUE STORE OPERATIONS
Viper Client
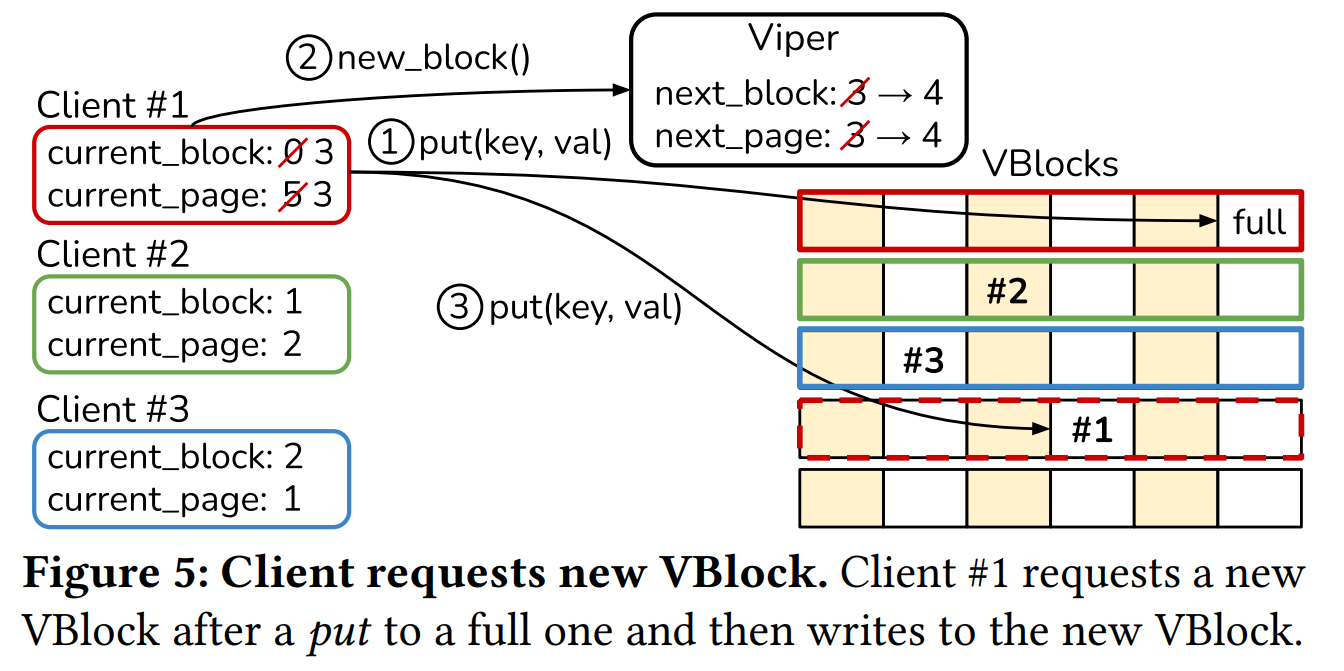
对于嵌入式的 KVs,为给定文件创建数据库句柄,如果文件不存在,数据库句柄将创建一个新数据库或打开现有数据库。这个句柄可以被多个线程使用并和 KVs 交互,然而,当 KVs 不控制或者拥有线程时,句柄自己将必须控制外部的并发访问。这种嵌入式KVS的示例是RocksDB 或 LevelDB。 对于放置请求,这意味着为每个请求提供一个新的插入位置。这个中央同步点很快成为瓶颈,在Viper中,我们通过引入Viper客户端来避免。
因为 Viper 是一个嵌入式 KVs,客户端不包含任何网络逻辑,它是一个轻量级的对象,向用户公开KVS操作界面,并包含有关在何处写入将来记录以减少Viper内部同步的信息。下图展示了客户端和 Viper 的交互流程,下面例子中,创建了三个客户端,每个客户端使用了自己的 VBlock 初始化,即不会有两个客户端将新纪录写入相同的 VBlock。为了表明一个 VBlock 是否被一个客户端持有,会在第一个 VPage 的 version lock 中设置一个 owned_bit。该位被用来空间回收和恢复 。然后,客户端将数据写入其当前的VBlock / VPage,并继续处理VPage,直到所有VPage都已满。一旦客户端因为数据已满而无法将数据放入其VBlock中(图中步骤1 ),将从 Viper 中请求新的 VBlock(步骤2 ),然后,Viper将下一个块返回给客户端,并原子更新next_block和next_page计数器。 Viper将next_block和next_page计数器存储在单个64位变量中,该变量可以通过 CAS 操作原子更新。 随机选择next_page 计数器,以实现DIMM上的均匀分布。当客户端收到其下一个块时,它将更新其引用,并将记录插入到新的VPage中(步骤3 )。这种方法显著减少了Viper内部的协调开销,因为它不需要为每个放置操作发布新的写入位置。如果 VBlock 能够容纳(例如100条记录),则开销减少了100倍,因为客户端每100次写入仅需要一个新位置
由于Viper支持空间回收,因此它还可以跟踪并发队列中的空闲块。如果队列中存在空闲块,则将其提供给客户端以供重用,而不是分配新的客户端。在这种情况下,该块将从队列中删除,并且next_block计数器保持不变。
Put
客户端发起一个 PUT 请求,伪代码如下所示,客户端首先在一个阻塞的调用中获取一个 VPage Lock,为了获得排他权限,version lock 被原子 CAS 更新 +1,即 0->1,变成一个奇数,如果客户端遇到一个奇数锁,将重试操作,一旦客户端有了对 VPage 的排他访问权限的时候,开始搜索下一个空闲的 slot,如果 VPage 满了,客户端释放该锁,更新其对应的 Page 和 Block 信息,然后重试 PUT 操作。为了更新对应的 page 和 block 信息,它要么前进到当前VBlock中的下一个VPage,要么从Viper请求一个新的VBlock
如果在当前 VPage 中有空闲的 slot,客户端将记录存储在空闲的 slot 上并持久化,为了把当前缓存行写到 PMem 上,Persist 方法向基础系统发出 clwb 调用,然后进行sfence调用。sfence 确保了正确的顺序,即在调用之后,数据保证能够被持久化。只有在数据保留之后,客户端才会更新并持久化 bitset(第10-11行)。这里的顺序很重要,因为 bitset 成为恢复的基础。如果该 bitset 指示已填充插槽,但未正确存储数据,则说明Viper处于不一致状态。
一旦数据持久化,客户端插入新的偏移量到 Offset Map 中,如果 Offset Map 包含键的条目,则旧值将被覆盖,并且客户端必须通过将相应位设置为 0(第15行)来确保删除旧位置的记录。 Offset Map 处理并发时,它保证在并发写入同一密钥的情况下,一个客户端将另一客户端添加的值视为旧的 offset,从而删除了另一客户端的值。最后,客户端释放 VPage上的锁,并返回一个布尔值,指示是插入了新密钥还是覆盖了现有密钥(第17-18行)。通过原子地存储另一个 +1 增量来释放该锁,从而使该锁再次成为偶数。
1 AcquireVPageLock ( v_page );
2 free_slot_idx = FindFreeSlot ( v_page . slot_bitset );
3 if ( free_slot_idx == max_bitset_size ) {
4 ReleaseLock ( v_page ); GetNewVPageOrVBlock ();
5 return Put(k, v);
6 }
7
8 v_page.slots [ free_slot_idx ] = {k, v};
9 Persist( v_page.slots [ free_slot_idx ]);
10 v_page . slot_bitset [ free_slot_idx ] = 1;
11 Persist ( v_page . slot_bitset );
12
13 offset = { block_num , page_num , free_slot_idx };
14 [is_new , old_offset ] = offset_map . Insert (k, offset );
15 if (! is_new ) DeleteOldRecord ( old_offset );
16
17 ReleaseLock ( v_page );
18 return is_new ;
template <typename K, typename V>
bool Viper<K, V>::Client::put(const K& key, const V& value, const bool delete_old) {
// 首先对 Page 加锁
v_page_->lock();
// 找到空闲的 slots
// We now have the lock on this page
std::bitset<VPage::num_slots_per_page>* free_slots = &v_page_->free_slots;
const data_offset_size_t free_slot_idx = free_slots->_Find_first();
// 判断是否还有空闲的 slots
if (free_slot_idx >= free_slots->size()) {
// Page is full. Free lock on page and restart.
v_page_->unlock();
update_access_information();
return put(key, value, delete_old);
}
// 找到了一个空闲的 slot 则持久化数据
// We have found a free slot on this page. Persist data.
// 将 Key Value 构造到 Vpage 中的 data
v_page_->data[free_slot_idx] = {key, value};
// 获取对应的 指针
typename VPage::VEntry* entry_ptr = v_page_->data.data() + free_slot_idx;
// 持久化指针指向的对应的数据, pmem_persist 为 PMDK 的方法
pmem_persist(entry_ptr, sizeof(typename VPage::VEntry));
// reset 空闲 slot 位图
free_slots->reset(free_slot_idx);
// 持久化位图信息
pmem_persist(free_slots, sizeof(*free_slots));
// 构建对应的 Offset 三元组
// Store data in DRAM map.
const KVOffset kv_offset{v_block_number_, v_page_number_, free_slot_idx};
KVOffset old_offset;
// 写入对应的索引信息 offset,并返回原有的索引信息
if constexpr (using_fp) {
auto key_check_fn = [&](auto key, auto offset) { return this->viper_.check_key_equality(key, offset); };
old_offset = this->viper_.map_.Insert(key, kv_offset, key_check_fn);
} else {
old_offset = this->viper_.map_.Insert(key, kv_offset);
}
// 判断是否为新插入的键
const bool is_new_item = old_offset.is_tombstone();
// 如果不是新插入的数据,即为覆盖写,又显示指定了要删除老数据
if (!is_new_item && delete_old) {
// Need to free slot at old location for this key
free_occupied_slot(old_offset, key);
}
v_page_->unlock();
// We have added one value, so +1
size_delta_++;
info_sync();
// 表明是新插入的键还是覆盖写的键
return is_new_item;
}
Crash Consistency
如果在持久化 bitset 或者删除一个老的记录过程中崩溃了,Viper 就会包含一个 Key 的两个 Value,为了保证一个确定的故障恢复和原子写入,Viper 选择更大的 <block_id, page_id, slot_id > 来解决冲突。我们注意到新值不是必要的,老的 block ids 在回收之后会被重用,但是它构成了恢复期间的确定性 tie-break,为了确保在确定可以恢复之前不能读取新值,客户端将保持 VPage 锁定,直到删除旧记录。在极少数情况下,这可能会导致死锁,因为两个客户端可能需要以相反的顺序锁定相同的两个 VPage。如果检测到死锁,即无法通过尝试获取锁,则客户端会将其需要删除的对象添加到全局列表中。死锁中的所有客户端都会连续检查此列表中是否有与当前VPage相匹配的设置,删除处的记录,然后将其从列表中删除。如果客户端注意到从列表中删除了该死锁,则死锁将得到解决,并且可以在解锁其VPage之后返回死锁。在具有5000万混合操作的微型基准测试中,Viper仅遇到两种类似死锁的情况。
Variable-Sized Records
插入变长的记录遵循上述伪代码中相似的过程,但是实际的写入不同。为了插入一个变长的记录,客户端首先从 VPage 的 metadata 中遍历 next_insert_position,然后使用 Persist 调用将记录写入到 PMem 的给定位置,只有这样,它才会将记录的元数据写入记录的前面。此顺序保证如果存在元数据,则记录将被永久存储。这与在固定大小的记录的插槽之后持久化 bitset 相同。当 Page 容纳不下该记录时,客户端检查是否没有值 fits 的键。如果 fits,则将值写入下一页,然后才将 Key 写入带有指示 value 长度为 0 的元数据,这告诉 Viper 该值存储在下一页上,以确保与上述相同的持久性保证。如果该键没有 fit,则将记录写入下一页,并且将元数据设置为当前页上的无效配置,指示在此标记之后不再存在任何数据。插入记录后,将更新 next_insert_position 以反映页面末尾或新位置
Get
为了扩展性,Viper 使用无锁的读。首先检查 Offset Map,没有的话报错,然后原子地读 VPage 的 version lock 到 l1,如果 l1 是奇数,即另一个客户端正持有一个排他锁,因此整个读操作需要重试,因为VPage修改可能已更改了检索到的偏移量。在未加锁的状态时,客户端读指定偏移量的。指针检索是在 Viper 的 VBlock 列表中查找该块的块ID,然后直接访问该 VBlock 的页面列表中的页面ID和VPage的插槽中的插槽ID。我们在这里注意到,VBlock内的VPage数组和VPage内的插槽在编译时是已知的,因此允许编译器将后两个查询组合为从初始查询开始的VBlock指针的简单指针算法。在返回值之前,它将再次原子地将 version lock 加载到 l2。如果 l1=l2,则未修改 VPage,并且可以安全地返回该值。如果l1≠l2,则可能会发生冲突,将重试整个读取操作。
检索大小可变的记录遵循相同的步骤,但是实际的记录查找略有不同。它不是从给定的插槽中读取记录,而是从VPage日志中的给定位置读取记录长度,然后根据其大小检索值。
Update
为了更新Viper中的值,用户可以调用update(Key,UpdateFn),其中UpdateFn是接收值并自动修改值的任意函数。由于Viper不会复制这些值,因此会在PMem中进行修改。为了避免部分更新异常,只能执行原子更新。但是,这使用户可以就地修改最多8字节的值(对于现代AVX-512 CPU,则为16/32/64)。这对于例如更新值的计数器或其他单独字段很有用。在Viper中更新与get类似,但是如果没有发生版本冲突,则不返回值,而是客户端获得排他锁并将UpdateFn应用于该值。因此,任何后续操作都知道已执行了修改
对于非原子更新,必须重新插入该值。为此,用户获取值,创建副本,修改它,最后调用具有新值的相同键的插入。这是许多KVS中的常用方法,如果无法进行就地修改,Viper总是会退回到该方法。这也是可变大小记录的方法,因为它们中的修改可能会更改其大小。在Viper中,记录紧密地包装在日志中,并且不允许任何后续的大小变化
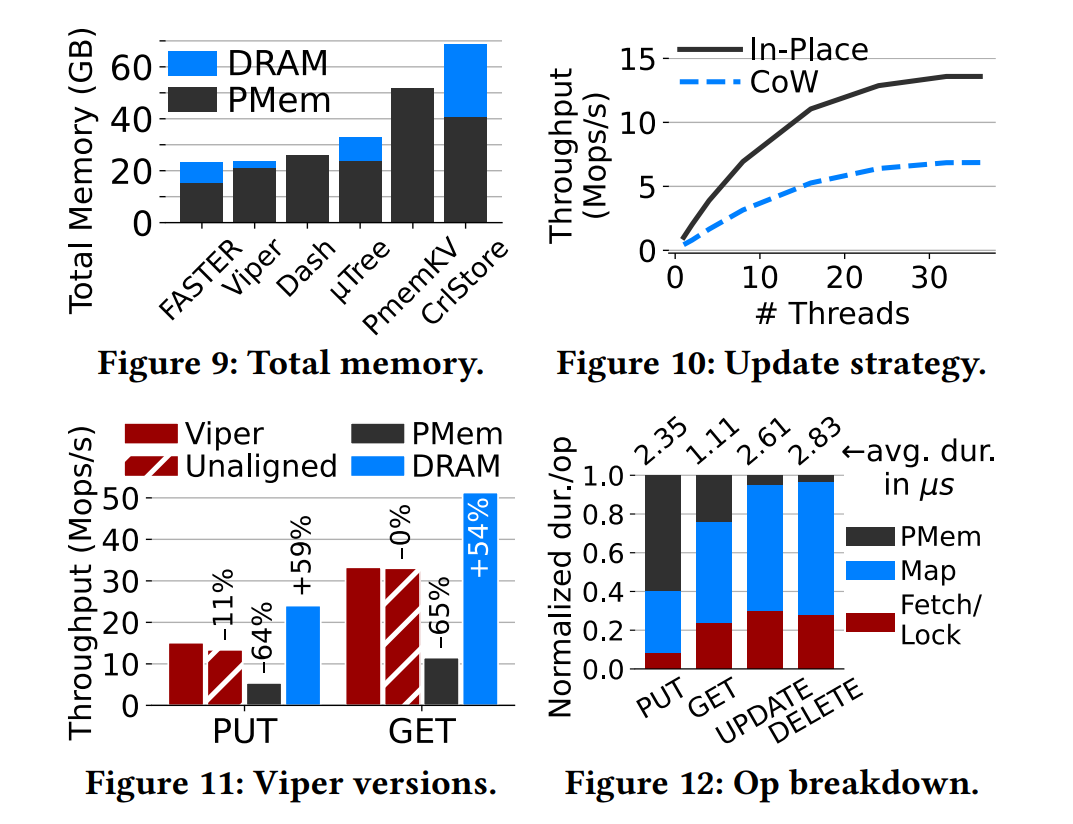
就地更新相对于传统的写时复制的两个主要优点是避免了序列化,并且减少了缓存行刷新,即,在Viper中仅需要一个Persist调用,因为没有元数据被更新。此外,最近的工作表明,对于PMem,就地修改优于写时复制。
Space Reclamation
在删除或重新插入各种记录之后,VPage在日志中包含许多可用的插槽或逻辑删除的记录。为了重用此可用空间,Viper运行了定期的后台空间回收进程。在此回收中,Viper扫描VPage的 bitset 以查看有多少可用插槽。如果VBlock中的可用插槽数大于可配置的阈值,并且客户端当前未“拥有”该VBlock,则将该VBlock压缩为一个新的VBlock,标记为“空闲”,然后添加到空闲块队列中。压缩VBlock等效于将每个记录重新插入该VBlock中。因此,当压缩多个VBlock时,记录将再次紧密打包。如果客户端读取当前正在压缩的记录,则它要么读取陈旧的偏移量,然后重试,因为已压缩的 VPage 的版本锁已更改,或者它读取了新的设置。每个VPage在其压缩的整个过程中都被锁定,以避免在整个过程中进行修改
对于可变大小的记录,Viper会检查每个VPage的元数据以获取此页面上的大约可用空间。如果VBlock达到可配置的阈值,则它将按照固定大小的过程进行压缩。压缩完VBlock后,在其第一个VPage的锁定字节中将一个空闲位标记为空闲。这样,Viper可以在恢复过程中识别出空闲的VBlock。此过程还可用于在VBlock列表的末尾解除VBlock的分配,从而在删除许多记录后减少其PMem占用空间
Recovery
持久性KVS需要能够从崩溃中恢复,或者需要在常规关闭后重新打开。在Viper中,我们将完全相同地处理这两种情况,因为所有必需的元数据在其正常操作模式下都会持续存在。 Viper在PMem中存储了少量的元数据,以跟踪分配的VBlock的数量,已使用的VBlock的数量以及总的内存映射大小。每次在PMem中分配新的VBlock时,元数据都会更新以反映分配的块总数。此外,每次将新的VBlock分配给客户端时,元数据中使用的块数都会增加。
当使用现有数据库打开Viper时,Viper会检查此元数据,并根据该元数据准备恢复。Viper 将现有的VBlock映射到其虚拟地址空间,并存储指向每个VBlock的指针,映射所有VBlock之后,Viper会检查已用块的数量并扫描这些块以检索其中的记录。对于每个VPage,Viper都会检查设置了哪些插槽(固定大小),或在日志中扫描未删除的记录(可变大小),然后将offset插入映射。这可以通过将不相交的VBlock范围分配给不同的线程来并行化。扫描完所有VBlock之后,Viper中的next_block计数器将更新为使用最高的block_id +1,以便新客户端接收到新的VBlock
Evaluation
其他系统
FASTER: 最先进的基于 HASH 的 KVS,可以使用 PMem 代替 SSD
pmem-RocksDB: https://software.intel.com/content/www/us/en/develop/articles/how-intel-optimized-rocksdb-code-for-persistent-memory-with-pmdk.html,Intel 官方发布的在 PMem 上构建 RocksDB
Dash: 最先进的针对 PMem 优化的 HASH 索引,与 PMDK 的持久性分配器一起
pmemkv: https://pmem.io/pmemkv/ Intel 发布的基于 HASH 的 KV 存储,使用 cmap 作为存储后端
µTree: 最先进的混和 B-Tree 实现,原生支持大 value。我们注意到,由于附加的范围查询支持的排序开销,对于单个记录操作,BTree的性能预计会略低。
提出了交叉引用日志(CRL),它通过在两个KVS之间保持交叉引用日志来弥合挥发性和持久性KVS之间的差距,其中一个在DRAM中,另一个在PMem中。由于CRL尚未公开,因此我们将其(CrlStore)与Intel的易失性TBB并发哈希图作为DRAM KVS,将持久性的图作为PMem KVS 一起使用,这两者都满足了CRL的每条记录锁定要求。由于CRL需要前端和后端线程,因此我们对所有写入操作都使用1:1映射,从而将结果限制在图中的18个线程中。我们没有采用作者提出的动态映射,因为后端线程构成了瓶颈。对于读请求只用前端线程
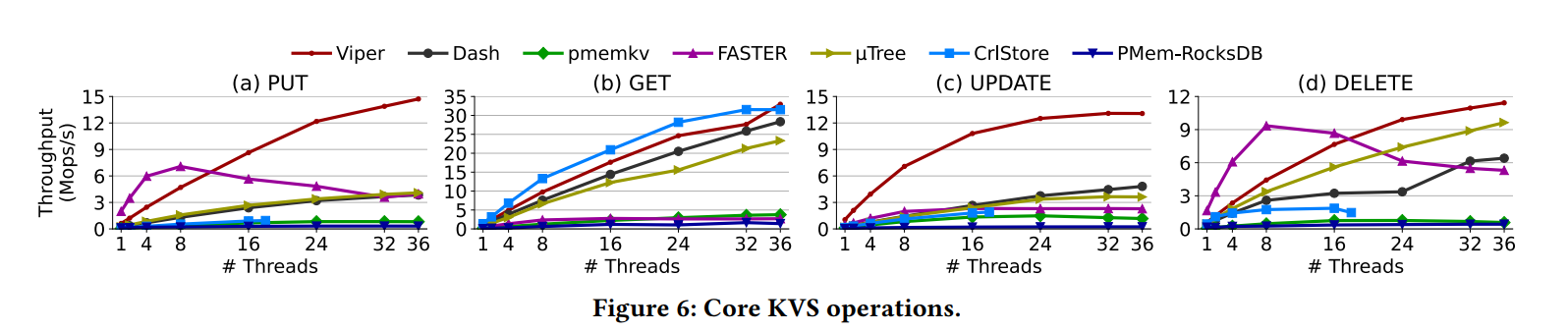
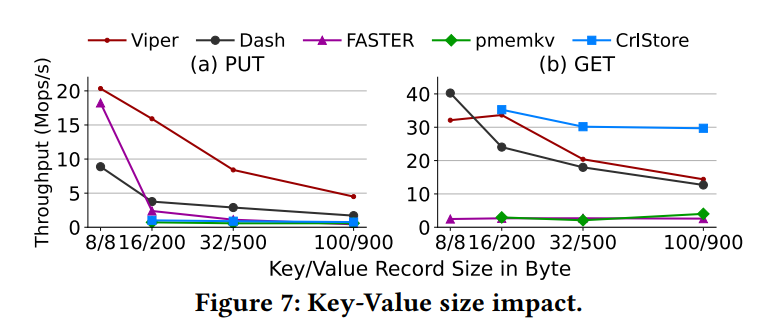
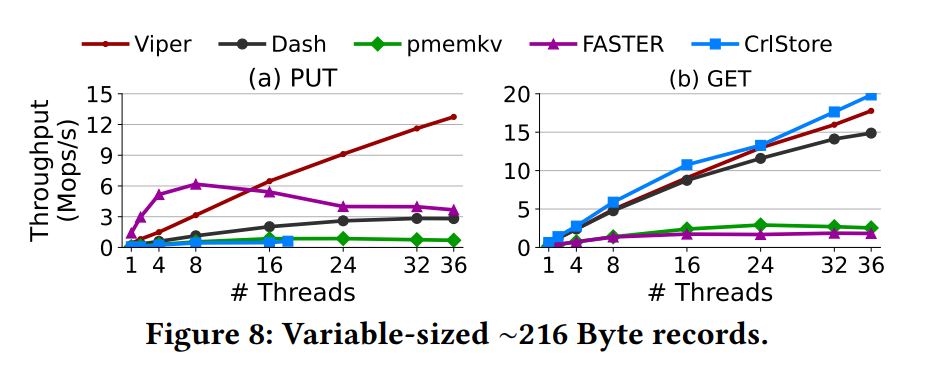
不同线程各种操作的性能测试
不同 KV 大小测试
可变长度的 Value 的测试
其他方面
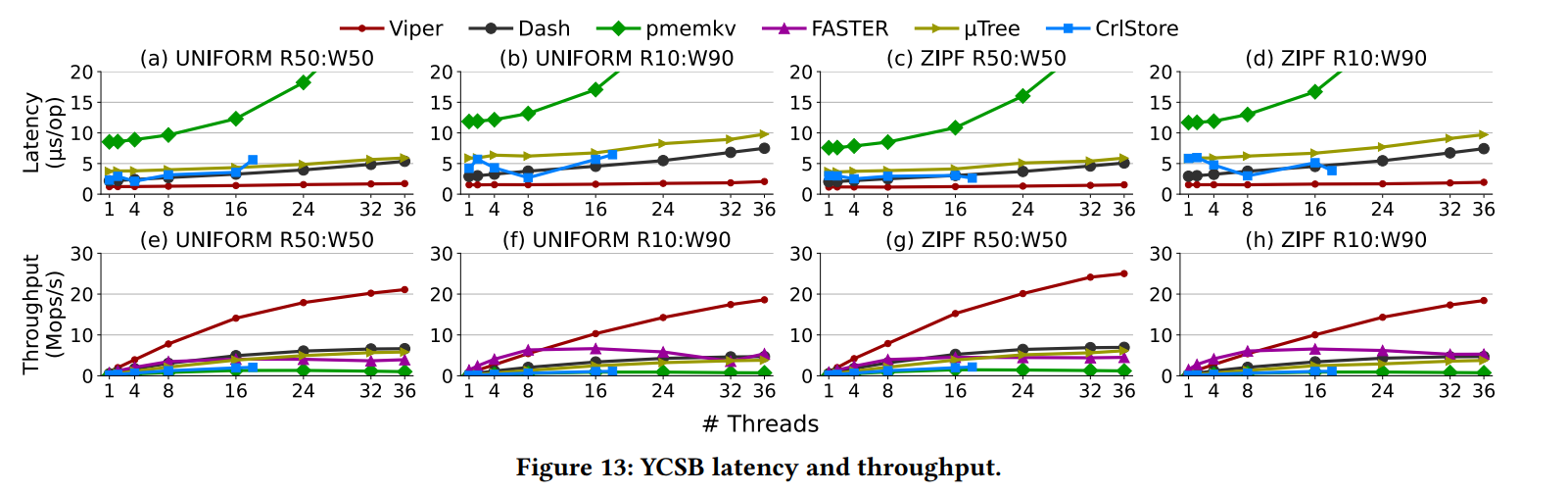
YCSB
Traditional KVS
in-memory KVS 针对纯内存中类似缓存的用例进行了优化,以实现最佳性能。它们不会持久保存数据,以避免在系统关闭或崩溃后以丢失数据为代价避免昂贵的磁盘访问
persisten KVs 以往的研究主要聚焦在如何避免昂贵的读写放大上,无论是 SSD 还是 HDD。比较流行的系统有 RocksDB、LevelDB、Cassandra 都使用了 LSM Tree 和一个内存中的表来减少写放大。为了确保内存中的表的数据的持久化,通常使用一个基于文件的 WAL 技术来保证,很快也就成为了瓶颈
SIGMOD'18-FASTER 则是一个使用了内存 HASH 索引和磁盘上的混和日志的结构来存储记录,并带有易失性的“tail”,可以进行就地更新。在崩溃期间,易失性尾部中的数据可能会丢失。尽管此方法在某些用例中效果很好,但我们的目标是在Viper中建立一个更强大的存储模型,以确保数据持久性。Viper 提出的持久性 KVS 则是利用 PMem 来代替磁盘从而支持快速高效的操作,而没有中心的基于日志的瓶颈。
PMem-Based Key-Value Stores
VLDB20-RStore : DRAM-PMem 混和 KVS,通过异步消息传递和日志结构化存储来降低尾延迟ASPLOS'20-FlatStore : 采用了基于记录批处理和从RDMA连接的请求缓冲区进行跨核窃取的混合设计。由于RStore和FlatStore被设计为KVS服务器,因此它们的核心设计决策与网络紧密耦合,包括控制自己的线程,以及通过用户空间网络减少网络开销 Viper 的设计是以嵌入式 KVS 为基础的,不要求网络交互,而且不控制自己的线程。
FAST’15-HiKV : 提出了一个混合索引,哈希索引存储在 PMem 上,B-Tree 索引存储在 DRAM 上,所有的点查询都在,但是,由于只有 B 树位于DRAM 中, 因此所有点查询都是在PMem上执行的,与Viper相比,这实际上使其成为仅PMem的KVS。LibreKV: 建立了一个混合索引,其中数据首先插入到基于DRAM的哈希图中,一旦达到一定程度,便合并到基于PMem的哈希图中。 但是,LibreKV无法提供一致性,因为在崩溃期间DRAM中的所有数据都会丢失。
HPCC'19-NVLevel : 是一个基于LSM树的KVS,它使用多个基于PMem的内存表,并在磁盘满后将它们压缩到磁盘上的SSTable中。 NVLevel使用磁盘作为其存储介质,因此受到类似于其他基于磁盘的KVS的限制。在Viper中,我们提出了针对特定硬件的PMem特定访问模式,以有效地直接在PMem中存储数据和从PMem直接获取数据。
PMem Data Structures
FAST'20 An Empirical Guide to the Behavior and Use of Scalable Persistent Memory
DaMoN'19 Persistent memory I/O primitives
arXiv'19 Basic Performance Measurements of the Intel Optane DC Persistent Memory Module